QUADRIVEN: A Framework for Qualitative Taxi Demand Prediction Based on Time-Variant Online Social Network Data Analysis



Abstract
:1. Introduction
- Most proposals address the problem of predicting taxi demand as a regression problem. Thus, they provide prediction outcomes in a quantitative manner (e.g., the future sheer number of pick-ups at a certain area of the city). However, this type of information might not be semantically meaningful in certain scenarios, as it may not refer to a certain contextual situation.
- Some proposals focus on anticipating taxi demand peaks in areas where the number of taxi pick-ups is expected to be much higher than in a normal situation. Nevertheless, there is a scarcity of proposals able to report a drop in the demand in spite of the fact that this information may be very valuable for operators as well [8,9].
- Current solutions usually rely on the data generated by the taxi service itself (e.g., GPS traces, pick-up and drop-off details, etc.) to build up the prediction models. This highly limits the scalability of the solutions, as they can only operate in cities with taxi services capable of generating and capturing the data required by the models.
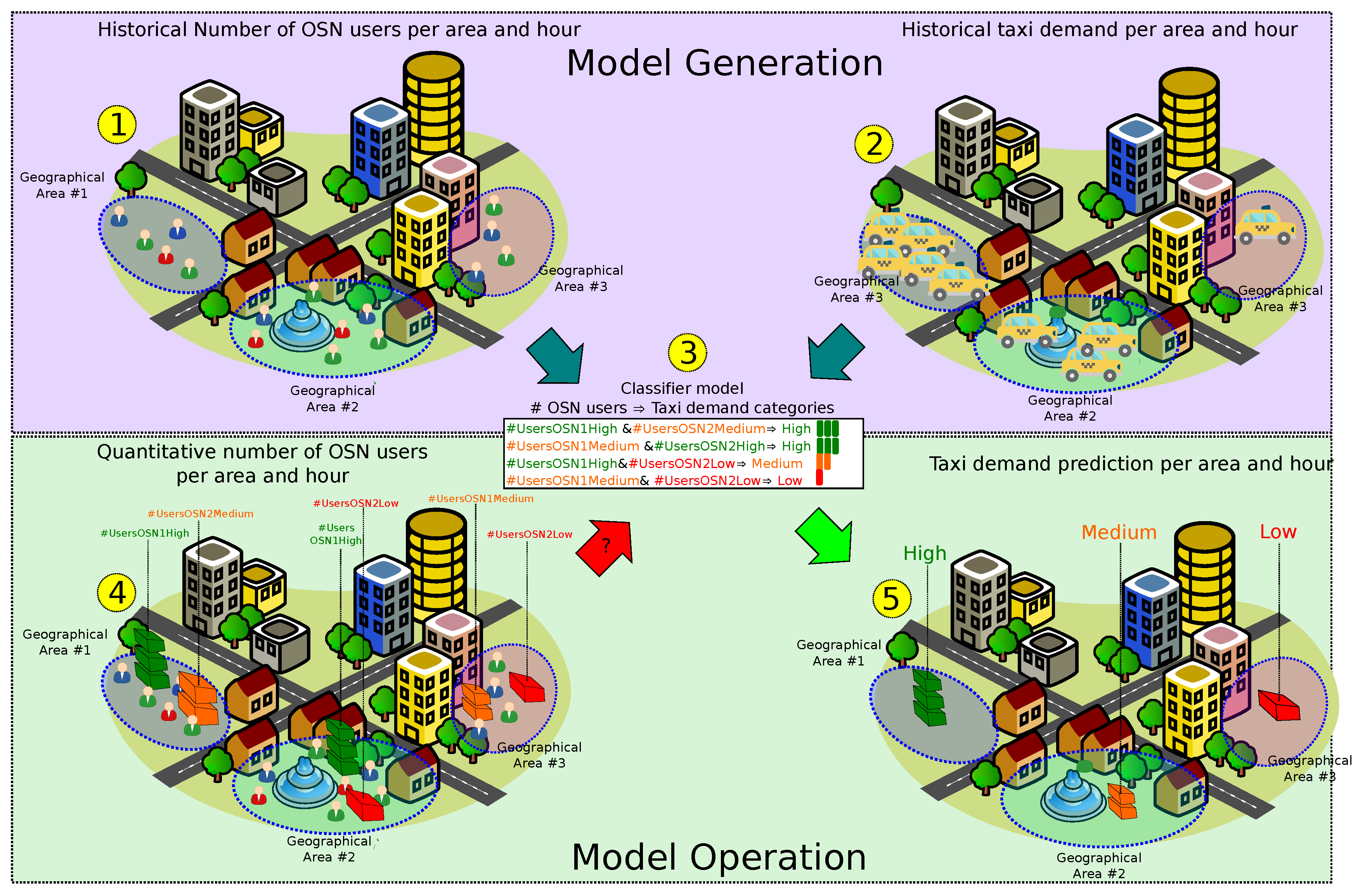
2. The QUADRIVEN Framework
2.1. Prediction Problem Statement
2.2. Data Description
2.2.1. Region Partitioning
2.2.2. Required Datasets
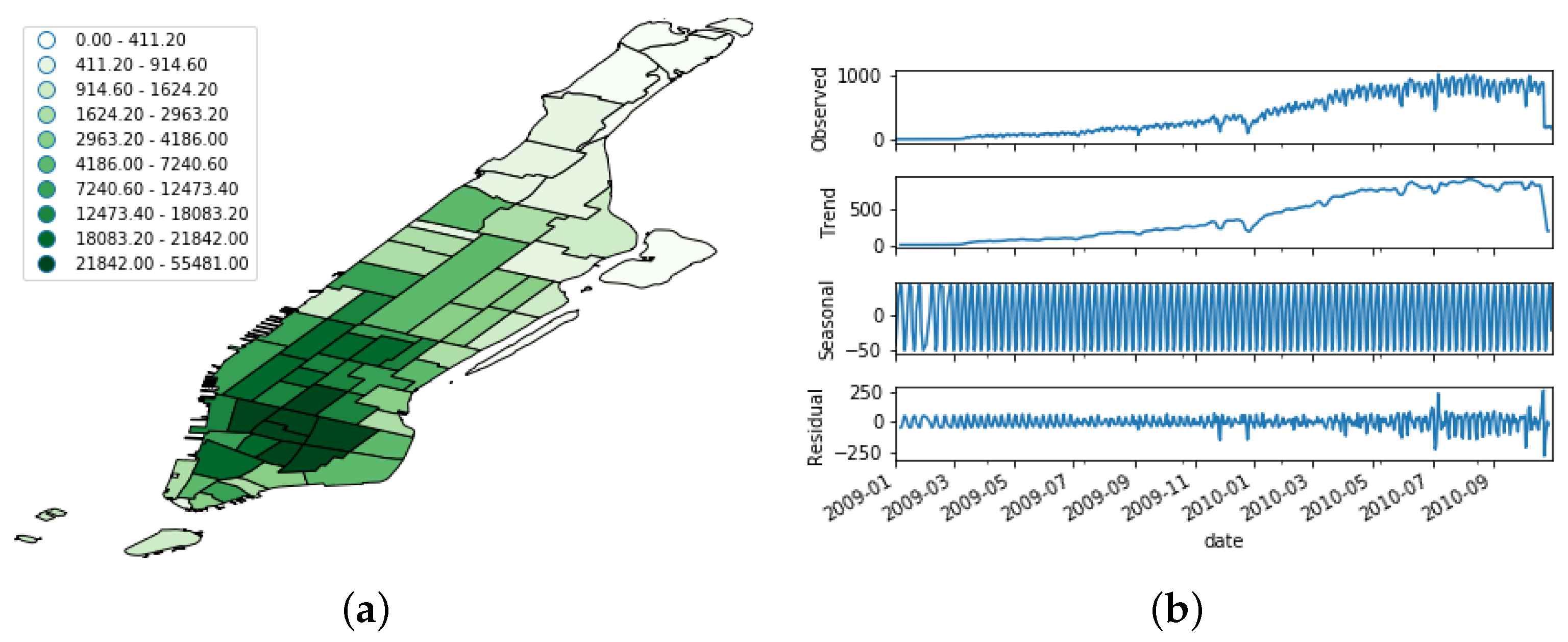
OSN Data
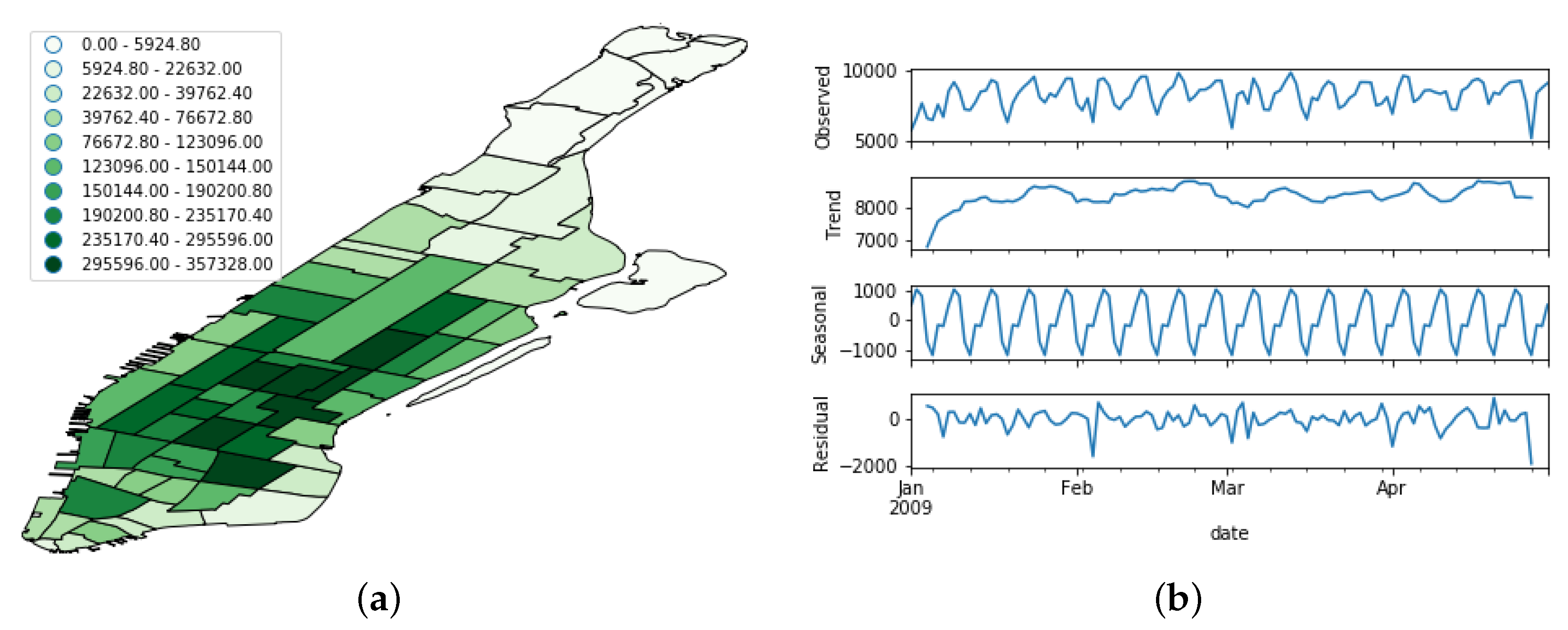
Original Taxi Demand Record Data
Meteorological Data
2.3. Correlational Study
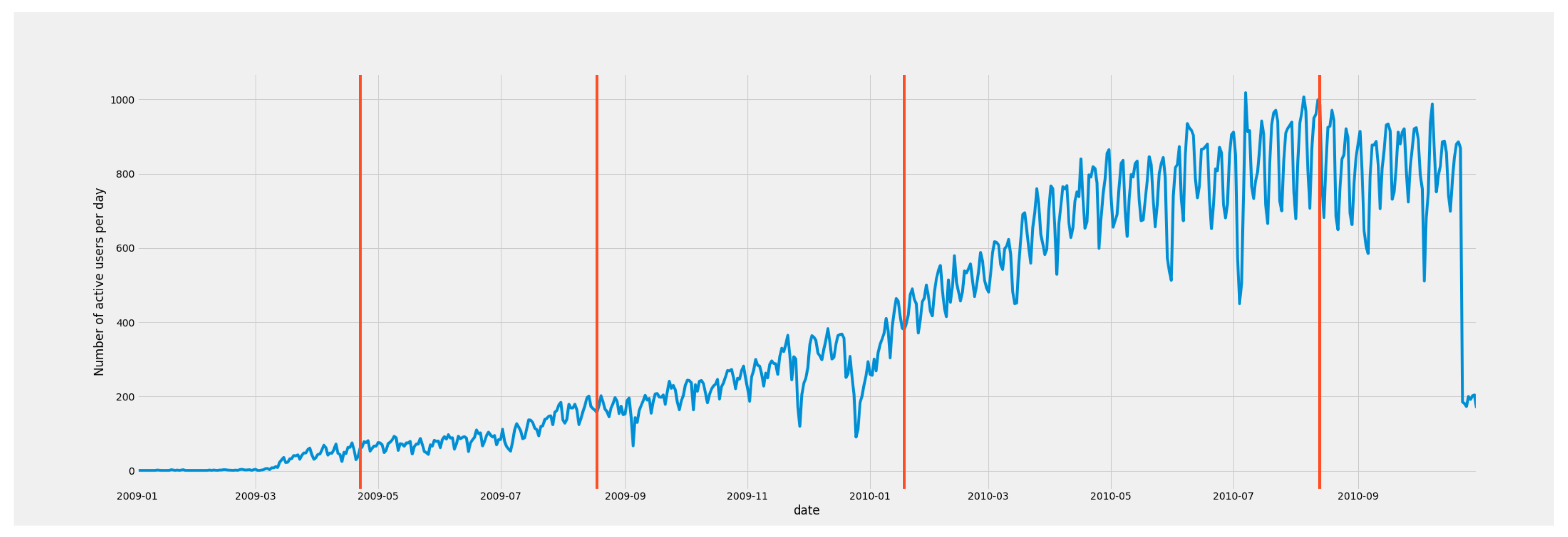
2.4. Calculation of the Number of Active Users
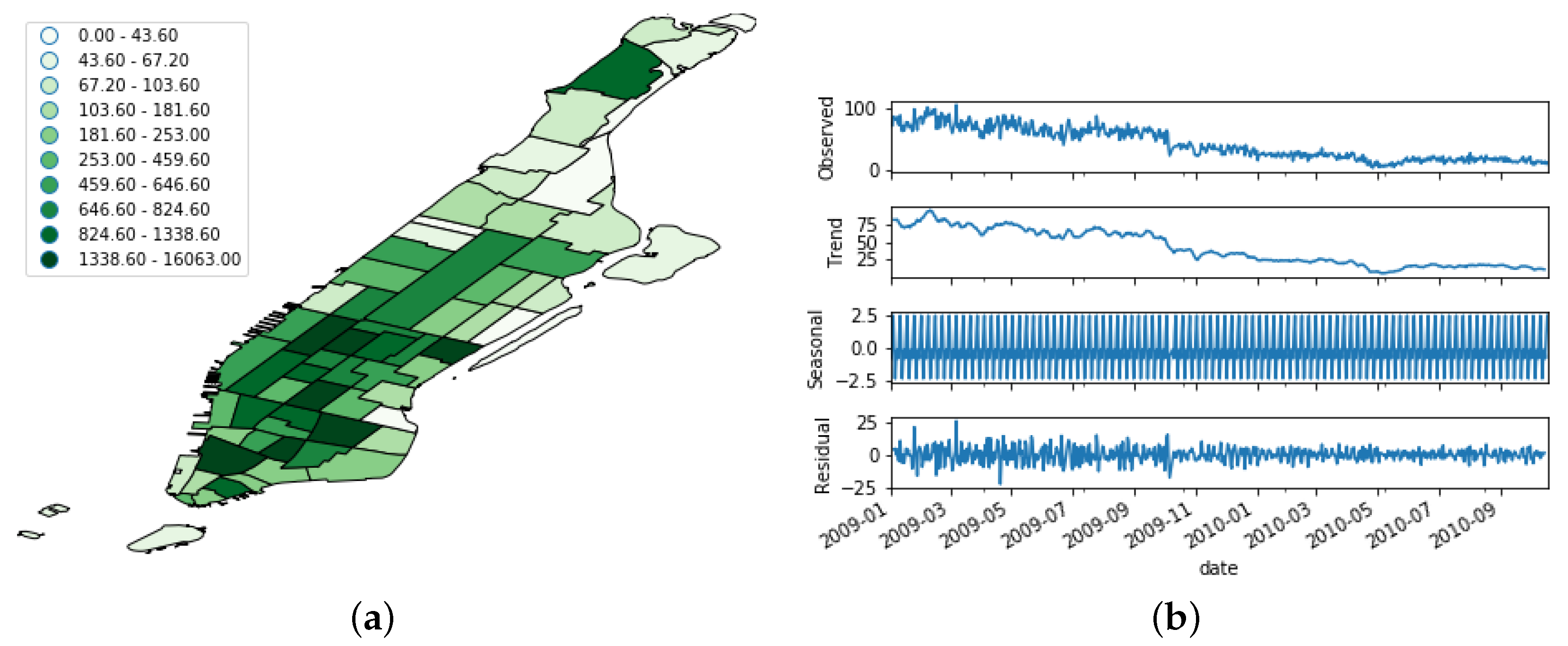
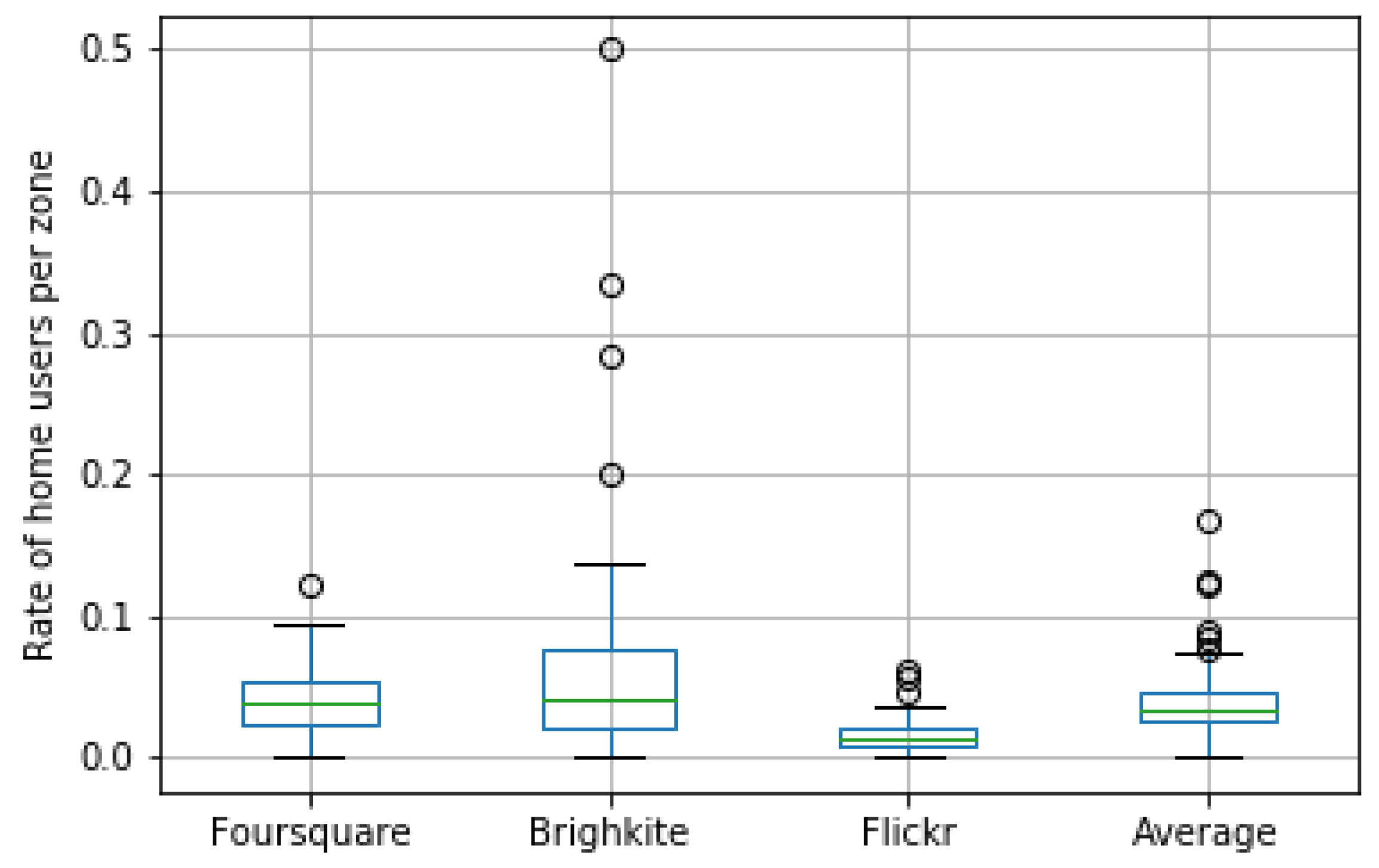
Home User Filtering
| Algorithm 1: Pseudo-code of the Z-scores calculation for OSN count data, including home-user data removal. |
 |
2.5. Calculation of the Taxi Demand Quantiles
- Firstly, we aggregated the records per taxi zone and hour for each of the dates in the 22-month period. Let us define as the number of taxi pick-ups at region r at hour h in day d.
- Next, we created a set comprising all the values for every region and hour. This gave rise to stratified sets . For example, the set comprised all the count values with the number of pick-ups at Region #4 at 9:00 a.m. for all the dates d of the original dataset.
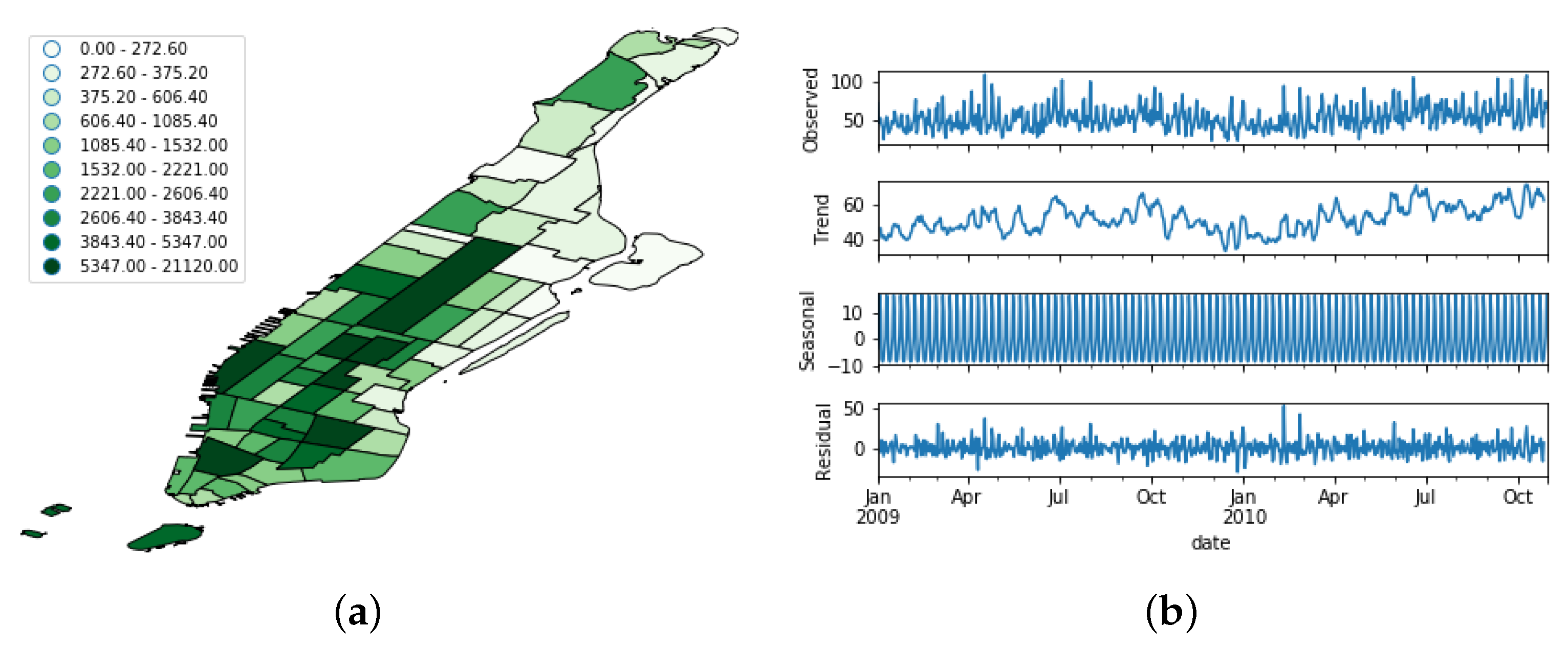
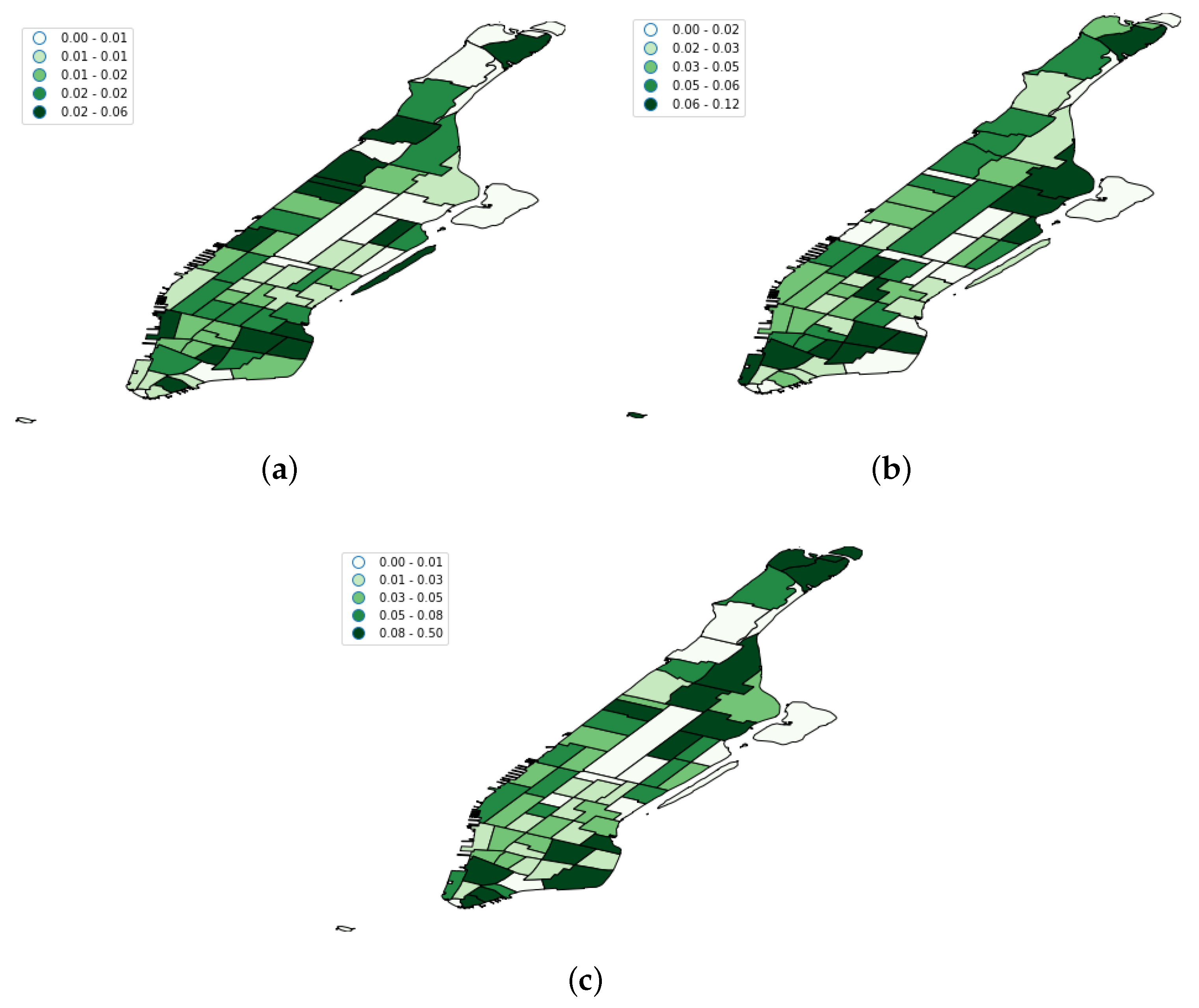
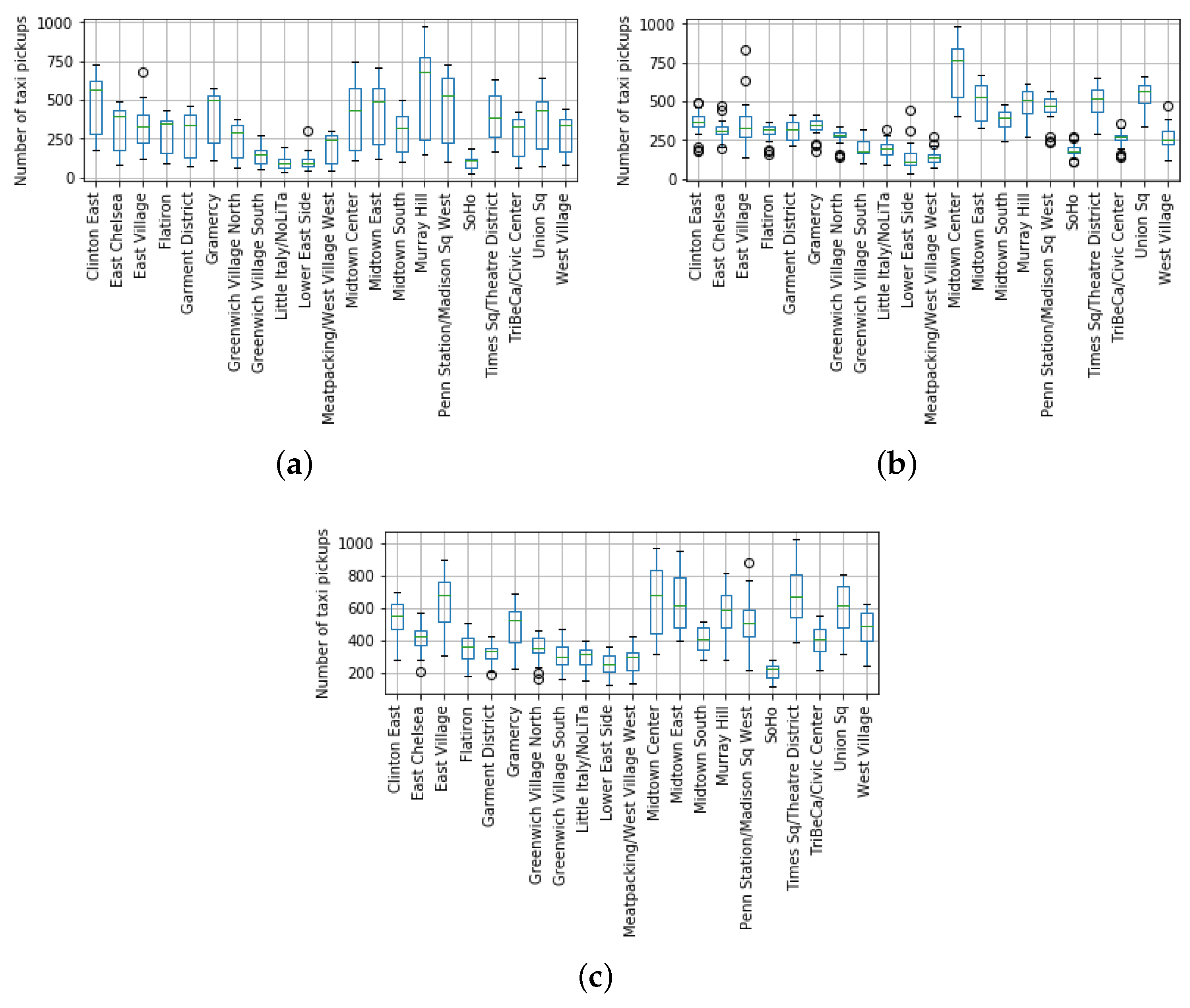
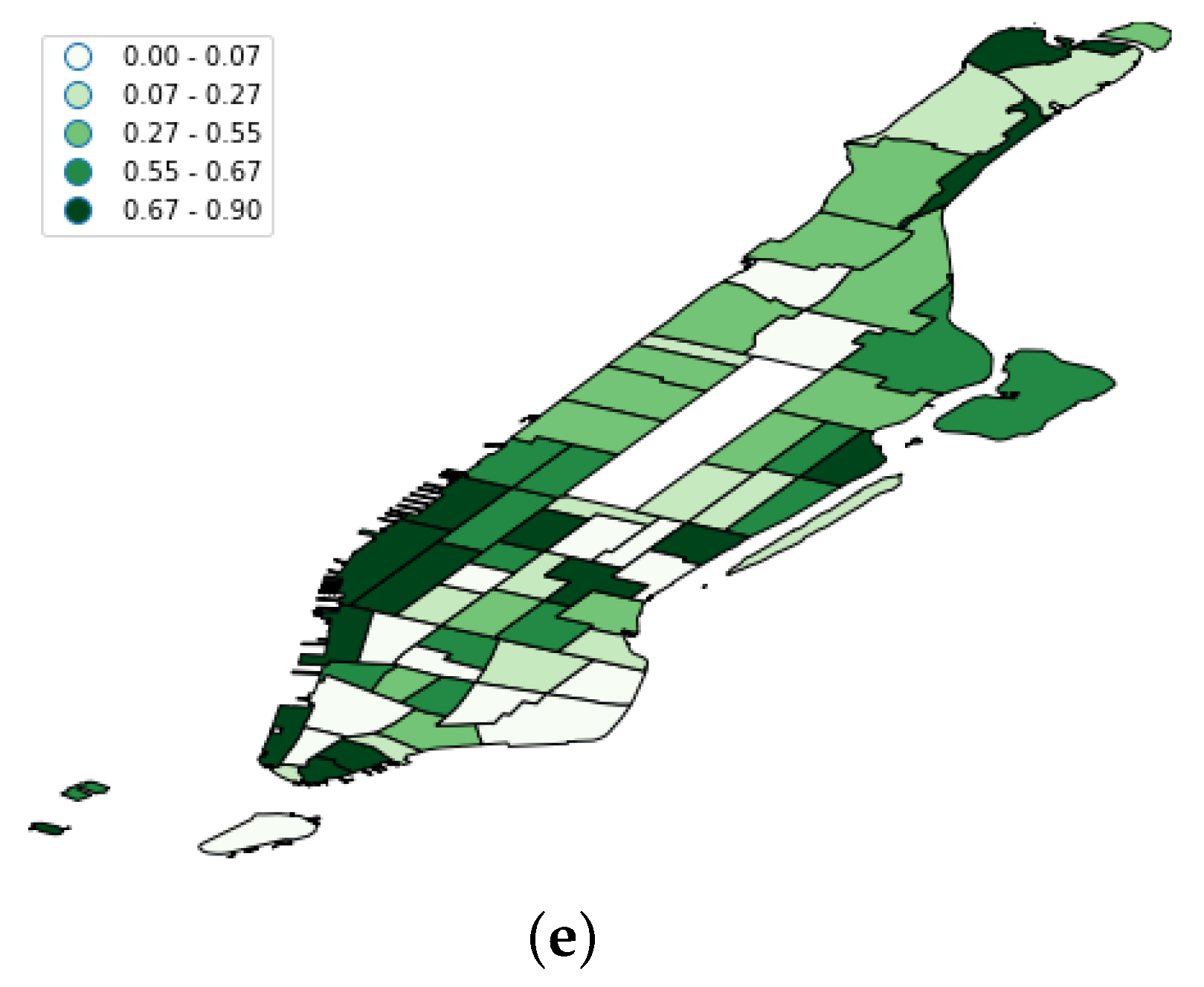
- Then, we calculated the lower () and upper quartiles () for each set. At this point, we should remark that these quartiles were calculated for each particular region at a single hour of the day. This is because the taxi demand profile meaningfully varied depending on the target region and the hour of the day, as Figure 11 shows. This way, the obtained quartiles actually represent low and high boundaries of the taxi demand behavior in a region regardless of seasonal patterns.
- Finally, we mapped each value to their corresponding quartile range (low, middle, high) defined as by means of the following if-then rules,
- –
- If , then the assigned label is .
- –
- If , then the assigned label is .
- –
- If , then the assigned label is .
2.6. Composition of the Classifier
- the target region r,
- the current hour of the day h,
- the current day of the week ,
- The z-scores of the three OSNs for region r at hour h,
- the current temperature t,
- the current rain level .
3. Evaluation of the Proposal
3.1. Evaluated Models
3.1.1. Conditional Random Fields
3.1.2. Random Forest
3.1.3. Support Vector Machine
3.1.4. Long Short Term Memory Neural Network
3.1.5. Fully Connected Neural Network
3.2. Implementation Details
3.3. Evaluation Settings
3.4. Evaluation Metrics
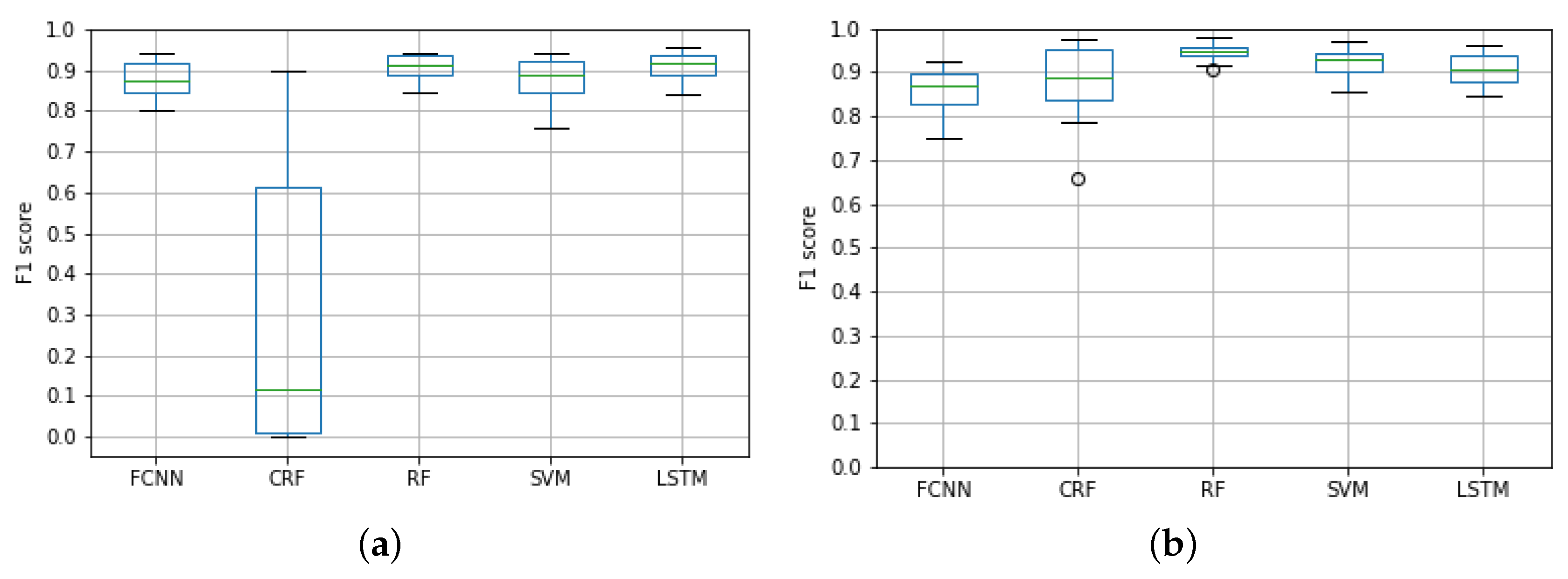
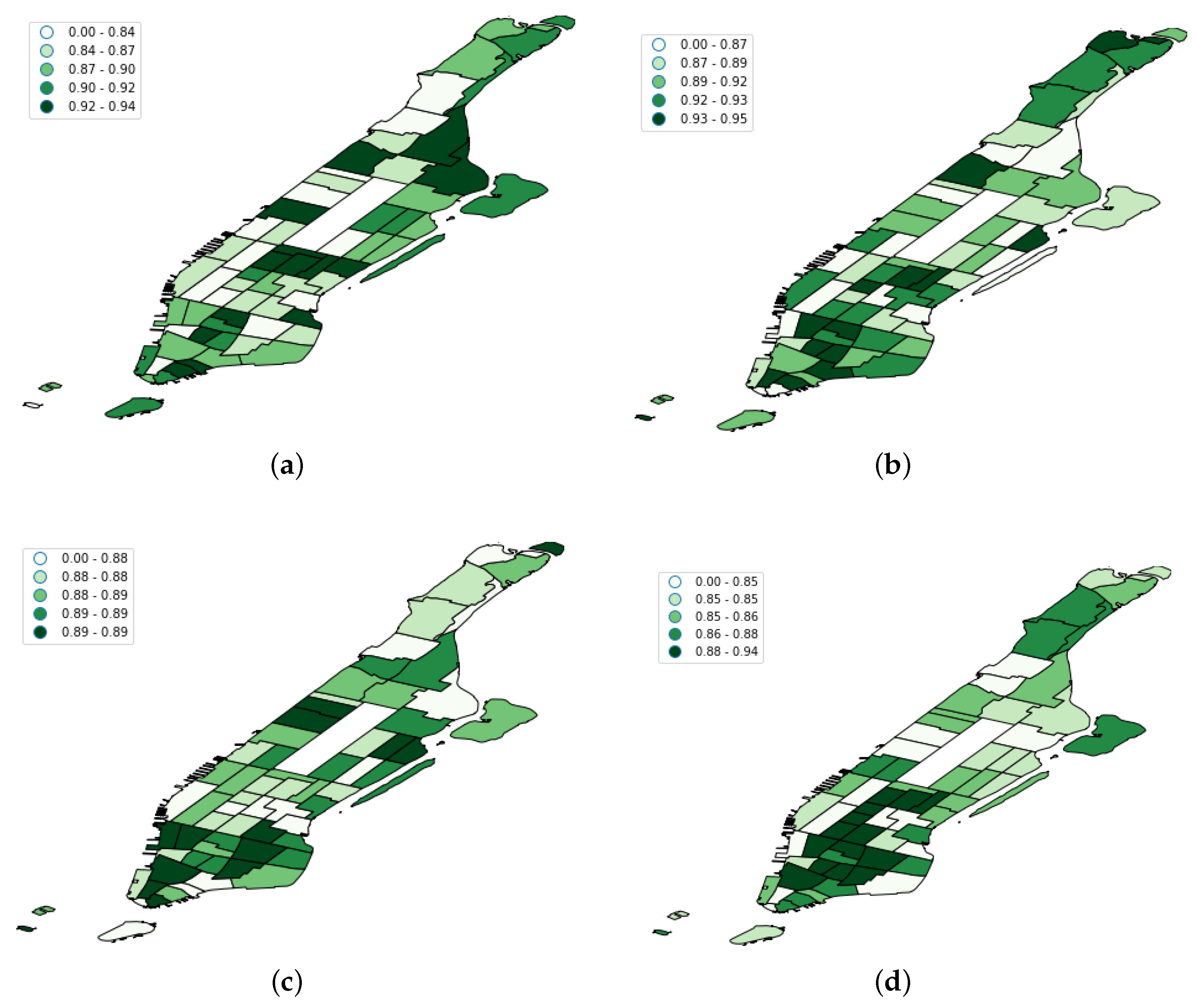
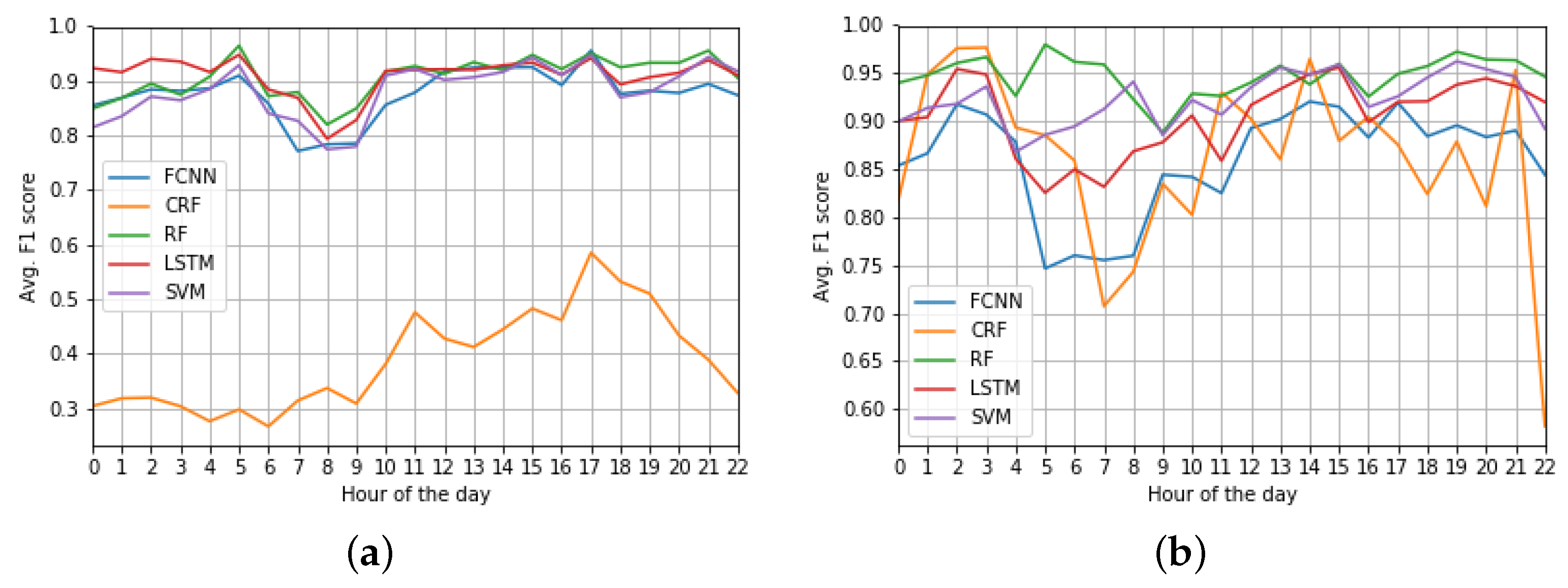
3.5. Results’ Discussion
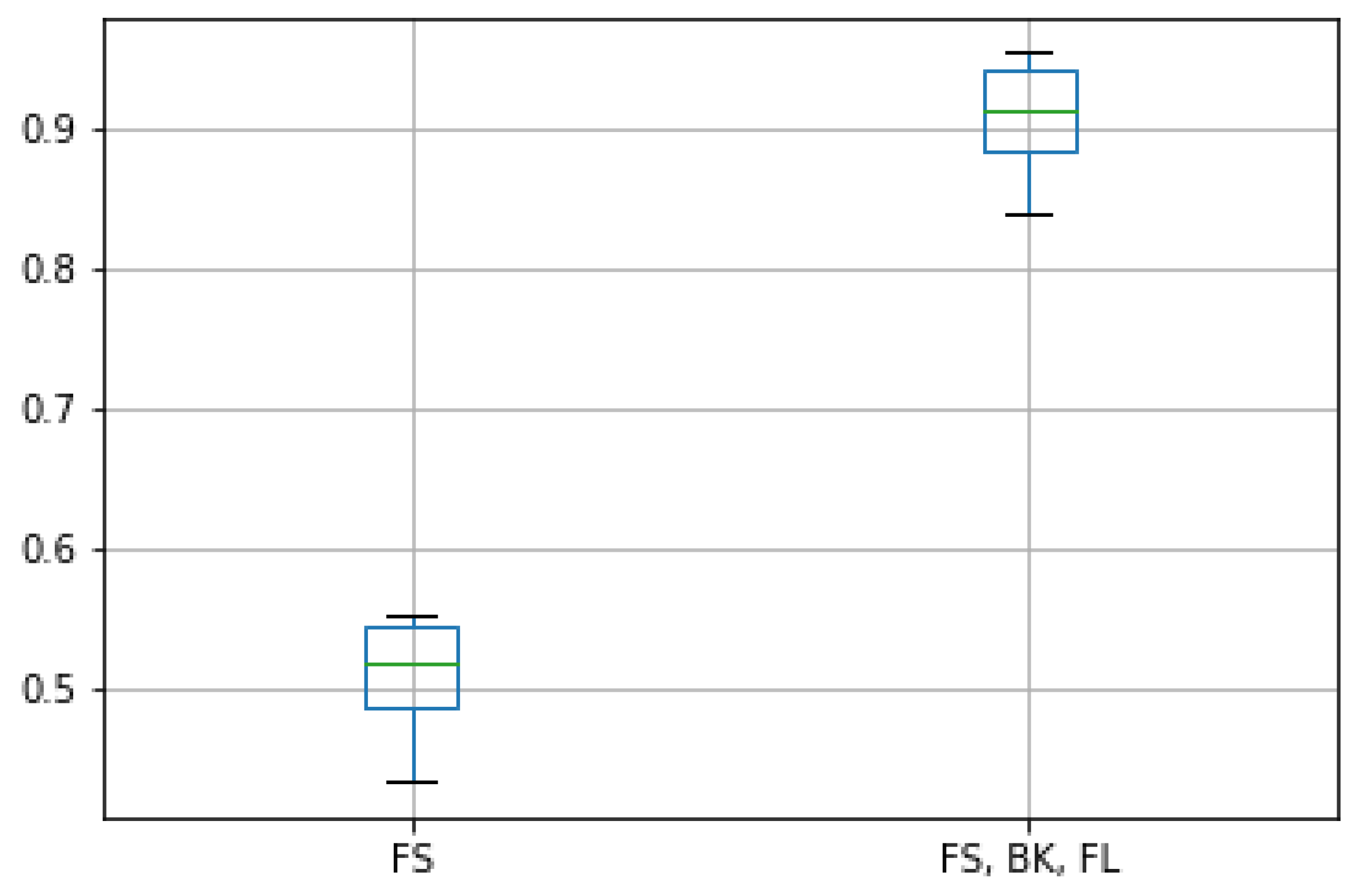
3.6. OSN Data Sources Comparison
4. Related Work
4.1. Input Data Sources
4.2. Data Mining Methods
4.3. Prediction Outcome
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Di, Q.; Wang, Y.; Zanobetti, A.; Wang, Y.; Koutrakis, P.; Choirat, C.; Dominici, F.; Schwartz, J.D. Air pollution and mortality in the Medicare population. N. Engl. J. Med. 2017, 376, 2513–2522. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Cai, Z.; Jiang, L.; Su, S.; Huang, X. Exploring urban taxi ridership and local associated factors using GPS data and geographically weighted regression. Cities 2019, 87, 68–86. [Google Scholar] [CrossRef]
- De Brébisson, A.; Simon, E.; Auvolat, A.; Vincent, P.; Bengio, Y. Artificial Neural Networks Applied to Taxi Destination Prediction. In Proceedings of the 2015th International Conference on ECML PKDD Discovery Challenge (ECMLPKDDDC’15), Porto, Portugal, 7–11 September 2015; Volume 1526, pp. 40–51. [Google Scholar]
- Yang, Y.; Yuan, Z.; Fu, X.; Wang, Y.; Sun, D. Optimization Model of Taxi Fleet Size Based on GPS Tracking Data. Sustainability 2019, 11, 731. [Google Scholar] [CrossRef]
- Peng, X.; Pan, Y.; Luo, J. Predicting high taxi demand regions using social media check-ins. In Proceedings of the 2017 IEEE International Conference on Big Data, Boston, MA, USA, 11–14 December 2017; pp. 2066–2075. [Google Scholar]
- Khezerlou, A.V.; Tong, L.; Street, W.N.; Li, Y. Predicting Urban Dispersal Events: A Two-Stage Framework through Deep Survival Analysis on Mobility Data. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 5199–5206. [Google Scholar]
- Ishiguro, S.; Kawasaki, S.; Fukazawa, Y. Taxi Demand Forecast Using Real-Time Population Generated from Cellular Networks. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 1024–1032. [Google Scholar]
- Smith, A.W.; Kun, A.L.; Krumm, J. Predicting Taxi Pickups in Cities: Which Data Sources Should We Use? In Proceedings of the 2017 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2017 ACM International Symposium on Wearable Computers, UbiComp ’17, Maui, HI, USA, 11–15 September 2017; pp. 380–387. [Google Scholar] [CrossRef]
- Liu, L.; Qiu, Z.; Li, G.; Wang, Q.; Ouyang, W.; Lin, L. Contextualized Spatial-Temporal Network for Taxi Origin-Destination Demand Prediction. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3875–3887. [Google Scholar] [CrossRef]
- Hawelka, B.; Sitko, I.; Beinat, E.; Sobolevsky, S.; Kazakopoulos, P.; Ratti, C. Geo-located Twitter as proxy for global mobility patterns. Cartogr. Geogr. Inf. Sci. 2014, 41, 260–271. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- James, N.A.; Kejariwal, A.; Matteson, D.S. Leveraging cloud data to mitigate user experience from ‘breaking bad’. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 3499–3508. [Google Scholar] [CrossRef]
- Kuang, L.; Yan, X.; Tan, X.; Li, S.; Yang, X. Predicting Taxi Demand Based on 3D Convolutional Neural Network and Multi-Task Learning. Remote Sens. 2019, 11, 1265. [Google Scholar] [CrossRef]
- Yao, H.; Wu, F.; Ke, J.; Tang, X.; Jia, Y.; Lu, S.; Gong, P.; Ye, J.; Li, Z. Deep multi-view spatial-temporal network for taxi demand prediction. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, Orleans, LA, USA, 2–7 February 2018; pp. 2588–2595. [Google Scholar]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.J. YFCC100M: The New Data in Multimedia Research. Commun. ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship and Mobility: User Movement in Location-Based Social Networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’11, San Diego, CA, USA, 21–24 August 2011; pp. 1082–1090. [Google Scholar] [CrossRef]
- Estevez, P.A.; Tesmer, M.; Perez, C.A.; Zurada, J.M. Normalized Mutual Information Feature Selection. IEEE Trans. Neural Netw. 2009, 20, 189–201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McPherson, G. Statistics in Scientific Investigation: Its Basis, Application, and Interpretation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Zheng, X.; Han, J.; Sun, A. A Survey of Location Prediction on Twitter. IEEE Trans. Knowl. Data Eng. 2018, 30, 1652–1671. [Google Scholar] [CrossRef] [Green Version]
- Lafferty, J.D.; McCallum, A.; Pereira, F.C. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williams College, WI, USA, 27 June–1 July 2001; pp. 282–289. [Google Scholar]
- Assam, R.; Seidl, T. Context-Based Location Clustering and Prediction Using Conditional Random Fields. In Proceedings of the 13th International Conference on Mobile and Ubiquitous Multimedia (MUM ’14), Melbourne, Victoria, Australia, 25–28 November 2014; pp. 1–10. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C.; Villa-Vialaneix, N. Random Forests for Big Data. Big Data Res. 2017, 9, 28–46. [Google Scholar] [CrossRef]
- Cuenca-Jara, J.; Terroso-Saenz, F.; Sanchez-Iborra, R.; Skarmeta-Gomez, A.F. Classification of Spatio-Temporal Trajectories Based on Support Vector Machines. In Advances in Practical Applications of Agents, Multi-Agent Systems, and Complexity: The PAAMS Collection; Demazeau, Y., An, B., Bajo, J., Fernández-Caballero, A., Eds.; Springer International Publishing: Cham, Switzerlands, 2018; pp. 140–151. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Tong, Y.; Chen, Y.; Zhou, Z.; Chen, L.; Wang, J.; Yang, Q.; Ye, J.; Lv, W. The Simpler The Better: A Unified Approach to Predicting Original Taxi Demands Based on Large-Scale Online Platforms. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’17, Halifax, NS, Canada, 13–17 August 2017; pp. 1653–1662. [Google Scholar] [CrossRef]
- Yan, A.; Howe, B. FairST: Equitable Spatial and Temporal Demand Prediction for New Mobility Systems. arXiv 2019, arXiv:1907.03827. [Google Scholar]
- Markou, I.; Rodrigues, F.; Pereira, F.C. Real-Time Taxi Demand Prediction using data from the web. In Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 1664–1671. [Google Scholar] [CrossRef]
- Zhou, Y.; Wu, Y.; Wu, J.; Chen, L.; Li, J. Refined Taxi Demand Prediction with ST-Vec. In Proceedings of the 26th International Conference on Geoinformatics, Kunming, China, 28–30 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Moreira-Matias, L.; Gama, J.; Ferreira, M.; Mendes-Moreira, J.; Damas, L. Predicting Taxi–Passenger Demand Using Streaming Data. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1393–1402. [Google Scholar] [CrossRef]
- Jiang, S.; Chen, W.; Li, Z.; Yu, H. Short-Term Demand Prediction Method for Online Car-Hailing Services Based on a Least Squares Support Vector Machine. IEEE Access 2019, 7, 11882–11891. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flickr | Foursquare | Brightkite | |
|---|---|---|---|
| Number of users | 5576 | 4531 | 2630 |
| Number of documents | 244,464 | 628,941 | 70,642 |
| OSN | Taxi Demand |
|---|---|
| Flickr | 0.9895 |
| Foursquare | 0.9871 |
| Brightkite | 0.9749 |
| Model | Parameter | Value |
|---|---|---|
| CRF | Training algorithm | Gradient descent |
| L1 regularization coeff. | 0.1 | |
| L2 regularization coeff. | 0.1 | |
| Max. iterations | 1000 | |
| RF | Number of estimators | 12,000 |
| Max. deep | 1100 | |
| SVM | Kernel | Radial Basis Function (RBF) |
| Gamma | 0.001 | |
| C | 1000 | |
| FCNN | Number of layers | 8 |
| Number neurons per layer | 128 | |
| Activation function | ReLU | |
| LSTM | Number of layers | 3 |
| Number neurons per layer | 50 | |
| Activation function | ReLU |
| Model | Predicted Taxi Range | True Taxi Range | ||
|---|---|---|---|---|
| RF | 0.763 | 0.232 | 0.005 | |
| 0.114 | 0.768 | 0.117 | ||
| 0.010 | 0.207 | 0.783 | ||
| SVM | 0.717 | 0.270 | 0.013 | |
| 0.059 | 0.792 | 0.149 | ||
| 0.100 | 0.161 | 0.829 | ||
| FCNN | 0.701 | 0.293 | 0.006 | |
| 0.088 | 0.797 | 0.115 | ||
| 0.011 | 0.248 | 0.741 | ||
| LSTM | 0.770 | 0.228 | 0.002 | |
| 0.059 | 0.840 | 0.100 | ||
| 0.000 | 0.152 | 0.846 | ||
| CRF | 0.561 | 0.435 | 0.004 | |
| 0.627 | 0.344 | 0.028 | ||
| 0.554 | 0.281 | 0.165 | ||
| Reference | Data Sources | Data Mining Method | Prediction Target | |||
|---|---|---|---|---|---|---|
| Temporal | Spatial | Meteorological | Primary Input Data | |||
| [24] | ✓ | ✓ | ✓ | taxi demand | regression/LR | quantitative taxi demand |
| [3] | ✓ | taxi GPS traces | regression/MLP | taxi destination | ||
| [13] | ✓ | ✓ | ✓ | taxi demand | regression/CNN, LSTM | quantitative taxi demand |
| [7] | ✓ | ✓ | taxi demand and CDRs | regression/AE | quantitative taxi demand | |
| [6] | ✓ | ✓ | taxi demand | regression/CNN | taxi demand peaks | |
| [25] | ✓ | ✓ | ✓ | bike demand | regression/CNN | quantitative bike demand |
| [2] | ✓ | ✓ | taxi demand and social media | regression/DT | quantitative taxi demand | |
| [26] | taxi demand and event data | regression/LR, GP | quantitative taxi demand | |||
| [12] | ✓ | ✓ | ✓ | taxi demand | regression/CNN, LSTM | quantitative taxi demand |
| [27] | ✓ | taxi demand | regression/SVR | quantitative taxi demand | ||
| [8] | ✓ | taxi demand and social media | regression/DT | quantitative taxi demand | ||
| [28] | ✓ | ✓ | taxi GPS traces | regression/EL | quantitative taxi demand | |
| [9] | ✓ | ✓ | ✓ | taxi demand | regression/ConvLSTM | quantitative taxi demand |
| [29] | ✓ | taxi demand | regression/LS-SVM | quantitative taxi demand | ||
| QUADRIVEN | ✓ | ✓ | social media | classification | qualitative taxi demand | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Terroso-Saenz, F.; Muñoz, A.; Cecilia, J.M. QUADRIVEN: A Framework for Qualitative Taxi Demand Prediction Based on Time-Variant Online Social Network Data Analysis. Sensors 2019, 19, 4882. https://0-doi-org.brum.beds.ac.uk/10.3390/s19224882
Terroso-Saenz F, Muñoz A, Cecilia JM. QUADRIVEN: A Framework for Qualitative Taxi Demand Prediction Based on Time-Variant Online Social Network Data Analysis. Sensors. 2019; 19(22):4882. https://0-doi-org.brum.beds.ac.uk/10.3390/s19224882
Chicago/Turabian StyleTerroso-Saenz, Fernando, Andres Muñoz, and José M. Cecilia. 2019. "QUADRIVEN: A Framework for Qualitative Taxi Demand Prediction Based on Time-Variant Online Social Network Data Analysis" Sensors 19, no. 22: 4882. https://0-doi-org.brum.beds.ac.uk/10.3390/s19224882