Smartphone Motion Sensor-Based Complex Human Activity Identification Using Deep Stacked Autoencoder Algorithm for Enhanced Smart Healthcare System



Abstract
:1. Introduction
- Propose a deep stacked autoencoder based deep learning algorithm for complex human activity identification using smartphone accelerometer data to improve accuracy and reduce over-fitting.
- Investigate the impact of fusing magnitude vector and rotation angle (pitch and roll) with tri-axis (3-D) accelerometer data to correct the effects of smartphone orientation on complex human activity identification.
- Extensive experimental settings to evaluate the proposed method using a smartphone acceleration sensor placed on the wrist, and pocket, and compare the performance with three conventional machine learning algorithms (Naïve Bayes, support vector machine, and linear discriminant analysis), and deep belief networks.
2. Related Works
2.1. Conventional Machine Learning Methods for Human Activity Identification
2.2. Deep Learning-Based Human Activity Recognition
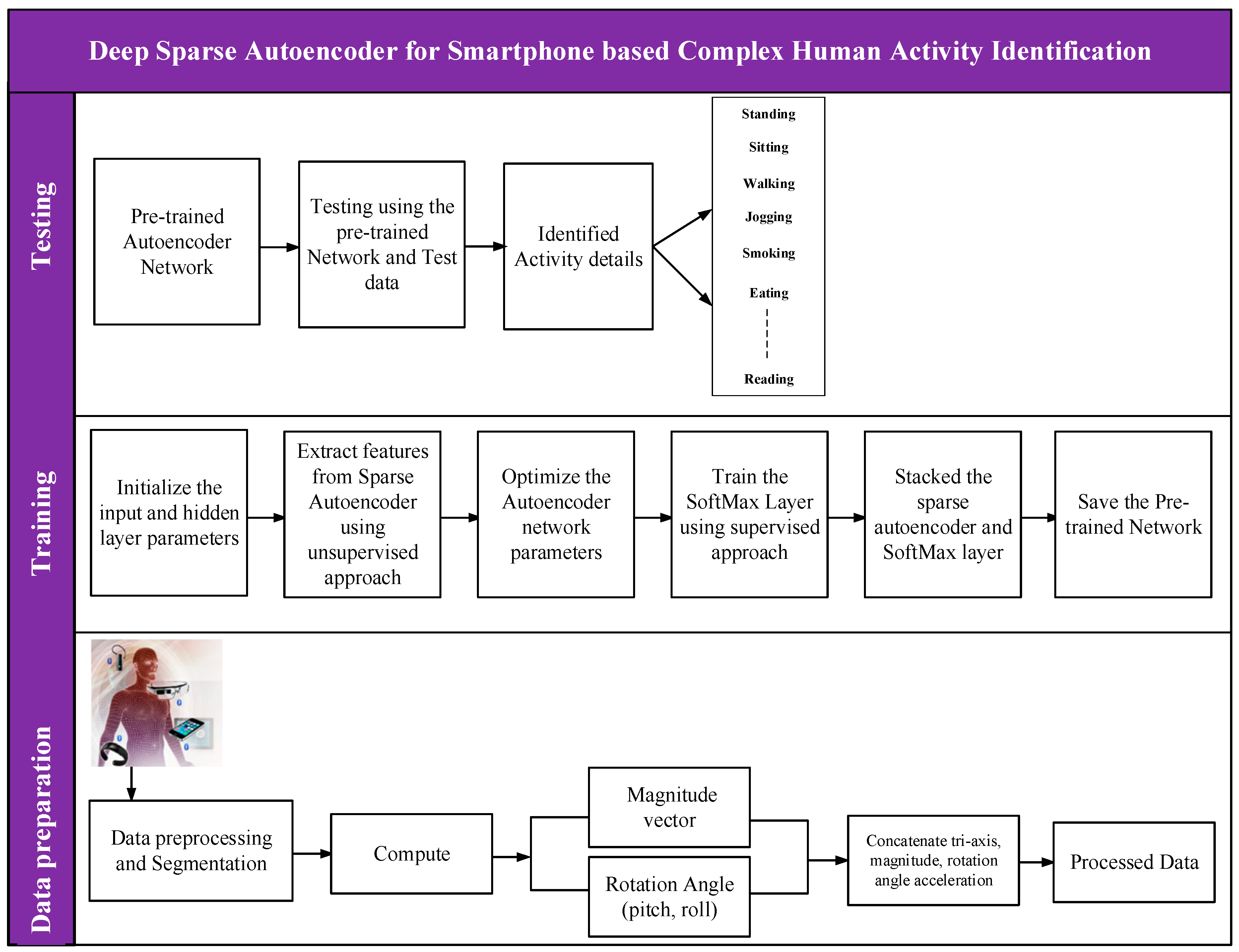
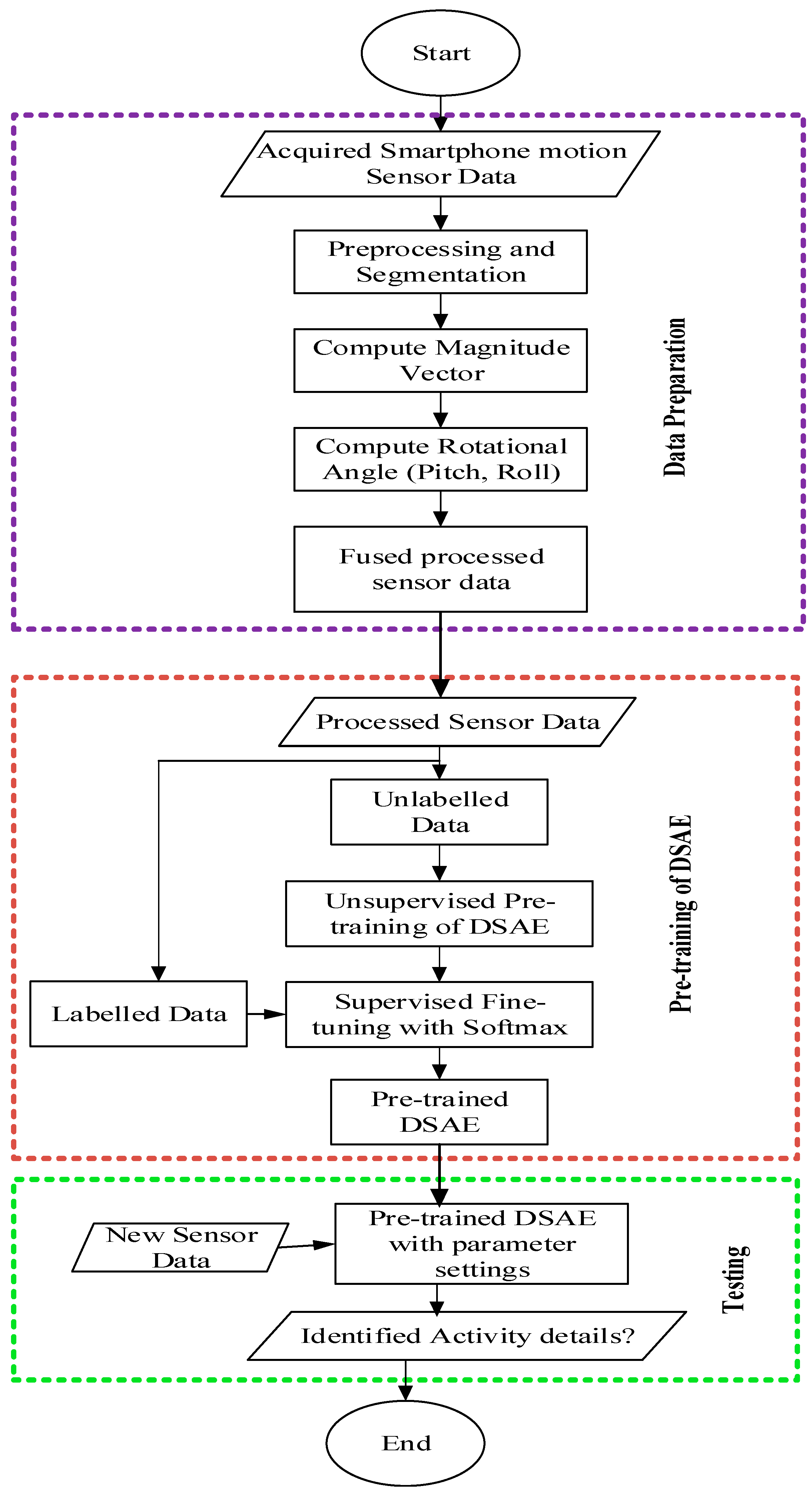
3. Methodology
3.1. Pre-Processing
3.2. Deep Learning Framework for Complex Human Activity Identification
3.2.1. Autoencoder
3.2.2. Deep Sparse Autoencoder
3.2.3. Softmax Classifier
| Algorithm 1. Deep learning-based complex activity identification training procedure. |
| 1: Input: Training acceleration sample 2: Output: Set of activity detail performances 3: Sensor Data preparation 4: Obtain the acceleration sensor data from smartphone 5: Segment the sensor data using sliding window 6: Compute the magnitude using Equation (16) 7: Compute the pitch-roll values using Equations (17) and (18) 8: Network Parameter Settings 9: Set the number of hidden layers and neurons 10: Max epoch values 11: Sparsity regularization values 12: Train the stacked autoencoder using greedy-wise layer approach 13: Compute the cost function of the autoencoder algorithm at each layer using Equations (3)–(5) 14: Set the sparsity regularization values using Equations (6)–(9) 15: Obtain the network output 16: Stack the pre-trained network with their parameter values 17: Train the Softmax classifier to estimate their parameters 18: Minimize the cost function 19: Fine-tune the stacked autoencoder network weights using gradient descent 20: Obtain the activity details |
3.3. Orientation Invariance in Smartphone-Based Human Activity Recognition
- (1)
- Three-axis accelerometer data;
- (2)
- Magnitude vector of the three-axis accelerometer data;
- (3)
- Pitch-roll of the accelerometer data;
- (4)
- Three-axis accelerometer data and computed magnitude vector;
- (5)
- Three-axis accelerometer and computed pitch-roll;
- (6)
- Three-axis accelerometer concatenated with magnitude vector, and pitch-roll angle.
3.4. Comparison with Conventional Machine Learning Methods
4. Experimental Design
4.1. Dataset Description
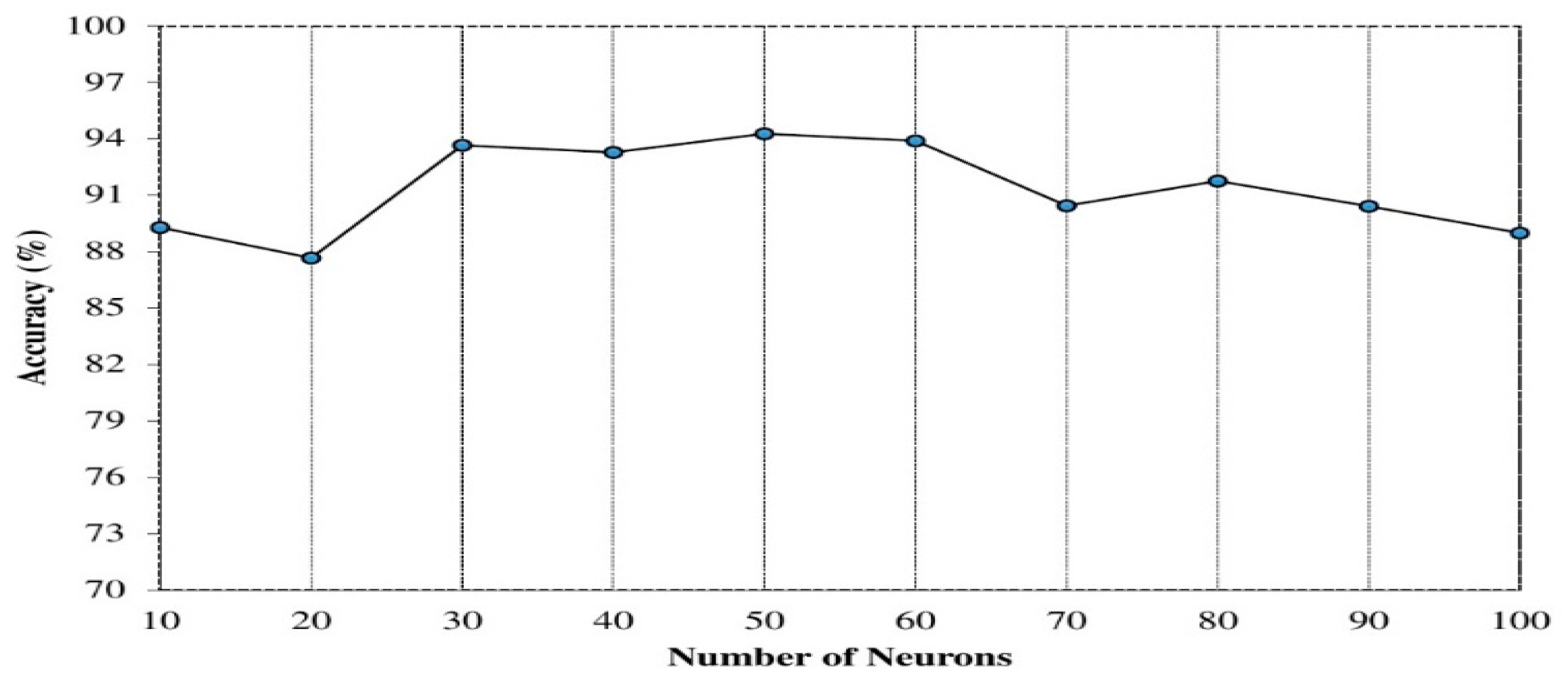
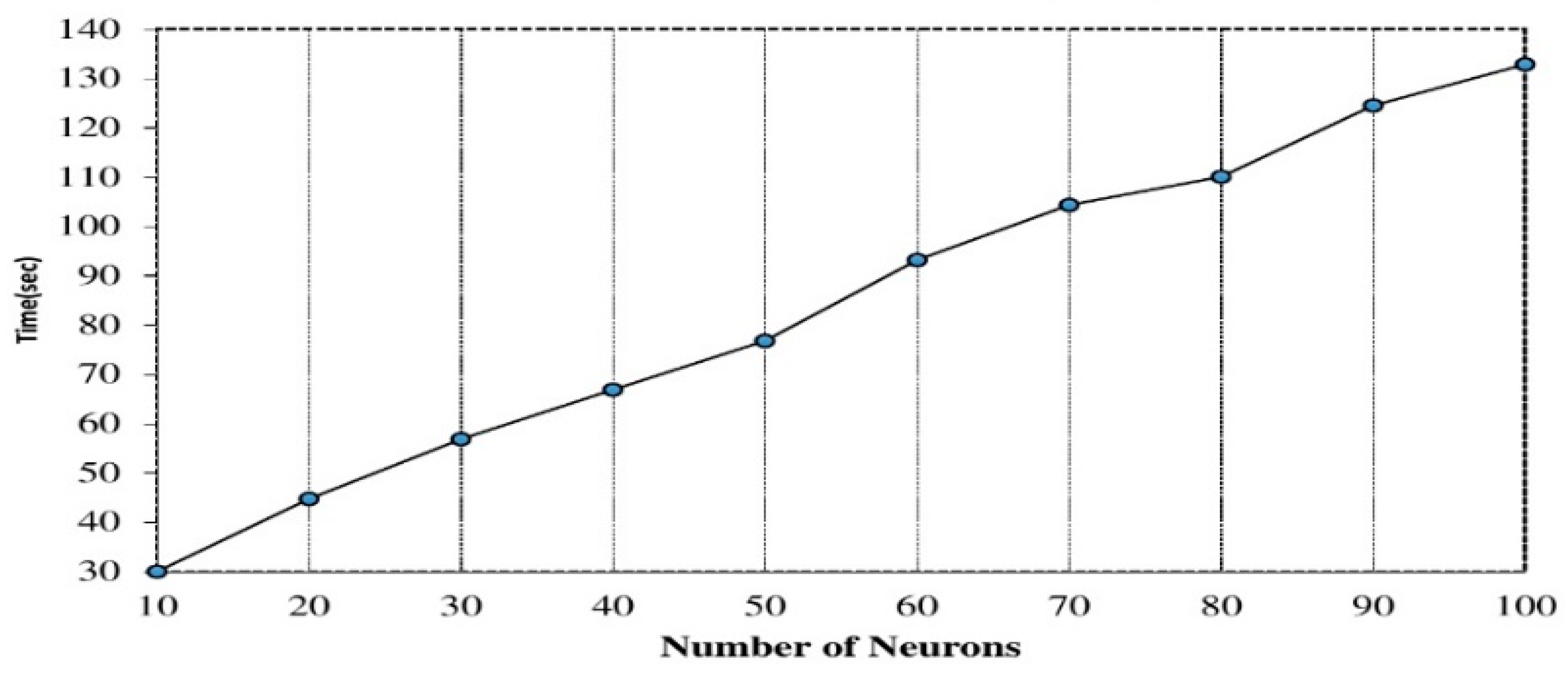
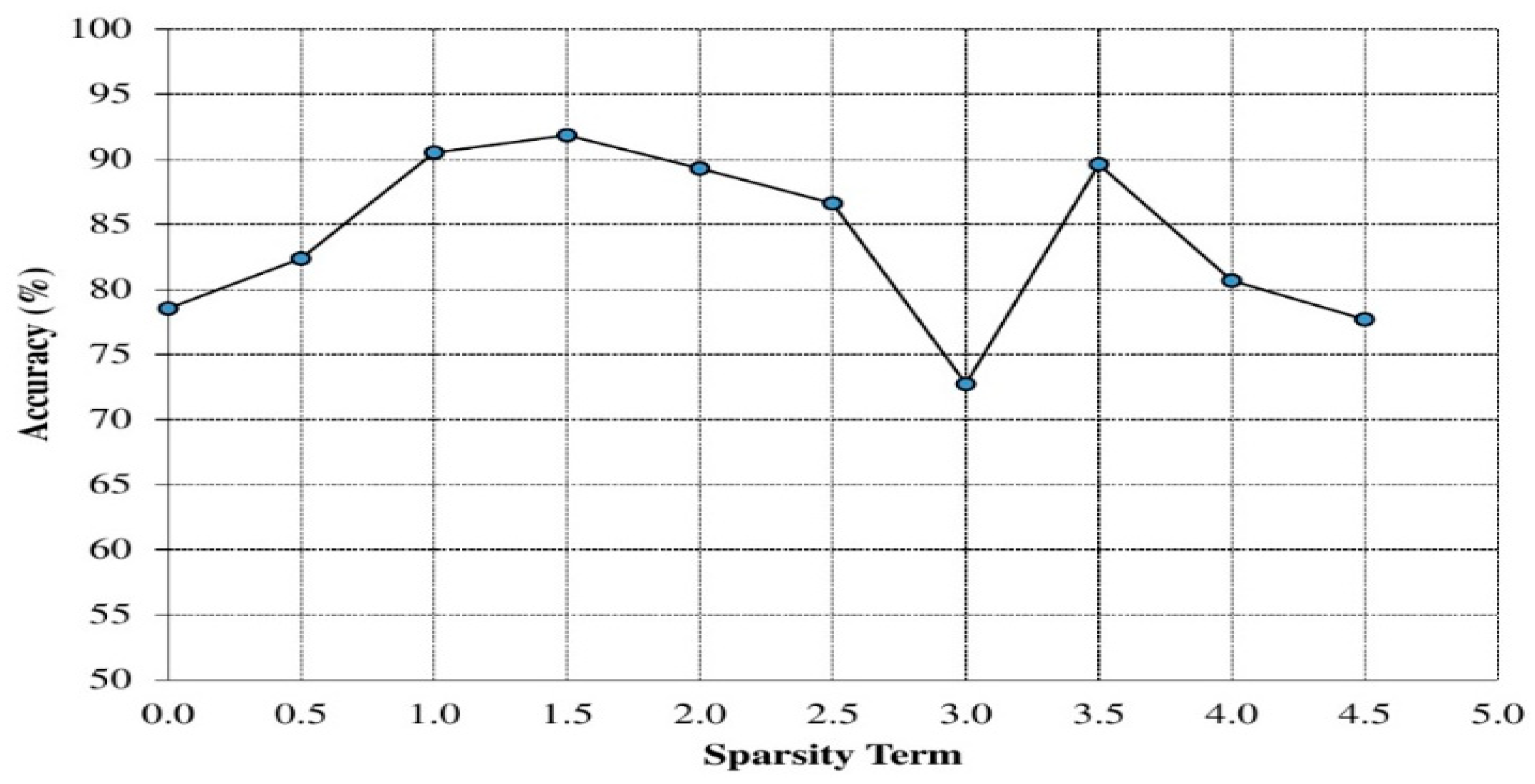
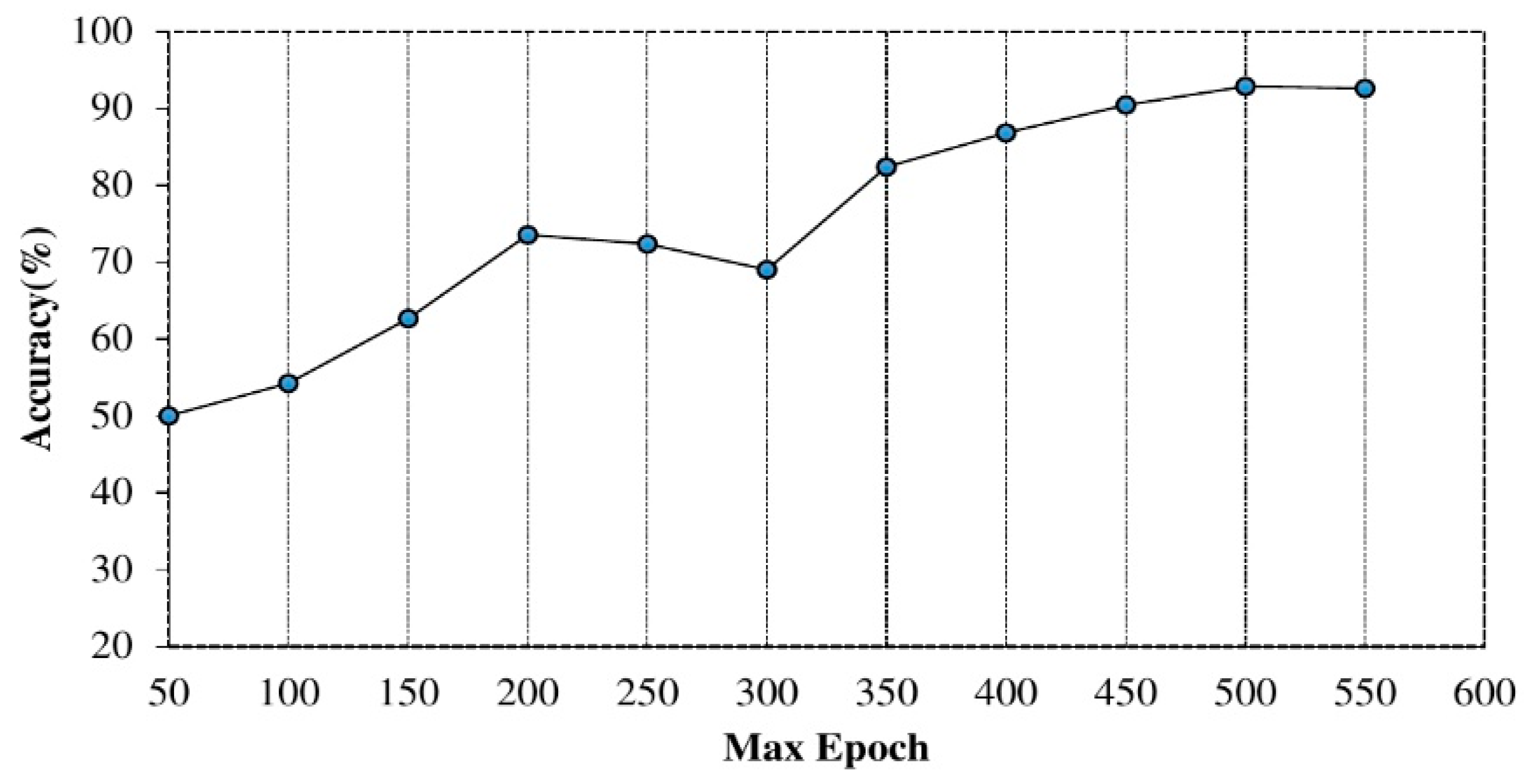
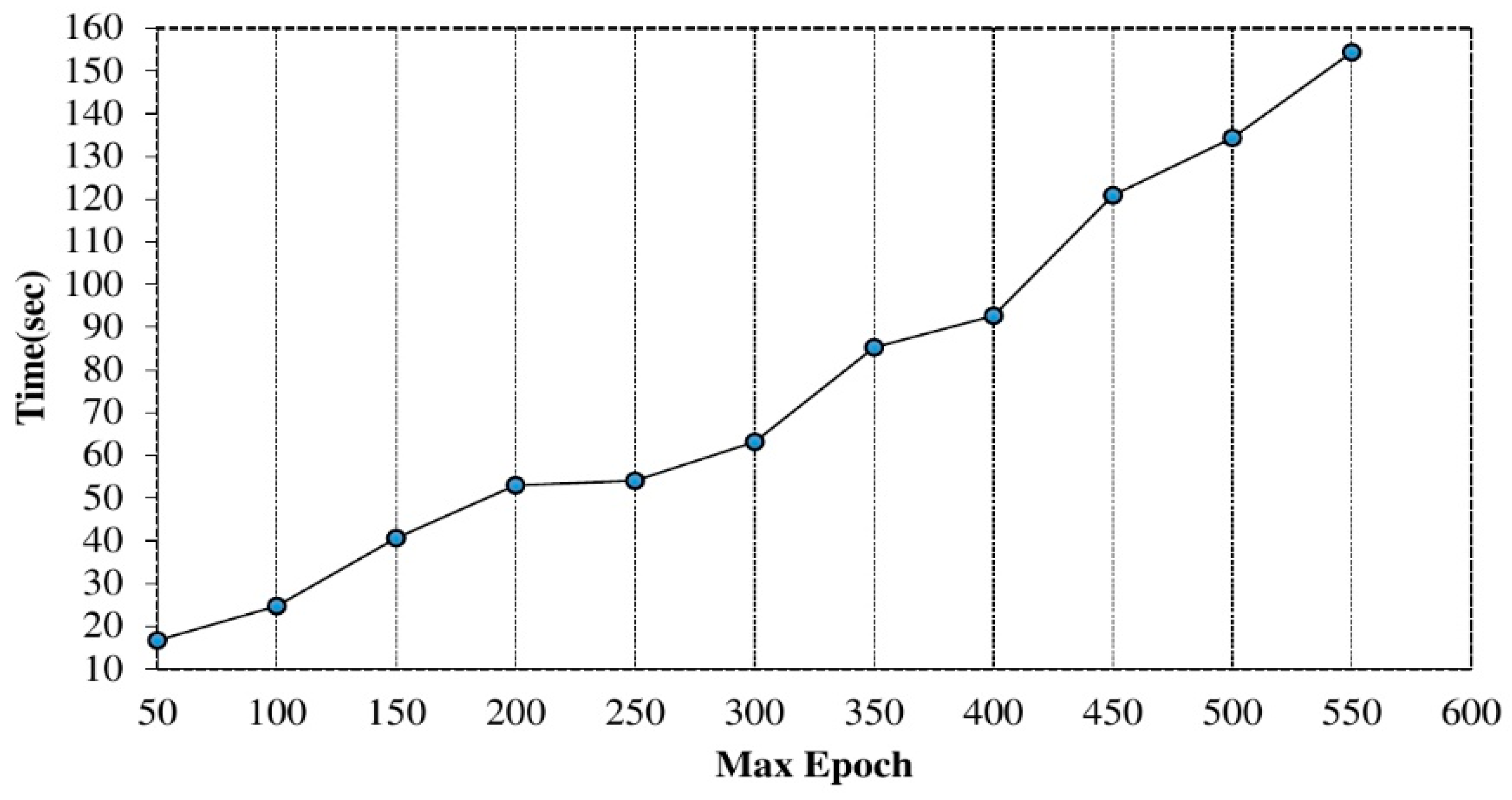
4.2. Experimental Settings and Parameter Selection
4.3. Evaluation Metrics
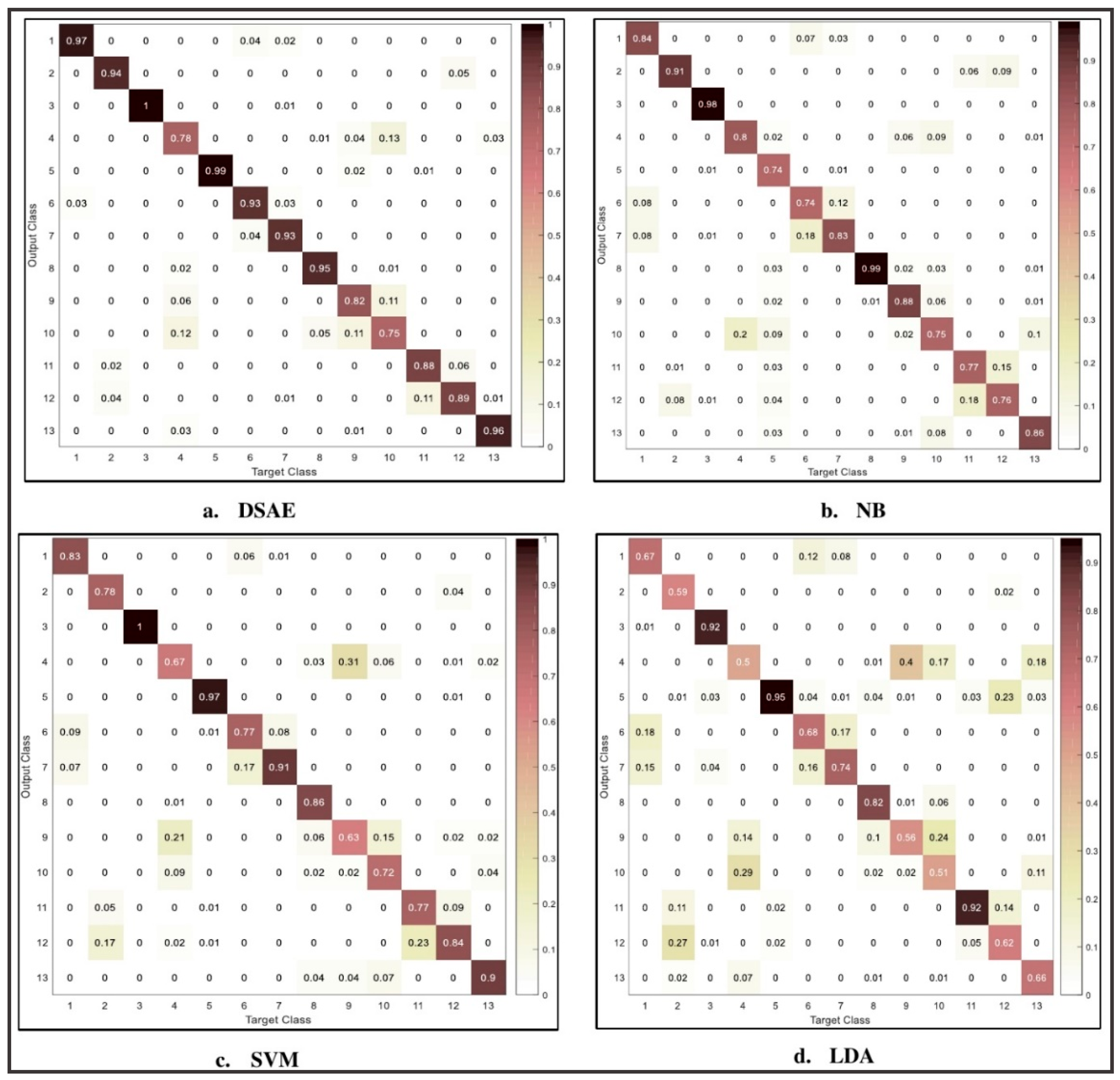
5. Experimental Results and Discussion
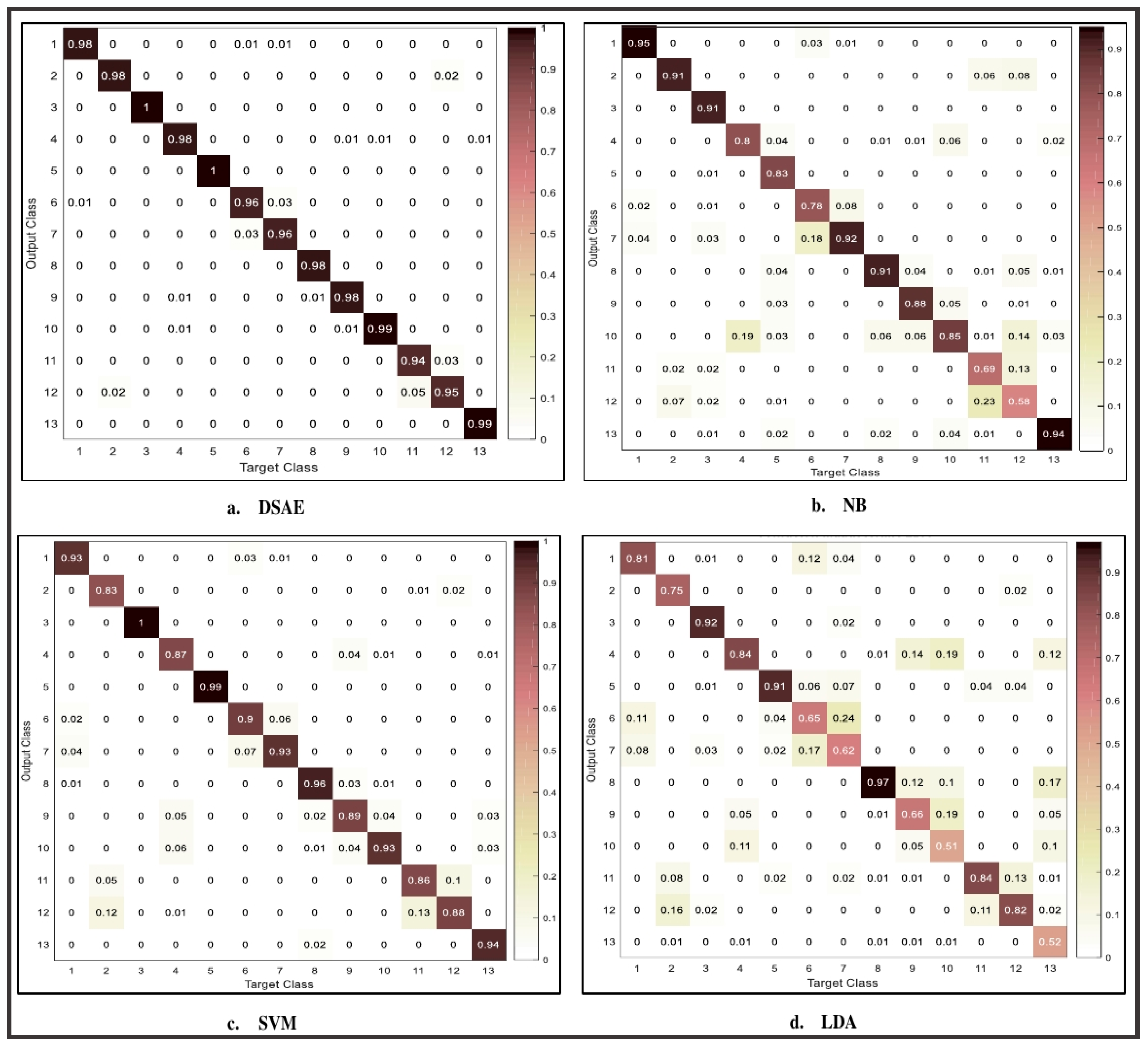
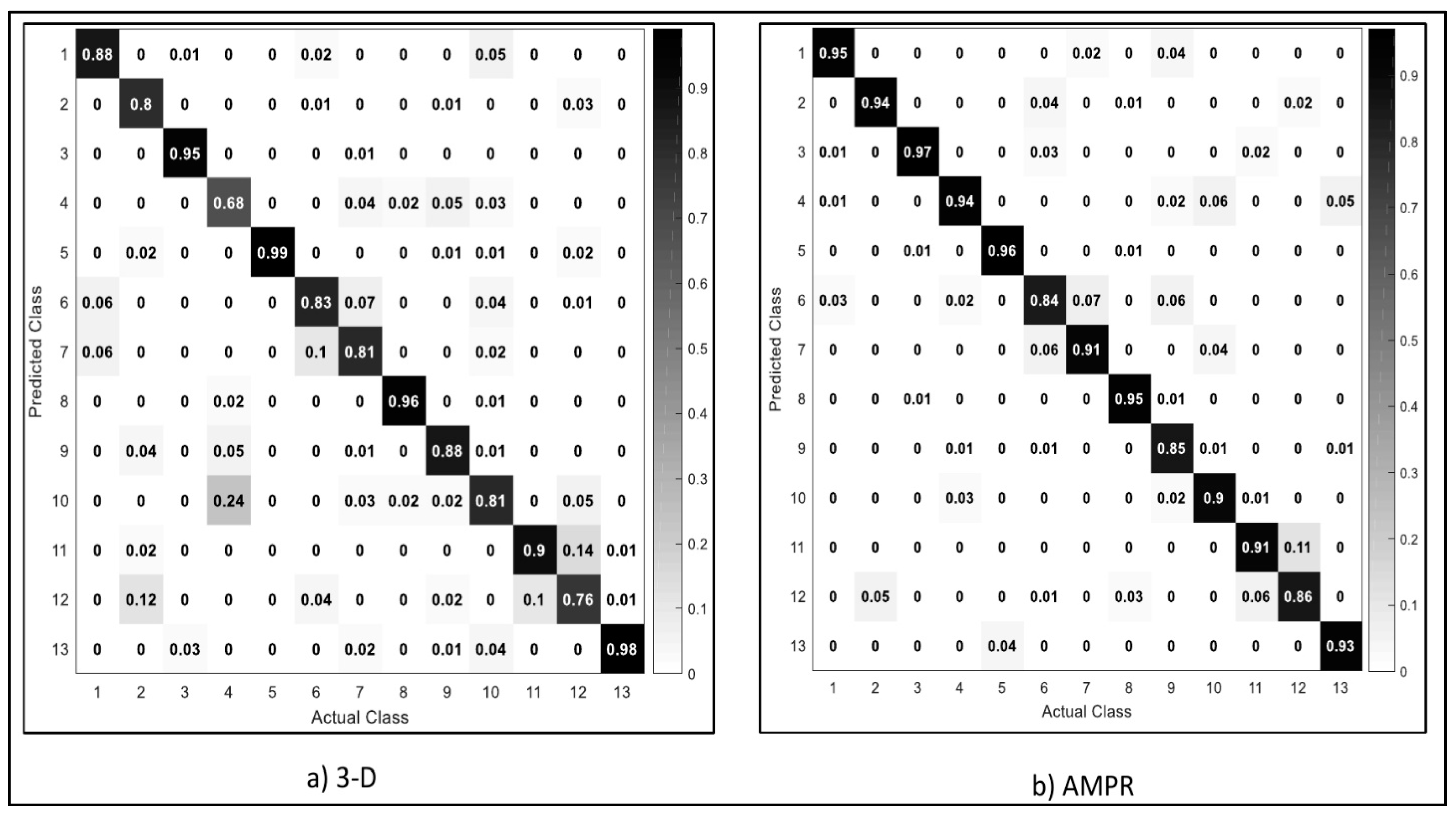
5.1. Performance Results on 3-D Acceleration, Magnitude, Pitch and Roll Values
5.2. Performance Results on the Fusion of 3-D Acceleration, Magnitude, Pitch and Roll Values
5.3. Comparison with Deep Belief Networks
6. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| Bi-LSTM | Bidirectional long short-term memory |
| CNN | Convolutional neural network |
| DSAE | Deep stacked autoencoder |
| FP | False positive |
| FN | False negative |
| GPU | Graphical processing unit |
| GPS | Global positioning system |
| IoT | Internet of Things |
| LDA | Linear discriminant analysis |
| LSTM | Long short-term memory |
| MAG | Magnitude vector |
| NB | Naïve Bayes |
| PCA | Principal component analysis |
| RAM | Random access memory |
| RNN | Recurrent neural network |
| SVM | Support vector machine |
| TN | True negative |
| TP | True positive |
| WHO | World Health Organization |
References
- Nweke, H.F.; Teh, Y.W.; Mujtaba, G.; Al-Garadi, M.A. Data fusion and multiple classifier systems for human activity detection and health monitoring: Review and open research directions. Inf. Fusion 2019, 46, 147–170. [Google Scholar] [CrossRef]
- WHO. Physical Activity Fact Sheets. 2018. Available online: http://www.who.int/mediacentre/factsheets/fs385/en/ (accessed on 15 February 2019).
- El Murabet, A.; Abtoy, A.; Touhafi, A.; Tahiri, A.; Amina, E.M.; Anouar, A.; Abdellah, T.; Abderahim, T. Ambient Assisted living system’s models and architectures: A survey of the state of the art. J. King Saud Univ. Comput. Inf. Sci. 2020, 32, 1–10. [Google Scholar] [CrossRef]
- Ahmed, N.; Rafiq, J.I.; Islam, R. Enhanced Human Activity Recognition Based on Smartphone Sensor Data Using Hybrid Feature Selection Model. Sensors 2020, 20, 317. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Asim, Y.; Azam, M.A.; Ehatisham-Ul-Haq, M.; Naeem, U.; Khalid, A. Context-Aware Human Activity Recognition (CAHAR) in-the-Wild Using Smartphone Accelerometer. IEEE Sens. J. 2020, 20, 4361–4371. [Google Scholar] [CrossRef]
- Dobbins, C.; Rawassizadeh, R.; Momeni, E. Detecting physical activity within lifelogs towards preventing obesity and aiding ambient assisted living. Neurocomputing 2017, 230, 110–132. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, J.; Havinga, P.J.M. Complex Human Activity Recognition Using Smartphone and Wrist-Worn Motion Sensors. Sensors 2016, 16, 426. [Google Scholar] [CrossRef]
- Almaslukh, B.; Al-Muhtadi, J.; Artoli, A.M. A robust convolutional neural network for online smartphone-based human activity recognition. J. Intell. Fuzzy Syst. 2018, 35, 1609–1620. [Google Scholar] [CrossRef]
- Zhao, H.; Hou, C.-N. Recognition of motion state by smartphone sensors using Bi-LSTM neural network. J. Intell. Fuzzy Syst. 2018, 35, 1733–1742. [Google Scholar] [CrossRef]
- Yu, J.; Sun, J.; Liu, S.; Luo, S. Multi-activity 3D human motion recognition and tracking in composite motion model with synthesized transition bridges. Multimed. Tools Appl. 2017, 77, 12023–12055. [Google Scholar] [CrossRef]
- Saha, J.; Chowdhury, C.; Biswas, S. Two phase ensemble classifier for smartphone based human activity recognition independent of hardware configuration and usage behaviour. Microsyst. Technol. 2018, 24, 2737–2752. [Google Scholar] [CrossRef]
- Peng, L.; Chen, L.; Wu, M.; Chen, G. Complex Activity Recognition Using Acceleration, Vital Sign, and Location Data. IEEE Trans. Mob. Comput. 2019, 18, 1488–1498. [Google Scholar] [CrossRef]
- Yang, J. Toward physical activity diary: Motion recognition using simple acceleration features with mobile phones. In Proceedings of the 1st International Workshop on Interactive Multimedia for Consumer Electronics, Beijing, China, 15–24 October 2009; pp. 1–10. [Google Scholar]
- Ignatov, A. Real-time human activity recognition from accelerometer data using Convolutional Neural Networks. Appl. Soft Comput. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Siirtola, P.; Röning, J. Revisiting Recognizing Human Activities User—Independently on Smartphones Based on Accelerometer Data—What Has Happened Since 2012? Int. J. Interact. Multimed. Artif. Intell. 2018, 5, 17. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Mujtaba, G.; Alo, U.R.; Al-Garadi, M.A. Multi-sensor fusion based on multiple classifier systems for human activity identification. Human-Cent. Comput. Inf. Sci. 2019, 9, 34. [Google Scholar] [CrossRef] [Green Version]
- Hemminki, S.; Nurmi, P.; Tarkoma, S. Accelerometer-based transportation mode detection on smartphones. In Proceedings of the 11th ACM Conference on Embedded Networked Sensor Systems—SenSys ’13, Rome, Italy, 11–15 November 2013; Association for Computing Machinery (ACM): New York, NY, USA; p. 13. [Google Scholar]
- Kamminga, J.; Le, D.V.; Meijers, J.P.; Bisby, H.; Meratnia, N.; Havinga, P.J. Robust Sensor-Orientation-Independent Feature Selection for Animal Activity Recognition on Collar Tags. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Yurtman, A.; Barshan, B. Activity Recognition Invariant to Sensor Orientation with Wearable Motion Sensors. Sensors 2017, 17, 1838. [Google Scholar] [CrossRef] [Green Version]
- Baños, O.; Damas, M.; Pomares, H.; Rojas, I. On the Use of Sensor Fusion to Reduce the Impact of Rotational and Additive Noise in Human Activity Recognition. Sensors 2012, 12, 8039–8054. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ngo, T.T.; Makihara, Y.; Nagahara, H.; Mukaigawa, Y.; Yagi, Y. Similar gait action recognition using an inertial sensor. Pattern Recognit. 2015, 48, 1289–1301. [Google Scholar] [CrossRef]
- Morales, J.; Agaian, S. Human activity recognition by smartphones regardless of device orientation. In Mobile Devices and Multimedia: Enabling Technologies, Algorithms, and Applications 2014; SPIE: Toulouse, France, 2014; Volume 9030, p. 90300I. [Google Scholar]
- Janidarmian, M.; Fekr, A.R.; Radecka, K.; Zilic, Z. A Comprehensive Analysis on Wearable Acceleration Sensors in Human Activity Recognition. Sensors 2017, 17, 529. [Google Scholar] [CrossRef] [PubMed]
- Hassan, M.M.; Gumaei, A.; AlSanad, A.; Alrubaian, M.; Fortino, G. A hybrid deep learning model for efficient intrusion detection in big data environment. Inf. Sci. 2020, 513, 386–396. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, H.; Ye, W. A Hybrid CNN–LSTM Network for the Classification of Human Activities Based on Micro-Doppler Radar. IEEE Access 2020, 8, 24713–24720. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Al-Garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Sansano-Sansano, E.; Montoliu, R.; Fernández, Ó.B. A study of deep neural networks for human activity recognition. Comput. Intell. 2020. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, A.K.; Tjondronegoro, D.; Chandran, V.; Trost, S. Physical Activity Recognition using Posterior-adapted Class-based Fusion of Multi-Accelerometers data. IEEE J. Biomed. Health Inform. 2018, 22, 678–685. [Google Scholar] [CrossRef]
- Incel, O.D. Analysis of Movement, Orientation and Rotation-Based Sensing for Phone Placement Recognition. Sensors 2015, 15, 25474–25506. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Shen, C. Performance Analysis of Smartphone-Sensor Behavior for Human Activity Recognition. IEEE Access 2017, 5, 3095–3110. [Google Scholar] [CrossRef]
- Ignatov, A.D.; Strijov, V.V. Human activity recognition using quasiperiodic time series collected from a single tri-axial accelerometer. Multimed. Tools Appl. 2015, 75, 7257–7270. [Google Scholar] [CrossRef]
- Muñoz-Organero, M.; Lotfi, A. Human Movement Recognition Based on the Stochastic Characterisation of Acceleration Data. Sensors 2016, 16, 1464. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Wei, Y.; Liu, L.; Zhong, J.; Sun, L.; Liu, Y. Towards unsupervised physical activity recognition using smartphone accelerometers. Multimed. Tools Appl. 2016, 76, 10701–10719. [Google Scholar] [CrossRef]
- Kwon, Y.; Kang, K.; Bae, C. Unsupervised learning for human activity recognition using smartphone sensors. Expert Syst. Appl. 2014, 41, 6067–6074. [Google Scholar] [CrossRef]
- Sarcevic, P.; Kincses, Z.; Pletl, S. Online human movement classification using wrist-worn wireless sensors. J. Ambient. Intell. Humaniz. Comput. 2017, 10, 89–106. [Google Scholar] [CrossRef]
- Hassan, M.M.; Uddin, Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Abu Alsheikh, M.; Niyato, D.; Lin, S.; Tan, H.-P.; Han, Z. Mobile big data analytics using deep learning and apache spark. IEEE Netw. 2016, 30, 22–29. [Google Scholar] [CrossRef] [Green Version]
- Bhattacharya, S.; Lane, N.D. From smart to deep: Robust activity recognition on smartwatches using deep learning. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops), Sydney, NSW, Australia, 14–18 March 2016; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G.-Z. A Deep Learning Approach to on-Node Sensor Data Analytics for Mobile or Wearable Devices. IEEE J. Biomed. Health Inform. 2016, 21, 56–64. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hassan, R.; Haque, S.M.; Hossain, M.I.; Hassan, M.M.; Alelaiwi, A. A novel cascaded deep neural network for analyzing smart phone data for indoor localization. Future Gener. Comput. Syst. 2019, 101, 760–769. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.-B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Yao, S.; Hu, S.; Zhao, Y.; Zhang, A.; Abdelzaher, T. DeepSense: A Unified Deep Learning Framework for Time-Series Mobile Sensing Data Processing. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 351–360. [Google Scholar]
- Kanjo, E.; Younis, E.M.; Ang, C.S. Deep learning analysis of mobile physiological, environmental and location sensor data for emotion detection. Inf. Fusion 2019, 49, 46–56. [Google Scholar] [CrossRef]
- Li, H.; Fu, K.; Yan, M.; Sun, X.; Sun, H.; Diao, W. Vehicle detection in remote sensing images using denoizing-based convolutional neural networks. Remote Sens. Lett. 2016, 8, 262–270. [Google Scholar] [CrossRef]
- Wang, L. Recognition of Human Activities Using Continuous Autoencoders with Wearable Sensors. Sensors 2016, 16, 189. [Google Scholar] [CrossRef]
- Almaslukh, B.; AlMuhtadi, J.; Artoli, A. An Effective Deep Autoencoder Approach for Online Smartphone-Based Human Activity Recognition. Int. J. Comput. Sci. Netw. Secur. 2017, 17, 160. [Google Scholar]
- Chen, G.; Wang, A.; Zhao, S.; Liu, L.; Chang, C.-Y. Latent feature learning for activity recognition using simple sensors in smart homes. Multimed. Tools Appl. 2017, 77, 15201–15219. [Google Scholar] [CrossRef]
- Muñoz-Organero, M.; Ruiz-Blazquez, R. Time-Elastic Generative Model for Acceleration Time Series in Human Activity Recognition. Sensors 2017, 17, 319. [Google Scholar] [CrossRef] [Green Version]
- Ni, Q.; Fan, Z.; Zhang, L.; Nugent, C.; Cleland, I.; Zhang, Y.; Zhou, N. Leveraging Wearable Sensors for Human Daily Activity Recognition with Stacked Denoising Autoencoders. Sensors 2020, 20, 5114. [Google Scholar] [CrossRef] [PubMed]
- Hassan, M.M.; Huda, S.; Uddin, Z.; Almogren, A.; Alrubaian, M. Human Activity Recognition from Body Sensor Data using Deep Learning. J. Med. Syst. 2018, 42, 99. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 1–33. [Google Scholar] [CrossRef]
- Ranzato, M.A.; Poultney, C.; Chopra, S.; LeCun, Y. Efficient Learning of Stacked Representations with an Energy-Based Model; Courant Institute of Mathematical Sciences: New York, NY, USA, 2007. [Google Scholar]
- Zhang, Y.-D.; Zhang, Y.; Hou, X.-X.; Chen, H.; Wang, S.-H. Seven-layer deep neural network based on stacked autoencoder for voxelwise detection of cerebral microbleed. Multimed. Tools Appl. 2017, 77, 1–18. [Google Scholar]
- Diro, A.A.; Chilamkurti, N. Distributed attack detection scheme using deep learning approach for Internet of Things. Future Gener. Comput. Syst. 2018, 82, 761–768. [Google Scholar] [CrossRef]
- Hinton, G.E. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Guo, J.; Yang, K.; Liu, H.; Yin, C.; Xiang, J.; Li, H.; Ji, R.; Gao, Y. A Stacked Sparse Autoencoder-Based Detector for Automatic Identification of Neuromagnetic High Frequency Oscillations in Epilepsy. IEEE Trans. Med. Imaging 2018, 37, 2474–2482. [Google Scholar] [CrossRef]
- Ustev, Y.E. User, Device, Orientation and Position Independent Human Activity Recognition on Smart Phones. Master’s Thesis, Bogazici University, Istanbul, Turkey, 2015. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. In Machine Learning; Springer: Berlin/Heidelberg, Germany, 1995; Volume 20, pp. 273–297. [Google Scholar]
- Shen, C.; Chen, Y.; Yang, G.; Guan, X. Toward Hand-Dominated Activity Recognition Systems With Wristband-Interaction Behavior Analysis. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 2501–2511. [Google Scholar] [CrossRef]
- Zdravevski, E.; Lameski, P.; Trajkovik, V.; Kulakov, A.; Chorbev, I.; Goleva, R.; Pombo, N.; Garcia, N. Improving Activity Recognition Accuracy in Ambient-Assisted Living Systems by Automated Feature Engineering. IEEE Access 2017, 5, 5262–5280. [Google Scholar] [CrossRef]
- Kim, K.S.; Choi, H.H.; Moon, C.S.; Mun, C.W. Comparison of k-nearest neighbor, quadratic discriminant and linear discriminant analysis in classification of electromyogram signals based on the wrist-motion directions. Curr. Appl. Phys. 2011, 11, 740–745. [Google Scholar] [CrossRef]
- Almaslukh, B.; Artoli, A.M.; Al-Muhtadi, J. A Robust Deep Learning Approach for Position-Independent Smartphone-Based Human Activity Recognition. Sensors 2018, 18, 3726. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Zhou, M.; Su, W.; Wu, M.; She, J.; Hirota, K. Softmax regression based deep stacked autoencoder network for facial emotion recognition in human-robot interaction. Inf. Sci. 2018, 428, 49–61. [Google Scholar] [CrossRef]
- Ehatisham-Ul-Haq, M.; Azam, M.A.; Amin, Y.; Shuang, K.; Islam, S.; Naeem, U.; Amin, Y. Authentication of Smartphone Users Based on Activity Recognition and Mobile Sensing. Sensors 2017, 17, 2043. [Google Scholar] [CrossRef] [Green Version]
- Gitanjali, J.; Ghalib, M.R. A Novel Framework for Human Activity Recognition with Time Labelled Real Time Sensor Data. New Rev. Inf. Netw. 2017, 22, 71–84. [Google Scholar] [CrossRef]
- Hassan, M.M.; Alam, G.R.; Uddin, Z.; Huda, S.; Almogren, A.; Fortino, G. Human emotion recognition using deep belief network architecture. Inf. Fusion 2019, 51, 10–18. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Deep Learning Methods | Descriptions | Strengths | Weaknesses |
|---|---|---|---|
| Deep belief networks [38,39,51] | Deep belief networks have direct connection to the lower layer of the network and hierarchically extract features from data. | Uses feedback mechanism to extract relevant features through unsupervised adaption. | High computation complexity due to high parameters initialization. |
| Convolutional neural networks [8,14,37,40,42] | Uses interconnected network structures to extract features that are invariant to distortion. | Widely utilized for human activity identification due to its ability to model time dependent data. It is invariant to changes in data distribution. | Requires large amount of training data to obtain discriminant features. In addition, it requires a high number of hyper-parameter optimization. |
| Recurrent neural networks [9,43,44] | Deep learning algorithm for modeling temporal changes in data. | Ability to extract temporal dependencies and complex changes in sequential data. | Difficult to train due to large parameter update and vanishing gradients. |
| Deep autoencoder algorithms [46,47,49,50] | Generative deep learning model that replicates copies of training data as input. | Reduces high-dimensional data to low dimensional feature vectors. This helps to reduce computational complexity. | Lack of scalability to high-dimensional data. It is difficult to train and optimize, especially for one layer autoencoder. |
| Activity Type | Activity List | Activity Durations |
|---|---|---|
| Static | Sitting | 3 min |
| Standing | 3 min | |
| Dynamic | Walking | 3 min |
| Jogging | 3 min | |
| Biking | 3 min | |
| Walking Upstairs | 3 min | |
| Walking Downstairs | 3 min | |
| Complex Sequence | Eating | 5 min |
| Typing | 5 min | |
| Writing | 5 min | |
| Drinking Coffee | 5 min | |
| Smoking | 5 min | |
| Giving Talks | 5 min |
| Parameters | Values |
|---|---|
| Hidden units | 60-40-30 |
| Sparsity terms | 1.5 |
| regularization | 0.001 |
| Max epoch | 500 |
| Activation function | Sigmoid |
| Accuracy | ||||
|---|---|---|---|---|
| DSAE | NB | SVM | LDA | |
| 3-D Acceleration | 0.9292 ± 0.0103 | 0.8420 ± 0.0048 | 0.8209 ± 0.0048 | 0.7194 ± 0.0147 |
| Magnitude | 0.4568 ± 0.0140 | 0.6050 ± 0.0087 | 0.4107 ± 0.0248 | 0.4160 ± 0.0080 |
| Pitch and Roll | 0.9297 ± 0.0053 | 0.7777 ± 0.0049 | 0.6202 ± 0.0082 | 0.4340 ± 0.0179 |
| Recall | ||||
| DSAE | NB | SVM | LDA | |
| 3-D Acceleration | 0.9290 ± 0.0107 | 0.8423 ± 0.0054 | 0.8202 ± 0.0049 | 0.7199 ± 0.0122 |
| Magnitude | 0.4601 ± 0.0107 | 0.6057 ± 0.0040 | 0.4107 ± 0.0239 | 0.4211 ± 0.0097 |
| Pitch and Roll | 0.9299 ± 0.0116 | 0.7778 ± 0.0093 | 0.6220 ± 0.0069 | 0.4356 ± 0.0170 |
| Specificity | ||||
| DSAE | NB | SVM | LDA | |
| 3-D Acceleration | 0.9941 ± 0.0009 | 0.9868 ± 0.0004 | 0.9851 ± 0.0004 | 0.9766 ± 0.0012 |
| Magnitude | 0.9548 ± 0.0012 | 0.9671 ± 0.0007 | 0.9509 ± 0.0020 | 0.9514 ± 0.0006 |
| Pitch and Roll | 0.9941 ± 0.0004 | 0.9815 ± 0.0003 | 96.84 ± 0.0007 | 0.9529 ± 0.0015 |
| Accuracy | ||||
|---|---|---|---|---|
| DSAE | NB | SVM | LDA | |
| 3-D Acceleration and magnitude | 0.9318 ± 0.0114 | 0.8419 ± 0.0041 | 0.8756 ± 0.0080 | 0.6983 ± 0.0173 |
| 3-D Acceleration and pitch and roll | 0.9704 ± 0.0041 | 0.8265 ± 0.0034 | 0.8870 ± 0.0059 | 0.7071 ± 0.0158 |
| 3-D Acceleration, magnitude, pitch and roll | 0.9713 ± 0.0041 | 0.8307 ± 0.0077 | 0.9084 ± 0.0049 | 0.7247 ± 0.0097 |
| Recall | ||||
| DSAE | NB | SVM | LDA | |
| 3-D Acceleration and magnitude | 0.9316 ± 0.0116 | 0.8419 ± 0.0041 | 0.8763 ± 0.0069 | 0.7013 ± 0.0162 |
| 3-D Acceleration and pitch and roll | 0.9703 ± 0.0041 | 0.8273 ± 0.0033 | 0.8875 ± 0.0062 | 0.7098 ± 0.0137 |
| 3-D Acceleration, magnitude, pitch and roll | 0.9712 ± 0.0039 | 0.8305 ± 0.0073 | 0.9083 ± 0.0057 | 0.7265 ± 0.0092 |
| Specificity | ||||
| DSAE | NB | SVM | LDA | |
| 3-D Acceleration and magnitude | 0.9943 ± 0.001 | 0.9868 ± 0.0003 | 0.9896 ± 0.0007 | 0.9741 ± 0.0014 |
| 3-D Acceleration and pitch and roll | 0.9975 ± 0.0003 | 0.9856 ± 0.0003 | 0.9906 ± 0.0005 | 0.9756 ± 0.0013 |
| 3-D Acceleration, magnitude, pitch and roll | 0.9976 ± 0.0003 | 0.9859 ± 0.0006 | 0.9924 ± 0.0005 | 0.9771 ± 0.0008 |
| Data | Methods | Accuracy | Recall | Sensitivity |
|---|---|---|---|---|
| Performance Results on DBN using each data sample | ||||
| 3-D acceleration | DSAE | 0.9292 ± 0.0103 | 0.9290 ± 0.0107 | 0.9941 ± 0.0009 |
| DBN | 0.8612 ± 0.0090 | 0.8607 ± 0.0101 | 0.9884 ± 0.0002 | |
| Magnitude | DSAE | 0.4568 ± 0.0140 | 0.4601 ± 0.0107 | 0.9548 ± 0.0012 |
| DBN | 0.5821 ± 0.0054 | 0.5878 ± 0.0076 | 0.9652 ± 0.0008 | |
| Pitch and roll | DSAE | 0.9297 ± 0.0053 | 0.9299 ± 0.0116 | 0.9941 ± 0.0004 |
| DBN | 0.7630 ± 0.0132 | 0.7620 ± 0.0101 | 0.9803 ± 0.0006 | |
| Performance Results on DBN using fusion of data samples | ||||
| 3-D Acceleration and magnitude | DSAE | 0.9318 ± 0.0114 | 0.9316 ± 0.0116 | 0.9943 ± 0.0010 |
| DBN | 0.8811 ± 0.0098 | 0.8824 ± 0.0086 | 0.9901 ± 0.0014 | |
| 3-D Acceleration and pitch and roll | DSAE | 0.9704 ± 0.0041 | 0.9703 ± 0.0041 | 0.9975 ± 0.0003 |
| DBN | 0.8277 ± 0.0059 | 0.8261 ± 0.0054 | 0.9856 ± 0.0004 | |
| 3-D Acceleration, magnitude, pitch and roll | DSAE | 0.9713 ± 0.0041 | 0.9712 ± 0.0039 | 0.9976 ± 0.0003 |
| DBN | 0.9157 ± 0.0077 | 0.9166 ± 0.0075 | 0.9930 ± 0.0005 | |
| Methods | Execution Time (milliseconds) | Error Rate (%) |
|---|---|---|
| Naïve Bayes (NB) | 22.7568 | 16.93 |
| Linear Discriminant analysis (LDA) | 18.4566 | 27.53 |
| Support vector machine (SVM) | 27.2124 | 9.16 |
| Deep Belief Networks (DBN) | 388.6811 | 8.43 |
| Proposed Method (DSAE) | 264. 7857 | 2.88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alo, U.R.; Nweke, H.F.; Teh, Y.W.; Murtaza, G. Smartphone Motion Sensor-Based Complex Human Activity Identification Using Deep Stacked Autoencoder Algorithm for Enhanced Smart Healthcare System. Sensors 2020, 20, 6300. https://0-doi-org.brum.beds.ac.uk/10.3390/s20216300
Alo UR, Nweke HF, Teh YW, Murtaza G. Smartphone Motion Sensor-Based Complex Human Activity Identification Using Deep Stacked Autoencoder Algorithm for Enhanced Smart Healthcare System. Sensors. 2020; 20(21):6300. https://0-doi-org.brum.beds.ac.uk/10.3390/s20216300
Chicago/Turabian StyleAlo, Uzoma Rita, Henry Friday Nweke, Ying Wah Teh, and Ghulam Murtaza. 2020. "Smartphone Motion Sensor-Based Complex Human Activity Identification Using Deep Stacked Autoencoder Algorithm for Enhanced Smart Healthcare System" Sensors 20, no. 21: 6300. https://0-doi-org.brum.beds.ac.uk/10.3390/s20216300