

From Turing to Transformers: A Comprehensive Review and Tutorial on the Evolution and Applications of Generative Transformer Models



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Background and Significance of Generative Models in AI
1.2. The Rise of Transformer Architectures
1.3. Purpose and Structure of the Paper
- Historical Evolution: We embark on a journey tracing the roots of computational theory, starting with the foundational concepts introduced by Alan Turing. This section provides a backdrop, setting the stage for the emergence of neural networks, the challenges they faced, and the eventual rise of transformer architectures.
- Tutorial on Generative Transformers: Transitioning from theory to practice, this section offers a practical approach to understanding the intricacies of generative transformers. Readers will gain insights into the architecture, training methodologies, and best practices, supplemented with code snippets and practical examples.
- Applications and Challenges: Building upon the foundational knowledge, we delve into the myriad applications of generative transformers, highlighting their impact across various domains. Concurrently, we address the challenges and ethical considerations associated with their use, fostering a balanced perspective.
- Conclusion and Future Directions: The paper concludes with a reflection on the current state of generative transformers, their potential trajectory, and the exciting possibilities they hold for the future of AI.
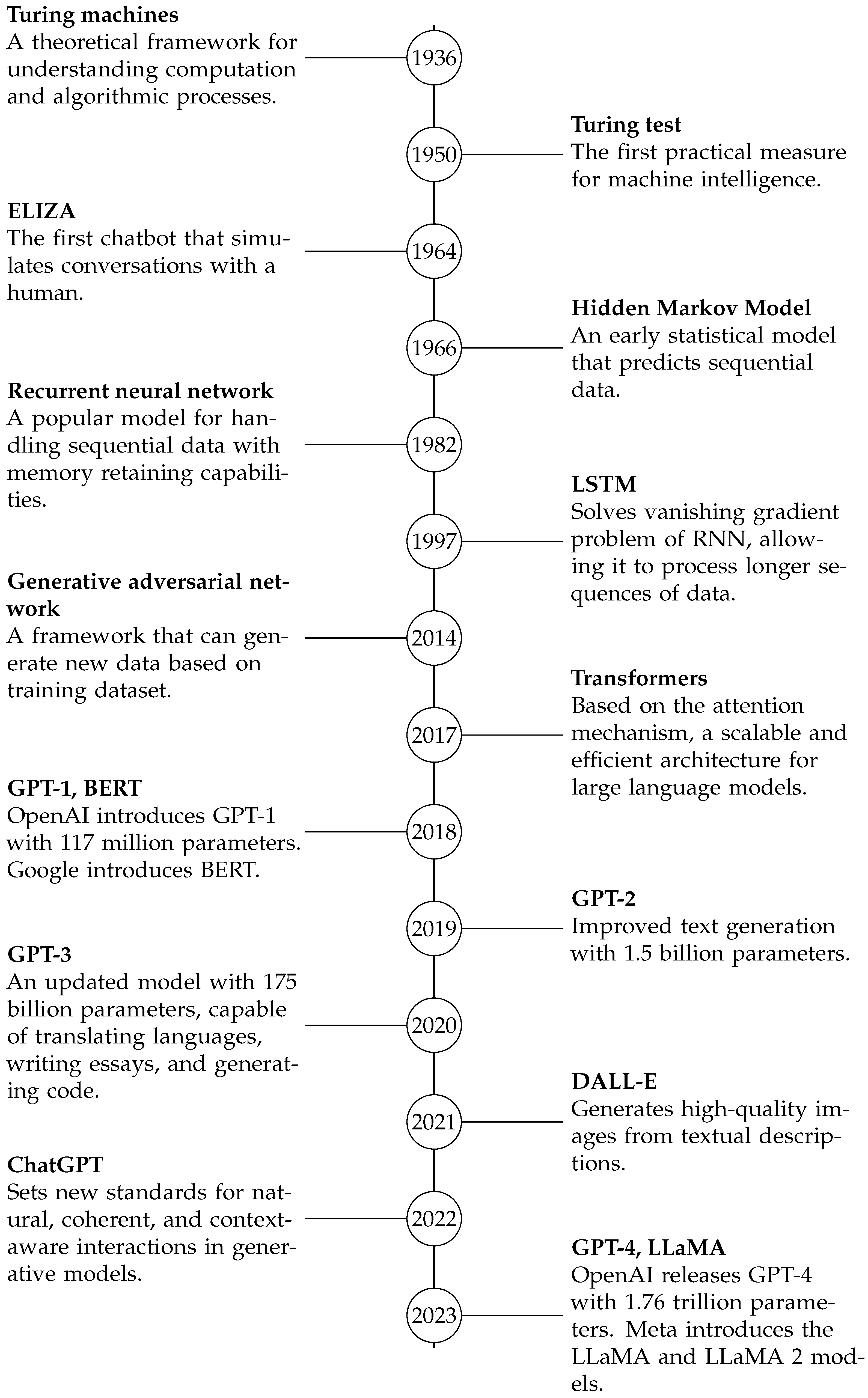
2. Historical Evolution
2.1. Turing Machines and the Foundations of Computation
2.1.1. Turing’s Impact on Artificial Intelligence and Machine Learning
2.1.2. From Turing’s Foundations to Generative Transformers
2.2. Early Neural Networks and Language Models
2.2.1. Introduction to Neural Networks
2.2.2. Evolution of Recurrent Neural Networks (RNNs)
2.2.3. Long Short-Term Memory (LSTM) Networks
2.3. The Advent of Transformers
2.3.1. Introduction to the Transformer Architecture
2.3.2. Advantages of Transformers
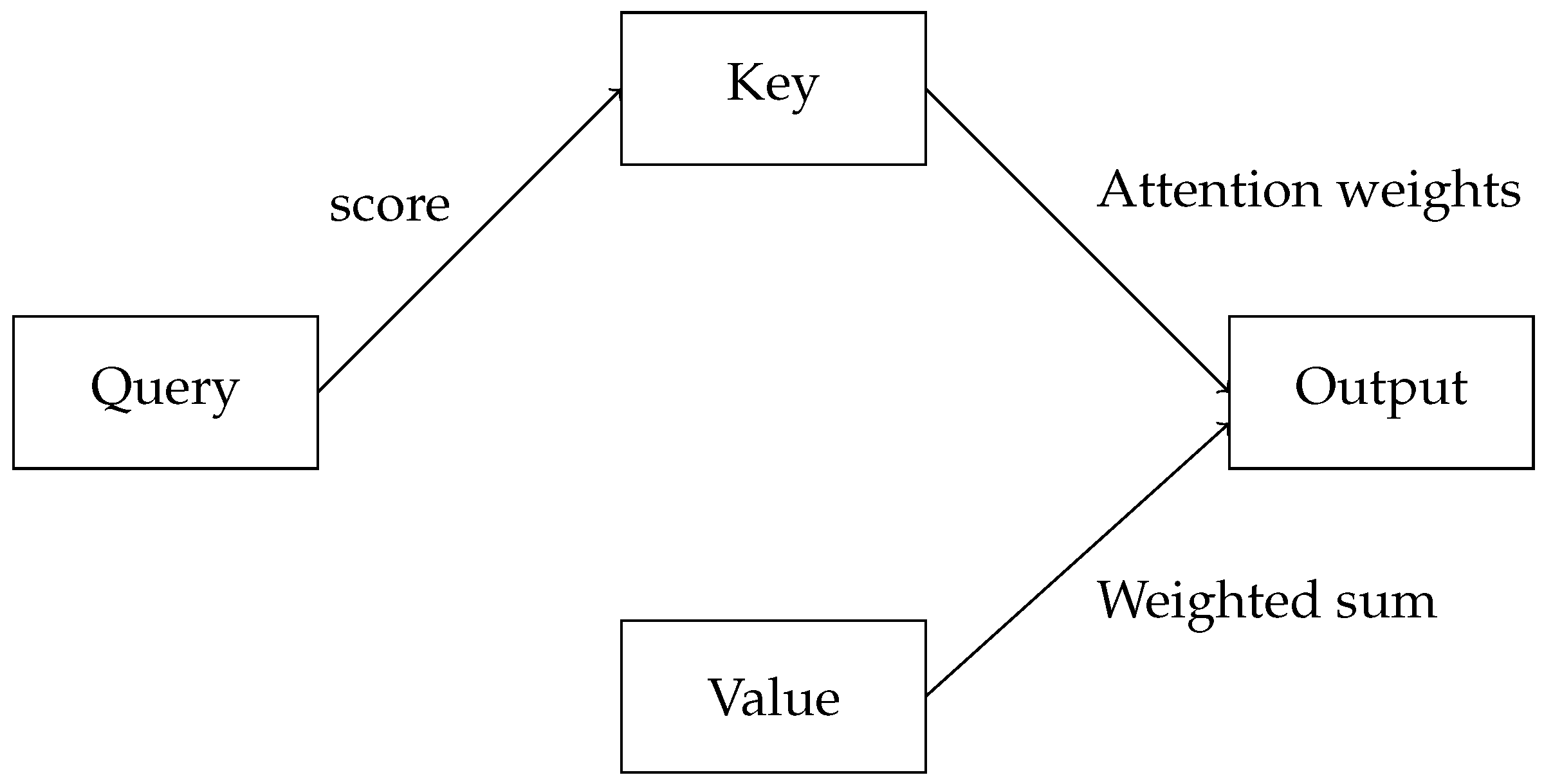
2.4. Attention Mechanism: The Heart of Transformers
2.4.1. Conceptual Overview of Attention
2.4.2. Mathematics of Attention
2.4.3. Significance in Transformers
2.5. Generative Transformers and Their Significance
2.5.1. GPT (Generative Pre-Trained Transformer) Series
2.5.2. Other Notable Generative Transformer Models
3. Tutorial on Generative Transformers
3.1. Basics of the Transformer Architecture
3.1.1. Overview
3.1.2. Attention Mechanism
- import torch
- import torch.nn.functional as F
- def scaled_dot_product_attention(q, k, v):
- matmul_qk = torch.matmul(q, k.transpose(-2, -1))
- d_k = q.size(-1) ** 0.5
- scaled_attention_logits = matmul_qk / d_k
- attention_weights = F.softmax(scaled_attention_logits, dim=-1)
- output = torch.matmul(attention_weights, v)
- return output, attention_weights
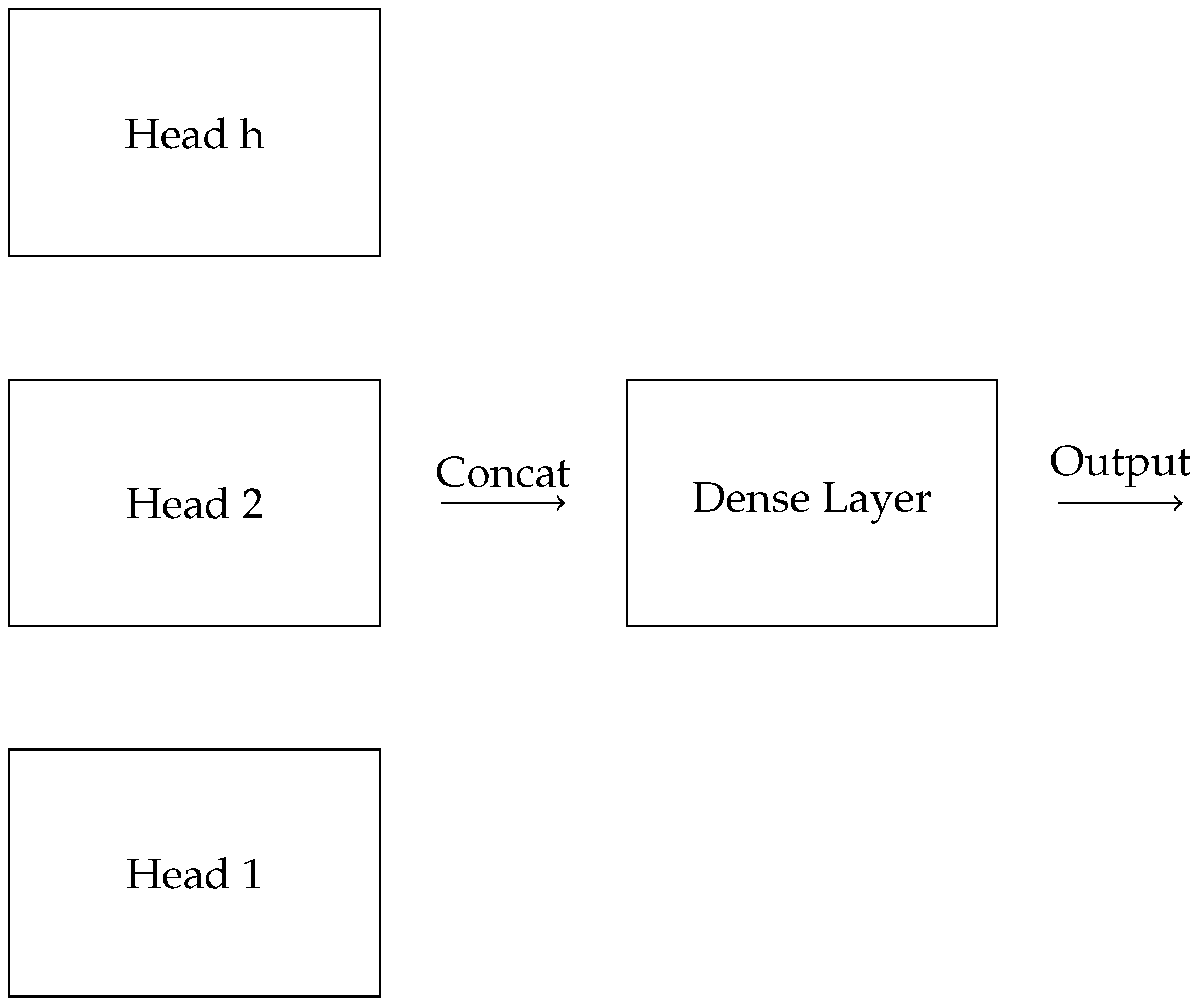
3.1.3. Multi-Head Attention
- class MultiHeadAttention(nn.Module):
- def __init__(self, d_model, num_heads):
- super(MultiHeadAttention, self).__init__()
- self.num_heads = num_heads
- # Dimension of the model
- self.d_model = d_model
- # Depth of each attention head
- self.depth = d_model
- # Linear layer for creating query, key and value matrix
- self.wq = nn.Linear(d_model, d_model)
- self.wk = nn.Linear(d_model, d_model)
- self.wv = nn.Linear(d_model, d_model)
- # Final linear layer to produce the output
- self.dense = nn.Linear(d_model, d_model)
3.1.4. Feed-Forward Neural Networks
- class PointWiseFeedForwardNetwork(nn.Module):
- def __init__(self, d_model, dff):
- super(PointWiseFeedForwardNetwork, self).__init__()
- self.fc1 = nn.Linear(d_model, dff)
- self.fc2 = nn.Linear(dff, d_model)
- ...
3.1.5. Self-Attention Mechanism
3.1.6. Positional Encoding
3.1.7. Multi-Head Attention
3.1.8. Encoder and Decoder Modules
- import torch.nn as nn
- class EncoderLayer(nn.Module):
- def __init__(self, d_model, num_heads):
- super(EncoderLayer, self).__init__()
- self.mha = MultiHeadAttention(d_model, num_heads)
- self.ffn = PointWiseFeedForwardNetwork(d_model, dff)
- # Layer normalization and dropout layers can be added here
- def forward(self, x):
- attn_output = self.mha(x, x, x)
- out1 = x + attn_output # Add & Norm
- ffn_output = self.ffn(out1)
- out2 = out1 + ffn_output # Add & Norm
- return out2
- class DecoderLayer(nn.Module):
- def __init__(self, d_model, num_heads):
- super(DecoderLayer, self).__init__()
- self.mha1 = MultiHeadAttention(d_model, num_heads)
- self.mha2 = MultiHeadAttention(d_model, num_heads)
- self.ffn = PointWiseFeedForwardNetwork(d_model, dff)
- # Layer normalization and dropout layers can be added here
- def forward(self, x, enc_output):
- attn1 = self.mha1(x, x, x)
- out1 = x + attn1 # Add & Norm
- attn2 = self.mha2(out1, enc_output, enc_output)
- out2 = out1 + attn2 # Add & Norm
- ffn_output = self.ffn(out2)
- out3 = out2 + ffn_output # Add & Norm
- return out3
3.2. Building a Simple Generative Transformer
3.2.1. Data Preprocessing and Tokenization
- from transformers import GPT2Tokenizer
- tokenizer = GPT2Tokenizer.from_pretrained(’gpt2-medium’)
- tokens = tokenizer.encode("Hello, world!")
3.2.2. Defining the Transformer Model
- class Transformer(nn.Module):
- def __init__(self, d_model, num_heads, num_layers):
- super(Transformer, self).__init__()
- self.encoder = nn.ModuleList([EncoderLayer(d_model, num_heads) for _ in range(num_layers)])
- self.decoder = nn.ModuleList([DecoderLayer(d_model, num_heads) for _ in range(num_layers)])
- def forward(self, src, tgt):
- enc_output = src
- for layer in self.encoder:
- enc_output = layer(enc_output)
- dec_output = tgt
- for layer in self.decoder:
- dec_output = layer(dec_output, enc_output)
- return dec_output
3.3. Advanced Techniques and Best Practices
3.3.1. Techniques for Improving Generation Quality
- torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
3.3.2. Handling Long Sequences and Memory Issues
3.3.3. Fine-Tuning and Transfer Learning
4. Applications and Use Cases
4.1. Text Generation for Creative Writing
4.2. Chatbots and Conversational Agents
4.3. Code Generation and Programming Assistance
4.4. Other Notable Applications
5. Challenges and Limitations
5.1. Model Interpretability
5.2. Hallucination in Text Generation
5.3. Ethical Considerations in Text Generation
5.4. Computational Requirements and Environmental Impact
6. The Future of Generative Transformers
6.1. Multimodal Models
6.2. Domain-Specific Models
6.3. Model Efficiency
6.4. Ethical AI
6.5. Interdisciplinary Integration
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Baum, L.E.; Petrie, T. Statistical inference for probabilistic functions of finite state Markov chains. Ann. Math. Stat. 1966, 37, 1554–1563. [Google Scholar] [CrossRef]
- Baum, L.E.; Eagon, J.A. An Inequality with Applications to Statistical Estimation for Probabilistic Functions of Markov Processes and to a Model for Ecology. 1967. Available online: https://community.ams.org/journals/bull/1967-73-03/S0002-9904-1967-11751-8/S0002-9904-1967-11751-8.pdf (accessed on 10 November 2023).
- Baum, L.E.; Petrie, T.; Soules, G.; Weiss, N. A maximization technique occurring in the statistical analysis of probabilistic functions of Markov chains. Ann. Math. Stat. 1970, 41, 164–171. [Google Scholar] [CrossRef]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Welling, M. An introduction to variational autoencoders. Found. Trends Mach. Learn. 2019, 12, 307–392. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Antoniou, A.; Storkey, A.; Edwards, H. Data augmentation generative adversarial networks. arXiv 2017, arXiv:1711.04340. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Deecke, L.; Vandermeulen, R.; Ruff, L.; Mandt, S.; Kloft, M. Image anomaly detection with generative adversarial networks. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2018, Dublin, Ireland, 10–14 September 2018; Proceedings, Part I 18. Springer: Berlin/Heidelberg, Germany, 2019; pp. 3–17. [Google Scholar]
- Yang, Q.; Yan, P.; Zhang, Y.; Yu, H.; Shi, Y.; Mou, X.; Kalra, M.K.; Zhang, Y.; Sun, L.; Wang, G. Low-dose CT image denoising using a generative adversarial network with Wasserstein distance and perceptual loss. IEEE Trans. Med. Imaging 2018, 37, 1348–1357. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3943–3956. [Google Scholar] [CrossRef]
- Oord, A.V.D.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Dhariwal, P.; Jun, H.; Payne, C.; Kim, J.W.; Radford, A.; Sutskever, I. Jukebox: A generative model for music. arXiv 2020, arXiv:2005.00341. [Google Scholar]
- Cetinic, E.; She, J. Understanding and creating art with AI: Review and outlook. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–22. [Google Scholar] [CrossRef]
- Bian, Y.; Xie, X.Q. Generative chemistry: Drug discovery with deep learning generative models. J. Mol. Model. 2021, 27, 71. [Google Scholar] [CrossRef]
- Stephenson, N.; Shane, E.; Chase, J.; Rowland, J.; Ries, D.; Justice, N.; Zhang, J.; Chan, L.; Cao, R. Survey of machine learning techniques in drug discovery. Curr. Drug Metab. 2019, 20, 185–193. [Google Scholar] [CrossRef]
- Martin, D.; Serrano, A.; Bergman, A.W.; Wetzstein, G.; Masia, B. Scangan360: A generative model of realistic scanpaths for 360 images. IEEE Trans. Vis. Comput. Graph. 2022, 28, 2003–2013. [Google Scholar] [CrossRef]
- Achlioptas, P.; Diamanti, O.; Mitliagkas, I.; Guibas, L. Learning representations and generative models for 3D point clouds. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 40–49. [Google Scholar]
- Khoo, E.T.; Lee, S.P.; Cheok, A.D.; Kodagoda, S.; Zhou, Y.; Toh, G.S. Age invaders: Social and physical inter-generational family entertainment. In Proceedings of the CHI’06 Extended Abstracts on Human Factors in Computing Systems, Montreal, QU, Canada, 22–27 April 2006; pp. 243–246. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Way, G.P.; Greene, C.S. Extracting a biologically relevant latent space from cancer transcriptomes with variational autoencoders. In Proceedings of the Pacific Symposium on Biocomputing 2018, Hawaii, HI, USA, 3–7 January 2018; World Scientific: Singapore, 2018; pp. 80–91. [Google Scholar]
- Sirignano, J.; Cont, R. Universal features of price formation in financial markets: Perspectives from deep learning. Quant. Financ. 2019, 19, 1449–1459. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat, F. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 10 November 2023).
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 17–19 June 2013; pp. 1310–1318. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A primer in BERTology: What we know about how BERT works. Trans. Assoc. Comput. Linguist. 2021, 8, 842–866. [Google Scholar] [CrossRef]
- Bubeck, S.; Chandrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv 2023, arXiv:2303.12712. [Google Scholar]
- Jiao, W.; Wang, W.; Huang, J.T.; Wang, X.; Tu, Z. Is ChatGPT a good translator? A preliminary study. arXiv 2023, arXiv:2301.08745. [Google Scholar]
- Gao, M.; Ruan, J.; Sun, R.; Yin, X.; Yang, S.; Wan, X. Human-like summarization evaluation with chatgpt. arXiv 2023, arXiv:2304.02554. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do Vision Transformers See Like Convolutional Neural Networks? arXiv 2021, arXiv:2108.08810. [Google Scholar]
- Paul, S.; Chen, P.Y. Vision transformers are robust learners. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2022; Volume 36, pp. 2071–2081. [Google Scholar]
- Nikolić, G.S.; Dimitrijević, B.R.; Nikolić, T.R.; Stojcev, M.K. A survey of three types of processing units: CPU, GPU and TPU. In Proceedings of the 2022 57th International Scientific Conference on Information, Communication and Energy Systems and Technologies (ICEST), Ohrid, Macedonia, 16–18 June 2022; pp. 1–6. [Google Scholar]
- Gozalo-Brizuela, R.; Garrido-Merchan, E.C. ChatGPT is not all you need. A State of the Art Review of large Generative AI models. arXiv 2023, arXiv:2301.04655. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. arXiv 2022, arXiv:2106.04554. [Google Scholar] [CrossRef]
- Kalyan, K.S.; Rajasekharan, A.; Sangeetha, S. Ammus: A survey of transformer-based pretrained models in natural language processing. arXiv 2021, arXiv:2108.05542. [Google Scholar]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches. Artif. Intell. Rev. 2021, 54, 5789–5829. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Shamshad, F.; Khan, S.; Zamir, S.W.; Khan, M.H.; Hayat, M.; Khan, F.S.; Fu, H. Transformers in medical imaging: A survey. Med. Image Anal. 2023, 88, 102802. [Google Scholar] [CrossRef]
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.S.; Khan, F.S. Transformers in remote sensing: A survey. Remote Sens. 2023, 15, 1860. [Google Scholar] [CrossRef]
- Wen, Q.; Zhou, T.; Zhang, C.; Chen, W.; Ma, Z.; Yan, J.; Sun, L. Transformers in time series: A survey. arXiv 2022, arXiv:2202.07125. [Google Scholar]
- Ahmed, S.; Nielsen, I.E.; Tripathi, A.; Siddiqui, S.; Ramachandran, R.P.; Rasool, G. Transformers in time-series analysis: A tutorial. Circuits Syst. Signal Process. 2023, 42, 7433–7466. [Google Scholar] [CrossRef]
- Turing, A.M. On computable numbers, with an application to the Entscheidungsproblem. J. Math 1936, 58, 5. [Google Scholar]
- Copeland, B.J. The Church-Turing Thesis. 1997. Available online: https://plato.stanford.edu/ENTRIES/church-turing/ (accessed on 10 November 2023).
- Bernays, P. Alonzo Church. An unsolvable problem of elementary number theory. Am. J. Math. 1936, 58, 345–363. [Google Scholar]
- Hodges, A. Alan Turing: The Enigma: The Book That Inspired the Film “The Imitation Game”; Princeton University Press: Princeton, NJ, USA, 2014. [Google Scholar]
- Turing, A.M. Proposed Electronic Calculator; National Physical Laboratory: London, UK, 1946.
- Machinery, C. Computing machinery and intelligence-AM Turing. Mind 1950, 59, 433. [Google Scholar]
- Turing, A. Intelligent machinery (1948). In The Essential Turing; Copeland, B.J., Ed.; Oxford Academic: Oxford, UK, 2004; pp. 395–432. [Google Scholar]
- Turing, A.M. The chemical basis of morphogenesis. Philos. Trans. R. Soc. London Ser. Biol. Sci. 1952, 237, 37–72. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 10 November 2023).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- OpenAI. GPT-4 Technical Report. 2023. Available online: http://xxx.lanl.gov/abs/2303.08774 (accessed on 10 November 2023).
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. Lamda: Language models for dialog applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Zhuang, B.; Liu, J.; Pan, Z.; He, H.; Weng, Y.; Shen, C. A survey on efficient training of transformers. arXiv 2023, arXiv:2302.01107. [Google Scholar]
- Xu, F.F.; Alon, U.; Neubig, G.; Hellendoorn, V.J. A systematic evaluation of large language models of code. In Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, New York, NY, USA, 13 June 2022; pp. 1–10. [Google Scholar]
- Hewitt, J.; Manning, C.D.; Liang, P. Truncation sampling as language model desmoothing. arXiv 2022, arXiv:2210.15191. [Google Scholar]
- Zhang, J.; He, T.; Sra, S.; Jadbabaie, A. Why gradient clipping accelerates training: A theoretical justification for adaptivity. arXiv 2019, arXiv:1905.11881. [Google Scholar]
- Lin, Y.; Han, S.; Mao, H.; Wang, Y.; Dally, W.J. Deep gradient compression: Reducing the communication bandwidth for distributed training. arXiv 2017, arXiv:1712.01887. [Google Scholar]
- Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv 2019, arXiv:1909.08053. [Google Scholar]
- Ziegler, D.M.; Stiennon, N.; Wu, J.; Brown, T.B.; Radford, A.; Amodei, D.; Christiano, P.; Irving, G. Fine-tuning language models from human preferences. arXiv 2019, arXiv:1909.08593. [Google Scholar]
- Dodge, J.; Ilharco, G.; Schwartz, R.; Farhadi, A.; Hajishirzi, H.; Smith, N. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. arXiv 2020, arXiv:2002.06305. [Google Scholar]
- He, R.; Liu, L.; Ye, H.; Tan, Q.; Ding, B.; Cheng, L.; Low, J.W.; Bing, L.; Si, L. On the effectiveness of adapter-based tuning for pretrained language model adaptation. arXiv 2021, arXiv:2106.03164. [Google Scholar]
- Shidiq, M. The use of artificial intelligence-based chat-gpt and its challenges for the world of education; from the viewpoint of the development of creative writing skills. In Proceedings of the International Conference on Education, Society and Humanity, Taipei, Taiwan, 28–30 June 2023; Volume 1, pp. 353–357. [Google Scholar]
- Ippolito, D.; Yuan, A.; Coenen, A.; Burnam, S. Creative writing with an ai-powered writing assistant: Perspectives from professional writers. arXiv 2022, arXiv:2211.05030. [Google Scholar]
- Köbis, N.; Mossink, L.D. Artificial intelligence versus Maya Angelou: Experimental evidence that people cannot differentiate AI-generated from human-written poetry. Comput. Hum. Behav. 2021, 114, 106553. [Google Scholar] [CrossRef]
- Hardalov, M.; Koychev, I.; Nakov, P. Towards automated customer support. In Artificial Intelligence: Methodology, Systems, and Applications, Proceedings of the 18th International Conference, AIMSA 2018, Varna, Bulgaria, 12–14 September 2018; Proceedings 18; Springer: Berlin/Heidelberg, Germany, 2018; pp. 48–59. [Google Scholar]
- Følstad, A.; Skjuve, M. Chatbots for customer service: User experience and motivation. In Proceedings of the 1st International Conference on Conversational User Interfaces, Dublin, Ireland, 22–23 August 2019; pp. 1–9. [Google Scholar]
- Finnie-Ansley, J.; Denny, P.; Becker, B.A.; Luxton-Reilly, A.; Prather, J. The robots are coming: Exploring the implications of openai codex on introductory programming. In Proceedings of the 24th Australasian Computing Education Conference, Melbourne, VIC, Australia, 14–18 February 2022; pp. 10–19. [Google Scholar]
- Värtinen, S.; Hämäläinen, P.; Guckelsberger, C. Generating role-playing game quests with gpt language models. IEEE Trans. Games 2022, 1–12. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Chefer, H.; Gur, S.; Wolf, L. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 782–791. [Google Scholar]
- Elhage, N.; Nanda, N.; Olsson, C.; Henighan, T.; Joseph, N.; Mann, B.; Askell, A.; Bai, Y.; Chen, A.; Conerly, T.; et al. A mathematical framework for transformer circuits. Transform. Circuits Thread 2021, 1. Available online: https://transformer-circuits.pub/2021/framework/index.html (accessed on 10 November 2023).
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Ganguli, D.; Hernandez, D.; Lovitt, L.; Askell, A.; Bai, Y.; Chen, A.; Conerly, T.; Dassarma, N.; Drain, D.; Elhage, N.; et al. Predictability and surprise in large generative models. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 1747–1764. [Google Scholar]
- Silva, A.; Tambwekar, P.; Gombolay, M. Towards a comprehensive understanding and accurate evaluation of societal biases in pre-trained transformers. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 2383–2389. [Google Scholar]
- Li, C. OpenAI’s GPT-3 Language Model: A Technical Overview. Lambda Labs Blog 2020. Available online: https://lambdalabs.com/blog/demystifying-gpt-3 (accessed on 10 November 2023).
- Xu, P.; Zhu, X.; Clifton, D.A. Multimodal learning with transformers: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12113–12132. [Google Scholar] [CrossRef] [PubMed]
- Pal, S.; Bhattacharya, M.; Lee, S.S.; Chakraborty, C. A Domain-Specific Next-Generation Large Language Model (LLM) or ChatGPT is Required for Biomedical Engineering and Research. Ann. Biomed. Eng. 2023, 1–4. [Google Scholar] [CrossRef]
- Wang, C.; Liu, X.; Yue, Y.; Tang, X.; Zhang, T.; Jiayang, C.; Yao, Y.; Gao, W.; Hu, X.; Qi, Z.; et al. Survey on factuality in large language models: Knowledge, retrieval and domain-specificity. arXiv 2023, arXiv:2310.07521. [Google Scholar]
- Wu, S.; Irsoy, O.; Lu, S.; Dabravolski, V.; Dredze, M.; Gehrmann, S.; Kambadur, P.; Rosenberg, D.; Mann, G. Bloomberggpt: A large language model for finance. arXiv 2023, arXiv:2303.17564. [Google Scholar]
- Floridi, L.; Cowls, J.; Beltrametti, M.; Chatila, R.; Chazerand, P.; Dignum, V.; Luetge, C.; Madelin, R.; Pagallo, U.; Rossi, F.; et al. An ethical framework for a good AI society: Opportunities, risks, principles, and recommendations. Ethics Gov. Policies Artif. Intell. 2021, 144, 19–39. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, E.Y.; Cheok, A.D.; Pan, Z.; Cai, J.; Yan, Y. From Turing to Transformers: A Comprehensive Review and Tutorial on the Evolution and Applications of Generative Transformer Models. Sci 2023, 5, 46. https://0-doi-org.brum.beds.ac.uk/10.3390/sci5040046
Zhang EY, Cheok AD, Pan Z, Cai J, Yan Y. From Turing to Transformers: A Comprehensive Review and Tutorial on the Evolution and Applications of Generative Transformer Models. Sci. 2023; 5(4):46. https://0-doi-org.brum.beds.ac.uk/10.3390/sci5040046
Chicago/Turabian StyleZhang, Emma Yann, Adrian David Cheok, Zhigeng Pan, Jun Cai, and Ying Yan. 2023. "From Turing to Transformers: A Comprehensive Review and Tutorial on the Evolution and Applications of Generative Transformer Models" Sci 5, no. 4: 46. https://0-doi-org.brum.beds.ac.uk/10.3390/sci5040046