1. Introduction
Remote-sensing technology is a kind of high and new technology for air to ground observation, whose primary use is military. However, with the development of economy and the improvement of living standard, it has been gradually used in civil field. By observing the ground at high altitude, the ground object information is obtained and analyzed systematically. Remote-sensing (RS) images are widely used for land cover classification, target identification and thematic mapping from local to global scales owing to its technical advantages such as multi-resolution, wide coverage, repeatable observation and multi/hyperspectral-spectral records. In view that the remote-sensing image tagging samples quantity is less, the traditional image classification method is also suitable for remote-sensing image classification task, such as image feature representation algorithm and small sample classification algorithm.
As a core problem in image-related applications, image-feature representation [
1,
2] exhibits a trend of transference from handcrafted to learning-based methods. Specifically, most of the early literature is based on handcrafted features. The most classical method is the bag-of-visual-words (BoVW) [
3] model. It is built with a histogram of vector-quantized local features and lacks the spatial distribution of local features in the image space. Then, sparse coding [
4] was reported to outperform BoVW in this area. Sparse coding permits a linear combination of a small number of codewords, while in BoVW, one local feature corresponds to only one codeword. Sparse coding also lacks the spatial orders of local features. Handcrafted features are limited in their ability to extract robust and transferable feature representation for image scene classification, and ignore many effective cues hiding in the image. In 2006, Hinton [
5] pointed out that deep neural networks could learn more profound and essential features of objects of interest, which led to tremendous performance enhancement. After that, many attempts have been made to utilize deep-learning methods to feature learning in remote-sensing images. As one of the most popular deep-learning models in image processing, convolutional neural networks (CNNs) currently dominate the computer-vision literature, achieving state-of-the-art performance in almost every topic to which they are applied.
Lazebnik [
6] introduced the spatial pyramid matching (SPM) model to add spatial information of local features to the BoVW model. The proposed method combines together subregion representation. The weights to evaluate the representation of the different subregions are fixed. The SPM model achieved excellent performance for image classification. Therefore, many studies have attempted to embed the spatial orders of local features into BoVW (e.g., Reference [
7]). To embed spatial orders into sparse codes, Reference [
8] considered a pair of spatially close features as a new local feature followed by sparse coding. BoVW and sparse codes are the sparse representations of the distribution of the local descriptors in the feature space. Dense representation of the distribution has been studied. Reference [
9] proposed the Global Gaussian (GG) approach that estimates distribution as a Gaussian distribution and builds the feature by arranging the elements of the mean and covariance of the Gaussian. Similarly, Reference [
10], which is a general GG form, proposed to embed local spatial information into a feature by calculating the local autocorrelations of any local features. In spatial pooling, Spatial Pyramid Representation (SPR) [
6] is popular for encoding the spatial distribution of local features. SPM with BoVW have been remarkably successful in terms of both scene and object recognition. As for sparse codes, state-of-the-art variants of the spatial pyramid model with linear SVMs work surprisingly well. The variations of sparse codes [
11] also utilize SPM.
Another core problem is to construct a visual classifier. Visual-classifier design is a fundamental issue in computer vision. Recently, representation-residual-based classifiers have attracted more attention due to the emerging paradigm of compressed sensing (CS). Representation-residual-based classifiers first obtained the representation of the test sample, and then measured the residual error from the training samples of each class. Zhang et al. [
12] proposed the collaborative representation-based classification (CRC) algorithm by using collaborative representation (
norm regularizer). Many researchers from the field of remote sensing are attracted by the superior performance of CRC. Li et al. [
13] proposed a joint collaborative-representation (CR) classification method that uses several complementary features to represent an image, including spectral value and spectral gradient features, Gabor texture features, and DMP features. In Reference [
14], Liu et al. introduced a hybrid collaborative representation with a kernels-based classification method (Hybrid-KCRC) that combined collaborative representation with class-specific representation, and improved classification rate in RS image classification.
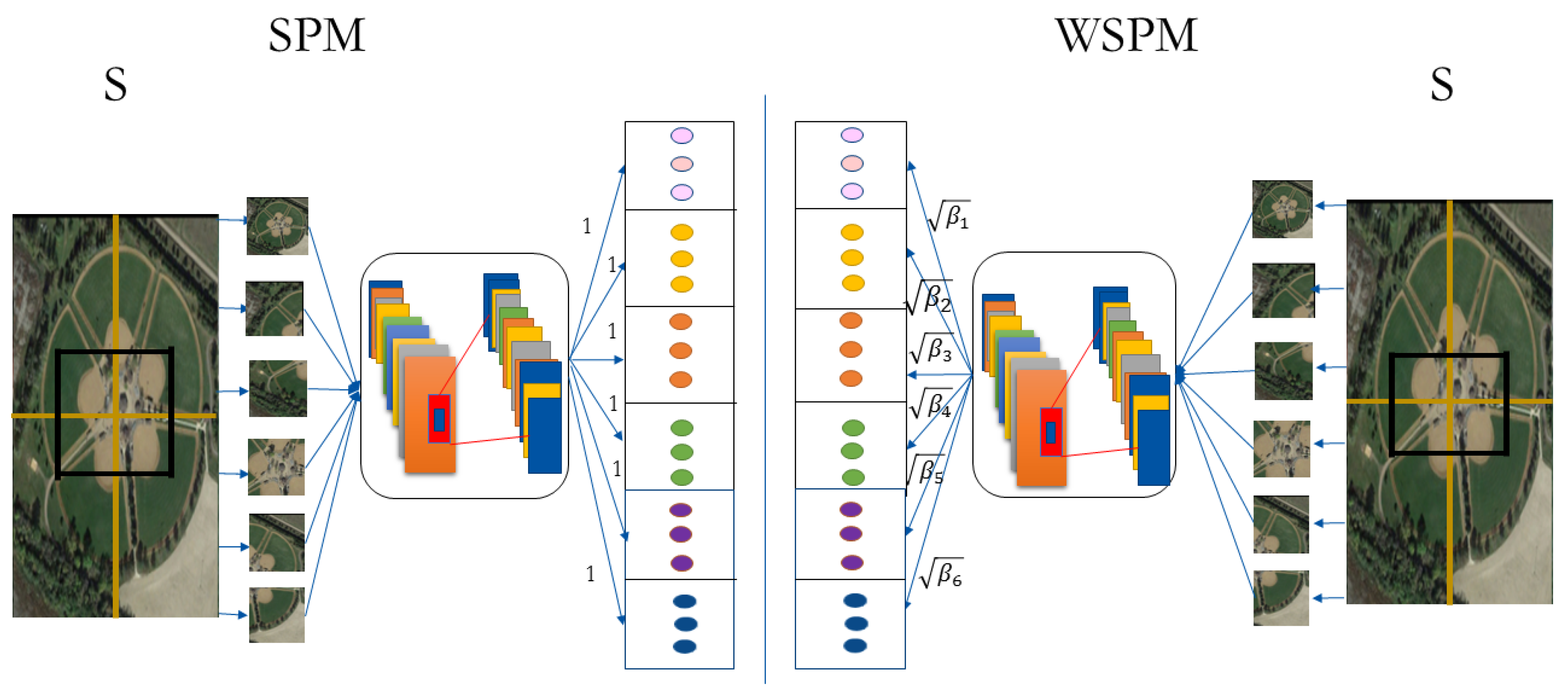
In this paper, we introduce a weighted spatial pyramid matching collaborative representation based classification (WSPM-CRC) method. The proposed method is capable of improving the performance of classifying remote-sensing images by embedding spatial pyramid matching to CRC. Moreover, we also combined the CRC method with the weighted spatial pyramid matching approach to learn the weights of different subregions in representing an image to further enhance classification performance. The scheme of our proposed method is listed in
Figure 1. Our work’s main focuses are threefold.
We introduce a spatial pyramid matching collaborative representation based classification method that embeds spatial pyramid matching to CRC.
To improve conventional spatial pyramid matching, where weights to evaluate the representation of different subregions are fixed, we learn the weights of different subregions.
The proposed spatial pyramid matching collaborative representation based classification method was evaluated on four benchmark remote-sensing-image datasets, and achieved state-of-the-art performance.
The rest of the paper is organized as follows.
Section 2 overviews several classical visual-recognition algorithms and proposes our spatial pyramid matching collaborative representation based classification. Then, experiment results and analysis are shown in
Section 3. Discussion about the experiment results and the proposed method are outlined in
Section 4. Finally, conclusions are drawn in
Section 5.
2. Proposed Method
In this section, we review related work about CRC. Then, we introduce work about SPM. Finally, we focus on introducing the WSPM.
2.1. CRC Overview
Zhang et al. [
12] proposed CRC, for which all training samples are concatenated together as the base vectors to form a subspace, and the test sample is described in the subspace. To be specific, given training samples
,
represents the training samples from the
class,
C represents the number of classes,
represents the number of training samples in the
class (
), and
D represents the sample dimensions. Suppose that
is a test sample, the objective function of CRC is as follows:
Here, , , , is the regularization parameter to control the tradeoff between fitting goodness and collaborative term (i.e., multiple entries in X participating in representing the test samples). The role of the regularization term is twofold. First, compared with no penalty term, norm stabilizesthe least-squares solution because matrix X may not be full-rank. Second, it introduces a certain amount of “sparsity” to collaborative representation , and indicates that it is the collaborative representation but not the norm sparsity that makes sparsity powerful for classification. Collaborative-representation-based classification effectively utilizes all training samples for visual recognition, and the objective function of CRC has analytic solutions.
2.2. Spatial Pyramid Matching Model
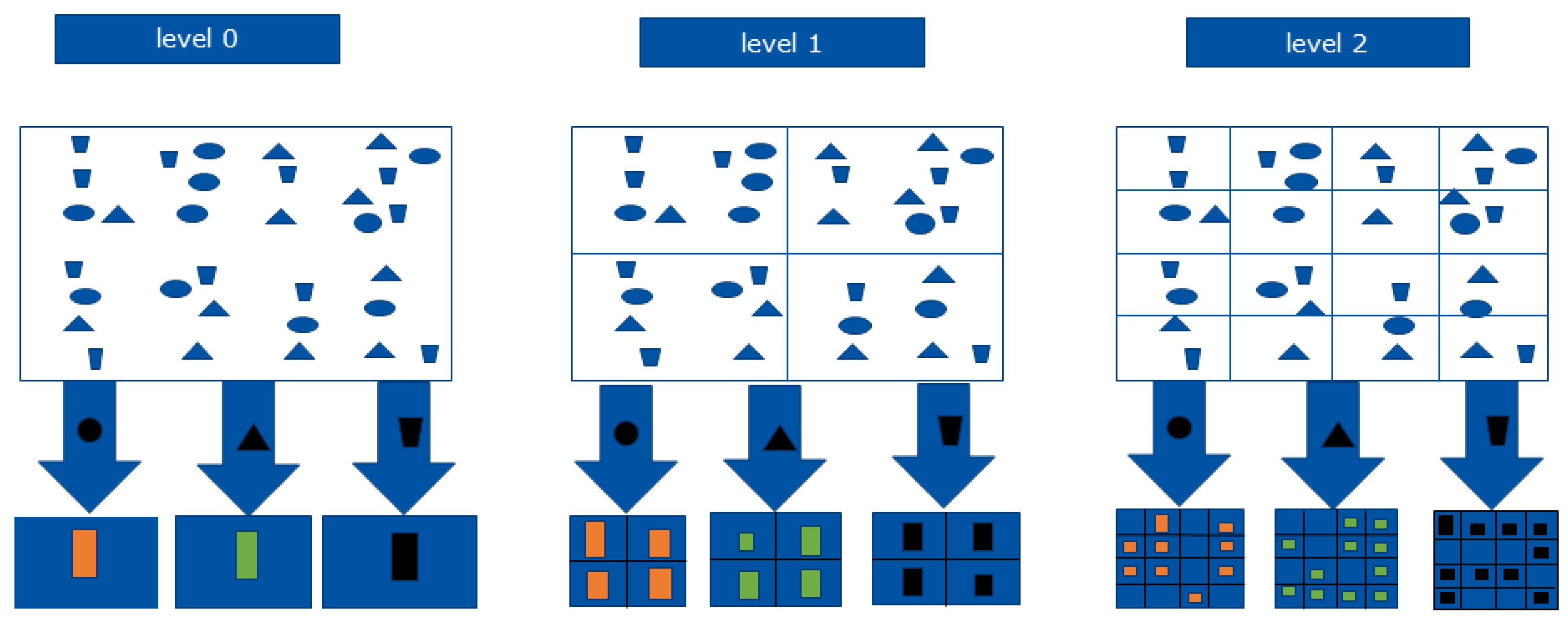
Svetlana Lazebnik et al. [
6] proposed the spatial pyramid matching algorithm to compensate for the lack of spatial information in representing an image. The SPM scheme is shown in
Figure 2. The image can be represented by three levels. At each level, the image is split into 1, 4, 16 segments. For each subimage, the feature is independently extracted. All features are concatenated to form a feature vector to describe the image. In this paper, we split the image into two levels. For each level, the image is split into 1 and 5 segments (left-upper, left-lower, right-upper, right-lower, center) as shown in
Figure 1. Assume
as the feature extracted from an image. The inner product of two image features
x and
y can be expressed as follows:
where
. The SPM model considers that each subimage equally contributes to represent the image. The superior performance of visual recognition is often achieved with the spatial pyramid method, which is to obtain spatial information of images by the statistical distribution of image-feature points at different resolutions. The image is divided into gradually fine grid sequences at all levels of the pyramid. However, the weights to evaluate the representation of different features are fixed.
2.3. Weighted Spatial Pyramid Matching Collaborative Representation
In this paper, we propose the weighted spatial pyramid matching collaborative representation based classification method to learn the weights of different features in representing an image. The weight of each subregion can be learned to achieve superior performance. We assume that
is the weighted feature extracted from an image. Then, the mode of weighted spatial pyramid matching is as follows:
Here, we take both strategies ( and ) into consideration, and both strategies are popular. is adopted because the objective function with constraint is easier to solve.
The objective function of our proposed weighted spatial pyramid matching collaborative representation is as follows:
2.4. Optimization of Objective Function
To optimize Equation (
4), it can be transformed as follows:
When is fixed, the partial derivative of to s is
Let , we can obtain the value of s,
With a fixed
s, to optimize objective Equation (
5), a Lagrange multiplier was adopted.
To optimize Equation (
8), it can be transformed as follows:
The partial derivative of to is
The partial derivative of to is
Let
be 0; the value of
with unknown parameter
is as follows:
Let be 0; the value of can be obtained.
2.5. Weighted Spatial Pyramid Matching Collaborative Representation Based Classification
After obtaining collaborative code
s, the weighted spatial pyramid matching collaborative representation based classification is to find the minimum value of the residual error for each class:
where,
represents features in the
class.
is the label of the testing sample, and
y belongs to the class that has minimal residual error. The learned weights hinges on a well-known idea: the reweighting scheme and the latter were used to learn Bayesian networks [
15]. The procedure of weighted spatial pyramid matching collaborative representation based classification is shown in Algorithm 1.
| Algorithm 1: Algorithm for spatial pyramid matching collaborative representation based classification. |
| Require: Training samples , , and test sample y |
| 1: Initial and s |
| 2: Update s by Equation (7)
|
| 3: Update by Equation (12)
|
| 4: Go back to update s and until the condition of convergence is satisfied
|
| 5: for ; ; do |
| 6: Code y with the weighted spatial pyramid matching collaborative representation algorithm.
|
| 7: Compute the residuals |
| 8: end for |
| 9: |
| 10: return |
3. Experiment Results
In this section, we show our experiment results on four remote-sensing-image datasets. To illustrate the significance of our method, we compared it with several state-of-the-art methods. In the following section, we first introduce the experiment settings. Then, we illustrate the experiment results on each aerial-image dataset.
3.1. Experiment Settings
To evaluate the effectiveness of the proposed SPM-CRC and WSPM-CRC, we applied it to the RSSCN7 [
16], UC Merced Land Use [
17], WHU-RS19 [
18], and AID datasets [
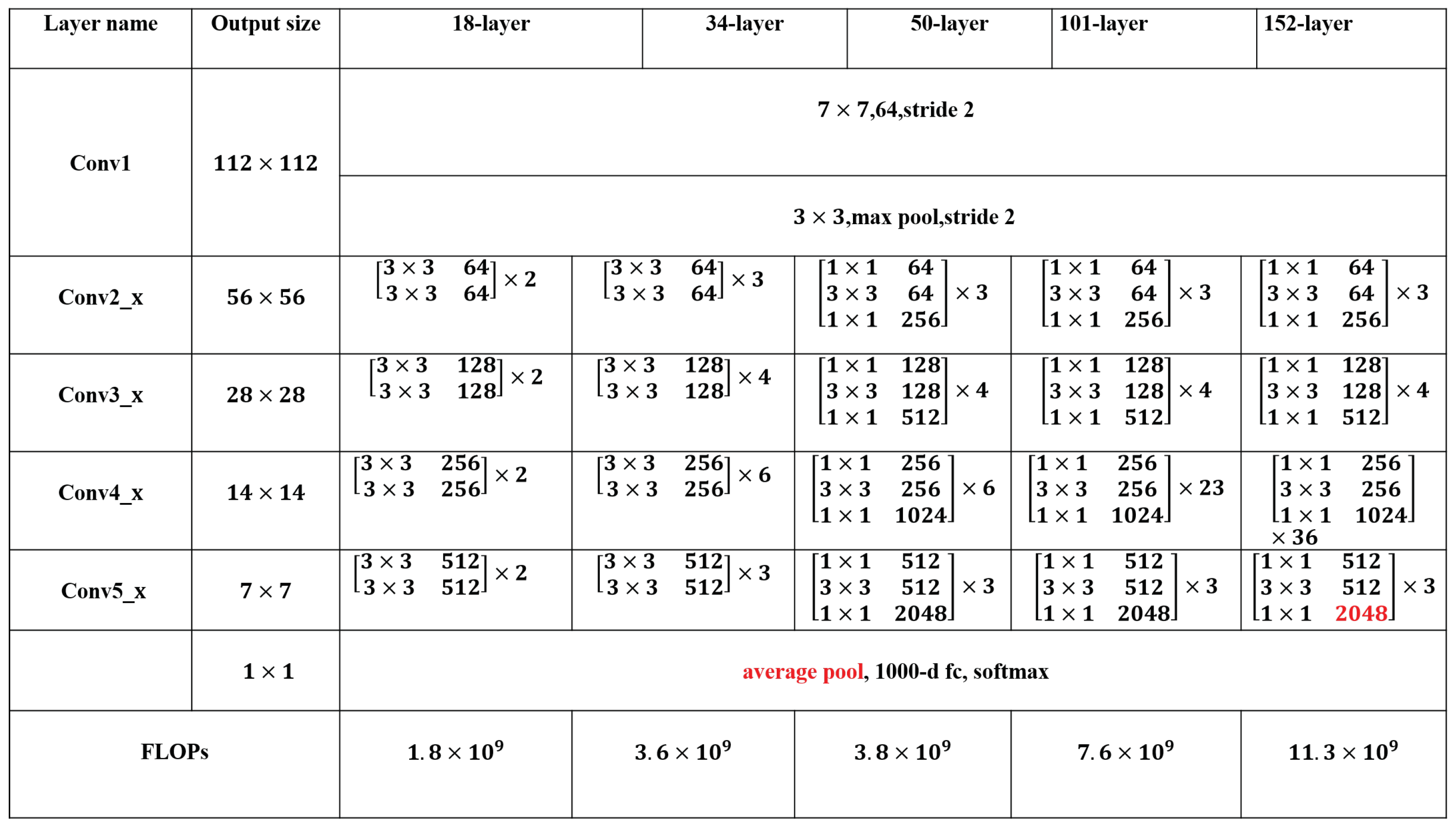
19]. For all datasets, we used two pretrained CNN models, i.e., ResNet [
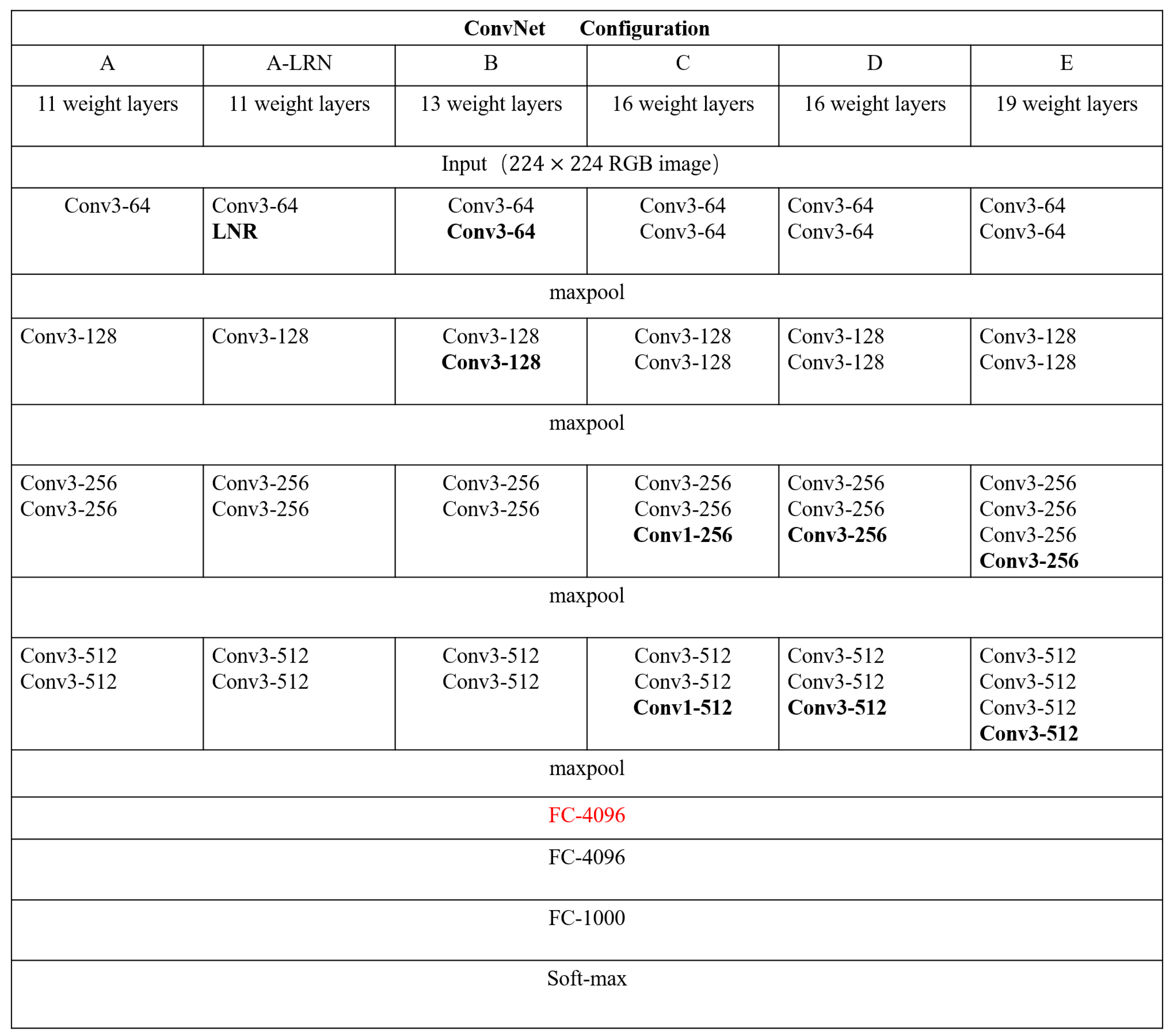
20] and VGG [
21], to extract the feature. For the ResNet model, the ’pool5’ layer was utilized as the output layer to extract a 2048-dimensional vector for each image (as shown in
Figure 3). For the VGG model, the ’fc6’ layer was utilized as the output layer to extract a 4096-dimensional vector for each image (As shown in
Figure 4). Spatial pyramid matching is utilized, where the image is split into two layers, each of which has 1 and 5 segments, respectively (As shown in
Figure 1). An image is represented as the concatenation of each segment with length 12,288-dimensional vector and 24,576-dimensional vector, respectively. The final feature of each image is
-normalized for better performance [
19]. To eliminate randomness, we randomly (repeatable) split the dataset into the train set and test set for 10 times, respectively. Average accuracy was recorded.
The proposed SPM-CRC and WSPM-CRC algorithms are compared with other classification algorithms, including nearest-neighbor (NN) classification, LIBLINEAR [
22], SOFTMAX, CRC [
12], hybrid-KCRC [
14], and SLRC-L2 [
23].
3.2. Experiment on UC Merced Land-Use Dataset
The UC Merced Land Use Dataset [
17] consists of 2100 land-use images in total, collected from aerial orthoimages with a pixel resolution of one foot. The original images were downloaded from the United States Geological Survey National Map of 20 U.S. regions. The pixel resolution of this public-domain imagery was 1 foot. Each image measured
pixels. These images were manually selected into 21 classes: agricultural, airplane, baseball diamond, beach, buildings, chaparral, dense residential, forest, freeway, golf course, harbor, intersection, medium-density residential, mobile-home park, overpass, parking lot, river, runway, sparse residential, storage tanks, and tennis courts. In
Figure 5, we list several samples from this dataset.
3.3. Parameter Tuning on UC Merced Land-Use Dataset
For the UC Merced Land Use Dataset, we randomly chose 20 images as the training samples and testing samples from each category, respectively. Only one parameter in the objection function of the SPM-CRC and WSPM-CRC algorithms needed to be specified. is an important parameter in the SPM-CRC and WSPM-CRC algorithms, which is used to adjust the tradeoff between reconstruction error and collaborative representation. Additionally, is tuned to achieve the best accuracy. For the feature extracted from both pretrained models, the optimal parameter is , for SPM-CRC and WSPM-CRC, respectively.
3.3.1. Confusion Matrix on UC Merced Land-Use Dataset
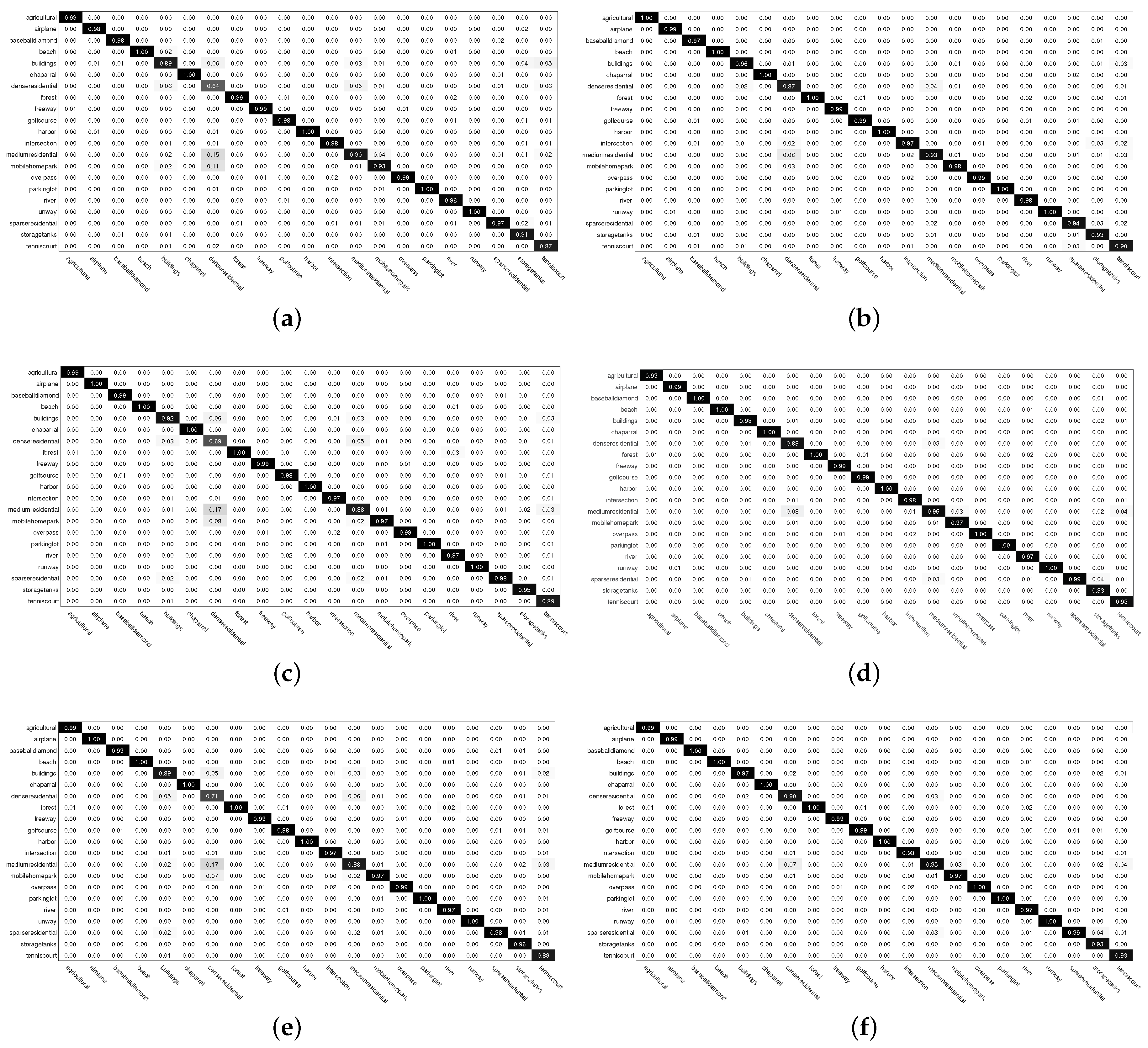
To further illustrate the superior performance of our proposed WPM-CRC method, we evaluated the classification rate per class of our method on the UC-Merced dataset using a confusion matrix. In this subsection, we randomly chose 80 images per class as training samples, and 20 images per class as testing samples. To eliminate randomness, we also randomly (repeatable) split the dataset into a train set and test set for 10 times, respectively. The confusion matrices are shown in
Figure 6. From
Figure 6, we can draw the following conclusions: (1) the ResNet model achieved better performance than the VGG model in most categories; (2) CRC with an SPM scheme achieved better performance than that without an SPM scheme; (3) compared with the SPM-CRC method, the WSPM-CRC method achieved better performance on the dense residential category.
3.3.2. Comparison with Several Classical Classifier Methods on UC Merced Land-Use Dataset
In this subsection, 20 and 20 samples per class were used for training and testing, respectively.
Table 1 illustrates the effectiveness of SPM-CRC and WSPM-CRC for classifying images. For the ResNet model, when
is
, WSPM-CRC algorithm achieves the highest accuracy of
. This is
higher than the CRC method, and
higher than the SPM-CRC method. For the VGG model, the WSPM-CRC algorithm exceeds the CRC method by
, and the SPM-CRC method by
.
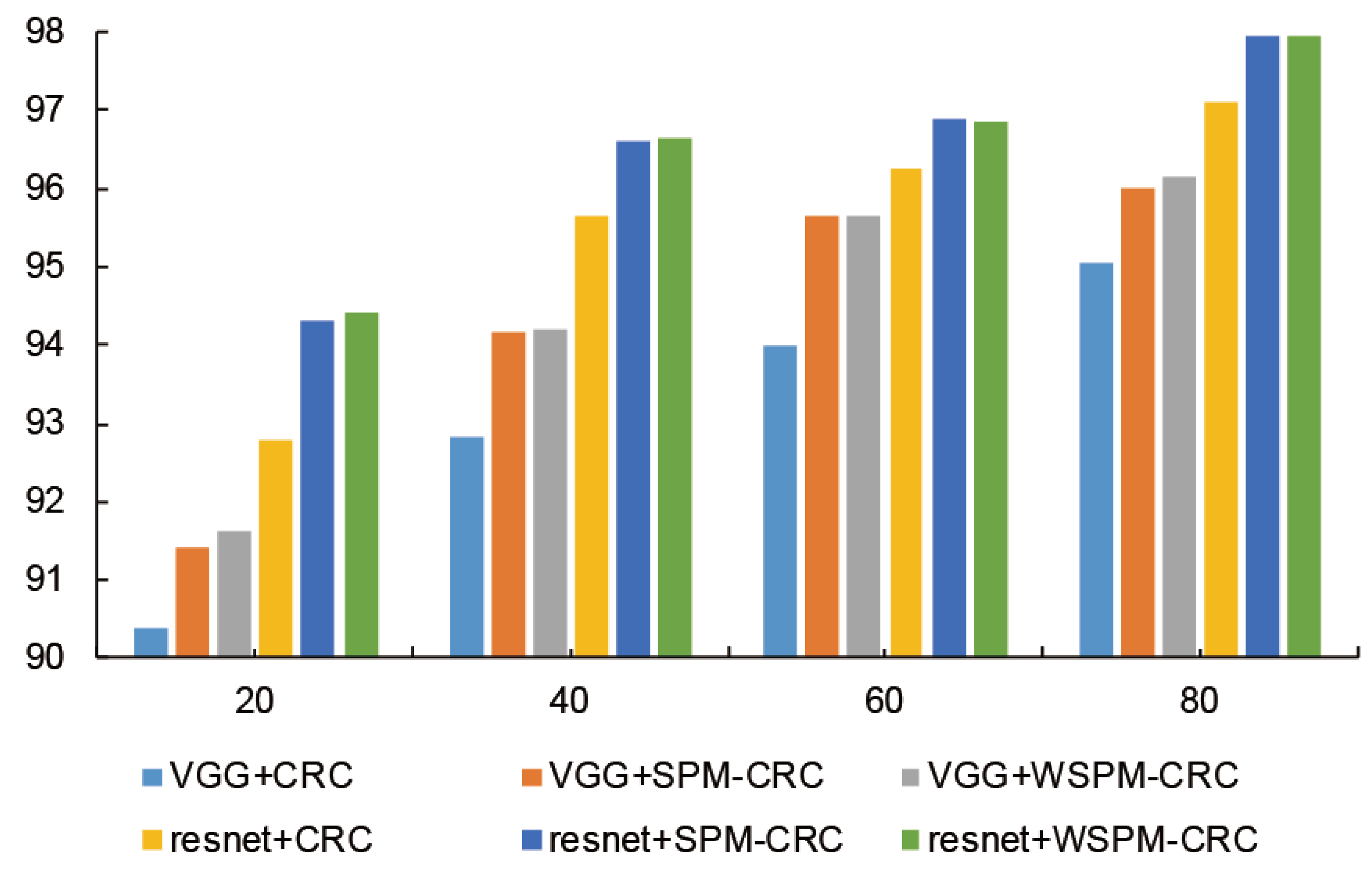
We increased the number of training samples in each category to evaluate the performance of our proposed WSPM-CRC method.
Figure 7 shows the classification rate on the UC-Merced dataset with 20, 40, 60, and 80 training samples in each category. From
Figure 7, we can conclude that our proposed WSPM-CRC method achieves superior performance to the CRC and SPM-CRC methods.
3.3.3. Comparison with State-of-the-Art Approaches
For comparison, we referred to previous work in the literature [
24,
25] and randomly selected
of images of each class as the training set, and the remaining
as the test set. Several baseline methods (e.g., liblinear and CRC) and state-of-the-art remote-sensing image-classification methods were used as the benchmark.
Table 2 shows the overall classification-rate accuracy of various remote-sensing image-classification methods. First, we compared the SPM-CRC and WSPM-CRC methods with liblinear and CRC. By comparing SPM-CRC and WSPM-CRC with the two baseline methods above, we found that the performance of SPM-CRC and WSPM-CRC was better than the two baseline methods. It is worth noting that the proposed WSPM-CRC is an improvement on the CRC method. Second, we compared SPM-CRC and WSPM-CRC with state-of-the-art remote-sensing image-classification results. Obviously, SPM-CRC and WSPM-CRC achieved the best performance. It should be noted that the feature utilized by CNN-W + VLAD with SVM, CNN-R + VLAD with SVM, and CaffeNet + VLAD is more effective than the feature extracted directly from the CNN (e.g., CaffeNet method, with
, versus CaffeNet + VLAD method, with
).
3.4. Experiment on RSSCN7 Dataset
RSSCN7 dataset consists of a total of 2100 land-use images collected from Google Earth. These images were manually selected into 7 classes: grassland, forest, farmland, industry, parking lot, residential, and river and lake region, where each class contains 400 images.
Figure 8 shows several sample images from the dataset.
First, for comparison, we randomly selected 100 images from each class as the training set, and 100 more images as the testing set. Optimal parameter
is
,
for ResNet + SPM-CRC, and ResNet + WSPM-CRC, respectively. Optimal parameter
is
,
for VGG+SPM-CRC, and VGG + WSPM-CRC, respectively. Recognition accuracy is shown in
Table 3. The best performance is marked with the bold. From
Table 3, we can see that the SPM-CRC and WSPM-CRC methods outperformed other conventional methods. The WSPM-KCRC algorithm achieved the highest accuracy with
.
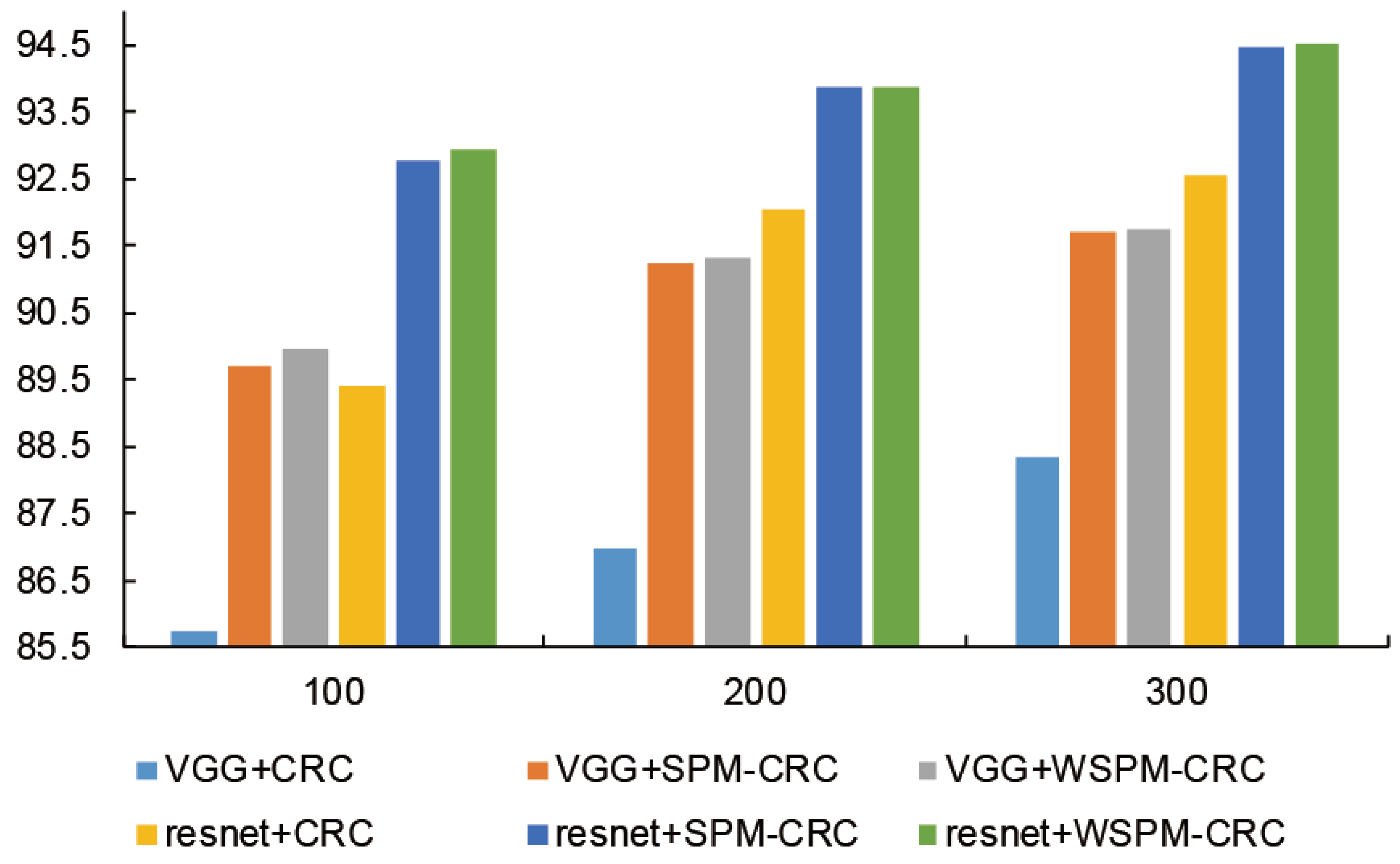
Second, we increased the number of training samples in each category to evaluate the performance of the SPM-CRC and WSPM-CRC methods.
Figure 9 shows the classification rate on the RSSCN7 dataset with 100, 200, and 300 training samples in each category. From
Figure 9, we found that both the SPM-CRC and WSPM-CRC method achieved superior performance to the baseline methods.
3.5. Experiment on the WHU-RS19 Dataset
WHU-RS19 dataset consists of 1005 aerial images in total, collected from Google Earth imagery. These images were manually selected into 19 classes.
Figure 10 shows several sample images from the dataset.
For comparison, we randomly selected 20 images from each class as the training set, and 20 more images as the testing set. Optimal parameter
is
,
for ResNet + SPM-CRC, and ResNet + WSPM-CRC, respectively. Optimal parameter
is
,
for VGG + SPM-CRC, and VGG + WSPM-CRC, respectively. Recognition accuracy is shown in
Table 4. The best performance is marked with the bold. From
Table 4, we can see that the SPM-CRC and WSPM-CRC methods outperformed other conventional methods.
3.6. Experiment on the AID Dataset
The AID dataset is a new large-scale aerial-image dataset composed of 30 aerial-scene types: airport, bare land, baseball field, beach, bridge, center, church, commercial, dense residential, desert, farmland, forest, industrial, meadow, medium residential, mountain, park, parking, playground, pond, port, railway station, resort, river, school, sparse residential, square, stadium, storage tanks and viaduct and collected from Google Earth imagery. In addition, the AID dataset consists of a total of 10,000 images. In
Figure 11, we show several images of this dataset.
For comparison, we randomly selected 20 images from each class as the training set and 20 more images as the testing set. OPptimal parameter
is
,
for ResNet + SPM-CRC, and ResNet + WSPM-CRC, respectively. Optimal parameter
is
,
for VGG + SPM-CRC, and VGG + WSPM-CRC, respectively. Recognition accuracy is shown in
Table 5. The best performance is marked with the bold. From
Table 5, we can see that the WSPM-CRC algorithm outperformed other conventional methods. The WSPM-CRC algorithm achieved the highest accuracy.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}