
Application of Soft Computing Techniques to Predict the Strength of Geopolymer Composites

 , , ,
, , , 
Abstract
:1. Introduction
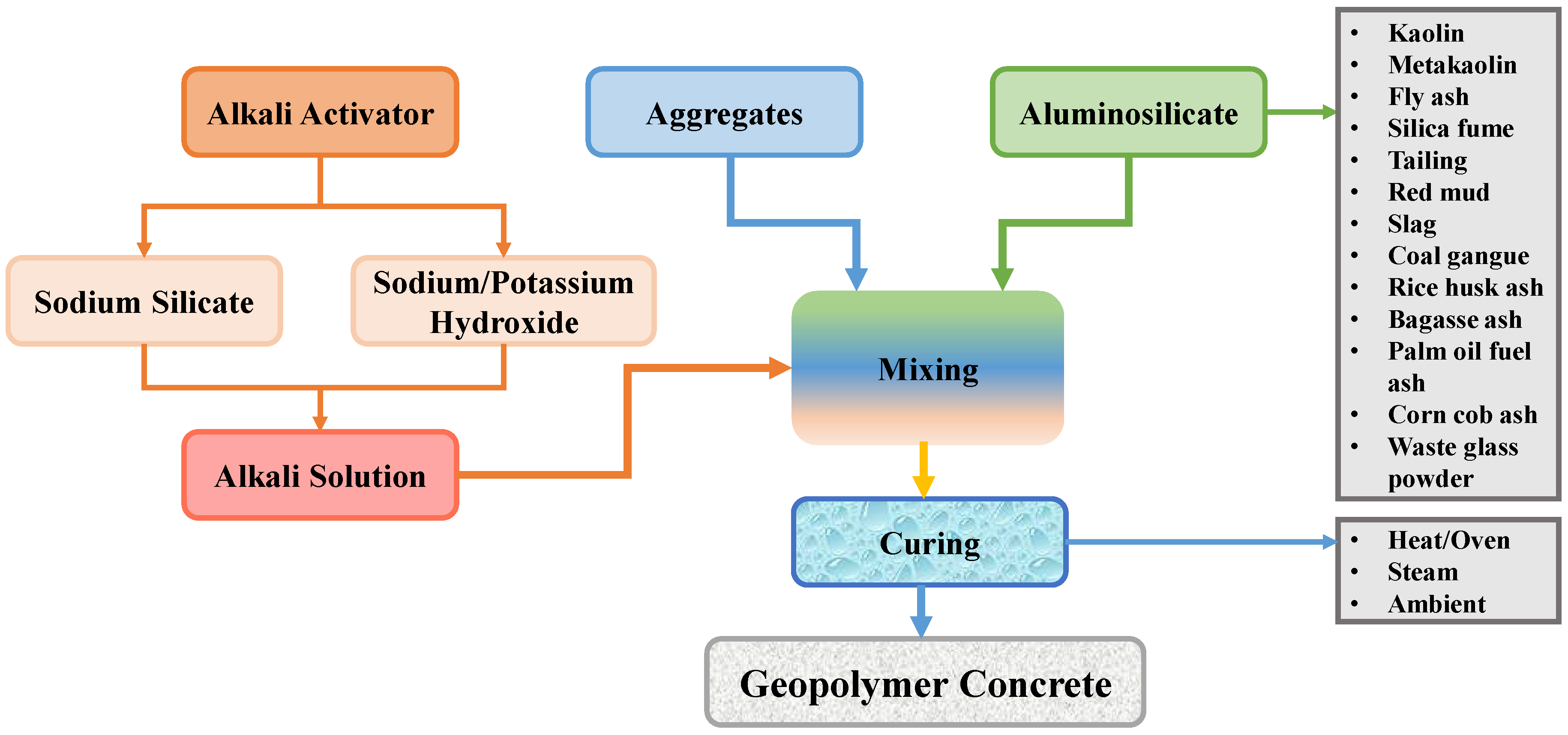
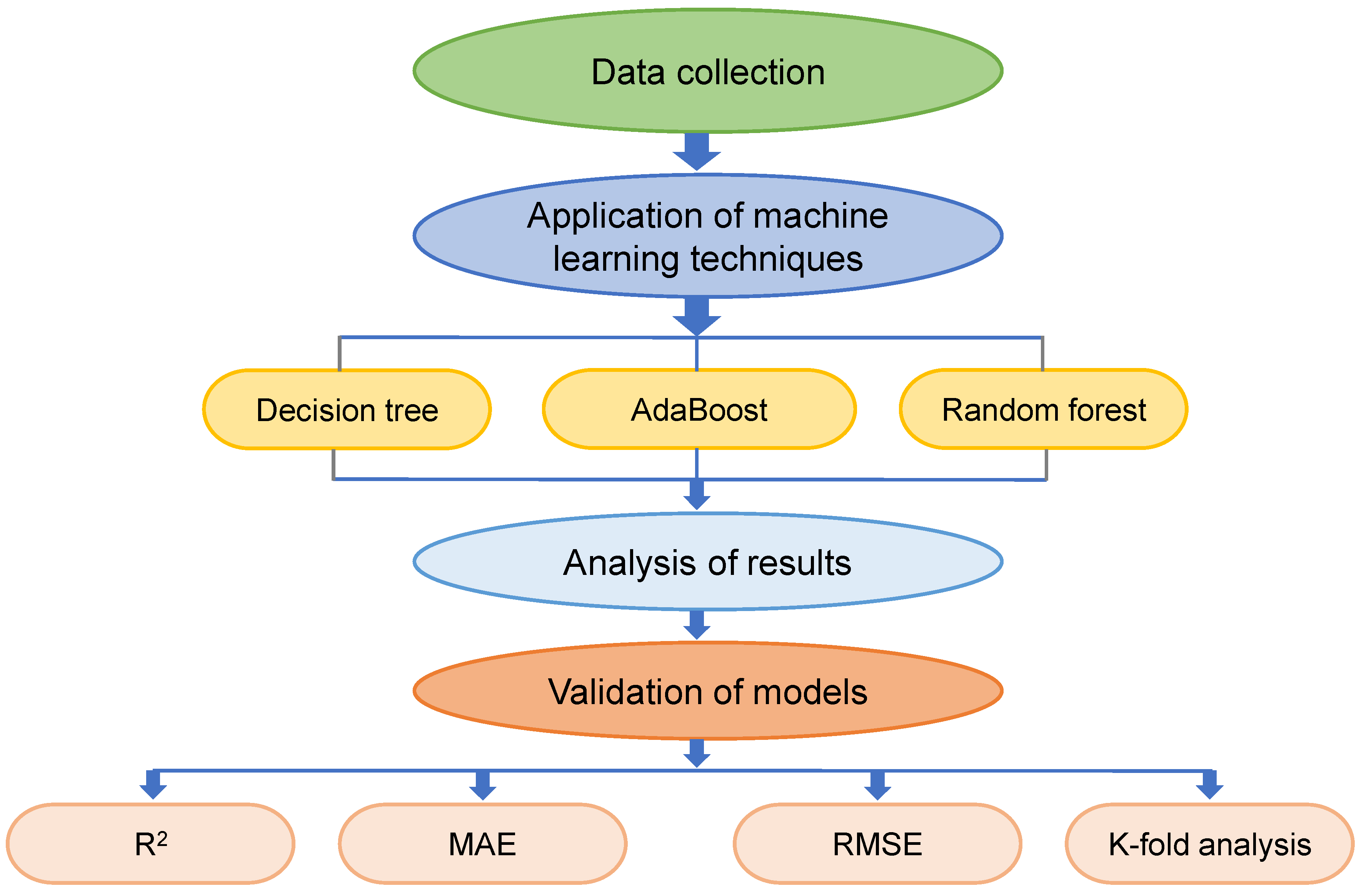
2. Methods
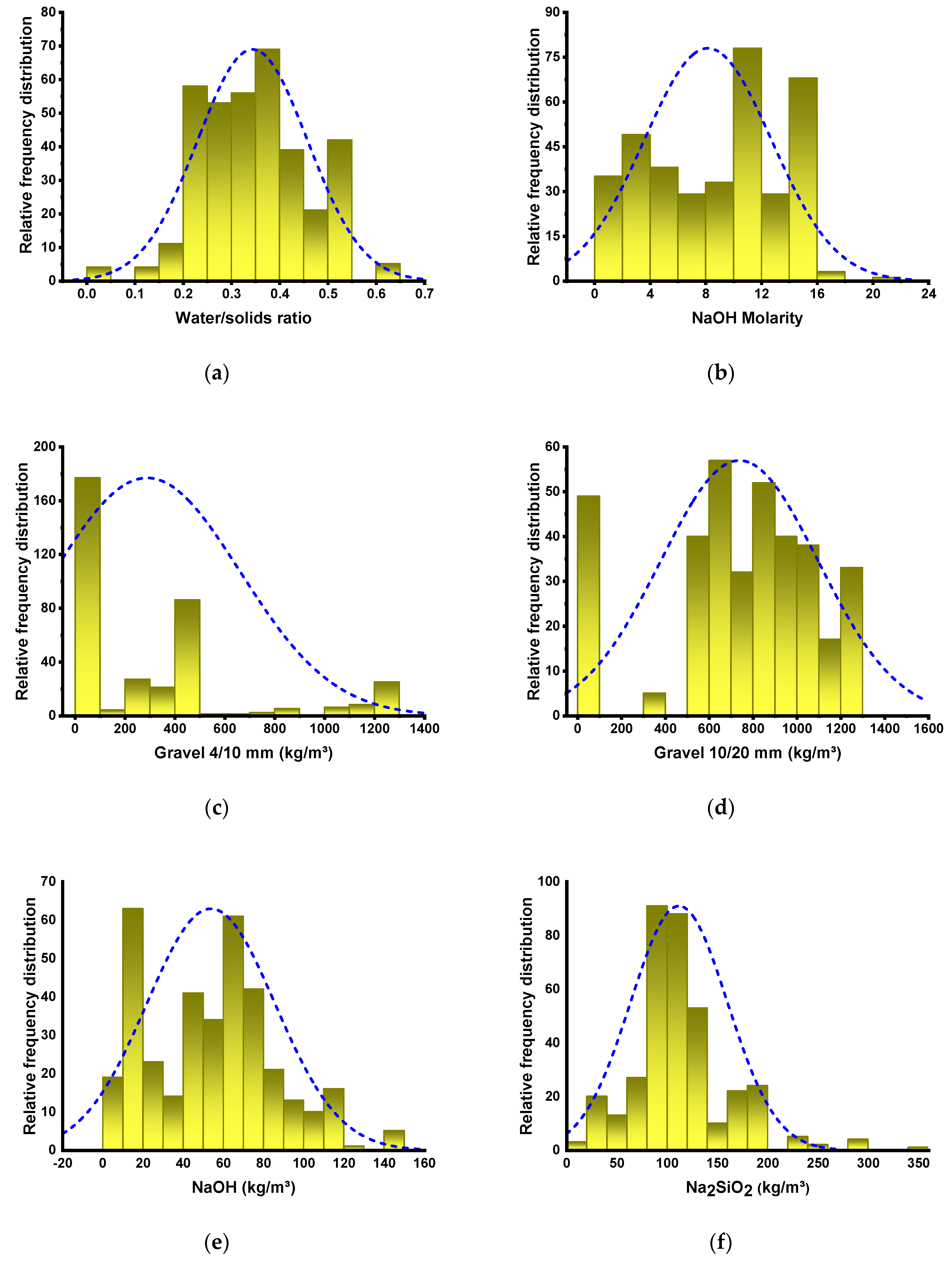
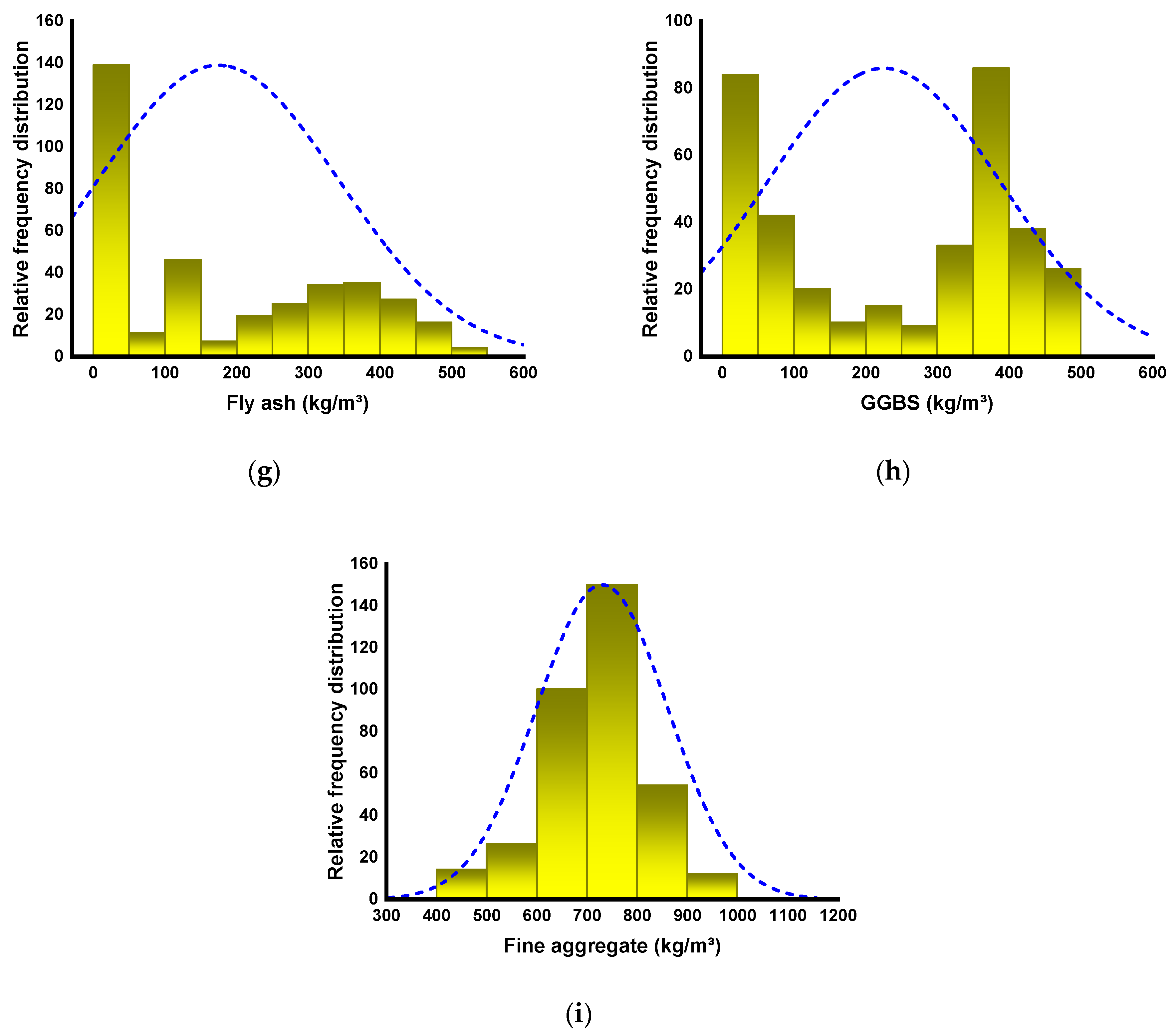
2.1. Description of Data
2.2. Machine Learning Algorithms Employed
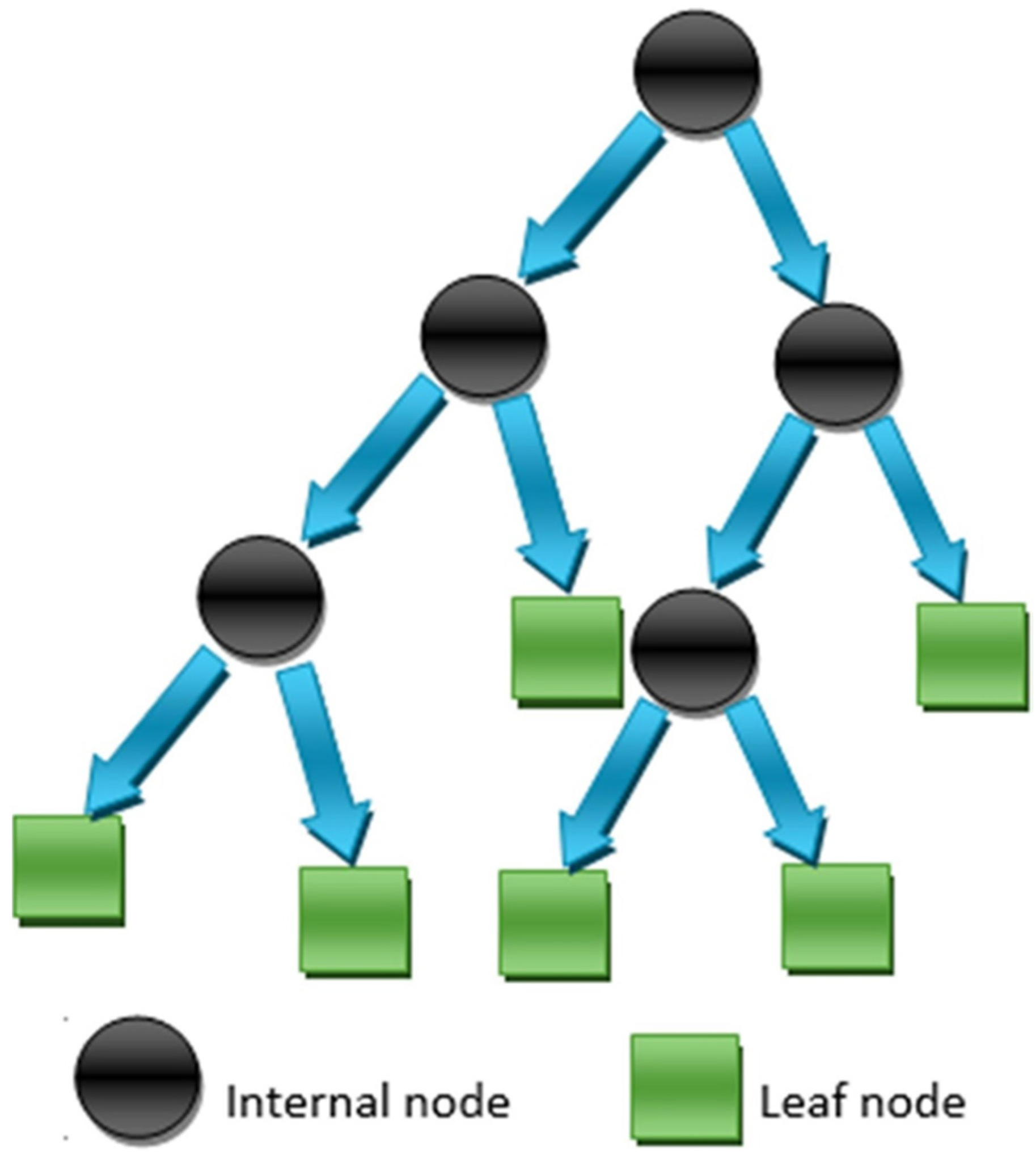
2.2.1. Decision Tree
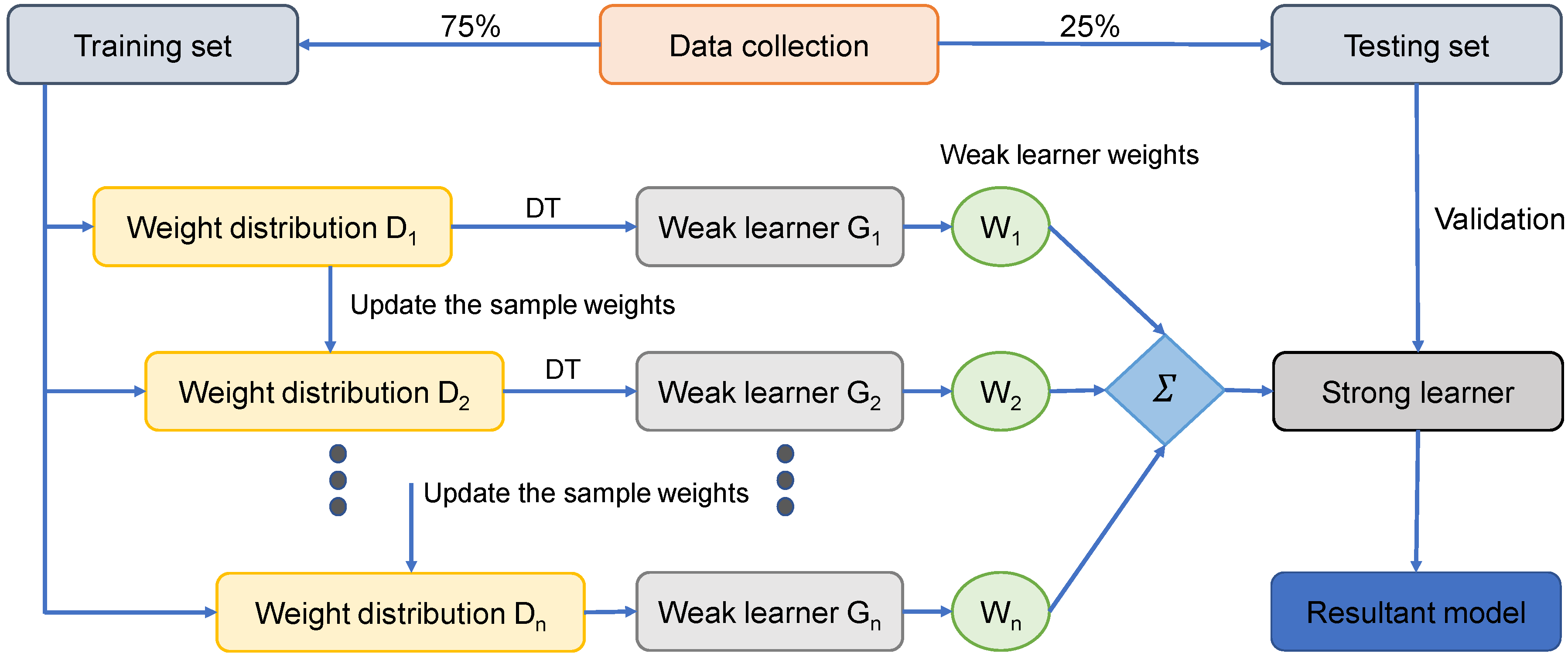
2.2.2. AdaBoost
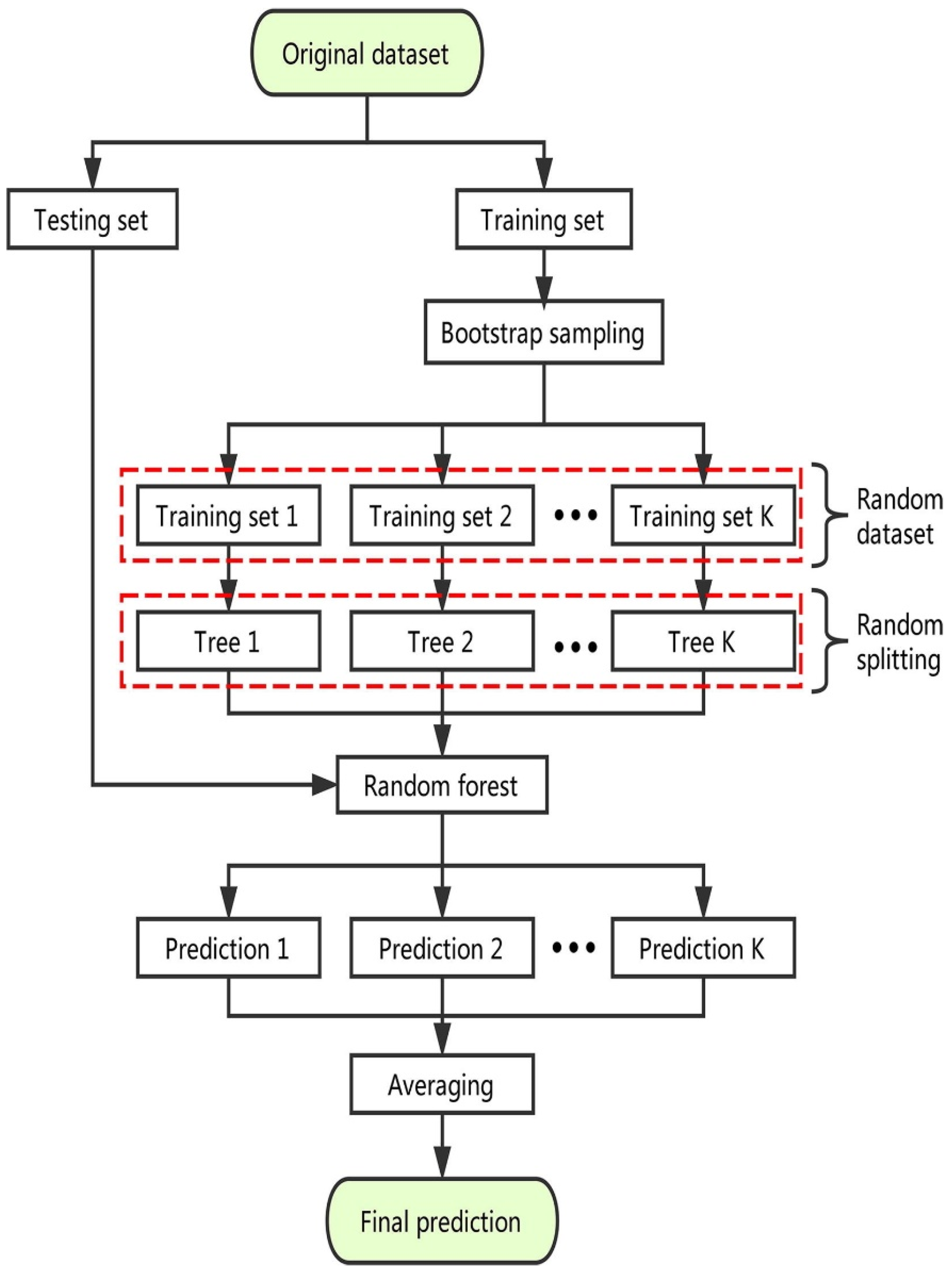
2.2.3. Random Forest
3. Models Results
3.1. Decision Tree Model
3.2. AdaBoost Model
3.3. Random Forest Model
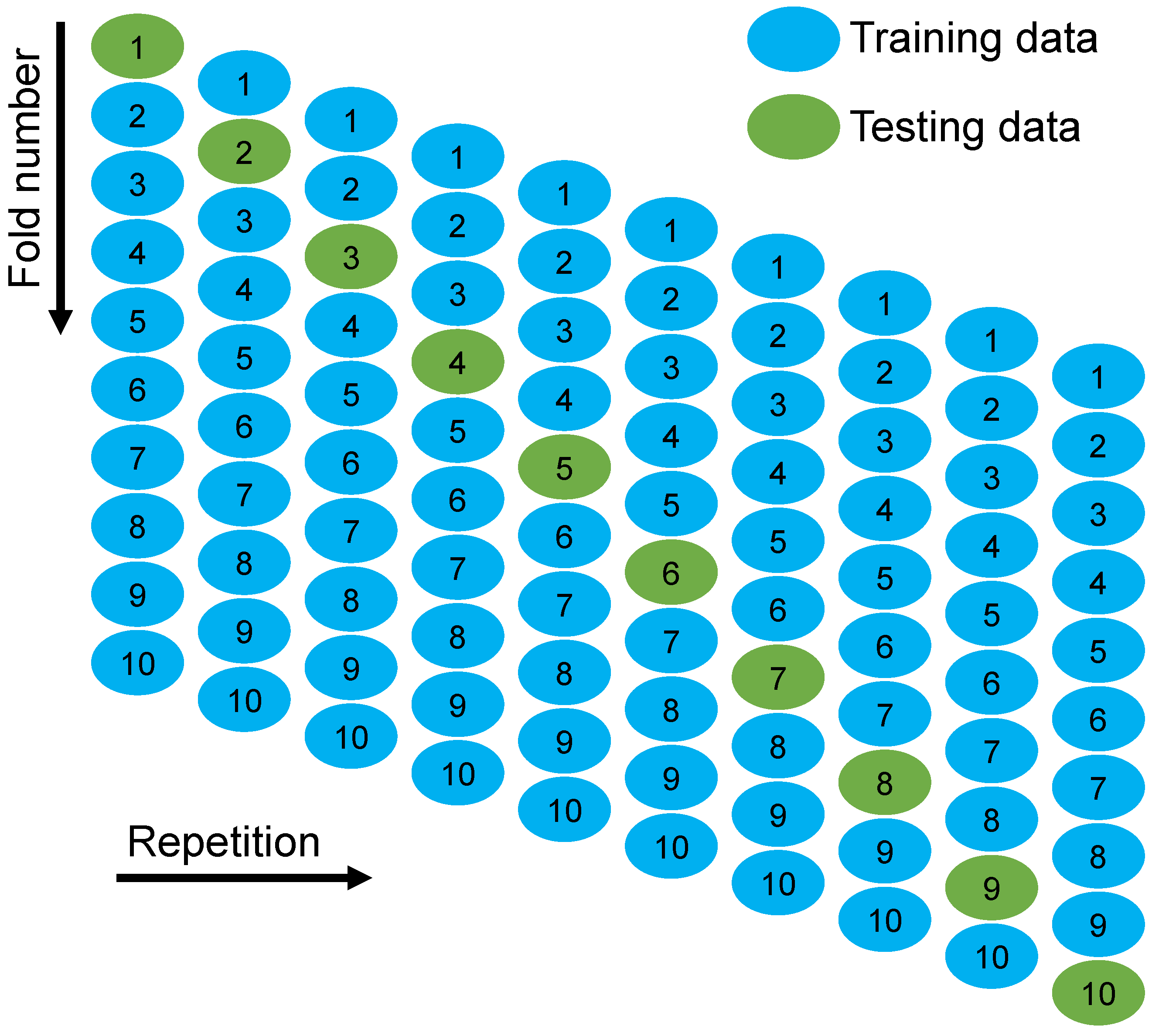
4. Validation of Models
5. Sensitivity Analysis
6. Discussions
6.1. Comparison of Machine Learning Models
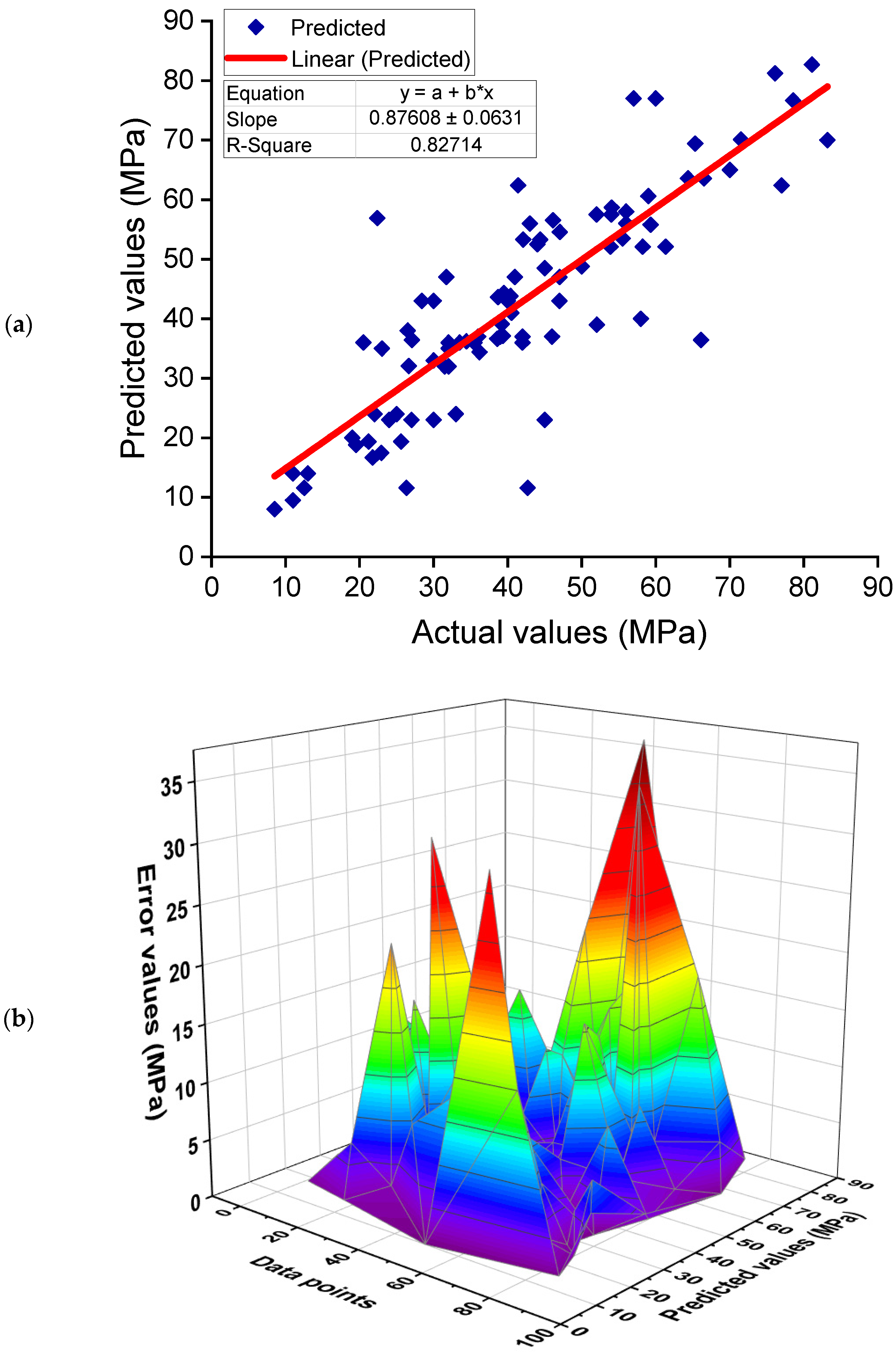
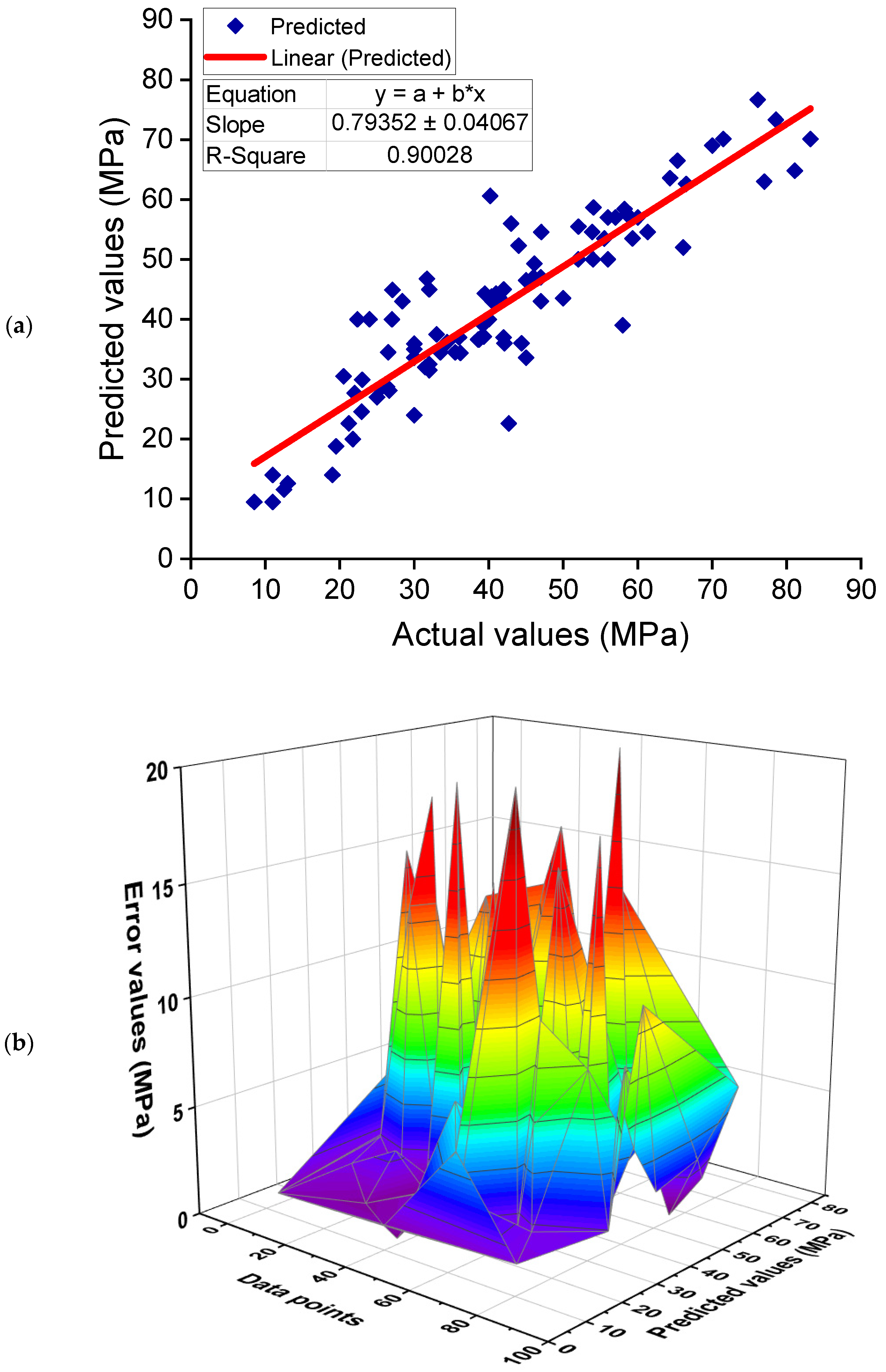
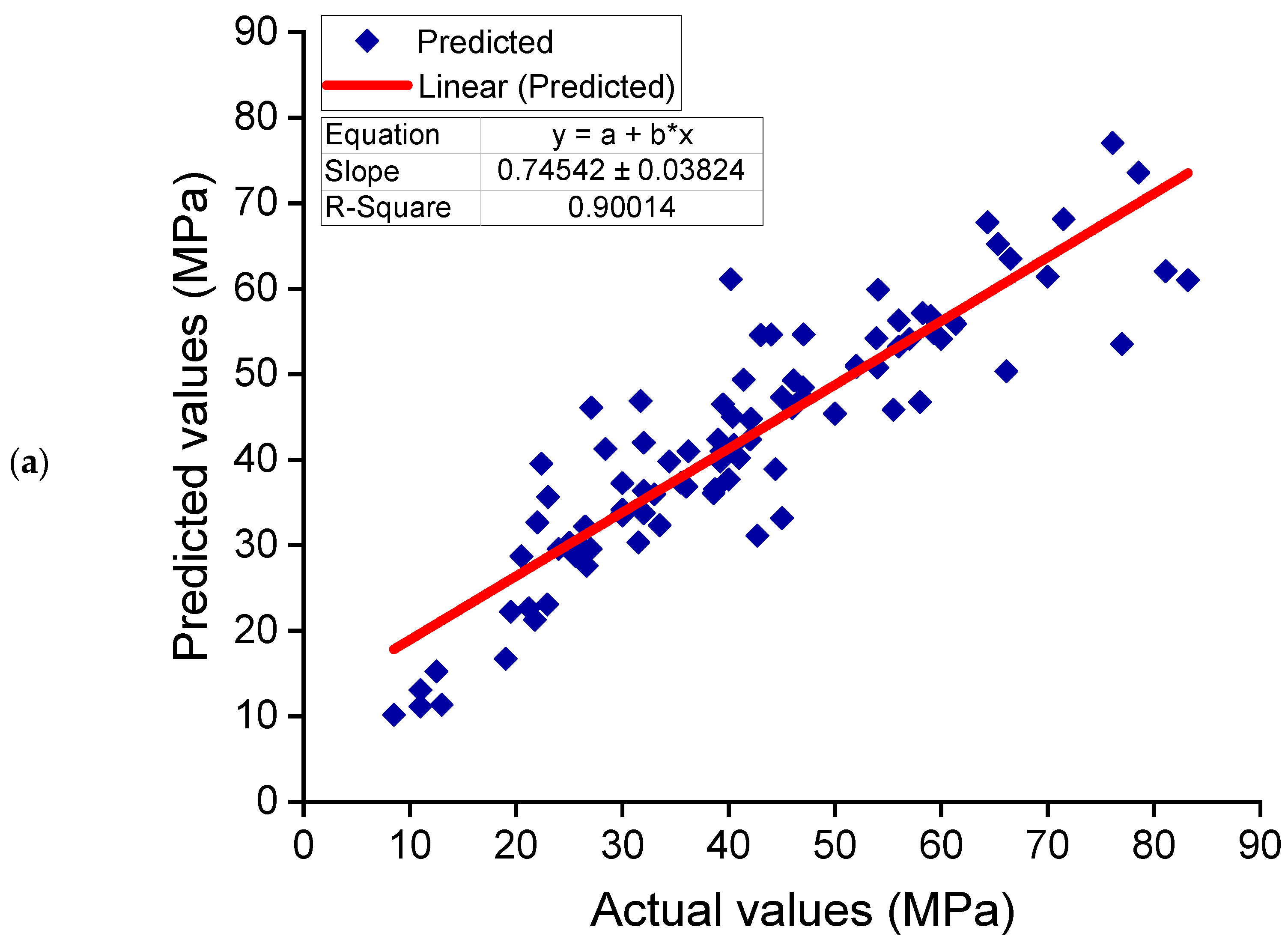
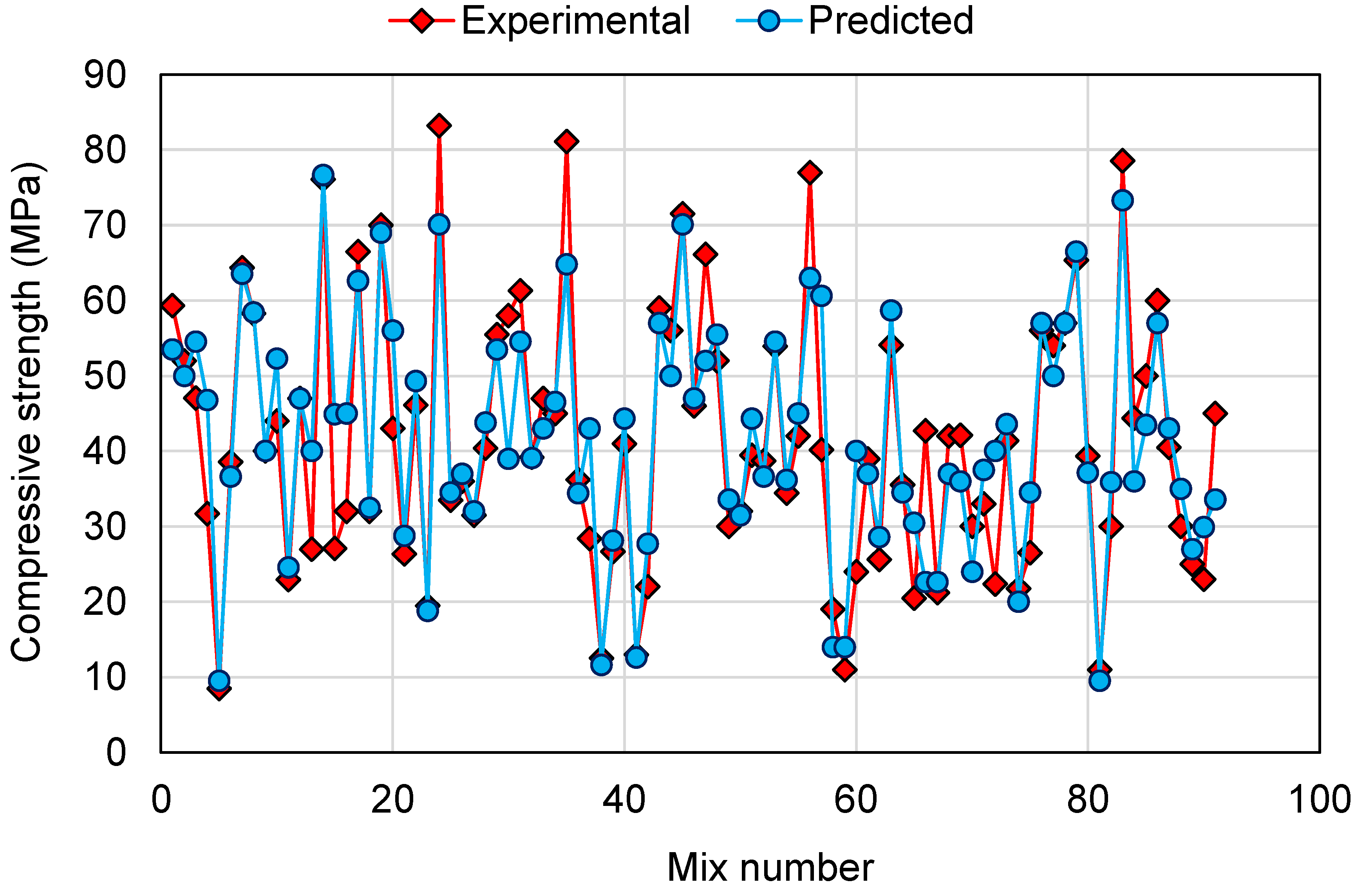
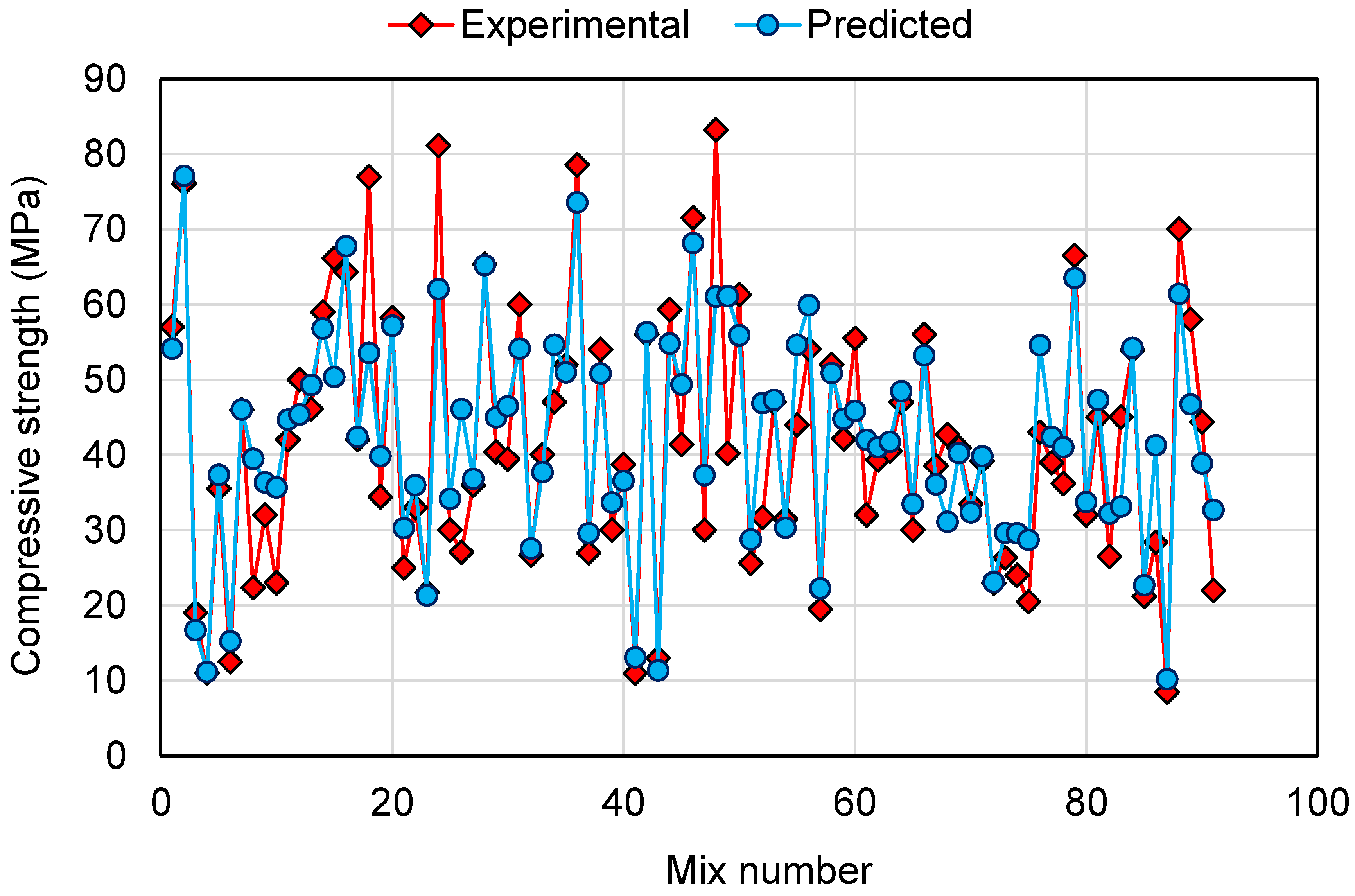
6.2. Comparison of Experimental and Predicted Results
7. Conclusions
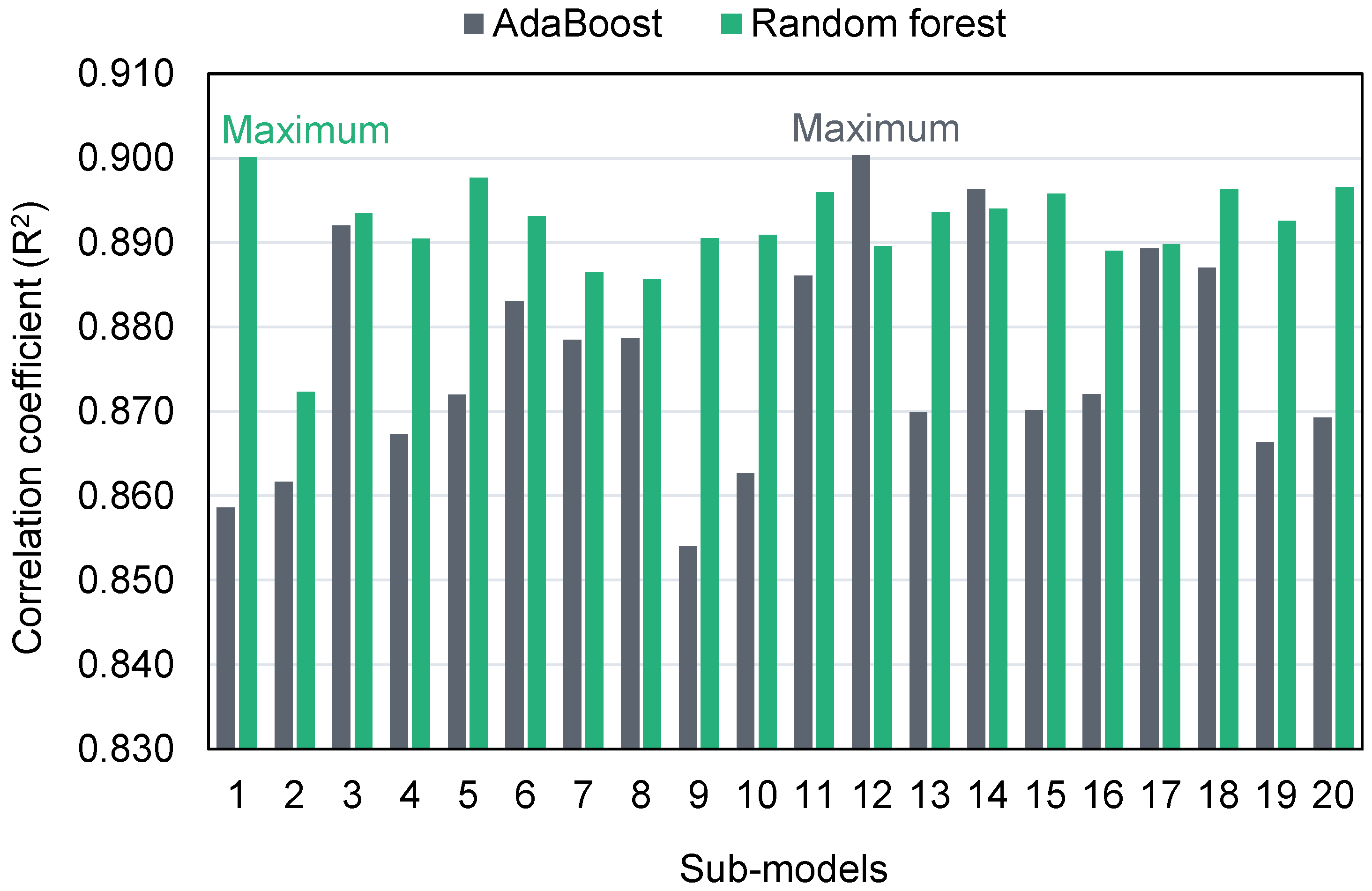
- Ensemble ML approaches (AdaBoost and RF) performed better than the individual ML technique (DT) at predicting the CS of GPCs, with the AdaBoost and RF models performing with a similar degree of precision. The correlation coefficients (R2) for the AdaBoost, RF and DT models were 0.90, 0.90, and 0.83, respectively.
- Statistical checks and k-fold analysis verified the model’s performance. Furthermore, these checks also confirmed the comparable accuracy of the AdaBoost and RF models. The lower deviation (MAE, MAPE, and RMSE) of the predicted results and higher R2 values of the ensembled models validated their higher precision.
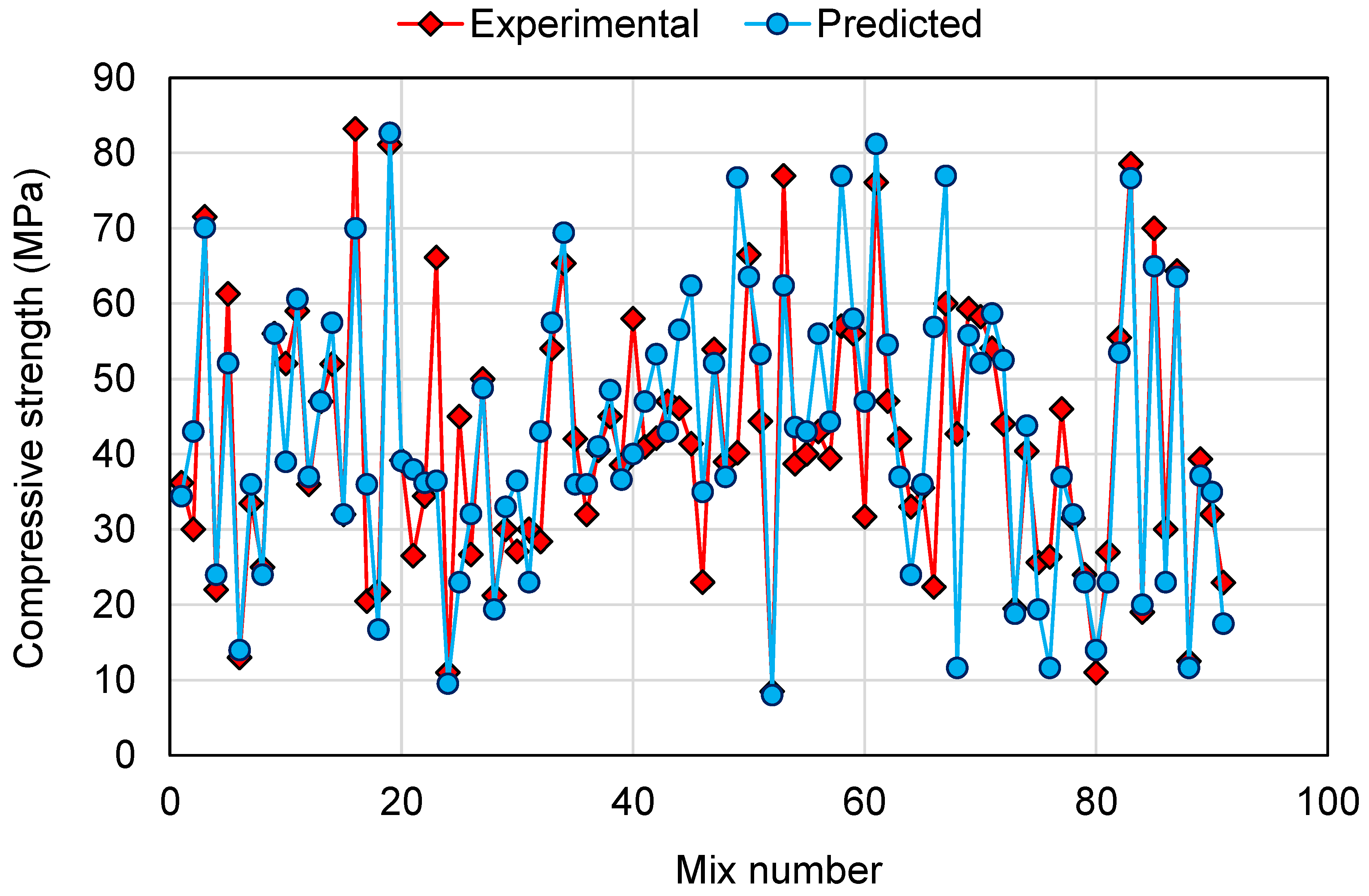
- The comparison of the experimental and predicted results further validated the higher accuracy of AdaBoost and RF models due to less deviation of the predicted results than the experimental results. On the other hand, the deviation of the DT model’s results was higher than the AdaBoost and RF models and is less recommended for estimating the CS of GPCs.
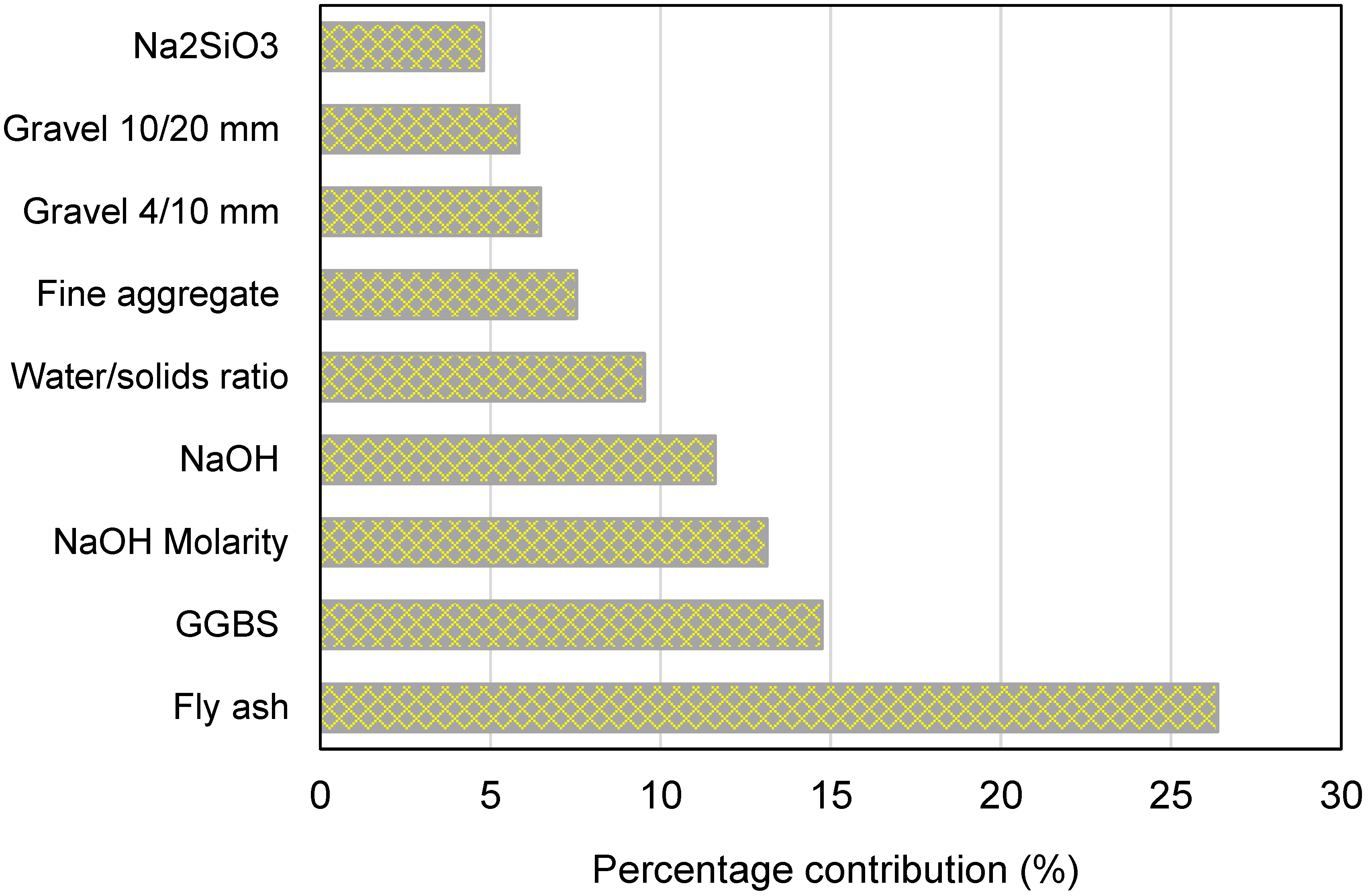
- Sensitivity analysis revealed that fly ash, ground granulated blast furnace slag, and NaOH molarity have a greater influence on the model’s outcome and account for 26.37%, 14.74%, and 13.12% of the contribution, respectively. However, NaOH, water/solids ratio, fine aggregate, gravel 4/10 mm, gravel 10/20 mm, and Na2SiO3 contributed 11.60%, 9.52%, 7.53%, 6.48%, 5.84%, and 4.80%, respectively, to the prediction of the outcome.
- This type of research will aid the construction sector by enabling the development of quick and cost-effective methods for predicting material strength. Additionally, by promoting eco-friendly construction using these strategies, the acceptance and use of GPC in construction will be expedited.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chu, S.H.; Ye, H.; Huang, L.; Li, L.G. Carbon fiber reinforced geopolymer (FRG) mix design based on liquid film thickness. Constr. Build. Mater. 2021, 269, 121278. [Google Scholar] [CrossRef]
- Khan, M.; Ali, M. Use of glass and nylon fibers in concrete for controlling early age micro cracking in bridge decks. Constr. Build. Mater. 2016, 125, 800–808. [Google Scholar] [CrossRef]
- Xie, C.; Cao, M.; Si, W.; Khan, M. Experimental evaluation on fiber distribution characteristics and mechanical properties of calcium carbonate whisker modified hybrid fibers reinforced cementitious composites. Constr. Build. Mater. 2020, 265, 120292. [Google Scholar] [CrossRef]
- Khan, M.; Ali, M. Effect of super plasticizer on the properties of medium strength concrete prepared with coconut fiber. Constr. Build. Mater. 2018, 182, 703–715. [Google Scholar] [CrossRef]
- Khan, M.; Cao, M.; Chaopeng, X.; Ali, M. Experimental and analytical study of hybrid fiber reinforced concrete prepared with basalt fiber under high temperature. Fire Mater. 2021, 46, 205–226. [Google Scholar] [CrossRef]
- Teja, K.V.; Sai, P.P.; Meena, T. Investigation on the behaviour of ternary blended concrete with scba and sf. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2017; p. 032012. [Google Scholar]
- Gopalakrishnan, R.; Kaveri, R. Using graphene oxide to improve the mechanical and electrical properties of fiber-reinforced high-volume sugarcane bagasse ash cement mortar. Eur. Phys. J. Plus 2021, 136, 1–15. [Google Scholar] [CrossRef]
- Schneider, M.; Romer, M.; Tschudin, M.; Bolio, H. Sustainable cement production—present and future. Cem. Concr. Res. 2011, 41, 642–650. [Google Scholar] [CrossRef]
- Cao, Z.; Shen, L.; Zhao, J.; Liu, L.; Zhong, S.; Sun, Y.; Yang, Y. Toward a better practice for estimating the CO2 emission factors of cement production: An experience from China. J. Clean. Prod. 2016, 139, 527–539. [Google Scholar] [CrossRef]
- Damtoft, J.S.; Lukasik, J.; Herfort, D.; Sorrentino, D.; Gartner, E.M. Sustainable development and climate change initiatives. Cem. Concr. Res. 2008, 38, 115–127. [Google Scholar] [CrossRef]
- Cleetus, A.; Shibu, R.; Sreehari, P.M.; Paul, V.K.; Jacob, B. Analysis and study of the effect of GGBFS on concrete structures. Int. Res. J. Eng. Technol. (IRJET), Mar Athanasius Coll. Eng. Kerala India 2018, 5, 3033–3037. [Google Scholar]
- Meesala, C.R.; Verma, N.K.; Kumar, S. Critical review on fly-ash based geopolymer concrete. Struct. Concr. 2020, 21, 1013–1028. [Google Scholar] [CrossRef]
- Huseien, G.F.; Shah, K.W.; Sam, A.R.M. Sustainability of nanomaterials based self-healing concrete: An all-inclusive insight. J. Build. Eng. 2019, 23, 155–171. [Google Scholar] [CrossRef]
- Ahmad, A.; Ahmad, W.; Aslam, F.; Joyklad, P. Compressive strength prediction of fly ash-based geopolymer concrete via advanced machine learning techniques. Case Stud. Constr. Mater. 2022, 16, e00840. [Google Scholar] [CrossRef]
- Burduhos Nergis, D.D.; Vizureanu, P.; Ardelean, I.; Sandu, A.V.; Corbu, O.C.; Matei, E. Revealing the influence of microparticles on geopolymers’ synthesis and porosity. Materials 2020, 13, 3211. [Google Scholar] [CrossRef] [PubMed]
- Azimi, E.A.; Abdullah, M.M.A.B.; Vizureanu, P.; Salleh, M.A.A.M.; Sandu, A.V.; Chaiprapa, J.; Yoriya, S.; Hussin, K.; Aziz, I.H. Strength development and elemental distribution of dolomite/fly ash geopolymer composite under elevated temperature. Materials 2020, 13, 1015. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marvila, M.T.; Azevedo, A.R.G.d.; Vieira, C.M.F. Reaction mechanisms of alkali-activated materials. Rev. IBRACON De Estrut. E Mater. 2021, 14. [Google Scholar] [CrossRef]
- Kaja, A.M.; Lazaro, A.; Yu, Q.L. Effects of Portland cement on activation mechanism of class F fly ash geopolymer cured under ambient conditions. Constr. Build. Mater. 2018, 189, 1113–1123. [Google Scholar] [CrossRef]
- Khater, H.M. Effect of calcium on geopolymerization of aluminosilicate wastes. J. Mater. Civ. Eng. 2012, 24, 92–101. [Google Scholar] [CrossRef]
- Ren, B.; Zhao, Y.; Bai, H.; Kang, S.; Zhang, T.; Song, S. Eco-friendly geopolymer prepared from solid wastes: A critical review. Chemosphere 2021, 267, 128900. [Google Scholar] [CrossRef]
- Podolsky, Z.; Liu, J.; Dinh, H.; Doh, J.H.; Guerrieri, M.; Fragomeni, S. State of the Art on the Application of Waste Materials in Geopolymer Concrete. Case Stud. Constr. Mater. 2021, 15, e00637. [Google Scholar] [CrossRef]
- Pu, S.; Zhu, Z.; Song, W.; Wang, H.; Huo, W.; Zhang, J. A novel acidic phosphoric-based geopolymer binder for lead solidification/stabilization. J. Hazard. Mater. 2021, 415, 125659. [Google Scholar] [CrossRef]
- Khan, M.; Ali, M. Improvement in concrete behavior with fly ash, silica-fume and coconut fibres. Constr. Build. Mater. 2019, 203, 174–187. [Google Scholar] [CrossRef]
- Singh, G.V.P.B.; Subramaniam, K.V.L. Production and characterization of low-energy Portland composite cement from post-industrial waste. J. Clean. Prod. 2019, 239, 118024. [Google Scholar] [CrossRef]
- Khan, M.; Cao, M.; Hussain, A.; Chu, S.H. Effect of silica-fume content on performance of CaCO3 whisker and basalt fiber at matrix interface in cement-based composites. Constr. Build. Mater. 2021, 300, 124046. [Google Scholar] [CrossRef]
- Amran, M.; Murali, G.; Fediuk, R.; Vatin, N.; Vasilev, Y.; Abdelgader, H. Palm oil fuel ash-based eco-efficient concrete: A critical review of the short-term properties. Materials 2021, 14, 332. [Google Scholar] [CrossRef] [PubMed]
- Pavithra, P.e.; Reddy, M.S.; Dinakar, P.; Rao, B.H.; Satpathy, B.K.; Mohanty, A.N. A mix design procedure for geopolymer concrete with fly ash. J. Clean. Prod. 2016, 133, 117–125. [Google Scholar] [CrossRef]
- Amran, M.; Fediuk, R.; Murali, G.; Avudaiappan, S.; Ozbakkaloglu, T.; Vatin, N.; Karelina, M.; Klyuev, S.; Gholampour, A. Fly ash-based eco-efficient concretes: A comprehensive review of the short-term properties. Materials 2021, 14, 4264. [Google Scholar] [CrossRef]
- Mohajerani, A.; Suter, D.; Jeffrey-Bailey, T.; Song, T.; Arulrajah, A.; Horpibulsuk, S.; Law, D. Recycling waste materials in geopolymer concrete. Clean Technol. Environ. Policy 2019, 21, 493–515. [Google Scholar] [CrossRef]
- Toniolo, N.; Boccaccini, A.R. Fly ash-based geopolymers containing added silicate waste. A review. Ceram. Int. 2017, 43, 14545–14551. [Google Scholar] [CrossRef]
- Van Deventer, J.S.J.; Provis, J.L.; Duxson, P. Technical and commercial progress in the adoption of geopolymer cement. Miner. Eng. 2012, 29, 89–104. [Google Scholar] [CrossRef]
- Buyondo, K.A.; Olupot, P.W.; Kirabira, J.B.; Yusuf, A.A. Optimization of production parameters for rice husk ash-based geopolymer cement using response surface methodology. Case Stud. Constr. Mater. 2020, 13, e00461. [Google Scholar] [CrossRef]
- de Azevedo, A.R.G.; Marvila, M.T.; Ali, M.; Khan, M.I.; Masood, F.; Vieira, C.M.F. Effect of the addition and processing of glass polishing waste on the durability of geopolymeric mortars. Case Stud. Constr. Mater. 2021, 15, e00662. [Google Scholar] [CrossRef]
- Suksiripattanapong, C.; Krosoongnern, K.; Thumrongvut, J.; Sukontasukkul, P.; Horpibulsuk, S.; Chindaprasirt, P. Properties of cellular lightweight high calcium bottom ash-portland cement geopolymer mortar. Case Stud. Constr. Mater. 2020, 12, e00337. [Google Scholar] [CrossRef]
- Asim, N.; Alghoul, M.; Mohammad, M.; Amin, M.H.; Akhtaruzzaman, M.; Amin, N.; Sopian, K. Emerging sustainable solutions for depollution: Geopolymers. Constr. Build. Mater. 2019, 199, 540–548. [Google Scholar] [CrossRef]
- Ferone, C.; Capasso, I.; Bonati, A.; Roviello, G.; Montagnaro, F.; Santoro, L.; Turco, R.; Cioffi, R. Sustainable management of water potabilization sludge by means of geopolymers production. J. Clean. Prod. 2019, 229, 1–9. [Google Scholar] [CrossRef]
- Paiva, H.; Yliniemi, J.; Illikainen, M.; Rocha, F.; Ferreira, V.M. Mine tailings geopolymers as a waste management solution for a more sustainable habitat. Sustainability 2019, 11, 995. [Google Scholar] [CrossRef] [Green Version]
- Naseri, H.; Jahanbakhsh, H.; Hosseini, P.; Nejad, F.M. Designing sustainable concrete mixture by developing a new machine learning technique. J. Clean. Prod. 2020, 258, 120578. [Google Scholar] [CrossRef]
- Feng, D.-C.; Liu, Z.-T.; Wang, X.-D.; Chen, Y.; Chang, J.-Q.; Wei, D.-F.; Jiang, Z.-M. Machine learning-based compressive strength prediction for concrete: An adaptive boosting approach. Constr. Build. Mater. 2020, 230, 117000. [Google Scholar] [CrossRef]
- Huang, Y.; Fu, J. Review on application of artificial intelligence in civil engineering. Comput. Modeling Eng. Sci. 2019, 121, 845–875. [Google Scholar] [CrossRef]
- Vu, Q.-V.; Truong, V.-H.; Thai, H.-T. Machine learning-based prediction of CFST columns using gradient tree boosting algorithm. Compos. Struct. 2021, 259, 113505. [Google Scholar] [CrossRef]
- Ahmad, A.; Chaiyasarn, K.; Farooq, F.; Ahmad, W.; Suparp, S.; Aslam, F. Compressive Strength Prediction via Gene Expression Programming (GEP) and Artificial Neural Network (ANN) for Concrete Containing RCA. Buildings 2021, 11, 324. [Google Scholar] [CrossRef]
- Song, H.; Ahmad, A.; Ostrowski, K.A.; Dudek, M. Analyzing the Compressive Strength of Ceramic Waste-Based Concrete Using Experiment and Artificial Neural Network (ANN) Approach. Materials 2021, 14, 4518. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.; Vu, T.; Vo, T.P.; Thai, H.-T. Efficient machine learning models for prediction of concrete strengths. Constr. Build. Mater. 2021, 266, 120950. [Google Scholar] [CrossRef]
- Sufian, M.; Ullah, S.; Ostrowski, K.A.; Ahmad, A.; Zia, A.; Śliwa-Wieczorek, K.; Siddiq, M.; Awan, A.A. An Experimental and Empirical Study on the Use of Waste Marble Powder in Construction Material. Materials 2021, 14, 3829. [Google Scholar] [CrossRef] [PubMed]
- Ziolkowski, P.; Niedostatkiewicz, M. Machine learning techniques in concrete mix design. Materials 2019, 12, 1256. [Google Scholar] [CrossRef] [Green Version]
- Mangalathu, S.; Jeon, J.-S. Machine learning–based failure mode recognition of circular reinforced concrete bridge columns: Comparative study. J. Struct. Eng. 2019, 145, 04019104. [Google Scholar] [CrossRef]
- Olalusi, O.B.; Awoyera, P.O. Shear capacity prediction of slender reinforced concrete structures with steel fibers using machine learning. Eng. Struct. 2021, 227, 111470. [Google Scholar] [CrossRef]
- Dutta, S.; Samui, P.; Kim, D. Comparison of machine learning techniques to predict compressive strength of concrete. Comput. Concr. 2018, 21, 463–470. [Google Scholar]
- Mangalathu, S.; Jeon, J.-S. Classification of failure mode and prediction of shear strength for reinforced concrete beam-column joints using machine learning techniques. Eng. Struct. 2018, 160, 85–94. [Google Scholar] [CrossRef]
- Song, Y.-Y.; Ying, L.U. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130. [Google Scholar]
- Hillebrand, E.; Medeiros, M.C. The benefits of bagging for forecast models of realized volatility. Econom. Rev. 2010, 29, 571–593. [Google Scholar] [CrossRef]
- Karbassi, A.; Mohebi, B.; Rezaee, S.; Lestuzzi, P. Damage prediction for regular reinforced concrete buildings using the decision tree algorithm. Comput. Struct. 2014, 130, 46–56. [Google Scholar] [CrossRef]
- Han, Q.; Gui, C.; Xu, J.; Lacidogna, G. A generalized method to predict the compressive strength of high-performance concrete by improved random forest algorithm. Constr. Build. Mater. 2019, 226, 734–742. [Google Scholar] [CrossRef]
- Grömping, U. Variable importance assessment in regression: Linear regression versus random forest. Am. Stat. 2009, 63, 308–319. [Google Scholar] [CrossRef]
- Nguyen, K.T.; Nguyen, Q.D.; Le, T.A.; Shin, J.; Lee, K. Analyzing the compressive strength of green fly ash based geopolymer concrete using experiment and machine learning approaches. Constr. Build. Mater. 2020, 247, 118581. [Google Scholar] [CrossRef]
- Prayogo, D.; Cheng, M.-Y.; Wu, Y.-W.; Tran, D.-H. Combining machine learning models via adaptive ensemble weighting for prediction of shear capacity of reinforced-concrete deep beams. Eng. Comput. 2020, 36, 1135–1153. [Google Scholar] [CrossRef]
- Feng, D.-C.; Liu, Z.-T.; Wang, X.-D.; Jiang, Z.-M.; Liang, S.-X. Failure mode classification and bearing capacity prediction for reinforced concrete columns based on ensemble machine learning algorithm. Adv. Eng. Inform. 2020, 45, 101126. [Google Scholar] [CrossRef]
- Farooq, F.; Nasir Amin, M.; Khan, K.; Rehan Sadiq, M.; Faisal Javed, M.; Aslam, F.; Alyousef, R. A comparative study of random forest and genetic engineering programming for the prediction of compressive strength of high strength concrete (HSC). Appl. Sci. 2020, 10, 7330. [Google Scholar] [CrossRef]
- Deepa, C.; SathiyaKumari, K.; Sudha, V.P. Prediction of the compressive strength of high performance concrete mix using tree based modeling. Int. J. Comput. Appl. 2010, 6, 18–24. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Water/Solids Ratio | NaOH Molarity | Gravel 4/10 mm (kg/m3) | Gravel 10/20 mm (kg/m3) | NaOH (kg/m3) | Na2SiO3 (kg/m3) | Fly Ash (kg/m3) | GGBS (kg/m3) | Fine Aggregate (kg/m3) |
|---|---|---|---|---|---|---|---|---|---|
| Minimum | 0 | 1 | 0 | 0 | 3.5 | 18 | 0 | 0 | 459 |
| Maximum | 0.63 | 20 | 1293.4 | 1298 | 147 | 342 | 523 | 450 | 1360 |
| Range | 0.63 | 19 | 1293.4 | 1298 | 143.5 | 324 | 523 | 450 | 901 |
| Median | 0.34 | 9.2 | 208 | 789 | 56 | 108 | 120 | 300 | 728 |
| Mode | 0.53 | 10 | 0 | 0 | 64 | 108 | 0 | 0 | 651 |
| Mean | 0.34 | 8.14 | 288.39 | 737.37 | 53.74 | 111.66 | 174.34 | 225.15 | 729.88 |
| Standard Error | 0.01 | 0.24 | 19.54 | 18.82 | 1.67 | 2.53 | 8.82 | 8.52 | 6.87 |
| Standard Deviation | 0.11 | 4.56 | 372.31 | 358.55 | 31.91 | 48.16 | 167.95 | 162.27 | 130.97 |
| Sum | 124.8 | 2955.1 | 104,684.3 | 267,664.9 | 19,508.8 | 40,532.7 | 63,286.0 | 81,728.1 | 264,947.8 |
| Model | MAE (MPa) | MAPE (%) | RMSE (MPa) |
|---|---|---|---|
| Decision tree | 7.016 | 16.020 | 10.432 |
| AdaBoost | 5.199 | 12.302 | 7.467 |
| Random forest | 5.325 | 12.420 | 7.602 |
| K-Fold | Decision Tree | AdaBoost | Random Forest | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | MAPE | RMSE | R2 | MAE | MAPE | RMSE | R2 | MAE | MAPE | RMSE | R2 | |
| 1 | 16.03 | 18.70 | 21.92 | 0.60 | 8.70 | 13.25 | 13.04 | 0.43 | 10.70 | 12.97 | 13.43 | 0.54 |
| 2 | 7.02 | 16.93 | 11.57 | 0.76 | 5.65 | 12.30 | 8.01 | 0.49 | 5.33 | 13.76 | 8.09 | 0.72 |
| 3 | 9.15 | 16.03 | 10.94 | 0.20 | 6.56 | 14.03 | 8.16 | 0.79 | 5.54 | 14.88 | 8.37 | 0.64 |
| 4 | 11.76 | 17.21 | 10.43 | 0.70 | 8.18 | 12.55 | 8.43 | 0.67 | 8.06 | 13.66 | 11.40 | 0.52 |
| 5 | 7.31 | 16.02 | 12.41 | 0.59 | 6.11 | 12.98 | 7.47 | 0.90 | 5.34 | 12.90 | 7.85 | 0.77 |
| 6 | 12.96 | 16.55 | 17.07 | 0.37 | 12.94 | 14.45 | 14.34 | 0.57 | 9.85 | 13.77 | 13.82 | 0.53 |
| 7 | 7.72 | 18.67 | 19.58 | 0.72 | 9.50 | 13.66 | 12.06 | 0.60 | 9.43 | 12.42 | 15.56 | 0.74 |
| 8 | 10.92 | 16.03 | 15.26 | 0.41 | 9.33 | 13.08 | 14.33 | 0.86 | 11.12 | 14.02 | 13.93 | 0.34 |
| 9 | 8.15 | 17.22 | 16.50 | 0.72 | 5.20 | 12.95 | 7.68 | 0.74 | 5.80 | 13.79 | 7.60 | 0.79 |
| 10 | 19.78 | 17.02 | 23.23 | 0.83 | 14.68 | 12.35 | 18.28 | 0.61 | 18.47 | 12.50 | 19.31 | 0.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Ahmad, W.; Ahmad, A.; Aslam, F.; Mohamed, A.; Vatin, N.I. Application of Soft Computing Techniques to Predict the Strength of Geopolymer Composites. Polymers 2022, 14, 1074. https://0-doi-org.brum.beds.ac.uk/10.3390/polym14061074
Wang Q, Ahmad W, Ahmad A, Aslam F, Mohamed A, Vatin NI. Application of Soft Computing Techniques to Predict the Strength of Geopolymer Composites. Polymers. 2022; 14(6):1074. https://0-doi-org.brum.beds.ac.uk/10.3390/polym14061074
Chicago/Turabian StyleWang, Qichen, Waqas Ahmad, Ayaz Ahmad, Fahid Aslam, Abdullah Mohamed, and Nikolai Ivanovich Vatin. 2022. "Application of Soft Computing Techniques to Predict the Strength of Geopolymer Composites" Polymers 14, no. 6: 1074. https://0-doi-org.brum.beds.ac.uk/10.3390/polym14061074