1. Introduction
Time series consist of repeated observations of the same quantity of interest over time. Often, these quantities are sampled on a regular time step (e.g., every minute/hour/day/week/month/year) so that one can define the notion of “next observation” or “previous observation” within the time series. While classical time series analysis and time series model generally assume these particular and optimal conditions [
1]; such conditions are not always encountered in real-world applications, e.g., in remote sensing. Remote sensing time series are generally built with images acquired at very specific dates that depend on the revisit time of the sensor. There is often a trade-off between spatial resolution and revisit time so the issue is particularly seen for high (HR) and very high resolution (VHR) images [
2,
3]. In addition, it is also quite common for some of the observations to be discarded because of the poor data quality (e.g., cloud cover, haze). Finally, as Earth Observation (EO) scientists generally rely on different sensors, multivariate time series analyses can rapidly become complicated because not only are the acquisition dates not equidistant within each time series, but it is also unlikely to have a match between the different sets of acquisition dates. In particular, this has important practical impacts when we want to measure the similarity between time series.
The classical tool for quantifying the similarity between time series is to estimate the temporal structure of the time series through their empirical autocorrelation function and their empirical cross-correlation function [
4]. In both cases, the idea is to estimate the correlation coefficients (CC) between observations distant of a given time lag. For irregularly sampled time series, one can rely on slotting methods that consist of grouping pairs of observations in classes of time distance [
5]. The same approach is used for the estimation of covariograms and semivariograms for spatial data [
4]. Unfortunately, these approaches generally require at least 30 pairs of observations in each of the classes in order to obtain reliable estimations [
6]. This is a major limitation for their application in the context of scarcely sampled time series. Alternatively, one would like to limit the similarity analysis on the estimated zero-lag CC (i.e., the classical CC). In any case, this is still sometimes beyond reach because of the lack of simultaneous observations. Another alternative that is inspired from speech recognition [
7] is dynamic time warping (DTW). It consists in warping the time axis for an optimal alignment of the time series. It is possible to constrain the warping to consider only pairs of observations that are not too far from each other, e.g., the Sakoe–Chiba band [
8]. The resulting time series share the same length but consist of padded sequences of the same values (when the time series are stretched) so the actual number of genuine observations is smaller. Recently, it has been applied to remote sensing applications as well, mainly in image classification (e.g., [
8] or [
9]). DTW does not directly provide an index of similarity. For that purpose, one can compute the CC between the aligned time series.
In this paper, we proposed to overcome the scarcity of the time series with a simple linear interpolation approach. The motivation is to obtain two time series with identical acquisition dates, so that the classical estimation of the CC is possible. We rely here on the CC because we are interested in the similarity between the time series (i.e., exhibiting the same patterns) compared to the more specific objectives of other existing indexes such as the index of agreement [
10,
11,
12] where the values between the time series must be comparable in absolute terms (e.g., same average, same standard deviation,…). While the resulting time series are a mix of genuine observations and synthetic values, we think that an interpolation between two consecutive dates is a valid and natural approach at least for continuous processes (e.g., vegetation/crop monitoring). Indeed, it directly translates the cognitive mechanisms that the analyst uses when one visually compares the two time series on the same graph. We opted for linear interpolations in order to keep the method as simple as possible. However, experimental results showed that using a shape-preserving piecewise cubic interpolation did not bring significant changes (results not shown here). Alternatively, choosing more advanced interpolation methods (e.g., splines) might also be an option but there is a risk of adding artifacts in the interpolated time series [
13].
After a short reminder of the theoretical characteristics of the CC estimator, the proposed approach is first tested on simulated time series with limited simultaneous observations. The results confirmed that our method provides accurate estimations of the CCs while overcoming the scarcity of the time series. The method is further illustrated on the comparison of real NDVI time series from Sentinel-2 and PlanetScope in The Netherlands, with the same results as found in the synthetic examples. Indeed, the two sets of time series were found to be very correlated, as expected (the average estimated CC was found to be equal to 0.93), while drastically reducing the number of undecided cases due to the lack of simultaneous observations (from 385 to 14 out of 1670).
2. Methodology
2.1. The Correlation Coefficient
The correlation coefficient (or Pearson’s correlation coefficient) can be used for assessing the similarity between the two time series [
10]. For paired observations (i.e., each observation is a pair of both quantities), the CC is generally estimated using the following estimator
where (
are the paired observations,
and
are the observed averages of the time series and
is the number of observed pairs.
The precision of this estimator is generally evaluated using Fisher’s transformation [
14]
and its inverse transformation
The main advantage of this transformation is that
is approximately following a normal distribution with a mean equal to
(where
the true unknown CC) and a variance approximately equal to
One can thus build the (
confidence interval for λ with
and use the inverse transformation in order to get the confidence interval for
where
,
and where
is the quantile of level
of the standard normal distribution.
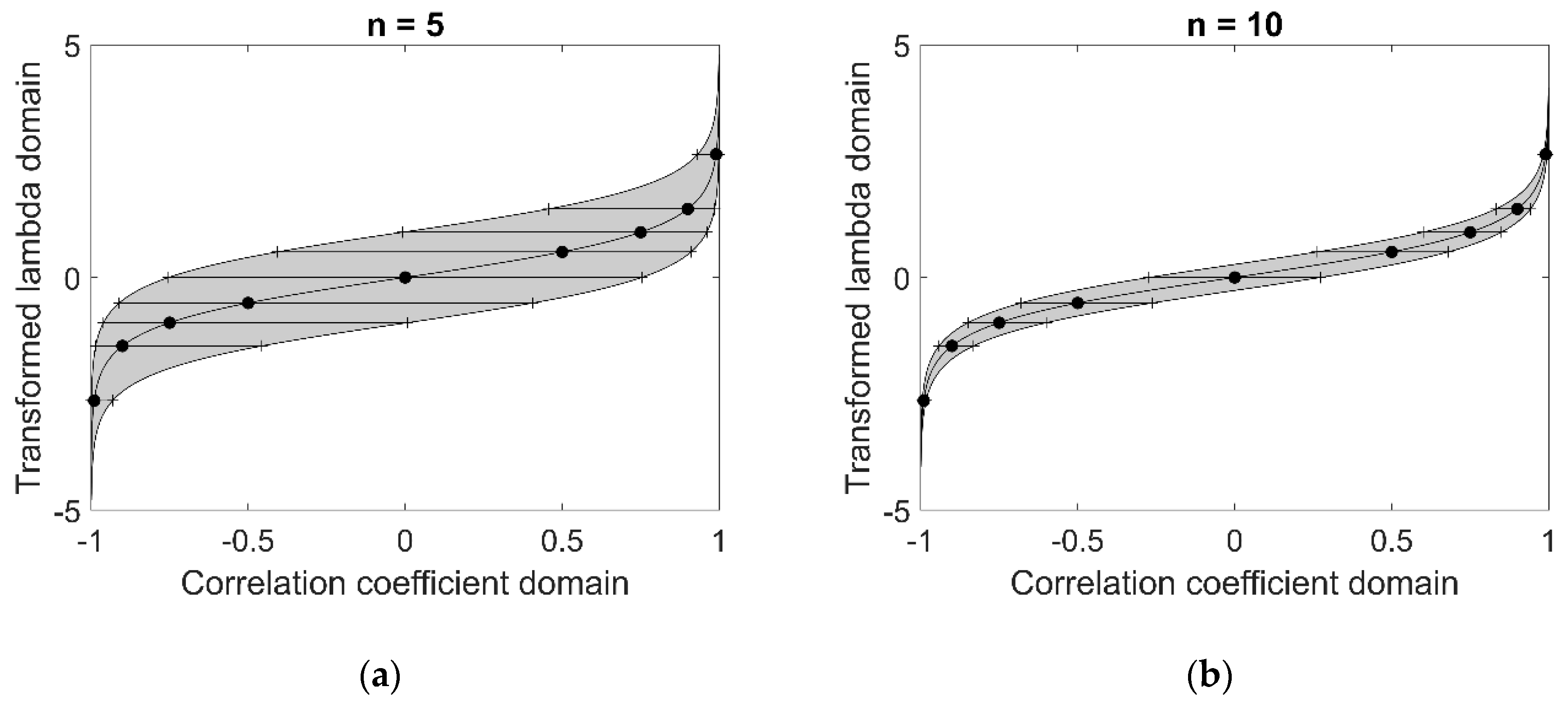
Figure 1 shows how the estimated confidence intervals change with different values of
(namely –0.99, –0.9, –0.75, –0.5, 0, 0.5, 0.75, 0.9 and 0.99) and
(namely 5 and 10). One can see that the confidence intervals are not centered around
(except for
) and that they are bounded to the
interval.
More generally, any quantile of level
can be estimated through Fisher’s transformations of Equations (2) and (3) with
where
and
is the quantile of level
of the standard normal distribution.
Using Equation (6), one can build any test on the true CC or estimate the probability that the CC exceeds a given threshold.
2.2. Generalization to Scarcely Sampled Time Series
When comparing two time series, one needs to have both time series sampled at the same dates. Unfortunately, this is a rare case. Most of the time, the time series come from different sources (e.g., two different satellite sensors) so that actual pairs of observations (i.e., on the same dates) are exceptions.
The general situation is thus two time series with
and
observations with
simultaneous observations where
.
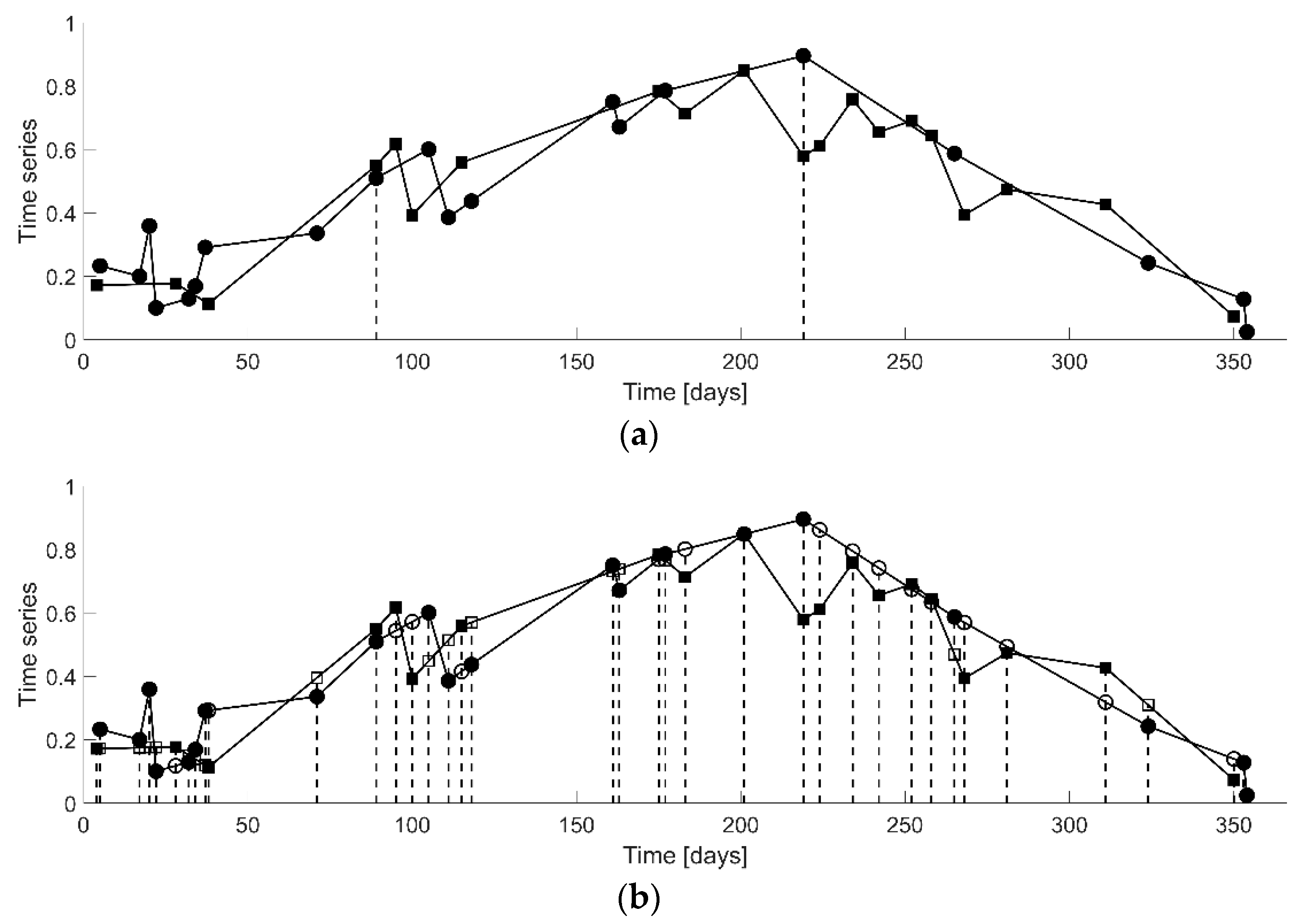
Figure 2 shows a synthetic example of two time series from two different sources (e.g., two different satellite sensors observed on the same agricultural parcel). In this example, each of the time series has 20 observations out of which only two dates coincide.
As could be seen from the synthetic example of
Figure 2, one would typically conclude that the two time series are similar. However, as only two dates coincide, it is not even possible to compute the CC (
Figure 2a). In order to circumvent this data issue, we propose to fill the gaps by interpolating each of the time series at the observed dates of the other time series (i.e., the union of the observed dates;
Figure 2b). This simple approach has many advantages:
It is a straightforward generalization of the particular case where all the dates coincide;
It is simple to implement (a linear interpolation is the simplest solution but others exist, e.g., cubic interpolation or splines);
It preserves the time dimension of the observations (i.e., values interpolated at new dates directly depend on the proximity to the observed dates);
It somewhat translates the intuitive visual comparison of the time series (as can be seen in the example of
Figure 2).
At this point, it is worth mentioning that the resulting time series do not constitute a genuine sample as some of the values are computed with the interpolation. Consequently, the general formula for the estimation of the variance of the estimation is not valid (i.e., we cannot take the union of the dates as
in the variance formula). There is an equivalent effective size
for the interpolated time series. Several different options were considered for the value of
. In the next section, we show, using simulations, that taking
(i.e., the number of dates in the shortest time series) is a good empirical rule-of-thumb for substituting the value of in Equations (4)–(6).
2.3. Comparison of the Methods
For the comparison of the two methods of estimation (i.e., with the simultaneous observations only or with the interpolation), we rely on the observed bias
the observed root mean square error (RMSE)
the observed percentage of missing estimation and the observed 95% central interval (i.e., estimated with the empirical quantiles), where
is the true CC.
In a second step, we want to verify that the variability is correctly estimated using the definition of in Equation (7) as a substitute of in Equations (2)–(6). In particular, we would like to compare this option against two alternatives:
(i.e., the geometric mean of the observed sample sizes)
(i.e., the arithmetic mean)
For this purpose, we compute the success rate of the different estimated 95% confidence intervals, i.e., the percentage of times that the true CC is contained in the estimated 95% confidence intervals (see Equation (5)).
In order to have a basis of reference, we also defined a control method that corresponds to the situation where both time series are observed on the union of both extracted sets of dates. As this control method is supposed to be the optimal situation (since the set of observed dates is the largest and there is no interpolation needed), we can build a confusion matrix between the estimated confidence intervals of the control method and the interpolation method with different criteria for . The overall accuracy (OA) can be computed using the number of agreement cases.
3. Results
3.1. Validation using Simulations
The proposed methodology is tested here using simulated time series. The main advantage of simulations is that all the information is known (in our case, the target CC between the two time series) and repeated simulations allow us to derive observed bias and variability of the estimators.
In this test, we relied on a three-step simulation algorithm. First, we simulate two time series over a year (i.e., their length is equal to ) with two sinusoidal functions and superposed them with white noise. Then, in order to simulate two scarce time series, we randomly select two numbers in the interval [10;20] and assign the values to variables and (i.e., the respective number of observations of the two time series). Finally, both time series are randomly subsampled for variables and , which represent a number of observation dates, thus a known sample size for each time series. As the actual observed dates are completely accidental, the number of simultaneous observations varies. We repeat this simulation algorithm 500,000 times. One can prove that this number of simultaneous observations is a random variable following a hypergeometric distribution with draws from objects with success states. Using the conventions above, there is between 91% and 99% chance that the number of simultaneous observations is strictly smaller than three, which is the worst condition for the estimation of a CC based only on simultaneous dates.
Among the multitude of potential curves, here we show two example cases: (i) with a small negative CC and (ii) with a strong positive CC. For each of the simulated pairs of time series, we estimate five CCs: (i) using the proposed methodology, (ii) using a slotting method with three different bin size (three, seven and 14 days), (iii) DTW with a Sakoe–Chiba band of 45 days (following [
8]) and, when possible, using the simultaneous observations only.
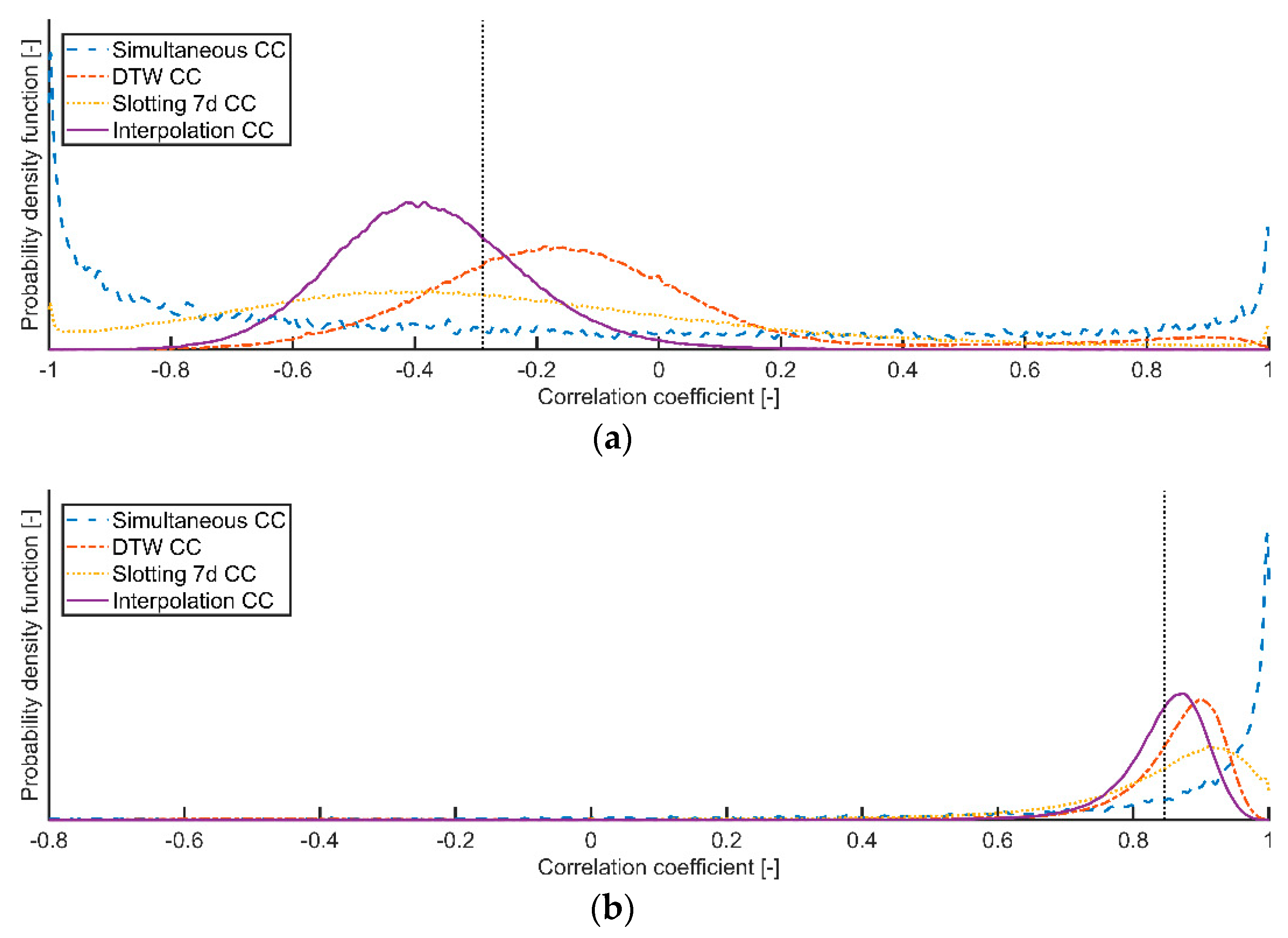
Figure 3 shows the observed distributions of these estimators. One clearly sees that the proposed method provides better estimations. All the statistics (e.g., the observed bias, the root mean square errors, the estimated quantiles) point in favor of our proposed method (see
Table 1 for the details). Finally, as anticipated, the coefficients could be estimated for only 3% of the simulations when using the simultaneous observations only, contrary to the proposed method where a 100% success rate was observed. The success rate of the slotting method lies between those of the simultaneous and our proposed method. Providing a reliable estimation even in extreme cases where the simultaneous observations are scarce is clearly the main advantage of our method.
Besides the estimation of the CCs, we also introduced a method for estimating the precision of the estimator (see Equations (4)–(6) for details). For that purpose, we proposed to substitute (i.e., the number of paired observations) with , which is the effective sample size. Three alternatives are tested: (i) the minimum of the sample sizes, (ii) the geometric mean of the sample sizes, and (iii) the arithmetic mean of the sample sizes.
As described in
Section 2.3, we computed the success rates of the estimated 95% confidence interval for each of the three criteria above (see
Table 2). For each of the three criteria, the success rate was larger than the objective 95%. This indicates that the confidence intervals are larger than expected, hence that each of them overestimate the variability. Such overestimated success rates were also observed for the control method (i.e., where no interpolation was needed). Thus, it does not invalidate the proposed method and the tested criteria for
.
As a second metric of comparison, the observed overall accuracy with the control method was slightly larger for the “minimum of the sample sizes” criterion.
3.2. Case Study: NDVI Time Series from Sentinel-2 and PlanetScope on Arable Cropland in The Netherlands
In this section, we show how the proposed method performs on real data.
For the definition of geometric boundaries of agriculture parcels, we used the Geospatial Aid Application (GSAA) dataset information publicly available through The Netherlands open geo-data infrastructure (
http://www.nationaalgeoregister.nl). NDVI time series were retrieved from two different image data sources; Sentinel-2 MultiSpectral Instrument (MSI) and PlanetScope imagery. The signal extraction from the Copernicus Sentinel-2 MSI was performed using the product type Level-2A (i.e., bottom atmosphere reflectance) acquired by both twin satellites, Sentinel-2A and Sentinel-2B. As far as the PlanetScope image data is concerned, a comparable product was selected as the analytic ortho scene SR (surface reflectance). In this particular application, we expect a large majority of similarity between pairs of time series since (i) pairs of time series are extracted for the same parcel, (ii) they are extracted over the same period of time, and (iii) Sentinel-2 and PlanetScope products have similar spectral bands.
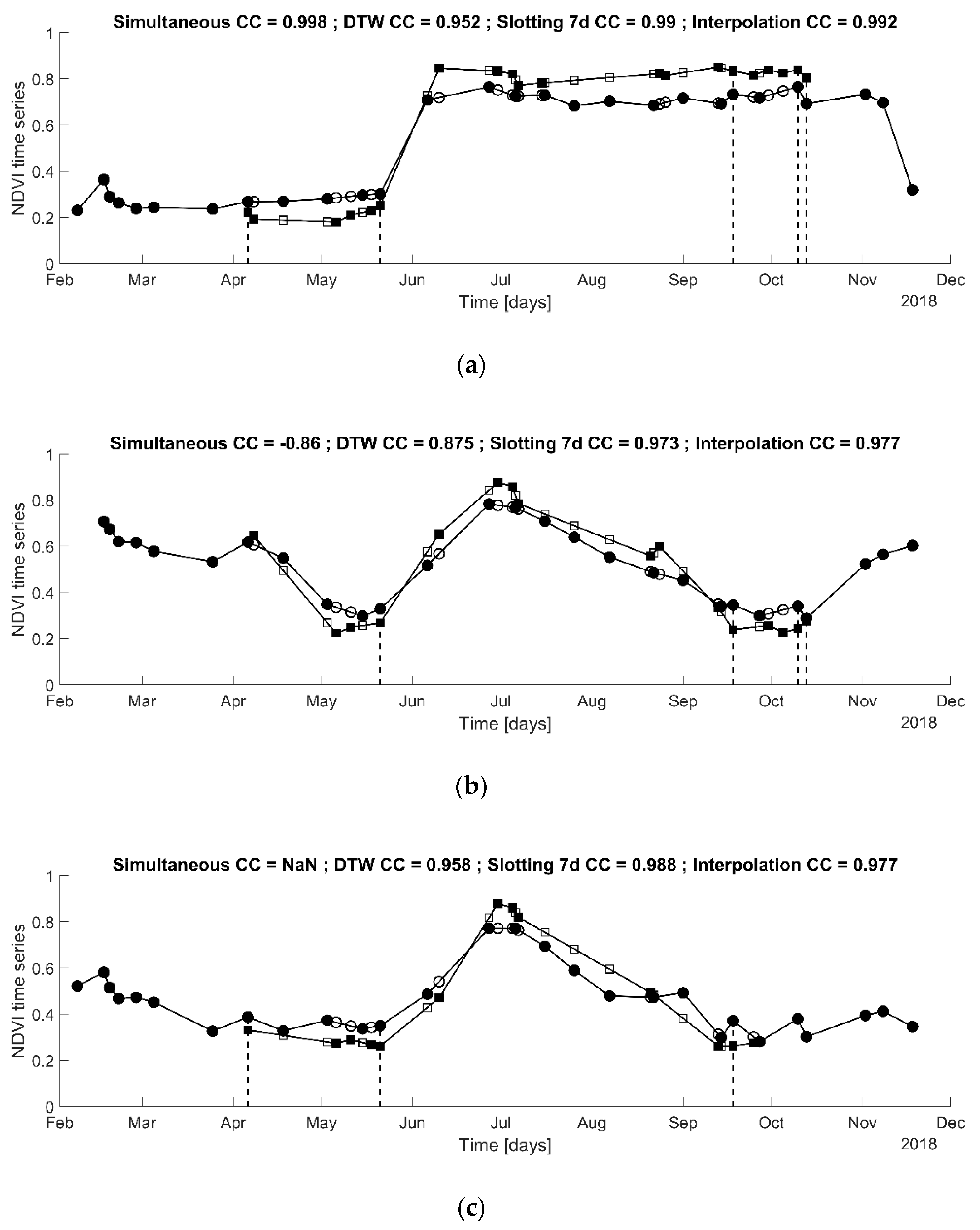
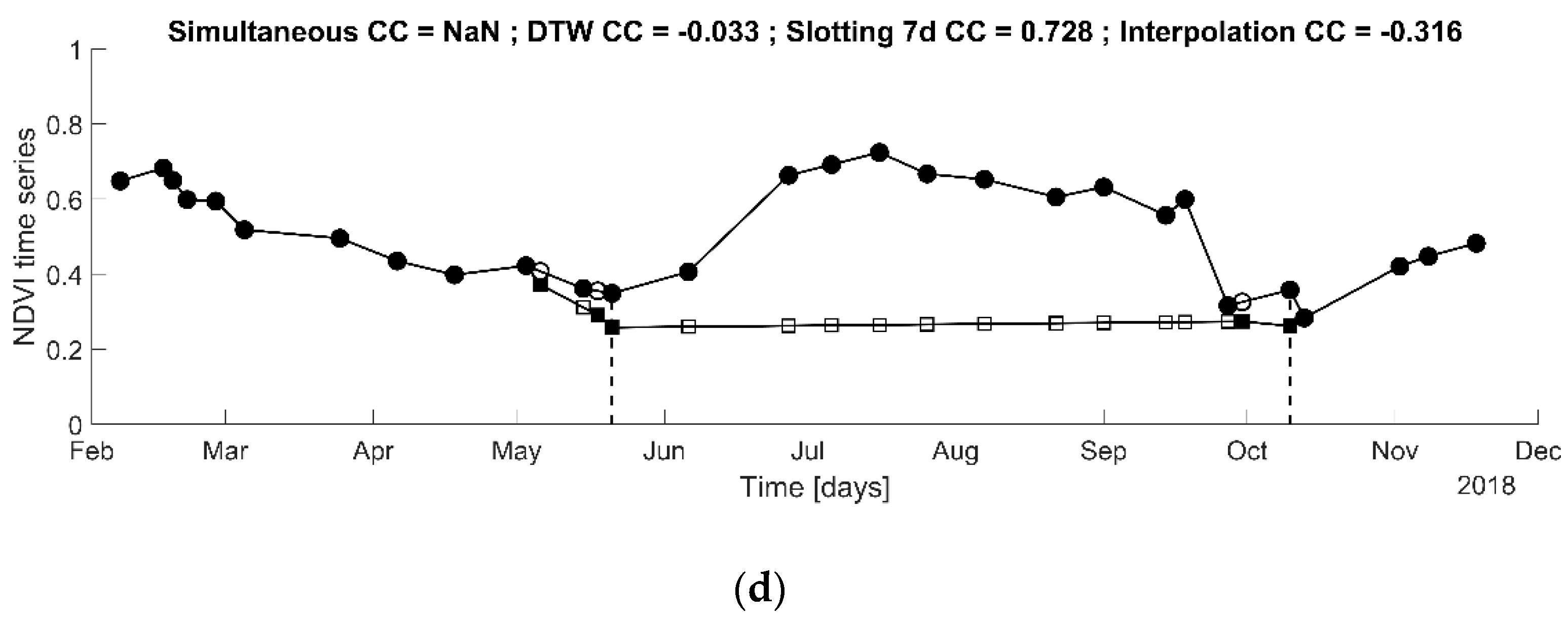
The time series of the 1670 parcels were processed by applying the same estimation methods as for the simulated examples. For the majority of the cases, all the methods performed correctly, having similar results (see
Figure 4). However, as expected, the estimation when using the simultaneous observations only could not be computed for 23% of the parcels (see
Table 3). For comparison, this occurred for only 0.8% when using the interpolation method. For each of the 14 cases, there were less than three Sentinel-2 images available, thus the CCs could not be computed. On average, when using the interpolation method, the estimated CCs were higher (0.93 against 0.87) and the observed range of the estimations is narrower (minimums are -0.32 versus -0.97). In addition, the statistical test on the hypothesis “
” with the alternative hypothesis “
” based on Equation (6) was accepted for only 78 cases when using the interpolation method against 432 when using the simultaneous observations. This shows again that the proposed method circumvents most of the limitations of the classical estimation of the CC.
4. Discussion
The results presented in the previous section show that the proposed method brings significant improvements when comparing severely scarcely sampled time series (i.e., less than 20 acquisition dates). It is based on the idea that gaps between observed dates can be interpolated in order to artificially increase the number of observations. Even though this is a very simple idea, it proved to be both valid and a natural translation of a visual interpretation of the time series. The CCs that were computed using this interpolation method were coherent with their visual interpretation counterparts.
As noted in the synthetic case study, we observed that the constructed 95% confidence intervals actually contained more than 99% of the true simulated CC even when no interpolation was performed (i.e., what we called the control method). However, we also validated in parallel (results not shown here) that Equation (4) is correct for uncorrelated series (i.e., and are correlated but the and the are not correlated together). This is a clear indication that the presence of trends in the series tends to decrease the actual variability of the estimated CCs compared to Equation (4). Nevertheless, if this is a limitation, it is related to the use of the CC itself, not on the use of the interpolation strategy. While this brings doubts of the validity of Equation (4) in the context of time series, it does not invalidate our proposed approach. Moreover, since the variability is overestimated, the constructed confidence intervals and equivalent statistical tests are more conservative (i.e., if the null hypothesis “” is rejected, it is very likely that it is a true rejection). In other words, the type I error is smaller than expected. The opposite case of an underestimated variability is riskier because the alternative hypothesis “” would then be accepted too easily (i.e., we believe that the test is at 95% but it is actually at a smaller percentage).
On the real data example, the estimations were consistently high for the large majority of the parcels. The only cases where the CCs were estimated as small corresponded to obvious lack of data in a crucial period of the crop season, such that no trend could actually be seen in the Sentinel-2 time series. On the contrary, in such conditions, we may expect a lower similarity between the time series because of this lack of information. For instance, in
Figure 4, one could argue that the slotting method is actually overestimating the similarity.
The precision of the estimations was also significantly improved. The number of accepted “” hypotheses significantly decreased when using the interpolation method. Indeed, more information were taken into account than merely using the simultaneous observations. The interpolation step translates the temporal evolution of the time series more adequately. The slotting method also showed some advantages, but it requires at least 20 observations in order to perform correctly. The DTW was able to bring some improvements but not as much as the slotting or interpolation methods.
Finally, the proposed interpolation method proved to be very efficient against the lack of simultaneous observations between the two time series. In the Dutch example, we observed a quasi disappearance of the cases where the CCs could not be computed (from 385 to only 14). This is a clear benefit of the proposed method since it drastically reduces the number of undecided cases (i.e., where there is not enough information for a conclusion). The slotting method proved to be an alternative but the results highly depend on the density and spread of the acquisition dates and on the bin size. Comparatively, the interpolation approach correctly brings added temporal information and helps fill the sampling gaps without requiring any parameters. Clearly, this benefit is less obvious for long time series observed on a regular time step with few missing data.
5. Conclusions
In this paper, we presented a simple method to quantify the similarity between scarce remotely sensed time series. The index is based on the Pearson’s correlation coefficient (CC) between the two time series. As we are interested in the similarity between the time series, the CC is computed on the raw time series (i.e., without removing the trends). The use of an interpolation step enables us to circumvent the issue of the scarcity of the time series. The theory of CC estimation was also extended to the estimation based on a mix between genuine observations and interpolated values.
The proposed method was tested both on simulated and real application data. It proved to be very efficient and specifically useful when the number of simultaneous observations is limited. Indeed, in such conditions, neither the cross- and autocorrelation functions nor a simple CC between the true pairs of observations can be accurately estimated. In many cases, the estimator cannot be computed at all. Limiting the computation to the zero-lag bin of the cross-correlation function is a possible alternative but at the cost of larger bin sizes, which might risk diluting the actual similarity with dissimilar pairs of observations. On the contrary, the interpolation step adequately brought the temporal information in order to cope with both the temporal gaps and the lack of simultaneous observations.
In our context, the objective was to evaluate the similarity between two time series for which the CC is a sufficient quantitative index. However, one could also extend the analysis to more complex indexes. After the same interpolation step, one can generalize the approach by replacing the CC with other types of indexes such as Spearman’s rho or Kendall’s tau [
15], an index of agreement [
10], or mutual information [
16]. This approach thus opens interesting avenues for the analysis of scarce remotely sensed time series.
Author Contributions
Conceptualization, D.F. and B.V.; methodology, D.F.; software, D.F. and C.W.; formal analysis, D.F.; investigation, D.F.; data curation, S.L. and C.W.; writing—original draft preparation, D.F.; writing—review and editing, D.F., B.V., C.W. and S.L.
Funding
This research received no external funding.
Acknowledgments
Authors would like to thank the Planet Labs Company for providing necessary image dataset and technical support regarding PlanetScope imagery and Planet’s platform. We are also very grateful to Davide De Marchi for sharing scripts and technical support for JEODPP platform and the two anonymous reviewers that helped improving this letter with their constructive comments and suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control, 2nd ed.; Holden-Day: San Francisco, CA, USA, 1970. [Google Scholar]
- Löw, F.; Duveiller, G. Defining the spatial resolution requirements for crop identification using optimal remote sensing. Remote Sens. 2014, 6, 9034–9063. [Google Scholar] [CrossRef]
- Di Salvo, A.; Faggioli, L.; Morelli, B. Orbit selection criteria for optical dual-use earth observation satellites. In Proceedings of the 63rd International Astronautical Congress. IAC 2012, Naples, Italy, 1–5 October 2012; pp. 5651–5661. [Google Scholar]
- Cressie, N. Statistics for Spatial Data, Revised ed.; John Wiley and Sons, Inc.: New York, NY, USA, 1993. [Google Scholar]
- Broersen, P.M.T.; Bos, R. Estimating time-series models from irregularly spaced data. IEEE Trans. Instrum. Meas. 2006, 55, 1124–1131. [Google Scholar] [CrossRef]
- Journel, A.G.; Huijbregts, C.J. Mining Geostatistics; Academic Press: London, UK, 1978; p. 194. [Google Scholar]
- Sakoe, H.; Chiba, S. Dynamic Programming Algorithm Optimization for Spoken Word Recognition. IEEE Trans. Acoust. 1978, 26, 43–49. [Google Scholar] [CrossRef]
- Csillik, O.; Belgiu, M.; Asner, G.P.; Kelly, M. Object-based time-constrained dynamic time warping classification of crops using Sentinel-2. Remote Sens. 2019, 11, 1257. [Google Scholar] [CrossRef]
- Maus, V.; Câmara, G.; Cartaxo, R.; Sanchez, A.; Ramos, F.M.; de Queiroz, G.R. A time-weighted dynamic time warping method for land-use and land-cover mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3729–3739. [Google Scholar] [CrossRef]
- Duveiller, G.; Fasbender, D.; Meroni, M. Revisiting the concept of a symmetric index of agreement for continuous datasets. Sci. Rep. 2016, 6, 19401. [Google Scholar] [CrossRef] [PubMed]
- Willmott, C.J. On the validation of models. Phys. Geogr. 1981, 2, 184–194. [Google Scholar] [CrossRef]
- Mielke, P. Meteorological applications of permutation techniques based on distance functions. In Handbook of Statistics; Krishnaiah, P., Sen, P., Eds.; Elsevier Science Publishers: New York, NY, USA, 1984; Volume 6, pp. 813–830. [Google Scholar]
- Trauth, M.H. MATLAB® Recipes for Earth Sciences, 4th ed.; Springer-Verlag: Berlin/Heidelberg, Germany, 2005; p. 172. [Google Scholar]
- Fisher, R.A. Statistical Methods for Research Workers, 9th ed.; Oliver and Boyd Ltd.: Edinburgh, UK, 1944; pp. 192–193. [Google Scholar]
- Liu, C.; Frazier, P.; Kumar, L. Comparative assessment of the measures of thematic classification accuracy. Remote Sens. Environ. 2007, 107, 606–616. [Google Scholar] [CrossRef]
- Hong, T.; Hart, K.; Soh, L.-K.; Samal, A. Using spatial data support for reducing uncertainty in geospatial applications. GeoInformatica 2014, 18, 63–92. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}