Influence of Scanner Position and Plot Size on the Accuracy of Tree Detection and Diameter Estimation Using Terrestrial Laser Scanning on Forest Inventory Plots



Abstract
:1. Introduction
2. Data and Methods
2.1. Study Area and Sample Plots
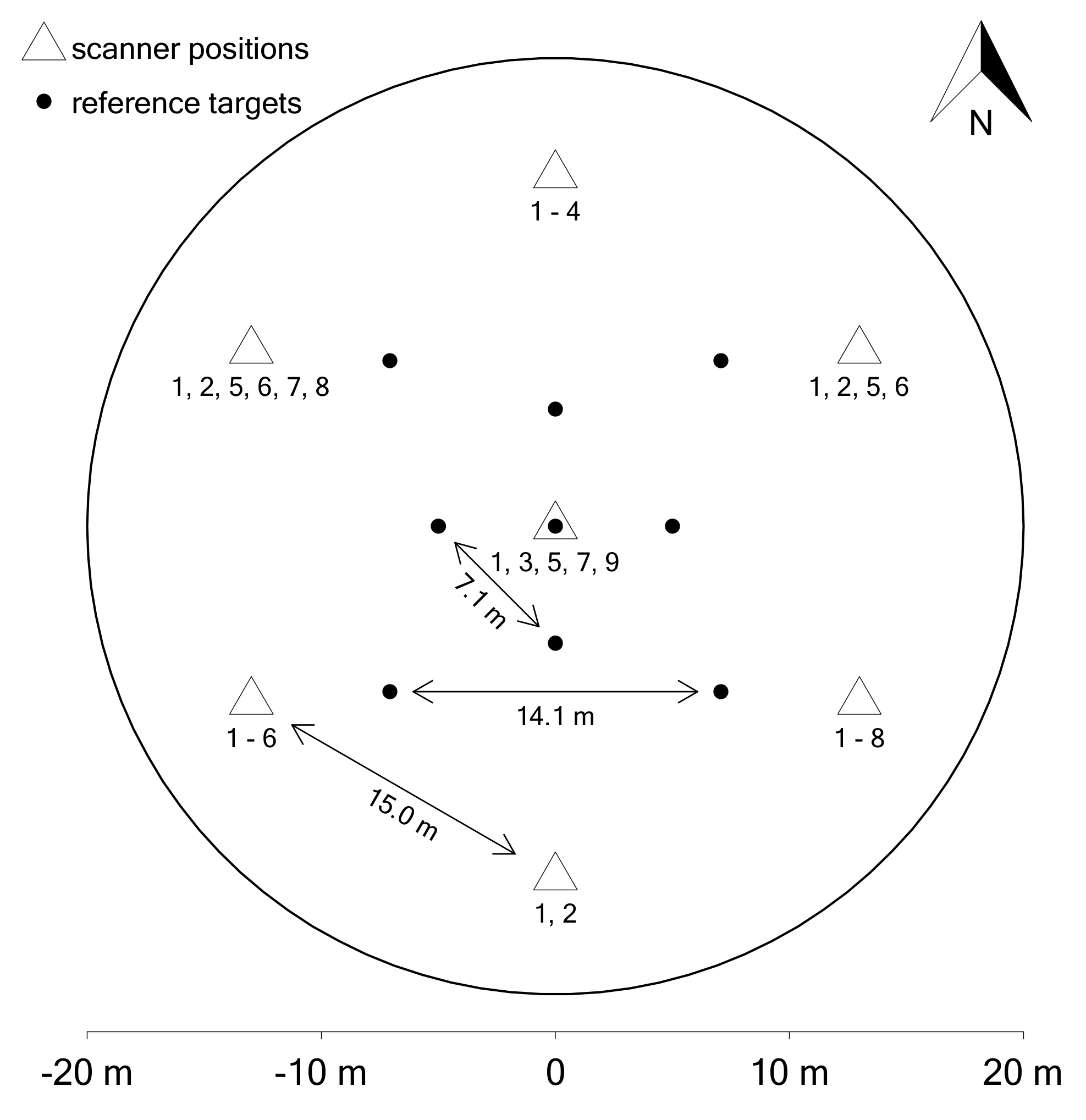
2.2. Instrumentation and Data Collection
2.3. Point Cloud Processing
2.4. Clustering, Detection of Tree Positions, and dbh Measurement
2.5. Reference Data
2.6. Test by Means of Independent Reference Data from an International Benchmark Project
2.7. Accuracy of Tree Detection and dbh Measurement
3. Results
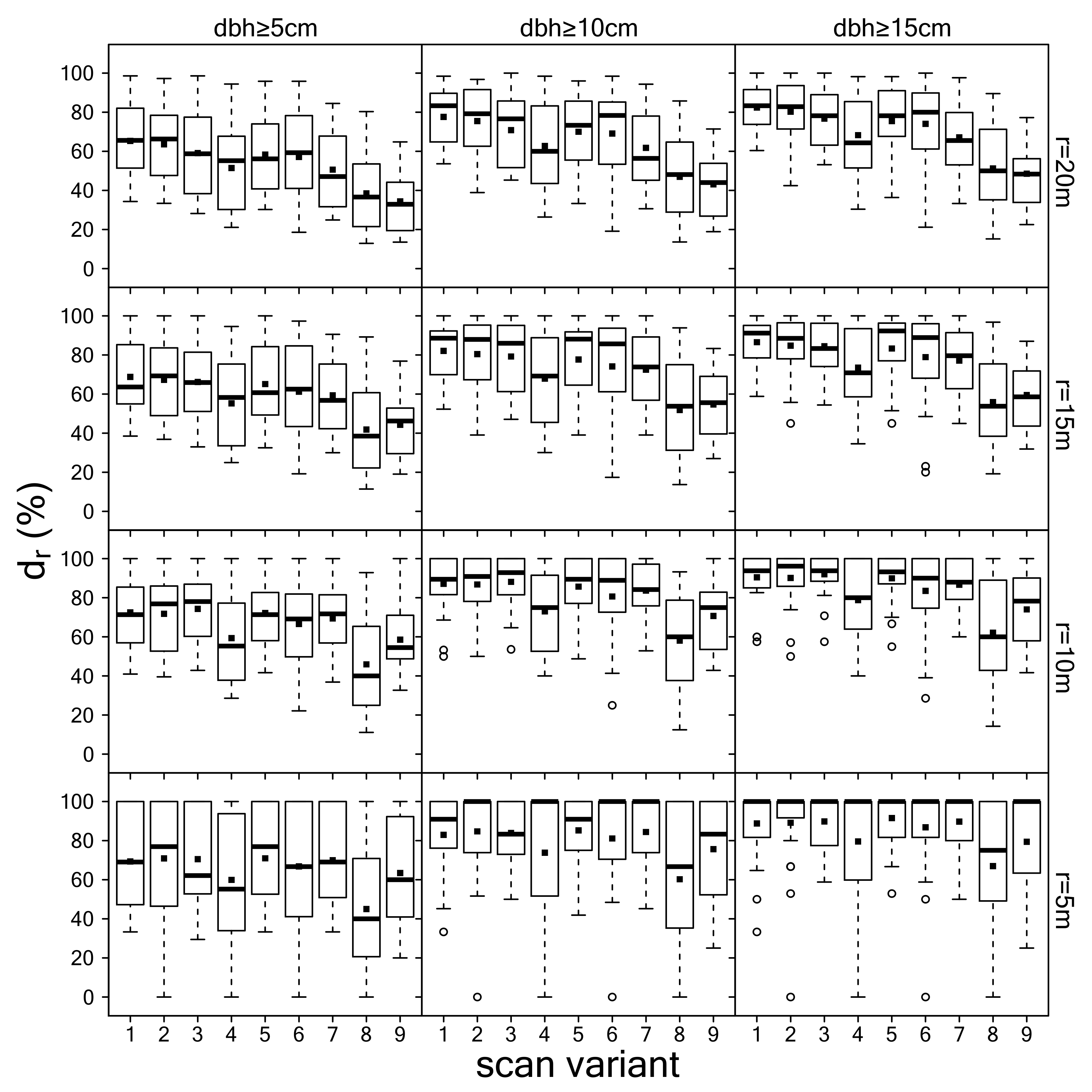
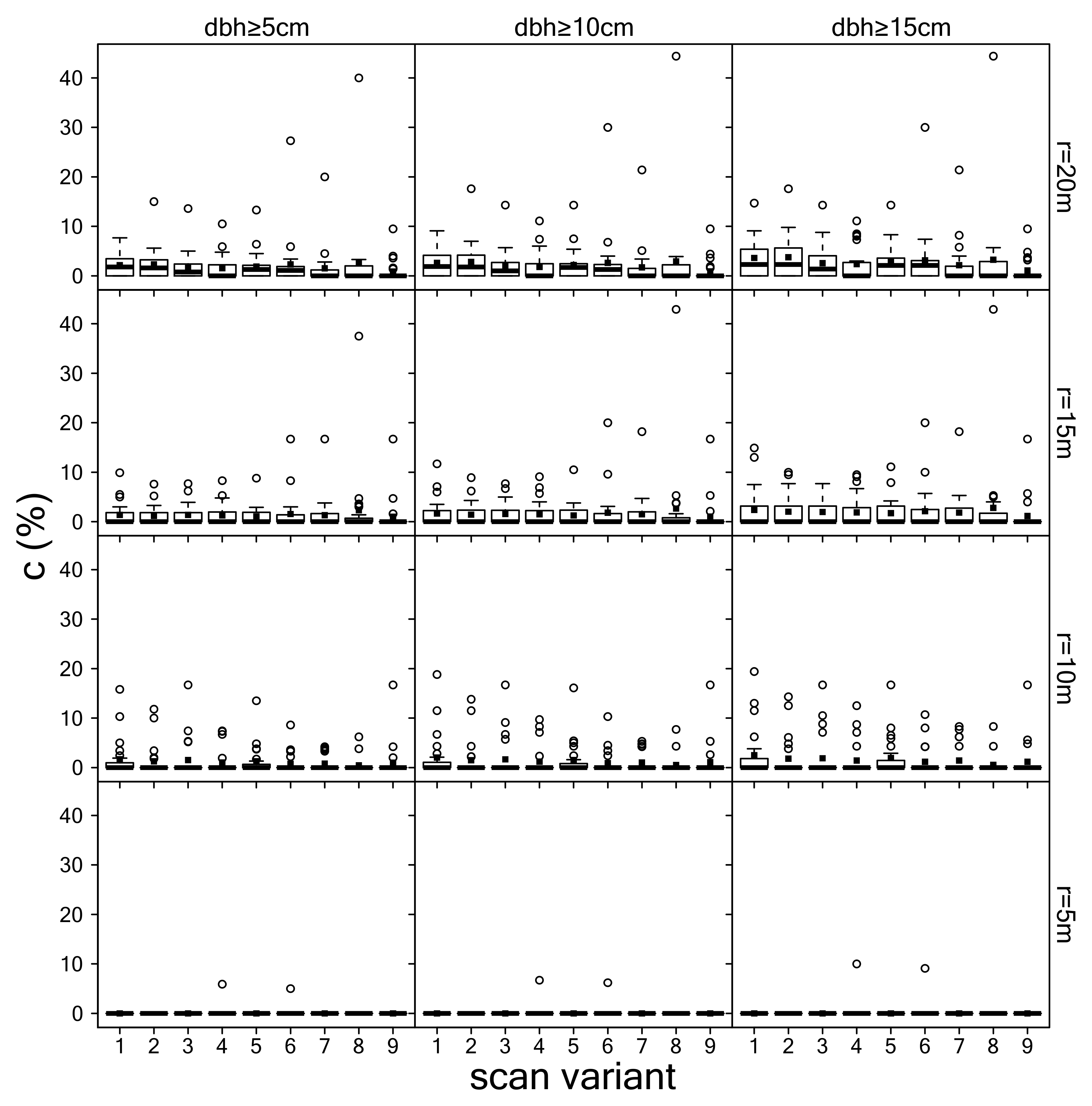
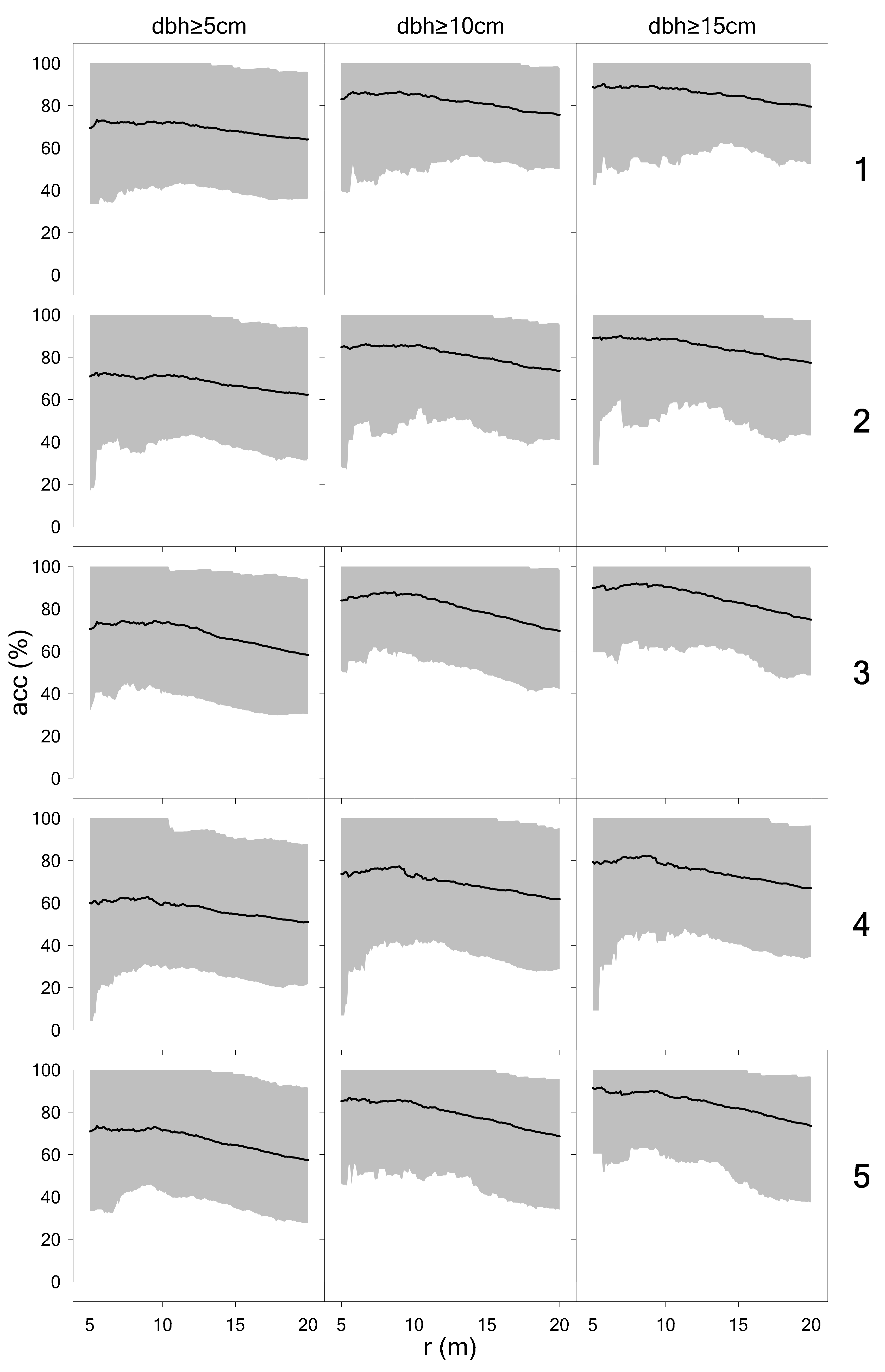
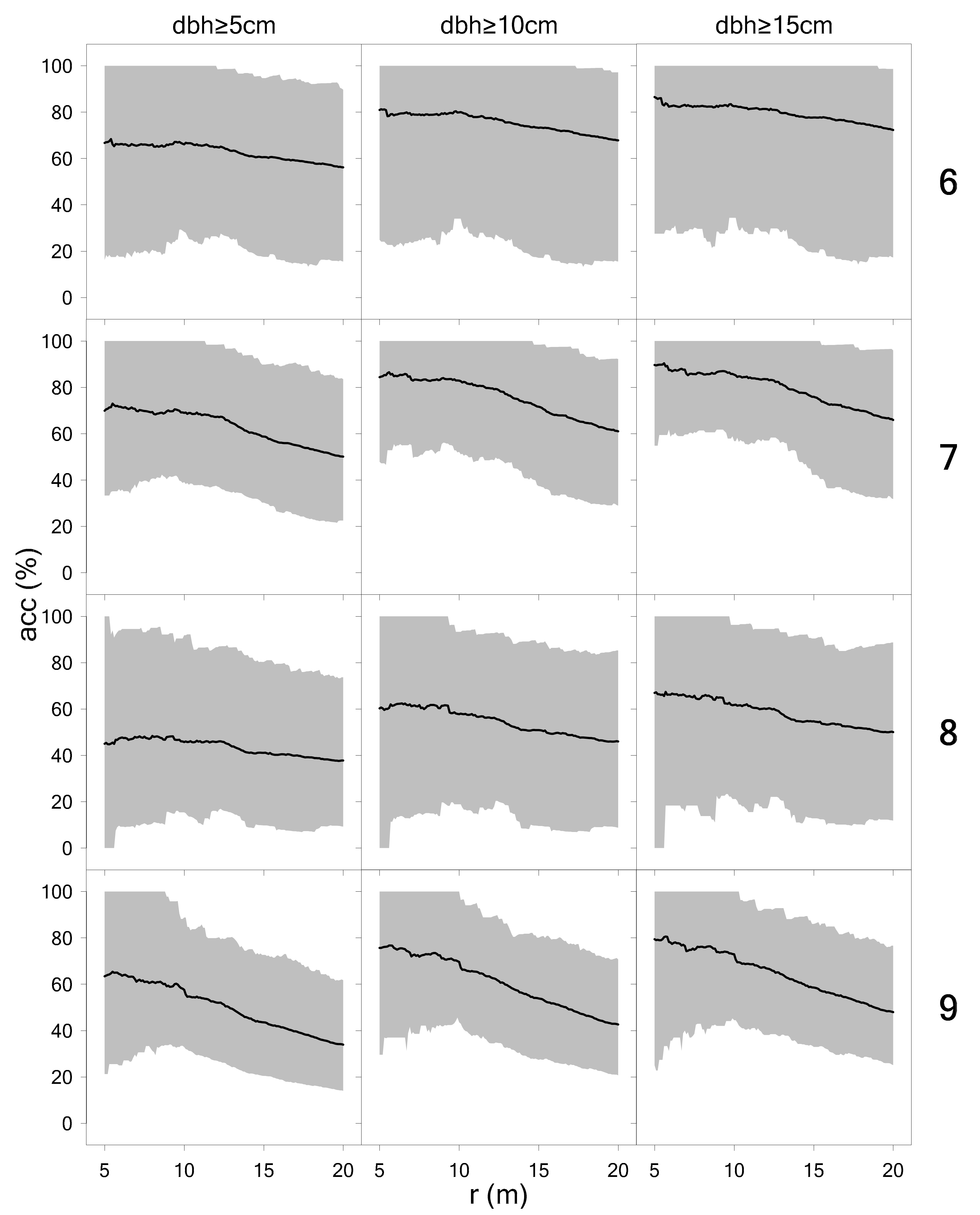
3.1. Detection of Tree Positions
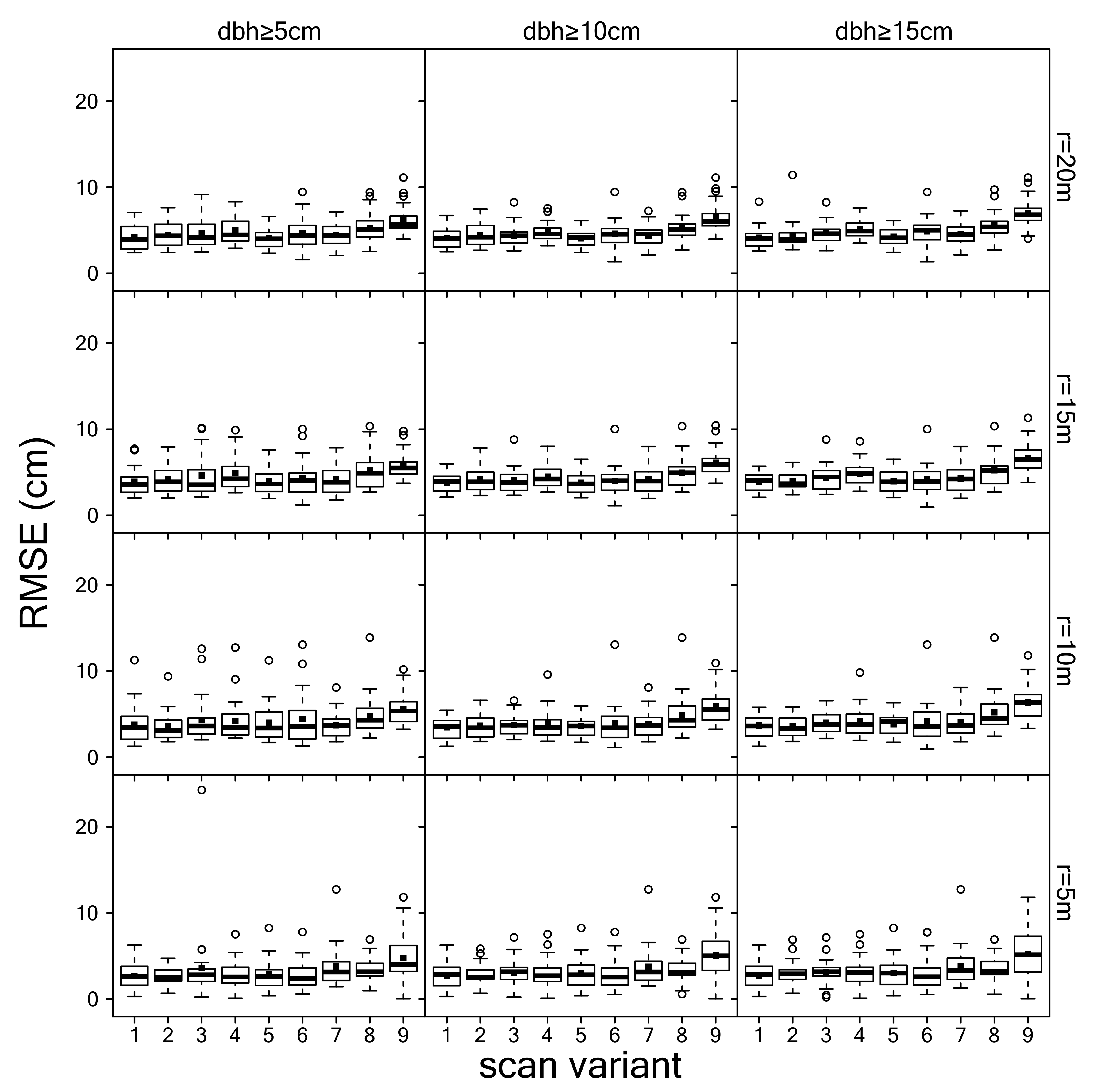
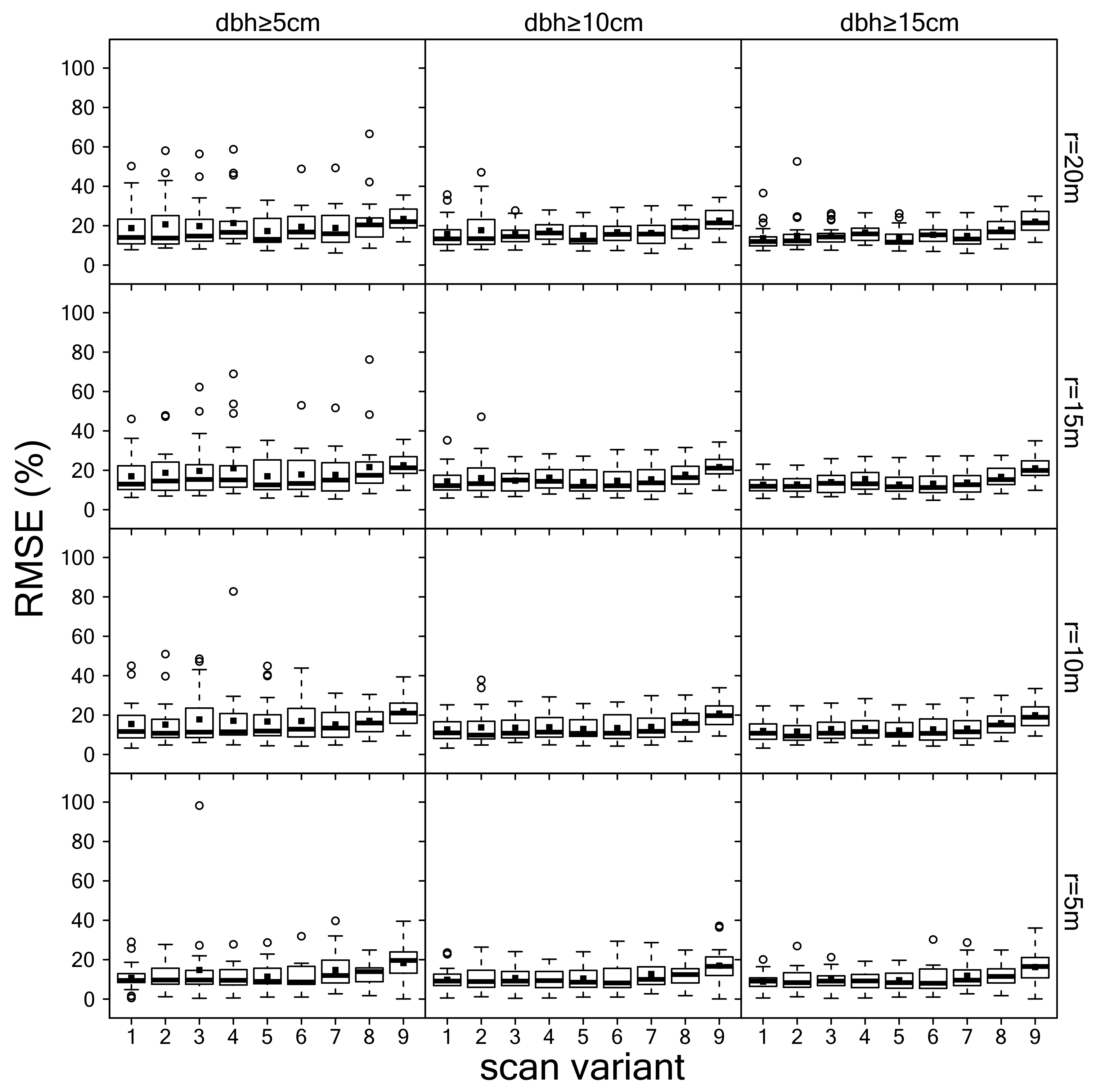
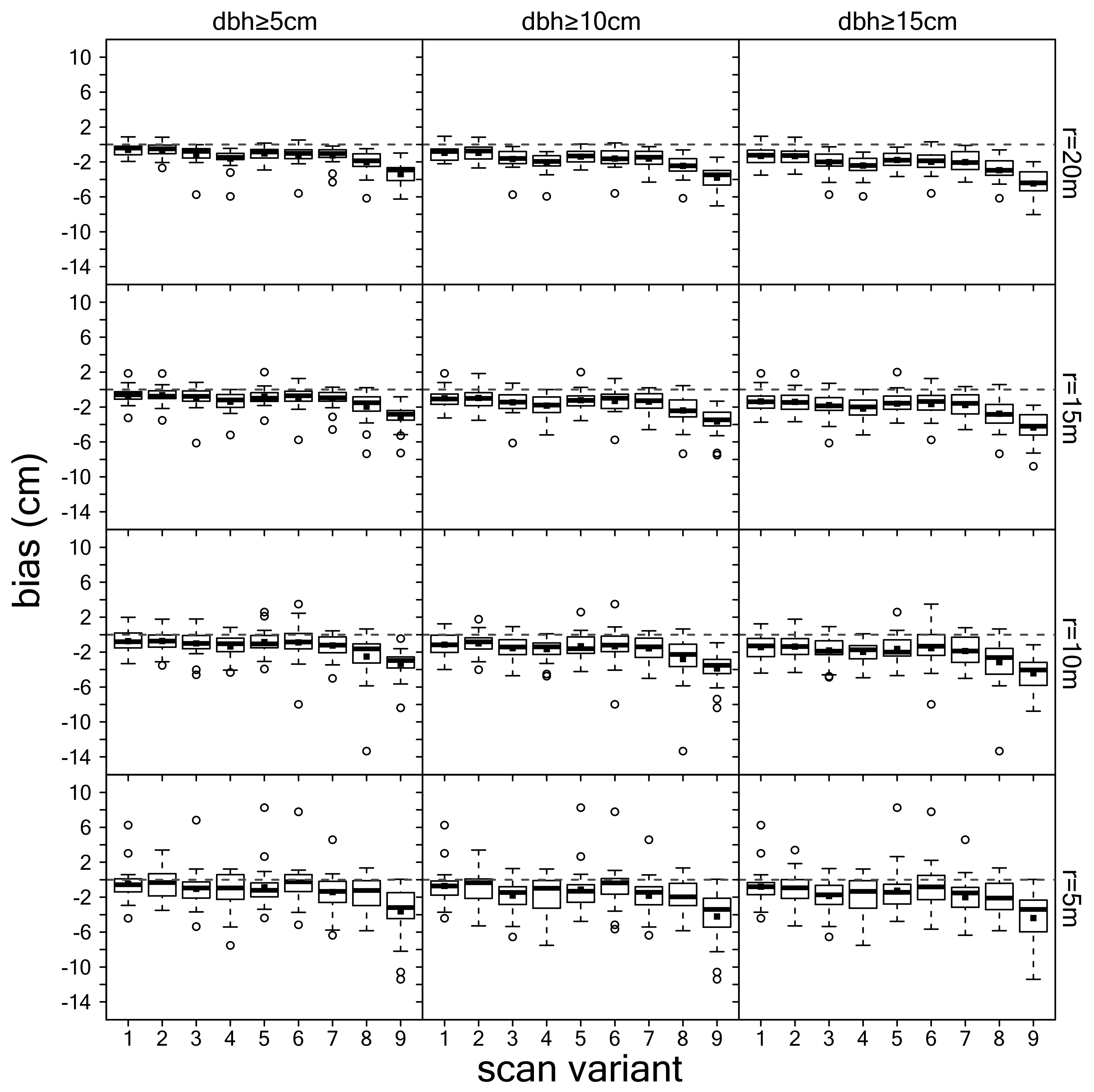
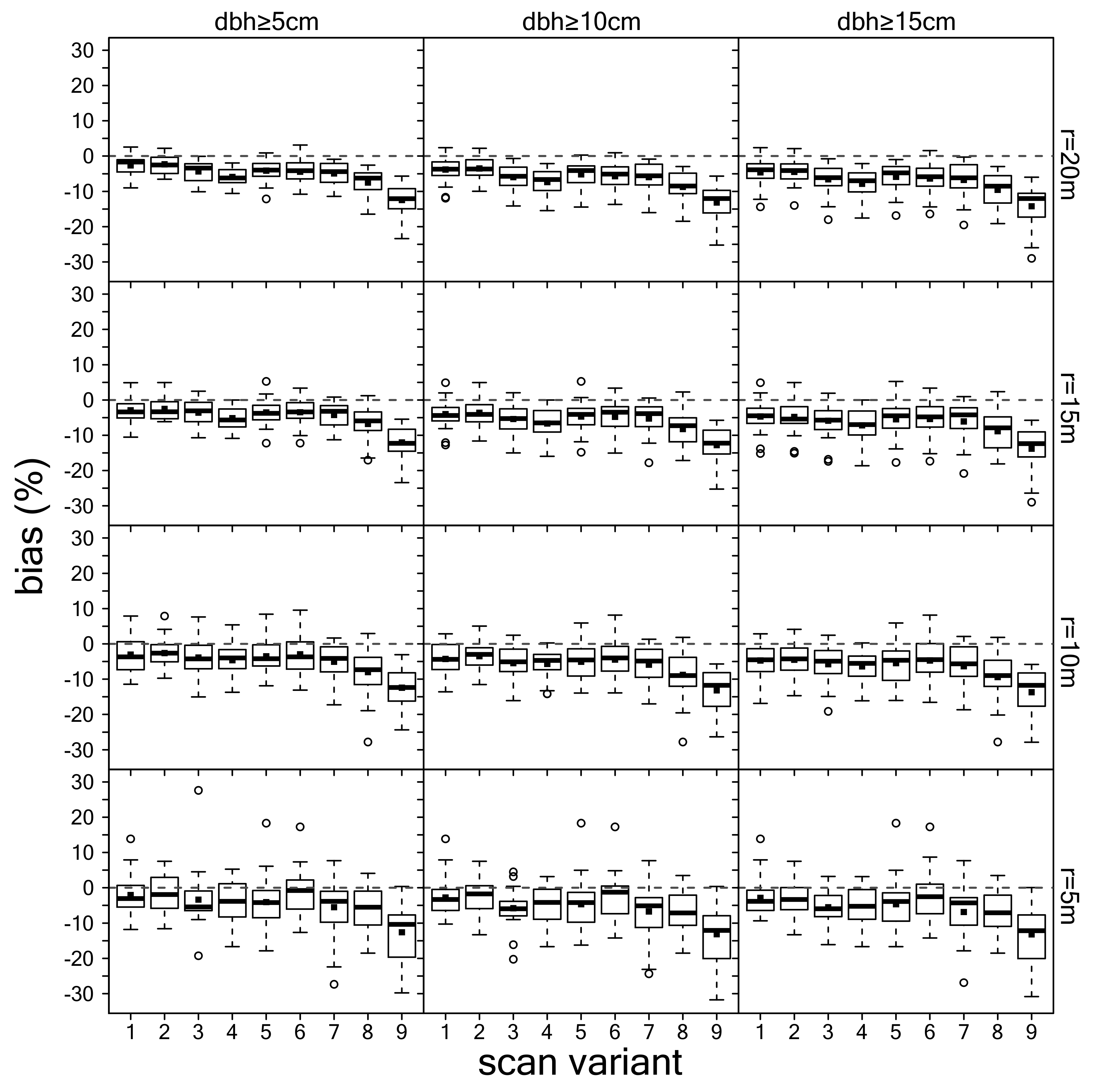
3.2. Estimation of dbh
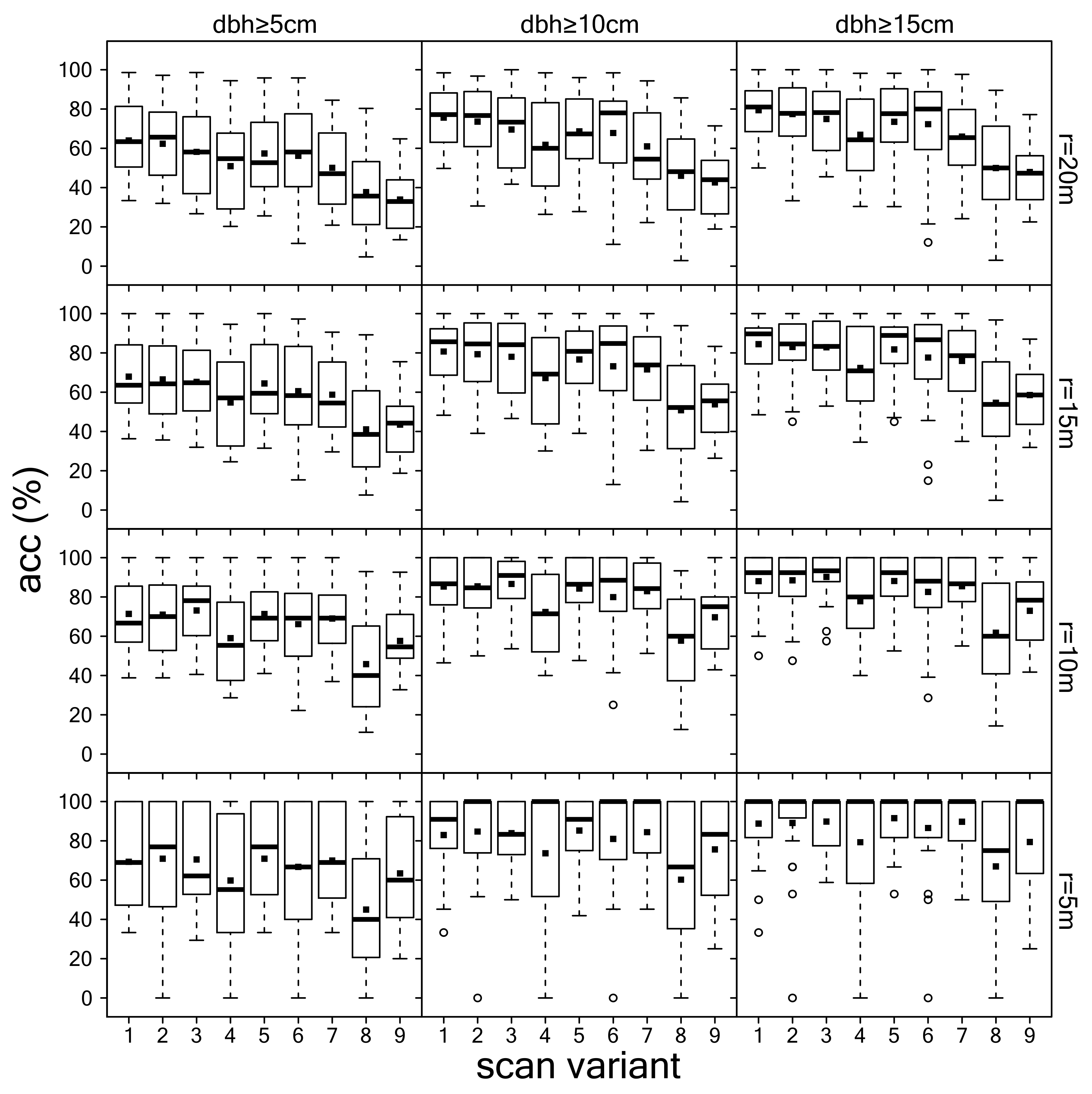
3.3. Summary Evaluation of Scan Variants
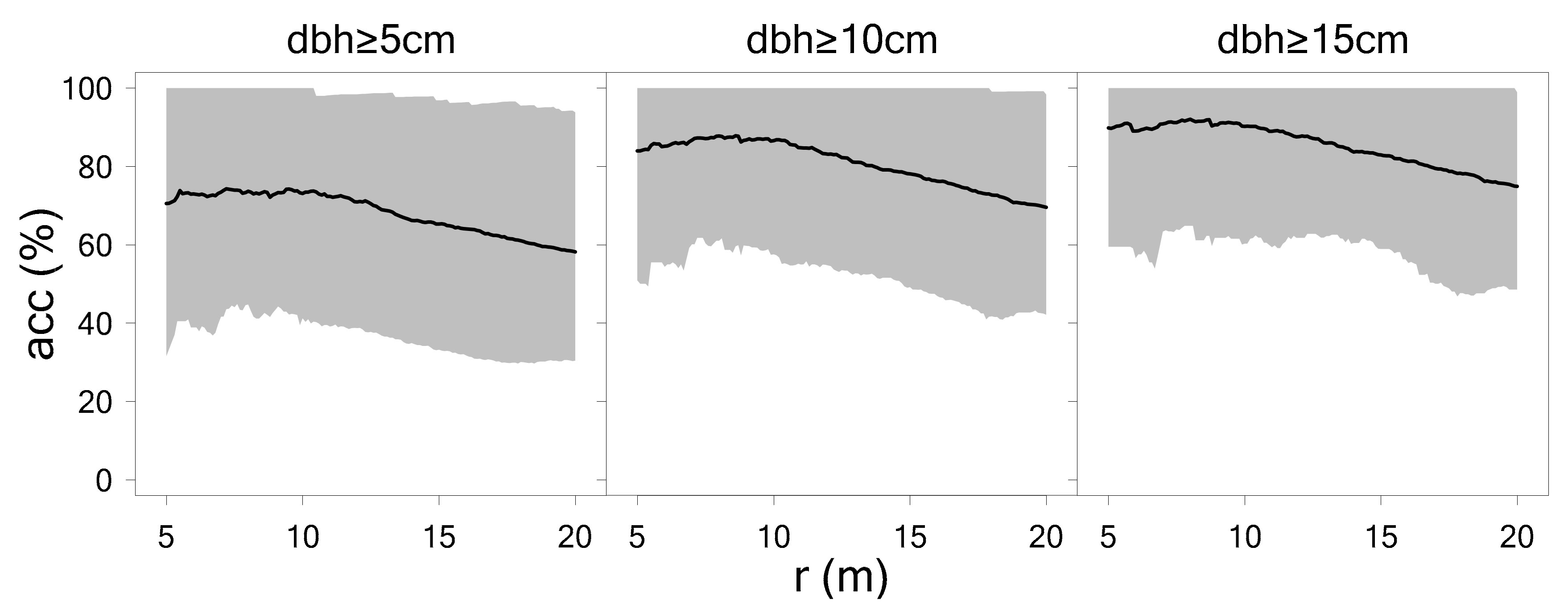
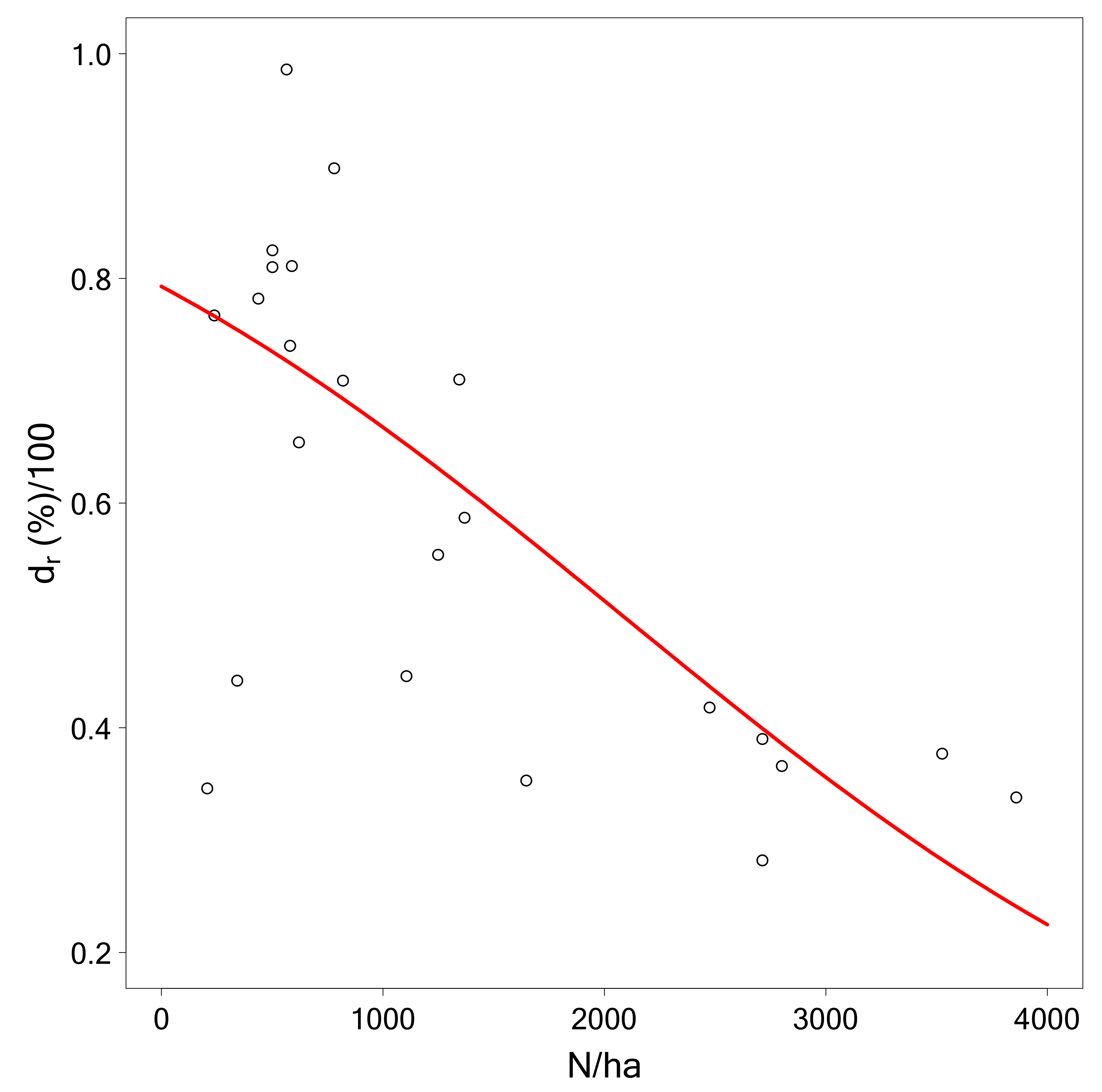
3.4. Relationship to Plot Radius and Environmental Variables
3.5. Results from Tests by Means of International Benchmark Data
4. Discussion
4.1. Comparison with Other Studies
4.2. Comparison of Scan Variants, Tree Detection, and dbh Measurement
4.3. Ranking of Scan Variants and Logistic Regression
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plot | Forest Type | Main Species | Stand Class | Regen- eration | dbh Range (cm) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 4 | Beech | 2 | 1 | 27.4 | 24.6 | 5.1–55.0 | 40.8 | 860 | 836 | 0.77 | 0.51 | 0.85 | 0.14 | 0.89 |
| 2 | 2 | Spruce and beech | 3 | 4 | 32.5 | 37.6 | 14.2–66.0 | 30.9 | 279 | 536 | 0.48 | 0.38 | 1.03 | 1.06 | 0.40 |
| 3 | 1 | Spruce | 3 | 1 | 24.1 | 29.3 | 5.4–56.3 | 41.3 | 613 | 790 | 0.65 | 0.28 | 1.12 | 0 | 0 |
| 4 | 2 | Spruce and beech | 1 | 0 | 22.4 | 15.0 | 5.0–38.7 | 52.3 | 2968 | 1305 | 0.66 | 0.43 | 0.76 | 0.49 | 0.50 |
| 5 | 3 | Beech | 1 | 0 | 34.2 | 9.7 | 5.0–37.3 | 36.7 | 4982 | 1088 | 0.74 | 0.46 | 0.77 | 0 | 1 |
| 6 | 4 | Beech and spruce | 3 | 3 | 22.4 | 25.5 | 5.1–68.0 | 37.0 | 724 | 748 | 1.10 | 0.47 | 0.89 | 0.9 | 0.75 |
| 7 | 1 | Spruce | 1 | 1 | 10.5 | 19.4 | 5.4–48.3 | 37.2 | 1257 | 837 | 0.62 | 0.44 | 0.95 | 0 | 0.00 |
| 8 | 2 | Spruce and beech | 1 | 0 | 11.0 | 11.0 | 5.1–46.8 | 53.9 | 5658 | 1517 | 0.67 | 0.46 | 0.72 | 0.68 | 0.27 |
| 9 | 2 | Spruce and beech | 1 | 0 | 51.0 | 12.0 | 5.1–31.3 | 55.3 | 4894 | 1505 | 0.63 | 0.42 | 0.9 | 0.56 | 0.36 |
| 10 | 1 | Spruce | 2 | 1 | 36.0 | 20.6 | 5.4–52.0 | 51.2 | 1536 | 1126 | 0.75 | 0.49 | 0.94 | 0.66 | 0.17 |
| 11 | 2 | Spruce and beech | 1 | 0 | 22.4 | 11.9 | 5.0–54.4 | 45.8 | 4114 | 1250 | 0.76 | 0.43 | 0.72 | 0.56 | 0 |
| 12 | 4 | Alder and spruce | 2 | 1 | 20.7 | 19.0 | 5.1–61.7 | 48.2 | 1695 | 1094 | 0.86 | 0.48 | 0.82 | 1.01 | 0.83 |
| 13 | 2 | Spruce and beech | 3 | 1 | 25.7 | 24.9 | 5.3–72.1 | 25.7 | 525 | 523 | 1.43 | 0.51 | 0.75 | 0.67 | 0.10 |
| 14 | 4 | Beech and spruce | 2 | 0 | 47.1 | 25.1 | 5.3–52.3 | 35.5 | 716 | 721 | 0.76 | 0.55 | 0.87 | 0.08 | 0.86 |
| 15 | 2 | Spruce and beech | 3 | 3 | 24.0 | 33.4 | 6.3–79.6 | 64.9 | 740 | 1179 | 0.95 | 0.46 | 0.92 | 0.64 | 0.27 |
| 16 | 2 | Spruce and beech | 3 | 1 | 14.2 | 35.2 | 5.7–64.8 | 48.9 | 501 | 869 | 0.47 | 0.41 | 0.87 | 0.66 | 0.44 |
| 17 | 1 | Spruce | 2 | 0 | 34.2 | 18.0 | 5.1–48.4 | 51.1 | 1997 | 1183 | 0.93 | 0.5 | 0.72 | 0 | 0 |
| 18 | 4 | Beech and spruce | 2 | 0 | 41.4 | 31.4 | 5.3–51.5 | 44.4 | 573 | 826 | 0.44 | 0.40 | 0.98 | 0.64 | 0.40 |
| 19 | 1 | Spruce | 2 | 0 | 25.7 | 17.2 | 5.1–48.0 | 64.6 | 2777 | 1525 | 1.04 | 0.48 | 0.67 | 0 | 0 |
| 20 | 2 | Spruce, fir, and beech | 3 | 1 | 37.8 | 25.4 | 5.1–57.7 | 51.1 | 1011 | 1035 | 1.01 | 0.47 | 0.81 | 1.00 | 0.13 |
| 21 | 2 | Spruce, pine, and beech | 3 | 2 | 20.7 | 30.3 | 5.2–61.9 | 46.3 | 645 | 875 | 0.78 | 0.52 | 0.77 | 1.16 | 0.07 |
| 22 | 4 | Beech and fir | 3 | 1 | 30.8 | 27.0 | 5.4–53.9 | 52.0 | 907 | 1028 | 0.71 | 0.56 | 0.93 | 0.66 | 0.80 |
| 23 | 4 | Beech and pine | 1 | 0 | 23.1 | 12.6 | 5.1–40.8 | 61.8 | 4942 | 1648 | 0.93 | 0.48 | 0.63 | 0.50 | 0.57 |
| Step No. | Step/Substep | Software | Package/Function | Parameters | |||
|---|---|---|---|---|---|---|---|
| 1 | Co-registration of scans | FARO | |||||
| 2 | Export in xyz format | SCENE | |||||
| 3 | Import data | LAStools | txt2las | ||||
| Coordinate transformation | las2las | rotate_xy reoffset | |||||
| Thinning the point cloud | lasthin | keep_every_nth 2 | |||||
| 4 | Split point cloud into tiles | lastile | tile_size 10 buffer 2 | ||||
| 5 | Filter | lasnoise | step 0.35 isolation 850 | ||||
| 6 | Classify points into ground points and nonground points Normalize relative to DEM | lasground | step 1 spike 0.4 bulge 0.5 offset 0.1 replace z | ||||
| 7 | Re-merge tiles and remove ground points | lastile | drop_classification 2 | ||||
| Splitting point cloud into tiles | lastile | tile_size 25 buffer 5 | |||||
| 8 | Export in txt format | las2txt | |||||
| 9 | Import data | R | data.table | fread() | |||
| 10a | Stage one clustering | Estimate cutoff distance | densityClust | estimateDC() | NeighbourRateLow = 0.005 NeighbourRateHigh = 0.001 | ||
| 10b | Calculate local density | densityClust() | DC = [estimated dc from estimateDc()] | ||||
| 10c | Find cluster centroids | findClusters() | rho = 2 delta = 0.5 | ||||
| 11 | Filter stage one clusters | various functions in base | |||||
| 12a | Stage two clustering | Estimate cutoff distance | densityClust | estimateDC() | NeighbourRateLow = 0.01 NeighbourRateHigh = 0.02 | ||
| 12b | Calculate local density | densityClust() | DC = [estimated dc from estimateDc()] | ||||
| 12c | Find cluster centroids | findClusters() | rho = 10 delta = 0.5 | ||||
| Join clusters with a distance of less than 50 cm | spatstat | connected.ppp() | R = 0.5 | ||||
| 13 | Diameter estimation | dbh in 13 vertical layers | edci | circMclust() | nx = 25 ny = 25 nr = 5 | ||
| conicfit | LMcircleFit | ||||||
| EllipseDirectFit | |||||||
| Upper diameter | edci | circMclust() | nx = 25 ny = 25 nr = 5 | ||||
| conicfit | LMcircleFit | ||||||
| EllipseDirectFit | |||||||
| 14 | Check criteria for diameters | various functions in base | |||||
| 15 | Assign tree locations | Assign points | spatstat | pppdist() | cutoff = 0.8 | ||
| Radius | dbh | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 20 m | ≥5 cm | 65.31 | 63.59 | 59.09 | 51.47 | 58.29 | 57.12 | 50.62 | 38.43 | 34.36 |
| 20 m | ≥10 cm | 77.57 | 75.47 | 70.82 | 62.71 | 69.98 | 69.09 | 61.76 | 46.93 | 43.09 |
| 20 m | ≥15 cm | 82.39 | 80.25 | 76.73 | 68.25 | 75.46 | 74.06 | 67.09 | 51.19 | 48.53 |
| 15 m | ≥5 cm | 68.80 | 67.25 | 66.17 | 55.26 | 65.13 | 61.22 | 59.38 | 41.89 | 44.31 |
| 15 m | ≥10 cm | 82.10 | 80.47 | 79.22 | 67.93 | 77.67 | 74.17 | 72.48 | 51.88 | 54.68 |
| 15 m | ≥15 cm | 86.54 | 84.75 | 84.50 | 73.51 | 83.31 | 78.92 | 77.11 | 55.91 | 59.49 |
| 10 m | ≥5 cm | 72.54 | 71.79 | 74.30 | 59.38 | 72.21 | 66.60 | 69.47 | 45.93 | 58.57 |
| 10 m | ≥10 cm | 87.19 | 86.81 | 88.16 | 73.08 | 85.72 | 80.66 | 83.68 | 58.06 | 70.68 |
| 10 m | ≥15 cm | 90.46 | 90.18 | 92.04 | 78.78 | 89.97 | 83.55 | 86.66 | 62.10 | 74.06 |
| 5 m | ≥5 cm | 69.33 | 70.89 | 70.52 | 59.91 | 70.93 | 66.81 | 69.94 | 45.00 | 63.41 |
| 5 m | ≥10 cm | 82.93 | 84.72 | 83.93 | 73.80 | 85.23 | 81.09 | 84.4 | 60.22 | 75.63 |
| 5 m | ≥15 cm | 88.75 | 89.11 | 89.80 | 79.55 | 91.50 | 86.79 | 89.69 | 66.96 | 79.40 |
| Radius | dbh | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 20 m | ≥5 cm | 2.16 | 2.32 | 1.77 | 1.55 | 1.89 | 2.32 | 1.53 | 2.59 | 0.87 |
| 20 m | ≥10 cm | 2.63 | 2.82 | 2.03 | 1.82 | 2.19 | 2.64 | 1.73 | 2.91 | 0.91 |
| 20 m | ≥15 cm | 3.62 | 3.75 | 2.57 | 2.36 | 2.82 | 3.14 | 2.17 | 3.25 | 1.08 |
| 15 m | ≥5 cm | 1.37 | 1.18 | 1.37 | 1.27 | 1.06 | 1.56 | 1.31 | 2.32 | 1.00 |
| 15 m | ≥10 cm | 1.66 | 1.43 | 1.57 | 1.49 | 1.27 | 1.83 | 1.51 | 2.66 | 1.05 |
| 15 m | ≥15 cm | 2.38 | 2.03 | 1.96 | 1.87 | 1.73 | 2.12 | 1.84 | 2.80 | 1.15 |
| 10 m | ≥5 cm | 1.69 | 1.26 | 1.50 | 1.01 | 1.25 | 0.77 | 0.81 | 0.43 | 1.00 |
| 10 m | ≥10 cm | 2.01 | 1.48 | 1.66 | 1.19 | 1.51 | 0.90 | 1.01 | 0.52 | 1.07 |
| 10 m | ≥15 cm | 2.50 | 1.80 | 1.87 | 1.42 | 1.93 | 1.18 | 1.42 | 0.55 | 1.18 |
| 5 m | ≥5 cm | 0 | 0 | 0 | 0.27 | 0 | 0.23 | 0 | 0 | 0 |
| 5 m | ≥10 cm | 0 | 0 | 0 | 0.30 | 0 | 0.28 | 0 | 0 | 0 |
| 5 m | ≥15 cm | 0 | 0 | 0 | 0.45 | 0 | 0.41 | 0 | 0 | 0 |
| Scan Variants Overall Accuracy acc(%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Radius | dbh | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 20 m | ≥5 cm | 64.00 | 62.32 | 58.19 | 50.89 | 57.37 | 56.18 | 50.08 | 37.72 | 33.92 |
| 20 m | ≥10 cm | 75.59 | 73.57 | 69.56 | 61.80 | 68.66 | 67.80 | 61.00 | 45.99 | 42.60 |
| 20 m | ≥15 cm | 79.42 | 77.40 | 74.91 | 66.87 | 73.53 | 72.29 | 65.95 | 49.99 | 47.94 |
| 15 m | ≥5 cm | 67.94 | 66.53 | 65.30 | 54.78 | 64.46 | 60.54 | 58.76 | 41.07 | 43.53 |
| 15 m | ≥10 cm | 80.73 | 79.33 | 78.07 | 67.19 | 76.66 | 73.23 | 71.63 | 50.84 | 53.83 |
| 15 m | ≥15 cm | 84.46 | 83.03 | 82.90 | 72.36 | 81.82 | 77.66 | 75.93 | 54.66 | 58.58 |
| 10 m | ≥5 cm | 71.36 | 70.94 | 73.06 | 58.96 | 71.28 | 66.10 | 68.97 | 45.74 | 57.55 |
| 10 m | ≥10 cm | 85.25 | 85.39 | 86.59 | 72.33 | 84.28 | 79.88 | 82.89 | 57.74 | 69.60 |
| 10 m | ≥15 cm | 88.00 | 88.43 | 90.18 | 77.78 | 88.07 | 82.51 | 85.46 | 61.75 | 72.90 |
| 5 m | ≥5 cm | 69.33 | 70.89 | 70.52 | 59.81 | 70.93 | 66.71 | 69.94 | 45.00 | 63.41 |
| 5 m | ≥10 cm | 82.93 | 84.72 | 83.93 | 73.65 | 85.23 | 80.95 | 84.40 | 60.22 | 75.63 |
| 5 m | ≥15 cm | 88.75 | 89.11 | 89.80 | 79.30 | 91.50 | 86.53 | 89.69 | 66.96 | 79.40 |







References
- Kershaw, J.A.; Ducey, M.J.; Beers, T.W.; Husch, B. Forest Mensuration; John Wiley & Sons, Ltd.: Chichester, UK, 2016; ISBN 9781118902028. [Google Scholar]
- Köhl, M.; Magnussen, S.; Marchetti, M. Sampling Methods, Remote Sensing and GIS Multiresource Forest Inventory, Tropical Forestry; Springer: Berlin/Heidelberg Germany, 2006; ISBN 978-3-540-32571-0. [Google Scholar]
- Kauffman, J.B.; Arifanti, V.B.; Basuki, I.; Kurnianto, S.; Novita, N.; Murdiyarso, D.; Donato, D.C.; Warren, M.W. Protocols for the Measurement, Monitoring, and Reporting of Structure, Biomass, Carbon Stocks and Greenhouse Gas Emissions in Tropical Peat Swamp Forests; Center for International Forestry Research (CIFOR): Bogor, Indonesia, 2017. [Google Scholar]
- Kramer, H.; Akça, A. Leitfaden zur Waldmesslehre, 5th ed.; Sauerländer, J.D., Ed.; Frankfurt am Main, Germany, 2008; ISBN 9783793908807. [Google Scholar]
- Liang, X.; Kankare, V.; Hyyppä, J.; Wang, Y.; Kukko, A.; Haggrén, H.; Yu, X.; Kaartinen, H.; Jaakkola, A.; Guan, F.; et al. Terrestrial laser scanning in forest inventories. ISPRS J. Photogramm. Remote Sens. 2016, 115, 63–77. [Google Scholar] [CrossRef]
- Liang, X.; Hyyppä, J.; Kaartinen, H.; Lehtomäki, M.; Pyörälä, J.; Pfeifer, N.; Holopainen, M.; Brolly, G.; Francesco, P.; Hackenberg, J.; et al. International benchmarking of terrestrial laser scanning approaches for forest inventories. ISPRS J. Photogramm. Remote Sens. 2018, 144, 137–179. [Google Scholar] [CrossRef]
- Ritter, T.; Schwarz, M.; Tockner, A.; Leisch, F.; Nothdurft, A. Automatic mapping of forest stands based on three-dimensional point clouds derived from terrestrial laser-scanning. Forests 2017, 8, 265. [Google Scholar] [CrossRef]
- Castelo, A.; Guedes, M.; Sotta, E.; Blanc, L. Measurement errors in forest inventories and comparison of biomass estimation methods. Rev. Ciências Agrárias 2018, 41, 861–869. [Google Scholar] [CrossRef] [Green Version]
- Field, H.L. Landscape Surveying; Cengage Learning: Delmar, CA, USA, 2012; ISBN 1111310602. [Google Scholar]
- Moskal, L.M.; Zheng, G. Retrieving forest inventory variables with terrestrial laser scanning (TLS) in urban heterogeneous forest. Remote Sens. 2012, 4, 1–20. [Google Scholar] [CrossRef]
- Schilling, A.; Schmidt, A.; Maas, H.-G. Tree Topology Representation from TLS Point Clouds Using Depth-First Search in Voxel Space. Photogramm. Eng. Remote Sens. 2012, 78, 383–392. [Google Scholar] [CrossRef]
- Watt, P.J.; Donoghue, D.N.M. Measuring forest structure with terrestrial laser scanning. Int. J. Remote Sens. 2005, 26, 1437–1446. [Google Scholar] [CrossRef]
- Maas, H.-G.; Bienert, A.; Scheller, S.; Keane, E. Automatic forest inventory parameter determination from terrestrial laser scanner data. Int. J. Remote Sens. 2008, 29, 1579–1593. [Google Scholar] [CrossRef]
- Vonderach, C.; Vögtle, T.; Adler, P.; Norra, S. Terrestrial laser scanning for estimating urban tree volume and carbon content. Int. J. Remote Sens. 2012, 33, 6652–6667. [Google Scholar] [CrossRef]
- Liu, J.; Liang, X.; Hyyppä, J.; Yu, X.; Lehtomäki, M.; Pyörälä, J.; Zhu, L.; Wang, Y.; Chen, R. Automated matching of multiple terrestrial laser scans for stem mapping without the use of artificial references. Int. J. Appl. Earth Obs. Geoinf. 2017, 56, 13–23. [Google Scholar] [CrossRef] [Green Version]
- Ritter, T.; Nothdurft, A. Automatic assessment of crown projection area on single trees and stand-level, based on three-dimensional point clouds derived from terrestrial laser-scanning. Forests 2018, 9, 237. [Google Scholar] [CrossRef]
- Henning, J.G.; Radtke, P.J. Detailed Stem Measurements of Standing Trees from Ground-Based Scanning Lidar. For. Sci. 2006, 52, 67–80. [Google Scholar] [CrossRef]
- Moorthy, I.; Miller, J.R.; Berni, J.A.J.; Zarco-Tejada, P.; Hu, B.; Chen, J. Field characterization of olive (Olea europaea L.) tree crown architecture using terrestrial laser scanning data. Agric. For. Meteorol. 2011, 151, 204–214. [Google Scholar] [CrossRef]
- Strahler, A.H.; Jupp, D.L.; Woodcock, C.E.; Schaaf, C.B.; Yao, T.; Zhao, F.; Yang, X.; Lovell, J.; Culvenor, D.; Newnham, G.; et al. Retrieval of forest structural parameters using a ground-based lidar instrument (Echidna®). Can. J. Remote Sens. 2008, 34, S426–S440. [Google Scholar] [CrossRef]
- Fardusi, M.J.; Fardusi, M.J.; Chianucci, F.; Barbati, A. Concept to Practice of Geospatial-Information Tools to Assist Forest Management and Planning under Precision Forestry Framework: A review. Ann. Silvic. Res. 2017, 41, 3–14. [Google Scholar] [CrossRef]
- Holopainen, M.; Kankare, V.; Vastaranta, M.; Liang, X.; Lin, Y.; Vaaja, M.; Yu, X.; Hyyppä, J.; Hyyppä, H.; Kaartinen, H.; et al. Tree mapping using airborne, terrestrial and mobile laser scanning–A case study in a heterogeneous urban forest. Urban For. Urban Green. 2013, 12, 546–553. [Google Scholar] [CrossRef]
- Kankare, V.; Liang, X.; Vastaranta, M.; Yu, X.; Holopainen, M.; Hyyppä, J. Diameter distribution estimation with laser scanning based multisource single tree inventory. ISPRS J. Photogramm. Remote Sens. 2015, 108, 161–171. [Google Scholar] [CrossRef]
- Erikson, M.; Vestlund, K. Finding tree-stems in laser range images of young mixed stands to perform selective cleaning. In Proceedings of the Scandlaser Scientific Workshop on Airborne Laser Scanning of Forests, Umea, Sweden, 3–4 September 2003; pp. 244–250. [Google Scholar]
- Lovell, J.L.; Jupp, D.L.B.; Culvenor, D.S.; Coops, N.C. Using airborne and ground-based ranging lidar to measure canopy structure in Australian forests. Can. J. Remote Sens. 2003, 29, 607–622. [Google Scholar] [CrossRef]
- Hopkinson, C.; Chasmer, L.; Young-Pow, C.; Treitz, P. Assessing forest metrics with a ground-based scanning lidar. Can. J. For. Res. 2004, 34, 573–583. [Google Scholar] [CrossRef] [Green Version]
- Thies, M.; Pfeifer, N.; Winterhalder, D.; Gorte, B.G.H. Three-dimensional reconstruction of stems for assessment of taper, sweep and lean based on laser scanning of standing trees. Scand. J. For. Res. 2004, 19, 571–581. [Google Scholar] [CrossRef]
- Olofsson, K.; Holmgren, J.; Olsson, H. Tree stem and height measurements using terrestrial laser scanning and the RANSAC algorithm. Remote Sens. 2014, 6, 4323–4344. [Google Scholar] [CrossRef]
- Lindberg, E.; Holmgren, J.; Olofsson, K.; Olsson, H. Estimation of stem attributes using a combination of terrestrial and airborne laser scanning. Eur. J. For. Res. 2012, 131, 1917–1931. [Google Scholar] [CrossRef] [Green Version]
- Koreň, M.; Mokroš, M.; Bucha, T. Accuracy of tree diameter estimation from terrestrial laser scanning by circle-fitting methods. Int. J. Appl. Earth Obs. Geoinf. 2017, 63, 122–128. [Google Scholar] [CrossRef]
- Yang, B.; Dai, W.; Dong, Z.; Liu, Y. Automatic forest mapping at individual tree levels from terrestrial laser scanning point clouds with a hierarchical minimum cut method. Remote Sens. 2016, 8, 372. [Google Scholar] [CrossRef]
- Huang, H.; Li, Z.; Gong, P.; Cheng, X.; Clinton, N.; Cao, C.; Ni, W.; Wang, L. Automated Methods for Measuring DBH and Tree Heights with a Commercial Scanning Lidar. Photogramm. Eng. Remote Sens. 2011, 77, 219–227. [Google Scholar] [CrossRef]
- Xi, Z.; Hopkinson, C.; Chasmer, L.; Xi, Z.; Hopkinson, C.; Chasmer, L. Automating Plot-Level Stem Analysis from Terrestrial Laser Scanning. Forests 2016, 7, 252. [Google Scholar] [CrossRef]
- Liang, X.; Kukko, A.; Hyyppä, J.; Lehtomäki, M.; Pyörälä, J.; Yu, X.; Kaartinen, H.; Jaakkola, A.; Wang, Y. In-situ measurements from mobile platforms: An emerging approach to address the old challenges associated with forest inventories. ISPRS J. Photogramm. Remote Sens. 2018, 143, 97–107. [Google Scholar] [CrossRef]
- Liang, X.; Litkey, P.; Hyyppä, J.; Kaartinen, H.; Vastaranta, M.; Holopainen, M. Automatic stem mapping using single-scan terrestrial laser scanning. IEEE Trans. Geosci. Remote Sens. 2012, 50, 661–670. [Google Scholar] [CrossRef]
- Brolly, G.; Király, G. Algorithms for Stem Mapping by Means of Terrestrial Laser Scanning. Acta Silv. Lignaria Hung. 2009, 5, 119–130. [Google Scholar]
- Murphy, G.E.; Acuna, M.A.; Dumbrell, I. Tree value and log product yield determination in radiata pine ( Pinus radiata) plantations in Australia: Comparisons of terrestrial laser scanning with a forest inventory system and manual measurements. Can. J. For. Res. 2010, 40, 2223–2233. [Google Scholar] [CrossRef]
- Lovell, J.L.; Jupp, D.L.B.; Newnham, G.J.; Culvenor, D.S. Measuring tree stem diameters using intensity profiles from ground-based scanning lidar from a fixed viewpoint. ISPRS J. Photogramm. Remote Sens. 2011, 66, 46–55. [Google Scholar] [CrossRef]
- Astrup, R.; Ducey, M.J.; Granhus, A.; Ritter, T.; von Lüpke, N. Approaches for estimating stand-level volume using terrestrial laser scanning in a single-scan mode. Can. J. For. Res. 2014, 44, 666–676. [Google Scholar] [CrossRef]
- Suraj Reddy, R.; Jha, C.S.; Rajan, K.S. Automatic Estimation of Tree Stem Attributes Using Terrestrial Laser Scanning in Central Indian Dry Deciduous Forests. Curr. Sci. 2018, 114, 201. [Google Scholar] [CrossRef]
- Oveland, I.; Hauglin, M.; Giannetti, F.; Kjørsvik, N.S.; Gobakken, T. Comparing three different ground based laser scanning methods for tree stem detection. Remote Sens. 2018, 10, 538. [Google Scholar] [CrossRef]
- Reddy, R.S.; Jha, C.S.; Rajan, K.S. Automatic Tree Identification and Diameter Estimation Using Single Scan Terrestrial Laser Scanner Data in Central Indian Forests. J. Indian Soc. Remote Sens. 2018, 46, 937–943. [Google Scholar] [CrossRef]
- Liang, X.; Hyyppä, J. Automatic stem mapping by merging several terrestrial laser scans at the feature and decision levels. Sensors 2013, 13, 1614–1634. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.; Kankare, V.; Xiaowei, Y.; Hyyppa, J.; Holopainen, M. Automated Stem Curve Measurement Using Terrestrial Laser Scanning. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1739–1748. [Google Scholar] [CrossRef]
- Hilker, T.; Coops, N.C.; Culvenor, D.S.; Newnham, G.; Wulder, M.A.; Bater, C.W.; Siggins, A. A simple technique for co-registration of terrestrial LiDAR observations for forestry applications. Remote Sens. Lett. 2012, 3, 239–247. [Google Scholar] [CrossRef]
- Antonarakis, A.S. Evaluating forest biometrics obtained from ground lidar in complex riparian forests. Remote Sens. Lett. 2011, 2, 61–70. [Google Scholar] [CrossRef]
- Abegg, M.; Kükenbrink, D.; Zell, J.; Schaepman, M.; Morsdorf, F.; Abegg, M.; Kükenbrink, D.; Zell, J.; Schaepman, M.E.; Morsdorf, F. Terrestrial Laser Scanning for Forest Inventories—Tree Diameter Distribution and Scanner Location Impact on Occlusion. Forests 2017, 8, 184. [Google Scholar] [CrossRef]
- Côté, J.-F.; Fournier, R.A.; Frazer, G.W.; Olaf Niemann, K. A fine-scale architectural model of trees to enhance LiDAR-derived measurements of forest canopy structure. Agric. For. Meteorol. 2012, 166–167, 72–85. [Google Scholar] [CrossRef]
- Van der Zande, D.; Jonckheere, I.; Stuckens, J.; Verstraeten, W.W.; Coppin, P. Sampling design of ground-based lidar measurements of forest canopy structure and its effect on shadowing. Can. J. Remote Sens. 2008, 34, 526–538. [Google Scholar] [CrossRef]
- Simonse, M.; Aschoff, T.; Spiecker, H.; Thies, M. Automatic determination of forest inventory parameters using terrestrial laser scanning. In Proceedings of the ScandLaser Scientific Workshop on Airborne Laser Scanning of Forests, Umea, Sweden, 3–4 September 2003; pp. 252–258. [Google Scholar]
- Eysn, L.; Pfeifer, N.; Ressl, C.; Hollaus, M.; Grafl, A.; Morsdorf, F.; Ressl, C.; Eysn, L.; Pfeifer, N.; Morsdorf, F.; et al. A Practical Approach for Extracting Tree Models in Forest Environments Based on Equirectangular Projections of Terrestrial Laser Scans. Remote Sens. 2013, 5, 5424–5448. [Google Scholar] [CrossRef] [Green Version]
- Yao, T.; Yang, X.; Zhao, F.; Wang, Z.; Zhang, Q.; Jupp, D.; Lovell, J.; Culvenor, D.; Newnham, G.; Ni-Meister, W.; et al. Measuring forest structure and biomass in New England forest stands using Echidna ground-based lidar. Remote Sens. Environ. 2011, 115, 2965–2974. [Google Scholar] [CrossRef]
- Calders, K.; Newnham, G.; Burt, A.; Murphy, S.; Raumonen, P.; Herold, M.; Culvenor, D.; Avitabile, V.; Disney, M.; Armston, J.; et al. Nondestructive estimates of above-ground biomass using terrestrial laser scanning. Methods Ecol. Evol. 2015, 6, 198–208. [Google Scholar] [CrossRef]
- Heinzel, J.; Huber, M.O. Constrained spectral clustering of individual trees in dense forest using terrestrial laser scanning data. Remote Sens. 2018, 10, 1056. [Google Scholar] [CrossRef]
- Liu, G.; Wang, J.; Dong, P.; Chen, Y.; Liu, Z. Estimating individual tree height and diameter at breast height (DBH) from terrestrial laser scanning (TLS) data at plot level. Forests 2018, 8, 398. [Google Scholar] [CrossRef]
- Olofsson, K.; Holmgren, J. Single tree stem profile detection using terrestrial laser scanner data, flatness saliency features and curvature properties. Forests 2016, 7, 207. [Google Scholar] [CrossRef]
- Liu, C.; Xing, Y.; Duanmu, J.; Tian, X. Evaluating different methods for estimating diameter at breast height from terrestrial laser scanning. Remote Sens. 2018, 10, 513. [Google Scholar] [CrossRef]
- Pitkänen, T.P.; Raumonen, P.; Kangas, A. Measuring stem diameters with TLS in boreal forests by complementary fitting procedure. ISPRS J. Photogramm. Remote Sens. 2019, 147, 294–306. [Google Scholar] [CrossRef]
- Bienert, A.; Georgi, L.; Kunz, M.; Maas, H.G.; von Oheimb, G. Comparison and combination of mobile and terrestrial laser scanning for natural forest inventories. Forests 2018, 8, 395. [Google Scholar] [CrossRef]
- Mohammed, H.I.; Majid, Z.; Izah, L.N. Terrestrial laser scanning for tree parameters inventory. IOP Conf. Ser. Earth Environ. Sci. 2018, 169, 012096. [Google Scholar] [CrossRef]
- Schodterer, H. Einrichtung eines permanenten Stichprobennetzes im Lehrforst; University of Natural Resources and Life Sciences: Wien, Austria, 1987. [Google Scholar]
- Bitterlich, W. Die Winkelzählprobe. Allg. Forst-Und Holzwirtsch. Ztg. 1948, 59, 4–5. [Google Scholar] [CrossRef]
- Bitterlich, W. Die Winkelzählprobe. Forstwiss. Cent. 1952, 71, 215–225. [Google Scholar] [CrossRef]
- Bitterlich, W. The Relascope Idea. Relative Measurements in Forestry; Commonwealth Agricultural Bureau: Wallingford, UK, 1984; ISBN 0851985394. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Reineke, L.H. Perfecting a stand-density index for evenage forests. J. Agric. Res. 1933, 46, 627–638. [Google Scholar]
- Fueldner, K. Strukturbeschreibung von Buchen-Edellaubholz-Mischwäldern; Georg-August-Universitaet Goettingen: Göttingen, Germany, 1995. [Google Scholar]
- Clark, P.J.; Evans, F.C. Distance to Nearest Neighbor as a Measure of Spatial Relationships in Populations. Ecology 1954, 35, 445–453. [Google Scholar] [CrossRef]
- FARO SCENE | FARO Technologies. Available online: https://www.faro.com/products/construction-bim-cim/faro-scene/ (accessed on 23 February 2019).
- Isenburg, M. LAStools-Efficient LiDAR Processing Software (Version 160429, Academic). Available online: https://rapidlasso.com/lastools/ (accessed on 23 February 2019).
- Axelsson, P. DEM generation from laser scanner data using adaptive TIN models. Int. Arch. Photogramm. Remote Sens. 2000, XXXIII, 110–117. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing, R Version 3.5.1; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Rodriguez, A.; Laio, A. Machine learning. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef]
- Pedersen, T.L.; Hughes, S.; Qiu, X. Densityclust: Clustering by Fast Search and Find of Density Peaks. R Package Version 0.3. 2017. Available online: https://cran.r-project.org/package=densityClust (accessed on 7 February 2019).
- Müller, C.H.; Garlipp, T. Simple consistent cluster methods based on redescending M-estimators with an application to edge identification in images. J. Multivar. Anal. 2005, 92, 359–385. [Google Scholar] [CrossRef] [Green Version]
- Garlipp, T. Edci: Edge Detection and Clustering in Images. R Package Version 1.1-3. 2018. Available online: https://CRAN.R-project.org/package=edci (accessed on 23 February 2019).
- Baddeley, A.; Rubak, E.; Turner, R. Spatial Point Patterns: Methodology and Applications with R; CRC Press: Boca Raton, FA, USA, 2015; ISBN 9781482210200. [Google Scholar]
- Veall, M.R.; Zimmermann, K.F. Pseudo-R2 measures for some common limited dependent variable models. J. Econ. Surv. 1996, 10, 241–259. [Google Scholar] [CrossRef]
- Zhang, W.; Wan, P.; Wang, T.; Cai, S.; Chen, Y.; Jin, X.; Yan, G. A Novel Approach for the Detection of Standing Tree Stems from Plot-Level Terrestrial Laser Scanning Data. Remote Sens. 2019, 11, 211. [Google Scholar] [CrossRef]
- Kelbe, D.; van Aardt, J.; Romanczyk, P.; van Leeuwen, M.; Cawse-Nicholson, K. Marker-Free Registration of Forest Terrestrial Laser Scanner Data Pairs With Embedded Confidence Metrics. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4314–4330. [Google Scholar] [CrossRef]
- Ducey, M.; Astrup, R. Adjusting for nondetection in forest inventories derived from terrestrial laser scanning. Can. J. Remote Sens. 2013. [Google Scholar] [CrossRef]
- Kankare, V.; Puttonen, E.; Holopainen, M.; Hyyppä, J. The effect of TLS point cloud sampling on tree detection and diameter measurement accuracy. Remote Sens. Lett. 2016, 7, 495–502. [Google Scholar] [CrossRef]
- Buckland, S.T.; Laake, J.L.; Anderson, D.R.; Burnham, K.P.; Lutz, S. Distance Sampling: Estimating Abundance of Biological Populations. J. Wildl. Manag. 2007, 59, 628. [Google Scholar] [CrossRef]
- Richardson, A.M. Advanced Distance Sampling. Ecology 2008, 89, 3550–3551. [Google Scholar] [CrossRef]
- Buckland, S.T.; Rexstad, E.A.; Marques, T.A.; Oedekoven, C.S. Distance Sampling: Methods and Applications; Methods in Statistical Ecology; Springer International Publishing: Cham, Switzerland, 2015; ISBN 978-3-319-19218-5. [Google Scholar]
- Olofsson, K.; Olsson, H. Estimating tree stem density and diameter distribution in single-scan terrestrial laser measurements of field plots: A simulation study. Scand. J. For. Res. 2018, 33, 365–377. [Google Scholar] [CrossRef]
- Seidel, D.; Ammer, C. Efficient measurements of basal area in short rotation forests based on terrestrial laser scanning under special consideration of shadowing. iForest-Biogeosci 2014, 7, 227. [Google Scholar] [CrossRef]
- De Vries, P.G. Sampling Theory for Forest Inventory; Springer: Berlin, Germany; Heidelberg, Germany, 1986; ISBN 978-3-540-17066-2. [Google Scholar]
- Henttonen, H.M.; Kangas, A. Optimal plot design in a multipurpose forest inventory. For. Ecosyst. 2015, 2, 31. [Google Scholar] [CrossRef] [Green Version]
- Bauwens, S.; Bartholomeus, H.; Calders, K.; Lejeune, P. Forest Inventory with Terrestrial LiDAR: A Comparison of Static and Hand-Held Mobile Laser Scanning. Forests 2016, 7, 127. [Google Scholar] [CrossRef]





| # Of Sample Plots | 23 | |||
| # Of Trees | 3894 | |||
| # Of Trees/Sample Plot | 169.3 | |||
| dbh Range (cm) | 5.0–79.6 | |||
| Mean | SD | Min | Max | |
| (%) | 27.8 | 10.4 | 10.5 | 51.0 |
| (cm) | 22.4 | 8.3 | 9.7 | 37.6 |
| (m2/ha) | 46.8 | 10.2 | 25.7 | 64.9 |
| (trees/ha) | 1953 | 1753 | 279 | 5658 |
| (trees/ha) | 1045 | 314 | 523 | 1648 |
| 0.79 | 0.23 | 0.44 | 1.43 | |
| 0.46 | 0.06 | 0.28 | 0.56 | |
| 0.84 | 0.12 | 0.63 | 1.12 | |
| 0.52 | 0.38 | 0 | 1.16 | |
| 0.38 | 0.34 | 0 | 1 | |
| Variant | Setting | # Of Scans | Scan Time (min) | Approx. Scanner Installation Time (min) | Approx. Sphere Installation Time (min) | Approx. Total Working Time Per Plot (min) |
|---|---|---|---|---|---|---|
| 1 | Hexagon with center | 7 | 77 | 21 | 5 | 103 |
| 2 | Hexagon without center | 6 | 66 | 18 | 5 | 89 |
| 3 | Triangle with center | 4 | 44 | 12 | 5 | 61 |
| 4 | Triangle without center | 3 | 33 | 9 | 5 | 47 |
| 5 | Rectangle with center | 5 | 55 | 15 | 5 | 75 |
| 6 | Rectangle without center | 4 | 44 | 12 | 5 | 61 |
| 7 | Diagonal with center | 3 | 33 | 9 | 5 | 47 |
| 8 | Diagonal without center | 2 | 22 | 6 | 5 | 33 |
| 9 | Single scan (only center) | 1 | 11 | 3 | 0 | 14 |
| Scan Variants RMSE in cm (RMSE in %) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Radius | dbh | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 20 m | ≥5 cm | 4.18 (18.78) | 4.48 (20.69) | 4.70 (19.78) | 5.06 (21.34) | 4.08 (17.29) | 4.70 (19.39) | 4.48 (18.85) | 5.29 (22.04) | 6.24 (23.43) |
| 20 m | ≥10 cm | 4.09 (15.83) | 4.48 (17.69) | 4.34 (15.74) | 4.79 (17.35) | 4.05 (15.10) | 4.61 (16.69) | 4.39 (16.28) | 5.20 (18.84) | 6.51 (22.59) |
| 20 m | ≥15 cm | 4.14 (13.66) | 4.43 (14.80) | 4.66 (14.92) | 5.14 (16.54) | 4.25 (13.77) | 4.87 (15.41) | 4.56 (14.77) | 5.57 (17.89) | 7.00 (22.05) |
| 15 m | ≥5 cm | 3.92 (16.98) | 4.20 (18.76) | 4.61 (19.70) | 4.92 (21.04) | 3.96 (16.98) | 4.28 (17.89) | 4.21 (17.71) | 5.22 (21.62) | 5.77 (22.62) |
| 15 m | ≥10 cm | 3.79 (14.43) | 4.15 (16.07) | 4.04 (14.79) | 4.49 (16.32) | 3.78 (14.12) | 4.01 (14.69) | 4.17 (15.41) | 4.95 (17.76) | 6.09 (21.64) |
| 15 m | ≥15 cm | 3.90 (12.65) | 3.98 (12.83) | 4.35 (13.98) | 4.83 (15.58) | 3.93 (12.79) | 4.15 (13.23) | 4.27 (13.78) | 5.22 (16.70) | 6.65 (21.00) |
| 10 m | ≥5 cm | 3.76 (15.46) | 3.63 (15.14) | 4.33 (17.76) | 4.22 (17.11) | 4.01 (16.70) | 4.41 (16.96) | 3.72 (15.20) | 4.81 (16.99) | 5.55 (21.83) |
| 10 m | ≥10 cm | 3.46 (12.70) | 3.65 (13.71) | 3.75 (13.58) | 3.93 (13.82) | 3.60 (12.94) | 3.94 (13.40) | 3.82 (13.95) | 4.91 (16.32) | 5.91 (20.69) |
| 10 m | ≥15 cm | 3.68 (11.89) | 3.64 (11.62) | 4.01 (12.85) | 4.14 (13.25) | 3.82 (12.17) | 4.17 (12.68) | 4.05 (13.06) | 5.20 (15.85) | 6.36 (19.88) |
| 5 m | ≥5 cm | 2.66 (10.78) | 2.69 (11.10) | 3.63 (14.77) | 2.93 (10.78) | 2.93 (11.41) | 2.87 (11.16) | 3.78 (14.78) | 3.45 (12.81) | 4.74 (18.30) |
| 5 m | ≥10 cm | 2.74 (9.80) | 2.85 (10.17) | 3.03 (10.64) | 2.97 (9.64) | 3.04 (10.40) | 2.96 (10.02) | 3.75 (12.71) | 3.43 (11.87) | 5.07 (16.97) |
| 5 m | ≥15 cm | 2.74 (8.85) | 3.03 (9.86) | 3.12 (9.93) | 3.07 (9.35) | 3.06 (9.56) | 3.09 (9.66) | 3.82 (11.84) | 3.56 (11.75) | 5.22 (16.25) |
| Scan Variants Bias in cm (Bias in %) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Radius | dbh | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 20 m | ≥5 cm | −0.62 (−2.64) | −0.63 (−2.33) | −1.18 (−4.36) | −1.61 (−5.93) | −1.03 (−4.12) | −1.21 (−4.12) | −1.26 (−4.91) | −2.03 (−7.51) | −3.39 (−12.48) |
| 20 m | ≥10 cm | −0.95 (−3.82) | −0.95 (−3.51) | −1.66 (−5.98) | −2.05 (−7.37) | −1.39 (−5.19) | −1.61 (−5.69) | −1.61 (−5.97) | −2.45 (−8.72) | −3.81 (−13.17) |
| 20 m | ≥15 cm | −1.31 (−4.59) | −1.34 (−4.47) | −2.03 (−6.57) | −2.42 (−7.85) | −1.77 (−5.85) | −1.99 (−6.35) | −2.02 (−6.74) | −2.95 (−9.57) | −4.47 (−14.23) |
| 15 m | ≥5 cm | −0.66 (−2.92) | −0.64 (−2.51) | −0.96 (−3.61) | −1.40 (−5.15) | −0.83 (−3.52) | −0.92 (−3.47) | −1.05 (−4.23) | −1.97 (−6.80) | −3.17 (−12.02) |
| 15 m | ≥10 cm | −1.01 (−4.00) | −0.96 (−3.61) | −1.47 (−5.40) | −1.83 (−6.67) | −1.22 (−4.70) | −1.31 (−4.77) | −1.37 (−5.25) | −2.39 (−8.24) | −3.66 (−12.80) |
| 15 m | ≥15 cm | −1.36 (−4.69) | −1.41 (−4.81) | −1.79 (−5.88) | −2.18 (−7.19) | −1.61 (−5.46) | −1.66 (−5.37) | −1.78 (−6.09) | −2.77 (−8.86) | −4.36 (−13.80) |
| 10 m | ≥5 cm | −0.75 (−3.05) | −0.73 (−2.62) | −1.01 (−3.85) | −1.35 (−4.62) | −0.85 (−3.52) | −0.89 (−2.94) | −1.25 (−5.07) | −2.51 (−7.99) | −3.35 (−12.42) |
| 10 m | ≥10 cm | −1.15 (−4.28) | −1.00 (−3.48) | −1.54 (−5.47) | −1.65 (−5.69) | −1.34 (−5.07) | −1.33 (−4.45) | −1.57 −5.91) | −2.79 (−8.76) | −3.89 (−13.18) |
| 10 m | ≥15 cm | −1.42 (−4.71) | −1.37 (−4.50) | −1.82 (−5.75) | −1.97 (−6.37) | −1.63 (−5.44) | −1.56 (−4.70) | −1.88 (−6.33) | −3.16 (−9.39) | −4.43 (−13.69) |
| 5 m | ≥5 cm | −0.46 (−2.06) | −0.52 (−1.77) | −1.04 (−3.35) | −1.34 (−3.73) | −0.86 (−4.06) | −0.38 (−1.14) | −1.42 (−5.51) | −1.58 (−5.56) | −3.63 (−12.60) |
| 5 m | ≥10 cm | −0.72 (−2.78) | −0.85 (−2.74) | −1.82 (−5.80) | −1.68 (−4.87) | −1.14 (−4.65) | −0.71 (−2.29) | −1.83 (−6.71) | −1.98 (−6.91) | −4.22 (−13.17) |
| 5 m | ≥15 cm | −0.81 (−2.86) | −0.95 (−3.08) | −1.86 (−5.53) | −1.82 (−5.21) | −1.26 (−4.65) | −0.74 (−2.42) | −2.00 (−6.86) | −2.10 (−7.05) | −4.40 (−13.18) |
| Scan Variant | Working Time Per Plot (min) | Overall Accuracy (%) | RMSE (cm) | Standardized Working Time Per Plot (0, … , 1) | Standardized Overall Accuracy (0, … , 1) | Standardized RMSE (0, … , 1) | Average Standardized Value | Overall Rank |
|---|---|---|---|---|---|---|---|---|
| 1 | 103 | 78.15 | 3.59 | 1.000 | 0.000 | 0.000 | 0.333 | 6 |
| 2 | 89 | 77.64 | 3.77 | 0.843 | 0.019 | 0.077 | 0.313 | 5 |
| 3 | 61 | 76.92 | 4.05 | 0.528 | 0.046 | 0.197 | 0.257 | 1 |
| 4 | 47 | 66.31 | 4.21 | 0.371 | 0.444 | 0.265 | 0.360 | 7 |
| 5 | 75 | 76.15 | 3.71 | 0.685 | 0.075 | 0.051 | 0.270 | 3 |
| 6 | 61 | 72.53 | 4.00 | 0.528 | 0.211 | 0.175 | 0.305 | 4 |
| 7 | 47 | 72.06 | 4.08 | 0.371 | 0.228 | 0.209 | 0.269 | 2 |
| 8 | 33 | 51.47 | 4.74 | 0.213 | 1.000 | 0.491 | 0.568 | 8 |
| 9 | 14 | 58.24 | 5.93 | 0.000 | 0.746 | 1.000 | 0.582 | 9 |
| Full Models | |||||||||
| Covariate | Coef. | Est. | SE | t Value | pValue | Est. | SE | t Value | pValue |
| 5.822 | 3.272 | 1.780 | 0.095 | −5.701 | 7.861 | −0.725 | 0.479 | ||
| 0.019 | 0.017 | 1.113 | 0.283 | −0.001 | 0.043 | −0.032 | 0.975 | ||
| dm | −0.028 | 0.047 | −0.606 | 0.553 | 0.061 | 0.134 | 0.458 | 0.654 | |
| −0.001 | <0.001 | −2.43 | 0.028 | 0.001 | 0.001 | 0.53 | 0.814 | ||
| −3.382 | 1.908 | −1.772 | 0.097 | −1.046 | 4.377 | −0.239 | 0.814 | ||
| −2.360 | 2.107 | −1.12 | 0.280 | −0.960 | 5.540 | −0.173 | 0.865 | ||
| 0.014 | 0.525 | 0.026 | 0.979 | 0.884 | 1.441 | 0.613 | 0.549 | ||
| 0.447 | 0.494 | 0.905 | 0.380 | 0.736 | 1.432 | 0.514 | 0.615 | ||
| 0.627 | 0.128 | ||||||||
| Final Models | |||||||||
| Covariate | Coef. | Est. | SE | t Value | pValue | Est. | SE | t value | pValue |
| 1.134 | 0.252 | 4.496 | <0.001 | −4.069 | 0.606 | −6.716 | <0.001 | ||
| −0.001 | <0.001 | −3.844 | 0.001 | ― | ― | ― | ― | ||
| 0.469 | ― | ||||||||
| Scan Mode | Plot ID | Complexity (%) | Tree Detection | |||||
|---|---|---|---|---|---|---|---|---|
| Complete- ness (%) | Rank | Correctness (%) | Rank | Mean accuracy (%) | Rank | |||
| MS | 1 | easy | 92.16 | 6 | 92.16 | 8 | 92.16 | 6 |
| 2 | easy | 85.71 | 84.71 | 85.21 | ||||
| 3 | medium | 45.58 | 13 | 97.10 | 5 | 62.04 | 9 | |
| 4 | medium | 67.53 | 96.30 | 79.39 | ||||
| 5 | difficult | 42.64 | 10 | 100.00 | 3 | 59.78 | 7 | |
| 6 | difficult | 34.19 | 97.56 | 50.63 | ||||
| mean | 61.30 | 9.7 | 94.64 | 5.3 | 71.53 | 7.3 | ||
| SS | 1 | easy | 58.82 | 13 | 83.33 | 12 | 68.97 | 13 |
| 2 | easy | 53.57 | 84.91 | 65.69 | ||||
| 3 | medium | 27.70 | 14 | 97.62 | 6 | 43.16 | 14 | |
| 4 | medium | 37.18 | 93.55 | 53.21 | ||||
| 5 | difficult | 11.45 | 12 | 93.75 | 8 | 20.41 | 12 | |
| 6 | difficult | 11.02 | 89.66 | 19.62 | ||||
| mean | 33.29 | 13 | 90.47 | 8.7 | 45.18 | 13 | ||
| Scan Mode | Plot ID | Complexity (%) | dbh | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE (cm) | Rank | bias (cm) | Rank | RMSE (%) | Rank | bias (%) | Rank | |||
| MS | 1 | easy | 1.22 | 5 | −0.40 | 7 | 5.09 | 8 | −1.67 | 9 |
| 2 | easy | 2.15 | −1.08 | 12.60 | −6.33 | |||||
| 3 | medium | 2.81 | 5 | −1.40 | 8 | 15.43 | 5 | −7.69 | 10 | |
| 4 | medium | 1.78 | −0.52 | 7.70 | −2.25 | |||||
| 5 | difficult | 4.36 | 7 | −1.52 | 8 | 23.71 | 6 | −8.27 | 8 | |
| 6 | difficult | 2.01 | −0.57 | 15.13 | −4.29 | |||||
| mean | 2.39 | 5.7 | −0.92 | 7.7 | 13.28 | 6.3 | −5.08 | 9 | ||
| SS | 1 | easy | 4.58 | 8 | −2.47 | 12 | 19.49 | 8 | −10.51 | 12 |
| 2 | easy | 3.97 | −1.97 | 21.21 | −10.52 | |||||
| 3 | medium | 5.11 | 7 | −3.70 | 13 | 27.32 | 7 | −19.78 | 12 | |
| 4 | medium | 4.40 | −2.00 | 16.12 | −7.33 | |||||
| 5 | difficult | 6.31 | 8 | −3.47 | 9 | 29.49 | 7 | −16.21 | 8 | |
| 6 | difficult | 3.55 | −0.25 | 25.19 | −1.77 | |||||
| mean | 4.65 | 7.7 | −2.31 | 11.3 | 23.14 | 7.3 | −11.02 | 10.7 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gollob, C.; Ritter, T.; Wassermann, C.; Nothdurft, A. Influence of Scanner Position and Plot Size on the Accuracy of Tree Detection and Diameter Estimation Using Terrestrial Laser Scanning on Forest Inventory Plots. Remote Sens. 2019, 11, 1602. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11131602
Gollob C, Ritter T, Wassermann C, Nothdurft A. Influence of Scanner Position and Plot Size on the Accuracy of Tree Detection and Diameter Estimation Using Terrestrial Laser Scanning on Forest Inventory Plots. Remote Sensing. 2019; 11(13):1602. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11131602
Chicago/Turabian StyleGollob, Christoph, Tim Ritter, Clemens Wassermann, and Arne Nothdurft. 2019. "Influence of Scanner Position and Plot Size on the Accuracy of Tree Detection and Diameter Estimation Using Terrestrial Laser Scanning on Forest Inventory Plots" Remote Sensing 11, no. 13: 1602. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11131602