1. Introduction
Sea oil pollution is considered a major threat to oceanic and coastal ecosystems, as well as for various naval-related human activities. Accidents at offshore oil drilling platforms or oil pipeline networks can provoke severe oil spills. Yet, illegal discharges of ballast and tank cleaning oily residues from oil tankers and ships are the main sources of relative pollution events [
1,
2,
3,
4]. The detection of oil slicks and early warning of the corresponding authorities is vital to attenuate the environmental disaster, control the oil spill dispersion and ensure that no human lives are in danger. Remote sensing has a crucial role towards this objective, since relevant approaches can offer efficient monitoring of marine environments and assist the oil spill detection.
More specific, synthetic aperture radar (SAR) mounted on aircrafts or satellites is comprised of the most common sensory equipment in marine remote sensing systems [
2,
3,
5]. The SAR sensor, as a microwave-based technology, emits radio wave pulses and receives their reflection in order to capture a representation of the target scene, widely known as SAR images [
1,
2]. The sensor is considered an ideal option due to the all-weather and varying illumination conditions effective operation, as well as its robustness to cloud occlusions [
1,
3,
5]. One of the main aspects of oil spreading over sea surface is that it dampens the capillary waves and so, the backscatter radio waves are suppressed. As a result, oil spills are depicted as black spots, contrary to the brighter regions which are usually related with unspoiled polluted sea areas [
2,
4]. Moreover, the wide coverage that the sensor can provide is of high significance, since oil spills could cover kilometers, as well as further contextual information, such as close-coastal region or vessels, which can be enclosed in the acquired image. However, similar dark instances could be identified in SAR images that might correspond to potential oil spills. Oceanic natural phenomena such as low wind speed regions, weed beds and algae blooms, wave shadows behind land, grease ice, etc. [
3,
6,
7,
8] can also be depicted as dark spots. These dark regions are frequently categorized as look-alikes, rendering the oil spill detection problem even more challenging.
Several classification methods have been proposed to discriminate oil spills from look-alikes over SAR images. In most cases, one specific process is followed, consisting of three main steps: (a) automatic detection of dark spots in the processed SAR image, (b) feature extraction from the initially identified regions, (c) classification as oil slick or regions including look-alikes. During the first step, binary segmentation is usually applied to the input image representation in order to retrieve the depicted black spots. The second phase involves the extraction of statistical features from the aforementioned segmented areas that might include potential oil spills. For the last processing step, either the entire image or sections that contain the black regions of interest are categorized as oil spills or look-alikes. Solberg et al. [
9] proposed an automated framework that relies on this three-phase process in order to classify SAR signatures between oil spills and look-alikes. Nonetheless, prior knowledge regarding the probability of oil spill existence must be provided to the classifier. Fiscella et al. [
10] proposed a similar probabilistic approach where the processed images are compared in order to define templates and subsequently classify them as oil spill or look-alike. Authors in [
11] presented a method to enhance the oil spill recognition system by involving wind history information and provided an estimation about their period of existence. Karantzalos and Argialas proposed in [
12] a pre-processing step that improves the classifier’s performance by employing a level-set method for SAR image segmentation in contrast of previous approaches where thresholds or edge detection techniques are applied. Following the most common processing pipeline, a fuzzy logic classifier was presented in [
13] to estimate the probability of a dark spot characterized as an oil spill. Although the classification process is automated, an extensive pre-processing phase is required in order to initially extract geographic features. A more object-oriented approach was initially introduced in [
14], where a fuzzy classifier was used to label dark spots, while in [
15] a decision tree module was used for detected dark spot objects classification. These methods exploited a multi-level segmentation scheme to reduce the false positives rate. Authors in [
16] deployed a decision tree forest for efficient feature selection for oil spill classification. Focusing mostly on the detection rather than the recognition of oil spills, Mercier et al. in [
17] inserted a semi-supervised detection method using wavelet decomposition on SAR images and a kernel-based abnormal detection scheme.
Considering their robustness in classification objectives, neural networks have also been reported as an efficient alternative in the oil spill detection research area. Neural networks were initially inserted in this research field in [
18] where pre-determined features from SAR images were fed to the network in order to estimate relevant labels. In addition, De Souza et al. [
19] utilized a neural network for the feature extraction phase towards enriching the internal representations of the input. Similar approaches [
20,
21] proposed to employ two subsequent neural networks. The first network was deployed to initially segment SAR images and to provide a more effective black spot detection framework while the second was utilized to distinguish oil spills from look-alikes. However, the whole pipeline was not an end-to-end trainable framework since pre-computed features must be provided to the second network for their classification. Authors in [
22] employed hand-crafted features to train a wavelet neural network, which classifies black spots captured in SAR images to oil spills and unspoiled water regions. Similarly, Stathakis et al. [
23] developed a shallow neural network in order to discriminate oil spills from look-alikes, focused on an optimal solution in terms of computational cost and detection accuracy. Towards this direction, genetic algorithms were used to identify the optimal subset of the extracted features and the optimal number of nodes in the network’s hidden layer. Finally, in [
24], a set of image filters and low-level descriptors were used to extract texture information from depicted black spots, which eventually was fed to a neural network, aiming to recognize the spatial patterns of oil spills.
In most cases, a binary classification procedure is involved in the aforementioned methods where either the entire input SAR image or sections are single-labeled as oil spill and/or look-alike. Due to its capabilities in monitoring wide territories, SAR sensor can include further contextual information such as ships, coastal construction, platforms, land, etc. These instances can be semantically meaningful to the classification process, e.g., it is expected that a dark spot with linear formation close to a ship might correspond to an oil spill discharged from the vessel, rather than a look-alike. Moreover, information regarding the presence of nearby coastal territories or ships is important for an early warning system and a decision making module towards mitigating the overall danger. Thus, a different classification approach is required in order to identify properly multi-class instances enclosed in SAR imagery. Furthermore, oil dispersion over sea surfaces is a dynamically evolved phenomenon affected by wind speed, sea currents, etc. Hence, oil slicks present extreme diversity in terms of shape and size. To consider also the physical features of the oil slicks and their dispersion, deep learning techniques can be utilized so that geometrical characteristics like shape, size etc. could be evaluated and efficiently replace the handcrafted features. Taking this into consideration, among with the existence of multi-class instances, semantic segmentation models could be deployed as robust alternatives to extract the rich informative content from SAR images. To this end, Yu et al. [
25] introduced adversarial learning of an
f-divergence function in order to produce the segmentation mask of a processed SAR image. The authors deployed a deep convolutional neural network (DCNN), denoted as generator, to produce a segmented instance of the input image and a subsequent DCNN, marked as a regressor, to minimize the
f-divergence between ground-truth and the generated segmentation result. Nonetheless, the approach is limited to one class (oil spill) segmentation without fully exploiting the pixel-wise classification that semantic segmentation methods can deliver. A convolutional autoencoder network was proposed in [
26] to semantically segment scanlines from the Side-Looking Airborne Radar (SLAR) images depicting oil spills and other maritime classes. However, the framework is limited to applying parallel autoencoders for every class, while the robustness of DCNN segmentation models cannot be fully exploited due to the limited number of SLAR data. Authors in [
27] presented a DCNN to semantically segment SAR images, yet the process was limited only to oil spill and look-alike identification. An extension of the model was presented in [
28] where oil spill, look-alike, land and ship instances were semantically segmented.
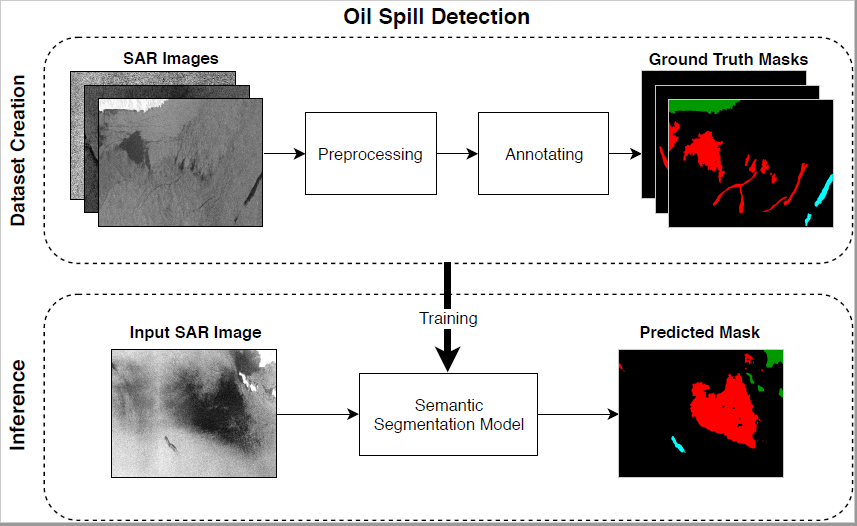
The aforementioned classification-based algorithms relied on abstract datasets for both training and testing and so a proper comparison between relevant approaches is irrelevant due to the lack of a common basis. Moreover, there is no compact formulation to evaluate the efficiency of each algorithm since inputs are manipulated differently following different evaluation techniques according to the corresponding algorithm. To overcome similar issues, we identified the need for a proper public dataset and deliver a common base for evaluating the results of relevant works. Thus, a new publicly available oil spill dataset is presented, aiming to establish a benchmark dataset for the evaluation of future oil spill detection algorithms. Current work relies on the early work of Krestenitis et al. [
28] and aims at providing a thorough analysis of multiple semantic segmentation DCNN models deployed for oil spill detection. It should be highlighted that all the tested models were trained and evaluated on the introduced dataset. The main objective is to demonstrate and highlight the significance of DCNN architectures coping the identification problem of oil spills over sea surfaces while the importance of utilizing a common benchmark dataset is also outlined by providing the developed dataset to the relevant research community.
The rest of this paper is organized as follows. In
Section 2 the building process of our oil spill dataset is presented and the employed DCNN models for semantic segmentation of SAR images are thoroughly described. The performance of each architecture is presented and compared in
Section 3, followed by the relevant discussion. Finally, conclusions are drawn in
Section 4.
4. Conclusions
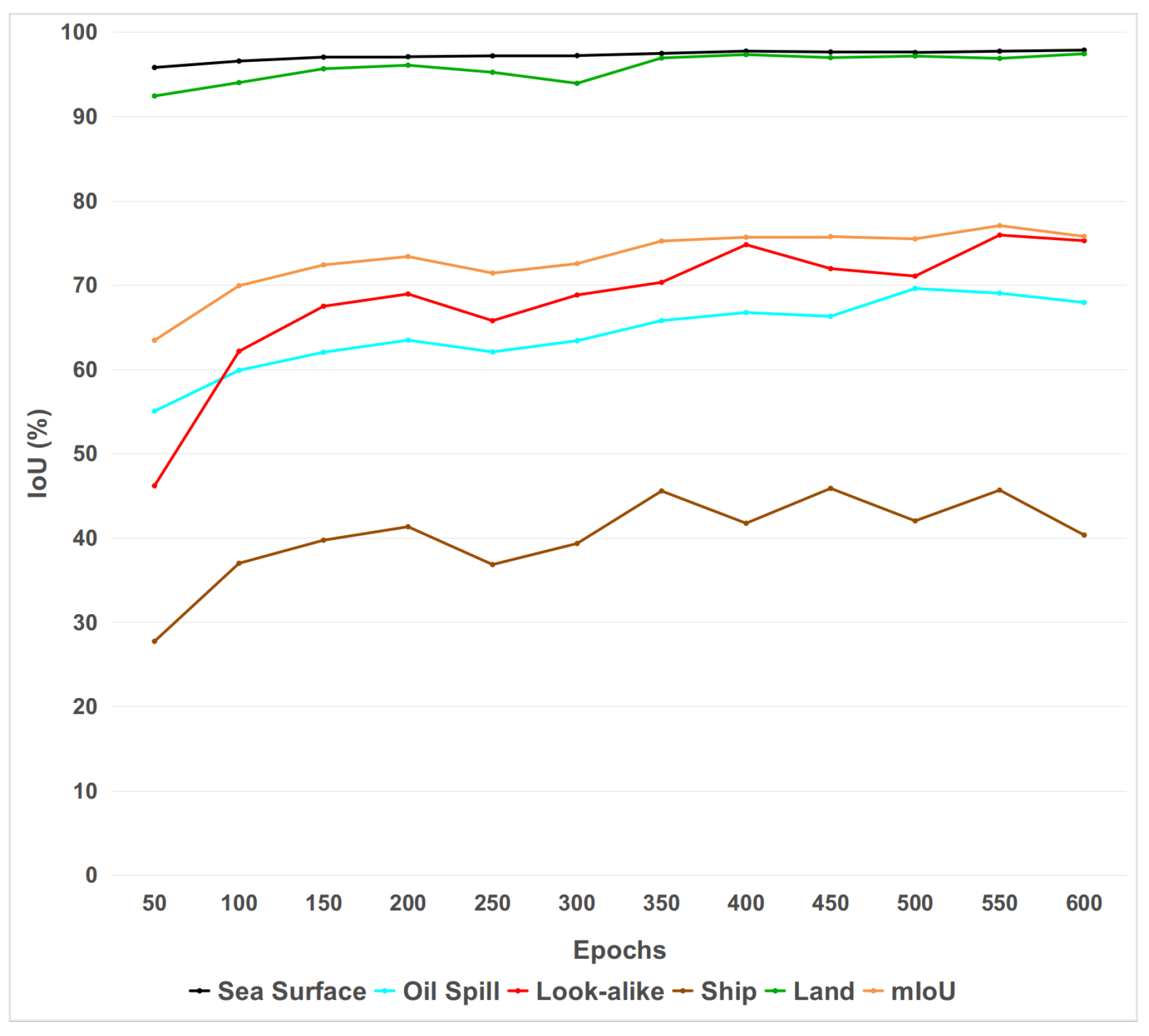
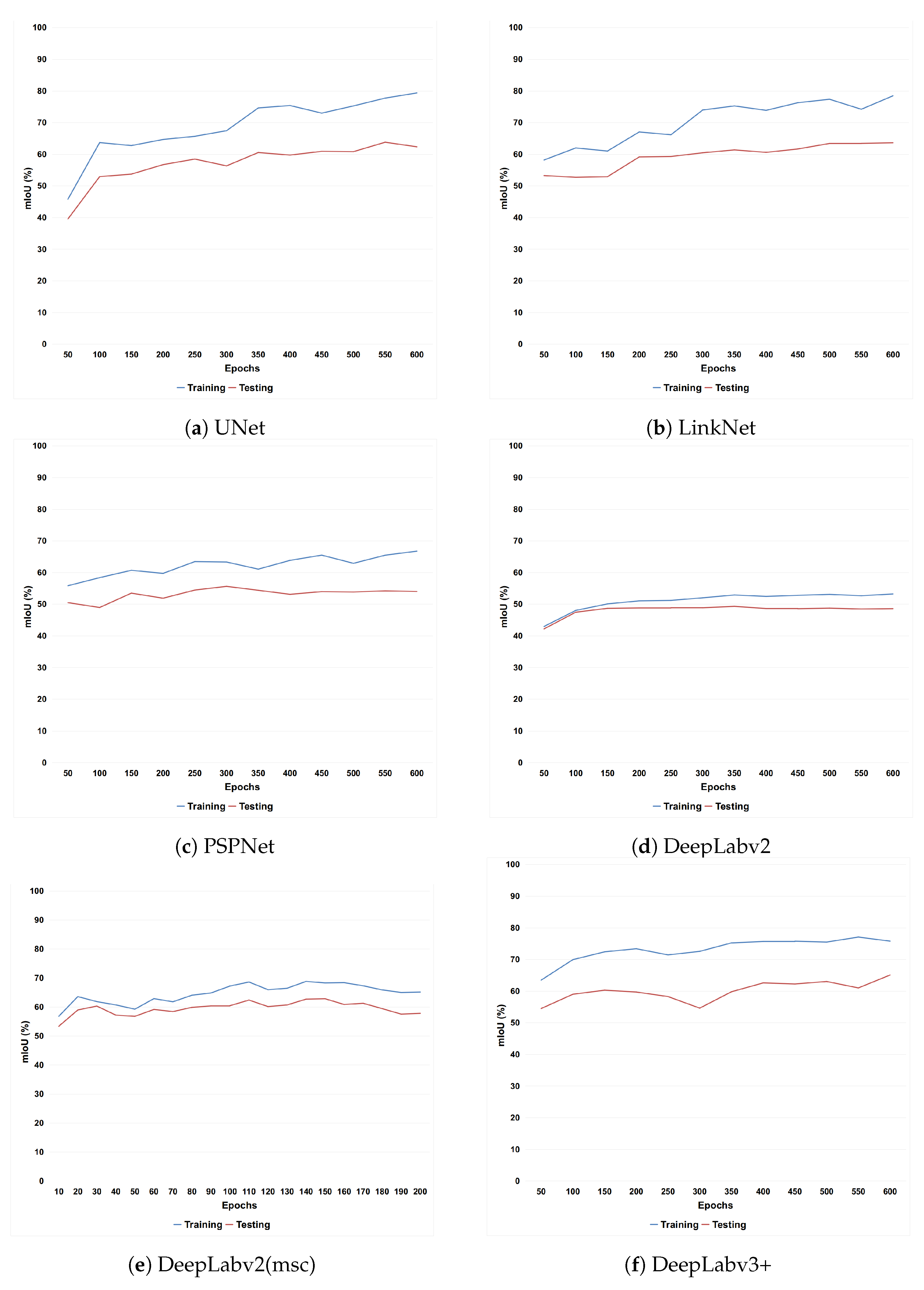
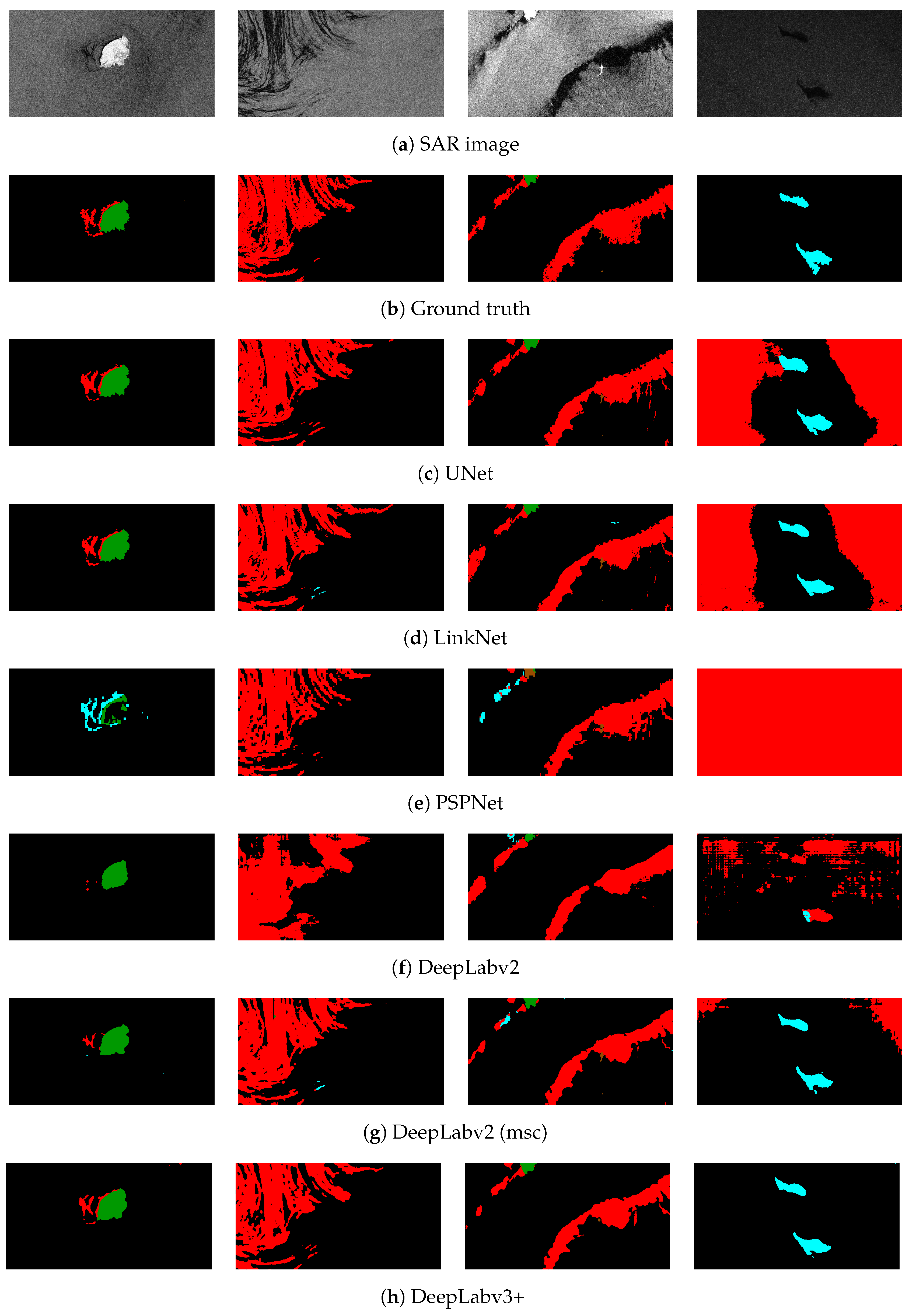
Oil spill comprises one of the major threats for the ocean and the coastal environment, hence, efficient monitoring and early warning is required to confront the danger and limit the environmental damage. Remote sensing via SAR sensors has a crucial role for this objective since they can provide high resolution images where possible oil spills might be captured. Various methods have been proposed in order to automatically process SAR images and distinguish depicted oil spills from look-alikes. As such, semantic segmentation by deploying DCNNs can be successfully applied in the oil spill detection field, since it can provide useful information regarding the depicted pollution scene. In addition, most methods utilize different datasets posing the provided results non-comparable. Based on these two aspects, the main contribution of the paper is twofold: analyze semantic segmentation algorithms and develop a common database consisted of SAR images.
More specifically, extensive experiments were conducted and focused on the use of different DCNN architectures for oil spill detection through semantic segmentation. Every deployed model was trained and evaluated using a common base as a dataset. In general, the DeepLabv3+ model scored the best performance reporting the highest accuracy in terms of IoU and high inference time. The semantic segmentation of SAR images comprises a very challenging task due to the required in situ distinction between the oil spills and look-alikes. The complexity of the posed problem was extensively discussed and accompanied with the relative figures. Finally, a further comparison of different DeepLab architectures was provided confirming the superiority of the DeepLabv3+ model compared to previous approaches. Moreover, the insertion of an annotated dataset consisted of SAR images was provided aiming at being utilized as a benchmark for oil spill detection methods. The presented dataset was developed for training and testing of the segmentation models nonetheless, it can be exploited also in different approaches. Thus, it is expected to contribute significantly towards the efficient application of relevant oil spill detectors.
In the future, accurate models trained on the developed dataset can be encapsulated in a wider framework for oil spill identification and decision making modules. Finally, the semantic segmentation approaches can be extended to other research fields exploiting remote sensing, such as flood or fire detection, precision agriculture, etc. Towards this direction, oil spill dataset can be utilized additionally to train robust backbones of the employed DCNN segmentation models, on a case-by-case basis.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}