
Deep Learning for Mapping Tropical Forests with TanDEM-X Bistatic InSAR Data

 , ,
, ,  , , and
, , and
Abstract
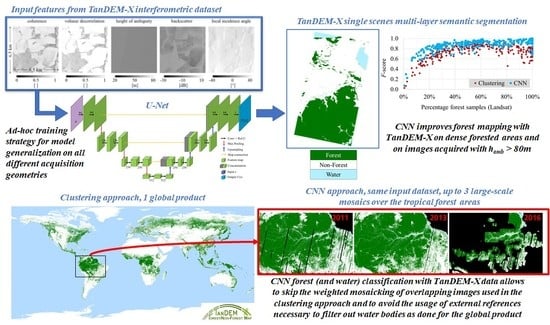
:
1. Introduction
2. Background Concepts and Data Sets
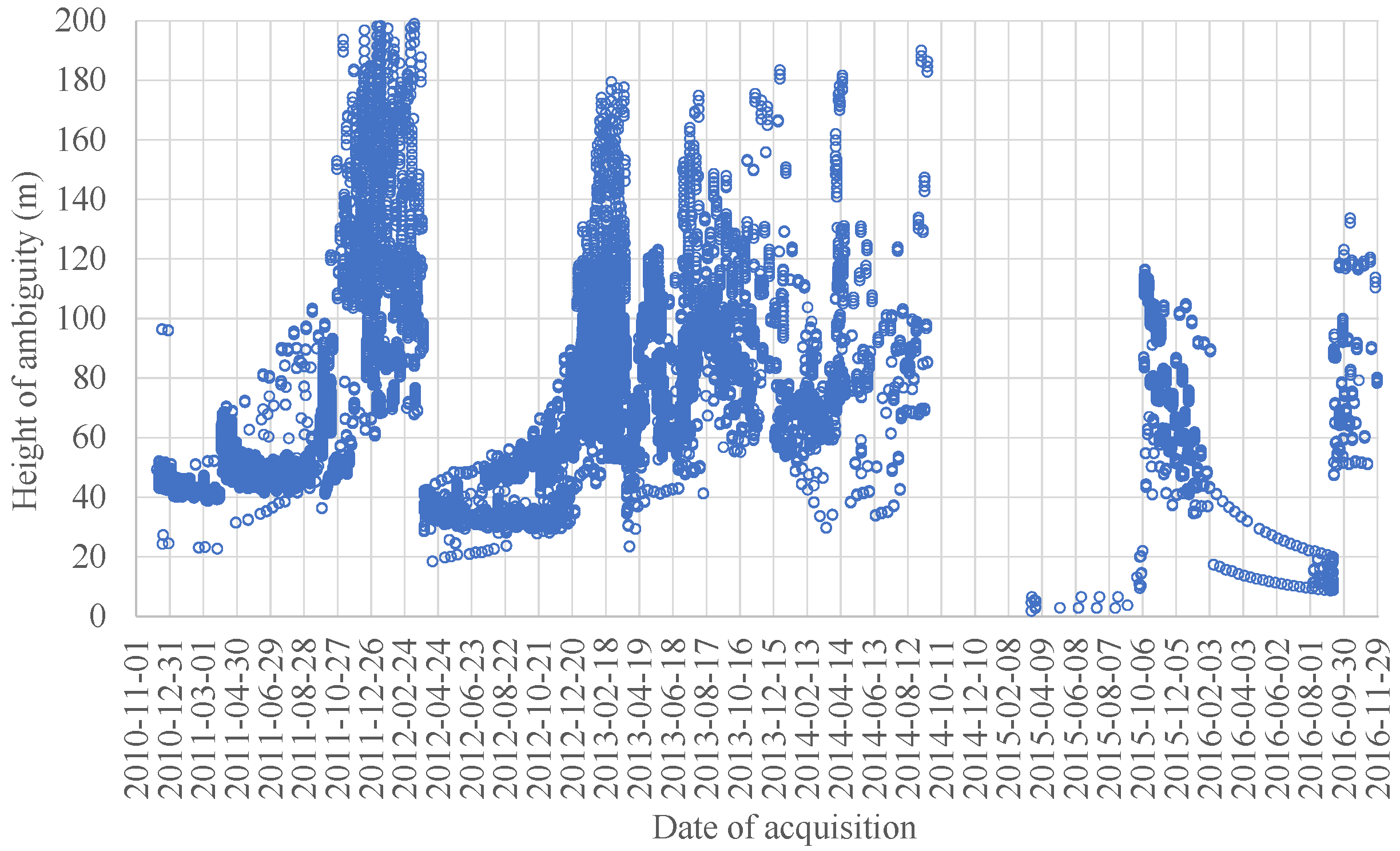
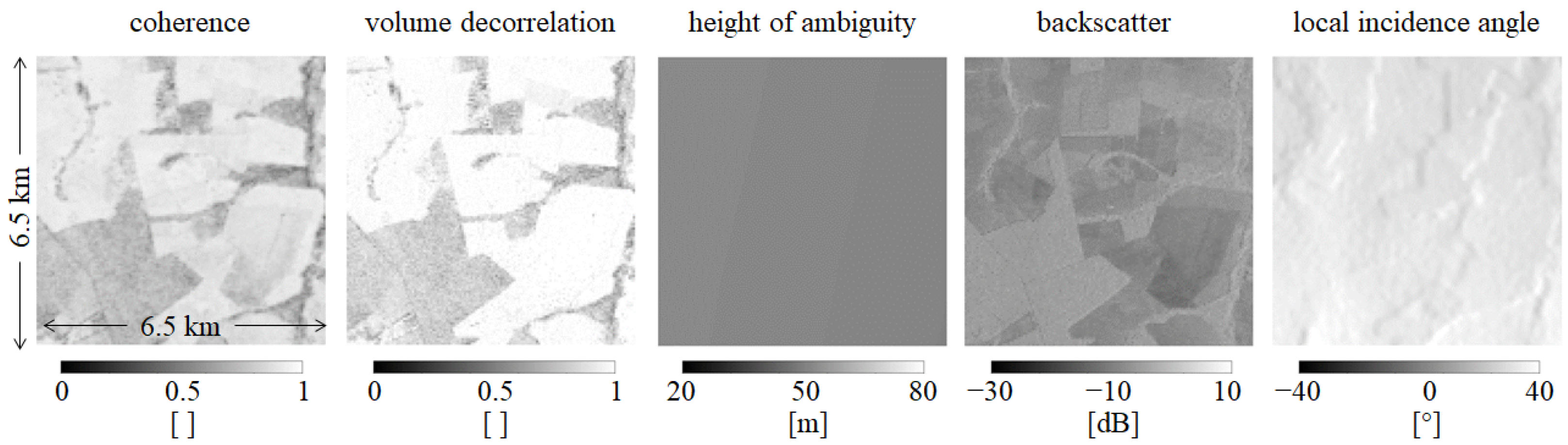
2.1. The TanDEM-X Interferometric Data Set and Its Properties
2.2. External Reference Data
- Landsat Tree Cover Map ([7,35]): This map is based on Landsat data acquired from 2000 to 2015. It is provided at a resolution of 30 m × 30 m and represents the percentage of forest covering the area defined by a 30 m pixel. Forest is defined as woody vegetation higher than 5 m. The tree cover map of 2010 has been used for training the U-Net on forest mapping.
- FROM-GLC Map ([8]): The FROM-GLC map has been used for the large-scale intercomparison of the generated mosaics. This land cover map has been generated at a pixel spacing of 10 m using a machine learning random forests classifier, trained on Landsat data acquired up to 2015, which has been updated to 2017 using additional multi-spectral data from the ESA Sentinel-2 mission.
- Palsar FNF Map ([10]): The PALSAR forest/non-forest map has been used for large-scale maps intercomparison. It is based on data acquired at the L band by the Japanese ALOS satellite series. The global PALSAR FNF map has been produced by thresholding the detected backscatter images acquired in cross polarization (HV channel) and it is provided with a 25 m pixel spacing. This map is available for 2010 and it is yearly updated starting from 2015.
- Sentinel-2 and Landsat Data: For validation purposes, we also utilized some specific multi-spectral Sentinel-2 and Landsat acquisitions over the Amazon rainforest.
3. Baseline Classification Approaches
3.1. Global Forest Mapping with TanDEM-X
3.2. Global Watershed-Based Water Mapping with TanDEM-X
4. Methods
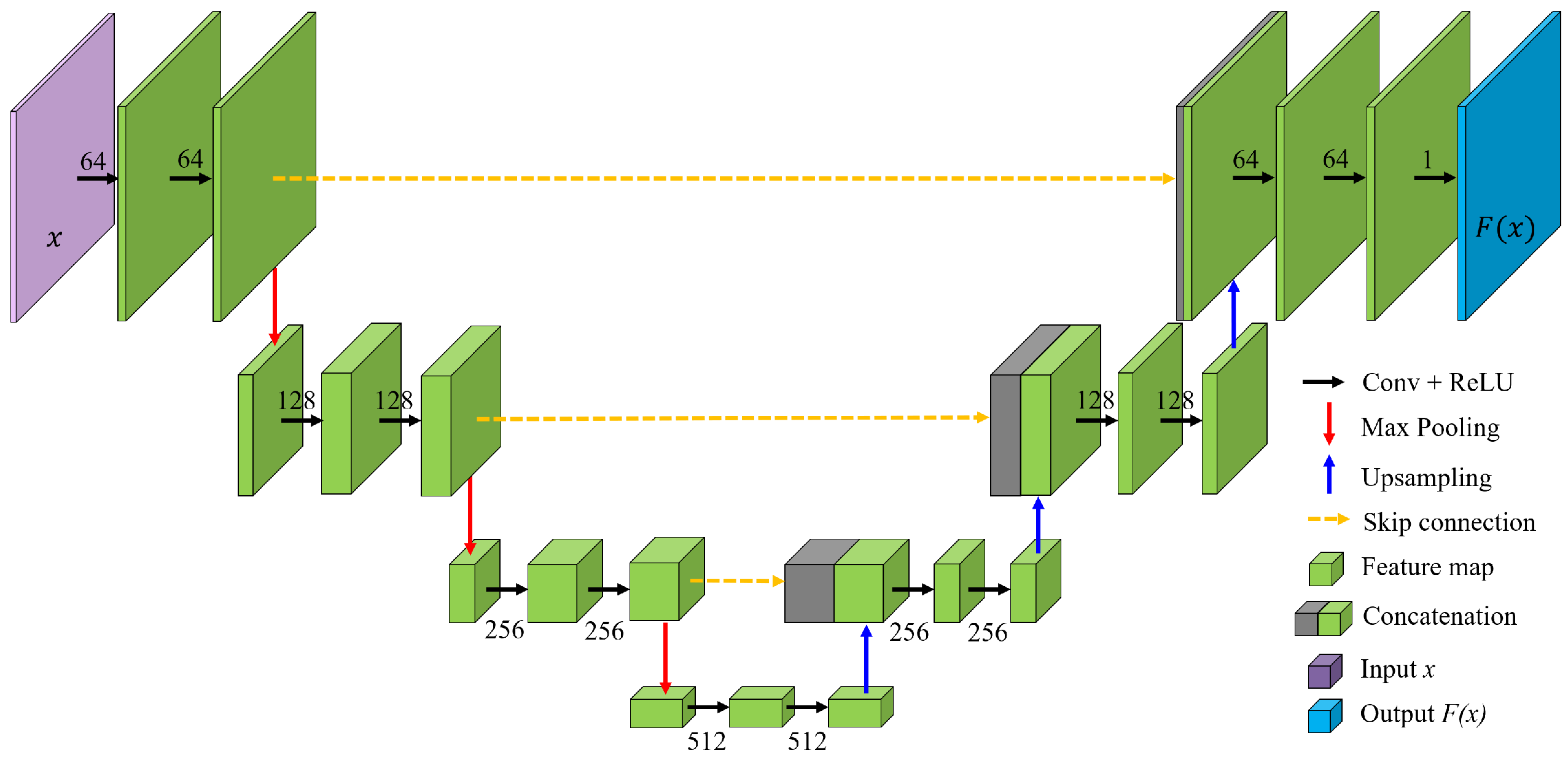
4.1. Proposed U-Net-like Architecture
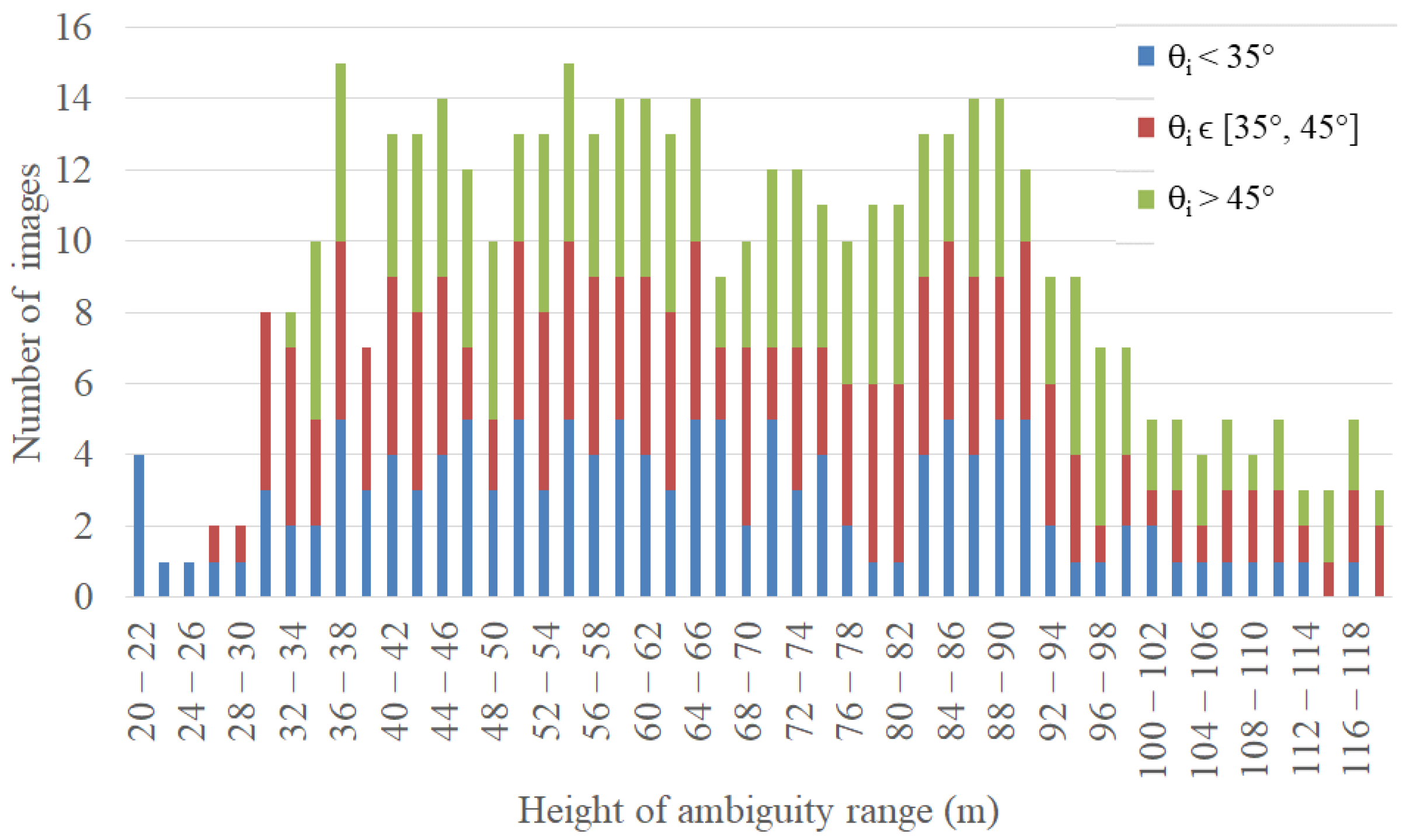
4.2. Generation of the Training Data Set
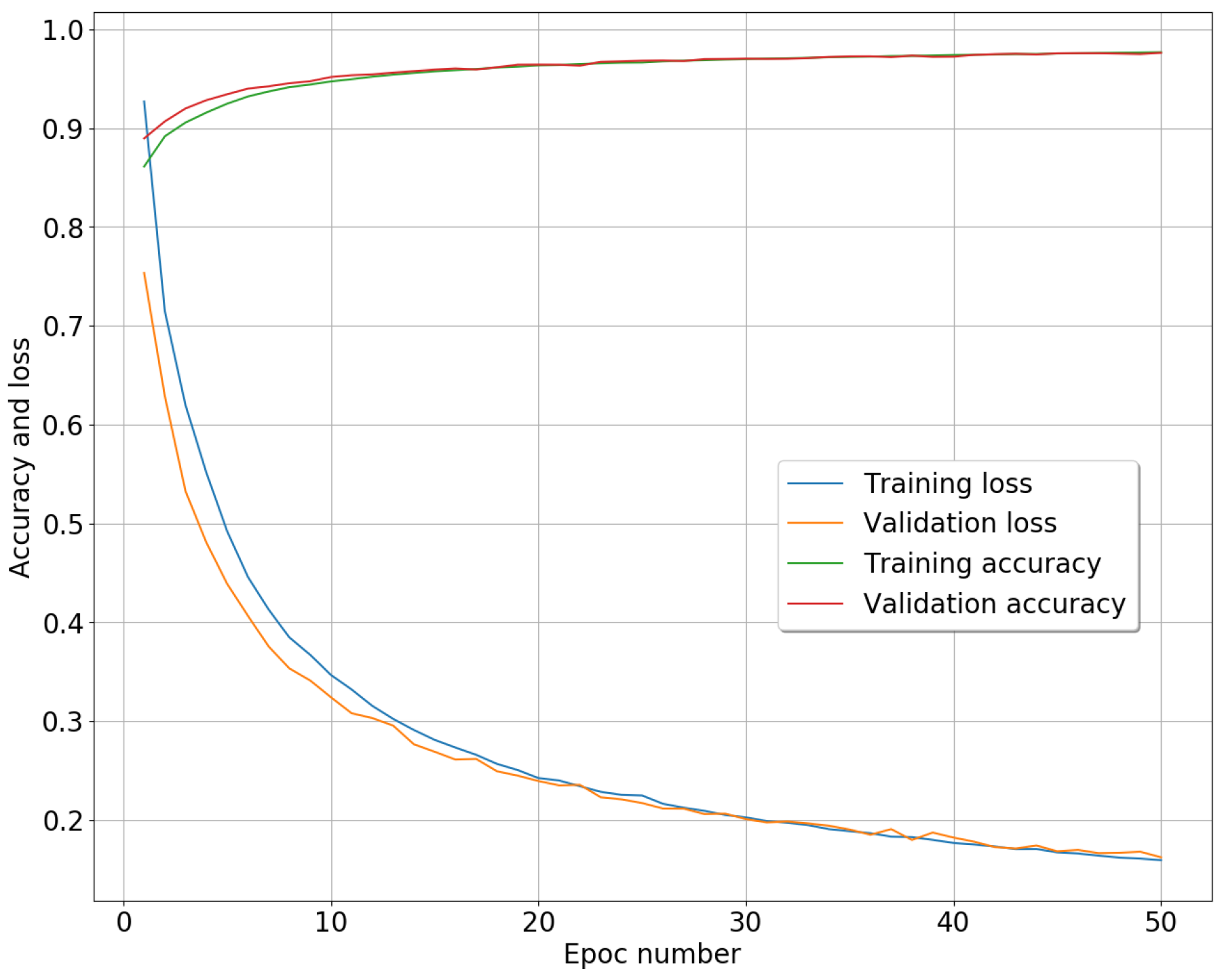
4.3. Training Process
4.4. Performance Assessment Metrics
- The overall accuracy () represents the overall correctly classified pixels, with respect to the total number of classified pixels, considering all land cover classes, and is defined as:
- The F-score, also called the -score, is an accuracy metric that ranges between 0 and 1 and is expressed as:
5. Results
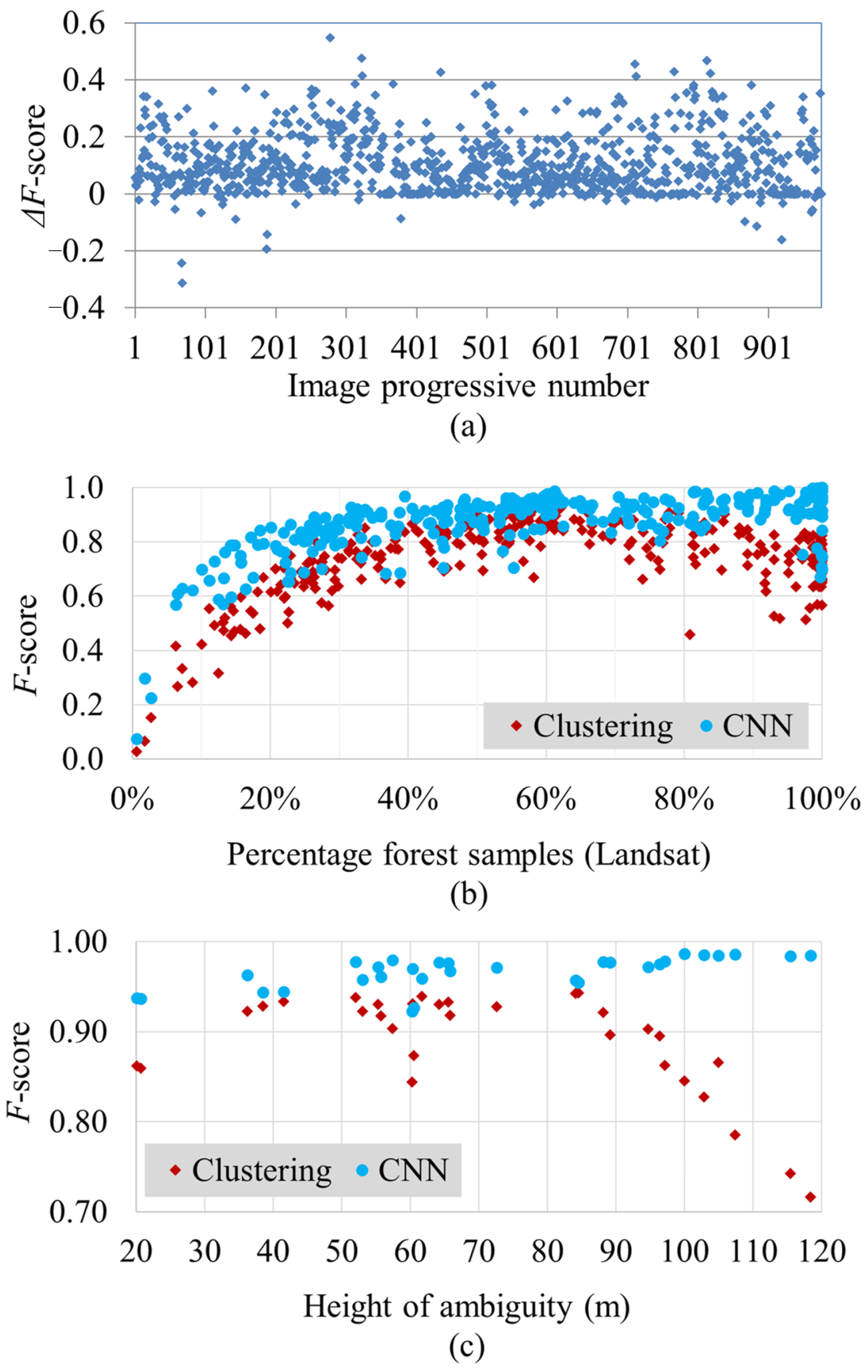
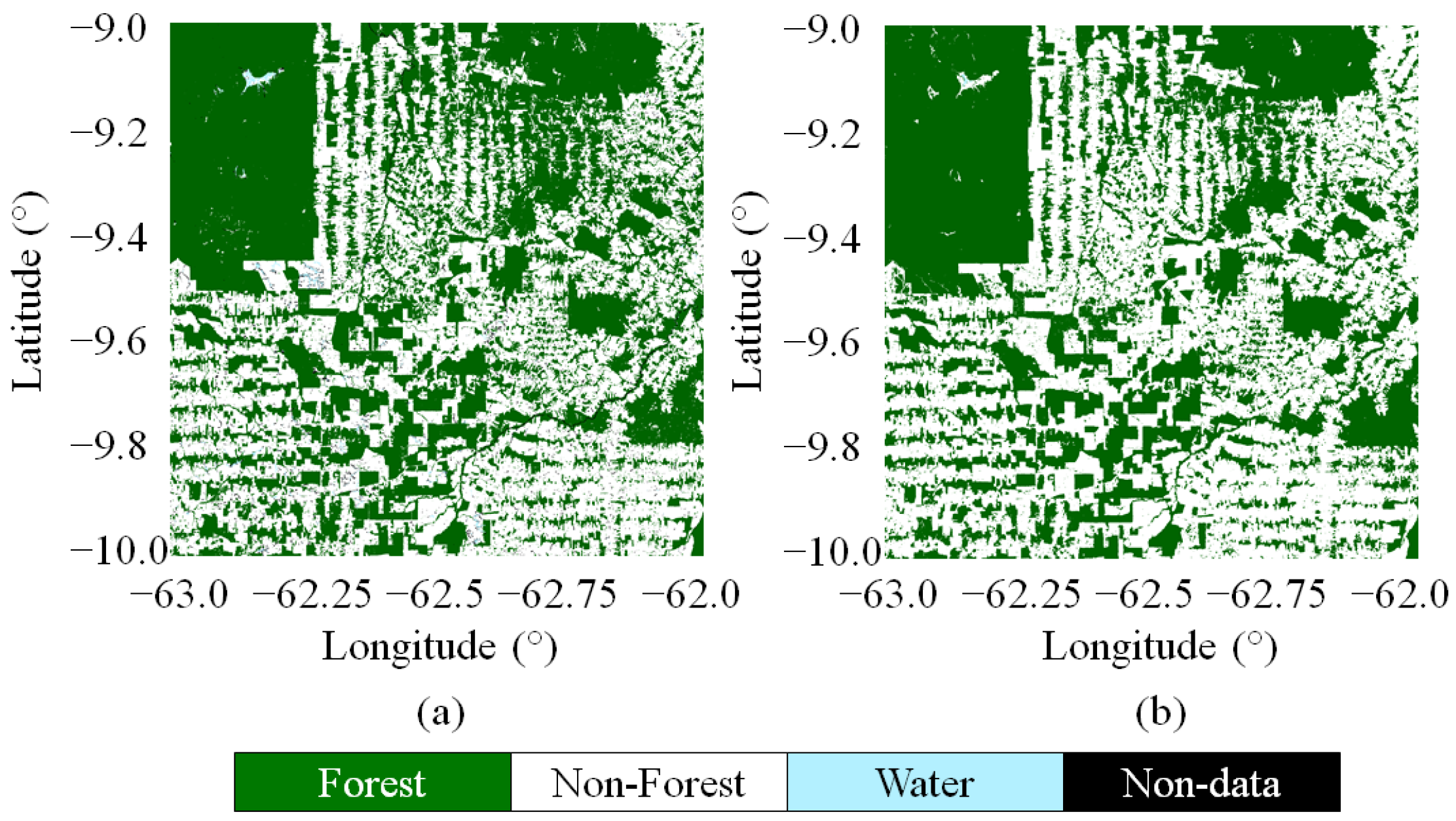
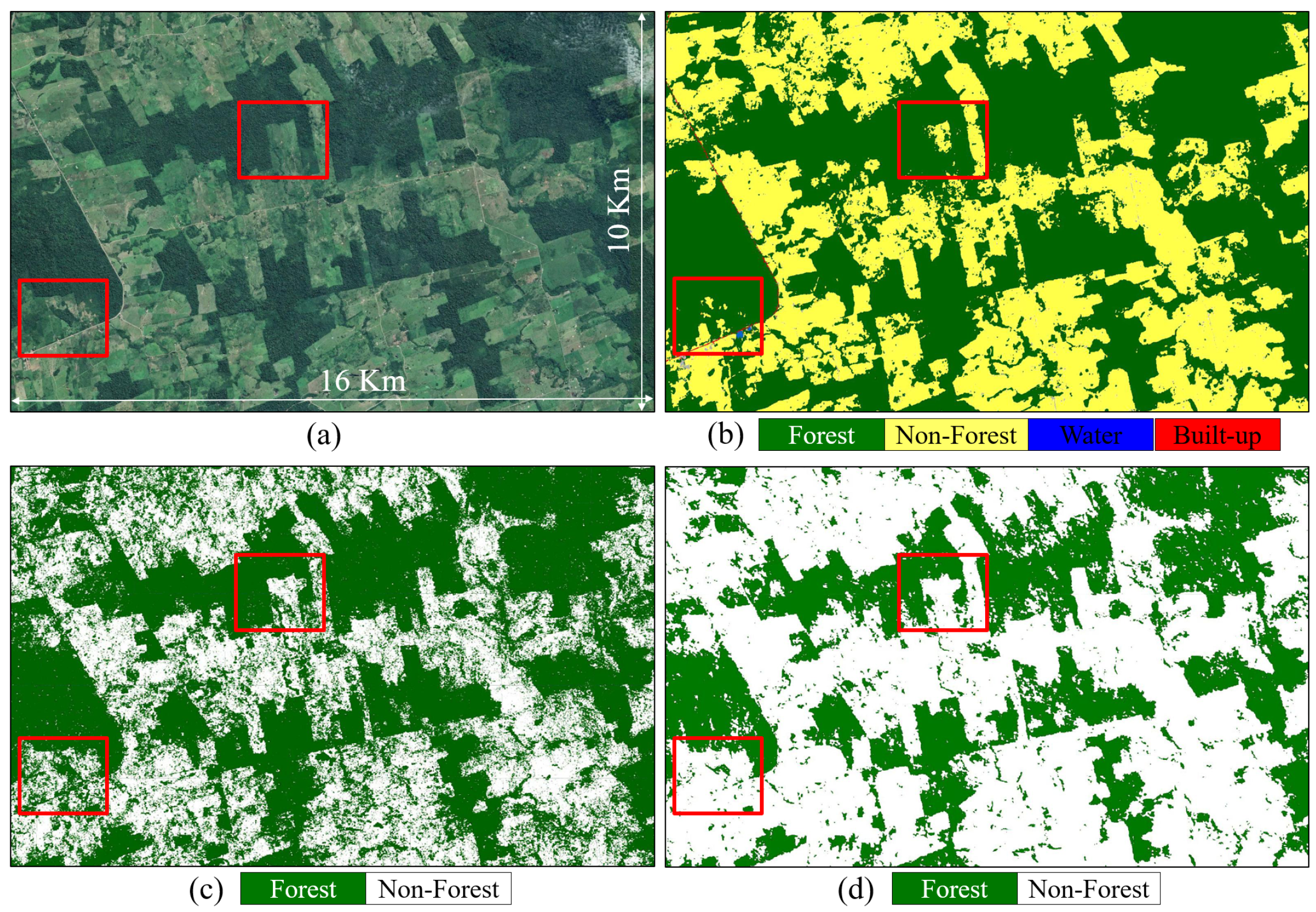
5.1. Single-Scene Classification
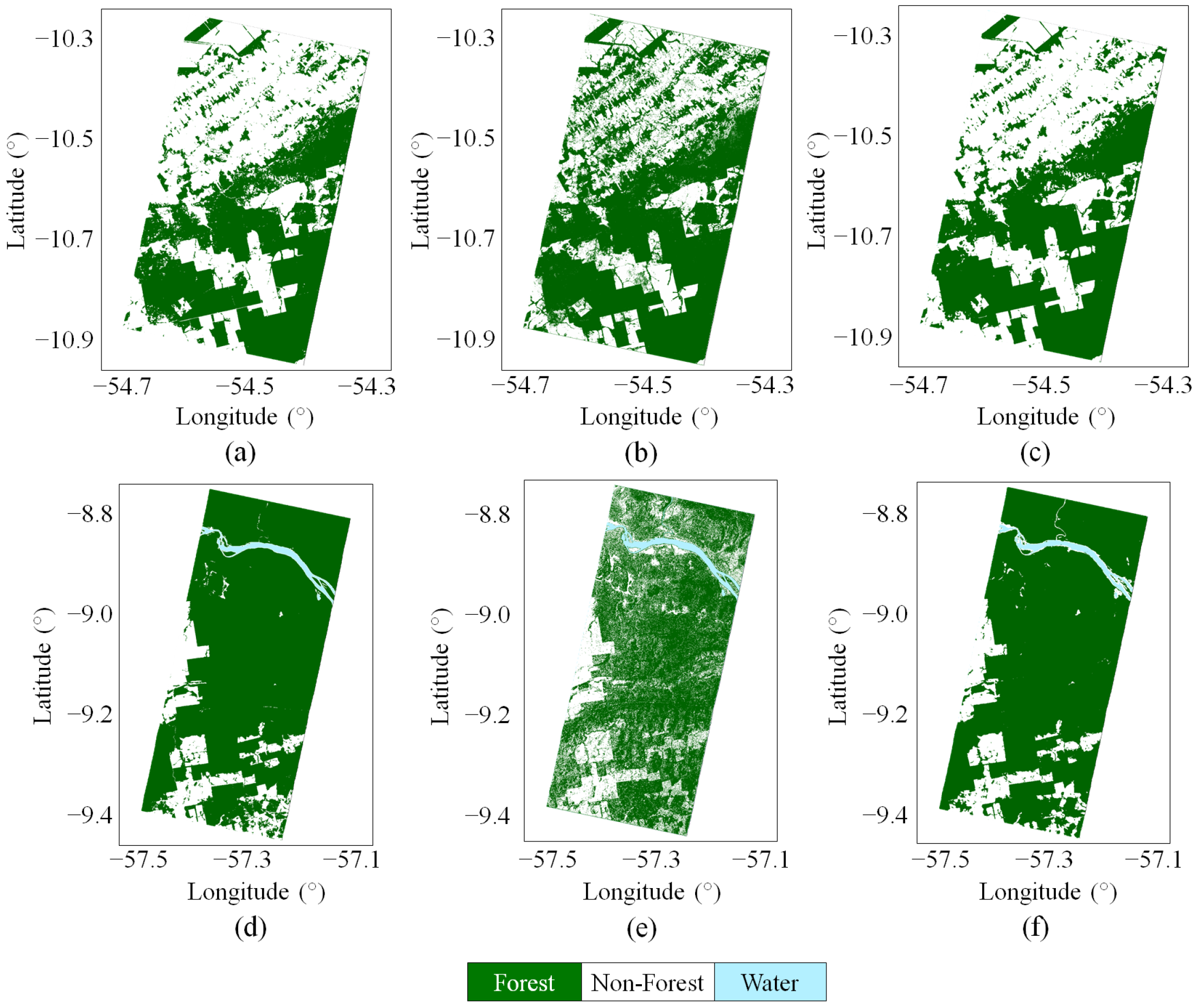
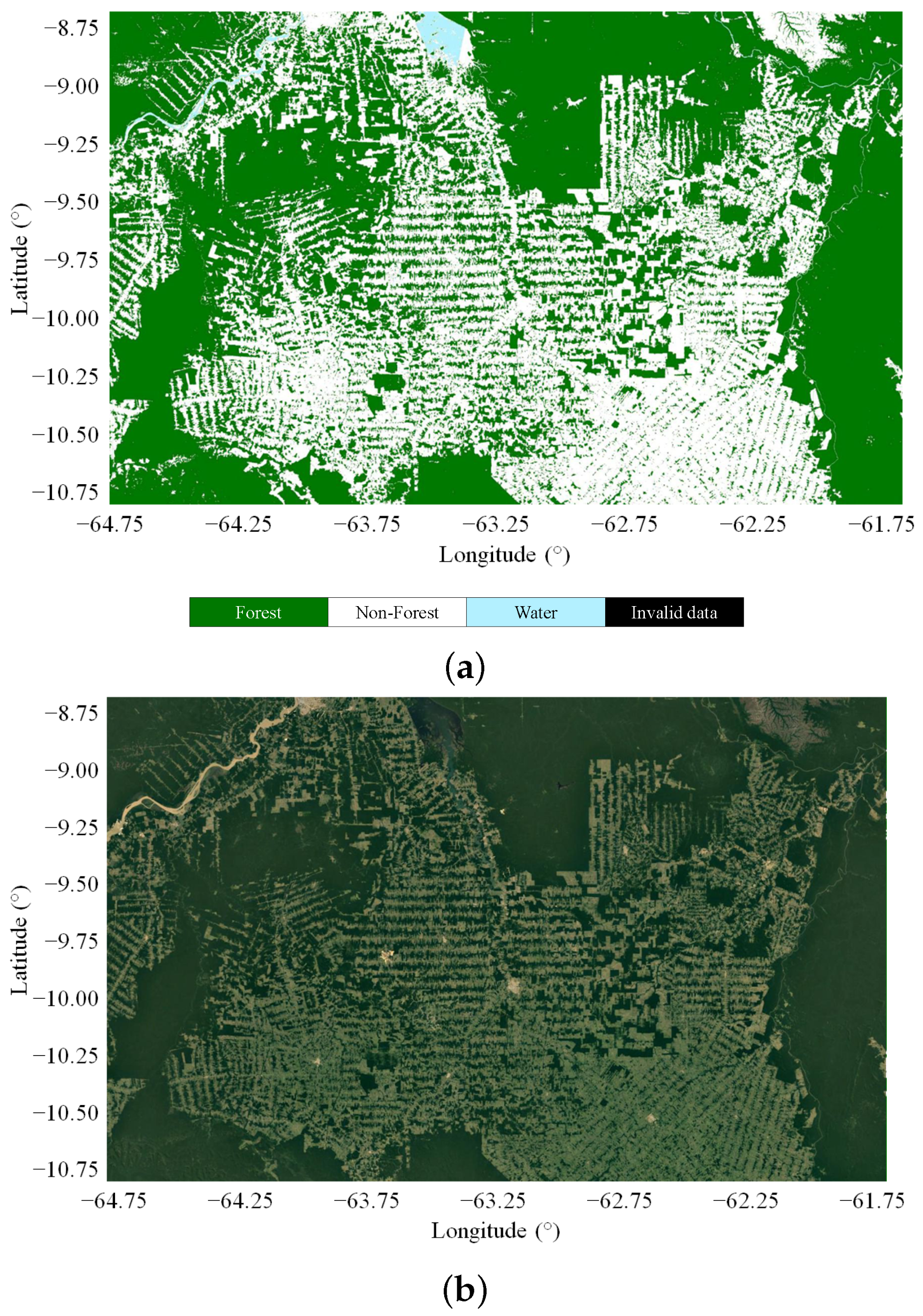
5.2. Large-Scale Mosaics
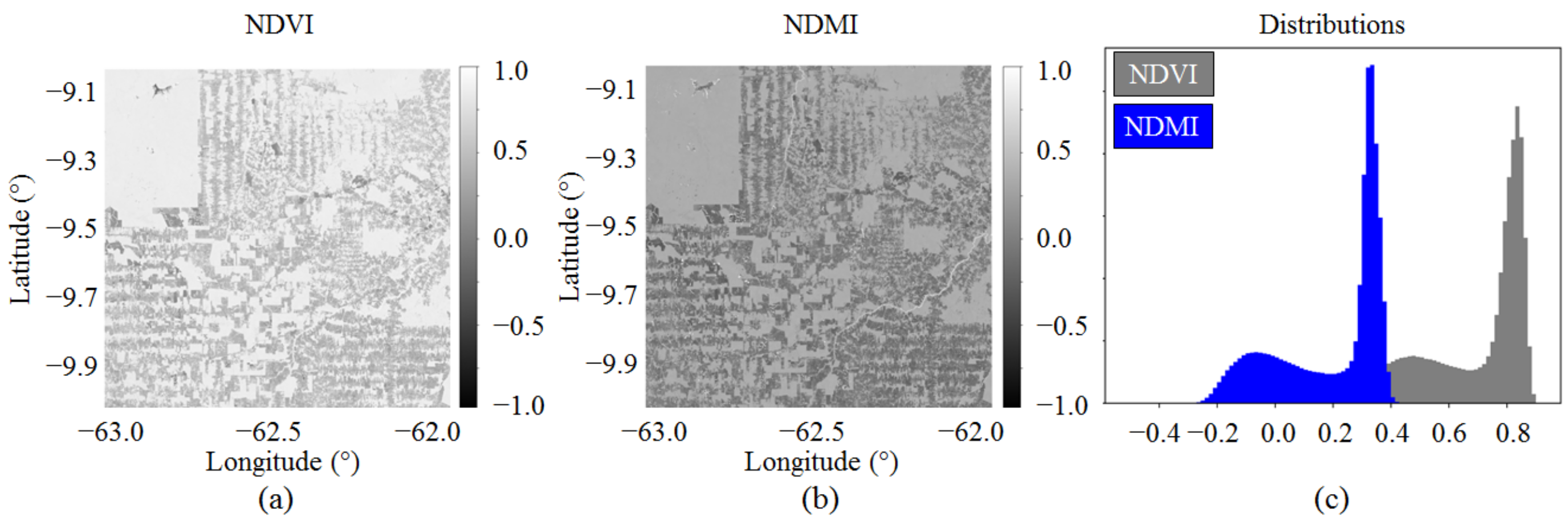
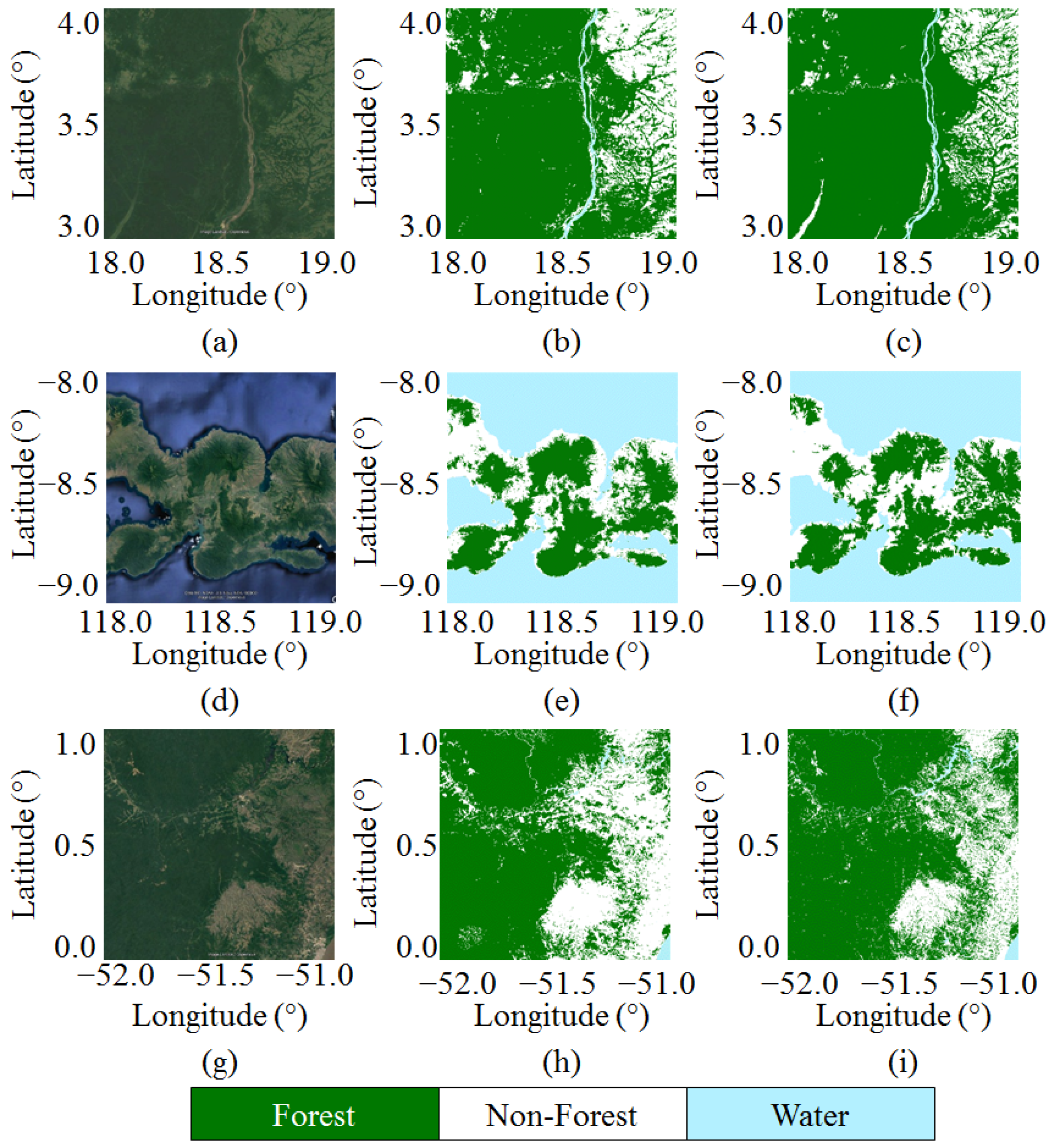
5.3. Local Validation with Sentinel-2 Data
5.4. Intercomparison with Global Products
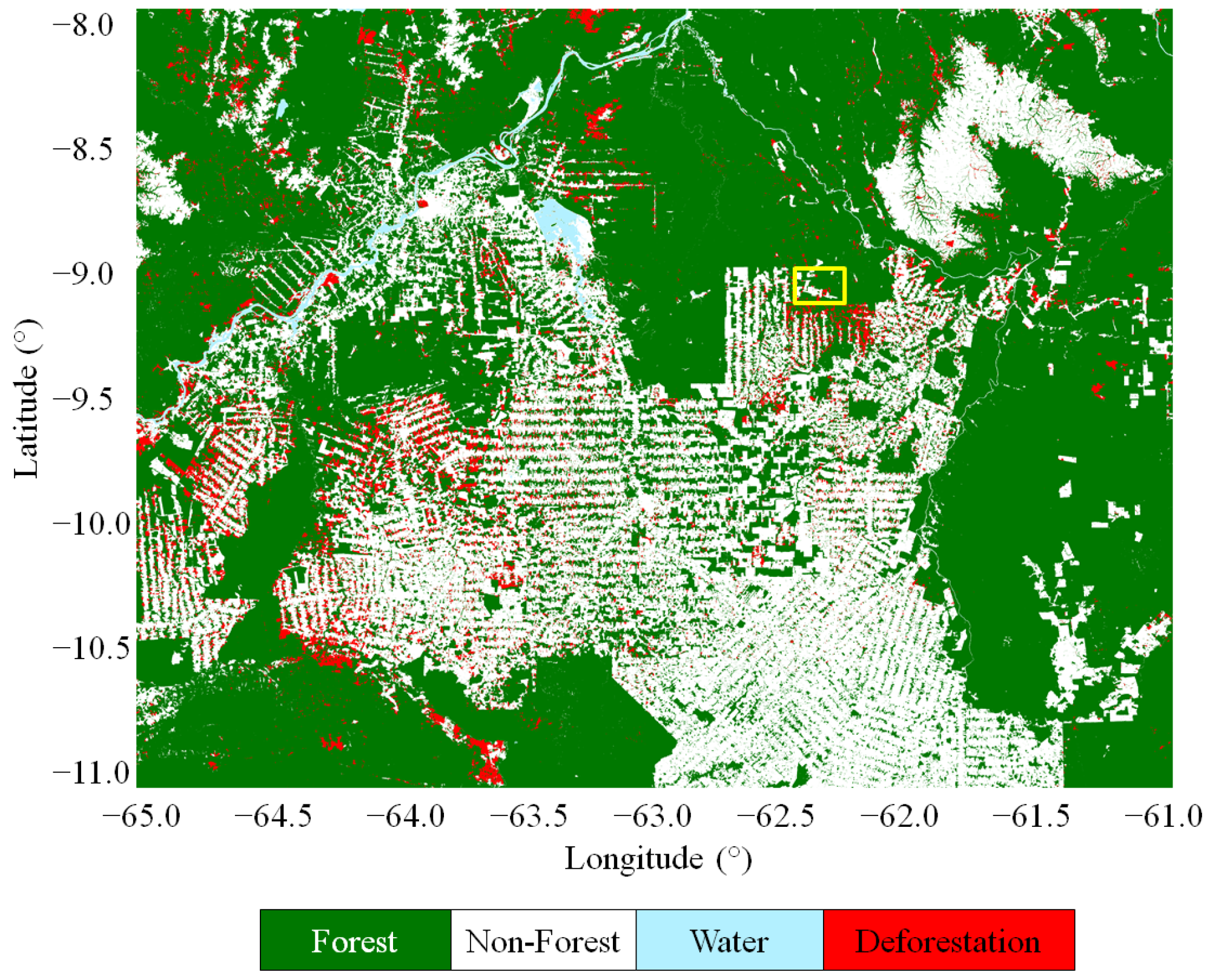
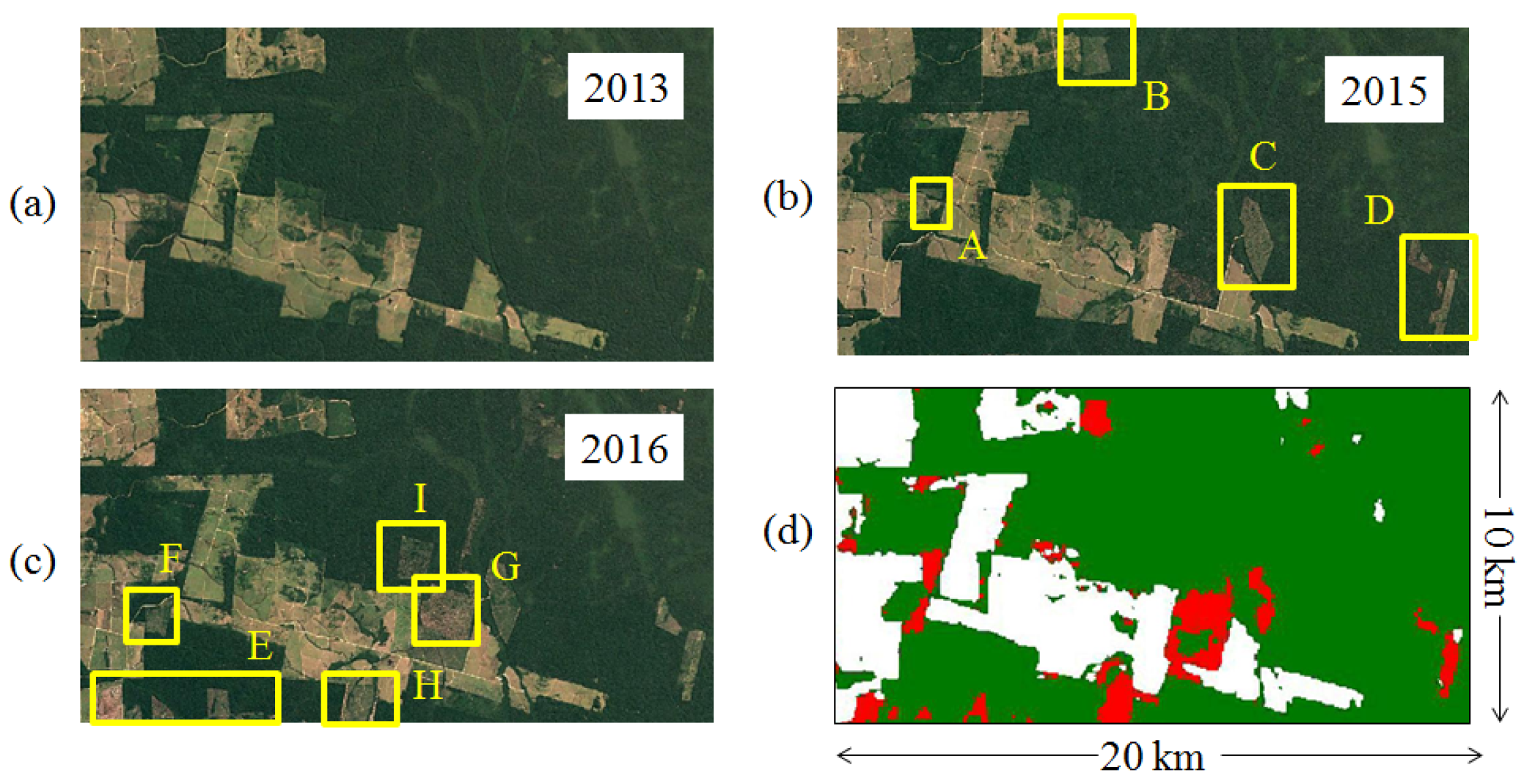
6. Potential for Change Detection and Deforestation Monitoring
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Silva-Junior, C.; Moreira Pessôa, A.C.; Carvalho, N.; dos Reis, J.A.; Anderson, L.; Aragão, L. The Brazilian Amazon deforestation rate in 2020 is the greatest of the decade. Nat. Ecol. Evol. 2021, 5, 144–145. [Google Scholar] [CrossRef]
- Gao, Y.; Skutsch, M.; Paneque-Gálvez, J.; Ghilardi, A. Remote sensing of forest degradation: A review. Environ. Res. Lett. 2020, 15, 103001. [Google Scholar] [CrossRef]
- Reiche, J.; Mullissa, A.; Slagter, B.; Gou, Y.; Tsendbazar, N.E.; Odongo-Braun, C.; Vollrath, A.; Weisse, M.J.; Stolle, F.; Pickens, A.; et al. Forest disturbance alerts for the Congo Basin using Sentinel-1. Environ. Res. Lett. 2021, 16, 024005. [Google Scholar] [CrossRef]
- Hansen, M.C.; Defries, R.S.; Townshend, J.R.G.; Sohlberg, R. Global land cover classification at 1 km spatial resolution using a classification tree approach. Int. J. Remote Sens. 2000, 21, 1331–1364. [Google Scholar] [CrossRef]
- Rast, M.; Bezy, J.L.; Bruzzi, S. The ESA Medium Resolution Imaging Spectrometer MERIS a review of the instrument and its mission. Int. J. Remote Sens. 1999, 20, 1681–1702. [Google Scholar] [CrossRef]
- Pagano, T.; Durham, R. Moderate Resolution Imaging Spectroradiometer (MODIS). Proc. SPIE 1993. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehamn, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-resolution global maps of 21st century forest coverage change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; De Keersmaecker, W.; Souverijns, N.; Brockmann, C.; Quast, R.; Wevers, J.; Grosu, A.; Paccini, A.; Vergnaud, S.; et al. ESA WorldCover 10 m 2020 v100. 2021. Available online: https://zenodo.org/record/5571936#.YvtTBTURVPY (accessed on 22 June 2022). [CrossRef]
- Shimada, M.; Itoh, T.; Motooka, T.; Watanabe, M.; Shiraishi, T.; Thapa, R.; Lucas, R. New global forest/non-forest maps from ALOS PALSAR data (2007–2010). Remote Sens. Environ. 2014, 155, 13–31. [Google Scholar] [CrossRef]
- Schlund, M.; von Poncet, F.; Hoekman, D.; Kuntz, S.; Schmullius, C. Importance of bistatic SAR features from TanDEM-X for forest mapping and monitoring. Remote Sens. Environ. 2014, 151, 16–26. [Google Scholar] [CrossRef]
- Martone, M.; Rizzoli, P.; Wecklich, C.; Gonzalez, C.; Bueso-Bello, J.L.; Valdo, P.; Schulze, D.; Zink, M.; Krieger, G.; Moreira, A. The Global Forest/Non-Forest Map from TanDEM-X Interferometric SAR Data. Remote Sens. Environ. 2018, 205, 352–373. [Google Scholar] [CrossRef]
- Krieger, G.; Moreira, A.; Fiedler, H.; Hajnsek, I.; Werner, M.; Younis, M.; Zink, M. TanDEM-X: A satellite formation for high-resolution SAR interferometry. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3317–3341. [Google Scholar] [CrossRef]
- Zink, M.; Moreira, A.; Hajnsek, I.; Rizzoli, P.; Bachmann, M.; Kahle, R.; Fritz, T.; Huber, M.; Krieger, G.; Lachaise, M.; et al. TanDEM-X: 10 Years of Formation Flying Bistatic SAR Interferometry. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3546–3565. [Google Scholar] [CrossRef]
- Rizzoli, P.; Martone, M.; Gonzalez, C.; Wecklich, C.; Bräutigam, B.; Borla Tridon, D.; Bachmann, M.; Schulze, D.; Fritz, T.; Huber, M.; et al. Generation and Performance Assessment of the Global TanDEM-X Digital Elevation Model. ISPRS J. Photogramm. Remote Sens. 2017, 132, 119–139. [Google Scholar] [CrossRef]
- Gonzalez, C.; Rizzoli, P. Landcover-Dependent Assessment of the Relative Height Accuracy in TanDEM-X DEM Products. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1892–1896. [Google Scholar] [CrossRef]
- Martone, M.; Rizzoli, P.; Krieger, G. Volume decorrelation effects in TanDEM-X interferometric SAR data. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1812–1816. [Google Scholar] [CrossRef]
- Rizzoli, P.; Dell’Amore, L.; Bueso-Bello, J.; Gollin, N.; Carcereri, D.; Martone, M. On the derivation of volume decorrelation from Tand-DEM-X bistatic coherence. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3504–3518. [Google Scholar] [CrossRef]
- Martone, M.; Sica, F.; Gonzalez, C.; Bueso-Bello, J.L.; Valdo, P.; Rizzoli, P. High-Resolution Forest Mapping from TanDEM-X Interferometric Data Exploiting Nonlocal Filtering. Remote Sens. 2018, 10, 1477. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Zhu, X.; Montazeri, S.; Ali, M.; Hua, Y.; Wang, Y.; Mou, L.; Shi, Y.; Xu, F.; Bamler, R. Deep Learning Meets SAR: Concepts, Models, Pitfalls, and Perspectives. IEEE Geosci. Remote Sens. Mag. 2021, 9, 143–172. [Google Scholar] [CrossRef]
- Mazza, A.; Sica, F.; Rizzoli, P.; Scarpa, G. TanDEM-X Forest Mapping Using Convolutional Neural Networks. Remote Sens. 2019, 11, 2980. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Rizzoli, P.; Martone, M.; Bräutigam, B. Global Interferometric Coherence Maps From TanDEM-X Quicklook Data. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1861–1865. [Google Scholar] [CrossRef]
- Bueso-Bello, J.; Martone, M.; González, C.; Sica, F.; Valdo, P.; Posovszky, P.; Pulella, A.; Rizzoli, P. The Global Water Body Layer from TanDEM-X Interferometric SAR Data. Remote Sens. 2021, 13, 5069. [Google Scholar] [CrossRef]
- Bamler, R.; Hartl, P. Synthetic aperture radar interferometry. Inverse Probl. 1998, 14, R1–R54. [Google Scholar]
- Touzi, R.; Lopes, A.; Bruniquel, J.; Vachon, P.W. Coherence estimation for SAR imagery. IEEE Trans. Geosci. Remote Sens. 1999, 37, 135–149. [Google Scholar] [CrossRef]
- Seymour, M.; Cumming, I. Maximum likelihood estimation for SAR interferometry. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 8–12 August 1994; pp. 2272–2275. [Google Scholar]
- Zebker, H.; Villasenor, J. Decorrelation in interferometric radar echoes. IEEE Trans. Geosci. Remote Sens. 1992, 30, 950–959. [Google Scholar] [CrossRef]
- Gatelli, F.; Guamieri, A.M.; Parizzi, F.; Pasquali, P.; Prati, C.; Rocca, F. The wavenumber shift in SAR interferometry. IEEE Trans. Geosci. Remote Sens. 1994, 32. [Google Scholar] [CrossRef]
- Bachmann, M.; Kraus, T.; Bojarski, A.; Schandri, M.; Böer, J.; Edmund Busche, T.; Bueso-Bello, J.L.; Grigorov, C.; Steinbrecher, U.; Buckreuss, S.; et al. The TanDEM-X Mission Phases—Ten Years of Bistatic Acquisition and Formation Planning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3504–3518. [Google Scholar] [CrossRef]
- Sexton, J.O.; Song, X.P.; Feng, M.; Noojipady, P.; Anand, A.; Huang, C.; Kim, D.H.; Collins, K.M.; Channan, S.; DiMiceli, C.; et al. Global, 30-m resolution continuous fields of tree cover: Landsat-based rescaling of MODIS vegetation continuous fields with lidar-based estimates of error. Int. J. Digit. Earth 2013, 6, 427–448. [Google Scholar] [CrossRef]
- Jähne, B.; Scharr, H.; Körkel, S.; Jähne, B.; Haußecker, H.; Geißler, P. Principles of Filter Design. In Handbook of Computer Vision and Applications; Academic Press: Cambridge, MA, USA, 1999; Volume 2, pp. 125–151. [Google Scholar]
- Beucher, S.; Lantuejoul, C. Use of Watersheds in Contour Detection. In Proceedings of the International Workshop on Image Processing: Real-time Edge and Motion Detection/Estimation, Rennes, France, 17–21 September 1979. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Rees, G. The Remote Sensing Data Book; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- D’Odorico, P.; Gonsamo, A.; Damm, A.; Schaepman, M.E. Experimental Evaluation of Sentinel-2 Spectral Response Functions for NDVI Time-Series Continuity. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1336–1348. [Google Scholar] [CrossRef]
- Pulella, A.; Santos, R.; Sica, F.; Posovszky, P.; Rizzoli, P. Multi-Temporal Sentinel-1 Backscatter and Coherence for Rainforest Mapping. Remote Sens. 2020, 12, 847. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 48. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| F-Score | |||||
|---|---|---|---|---|---|
| 2016 | Samples | OA | Non-Forest | Water | Forest |
| S. America | >1% | 66.87 (93) | 74.30 (47) | 84.29 (95) | |
| >5% | 84.40 (96) | 71.03 (83) | 85.09 (24) | 85.08 (94) | |
| >10% | 73.33 (75) | 87.80 (15) | 86.43 (92) | ||
| F-Score | |||||
|---|---|---|---|---|---|
| 2011 | Samples | OA | Non-Forest | Water | Forest |
| S. America | >1% | 68.45 (432) | 63.70 (230) | 86.25 (582) | |
| >5% | 89.72 (586) | 77.06 (318) | 76.87 (64) | 87.05 (576) | |
| >10% | 78.93 (281) | 82.83 (31) | 87.96 (567) | ||
| Africa | >1% | 61.78 (234) | 88.77 (66) | 82.48 (301) | |
| >5% | 85.81 (302) | 71.11 (172) | 95.99 (33) | 82.70 (300) | |
| >10% | 74.39 (148) | 97.11 (26) | 83.49 (296) | ||
| Asia | >1% | 64.35 (516) | 97.30 (583) | 71.30 (500) | |
| >5% | 86.20 (638) | 66.73 (392) | 98.41 (554) | 77.47 (411) | |
| >10% | 69.00 (311) | 98.69 (537) | 79.02 (358) | ||
| 2013 | Samples | Non-Forest | Water | Forest | |
| S. America | >1% | 66.11 (467) | 59.04 (251) | 85.96 (580) | |
| >5% | 89.79 (589) | 76.03 (345) | 55.49 (84) | 88.04 (563) | |
| >10% | 80.01 (288) | 54.41 (44) | 89.21 (551) | ||
| Africa | >1% | 60.90 (221) | 78.46 (88) | 83.61 (301) | |
| >5% | 86.06 (301) | 71.49 (158) | 90.34 (38) | 83.62 (300) | |
| >10% | 74.84 (133) | 97.90 (29) | 84.00 (297) | ||
| Asia | >1% | 65.72 (515) | 97.86 (576) | 75.68 (511) | |
| >5% | 88.38 (630) | 68.91 (382) | 98.93 (546) | 80.09 (426) | |
| >10% | 71.30 (293) | 99.04 (531) | 82.52 (370) | ||
| 2016 | Samples | Non-Forest | Water | Forest | |
| S. America | >1% | 70.52 (258) | 70.49 (92) | 86.98 (290) | |
| >5% | 88.06 (296) | 76.18 (211) | 79.57 (47) | 87.25 (289) | |
| >10% | 79.31 (180) | 85.53 (25) | 87.47 (288) | ||
| F-Score | |||||
|---|---|---|---|---|---|
| 2013 | Samples | Non-Forest | Water | Forest | |
| S. America | >1% | 67.63 (462) | 74.17 (222) | 86.60 (583) | |
| >5% | 90.61 (589) | 78.79 (332) | 85.70 (60) | 87.28 (577) | |
| >10% | 81.27 (280) | 88.04 (32) | 88.50 (564) | ||
| Africa | >1% | 62.86 (263) | 86.31 (84) | 78.98 (300) | |
| >5% | 85.56 (303) | 71.73 (206) | 96.54 (36) | 79.78 (295) | |
| >10% | 74.34 (183) | 98.64 (29) | 81.03 (287) | ||
| Asia | >1% | 66.16 (425) | 95.68 (609) | 81.05 (545) | |
| >5% | 90.41 (634) | 72.58 (284) | 98.19 (567) | 83.35 (469) | |
| >10% | 73.63 (214) | 98.81 (545) | 84.66 (418) | ||
| 2016 | Samples | Non-Forest | Water | Forest | |
| S. America | >1% | 69.88 (255) | 61.34 (111) | 87.11 (290) | |
| >5% | 87.58 (296) | 75.64 (206) | 66.36 (56) | 87.38 (289) | |
| >10% | 77.77 (178) | 78.77 (28) | 87.59 (288) | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bueso-Bello, J.-L.; Carcereri, D.; Martone, M.; González, C.; Posovszky, P.; Rizzoli, P. Deep Learning for Mapping Tropical Forests with TanDEM-X Bistatic InSAR Data. Remote Sens. 2022, 14, 3981. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14163981
Bueso-Bello J-L, Carcereri D, Martone M, González C, Posovszky P, Rizzoli P. Deep Learning for Mapping Tropical Forests with TanDEM-X Bistatic InSAR Data. Remote Sensing. 2022; 14(16):3981. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14163981
Chicago/Turabian StyleBueso-Bello, Jose-Luis, Daniel Carcereri, Michele Martone, Carolina González, Philipp Posovszky, and Paola Rizzoli. 2022. "Deep Learning for Mapping Tropical Forests with TanDEM-X Bistatic InSAR Data" Remote Sensing 14, no. 16: 3981. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14163981