
XCycles Backprojection Acoustic Super-Resolution
by
 , , , , , , and
, , , , , , and
Feras Almasri
1,2,* ,
,
Jurgen Vandendriessche
1,
Laurent Segers
1,
Bruno da Silva
1,3,*,
An Braeken
1,
Kris Steenhaut
1,3,
Abdellah Touhafi
1,3 and
Olivier Debeir
2 1
Department of Engineering Sciences and Technology (INDI), Vrije Universiteit Brussel, 1050 Brussels, Belgium
2
Laboratory of Image Synthesis and Analysis (LISA), Université Libre de Bruxelles, 1050 Brussels, Belgium
3
Department of Electronics and Informatics (ETRO), VUB, 1050 Brussels, Belgium
*
Authors to whom correspondence should be addressed.
Sensors 2021, 21(10), 3453; https://0-doi-org.brum.beds.ac.uk/10.3390/s21103453
Submission received: 16 March 2021
/
Revised: 5 May 2021
/
Accepted: 12 May 2021
/
Published: 15 May 2021
(This article belongs to the Collection Machine Learning and AI for Sensors)
Abstract
:The computer vision community has paid much attention to the development of visible image super-resolution (SR) using deep neural networks (DNNs) and has achieved impressive results. The advancement of non-visible light sensors, such as acoustic imaging sensors, has attracted much attention, as they allow people to visualize the intensity of sound waves beyond the visible spectrum. However, because of the limitations imposed on acquiring acoustic data, new methods for improving the resolution of the acoustic images are necessary. At this time, there is no acoustic imaging dataset designed for the SR problem. This work proposed a novel backprojection model architecture for the acoustic image super-resolution problem, together with Acoustic Map Imaging VUB-ULB Dataset (AMIVU). The dataset provides large simulated and real captured images at different resolutions. The proposed XCycles BackProjection model (XCBP), in contrast to the feedforward model approach, fully uses the iterative correction procedure in each cycle to reconstruct the residual error correction for the encoded features in both low- and high-resolution space. The proposed approach was evaluated on the dataset and showed high outperformance compared to the classical interpolation operators and to the recent feedforward state-of-the-art models. It also contributed to a drastically reduced sub-sampling error produced during the data acquisition.
1. Introduction
Single-image upscaling, known as Single-Image Super-Resolution (SISR), is a classical computer vision problem, used to increase the spatial resolution of digital images. The process aims to recover fine detail High-Resolution (HR) image from a single coarse Low-Resolution (LR) image. It is an inherently ill-posed inverse problem, as multiple downsampled HR images could correspond to a single LR image. Reciprocally, upsampling an LR image with a 2× scale factor requires mapping one input value into four values in the high-resolution image, which is usually intractable. It has a wide range of applications, such as digital display technologies, remote sensing, medical imaging care, and security and data content processing. Classical upscaling methods, based on interpolation operators, have been used for this problem for decades, and it remains an active topic of research in image processing. Despite their achieved progress, the upscaled images are still lacking fine details in texture-rich areas. Recently, the development of deep learning methods has witnessed remarkable progress achieving performance on various benchmarks [1,2] both quantitatively and qualitatively with enhanced details in texture-rich areas.
The computer vision community has paid more attention to the development of visible sensor images, and over the last decade, non-visible light sensors such as infrared, acoustic, and depth imaging sensors were only used in very specific applications. The images produced by those sensors lack the consideration of the potential benefits of the non-visible spectrum due to their low spatial resolution, the high cost incurred as their price increases dramatically with the increase of their resolution [3], and the lack of publicly available datasets. At this time, there is no acoustic imaging dataset designed for the SR problem. With the need to develop a vision-based system that benefits from the non-visible spectrum, acoustic sensors have recently received much attention as they allow visualization of the intensity of sound waves. The sound intensity in an acoustic heat map format can be graphically represented in order to facilitate the identification and localization of sound sources.
In contrast to visible or infrared cameras, there is not a single sensor for acoustic imaging, but rather an array of sensors. As a result, the image resolution in acoustic cameras is directly related to their computational demand, requiring hardware accelerators such as Graphical Processor Units (GPUs) [4] or Field-Programmable Gate Arrays (FPGAs) [5,6]. Consequently, available acoustic cameras offer a relatively low resolution, ranging from to pixels per image and at a relatively low frames-per-second rate [7,8]. Acoustic imaging presents a high computational cost and is therefore often prohibitive for embedded systems without hardware accelerators. Moreover, it also suffers from a subsampling error in the phase delay estimation. As a result, there is a significant degradation in the quality of the output acoustic image [9], which manifests in artifacts that directly affect the sound source localization [10]. Due to the limitation in acoustic data acquisition, methods to enhance the precision of a measurement with respect to spatial resolution and to reduce artifacts becomes more important.
Learning-based SISR methods rely on high- and low-resolution image pairs generated artificially. The conventional approach is generally by downsampling the images using a bicubic interpolation operator and adding both noise and blur to generate corresponding low-resolution images. However, such image pairs do not exist in real-world problems, and the artificially generated images have a considerable number of artifacts from smoothing, removing sensor noise, and other natural image characteristics. This poses a problem as models trained on these images cannot be generalized to another unknown source of image degradation or natural image characteristics. There are a few contributions where the image pairs were obtained from different cameras in the visible imaging, but none in the acoustic imaging.
Based on these facts, the main contributions of the proposed work are threefold:
- A novel backprojection model architecture was proposed to improve the resolution of the acoustic images. The proposed XCycles BackProjection model (XCBP), in contrast to the feedforward model approach, fully uses the iterative correction procedure. It takes low- and high-resolution encoded features together to extract the necessary residual error correction for the encoded features in each cycle.
- The acoustic map imaging dataset (https://0-doi-org.brum.beds.ac.uk/10.5281/zenodo.4543786), provided simulated and real captured images with multiple scales factor (×2, ×4, ×8). Although these images shared similar technical characteristics, they lacked artificial artifacts caused by the conventional downsampling strategy. Instead, they had more natural artifacts simulating the real-world problem. The dataset consisted of low- and high-resolution images with double-precision fractional delays and sub-sampling phase delay error. To the best of the authors’ knowledge, this is the first work to provide such a large dataset with its specific characteristics for the SISR problem and the sub-sampling phase delay error problem;
- The proposed benchmark and the developed method outperformed the classical interpolation operators and the recent feedforward state-of-the-art models and drastically reduced the sub-sampling phase delay error estimation.
- The proposed model contributed to the Thermal Image Super-Resolution Challenge—PBVS 2021 [11] and won the first place with superior performance in the second evaluation when the LR image and HR image are captured with different cameras.
2. Related Work
Plentiful methods have been proposed for image SR in the computer vision community. The original work of introducing deep learning-based methods for the SR problem by Dong et al. [1] opened new horizons in this SR problem domain. Their proposed model SRCNN achieved superior performance against all previous works. The architecture formulation of the SRCNN aims to learn a hierarchical sequence of encoded features and upsample them to reconstruct the final SR image, where the entire learning process can be seen as an end-to-end feedforward manner. In this work, we focused on works related to the Convolutional Neural Network (CNN) architecture formulations proposed for the residual error correction approach in contrast to the feedforward manner.
The SRCNN aims to learn an end-to-end mapping function between the bicubic upsampled image and its correspondent high-resolution image, where the last reconstruction layer serves as an encoder from the feature space to the super-resolved image space. To speed up the procedure and to reduce the problem complexity, which is proportional to the input image size, Dong et al. [12] and Shi et al. [13] proposed faster and learnable upsampling models. Instead of using an interpolated image as an input, they speed up the procedure by reducing the complexity of the encoded features while training upsampling modules at the very end of the network.
The HR image can be seen as the components of low-frequency (LF) features (coarse image) and high-frequency (HF) features (residual fine-detail image). The results of the classical interpolation operators and the previous deep learning-based models have high peak signal-to-noise ratios (PSNRs), but they lack HF features [14]. As the super-resolved image contains LF features, Kim et al. [2] proposed the VDSR model, which predicts the residual HF features and adds them to the coarse super-resolved image. Their proposed model showed superior performance compared to the previous approaches. Introducing residual networks and skip connections with residual feature correction exhibits improved performance in the SR problem [2,14,15,16,17], which also allows end-to-end feedforward to have deeper networks.
In contrast to this simple feedforward approach, Irani et al. [18] proposed a model that reconstructs the backprojected error in the LR space and adds the residual error to the super-resolved image. Influenced by this work, Haris et al. [19] proposed an iterative error correction feedback mechanism to guide the reconstruction of the final SR output. Their approach was a model of iterative up- and down-sampling blocks that takes all previously upscaled features and fuses them to reconstruct the SR image. Inspired by [18,19], the VCycles Backprojection upscaling network (VCBP) [20] was first introduced in the Perception Beyond the Visible Spectrum (PBVS2020) challenge. The model was designed in iterative modules with shared parameters to produce a light SR model dedicated for thermal applications, which limits its performance. In VCBP, the iterative error correction happens in the low-resolution space, and in each iteration, the reconstructed residual features are added to the HR encoded feature space. In VCBPv2 [21], the parameters are not shared within the modules, and the iterative error correction happens in both the low- and high-resolution space. It follows the design of Haris et al. [19] of using iterative up- and down-sampling layers to process the features in the inner Loop. Although this technique increases the efficiency of the model, it restricts the depth from extracting important residual features from the encoded feature space.
The iterative error correction mechanism in the feature space is very important for the HF features’ reconstruction in the SR problem. If the model pays more attention to this correction procedure in the upsampled HR and the LR feature space, it might be possible to obtain improvements in the residual HF detail in the super-resolved image. This paper proposed a fully iterative backprojection error mechanism network to reconstruct the residual error correction for the encoded features in both low- and high-resolution spaces.
3. Acoustic Beamforming
Acoustic cameras acquire their input signal from arrays of microphones placed in well-defined patterns for high spatial resolution. Microphone arrays come in different shapes and sizes, offering different possibilities for locating a neighboring sound source. The process of locating a sound source with a microphone array is referred to as the beamforming method. Beamforming methods comprise several families of algorithms, including the Delay-and-Sum (DaS) beamformers [22,23,24], the Generalized Sidelobe Cancellation (GSC) beamformers [25,26,27], beamformers based on the MUltiple SIgnal Classification (MUSIC) algorithm [28,29], and beamformers based on the Estimation of Signal Parameters via Rotational Invariance Technique (ESPRIT) algorithm [30,31].
3.1. Delay and Sum Beamforming
The well-known DaS is the most popular beamformer and was the one selected to generate the acoustic images in this work. The beamformer steers the microphone array in a particular direction by delaying samples from the different microphones. The acoustic signals originating from the steering direction are amplified, while acoustic signals coming from other directions are suppressed. The principle of DaS beamforming can be seen in Figure 1 as:
Here, is the output of the beamformer for a microphone array of M microphones and is the sample from microphone m delayed by a time . The time delay in a given steering direction is obtained by computing the dot product between the vector , describing the location of microphone m in the array, and the unitary steering vector . The delay factor is normalized by the speed of sound (c) in air.
The principle described is valid in the continuous time domain. Therefore, the principle of DaS is extended with the sampling frequency so that a form of index is obtained:
This value can be rounded to the nearest integer to facilitate array indexing:
For a sufficiently high sampling frequencies at the DaS stage, offers a fine-grained indexing nearing so that:
Based on these equations, the output values of the DaS method in the time domain with current reference sample index i yields:
Equation (6) can be transformed into the z-domain by applying the z-domain delay identity so that:
From Equation (7), one can compute the average Steered Response Power (SRP) over L samples for each of the steering vectors with:
By computing the SRP values for each of the steering vectors, a matrix of SRP values can be generated. When all steering vectors have the same elevation, the matrix will be one dimensional, and a polar plot can be used for visualization and finding the origin of the sound source. On the other hand, when the steering vectors have a changing elevation, the matrix will be two dimensional. When this matrix is normalized and, optionally, a colormap is applied to it, the acoustic heat map is obtained.
Examples of the SRP are depicted in Figure 2. In (a), a regular beamforming in two dimensions is computed and is pointing to an angle of towards an acoustic source of 4 kHz. The same principle can be applied to obtain an acoustic image (c,d) when the steering vectors are distributed in 3D space (changing elevation). In (b), the frequency response of a given microphone array can be found. In this case, a sound source is located at an angle of relative to the microphone array. The frequency response allows the user to identify whether a given microphone array is likely to detect a given set of acoustic frequencies well.
3.2. Fractional Delays
The DaS beamforming technique properly delays the input audio samples to generate constructive interference for a particular steered direction. These time delays are obtained based on Equation (3) and rounded following Equation (4). The DaS beamforming technique based on these rounded indices provides accurate results when sufficiently high sampling frequencies (i.e., typically beyond 1 MHz) at the DaS stage are chosen. This method, however, may suffer from output degradation in the opposite case [32]. Due to the sampling frequency, the demodulation of the Pulse Density Modulation (PDM) signals and filtering of the PDM Micro Electro-Mechanical Systems (MEMSs) microphones, there exist an error in the estimation of the time delays corresponding to the phase delays of the microphones’ signals when applying DaS beamforming. Variations of this phenomenon have also been observed in early modem synchronization, speech coding, musical instruments modeling, and realignment of multiple telecommunication signals [33].
This kind of degradation is shown in Figure 3, where the input sampling frequency was set to 3125 kHz, but the sampling frequency at the DaS stage is limited to 130.2 kHz. A sound source is placed at an angle of from the UMAP microphone array. In the case of the DaS method with index rounding (fractional disabled, red curve), the microphone array allows the user to find the sound source in an angular area of approximately . However, the staircase-like response suggests two different closely located sound sources since the graph describes a valley at the supposed steering orientation. To alleviate this phenomenon, fractional delays can be used to minimize the effects of rounded integer delays and are generally used at the FIR filtering stage [33]. Fractional delays can be used in both the time and frequency domains. The method has the advantage of being more flexible in the frequency domain with the added cost of demanding more intense computations. Several time-domain-based implementations also exist and are generally based on sample interpolation.
Based on the floor and the ceiling of the index, a linear interpolation can be applied at the DaS stage:
With the double-precision weighing coefficient :
Double-precision computations demand a great amount of computational power, which is unavailable on constrained devices such as embedded systems and can lead to intolerable execution times and low frame rates. Luckily, double-precision delays can be changed into fractional delays . To do so, the double-precision weighing coefficient is scaled with the number of bits n used in the fraction and rounded to the nearest natural number.
The fractional delays range from up to . In the case where the rounding function returns , both the and the are increased with one index, while is reset to . This approach prevents index overlap between two rounding areas. The resulting output values can be calculated using:
In Equation (13), the nominator and denominator are both scaled with a factor as compared to Equation (10). The main advantage of the latter is that since the denominator remains a power of two, a simple bit-shift operation can be used instead of a full division mechanism in computationally constrained devices.
The effects of the fractional delays are demonstrated in Figure 3. A higher value of the bitwidth n allows a more fine-grained DaS computation. For values of n beyond four, the resulting response is almost equal to the response of the DaS with double-precision interpolation.
In addition to a single-response result, the effect of fractional delays is also visible in the waterfall diagrams of the microphone array (Figure 4). When no fractional delays are used, many vertical stripes are visible, indicating truncation errors during beamforming. By using fractional delays, these stripes gradually disappear until eight bits (“Fractional 8”) are used. Fractional delays with a resolution of eight bits and beyond result in the same response as double-precision fractional delays. Due to the chosen beamforming architecture, the frequency waterfall diagram of the proposed architecture differs from the theoretically obtainable diagram.
4. Acoustic Map Imaging Dataset
This section first introduces the characteristics of the target acoustic camera [6] and the imaging emulator [34]. The procedure for capturing multiple scale acoustic map images, the analysis of the dataset, and the applied standardization procedure are also described.
4.1. Acoustic Camera Characteristics
Acoustic cameras, such as the Multi-Mode Multithread Acoustic Camera (M3-AC) described in [6], acquire the acoustic signal using multiple microphones, which convert the acoustic signal into a digital signal. In addition, microphone arrays allow the calculation of the Direction of Arrival (DoA) for a given sound source. The microphone array geometry has a direct impact on the acoustic camera response for DaS beamforming (Equation (1)). Figure 5 depicts the microphone array geometry used by the M3-AC. The microphones are distributed in two circles, with four microphones located in the inner circle, while the remaining eight microphones are located in the outer circle. The shortest distance between two microphones is 23.20 mm, and the longest distance is 81.28 mm.
The type of microphone, the sampling methods, and the signal processing methods influence the final outcome of the beamforming. For instance, the microphone array of M3-AC is composed of MEMS microphones with a PDM output. Despite the benefit of using digital MEMS microphones, there is a need for a PDM demodulation in order to retrieve the acquired audio. Each microphone converts the acoustic into a one-bit PDM signal by using a Sigma-Delta modulator [35]. This modulator typically runs between 1 and 3 MHz and oversamples the signal.
To retrieve the encoded acoustic signal, a set of cascaded filters are applied to simultaneously decimate and recondition the signal into a Pulse Coded Modulation (PCM) format (Figure 6). Both the geometry of the microphone array and the signal processing of the acoustic signal have a direct impact on the acoustic camera response. Evaluation tools such as the Cloud-based Acoustic Beamforming Emulator (CABE) enable an early evaluation of an array’s geometries and the frequency response of the acoustic cameras [34].
4.2. Generation of Acoustic Datasets
Traditional datasets for SR consist of high-resolution images that are downsampled and blurred to generate the low-resolution image, or they use different cameras to generate two images of the same scene [36]. When using two cameras, the frames require some realignment to compensate the different positions of the two cameras.
The CABE is used to generate the acoustic images. The CABE can emulate the behavior of the traveling sound, microphones, and stages that are required for generating the acoustic heat map. The main advantages of using an emulator over real-life acoustic heat maps are consistency and space. First, considering the consistency, using an emulator makes it is possible to replicate the exact same acoustic circumstances multiple times for different resolutions and different configurations. One could generate the same acoustic image with two different microphone arrays for example or use a different filtering stage.
Second, considering space, an emulator eliminates the requirement of having access to anechoic boxes or an anechoic chamber. This allows one to generate acoustic images with sound sources that are several meters away from the microphone array. In order to achieve the same results in a real-world scenario, a large anechoic chamber is required. If one has access to such a chamber, the CABE could still be used. The CABE has the option to use PDM signals from real-life captured recordings to generate the acoustic heat maps. Doing so will omit everything that comes before the filtering stage and replace it by the PDM signals from the real-life recording.
In order to have a representative dataset, the same architecture as in [34] was used. The order of the filters and the decimation factor can be found in Table 1. To compensate for the traveling time of the wave, each emulation starts after 50 ms and lasts for 50 ms. For all emulations, a Field of View (FOV) of 60° in both directions was used.
4.3. Dataset Properties
Scale: The key application of our proposed acoustic map imaging dataset is to upscale the spatial resolution of a low-resolution image by multiple scale factors (×2, ×4, ×8). To realize this, eight different sets of images were generated, each containing 4624 images. Four different resolutions were used: the HR ground truth images of size () and three different scale sets of LR images of size (, and ). For each resolution, one dataset was generated using fractional delays and another without fractional delays, as shown in Figure 7 with a total of 36,992 images. In real-world use, acoustic sensor resolution is very small and suffers from a sub-sampling error in the phase delay estimation. This results in artifacts and poor image quality compared to the simulated images. The benchmark used was chosen to simulate these real-world difficulties in order to enhance the super-resolved images. This was also consistent with the proposed real captured images set.
Real captured images: Acoustic maps were generated from recordings of the M3-AC acoustic camera [6]. The sound sources were placed at different angles without any relation to the positions of the sound sources for the acoustic images generated using the CABE. The acoustic heat maps were generated with the resolutions corresponding to the ×2, ×4, and ×8 scale factors without fractional delays and one double-precision set representing the corresponding HR ground truth. Real-world captured images could have different natural characteristics. This poses a problem as models trained on artificial images cannot generalize to another unknown source of image degradation. The purpose of the real captured images was to evaluate whether the proposed method could generalize over the unknown data. For this reason, the real captured images were not used during training; instead, they were all exclusively used as test data.
Acquisition: Each image contained two sound sources, positioned at a distance of one meter from the center of the array and mirrored from each other. The sound sources were placed at angles between 60° and 90° in steps of 2° for a total of 16 positions. No vertical elevation was used. The frequency of the two sound sources was changed independently of each other from 2 kHz to 10 kHz in steps of 500 Hz, across the eight different sets. By using two sound sources, some acoustic images suffered from problems with the angular resolution (Rayleigh criterion) where the distance between the two sound sources became too small to distinguish one from the other. For instance, when both sound sources were placed at 90°, they overlapped and became one sound source.
Normalization: Natural images in SISR problem are logged in the uint8 data type, which is in agreement with the most recent thermal image benchmarks. Although acoustic and thermal sensors allow the generation of raw data logged in float representation, which consists of rich information, this could produce a problem in the validation consistency between benchmarks. To avoid technical problems with the validation, the proposed benchmark was standardized with the current research line to be compatible with published datasets in other SISR domains.
The registered sound amplitude in acoustic map imaging depends on the sound volume, the chosen precision during the computation, and the number of microphones. The more microphones that are used during the computations, the higher the amplitude will be in the registered map. This can generate high variant values in the minimum-maximum value range. Due to this, it is not possible to preserve the local dynamic range of the images and to normalize them using fixed global values. It may also cause a problem with the unknown examples. Any method of contrast or histogram equalization could harm the images and cause the loss of important information. Consequently, instance min-max normalization as in Equation (14) and the uint8 data type were used. We denote I and the original image and its normalized version; and . The images were then converted to grayscale in the range [0–255] and saved as PNG format with zero compression.
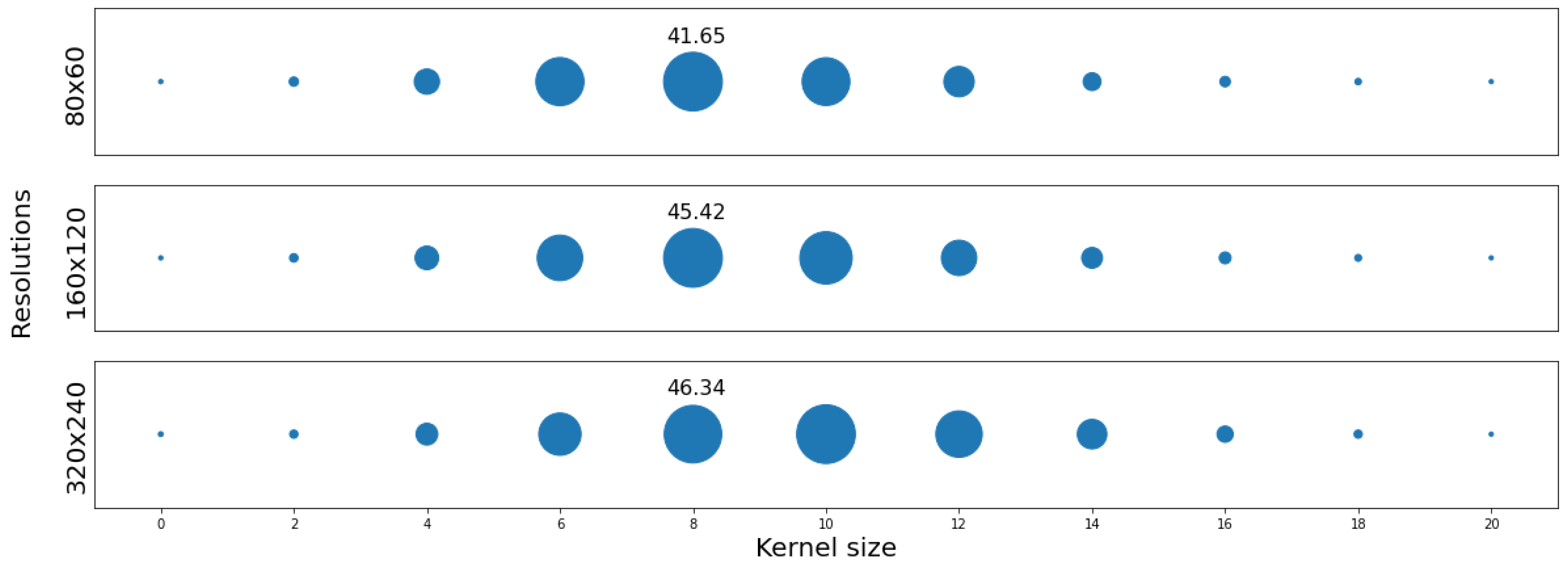
Baseline approach: The authors believe that this is the first work to provide as large a dataset of acoustic map imaging pairs captured with four different scales in an emulator and in the real world. The PSNR and the Structural Similarity Index Measure (SSIM) metrics are reported for reference in SISR problems. A bicubic algorithm was used as a baseline model for validation comparison for the super-resolved images. To reduce quality degradation caused by subsampling errors in phase delay estimation, a Gaussian kernel with different kernel sizes was used on top of the bicubic output to reduce the artifacts. Figure 8 shows that a Gaussian kernel with size of eight achieved the best PSNR results for the three resolutions.
Train and test set: Because of the large number of images in the dataset and to avoid possible overfitting due to shared similarities in the images, ninety-six samples were drawn for the test set from the images with low PSNR value. The test set sampling procedure was processed on the PSNR distribution built on the 8× bicubic upscaled images. The sampling toward the low PSNR value images was processed using a Kernel Density Estimator (KDE) skewed distribution. In the end, the test set became biased with more complex examples.
5. XCycles Backprojection Network
5.1. Network Architecture
The baseline model of the proposed method was comprised of two main modules: Cycle Features Correction (CFC) and Residual Features Extraction (RFE). As shown in Figure 9, the architecture of XCBP was unfolded with X CFCs, as each cycle contained one RFE module. The value of x was an odd number since two consecutive cycles were mandatory for the final results. The model used only one convolutional layer (Encoder (E)) to extract the shallow features F from the low-resolution input image and its pre-upsampled version , shown in Equation (15). The pre-upsampling module can take any method, such as a classical pre-defined upsampling operator, transposed convolution [12], sub-pixel convolution [13], or resize-convolution [37].
The term denotes the encoded features in the low-resolution space, whereas denotes the encoded features of the pre-upsampled image in the high-resolution space. The Decoder (D) of only one convolutional layer uses the final features corrected by the CFC in cycle X to reconstruct the super-resolved image .
The CFC module serves as a feature correction mechanism. It was designed to supply the encoded features of the two parallel feature spaces to its RFE module for further feature extraction and corrects the encoded features once at a time. The output of its RFE module is backprojected by addition to one of the two parallel feature spaces. The backprojection serves to correct the previous features’ location in both encoded features’ manifold in contrast to [20]. By having the two feature spaces as the input, the model uses the encoded features and its corresponding super-resolved features to find the best correction in each feature space. This correction is very helpful for images captured with different devices, with different geometrical registration, that suffer from a misalignment problem.
The CFC adds the output in an alternate cycle. For each cycle, it adds the correction either to the low-resolution feature space or to the super-resolved feature space . In , the output of the RFE passes by the Upsampler (U) before adding the correction to match the scale of the features, as shown in Equation (17).
The Upsampler (U) is a resize-convolution [37] sub-module consisting of a pre-defined nearest-neighbor interpolation operator of scale factor ×2, and a convolution layer with a receptive field of size 5 × 5 pixels represented by two stacked 3 × 3 convolutions.
5.2. Residual Features Extraction Module
The Residual Features Extraction module (RFE) in each CFC depicted in Figure 9 was designed to extract features from the two parallel feature spaces and . After each cycle correction in one of the feature spaces, the encoded features change their characteristics and allocate a new location in the feature space. The RFE module takes both features as the input and extracts new residual features for the next feature space correction procedure, based on the similarity and non-similarity between previously corrected feature spaces.
As depicted in Figure 10, the RFE module has two identical sub-modules (Internal features encoder (I)) responsible for extracting deep features from the two parallel spaces. One (I) for each of the feature spaces of only one convolutional layer, with strided convolution in the high-resolution space to adapt to the different resolution scale. The two deep encoded features are then concatenated, and a pointwise convolution layer [38] transforms them to their original channel space size.
The main core of the RFE module consists of three levels L of double activated convolution layers connected sequentially. The output of the three L levels, defined as the inner skip connections, are concatenated together, creating dense residual features before a pointwise convolution layer returns them to their original channel space size. Finally, the output of the merger layer is fed to a channel attention module, inspired by the RCAN model [17], to weight each residual channel priority before it is added to the outer skip connection of the main merger.
5.3. Implementation Details
The final XCBP proposed model was constructed with X = 8 cycles. All convolution layers were set to 3 × 3 except for the channel reduction, whose kernel size was 1 × 1, to transform the concatenated features to their original channel space size. All features were encoded and decoded with 128 feature channels. Convolution layers with kernel size 3 × 3 used the reflection-padding strategy and the PReLU [39] activation function when activation was stated. The reduction ratio was set to 16 in the channel attention module.
6. Experiments
6.1. Training Settings
The experiments were implemented in PyTorch 1.3.1 and performed on an NVIDIA TITAN XP. Ninety percent of the training images were selected, with a total of 4067 image pairs. Data augmentation was performed on the training images with random rotation of and horizontal and vertical flip. A single configuration was used for all experiments and all scale factors. The Adam optimizer and L1 loss were adopted [40] using the default parameter values of zero weight decay and a learning rate initialized to with a step decay of after 500 epochs. The output SR image size for all experiments was with a minibatch size of 8 batches.
After every epoch, the validation metric was run on the current model, and the model with the highest PSNR value was recorded for inference. The model of scale ×2 was trained first. Subsequently, the model was frozen, and the model of scale ×4 was added and trained. The same procedure was performed for the model of scale ×8.
6.2. Results
Table 2 shows a quantitative comparison of the best average score for the ×2, ×4, and ×8 super-resolved images compared to the baseline methods: bicubic (MATLAB bicubic operator is used in all experiments), bicubic with a Gaussian of kernel eight, and deep learning SoTA models. The proposed model outperformed the baselines in all of the experiments with significant results. It is also important to note that the model achieved better results on the real captured images as compared with the baselines. This demonstrated that the proposed method could generalize on an unknown acoustic map imaging distribution.
Despite the quality of the experimental quantitative comparison, the super-resolution problem demands an analytical comparison, as it is not possible to rely only on quantitative standardized metrics such as the PSNR/SSIM. Figure 11 and Figure 12 show comparisons of the achieved results with the baselines: bicubic upscaled image and bicubic and Gaussian upscaled image on the (×4, ×8) scale factors, using images from the simulated test set. It was observed that for the three scaling factors, the proposed model achieved better perceptual results. Given the smooth nature of the acoustic map imaging, applying a Gaussian kernel to the upscaled images greatly enhanced their quality and reduced the artifacts. Although the (bicubic + Gaussian) model achieved excellent results, it was shown that this proposed model surpassed it in the quantitative and analytical comparison.
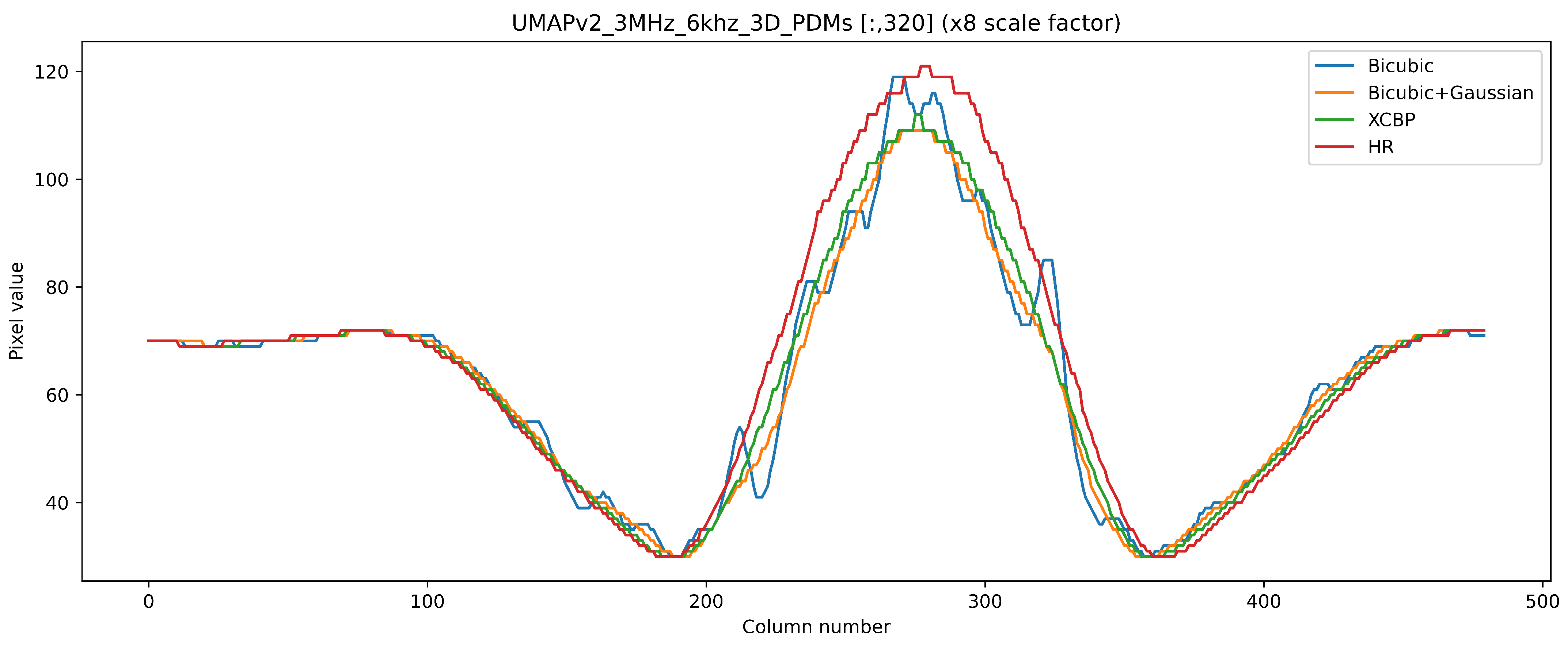
To confirm further, a row profile test was run on the images to observe the output with the closest result to the ground truth with fewer artifacts. In Figure 13, it is seen that using only the bicubic operator had several false positive sound source maxima because of the sub-sampling artifacts, which were propagated by the operator from the LR image to the super-resolved image, unlike the (bicubic + Gaussian) model and the proposed one, which removed the false positive artifacts and came closer to the ground truth. It was also observed that the proposed model outperformed the (bicubic + Gaussian) model and had higher similarities to the row profile ground truth.
The obtained images were indeed very similar to the original ground truth HR images. Though this was subjectively confirmed in the cropped regions, the same conclusions can be drawn after observing the entire image such as in Figure 14. Thus, it was shown that this model can upscale the LR image and correct artifacts caused by the sub-sampling error in the three scale factors.
Both the increase in resolution and the reduction of artifacts helped to improve the quality of the acoustic images and acoustic cameras. First of all, the reduction in noise helped the overall image quality and readability for humans of set images. A second improvement was the frame rate of acoustic cameras. In order to increase the resolution of an acoustic camera without upscaling, one needs to compute more steering vectors and perform more beamforming operations. Beamforming operations are computationally intensive, meaning that increasing the number of steering vectors or the resolution of an acoustic image also increases the computational load and time to generate one acoustic image, giving a trade-off between resolution and frame rate. Using super-resolution to both upscale and reduce the artifacts of nonfractional delays tackled these two problems at the same time. The acoustic camera could generate the acoustic image at a lower resolution and higher frame rate without the need for fractional delays because the super-resolution improved the resolution and quality, without affecting the frame rate.
The super-resolution also allowed better pinpointing the direction sound was coming from and distinguishing sound sources. Outliers caused by the fractional delays were removed, and the increased resolution helped to better estimate the angle of arrival of the sounds. In order to determine what the origin of the sound was instead of the angle of arrival, acoustic images were combined with images from RGB cameras. RGB cameras have a higher resolution. To overlay acoustic images with RGB images, both must have the same resolution by increasing the resolution of the acoustic image, decreasing the resolution of the RGB image, or a combination of both. Here, the super resolution can help to match the resolution of the acoustic image with the resolution of the RGB camera.
The similarities in the acquisition of the developed acoustic map imaging dataset may lead to characteristics similarities in the image distribution and to overfitting the data. Given this, the proposed model was tested on real captured images to study its ability to generalize over an unseen data distribution. Although the real captured images still shared characteristics with the simulated images in terms of the number of sound sources and their frequency, they were recorded using different equipment and in another environment, which reduced the possibility of overfitting. Figure 14 shows comparisons of the results with the baselines: bicubic upscaled image, bicubic and Gaussian upscaled image on a ×8 scale factor, and using real captured images from the test set. It was observed that the proposed model was more capable of upscaling images and reducing artifacts on unseen data as compared to other interpolation operators.
7. Conclusions
This work proposed the XCycles BackProjection model (XCBP) for highly accurate acoustic map image super-resolution. The model extracted the necessary residual features in the parallel (HR and LR) spaces and applied feature correction. The model outperformed the current state-of-the-art models and drastically reduced the sub-sampling phase delay error estimation in the acoustic map imaging. An acoustic map imaging dataset, which provided simulated and real captured images with multiple scale factors (×2, ×4, ×8), was also proposed. The dataset contained low- and high-resolution images with double-precision fractional delays and sub-sampling phase delay error. The proposed dataset can encourage the development of better solutions related to acoustic map imaging.
Author Contributions
Conceptualization, F.A., B.d.S. and J.V.; methodology, F.A., B.d.S. and J.V.; software, F.A.; validation, F.A.; formal analysis, F.A.; investigation, F.A., B.d.S. and J.V.; resources, F.A., B.d.S. and J.V.; data curation, J.V. and L.S.; writing—original draft preparation, F.A., B.d.S. and J.V.; writing—review and editing, F.A., J.V., L.S. and B.d.S.; visualization, F.A.; supervision, A.T., A.B., K.S. and O.D.; project administration, O.D.; funding acquisition, A.T. and O.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by the European Regional Development Fund (ERDF) and the Brussels-Capital Region-Innoviris within the framework of the Operational Programme 2014–2020 through the ERDF-2020 Project ICITYRDI.BRU. This work is also part of the COllective Research NETworking (CORNET) project “AITIA: Embedded AI Techniques for Industrial Applications” [41]. The Belgian partners are funded by VLAIO under Grant Number HBC.2018.0491, while the German partners are funded by the BMWi (Federal Ministry for Economic Affairs and Energy) under IGF-Project Number 249 EBG.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset is available online at https://0-doi-org.brum.beds.ac.uk/10.5281/zenodo.4543785.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Almasri, F.; Debeir, O. Multimodal sensor fusion in single thermal image super-resolution. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 418–433. [Google Scholar]
- Fréchette-Viens, J.; Quaegebeur, N.; Atalla, N. A Low-Latency Acoustic camera for Transient Noise Source Localization. In Proceedings of the 8th Berlin Beamforming Conference, BeBeC-2020S01, Berlin, Germany, 2–3 March 2020. [Google Scholar]
- Da Silva, B.; Segers, L.; Rasschaert, Y.; Quevy, Q.; Braeken, A.; Touhafi, A. A Multimode SoC FPGA-Based Acoustic Camera for Wireless Sensor Networks. In Proceedings of the 2018 13th International Symposium on Reconfigurable Communication-Centric Systems-on-Chip (ReCoSoC), Lille, France, 9–11 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Vandendriessche, J.; da Silva, B.; Lhoest, L.; Braeken, A.; Touhafi, A. M3-AC: A Multi-Mode Multithread SoC FPGA Based Acoustic Camera. Electronics 2021, 10, 317. [Google Scholar] [CrossRef]
- Zimmermann, B.; Studer, C. FPGA-based real-time acoustic camera prototype. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems (ISCAS), Paris, France, 30 May–2 June 2010; p. 1419. [Google Scholar]
- Izquierdo, A.; Villacorta, J.J.; del Val Puente, L.; Suárez, L. Design and evaluation of a scalable and reconfigurable multi-platform system for acoustic imaging. Sensors 2016, 16, 1671. [Google Scholar] [CrossRef] [Green Version]
- Grondin, F.; Glass, J. SVD-PHAT: A fast sound source localization method. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 4140–4144. [Google Scholar]
- Zotkin, D.N.; Duraiswami, R. Accelerated speech source localization via a hierarchical search of steered response power. IEEE Trans. Speech Audio Process. 2004, 12, 499–508. [Google Scholar] [CrossRef]
- Rivadeneira, R.E.; Sappa, A.D.; Vintimilla, B.X.; Nathan, S.; Kansal, P.; Mehri, A.; Ardakani, P.; Dalal, A.; Akula, A.; Sharma, D.; et al. Thermal Image Super-Resolution Challenge—PBVS 2021. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Virtual, 19–25 June 2021. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2016; Volume 9906, pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Irani, M.; Peleg, S. Improving resolution by image registration. CVGIP Graph. Model. Image Process. 1991, 53, 231–239. [Google Scholar] [CrossRef]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1664–1673. [Google Scholar]
- Rivadeneira, R.E.; Sappa, A.D.; Vintimilla, B.X.; Guo, L.; Hou, J.; Mehri, A.; Behjati Ardakani, P.; Patel, H.; Chudasama, V.; Prajapati, K.; et al. Thermal Image Super-Resolution Challenge-PBVS 2020. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 96–97. [Google Scholar]
- Wei, P.; Lu, H.; Timofte, R.; Lin, L.; Zuo, W.; Pan, Z.; Li, B.; Xi, T.; Fan, Y.; Zhang, G.; et al. AIM 2020 challenge on real image super-resolution: Methods and results. arXiv 2020, arXiv:2009.12072. [Google Scholar]
- Tashev, I.; Malvar, H.S. A New Beamformer Design Algorithm for Microphone Arrays. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP’05), Philadelphia, PA, USA, 23 March 2005; Volume 3, pp. iii/101–iii/104. [Google Scholar] [CrossRef] [Green Version]
- Tiete, J.; Dominguez, F.; Silva, B.; Segers, L.; Steenhaut, K.; Touhafi, A. SoundCompass: A Distributed MEMS Microphone Array-Based Sensor for Sound Source Localization. Sensors 2014, 14, 1918–1949. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taghizadeh, M.J.; Garner, P.N.; Bourlard, H. Microphone Array Beampattern Characterization for Hands-Free Speech Applications. In Proceedings of the 2012 IEEE 7th Sensor Array and Multichannel Signal Processing Workshop (SAM), Hoboken, NJ, USA, 17–20 June 2012; pp. 465–468. [Google Scholar] [CrossRef] [Green Version]
- Herbordt, W.; Kellermann, W. Computationally Frequency-Domain Realization of Robust Generalized, Sidelobe Cancellers. In Proceedings of the 2001 IEEE Fourth Workshop on Multimedia Signal Processing (Cat. No.01TH8564), Cannes, France, 3–5 October 2001; pp. 51–55. [Google Scholar] [CrossRef]
- Lepauloux, L.; Scalart, P.; Marro, C. Computationally Efficient and Robust Frequency-Domain GSC. In Proceedings of the 12th IEEE International Workshop on Acoustic Echo and Noise Control, Tel-Aviv, Israel, 30 August–2 September 2010. [Google Scholar]
- Rombouts, G.; Spriet, A.; Moonen, M. Generalized Sidelobe Canceller Based Combined Acoustic Feedback-and Noise Cancellation. Signal Process. 2008, 88, 571–581. [Google Scholar] [CrossRef]
- Gao, S.; Huang, Y.; Zhang, T.; Wu, X.; Qu, T. A Modified Frequency Weighted MUSIC Algorithm for Multiple Sound Sources Localization. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Birnie, L.; Abhayapala, T.D.; Chen, H.; Samarasinghe, P.N. Sound Source Localization in a Reverberant Room Using Harmonic Based Music. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 651–655. [Google Scholar]
- Jo, B.; Choi, J.W. Direction of Arrival Estimation Using Nonsingular Spherical ESPRIT. J. Acoust. Soc. Am. 2018, 143, 181–187. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Huang, Q.; Zhang, L.; Fang, Y. Direction of Arrival Estimation Using Distributed Circular Microphone Arrays. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018; pp. 182–185. [Google Scholar] [CrossRef]
- Maskell, D.L.; Woods, G.S. The estimation of subsample time delay of arrival in the discrete-time measurement of phase delay. IEEE Trans. Instrum. Meas. 1999, 48, 1227–1231. [Google Scholar] [CrossRef]
- Laakso, T.I.; Valimaki, V.; Karjalainen, M.; Laine, U.K. Splitting the unit delay [FIR/all pass filters design]. IEEE Signal Process. Mag. 1996, 13, 30–60. [Google Scholar] [CrossRef]
- Segers, L.; Vandendriessche, J.; Vandervelden, T.; Lapauw, B.J.; da Silva, B.; Braeken, A.; Touhafi, A. CABE: A Cloud-Based Acoustic Beamforming Emulator for FPGA-Based Sound Source Localization. Sensors 2019, 19, 3906. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hegde, N. Seamlessly Interfacing MEMs Microphones with Blackfin Processors. 2010. Available online: https://www.analog.com/media/en/technical-documentation/application-notes/EE-350rev1.pdf (accessed on 14 January 2019).
- Rivadeneira, R.; Sappa, A.; Vintimilla, B. Thermal Image Super-resolution: A Novel Architecture and Dataset. In Proceedings of the VISIGRAPP 2020—15th International Conference on Computer Vision Theory and Applications, Valletta, Malta, 27–29 February 2020; pp. 111–119. [Google Scholar] [CrossRef]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A learned representation for artistic style. arXiv 2016, arXiv:1610.07629. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Brandalero, M.; Ali, M.; Le Jeune, L.; Hernandez, H.G.M.; Veleski, M.; da Silva, B.; Lemeire, J.; Van Beeck, K.; Touhafi, A.; Goedemé, T.; et al. AITIA: Embedded AI Techniques for Embedded Industrial Applications. In Proceedings of the 2020 International Conference on Omni-Layer Intelligent Systems (COINS), Barcelona, Spain, 31 August–2 September 2020; pp. 1–7. [Google Scholar]
Figure 1.
Principle of acoustic beamforming based on the delay and sum method.

Figure 2.
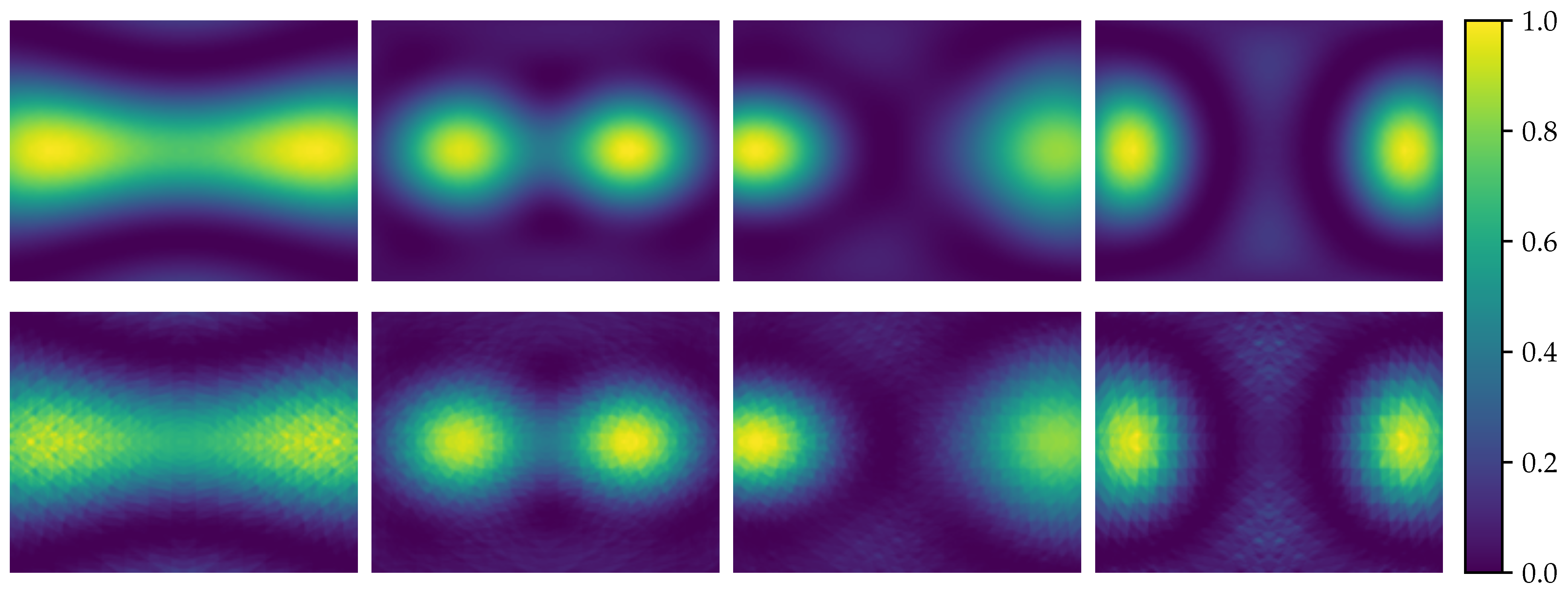
Examples of an SRP obtained with the microphone array described in Section 4. A traditional 2-dimensional SRP of a single frequency pointing to an angle of can be obtained (a). By combining multiple frequencies into one waterfall diagram, one can visualize the frequency response of a given microphone array (b). An acoustic heat map of a 3D situation (c,d) can also be obtained where the yellow color depicts the highest probability of finding a sound source. The first heat map (c) is obtained with fractional delays in double precision format, whereas the last heat map (d) is obtained without fractional delays.
Figure 2.
Examples of an SRP obtained with the microphone array described in Section 4. A traditional 2-dimensional SRP of a single frequency pointing to an angle of can be obtained (a). By combining multiple frequencies into one waterfall diagram, one can visualize the frequency response of a given microphone array (b). An acoustic heat map of a 3D situation (c,d) can also be obtained where the yellow color depicts the highest probability of finding a sound source. The first heat map (c) is obtained with fractional delays in double precision format, whereas the last heat map (d) is obtained without fractional delays.

Figure 3.
Effects of fractional DaS while detecting a sound source of 2 kHz with the UMAP microphone array. The theoretical response is given as a reference.
Figure 3.
Effects of fractional DaS while detecting a sound source of 2 kHz with the UMAP microphone array. The theoretical response is given as a reference.

Figure 4.
Waterfall diagrams of the UMAP microphone array with different settings of fractional delays, ranging from beamforming without fractional delays (“fractional disabled”) until fractional delay with a resolution of 8 bits. The methods with 8 bits and double precision fractional delays are represented by the “double” since they both give the same results. The waterfall diagram of the theoretical beamforming is given as a reference.
Figure 4.
Waterfall diagrams of the UMAP microphone array with different settings of fractional delays, ranging from beamforming without fractional delays (“fractional disabled”) until fractional delay with a resolution of 8 bits. The methods with 8 bits and double precision fractional delays are represented by the “double” since they both give the same results. The waterfall diagram of the theoretical beamforming is given as a reference.

Figure 5.
The microphone array used by the M3-AC consists of 12 digital (PDM) microphones. The microphone array is shown in the left image, while the right diagram represents the microphone layout.
Figure 5.
The microphone array used by the M3-AC consists of 12 digital (PDM) microphones. The microphone array is shown in the left image, while the right diagram represents the microphone layout.

Figure 6.
Several cascaded filters are used to demodulate the 1-bit PDM signal generated by the digital MEMS microphones in order to retrieve the original acoustic information in Pulse Coded Modulation (PCM) format. The audio signals are then beamformed by the DaS beamformer. The SRP values are finally used to generate acoustic heat maps.
Figure 6.
Several cascaded filters are used to demodulate the 1-bit PDM signal generated by the digital MEMS microphones in order to retrieve the original acoustic information in Pulse Coded Modulation (PCM) format. The audio signals are then beamformed by the DaS beamformer. The SRP values are finally used to generate acoustic heat maps.

Figure 7.
Acoustic map examples of the test set with double-precision high resolution (top) and fractional delay precision high resolution (bottom).
Figure 7.
Acoustic map examples of the test set with double-precision high resolution (top) and fractional delay precision high resolution (bottom).

Figure 8.
PSNR distribution of the upscaled test set images without fractional delays with scale factors of (×2, ×4, ×8). The upscaling was done with the bicubic interpolation operator. Gaussian kernels ranging from 0 to 20 were used on top to smooth the results. The upscaled images with Gaussian kernel of size 8 achieved the best PSNR results for the three resolutions.
Figure 8.
PSNR distribution of the upscaled test set images without fractional delays with scale factors of (×2, ×4, ×8). The upscaling was done with the bicubic interpolation operator. Gaussian kernels ranging from 0 to 20 were used on top to smooth the results. The upscaled images with Gaussian kernel of size 8 achieved the best PSNR results for the three resolutions.

Figure 9.
XCycles backprojection network architecture.

Figure 10.
Residual features extraction module.

Figure 11.
Visual comparison on a cropped region of ×4 SR results between: (HR), ground truth High-Resolution image. (B), Bicubic upscaled image. (B+G), Bicubic and Gaussian upscaled image. (XCBP), our model upscaled image.
Figure 11.
Visual comparison on a cropped region of ×4 SR results between: (HR), ground truth High-Resolution image. (B), Bicubic upscaled image. (B+G), Bicubic and Gaussian upscaled image. (XCBP), our model upscaled image.

Figure 12.
Visual comparison on a cropped region of ×8 SR results between: (HR), ground truth High-Resolution image. (B), Bicubic upscaled image. (B+G), Bicubic and Gaussian upscaled image. (XCBP), our model upscaled image.
Figure 12.
Visual comparison on a cropped region of ×8 SR results between: (HR), ground truth High-Resolution image. (B), Bicubic upscaled image. (B+G), Bicubic and Gaussian upscaled image. (XCBP), our model upscaled image.

Figure 13.
Row profile comparison of the real captured ×8 SR result. The bicubic operator propagated the sub-sampling error to the SR image creating a false positive peak amplitude. Bicubic + Gaussian and XCBP removed the sub-sampling artifacts and looked very similar to the HR ground-truth image with the XCBP result being the closest output to the HR values.
Figure 13.
Row profile comparison of the real captured ×8 SR result. The bicubic operator propagated the sub-sampling error to the SR image creating a false positive peak amplitude. Bicubic + Gaussian and XCBP removed the sub-sampling artifacts and looked very similar to the HR ground-truth image with the XCBP result being the closest output to the HR values.

Figure 14.
Visual comparison of real captured ×8 SR results. Left to right: high-resolution image, bicubic upscaled image, bicubic and Gaussian upscaled image, XCBP model upscaled image.
Figure 14.
Visual comparison of real captured ×8 SR results. Left to right: high-resolution image, bicubic upscaled image, bicubic and Gaussian upscaled image, XCBP model upscaled image.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Configuration used in the CABE to generate the acoustic images.
| Parameter | Value |
|---|---|
| Microphone array | UMAP |
| Beamforming method | Filtering + delay and sum |
| Filtering method | 3125khz_cic24_fir1_ds4 |
| Sampling frequency () | 3125 kHz |
| Order CIC filter () | 4 |
| Decimation factor CIC filter () | 24 |
| Order FIR filter () | 23 |
| Decimation factor FIR filter () | 4 |
| SRP in block mode | yes |
| SRP length | 64 |
| Emulation start time | 50 ms |
| Emulation end time | 100 ms |
Table 2.
Average PSNR/SSIM comparison for ×2, ×4, and ×8 scale factors in the test set between our solutions, interpolation operators, and STOA methods. Best numbers are shown in bold.
Table 2.
Average PSNR/SSIM comparison for ×2, ×4, and ×8 scale factors in the test set between our solutions, interpolation operators, and STOA methods. Best numbers are shown in bold.
| Methods | Simulated | Real Captured | ||||
|---|---|---|---|---|---|---|
| Scale ×2 | Scale ×4 | Scale ×8 | Scale ×2 | Scale ×4 | Scale ×8 | |
| Bicubic | 38.00/0.9426 | 38.16/0.9548 | 37.81/0.9728 | 37.36/0.9513 | 37.31/0.9615 | 36.93/0.9764 |
| Bicubic-Gaussian | 46.34/0.9942 | 45.47/0.9943 | 41.48/0.9935 | 40.99/0.9954 | 40.46/0.9954 | 38.82/0.9946 |
| SRCNN | 47.00/0.9934 | 46.49/0.9941 | 44.87/0.9938 | 42.24/0.9940 | 42.25/0.9941 | 42.07/0.9943 |
| VDSR | 50.98/0.9963 | 50.89/0.9963 | 49.98/0.9954 | 44.23/0.9952 | 44.28/0.9950 | 43.47/0.9942 |
| RCAN | 54.65/0.9978 | 55.19/0.9980 | 54.63/0.9978 | 46.82/0.9971 | 46.57/0.9967 | 48.88/0.9962 |
| XCBP-AC | 54.83/0.9977 | 55.49/0.9979 | 55.77/0.9980 | 44.64/0.9970 | 46.66/0.9970 | 46.58/0.9968 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Almasri, F.; Vandendriessche, J.; Segers, L.; da Silva, B.; Braeken, A.; Steenhaut, K.; Touhafi, A.; Debeir, O. XCycles Backprojection Acoustic Super-Resolution. Sensors 2021, 21, 3453. https://0-doi-org.brum.beds.ac.uk/10.3390/s21103453
AMA Style
Almasri F, Vandendriessche J, Segers L, da Silva B, Braeken A, Steenhaut K, Touhafi A, Debeir O. XCycles Backprojection Acoustic Super-Resolution. Sensors. 2021; 21(10):3453. https://0-doi-org.brum.beds.ac.uk/10.3390/s21103453
Chicago/Turabian StyleAlmasri, Feras, Jurgen Vandendriessche, Laurent Segers, Bruno da Silva, An Braeken, Kris Steenhaut, Abdellah Touhafi, and Olivier Debeir. 2021. "XCycles Backprojection Acoustic Super-Resolution" Sensors 21, no. 10: 3453. https://0-doi-org.brum.beds.ac.uk/10.3390/s21103453
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.