
Spatial–Spectral Cross-Correlation Embedded Dual-Transfer Network for Object Tracking Using Hyperspectral Videos


Abstract
:
1. Introduction
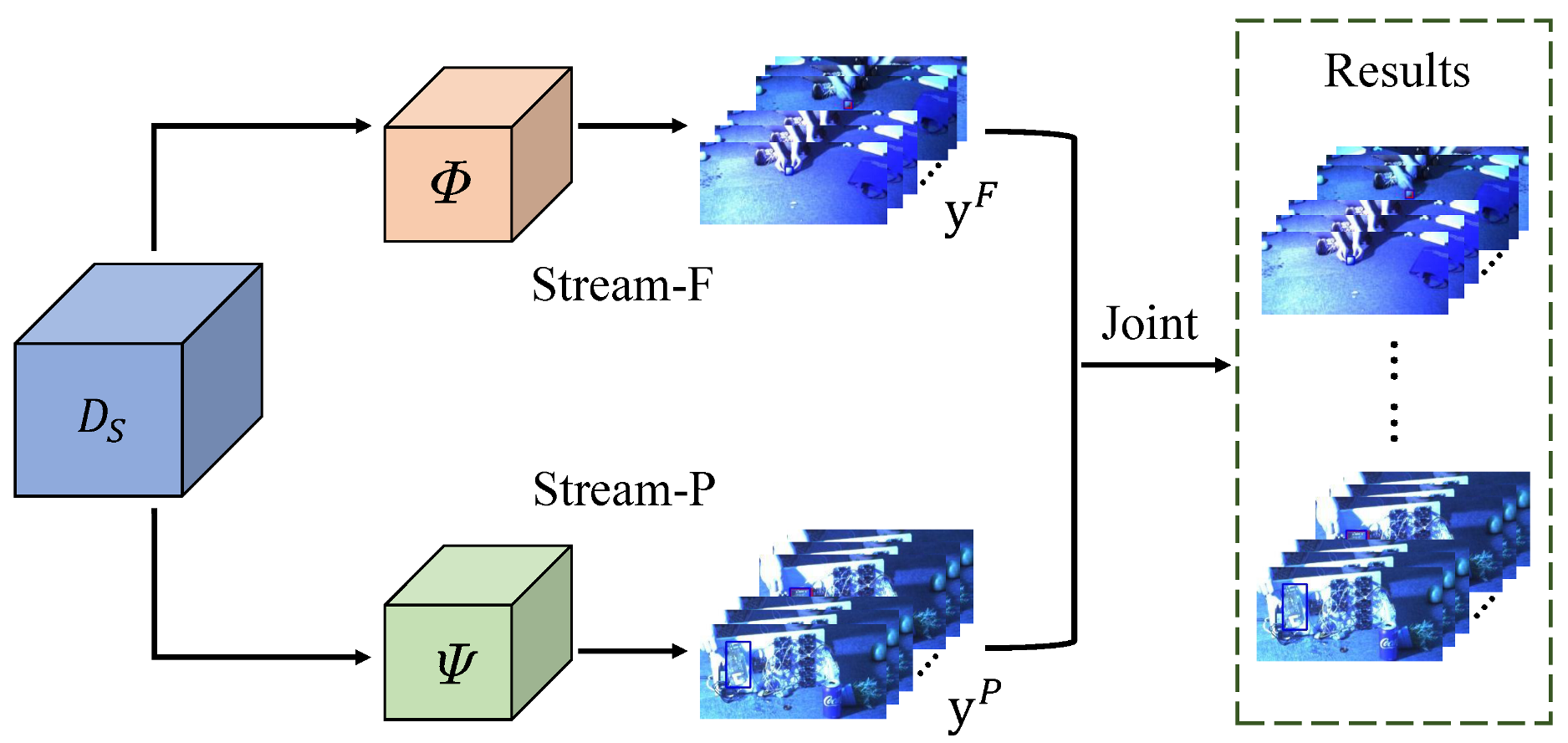
- For the first time, transfer learning technology was successfully applied in the field of HS object tracking. In particular, a new dual-transfer strategy is proposed—that is, the transfer learning method is adaptively selected according to the prior knowledge of the sample category, which not only solves the thorny problem of a lack of labeled data when learning deep models in the HS field but also verifies the applicability of transfer learning technology in the field of HS object tracking to a certain extent. This provides a flexible direction for future HS tracking research.
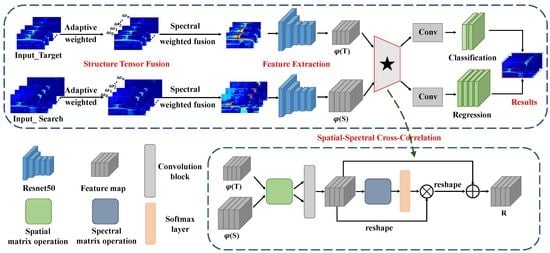
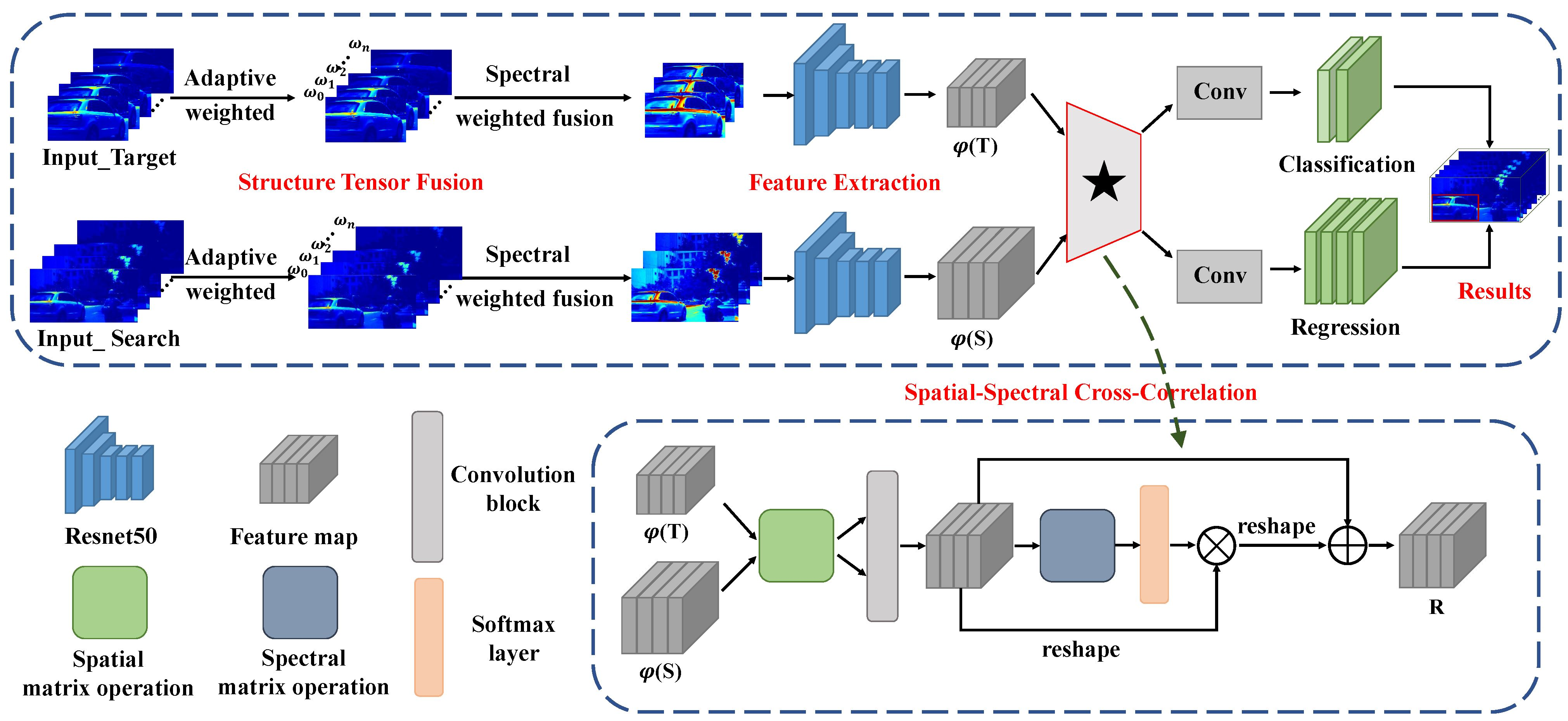
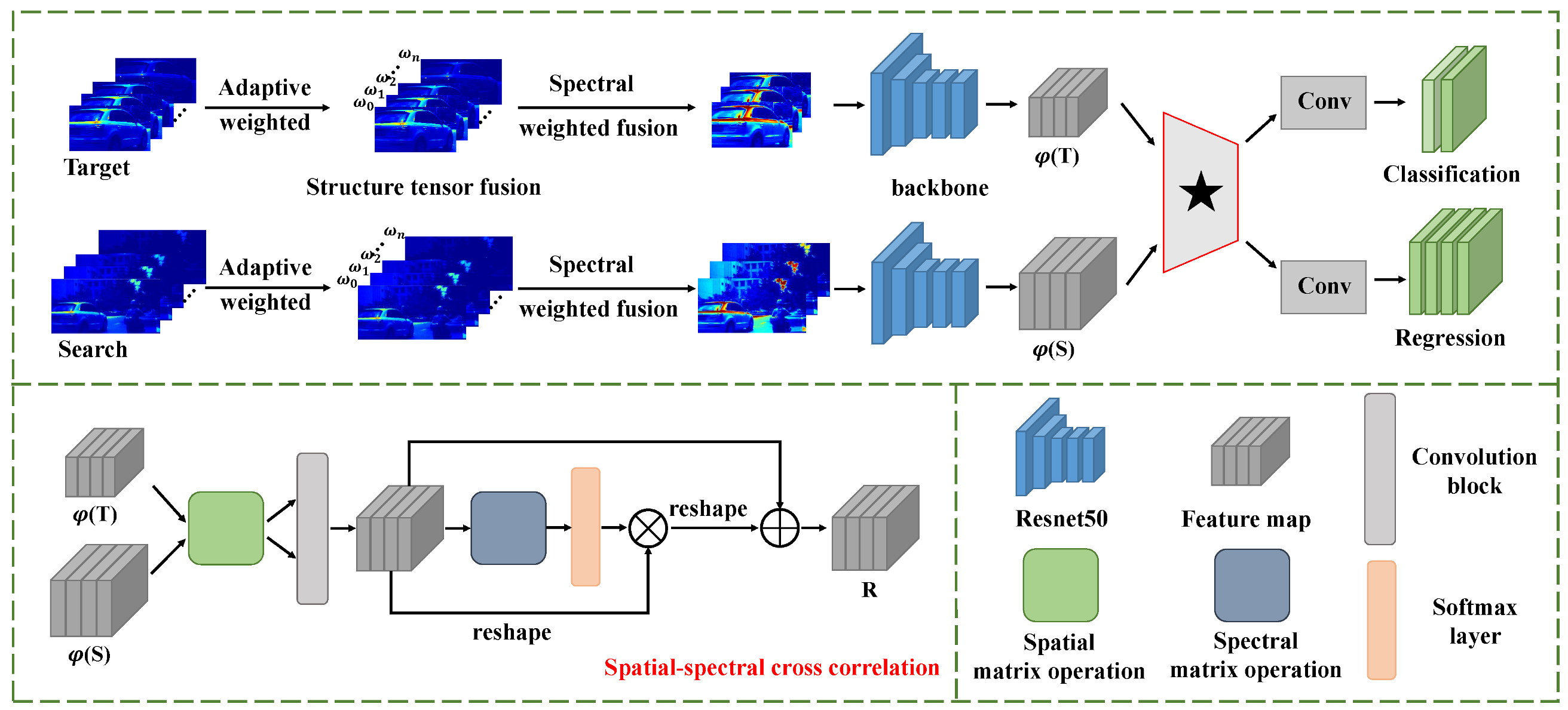
- For fully utilizing the spatial structure identification ability of the spatial dimension and the material identification ability of the spectral dimension in the HSIs, a novel spatial–spectral cross-correlation module is designed to better embed the spatial information and material information between the two branches of the Siamese network.
- Considering the high-dimensional characteristic of HS videos, we introduce an effective spectral weighted fusion method based on ST to gain the inputs of CNNs that consider the contribution rate to the significant information of each selected band to make our network more efficient.
- The experimental results demonstrate that, compared to the state of the art, the proposed SSDT-Net tracker offers more satisfactory performance based on a similar speed to the traditional color trackers. We provide an efficient and enlightening scheme for HS object tracking.
2. Related Work
2.1. Hyperspectral Video Technology
2.2. Siamese Network-Based Trackers
3. Proposed Method
3.1. Dual Transfer
3.2. Spectral Weighted Fusion
3.3. Common Feature Extraction
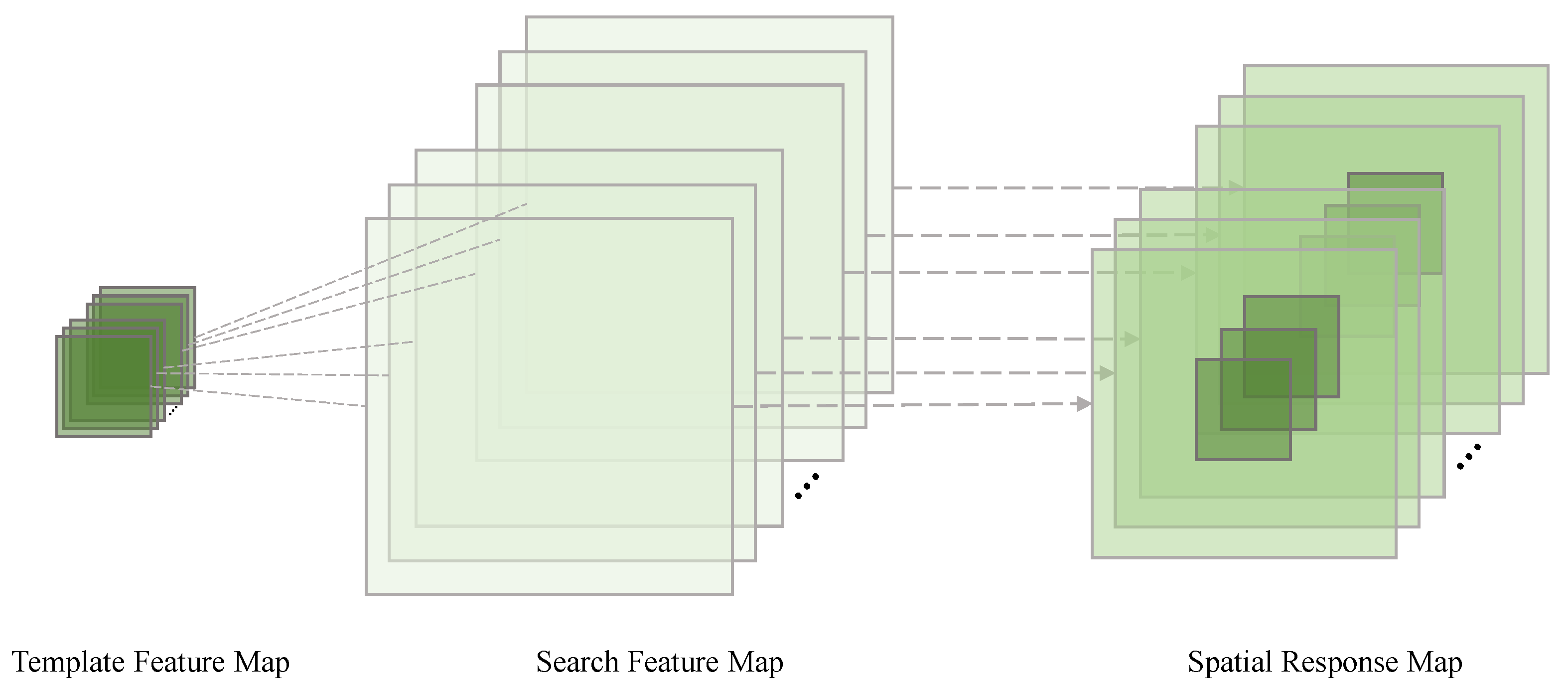
3.4. Spatial–Spectral Cross-Correlation
3.5. Bounding Box Prediction
4. Experiments
4.1. Experimental Setup
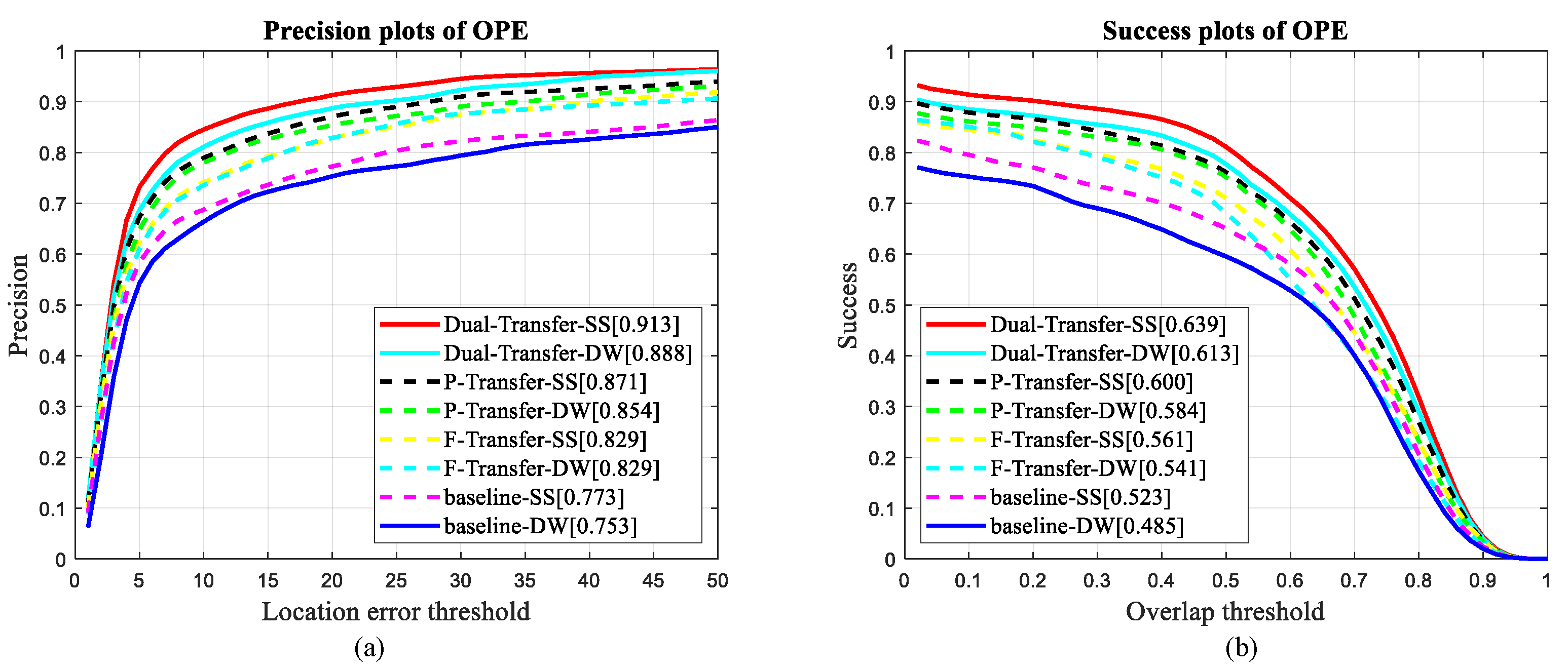
4.2. Ablation Study
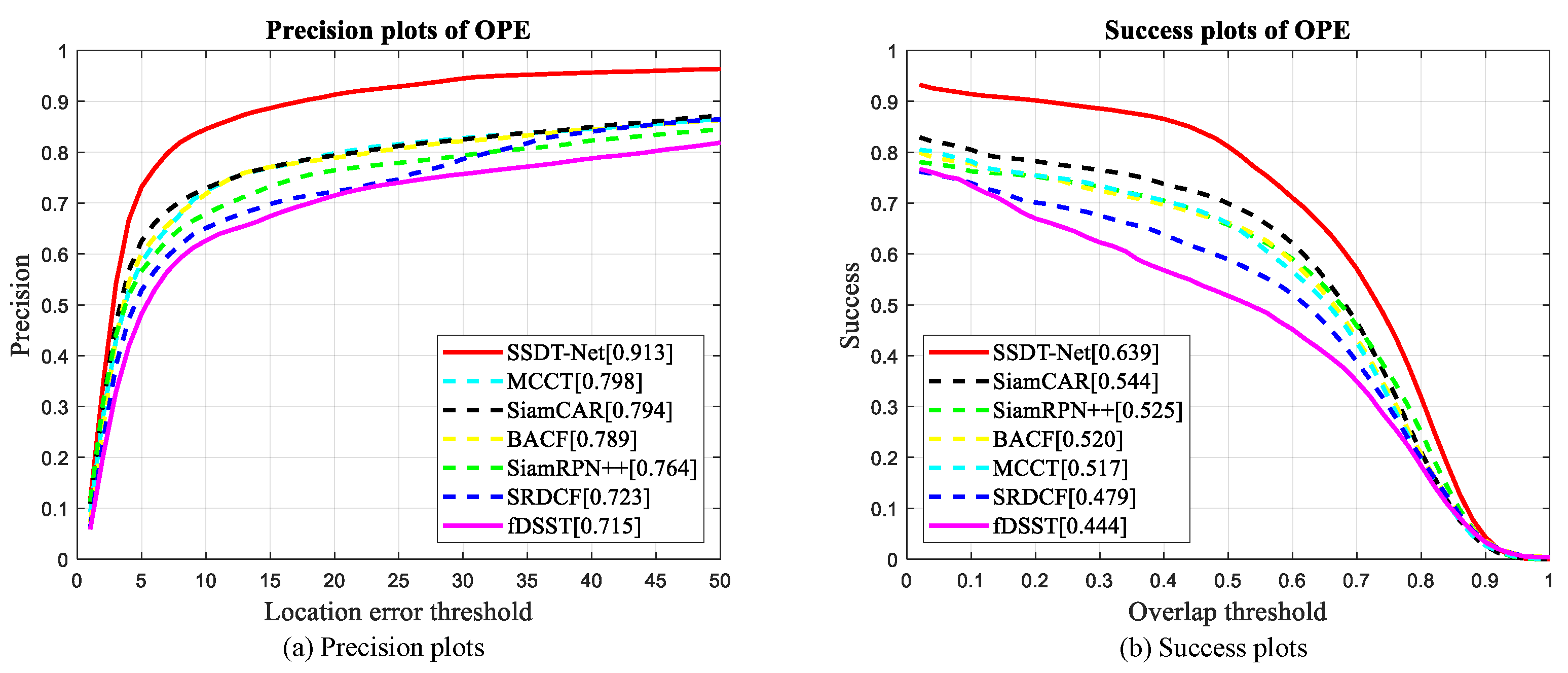
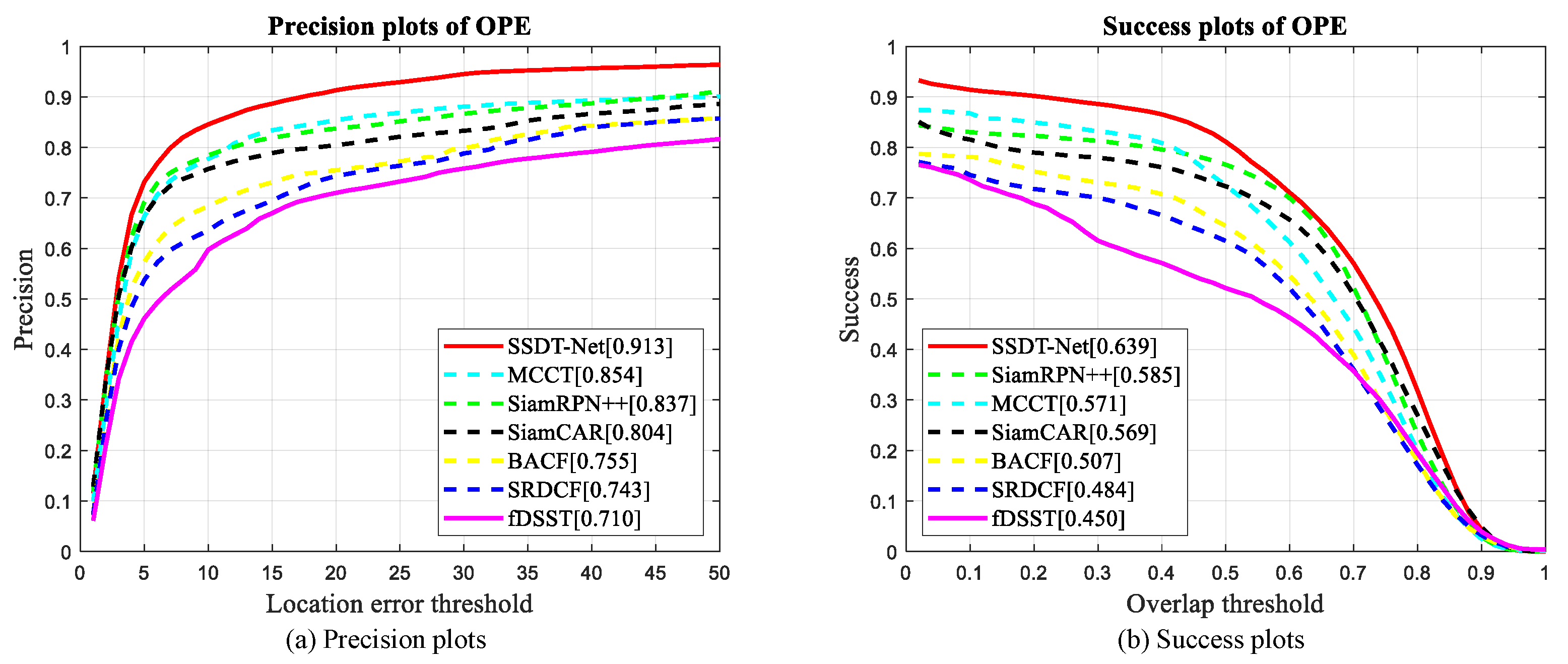
4.3. Quantitative Comparison with the State-Of-The-Art Color Trackers
4.4. Quantitative Comparison with the State-Of-The-Art Hyperspectral Trackers
4.5. Running Time Comparison
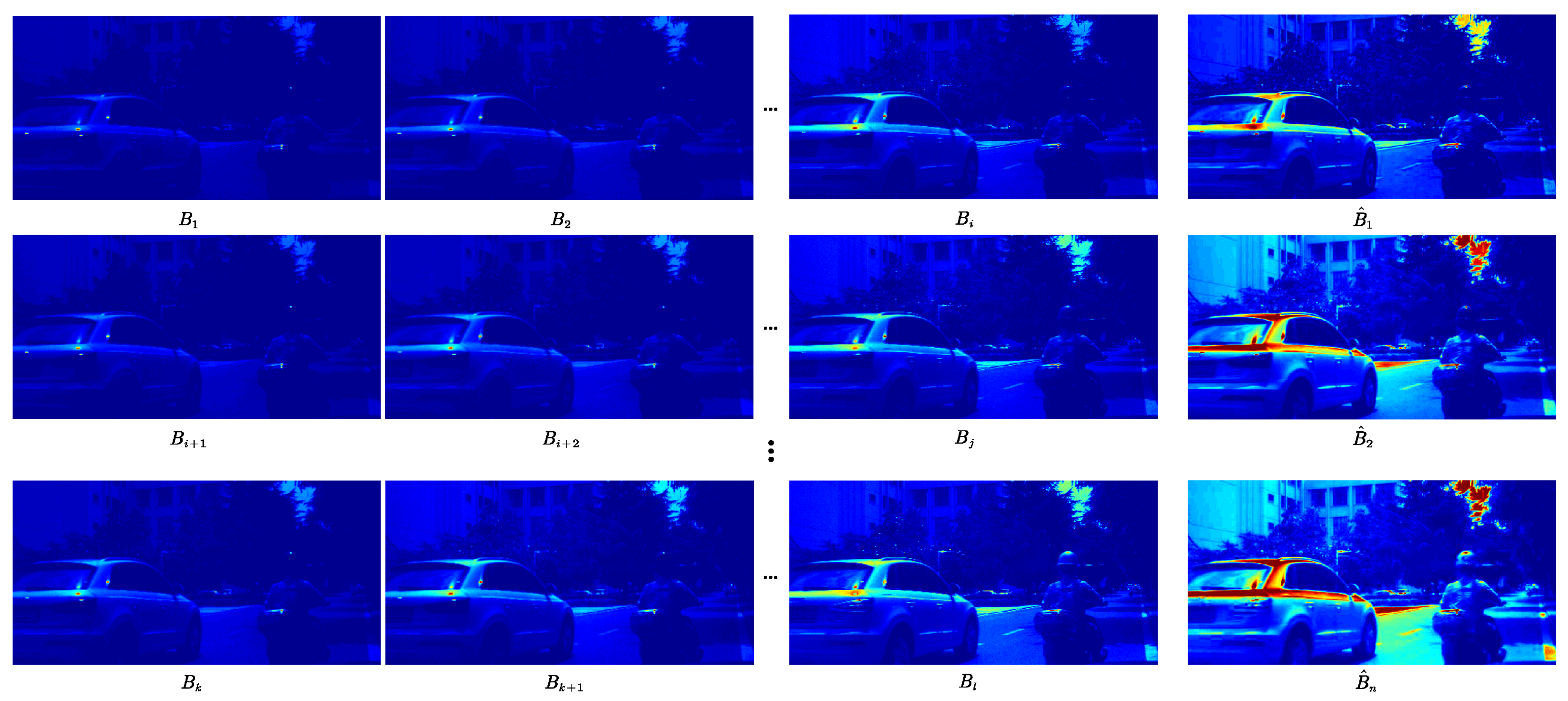
4.6. Demonstrations of Visual Tracking Results
5. Discussion
- 1.
- As shown in Section 3.2, we directly use the spectral weighted fusion module based on the ST to fuse the data at the input end of the network to reduce the dimension and perform the fusion operation at the input of the network; although the tracker can obtain excellent speed, it will cause a great deal of loss of information, and the material identification characteristics of HS data will limit the performance improvement of the tracker. Therefore, in the following research, we can consider the fusion of feature maps after feature extraction on the network so as to make better use of the spectral information of HS data.
- 2.
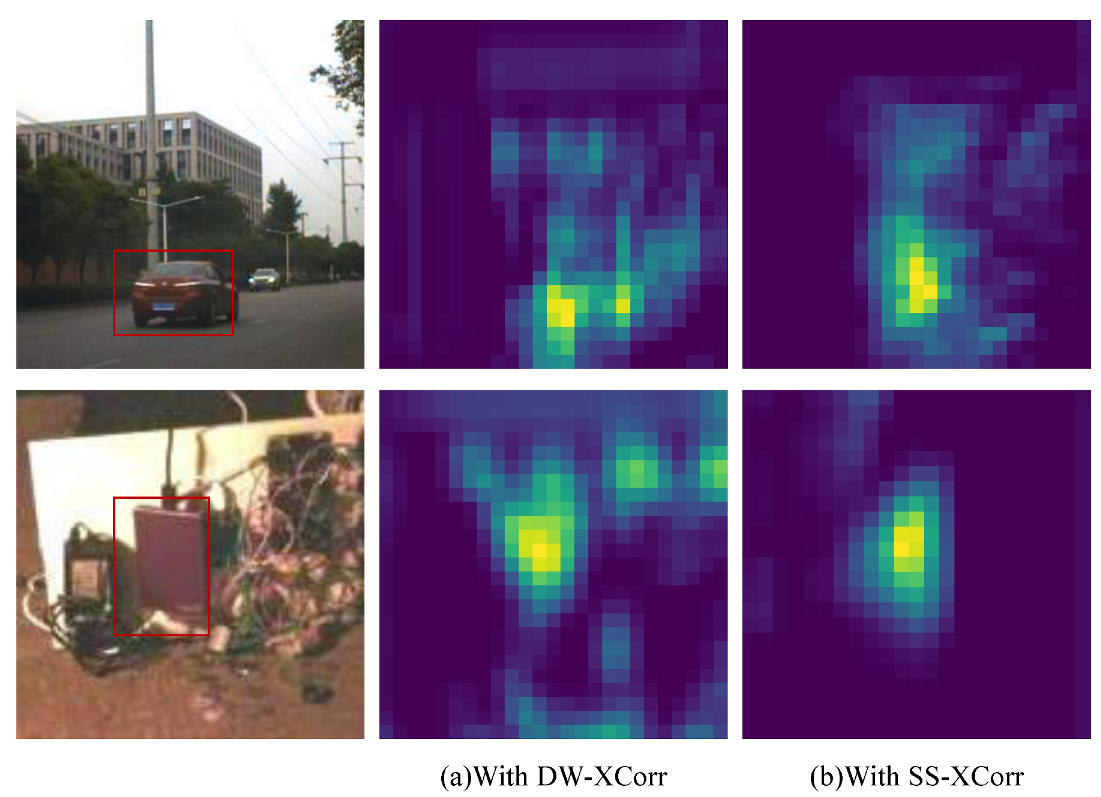
- The experimental results show that the spectral cross-correlation module plays a role, improves the subjective and objective effects, and proves the effectiveness of spectral information for target recognition. Therefore, we can consider further investigation of spectral cross-correlation operations.
- 3.
- Regarding the cross-correlation module of the Siamese network, the correlation operation itself is a local linear matching process, and it is easy to lose semantic information and fall into a local optimum, which may become a bottleneck in designing high-precision tracking algorithms. Therefore, inspired by Transformer, we consider using the attention mechanism to perform cross-correlation operation, which requires further study.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| HS | Hyperspectral |
| CNN | Convolutional neural network |
| ST | Structure tensor |
| DW-XCorr | Depth-wise cross-correlation |
| SS-XCorr | Spatial–spectral cross-correlation |
| AUC | Area under the curve |
| DP@20P | Distance precision scores at a threshold of 20 pixels |
| SGD | Stochastic gradient descent |
References
- Marvasti-Zadeh, S.M.; Cheng, L.; Ghanei-Yakhdan, H.; Kasaei, S. Deep Learning for Visual Tracking: A Comprehensive Survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 1–26. [Google Scholar] [CrossRef]
- Gao, J.; Zhang, T.; Yang, X.; Xu, C. Deep Relative Tracking. IEEE Trans. Image Process. 2017, 26, 1845–1858. [Google Scholar] [CrossRef]
- Liang, J.; Zhou, J.; Tong, L.; Bai, X.; Wang, B. Material based salient object detection from hyperspectral images. Pattern Recognit. 2018, 76, 476–490. [Google Scholar] [CrossRef] [Green Version]
- Okwuashi, O.; Ndehedehe, C.E. Deep support vector machine for hyperspectral image classification. Pattern Recognit. 2020, 103, 107298. [Google Scholar] [CrossRef]
- Qian, K.; Zhou, J.; Xiong, F.; Zhou, H.; Du, J. Object tracking in hyperspectral videos with convolutional features and kernelized correlation filter. In International Conference on Smart Multimedia; Springer: Berlin/Heidelberg, Germany, 2018; pp. 308–319. [Google Scholar]
- Xiong, F.; Zhou, J.; Qian, Y. Material based object tracking in hyperspectral videos. IEEE Trans. Image Process. 2020, 29, 3719–3733. [Google Scholar] [CrossRef] [PubMed]
- Uzkent, B.; Rangnekar, A.; Hoffman, M.J. Tracking in aerial hyperspectral videos using deep kernelized correlation filters. IEEE Trans. Geosci. Remote Sens. 2018, 57, 449–461. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Li, Z.; Xiong, F.; Zhou, J.; Wang, J.; Lu, J.; Qian, Y. BAE-Net: A Band Attention Aware Ensemble Network for Hyperspectral Object Tracking. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2106–2110. [Google Scholar]
- Song, Y.; Ma, C.; Wu, X.; Gong, L.; Bao, L.; Zuo, W.; Shen, C.; Lau, R.W.; Yang, M.H. Vital: Visual tracking via adversarial learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8990–8999. [Google Scholar]
- Li, Z.; Ye, X.; Xiong, F.; Lu, J.; Zhou, J.; Qian, Y. Spectral-Spatial-Temporal Attention Network for Hyperspectral Tracking. Available online: http://www.ieee-whispers.com/wp-content/uploads/2021/03/WHISPERS_2021_paper_55.pdf (accessed on 26 March 2021).
- Liu, Z.; Wang, X.; Shu, M.; Li, G.; Sun, C.; Liu, Z.; Zhong, Y. An Anchor-Free Siamese Target Tracking Network for Hyperspectral Video. Available online: http://www.ieee-whispers.com/wp-content/uploads/2021/03/WHISPERS_2021_paper_52.pdf (accessed on 26 March 2021).
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Geosci. Remote Sens. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 749–765. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H. End-to-end representation learning for correlation filter based tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2805–2813. [Google Scholar]
- Wang, Q.; Gao, J.; Xing, J.; Zhang, M.; Hu, W. Dcfnet: Discriminant correlation filters network for visual tracking. arXiv 2017, arXiv:1704.04057. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018; pp. 101–117. [Google Scholar]
- Pitie, F.; Kokaram, A. The linear monge-kantorovitch linear colour mapping for example-based colour transfer. In Proceedings of the 4th European Conference on Visual Media Production, London, UK, 27–28 November 2007; pp. 1–9. [Google Scholar]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A twofold siamese network for real-time object tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4834–4843. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning dynamic siamese network for visual object tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1763–1771. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Han, Y.; Huang, G.; Song, S.; Yang, L.; Wang, H.; Wang, Y. Dynamic neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Xie, W.; Jiang, T.; Li, Y.; Jia, X.; Lei, J. Structure tensor and guided filtering-based algorithm for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4218–4230. [Google Scholar] [CrossRef]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Robust Visual Tracking via Hierarchical Convolutional Features. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 25, 670–674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Real, E.; Shlens, J.; Mazzocchi, S.; Pan, X.; Vanhoucke, V. Youtube-boundingboxes: A large high-precision human-annotated data set for object detection in video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5296–5305. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Kiani Galoogahi, H.; Fagg, A.; Lucey, S. Learning background-aware correlation filters for visual tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1135–1143. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Discriminative scale space tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1561–1575. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, N.; Zhou, W.; Tian, Q.; Hong, R.; Wang, M.; Li, H. Multi-cue correlation filters for robust visual tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4844–4853. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6269–6277. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transfer Strategy | Corr | AUC | DP@20P |
|---|---|---|---|
| Baseline | DW | 0.4848 | 0.7533 |
| SS | 0.5233 | 0.7727 | |
| Feature-based Transfer | DW | 0.5414 | 0.8289 |
| SS | 0.5608 | 0.8289 | |
| Parameter-based Transfer | DW | 0.5839 | 0.8540 |
| SS | 0.6001 | 0.8710 | |
| Dual-transfer | DW | 0.6126 | 0.8875 |
| SS | 0.6391 | 0.9132 |
| Tracker | HS/False-Color Videos | Color Videos | ||
|---|---|---|---|---|
| AUC | DP@20P | AUC | DP@20P | |
| BACF | 0.5198 | 0.7889 | 0.5072 | 0.7549 |
| fDSST | 0.4442 | 0.7149 | 0.4499 | 0.7099 |
| MCCT | 0.5170 | 0.7984 | 0.5709 | 0.8542 |
| SRDCF | 0.4793 | 0.7229 | 0.4837 | 0.7433 |
| SiamRPN++ | 0.5253 | 0.7643 | 0.5852 | 0.8371 |
| SiamCAR | 0.5441 | 0.7936 | 0.5688 | 0.8044 |
| SSDT-Net | 0.6391 | 0.9132 | - | - |
| Video | SSDT-Net | MHT | BAE-Net | SST-Net |
|---|---|---|---|---|
| Hyperspectral | 0.6391 | 0.6080 | 0.6060 | 0.6230 |
| Videos | SSDT-Net | MHT | BACF | fDSST |
|---|---|---|---|---|
| RGB | - | - | 60.6 | 120.6 |
| Hyperspectral/False-Color | 35.7 | 6.09 | 66.36 | 120.1 |
| Videos | MCCT | SRDCF | SiamRPN++ | SiamCAR |
| RGB | 7.5 | 24.3 | 35.2 | 52.3 |
| Hyperspectral/False-Color | 7.3 | 25.8 | 35.5 | 52.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, J.; Liu, P.; Xie, W.; Gao, L.; Li, Y.; Du, Q. Spatial–Spectral Cross-Correlation Embedded Dual-Transfer Network for Object Tracking Using Hyperspectral Videos. Remote Sens. 2022, 14, 3512. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14153512
Lei J, Liu P, Xie W, Gao L, Li Y, Du Q. Spatial–Spectral Cross-Correlation Embedded Dual-Transfer Network for Object Tracking Using Hyperspectral Videos. Remote Sensing. 2022; 14(15):3512. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14153512
Chicago/Turabian StyleLei, Jie, Pan Liu, Weiying Xie, Long Gao, Yunsong Li, and Qian Du. 2022. "Spatial–Spectral Cross-Correlation Embedded Dual-Transfer Network for Object Tracking Using Hyperspectral Videos" Remote Sensing 14, no. 15: 3512. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14153512