1. Introduction
Over the last decade, the development of information and communication technology (ICT) and the Internet have led to massive amounts of data being generated in various fields. The term “big data” is used to describe this phenomenon in the digital world [
1]. Big data plays an increasingly significant role in the development of the economy and society [
2], garnering attention in both academia and in business [
3]. Recent literature describes big data as the next “management revolution” [
4], “the fourth paradigm of science” [
5], and the “the key to sustainable innovation within an Industry 4.0 factory” [
6]. Due to these potentials social and economic benefits, many government agencies have formulated relevant policies to promote the development of big data. Similarly, understanding that big data is a crucial basic strategic resource, China’s “13th Five-Year Plan” propose measures to promote the use of big data in an efficient way. Due to these factors, big data has become a mainstream activity of many organizations [
7]. According to the Gartner’s 2015 survey, 76% of global business are planning to invest in big data. Additionally, the China Academy of ICT survey showed that 56% of Chinese enterprises are planning to adopt big data.
Although the significance of big data is widely recognized, there is still no single clear definition of it [
8]. In 2011, the International Data Corporation defined big data as follows: “big data technologies describe a new generation of technologies and architectures designed to economically extract value from very large volumes of a wide variety of data by enabling high-velocity capture, discovery, and/or analysis” [
9]. This concept is generally recognized because it embodies the characteristic “4Vs” of big data: Volume, Variety, Velocity, and Value. Furthermore, the definition reveals the essential aim of big data, which is discovering hidden values [
10]. The United Nations’ Department of Economic and Social Affairs classified big data into three categories: social networks (such as data from Facebook or other social media platforms and Internet searches), traditional business systems (such as data concerning e-commerce transactions), and the Internet of Things (such as data from mobile phone tracking) [
11]. The data from these different sources are widely used in multiple fields such as scientific research, government management, and the global economy. This study focuses on the application of big data in commerce and the business field.
Big data can be useful to enterprises from all industries in identifying customer needs, improving productivity, and gaining a competitive advantage. More importantly, big data plays a new and important role in achieving sustainable economic development [
12]. Sustainability consists of three aspects: environmental, economic, and social sustainability [
13]. Enterprises can improve their contributions to these three areas by using big data to develop resources and boost operational efficiency. Depending on the industry, enterprises can use big data to reduce environmental impact, produce individually tailored goods and services, provide better living experiences, and create many opportunities for innovation and business models. In short, the implementation of big data systems and the use of big data in general can improve sustainability immeasurably [
14].
Due to large volumes of data and time constraints regarding processing speed, the adoption of big data is a complex process that includes data collection, organization, storage, analysis, mining, and application [
15]. There are many prerequisites for the adoption of big data—such as a well-developed IT infrastructure, the talents of specialist big data analysts, and special analytical tools—to address technical challenges [
16]. However, the most important challenge in the adoption of big data is constructing an appropriate model and identifying managerial concerns [
17]. This may enable enterprises to consider all the factors that may affect the adoption of big data. However, many companies have little or no knowledge about the concept or use of big data.
Identifying the key factors is a well-known method for conducting a structured system analysis and has been used for effective IT management [
18]. Since big data forms part of the larger concept of IT, finding the key influencing factors concerning the adoption of big data is of great interest to both academics and business managers. Several studies have been carried out, presenting a variety of influencing factors concerning the adoption of big data. However, existing literature focused mainly on qualitative research, with most of the studies being based on only one or a small number of dimensions. This indicates a lack of quantitative evaluation and the analysis of the relationships between the influencing factors. The fragmented findings of previous studies point to an urgent need for comprehensive research that can provide clear and systematic insight for scholars and provide guidance concerning the implementation and practice of big data for business managers. To address this gap, this paper aims to provide a systematic study of the influencing factors of big data adoption to broaden the understanding of big data and to assist Chinese enterprises with the adoption of big data. More specifically, we focused on three research objectives:
To construct a system that determines the influencing factors for the adoption of big data by Chinse enterprises
To explore the relationship among the influencing factors
To identify the key factors and calculate the weight of each factor
The remainder of this study is organized as follows:
Section 2 contains a literature review and describes the model constructed to determine the influencing factors for the adoption of big data.
Section 3 introduced the research methodology and the computational procedure.
Section 4 documents the analysis of the relationships among the influencing factors and presents the results.
Section 5 discussed the research results and is followed by conclusion in
Section 6.
2. Theoretical Framework
The factors that influence the adoption of big data that have been highlighted by very few researchers. For instance, Brinkhues et al. proposed some of the factors that influence data capabilities to be IT infrastructure, data resources, financial support, and cost and earnings expectations [
19]. From a knowledge management perspective, Izhar and Shoid suggested that data quality, capacity, infrastructure, and big data awareness were critical factors for the implementation of big data [
20]. By investigating Chinese enterprises, Cheng and Li proposed the following factors concerning big data adoption: data talent, technical ability, organizational culture, organizational structure, and data policies [
21]. Based on resource-based view, Hu summarized factors that affected enterprises’ motivation to use big data, which include technical capacity, environmental pressure, expected earnings, data resources, and data quality [
22]. All these factors should not be seen as independent concepts, as they are all interrelated. These factors and their relationships with each other mean that analyzing the adoption of big data from a systematic perspective could yield convincing results. Previous studies have presented analyses of the interaction mechanism among the different factors. However, framework for these influencing factors which cover all dimensions is scarce.
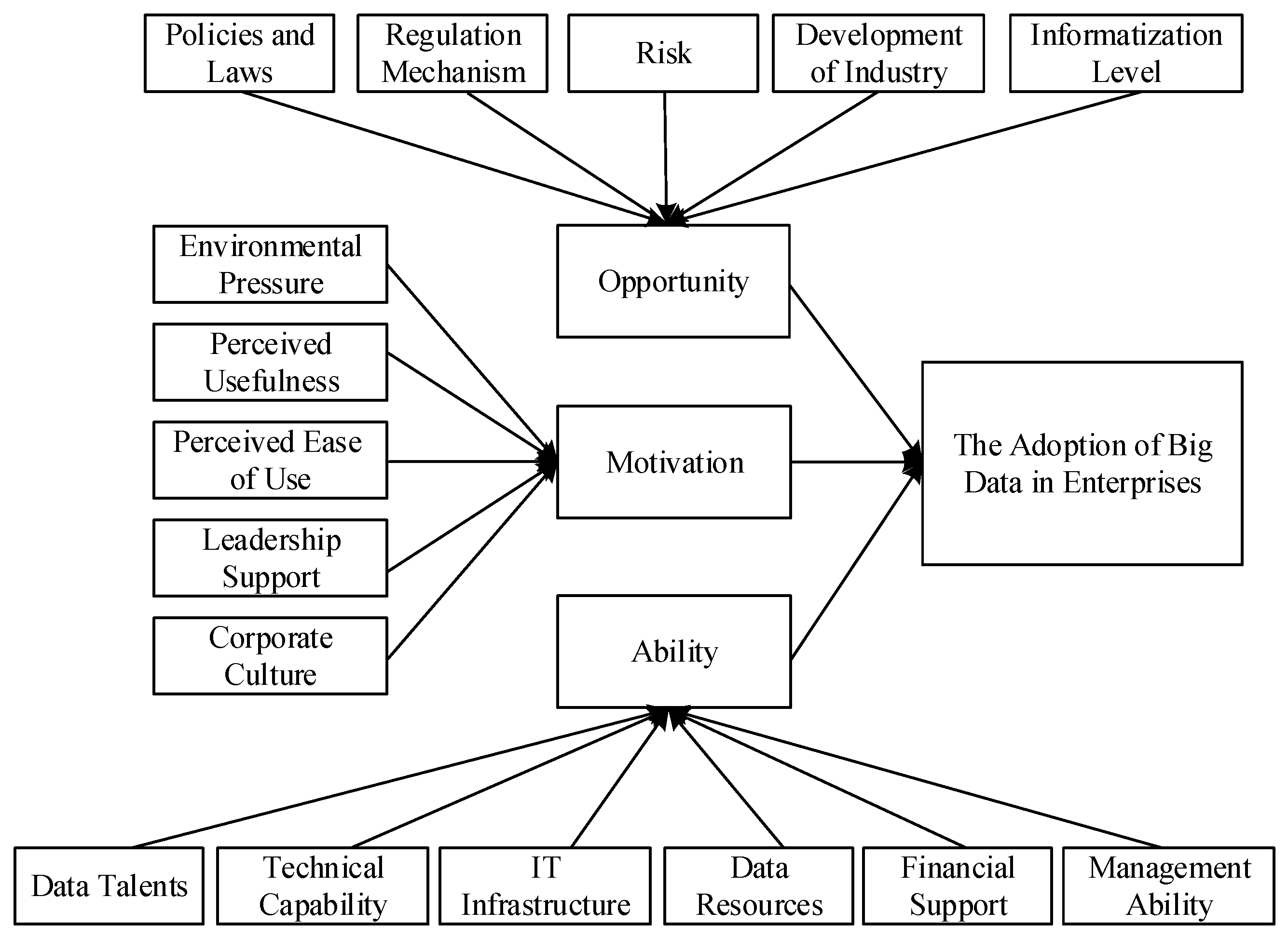
To address this problem, this study employs the Motivation–Opportunity–Ability (MOA) model. The MOA model is a relatively well-known theoretical framework within the field of organizational theory [
23]. Ölander & Thøgerson was first to comprehensively analyze and explain the three basic constructs of the MOA model and the relationships between them [
24]. The principle of the MOA framework states that each item of motivation, opportunity, and ability is indispensable for the framework to lead to the desired outcome [
25]. The MOA framework is characterized as a meta-theory [
26] and provides a complete analysis framework to explain individual or organizational behaviors from both subjective and objective perspectives. Therefore, the framework has good stability and predictability [
27] which is why it is widely used in various research areas such as the adoption of innovations, business decision-making, marketing, and knowledge management [
28]. For example, when analyzing enterprises’ behavior, Zhang applied the MOA theory to explain companies’ behavioral patterns when they constructed a structural hole in the coalition organization [
25]. Additionally, Chai and Baudelaire analyzed the main obstacles to the improvement of energy efficiency in Singapore’s basic industries based on the MOA model [
29].
Following these previous studies, we propose that big data adoption not only relies on enterprises’ motivation and ability but is also upon how closely linked these enterprises are to specific opportunities within the market and the environment. When associated with an opportunity, the subject’s ability and motivation become more greater [
30]. Therefore, the MOA model is suitable to analyze the influencing factors for enterprises’ big data adoption. This study uses the model to construct a framework which in turn examines enterprises’ behavior in-depth. This study also uses expert interviews to summarizes the influencing factors from relevant literatures on the adoption of big data. After the influencing factors have been discovered, they are divided into three dimensions within the MOA framework. The index system is shown in
Table 1.
As discussed above, the framework consists of three factors; motivation, opportunity, and ability. We discuss each factor briefly below.
Motivation. The term motivation refers to the desire and willingness to engage in a certain behavior [
42] and it is an intrinsic reason for the adoption of big data. There are many factors that may increase the motivation of enterprises, such as leadership support [
39], environmental pressure [
20], and corporate culture [
33]. Moreover, based on the technology acceptance model (TAM), perceived usefulness and perceived ease of use also play an important role for the desire of organizations. Drawing on the current literature mentioned above, we determine five indicators that comprise the dimension of motivation (
to
shown in
Table 1).
Opportunity. Opportunity refers to a collection of external environmental or contextual elements that are not controlled by the subject and enable action [
43]. It is clear that the regulation mechanism, policies and laws concerning big data contribute to the legal environment for the adoption of big data [
36] while the development of industry [
32] and its information level [
23] form the industrial foundation. However, Ekbia et al. found that external risk may have a negative impact on enterprises’ activities [
41]. We therefore determine five indicators (
to
shown in
Table 1) to describe the dimension of opportunity.
Ability. Ability refers to the knowledge and skills that an entity or enterprise possesses which are relevant to certain behaviors [
28]. Because of the technology-intensive nature of big data implementation, enterprises’ ability concerning big data cannot improve without the support of data talents [
37], technical capability [
40], financial support [
38] and data resources [
41]. Additionally, it is important to note that IT infrastructure provides the basis for execution of big data, making it an essential element [
19]. Lastly, solid management ability would increase the efficiency of big data project. Consequently, we put forward six indicators (
to
shown in
Table 1) that comprise the dimension of ability.
The MOA theoretical framework for this study—including the three dimensions and the 16 sub-variables—is shown in
Figure 1.
5. Discussions
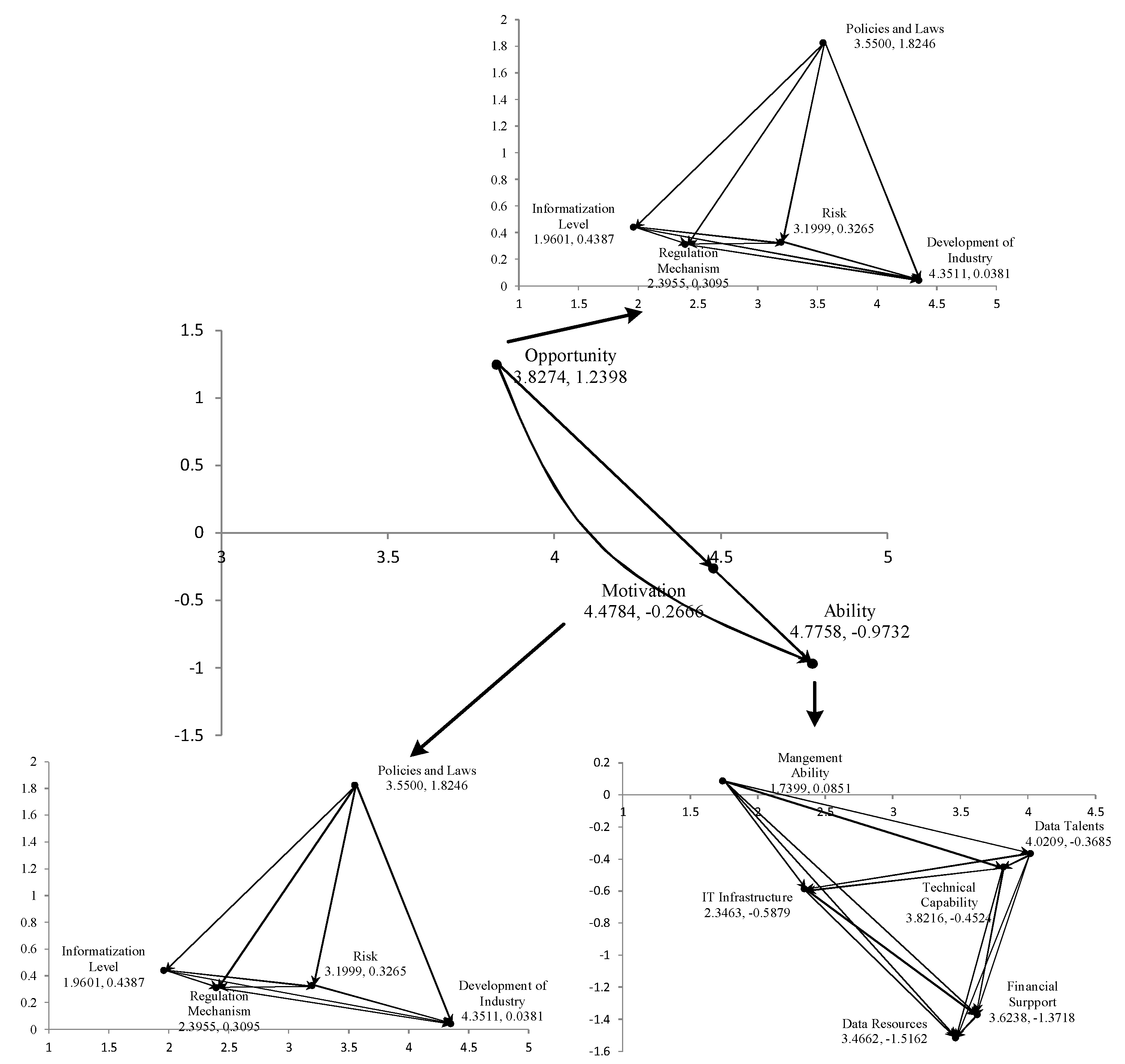
The model to determine enterprises’ big data adoption is illustrated by using an NRM (
Figure 2). The dimension of opportunity (
) has the highest value of the three dimensions. This means that it needs to be prioritized for enterprises’ big data adoption which can enhance their motivation and ability. From this information, we derive that the government and business need to improve the top design first to provide good opportunities for enterprises to implement big data. The dimension of Ability has the highest value (
) means that it plays a pivotal part in adoption of big data. In term of factors, the value of policies and laws (
) is the highest. This means that the government needs to recognize the importance of suitable policies and laws pertaining to the promotion of big data adoption and act to instate these policies and laws as soon as possible.
We identified seven key factors from the results of the DANP analysis. The following strategic recommendations are proposed to promote the adoption of big data by Chinese enterprises.
Of the seven identified factors, leadership support and perceived usefulness belong to the dimension of motivation. Since it has the highest value of all the factors, leadership support demands that senior managers of enterprises should change their attitude towards understanding and development of big data, establish big data thinking, and lead their enterprise towards the implementation of big data. Perceived usefulness is the next key factor. If enterprises can perceive the usefulness of big data, they will be likely to adopt big data more enthusiastically. Therefore, enterprises should be encouraged to recognize the importance of big data for improving their operational efficiency and enhancing management level and corporate image. Furthermore, if enterprises recognize the scope and prospects of big data and its expected contributions, they will adopt big data as soon as possible. We therefore state that the cognition of big data (perceived usefulness) can motivate enterprises to adopt big data.
The development of the big data industry is a key factor in the opportunity dimension. Developing the big data industry cannot only can accelerate the cultivation of data talents and technological development, but also provide data trade platforms to increase data resources, which will encourage the development of big data. Moreover, industrial development can simultaneously create external conditions and have a demonstrational effect. It is, therefore, crucial for enterprises’ big data adoption to cultivate leading enterprises, establish big data industry clusters, and optimize a big data industry chain. For example, the establishment of big data industry in Guiyang not only promoted the development of big data in general, but also accelerated the adoption of big data in local government and enterprises, which in turn led to economic development in the whole region.
Financial support, data talents, data resources and technological capability are four key factors in the dimension of ability. The results revealed that all aspects of ability are crucial for the adoption of big data. If enterprises aim to benefit from big data, they should implement a series of processes which include data acquisition, storage, transmission, and analysis. Each process requires funds to provide the required human and material resources and to address possible risks. A lack of funds could obviously lead to failure of the business adoption of big data. As one of the basic conditions for big data adoption, the factor of data resources not only depends upon the enterprise itself to improve data resources acquisition, but the support of government and society to expand data sources and promote data sharing and transactions. The significance of big data does not lie in the accumulation of data, but rather in the insight into the value of data through data analysis. To implement the necessary measures, enterprises need to strengthen their personnel training as well as acquire data talents to improve their advanced technology in real-time. By investigating and implementing the above measures, enterprises can enhance the technical capacity, translate data into knowledge, and promote productivity and the bottom line.
6. Conclusions and Future Research
Although the adoption of big data may provide many benefits to organizations, enterprises should acknowledge and resolve the challenges concerning the adoption of big data before it can add value to their businesses. The process of big data adoption consists of many interrelated factors that may affect enterprises’ activities. Understanding those factors clearly can facilitate the effective use of big data within organizations. Therefore, a comprehensive framework is required for the development and operation of big data.
After a detailed literature review, experts’ opinions were acquired and used to construct an MOA theoretical framework to understand the interdependencies among various factors. This method also expanded the scope of the MOA theory. Our study established an index system from a Chinese perspective and emphasized the importance of coordination of the three dimensions of the model: motivation, opportunity, and ability. The framework provides valuable insight for scholars and managers concerning the full spectrum of factors that influence the adoption of big data. Although some factors in our model have previously been tested in other technology innovation frameworks, this study presents unique factors in the context of big data adoption. An example is data resources that have not been mentioned in other IT adoption studies. However, it is an important factor in this study due to the particular characteristics of big data. Similarly, privacy and security issues pertaining to big data make policies and laws another important factor.
The model used the DEMATEL method to analyze the relationships between the main dimensions and the 16 sub-variables or factors and constructed an NRM. Next, the DANP method was used to do a quantitative analysis, calculate the index weights, and identify the key influencing factors. Using the DANP method corrected the shortcomings of the ANP method and reflected the interdependent feedback relationships among the factors. This ensured that the results were scientific and reasonable. The results illustrate the change in factor weights in big data. For example, according to the factor weights, leadership support is the most significant factor. We believe that this has arisen for two reasons: The first is the unique business context of China, and the second is the fact that big data is changing the methods and models of business management.
Referring to practical implications for enterprises, the conclusions can provide theoretical support and meaningful practical guidance to enterprises to accomplish big data adoption. The framework explained that the development of big data differs from other technological development strategies and government agencies should encourage the development and actively participate in the process of providing policies and support from a legal point of view. Furthermore, this study could assist enterprises in finding the disadvantages in adopting big data. The results could make managers aware of both the positive and the negative aspects of big data adoption in their enterprises and thus enable them to improve weaknesses and make the suitable decisions.
This study provided several contributions but still has some limitations. First, this study was conducted using a small sample size of experts. In the future, a larger sample size may provide more explanatory power. It may also allow a more in-depth analysis to attain results with a more general applicability. Second, this study was conducted in China using Chinese businesses with specific characteristics. These contextual characteristics may influence the understanding of big data adoption practices. Therefore, replications of this study in different geographical contexts and a comparison of the results may represent an important next step. Finally, the results of this study have not been empirically tested. Therefore, future research may invite enterprises to be part of our research to test the findings of this paper. This may provide more managerial implications.

 ,
, 
{kind=link}
{kind=link}



