Face Detection in Nighttime Images Using Visible-Light Camera Sensors with Two-Step Faster Region-Based Convolutional Neural Network

Abstract
:1. Introduction
2. Related Works
3. Contributions
- -
- This is the first face detection study using CNN for visible-light images taken at nighttime. Through CNN, our method automatically extracts features from nighttime images with high noise and blur levels, and it shows a high detection performance. Moreover, to improve the nighttime face detection performance, we use the HE method as preprocessing to increase both the contrast of images and the visibility of faces.
- -
- The Faster R-CNN model uses anchor boxes of various scales and aspect ratios to detect various types of objects; in this study, however, we use only anchor boxes of appropriate scales and aspect ratios to enhance the learning optimization speed and accuracy to detect faces at nighttime and in remote environments.
- -
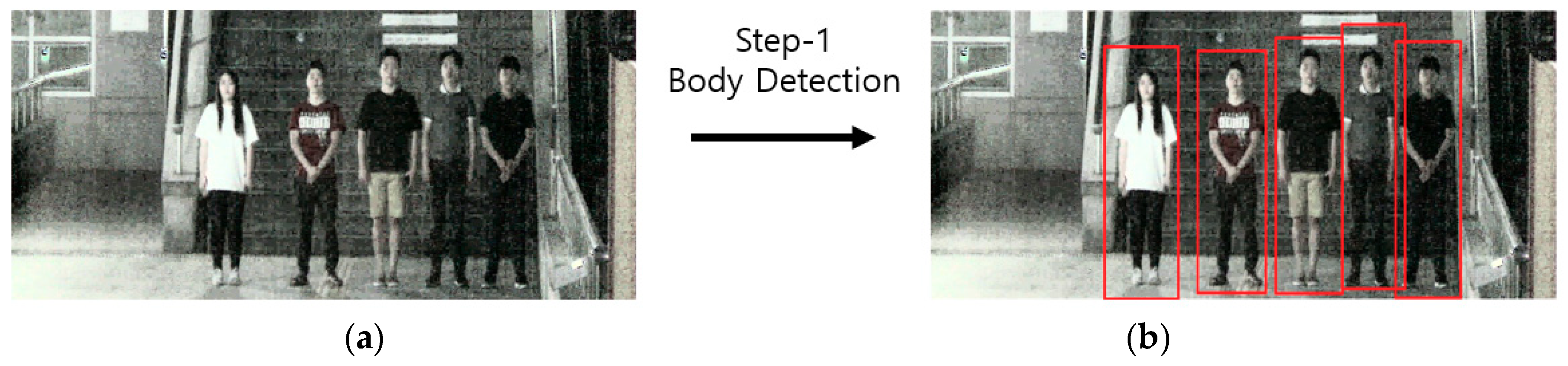
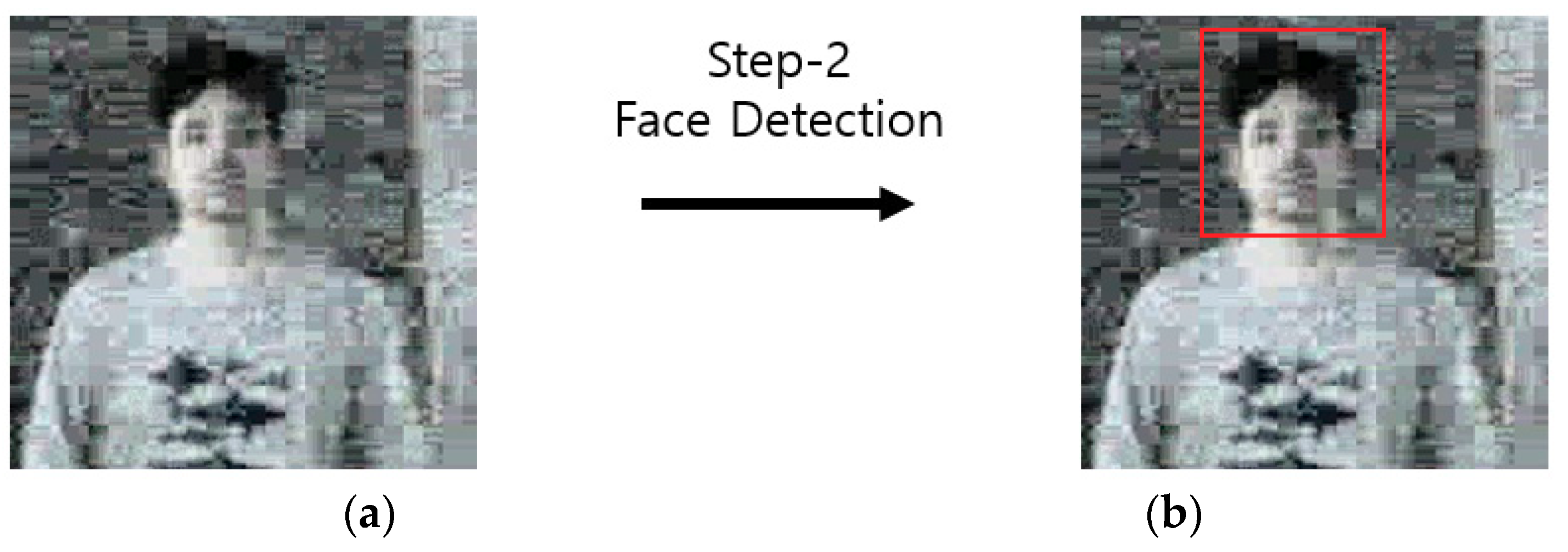
- Because it is difficult to find the face immediately at night with low intensity of illumination and contrast, our method uses the step-1 Faster R-CNN to first detect the body area, because it has a larger size compared to the face, to increase the detection rate. Our method improves the detection accuracy by locating the face with the Two-Step Faster R-CNN by setting the upper body region of the found body as ROI.
- -
- We form DNFD-DB1 and Two-Step Faster R-CNN models from the images acquired with a single visible-light camera at night, and make them available for use by other researchers [36].
4. Proposed Method
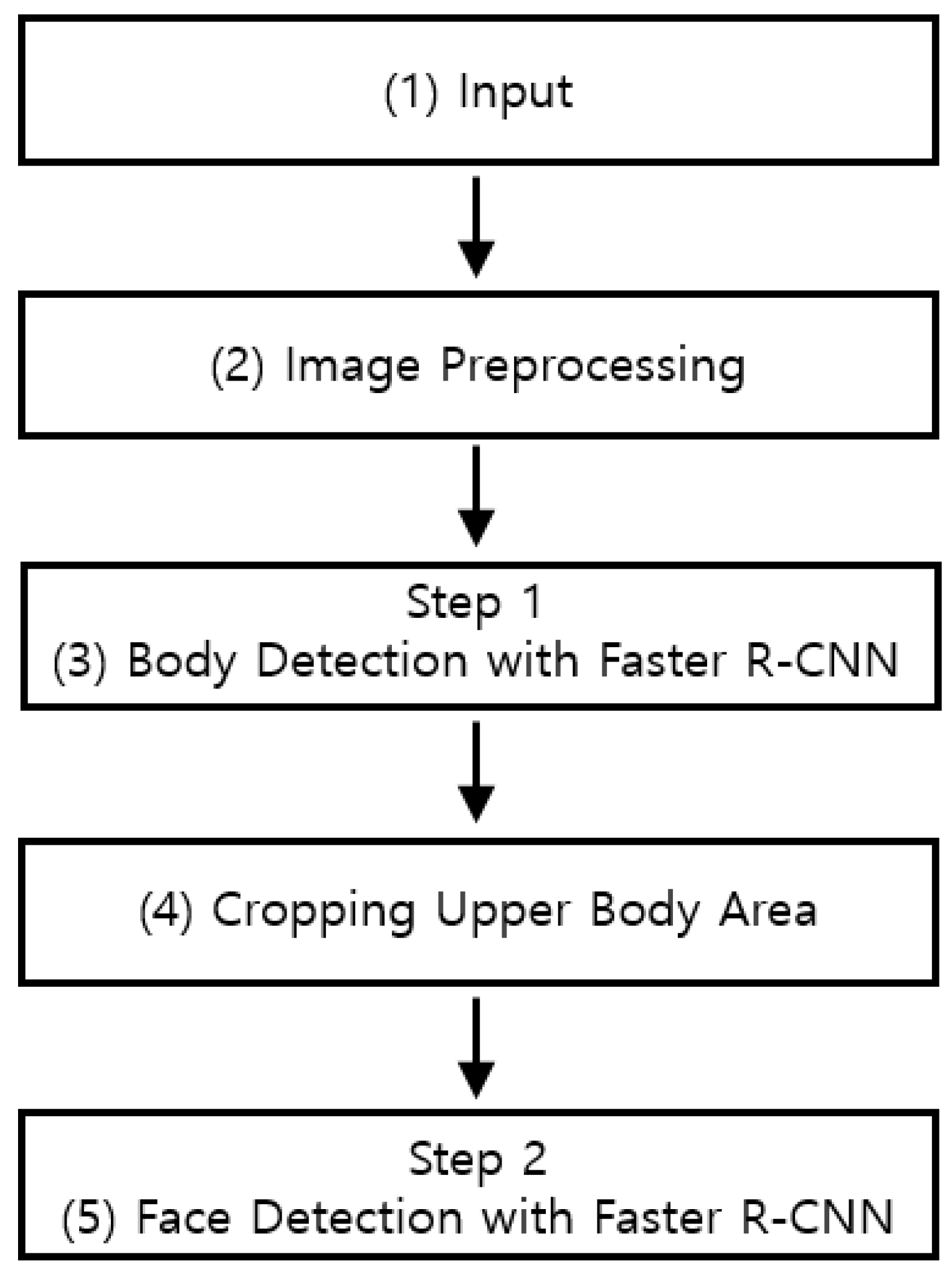
4.1. Overview of the Proposed Approach
4.2. Image Preprocessing
4.3. Two-Step Faster Region-Based Convolutional Neural Network (R-CNN)
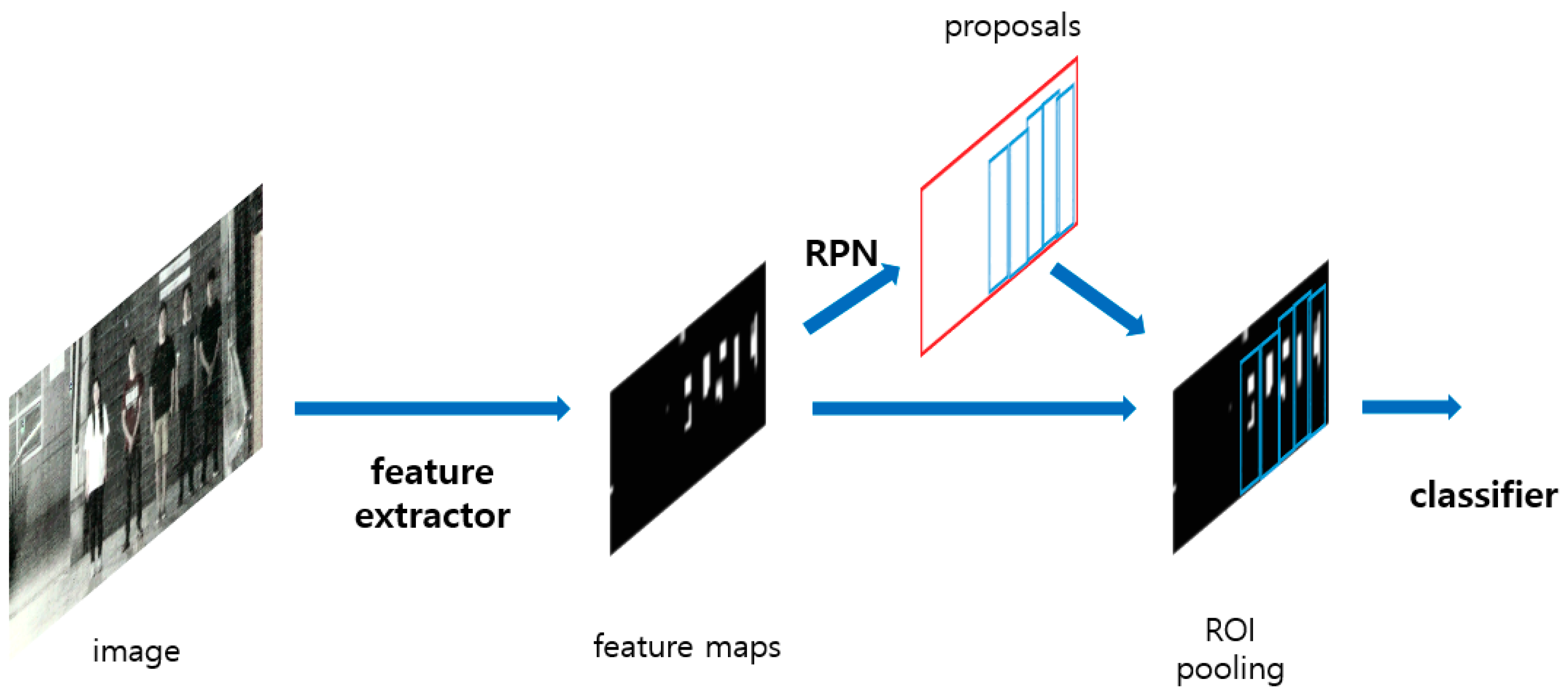
4.3.1. Details of Faster Region-Based Convolutional Neural Network
4.3.2. Step 1 Body Detection with Faster Region-based Convolutional Neural Network
4.3.3. Step 2 Face Detection with Faster Region-based Convolutional Neural Network
4.3.4. Differences between Original Faster R-CNN and Our Two-Step Faster R-CNN
- -
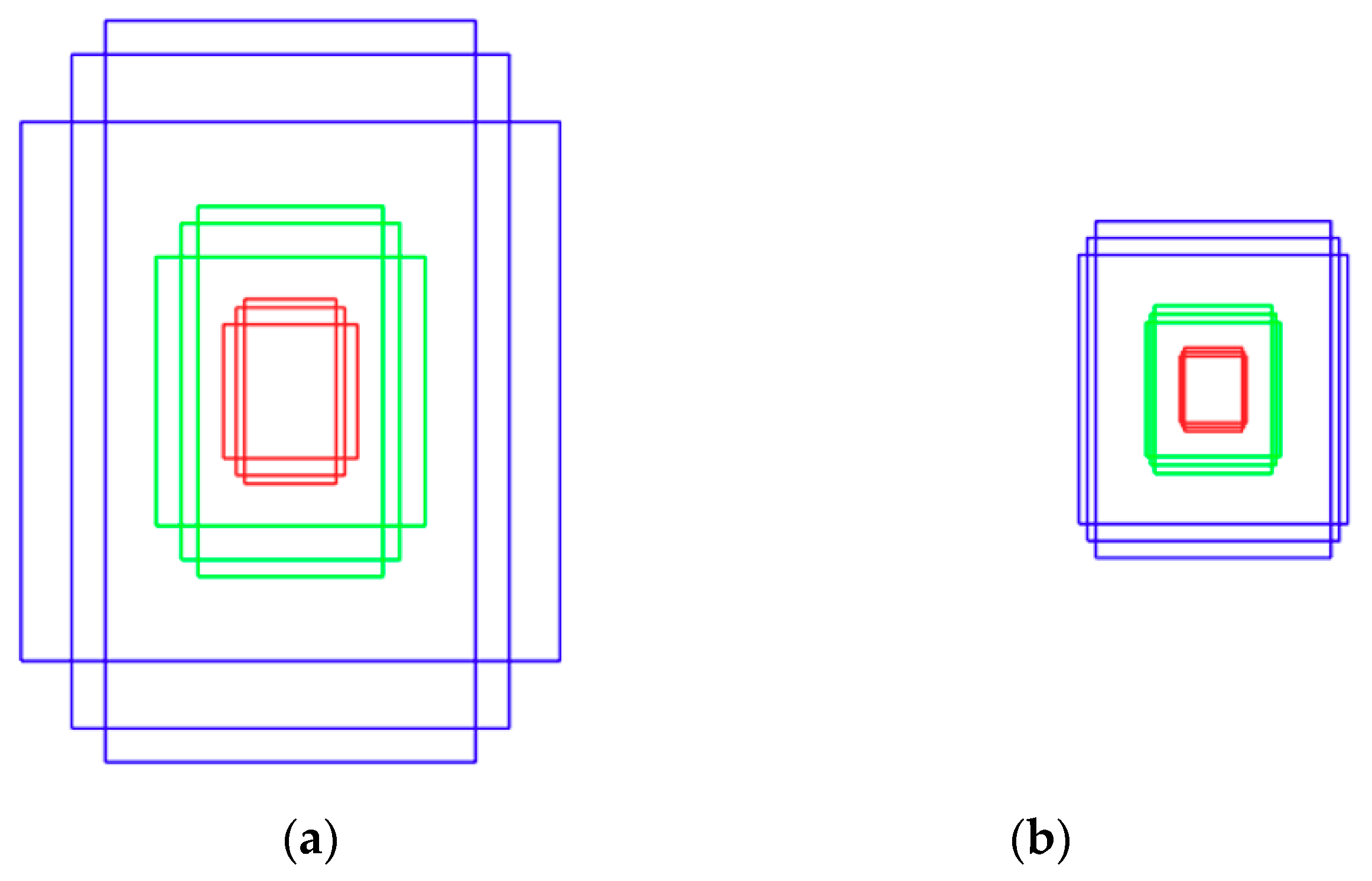
- The existing Faster R-CNN [14] uses nine anchor boxes of three scales and three aspect ratios to detect various objects. In our Step 1 body detection with Faster R-CNN (Section 4.3.2), longitudinal shape of boxes are used because the body of a standing person is to be detected; nine different anchor boxes of three scales (128 × 128, 256 × 256, and 512 × 512) and three aspect ratios (1:1, 1:1.5, and 1:2) are used as shown in Figure 6a to improve the learning optimization speed and accuracy.
- -
- In our two-step face detection with Faster R-CNN (Section 4.3.3), to detect faces in the upper body image, just as in the step-1 Faster R-CNN, the existing Faster R-CNN is also modified to two classes (face and background), whereas original Faster R-CNN is used for the classification of 21 classes [14].
- -
- In our two-step face detection with Faster R-CNN (Section 4.3.3), the part before the last max pooling layer of the pretrained VGG face-16 [43] is used as a feature extractor, whereas original Faster R-CNN uses the pretrained VGG Net-16 [41] for the feature extractor [14].
- -
- The existing Faster R-CNN [14] uses nine anchor boxes of three scales and three aspect ratios to detect various objects. In our two-step face detection with Faster R-CNN (Section 4.3.3), nine different anchor boxes of three scales (64 × 64, 128 × 128, and 256 × 256) and three aspect ratios (1:1, 1:1.2, and 1:4) are used as shown in Figure 6b, considering the size and ratio of the face.
- -
- As a two-step scheme, our method sequentially performs the detections of body and face areas, and locates the face inside a limited body area. By using our two-step-based method, the processing time by original Faster R-CNN can be reduced while maintaining the accuracy of face detection by Faster R-CNN.
5. Experimental Results and Analysis
5.1. Experimental Database and Environment
5.2. Training of Two-Step Faster R-CNN
5.3. Testing of Two-Step Faster R-CNN
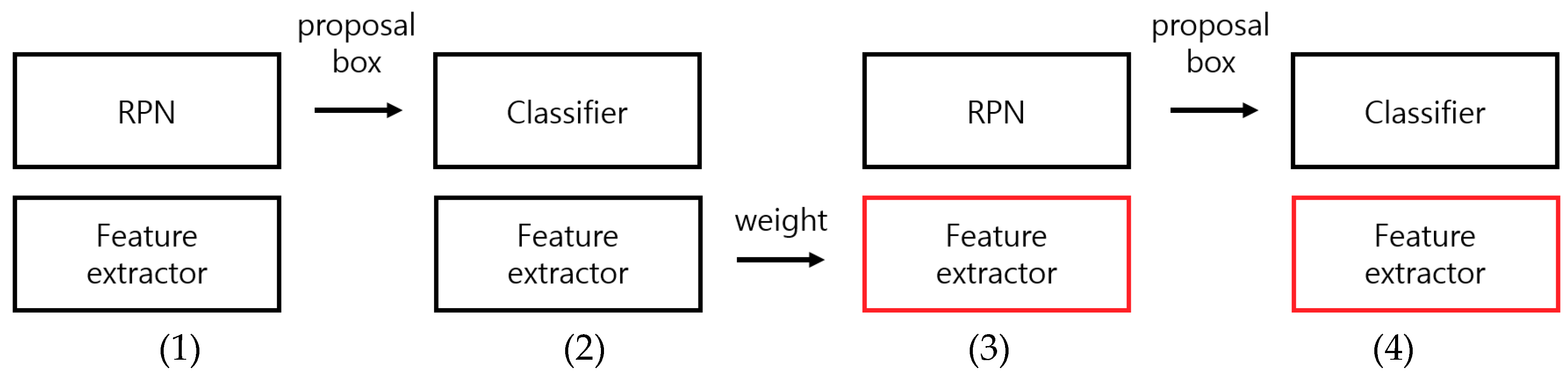
5.3.1. Comparative Experiments with RPN and Faster R-CNN in Body Detection Stage
5.3.2. Comparative Experiments with Original Nighttime Image and Histogram Equalization-Processed Image
5.3.3. Comparative Experiments with Two-Step Faster R-CNN and Single Faster R-CNN
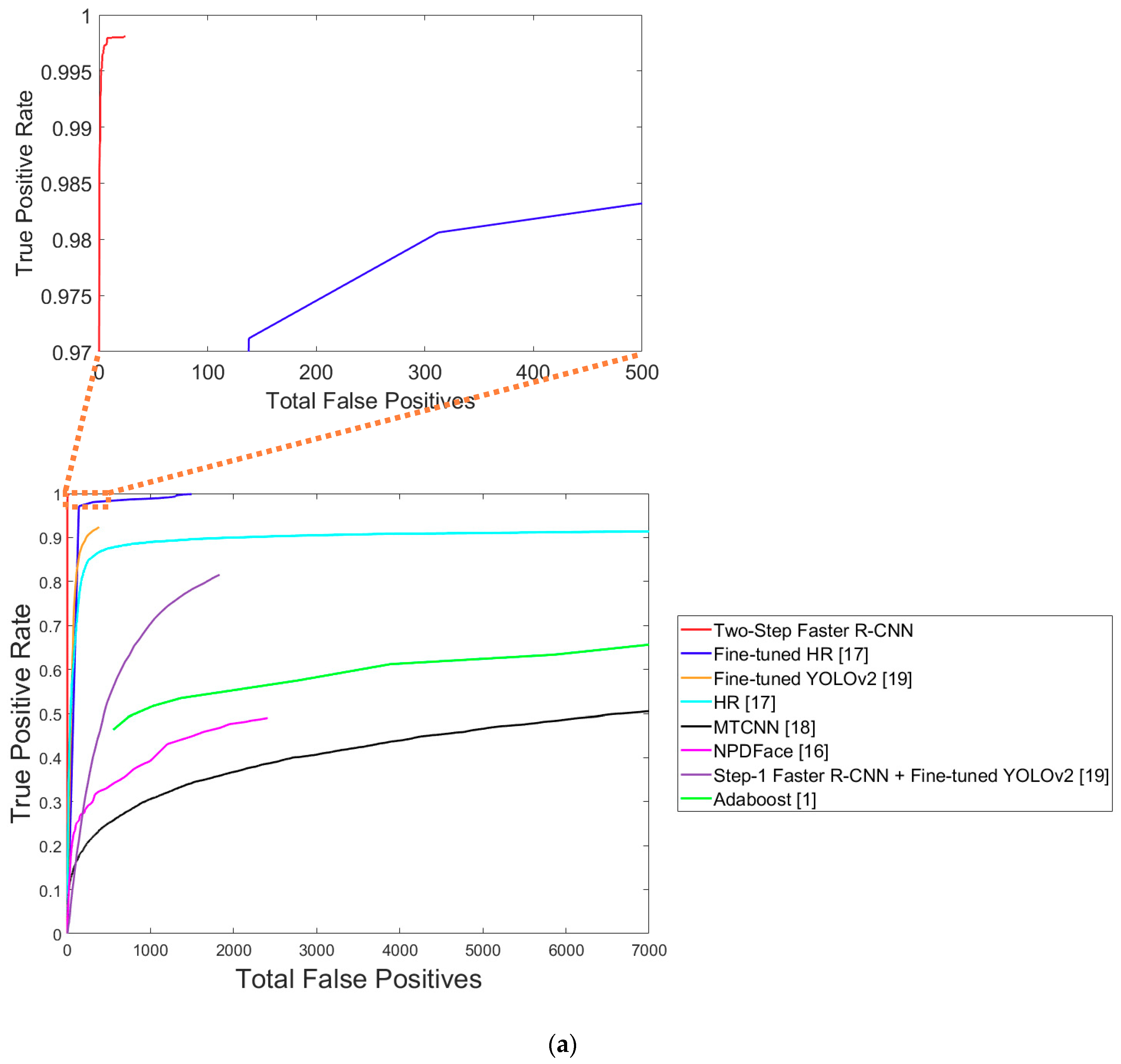
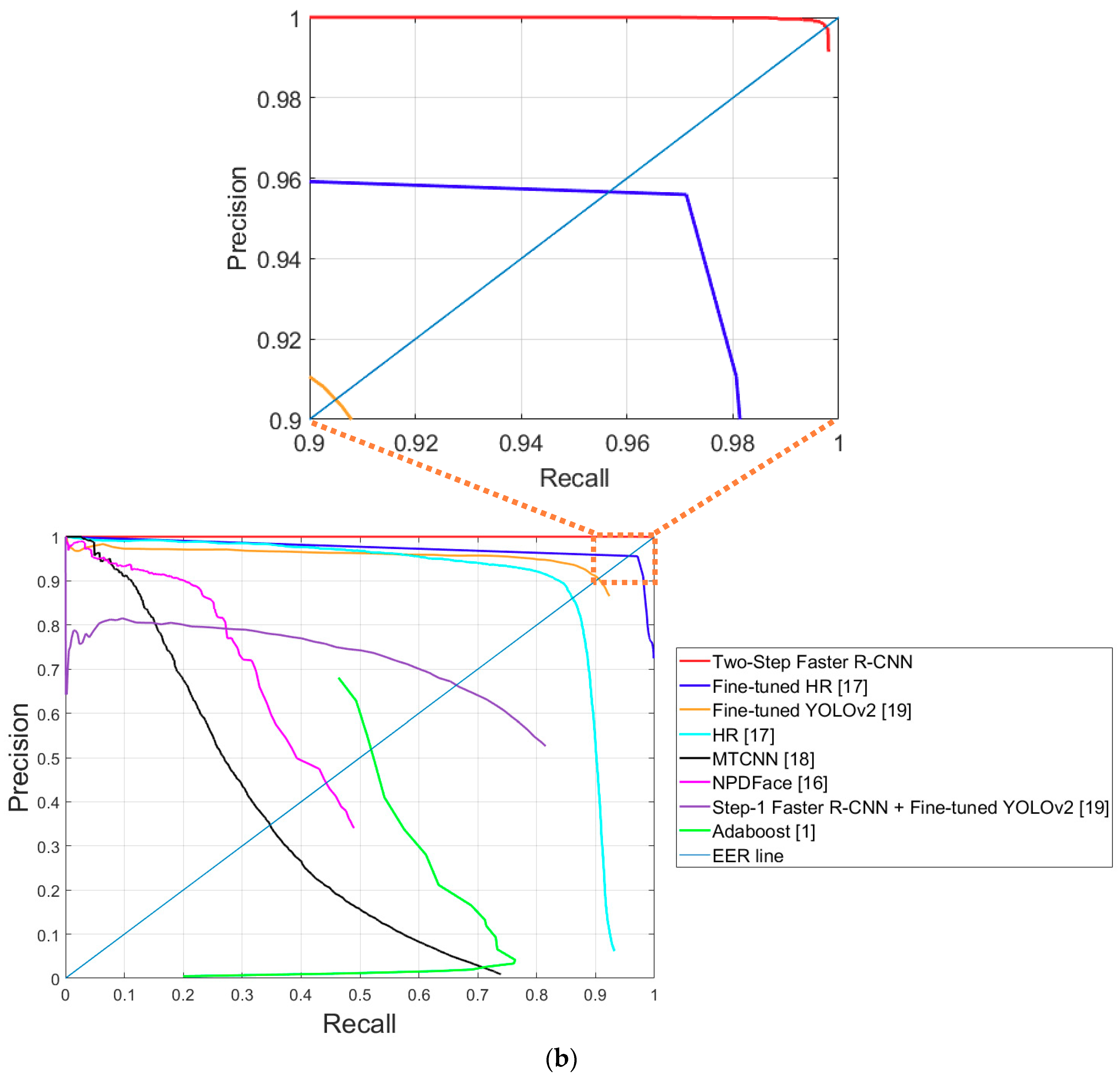
5.3.4. Comparative Experiments of Proposed Method with Previous Methods
Descriptions of Previous Methods
Comparative Experiments
5.3.5. Comparative Experiments of Proposed Method with Previous Methods Using Open Database
5.3.6. Analyses
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Number of Filters | Size of Feature Map (Height × Width × Channel) | Size of Kernel (Height × Width × Channel) | Number of Strides | Number of Paddings |
|---|---|---|---|---|---|
| Input layer [image] | 300 × 800 × 3 | ||||
| Conv1_1 (1st convolutional layer) | 64 | 300 × 800 × 64 | 3 × 3 × 3 | 1 × 1 | 1 × 1 |
| Relu1_1 | 300 × 800 × 64 | ||||
| Conv1_2 (2nd convolutional layer) | 64 | 300 × 800 × 64 | 3 × 3 × 64 | 1 × 1 | 1 × 1 |
| Relu1_2 | 300 × 800 × 64 | ||||
| Max pooling layer | 1 | 150 × 400 × 64 | 2 × 2 × 1 | 2 × 2 | 0 × 0 |
| Conv2_1 (3rd convolutional layer) | 128 | 150 × 400 × 128 | 3 × 3 × 64 | 1 × 1 | 1 × 1 |
| Relu2_1 | 150 × 400 × 128 | ||||
| Conv2_2 (4th convolutional layer) | 128 | 150 × 400 × 128 | 3 × 3 × 128 | 1 × 1 | 1 × 1 |
| Relu2_2 | 150 × 400 × 128 | ||||
| Max pooling layer | 1 | 75 × 200 × 128 | 2 × 2 × 1 | 2 × 2 | 0 × 0 |
| Conv3_1 (5th convolutional layer) | 256 | 75 × 200 × 256 | 3 × 3 × 128 | 1 × 1 | 1 × 1 |
| Relu3_1 | 75 × 200 × 256 | ||||
| Conv3_2 (6th convolutional layer) | 256 | 75 × 200 × 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 |
| Relu3_2 | 75 × 200 × 256 | ||||
| Conv3_3 (7th convolutional layer) | 256 | 75 × 200 × 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 |
| Relu3_3 | 75 × 200 × 256 | ||||
| Max pooling layer | 1 | 38 × 100 × 256 | 2 × 2 × 1 | 2 × 2 | 0 × 0 |
| Conv4_1 (8th convolutional layer) | 512 | 38 × 100 × 512 | 3 × 3 × 256 | 1 × 1 | 1 × 1 |
| Relu4_1 | 38 × 100 × 512 | ||||
| Conv4_2 (9th convolutional layer) | 512 | 38 × 100 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| Relu4_2 | 38 × 100 × 512 | ||||
| Conv4_3 (10th convolutional layer) | 512 | 38 × 100 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| Relu4_3 | 38 × 100 × 512 | ||||
| Max pooling layer | 1 | 19 × 50 × 512 | 2 × 2 × 1 | 2 × 2 | 0 × 0 |
| Conv5_1 (11th convolutional layer) | 512 | 19 × 50 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| Relu5_1 | 19 × 50 × 512 | ||||
| Conv5_2 (12th convolutional layer) | 512 | 19 × 50 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| Relu5_2 | 19 × 50 × 512 | ||||
| Conv5_3 (13th convolutional layer) | 512 | 19 × 50 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| Relu5_3 | 19 × 50 × 512 |
| Layer Type | Number of Filters | Size of Feature Map (Height × Width × Channel) | Size of Kernel (Height × Width × Channel) | Number of Strides | Number of Paddings |
|---|---|---|---|---|---|
| Input layer [Conv5_3] | 19 × 50 × 512 | ||||
| Conv6 (14th convolutional layer) Relu6 | 512 | 19 × 50 × 512 19 × 50 × 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 |
| Classification (convolutional layer) Softmax | 18 | 19 × 50 × 18 19 × 50 × 18 | 1 × 1 × 512 | 1 × 1 | 0 × 0 |
| Regression (convolutional layer) | 36 | 19 × 50 × 36 | 1 × 1 × 512 | 1 × 1 | 0 × 0 |
| Layer Type | Size of Output |
|---|---|
| Input layer | |
| [Conv5_3] | 19 × 50 × 512 |
| [region proposals] | 300 × 4 * |
| ROI pooling layer | 7 × 7 × 512 × 300 |
| Fc6 (1st fully connected layer) | 4096 × 300 |
| Relu6 | 4096 × 300 |
| Dropout6 | 4096 × 300 |
| Fc7 (2nd fully connected layer) | 4096 × 300 |
| Relu7 | 4096 × 300 |
| Dropout7 | 4096 × 300 |
| Classification (fully connected layer) | 2 ** × 300 |
| Softmax | 2 × 300 |
| Regression (fully connected layer) | 4 × 300 |
References
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. I-511–I-518. [Google Scholar]
- Jin, H.; Liu, Q.; Lu, H.; Tong, X. Face detection using improved LBP under Bayesian framework. In Proceedings of the 3rd International Conference on Image and Graphics, Hong Kong, China, 18–20 December 2004; pp. 306–309. [Google Scholar]
- Zhang, L.; Chu, R.; Xiang, S.; Liao, S.; Li, S.Z. Face detection based on multi-block LBP representation. In Proceedings of the International Conference on Biometrics, Seoul, Korea, 27–29 August 2007; pp. 11–18. [Google Scholar]
- Rekha, N.; Kurian, M.Z. Face detection in real time based on HOG. Int. J. Adv. Res. Comput. Eng. Technol. 2014, 3, 1345–1352. [Google Scholar]
- Cerna, L.R.; Cámara-Chávez, G.; Menotti, D. Face detection: Histogram of oriented gradients and bag of feature method. In Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition, Las Vegas, NV, USA, 22–25 July 2013; pp. 1–5. [Google Scholar]
- Pavlidis, I.; Symosek, P. The imaging issue in an automatic face/disguise detection system. In Proceedings of the IEEE Workshop on Computer Vision Beyond the Visible Specturm: Methods and Applications, Hilton Head, SC, USA, 16 June 2000; pp. 15–24. [Google Scholar]
- Zin, T.T.; Takahashi, H.; Toriu, T.; Hama, H. Fusion of infrared and visible images for robust person detection. In Image Fusion; Ukimura, O., Ed.; InTech: Rijeka, Croatia, 2011; pp. 239–264. [Google Scholar]
- Agrawal, J.; Pant, A.; Dhamecha, T.I.; Singh, R.; Vatsa, M. Understanding thermal face detection: Challenges and evaluation. In Face Recognition across the Imaging Spectrum; Bourlai, T., Ed.; Springer International Publishing: Basel, Switzerland, 2016; pp. 139–163. [Google Scholar]
- Ma, C.; Trung, N.T.; Uchiyama, H.; Nagahara, H.; Shimada, A.; Taniguchi, R.-I. Adapting local features for face detection in thermal image. Sensors 2017, 17, 1–31. [Google Scholar] [CrossRef] [PubMed]
- Murphy-Chutorian, E.; Doshi, A.; Trivedi, M.M. Head pose estimation for driver assistance systems: A robust algorithm and experimental evaluation. In Proceedings of the IEEE Intelligent Transportation Systems Conference, Seattle, WA, USA, 30 September–3 October 2007; pp. 709–714. [Google Scholar]
- Hao, X.; Chen, H.; Yang, Y.; Yao, C.; Yang, H.; Yang, N. Occupant detection through near-infrared imaging. Tamkang J. Sci. Eng. 2011, 14, 275–283. [Google Scholar]
- Lemoff, B.E.; Martin, R.B.; Sluch, M.; Kafka, K.M.; McCormick, W.; Ice, R. Automated night/day standoff detection, tracking, and identification of personnel for installation protection. In Proceedings of the SPIE 8711, Sensors, and Command, Control, Communications, and Intelligence (C3I) Technologies for Homeland Security and Homeland Defense XII, Baltimore, MD, USA, 29 April–3 May 2013; pp. 87110N-1–87110N-9. [Google Scholar]
- Hu, M.; Zhai, G.; Li, D.; Fan, Y.; Duan, H.; Zhu, W.; Yang, X. Combination of near-infrared and thermal imaging techniques for the remote and simultaneous measurements of breathing and heart rates under sleep situation. PLoS ONE 2018, 13, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3305. [Google Scholar]
- Liao, S.; Jain, A.K.; Li, S.Z. A fast and accurate unconstrained face detector. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 211–223. [Google Scholar] [CrossRef] [PubMed]
- Hu, P.; Ramanan, D. Finding tiny faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2007; pp. 1522–1530. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Lienhart, R.; Maydt, J. An extended set of haar-like features for rapid object detection. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; pp. I-900–I-903. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Shamia, D.; Chandy, D.A. Analyzing the performance of Viola Jones face detector on the LDHF database. In Proceedings of the IEEE International Conference on Siginal Processing and Communication, Coimbatore, India, 28–29 July 2017; pp. 312–315. [Google Scholar]
- Ojo, J.A.; Adeniran, S.A. Illumination invariant face detection using hybrid skin segmentation method. Eur. J. Comput. Sci. Inf. Technol. 2013, 1, 1–9. [Google Scholar]
- Chow, T.-Y.; Lam, K.-M.; Wong, K.-W. Efficient color face detection algorithm under different lighting conditions. J. Electron. Imaging 2006, 15, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Zhang, D.; Zhang, K.; Hu, K.; Yang, L. Real-time face detection during the night. In Proceedings of the 4th International Conference on Systems and Informatics, Hangzhou, China, 11–13 November 2017; pp. 582–586. [Google Scholar]
- Moazzam, M.G.; Parveen, M.R.; Bhuiyan, M.A.-A. Human face detection under complex lighting conditions. Int. J. Adv. Comput. Sci. Appl. 2011, 85–90. [Google Scholar] [CrossRef]
- Cai, J.; Goshtasby, A. Detecting human faces in color images. Image Vis. Comput. 1999, 18, 63–75. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning; Addison-Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Laytner, P.; Ling, C.; Xiao, Q. Robust face detection from still images. In Proceedings of the IEEE Symposium on Computational Intelligence in Biometrics and Identity Management, Orlando, FL, USA, 9–12 December 2014; pp. 76–80. [Google Scholar]
- Rizwan, M.; Islam, M.K.; Habib, H.A. Local enhancement for robust face detection in poor SNR images. Int. J. Comput. Sci. Netw. Secur. 2009, 9, 93–96. [Google Scholar]
- Comaschi, F.; Stuijk, S.; Basten, T.; Corporaal, H. RASW: A run-time adaptive sliding window to improve Viola-Jones object detection. In Proceedings of the 7th International Conference on Distributed Smart Cameras, Palm Springs, CA, USA, 29 November–1 October 2013; pp. 1–6. [Google Scholar]
- Kang, D.; Han, H.; Jain, A.K.; Lee, S.-W. Nighttime face recognition at large standoff: Cross-distance and cross-spectral matching. Pattern Recognit. 2014, 47, 3750–3766. [Google Scholar] [CrossRef]
- Chhapre, S.; Jadhav, P.; Sonawane, A.; Korani, P. Night time face recognition at large standoff. Int. Res. J. Eng. Technol. 2017, 2, 2799–2802. [Google Scholar]
- Nicolo, F.; Schmid, N.A. Long range cross-spectral face recognition: Matching SWIR against visible light images. IEEE Trans. Inf. Forensic Secur. 2012, 7, 1717–1726. [Google Scholar] [CrossRef]
- Bourlai, T.; Dollen, J.V.; Mavridis, N.; Kolanko, C. Evaluating the efficiency of a night-time, middle-range infrared sensor for applications in human detection and recognition. In Proceedings of the SPIE, Infrared Imaging Systems: Design, Analysis, Modeling, and Testing XXIII, Baltimore, MD, USA, 23–27 April 2012; pp. 83551B-1–83551B-12. [Google Scholar]
- Dongguk Night-Time Face Detection Database (DNFD-DB1) and Algorithm Including CNN Model. Available online: http://dm.dgu.edu/link.html (accessed on 29 June 2018).
- Menotti, D.; Najman, L.; Facon, J.; Araújo, A.D. Multi-histogram equalization methods for contrast enhancement and brightness preserving. IEEE Trans. Consum. Electron. 2007, 53, 1186–1194. [Google Scholar] [CrossRef]
- Aditya, K.P.; Reddy, V.K.; Ramasangu, H. Enhancement technique for improving the reliability of disparity map under low light condition. Procedia Technol. 2014, 14, 236–243. [Google Scholar] [CrossRef]
- Lee, S.-L.; Tseng, C.-C. Color image enhancement using histogram equalization method without changing hue and saturation. In Proceedings of the IEEE International Conference on Consumer Electronics, Taipei, Taiwan, 12–14 June 2017; pp. 305–306. [Google Scholar]
- Abdullah-Al-Wadud, M.; Kabir, M.H.; Dewan, M.A.A.; Chae, O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Russakovsky, O.; Deng, J.A.A.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Dodge, S.; Karam, L. A study and comparison of human and deep learning recognition performance under visual distortions. In Proceedings of the 26th International Conference on Computer Communication and Networks, Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–7. [Google Scholar]
- Dodge, S.; Karam, L. Understanding how image quality affects deep neural networks. In Proceedings of the 8th International Conference on Quality of Multimedia Experience, Lisbon, Portugal, 6–8 June 2016; pp. 1–6. [Google Scholar]
- Webcam C600. Available online: http://www.logitech.com/en-us/support/5869 (accessed on 2 May 2018).
- Open Database of Fudan University. Available online: https://cv.fudan.edu.cn/_upload/tpl/06/f4/1780/template1780/humandetection.htm (accessed on 26 March 2018).
- GeForce GTX 1070. Available online: https://www.geforce.co.uk/hardware/desktop-gpus/geforce-gtx-1070/specifications (accessed on 31 January 2018).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Matlab 2017a. Available online: https://www.mathworks.com/company/newsroom/mathworks-announces-release-2017a-of-the-matlab-and-simulink-pro.html (accessed on 17 August 2018).
- CUDA. Available online: https://en.wikipedia.org/wiki/CUDA (accessed on 17 August 2018).
- CUDNN. Available online: https://developer.nvidia.com/cudnn (accessed on 17 August 2018).
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Precision and Recall. Available online: https://en.wikipedia.org/wiki/Precision_and_recall (accessed on 5 July 2018).
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Student’s t-Test. Available online: https://en.wikipedia.org/wiki/Student%27s_t-test (accessed on 20 August 2018).
- Nakagawa, S.; Cuthill, I.C. Effect size, confidence interval and statistical significance: A practical guide for biologists. Biol. Rev. 2007, 82, 591–605. [Google Scholar] [CrossRef] [PubMed]
- Cohen, J. A power primer. Psychol. Bull. 1992, 112, 155–159. [Google Scholar] [CrossRef] [PubMed]
- Darknet: Open Source Neural Networks in C. Available online: https://pjreddie.com/darknet/ (accessed on 26 August 2018).
- Caffe. Available online: http://caffe.berkeleyvision.org/installation.html (accessed on 26 August 2018).



















| Category | Method | Advantages | Disadvantages | |
|---|---|---|---|---|
| Multiple camera-based method | Dual-band system of NIR and SWIR cameras [6] |
|
| |
| Single camera-based methods | Using thermal camera | Multi-slit method [7], Haar + LBP [8], Haar + HOG + AMB-LTP [9] |
| |
| Using NIR or SWIR camera | Three adaboost cascades [10], occupant detection with adaboost [11], cascade pattern detector [12], adaboost + FCN [13], Viola-Jones face detector [22], manually detected (or detected by commercial software) face region [32,33,34,35] |
| The intensity and angle of IR illuminator need to be adjusted according to its distance from the object. | |
| Using visible-light camera | Hybrid skin segmentation [23], region-based skin-color segmentation [24], adaboost with PRO-NPD features [25], face detection using GA [26], RASW-based Viola-Jones face detector [31], manually detected (or detected by commercial software) face region [32,33,34,35] | The price of camera is low. |
| |
| Image enhancement for face detection [29,30] |
|
| ||
| Two-Step Faster R-CNN (proposed method) |
| Training data and time to learn CNN are required. | ||
| DNFD-DB1 | Subset 1 | Subset 2 |
|---|---|---|
| Number of people | 10 | 10 |
| Number of images | 848 | 1154 |
| Number of augmented images | 1696 | 2308 |
| Number of face annotations | 4286 | 5809 |
| Resolution (width × height) (pixels) | 1600 × 600 | |
| Width of face (min – max) (pixels) | 45 − 80 | |
| Height of face (min – max) (pixels) | 48 − 86 | |
| Environment of database |
| |
| Models | DNFD-DB1 Subsets | Recall | Precision | Average Recall | Average Precision |
|---|---|---|---|---|---|
| RPN | 1st fold | 99.16 | 99.16 | 98.34 | 98.34 |
| 2nd fold | 97.52 | 97.52 | |||
| Step-1 Faster R-CNN | 1st fold | 99.97 | 99.97 | 99.94 | 99.94 |
| 2nd fold | 99.91 | 99.91 |
| Input Image | DNFD-DB1 Subsets | Recall | Precision | Average Recall | Average Precision |
|---|---|---|---|---|---|
| Original nighttime image (without preprocessing) | 1st fold | 98.83 | 98.83 | 98.50 | 98.50 |
| 2nd fold | 98.17 | 98.17 | |||
| HE-processed image | 1st fold | 99.89 | 99.89 | 99.76 | 99.76 |
| 2nd fold | 99.63 | 99.63 |
| Methods | DNFD-DB1 Subsets | Recall | Precision | Average Recall | Average Precision | #FP | #FN |
|---|---|---|---|---|---|---|---|
| Single Faster R-CNN | 1st fold | 79.93 | 79.93 | 79.04 | 79.04 | 2115.9 | 2115.9 |
| 2nd fold | 78.15 | 78.15 | |||||
| Two-Step Faster R-CNN | 1st fold | 99.89 | 99.89 | 99.76 | 99.76 | 24.2 | 24.2 |
| 2nd fold | 99.63 | 99.63 |
| Methods | Recall (avg.(std.)) | Precision (avg.(std.)) | #FP | #FN |
|---|---|---|---|---|
| MTCNN [18] | 34.74 (0.0834) | 34.74 (0.0211) | 1579.4 | 1579.4 |
| NPDFace [16] | 44.26 (0.0126) | 44.26 (0.0506) | 1345.4 | 1345.4 |
| Adaboost [1] | 51.88 (0.0143) | 51.88 (0.0225) | 1029.8 | 1029.8 |
| Step-1 Faster R-CNN + Fine-tuned YOLOv2 [19] | 66.36 (0.0363) | 66.36 (0.0182) | 862.5 | 862.5 |
| HR [17] | 86.12 (0.0216) | 86.12 (0.0360) | 338.8 | 338.8 |
| Fine-tuned YOLOv2 [19] | 90.49 (0.0087) | 90.49 (0.0166) | 251.2 | 251.2 |
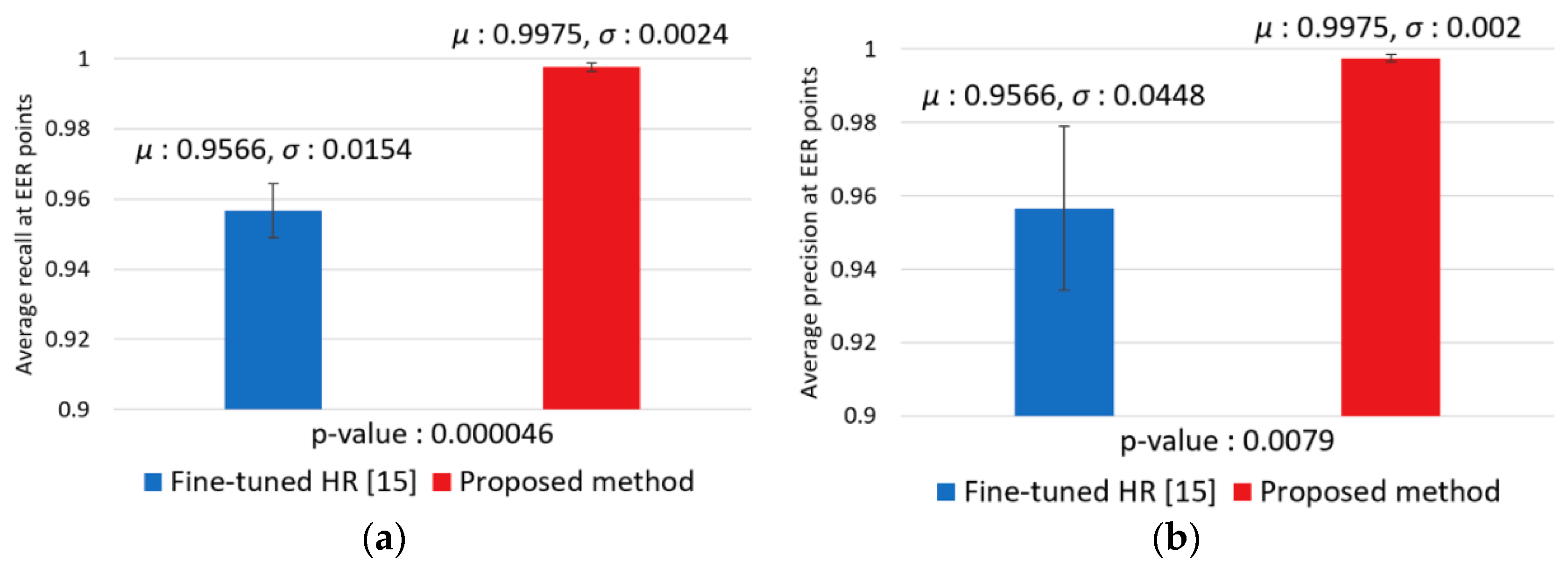
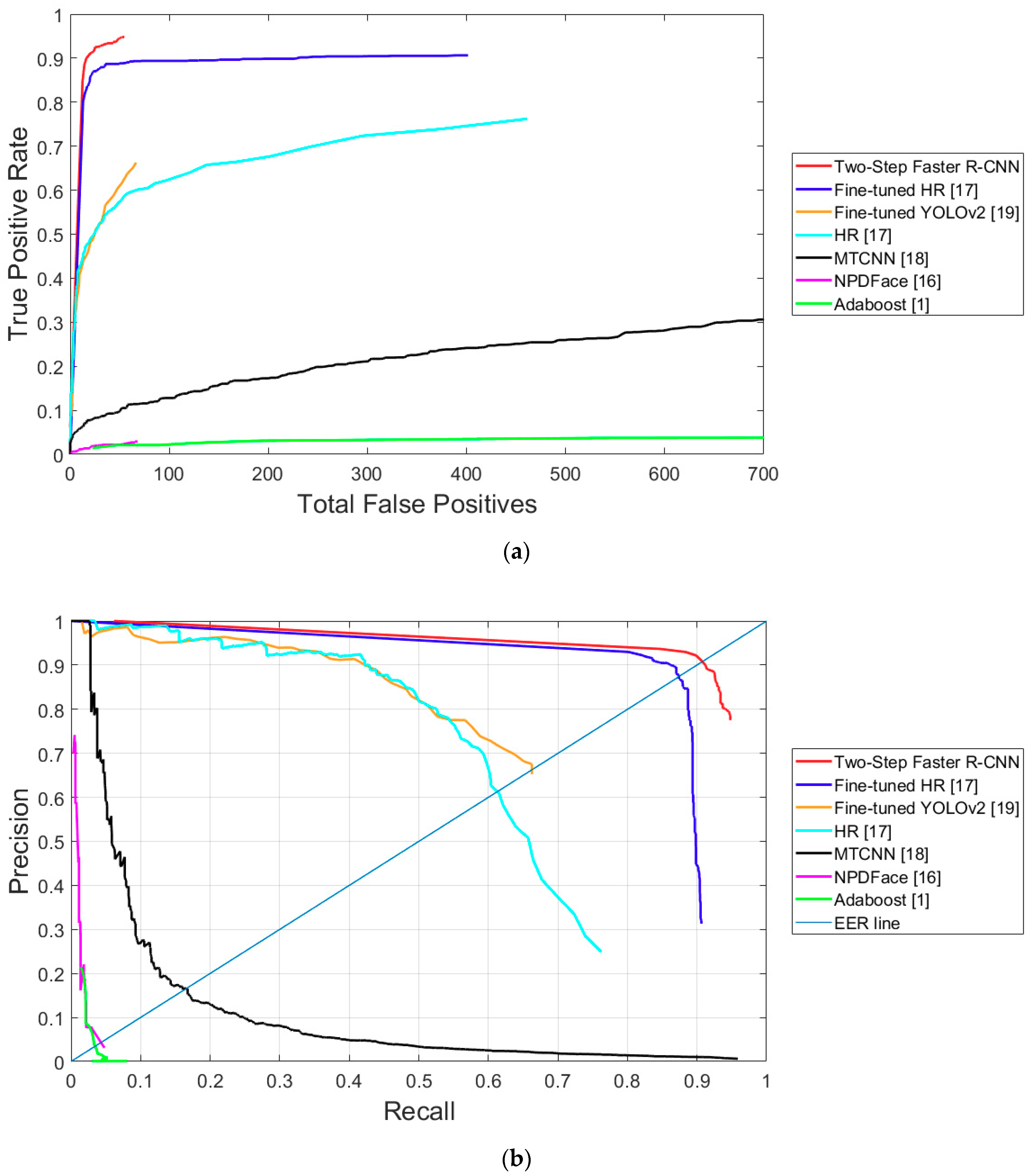
| Fine-tuned HR [17] | 95.66 (0.0154) | 95.66 (0.0448) | 137.9 | 137.9 |
| Two-Step Faster R-CNN (proposed method) | 99.75 (0.0024) | 99.75 (0.0020) | 6.9 | 6.9 |
| Methods | Recall (avg.(std.)) | Precision (avg.(std.)) |
|---|---|---|
| Adaboost [1] | 3.43 (0.0098) | 3.43 (0.0102) |
| NPDFace [16] | 4.18 (0.0177) | 4.18 (0.0348) |
| MTCNN [18] | 16.53 (0.0361) | 16.53 (0.0277) |
| HR [17] | 61.31 (0.0798) | 61.31 (0.0430) |
| Fine-tuned YOLOv2 [19] | 66.23 (0.0255) | 66.23 (0.0462) |
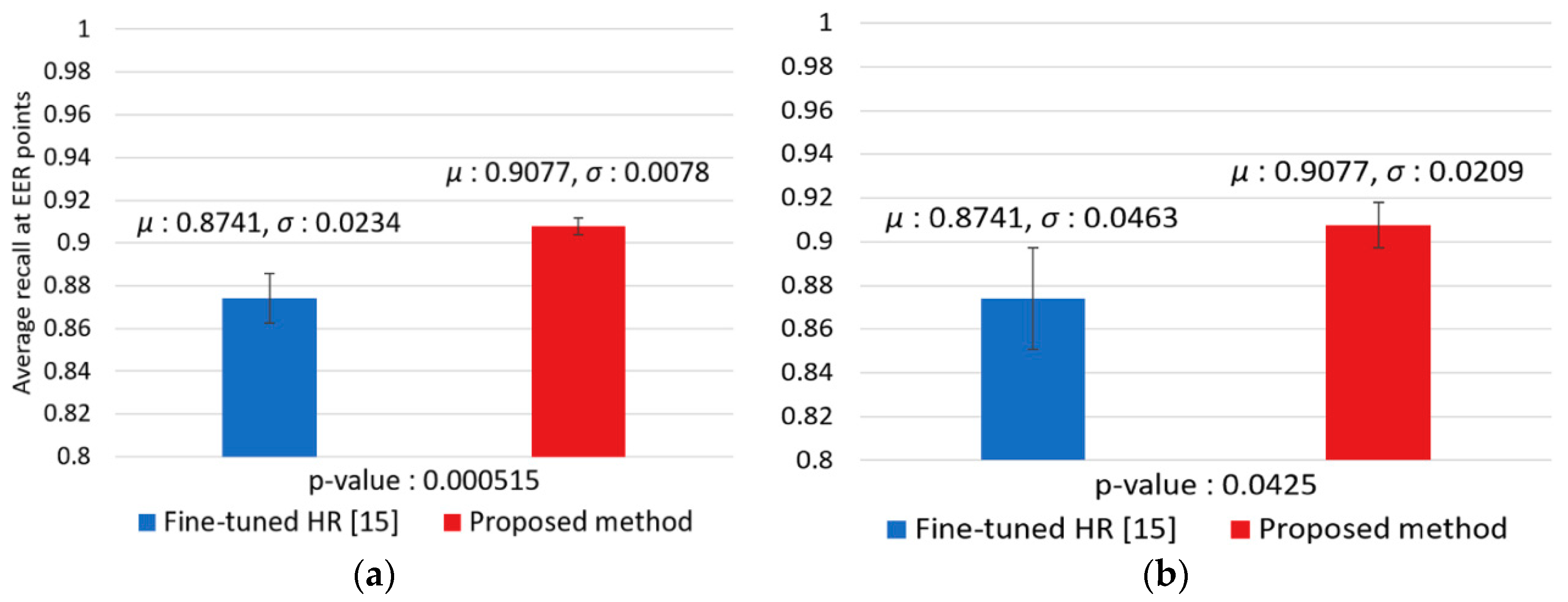
| Fine-tuned HR [17] | 87.41 (0.0234) | 87.41 (0.0463) |
| Two-Step Faster R-CNN (Proposed method) | 90.77 (0.0078) | 90.77 (0.0209) |
| Methods | Processing Time |
|---|---|
| MTCNN [18] | 122 |
| NPDFace [16] | 47 |
| Adaboost [1] | 70 |
| HR [17] | 1182 |
| Fine-tuned YOLOv2 [19] | 23 |
| Fine-tuned HR [17] | 1182 |
| Step-1 Faster R-CNN + Fine-tuned YOLOv2 [19] | 98.4 |
| Two-Step Faster R-CNN (proposed method) | 315 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, S.W.; Baek, N.R.; Kim, M.C.; Koo, J.H.; Kim, J.H.; Park, K.R. Face Detection in Nighttime Images Using Visible-Light Camera Sensors with Two-Step Faster Region-Based Convolutional Neural Network. Sensors 2018, 18, 2995. https://0-doi-org.brum.beds.ac.uk/10.3390/s18092995
Cho SW, Baek NR, Kim MC, Koo JH, Kim JH, Park KR. Face Detection in Nighttime Images Using Visible-Light Camera Sensors with Two-Step Faster Region-Based Convolutional Neural Network. Sensors. 2018; 18(9):2995. https://0-doi-org.brum.beds.ac.uk/10.3390/s18092995
Chicago/Turabian StyleCho, Se Woon, Na Rae Baek, Min Cheol Kim, Ja Hyung Koo, Jong Hyun Kim, and Kang Ryoung Park. 2018. "Face Detection in Nighttime Images Using Visible-Light Camera Sensors with Two-Step Faster Region-Based Convolutional Neural Network" Sensors 18, no. 9: 2995. https://0-doi-org.brum.beds.ac.uk/10.3390/s18092995