An Adaptive Trajectory Clustering Method Based on Grid and Density in Mobile Pattern Analysis

1
College of Computer and Information, Hohai University, Nanjing 210098, China
2
School of Computer Information & Engineering, Changzhou Institute of Technology, Changzhou 213032, China
*
Author to whom correspondence should be addressed.
Sensors 2017, 17(9), 2013; https://0-doi-org.brum.beds.ac.uk/10.3390/s17092013
Submission received: 14 July 2017
/
Revised: 29 August 2017
/
Accepted: 30 August 2017
/
Published: 2 September 2017
(This article belongs to the Special Issue Sensors for Transportation)
Abstract
:Clustering analysis is one of the most important issues in trajectory data mining. Trajectory clustering can be widely applied in the detection of hotspots, mobile pattern analysis, urban transportation control, and hurricane prediction, etc. To obtain good clustering performance, the existing trajectory clustering approaches need to input one or more parameters to calibrate the optimal values, which results in a heavy workload and computational complexity. To realize adaptive parameter calibration and reduce the workload of trajectory clustering, an adaptive trajectory clustering approach based on the grid and density (ATCGD) is proposed in this paper. The proposed ATCGD approach includes three parts: partition, mapping, and clustering. In the partition phase, ATCGD applies the average angular difference-based MDL (AD-MDL) partition method to ensure the partition accuracy on the premise that it decreases the number of the segments after the partition. During the mapping procedure, the partitioned segments are mapped into the corresponding cells, and the mapping relationship between the segments and the cells are stored. In the clustering phase, adopting the DBSCAN-based method, the segments in the cells are clustered on the basis of the calibrated values of parameters from the mapping procedure. The extensive experiments indicate that although the results of the adaptive parameter calibration are not optimal, in most cases, the difference between the adaptive calibration and the optimal is less than 5%, while the run time of clustering can reduce about 95%, compared with the TRACLUS algorithm.
1. Introduction
In recent years, with the rapid development of sensor technology and smart phones, GPS devices are widely applied to track moving objects, e.g., humans, vehicles, and animals, which can produce huge amounts of trajectory data every day. The trajectory data is the spatial-temporal data series from the moving objects with different timestamps. They contain a lot of information and help us understand the behaviors of the moving objects more directly. For example, zoologists can cluster the paths of animals to study the migration of animals [1]. Meteorologists explore the movement path of hurricanes through clustering and correlation analysis to improve the capabilities in disaster early warning and prevention [2]. Based on the clustering analysis of the movement patterns of vehicles, traffic managers can plan urban roads to mitigate the traffic jams [3,4]. For example, Yue et al. proposed the single-linkage clustering method to analyze taxi trajectory data to detect the time-dependent hot spots and movement patterns for urban traffic planning [5]. Moreover, a mobility-based clustering of vehicle trajectories was presented to detect hotspots and avoid the traffic jams [6].
Clustering analysis is one of the most important methods used in trajectory data mining. Trajectory clustering approaches can be applied in hotspot path analysis, mobility pattern analysis, and urban planning. At present, the trajectory clustering approaches include two types [7]: the first cluster the trajectory data based on the similarity of the full sequences. In other words, they take the whole trajectory as a unit to cluster the trajectory data. Those approaches have good effects on the clustering for the simple trajectories, however, they have negative effects for complex trajectories due to the fact they ignore the local detail sequences. The second type cluster the trajectory data based on the similarity of the sub-sequences. This means that the whole complex trajectory sequence is divided into several segments, which can be clustered with one segment as a unit. The second approaches have the ability to recognize the local features of complex trajectories.
Nonetheless, most available trajectory clustering algorithms depend on the calibration of one or multiple parameters. Meanwhile, the parameter values have a great influence on the effect of clustering. To reduce the complexity and workload of parameter calibration in trajectory clustering, a method called Adaptive Trajectory Clustering approach based on Grid and Density (ATCGD) is proposed in this paper. ATCGD firstly divides the trajectory data into multiple discrete segments through the average angular difference-based MDL (AD-MDL) algorithm. All of the discrete segments are mapped into the corresponding cells. Then, it calculates the average distance among the different segments in each cell, and the average number of the trajectory segments in each cell. Finally, adopting a DBSCAN-based approach, ATCGD carries out the adaptive parameter calibration based on the above data to realize effective and accurate trajectory clustering. As an illustration of the capabilities of the proposed method, we evaluate the performance of ATCGD approach on clustering quality and cost using two data sets from the random trajectories and hurricane trajectories in the Atlantic Ocean. The experimental results indicate that although the results of the adaptive parameter calibration are not optimal, in most cases, the difference between the adaptive calibration and the optimal one is less than 5%, while the run time of clustering can be reduced by about 95%.
The remainder of this paper is organized as follows: Section 2 discusses the related works and analyzes their drawbacks. The discrete trajectory partition algorithm, that is the average angular difference-based MDL (AD-MDL), is discussed in Section 3. Section 4 presents the proposed ATCGD approach, and the performance evaluations are given in Section 5. Discussion and conclusions are given in Section 6.
2. Related Work
2.1. Trajectory Clustering Approaches
Trajectory data can be regarded as time sequence data. Trajectory clustering is an important part of clustering analysis. To study the trajectory clustering of mobile objects, Gaffney et al. presented the mixture regression model-based trajectory clustering algorithm [8]. Furthermore, considering the temporal feature of trajectories, the spatial distance of the mobile objects was expanded to the spatial-temporal distance of the trajectories [9]. The time-focused trajectories clustering of moving objects algorithm, TFCTMO, was proposed based on the spatial-temporal distance. To obtain the moving cluster in the spatial-temporal trajectory data, the filter-based spatial-temporal clustering algorithm was discussed [10]. The filter-based cluster algorithm first filtered the trajectory data in the different time-scale ranges, and then clustered the data in the spatial-scale range within the same timestamp. All of the above clustering algorithms are based on the similarity of the full sequences.
Lee et al. thought that the clustering approaches based on the full sequences may have negative effects for complex trajectories due to the fact they ignore the local partial similarity [11]. Moreover, they put forward a partition-and-group framework and clustering algorithm—TRACLUS—that divides the whole trajectory into several segments and clusters them through the DBSCAN method [12,13,14]. The TRACLUS algorithm can recognize the local partial similarity of trajectories, however, in order to obtain good clustering quality, TRACLUS requires a large amount of workload to calibrate two parameters (the scanning range and the density of each group). At the same time, the values of the two parameters are sensitive to the different data sets. In order to reduce the complexity and workload of parameter calibration, some parameter adaptive clustering algorithms based on the DBSCAN were put forward. For example, a self-adaptive density-based clustering algorithm (SA-DBSCAN) was presented in [15]. In the SA-DBSCAN approach, the distance of every object-pair in the data set is calculated as the input of two parameters and . Although SA-DBSCAN can achieve good accuracy, it results in high computational complexity O(n2). Furthermore, through integrating the Affinity Propagation (AP) clustering method with DBSCAN, an AP-based clustering algorithm (APSCAN) was presented to cluster the objects without parameters [16]. However, the APSCAN algorithm still needs to compute the distance of every object-pair and thus exhibits high complexity. To further realize adaptive parameter calibration, the GCMDDBSCAN clustering algorithm established grid cells based on the various data, and then clustered the data based on optimal values of parameters and with the cell as a unit [17].
From the above analysis, all of the DBSCAN-based clustering algorithms can achieve the adaptive parameter clustering for the simple object data. Considering the spatial and temporal characteristics of trajectory data, which differs from that of the simple object data, the trajectory clustering algorithm should reduce the computation complexity of clustering algorithms, especially in large-scale vehicle trajectories from intelligent systems. Based on the analysis of the DBSCAN-based clustering algorithms with adaptive parameter calibration, an Adaptive Trajectory Clustering approach based on Grid and Density (ATCGD) is proposed in this paper. ATCGD firstly divides the trajectory data into discrete trajectory segments based on the MDL-based method. All of the segments are mapped into the corresponding cells. Then, it calculates the average distance among the different segments in each grid cell, and the average number of the trajectory segments in each cell. Finally, adopting the idea of the DBSCAN-based method, ATCGD carries out the adaptive parameter calibration based on the above data to realize effective and accurate trajectory clustering.
Li et al. found that the existing trajectory algorithms focused on the static data and cannot deal with the problem of the data dynamic growth [18], so an incremental clustering framework of the trajectory, TCMM, was presented. In the TCMM framework, the whole trajectory was divided into several sequences and micro-clusters were established and dynamically maintained. The K-means method was also applied to the trajectory clustering problem [19]. However, it needed to determine the value of K in advance and cannot deal with noisy data, which results in poor performance in actual applications. Furthermore, the space covered by the trajectories was divided into cells. The trajectory clustering based on cells was proposed to cluster the grids when each cell is an object [20]. The cells-based clustering algorithm can exhibit good processing performance, while it ignores the differences among the sequences and leads to the poor clustering accuracy.
2.2. Trajectory Partition Methods
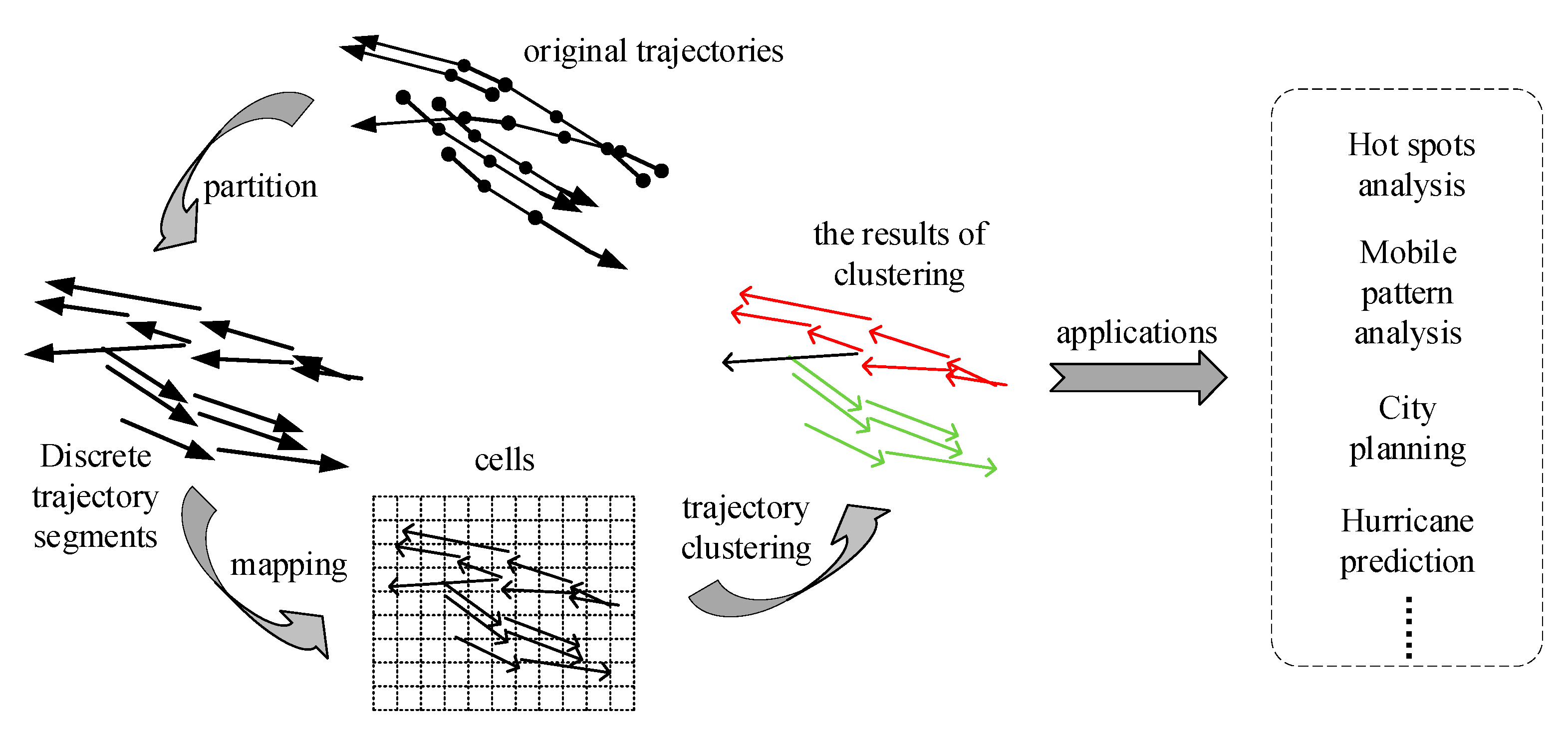
The proposed ATCGD algorithm includes three parts: partition, mapping, and clustering, as shown in Figure 1. In the partition phase, ATCGD applies the average angular difference-based MDL (AD-MDL) partition method to ensure the partition accuracy on the premise that it decreases the number of the segments after the partition. During the mapping procedure, the partitioned segments are mapped into the corresponding cells, and the mapping relationship between the segment and the cell are stored. In the clustering phase, adopting the DBSCAN-based method, the segments in the cells are clustered on the basis of the computed values of parameters from the mapping procedure. The clustering results can be applied in hotspot paths analysis, mobility pattern analysis, and urban planning.
In the field of trajectory partition, most of trajectory partition approaches rely on trajectory compression algorithms. The classical one is the Douglas-Peucker (DP) algorithm [21]. It detects some unnecessary points by calculating the information loss. Through introducing the concept of “window”, that is the segment, into the information loss computation, the OPening Window algorithm (OPW) was proposed [22]. OPW uses iterations to compress the trajectories with one “window” as one unit, instead of one whole trajectory as one unit. Using an iterations method, OPW can greatly reduce the computation cost. Afterwards, taking the time dimension into consideration, the Top-Down Time Ratio (TD-TR) algorithm was presented [12], and the optimal upper bound of errors compression algorithm (SQUISH-E) was proposed [23].
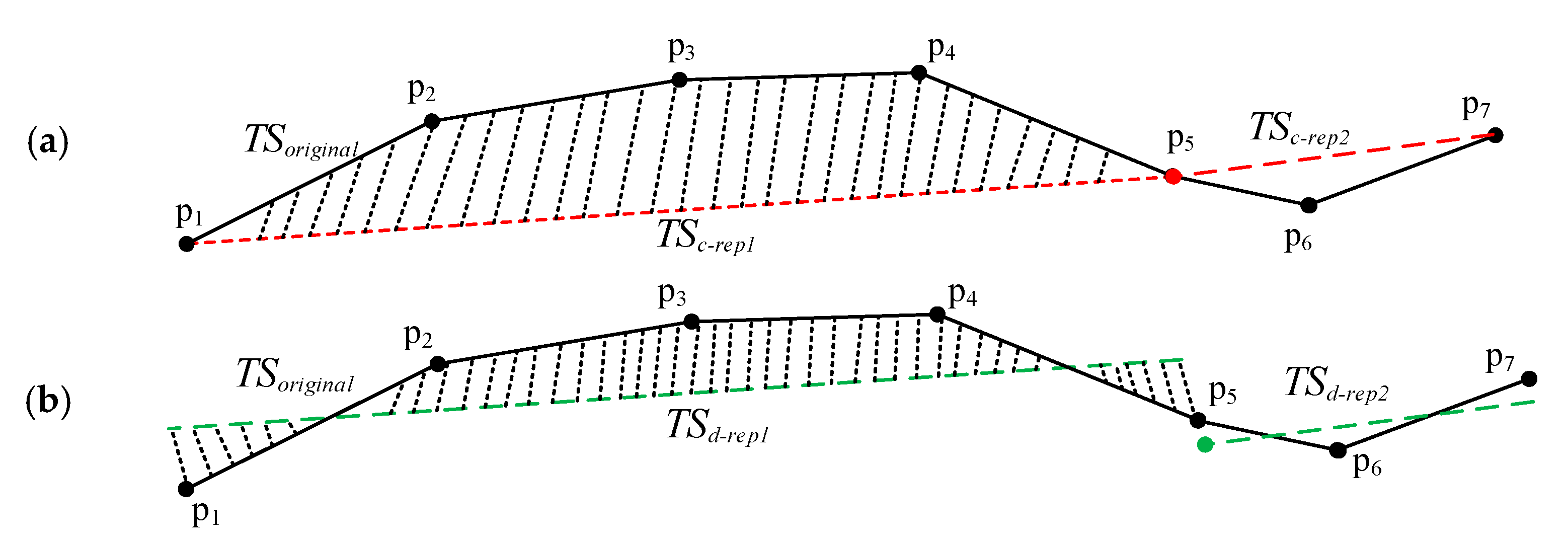
These further improved the applicability of the compression algorithms in the GPS trajectory data. Lee et al. put forward the trajectory partition algorithm based on the Minimum Description Length (MDL) [11], which can effectively compress data as well as ensure the accuracy of the compressed data. From the above analysis of compression algorithms, it can be found that most of the compression algorithms try to obtain successive sequences of trajectory, which means all segments are end-to-end. However, continuity is unnecessary to the clustering of the trajectory segments. We can improve the accuracy of the compressed data when dealing with the discrete segments of trajectory. As shown in Figure 2a,b, and marked with the red line, are the continuous representative segments of the original trajectory data ; and and , marked with the green line, are the discrete representative segments, respectively. The dash area represents the area difference between the representative segments and the original trajectory. It is obvious that the area difference between and is greater than that between and .
In this paper, adopting the AD-MDL discrete trajectories partition method, the proposed ATCGD trajectory clustering approach can map all of the segments into the corresponding cells. Then, based on the idea of the DBSCAN-based method, the segments are clustered through the calibration of adaptive parameters with the mapping relationship. The experimental results illustrate that the ATCGD approach can improve the effectiveness of clustering as well as ensure the accuracy.
3. Discrete Partitioning of Trajectories
3.1. Distance Measure Between the Trajectory Segments
Definition 1 (trajectory).
With a given Euclidean space, a trajectory is composed of a series of trajectory points, expressed as , where the discrete trajectory points are sorted by timestamp, Pi refers to the trajectory point i, , and n represents the number of points in the trajectory.
Definition 2 (sub-trajectory segment).
Two adjacent discrete trajectory points and are connected to form a trajectory segment , which is a sub-trajectory segment, denoted as .
A trajectory sequence consists of a series of discrete points. Two adjacent discrete points are connected to form a sub-trajectory segment. Due to the massive amount of trajectory data generated by mobile phones and other GPS equipment, the trajectory data compression is an important task for the sub-trajectory segments clustering. To reduce the workload of clustering all of the trajectory data, it should first partition the trajectory into the multiple sub-trajectory segments by adopting the appropriate compression algorithm.
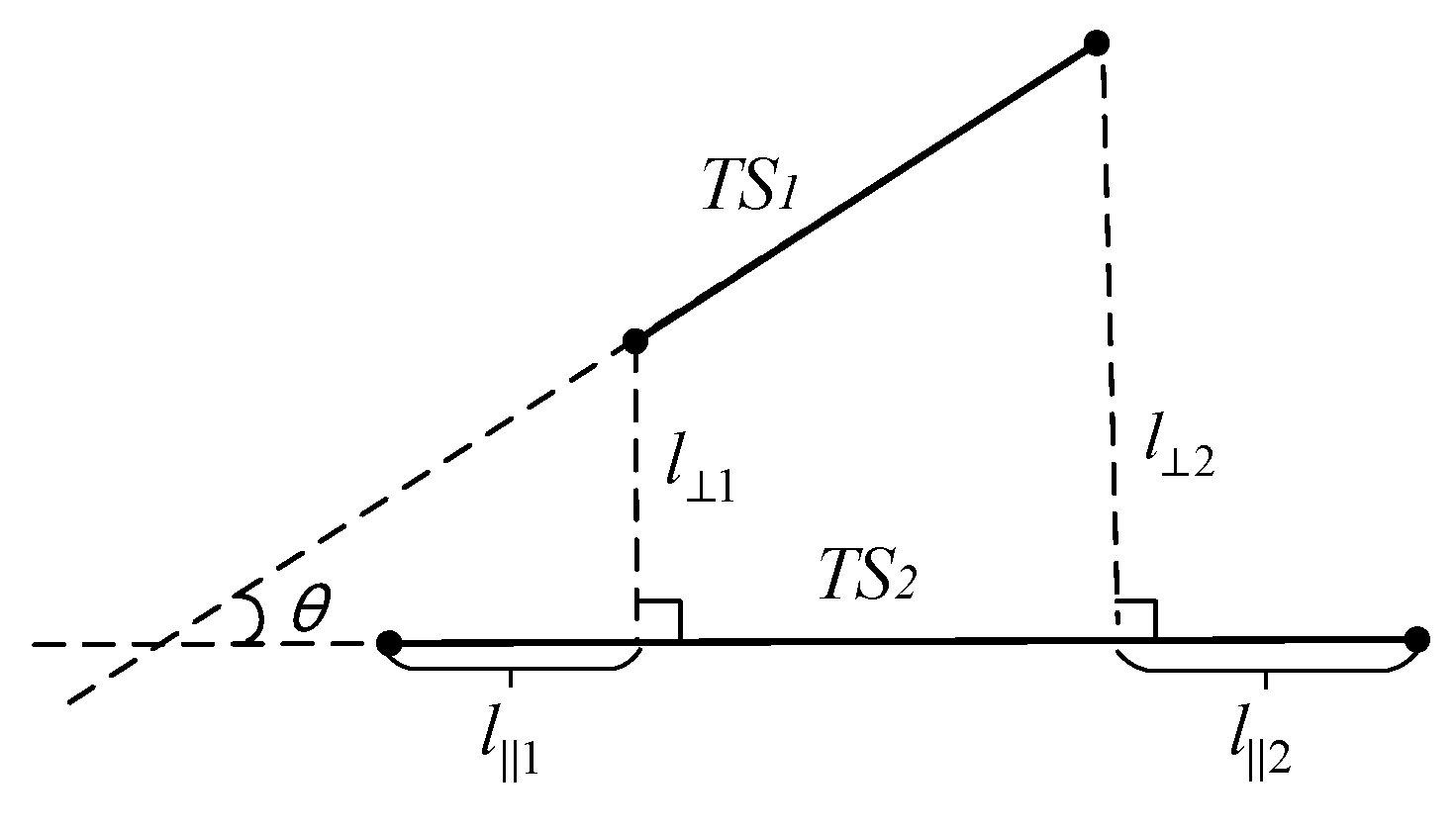
Lee et al. proposed a method to calculate the distance between two sub-trajectory segments with the weighted sum of the horizontal distance, vertical distance, and angular distance [10]. That distance of trajectory segments is suitable to the trajectory clustering. The horizontal distance can effectively avoid the noisy data problem when the distance between the two long trajectory segments is long. However, the angular distance may cause the problem of the short trajectory segments priority, which means that the shorter the trajectory segment is, the smaller the angular distance is. To solve the problem of the short trajectory segments priority, a new method to calculate the distance between the different segments is presented in this paper. As shown in Figure 3, is the shorter trajectory segments and is the longer one. and are the minimum and maximum vertical distance from any point in to the segment , respectively. and are the distance from the corresponding intersection to the endpoint, respectively. is the vertical distance between the two segments calculated with and . is the horizontal distance between the two segments calculated with and , is the angle between the two segments and , as shown in Equations (1) and (2):
The distance between the two segments and can be computed as shown in Equation (3):
3.2. Discrete Representative Trajectory Segments
Definition 3 (representative trajectory segments).
Given a set of the trajectory segments , can be represented with a trajectory segment as the representative trajectory segment.
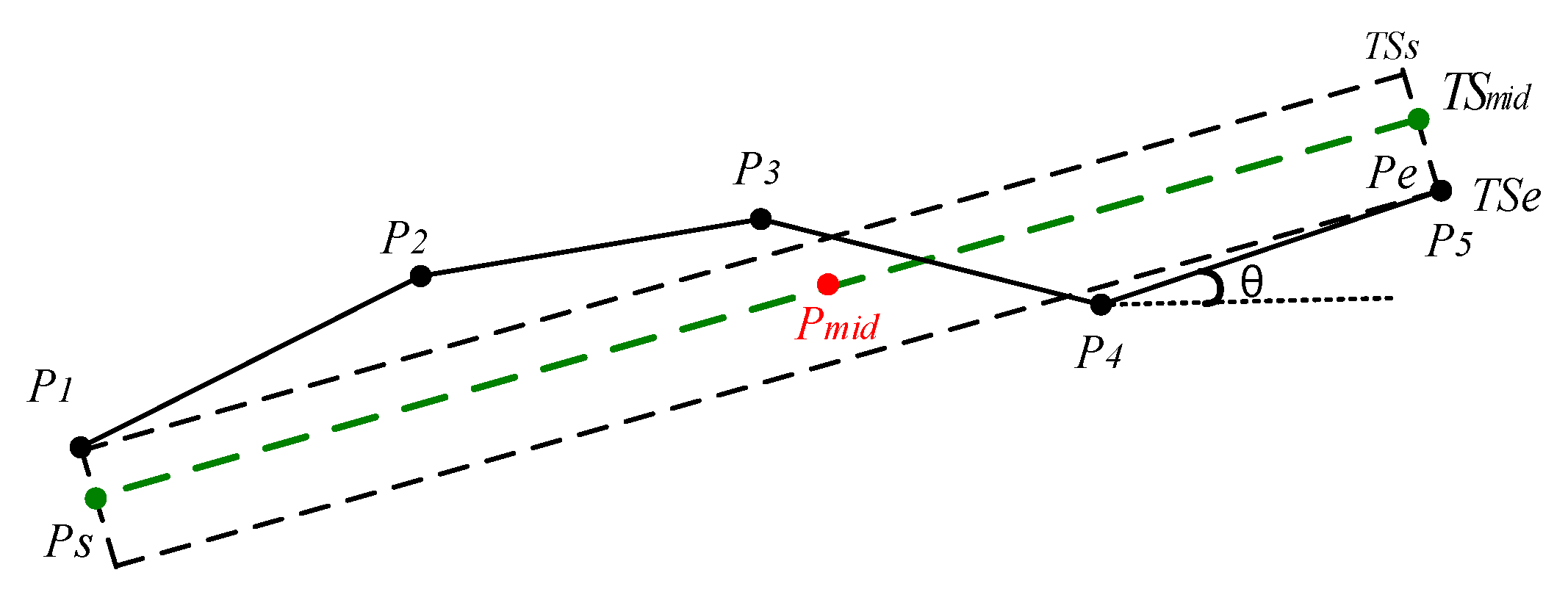
According to the discussion in Section 2, from Figure 2a,b, it is obvious that the area difference between and is greater than that between and . In order to reduce the area difference between the set of the partitioned segments and the original whole trajectory, ATCGD approach applies the discrete representative trajectory segments to replace the original whole trajectory, instead of the continuous representative trajectory segments. Figure 4 illustrates the discrete representative segments. As shown in Figure 4, denotes the trajectory point in the original trajectory. is the middle point in the original trajectory, where , .
In Figure 4, is the trajectory line through the middle point . Suppose that represents the clockwise angle between the trajectory segment and the horizontal line, where . is the clockwise angle between the trajectory segment and the horizontal line. can be calculated as follows:
Then, it makes two vertical lines from two endpoints of original trajectory and to the line , and intersects at the points and , respectively. The trajectory segment is just the representative trajectory segment of the original trajectory , denoted as . The coordinate values of the intersection can be calculated with Equation (5):
In the same way, the coordinate values of the intersection can be calculated. It is obvious that the representative trajectory segments via the above method are discrete and cannot be end-to-end.
From Figure 2, the area difference between and is greater than that between and . Therefore, this discreteness cannot take negative effect on the clustering results, instead it can generate the more accurate representative segments of the original trajectory.
To evaluate the accuracy of the representative trajectory segments, the cumulative distance difference between the discrete representative trajectory segment and the set of the original continuous segments is introduced, which is represented as . Because the vertical distance is one major impact factor on the difference between the representative trajectory segment and the original ones, the vertical distance is adopted to compute the cumulative distance difference, as shown in Equation (6):
where is the number of the original segments. The smaller is, the more accurate the representative trajectory segment is. Meanwhile, in order to verify the accuracy of the discrete representative trajectory segments, 1000 trajectories from the GeoLife data sets [24] are randomly selected. Assume that represents the cumulative distance difference between the discrete representative segment and the original trajectory segment. represent the cumulative distance difference between the continuous representative segment and the original one. The experimental results are that there are in the 982 trajectories from the 1000 trajectories, while there is only in the 18 trajectories. The experimental results indicate that the discrete representative trajectory segment can substitute the original one more accurately.
3.3. Discrete Trajectory Partition Algorithm
From daily life experience, we know that the trajectory variations of people’s or vehicle’s movements are always relatively smooth. That is to say, there are very small changes in the angle between the two adjacent trajectory segments. To further quantify the variations of trajectories, the average angular difference is introduced. Given a trajectory data , the average angular difference can be calculated as shown in Equation (7):
Lee et al. put forward the trajectory partition algorithm based on the Minimum Description Length (MDL) to compress data [8]. MDL is derived from Information Theory, which can be used to describe a given data set using fewer symbols than needed to describe the data literally. In essence, MDL can be applied to data compression. In the trajectory data compression, MDL can obtain a tradeoff between the number of sub-trajectory segments and the accuracy of the trajectories partition results, but MDL has high computational complexity to obtain the partitioned segments. In order to reduce the complexity of the trajectories partition, the average Angular Difference-based MDL (AD-MDL) is proposed to compress the trajectory data and partition the trajectories. AD-MDL consists of two phases: data filtering and trajectory partition.
In the data filtering phase, it eliminates the obvious outliers with the minimum cost based on the average angular difference , which can reduce the computation workload during the trajectory partitioning. At first, the original trajectory data can be partitioned into multiple continuous segments. During the procedure of data filtering, the average angular difference is considered as the filtering factor. The filter threshold is . For each continuous sub-trajectory segment, if its average angular difference is greater than the threshold , the starting point of that sub-trajectory segment should be added into the set of the candidate trajectory points . Otherwise, the starting point of the segment is considered as an outlier and cannot be processed in the trajectory partition phase. After the data filtering, it can get the set of the candidate trajectory points . A GeoLife data set is introduced as an example to evaluate the performance on data compression. Based on the experimental results, it can be found that the AD-MDL can realize the 39% compression rate when the threshold value is . Thus, it can greatly reduce the computation overhead in the trajectory partition phase.
In the trajectory partition phase, MDL method is still adopted to partition the compressed trajectories into discrete representative trajectories. During the data compression procedure, the overhead of MDL usually includes two parts: and . is the hypothesis, and is the described data. is the overhead of describing the hypothesis and is the overhead to describe the under the hypothesis . MDL aims to find the optimal H to describe D to minimize the sum of and . As to the trajectory partition, is the set of discrete representative trajectory segments, and is the original trajectory data. represents the total length of the all discrete representative segments. represents the difference between the discrete representative segments and the original trajectory. It is obvious that the greater number of the selected candidate points is, the more accuracy of the partition is. The greater is and the smaller is, which results in the high accuracy and high computation cost. Otherwise, it results in the low overhead and poor accuracy. When the sum of and is minimum, the trajectory partition can reach the tradeoff between the accuracy and computation cost. and can be computed as follows Equation (8):
where represents the discrete trajectory segment from the candidate point to , is the original trajectory segment in the , and means the length of the discrete trajectory segment from the point to .
To obtain the optimal trajectory partition, it should compute the global optimal solution to the minimum sum of and , which results in the high computation overhead. To reduce the computation cost, we adopt a greedy solution to find the local optimal results to replace the global optimal results.
Suppose and are two candidate points from . represents the minimum description length of part of trajectory segment and . represents the original trajectory length of the segment , that is, . From the point as the starting point, if , it reveals that all of the trajectory points in the segment are not trajectory characteristic points and the corresponding trajectory segment cannot be added into the set of the discrete representative segment, denoted as . Otherwise, the points in the segment are trajectory characteristic points and the corresponding segment can be transformed into the discrete representative segment with the Equations (4) and (5) discussed in Section 3.2.
According to the above discussion, the average Angular Difference-based MDL (AD-MDL) algorithm can be used to compress the trajectory data and create the discrete representative segments. The pseudo-code of the AD-MDL algorithm (Algorithm 1) is as given below. The AD-MDL trajectory partition algorithm contains two phases, the first one is the data filtering and the second one is to create the discrete representative trajectory segments. In the data filtering phase, part of the trajectory points is selected as the candidate point for the trajectory partition phase, based on the average angular difference. Thus, it can reduce the number of trajectory points to create the discrete representative segments and reduce the computation time in the second phase.
| Algorithm 1. AD-MDL: The Average Angular Difference-Based MDL Trajectories Partition Algorithm. |
|
As shown in lines 1 to 7 of the AD-MDL algorithm, if the average angular difference is not greater than the threshold , a new trajectory point is added. Otherwise, the new added trajectory point is the characteristic point and is added into the set of candidate points . In the trajectory partition phase, in order to obtain the clustering accuracy as well as the low complexity, the MDL-based method is adopted to create the discrete representative segments. As shown in the line 8 to line 14 of the AD-MDL algorithm, if there is , the trajectory points between the and are non-characteristic points, and the successive point is included. If , the trajectory points between the and are characteristic points and the corresponding segment is added into the set of discrete representative segments . The AD-MDL algorithm traverses all of the trajectory points twice, so the computation complexity is , where is the total number of trajectory points.
4. Trajectory Clustering Based on Grid and Density
4.1. Grid Partition
We can get the discrete representative trajectory segments with the AD-MDL algorithm. After the trajectory partitioning, the partitioned segments should be mapped into the appropriate cells with the clustering method based on the grid and density, which is the task of the grid partition phase. The trajectory clustering based on the density should follow the principle of the cluster size from small to big. Suppose that the average number of the trajectory segments in each cell is represented as . The value of should be as small as possible, which means that the average number of the trajectory segments should be minimum in each cell. However, in order to conduct the trajectories clustering based on the density, it needs to compute the distances among the different trajectory segments for each cell, which results in the heavy overhead of computation. In the experiments of Section 5.3, it can be found that the minimum value of cannot obtain the optimum of clustering. Through a lot of experiments, when , it can obtain the best clustering quality.
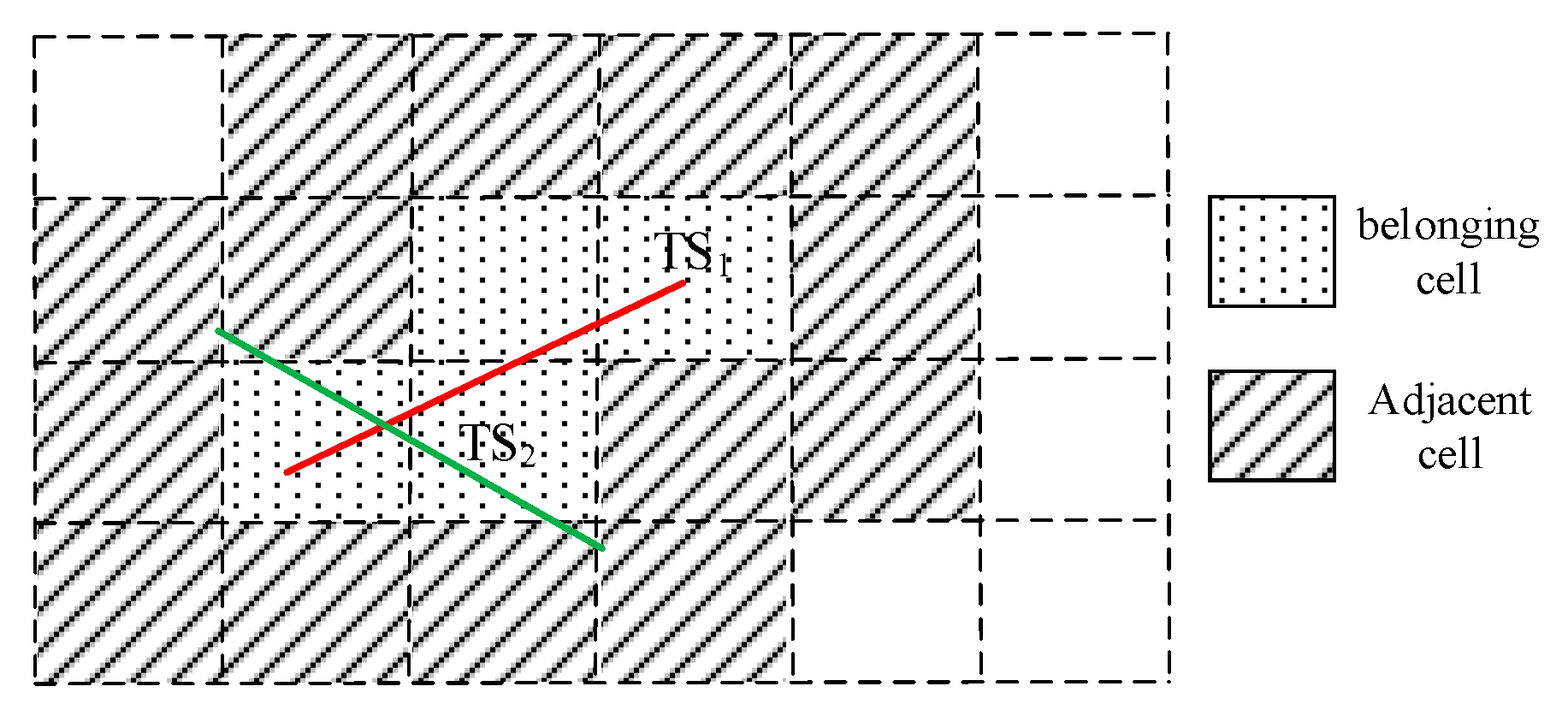
Definition 4 (belonging cell).
The cells are passed by the trajectory segment are defined as the belonging cells of , represented as . The number of belonging cells of is . As shown in the Figure 5, the cells with point shaded are the belonging cells of the trajectory segment , and .
Definition 5 (adjacent cell).
The cells are adjacent to one of the belonging cells of the trajectory segment are defined as the adjacent cells of , represented as . The number of adjacent cells of is . As shown in the Figure 5, the cells with oblique lines shadow are the adjacent cells of the trajectory segment , and .
Definition 6 (cell density).
Suppose a certain cell , the number of the trajectory segments passing through the is defined as the cell density of , denoted as .
During the procedure of the grid partition and mapping the trajectory segments into the corresponding cells, it needs to traverse every trajectory segment and recognize all of the belonging cells and adjacent cells of every segment, as well as every cell’s density. Those computation results are the inputs for the trajectory clustering.
4.2. Trajectory Clustering Algorithm
The DBSCAN-based clustering approaches should calibrate the values of two parameters and . and denote the radius of neighbor cells and the threshold of density of the trajectory segments, respectively. In Section 4.1, we could obtain the average distance among the different segments in each cell, and the average number of the trajectory segments in each cell. With the DBSCAN-based clustering approach, the ATCGD trajectory clustering approach carries out the adaptive parameters calibration and , based on the above data to realize the effective and accurate trajectory clustering.
Definition 7 (neighborhood of trajectory segment).
Suppose there are two trajectory segments and in , that is and , where is the set of the discrete partitioned trajectory segments. If there has , where is the radius of the neighbor cells, is the neighborhood of trajectory segment with , denoted as .
From Definition 7, all of the trajectory segments, whose distance from the segment is less than in the set , are the neighborhood of trajectory segment with . The size of radius of the neighbor cells can determine the size of for the trajectory segment . Next, we will discuss the procedure of adaptive parameter calibration for .
It selects the cells with density greater than 1, that is , where , is the number of cells. Suppose the number of the selected cells with is , is the cell density of , is the trajectory segments passing through . The radius of the neighbor cells can be computed as follows:
where is the expected value of for the , and represents the average expected value of for all of the cells. From the discussion in Section 4.1, we set to obtain good clustering quality. Due to the value of is enough small, the distances among the different trajectory segments in each cell are very short. The maximum distance among the trajectory segments in the is selected as the expected value of of the . The radius of the neighbor cells is the sum of the average expected value and the standard deviation of all cells’ expected values. For any one cell , its cell density is constant. The computation complexity of is , where is the number of the cells.
Definition 8 (segment density).
Suppose there is one trajectory segment in , the density of is defined as the number of trajectory segments in its neighborhood, denoted as . That is .
Definition 9 (core segment).
Suppose there is one trajectory segment in , and is the threshold of density of the trajectory segments. If , the trajectory segment is defined as the core segment of . Otherwise, is non-core segment of . The set of core segments is denoted as and the set of non-core segments is denoted as .
In the ATCGD trajectory clustering approach, the threshold value of is not fixed and may vary with the different number of the belonging cells of the trajectory segments. In the applications, if the density of the trajectory segment is not less than the mean value through the statistical results, it can be considered that the density of the segment , , can meet the requirements of trajectory clustering. For the trajectory segment , the corresponding threshold is set to . On the other hand, one trajectory segment may pass through one or more cells, and one cell can be covered by one or more trajectory segments. is the average number of the trajectory segments in each cell. can be further improved considering the many-to-many relationship between the and the for each segment and grid cell. The modified is denoted as and can be computed as Equation (10):
where is the number of the cells, and is the total number of the trajectory segments.
Definition 10 (directly density-reachable).
Suppose there are two trajectory segments and in , that is and . If and , are said to be directly density-reachable from . By Definition 10, no trajectory segments are directly density-reachable from a non-core segment.
Definition 11 (density-reachable).
Suppose there are trajectory segments in , that is , where and . If is the directly density-reachable from , then is the density-reachable from .
The density-based trajectory clustering procedure includes three phases. The first phase is to map the discrete trajectory segments into the cell. Suppose there are discrete representative trajectory segments obtained with the discrete trajectory partition algorithm (AD-MDL). is set to 2, and the area can be divided into cells. Then, it can calibrate two parameters and to set the scanning radius of cells and the threshold of density of the trajectory segments and form a cluster, respectively, based on the Equations (9) and (10). The second phase is to execute the grid and density-based clustering with DBSCAN-based method. It starts with an arbitrary trajectory segment that has not been visited. The ’s neighborhood is retrieved, and if its density is greater than , a cluster is started. Otherwise, the trajectory segment is labeled as noise. If the trajectory segment is found to be a dense part of a cluster, its neighborhood is also part of that cluster. All of the trajectory segments that are found within the neighborhood are added, as is their own neighborhood when they are also dense. This process continues until the density-reachable cluster is completely found. Then, a new unvisited trajectory segment is retrieved and processed, leading to the discovery of a further cluster or noise. After the trajectory clustering, the set of the candidate clusters, , are created. However, if one candidate cluster is not dense, which cannot meet the application’s requirement for the clustering quality. The last phase is to check the cardinality for each cluster. For one candidate cluster , if the number of trajectory segments in the cluster is not greater than , where is the number of the cells, the cluster should be the final cluster and be removed from the set of the candidate clusters.
Based on the procedure of the density-based trajectory clustering, it can be found that a trajectory that is neither a core segment nor directly-reachable is called as a noise segment. A cluster should satisfy two properties: all trajectory segments within the cluster are mutually density-reachable; and if a trajectory segment is density-reachable from any segment of the cluster, it is part of the cluster as well.
The density-based trajectory clustering algorithm can be expressed in pseudo-code as follows.
| Algorithm 2. The Density-Based Trajectory Clustering Algorithm. |
|
From Algorithm 2, the density-based trajectory cluster algorithm includes three phases. From line 1 to line 2, the area is divided into the appropriate number of cells and the segments are mapped into the corresponding cells. Meanwhile, it executes the adaptive parameter calibration for and . The complexity of the first phase is . The clustering phase is from the line 3 to line 18, which adopts the DBSCAN-based method to cluster the discrete segments with the values of adaptive calibrated parameters, and get the candidate clusters. The complexity of clustering procedure is . To further check the results of clustering, it checks the density of each cluster. If the density of cluster is not greater than the average density, the candidate cluster should be removed, as shown from line 19 to line 22. As a whole, the complexity of the trajectory clustering based on the density is .
5. Performance Evaluation
5.1. Experimental Setup
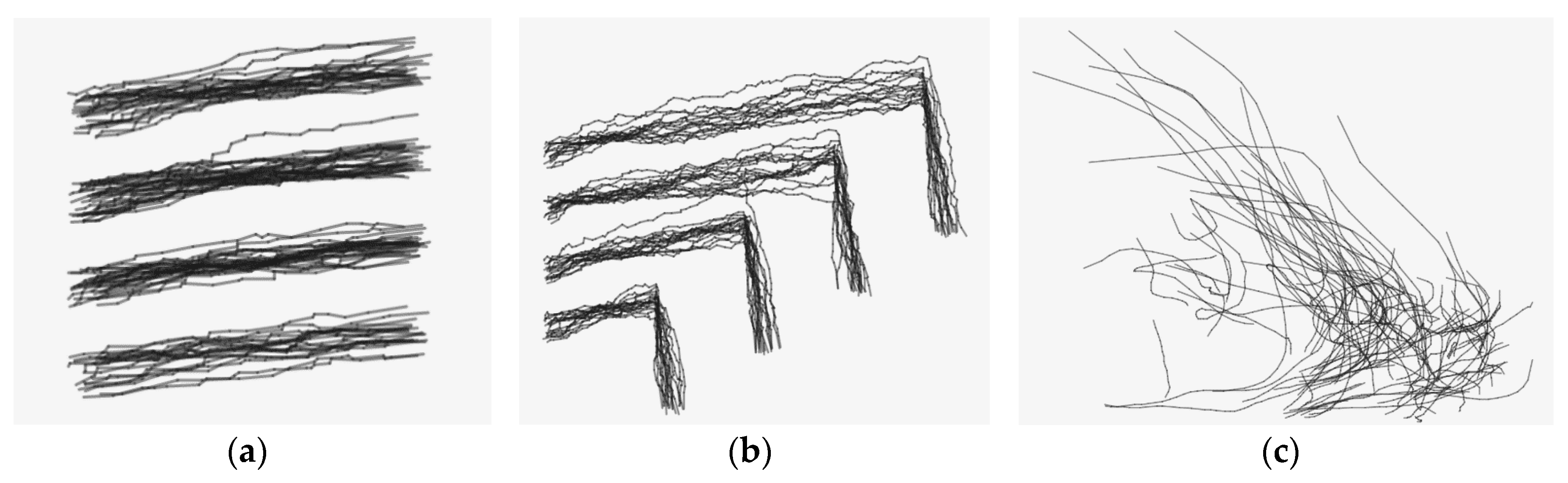
To evaluate the clustering performance of proposed trajectory cluster approach-ATCGD, two data sets are introduced. One is a series of randomly generated trajectories (hereafter referred to as Random Trajectory, RT), as shown in Figure 6a,b. The other is hurricane trajectory data in the Atlantic Ocean provided by American Weather Information System Company, referred to as Hurricane Track (HT) as shown in Figure 6c. RT data includes two patterns: RT1 and RT2. RT1 has about 100 trajectories and 2000 trajectory segments. Those trajectories can be clearly divided into four groups from top to bottom. RT2 has about 100 trajectories and 7000 trajectory segments, and is more complicated than RT1. The trajectories in RT2 are also divided into four groups. The trajectories in the RT1 and RT2 sets are similar to the trajectory data from vehicle movement, thus, RT1 and RT2 can represent a data set from a real application. The HT data set includes the hurricane track information about latitude, longitude, and the highest wind speed from 1851. The frequency of sampling is once for every 6 h. The experiments extract 100 hurricane trajectories with 2465 trajectory segments from 1940, which includes the latitude and longitude of the hurricane track.
To further evaluate the clustering quality of the proposed ATCGD approach, one metric is introduced as the standard to evaluate the clustering effect [10]. includes two parts: one is the sum of squared error () and the other is the penalty value of noise. The can be calculated as follows:
where is the noise set, is the number of the cluster of the trajectory segments, and represents the cluster of trajectory segments. is the number of the trajectory segments in the cluster. is the number of the noise trajectories. The sum of squared error () can be calculated with , which reflects the distances between the different trajectory segments in each cluster. The smaller value of is and the greater value of is, it can obtain smaller . In the applications, if it can calibrate appropriate values of two parameters and , it can exhibit good cluster quality. At the same time, the noise trajectory data are considered when calculating the value of . is used to calculate the sum of squared distances between the any noise trajectory segments, which is as the penalty. Therefore, the value of and the quality of the clustering exhibits the negative correlation. The smaller the metric value of is, the higher quality of the clustering is.
5.2. Clustering Performance
Figure 7 shows the clustering results with the RT1, RT2 and HT data sets, respectively. As shown in Figure 7, the different clusters are represented with different colors. From Figure 7a, the proposed ATCGD approach can cluster those trajectory data into four groups with high accuracy, which is in accordance with the expectation. Compared to the original trajectory data, it can be found that some trajectory segments are recognized as the noise. Figure 7b illustrates the clustering results with RT2. In contrast with RT1, the trajectories of RT2 exhibit apparent non-smoothness. This reveals that RT2 has greater difficulty than RT1 in clustering, but the ATCGD approach can still cluster those trajectories into four different groups. Therefore, the ATCGD can effectively be applied to the vehicle trajectory data, which has high similarity to the RT data set. Figure 7c shows the HT clustering results. From Figure 6c, the trajectories in the HT data set are much more complicated than those in the RT data set. The ATCGD approach can classify those hurricane data into two clusters, which conforms to the expectation. It implies that the ATCGD approach can also provide effective clustering for complex trajectory data.
5.3. Comparison Analysis
To further quantify the accuracy of the ATCGD clustering approach, we compare the ATCGD approach with TRACLUS in terms of . Due to the slight differences about the distance calculation of the trajectory segments between the ATCGD and TRACLUS, it adopts the proposed distance computation equation between the trajectory segments in this paper, shown in Equation (3), to calculate .
In the experiments, the different number of trajectories from RT and HT data sets are selected to evaluate the clustering quality. Thus 100, 200, 300, 400 hurricane track trajectories since 1940 from the HT data set are randomly selected and denoted as HT-100, HT-200, HT-300, and HT-400, respectively. Meanwhile, we apply the parameter calibration method proposed in the TRACLUS algorithm to conduct the experiments for twenty times and get the 20 different combination results of the two parameters and . The minimum of combination results, that is the minimum , is taken as the results of the TRACLUS algorithm. The experimental results of the ATCGD and TRACLUS algorithm are listed in Table 1.
From Table 1, it can be seen that the run time of TRACLUS algorithm is much higher than that of the ATCGD method. Meanwhile, the difference in the run times becomes greater between the two algorithms as the data size increases. The reason is that the ATCGD approach adopts the belonging cells and adjacent cells to determine the candidate set, which can be used to compute the neighborhood of . That method can greatly improve the efficiency and reduce the execution time of the trajectory clustering. The computation complexity of the ATCGD approach is based on the analysis in the Section 4.2. On the contrary, without the index scheme, the computation complexity of the TRACLUS algorithm is up to , where is the number of trajectory points. On the other hand, as to the metric of the clustering quality , the ATCGD approach does not appear to be much different from the TRACLUS algorithm. The ATCGD can obtain slightly better than the TRACLUS algorithm. In most cases, the value of in the ATCGD is smaller than that in the TRACLUS, except the HT-400 and RT2 data sets. The reason is that the ATCGD approach adopts the adaptive parameters calibration method to obtain the values close to the optimum, thus it can exhibit the good quality of clustering with the lower computation cost. While the TRACLUS algorithm can obtain the near-optimal combination results of two parameters and through the large number of parameters calibrations, which results in the high accuracy and high computation complexity. If the combination results of two parameters are inappropriate, the TRACLUS algorithm will obtain the poor quality of trajectory clustering.
5.4. Parameter Sensitive Analysis
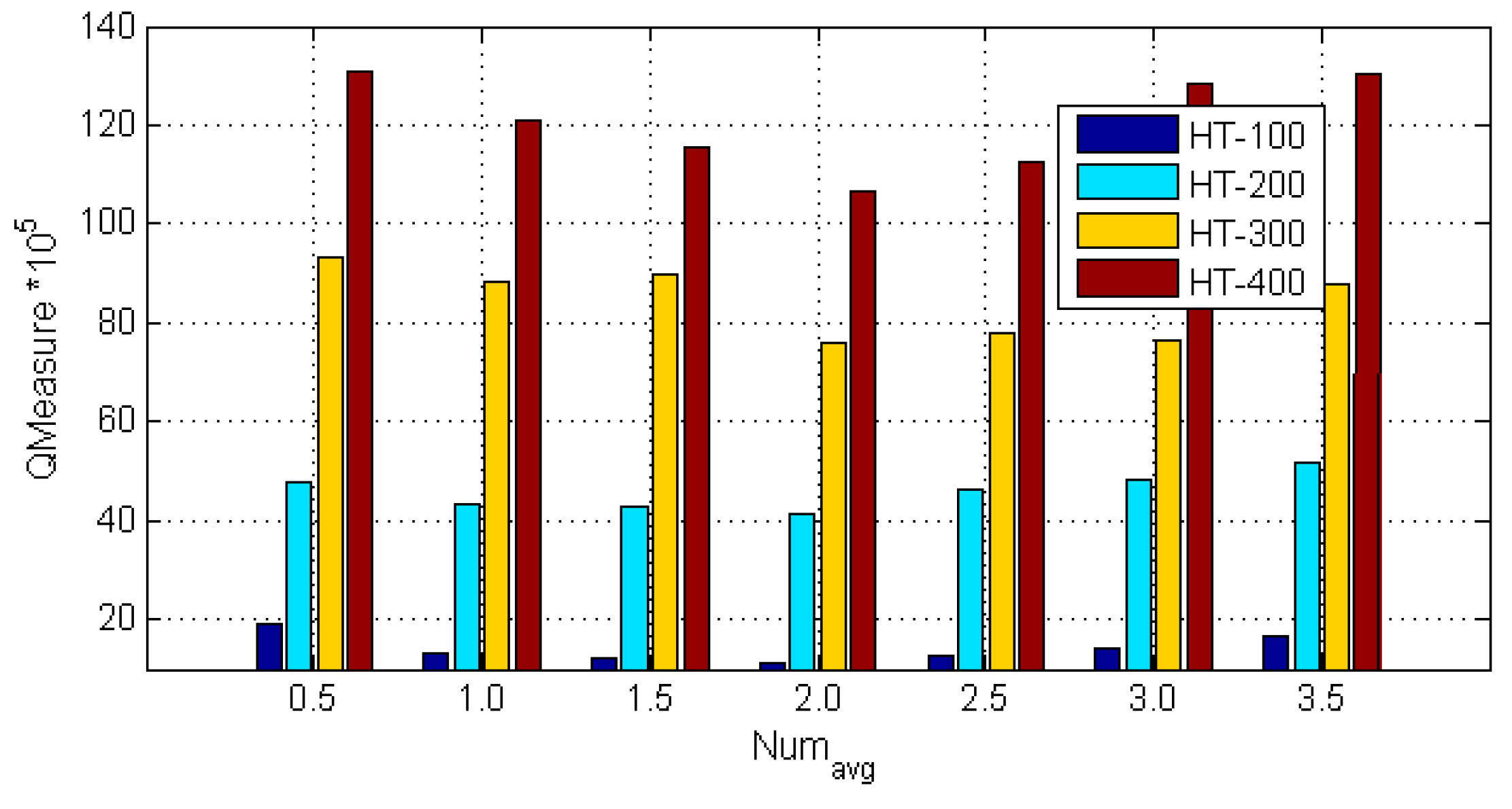
In order to further provide the quantitative analysis of the parameter values of , the HT-100, HT-200, HT-300, and HT-400 data sets are used to compute the quality of clustering metric with the different values of . The experimental results are shown in the Figure 8. When , the value of is minimum for all of the data sets. When , the value of decreases with the increase of . On the contrary, when , the value of increases with the increase of . Based on the experimental results, when the ATCGD approach sets to 2, it can get better quality of the trajectory clustering.
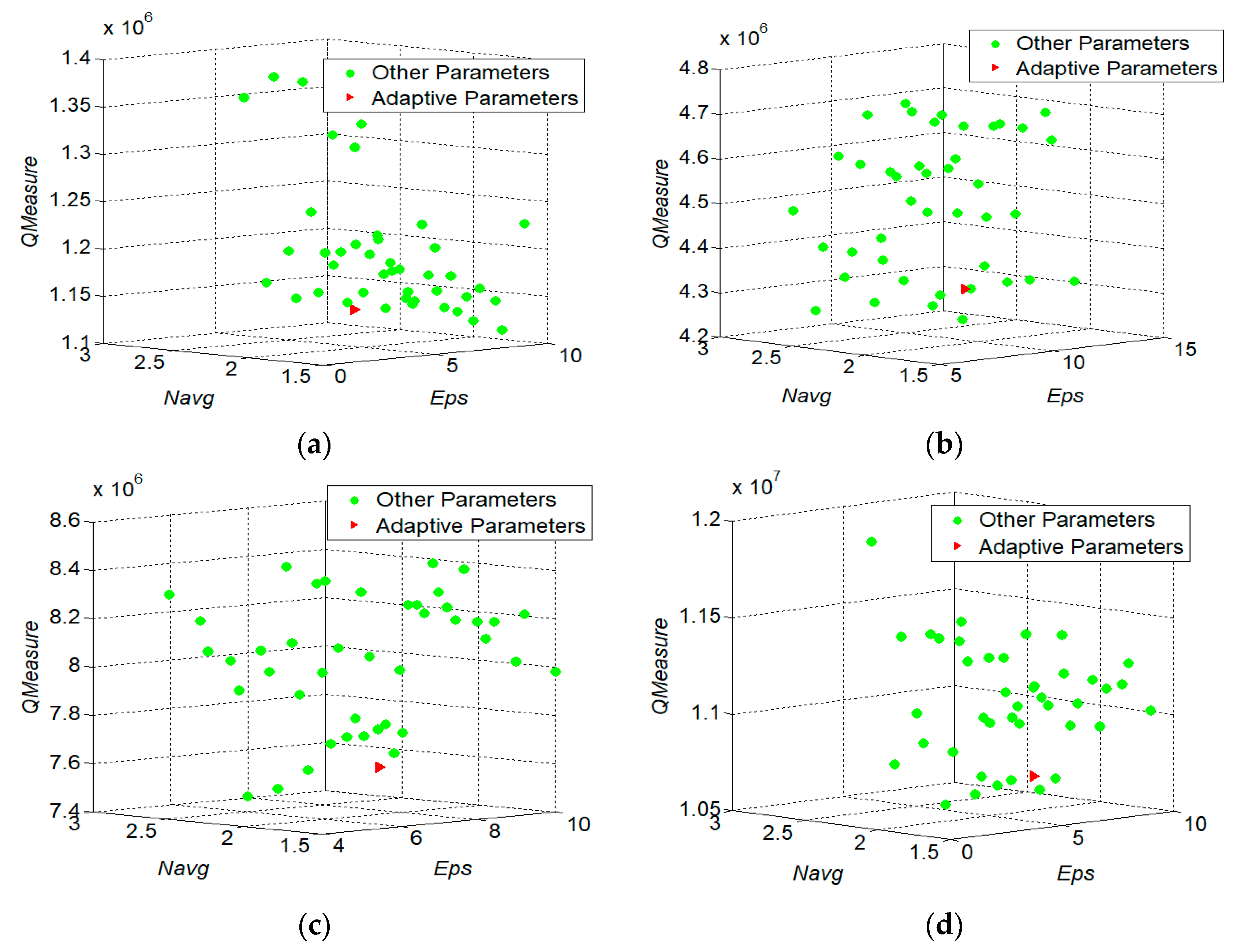
To verify the correctness of the parameters calibration, two parameters and ( can be computed based on ) are selected for the sensitivity analysis. The data sets are still HT-100, HT-200, HT-300, and HT-400. We compare the different values of with different combination of and as well as the adaptive calibration values of those two parameters and . The value range of is and the step is 1. The value range of is and the step is 0.2. Figure 9 illustrates the distributions of with different values of and in the data sets of HT-100, HT-200, HT-300, and HT-400. As shown in Figure 9, the red points are the results of adaptive parameter calibration for and ; the green points are the results of different combinations with different values of and
From Figure 9, it can be found that there is a large variation range of with the different combinations of two parameters’ values, when adopting the TRACLUS algorithm. While the ATCGD approach can get the small value of . The reason is that it adopts the adaptive parameters calibration method to compute the value of . On the other hand, if the difference between the values of by adopting the adaptive parameters calibration and the optimal combination is smaller, the ATCGD approach can obtain higher quality of trajectories clustering. Moreover, although the results of the adaptive parameter calibration are not optimal, in most cases, the difference between the values of with the adaptive calibration and the optimal combination is less than 5%. It indicates that the adaptive calibrated parameters and can gain good clustering effects.
6. Conclusions
Clustering analysis is one of the most important issues in trajectory data mining. Trajectory clustering can be widely applied in hotspots detection, mobile pattern analysis, urban transportation control, hurricane prediction, etc. Many trajectory clustering algorithms have been proposed to obtain good clustering performance. Nonetheless, most available trajectory clustering algorithms depend on calibration of one or multiple parameters. Meanwhile, the values of these parameters have a great influence on the effect of clustering. To reduce the complexity and overhead of parameter calibration in trajectory clustering, an Adaptive Trajectory Clustering approach based on Grid and Density, ATCGD, was proposed in this paper. ATCGD firstly divides the trajectory data into multiple discrete segments through the proposed the average angular difference-based MDL (AD-MDL) algorithm. All of the discrete segments are mapped into the corresponding cells. Then, it calculates the average distance among the different segments in each cell, and the average number of the trajectory segments in each cell. Finally, adopting a DBSCAN-based approach, ATCGD carries out an adaptive parameter calibration based on the above data to realize effective and accurate trajectory clustering. With two data sets from random trajectories and hurricane trajectories on the Atlantic Ocean, we evaluate the performance of the ATCGD approach on clustering quality and cost. The experimental results indicate that although the results of the adaptive parameter calibration are not optimal, in most cases, the difference between the adaptive calibration and the optimal is less than 5%, while the run time of clustering can be reduced by about 95%.
Acknowledgments
This study was supported by the National Key Technology Research and Development Program of the Ministry of Science and Technology of China under Grant No. 2016YFC0400910, 2017ZX07104001, 2013BAB06B04; the Fundamental Research Funds for the Central Universities under Grant No. 2015B22214, 2017B20914, 2017B16814, 2017B42214; NSF-China and Guangdong Province Joint Project: U1301252. The authors are grateful to the reviewers for their comments which greatly improved the quality of the paper.
Author Contributions
All four authors have contributed to the work presented in this paper. Yingchi Mao and Haishi Zhong, Hai Qi formed the initial idea. Yingchi Mao, Haishi Zhong, and Ping Ping developed the overall theoretical structure of the research. Yingchi Mao and Haishi Zhong conceived and designed the experiments. Haishi Zhong performed the experiments; Yingchi Mao, Haishi Zhong and Xiaofang Li analyzed the experimental results. Hai Qi and Xiaofang Li provided the experiment dataset. All authors worked collaboratively on writing main text paragraph.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Melnychuk, M.C.; Welch, D.W.; Walters, C.J. Spatio-temporal migration patterns of Pacific salmon smolts in rivers and coastal marine waters. PLoS ONE 2010, 5, e12916. [Google Scholar] [CrossRef] [PubMed]
- Andraca-Gómez, G.; Ordano, M.; Boege, K.; Domínguez, C.A.; Piñero, D.; Pérez-Ishiwara, R.; Pérez-Camacho, J.; Cañizares, M.; Fornoni, J. A potential invasion route of Cactoblastis cactorum within the Caribbean region matches historical hurricane trajectories. Biol. Invasions 2015, 17, 1397–1406. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Zhang, C.; Xie, W.; Xie, X.; Sun, G.; Huang, Y. T-drive: Driving directions based on taxi trajectories. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 99–108. [Google Scholar]
- Serna, C.G.; Ruichek, Y. Dynamic Speed Adaptation for Pat Tracking Based on Curvature Information and Speed Limits. Sensors 2017, 17, 1383. [Google Scholar] [CrossRef] [PubMed]
- Yue, Y.; Zhuang, Y.; Li, Q.; Mao, Q. Mining Time-dependent Attractive Areas and Movement Patterns from Taxi Trajectory Data. In Proceedings of the 2009 International Conference on Geoinformatics, Fairfax, VA, USA, 12–14 August 2009; pp. 1–6. [Google Scholar]
- Liu, S.; Liu, Y.; Ni, L.M.; Fan, J.; Li, M. Towards mobility-based clustering. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 919–928. [Google Scholar]
- Ma, L.B.; Li, P. Spatio-temporal Trajectory Clustering Based on Automatic Subspace Clustering Algorithm. Geogr. Geo-Inf. Sci. 2014, 30, 7–11. [Google Scholar]
- Gaffney, S.; Smyth, P. Trajectory clustering with mixtures of regression models. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 63–72. [Google Scholar]
- Nanni, M.; Pedreschi, D. Time-focused clustering of trajectories of moving objects. J. Intell. Inf. Syst. 2006, 27, 267–289. [Google Scholar] [CrossRef]
- Kalnis, P.; Mamoulis, N.; Bakiras, S. On discovering moving clusters in spatio-temporal data. In Proceedings of the International Symposium on Spatial and Temporal Databases, Angra dos Reis, Brazil, 22–24 August 2005; pp. 364–381. [Google Scholar]
- Lee, J.G.; Han, J.; Whang, K.Y. Trajectory clustering: A partition-and-group framework. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 593–604. [Google Scholar]
- Ram, A.; Sharma, A.; Jalal, A.S.; Agrawal, A.; Singh, R. An Enhanced Density Based Spatial Clustering of Applications with Noise. In Proceedings of the IACC 2009, IEEE International Advance Computing Conference, Patiala, India, 6–7 March 2009; pp. 1475–1478. [Google Scholar]
- Peng, C.; Guoyou, S.; Shuang, L.; Jian, Y. An incremental density based spatial clustering of application with noise algorithm based on partition index. J. Comput. Theor. Nanosci. 2016, 13, 10273–10280. [Google Scholar] [CrossRef]
- Hassanin, M.F.; Hassan, M.; Shoeb, A. DDBSCAN: Different Densities-Based Spatial Clustering of Applications with Noise. In Proceedings of the International Conference on Control, Instrumentation, Communication and Computational Technologies, Kumaracoil, India, 18–19 December 2015. [Google Scholar]
- Xia, L.N.; Jing, J.W. SA-DBSCAN: A self-adaptive density-based clustering algorithm. J. Grad. Sch. Chin. Acad. Sci. 2009, 26, 530–538. [Google Scholar]
- Chen, X.; Liu, W.; Qiu, H.; Lai, J. APSCAN: A parameter free algorithm for clustering. Pattern Recognit. Lett. 2011, 32, 973–986. [Google Scholar] [CrossRef]
- Zhang, L.; Xu, Z.; Si, F. GCMDDBSCAN: Multi-density DBSCAN Based on Grid and Contribution. In Proceedings of the International Conference on Dependable, Autonomic and Secure Computing, Chengdu, China, 21–22 December 2013; pp. 502–507. [Google Scholar]
- Li, Z.; Lee, J.G.; Li, X.; Han, J. Incremental clustering for trajectories. In Proceedings of the 15th International Conference on Database Systems for Advanced Applications, Tsukuba, Japan, 1–4 April 2010; pp. 32–46. [Google Scholar]
- Khairat, H.; Sitanggang, I.S.; Nuryanto, D.E. Clustering Haze Trajectory of Peatland Fires in Riau Province Using K-Means Algorithm. EES 2017, 58, 012059. [Google Scholar] [CrossRef]
- Li, J.; Yang, M.; Liu, N.; Wang, Z.; Yu, L. A Trajectory Data Clustering Method Based on Dynamic Grid Density. Int. J. Grid Distrib. Comput. 2015, 8, 1–8. [Google Scholar] [CrossRef]
- Ebisch, K. Short Note: A Correction to Douglas-Peucker Line Generalization Algorithm. Comput. Geosci. 2002, 28, 995–997. [Google Scholar] [CrossRef]
- Meratnia, N.; Rolf, A. Spatiotemporal compression techniques for moving point objects. In Proceedings of the 9th International Conference on Extending Database Technology, Crete, Greece, 14–18 March 2004; pp. 765–782. [Google Scholar]
- Muckell, J.; Olsen, P.W.; Hwang, J.H.; Lawson, C.T.; Ravi, S.S. Compression of trajectory data: A comprehensive evaluation and new approach. GeoInformatica 2014, 18, 435–460. [Google Scholar] [CrossRef]
- Zheng, Y.; Xie, X.; Ma, W.Y. GeoLife: A Collaborative Social Networking Service among User, Location and Trajectory. IEEE Data Eng. Bull. 2010, 33, 32–39. [Google Scholar]
Figure 1.
The illustration of the proposed ATCGD approach.

Figure 2.
Illustration of the continuous representative segments and the discrete representative segments. (a) The continuous trajectory segments; and (b) The discrete trajectory segments.
Figure 2.
Illustration of the continuous representative segments and the discrete representative segments. (a) The continuous trajectory segments; and (b) The discrete trajectory segments.

Figure 3.
The illustration of distance measure between the two trajectory segments.

Figure 4.
The diagram of the discrete representative trajectory segment.

Figure 5.
Schematic diagram of the belonged Cell and adjacent Cell.

Figure 6.
The trajectory in the RT and HT datasets. (a) RT1; (b) RT2; and (c) HT.

Figure 7.
The clustering results on the RT and HT dataset, (a) RT1; (b) RT2; and (c) HT.

Figure 8.
values under different .

Figure 9.
Experimental results of parameter adaptive analysis, (a) HT-100; (b) HT-200; (c) HT-300; and (d) HT-400.
Figure 9.
Experimental results of parameter adaptive analysis, (a) HT-100; (b) HT-200; (c) HT-300; and (d) HT-400.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparison of clustering quality between ATCGD and TRACLUS.
| TRACLUS | ATCGD | |||
|---|---|---|---|---|
| QMeasure | Run Time (s) | QMeasure | Run Time (s) | |
| HT-100 | 1,486,875 | 1.25 | 1,140,856 | 0.14 |
| HT-200 | 5,416,222 | 5.84 | 4,327,626 | 0.23 |
| HT-300 | 8,164,510 | 15.75 | 7,602,455 | 0.44 |
| HT-400 | 9,741,195 | 26.34 | 10,682,513 | 0.61 |
| RT1 | 461,437 | 1.07 | 39,426 | 0.09 |
| RT2 | 164,351 | 21.75 | 176,269 | 0.57 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Mao, Y.; Zhong, H.; Qi, H.; Ping, P.; Li, X. An Adaptive Trajectory Clustering Method Based on Grid and Density in Mobile Pattern Analysis. Sensors 2017, 17, 2013. https://0-doi-org.brum.beds.ac.uk/10.3390/s17092013
AMA Style
Mao Y, Zhong H, Qi H, Ping P, Li X. An Adaptive Trajectory Clustering Method Based on Grid and Density in Mobile Pattern Analysis. Sensors. 2017; 17(9):2013. https://0-doi-org.brum.beds.ac.uk/10.3390/s17092013
Chicago/Turabian StyleMao, Yingchi, Haishi Zhong, Hai Qi, Ping Ping, and Xiaofang Li. 2017. "An Adaptive Trajectory Clustering Method Based on Grid and Density in Mobile Pattern Analysis" Sensors 17, no. 9: 2013. https://0-doi-org.brum.beds.ac.uk/10.3390/s17092013
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.