An Efficient Representation-Based Subspace Clustering Framework for Polarized Hyperspectral Images

 ,
,
Abstract
:
1. Introduction
2. Representation-Based Subspace Clustering for Hyperspectral Images
2.1. Representation-Based Subspace Clustering
2.2. Representation-Based Subspace Clustering for HSIs
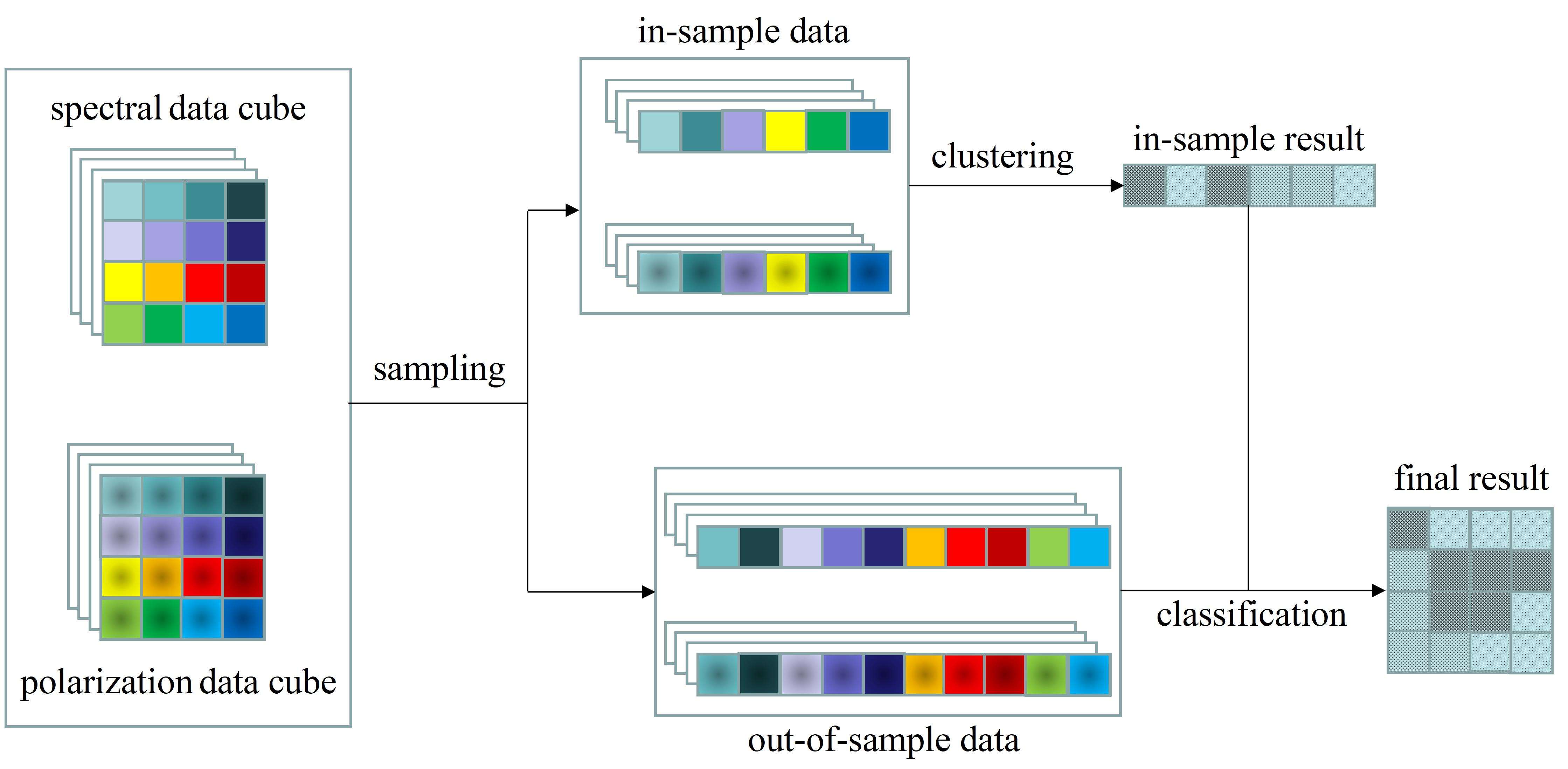
3. Proposed Efficient Representation-Based Subspace Clustering Framework for Polarized Hyperspectral Images
3.1. Representation-Based Clustering Framework for PHSIs
3.2. The Sampling-Clustering-Classification Strategy
| Algorithm 1 FPS-SSC, FPS-LRR and FPS-LSR |
| Input: Spectral dataset and polarized dataset ; the desired number of clusters , , , , , and . Main algorithm:
A 2-D matrix which records the labels of the clustering result of the polarized hyperspectral images. |
4. Experimental Results and Discussion
4.1. Instrument and Data
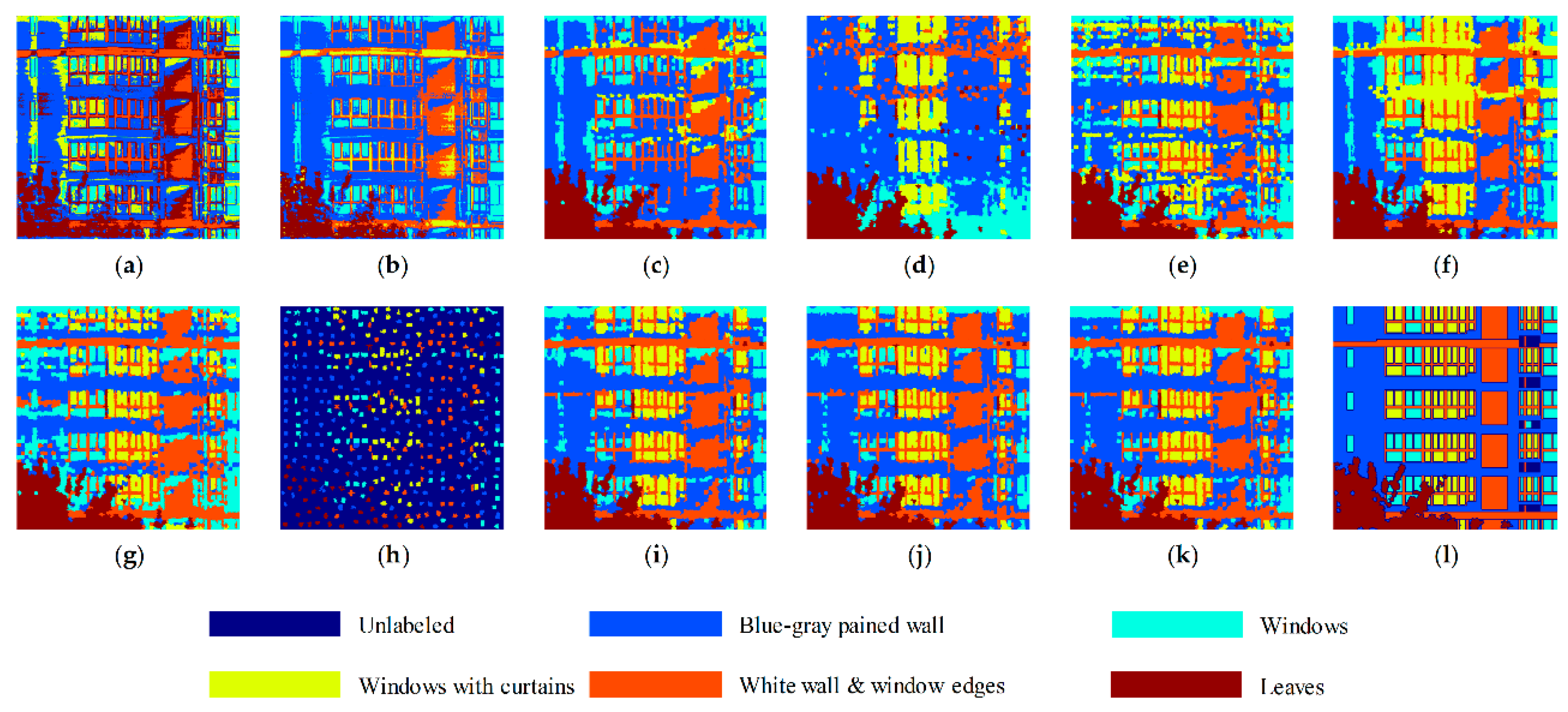
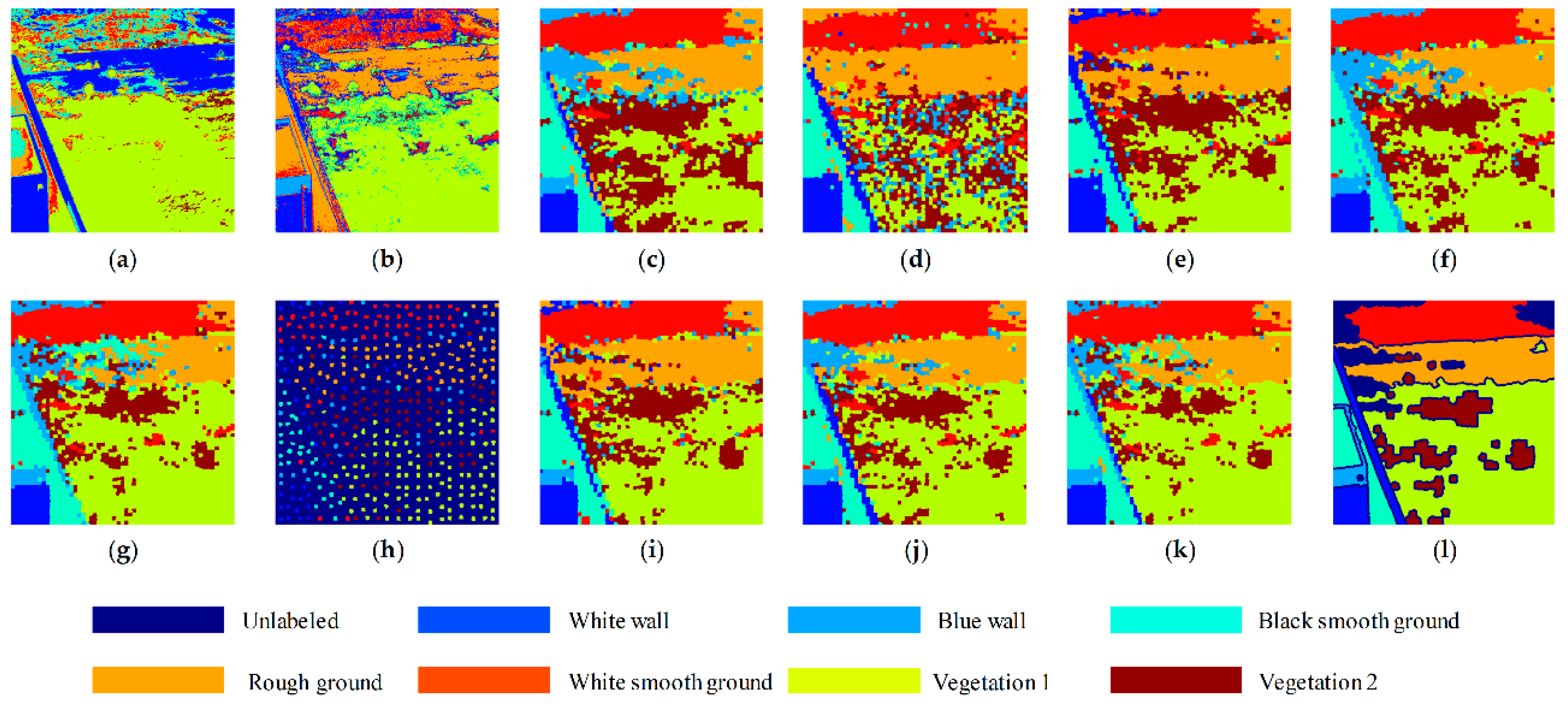
4.2. Clustering Results and Discussion
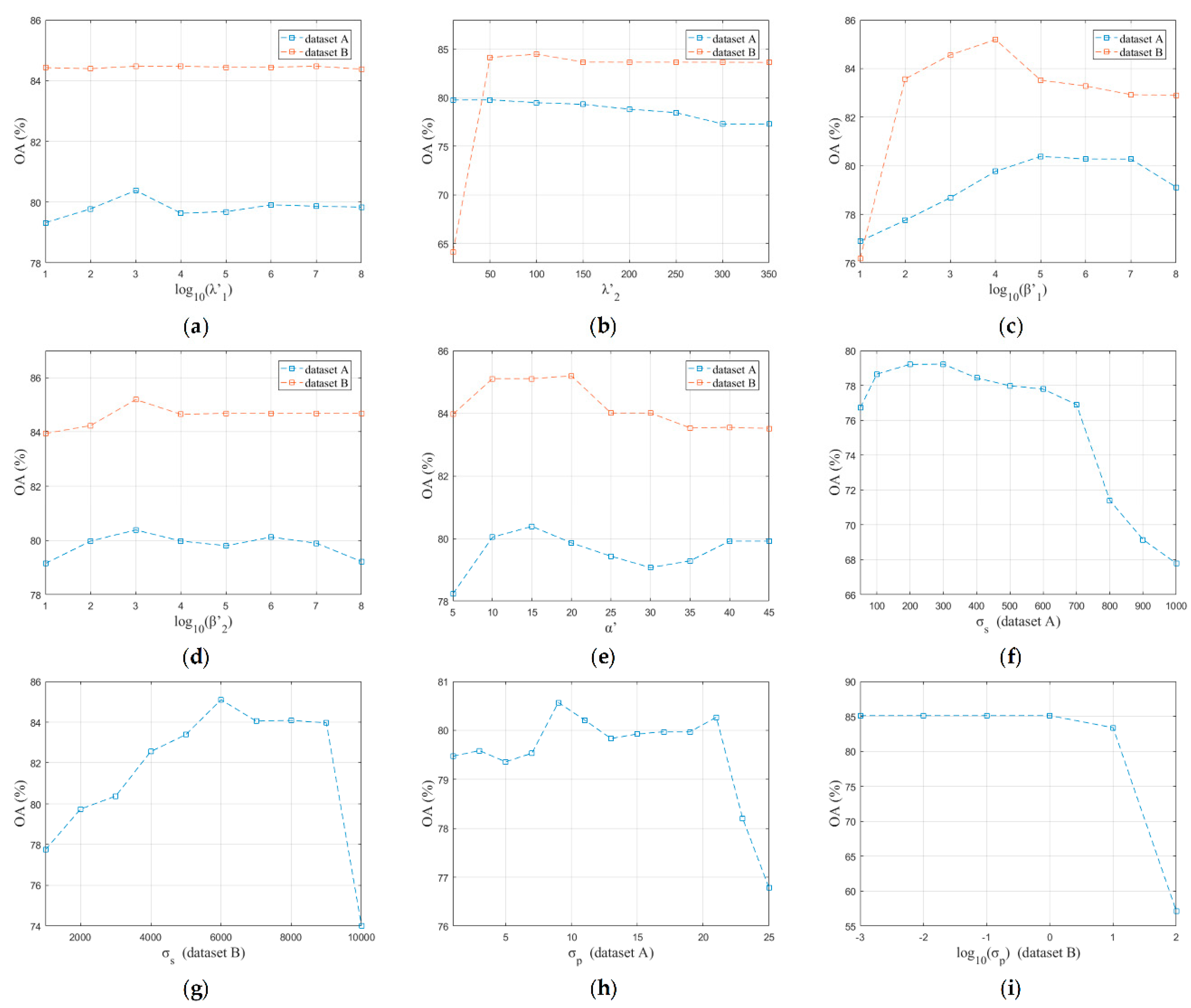
4.3. Sensitivity of Parameters
4.4. Selection of In-Sample Data and the Number of Superpixels
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Curran, P.J. A photographic method for the recording of polarized visible light for soil surface moisture indications. Remote Sens. Environ. 1978, 7, 305–322. [Google Scholar] [CrossRef]
- Deschamps, P.-Y. The POLDER mission: Instrument characteristics and scientific objectives. IEEE Trans. Geosci. Remote Sens. 1994, 32, 598–615. [Google Scholar] [CrossRef]
- Wolff, L.B. Polarization-based material classification from specular reflection. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 1059–1071. [Google Scholar] [CrossRef]
- Wolff, L.B.; Boult, T.E. Constraining object features using a polarization reflectance model. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 635–657. [Google Scholar]
- Palubinskas, G.; Datcu, M.; Pac, R. Clustering algorithms for large sets of heterogeneous remote sensing data. Proc. IGARSS 1999, 3, 1591–1593. [Google Scholar]
- Barni, M.; Garzelli, A.; Mecocci, A.; Sabatini, L. A robust fuzzy clustering algorithm for the classification of remote sensing images. Proc. IGARSS 2000, 5, 2143–2145. [Google Scholar]
- Paoli, A.; Melgani, F.; Pasolli, E. Clustering of Hyperspectral Images Based on Multiobjective Particle Swarm Optimization. IEEE Trans. Geosci. Remote Sens. 2009, 47, 4175–4188. [Google Scholar] [CrossRef]
- Li, S.; Zhang, B.; Li, A.; Jia, X. Hyperspectral imagery clustering with neighborhood constraints. IEEE Geosci. Remote Sens. Lett. 2013, 10, 588–592. [Google Scholar] [CrossRef]
- Bo, R.; Biao, H. Sparse Subspace Clustering-Based Feature Extraction for PolSAR Imagery Classification. Remote Sens. 2018, 10, 391. [Google Scholar] [Green Version]
- Murphy, J.M.; Maggioni, M. Unsupervised Clustering and Active Learning of Hyperspectral Images with Nonlinear Diffusion. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1829–1845. [Google Scholar] [CrossRef]
- Saranathan, A.M.; Parente, M. On Clustering and Embedding Mixture Manifolds using a Low Rank Neighborhood Approach. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3890–3903. [Google Scholar] [CrossRef]
- Chunmin, Z.; Qiwei, L. High throughput static channeled interference imaging spectropolarimeter based on a Savart polariscope. Opt. Express 2016, 24, 23314–23332. [Google Scholar]
- Elhamifar, E.; Vidar, R. Sparse subspace clustering: Algorithm, theory, and application. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.C.; Lin, Z.C.; Yu, Y. Robust subspace segmentation by low-rank representation. In Proceedings of the 27th International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 663–670. [Google Scholar]
- Canyi, L.; Hai, M. Robust and efficient subspace segmentation via least squares regression. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 347–360. [Google Scholar]
- Zhang, H.; Zhai, H.; Zhang, L.; Li, P. Spectral-spatial sparse subspace clustering for hyperspectral remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3672–3684. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P.; Plaza, A. A new sparse subspace clustering algorithm for hyperspectral remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 43–47. [Google Scholar] [CrossRef]
- Afonso, M.V.; Bioucas-Dias, J.M.; Figueiredo, M.A.T. An augmented Lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE Trans. Image Process. 2011, 20, 681–695. [Google Scholar] [CrossRef] [PubMed]
- Mota, J.F.; Xavier, J.W.F.; Aguiar, P.M.Q.; Puschel, M. D-ADMM: A communication-efficient distributed algorithm for separable optimization. IEEE Trans. Signal Process. 2013, 61, 2718–2723. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Proc. Adv. Neural Inf. Process. Syst. 2002, 2, 849–856. [Google Scholar]
- Zhang, G.; Jia, X.; Kwok, N.M. Super pixel based remote sensing image classification with histogram descriptors on spectral and spatial data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 4335–4338. [Google Scholar]
- Zhang, G.; Jia, X.; Hu, J. Superpixel-based graphical model for remote sensing image mapping. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5861–5871. [Google Scholar] [CrossRef]
- Radhakrishna, A. SLIC Superpixels Compared to State-of-the-art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar]
- Peng, X.; Zhang, L.; Yi, Z. Scalable sparse subspace clustering. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 430–437. [Google Scholar]
- Gillis, N.; Kuang, D.; Park, H. Hierarchical Clustering of Hyperspectral Images Using Rank-Two Nonnegative Matrix Factorization. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2066–2078. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Subject to | ||
|---|---|---|---|
| SSC [13] | |||
| LRR [14] | |||
| LSR [15] |
| Method | Classes | k-Means | R2NMF | SSC-S0 | SSC-DOLP | PS-SSC | PS-LRR | PS-LSR | FPS-SSC | FPS-LRR | FPS-LSR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AC (%) | Blue-gray painted wall | 69.93 | 81.67 | 73.24 | 10.05 | 63.18 | 62.94 | 57.14 | 80.70 | 84.31 | 79.63 |
| Windows | 50.94 | 76.90 | 79.74 | 64.75 | 72.99 | 81.28 | 84.29 | 70.18 | 59.60 | 64.40 | |
| Windows with curtains | 30.72 | 0.07 | 1.78 | 89.08 | 69.40 | 88.99 | 73.37 | 83.59 | 81.65 | 81.86 | |
| White wall and window edges | 45.94 | 52.18 | 65.71 | 13.50 | 64.60 | 66.12 | 76.52 | 71.93 | 75.85 | 76.77 | |
| Leaves | 73.60 | 77.07 | 98.58 | 97.46 | 97.69 | 96.12 | 95.44 | 96.34 | 94.87 | 96.04 | |
| OA (%) | 57.49 | 63.25 | 66.02 | 35.84 | 69.07 | 72.46 | 71.02 | 79.44 | 80.40 | 79.36 | |
| Running time (s) | 31.32 | 18.03 | 230.2 | 223.2 | 378.6 | 371.3 | 112.9 | 58.33 | 59.89 | 55.00 | |
| Method | Classes | k-means | R2NMF | SSC-S0 | SSC-DOLP | PS-SSC | PS-LRR | PS-LSR | FPS-SSC | FPS-LRR | FPS-LSR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AC(%) | White wall | 95.95 | 71.75 | 80.88 | 88.77 | 89.45 | 58.04 | 58.04 | 86.16 | 90.90 | 64.37 |
| Blue wall | 0 | 74.02 | 71.69 | 0.00 | 0.00 | 81.89 | 75.09 | 63.59 | 69.19 | 74.87 | |
| Black smooth ground | 14.57 | 0 | 93.29 | 91.26 | 87.92 | 91.43 | 92.46 | 91.30 | 91.39 | 93.26 | |
| White smooth ground | 90.56 | 84.58 | 90.89 | 87.01 | 89.49 | 91.73 | 91.15 | 89.20 | 91.96 | 91.80 | |
| Rough ground | 2.54 | 81.62 | 81.57 | 95.82 | 93.87 | 81.52 | 62.99 | 93.71 | 86.20 | 76.55 | |
| Vegetation 1 | 18.42 | 46.10 | 62.09 | 42.03 | 71.70 | 75.53 | 88.21 | 80.82 | 82.79 | 90.56 | |
| Vegetation 2 | 0.51 | 10.90 | 89.57 | 51.05 | 89.48 | 85.61 | 72.42 | 82.22 | 79.12 | 65.31 | |
| OA (%) | 50.11 | 64.61 | 75.70 | 64.04 | 80.68 | 80.20 | 81.46 | 85.10 | 85.28 | 84.58 | |
| Running time (s) | 11.05 | 8.35 | 235.2 | 219.2 | 369.6 | 373.2 | 115.6 | 55.45 | 59.81 | 44.03 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhang, C.; Mu, T.; Yan, T.; Chen, Z.; Wang, Y. An Efficient Representation-Based Subspace Clustering Framework for Polarized Hyperspectral Images. Remote Sens. 2019, 11, 1513. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11131513
Chen Z, Zhang C, Mu T, Yan T, Chen Z, Wang Y. An Efficient Representation-Based Subspace Clustering Framework for Polarized Hyperspectral Images. Remote Sensing. 2019; 11(13):1513. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11131513
Chicago/Turabian StyleChen, Zhengyi, Chunmin Zhang, Tingkui Mu, Tingyu Yan, Zeyu Chen, and Yanqiang Wang. 2019. "An Efficient Representation-Based Subspace Clustering Framework for Polarized Hyperspectral Images" Remote Sensing 11, no. 13: 1513. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11131513