
Evaluation of Open-Source and Pre-Trained Deep Convolutional Neural Networks Suitable for Player Detection and Motion Analysis in Squash


Abstract
:1. Introduction
- RQ1: How many HPE-CNNs available today are ready to use for out-of-the-box inference on squash data for motion analysis?
- RQ2: To what extent and with what accuracy do they allow motion analysis in squash?
- RQ3: Can the data obtained from the HPE-CNNs selected in RQ2 be easily used to provide insight to coaches and athletes?
1.1. Related Work
1.2. Organization
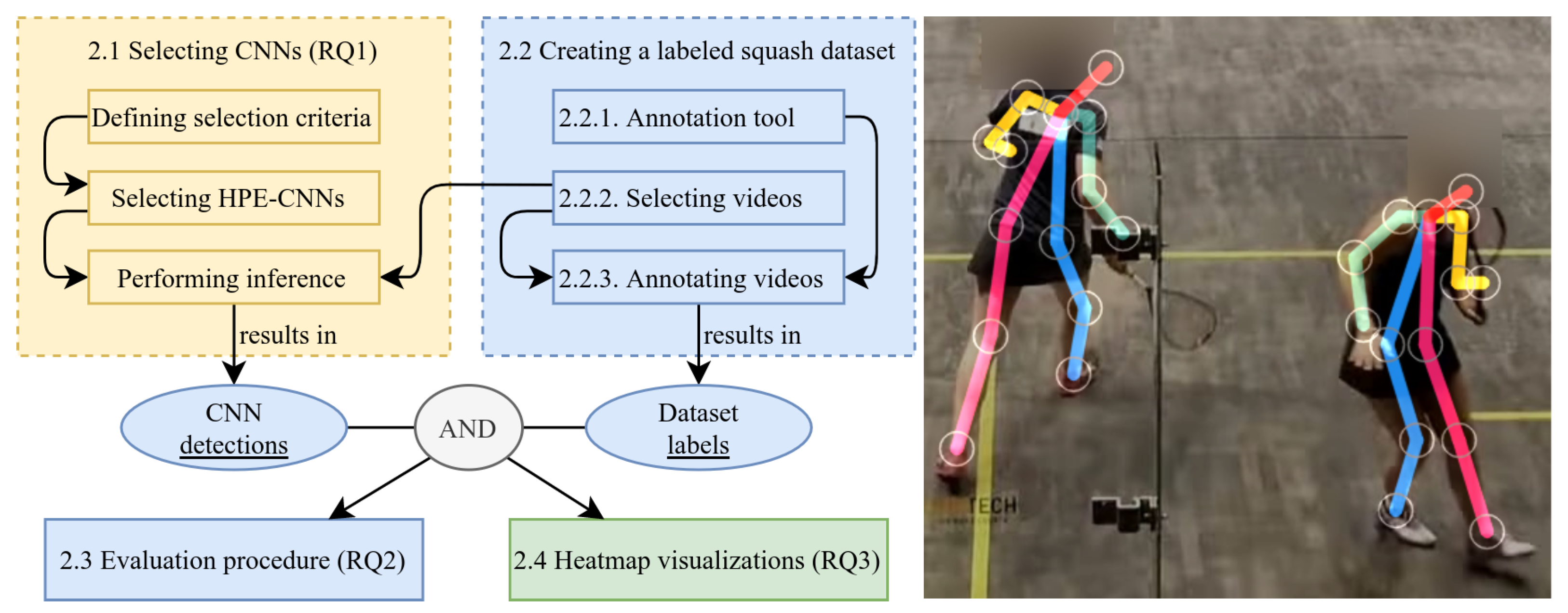
2. Materials and Methods
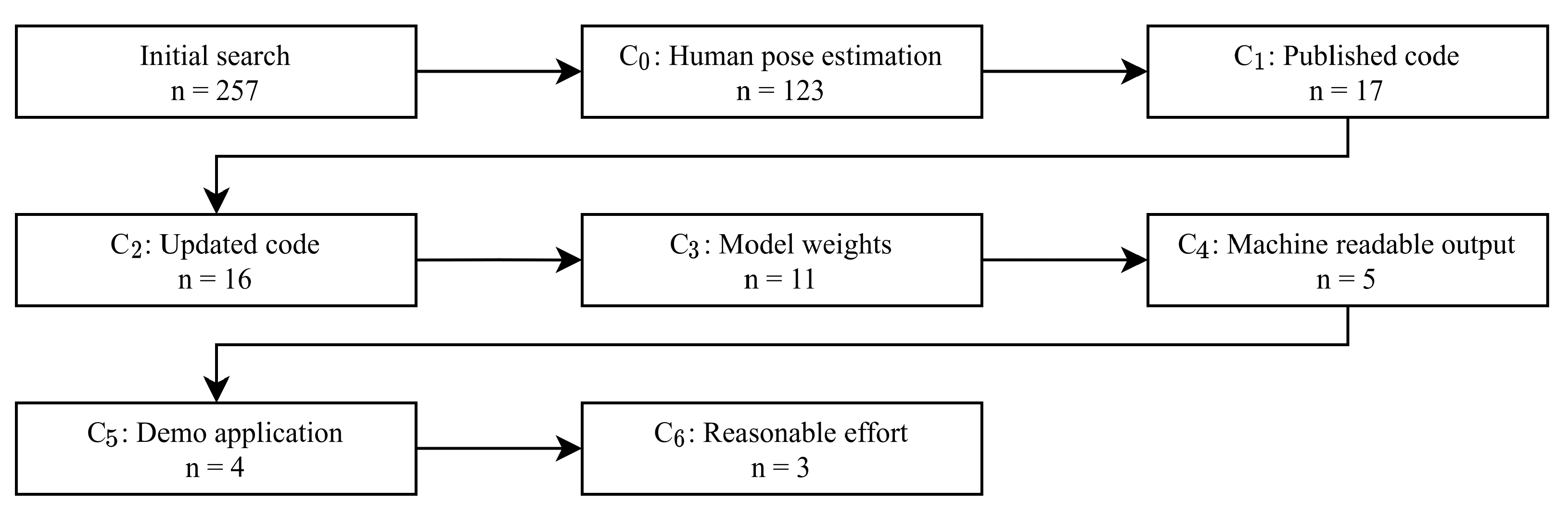
2.1. Selecting CNNs
- C0:
- Multi-Person/Multi-Feet detection;
- C1:
- Published and implemented source code;
- C2:
- Code must be up to date;
- C3:
- Available pre-trained model weights;
- C4:
- Machine-readable output;
- C5:
- Demo/Showcase application;
- C6:
- Reasonable effort in setting up.
2.2. Creating a Labeled Squash Dataset
2.2.1. Annotation Tool
- R0:
- Step through single frames in videos;
- R1:
- Assign identifiers to objects of interest (OOI);
- R2:
- Annotate OOI locations as points in frames;
- R3:
- Annotate events for individual frames;
- R4:
- Export annotations in a machine-readable format.
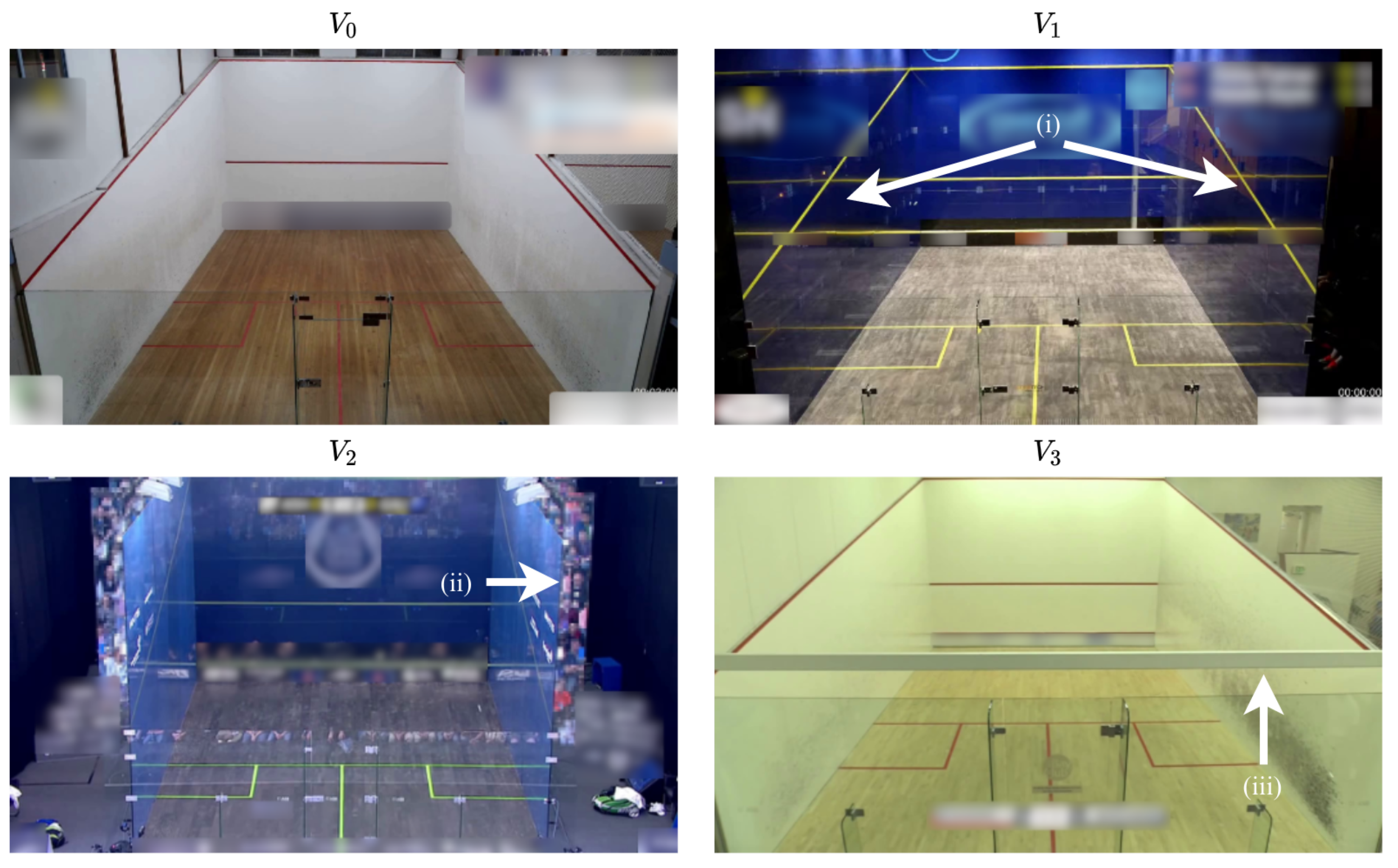
2.2.2. Selecting Videos
2.2.3. Annotating Videos
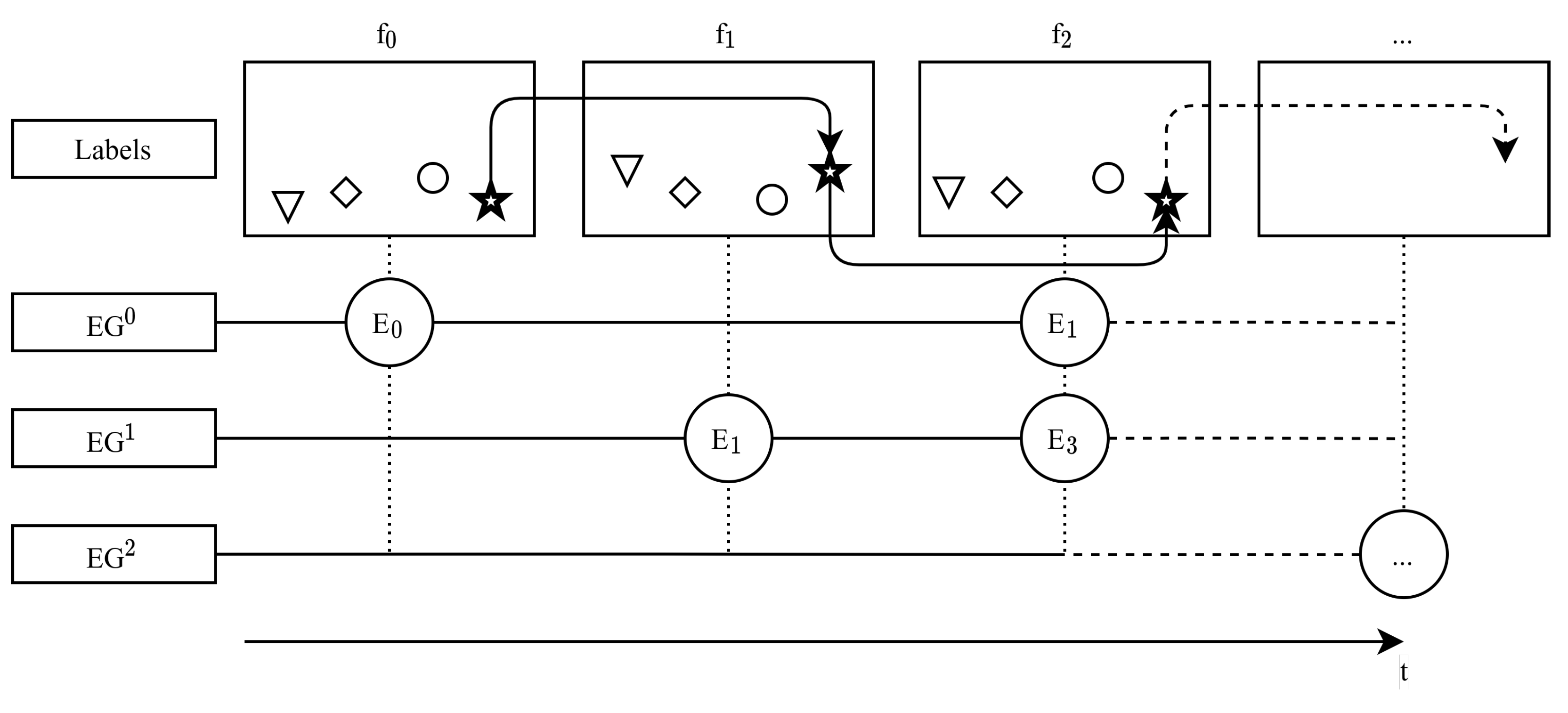
2.3. Evaluation Procedure
2.3.1. Evaluation Metrics
2.3.2. Grouping Options for Evaluation
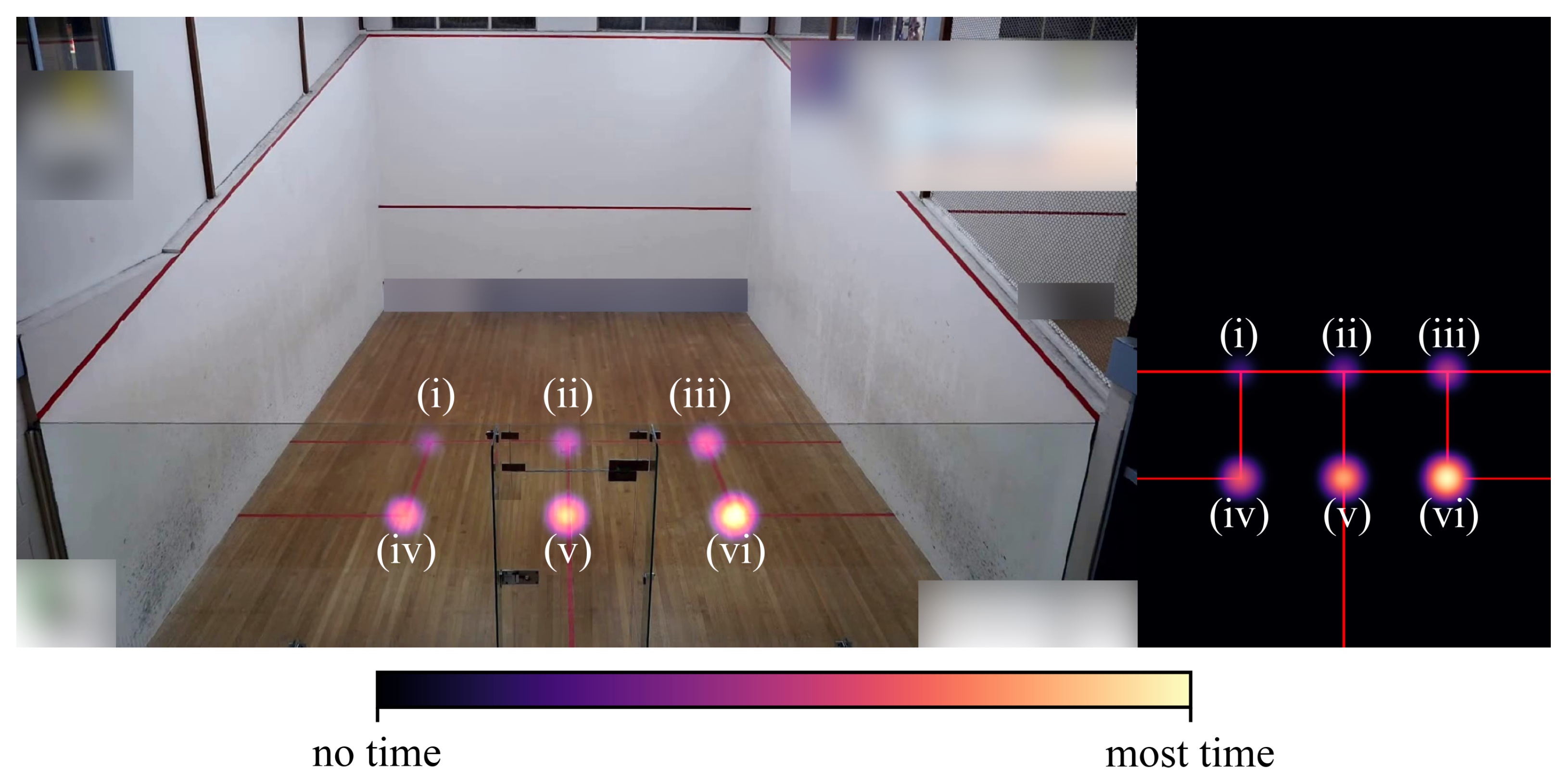
2.4. Heatmap Visualizations
2.4.1. Overlay Heatmaps
2.4.2. Top-Down Heatmaps
3. Results
3.1. Dataset Statistics
3.2. HPE-CNN Evaluation Results
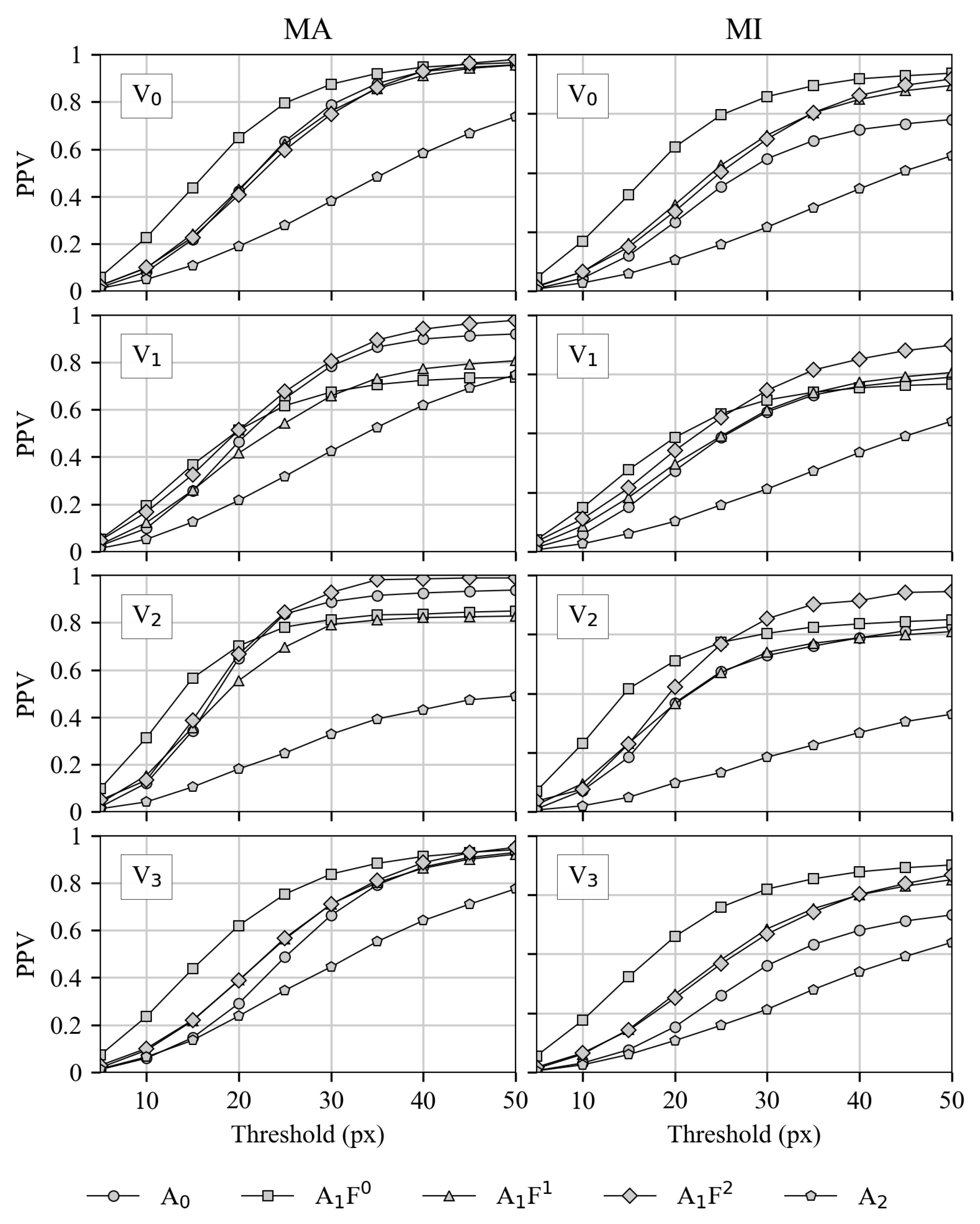
3.2.1. Precision for Both Matching Variants
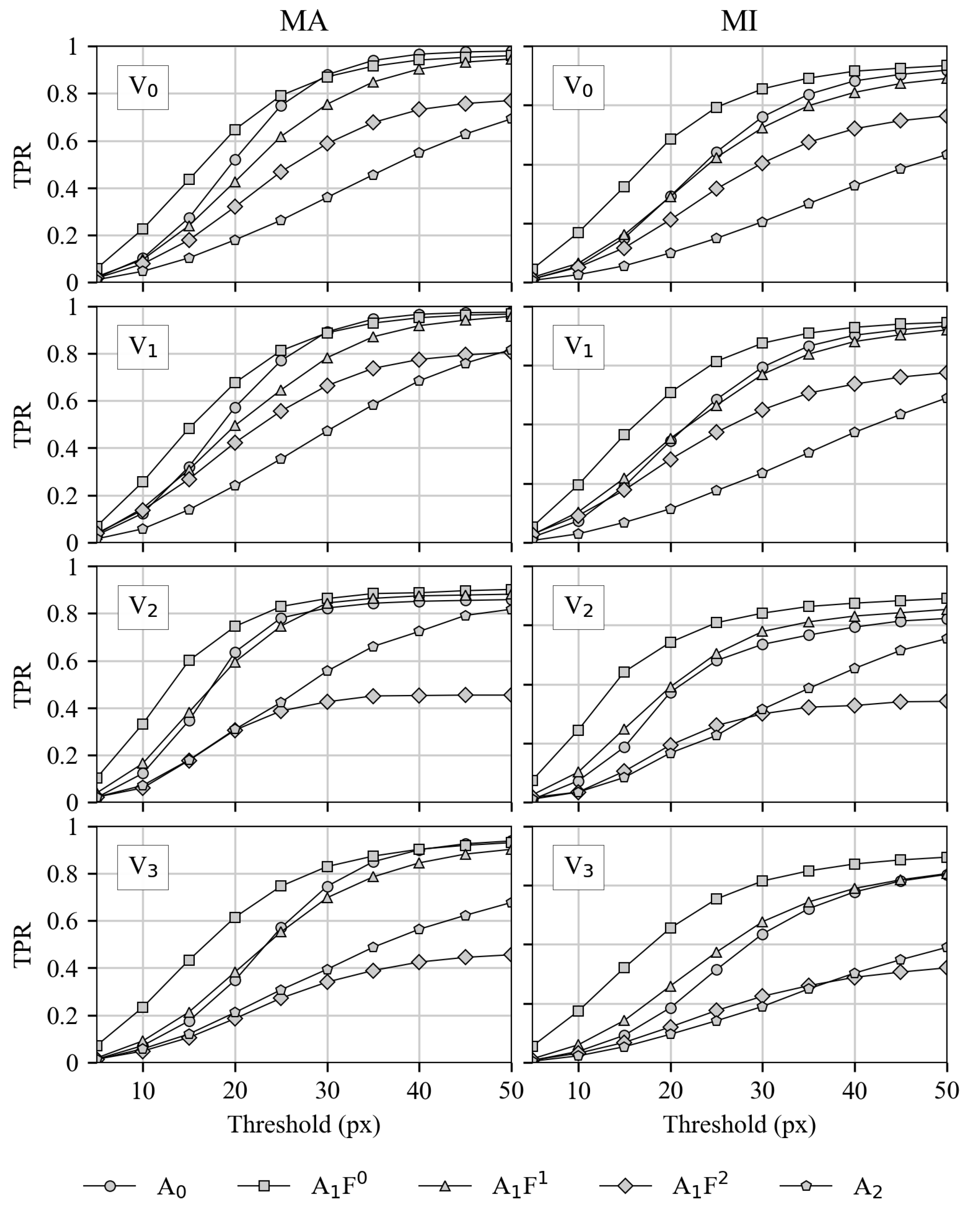
3.2.2. Recall for Both Matching Variants
3.2.3. Combination of Precision and Recall
3.2.4. Balanced Metrics
3.2.5. Average Precision
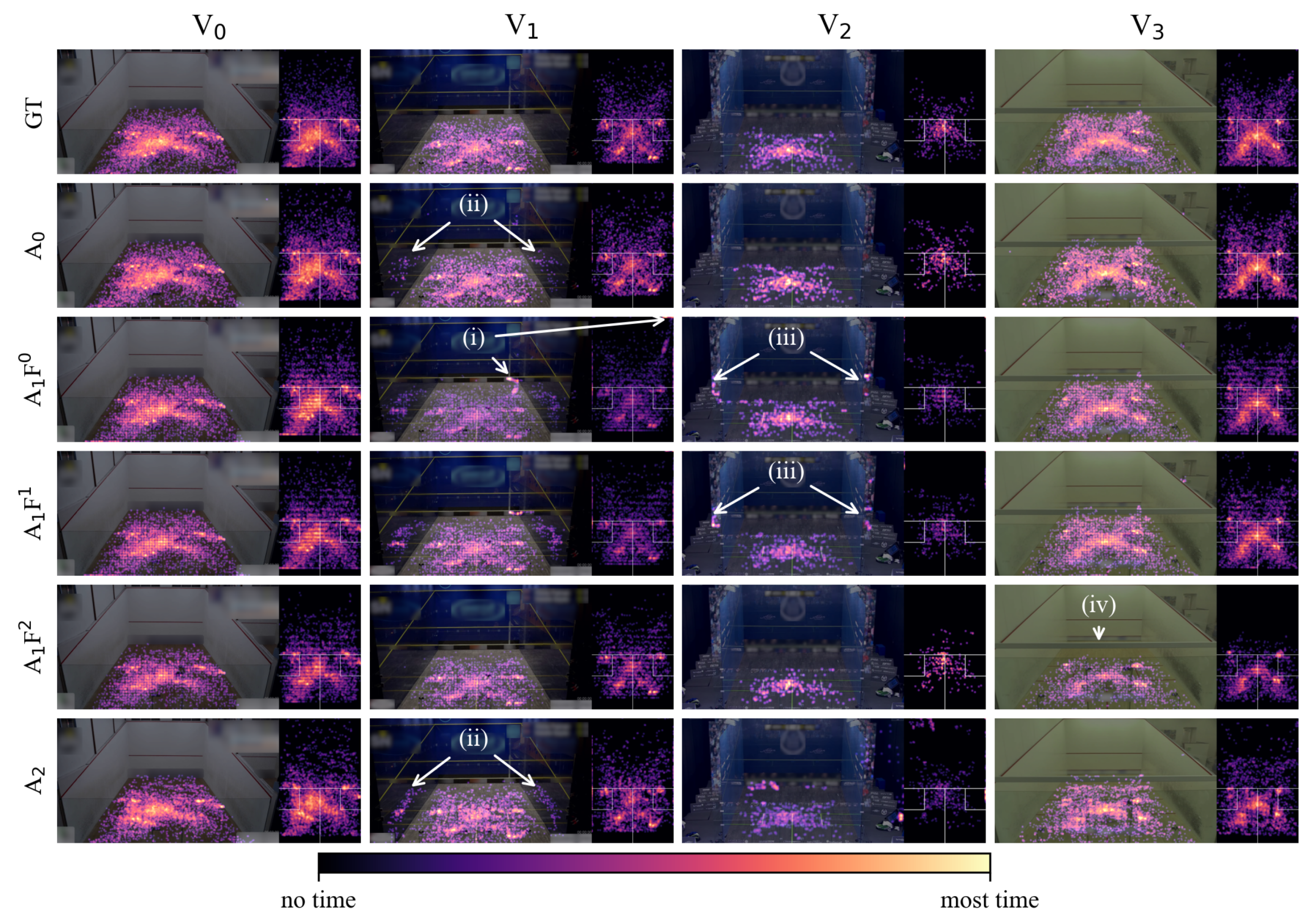
3.3. Heatmap Visualization
3.3.1. Heatmap Post-Processing
3.3.2. Processing Speed
4. Discussion
- RQ1: We found that three different HPE-CNNs out of five variants are ready to use for out-of-the-box inference on squash data for motion analysis;
- RQ2: Overall, our evaluation procedure has shown sufficient accuracy for the identified HPE-CNNs on a domain-specific squash dataset;
- RQ3: Our heatmap visualization technique has been shown to technically be able to present detections or labels for visual assessment.
4.1. HPE-CNN Evaluation
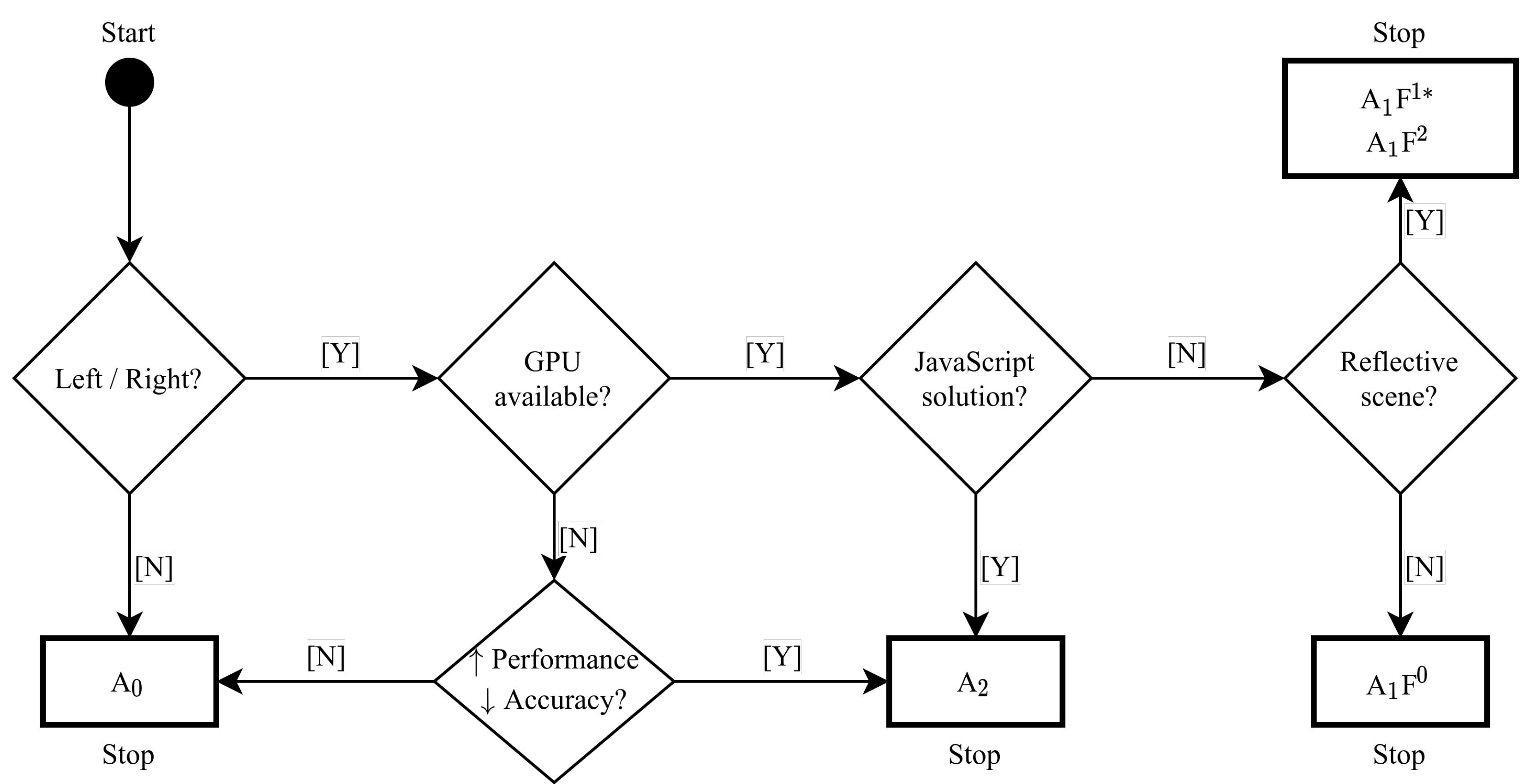
4.2. Decision Flow Chart for HPE-CNN Selection
5. Conclusions
Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| FN | False Negative |
| FP | False Positive |
| GPU | Graphics Processing Unit |
| HPE | Human Pose Estimation |
| JSON | JavaScript Object Notation |
| OOI | Objects Of Interest |
| PPV | Positive Predictive Value |
| TN | True Negative |
| TP | True Positive |
| TPR | True Positive Rate |
References
- Gabbett, T.J. The training—Injury prevention paradox: Should athletes be training smarter and harder? Br. J. Sport. Med. 2016, 50, 273–280. [Google Scholar] [CrossRef] [Green Version]
- Pantelopoulos, A.; Bourbakis, N. A Survey on Wearable Sensor-Based Systems for Health Monitoring and Prognosis. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2010, 40, 1–12. [Google Scholar] [CrossRef] [Green Version]
- van der Kruk, E.; Reijne, M.M. Accuracy of human motion capture systems for sport applications; state-of-the-art review. Eur. J. Sport Sci. 2018, 18, 806–819. [Google Scholar] [CrossRef] [PubMed]
- Cummins, C.; Orr, R.; O’Connor, H.; West, C. Global Positioning Systems (GPS) and Microtechnology Sensors in Team Sports: A Systematic Review. Sport. Med. 2013, 43, 1025–1042. [Google Scholar] [CrossRef] [PubMed]
- Memmert, D.; Lemmink, K.A.P.M.; Sampaio, J. Current Approaches to Tactical Performance Analyses in Soccer Using Position Data. Sport. Med. 2016, 47, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Vučković, G.; James, N.; Hughes, M.; Murray, S.; Milanović, Z.; Perš, J.; Sporiš, G. A new method for assessing squash tactics using 15 court areas for ball locations. Hum. Mov. Sci. 2014, 34, 81–90. [Google Scholar] [CrossRef]
- Vučković, G.; Dežman, B.; Perš, J.; Kovačič, S. Motion analysis of the international and national rank squash players. In Proceedings of the 4th International Symposium on Image and Signal Processing and Analysis (ISPA), Zagreb, Croatia, 15–17 September 2005; pp. 334–338. [Google Scholar] [CrossRef]
- Vučković, G.; Perš, J.; James, N.; Hughes, M. Tactical use of the T area in squash by players of differing standard. J. Sport. Sci. 2009, 27, 863–871. [Google Scholar] [CrossRef]
- Vučković, G.; Perš, J.; James, N.; Hughes, M. Measurement error associated with the SAGIT/Squash computer tracking software. Eur. J. Sport Sci. 2010, 10, 129–140. [Google Scholar] [CrossRef]
- Ciresan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.P.; Wang, L.; Gupta, S.; Goli, H.; Padmanabhan, P.; Gulyás, B. 3D Deep Learning on Medical Images: A Review. Sensors 2020, 20, 5097. [Google Scholar] [CrossRef]
- O’Shea, T.; Hoydis, J. An Introduction to Deep Learning for the Physical Layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef] [Green Version]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescape, A. Mobile Encrypted Traffic Classification Using Deep Learning: Experimental Evaluation, Lessons Learned, and Challenges. IEEE Trans. Netw. Serv. Manag. 2019, 16, 445–458. [Google Scholar] [CrossRef]
- Pobar, M.; Ivasic-Kos, M. Mask R-CNN and Optical Flow Based Method for Detection and Marking of Handball Actions. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ma, Y.; Feng, S.; Wang, Y. Fully-Convolutional Siamese Networks for Football Player Tracking. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 330–334. [Google Scholar] [CrossRef]
- Reilly, T. A motion analysis of work-rate in different positional roles in professional football match-play. J. Hum. Mov. Stud. 1976, 2, S87–S97. [Google Scholar]
- Kirkup, J.A.; Rowlands, D.D.; Thiel, D.V. Team Player Tracking Using Sensors and Signal Strength for Indoor Basketball. IEEE Sens. J. 2016, 16, 4622–4630. [Google Scholar] [CrossRef]
- Moeslund, T.B.; Granum, E. A Survey of Computer Vision-Based Human Motion Capture. Comput. Vis. Image Underst. 2001, 81, 231–268. [Google Scholar] [CrossRef]
- Cheung, G.K.M.; Kanade, T.; Bouguet, J.Y.; Holler, M. A real time system for robust 3D voxel reconstruction of human motions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2000, Hilton Head, SC, USA, 15 June 2000; pp. 714–720. [Google Scholar] [CrossRef]
- de Aguiar, E.; Theobalt, C.; Stoll, C.; Seidel, H.P. Marker-less Deformable Mesh Tracking for Human Shape and Motion Capture. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, L.; Sturm, J.; Cremers, D.; Lee, D. Real-time human motion tracking using multiple depth cameras. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura-Algarve, Algarve, Portugal, 7–12 October 2012; pp. 2389–2395. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Wei, H.; Ferryman, J. A survey of human motion analysis using depth imagery. Pattern Recognit. Lett. 2013, 34, 1995–2006. [Google Scholar] [CrossRef]
- Choppin, S.; Wheat, J. The potential of the Microsoft Kinect in sports analysis and biomechanics. Sport. Technol. 2013, 6, 78–85. [Google Scholar] [CrossRef]
- He, Z.D.; Hu, R.M.; Xu, J.C. The Development of Badminton Auxiliary Training System Based on Kinect Motion Capture. Adv. Mater. Res. 2014, 926–930, 2735–2738. [Google Scholar] [CrossRef]
- van Diest, M.; Stegenga, J.; Wörtche, H.J.; Postema, K.; Verkerke, G.J.; Lamoth, C.J.C. Suitability of Kinect for measuring whole body movement patterns during exergaming. J. Biomech. 2014, 47, 2925–2932. [Google Scholar] [CrossRef]
- Alabbasi, H.; Gradinaru, A.; Moldoveanu, F.; Moldoveanu, A. Human motion tracking & evaluation using Kinect V2 sensor. In Proceedings of the 2015 E-Health and Bioengineering Conference (EHB), Iasi, Romania, 19–21 November 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Chun, K.J.; Lim, D.; Kim, C.; Jung, H.; Jung, D. Use of the Microsoft Kinect system to characterize balance ability during balance training. Clin. Interv. Aging 2015, 1077. [Google Scholar] [CrossRef] [Green Version]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: New York, NY, USA, 2003. [Google Scholar]
- Yoon, Y.; Hwang, H.; Choi, Y.; Joo, M.; Oh, H.; Park, I.; Lee, K.H.; Hwang, J.H. Analyzing Basketball Movements and Pass Relationships Using Realtime Object Tracking Techniques Based on Deep Learning. IEEE Access 2019, 7, 56564–56576. [Google Scholar] [CrossRef]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Liang, Q.; Wu, W.; Yang, Y.; Zhang, R.; Peng, Y.; Xu, M. Multi-Player Tracking for Multi-View Sports Videos with Improved K-Shortest Path Algorithm. Appl. Sci. 2020, 10, 864. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Peng, Y. Real-Time Possessing Relationship Detection for Sports Analytics. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 7373–7378. [Google Scholar] [CrossRef]
- Zhang, S.; Lan, S.; Bu, Q.; Li, S. YOLO based Intelligent Tracking System for Curling Sport. In Proceedings of the 2019 IEEE/ACIS 18th International Conference on Computer and Information Science (ICIS), Beijing, China, 17–19 June 2019; pp. 371–374. [Google Scholar] [CrossRef]
- Zhao, Z.; Lan, S.; Zhang, S. Human Pose Estimation based Speed Detection System for Running on Treadmill. In Proceedings of the 2020 International Conference on Culture-oriented Science & Technology (ICCST), Beijing, China, 28–31 October 2020; pp. 524–528. [Google Scholar] [CrossRef]
- Kurose, R.; Hayashi, M.; Ishii, T.; Aoki, Y. Player pose analysis in tennis video based on pose estimation. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Giles, B.; Kovalchik, S.; Reid, M. A machine learning approach for automatic detection and classification of changes of direction from player tracking data in professional tennis. J. Sport. Sci. 2019, 38, 106–113. [Google Scholar] [CrossRef]
- Žemgulys, J.; Raudonis, V.; Maskeliūnas, R.; Damaševičius, R. Recognition of basketball referee signals from videos using Histogram of Oriented Gradients (HOG) and Support Vector Machine (SVM). Procedia Comput. Sci. 2018, 130, 953–960. [Google Scholar] [CrossRef]
- Anand, A.; Sharma, M.; Srivastava, R.; Kaligounder, L.; Prakash, D. Wearable Motion Sensor Based Analysis of Swing Sports. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 261–267. [Google Scholar] [CrossRef]
- He, D.; Li, L.; An, L. Study on Sports Volleyball Tracking Technology Based on Image Processing and 3D Space Matching. IEEE Access 2020, 8, 94258–94267. [Google Scholar] [CrossRef]
- Guo, T.; Tao, K.; Hu, Q.; Shen, Y. Detection of Ice Hockey Players and Teams via a Two-Phase Cascaded CNN Model. IEEE Access 2020, 8, 195062–195073. [Google Scholar] [CrossRef]
- von Braun, M.S.; Frenzel, P.; Käding, C.; Fuchs, M. Utilizing Mask R-CNN for Waterline Detection in Canoe Sprint Video Analysis. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 3826–3835. [Google Scholar] [CrossRef]
- Ascenso, G.; Yap, M.H.; Allen, T.B.; Choppin, S.S.; Payton, C. FISHnet: Learning to Segment the Silhouettes of Swimmers. IEEE Access 2020, 8, 178311–178321. [Google Scholar] [CrossRef]
- Chen, H.T.; Chou, C.L.; Fu, T.S.; Lee, S.Y.; Lin, B.S.P. Recognizing tactic patterns in broadcast basketball video using player trajectory. J. Vis. Commun. Image Represent. 2012, 23, 932–947. [Google Scholar] [CrossRef]
- PapersWithCode. PapersWithCode. Available online: https://paperswithcode.com/ (accessed on 22 April 2020).
- Insafutdinov, E.; Andriluka, M.; Pishchulin, L.; Tang, S.; Levinkov, E.; Andres, B.; Schiele, B. ArtTrack: Articulated Multi-Person Tracking in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1293–1301. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1302–1310. [Google Scholar] [CrossRef] [Green Version]
- Insafutdinov, E.; Pishchulin, L.; Andres, B.; Andriluka, M.; Schiele, B. DeeperCut: A Deeper, Stronger, and Faster Multi-person Pose Estimation Model. In Computer Vision – ECCV 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 34–50. [Google Scholar] [CrossRef] [Green Version]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision – ECCV 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards Accurate Multi-person Pose Estimation in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3711–3719. [Google Scholar] [CrossRef] [Green Version]
- Papandreou, G.; Zhu, T.; Chen, L.C.; Gidaris, S.; Tompson, J.; Murphy, K. PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model. In Computer Vision—ECCV 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 282–299. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Bréhéret, A. Pixel Annotation Tool. 2017. Available online: https://github.com/abreheret/PixelAnnotationTool (accessed on 30 June 2021).
- Wada, K. Labelme: Image Polygonal Annotation with Python. 2016. Available online: https://github.com/wkentaro/labelme (accessed on 30 June 2021).
- OpenCV. Computer Vision Annotation Tool (CVAT) [Software]. 2016. Available online: https://github.com/opencv/cvat (accessed on 30 June 2021).
- Google. YouTube. Available online: https://www.youtube.com/ (accessed on 19 April 2021).
- World Squash Federation. Specifications For Squash Courts. 2016. Available online: http://www.worldsquash.org/wp-content/uploads/2017/11/171128_Court-Specifications.pdf (accessed on 25 March 2020).
- Brumann, C.; Kukuk, M. Towards a better understanding of the overall health impact of the game of squash: Automatic and high-resolution motion analysis from a single camera view. Curr. Dir. Biomed. Eng. 2017, 3, 819–823. [Google Scholar] [CrossRef] [Green Version]
- Vitale, C.; Agosti, V.; Avella, D.; Santangelo, G.; Amboni, M.; Rucco, R.; Barone, P.; Corato, F.; Sorrentino, G. Effect of Global Postural Rehabilitation program on spatiotemporal gait parameters of parkinsonian patients: A three-dimensional motion analysis study. Neurol. Sci. 2012, 33, 1337–1343. [Google Scholar] [CrossRef]
- Wang, J.; Spicher, N.; Warnecke, J.M.; Haghi, M.; Schwartze, J.; Deserno, T.M. Unobtrusive Health Monitoring in Private Spaces: The Smart Home. Sensors 2021, 21, 864. [Google Scholar] [CrossRef] [PubMed]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapè, A. MIMETIC: Mobile encrypted traffic classification using multimodal deep learning. Comput. Netw. 2019, 165, 106944. [Google Scholar] [CrossRef]
- Gumaei, A.; Hassan, M.M.; Alelaiwi, A.; Alsalman, H. A Hybrid Deep Learning Model for Human Activity Recognition Using Multimodal Body Sensing Data. IEEE Access 2019, 7, 99152–99160. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Title and Reference | Application |
|---|---|---|
| 2020 | Multi-Player Tracking for Multi-View Sports Videos with Improved K-Shortest Path Algorithm [31] | Basketball |
| 2020 | Real-Time Possessing Relationship Detection for Sports Analytics [32] | Frisbee & Football (soccer) |
| 2020 | Study on Sports Volleyball Tracking Technology Based on Image Processing and 3D Space Matching [39] | Volleyball |
| 2020 | Detection of Ice Hockey Players and Teams via a Two-Phase Cascaded CNN Model [40] | Ice Hockey |
| 2020 | Utilizing Mask R-CNN for Waterline Detection in Canoe Sprint Video Analysis [41] | Canoe |
| 2020 | FISHnet: Learning to Segment the Silhouettes of Swimmers [42] | Swimming |
| 2020 | Human Pose Estimation based Speed Detection System for Running on Treadmill [34] | Running |
| 2019 | Analyzing Basketball Movements and Pass Relationships Using Realtime Object Tracking Techniques Based on Deep Learning [29] | Basketball |
| 2019 | A machine learning approach for automatic detection and classification of changes of direction from player tracking data in professional tennis [36] | Tennis |
| 2019 | YOLO based Intelligent Tracking System for Curling Sport [33] | Curling |
| 2018 | Recognition of basketball referee signals from videos using Histogram of Oriented Gradients (HOG) and Support Vector Machine (SVM) [37] | Basketball |
| 2018 | Player Pose Analysis in Tennis Video based on Pose Estimation [35] | Tennis |
| 2018 | Mask R-CNN and Optical Flow Based Method for Detection and Marking of Handball Actions [14] | Handball |
| 2017 | Wearable Motion Sensor Based Analysis of Swing Sports [38] | Tennis, Badminton, Squash |
| 2012 | Recognizing tactic patterns in broadcast basketball video using player trajectory [43] | Basketball |
| Identifier | Name | Training Data | Architecture | Runtime (FPS) |
|---|---|---|---|---|
| A | Arttrack [45,47] | MPII [48] | ResNet-101 | 4.55 |
| AF | OpenPose [46] | COCO [49] + Foot [46] | VGG-19 | 8.8 |
| AF | OpenPose [46] | COCO [49] | VGG-19 | 8.8 |
| AF | OpenPose [46] | MPII [48] | VGG-19 | 8.8 |
| A | PoseNet [50,51] | COCO [49] | MobileNetV1 | 10.0 |
| Tool | R | R | R | R | R |
|---|---|---|---|---|---|
| LM | + | + | / | – | + |
| PAT | – | / | / | – | + |
| CVAT | + | + | + | – | + |
| Our Tool | + | + | + | + | + |
| Resolution (w,h) | FPS | Frames | Frames Resampled | Court Aspects | |
|---|---|---|---|---|---|
| V | (1920, 1080) | 50 | 1886 | default | |
| V | (1920, 1080) | 50 | 869 | reflective, glass | |
| V | (1280, 720) | 25 | 3646 | 146 | reflective, glass, mirrored audience |
| V | (1920, 1080) | 25 | 1431 | default, white support beam |
| V | V | V | V | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Rally Frames | (%) | 1030 | (54.6) | 385 | (44.3) | 126 | (86.3) | 806 | (56.3) |
| Non-Rally Frames | (%) | 856 | (45.4) | 484 | (55.7) | 20 | (13.7) | 625 | (43.7) |
| Total Frames | 1886 | 869 | 146 | 1431 | |||||
| Labels | (per frame) | 7253 | (3.85) | 3346 | (3.85) | 572 | (3.92) | 5075 | (3.55) |
| Detections by A | (%) | 9078 | (125.1) | 4207 | (125.7) | 575 | (100.5) | 6114 | (120.5) |
| Detections by AF | (%) | 7225 | (99.6) | 4404 | (131.6) | 603 | (105.4) | 5032 | (99.2) |
| Detections by AF | (%) | 7203 | (99.3) | 3979 | (118.9) | 609 | (106.5) | 4985 | (98.2) |
| Detections by AF | (%) | 5703 | (78.6) | 2757 | (82.4) | 261 | (45.6) | 2434 | (48.0) |
| Detections by A | (%) | 6875 | (94.8) | 3728 | (111.4) | 969 | (169.4) | 4523 | (89.1) |
| V | V | V | V | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Metric | MA | MI | MA | MI | MA | MI | MA | MI | |
| A | F | 0.968 | 0.803 | 0.946 | 0.817 | 0.896 | 0.781 | 0.933 | 0.724 |
| TS | 0.937 | 0.670 | 0.897 | 0.691 | 0.812 | 0.640 | 0.874 | 0.568 | |
| AF | F | 0.963 | 0.919 | 0.836 | 0.804 | 0.874 | 0.837 | 0.935 | 0.872 |
| TS | 0.928 | 0.851 | 0.718 | 0.672 | 0.778 | 0.720 | 0.878 | 0.774 | |
| AF | F | 0.951 | 0.866 | 0.875 | 0.822 | 0.854 | 0.788 | 0.911 | 0.806 |
| TS | 0.906 | 0.764 | 0.778 | 0.697 | 0.744 | 0.651 | 0.837 | 0.675 | |
| AF | F | 0.862 | 0.789 | 0.883 | 0.788 | 0.622 | 0.586 | 0.616 | 0.541 |
| TS | 0.757 | 0.652 | 0.790 | 0.650 | 0.452 | 0.415 | 0.445 | 0.371 | |
| A | F | 0.714 | 0.556 | 0.780 | 0.580 | 0.613 | 0.517 | 0.723 | 0.516 |
| TS | 0.555 | 0.385 | 0.639 | 0.408 | 0.442 | 0.349 | 0.566 | 0.348 | |
| AP | AP | AP | AP | AP | AP | ||
|---|---|---|---|---|---|---|---|
| V | AF | 0.849 | 0.916 | 0.947 | 0.968 | 0.975 | 0.979 |
| AF | 0.610 | 0.771 | 0.871 | 0.923 | 0.951 | 0.962 | |
| AF | 0.518 | 0.679 | 0.802 | 0.878 | 0.913 | 0.932 | |
| A | 0.240 | 0.329 | 0.422 | 0.509 | 0.589 | 0.652 | |
| V | AF | 0.858 | 0.925 | 0.952 | 0.969 | 0.975 | 0.978 |
| AF | 0.638 | 0.777 | 0.866 | 0.910 | 0.935 | 0.950 | |
| AF | 0.643 | 0.749 | 0.836 | 0.874 | 0.902 | 0.914 | |
| A | 0.224 | 0.299 | 0.387 | 0.473 | 0.552 | 0.638 | |
| V | AF | 0.936 | 0.948 | 0.963 | 0.966 | 0.967 | 0.969 |
| AF | 0.812 | 0.907 | 0.936 | 0.951 | 0.954 | 0.957 | |
| AF | 0.819 | 0.906 | 0.938 | 0.945 | 0.952 | 0.952 | |
| A | 0.454 | 0.542 | 0.645 | 0.720 | 0.777 | 0.821 | |
| V | AF | 0.857 | 0.917 | 0.947 | 0.964 | 0.972 | 0.976 |
| AF | 0.577 | 0.732 | 0.823 | 0.877 | 0.905 | 0.921 | |
| AF | 0.524 | 0.674 | 0.775 | 0.847 | 0.888 | 0.911 | |
| A | 0.223 | 0.310 | 0.415 | 0.502 | 0.580 | 0.646 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brumann, C.; Kukuk, M.; Reinsberger, C. Evaluation of Open-Source and Pre-Trained Deep Convolutional Neural Networks Suitable for Player Detection and Motion Analysis in Squash. Sensors 2021, 21, 4550. https://0-doi-org.brum.beds.ac.uk/10.3390/s21134550
Brumann C, Kukuk M, Reinsberger C. Evaluation of Open-Source and Pre-Trained Deep Convolutional Neural Networks Suitable for Player Detection and Motion Analysis in Squash. Sensors. 2021; 21(13):4550. https://0-doi-org.brum.beds.ac.uk/10.3390/s21134550
Chicago/Turabian StyleBrumann, Christopher, Markus Kukuk, and Claus Reinsberger. 2021. "Evaluation of Open-Source and Pre-Trained Deep Convolutional Neural Networks Suitable for Player Detection and Motion Analysis in Squash" Sensors 21, no. 13: 4550. https://0-doi-org.brum.beds.ac.uk/10.3390/s21134550