Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review

 ,
,  ,
, 
 and
and 
Abstract
:
1. Introduction
2. Background
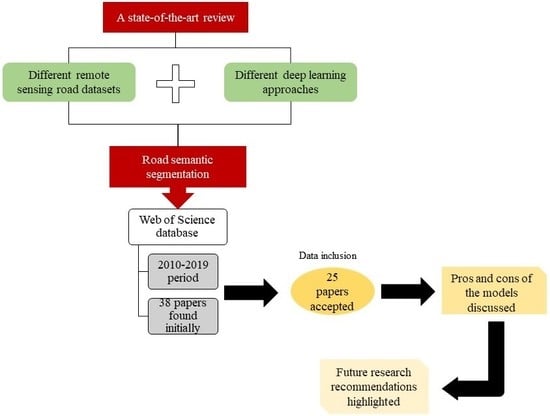
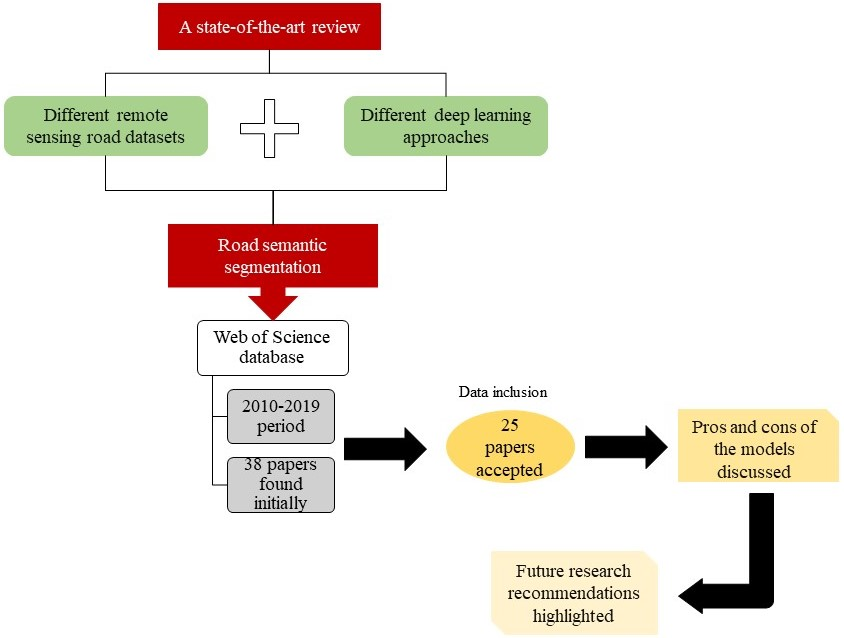
3. Methodology
- The full text of the papers was not provided by publishers;
- Remote sensing images were not used in the papers.
- Articles written in English;
- Peer-reviewed papers, such as conferences and journals;
- Published papers during the 10-year period (i.e., 2010–2019);
- Products that revealed a deep learning technique for road extraction from remote sensing images.
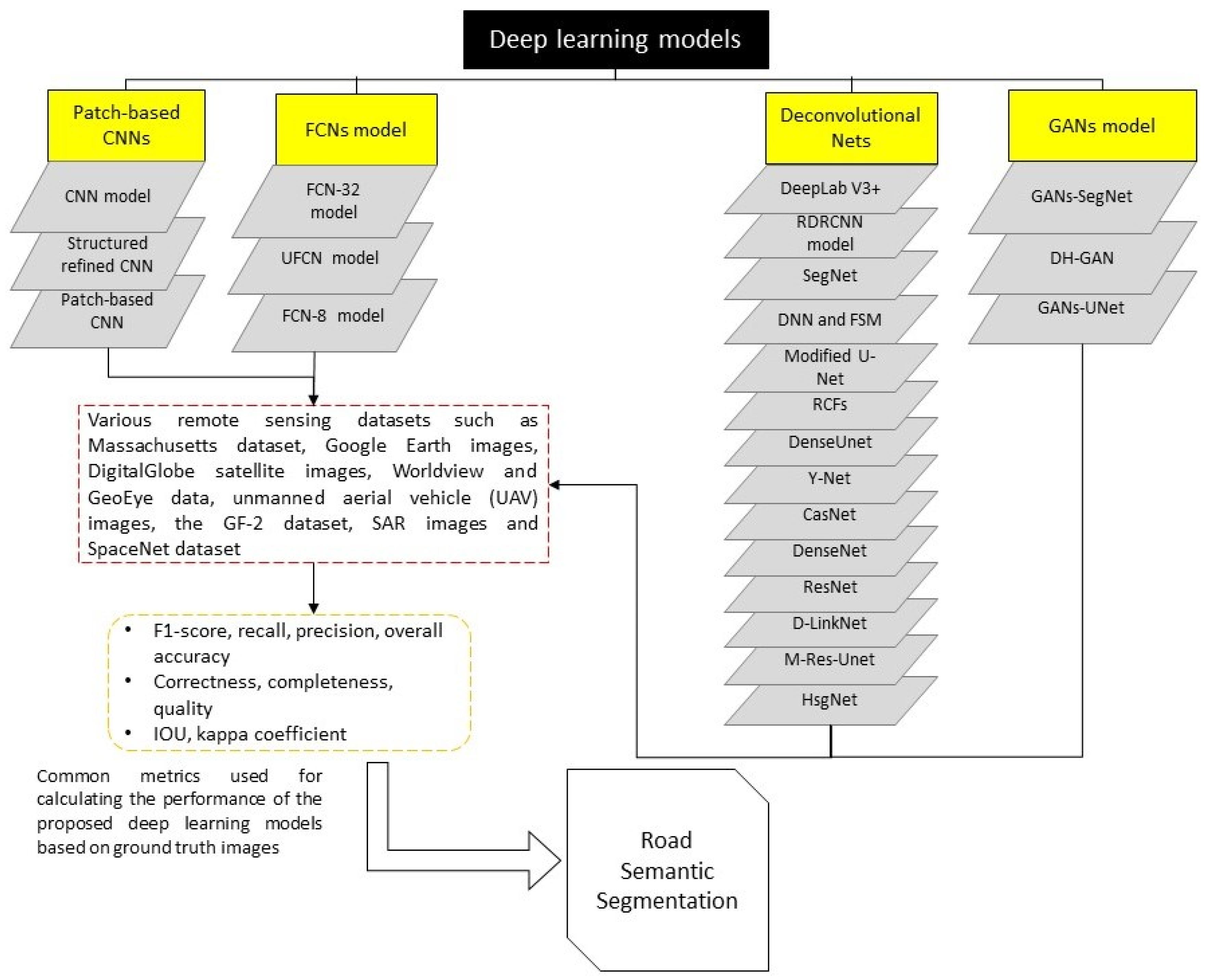
4. Results
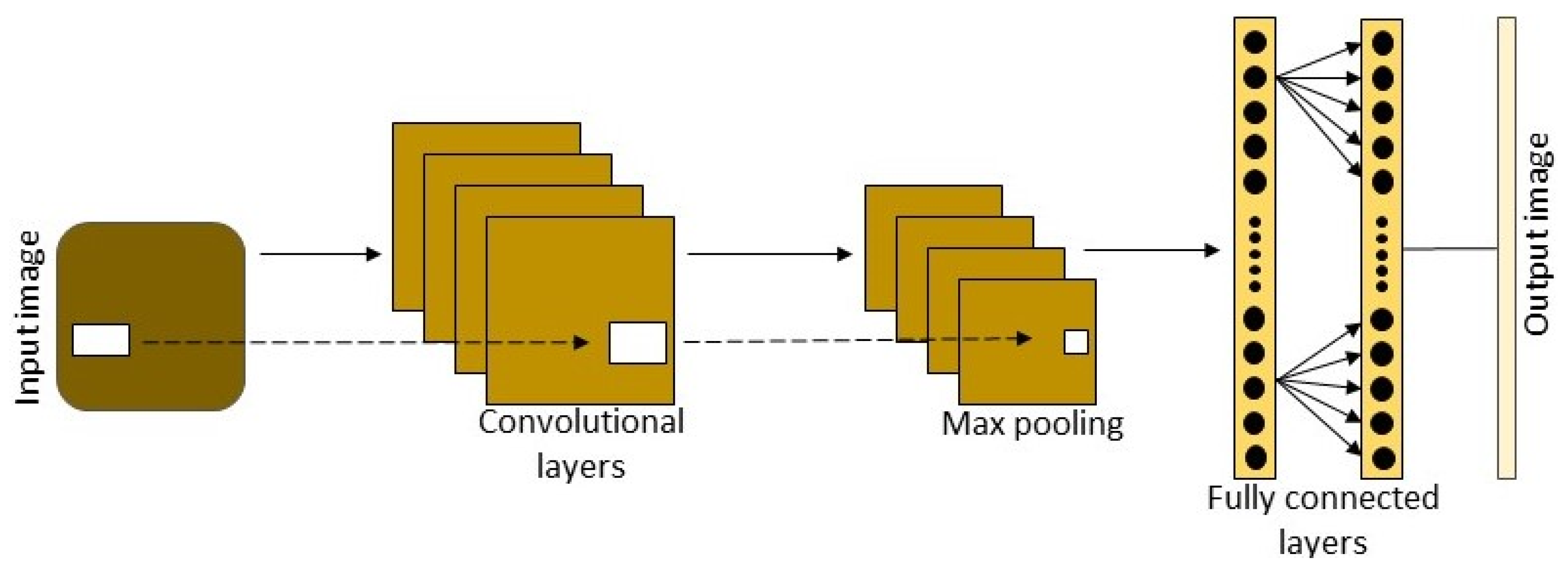
4.1. Road Extraction Based on the Patch-Based CNN Model
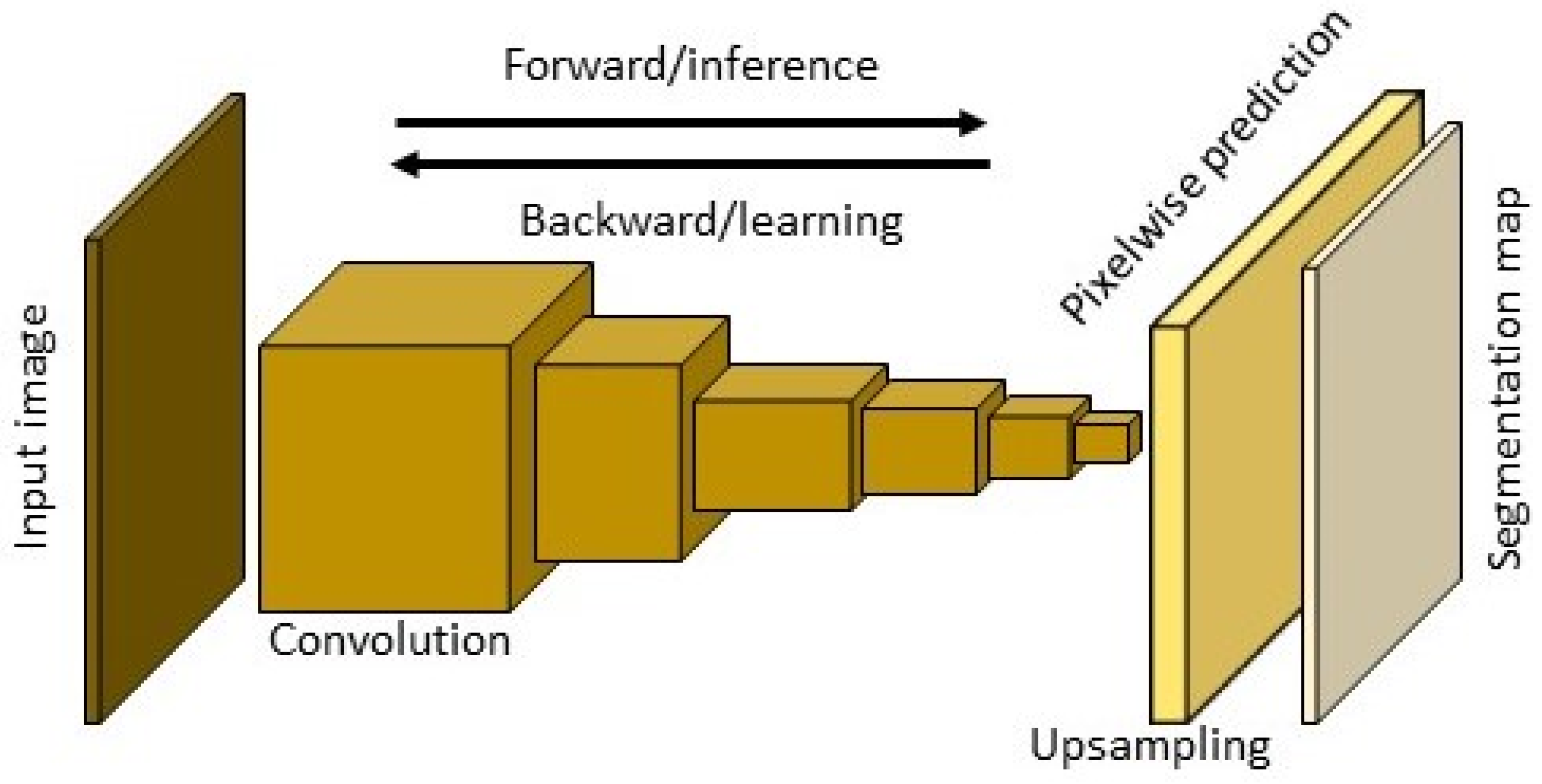
4.2. Road Extraction Based on the FCNs Model
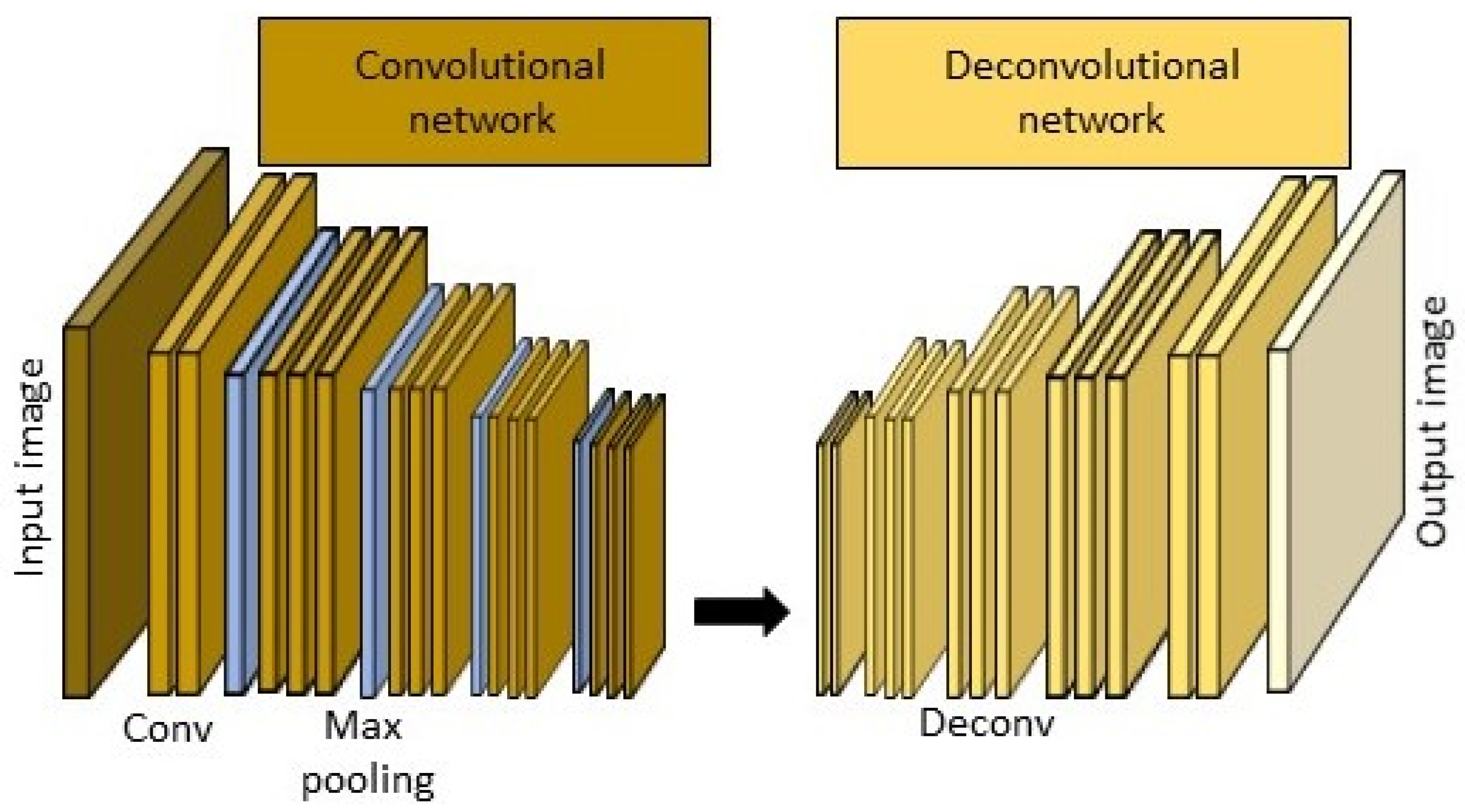
4.3. Road Extraction Based on the Deconvolutional Neural Networks (Dense Net)
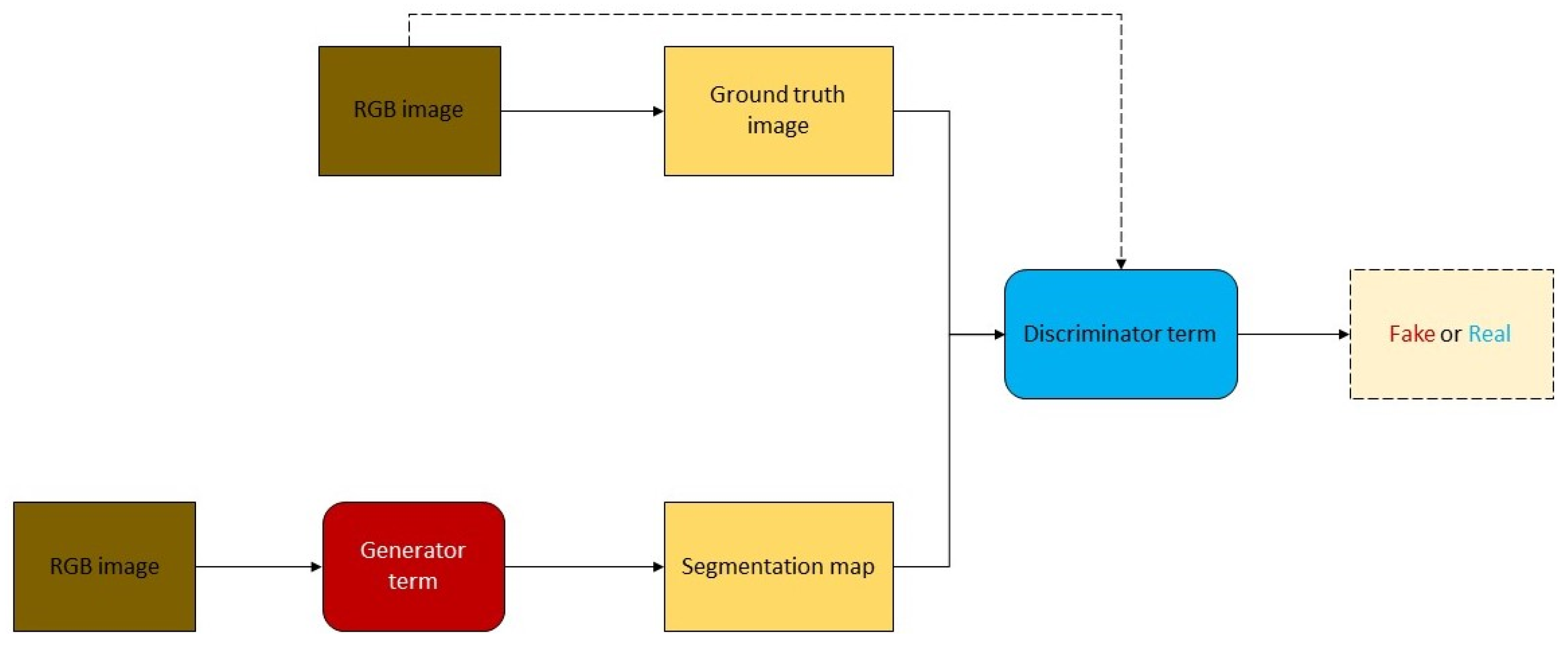
4.4. Road Extraction Based on the GANs Model
5. Discussion
6. Conclusions
- The capabilities of deep learning methods for road extraction are more effective than those of regular approaches.
- When the complexity of images is high and various road types are present, the accuracy of the models is low. Therefore, mixing robust pre- and postprocessing techniques is recommended and useful to achieve satisfactory results.
- The appropriateness of deep learning approaches for road extraction pertaining to different variables, such as architecture, data, and hyperparameters, is determined.
- The low efficiency of the proposed methods in terms of data quality, training dataset, and model hyperparameters is presented.
- Occlusions, such as shadows, cars, and buildings, are similar to road features, such as colors, reflectance, and patterns. Road extraction remains challenging owing to such issues.
- Further research is required to build detailed techniques with high precision. CNNs trained by one dataset may be inconsistent with other scenes. Nonetheless, if training datasets are adequate and a deep learning model can be created effectively, then the model can be implemented properly on most prevalent datasets.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Abdullahi, S.; Pradhan, B.; Jebur, M.N. GIS-based sustainable city compactness assessment using integration of MCDM, Bayes theorem and RADAR technology. Geocarto Int. 2015, 30, 365–387. [Google Scholar] [CrossRef]
- Youssef, A.M.; Sefry, S.A.; Pradhan, B.; Alfadail, E.A.; Risk. Analysis on causes of flash flood in Jeddah city (Kingdom of Saudi Arabia) of 2009 and 2011 using multi-sensor remote sensing data and GIS. Geomat. Nat. Hazards 2016, 7, 1018–1042. [Google Scholar] [CrossRef]
- Weng, Q. Remote sensing of impervious surfaces in the urban areas: Requirements, methods, and trends. Remote Sens. Environ. 2012, 117, 34–49. [Google Scholar] [CrossRef]
- Wijesingha, J.S.J. Automatic road feature extraction from high resolution satellite images using LVQ neural networks. Asian J. Geoinform. 2013, 13, 30–36. [Google Scholar]
- Kahraman, I.; Turan, M.K.; Karas, I.R. Road detection from high satellite images using neural networks. Int. J. Modeling Optim. 2015, 5, 304–307. [Google Scholar] [CrossRef]
- Shi, W.; Miao, Z.; Debayle, J.; Sensing, R. An integrated method for urban main-road centerline extraction from optical remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3359–3372. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, L.; Wang, C.; Zhuo, L.; Tian, Q.; Liang, X. Road recognition from remote sensing imagery using incremental learning. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2993–3005. [Google Scholar] [CrossRef]
- Hormese, J.; Saravanan, C. Automated road extraction from high resolution satellite images. Procedia Technol. 2016, 24, 1460–1467. [Google Scholar] [CrossRef] [Green Version]
- Abdollahi, A.; Bakhtiari, H.R.R.; Nejad, M.P. Investigation of SVM and level set interactive methods for road extraction from google earth images. J. Indian Soc. Remote Sens. 2018, 46, 423–430. [Google Scholar] [CrossRef]
- Bakhtiari, H.R.R.; Abdollahi, A.; Rezaeian, H. Semi automatic road extraction from digital images. Egypt. J. Remote Sens. Space Sci. 2017, 20, 117–123. [Google Scholar] [CrossRef]
- Liu, B.; Wu, H.; Wang, Y.; Liu, W. Main road extraction from zy-3 grayscale imagery based on directional mathematical morphology and vgi prior knowledge in urban areas. PLoS ONE 2015, 10, e0138017. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miao, Z.; Shi, W.; Gamba, P.; Li, Z. An object-based method for road network extraction in VHR satellite images. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 2015, 8, 4853–4862. [Google Scholar] [CrossRef]
- Grinias, I.; Panagiotakis, C.; Tziritas, G.; Sensing, R. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. ISPRS J. Photogramm. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- Sghaier, M.O.; Lepage, R. Road extraction from very high resolution remote sensing optical images based on texture analysis and beamlet transform. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 2016, 9, 1946–1958. [Google Scholar] [CrossRef]
- He, C.; Liao, Z.-X.; Yang, F.; Deng, X.-P.; Liao, M.-S. Road extraction from SAR imagery based on multiscale geometric analysis of detector responses. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 2012, 5, 1373–1382. [Google Scholar]
- Cheng, J.; Ding, W.; Ku, X.; Sun, J. Road Extraction from High-Resolution SAR Images via Automatic Local Detecting and Human-Guided Global Tracking. Int. J. Antennas Propag. 2012, 2012, 1–10. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R. Hierarchical graph-based segmentation for extracting road networks from high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2017, 126, 245–260. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, Z.; Xie, Z.; Wu, L. Quality assessment of building footprint data using a deep autoencoder network. Int. J. Geogr. Inf. Sci. 2017, 31, 1929–1951. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Segment-before-detect: Vehicle detection and classification through semantic segmentation of aerial images. Remote Sens. 2017, 9, 368. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. 2016, 3, 271–282. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Qin, Q.; Gao, Z.; Zhao, J.; Ye, X. A new approach to urban road extraction using high-resolution aerial image. ISPRS Int. J. Geo-Inf. 2016, 5, 114. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Wu, G.; Zhang, F.; Du, Q. Hyperspectral image classification using deep pixel-pair features. IEEE Trans. Geosci. Remote Sens. 2017, 55, 844–853. [Google Scholar] [CrossRef]
- Senthilnath, J.; Dokania, A.; Kandukuri, M.; Ramesh, K.; Anand, G.; Omkar, S. Detection of tomatoes using spectral-spatial methods in remotely sensed RGB images captured by UAV. Biosyst. Eng. 2016, 146, 16–32. [Google Scholar] [CrossRef]
- Wegner, J.D.; Montoya-Zegarra, J.A.; Schindler, K. A higher-order CRF model for road network extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1698–1705. [Google Scholar]
- Maurya, R.; Gupta, P.; Shukla, A.S. Road extraction using k-means clustering and morphological operations. In Proceedings of the 2011 International Conference on Image Information Processing, Shimla, India, 3–5 November 2011; pp. 1–6. [Google Scholar]
- Mattyus, G.; Wang, S.; Fidler, S.; Urtasun, R. Enhancing road maps by parsing aerial images around the world. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1689–1697. [Google Scholar]
- Mena, J.B.; Malpica, J.A. An automatic method for road extraction in rural and semi-urban areas starting from high resolution satellite imagery. Pattern Recognit. Lett. 2005, 26, 1201–1220. [Google Scholar] [CrossRef]
- Zhu, C.; Shi, W.; Pesaresi, M.; Liu, L.; Chen, X.; King, B. The recognition of road network from high-resolution satellite remotely sensed data using image morphological characteristics. Int. J. Remote Sens. 2005, 26, 5493–5508. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Vateekul, P.; Jitkajornwanich, K.; Lawawirojwong, S. An enhanced deep convolutional encoder-decoder network for road segmentation on aerial imagery. In International Conference on Computing and Information Technology; Springer: Berlin/Heidelberg, Germany, 2017; pp. 191–201. [Google Scholar] [CrossRef]
- Tang, S.; Yuan, Y. Object Detection Based on Convolutional Neural Network; Stanford University: Stanford, CA, USA, 2015; Available online: http://cs231n.stanford.edu/reports/2015/pdfs/CS231n_final_writeup_sjtang.pdf (accessed on 5 January 2020).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ševo, I.; Avramović, A. Convolutional Neural Network Based Automatic Object Detection on Aerial Images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 740–744. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D. Dense Semantic Labeling of Subdecimeter Resolution Images With Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 881–893. [Google Scholar] [CrossRef] [Green Version]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Fully convolutional neural networks for remote sensing image classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 June 2016; pp. 5071–5074. [Google Scholar]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple object extraction from aerial imagery with convolutional neural networks. Electron. Imaging 2016, 2016, 1–9. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Cui, W.; Jiang, H. Fully convolutional networks for building and road extraction: Preliminary results. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 June 2016; pp. 1591–1594. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to Detect Roads in High-Resolution Aerial Images; Springer: Berlin/Heidelberg, Germany, 2010; pp. 210–223. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; The, P.G. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. Ann. Intern. Med. 2009, 151, 264. [Google Scholar] [CrossRef] [Green Version]
- Min, H.-S.J.; Beyeler, W.; Brown, T.; Son, Y.J.; Jones, A.T. Toward modeling and simulation of critical national infrastructure interdependencies. IIE Trans. 2007, 39, 57–71. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sensing Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Dalla Mura, M. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Liu, R.; Miao, Q.; Song, J.; Quan, Y.; Li, Y.; Xu, P.; Dai, J. Multiscale road centerlines extraction from high-resolution aerial imagery. Neurocomputing 2019, 329, 384–396. [Google Scholar] [CrossRef]
- Li, P.; Zang, Y.; Wang, C.; Li, J.; Cheng, M.; Luo, L.; Yu, Y. Road network extraction via deep learning and line integral convolution. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 June 2016; pp. 1599–1602. [Google Scholar] [CrossRef]
- Varia, N.; Dokania, A.; Senthilnath, J. DeepExt: A Convolution Neural Network for Road Extraction using RGB images captured by UAV. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1890–1895. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N. Extraction of road features from UAV images using a novel level set segmentation approach. Int. J. Urban Sci. 2019. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F. Detecting cars in UAV images with a catalog-based approach. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6356–6367. [Google Scholar] [CrossRef]
- Yang, B.; Chen, C. Automatic registration of UAV-borne sequent images and LiDAR data. ISPRS J. Photogramm. Remote Sens. 2015, 101, 262–274. [Google Scholar] [CrossRef]
- Kestur, R.; Farooq, S.; Abdal, R.; Mehraj, E.; Narasipura, O.; Mudigere, M. UFCN: A fully convolutional neural network for road extraction in RGB imagery acquired by remote sensing from an unmanned aerial vehicle. J. Appl. Remote Sens. 2018, 12, 016020. [Google Scholar] [CrossRef]
- Henry, C.; Azimi, S.M.; Merkle, N. Road Segmentation in SAR Satellite Images With Deep Fully Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Song, J.; Chen, M.; Yang, Z. Road network extraction: A neural-dynamic framework based on deep learning and a finite state machine. Int. J. Remote Sens. 2015, 36, 3144–3169. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Road Segmentation of Remotely-Sensed Images Using Deep Convolutional Neural Networks with Landscape Metrics and Conditional Random Fields. J. Remote Sens. 2017, 9, 680. [Google Scholar] [CrossRef] [Green Version]
- Constantin, A.; Ding, J.-J.; Lee, Y.-C. Accurate Road Detection from Satellite Images Using Modified U-net. In Proceedings of the 2018 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Chengdu, China, 26–30 October 2018; pp. 423–426. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Hong, Z.; Ming, D.; Zhou, K.; Guo, Y.; Lu, T. Road Extraction From a High Spatial Resolution Remote Sensing Image Based on Richer Convolutional Features. IEEE Access 2018, 6, 46988–47000. [Google Scholar] [CrossRef]
- Xin, J.; Zhang, X.; Zhang, Z.; Fang, W. Road Extraction of High-Resolution Remote Sensing Images Derived from DenseUNet. Remote Sens. 2019, 11, 2499. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Xu, L.; Rao, J.; Guo, L.; Yan, Z.; Jin, S. A Y-Net deep learning method for road segmentation using high-resolution visible remote sensing images. Remote Sens. Lett. 2019, 10, 381–390. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef] [Green Version]
- Buslaev, A.; Seferbekov, S.; Iglovikov, V.; Shvets, A. Fully convolutional network for automatic road extraction from satellite imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 207–210. [Google Scholar] [CrossRef] [Green Version]
- Zhou, L.; Zhang, C.; Wu, M. D-linknet: Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar] [CrossRef]
- Doshi, J. Residual inception skip network for binary segmentation. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 216–219. [Google Scholar] [CrossRef]
- Xu, Y.; Feng, Y.; Xie, Z.; Hu, A.; Zhang, X. A Research on Extracting Road Network from High Resolution Remote Sensing Imagery. In Proceedings of the 2018 26th International Conference on Geoinformatics, Kunming, China, 28–30 June 2018; pp. 1–4. [Google Scholar] [CrossRef]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Liu, X. Road segmentation of cross-modal remote sensing images using deep segmentation network and transfer learning. Ind. Robot Int. J. 2018. [Google Scholar] [CrossRef]
- Xia, W.; Zhang, Y.-Z.; Liu, J.; Luo, L.; Yang, K. Road Extraction from High Resolution Image with Deep Convolution Network—A Case Study of GF-2 Image. Proceedings 2018, 2, 325. [Google Scholar] [CrossRef] [Green Version]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road Extraction from High-Resolution Remote Sensing Imagery Using Refined Deep Residual Convolutional Neural Network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.; Miao, F.; Zhou, K.; Peng, J. HsgNet: A Road Extraction Network Based on Global Perception of High-Order Spatial Information. ISPRS Int. J. Geo-Inf. 2019, 8, 571. [Google Scholar] [CrossRef] [Green Version]
- Shi, Q.; Liu, X.; Li, X. Road detection from remote sensing images by generative adversarial networks. IEEE Access 2018, 6, 25486–25494. [Google Scholar] [CrossRef]
- Costea, D.; Marcu, A.; Slusanschi, E.; Leordeanu, M. Creating roadmaps in aerial images with generative adversarial networks and smoothing-based optimization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2100–2109. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic segmentation using adversarial networks. arXiv 2016, arXiv:1611.08408. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Dai, J.; Zhu, T.; Wang, Y.; Ma, R.; Fang, X. Road extraction from high-resolution satellite images based on multiple descriptors. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 2020, 13, 227–240. [Google Scholar] [CrossRef]
- Ghasemkhani, N.; Vayghan, S.S.; Abdollahi, A.; Pradhan, B.; Alamri, A. Urban Development Modeling Using Integrated Fuzzy Systems, Ordered Weighted Averaging (OWA), and Geospatial Techniques. Sustainability 2020, 12, 809. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approaches | Complexity | Output | Smoothness |
|---|---|---|---|
| Models based on GANs |
|
|
|
| Models based on CNNs |
|
|
|
| Models based on FCNs |
|
|
|
| Models based on deconvolutional nets |
|
|
|
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12091444
Abdollahi A, Pradhan B, Shukla N, Chakraborty S, Alamri A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sensing. 2020; 12(9):1444. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12091444
Chicago/Turabian StyleAbdollahi, Abolfazl, Biswajeet Pradhan, Nagesh Shukla, Subrata Chakraborty, and Abdullah Alamri. 2020. "Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review" Remote Sensing 12, no. 9: 1444. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12091444