RDCRMG: A Raster Dataset Clean & Reconstitution Multi-Grid Architecture for Remote Sensing Monitoring of Vegetation Dryness

 , ,
, ,  , , , , ,
, , , , ,
Abstract
:
1. Introduction
2. Multi-Grid Architecture Design Method
2.1. Design Target and Principles
- The RDCRMG has a multi-leveled grid structure with a rigorous nested relationship and can be applied to multi-spatial resolution raster data storage.
- The RDCRMG contains an efficient coding scheme.
- The positional correspondence of adjacent level grids can be calculated by a simple linear formula.
- Grids at the same level have inerratic grid shapes with consistent areas and can be applied to the raster data model.
- Grids at the same level have simple positional relationships with each other.
- Spatial-temporal query conditions can be converted to data paths through a simple numerical method.
- The grid structures have good compatibility with the universal spatial data organization mode.
- The grid partitioning and encoding strategy has good universality and can be conveniently integrated with other grid systems or applications.
- The grid partitioning strategy is appropriate for data-intensive computing.
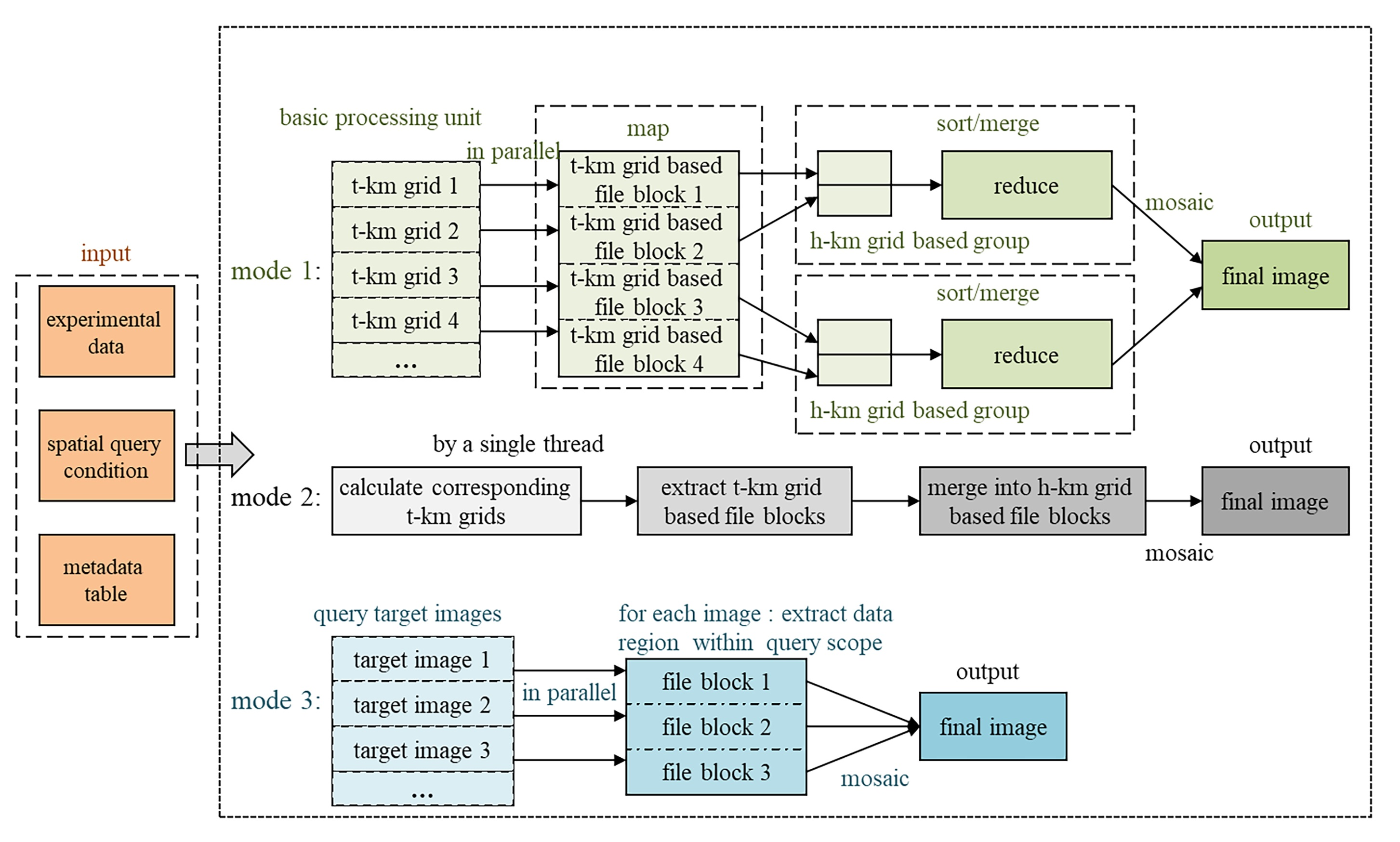
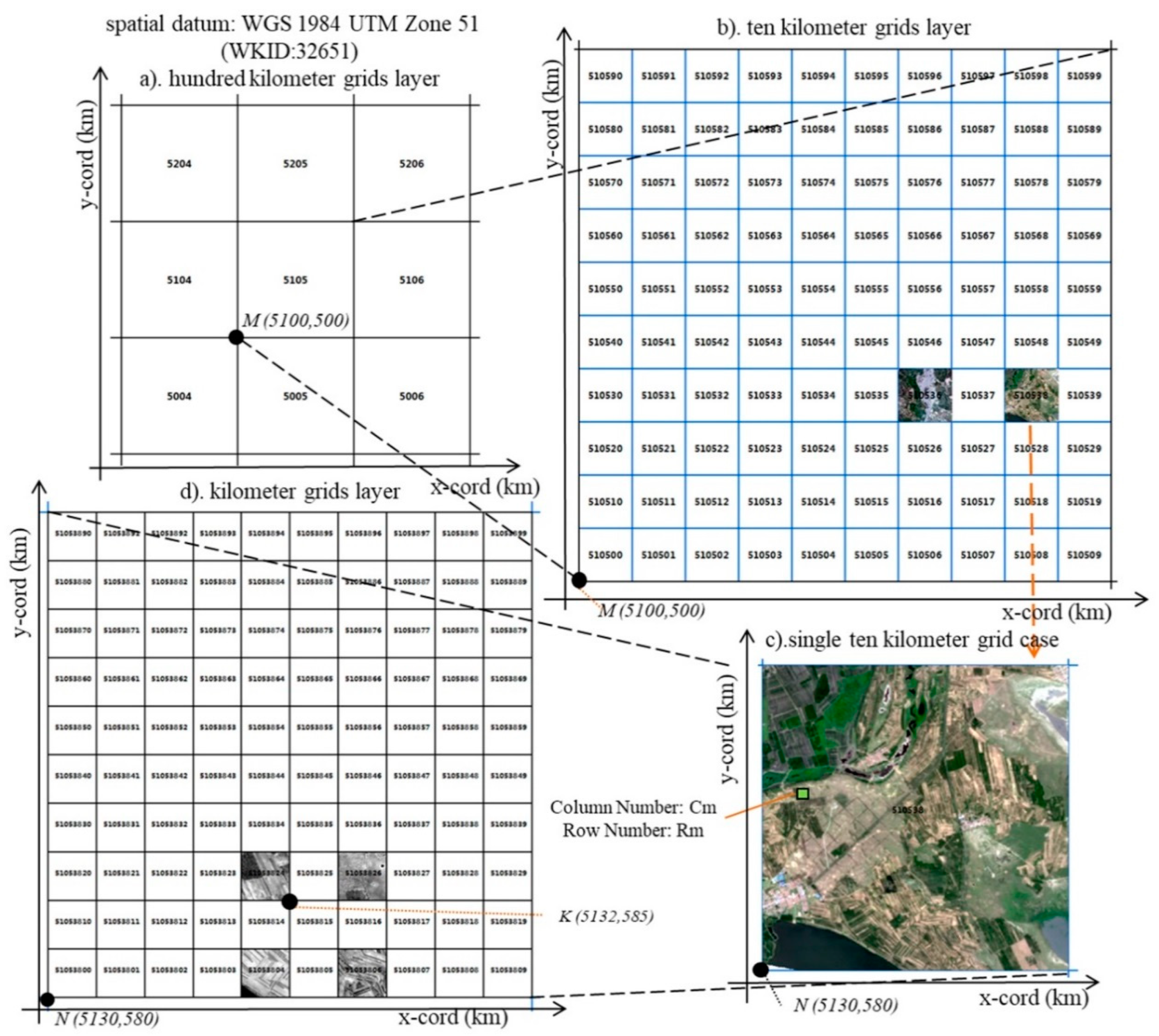
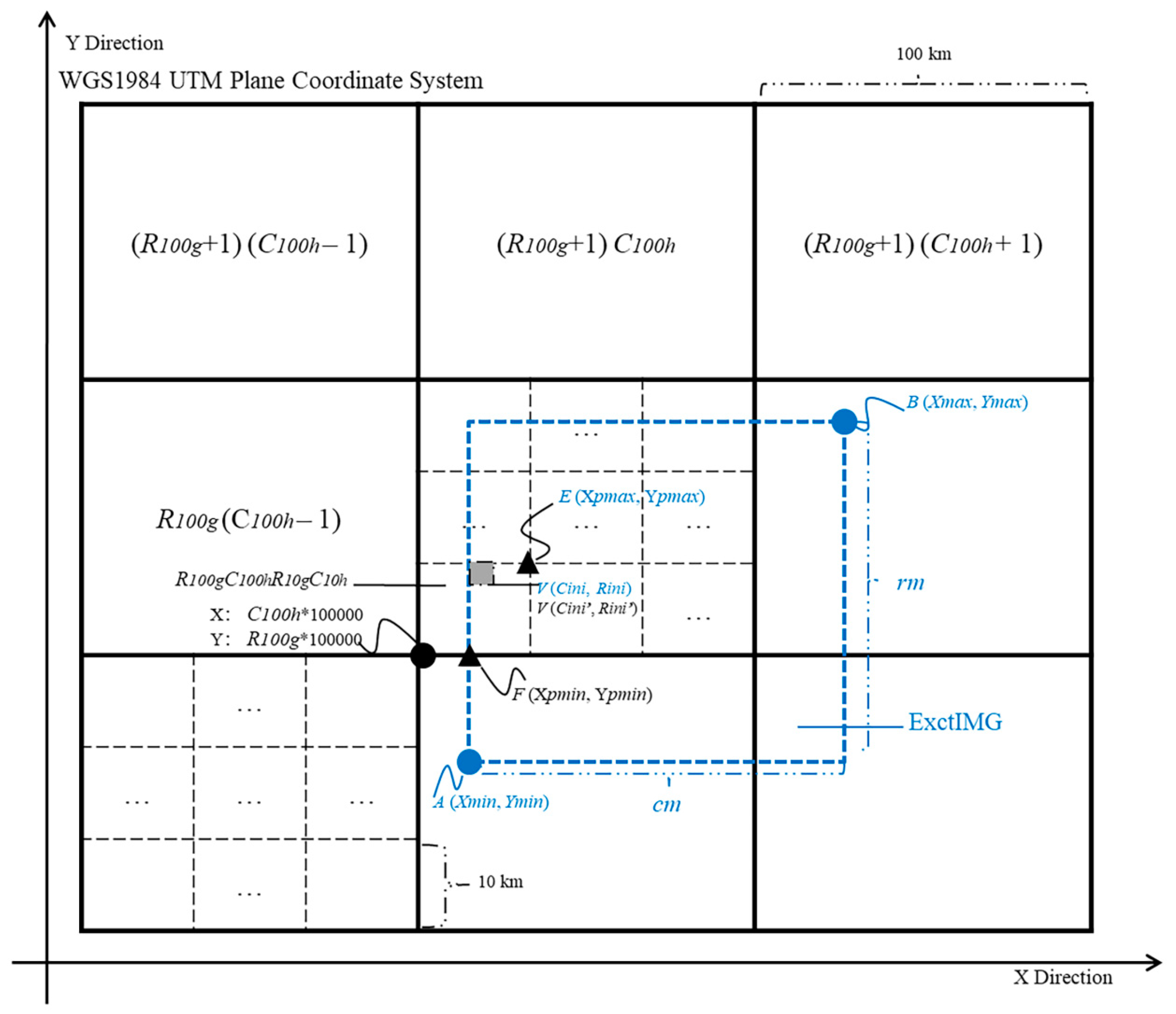
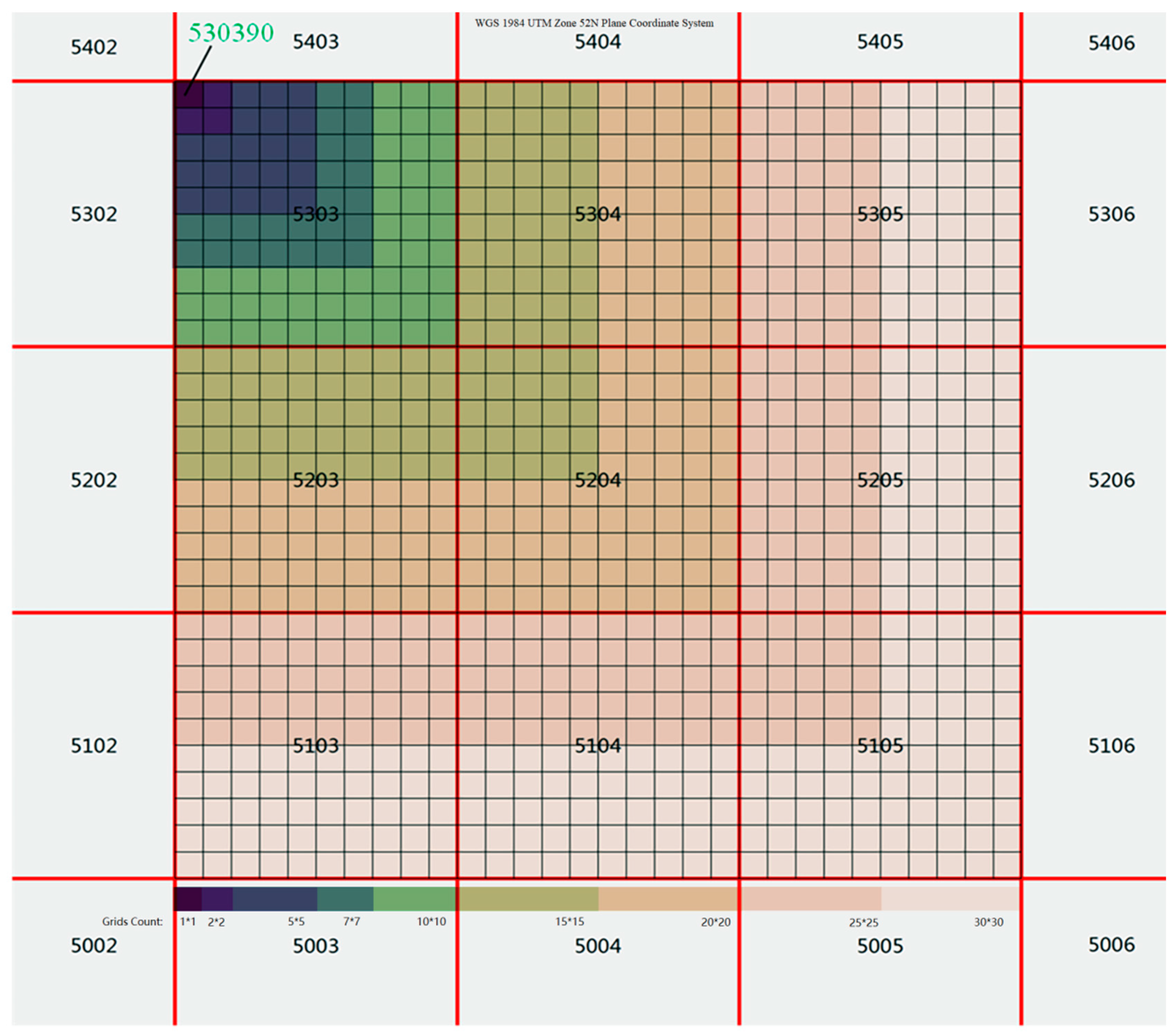
2.2. Multi-Grid Spatial Reference
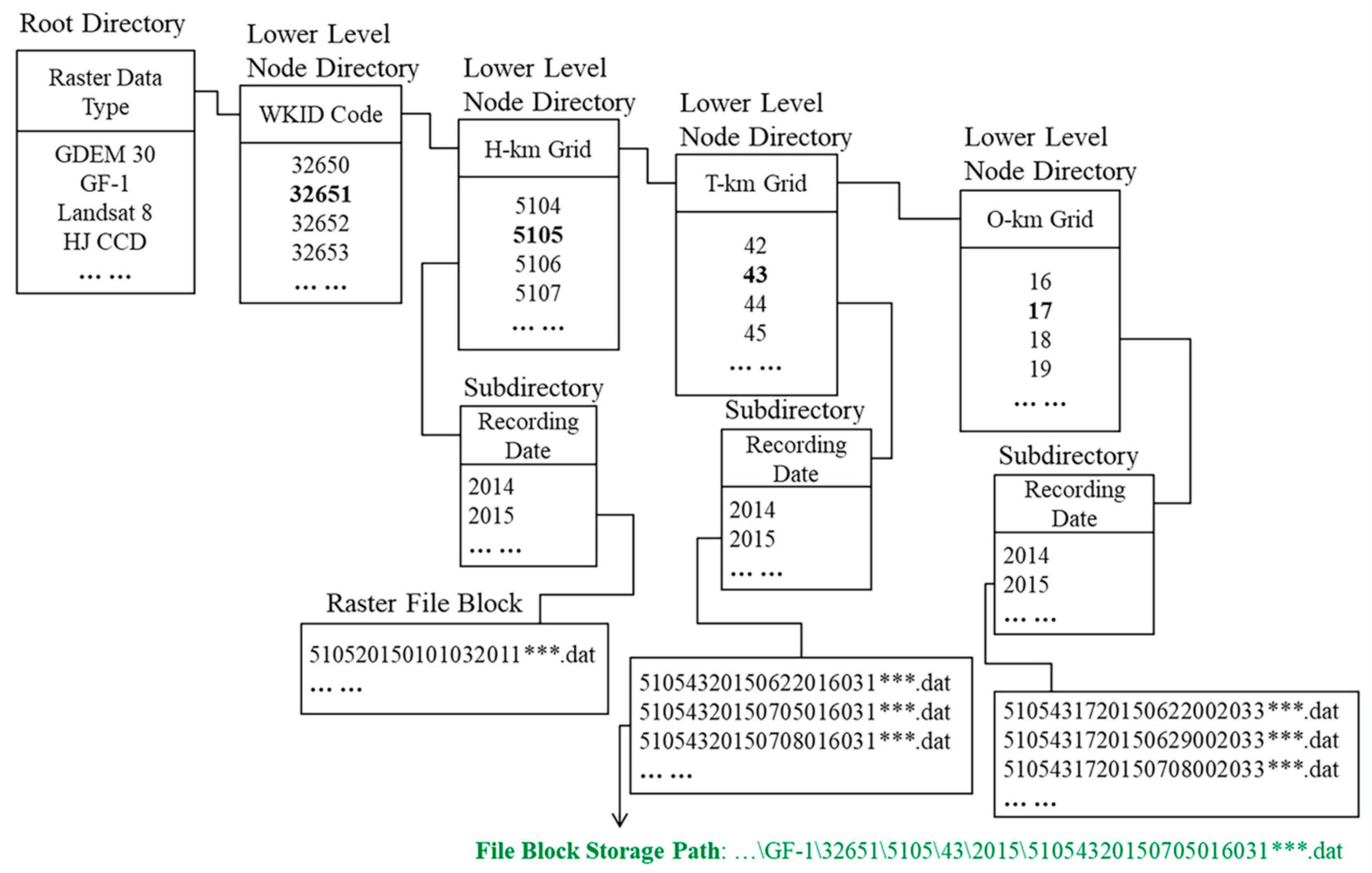
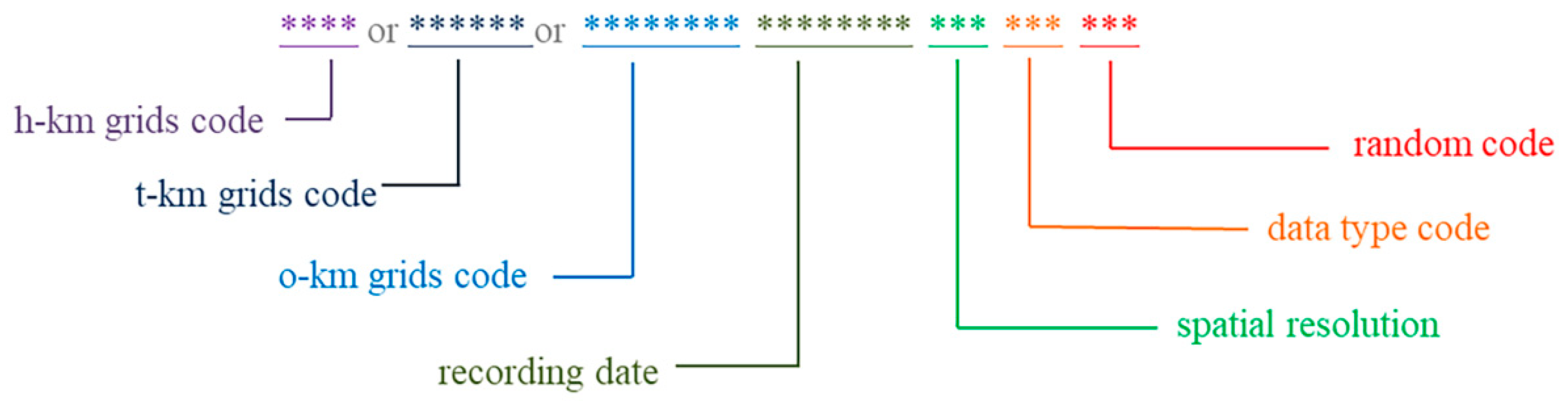
2.3. Mutil-Grid Partition and Coding Strategy
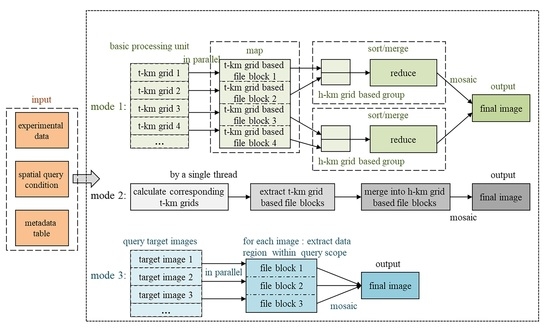
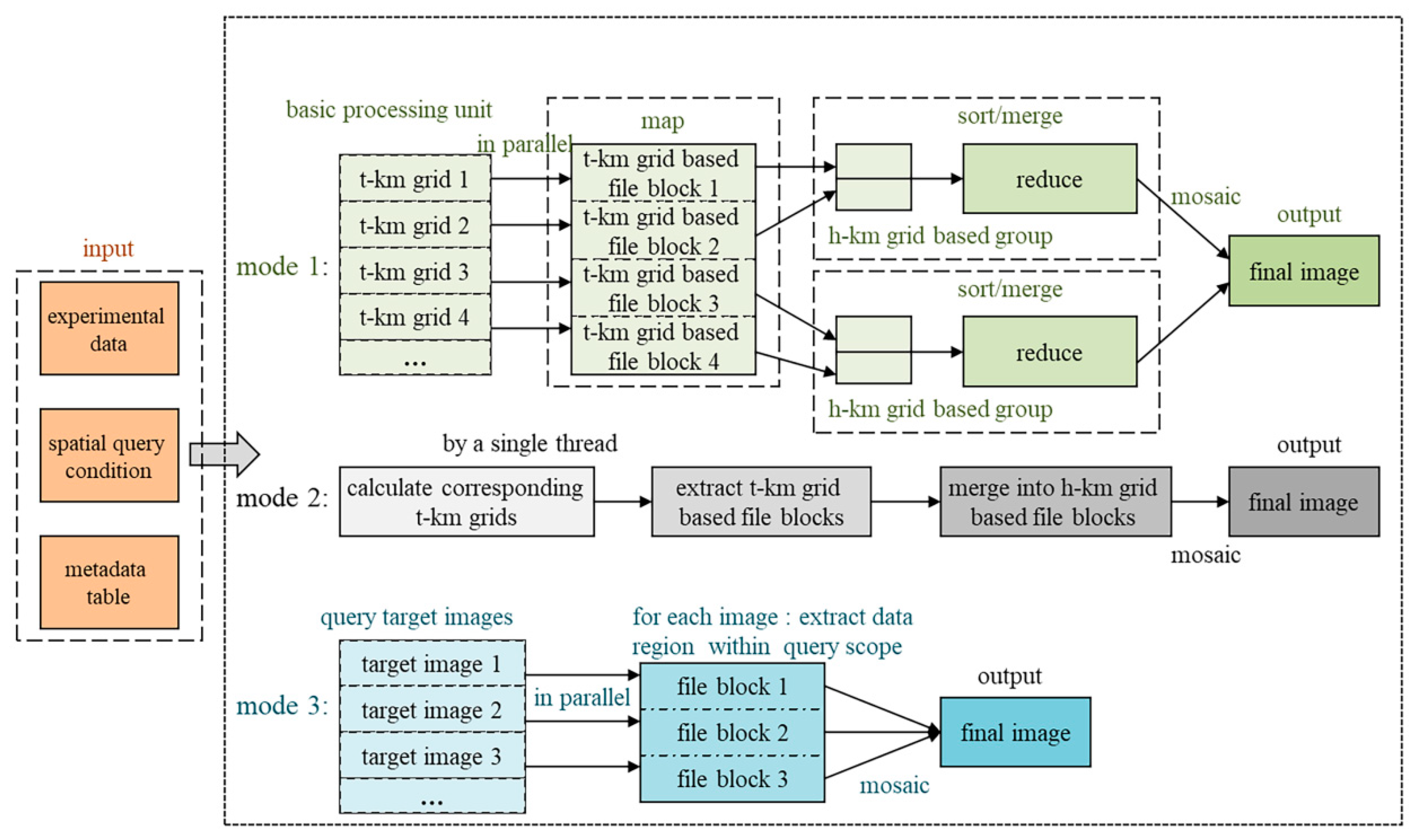
2.4. Mutil-Grid Based Data Retrieval Strategy
- It uses the LSR of the spatial query range for data retrieval and transforming the spatial geometric relationship analysis to linear grid codes calculations and file blocks mosaics. While data redundancy may be increased, the computation complexity can be dramatically reduced.
- The data retrieval task can be easily assigned to several grid groups and executed in parallel. For each grid group, the relevant file blocks are merged similarly to jigsaw puzzles.
- The final result can be several independent images, which make it more efficient for image calculation and expression, especially when the query scope is large.
3. RDCRMG-Based Raster Data Extraction Results
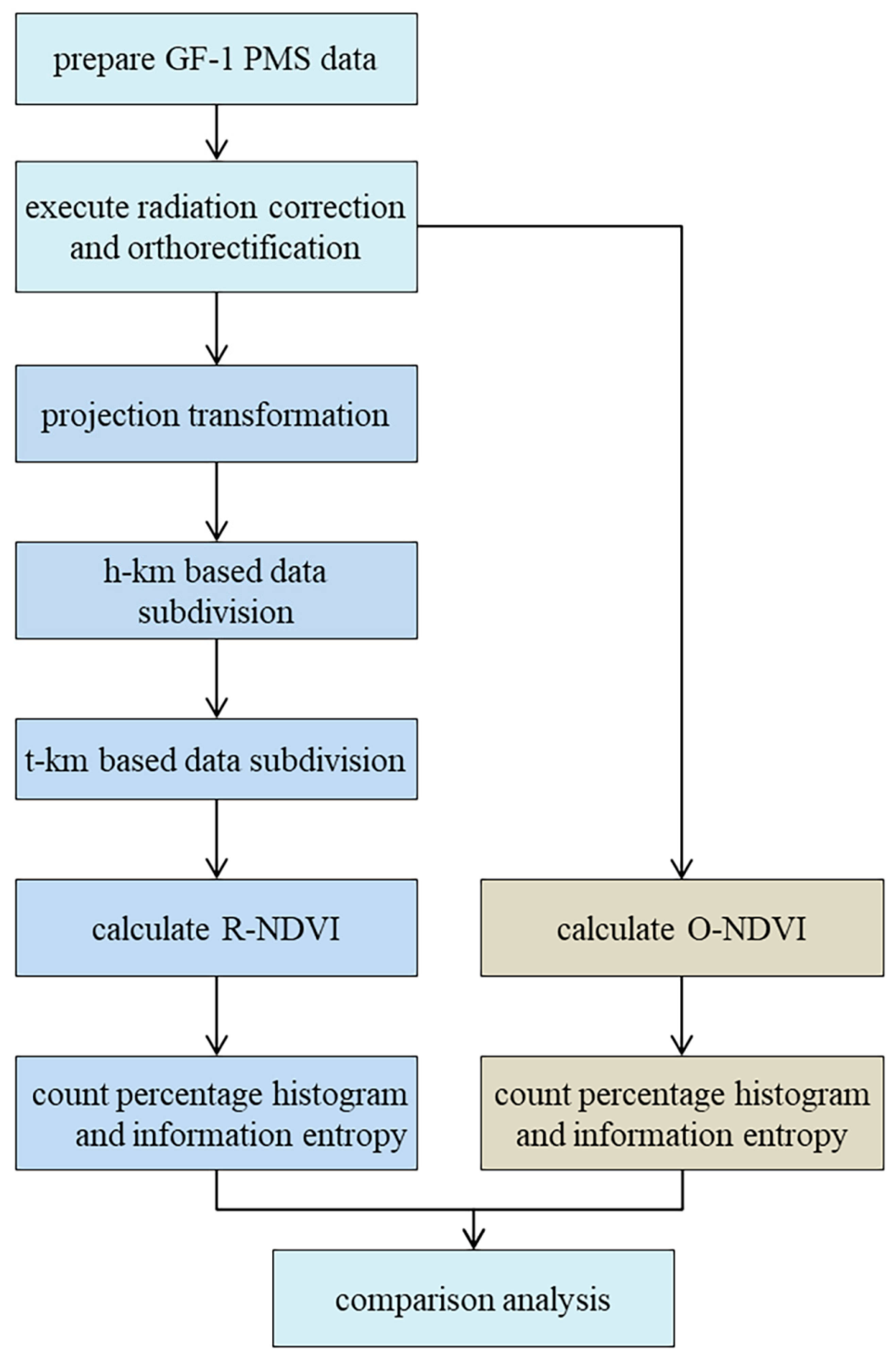
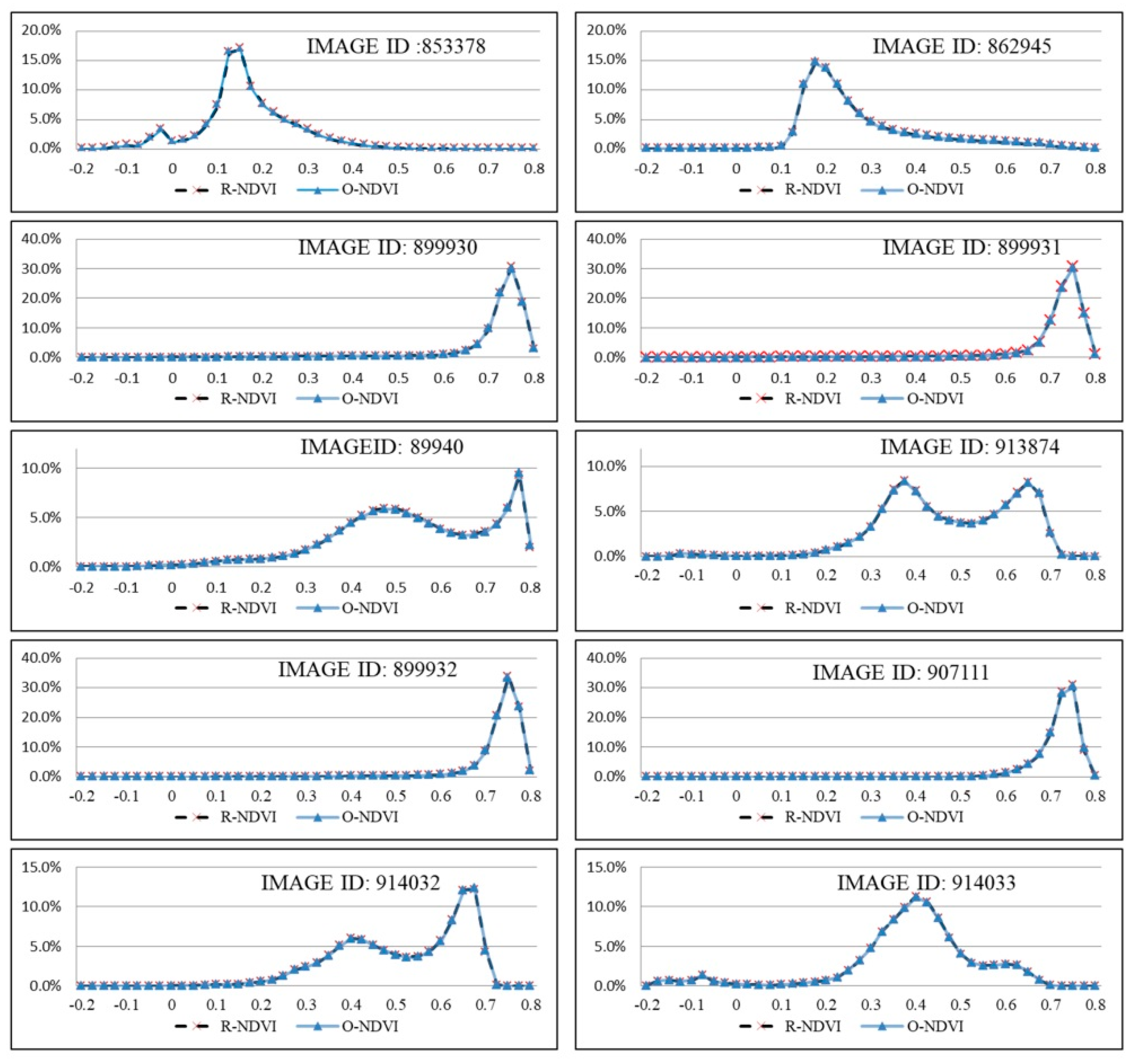
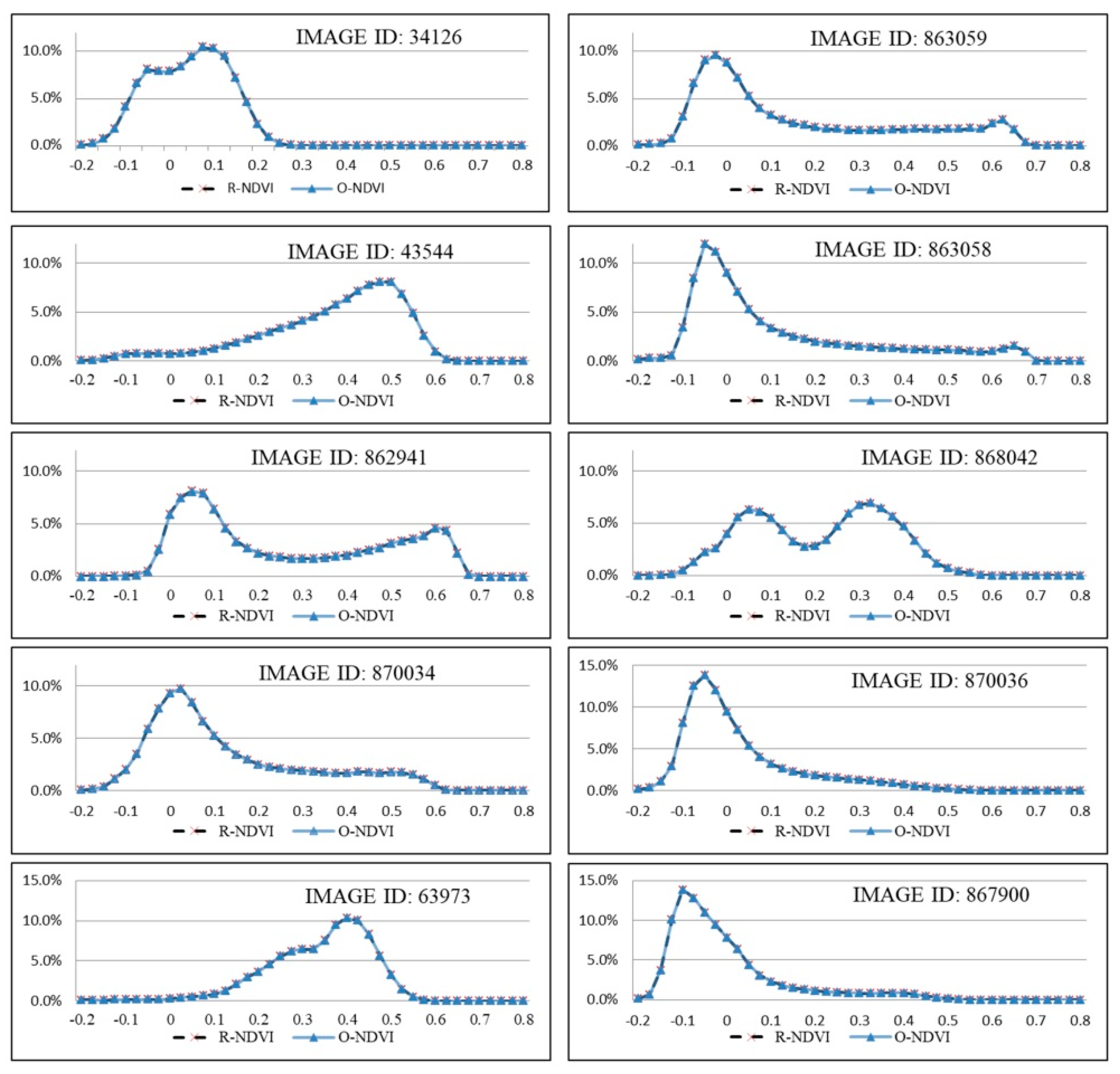
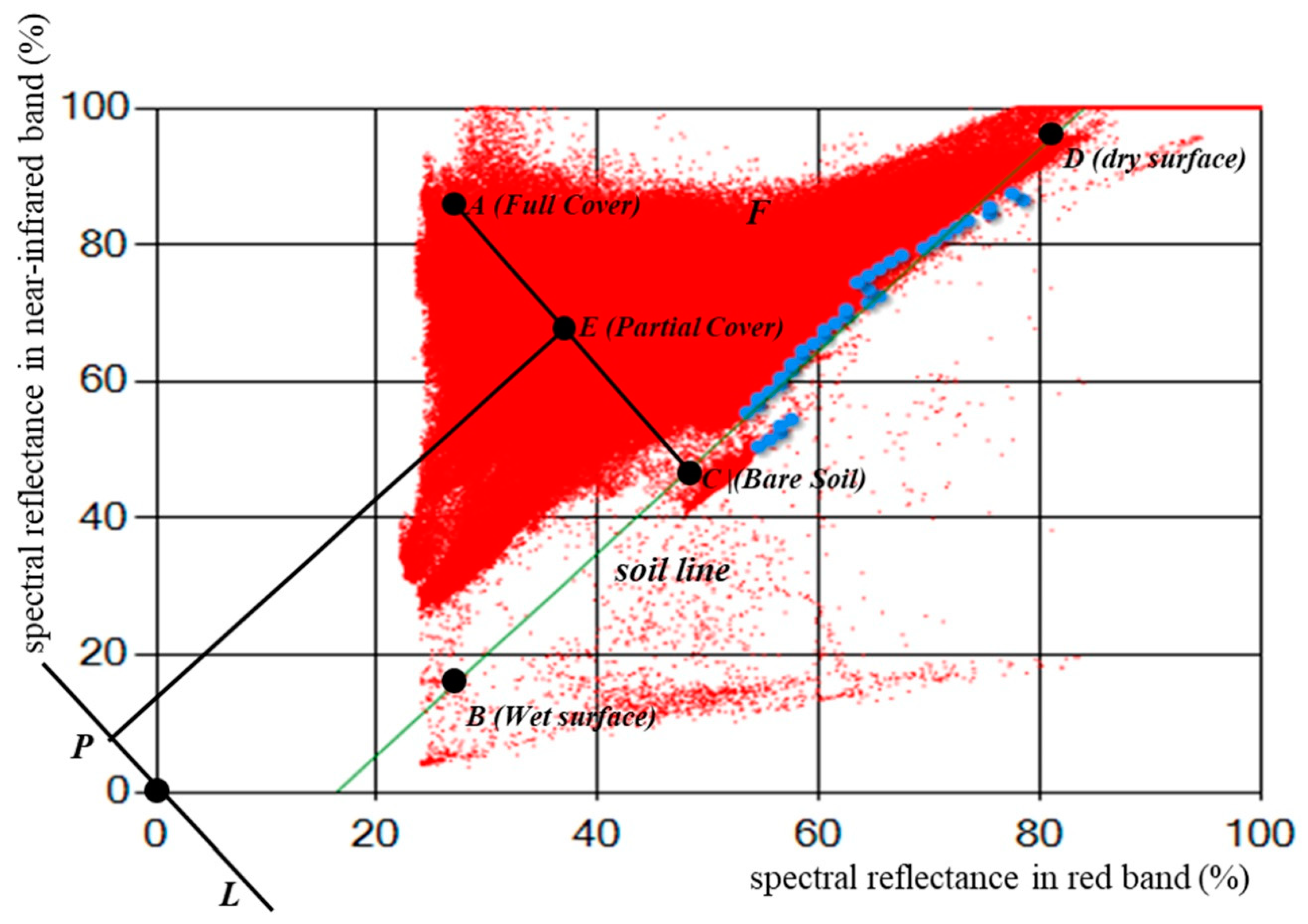
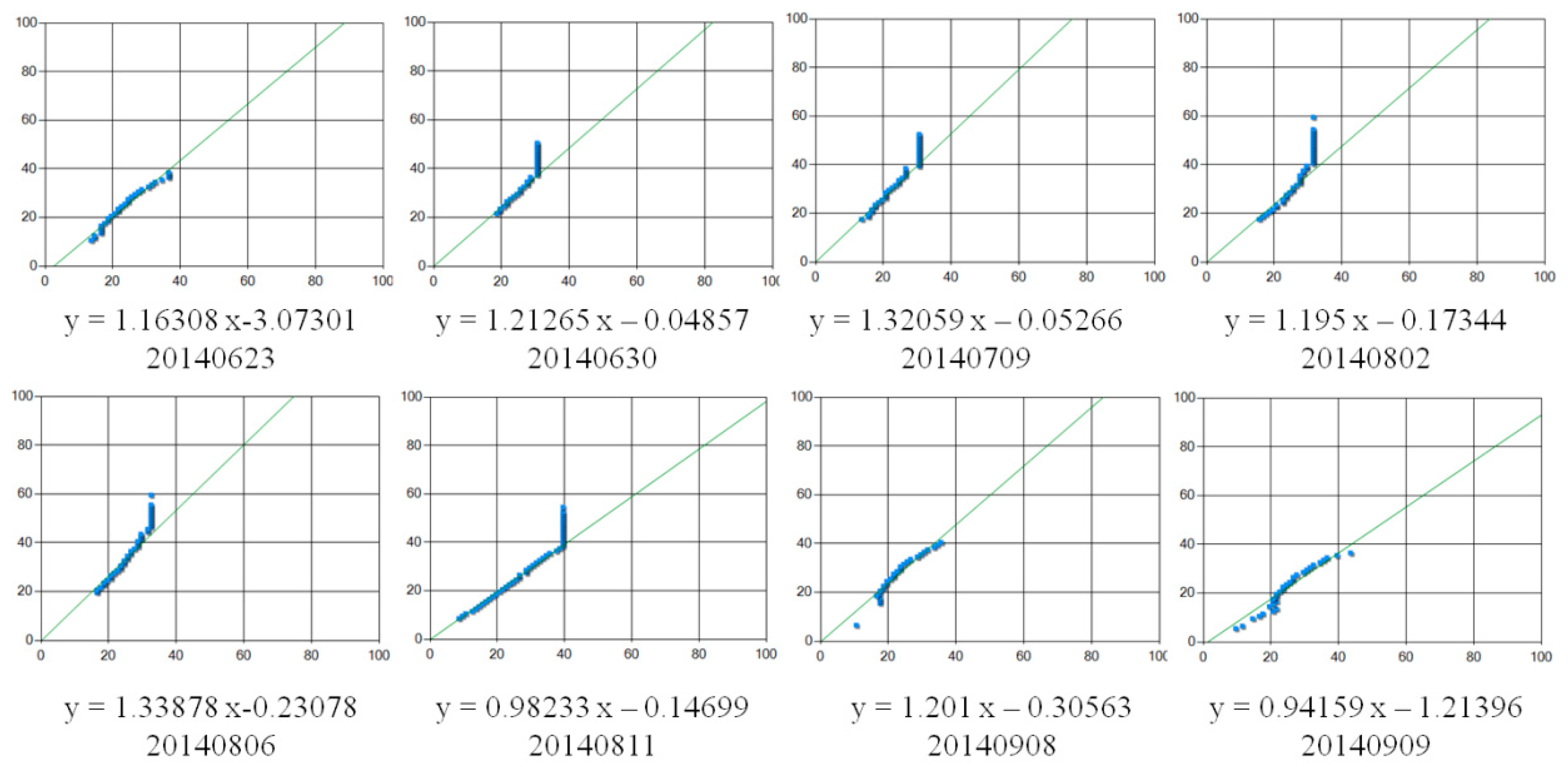
3.1. Pixel Spectral Reflectance Variation Detection
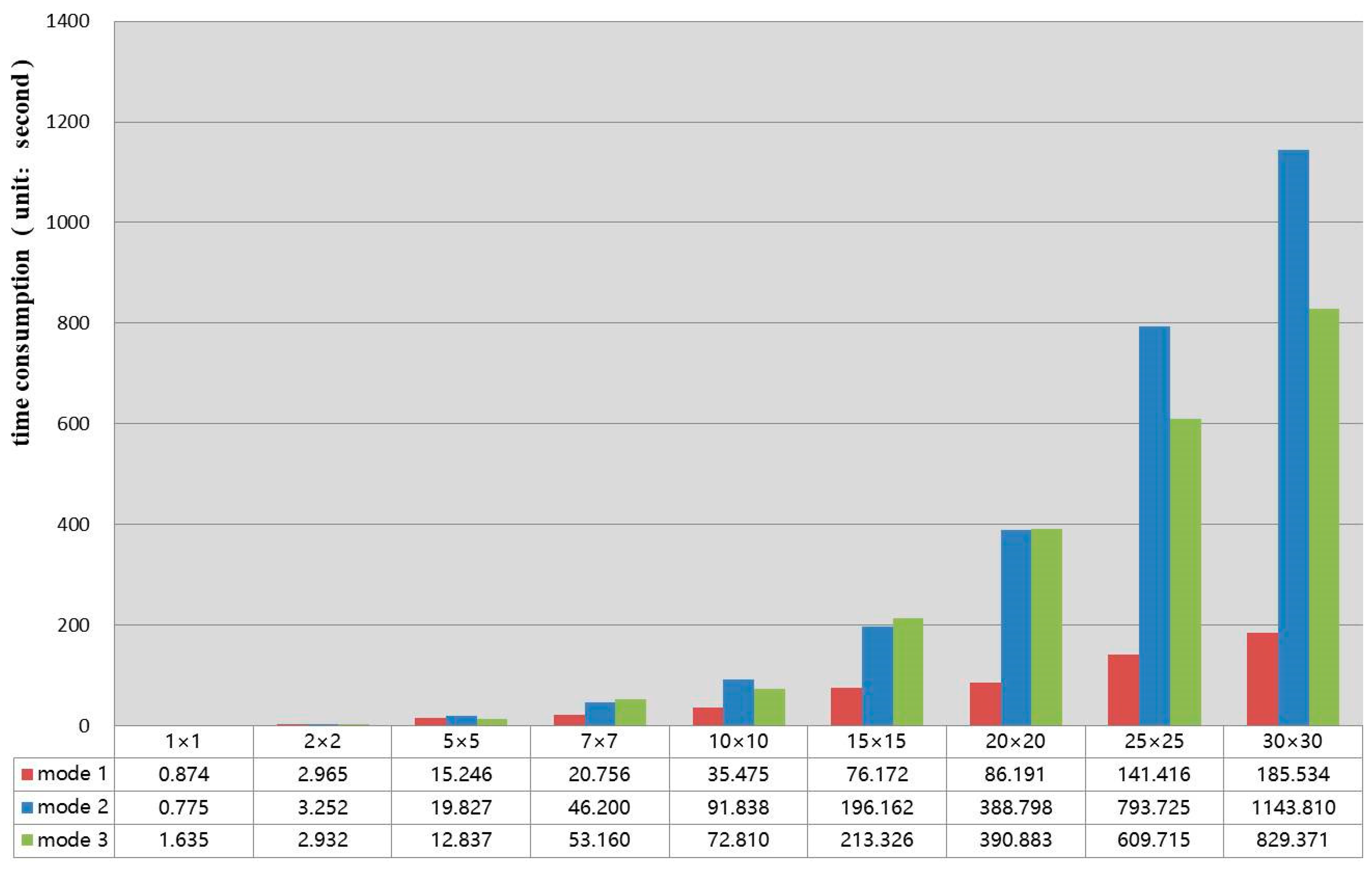
3.2. Data Extraction Efficiency Test
4. RDCRMG-Based Vegetation Dryness Monitoring Application Results
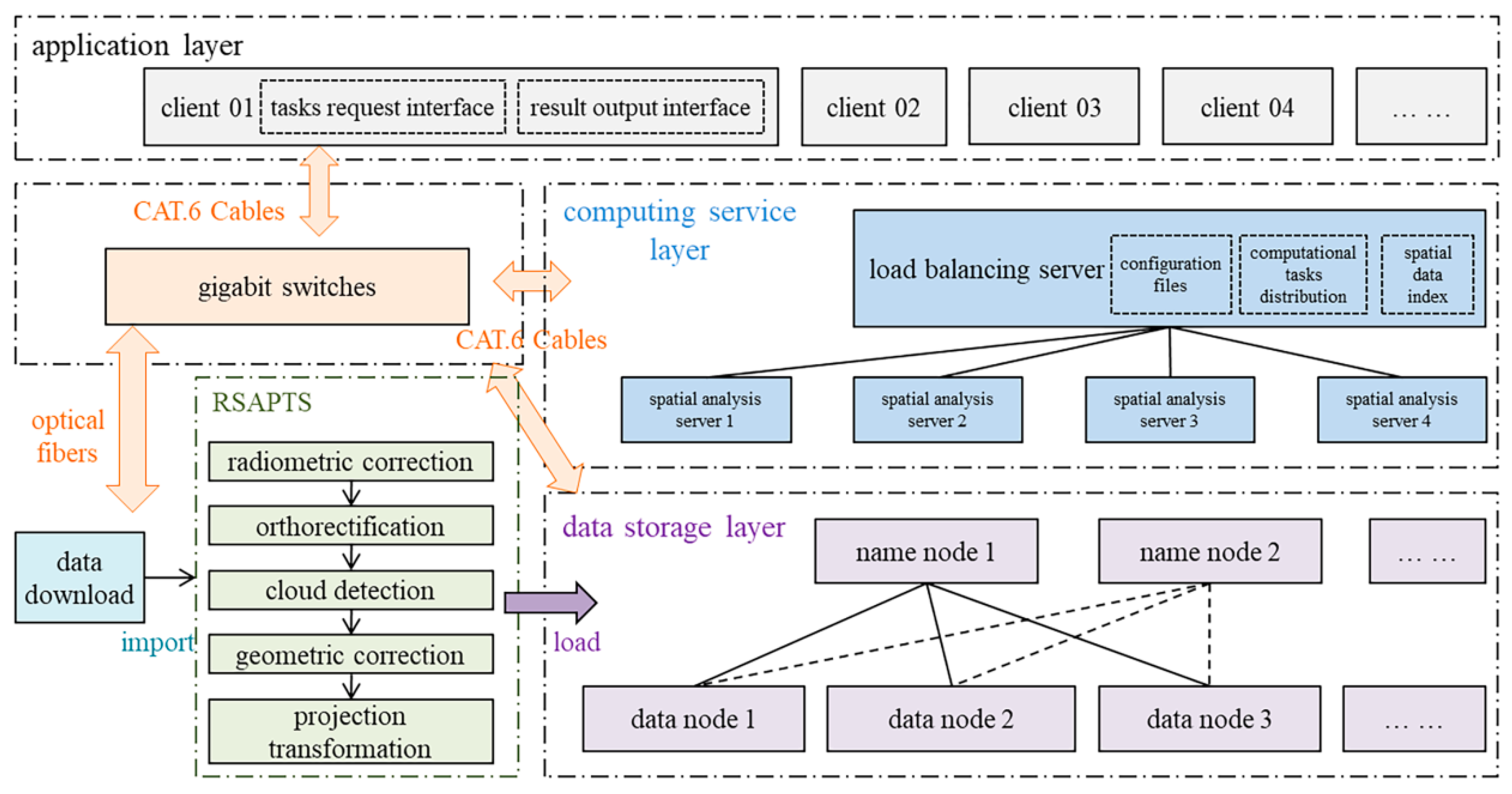
4.1. Experimental Environment
4.2. Automatic Vegetation Dryness Monitoring Strategy
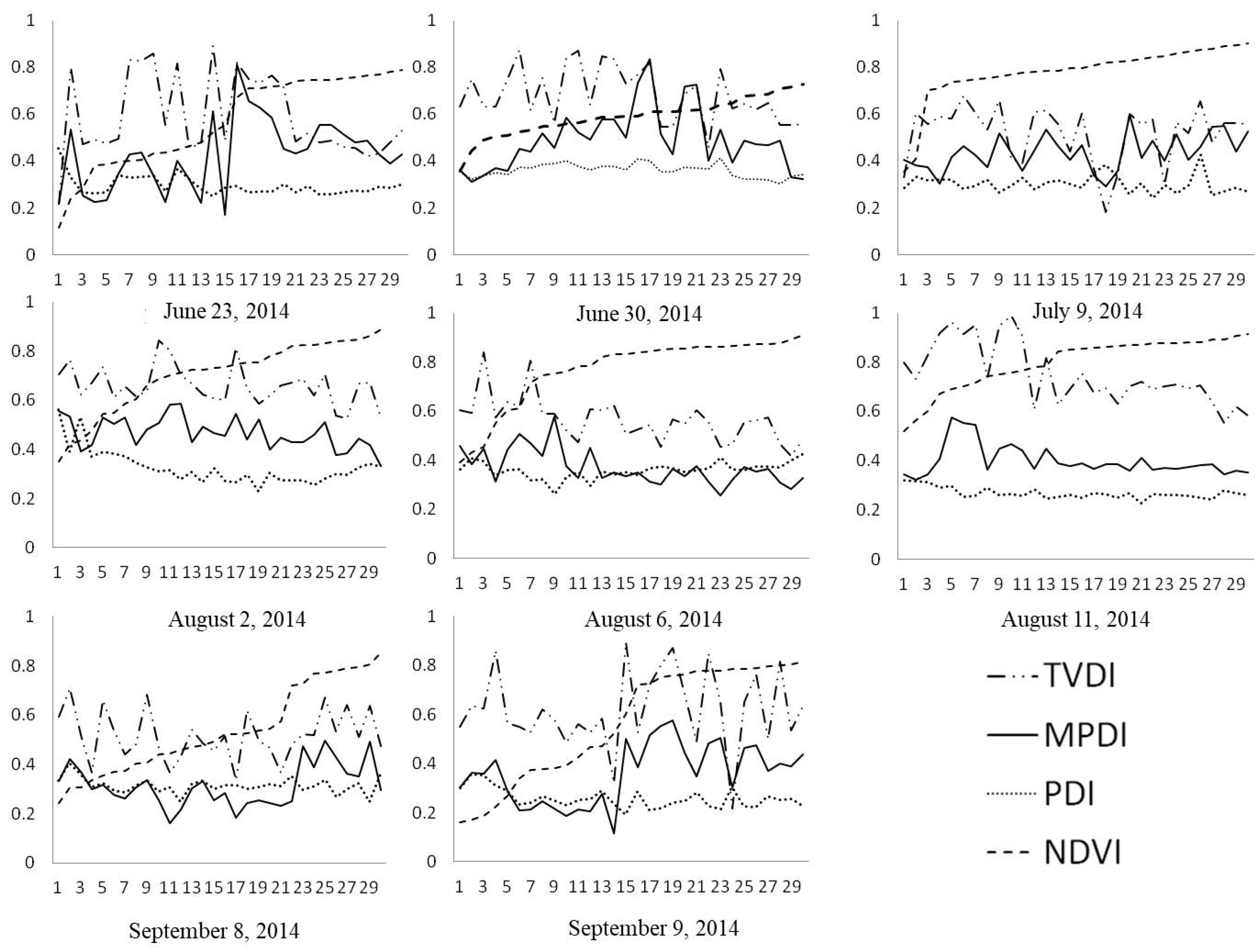
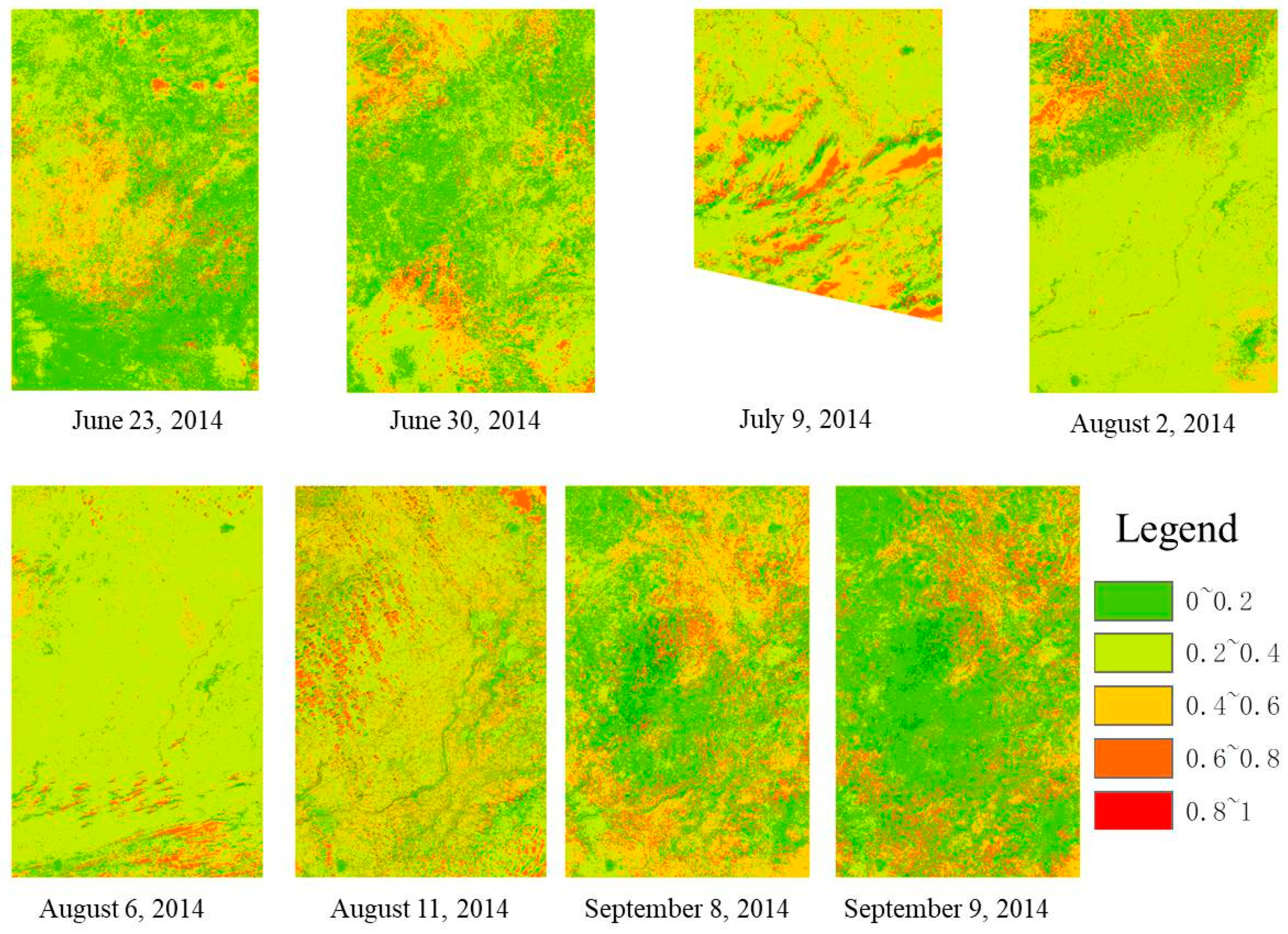
4.3. MPDI/PDI-Based Remote Sensing Monitoring Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, L.; Liu, J.; Yang, F.; Fu, C.; Teng, F.; Gao, J. Early recognition of winter wheat area based on GF-1 satellite. Trans. Chin. Soc. Agric. Eng. 2015, 31, 194–201. [Google Scholar]
- Agrawal, S.; Joshi, P.K.; Shukla, Y.; Roy, P.S. SPOT VEGETATION multi temporal data for classifying vegetation in south central Asia. Curr. Sci. 2003, 85, 140–140. [Google Scholar]
- Carleer, A.; Wolff, E. Exploitation of very high resolution satellite data for tree species identification. Photogramm. Eng. Remote Sens. 2004, 70, 135–140. [Google Scholar] [CrossRef]
- Huang, J.; Tian, L.; Liang, S.; Ma, H.; Becker-Reshef, I.; Huang, Y.; Su, W.; Zhang, X.; Zhu, D.; Wu, W. Improving winter wheat yield estimation by assimilation of the leaf area index from Landsat TM and MODIS data into the WOFOST model. Agric. For. Meteorol. 2015, 204, 106–121. [Google Scholar] [CrossRef]
- Huang, J.; Ma, H.; Su, W.; Zhang, X.; Huang, Y.; Fan, J.; Wu, W. Jointly Assimilating MODIS LAI and ET Products into the SWAP Model for Winter Wheat Yield Estimation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4060–4071. [Google Scholar] [CrossRef]
- Huang, J.; Wu, S.; Liu, X.; Ma, G.; Ma, H.; Wu, W.; Zou, J. Regional winter wheat yield forecasting based on assimilation of remote sensing data and crop growth model with Ensemble Kalman method. Trans. Chin. Soc. Agric. Eng. 2012, 28, 142–148. [Google Scholar]
- Huang, J.; Ma, H.; Tian, L.; Wang, P.; Liu, J. Comparison of remote sensing yield estimation methods for winter wheat based on assimilating time-sequence LAI and ET. Trans. Chin. Soc. Agric. Eng. 2015, 31, 197–203. [Google Scholar]
- GonzalezFlor, C.; Serrano, L.; Gorchs, G. Assessment of grape yield and composition using the reflectance based Water Index in Mediterranean rainfed vineyards. Remote Sens. Environ. 2012, 118, 249–258. [Google Scholar] [Green Version]
- Main, R.; Cho, M.A.; Mathieu, R.; O’Kennedy, M.M.; Ramoelo, A.; Koch, S. An investigation into robust spectral indices for leaf chlorophyll estimation. ISPRS J. Photogramm. Remote Sens. 2011, 66, 751–761. [Google Scholar] [CrossRef]
- Zarco-Tejada, P.J.; Miller, J.R.; Morales, A.; Berjón, A.; Agüera, J. Hyperspectral indices and model simulation for chlorophyll estimation in open-canopy tree crops. Remote Sens. Environ. 2004, 90, 463–476. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Guo, H.D.; Annoni, A.; Bian, L.; de Bie, K.; Campbell, F.; Craglia, M.; Ehlers, M.; van Genderen, J.; Jackson, D.; et al. Next-generation Digital Earth. Proc. Natl. Acad. Sci. USA. 2012, 109, 11088–11094. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, C.X.; Song, X.M.; Zhou, C.H.; Zhu, Y. Generic cumulative annular-bucket histogram for spatial selectivity estimation of spatial database management system. Int. J. Geogr. Inf. Sci. 2013, 27, 339–362. [Google Scholar] [CrossRef]
- Cheng, C.X.; Niu, F.Q.; Cai, J.; Zhu, Y.L. Extensions of GAP-tree and its implementation based on a non-topological data model. Int. J. Geogr. Inf. Sci. 2008, 22, 657–673. [Google Scholar] [CrossRef]
- Cheng, C.X.; Lu, F.; Cai, J. A quantitative scale-setting approach for building multi-scale spatial databases. Comput. Geosci. 2009, 35, 204–2209. [Google Scholar] [CrossRef]
- Fekete, G. Rendering and managing spherical data with sphere quadtrees. In Proceedings of 90 Proceedings of the 1st conference on Visualization, San Francisco, CA, USA, 23–26 October 1990. [Google Scholar]
- Fekete, G.; Treinish, L.A. Sphere quadtrees: A new data structure to support the visualization of spherically distributed data. In Extracting Meaning from Complex Data: Processing, Display, Interaction, Proceedings of the Electronic Imaging: Advanced Devices and Systems, Santa Clara, CA, USA, 11–16 February 1990; SPIE: Bellingham, WA, USA, 1990; Volume 1259. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Yang, S.R. A hierarchical spatial data structure for global geographic information systems. CVGIP Graph. Models Image Process. 1992, 54, 31–44. [Google Scholar] [CrossRef] [Green Version]
- Dutton, G. Universal Geospatial Data Exchange via Global Hierarchical Coordinates. In Proceedings of the International Conference on Discrete Global Grids, Santa Barbara, CA, USA, 26–28 March 2000. [Google Scholar]
- Dutton, G. Encoding and handling geospatial data with hierarchical triangular meshes. In Proceedings of the 7th International Symposium on Spatial Data Handling, Delft, The Netherlands, 12–16 August 1996. [Google Scholar]
- Zhou, M.Y.; Jian, J.C.; Gong, J.Y. A pole-oriented discrete global grid system: Quaternary quadrangle mesh. Comput. Geosci. 2013, 61, 133–143. [Google Scholar] [CrossRef]
- Lukatela, H. Hipparchus. Data Structure: Points, Lines and Regions in Spherical Voronoi Grid. In Proceedings of the 9th International Symposium on Computer Assisted Cartography, Baltimore, MD, USA, 2–7 April 1989. [Google Scholar]
- Wang, L.; Zhao, X.S.; Zhao, L.F. Multi-level QTM Based Algorithm for Generating Spherical Voronoi Diagram. J. Wuhan Univ. 2015, 40, 1111–1115, 1122. [Google Scholar]
- Chen, S.P.; Zhou, C.H.; Chen, Q.X. New Generation of Grid Mapping. Sci. Surv. Mapp. 2004, 29, 1–4. [Google Scholar]
- Li, D.R.; Xiao, Z.F.; Zhu, X.Y. Research on Grid Division and Encoding of Spatial Information Multi-Grids. Acta Geod. Cartograph. Sin. 2006, 1, 010. [Google Scholar]
- Li, D.R.; Zhu, X.Y; Gong, J.Y. From Digital Map to Spatial Information Multi-grid—A Thought of Spatial Information Multi-grid Theory. J. Wuhan Univ. 2003, 6, 642–650. [Google Scholar]
- Li, D.R. On the Typical Applications of Spatial Information Multi Grid. J. Wuhan Univ. 2004, 11, 945–950. [Google Scholar]
- Li, D.R.; Shao, Z.F. Spatial Information Multi- grid and Its Functions. Geosp. Inf. 2005, 3, 1–3 and 5. [Google Scholar]
- Bjørke, J.T.; Grytten, J.K.; Hæger, M.; Nilsen, S. A Global Grid Model based on Constant Area Quadrilaterals. In Proceedings of the 9th Scandinavian Research Conference on Geographical Information Science, Espoo, Finland, 4–6 June 2003. [Google Scholar]
- Bjørke, J.T.; Nilsen, S. Examination of aconstant- area quadrilateral grid in representation of global digital elevation models. Int. J. Geogr. Inf. Sci. 2005, 8, 653–664. [Google Scholar]
- Goodchild, M.F. Geographical Grid Models for Environ-mental Monitoring and Analysis across the Globe (panel session). In Proceedings of the GIS/LIS 94 Conference, Phoenix, AZ, USA, 25–27 October 1994. [Google Scholar]
- Kimerling, A.J.; Sahr, K.; White, D.; Song, L. Comparing Geo-metrical Properties of Global Grids. Cartogr. Geogr. Inf. Sci. 1999, 26, 271–287. [Google Scholar] [CrossRef]
- Cheng, C.Q.; Ren, F.H.; Pu, G.L. An Introduce to Spatial Information Subdivision Organization; Science Press: Beijing, China, 2012. [Google Scholar]
- Lu, X.F.; Cheng, C.Q.; Gong, J.Y.; Guan, L. Review of data storage and management technologies for massive remote sensing data. Sci. China-Technol. Sci. 2011, 54, 3220–3232. [Google Scholar] [CrossRef]
- Song, S.H. Global Remote Sensing Data Subdivision Organization Based on GeoSOT. Acta Geod. Cartogr. Sin. 2014, 43, 869–876. [Google Scholar]
- Cheng, C.Q. The Global Subdivision Grid Based on Extended Mapping Division and Its Address Coding. Acta Geod. Cartogr. Sin. 2010, 39, 295–302. [Google Scholar]
- Lewis, A.; Oliver, S.; Lymburner, L.; Evans, B.; Wyborn, L.; Mueller, N.; Raevksi, G.; Hooke, J.; Woodcock, R.; Sixsmith, J.; et al. The Australian Geoscience Data Cube—Foundations and lessons learned. Remote Sens. Environ. 2017, 202, 276–292. [Google Scholar] [CrossRef]
- Ye, S. Research on application of Remote Sensing Tupu—take monitoring of meteorological disaster for example. Acta Geod. Cartogr. Sin. 2018, 47, 892–892. [Google Scholar]
- Yao, X.C.; Mokbel, M.F.; Alarabi, L.; Eldawy, A.; Yang, J.; Yun, W.; Li, L.; Ye, S.; Zhu, D. Spatial coding-based approach for partitioning big spatial data in Hadoop. Comput. Geosci. 2017, 106, 60–67. [Google Scholar] [CrossRef]
- Yao, X.; Mokbel, M.; Ye, S.; Li, G.; Alarabi, L.; Eldawy, A.; Zhao, Z.; Zhao, L.; Zhu, D. LandQv2: A MapReduce-Based System for Processing Arable Land Quality Big Data. ISPRS Int. J. Geoinf. 2018, 7, 271. [Google Scholar] [CrossRef]
- Yao, X.C.; Yang, J.Y.; Li, L.; Ye, S.J.; Yun, W.J.; Zhu, D.H. Parallel Algorithm for Partitioning Massive Spatial Vector Data in Cloud Environment. J. Wuhan Univ. 2017, 10, 1–6. [Google Scholar]
- Ye, S.; Zhang, C.; Wang, Y.; Liu, D.; Du, Z.; Zhu, D. Design and implementation of automatic orthorectification system based on GF-1 big data. Trans. Chin. Soc. Agric. Eng. 2017, 33, 266–273. [Google Scholar]
- Yuan, W.; Sijing, Y.; Yueli, Y. Contrast of automatic geometric registration algorithms for GF-1 remote sensing image. Trans. Chin. Soc. Agric. Mach. 2015, 46, 260–266. [Google Scholar]
- Ye, S.; Yan, T.; Yue, Y.; Lin, W.; Li, L.; Yao, X.; Mu, Q.; Li, Y.; Zhu, D. Developing a reversible rapid coordinate transformation model for the cylindrical projection. Comput. Geosci. 2016, 89, 44–56. [Google Scholar] [CrossRef]
- Ghulam, A.; Qin, Q.; Zhan, Z. Designing of the perpendicular drought index. Environ. Geol. 2007, 52, 1045–1052. [Google Scholar] [CrossRef]
- Ghulam, A.; Qin, Q.; Teyip, T.; Li, Z. Modified perpendicular drought index (MPDI): A real-time drought monitoring method. ISPRS J. Photogramm. Remote Sens. 2007, 62, 150–164. [Google Scholar] [CrossRef]
- Bayarjargal, Y.; Karnieli, A.; Bayasgalan, M.; Khudulmur, S.; Gandush, C.; Tucker, C.J. A comparative study of NOAA–AVHRR derived drought indices using change vector analysis. Remote Sens. Environ. 2006, 105, 9–22. [Google Scholar] [CrossRef]
- Ji, L.; Peters, A. Assessing vegetation response to drought in the northern Great Plains using vegetation and drought indices. Remote Sens. Environ. 2003, 87, 85–98. [Google Scholar] [CrossRef]
- Martínez-Fernández, J.; González-Zamora, A.; Sánchez, N.; Gumuzzio, A.; Herrero-Jiménez, C.M. Satellite soil moisture for agricultural drought monitoring: Assessment of the SMOS derived Soil Water Deficit Index. Remote Sens. Environ. 2016, 177, 277–286. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Data Type | Modified Spatial Resolution * | Grid Level | Matrix Size | Data Type Code |
|---|---|---|---|---|---|
| 1 | GDEM | 32 | h-km grid | 3125 × 3125 | 011 |
| 2 | GlobalLand30 | 32 | h-km grid | 3125 × 3125 | 021 |
| 3 | GF-1 WFV Multispectral | 16 | t-km grid | 625 × 625 | 031 |
| 4 | Sentinel 2A | 10 | t-km grid | 1000 × 1000 | 041 |
| 5 | GF-1 PMS Multispectral | 8 | t-km grid | 1250 × 1250 | 032 |
| 6 | RapidEye | 5 | t-km grid | 2000 × 2000 | 051 |
| 7 | GF-2 PMS Multispectral | 4 | t-km grid | 2500 × 2500 | 034 |
| 8 | GF-1 PMS Panchromatic | 2 | o-km grid | 500 × 500 | 033 |
| 9 | GF-2 PMS Panchromatic | 1 | o-km grid | 1000 × 1000 | 035 |
| 10 | World View-1 | 0.5 | o-km grid | 2000 × 2000 | 061 |
| Group A | Group B | ||||||
|---|---|---|---|---|---|---|---|
| Image ID | Image ID | Image ID | Image ID | ||||
| 853378 | 0.0002761 | 899930 | 0.0008951 | 34126 | 0.0000965 | 863059 | 0.0000519 |
| 862945 | 0.0004677 | 899931 | 0.0004937 | 43544 | 0.0000243 | 867900 | 0.0000748 |
| 907111 | 0.0001211 | 899932 | 0.0009110 | 63973 | 0.0000770 | 868042 | 0.0000916 |
| 914032 | 0.0003259 | 899940 | 0.0004031 | 862941 | 0.0000967 | 870034 | 0.0000515 |
| 914033 | 0.0002150 | 913874 | 0.0004272 | 863058 | 0.0000266 | 870036 | 0.000317 |
| Group A | Group B | ||||||
|---|---|---|---|---|---|---|---|
| Image ID | Observing Date | of O-NDVI | of R-NDVI | Image ID | Observing Date | of O-NDVI | of R-NDVI |
| 853378 | 10 June 2015 | 6.2291147 | 6.2212885 | 34126 | 15 June 2015 | 6.1041904 | 6.1042737 |
| 862945 | 14 June 2015 | 6.3906426 | 6.3820948 | 43544 | 5 July 2013 | 6.8720507 | 6.8718363 |
| 907111 | 9 July 2015 | 4.8870048 | 4.8579931 | 63973 | 6 August 2013 | 6.4693812 | 6.4680682 |
| 914032 | 13 July 2015 | 6.5100051 | 6.5040877 | 862941 | 14 June 2015 | 6.9930203 | 6.9909612 |
| 914033 | 13 July 2015 | 6.6216194 | 6.6125231 | 863058 | 14 June 2015 | 6.8748594 | 6.8737988 |
| 899930 | 5 July 2015 | 5.2704958 | 5.2540650 | 863059 | 14 June 2015 | 7.0331230 | 7.0320470 |
| 899931 | 5 July 2015 | 5.2082725 | 5.1953808 | 867900 | 17 June 2015 | 6.3188119 | 6.3181604 |
| 899932 | 5 July 2015 | 4.9820212 | 4.9622307 | 868042 | 17 June 2015 | 6.8142379 | 6.8151115 |
| 899940 | 5 July 2015 | 6.9523657 | 6.9416525 | 870034 | 18 June 2015 | 6.8816083 | 6.8804745 |
| 913874 | 13 July 2015 | 6.6584797 | 6.6421337 | 870036 | 18 June 2015 | 6.4055547 | 6.4055478 |
| Monitoring Date | GF-1 WFV | MODIS LST | MODIS NDVI |
|---|---|---|---|
| 23 June 2014 | L1A0000258243;L1A0000258242; L1A0000258241 | MOD11A1.A2014174.h27v04.005.2014175145250.hdf | MOD13A2.A2014177.h27v04.006.2015288071235.hdf |
| 30 June 2014 | L1A0000263577; L1A0000263576 | MOD11A1.A2014181.h27v04.005.2014182104028.hdf | MOD13A2.A2014193.h27v04.006.2015289002318.hdf |
| 9 July 2014 | L1A0000271504; | MOD11A1.A2014190.h27v04.005.2014191111312.hdf | MOD13A2.A2014209.h27v04.006.2015289031042.hdf |
| 2 August 2014 | L1A0000293356;L1A0000293355; L1A0000293368;L1A0000293367 | MOD11A1.A2014214.h27v04.005.2014215101849.hdf | MOD13A2.A2014225.h27v04.006.2015289160437.hdf |
| 6 August 2014 | L1A0000296974;L1A0000296973; L1A0000296990 | MOD11A1.A2014218.h27v04.005.2014219103329.hdf | MOD13A2.A2014225.h27v04.006.2015289160437.hdf |
| 11 August 2014 | L1A0000301288;L1A0000301287; L1A0000301299;L1A0000301298 | MOD11A1.A2014223.h27v04.005.2014224102859.hdf | MOD13A2.A2014225.h27v04.006.2015289160437.hdf |
| 8 September 2014 | L1A0000336275;L1A0000336274; L1A0000336287;L1A0000336286 | MOD11A1.A2014251.h27v04.005.2014252113357.hdf | MOD13A2.A2014225.h27v04.006.2015289160437.hdf |
| 9 September 2014 | L1A0000333819;L1A0000333818; L1A0000333817 | MOD11A1.A2014252.h27v04.005.2014253150312.hdf | MOD13A2.A2014225.h27v04.006.2015289160437.hdf |
| Monitoring Date | R2 of MPDI and TVDI | R2 of PDI and TVDI |
|---|---|---|
| 23 June 2014 | 0.3632 | 0.0001 |
| 30 June 2014 | 0.3441 | 0.2755 |
| 9 July 2014 | 0.3816 | 0.083 |
| 2 August 2014 | 0.4509 | 0.0089 |
| 6 August 2014 | 0.4247 | 0.0653 |
| 11 August 2014 | 0.5561 | 0.0236 |
| 8 September 2014 | 0.4401 | 0.0587 |
| 9 September 2014 | 0.5163 | 0.087 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, S.; Liu, D.; Yao, X.; Tang, H.; Xiong, Q.; Zhuo, W.; Du, Z.; Huang, J.; Su, W.; Shen, S.; et al. RDCRMG: A Raster Dataset Clean & Reconstitution Multi-Grid Architecture for Remote Sensing Monitoring of Vegetation Dryness. Remote Sens. 2018, 10, 1376. https://0-doi-org.brum.beds.ac.uk/10.3390/rs10091376
Ye S, Liu D, Yao X, Tang H, Xiong Q, Zhuo W, Du Z, Huang J, Su W, Shen S, et al. RDCRMG: A Raster Dataset Clean & Reconstitution Multi-Grid Architecture for Remote Sensing Monitoring of Vegetation Dryness. Remote Sensing. 2018; 10(9):1376. https://0-doi-org.brum.beds.ac.uk/10.3390/rs10091376
Chicago/Turabian StyleYe, Sijing, Diyou Liu, Xiaochuang Yao, Huaizhi Tang, Quan Xiong, Wen Zhuo, Zhenbo Du, Jianxi Huang, Wei Su, Shi Shen, and et al. 2018. "RDCRMG: A Raster Dataset Clean & Reconstitution Multi-Grid Architecture for Remote Sensing Monitoring of Vegetation Dryness" Remote Sensing 10, no. 9: 1376. https://0-doi-org.brum.beds.ac.uk/10.3390/rs10091376