
A Combined Method for MEMS Gyroscope Error Compensation Using a Long Short-Term Memory Network and Kalman Filter in Random Vibration Environments


Abstract
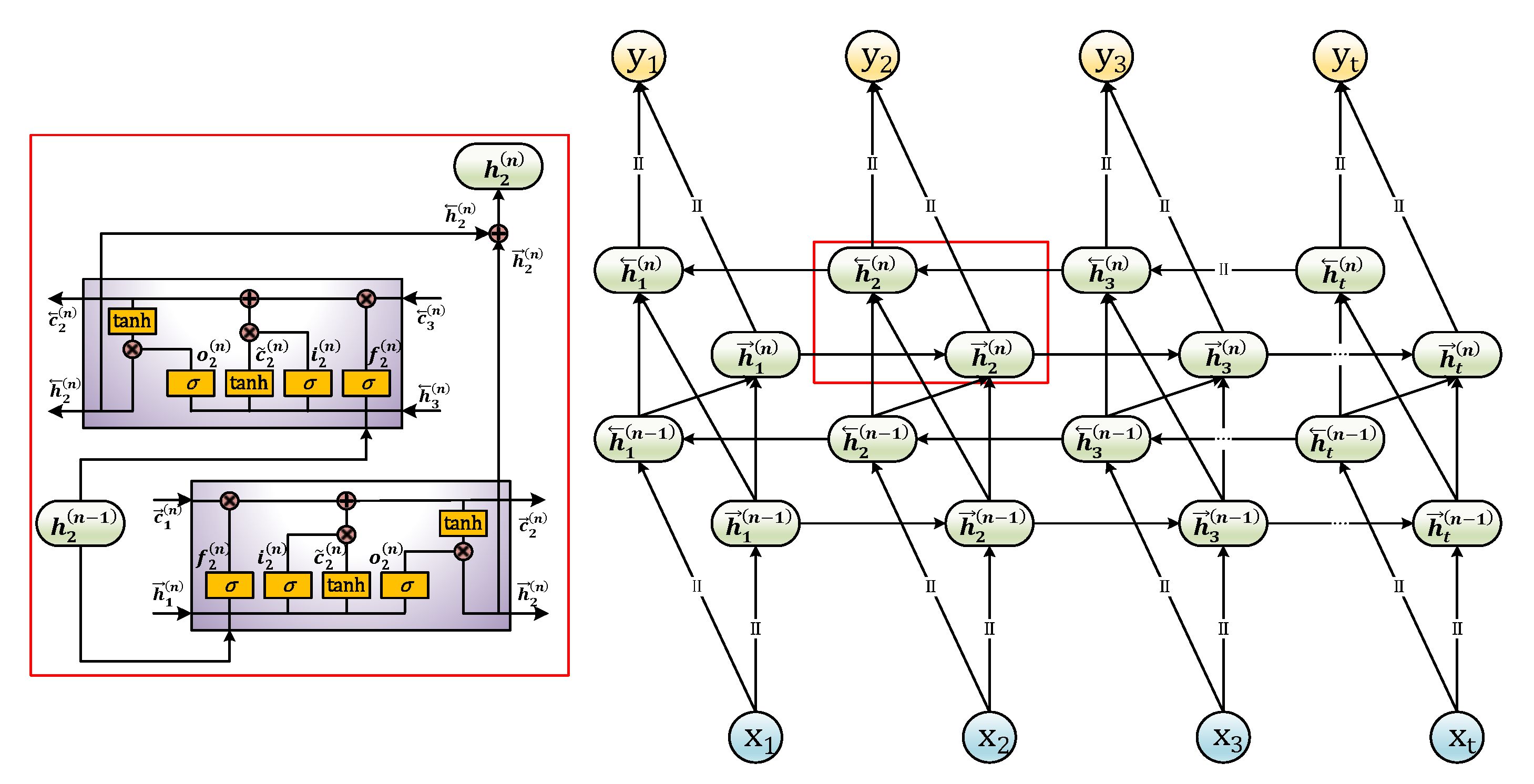
:1. Introduction
- (1)
- The combination of LSTM network and Kalman filter is applied to MEMS gyroscope error compensation in random vibration environments;
- (2)
- The proper input data step and the network topology are explored, and the error compensation performance of the bidirectional LSTM (BiLSTM) network and other recurrent neural network (RNN) variants are compared;
- (3)
- In designing the Kalman filter, the EM algorithm is used to estimate the parameters. It is compared with the ARMA model, a parameter estimation method commonly used in research of the MEMS gyroscope error compensation problem.
2. Method
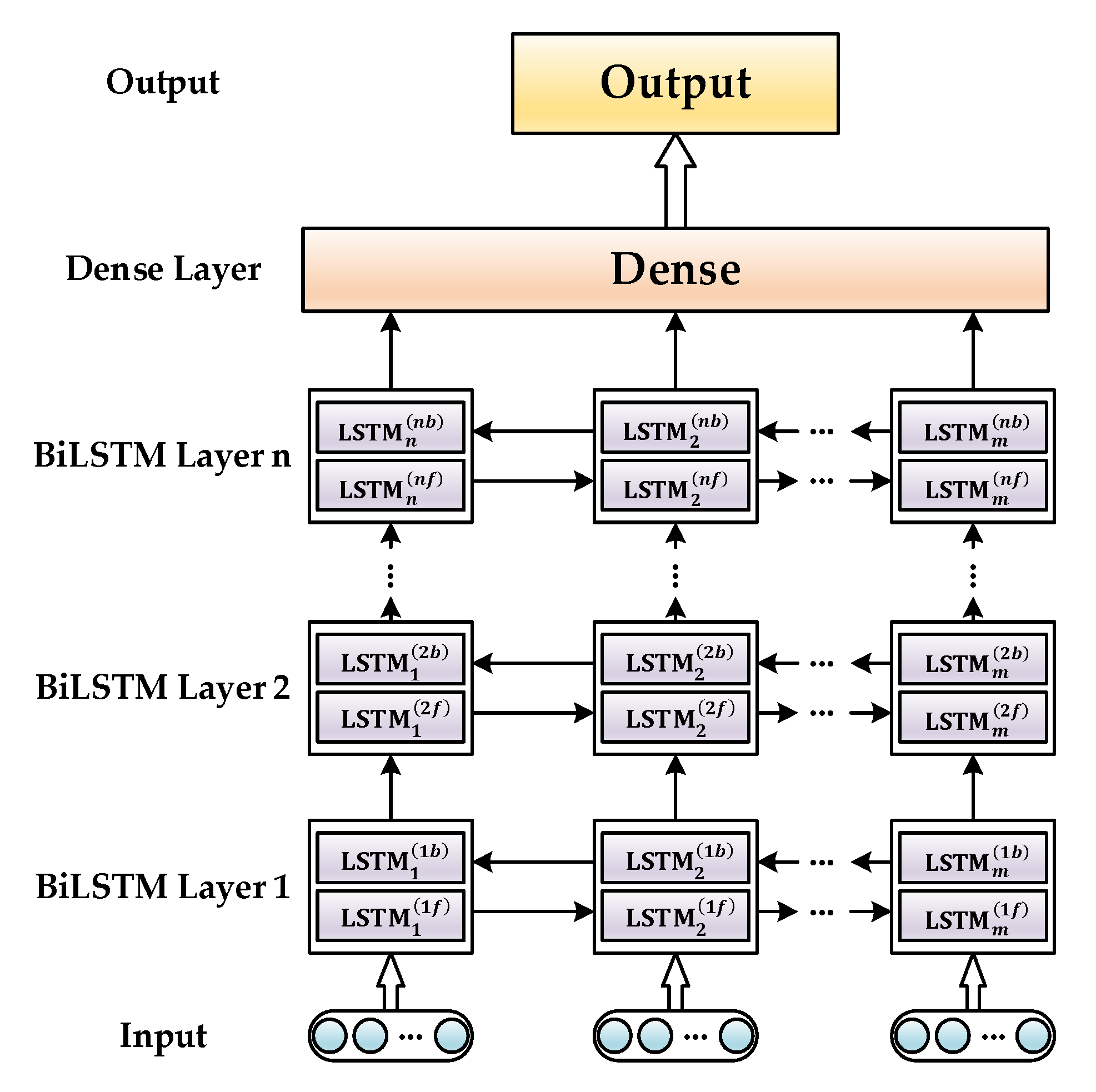
2.1. Multi-Layer BiLSTM Network and Kalman Filter
2.2. Kalman Filter Design with ARMA Model
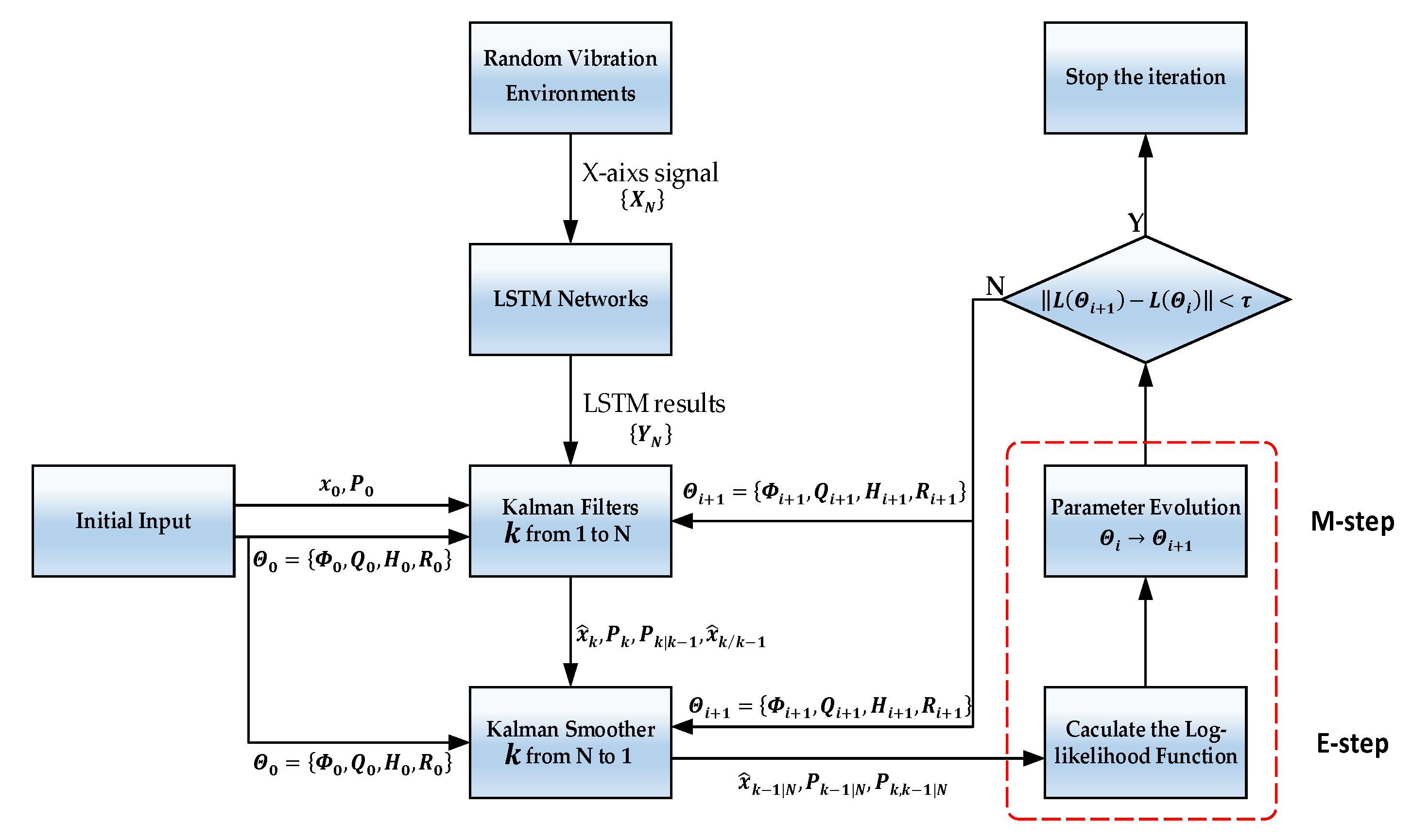
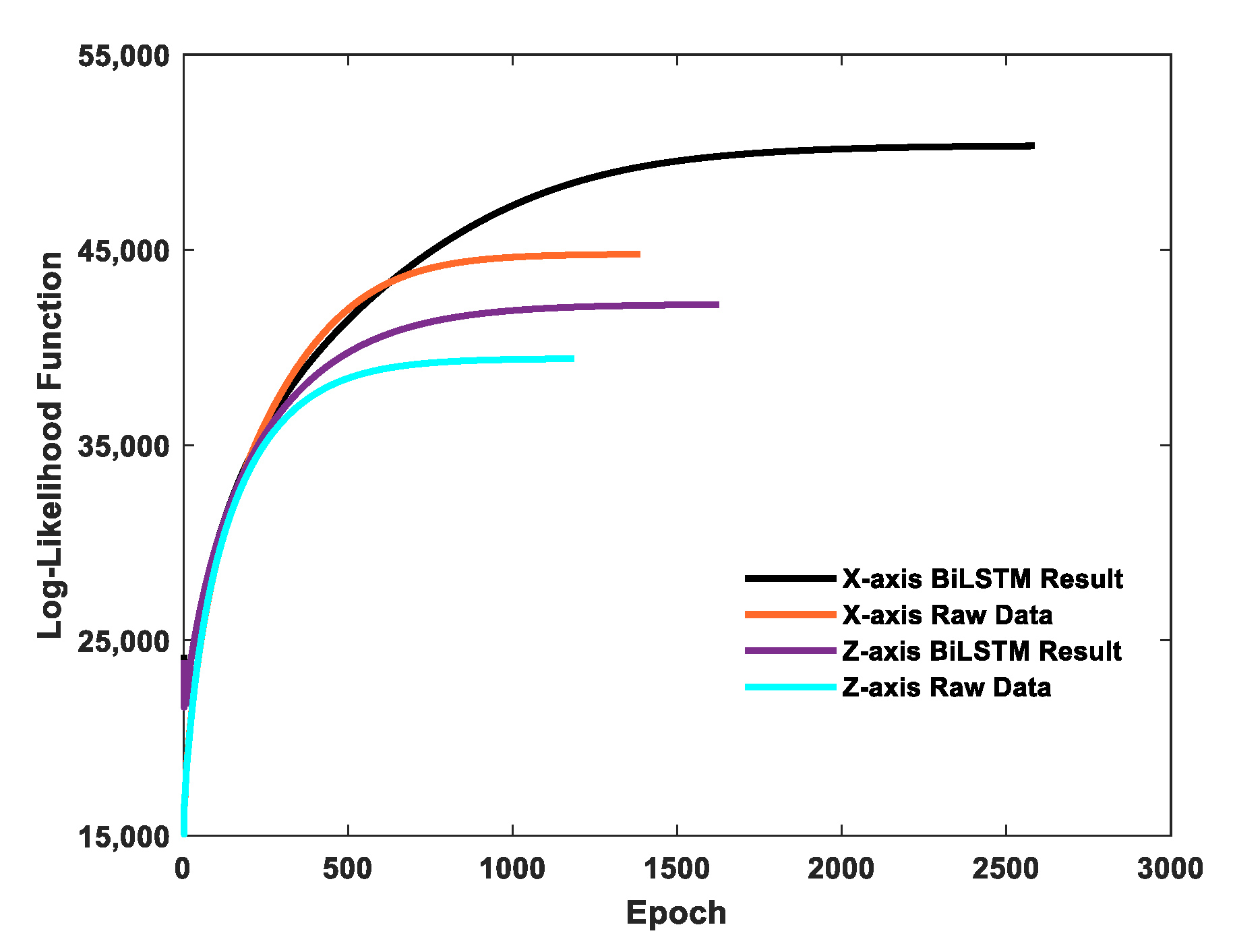
2.3. Kalman Filter Design with EM Algorithm
3. Experiments and Results
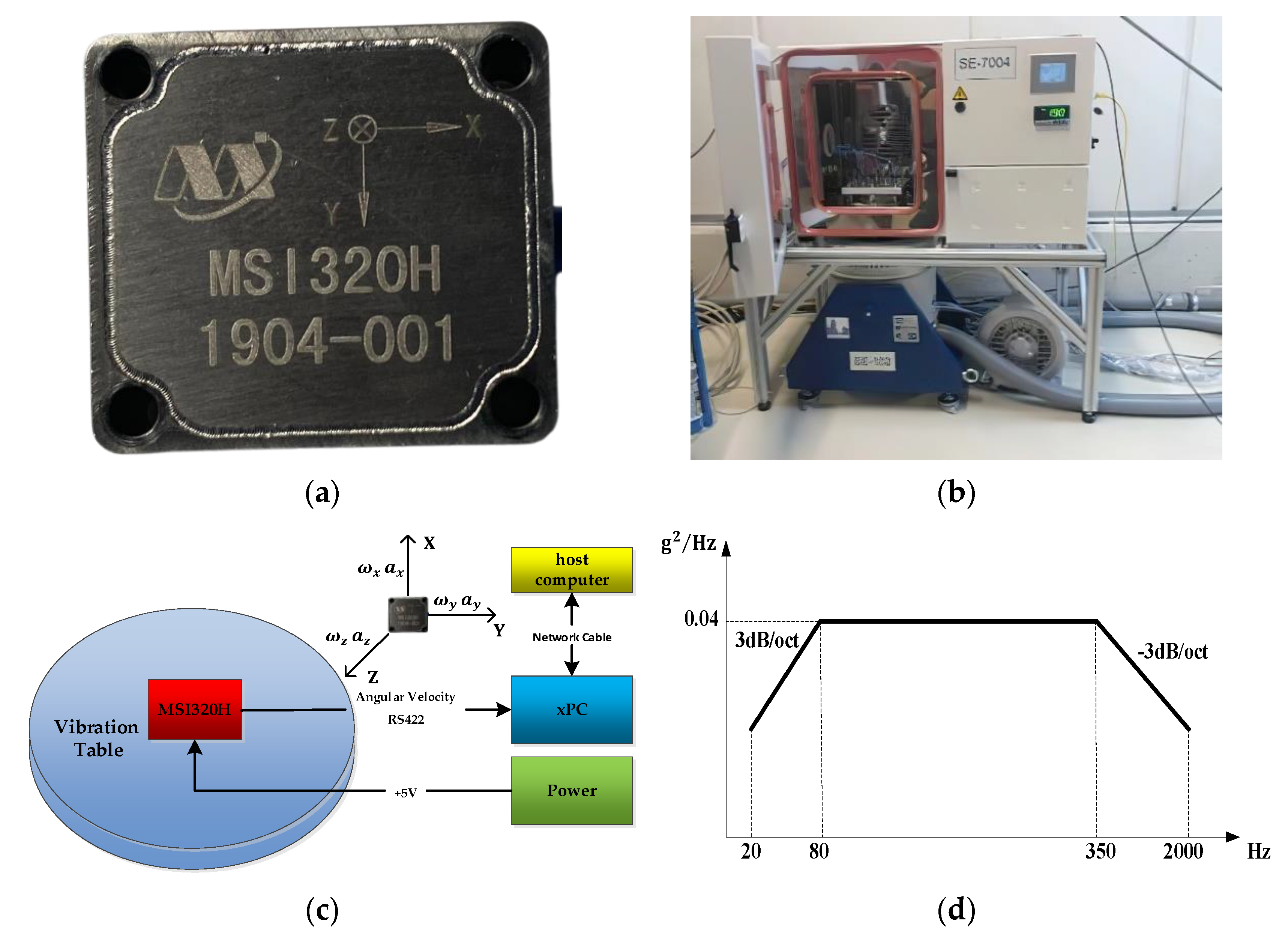
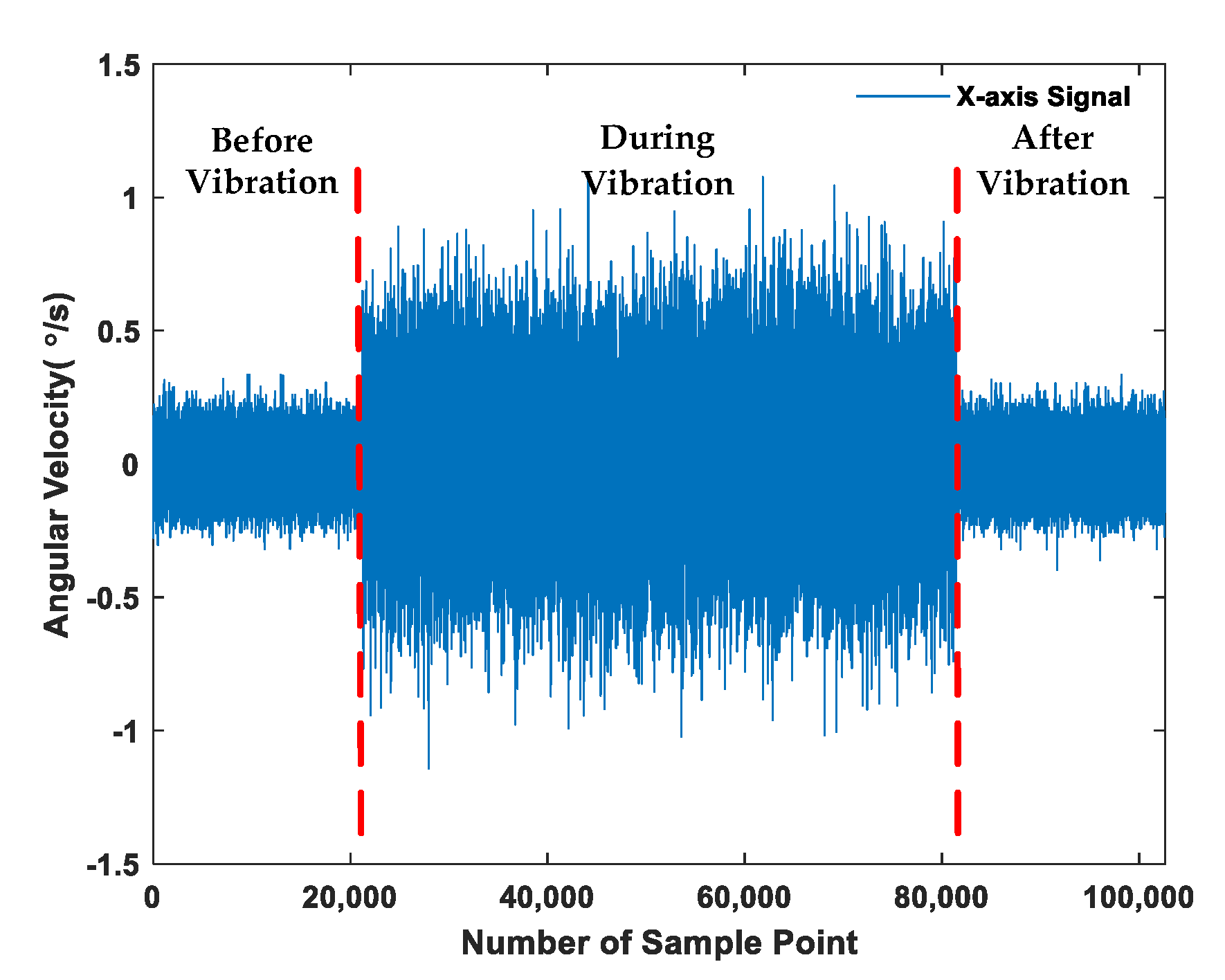
3.1. Data Acquisition
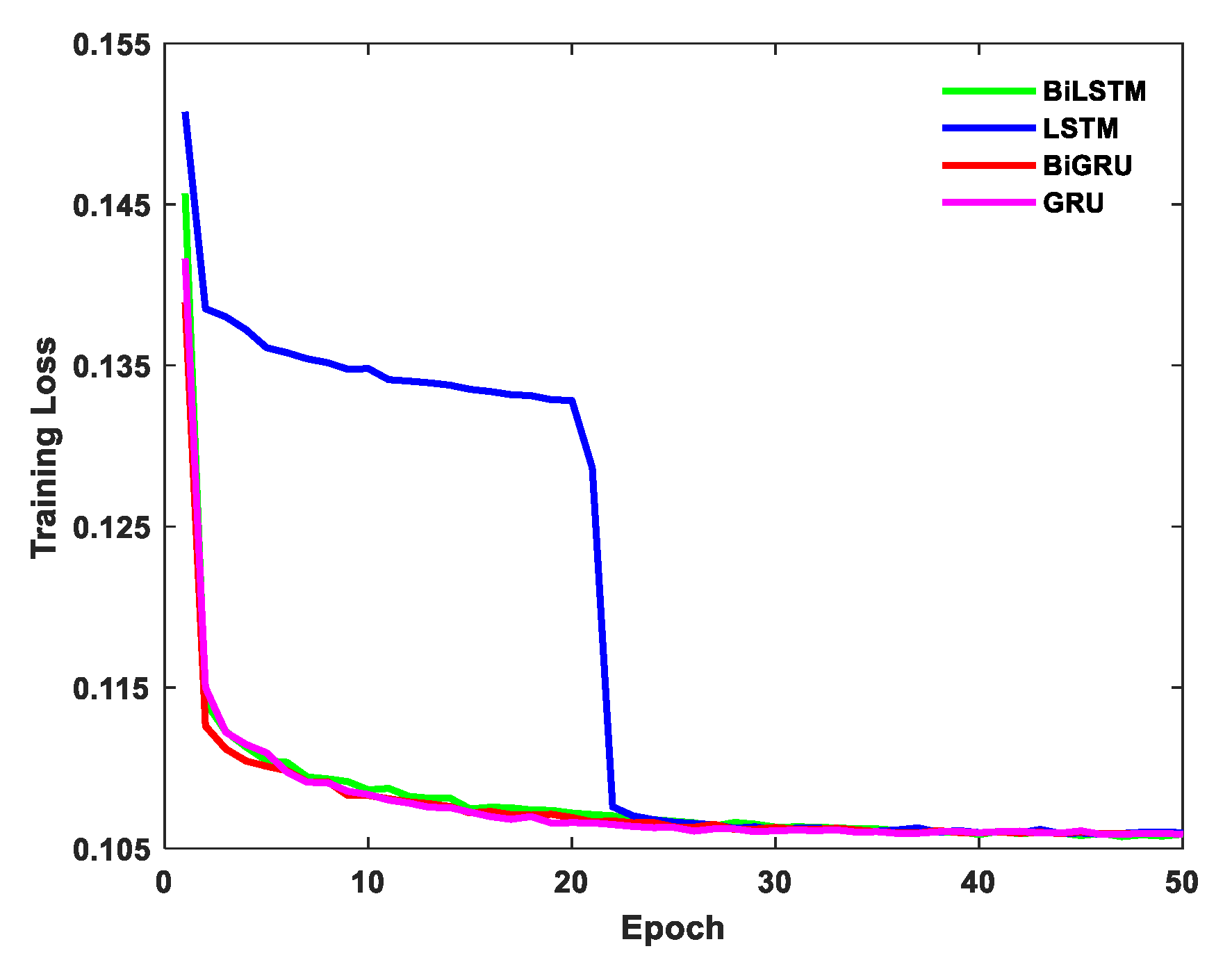
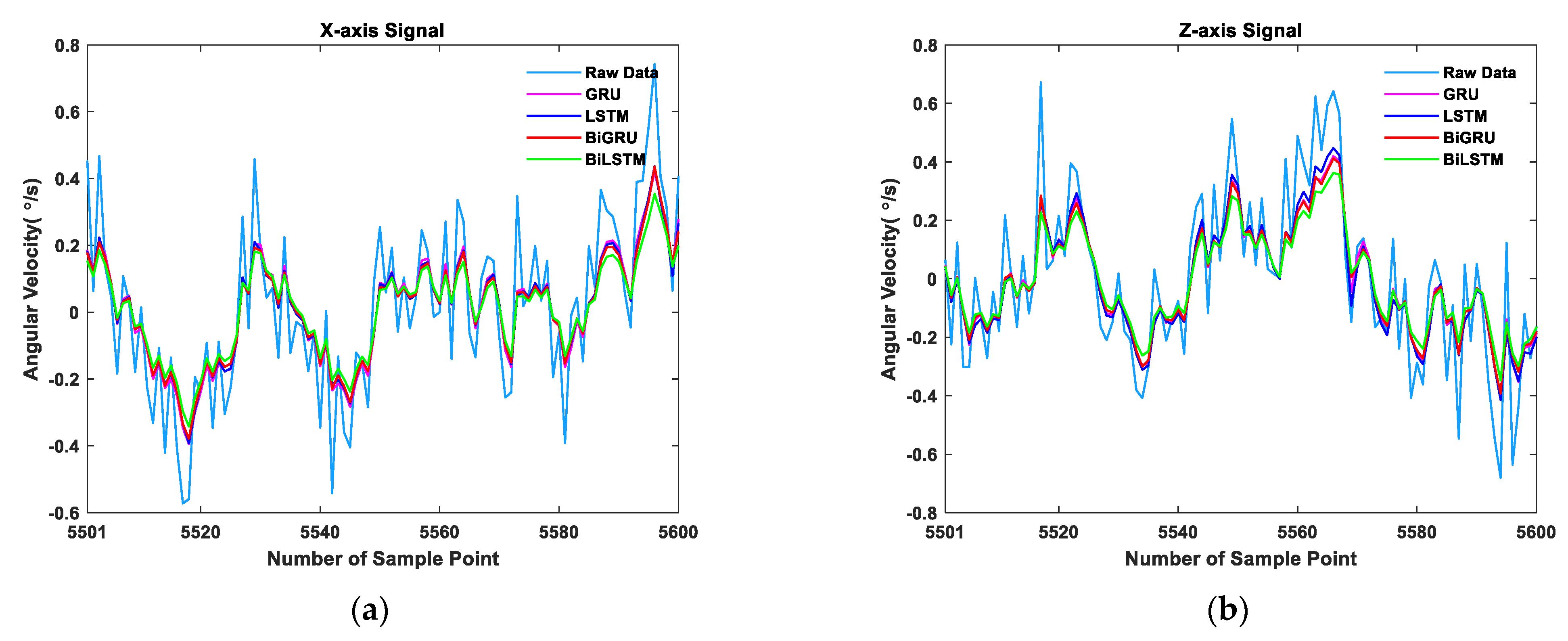
3.2. Comparison of BiLSTM and Other RNN Variants
3.3. Comparison of LSTM-EM-KF and LSTM-ARMA-KF
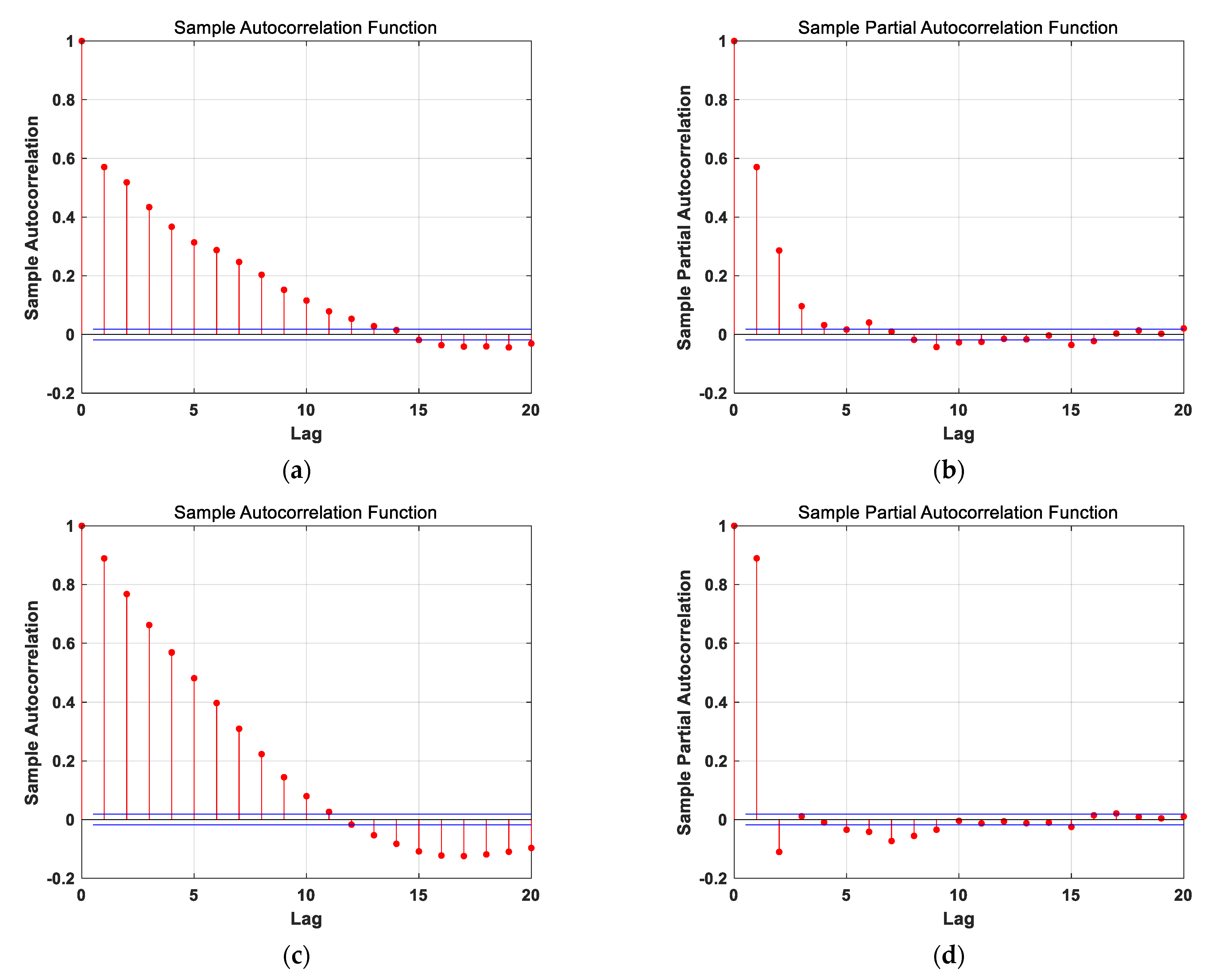
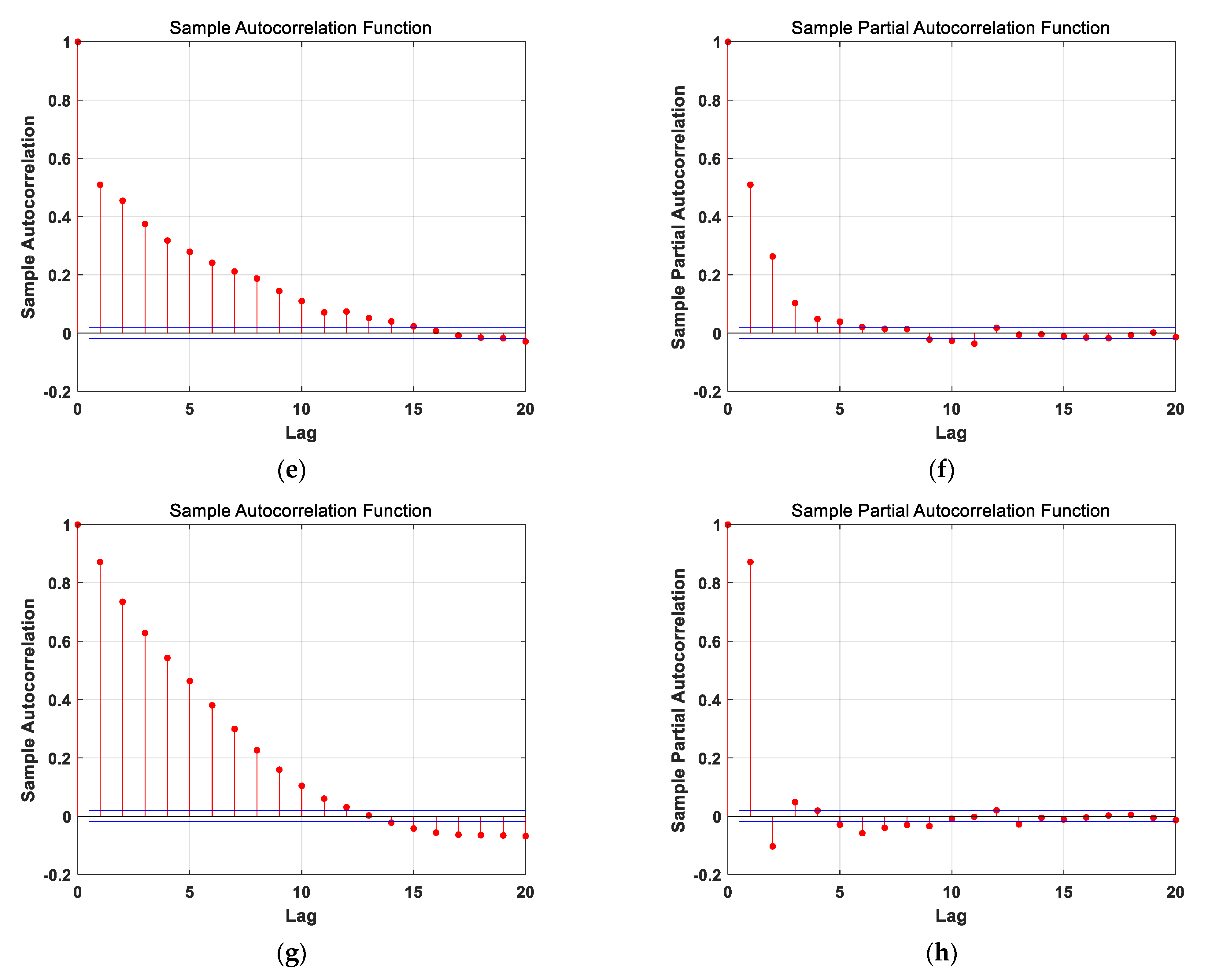
3.3.1. Estimating Kalman Filter Parameters Using the ARMA Model
3.3.2. Estimating Kalman Filter Parameters Using the EM Algorithm
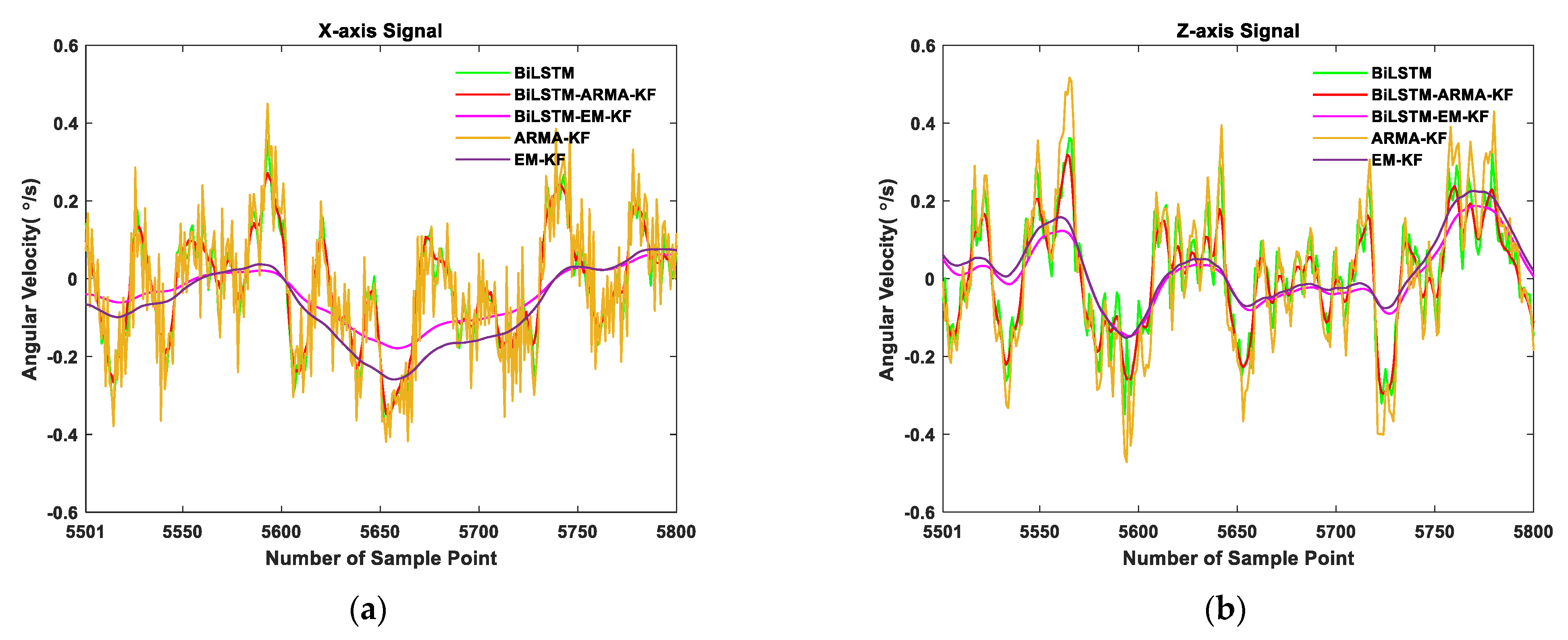
3.3.3. Kalman Filtering Results
4. Conclusions
- (1)
- After exploring proper input data step size and network topology, the network was trained, and the test results showed that the BiLSTM network outperformed the LSTM network, the GRU network, and the BiGRU network in gyroscope error compensation;
- (2)
- Combining the BiLSTM network with the EM-KF method can improve their gyroscopic error compensation performance;
- (3)
- In the classical gyroscope error compensation method, the ARMA-KF method, tedious data testing and model checking are required. In contrast, the EM-KF method only needs to set the initial parameters and the convergence value, which is much easier to apply. Moreover, the ARMA-KF method parameters cannot be updated through the filtering process, which means that satisfactory results cannot be obtained if the parameters are not defined correctly before the filtering process. From the filtering results, compared with BiLSTM-ARMA-KF, the standard deviation of the BiLSTM-EM-KF results were 46.54% and 22.30% lower, in x-axis and z-axis, and the output curve was smoother, which proves the effectiveness of the proposed method in this paper.
Author Contributions
Funding
Conflicts of Interest
Appendix A. Stationarity and Normality Tests

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ,,,, Significance Level, Confidence Interval. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.0615 | 0.0583 | 0.0516 | 0.0621 | 0.0664 | 0.0572 | 0.0640 | 0.0545 | 0.0571 | 0.0628 | |
| 0.0011 | −0.0021 | −0.0088 | 0.0017 | 0.0060 | −0.0032 | 0.0036 | −0.0059 | −0.0033 | 0.0024 | |
| r | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||
| 0.0601 | 0.0602 | 0.0565 | 0.0743 | 0.0585 | 0.0655 | 0.0532 | 0.0693 | 0.0588 | 0.0557 | |
| −0.0003 | −0.0002 | −0.0039 | 0.0139 | −0.0019 | 0.0051 | −0.0072 | 0.0089 | −0.0016 | −0.0047 | |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 | ||||
| ,,,, Significance Level, Confidence Interval. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.0189 | 0.0177 | 0.0144 | 0.0192 | 0.0198 | 0.0163 | 0.0191 | 0.0154 | 0.0159 | 0.0192 | |
| 0.0014 | 0.0002 | −0.0031 | 0.0017 | 0.0023 | −0.0012 | 0.0016 | −0.0022 | −0.0016 | 0.0017 | |
| r | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||
| 0.0176 | 0.0178 | 0.0159 | 0.0224 | 0.0149 | 0.0191 | 0.0144 | 0.0205 | 0.0166 | 0.0150 | |
| 0.0001 | 0.0003 | −0.0016 | 0.0049 | −0.0026 | 0.0016 | −0.0031 | 0.0030 | −0.0009 | −0.0025 | |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 | ||||
| ,,,, Significance Level, Confidence Interval. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.0673 | 0.0565 | 0.0639 | 0.0694 | 0.0611 | 0.0570 | 0.0489 | 0.0533 | 0.0556 | 0.0539 | |
| 0.0077 | −0.0031 | 0.0043 | 0.0098 | 0.0015 | −0.0026 | −0.0107 | −0.0063 | −0.0040 | −0.0057 | |
| r | 1 | 2 | 3 | 4 | ||||||
| 0.0577 | 0.0671 | 0.0642 | 0.0645 | 0.0585 | 0.0619 | 0.0516 | 0.0622 | 0.0620 | 0.0560 | |
| −0.0019 | 0.0075 | 0.0046 | 0.0049 | −0.0011 | 0.0023 | −0.0080 | 0.0026 | 0.0024 | −0.0036 | |
| 5 | 6 | 7 | 8 | 9 | 10 | |||||
| ,,,, Significance Level, Confidence Interval. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.0216 | 0.0159 | 0.0200 | 0.0227 | 0.0180 | 0.0168 | 0.0139 | 0.0160 | 0.0158 | 0.0158 | |
| 0.0033 | −0.0024 | 0.0017 | 0.0044 | −0.0003 | −0.0015 | −0.0044 | −0.0023 | −0.0025 | −0.0025 | |
| r | 1 | 2 | 3 | 4 | ||||||
| 0.0173 | 0.0217 | 0.0213 | 0.0208 | 0.0175 | 0.0197 | 0.0154 | 0.0199 | 0.0191 | 0.0162 | |
| −0.0010 | 0.0034 | 0.0030 | 0.0025 | −0.0008 | 0.0014 | −0.0029 | 0.0016 | 0.0008 | −0.0021 | |
| 5 | 6 | 7 | 8 | 9 | 10 | |||||
| x-axis Raw Data | x-axis BiLSTM Network Results | z-axis Raw Data | z-axis BiLSTM Network Results | |
|---|---|---|---|---|
| Skewness ξ | 2.8329 | 2.7283 | 2.7294 | 2.8156 |
| Kurtosis υ | 0.0177 | −0.1077 | −0.0631 | −0.0170 |
Appendix B. Determine the ARMA Model Order


| p = 0 | p = 1 | p = 2 | p = 3 | |
|---|---|---|---|---|
| q = 0 | −4350.7006 | −5373.4026 | −5483.9134 | |
| q = 1 | −2378.8661 | −5480.4267 | −5503.6485 | −5503.2634 |
| q = 2 | −3784.2642 | −5501.9738 | −5502.2446 | −5501.9462 |
| q = 3 | −4524.5464 | −5504.1306 | −5502.9798 | −5514.9860 |
| p = 0 | p = 1 | p = 2 | p = 3 | |
|---|---|---|---|---|
| q = 0 | −33245.8540 | −33390.6679 | −33390.1658 | |
| q = 1 | −24407.6844 | −33392.3127 | −33390.3534 | −33387.4822 |
| q = 2 | −28837.8009 | −33390.3543 | −33391.2919 | −33390.0297 |
| q = 3 | −30742.3669 | −33388.3649 | −33390.0548 | −33456.4704 |
| p = 0 | p = 1 | p = 2 | p = 3 | |
|---|---|---|---|---|
| q = 0 | −3384.5655 | −4241.9726 | −4367.2696 | |
| q = 1 | −1992.4063 | −4410.0138 | −4414.9553 | −4417.2529 |
| q = 2 | −3107.6730 | −4414.3979 | −4414.5702 | −4415.3240 |
| q = 3 | −3612.4223 | −4417.6140 | −4415.7666 | −4414.6351 |
| p = 0 | p = 1 | p = 2 | p = 3 | |
|---|---|---|---|---|
| q = 0 | −31059.1193 | −31186.5670 | −31212.5235 | |
| q = 1 | −23478.3934 | −31198.8844 | −31202.3767 | −31212.2053 |
| q = 2 | −27430.5011 | −31206.1886 | −31221.9048 | −31228.0632 |
| q = 3 | −29112.3646 | −31212.9557 | −31211.5881 | −31262.0166 |
| x-axis Raw Data | x-axis BiLSTM Network Results | z-axis Raw Data | z-axis BiLSTM Network Results | |
|---|---|---|---|---|
| Durbin–Watson test value | 1.9997 | 2.0064 | 1.9998 | 1.9903 |
References
- Brown, A.K. Gps/ins uses low-cost mems imu. IEEE Aerosp. Electron. Syst. Mag. 2005, 20, 3–10. [Google Scholar] [CrossRef]
- Noureldin, A.; Karamat, T.B.; Eberts, M.D.; El-Shafie, A. Performance enhancement of MEMS-based INS/GPS integration for low-cost navigation applications. IEEE Trans. Veh. Technol. 2008, 58, 1077–1096. [Google Scholar] [CrossRef]
- Chia, J.; Low, K.; Goh, S.; Xing, Y. In A low complexity Kalman filter for improving MEMS based gyroscope performance. In Proceedings of the 2016 IEEE Aerospace Conference, Big Sky, MO, USA, 5–12 March 2016; pp. 1–7. [Google Scholar]
- Mohammadi, Z.; Salarieh, H. Investigating the effects of quadrature error in parametrically and harmonically excited MEMS rate gyroscopes. Measurement 2016, 87, 152–175. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, Y.; Wu, W.; Wu, M.; Hu, X. Improved multi-position calibration for inertial measurement units. Meas. Sci. Technol. 2009, 21, 015107. [Google Scholar] [CrossRef]
- Fong, W.; Ong, S.; Nee, A. Methods for in-field user calibration of an inertial measurement unit without external equipment. Meas. Sci. Technol. 2008, 19, 085202. [Google Scholar] [CrossRef]
- Huang, L. Auto regressive moving average (ARMA) modeling method for Gyro random noise using a robust Kalman filter. Sensors 2015, 15, 25277–25286. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Narasimhappa, M.; Nayak, J.; Terra, M.H.; Sabat, S.L. ARMA model based adaptive unscented fading Kalman filter for reducing drift of fiber optic gyroscope. Sens. Actuators 2016, 251, 42–51. [Google Scholar] [CrossRef]
- Seong, S.M.; Lee, J.G.; Park, C.G. Equivalent ARMA model representation for RLG random errors. IEEE Trans. Aerosp. Electron. Syst. 2000, 36, 286–290. [Google Scholar] [CrossRef]
- Quinchia, A.G.; Ferrer, C.; Falco, G.; Falletti, E.; Dovis, F. In Analysis and modelling of MEMS inertial measurement unit. In Proceedings of the 2012 International Conference on Localization and GNSS, Starnberg, Germany, 25–27 June 2012; pp. 1–7. [Google Scholar]
- Kang, C.H.; Kim, S.Y.; Park, C.G. Improvement of a low cost MEMS inertial-GPS integrated system using wavelet denoising techniques. Int. J. Aeronaut. Space Sci. 2011, 12, 371–378. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.S.; Yang, T. Modeling and compensation of MEMS gyroscope output data based on support vector machine. Measurement 2012, 45, 922–926. [Google Scholar] [CrossRef]
- Bhatt, D.; Aggarwal, P.; Bhattacharya, P.; Devabhaktuni, V. An enhanced mems error modeling approach based on nu-support vector regression. Sensors 2012, 12, 9448–9466. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- El-Rabbany, A.; El-Diasty, M. An efficient neural network model for de-noising of MEMS-based inertial data. J. Navig. 2004, 57, 407. [Google Scholar] [CrossRef]
- Jiang, C.; Chen, S.; Chen, Y.; Zhang, B.; Feng, Z.; Zhou, H.; Bo, Y. A MEMS IMU de-noising method using long short term memory recurrent neural networks (LSTM-RNN). Sensors 2018, 18, 3470. [Google Scholar] [CrossRef] [Green Version]
- Jiang, C.; Chen, S.; Chen, Y.; Bo, Y.; Han, L.; Guo, J.; Feng, Z.; Zhou, H. Performance analysis of a deep simple recurrent unit recurrent neural network (SRU-RNN) in MEMS gyroscope de-noising. Sensors 2018, 18, 4471. [Google Scholar] [CrossRef] [Green Version]
- Jiang, C.; Chen, Y.; Chen, S.; Bo, Y.; Li, W.; Tian, W.; Guo, J. A mixed deep recurrent neural network for MEMS gyroscope noise suppressing. Electronics 2019, 8, 181. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Bo, Y.; Jiang, C. A MEMS Gyroscope Noise Suppressing Method Using Neural Architecture Search Neural Network. Math. Probl. Eng. 2019, 2019, 5491243. [Google Scholar] [CrossRef] [Green Version]
- Barbour, N.M. Inertial Navigation Sensors; Charles Stark Draper Lab Inc.: Cambridge, MA, USA, 2010. [Google Scholar]
- Jafari, M.; Najafabadi, T.A.; Moshiri, B.; Tabatabaei, S.S.; Sahebjameyan, M. PEM stochastic modeling for MEMS inertial sensors in conventional and redundant IMUs. IEEE Sens. J. 2014, 14, 2019–2027. [Google Scholar] [CrossRef]
- Cho, J.Y. High-Performance Micromachined Vibratory Rate and Rate-Integrating Gyroscopes. Ph.D. Thesis, University of Michigan, Ann Arbor, MI, USA, 2012. [Google Scholar]
- Park, B.S.; Han, K.; Lee, S.; Yu, M. Analysis of compensation for a g-sensitivity scale-factor error for a MEMS vibratory gyroscope. J. Micromech. Microeng. 2015, 25, 115006. [Google Scholar] [CrossRef]
- Dean, R.; Flowers, G.; Hodel, S.; MacAllister, K.; Horvath, R. In Vibration Isolation of MEMS Sensors for Aerospace Applications. In Proceedings of the SPIE Proceedings Series; SPIE: Bellingham, WA, USA, 2002; pp. 166–170. [Google Scholar]
- Reid, J.R.; Bright, V.M.; Kosinski, J.A. A micromachined vibration isolation system for reducing the vibration sensitivity of surface transverse wave resonators. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 1998, 45, 528–534. [Google Scholar] [CrossRef]
- Reid, J.R.; Bright, V.M.; Stewart, J.T.; Kosinski, J.A. In Reducing the normal acceleration sensitivity of surface transverse wave resonators using micromachined isolation systems. In Proceedings of the 1996 IEEE International Frequency Control Symposium, Honolulu, HI, USA, 5–7 June 1996; pp. 464–472. [Google Scholar]
- Dean, R.; Flowers, G.; Sanders, N.; Horvath, R.; Johnson, W.; Kranz, M.; Whitley, M. Experimental validation and testing of components for active damping control for micromachined mechanical vibration isolation filters using electrostatic actuation. In Smart Structures and Materials 2006: Smart Electronics, MEMS, BioMEMS, and Nanotechnology; International Society for Optics and Photonics: Bellingham, WA, USA, 2006; p. 61721C. [Google Scholar]
- Kim, J.M.; Mok, S.H.; Leeghim, H.; Lee, C.Y. Vibration-Robust Attitude and Heading Reference System Using Windowed Measurement Error Covariance. Int. J. Aeronaut. Space Sci. 2017, 18, 555–564. [Google Scholar] [CrossRef]
- Wu, Z.; Yao, M.; Ma, H.; Jia, W. De-noising MEMS inertial sensors for low-cost vehicular attitude estimation based on singular spectrum analysis and independent component analysis. Electron. Lett. 2013, 49, 892–893. [Google Scholar] [CrossRef]
- Hao, X.Y.; Li, M.; Han, X.F.; Jia, H.G. In Analysis on the influence of random vibration on MEMS gyro precision and error compensation. In Applied Mechanics and Materials; Trans Tech Publications: Stafa, Switzerland, 2012; pp. 4164–4168. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Schmidhuber, J. In Framewise phoneme classification with bidirectional LSTM networks. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; pp. 2047–2052. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. Mar 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Kustiawan, I.; Chi, K.H. Handoff decision using a Kalman filter and fuzzy logic in heterogeneous wireless networks. IEEE Commun. Lett. 2015, 19, 2258–2261. [Google Scholar] [CrossRef]
- Hosseinyalamdary, S. Deep Kalman filter: Simultaneous multi-sensor integration and modelling; A GNSS/IMU case study. Sensors 2018, 18, 1316. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Peng, C.; Mou, D.; Li, M.; Quan, W. An adaptive filtering approach based on the dynamic variance model for reducing MEMS gyroscope random error. Sensors 2018, 18, 3943. [Google Scholar] [CrossRef] [Green Version]
- Yan, Y.; Guo, P.; Liu, L. In A novel hybridization of artificial neural networks and ARIMA models for forecasting resource consumption in an IIS web server. In Proceedings of the 2014 IEEE International Symposium on Software Reliability Engineering Workshops, Naples, Italy, 3–6 November 2014; pp. 437–442. [Google Scholar]
- Lőrincz, I.; Tajmar, M. Identification of error sources in high precision weight measurements of gyroscopes. Measurement 2015, 73, 453–461. [Google Scholar] [CrossRef] [Green Version]
- Shumway, R.H.; Stoffer, D.S. An approach to time series smoothing and forecasting using the EM algorithm. J. Time Ser. Anal. 1982, 3, 253–264. [Google Scholar] [CrossRef]
- Wu, C.J. On the convergence properties of the EM algorithm. Ann. Stat. 1983, 11, 95–103. [Google Scholar] [CrossRef]
- Andrieu, C.; Doucet, A. In Online expectation-maximization type algorithms for parameter estimation in general state space models. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, Hong Kong, China, 6–10 April 2003; p. VI-69. [Google Scholar]
- Wen, Q.; Ge, Z.; Song, Z. Data-based linear Gaussian state-space model for dynamic process monitoring. AIChE J. 2012, 58, 3763–3776. [Google Scholar] [CrossRef]
- Mirikitani, D.; Nikolaev, N. Nonlinear maximum likelihood estimation of electricity spot prices using recurrent neural networks. Neural Comput. Appl. 2011, 20, 79–89. [Google Scholar] [CrossRef]
- Moore, T.J.; Sadler, B.M.; Kozick, R.J. Maximum-likelihood estimation, the Cramér–Rao bound, and the method of scoring with parameter constraints. IEEE Trans. Signal. Process. 2008, 56, 895–908. [Google Scholar] [CrossRef]
- Hesar, H.D.; Mohebbi, M. An Adaptive Kalman Filter Bank for ECG Denoising. IEEE J. Biomed. Health Inform. 2020, 25, 13–21. [Google Scholar] [CrossRef]
- Hartikainen, J.; Solin, A.; Särkkä, S. Optimal Filtering with Kalman Filters and Smoothers—A Manual for MATLAB Toolbox EKF/UKF; Aalto University School of Science: Espoo, Finland, 2011. [Google Scholar]
- Rousseeuw, P.J.; Leroy, A.M. Robust Regression and Outlier Detection; John Wiley & Sons: Hoboken, NJ, USA, 2005; Volume 589. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]









| GYRO | Input range | ±1800°/s |
| Bias instability (Allan variance) | 36°/h | |
| Angular random walk (Allan variance) | 0.4°/√h | |
| Bandwidth (−3 dB) | ≥220 Hz | |
| GENERAL | Sample rate | 1001000 Hz |
| Weight | ≤25 g | |
| Supply voltage | 5.0 ± 0.5 V | |
| RS422 transmission bit rate | 921600 bps | |
| Mechanical shock, any direction | ≥20,000 g |
| The output dimension of dense layer | 1 |
| Activation function of dense layer | ReLU |
| Dropout rate | 0.5 |
| Batch size | 256 |
| Training epoch | 50 |
| Learning rate | 0.001 |
| Number of Hidden Layers | Number of Hidden Units | Input Data Step | STD (°/s) | Time/Epoch |
|---|---|---|---|---|
| 10 | 64 | 5 | 0.1551 | 23 s |
| 10 | 64 | 10 | 0.1481 | 38 s |
| 10 | 64 | 15 | 0.1483 | 60 s |
| 10 | 64 | 20 | 0.1346 | 82 s |
| 10 | 64 | 25 | 0.1368 | 98 s |
| 10 | 64 | 30 | 0.1501 | 115 s |
| Number of Hidden Layers | Number of Hidden Units | Input Data Step | STD (°/s) | Time/Epoch |
|---|---|---|---|---|
| 10 | 8 | 20 | 0.1504 | 82 s |
| 10 | 16 | 20 | 0.1459 | 82 s |
| 10 | 32 | 20 | 0.1559 | 81 s |
| 10 | 64 | 20 | 0.1346 | 82 s |
| 10 | 128 | 20 | 0.1326 | 81 s |
| 10 | 256 | 20 | 0.1468 | 88 s |
| Number of Hidden Layers | Number of Hidden Units | Input Data Step | STD (°/s) | Time/Epoch |
|---|---|---|---|---|
| 1 | 128 | 20 | 0.1493 | 10 s |
| 2 | 128 | 20 | 0.1513 | 19 s |
| 3 | 128 | 20 | 0.1597 | 27 s |
| 4 | 128 | 20 | 0.1557 | 34 s |
| 5 | 128 | 20 | 0.1658 | 42 s |
| 6 | 128 | 20 | 0.1505 | 50 s |
| 7 | 128 | 20 | 0.1470 | 58 s |
| 8 | 128 | 20 | 0.1459 | 66 s |
| 9 | 128 | 20 | 0.1542 | 75 s |
| 10 | 128 | 20 | 0.1326 | 81 s |
| 11 | 128 | 20 | 0.1405 | 90 s |
| 12 | 128 | 20 | 0.1393 | 98 s |
| x-axis | STD (°/s) | Percentage |
|---|---|---|
| Raw data | 0.2493 | |
| BiLSTM | 0.1326 | 53.19% |
| LSTM | 0.1543 | 61.89% |
| BiGRU | 0.1501 | 60.21% |
| GRU | 0.1604 | 64.34% |
| z-axis | STD (°/s) | Percentage |
|---|---|---|
| Raw data | 0.2400 | |
| BiLSTM | 0.1353 | 56.38% |
| LSTM | 0.1550 | 64.58% |
| BiGRU | 0.1504 | 62.67% |
| GRU | 0.1574 | 65.58% |
| x-axis raw data | |||||
| x-axis BiLSTM | |||||
| z-axis raw data | |||||
| z-axis BiLSTM |
| x-axis raw data | 0.9723 | 0.1350 | 0.0016 | 0.1181 |
| x-axis BiLSTM | 0.9738 | 0.3422 | 0.0016 | 0.2852 |
| z-axis raw data | 0.9471 | 0.1327 | 0.0065 | 0.1155 |
| z-axis BiLSTM | 0.9530 | 0.2983 | 0.0044 | 0.2430 |
| x-axis | STD (°/s) | Percentage |
|---|---|---|
| Raw data | 0.2493 | |
| BiLSTM | 0.1326 | 53.19% |
| ARMA-KF | 0.1618 | 64.90% |
| EM-KF | 0.0943 | 37.83% |
| BiLSTM-ARMA-KF | 0.1201 | 48.17% |
| BiLSTM-EM-KF | 0.0642 | 25.75% |
| z-axis | STD (°/s) | Percentage |
|---|---|---|
| Raw data | 0.2400 | |
| BiLSTM | 0.1353 | 56.38% |
| ARMA-KF | 0.1853 | 77.21% |
| EM-KF | 0.1098 | 45.75% |
| BiLSTM-ARMA-KF | 0.1233 | 51.38% |
| BiLSTM-EM-KF | 0.0958 | 39.92% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, C.; Cai, S.; Yang, Y.; Xu, W.; Shen, H.; Chu, H. A Combined Method for MEMS Gyroscope Error Compensation Using a Long Short-Term Memory Network and Kalman Filter in Random Vibration Environments. Sensors 2021, 21, 1181. https://0-doi-org.brum.beds.ac.uk/10.3390/s21041181
Zhu C, Cai S, Yang Y, Xu W, Shen H, Chu H. A Combined Method for MEMS Gyroscope Error Compensation Using a Long Short-Term Memory Network and Kalman Filter in Random Vibration Environments. Sensors. 2021; 21(4):1181. https://0-doi-org.brum.beds.ac.uk/10.3390/s21041181
Chicago/Turabian StyleZhu, Chenhao, Sheng Cai, Yifan Yang, Wei Xu, Honghai Shen, and Hairong Chu. 2021. "A Combined Method for MEMS Gyroscope Error Compensation Using a Long Short-Term Memory Network and Kalman Filter in Random Vibration Environments" Sensors 21, no. 4: 1181. https://0-doi-org.brum.beds.ac.uk/10.3390/s21041181