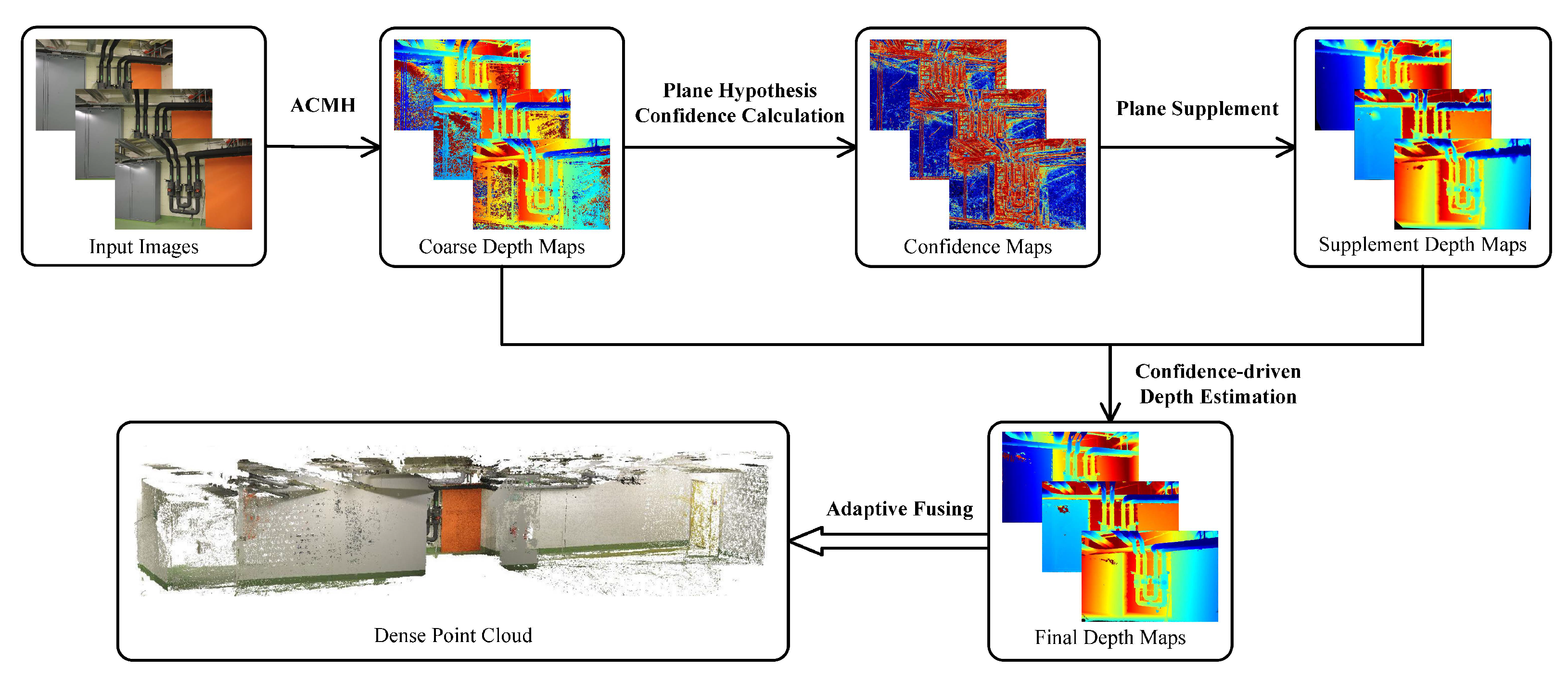
4.2. Plane Hypothesis Confidence Calculation
During the original depth estimation, photometric consistency appears as the problem of fuzzy matching in weakly textured regions. The problem is demonstrated by the fact that the depth of the incorrect plane hypothesis can make it possible to match highly similar regions between multiple views, making the multiview matching cost lack credibility. Ref. [
15] attempts to add geometric consistency constraints to the multiview matching cost to reduce the erroneous plane hypotheses in weakly textured regions. Ref. [
31] tries to add local consistency constraints to eliminate incorrect plane hypotheses.
However, photometric consistency would perfectly characterize the structure of the objects or scenes in structured scenes. Adding constraints to the matching cost certainly allows the fuzzy matching problem that occurs in weakly textured regions to be solved to some extent. However, the new constraints may blur the geometric details in the object or scene.
In contrast, we would like to capture which plane hypotheses are accurate enough to be represented the real objects or scenes after each depth estimate. Therefore, we propose a new confidence calculation method. The confidence expresses the degree of reliability of each plane hypothesis. For the plane hypothesis with large confidence, we consider that the plane hypothesis would accurately indicate the real surface of the scene or object. The plane hypothesis with low confidence is considered to be an incorrect estimation, and these incorrect plane hypotheses need to be filtered or upgraded. In the confidence calculation, the confidence is divided into two parts, including the multiview confidence and the patch confidence.
In multiview stereo, an assumption is that a reliable plane hypothesis should be geometrically stable between multiple views. Thus, based on the relationship of multiple views, a measure of multiview confidence is established firstly, which means the consistency degree of plane hypotheses among multiple views.
Note that the multiview confidence is calculated based on all neighboring views. The component of multiview confidence, which is calculated between the current view and one neighboring view, is defined as the view confidence.
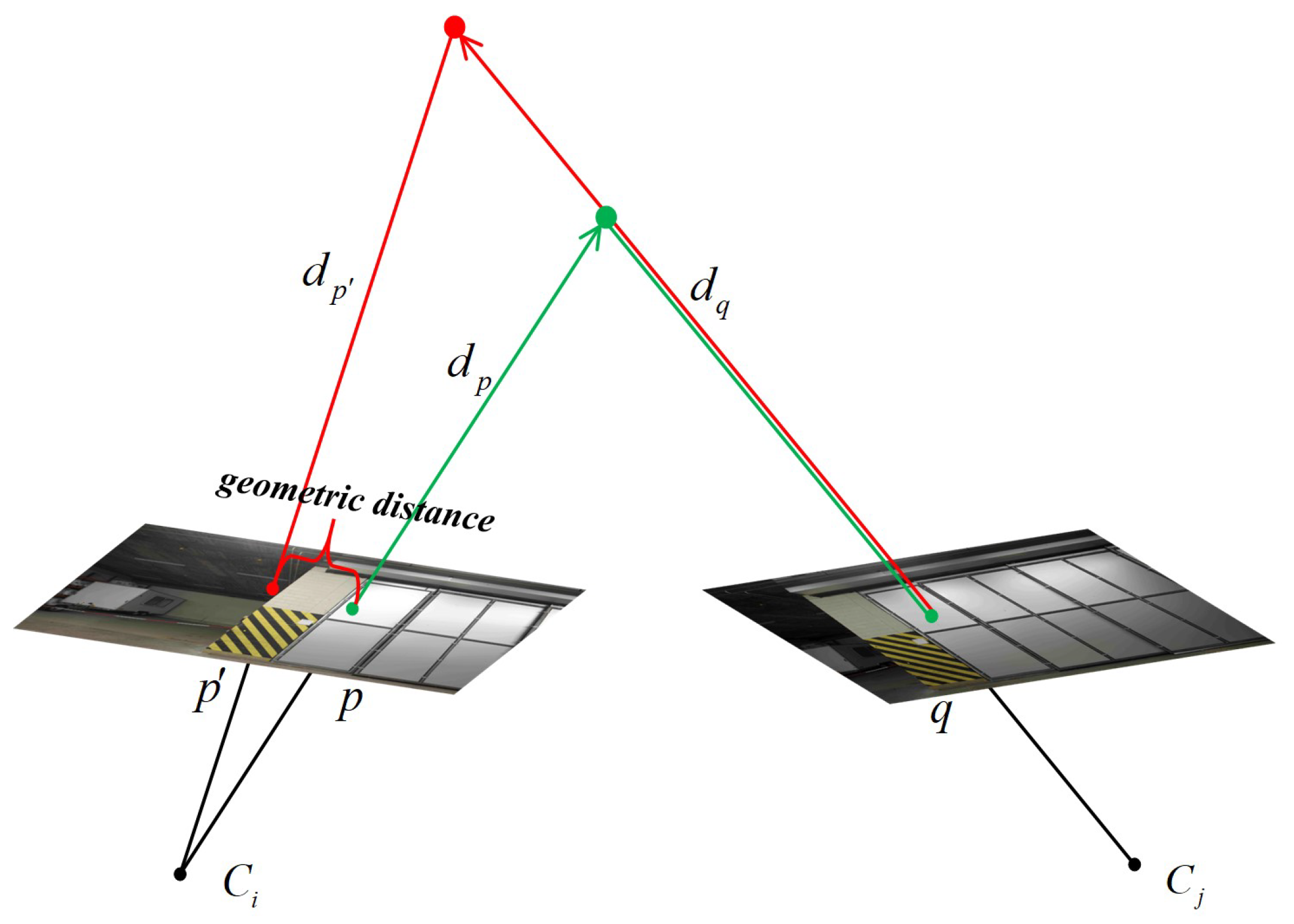
Given a pixel
p, its plane hypothesis
is
. The multiview geometry is obtained as shown in
Figure 3. The camera projection matrix from the current view
to the neighboring view
is calculated according to
. The pixel
p is projected into the neighboring view
to obtain the projected pixel
q, and the plane hypothesis
of
q would be obtained in the neighboring view. The pixel
q is reprojected back into the current view to obtain the reprojection point
according to the camera projection matrix from the neighboring view to the current view, which is calculated with
. By reprojecting the point
, the plane hypothesis
of
corresponding to the current view
can be obtained.
The view relationship between the current view and
j-th neighboring view can be described via the reprojection distance
, depth relative error
, normal pinch error
, and the matching cost
. Therefore,
,
,
is calculated according to the pixel
p,
and the plane hypothesis
,
. Then, the view confidence consists of the geometric confidence
, the depth confidence
, the normal confidence
, and the cost confidence
, which are calculated via the Gaussian function,
where
,
,
and
are constants in the
,
,
and
, respectively.
In a set of neighboring views
, there exist
J sets of confidence relations for neighboring view. The multiview confidence is calculated as the average of the view confidence with all neighboring views:
A good plane hypothesis should be supported by multiple neighboring views. When the number of neighboring views that maintain consistency is increased, the trustworthiness of the planar hypothesis is improved. Meanwhile, the geometric stability in multiple views is increased. However, the camera’s pose variation and the presence of occlusion determine that not all regions in a view can be consistent with multiple views. Specifically, some regions in a view are only visible in a limited number of neighboring views. Thus, in these regions, calculating the view confidence with all neighboring views may cause the correct plane hypothesis to be judged as unreliable. To this end, the multiview confidence calculation is modified to be the average of the best
K neighboring views among all neighboring views.
The global spatial information is fully considered in the multiview confidence, which is based on the consistency of multiple measurements. The multiview confidence calculation makes most plane hypotheses easy to calculate as reliable estimates with high confidence. However, for some plane hypotheses that are correctly estimated in current view, erroneous multiview confidences are calculated because of wrong plane hypotheses in neighboring views. In addition, because of similar plane hypotheses in multiple views, some noise in the current view may be calculated as high-confidence and retained, especially in weakly textured regions.
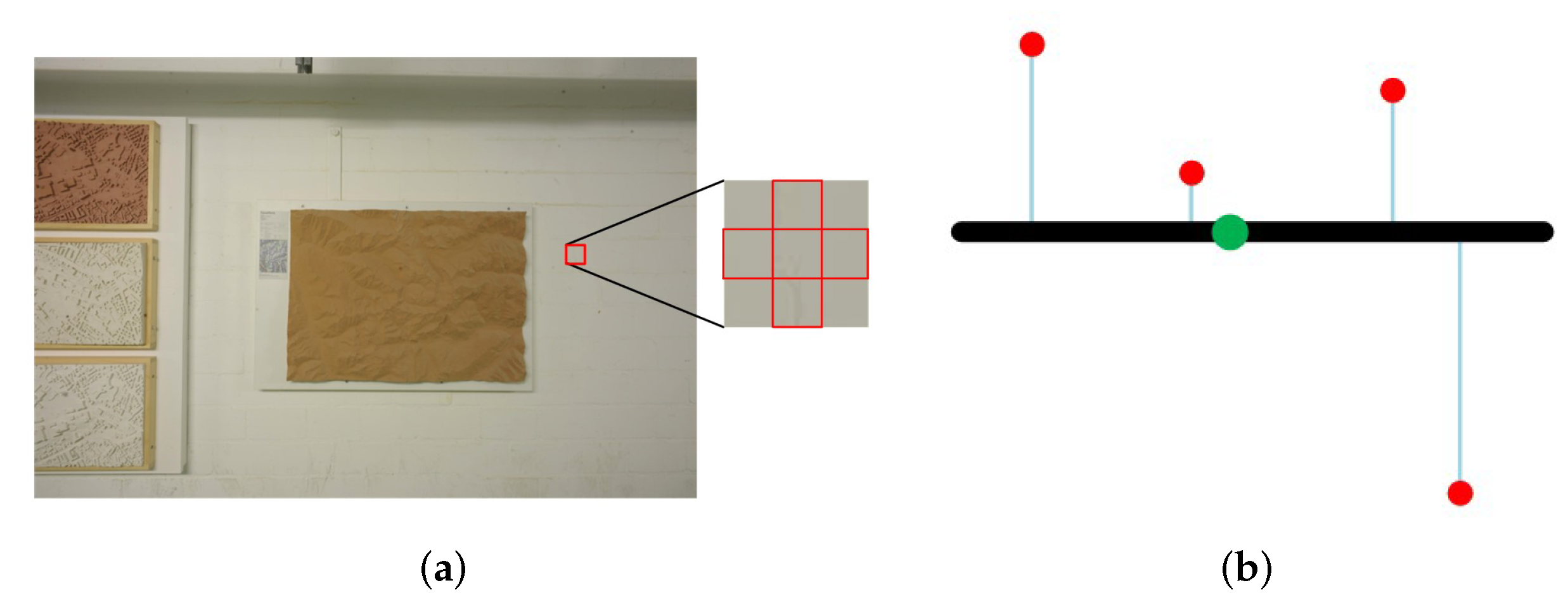
In order to reduce the calculation of error confidence, a patch confidence measure based on depth local consistency is added, which only relies on the information in the current view. In the PatchMatch algorithm [
5,
45], a key statement is that relatively large regions of pixels can be modeled by an approximately 3D plane. It allows the same plane hypotheses to be shared within the pixel regions. The statement can be beneficial to help exploit the local information in a view. To this end, the patch confidence is structured as a calculation based on the consistency of local planes. For each pixel in the current view, a cruciform patch is constructed, centered on the pixel. Firstly, a 3D local plane is constructed in the camera coordinate via the central pixel’s 3D point
and its corresponding plane hypothesis. Secondly, neighboring pixels in a cruciform patch are projected into the same camera coordinate to obtain 3D points
. The average Euclidean distance from the 3D points of neighboring pixels to the local 3D plane is calculated (refer to
Figure 4),
where
N is the number of pixels in a cruciform patch and
is the normal of patch center pixel.
,
,
are the three components of normal
.
Based on the calculated average Euclidean distance, patch confidence is constructed by the Gaussian function as well:
where
is a constant parameter of patch confidence.
Finally, via the calculated multiview confidence and patch confidence, the confidence of the pixel
p can be expressed as
4.3. Plane Supplement and Confidence-Driven Depth Estimation
The purpose of the propagation scheme is that the reasonable plane hypotheses can be propagated to other pixels in the same plane, making the estimation accurate and reliable. However, in the weakly textured regions, it is difficult to select the correct plane hypothesis using the matching cost function based on luminosity consistency, because the weakly textured regions usually do not contain discriminative information. This makes it difficult for incorrect plane hypotheses to be replaced by correct neighborhood candidate planes via the propagation scheme, and these incorrect plane hypotheses may be propagated to other pixels due to the propagation scheme.
This means that relying on existing plane hypotheses cannot help the reconstruction of weakly textured regions. Ref. [
18] chooses the base point via photometric consistency cost to generate the prior plane and introduces them into the calculation of multiview matching cost. However, the photometric consistency is not reliable in weakly textured regions, giving prior planes wrong plane hypotheses. In addition, the photometric consistency cost of incorrect planar hypothesis may be sufficiently small in weakly textured regions. Despite using prior planes as a constraint in the calculation of multiview matching cost, it does not allow these errors to recompute an aggregation cost large enough to be replaced by correct plane hypotheses contained in prior planes. It keeps the wrong plane hypotheses in weakly textured regions of depth maps.
In
Section 4.2, the confidence is proposed to discriminate the accuracy and reliability of plane hypotheses to avoid misjudgment of photometric consistency in weakly textured regions. After the plane hypothesis confidence calculation, pixels with high confidence (we set the confidence threshold
to 0.8) are extracted from the coarse depth map. The key observation behind this is that these pixels with high confidence mostly contain the structure of 3D scenes. Meanwhile, the planar hypotheses of extracted pixels are accurate and reliable, because they are supported by multiple views and are consistent in local planes. Using the extracted pixels as base points, the images are divided into multiple triangular primitives with different sizes using Delaunay triangulation [
46]. Then, based on the depths of the three base points in the triangular primitives, a local 3D plane where the triangular primitives are located is constructed. For the low-confidence pixels contained in each triangular primitive, they are projected into the local 3D plane to obtain new depths, resulting in additional supplemental depth maps.
The supplemental planes perform well in weakly textured regions, especially those with large planes. However, some edge regions are blurred, which is contrary to photometric consistency. The coarse depth map that depends on photometric consistency is calculated with higher confidence than the supplemental depth map in these edge regions. Conversely, the confidence of the supplemental depth map is better than the coarse depth map in weakly textured regions.
Thus, the coarse depth map and supplemental depth map are jointly fed to a comparison module. Specifically, after obtaining the supplemental depth maps, the plane hypothesis confidence calculation module is reapplied to calculate the confidence for each plane hypothesis in the supplemental depth map. The confidences calculated in the supplemental depth map are compared with the coarse depth map, and the planar hypotheses with higher confidence are retained.
Subsequently, the retained plane hypotheses are used as the initial values for the confidence-driven depth estimation. An important reason for confidence-driven depth estimation is that there are still some erroneous plane hypotheses mixed in with the retained plane hypotheses. These noises tend to exhibit low confidence in both the supplemental depth maps and the coarse depth maps. These noises can be effectively reduced with the help of the propagation mechanism and the modified cost function. The results obtained by combining the supplemental depth maps and the coarse depth maps lose partial structural details. Since the photometric consistency cost has a significant result in textured regions, it is possible to exploit this advantage to help the recuperation of these textured regions. In addition, plane supplementation has a significant recovery for planar surfaces in weakly textured regions. However, there is a subtle variation in the plane hypotheses in curved surfaces of weakly textured regions, which causes a slight decrease in the accuracy of our plane supplement. The propagation step and the refinement step in the depth estimation can effectively help these curved surfaces to produce the correct variations of plane hypotheses instead of keeping them in the same plane.
In the confidence-driven depth estimation, the processes of propagation and refinement are kept in line with the ACMH [
22], which are reviewed in
Section 3. In particular, for the multiview matching cost calculation, confidence is used as a constraint to limit the propagation of incorrect plane hypotheses with low confidence to other pixels. Meanwhile, planar hypotheses with high confidence can be easily propagated to other pixels of the same plane with the help of the propagation scheme. According to the Equation (
6), the confidence-driven multiview matching cost function is modeled as
where
is the confidence of pixel
p, which is calculated with the plane hypothesis
, and
is a weight constant.
For weakly textured regions, the matching cost of photometric consistency computed by different plane hypotheses is usually similar because of the lack of distinguishability information. It causes the propagation mechanism in traditional MVS to easily transmit erroneous plane hypotheses to other pixels in these regions, and is difficult to replace. According to the modified confidence-driven multiview matching cost, the determining factor for propagation mechanism to judge the reliability of the candidate plane hypotheses is confidence. Because the confidence level calculated in the noise is small, the multiview matching cost calculated in the noise is larger than the correct plane hypothesis. Thus, the confidence-driven multiview matching cost would be helpful to address the problem of propagation mechanism for candidate plane hypothesis selection. Meanwhile, plane hypotheses with high confidence can be easily transmitted to pixels in the same plane because they are computed at a low cost. For the structural detail regions, the important factor that dominates the propagation mechanism’s selection of candidate plane hypotheses changes to the photometric consistency matching cost. The reason is that the calculated confidences are all great in these regions. Thus, the detail regions that were previously blurred and erroneous would be improved.
To avoid the complexity of repeated confidence calculations due to changes in plane hypotheses, the confidence-driven depth estimation is restricted to obtaining the final depth maps with one propagation. Via this confidence-driven depth estimation, the final depth maps preserve the structural details well and improve the estimation quality of weakly textured regions.
4.4. Adaptive Fusion
After depth estimation, all the depth maps of views are obtained. In the depth map fusion step, all the depth maps are merged into the dense point clouds. In [
6,
7], all the depth maps are fused by consistent matching with a fixed threshold. Specifically, for each pixel, it is projected into each neighboring view via its depth of plane hypothesis. Then, it is reprojected back to current view by the depth of hypothesis, which is in the neighboring view. The corresponding matching relationship can be obtained based on the reprojected point and the pixel in the current view. A consistent matching is defined as satisfying the consistent constraints, including depth difference
and normal angle
. For all neighboring views, if there exist
neighboring views (defining
as the view constraint) satisfying the consistent matching, the hypothesis is accepted. Finally, all pixels that satisfy the consistency matching are projected into the 3D space and averaged into uniform 3D points, thus becoming part of the dense 3D point clouds. Refs. [
15,
18,
22] further tighten the consistent constraints of consistency matching on this depth fusion approach; the reprojection geometry error
should be satisfied.
However, we observe that such a depth map fusion approach relies on fixed consistent constraints and fixed view constrain. There are always situations where some regions of the current view are only visible in a limited number of neighboring views. Then, too large a view constraint will cause these regions cannot to be fused into the dense point clouds, resulting in a lack of completeness. Too small a view constraint ensures the fusion of these areas, but leads to a decrease in the overall reconstruction quality, especially in terms of accuracy.
To solve this problem, an adaptive depth fusion approach is developed. Specifically, the view weight is added to each neighboring view when calculating the multiview matching cost. Such view weights can reflect the visibility relationships of pixels in multiple views. At the end of the last depth estimation, the view weights corresponding to all neighboring views of all pixels are retained. In the depth map fusion step, firstly, all neighborhood view weights corresponding to each pixel are sorted from large to small. Secondly, based on the distribution changes of neighborhood view weights, the view constraints
can be adjusted adaptively.
where
denotes the
j-th sorted view weight of neighboring views.
is the threshold of the view weight. After sorting, the comparison starts from the largest neighborhood view weight to the threshold of view weight. For the view weight
, we consider the pixel to be visible in corresponding neighboring view. The view constraint is adaptively adjusted to the number of neighboring views accumulated. Until the
j-th view weight
, we consider that the pixel’s visibility starts to be insufficient. In addition, the main goal of our adaptive fusion is to ensure accuracy while improving the integrity of invisible regions. The increase in view constraint indicates that the visibility of the regions is satisfied in multiple neighborhood views, but it becomes difficult to satisfy the consistency of plane hypotheses between multiple views. To prevent the influence of excessive view constraint on the completeness of these regions, the view constraint is phased at the maximum value of 4.
Simultaneously, to ensure as much as possible that the adaptive view constraints are adjusted by visibility judgments rather than resulting in incorrect plane hypotheses, the consistency constraints of consistent matching are adaptively adjusted according to the size of the view constraint. For pixels with small view constraints, the consistency constraints are tightened to ensure that their plane hypotheses are accurate enough. For pixels with large view constraints, the consistency constraints are relaxed appropriately, allowing the pixels supported via multiple neighboring views to be easily merged into point clouds to improve the completeness of reconstruction.
where
,
,
is the strictest consistency constraint when the view constraint
is 1. With the view constraint increased, the consistency constraints become loose, making pixels easy to be merged into dense point clouds when they are visible among multiple views.
In addition, for outdoor scenes, the sky regions become redundant in the dense point clouds, because the sky regions lack true depth. Through a guided-filter-based mask refinement method, Ref. [
47] uses a neural network and weighted guided upsampling to create accurate sky alpha masks at high resolution, resulting in the segmentation of sky regions. Thus, before the beginning of the depth fusion step, the method in [
47] is applied to filter out the plane hypotheses of sky regions contained in the depth maps. The sky-filtering step has almost no effect on the calculation of the quantifiers. However, we can obtain clean depth maps as well as dense point clouds.
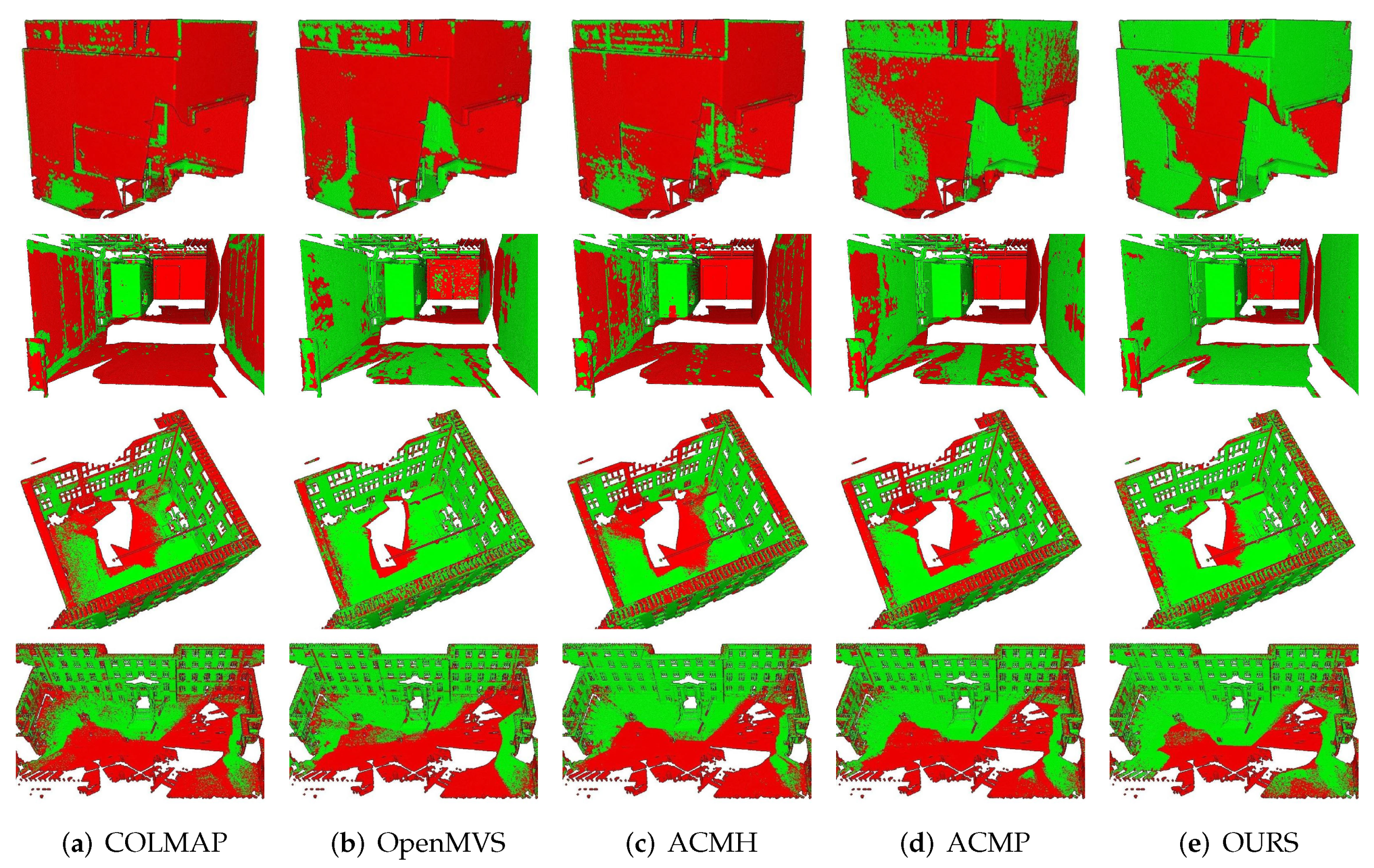
With the depth map fusion approach described above, we can obtain dense 3D point clouds with high completeness and accuracy.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}