1. Introduction
Wind power makes use of air flow through wind turbines to mechanically power generators for electric power. The total global installed capacity reached 487 GW by the end of 2016, and new installed capacity was more than 54.6 GW in 2016, of which 23.4 GW of new installations in China powered this growth in large part [
1]. The rapid increase of global installation capacity means that one of the largest onshore wind farms, Gansu Wind Farm [
2], which has installed capacity of over 6000 MW, has already started operation. In order to ensure reliability and safe operation, detailed analysis of the situation of large wind farms is an important task for wind farm management and decision-making.
Assessing wind energy resources involves analyzing and evaluating the long-term wind energy reserves of wind farms [
3]. Through detailed assessment of the time series of a wind farm, some characteristics of wind energy are calculated, such as average wind speed, average wind power density, effective wind power density, and available hours. The probability statistics method uses a variety of distribution functions (such as Rayleigh distribution, gamma distribution, logistic distribution, and Weibull distribution [
4]) to fit the probability distribution of wind speed and find the optimal probability distribution function. When the optimal probability distribution function is found, its parameters need to be estimated by a numerical method or optimization algorithm. For example, Mohammadi et al. [
5] used multinumerical methods to evaluate the parameters of the Weibull distribution. Wu et al. [
6] compared three probably density functions and selected the best one to apply the wind energy assessment. For the optimization parameters, three particle swarm optimization algorithms and 18 differential evolution algorithms were used to estimate the parameters of the Weibull distribution.
However, numerical estimation methods such as moments estimate [
7], maximum likelihood estimate [
8], and least squares estimate [
9], have some disadvantages and restricted conditions. For example, the method of moment can only be used in the distribution when the population origin moment exists and the moment only has some of the information, and this method only has good performance when the sample size is large. The maximum likelihood estimation must incorporate the sample distribution. It is more complicated to incorporate the likelihood equations, which often obtain the approximate solution by computer iterative computation. However, the least squares method has two kinds of defects. If the noise of the model is colored noise, the estimation result of the least squares is a biased estimation; with increasing data size, “data saturation” will appear.
Due to the defects of the above methods, in this paper, four optimization algorithms (firefly algorithm [
10], genetic algorithm [
11], ant colony algorithm [
12], and cuckoo search algorithm [
13]) are used to optimize and determine the shape (k) and scale (c) parameters of the Weibull distribution function for calculating wind power density.
The wind energy assessment is used to analyze long-term wind energy reserves and calculate long-term electricity production. However, the wind energy assessment is not comprehensive in the detailed analysis of wind farms. At same time, it is important to master future changes of wind speed. Over the past few decades, many researchers have proposed methods of wind speed forecasting. For example, Cassola et al. [
14] improved the forecasting performance of wind speed by using a Kalman filtering technique to correct the numerical weather prediction model output. Liu et al. [
15] proposed two hybrid models based on Auto-Regressive and Moving Average Model (ARMA) and nonparametric models, and showed that nonparametric-based hybrid models generally outperformed the other models. Tascikaraoglu et al. [
16] proposed a novel wind speed prediction model using wavelet transform and spatiotemporal methods, which improved the short-term wind speed forecasting relative to other benchmark models. Xiao et al. [
17] developed a hybrid wavelet neural network (WNN) model with an improved cuckoo search algorithm. The above studies used four classes to forecast wind speed: physical model, conventional statistical model, spatial correlation model, and artificial intelligence model.
However, traditional forecasting methods have some defects. For example, the physical methods require considerable observed data with limited simulation scale and consume a lot of computing resources, which are expensive to obtain [
18]. On the other hand, these methods are more suitable for weather forecasting instead of wind speed forecasting [
19]. Statistical models cannot address forecasting with high noise and fluctuation, irregular nonlinear trends, or features of wind speed series data, which is mainly limited by the prior assumption of linear form among time series. The spatial correlation model [
20] makes it quite difficult to implement perfect wind speed forecasting due to the vast quantities of information that need to be considered and collected, such as wind speed values of many spatially correlated sites. There are still many disadvantages and defects with artificial intelligence methods, for example, easily getting into local optimum, overfitting, and exhibiting a relatively low convergence rate [
21].
In view of the disadvantages of wind energy resource assessment and traditional forecasting models, in this paper, a wind energy analysis system that includes an assessment module and a forecasting module is developed. The system can be an effective estimation and forecasting tool for large wind farms.
The major contributions of this paper are as follows:
- (1)
A wind energy analysis system including an assessment of wind energy resources and forecasting of wind speed time series, is developed and applied. The purpose of the wind energy assessment is to analyze the wind energy reserves of the wind farm, and the purpose of wind speed forecasting is to master the future changes of wind speed.
- (2)
To effectively assess wind energy, the performance of different probability density functions (PDFs) is compared so as to select the best one. As one of the most suitable probability distributions, the probability density function is the most applicable approach to describe the distribution of wind speed in this case.
- (3)
When the parameters of the probability density function are determined, in place of the numerical estimation method, which has some defects for estimation parameters, the optimization algorithm can effectively obtain optimal parameters.
- (4)
Because actual wind speed has chaotic noise, which will decrease the accuracy of the forecasting, data preprocessing technology is employed to reduce noise and uncertainty of wind speed series.
- (5)
A wind speed forecasting module, which includes a data preprocessing module, parameter optimization module, and forecasting module, is developed. In order to determine the parameters of the least squares support vector machine (LSSVM), a hybrid optimization algorithm is proposed. The new optimization algorithm uses the steepest descent to improve the convergence rate of the cuckoo search algorithm, which can effectively improve the forecasting accuracy of the LSSVM.
2. Model Construction
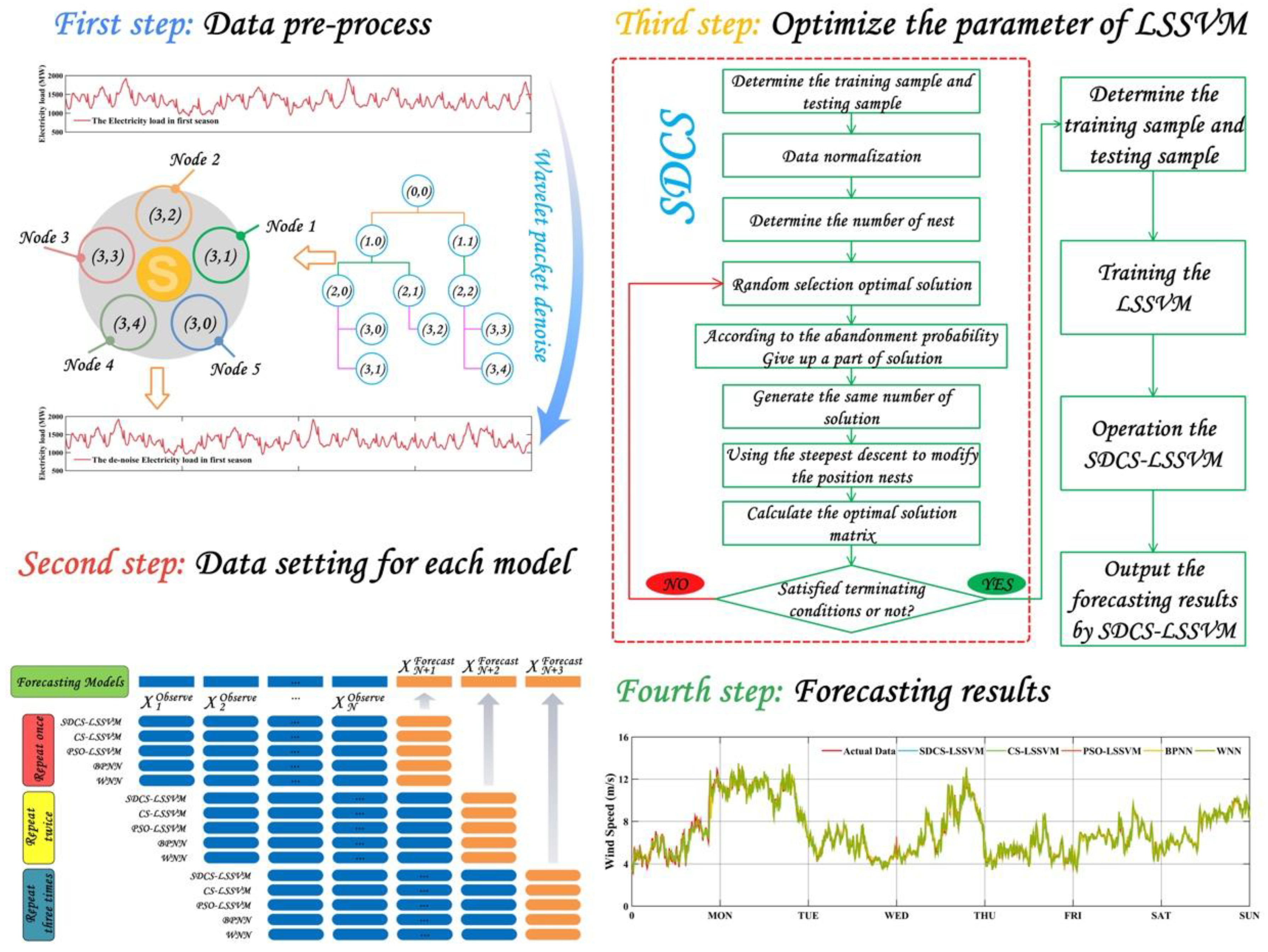
This part mainly introduces the composition of the hybrid algorithm and the detailed steps. Step one: introduce correlation algorithm for wind speed data analysis. Step two: actual wind speed data is processed by wavelet packet transform, which is used to establish the LSSVM. Then the modified cuckoo search algorithm is used to optimize the parameters of the LSSVM.
2.1. The Correlation Algorithm for Wind Speed Data Analysis
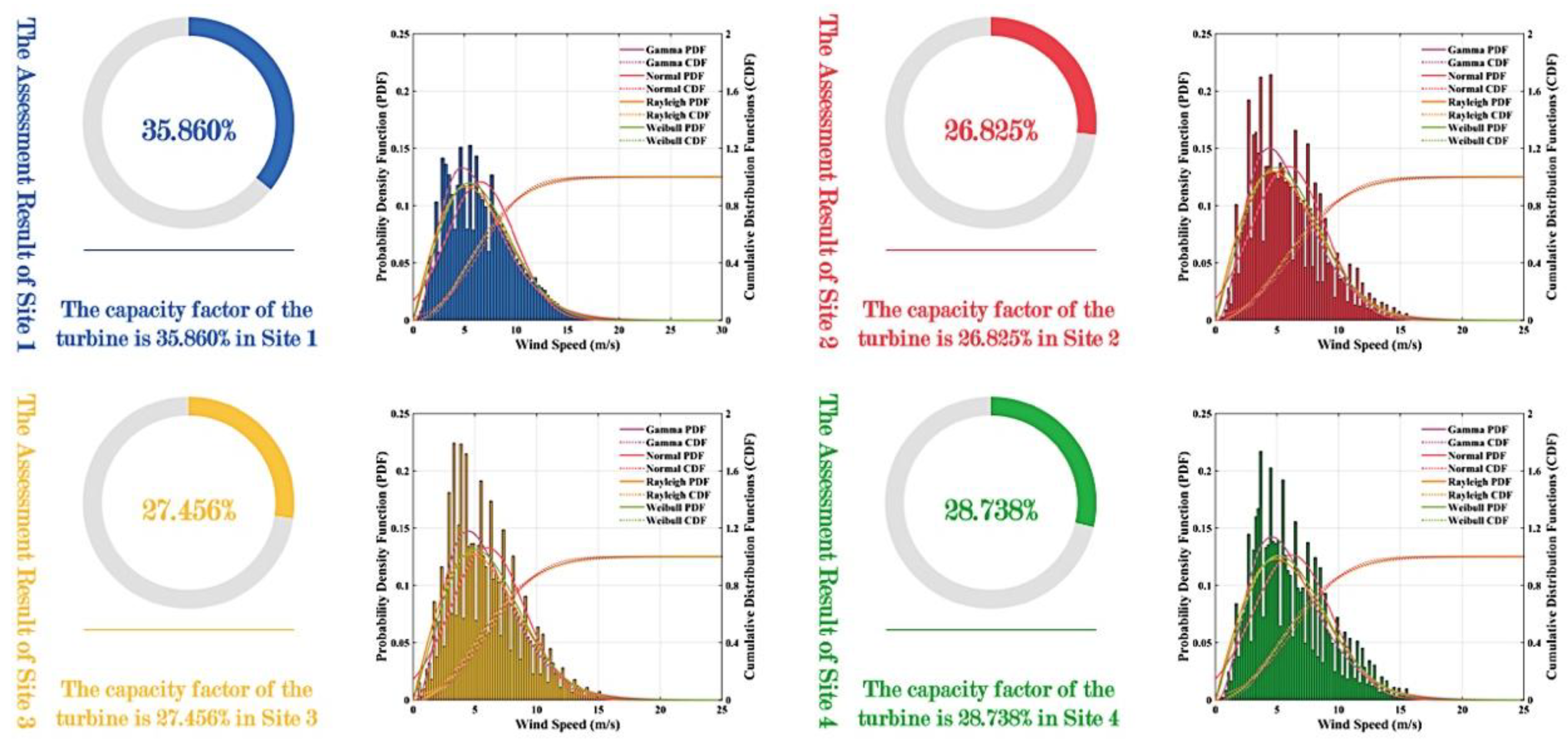
At a wind farm, the air density and natural terrain environment are constant, which has less influence on wind energy resources. Only the wind speed will change with the movement of the atmosphere. Thus, the frequency distribution of wind speed can measure the distribution of wind energy resources at the wind farm. In this paper, four kinds of probability distribution are used to fit the wind density [
22].
Table 1 shows the different probability density functions.
In order to determine the parameters of the probability density functions, in this paper, four kinds of optimization algorithm are employed: differential evolution algorithm [
23], particle swarm optimization algorithm [
24], cuckoo search algorithm [
23], and genetic algorithm [
22].
The performance of a wind turbine installed at a given site can be examined by the amount of mean power output over a period of time (
Pout) and the conversion efficiency or capacity factor [
23] of the turbine. The mean power output
Pout can be calculated using the following expression based on the Weibull distribution function:
where
vc,
vr,
vf are the cut-in wind speed, rated wind speed, and cut-off wind speed, respectively. It should be mentioned that the above expressions are only valid for the assessment of wind turbines.
2.2. The Method of Data Pre-Processing: Wavelet Packet Transform
In the wavelet packet framework, compression and denoising ideas are exactly the same as those developed in the wavelet framework. The only difference is that wavelet packets [
24] offer a more complex and flexible analysis, because in wavelet packet analysis, the details as well as the approximations are split.
A single wavelet packet decomposition gives a lot of bases from which to look for the best representation with respect to a design objective. This can be done by finding the “best tree” based on an entropy criterion.
Denoising and compression are interesting applications of wavelet packet analysis. The wavelet packet denoising or compression procedure involves four steps:
- Step 1:
Decomposition. For a given wavelet, compute the wavelet packet decomposition of signal x at level N.
- Step 2:
Computation of the best tree. For a given entropy, compute the optimal wavelet packet tree. Of course, this step is optional. The graphical tools provide a “Best Tree” button to make this computation quick and easy.
- Step 3:
Thresholding of wavelet packet coefficients. For each packet (except for the approximation), select a threshold and apply thresholding to coefficients.
The graphical tools automatically provide an initial threshold based on balancing the amount of compression and retained energy. This threshold is a reasonable first approximation for most cases. However, in general, you will have to refine your threshold by trial and error so as to optimize the results to fit your particular analysis and design criteria.
The tools facilitate experimentation with different thresholds and make it easy to alter the trade-off between the amount of compression and retained signal energy.
- Step 4:
Reconstruction. Compute wavelet packet reconstruction based on the original approximation coefficients at level N and the modified coefficients.
2.3. L.SSVM (Least Square Support Vector Machine)
Least squares support vector machine, proposed by Suyken et al. [
25], is an improved support vector machine, and is one of the important results of statistical learning theory in recent years. Compared with the traditional method of SVM, LSSVM has the following advantages: (1) equality constraints replace the inequality constraints in the traditional SVM algorithm; and (2) solving the quadratic program is changed into solving the linear equations directly.
The least squares support vector machine algorithm is described as follows:
For a given training set (
pi, qi), where
i = 1,2,3,⋯,
n,
,
, LSSVM uses a nonlinear mapping
ϕ(
p) to map samples from the original space
Rn to the feature space, and
ϕ(
pi) to construct the optimal decision function in high-dimensional feature space:
Therefore, the nonlinear estimation function is transformed into a linear high-dimensional feature space estimation function, and looking for
ω,
b is minimized through the structural risk minimization principle:
In Equation (3),
controls the complexity of the model;
C is the regularization parameter that controls the severity of the error samples; and
Remp is the error control function that is an insensitive loss function of
ε. The frequently used loss functions are linear
ε loss function, quadratic
ε loss function, and Huberg loss function. Different forms of support vector machine can be constructed by selecting different loss functions. According to the structural risk minimization principle, a regression problem is expressed as a constrained optimization problem:
where
C is constant and
b deviates. If we use the Lagrange method to solve this optimization problem, it will become:
2.4. Modified Cuckoo Search Algorithm
Cuckoo search [
11] is a random global search algorithm and an optimization algorithm, just like genetic algorithm (GA) and particle swarm optimization (PSO), based on groups. In nature, cuckoos search randomly for nests in which to lay eggs. Yang and Suash assume the following idealized rules:
- (1)
Every cuckoo lays one egg at every turn, and dumps its egg in a randomly chosen nest.
- (2)
The best nest with high-quality eggs will be preserved by the next generation.
- (3)
The number of available nests is fixed (we assume that the number is n), and the egg laid by a cuckoo is discovered by the host bird with a probability Pa ∈ [0, 1]. In this case, the host bird can discard the egg or simply abandon the nest and build a new nest.
For the sake of simplicity, we can use the following simple statement that each egg in the nest represents a solution, and a cuckoo egg represents a new solution. The purpose is to use new and potentially better solutions to replace a bad solution in the nest. Certainly, this algorithm can be extended to more complex cases in which each nest with a plurality of eggs represents a set of solutions. At present, we adopt the simplest approach that there is only one egg in each nest.
Based on these three ideal conditions, the formula of the cuckoo search path and update position is shown as the following:
In this formula, shows the nest location of the tth generation where the ith bird’s nest lies and ( > 0) is step length, and in most cases, = 1.
The formula makes up a random walk equation in essence; a random walk is a Markov chain, and its future position depends on the current position (the first item of the last equation) and the transition probability (the second item).
is point-to-point multiplication;
is a random search path, and random step is Levy distribution:
Therefore, the main steps of the cuckoo search algorithm can be described as follows:
- Step 1:
f(x) is an objective function, X = (x1, ⋯, xd)T. Population is initialized and the initial position Xi(i = 1,2, ⋯, n) of n nests is randomly generated. The algorithm parameters are set.
- Step 2:
Calculate the objective function value for each bird’s nest and record the current optimal solution.
- Step 3:
Hold back the last generation’s optimal nest location and update Equation (7) according to the position, then update the remaining nest locations.
- Step 4:
The current nest position is compared with the previous generation; if the current nest position is better, it will be the best position.
- Step 5:
A random number R is the possibility that the nest’s host finds the extrinsic eggs and is compared with Pa; if R > Pa, the position of the nest is changed and a new position is determined.
- Step 6:
Return to step 2 if the end conditions are not met.
- Step 7:
The global optimal position is output.
The steepest descent algorithm [
26] is one of the oldest optimization algorithms, and is simple and intuitive. At present, more effective hybrid optimization algorithms are based on the steepest descent algorithm.
To overcome the defects of the cuckoo search algorithm, by using the steepest descent method, the iteration process can be expressed in the following steps:
- Step 1:
Select the initial point and preset stop error and k: = ().
- Step 2:
Calculate . If jumps out of iteration, output , otherwise take step 3.
- Step 3:
Take .
- Step 4:
Perform one-dimensional search to obtain and make f. Turn , k: = k + 1 to step 2.
The cuckoo search algorithm is used to preserve the optimal solution of the hatched birds, and the steepest descent method is used to iterate and modify the location of the nest to obtain the optimal solution matrix.
2.5. Structure of the Proposed Integrated Forecasting Framework
The wavelet packet transform extracts the multiscale spatial energy feature of the original wind speed. It is noteworthy that the applications of the wavelet packet transform need to select two hyperparameters: wavelet function and decomposition level. At present, no study discusses how to select the value of these two hyperparameters; their values can depend on the type of original wind speed time series to be analyzed. The procedure of the wavelet packet transform is displayed in
Figure 1 (first step).
From
Figure 1 (second step), the data setting for each model with length N (the number of the training sample) is fixed according to the original time series. For example, suppose the last 144 points of the wind speed time series with length of 1152 (
N = 1008) will be forecasted, and the data structure is shown in
Figure 1 (second step).
It must be noted that there is one step ahead of forecasting h = 1 of different wind farm sites in this paper.
After the wavelet packet transform, the filtered wind speed time series is input to the optimized least squares support vector machine. The overall flowchart of the proposed hybrid forecasting model is shown in
Figure 1 (third step).
It is remarkable that the original wind speed time series divides into a training sample and a testing sample. Moreover, in the process of training the least squares support vector machine, the input data is filtered time series and the output data is original wind speed time series of the training sample, and in the testing process, the input data is also filtered time series and the output is test sample.
4. Discussion the Forecasting Accuracy for Each Model
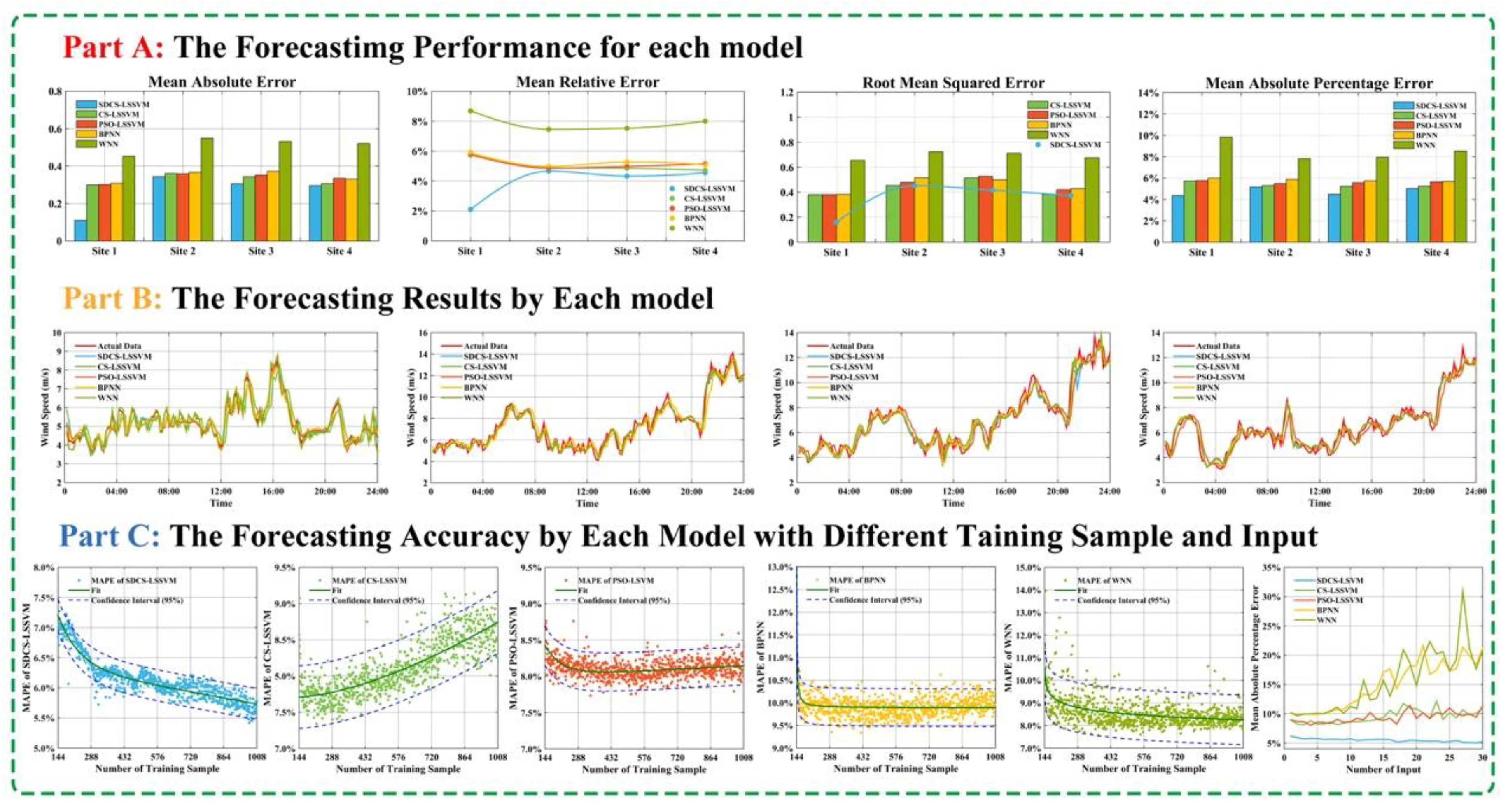
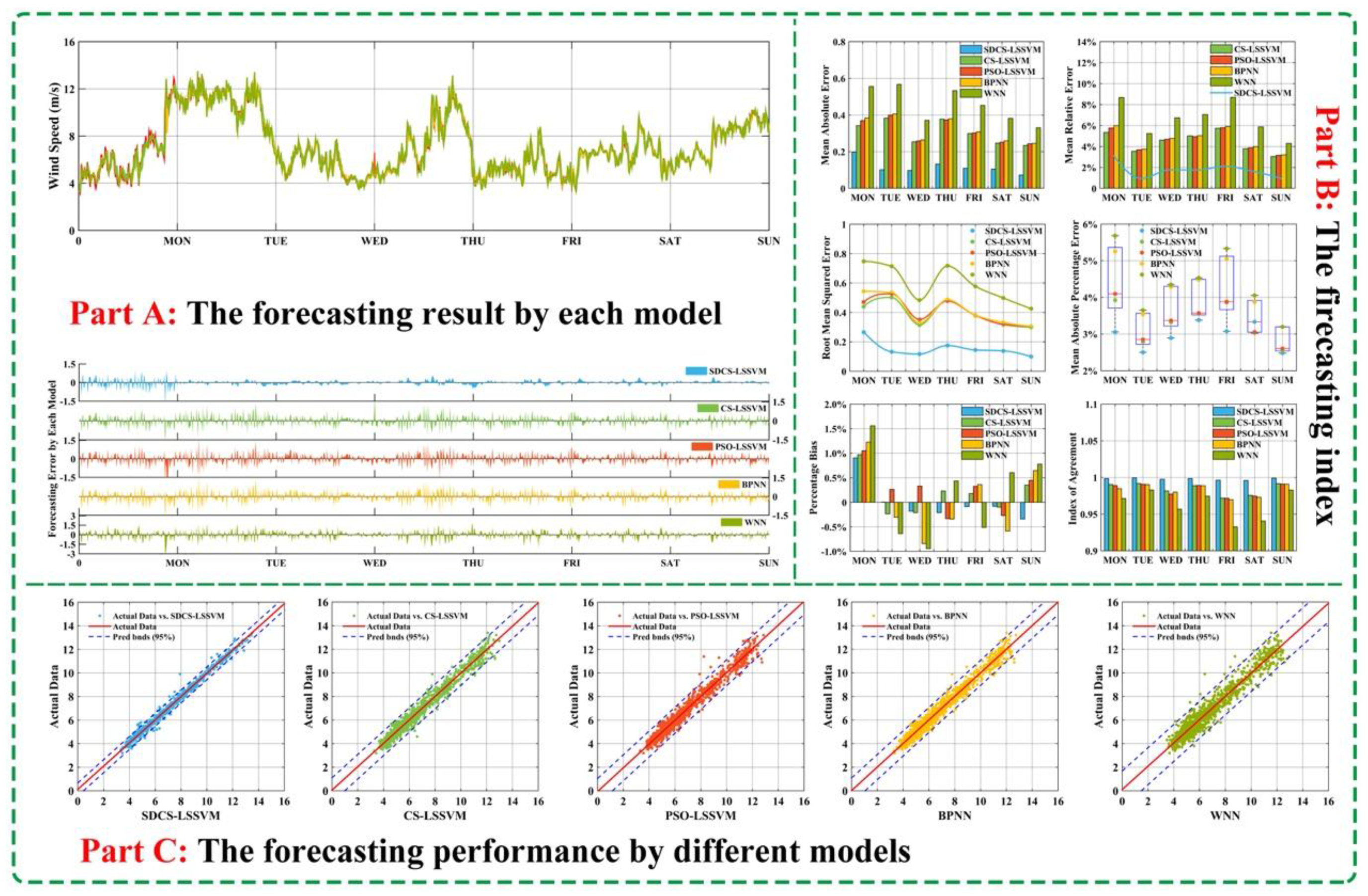
Finally, the above criteria are some of the most common standards; in fact, these criteria cannot appropriately judge the effectiveness of the forecasting method. The reason is that the different index series have different dimensions, so these criteria cannot be used directly. Even for similar sequences that have the same dimensions, the same period index values are different, so the above standard cannot show that the forecasting methods are equally effective. Therefore, this paper uses forecasting effectiveness (FE) to supplement the above criteria.
We presume that the observation sequence value is {xt, t = 1, 2, ∙∙∙, N} and is the estimated value. The following concepts can be obtained:
In this formula, et is relative forecasting error at time t, t = 1, 2, ⋯, N. Obviously, 0 ≤ |et| ≤ 1.
Definition 2. Let At = 1 − |et| be forecasting accuracy at time t, t = 1, 2, ⋯, N. Obviously, 0 ≤ At ≤ 1; if > 1, At = 0, and this shows that the forecasting method is invalid at time t.
From Definition 2, et has randomness, so {At, t = 1, 2, ∙∙∙, N} is a random variable sequence.
Definition 3. Let mk =
be the forecasting effectiveness element, k is a positive integer, and {Qt, t = 1, 2, ⋯, N} is the discrete probability distribution of the forecasting method at time t. , Qt > 0.
If the discrete probability distribution is not ascertained, we can set Qt = 1/N, t = 1,2, ∙∙∙, N.
Definition 4. Let H be a k-dimensional continuous function, then H(m1, m2, ⋯, mk) is k-order forecast effectiveness.
Definition 5. If H(x) = x is a one-dimensional continuous function, H(m1) = m1 is one-order forecast effectiveness; if H(x, y) = x(1 − ) is a two-dimensional continuous function, H(m1, m2) = x(1 − is two-order forecasting effectiveness.
In particular, we use two-order forecast effectiveness in this paper. Moreover, two-order forecasting effectiveness of the proposed hybrid model is maximum from the following simulation results. From
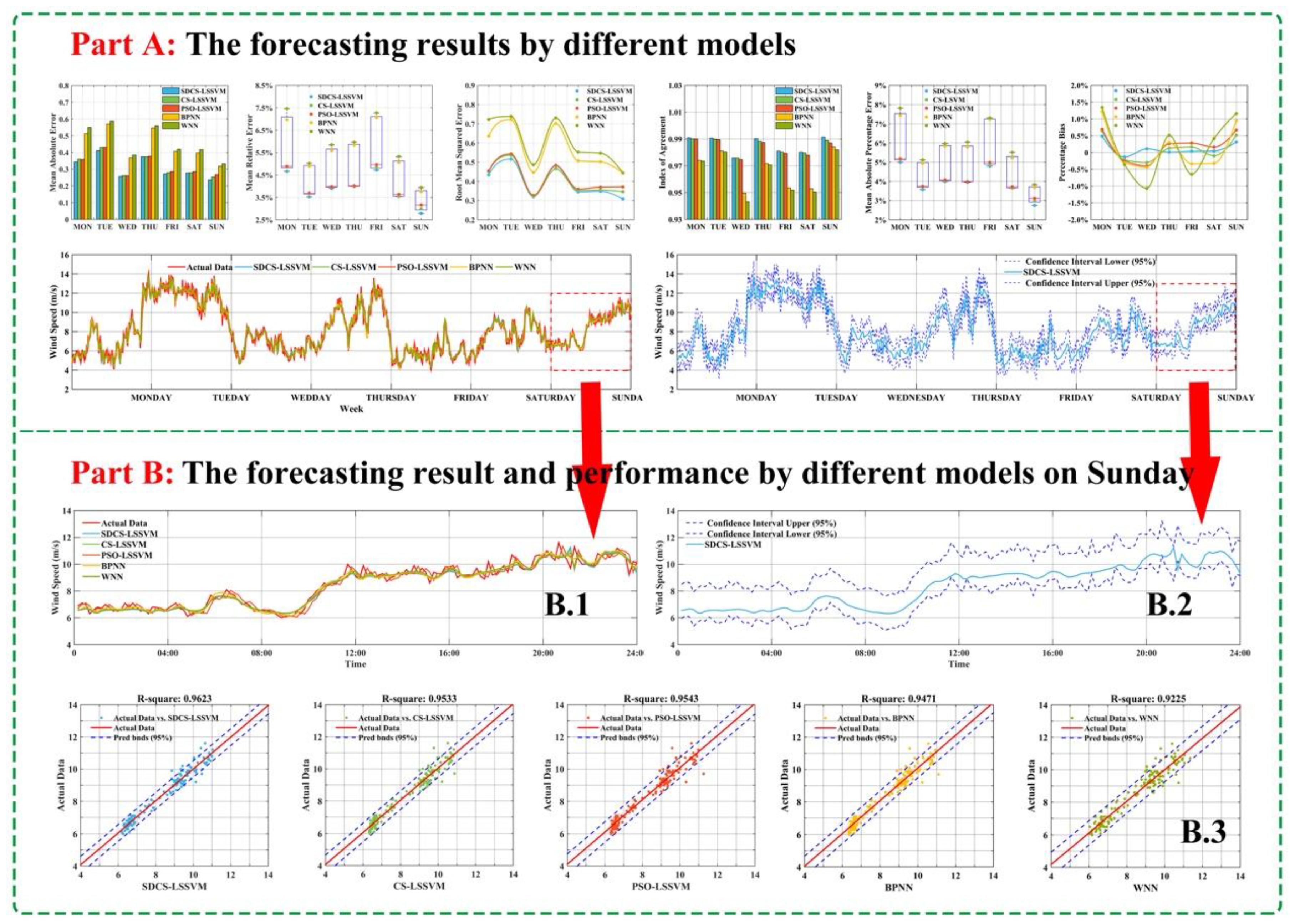
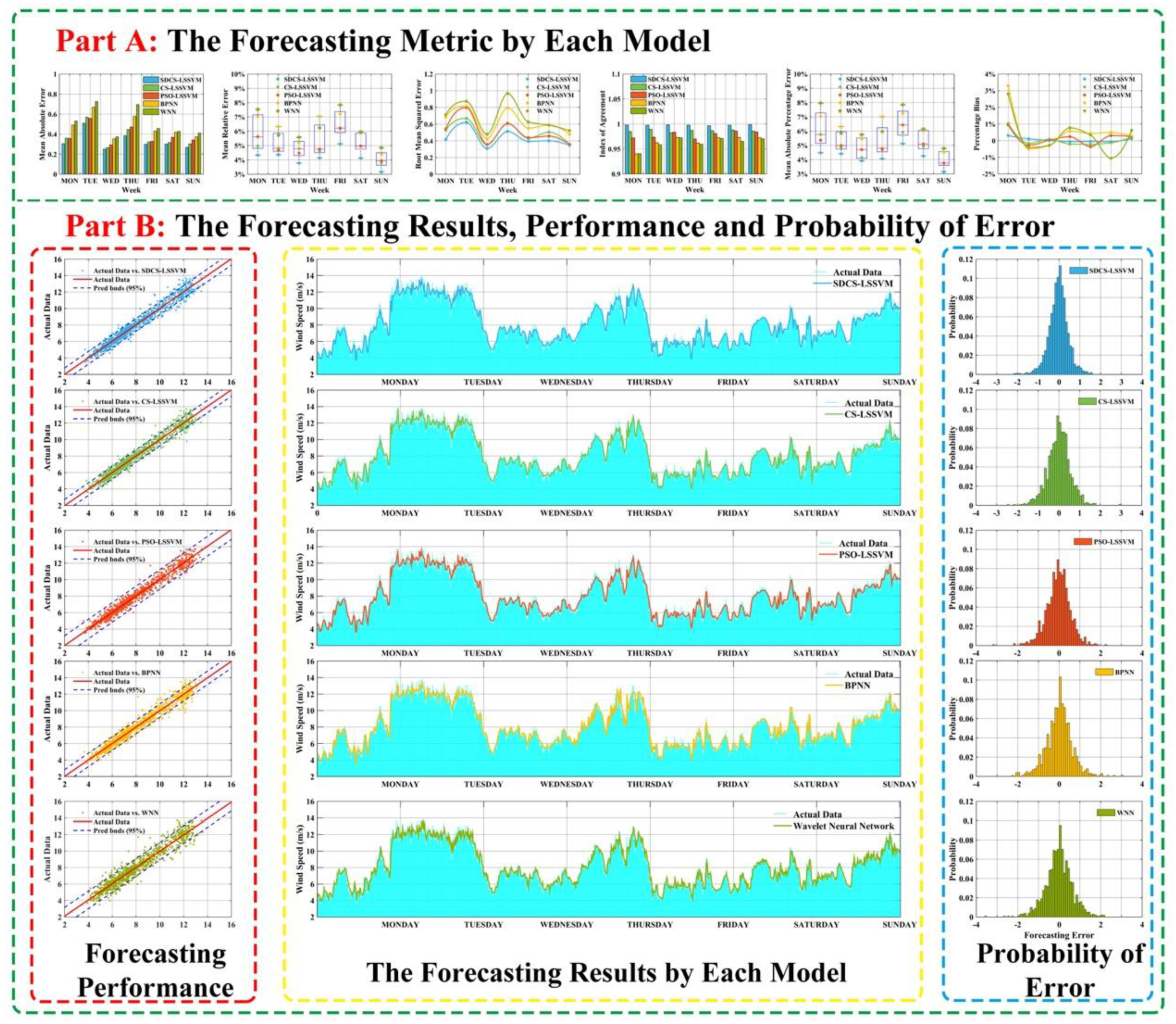
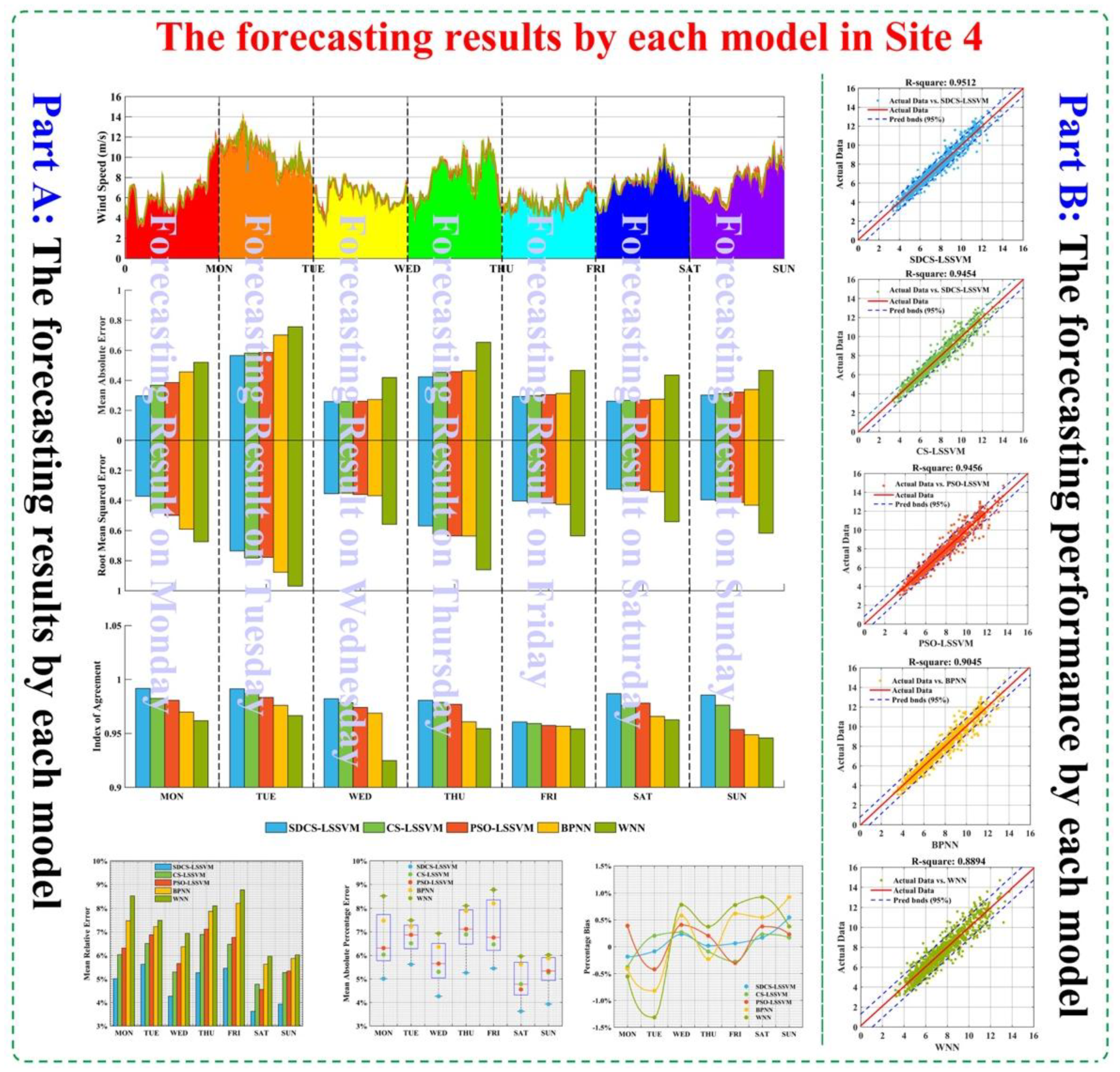
Table 10 we can clearly see that second-order forecasting effectiveness offered by the proposed hybrid model outperforms the other four models for wind speed forecasting at different sites. For example, for Site 1, second-order values of WPT-SDCS-LSSVM from Monday to Sunday are 0.93728, 0.99108, 0.98144, 0.98225, 0.97296, 0.98165, and 0.99103, respectively, which are larger than the other model.
Remark 4. The results indicate that the proposed hybrid model is more valid than and significantly superior to the other models. Accordingly, the proposed model can satisfactorily approximate the observed actual wind speed time series.
5. Conclusions
With the increasing utilization of renewable energy in recent years, wind energy is the largest new energy reserve, and the development and integration of wind energy resources into the power system are rapidly growing. It is noteworthy that both accuracy and stability should be regarded as equally vital in the forecasting field; thus, developing techniques to simultaneously achieve satisfactory accuracy and stability is imperative. However, because of the unique features of wind speed (uncertainty and intermittency), it is difficult to obtain satisfactory forecasting results using single models. To overcome this challenge, this research proposes a hybrid model based on an LS-SVM model that employs a modified cuckoo search algorithm to optimize the parameters of forecasting models for 10-min wind speed forecasting. Wavelet packet transform (WTP) in each WTP-ANN model is applied to denoise the wind speed series to improve the forecasting accuracy. Overall, for forecasting accuracy, the average MAPE values of WTP-BPNN, WTP-WNN, WPT-PSO-LSSVM, WPT-CS-LSSVM, and the hybrid model are 2.7565%, 3.0197%, 3.6897%, 3.0336%, and 1.5944%, respectively. Therefore, the proposed hybrid model can obtain satisfactory forecasting results for wind speed forecasting compared with the other four models. In addition, the fluctuations of MAPE values at each forecasting point are the smallest for the proposed hybrid model, which indicates that the model can improve the accuracy of wind speed forecasting. Moreover, the discussion of the hypothesis test and forecasting availability is used to evidence the superiority of the hybrid model compared to other models in this paper. As demonstrated by an instance based on a wind farm, the improvements in forecasting accuracy are significant for integrating electricity generated by wind energy into the grid with minimum risk and maximum benefit. The proposed hybrid model, which provides high forecasting accuracy, can be employed for wind farm dispatch and could improve the utilization of renewable energy.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






