1. Introduction
Object detection based on remote sensing images is currently a research topic of interest in the field of image processing. As military and civilian infrastructures, airports play important roles in various processes, such as aircraft transportation and energy supply. However, because airports have complex backgrounds and varying shapes and sizes, accurate and real-time airport detection remains problematic and challenging.
Deep learning has become a leading research topic in industry and academia. Zhu et al. [
1] proposed that deep learning has been rapidly developed in image analysis tasks, including image indexing, segmentation, and object classification and detection. At the same time, deep learning also promotes the development of remote sensing image analysis. Object detection is an important task in remote sensing image analysis. Compared with traditional classifiers based on manually designed features, convolutional neural networks have better representation characteristics of abstract features. Therefore, more and more scholars have begun to study object detection based on convolutional neural networks in remote sensing images, such as vehicle detection [
2,
3], oil tank detection [
4], aircraft detection [
5], and ship detection [
6]. To date, a variety of airport detection methods have been proposed, and they can be divided into two categories: edge-based detection [
7,
8,
9,
10,
11,
12] and detection based on region segmentation [
13,
14]. Edge-based detection focuses on the characteristics of the lines at edges, and achieves airport detection through the detection of runways. This approach is fast and simple but susceptible to interference from non-airport objects with long straight-line features. Airport detection based on region segmentation focuses on the distinct structural features of airports, but such methods have significant efficiency issues that are difficult to overcome due to the problem of overlapping sliding windows. In summary, the major problems and shortcomings of the aforementioned methods are as follows. The sliding window strategy lacks objected detection, and it has high temporal complexity and window redundancy. Additionally, the manually designed features of this method are not sufficiently robust to account for variations derived from airport diversity.
In recent years, deep learning has provided new methods of airport detection. The transfer learning ability of convolutional neural networks (CNNs) has been used to recognize airport runways and airports [
15,
16]. CNNs have also been used to extract multi-scale deep fusion features from images that were then classified using support vector machine methods [
17]. However, these methods mainly use only the powerful feature extraction or classification capabilities of the associated CNNs, and the region proposal methods are based on manual methods such as edge or region segmentation, in which the limitations of traditional methods remain. In 2014, Girshick et al. [
18] proposed region-based convolutional neural networks (R-CNNs), which made breakthroughs in object detection and considerably improved object detection based on deep learning. Girshick [
19] proposed a region of interest (RoI) pooling layer to extract a fixed-length feature vector from the feature map at a single scale. To further improve the accuracy and speed of R-CNNs, Ren et al. [
20] later proposed Faster R-CNNs, a successor to R-CNNs, which uses region proposal networks (RPNs) to replace the selective search (SS) algorithm [
21] as the region proposal method. This approach enables the sharing of convolutional layers between the RPNs and the subsequent detection networks, which significantly improves the speed of the algorithm. The training of a deep learning model requires a large amount of sample data, but the number of airport remote sensing images is insufficient for training a network model. However, the large number of successful applications of transfer learning theory [
22] in object recognition and detection tasks represents a potential direction for solving the problem of inadequate airport data.
Thus, in this study, using an end-to-end Faster R-CNN as the basic framework and based on the establishment of a remote sensing image database, we perform transfer learning with pretraining models, improve and optimize the network model and ultimately achieve fast and accurate airport detection.
The main contributions of this study are as follows.
A fast and accurate detection model is developed for airport detection based on remote sensing images. Unlike the conventional methods that involve a sliding window with manual operations and simply use a CNN as the classification tool, the method developed in this study integrates object detection in a deep network framework that enables the sharing of the convolution layer between the front-end cascade RPNs and the subsequent multi-threshold detection networks, and this method features an entire end-to-end framework.
A remote sensing image database is established, and the amount of data is artificially increased using a data expansion technique to prevent the overfitting of the training model. This approach provides the foundation for subsequent applications of the deep learning model in the field of airport detection.
The concept of “divide and conquer” is introduced to improve the RPN and establish the network structure by proposing a cascade region. This technique is simple to implement and has a very small additional computational cost; moreover, it can enhance airport detection performance by improving the quality of the candidate boxes.
The loss function of the detection networks indiscriminately processes the detection boxes that have an intersection over union (IoU) greater than the threshold, which leads to poor positioning accuracy; thus, multiple IoU training thresholds are introduced to improve the loss function and the accuracy of airport detection.
Hard example mining is employed to use hard examples in model training to improve the object discriminative ability and training effectiveness of the networks. This method yields optimal performance for the network model.
2. Materials and Methods
We first introduce the network architecture of Faster R-CNN, and then present some specific improvement of the proposed method. The flowchart of the proposed algorithm is shown in
Figure 1.
2.1. Related Work
The overall structure of the Faster R-CNN is shown in
Figure 2, in which one image is used as the input, and the prediction probability value and object detection box of the object category are used as the output. This method mainly involves RPNs and detection networks, which include RoI pooling layers, fully connected layers, and classification and regression layers. Because the two networks share the convolutional layer, which enables object detection to be unified in a deep network framework, the entire network framework has end-to-end characteristics.
2.1.1. Region Proposal Networks
After the convolutional feature map processed by the RPNs [
20] is outputted by the shared convolutional layer, the rectangle candidate box sets, as shown in
Figure 3, are generated. RPNs uses a sliding window that is 3 × 3 in size to perform the convolutional operation on the feature map, in which each sliding window is mapped to a lower-dimensional vector. After the convolutional operation using the 1 × 1 convolution kernel, the results are outputted to classification layers and regression layers to simultaneously conduct object classification and position regression for the candidate boxes. Notably, the classification process determines the presence or absence of a discriminative object rather than a specific category, and position regression refers to the translation scaling parameter of the candidate box.
To accommodate multi-scale objects, candidate boxes with multiple sizes and aspect ratios at each location on the convolutional feature map are considered. The parametric representation of a candidate box is called an anchor, and each anchor corresponds to a set of sizes and aspect ratios. For each sliding window, three sizes (128
2, 256
2, and 512
2 pixels) and three aspect ratios (1:1, 1:2, and 2:1)—i.e., 9 types of anchors—are considered to address the multi-scale objects in the image. For the positioning accuracy of the bounding box, employ the IoU formula. The IoU indicates the degree of overlap between bounding box A and the ground truth B, as shown in the Equation (1). The larger the IoU, the more accurate the positioning of bounding box A.
To train the RPNs, each anchor is assigned a binary tag. A positive tag (object) is assigned to two types of anchors: the anchor that has the highest IoU for a certain “ground truth” box, and anchors that have an IoU greater than 0.7 for any manually tagged box. A negative tag (non-object) is assigned to any anchor that has an IoU lower than 0.3 for all the manually tagged boxes. Based on the multi-task loss principle [
12], the two tasks—object classification and candidate box regression—are simultaneously completed and, thus, the loss function of the RPNs is defined as follows:
where
is the index of the anchor in a small batch of samples and
is the prediction probability of the event that the
anchor contains the object. If the true tag of the anchor is positive, then
. If the true tag of the anchor is negative, then
. Here,
represents the parameterized coordinates of the candidate box, and
represents the coordinates of the manually tagged box.
and
are normalization constants that represent the number of samples in the small batch and number of anchors, respectively. Here,
is an adjustable equilibrium weight, and
and
are classification and regression losses, respectively, which are defined as follows:
2.1.2. Non-Maximum Suppression
In the candidate boxes generated by the RPNs, multiple candidate boxes could surround the same object and overlap in large numbers. Therefore, based on the object classification score of the candidate box, Non-maximum suppression (NMS) is used to eliminate candidate boxes with a low score and reduce redundancy. Essentially, NMS is an iteration-traversal-elimination process in which the number of candidate boxes can be drastically reduced through setting the IoU threshold without affecting the accuracy of airport detection.
2.1.3. Region of Interest Pooling Layer
Many incidences of overlap among thousands of candidate regions (the region within a candidate box) can be present and result in a high time cost for feature extraction. Because of the existence of a certain mapping relationship between the candidate region feature map and the complete feature map, feature extraction can be first performed on the entire image and, then, the corresponding RoI feature vector of the candidate region is mapped directly without repetitively extracting features, thereby reducing the time cost of the model. Mini-batch sample training is used for the convolutional operations of the shared candidate regions. For each mini-batch, , candidate regions are sampled; i.e., a total of candidate regions are used from the same image and share the convolutional operations.
2.2. The Proposed Method
2.2.1. Transfer Learning
For each of the object tasks, traditional machine learning algorithms must be retrained, but transfer learning can learn the common features of multiple tasks and apply them to new object tasks [
22]. The lower convolutional layers in the CNNs only learn low-level semantic features, such as edges and colors, which are identical in airport images and normal natural images, as shown in
Figure 4. The higher convolutional layers extract more complex and abstract features, such as shapes and other combined features, and the final convolutional layers and fully connected layers play decisive roles in various tasks. Therefore, in new airport detection tasks, the parameters of the lower convolutional layers in the pretraining model remain unchanged or are iterated at a small learning rate to ensure that the common features previously learned can be transferred to a new task. In this study, the pretraining network VGG16 [
23] in ImageNet [
24], a large-scale recognition database, is used to initialize the weight parameters of the shared convolution layers. Then, the airport database is used to perform fine-tuned training. The result shows that transfer learning using the initial values of VGG16 is very effective.
2.2.2. Cascade Region Proposal Networks
The ideal region proposal method is to generate as few candidate boxes as possible but to cover every target in the image, while a large number of background regions still exist in the airport candidate boxes generated by the RPNs. The performance can be enhanced by reducing the number of candidate boxes generated by clustering [
25], and the quality of the candidate boxes can be improved by reordering the candidate boxes via the CNNs [
26]. These methods inspired us to adopt the strategy of “divide and conquer” to improve the RPNs, and we propose the cascade RPNs structure shown in
Figure 5.
Two standard RPNs are connected in tandem, of which the first generates candidate boxes using the correspondence between the sliding window and the anchor, and the second generates candidate boxes using the correspondence between the input candidate boxes and the anchors on the feature map. Based on the classification score of each candidate box, NMS is used after each RPN to further reduce redundancy. To match the network model with the airport detection task, the dimension and aspect ratio of the anchors in the RPNs are set based on the airport size and shape features in the dataset and experimental verification, as shown in
Table 1.
2.2.3. Multi-Threshold Detection Networks
The RoI feature vector is exported to the fully connected layer and ultimately outputted from two peer output layers. One outputs the prediction probability of the background and the object from the
category, and the other outputs the regression value of the detection box of the object from the
category
. Overall, loss function
is used in joint training.
where
,
,
and
are the classification loss, the regression loss of the detection box, the regression object value of the detection box, and the prediction object value of the category, respectively
in Equation (5) is the loss function of robustness, details of which can be found in reference [
14]. When using loss function
to train the candidate boxes, if the IoU of the candidate box and a certain manually tagged box is greater than the threshold of 0.5, then the candidate box is assigned to the category of manually tagged box
; otherwise,
; i.e., it falls into the background category, as shown in Equation (7).
In Equation (6), the classification loss simply divides all detection boxes into two categories and indiscriminately processes detection boxes with an IoU greater than the threshold value, which leads to poor final airport positioning accuracy. In fact, candidate boxes with a high IoU should be detected better than those with a low IoU. Airport detection is not only about pursuing a high recognition rate; the accuracy of airport positioning is equally important, and enhancing the positioning accuracy can improve the final airport detection rate. Therefore, in this study, the classification loss is improved. Specifically, classification loss is defined as the integral of
under IoU threshold
. For simplicity, a rectangular method is used to approximate the definite integral:
where
is the prediction object value of the category when the threshold is
;
is the prediction probability when the threshold is
; and
is the number of divisions in the interval of the definite integral. The term
is detailed in Equation (3), and the final loss function can be rewritten as follows:
where
for the threshold
and the prediction probability ultimately outputted by the network model is the average of
at various thresholds. We refer to our modified networks as “Multi-threshold” detection networks.
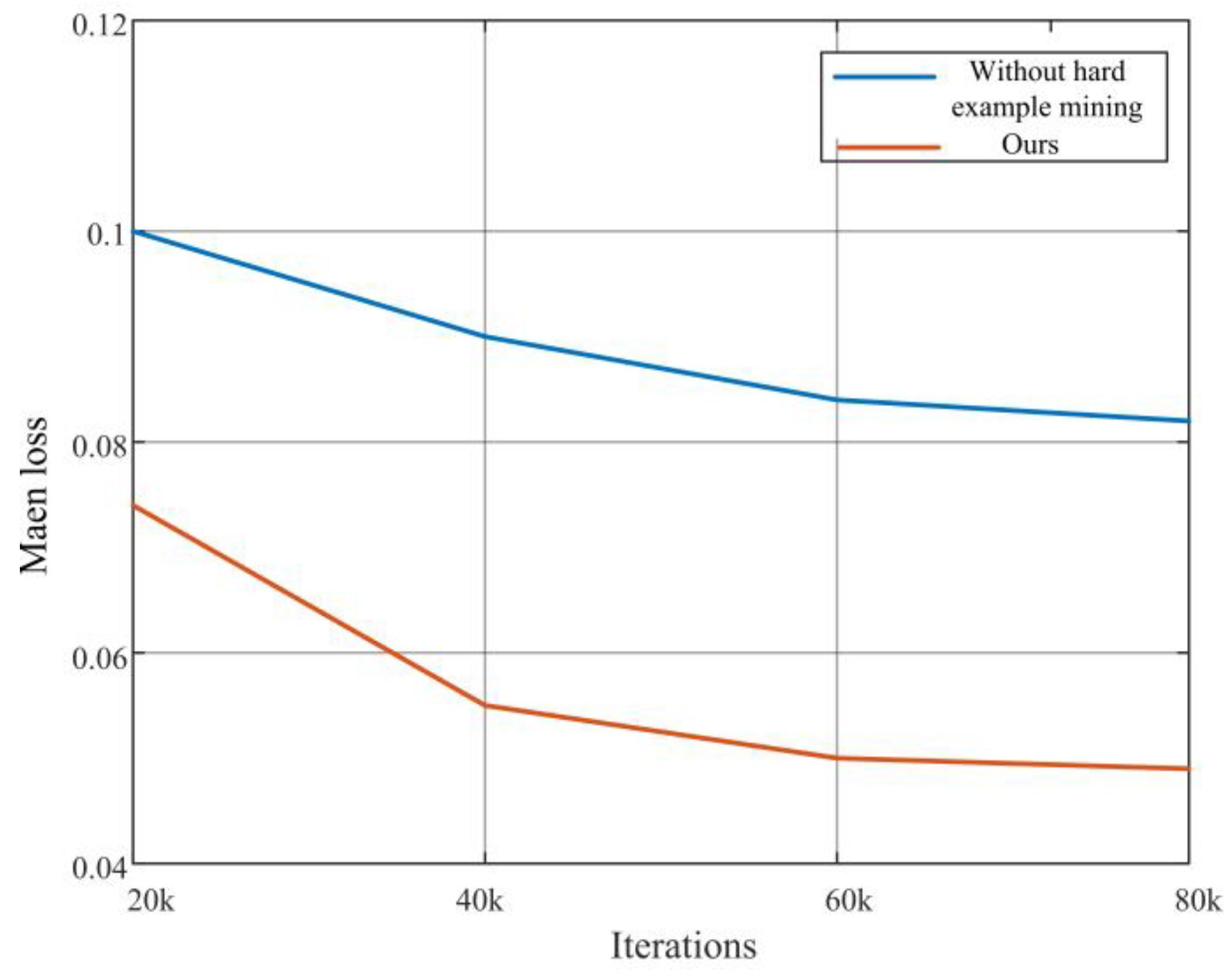
2.2.4. Hard Example Mining
The sample training set always contains a large proportion of easy examples and a few hard examples, of which the former have little training significance and the latter, characterized by diversity and high loss values, have a considerable impact on the classification and detection results. Utilizing these hard examples can enhance the discrimination ability of the network based on the object. The issue of category imbalance is not a new challenge, and the idea of dataset bootstrapping [
27] has been successfully applied in the training process of many detection tasks. This method is also known as hard example mining. Recently, the A-Fast-RCNN object detection model [
28], which uses generative adversarial nets to produce occlusion and deformation examples, is also regarded as an example mining approach. Example mining is most important for airports with limited data. Thus, in this study, the concept of hard example mining is employed to make example training more efficient. The overall structure of the method is shown in
Figure 6.
We propose a simple yet effective hard example mining algorithm for training detection networks. The alternating steps are: (a) for some period of time a fixed model is used to find new examples to add to the active training set; (b) then, the model is trained on the fixed active training set. More specifically, the original detection network is duplicated into two sets designated Network A and Network B, which share network parameters. Network A involves only forward operations, and Network B is a standard detection network with both forward and backward operations.
The flowchart of the hard example mining is shown in
Figure 7. First, for an input image at stochastic gradient descent (SGD) iteration, t, a convolutional (conv) feature map is computed by using the conv network. Second, the corresponding feature maps are generated for their respective candidate regions, instead of a sampled mini-batch, through RoI pooling layers, and then outputted to Network A for forward transfer and the calculation of the loss value. This step only involves RoI pooling layer, fully connected layers, and loss computation. The loss represents the current network’s execution of each candidate region. Third, the hard example sampling module sorts the loss values of all the candidate regions and selects
examples for which the current network performs worst. Finally,
hard examples are outputted to Network B for normal model training. The input to Network A is all the candidate regions
of
images rather than the mini-batch
, and the batch input to Network B is
. Most forward calculations are shared between candidate regions, so the extra calculations required to forward all candidate regions are relatively small. In addition, since only a small amount of candidate regions is selected to update the model, the backward pass is not more expensive than before.
2.3. Network Training
To overcome training difficulty issues and avoid overfitting due to small sample sizes, the weights of the shared convolutional layers are initialized with the pretraining network VGG16, and the weights of the remaining layers are initialized based on a Gaussian distribution with a mean of 0 and a standard deviation of 0.01. The basic learning, momentum and weight decay coefficients of the network are 0.001, 0.9, and 0.0005, respectively. To enable the sharing of convolutional layers between the cascade RPNs and multi-threshold detection networks, an alternate optimization strategy is adopted to train the entire network in four steps.
Step 1 involves training the cascade RPNs and outputting the airport candidate box sets. After the initialized candidate boxes of the pretraining network VGG16 generate network weights, end-to-end fine-tune training is performed. After the training is completed, the airport candidate box sets are outputted.
Step 2 involves training the candidate box detection network. After the network weights are tested by the initialized candidate boxes of network VGG16, the airport candidate boxes generated in Step 1 are used to train the multi-threshold detection network. At this time, the two networks do not share convolutional layers.
Step 3 involves fine tuning the cascade RPNs and outputting the airport candidate box sets. The cascade RPNs are initialized using the final weights of the detection network obtained from Step 2 to set the weights of the shared convolutional layers, and only the layers unique to the cascade RPNs are fine tuned. After training is completed, the airport candidate box sets are outputted. During this process, the two networks share convolutional layers.
Step 4 involves fine tuning the training network model again. The weight parameters of the shared convolutional layers and cascade RPNs are kept constant, the fully connected layers of the detection network are tuned using the airport candidate boxes outputted in Step 3, and ultimately, the convolution layer-sharing airport detection network is obtained.
5. Conclusions
In this study, we designed an end-to-end airport detection method for remote sensing images using a region-based convolutional neural network as the basic framework. In this method, transfer learning of the pretraining network is used to solve the problem of inadequate airport image data, and the cascade RPNs improve the quality of the candidate boxes through further screening and optimizing the candidate boxes. After fully accounting for the influence of the IoU training threshold on the positioning accuracy, the multi-threshold detection networks are proposed, which ultimately enhance DR. Mining hard examples makes training more efficient, and the sharing of convolutional layers between the cascade RPNs and the detection networks during model training greatly improves the efficiency of airport detection. The experimental results show that the method proposed in this study can accurately detect various types of airports in complex backgrounds, and that it is superior to existing detection methods. A gap remains between the processing speed and instantaneity, which will be the focus of our future studies. Nonetheless, the proposed method is of theoretical and practical significance for real-time and accurate airport detection.
In this paper, using the Faster R-CNN algorithm as the basic framework, we achieved state-of-the-art detection accuracy and computational speed. In addition, there would be value in testing other CNN-based object detection algorithms, such as You Only Look Once (YOLO) and Single Shot Detector (SSD). This will also be a topic of our future research work.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}