1. Introduction
Being physically active is critical for older people to reduce their risk of developing comorbidities, and extending quality life years [
1]. The physical activity (PA) guidelines for older Australians [
2] recommends engaging in moderate-intensity PA for at least 30 min every day. However, Australia’s health report indicates that 75% of Australians aged 65 and over do not meet these physical activity guidelines [
3]. PA monitoring under free-living conditions can help determine whether the accumulation of PA meets the recommended levels, which can be used for feedback. Moreover, older people tend to increase their activity levels when monitoring PA, likely because monitoring increases motivation to achieve a PA goal [
4].
An activity classification method with high accuracy is key to providing appropriate feedback to older people. Although many classification algorithms have been proposed for sensor-based activity recognition, most studies have targeted younger adults. Due to potential differences in movement features between the two age groups, the algorithms trained on young people may not be as accurate when applied to data from older people [
5]. Therefore, there is a need to develop a classifier tailored for older people. As a small number of studies have specifically focused on older people using inertial sensors fixed to the trunk [
6,
7,
8,
9]. These studies utilized a combination of accelerometry, gyroscopes, and magnetometers, which were processed using neural networks, support vector machines, decision trees, or random forests to achieve accuracies of 82–93% [
6,
7,
8,
9]. These studies highlighted that accurate activity classification in older people is feasible.
However, despite high accuracy, a major downside of the abovementioned methods is that they adopted approaches which require extracting features manually based on domain knowledge and expertise. Because these hand-crafted features only contain some of the available discriminative information, their ability to differentiate activities is likely suboptimal [
10]. Artificial neural networks based on deep learning techniques have been proposed for activity recognition without the need for hand-crafted feature extraction. Among all deep learning techniques, the convolutional neural network (CNN) and long short-term memory (LSTM) are commonly used for activity recognition [
9,
11,
12]. Ignatov [
13] proposed a 1D CNN model for simple physical activity classification based on triaxial acceleration data with six activity classes, and the model achieved a high accuracy of 93%. A multichannel CNN model has been designed in [
11] to process data from multiple inertial measurement units (IMUs) in parallel channels. LSTM was combined with a CNN in [
14], and compared to a CNN alone, with the hybrid model (DeepConvLSTM) improving the result by six percent. Due to their flexibility, neural networks with various architectures have been developed and have achieved state-of-the-art results. Unfortunately, there is no direct comparison of the performance among neural networks with different architectures for activity recognition. Moreover, how these deep learning algorithms work for an older cohort is worth investigating.
Another important consideration in the development of an activity recognition algorithm is the acceptability of the data collection method to users. To be specific, when using a wearable device to monitor PA in daily life, in order to achieve accurate insight in one’s behavior, older people must wear the device for at least four days [
12], which may cause discomfort and inconvenience. On the contrary, smartphones with built-in inertial sensors can be used to gain insight into PA: while users are performing daily activities, the built-in sensors can reliably capture kinematic features [
15] for activity recognition. In addition, the increasing popularity of smartphones in older people [
16] makes it possible to use their own devices to perform activity monitoring. Smartphone PA monitoring does need to consider battery life, and the strain associated with certain sensing modalities such as gyroscopes. Hence, an accelerometry-based activity recognition method seems most appropriate.
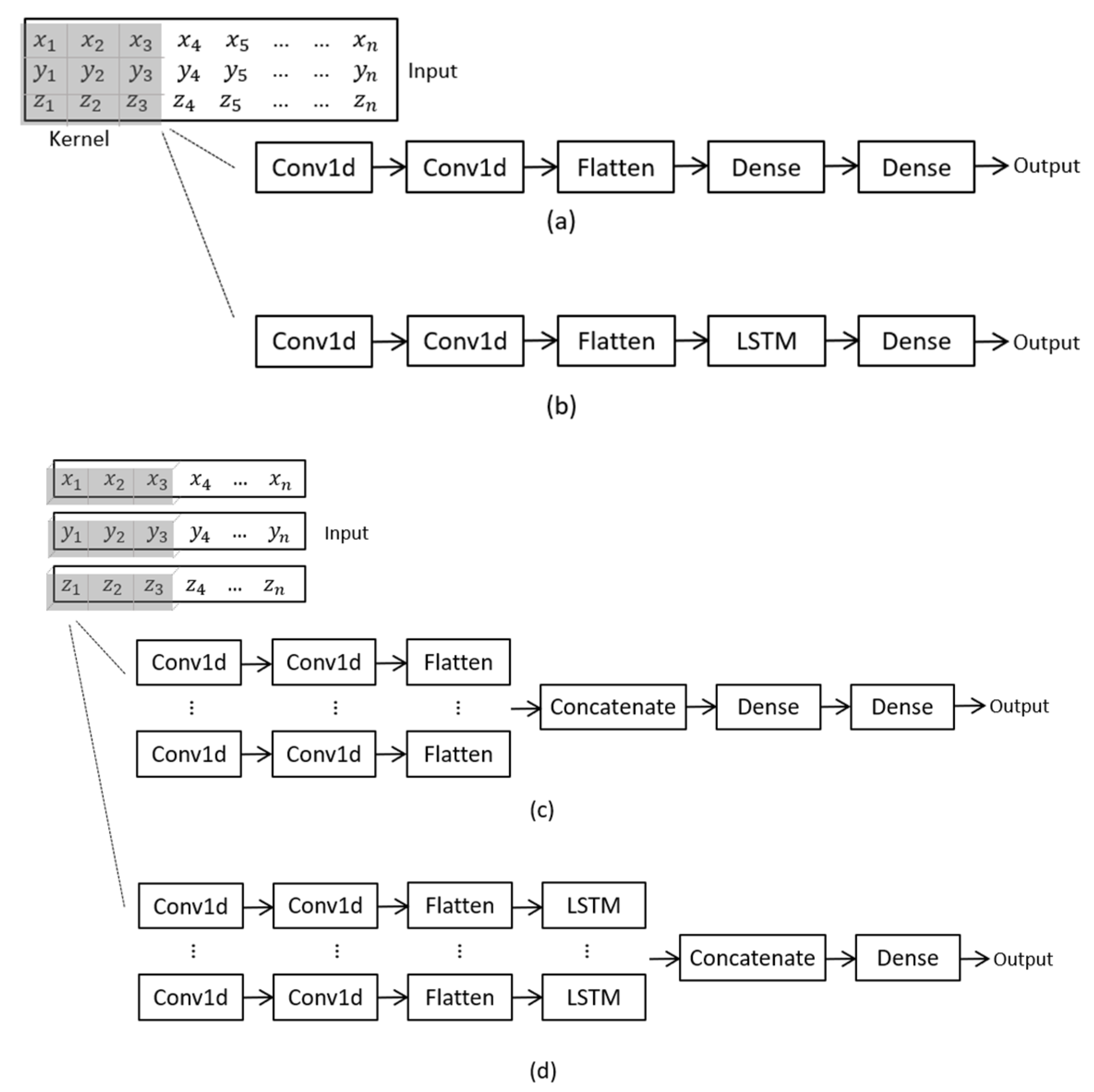
This study aims to develop a classifier for accelerometry-based activity recognition in older people. Several common types activities, including lying, sitting, standing, transition, walking, walking down and walking up stairs were investigated. Among these activities, because transitioning, walking down, and walking up are closely related to the balance and the risk of falls in older people [
11,
13,
14], we paid special attention to the classification performance of the algorithms on these activities. Four models, including a 1D CNN, a multichannel CNN, a CNN-LSTM, and a multichannel CNN-LSTM were built to explore the best architecture for this task. These models were trained on a dataset collected from older people using a smartphone. The classification and computing performance of these models was compared. Finally, the hyperparameters of the best performing model were tuned for an improved classification result, and the trained model is openly provided for further validation and use by the community.
4. Discussion
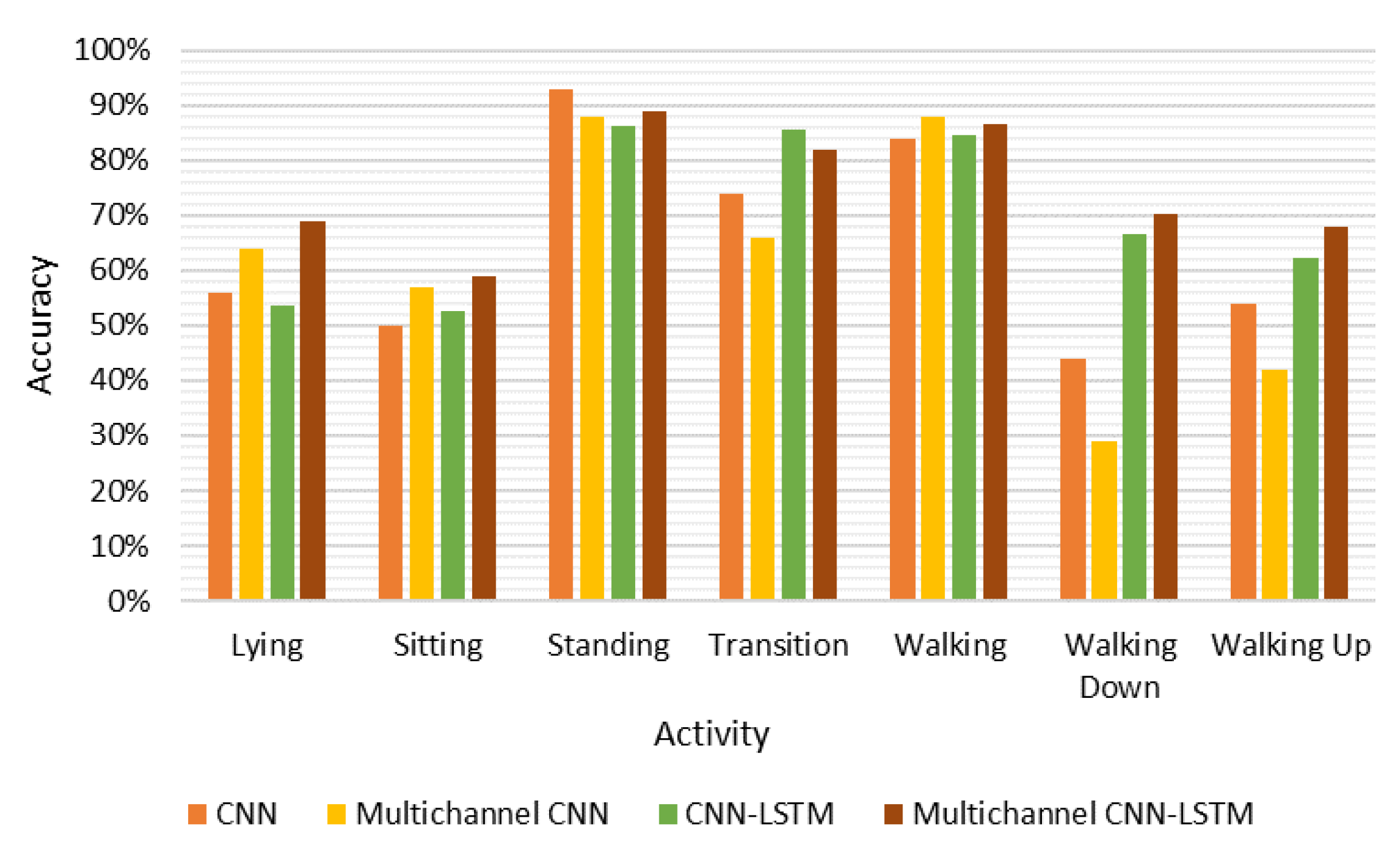
This study evaluated the classification accuracy and computational efficiency of four deep learning architectures in performing smartphone accelerometry-based activity recognition in older people. It used data of a previous study [
5] that compared the generalizability of machine learning algorithms between younger and older people. Our classification results indicated that both multichannel and hybrid architectures can improve the prediction performance of the baseline CNN. When combining these two architectures, the hybrid architecture may be the dominant reason for the increased scores, as the CNN-LSTM yielded higher macro F1-scores than the multichannel CNN. Therefore, it can be inferred that the hybrid model uses the advantages of both CNN and LSTM in terms of extracting regional features within short time steps and temporal structure across a sequence. In addition, since the network size of the hybrid models was lower, there is a smaller chance of overfitting [
27], which may have resulted in their higher generalizability to the validation dataset.
The multichannel architecture can generate great flexibility in designing hyperparameters. Firstly, it allows the use of different kernel sizes for separate channels, and thus enabling the network to capture both local and global patterns. Secondly, the number of kernels assigned to each channel can be different, depending on how complex the signal pattern input to the channel is. Thirdly, for the multichannel CNN-LSTM, the depth of the convolutional and LSTM layer can vary between channels, considering the trade-off between accuracy and generalization ability. The computational cost of the multichannel CNN was double that of the baseline CNN, with only a small improvement in overall accuracy (73.4% to 75.5%). Therefore, when using the CNN algorithm alone, a multichannel architecture may not be the best solution.
The developed multichannel CNN-LSTM algorithm was the most accurate approach, which seems feasible for implementation for long-term monitoring in older people. It is a smartphone-based algorithm that allows the smartphone to be set up in a way that is consistent with most people’s habits [
28] (i.e., being placed in a pants pocket), and to collect data unobtrusively. Future development could consider recalibrating the reference frame of the IMU signals to the world to account for orientation changes over time [
29]. In order to minimize computational cost, which has been recognized as one of the challenges in real-time activity recognition using deep learning algorithms [
30], only the accelerometer was applied for activity recognition. Although classifiers can perform better when combining acceleration and gyroscope [
9], additional sensors can drain battery life [
31]. Despite these restrictions, the model’s classification accuracy of 81.1% is comparable to the 82–93% accuracy reported previously by studies that included more sensing modalities [
6,
7,
8,
9]. This is quite impressive given that these studies did not always split their data on an individual level or used validation, and were performed in considerably smaller sample sizes (i.e., 7–20 participants vs. our 53 participants).
While this study provides valuable insight into models for activity recognition in older people, it however also has its limitations. The main limitation of this study was the hyperparameter setting. When evaluating the four deep learning models, the batch size for each model were set to be the same, as well as the number of training epochs, for the convenience of comparison. However, there is no one-size-fits-all solution in the optimal selection of the hyperparameters, and since the hyperparameter values have a significant effect on the performance of the classifiers [
32], changing these values could have led to different results. In addition, the computational cost depends on the device used for implementation, and the cost may vary when using a different device. Further investigation is required to understand how well the multichannel CNN-LSTM algorithm performs on smartphones in terms of computational efficiency.
Another issue was related to the smartphone use and placement. Since the smartphone was placed in the pants pocket, our results may not generalize to other sensor placements which could be addressed in future studies. In addition, smartphones are used for more than activity tracking and may not always be worn in one’s pocket. Future studies could consider development of an algorithm to detect whether the phone is in use or worn in the pants pocket. Moreover, the pants pocket placement may not be effective to capture upper body movements or arm movements, which are common during daily activities such as cooking and vacuuming. As a result, equipping a sensor such as a smartwatch on upper limbs may be essential for complex activities recognition. Future research should consider regrouping activities and adding in additional sensors or devices such as smartwatches to improve classification performance. For instance, the static activities that do not contribute to the accumulation of the PA level, such as lying and sitting, may be grouped into the resting activity as proposed by Khan et al. [
33] for an improved performance. Furthermore, as indicated by Voicu et al. [
34], walking upstairs and downstairs are easily confused with levelled walking, therefore collecting more data with, e.g., barometric pressure sensors during these activities might enable the classifier to learn more discriminative features.
Our trained algorithm is freely available for clinical and research applications (osf.io/47vx6); however, generalizability needs to be established. With ageing, functional capacity declines [
35] and gait and balance disorders arise [
36]. As a result, the model that is trained on data from a finite group of participants may not suit a more heterogeneous group. We used data of 53 older people, which was considerably more than the 1 to 23 of participants in previous studies [
6,
7,
8,
9]. In addition, our data included both non-frail and frail participants. As reported by Del Rosario et al. [
5], the generalizability of the multichannel CNN-LSTM was assumed to be better than the algorithms that were trained on a smaller data set. Another way to manage heterogeneity is to personalize the classifier. Personalized activity recognition using transfer learning technique was proven to be valid by Tahavori et al. [
37]. This technique achieved a high testing accuracy by using two training steps: a CNN was first pre-trained on the training participants, and then the output layer was retrained with only three labelled samples from the new participants. Because personalized activity recognition requires retraining the algorithm for every user, it may be better to choose a robust algorithm with good generalizability for most of the non-frail users, and implement the personalized technique for users who have abnormal gait and need particular attention.

 ,
, 
{kind=link}
{kind=link}

