3.1. Association Rule Mining (ARM)
ARM is one of the data mining techniques used to elicit useful knowledge from tremendous databases [
21]. ARM, using an apriori algorithm, provides rules in the form of ‘X → Y’, where X and Y are sets of items. X and Y can be regarded as the “If” part and the “Then” part respectively [
5], which means the causality of X and Y. For example, ARM shows the rule that if X happens then, Y will have higher probability, that is, X could be described as a cause of Y because probability of Y is changed by manipulating X [
22].
A rule mining process can be divided into two main steps. First, this algorithm investigates a database to find item sets (e.g., defect causes) satisfying predefined minimum
Support. Second, rules are generated above predefined minimum
Confidence.
Support,
Confidence criteria which are defined as follows:
Support is the probability that the antecedent (i.e.,
i) and the consequent (i.e.,
j) appear together in one instance.
Confidence is the conditional probability of the consequent given the antecedent. These measures could reflect relationship of defect causes in terms of co-occurrence. However,
Confidence is limited in that it does not take into account the baseline frequency of the consequence, which makes it misleading interdependence. In order to overcome the deficiency of
Confidence,
Lift measure was introduced in the late 90’s.
Lift overcomes this limitation by dividing the
Confidence (conditional probability)
by the frequency of the consequent
P (
j). In other words,
Lift =
. As such, when the frequency of the consequent
P (
j) is higher than Confidence
(denominator > numerator),
Lift becomes less than one, which means “
i and
j appear less frequently together in the data than expected under the assumption of conditional independency” (refer to Brijs et al [
23] for more details).
This represents how much the probability of j would increase if i happens. If Lift (i→j) > 1 then, i and j are dependent and complementary. If Lift (j→i) = 1, i and j are independent, and if Lift (i→j) < 1, i and j are substitutive. That is, Lift can be regarded as a criterion judging whether causality between two items exists or not. In terms of defect management, preventing a cause, which has high Lift value, means that others affected by the cause will reduce their probability of occurrence. In other words, it is more efficient to manage a couple of causes by manipulating each of their probabilities, rather than controlling all causes. This concept, which focuses on discovering major causes, is useful to provide practitioners with an efficient way to manage defects. Accordingly, this paper quantifies causality among defect causes by this measurement of ARM.
The process of quantifying causality among defect causes by using ARM in this paper is: (1)
Transformation into Sparse Matrix: Generally, sparse matrix means the matrix which relatively has many ‘0’. ARM cannot deal with nominal variables, but the defect causes are defined in the form of a string of words (i.e., a nominal variable). Thus, the form of data should be converted into sparse matrix which has only ‘0’ and ‘1’ (see
Table 1), which means whether each cause occurs or not. If a certain defect is caused only by ‘Careless mistake of labors’ and ‘Interference by other tasks’, it could be described in sparse matrix that the values of the two causes, which contribute to the defect, are ‘1’ and those of others are ‘0’. (2)
Causality Elicitation: Based on the data transformed into sparse matrix, an apriori algorithm is utilized. As mentioned above, this approach provides three measurements of
Lift, one of measurements, means a climb rate of probability of consequent. For example, if the
Lift (‘Careless mistake of labors’ → ‘Interference by other tasks’) is 2, the probability of ‘Interference by other tasks’ would rise twice if ‘Careless mistake of labors’ occurs.
3.2. Social Network Analysis
As previously mentioned, a defect occurs when a couple of causes combine. Thus, a cause would have a great deal of relationships with other causes, even though they are not directly linked. That is, it is necessary to account for the fact that some causes ‘
indirectly’ affect other causes [
6]. For example, in case that
i and
j have influence on
j and
k, respectively (i.e.,
i →
j →
k),
i and
k can be considered to be indirectly related, that is, the causes of a defect form a network. However, ARM cannot accommodate the indirect relationship of causes. To make up for this weak point, SNA is used to investigate the magnitude of effect belonging to pairs of causes linked indirectly.
SNA literally analyses a network which consists of a set of actors and a set of links connecting them [
24]. Actors and their actions are considered to be interdependent rather than autonomous, and links between actors are routes for transferring resources [
25]. As such, SNA, recently, has been applied to research on several industries (e.g., biology: [
26]; markets: [
27]; medical science: [
28,
29]) to find meaningful patterns for a certain purpose.
If relational data are prepared in the form of a matrix as in
Table 2, those would be conveniently converted into a network.
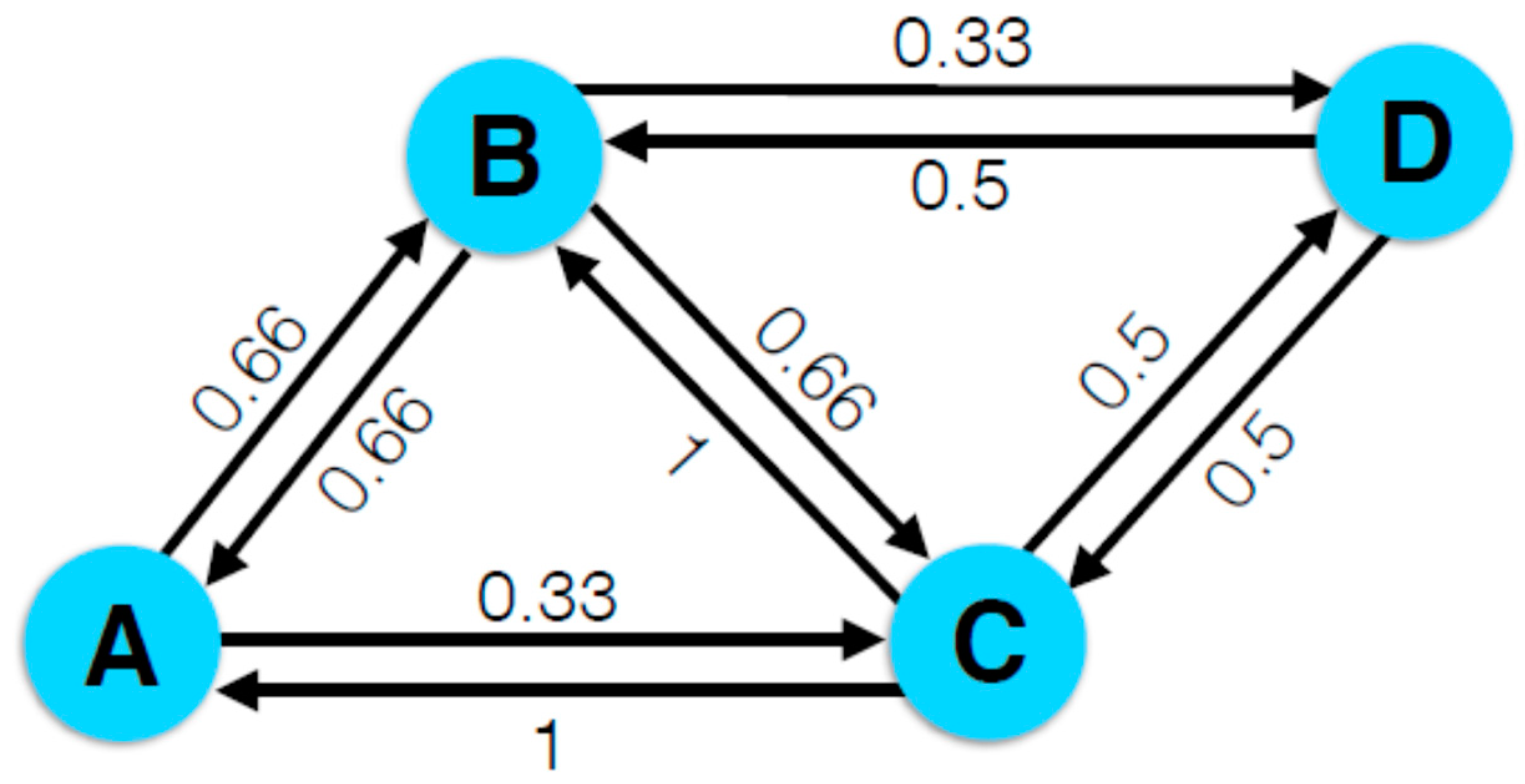
Figure 1 shows an example of a weighted graph and its relationships (links) between nodes (actors) have unique values based on
Table 2. The weights in a weighted graph can be depicted by the thickness of a link. SNA can be used to analyze relational data, such as kinship patterns, community structure, interlocking directorships and so forth [
28], and the relationship can be expressed as any numerical value (i.e., a weight) by placing the values having an unique meaning on the strength of relations, such as the degree of closeness among friends. From this point of view, in this paper, the
Confidence from ARM can be allotted to the links between actors in a network and, by this, the level of causality (i.e.,
Lift) between causes can be calculated. For example,
Figure 1 illustrates how each causes differ in influence on the probability of each other. The probability of B will be changed to 100% when C appears. By contrast, that will be 50% when D appears (see
Table 2 and
Figure 1).
Several metrics have been developed to analyze relationship between actors in a social network. These metrics are mainly used to determine which actor is more central (i.e., plays a more important role) than other actors in a network [
24,
30]. In light of finding the centrality of an actor, three main centrality measures have been utilized:
Degree,
Betweeness and
Closeness (refer to Opsahl et al. [
31] for a review of centrality measures).
Degree centrality measures the degree of linkage (i.e., relationship) between a node and other nodes ‘directly’ linked to the node.
Betweenness centrality measures how often a node occurs on all shortest paths between two nodes. On the other hand,
closeness centrality measures the centrality not only from the directly linked nodes to a node in a network, but also that of the nodes that are indirectly linked to the node [
32]. For this reason,
closeness centrality is typically used for measuring how fast information will spread from one node in a network to all other nodes, or, in a network planning situation whose nodes are favorable starting points [
33]. Given that construction systems are tightly coupled systems where some events that occurred in one part of the system may cause events in other parts [
19], amongst the three fundamental measures of centrality,
Closeness is of interest in this paper since it provide means for quantifying an actor’s contribution to the global network [
6].
Closeness was introduced by Bavelas [
34] who argued that “a message originating in the most central position in a network would spread throughout the entire network in minimum time”. Hakimi [
35] and Sabidussi [
36] also defined the most central actor in a network as the one consuming the minimum cost and time. In defect management, managing the cause, which has the highest
Closeness in a network, would be the most relevant way in terms of the efficiency.
Closeness is a metric to measure the degree to which an actor is close to others in a network [
24].
Closeness has been measured by Sabidussi [
36], which is one of several studies dealing with that, and this is regarded to be the simplest and most natural [
24]. He proposed that
closeness is calculated by sum of the geodesic (i.e., the shortest path) distances from an actor to all other actors. However, this has a difficulty in applying to a weighted network where each link between actors has a different amount of strength. Based on this recognition, a couple of studies have tried to quantify
Closeness in a weighted network. Dijkstra [
37] proposed an algorithm which discovers the path of least resistance, and asserted that this algorithm is for networks in which the weights represent costs of transmitting. It means that the path having the least sum of weights is the best route for transmitting because the route costs the least. By contrast, Newman [
38] and Brandes [
39] inverted the weights for networks where weights represent positive strengths rather than resistance. In these papers, weights are inverted before applying Dijkstra’s algorithm to assess strengths of links. Those studies [
37,
38,
39] allow to quantify
Closeness in a weighted network. However, Aljassmi et al. [
6] argued that they are not suitable to quantify probabilistically weighted links because causal paths follow the multiplication rule of probability. Thus, they introduced the concept of probabilistic reachability query from Zhu et al. [
40].
Reachability quantifies upper-bound probabilities, which means it accounts for the most probable causal path connecting two entities, rather the sum of all possible causal paths (i.e., as in OR gates) [
6]. The concept of
Reachability makes the Markov assumption (i.e., the probability of going from one state to another depends only on the current state of the system, and thus is not influenced by additional information about past states).
Reachability from an actor (
) to another actor (
) is defined as follows:
Referring to the graph in
Figure 1, D can be triggered by A through either A → B → D or A → C → D, but A → B → D is more probable. Therefore,
Reachability (A → D) = 0.66 × 0.33 = 0.22. With
Reachability, the indirect influence of defect causes can be estimated (see
Table 3).
In this paper, a ‘
Net-Lift’ (
NLift) measure is introduced to overcome the limitation of the original
Lift, which only accounts for direct causalities.
Net-Lift simply replaces the numerator in Equation 3,
P(i | k), with
Reachability:
. In light of this adjustment,
NLift implies the degree to which an actor has direct, and also indirect, influence on the probabilities of other actors in a network.
NLlift can be formally expressed as:
Proceeding with the above example,
NLift (A → D) = 0.2178/0.4 = 0.544. This infers that A and D are negatively dependent, which may be clearly observed from the raw data in
Table 1. Thus,
Causal Closeness (CC) can be considered as sum of
reachability from an actor (
) to all other (k) actors (Aljassmi et al. 2014). Formally, CC can be defined as follows:
Table 4 shows an example of matrix for actor interdependencies using
NLift.






{kind=link}
{kind=link}
{kind=link}