
Comparison of Pre-Trained YOLO Models on Steel Surface Defects Detector Based on Transfer Learning with GPU-Based Embedded Devices
Abstract
:1. Introduction
- Firstly, we compare the accuracy and speed of YOLOv5, YOLOX and YOLOv7 for real-time steel surface defects detectors. In detail, we conduct training experiments on these pre-trained models of the YOLO family with the transfer learning method on the NEU-DET dataset.
- Secondly, we deploy trained models on 3 devices to verify the feasibility of these models for real-time application, including the advanced high-computing PC GPU server with four RTX 2080, NVIDIA Jetson Xavier, and Jetson Nano to evaluate their real-time performance for steel surface defects detector.
2. Related Work
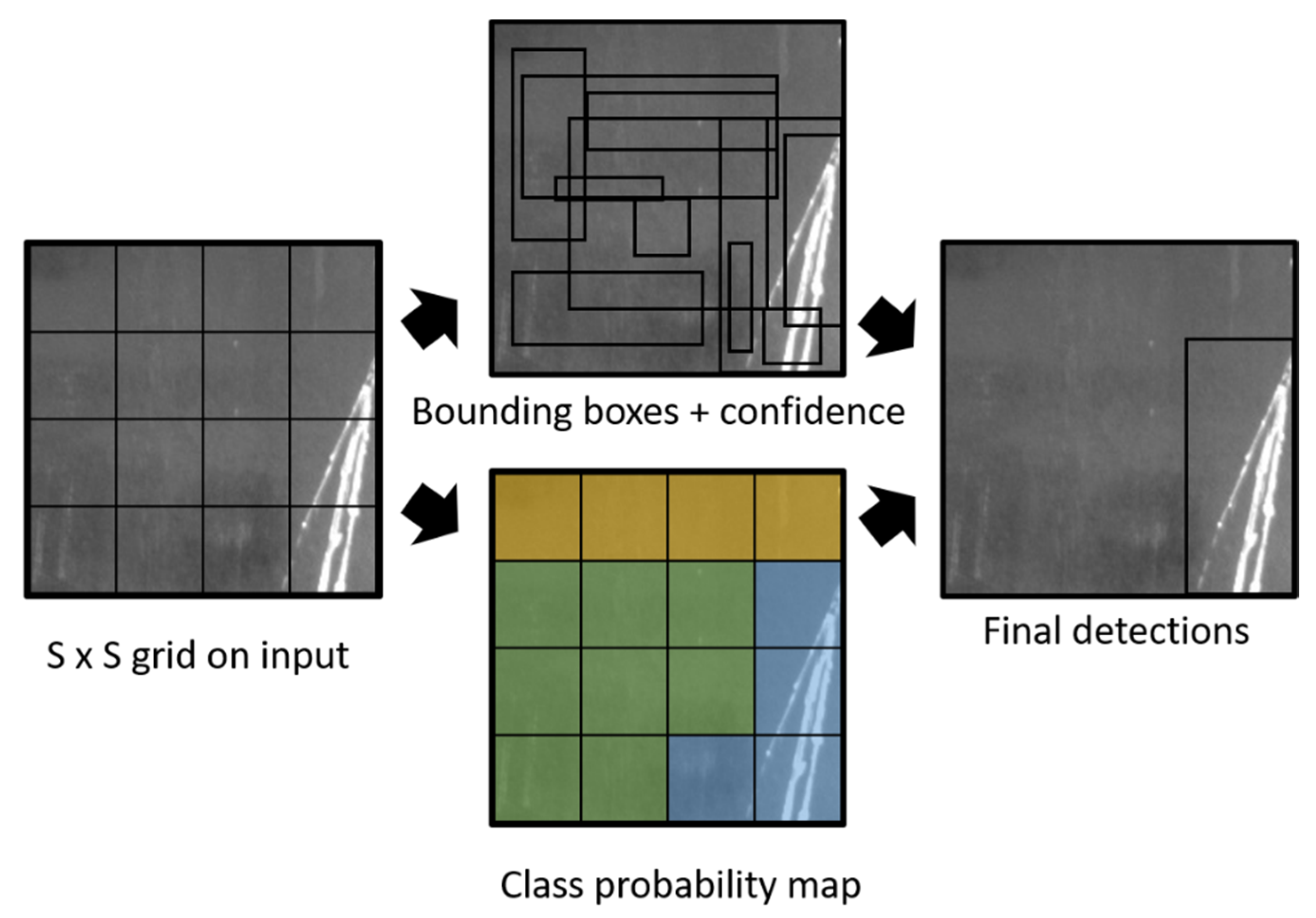
3. YOLO Models Architecture
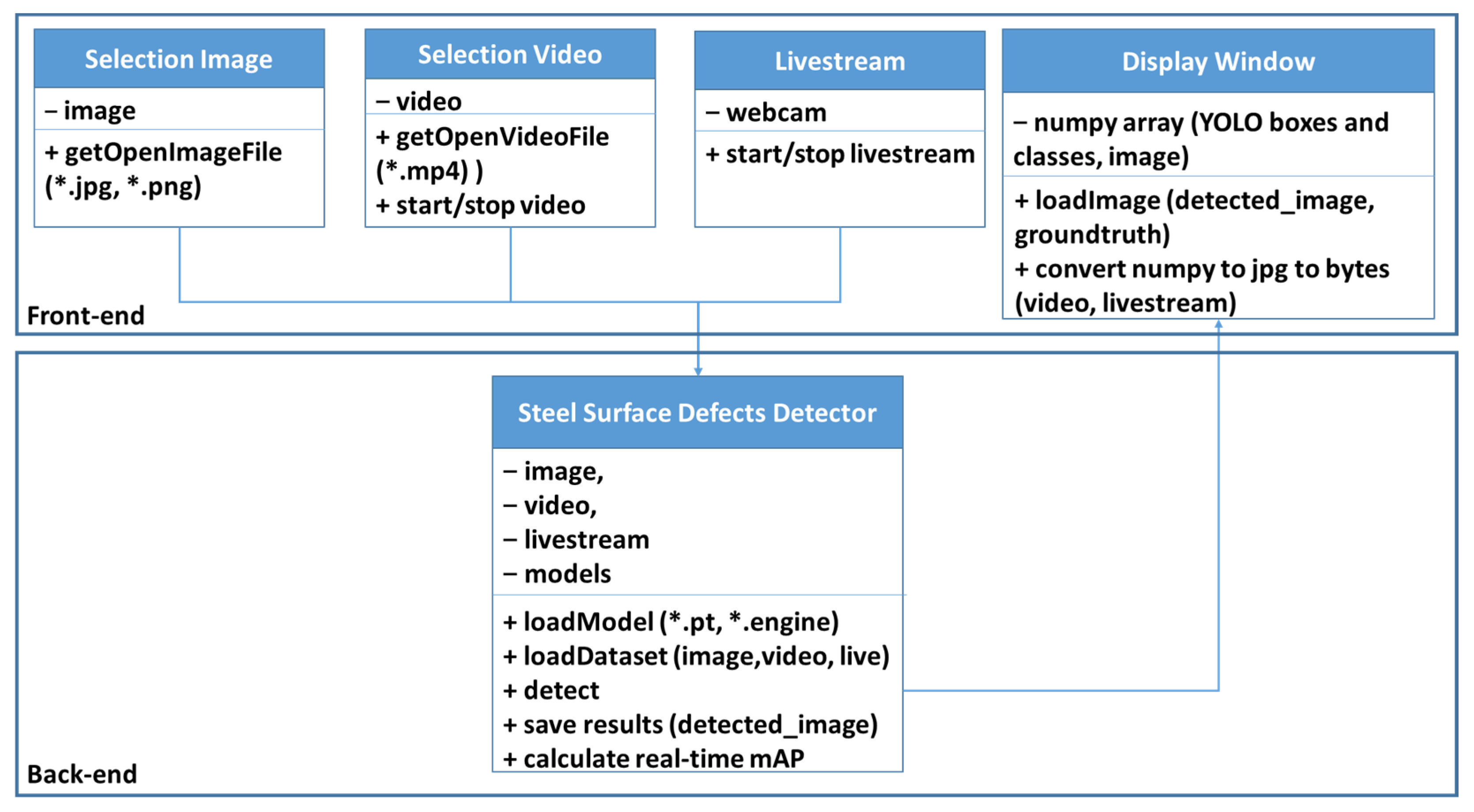
4. Experiments Setup
4.1. Training Environment
4.2. Deployment Devices Configuration
5. Experimental Results and Discussion
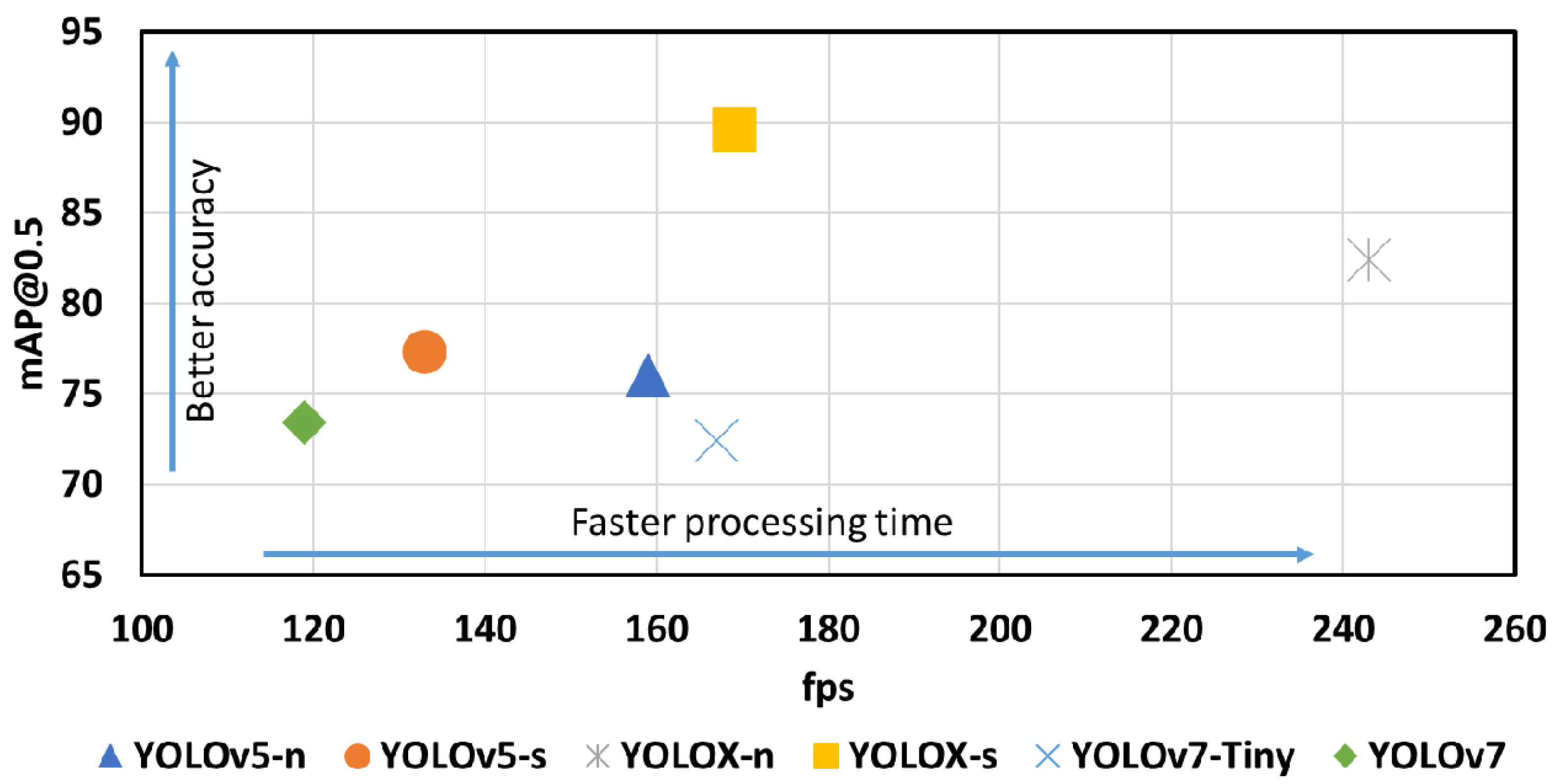
5.1. Training Models Results
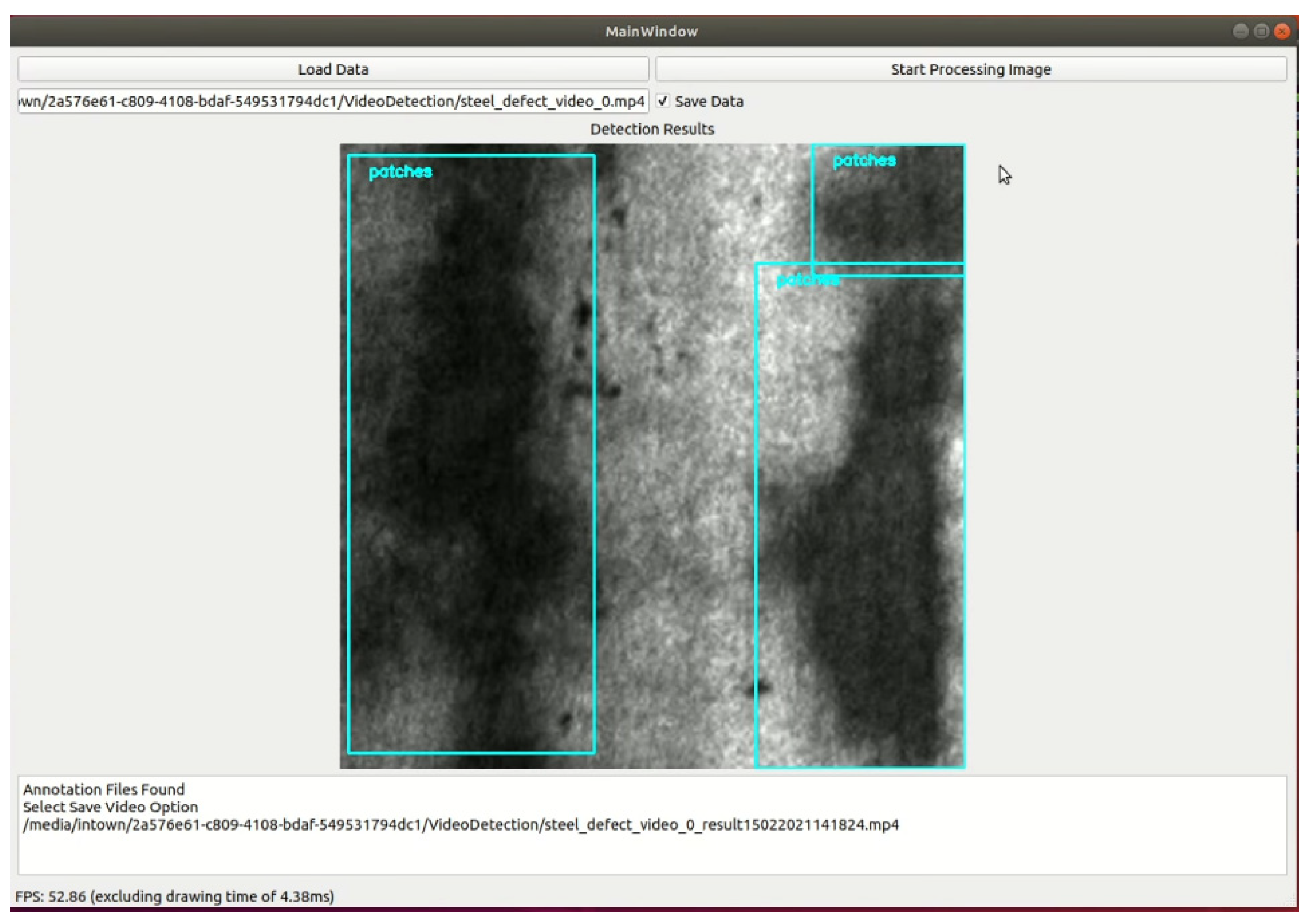
5.2. Deployment on Devices Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xing, J.; Jia, M. A convolutional neural network-based method for workpiece surface defect detection. Measurement 2021, 176, 109185. [Google Scholar] [CrossRef]
- Chen, Y.; Ding, Y.; Zhao, F.; Zhang, E.; Wu, Z.; Shao, L. Surface Defect Detection Methods for Industrial Products: A Review. Appl. Sci. 2021, 11, 7657. [Google Scholar] [CrossRef]
- Ren, Z.; Fang, F.; Yan, N.; Wu, Y. State of the Art in Defect Detection Based on Machine Vision. Int. J. of Precis. Eng. Manuf.-Green Tech. 2022, 9, 661–691. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ren, Q.; Geng, J.; Li, J. Slighter Faster R-CNN for real-time detection of steel strip surface defects. 2018 Chin. Autom. Congr. (CAC) 2018, 2018, 2173–2178. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Li, J.; Su, Z.; Geng, J.; Yin, Y. Real-time Detection of Steel Strip Surface Defects Based on Improved YOLO Detection NetworkScienceDirect. IFAC-Pap. 2018, 51, 76–81. [Google Scholar]
- Zhang, J.; Kang, X.; Ni, H.; Ren, F. Surface defect detection of steel strips based on classification priority YOLOv3-dense network. Ironmak. Steelmak. 2021, 48, 547–558. [Google Scholar] [CrossRef]
- Lv, X.; Duan, F.; Jiang, J.-J.; Fu, X.; Gan, L. Deep Metallic Surface Defect Detection: The New Benchmark and Detection Network. Sensors 2020, 20, 1562. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, X.; Lv, J.; Fang, Y.; Du, S. Online Detection of Surface Defects Based on Improved YOLOV3. Sensors 2022, 22, 817. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Tian, X.; Liu, X.; Liu, Y.; Shi, X. A Two-Stage Industrial Defect Detection Framework Based on Improved-YOLOv5 and Optimized-Inception-ResnetV2 Models. Appl. Sci. 2022, 12, 834. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Available online: https://github.com/ultralytics/yolov5/tree/v6.2 (accessed on 12 December 2022).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, highperformance deep learning library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alche-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Redmon, J. Darknet: Open Source Neural Networks in c. 2013–2016. Available online: http://pjreddie.com/darknet/ (accessed on 12 December 2022).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Li, C.; Li, L.; Jiang, H. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Long, X.; Deng, K.; Wang, G. PP-YOLO: An Effective and Efficient Implementation of Object Detector. arXiv 2020, arXiv:2007.12099. [Google Scholar]
- Available online: http://faculty.neu.edu.cn/songkechen/zh_CN/zdylm/263270/list/index.html (accessed on 12 December 2022).
- Everingham, M.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The Open Images Dataset V4. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Jetson Modules. Available online: https://developer.nvidia.com/embedded/jetson-modules (accessed on 12 December 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Dataset | Algorithms | Results |
|---|---|---|---|
| Ref. [12] 2022 | Enriched-NEU-DET 2224 images Train/Test/Validation Set: 6/2/2 Image Size: 576 × 576 | Improved YOLOv5 | 78.1% |
| Ref. [11] 2022 | Conventional NEU-DET Train: Testing: Resolution:416 × 416 | IMN-YOLOv3-Pytorch | 86.96% 80.959 fps (GPU Tesla V100) |
| Ref. [10] 2020 | Conventional NEU-DET | Improved SSD with negative hard mining | 72.4% 27 ms (GPU RTX 2080Ti) |
| Ref. [9] 2020 | Relabeled Crazing defects Of Conventional NEU-DET | CP-YOLOv3-DarkNet | 82.73% 9.68 ms (GPU GP102 TITAN X) |
| Ref. [8] 2018 | Private Dataset | Improved YOLO | 97.55% 83 fps (GPU RTX 1080Ti) |
| Ref [5] 2018 | Private Dataset | Slighter Faster R-CNN | 98.32% 20 fps |
| Dataset Number | Training/Testing Set | Defect Name | Defects |
|---|---|---|---|
| 1800 images | Training set (1440 images) | Crazing | |
| Inclusion | |||
| Patches | |||
| Pitted Surface | |||
| Rolled-in Scale | |||
| Scratches | |||
| Testing set (360 images) 845 labels | Crazing | 137 | |
| Inclusion | 190 | ||
| Patches | 189 | ||
| Pitted Surface | 79 | ||
| Rolled-in Scale | 137 | ||
| Scratches | 113 |
| Device | Configuration |
|---|---|
| Operating System | Ubuntu 20.04 |
| Processor | Intel® Xeon(R) Silver 4210 CPU @ 2.20 GHz × 40 |
| GPU | RTX 2080 10 G × 2 |
| GPU accelerator | CUDA 11.2, Cudnn 8.1 |
| Framework | PyTorch 1.9.1 |
| Complier IDE | Pycharm |
| Scripting language | Python 3.6 |
| Devices/ Configurations | NVIDIA Jetson Xavier AGX | NVIDIA Jetson Nano |
|---|---|---|
| AI Performance | 5.5–11 TFLOPS (FP16) 20–32 TOPS (INT8) | 0.5 TFLOPS (FP16) |
| CPU | 8-core NVIDIA Carmel Arm®v8.2 64-bit CPU 8 MB L2 + 4 MB L3 | Quad-Core Arm Cortex-A57 MPCore |
| GPU | 512-core NVIDIA Volta™ GPU with 64 Tensor Cores | 128-core NVIDIA Maxwel GPU |
| DL accelerator | 2x NVDLA v1 | N/A |
| Memory | 64 GB 256-bit LPDDR4x 136.5 GB/s | 4 GB 64-bit LPDDR4 25.6 GB/s |
| Price | $99 | $699 |
| Pytorch Models Weights | Pre-Trained Model Parameters | [email protected] | [email protected] | P | R | fps | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Cr | In | Pa | Pi | Ri | Sc | ||||||
| YOLOv5-n | 280 layer, 3M paras, 4.3 GFLOPs 6.7 MB | 40.1 | 87.3 | 90.4 | 82.7 | 64.0 | 91.4 | 76.0 | 77.3 | 70.7 | 159 |
| YOLOv5-s | 280 layers, 12.3M paras, 16.2 GLOPs 25.2 MB | 46.1 | 82.2 | 91.1 | 87.8 | 64.9 | 91.8 | 77.3 | 76.6 | 73.0 | 133 |
| YOLOX-n | -- 0.91M paras, 1.08 GLOPs 7.6 MB | 60.6 | 86.8 | 90.1 | 82.2 | 76.1 | 98.3 | 82.4 | -/- | -/- | 243 |
| YOLOX-s | -- 9M paras, 26.8 GFLOPs 71.8 MB | 72.8 | 90.2 | 99.3 | 89.3 | 87.7 | 98.3 | 89.6 | -/- | -/- | 169 |
| YOLOv7-Tiny | 263 layers, 6M paras, 13.2 GLOPs 12.3 MB | 37.0 | 82.8 | 87.8 | 82.3 | 55.5 | 89.0 | 72.4 | 65.8 | 72.8 | 167 |
| YOLOv7 | 415 layers, 37.2M paras, 104.8 GLOPs 74.9 MB | 36.8 | 85.6 | 88.1 | 80.7 | 58.7 | 90.4 | 73.4 | 68.3 | 73.7 | 119 |
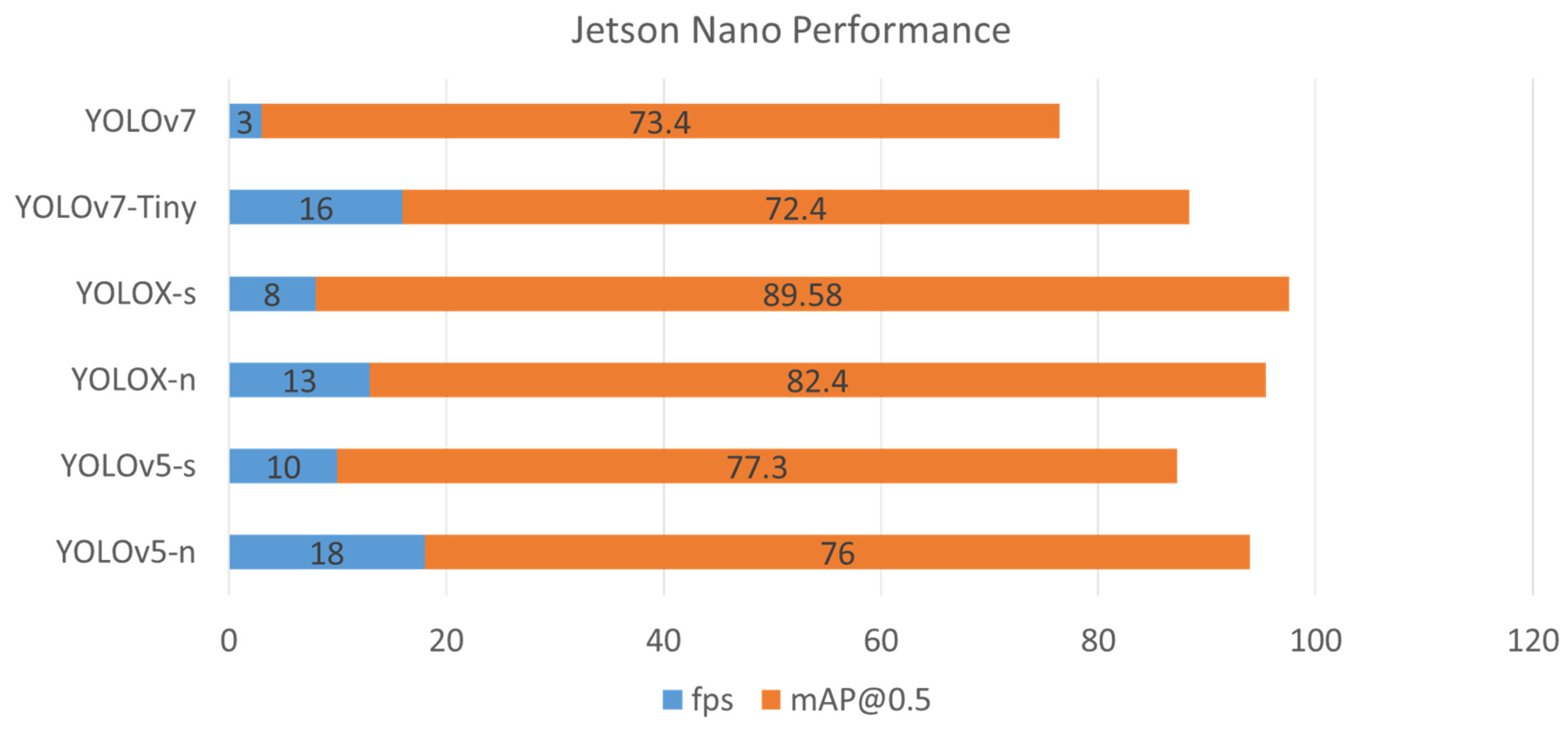
| TensorRT Models Weight | Model Size (MB) | NVIDIA Jetson Devices | Inference Time (ms) | FPS |
|---|---|---|---|---|
| YOLOv5-n | 19.6 | Xavier AGX | 20 | 48 |
| Nano | 54.7 | 18 | ||
| YOLOv5-s | 66.2 | Xavier AGX | 44 | 23 |
| Nano | 99.9 | 10 | ||
| YOLOX-n | 4.7 | Xavier AGX | 24.87 | 40 |
| Nano | 78.13 | 13 | ||
| YOLOX-s | 21.5 | Xavier AGX | 31.64 | 32 |
| Nano | 128.87 | 8 | ||
| YOLOv7-Tiny | 15 | Xavier AGX | 25.1 | 40 |
| Nano | 63 | 16 | ||
| YOLOv7 | 135 | Xavier AGX | 58.6 | 17 |
| Nano | 319 | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, H.-V.; Bae, J.-H.; Lee, Y.-E.; Lee, H.-S.; Kwon, K.-R. Comparison of Pre-Trained YOLO Models on Steel Surface Defects Detector Based on Transfer Learning with GPU-Based Embedded Devices. Sensors 2022, 22, 9926. https://0-doi-org.brum.beds.ac.uk/10.3390/s22249926
Nguyen H-V, Bae J-H, Lee Y-E, Lee H-S, Kwon K-R. Comparison of Pre-Trained YOLO Models on Steel Surface Defects Detector Based on Transfer Learning with GPU-Based Embedded Devices. Sensors. 2022; 22(24):9926. https://0-doi-org.brum.beds.ac.uk/10.3390/s22249926
Chicago/Turabian StyleNguyen, Hoan-Viet, Jun-Hee Bae, Yong-Eun Lee, Han-Sung Lee, and Ki-Ryong Kwon. 2022. "Comparison of Pre-Trained YOLO Models on Steel Surface Defects Detector Based on Transfer Learning with GPU-Based Embedded Devices" Sensors 22, no. 24: 9926. https://0-doi-org.brum.beds.ac.uk/10.3390/s22249926