Spatial–Spectral Fusion in Different Swath Widths by a Recurrent Expanding Residual Convolutional Neural Network


Abstract
:
1. Introduction
2. Methodology
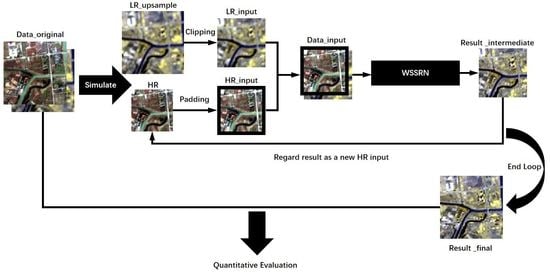
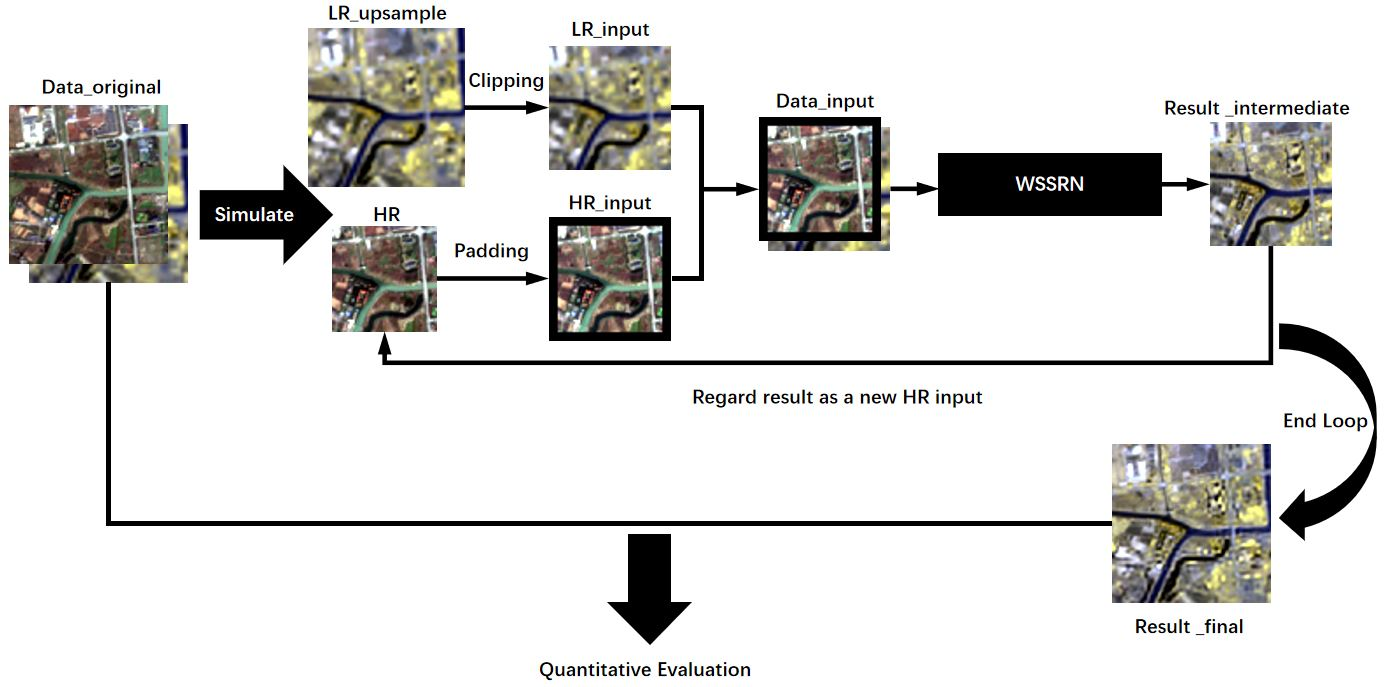
2.1. Width-Space-Spectrum Fusion
2.2. Network Framework
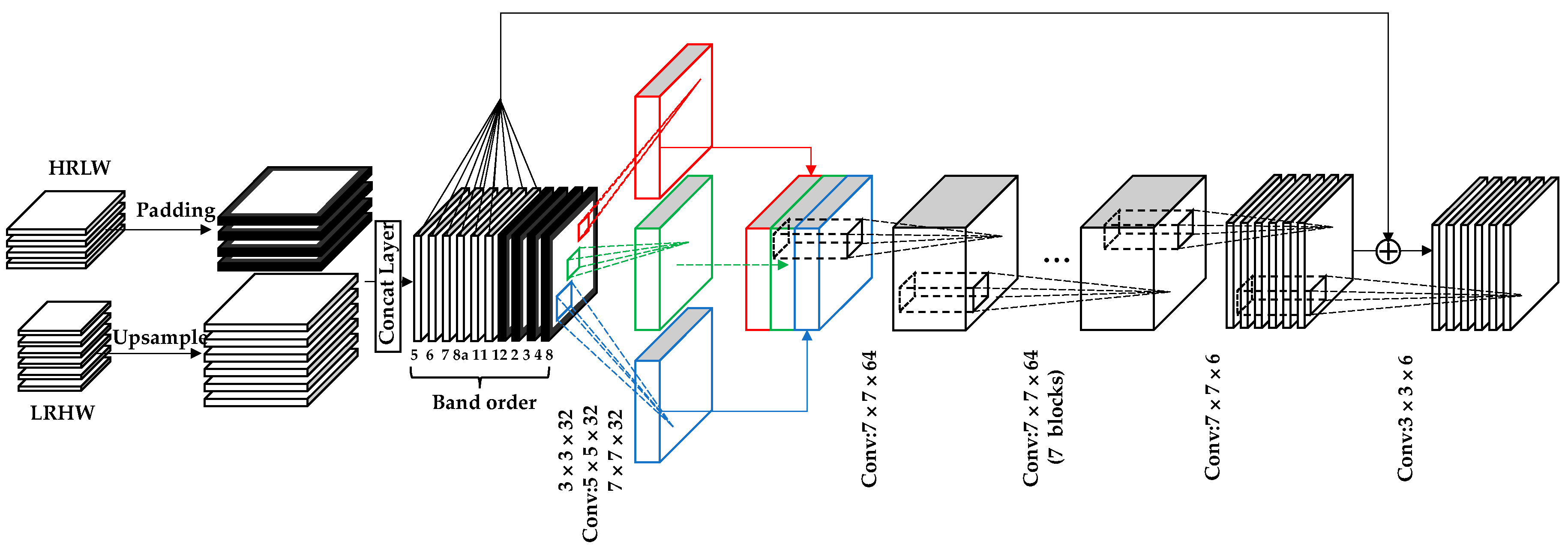
2.3. The Residual Convolutional Neural Network
2.4. Multi-Scale Feature Extraction
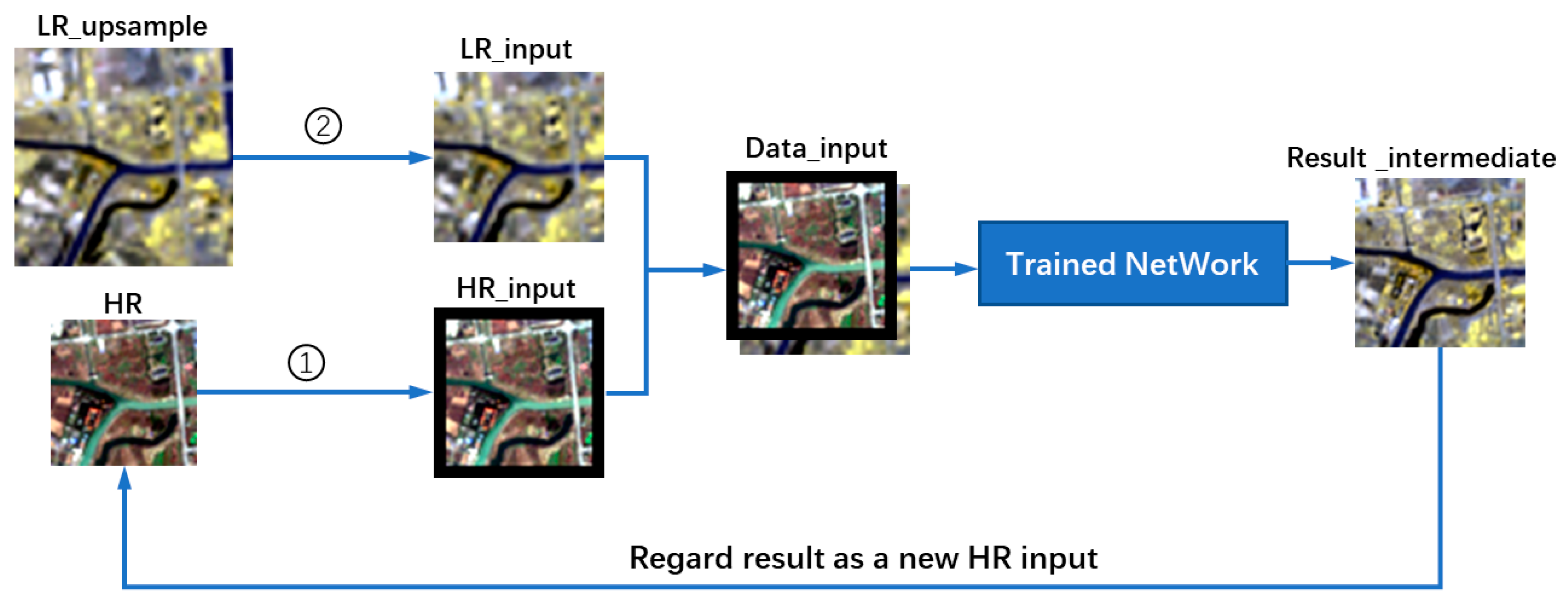
2.5. Recurrent Expanding Strategy
3. Experimental Results and Analysis
3.1. Datasets
3.1.1. Training Datasets
3.1.2. Test Datasets
3.2. Implementation Details
3.2.1. Parameter Setting and Network Training
3.2.2. Compared Algorithms and the Quantitative Evaluation
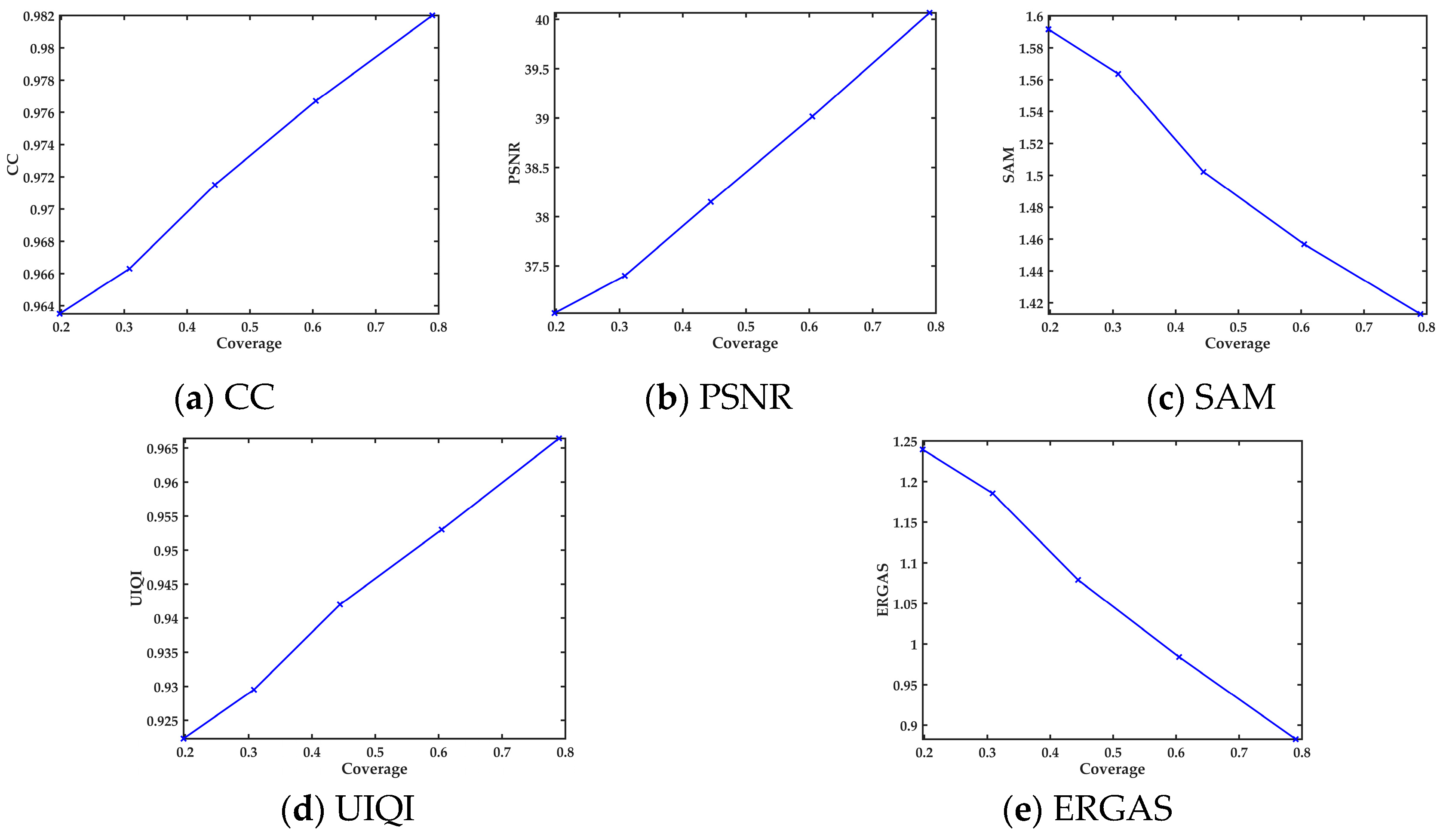
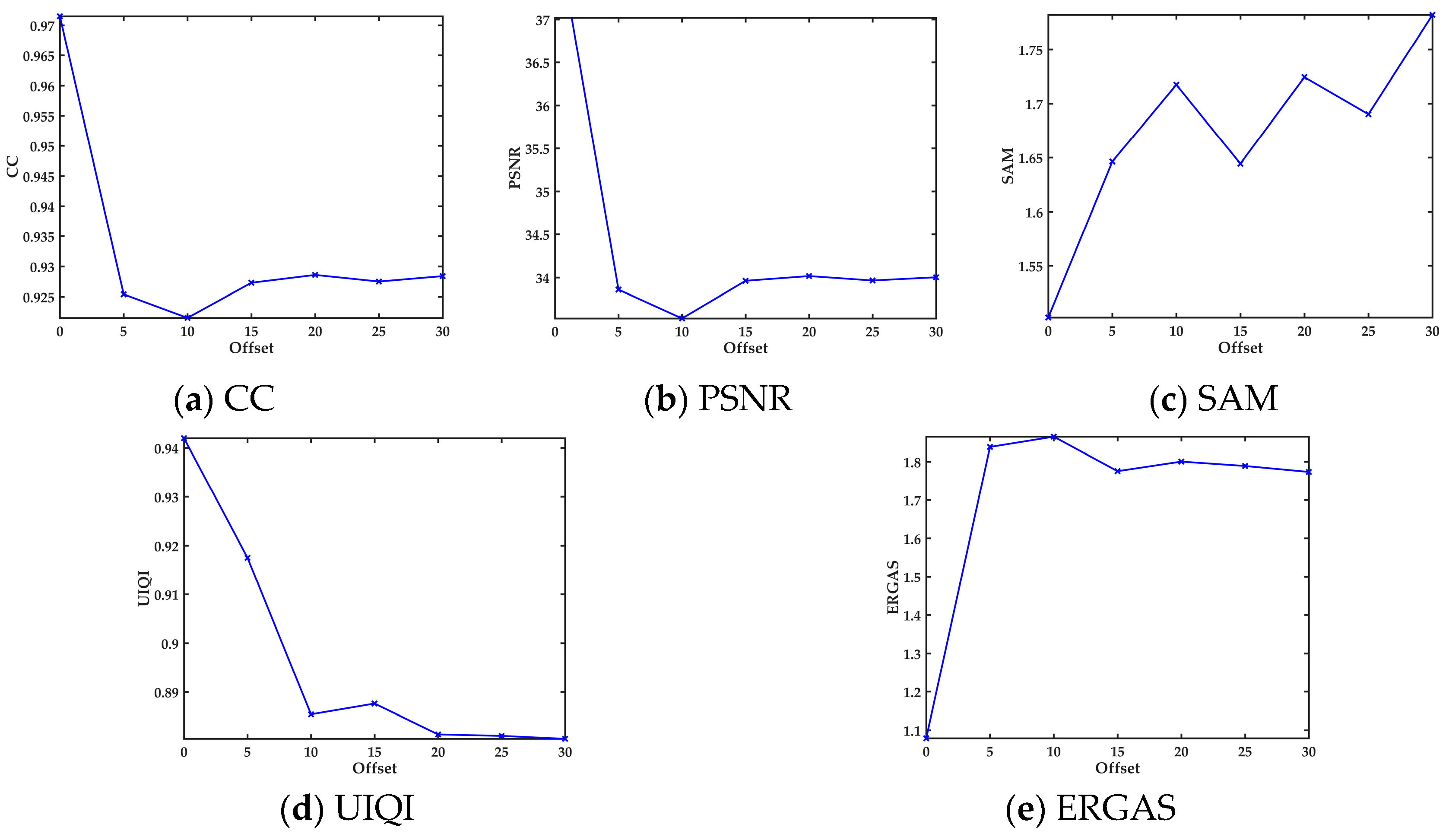
3.3. Sensitivity Analysis for the Overlapping Region
3.3.1. Coverage Ratio
3.3.2. Offset Position
3.4. Simulated Experiment
3.5. Real-Data Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, J.; Liu, X.; Yuan, Q.; Shen, H.; Zhang, L. Antinoise Hyperspectral Image Fusion by Mining Tensor Low-Multilinear-Rank and Variational Properties. IEEE Trans. Geosci. Remote Sens. 2019. [Google Scholar] [CrossRef]
- Gillespie, A.R.; Kahle, A.B.; Walker, R.E. Color enhancement of highly correlated images. 2. Channel ratio and chromaticity transformation techniques. Remote Sens. Environ. 1987, 22, 343–365. [Google Scholar] [CrossRef]
- Chavez, P.S.; Kwarteng, A.Y. Extracting spectral contrast in Landsat thematic mapper image data using selective principal component analysis. Photogramm. Eng. Remote Sens. 1989, 55, 339–348. [Google Scholar]
- Tu, T.M.; Huang, P.S.; Hung, C.L.; Chang, C.P. A fast intensity hue-saturation fusion technique with spectral adjustment for IKONOS imagery. IEEE Geosci. Remote Sens. Lett. 2004, 1, 309–312. [Google Scholar] [CrossRef]
- Laben, C.A.; Brower, B.V. Process for enhancing the spatial resolution of multispectral imagery using pan-sharpening. U.S. Patents 6,011,875, 4 January 2000. [Google Scholar]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A. Context-driven fusion of high spatial and spectral resolution images based on oversampled multiresolution analysis. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2300–2312. [Google Scholar] [CrossRef]
- Nencini, F.; Garzelli, A.; Baronti, S.; Alparone, L. Remote sensing image fusion using the curvelet transform. Inf. Fusion 2007, 8, 143–156. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. MTF tailored multiscale fusion of high-resolution MS and pan imagery. Photogramm. Eng. Remote Sens. 2006, 72, 591–596. [Google Scholar] [CrossRef]
- Palsson, F.; Sveinsson, J.R.; Ulfarsson, M.O.; Benediktsson, J.A. MTF-based deblurring using a wiener filter for CS and MRA pansharpening methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2255–2269. [Google Scholar] [CrossRef]
- Liu, J.G. Smoothing filter-based intensity modulation: A spectral preserve image fusion technique for improving spatial details. Int. J. Remote Sens. 2000, 21, 3461–3472. [Google Scholar] [CrossRef]
- Garzelli, A.; Nencini, F.; Capobianco, L. Optimal MMSE pan sharpening of very high resolution multispectral images. IEEE Trans. Geosci. Remote Sens. 2008, 46, 228–236. [Google Scholar] [CrossRef]
- Garzelli, A. Pansharpening of multispectral images based on nonlocal parameter optimization. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2096–2107. [Google Scholar] [CrossRef]
- Fasbender, D.; Radoux, J.; Bogaert, P. Bayesian data fusion for adaptable image pansharpening. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1847–1857. [Google Scholar] [CrossRef]
- Zhang, L.; Shen, H.; Gong, W.; Zhang, H. Adjustable model-based fusion method for multispectral and panchromatic images. IEEE Trans. Syst. Man Cybern. B Cybern. 2012, 42, 1693–1704. [Google Scholar] [CrossRef]
- Palsson, F.; Sveinsson, J.R.; Ulfarsson, M.O. A new pansharpening algorithm based on total variation. IEEE Geosci. Remote Sens. Lett. 2014, 11, 318–322. [Google Scholar] [CrossRef]
- Shen, H.; Meng, X.; Zhang, L. An integrated framework for the spatio–temporal–spectral fusion of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7135–7148. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, H.; Shen, H.; Zhang, L. A practical compressed sensing-based pan-sharpening method. IEEE Geosci. Remote Sens. Lett. 2012, 9, 629–633. [Google Scholar] [CrossRef]
- Song, H.; Huang, B.; Liu, Q.; Zhang, K. Improving the Spatial Resolution of Landsat TM/ETM+ Through Fusion With SPOT5 Images via Learning-Based Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1195–1204. [Google Scholar] [CrossRef]
- Huang, W.; Xiao, L.; Wei, Z.; Liu, H.; Tang, S. A New Pan-Sharpening Method With Deep Neural Networks. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1037–1041. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef]
- Yuan, Q.; Wei, Y.; Meng, X.; Shen, H.; Zhang, L. A Multiscale and Multidepth Convolutional Neural Network for Remote Sensing Imagery Pan-Sharpening. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 978–989. [Google Scholar] [CrossRef]
- Wei, Y.; Yuan, Q.; Shen, H.; Zhang, L. Boosting the Accuracy of Multispectral Image Pansharpening by Learning a Deep Residual Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1795–1799. [Google Scholar] [CrossRef] [Green Version]
- Palsson, F.; Sveinsson, J.; Ulfarsson, M. Sentinel-2 Image Fusion Using a Deep Residual Network. Remote Sens. 2018, 10, 1290. [Google Scholar] [CrossRef]
- Wang, Q.; Shi, W.; Li, Z.; Atkinson, P.M. Fusion of Sentinel-2 images. Remote Sens. Environ. 2016, 187, 241–252. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Blackburn, G.A.; Onojeghuo, A.O.; Dash, J.; Zhou, L.; Zhang, Y.; Atkinson, P.M. Fusion of Landsat 8 OLI and Sentinel-2 MSI Data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3885–3899. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Shi, W.; Atkinson, P.M.; Zhao, Y. Downscaling MODIS images with area-to-point regression kriging. Remote Sens. Environ. 2015, 166, 191–204. [Google Scholar] [CrossRef]
- Yi, C.; Zhao, Y.; Chan, J.C. Hyperspectral Image Super-Resolution Based on Spatial and Spectral Correlation Fusion. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4165–4177. [Google Scholar] [CrossRef]
- Sun, X.; Zhang, L.; Yang, H.; Wu, T.; Cen, Y.; Guo, Y. Enhancement of Spectral Resolution for Remotely Sensed Multispectral Image. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2015, 8, 2198–2211. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Lanaras, C.; Bioucas-Dias, J.; Galliani, S.; Baltsavias, E.; Schindler, K. Super-resolution of Sentinel-2 images: Learning a globally applicable deep neural network. ISPRS J. Photogramm. Remote Sens. 2018, 146, 305–319. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhang, Q.; Yuan, Q.; Zeng, C.; Li, X.; Wei, Y. Missing data reconstruction in remote sensing image with a unified spatial-temporal-spectral deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4274–4288. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhang, Q.; Li, J.; Shen, H.; Zhang, L. Hyperspectral image denoising employing a spatial-spectral deep residual convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1205–1218. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Li, J.; Yuan, Q.; Shen, H.; Meng, X.; Zhang, L. Hyperspectral Image Super-Resolution by Spectral Mixture Analysis and Spatial–Spectral Group Sparsity. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1250–1254. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band | B1 | B2 | B3 | B4 | B5 | B6 | B7 | B8 | B8a | B9 | B10 | B11 | B12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Wavelength (nm) | 443 | 490 | 560 | 665 | 705 | 740 | 783 | 842 | 865 | 945 | 1380 | 1610 | 2190 |
| Width (nm) | 20 | 65 | 35 | 30 | 15 | 15 | 20 | 115 | 20 | 20 | 30 | 90 | 180 |
| Resolution (m) | 60 | 10 | 10 | 10 | 20 | 20 | 20 | 10 | 20 | 60 | 60 | 20 | 20 |
| Configuration | |
|---|---|
| Layer 1_1 Layer 1_2 Layer 1_3 | Conv + ReLU: size=3, stride=1, pad=1 Conv + ReLU: size=5, stride=1, pad=2 Conv + ReLU: size=7, stride=1, pad=3 |
| 9 Layers | Conv + ReLU: size=7, stride=1, pad=3 |
| Layer 11 | Conv + ReLU: size=3, stride=1, pad=1 |
| Method | Index | Band 5 | Band 6 | Band 7 | Band 8a | Band 11 | Band 12 |
|---|---|---|---|---|---|---|---|
| Bicubic | CC | 0.94 | 0.94 | 0.94 | 0.94 | 0.97 | 0.96 |
| PSNR | 35.11 | 32.06 | 30.84 | 29.78 | 31.24 | 31.64 | |
| SSIM | 0.89 | 0.86 | 0.85 | 0.84 | 0.89 | 0.88 | |
| SAM | 1.76 | ||||||
| ERGAS | 1.55 | ||||||
| SRCNN | CC | 0.95 | 0.95 | 0.95 | 0.96 | 0.98 | 0.97 |
| PSNR | 35.27 | 32.80 | 31.67 | 30.64 | 31.92 | 31.24 | |
| SSIM | 0.92 | 0.90 | 0.89 | 0.89 | 0.93 | 0.92 | |
| SAM | 2.18 | ||||||
| ERGAS | 1.4868 | ||||||
| VDSR | CC | 0.97 | 0.96 | 0.96 | 0.96 | 0.98 | 0.98 |
| PSNR | 37.35 | 34.30 | 32.89 | 31.95 | 34.50 | 34.62 | |
| SSIM | 0.93 | 0.92 | 0.91 | 0.91 | 0.94 | 0.93 | |
| SAM | 1.48 | ||||||
| ERGAS | 1.15 | ||||||
| WSSRN | CC | 0.97 | 0.97 | 0.97 | 0.97 | 0.99 | 0.98 |
| PSNR | 37.23 | 34.98 | 33.70 | 32.88 | 34.71 | 34.60 | |
| SSIM | 0.95 | 0.94 | 0.94 | 0.94 | 0.95 | 0.94 | |
| SAM | 1.57 | ||||||
| ERGAS | 1.09 | ||||||
| Method | Index | Band 5 | Band 6 | Band 7 | Band 8a | Band 11 | Band 12 |
|---|---|---|---|---|---|---|---|
| Bicubic | CC | 0.9587 | 0.9647 | 0.9642 | 0.9674 | 0.9811 | 0.9735 |
| PSNR | 36.51 | 33.89 | 32.69 | 31.77 | 33.16 | 33.39 | |
| SSIM | 0.9373 | 0.9254 | 0.9194 | 0.9173 | 0.9372 | 0.9254 | |
| SAM | 1.59 | ||||||
| ERGAS | 1.25 | ||||||
| SRCNN | CC | 0.9624 | 0.9697 | 0.9705 | 0.9727 | 0.9842 | 0.9748 |
| PSNR | 36.57 | 34.31 | 33.12 | 32.12 | 33.37 | 32.92 | |
| SSIM | 0.9456 | 0.9392 | 0.9359 | 0.9345 | 0.9501 | 0.9384 | |
| SAM | 1.85 | ||||||
| ERGAS | 1.24 | ||||||
| VDSR | CC | 0.9656 | 0.9715 | 0.9720 | 0.9744 | 0.9864 | 0.9789 |
| PSNR | 37.35 | 34.62 | 33.66 | 32.77 | 34.66 | 34.45 | |
| SSIM | 0.9472 | 0.9412 | 0.9366 | 0.9352 | 0.9535 | 0.9415 | |
| SAM | 1.60 | ||||||
| ERGAS | 1.11 | ||||||
| WSSRN | CC | 0.9646 | 0.9724 | 0.9719 | 0.9747 | 0.9868 | 0.9796 |
| PSNR | 37.23 | 34.98 | 33.70 | 32.88 | 34.71 | 34.60 | |
| SSIM | 0.9457 | 0.9421 | 0.9367 | 0.9362 | 0.9538 | 0.9423 | |
| SAM | 1.57 | ||||||
| ERGAS | 1.09 | ||||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Li, J.; Yuan, Q.; Li, H.; Shen, H. Spatial–Spectral Fusion in Different Swath Widths by a Recurrent Expanding Residual Convolutional Neural Network. Remote Sens. 2019, 11, 2203. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11192203
He J, Li J, Yuan Q, Li H, Shen H. Spatial–Spectral Fusion in Different Swath Widths by a Recurrent Expanding Residual Convolutional Neural Network. Remote Sensing. 2019; 11(19):2203. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11192203
Chicago/Turabian StyleHe, Jiang, Jie Li, Qiangqiang Yuan, Huifang Li, and Huanfeng Shen. 2019. "Spatial–Spectral Fusion in Different Swath Widths by a Recurrent Expanding Residual Convolutional Neural Network" Remote Sensing 11, no. 19: 2203. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11192203