A Novel Hyper-Heuristic for the Biobjective Regional Low-Carbon Location-Routing Problem with Multiple Constraints

 ,
,
Abstract
:1. Introduction
- Problem domain. We first consider biobjective optimization for the RLCLRP with simultaneous pickup and delivery, hard time windows, and a heterogeneous fleet.
- Problem model. A novel and simple mixed-integer programming model is defined.
- Solution method. This work develops a quantum-inspired selection strategy (QS) as a high-level heuristic in the framework of MOHH.
- Managerial insights. This paper provides several management suggestions by analyzing the effects of depots, clients, and fleet composition on key performance indicators, such as travel distance, travel time, CE, and operational cost.
2. Literature Review
2.1. Fuel Consumption and Carbon Emission Review
2.2. LCLRP Application Review
2.3. Hyper-Heuristic Review
3. Mathematical Model
3.1. Description and Assumptions of the Proposed Problem
3.2. Mathematical Model of the Proposed Problem
3.3. Other Vaild Constraints
4. Proposed Hyper-Heuristic
4.1. Problem Domain
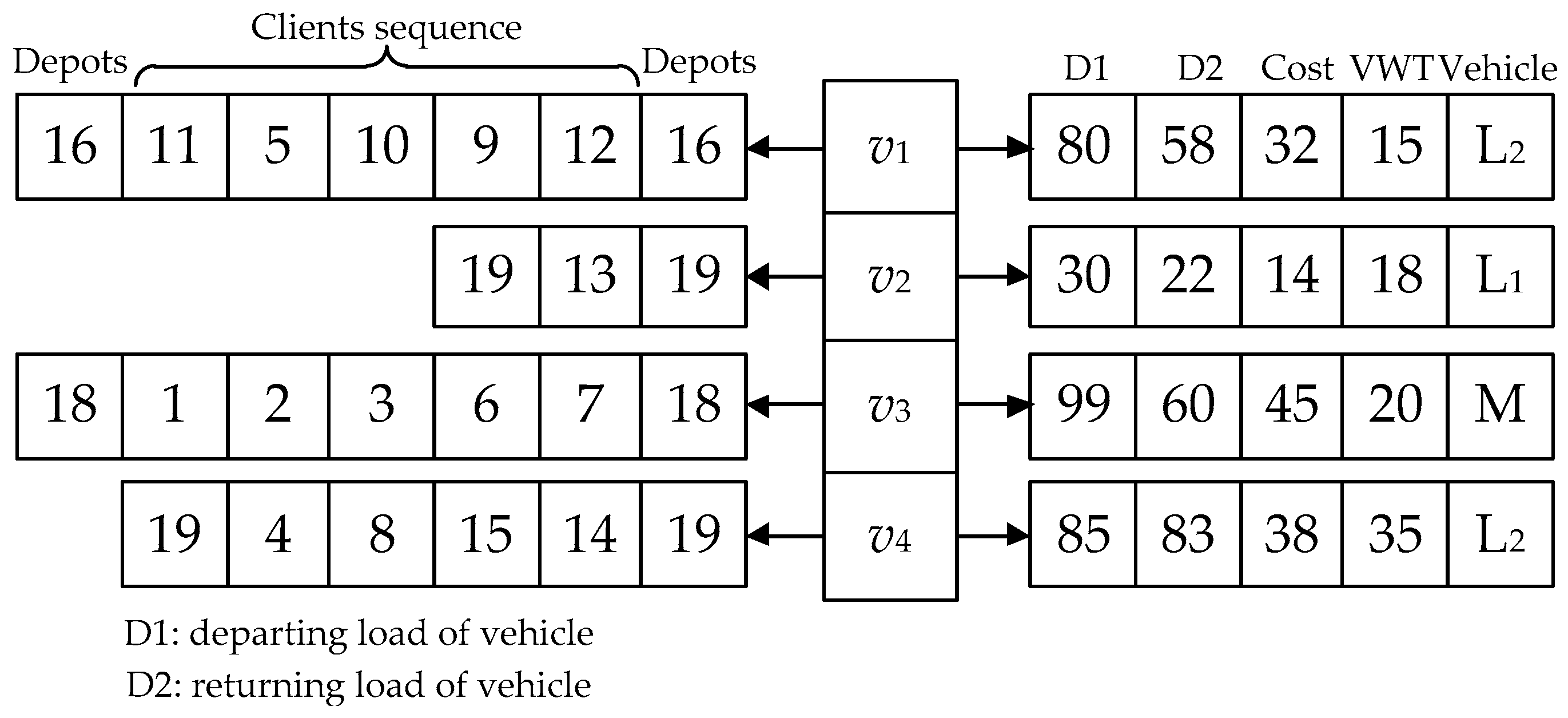
4.1.1. Chromosome Representation
4.1.2. Pool of Low-Level Heuristics
| Algorithm 1. General framework of multi-objective algorithm for LCLRP |
 |
- Mu 2: Decomposition. Routes with vehicles of type L2 and M are randomly (0.5) decomposed into two vehicles with a lower load.
- Mu 3: Interchange. One-third to two-thirds of routes with at least two clients are randomly selected to swap one client with another.
- Mu 4: Shift. Shifts a client into any place of another route.
- NDLS 1: 2-Opt. Exchanges two edges between different routes.
- NDLS 2: Swap. Swaps one client between different routes.
- NDLS 3: Swap of a segment. Swaps two or three clients between different routes.
- NDLS 4: Relocation. Relocates a single client into another route.
- NDLS 5: Relocation of a segment. Relocates two or three clients into another route.
- NDLS 6: Decomposition 2. Decomposes all routes with at least two clients into two vehicles.
4.2. High-Level Control Stratrgy
4.2.1. Proposed High-Level Selection Strategy
| Algorithm 2. Pseudo code of calculating rotation direction and angle |
 |
| Algorithm 3. Quantum-inspired learning selection strategy |
 |
4.2.2. Proposed High-Level Acceptance Criterion
4.3. Framework of the Proposed Hyper-Heuristic
| Algorithm 4. Framework of the Quantum-inspired Hyper-heuristc |
 |
5. Computational Experiments and Analyses
5.1. Implementation Aspects and Configuration of Parameters
5.2. Test Instances
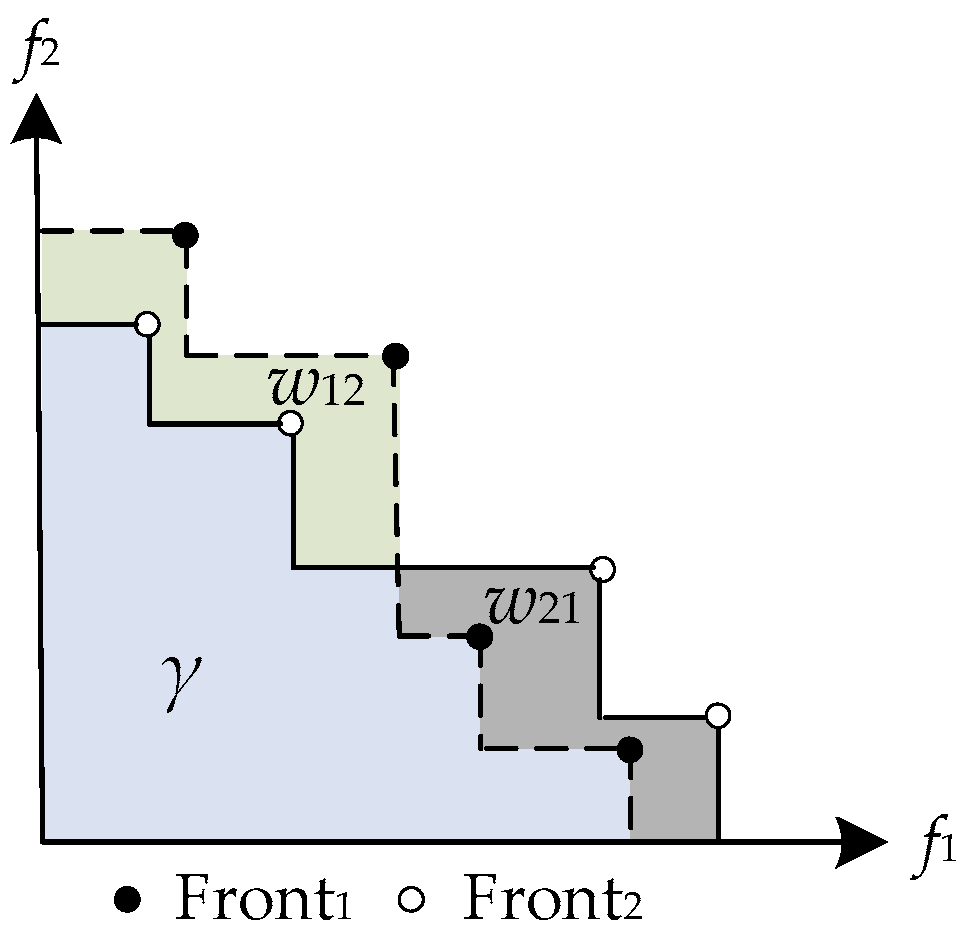
5.3. Performance Metrics
5.4. Efficiency of the Proposed Hyper-heuristics
5.5. Efficiency of Nine Pairs in MOHH
5.6. Efficiency of the Proposed Mathematical Model
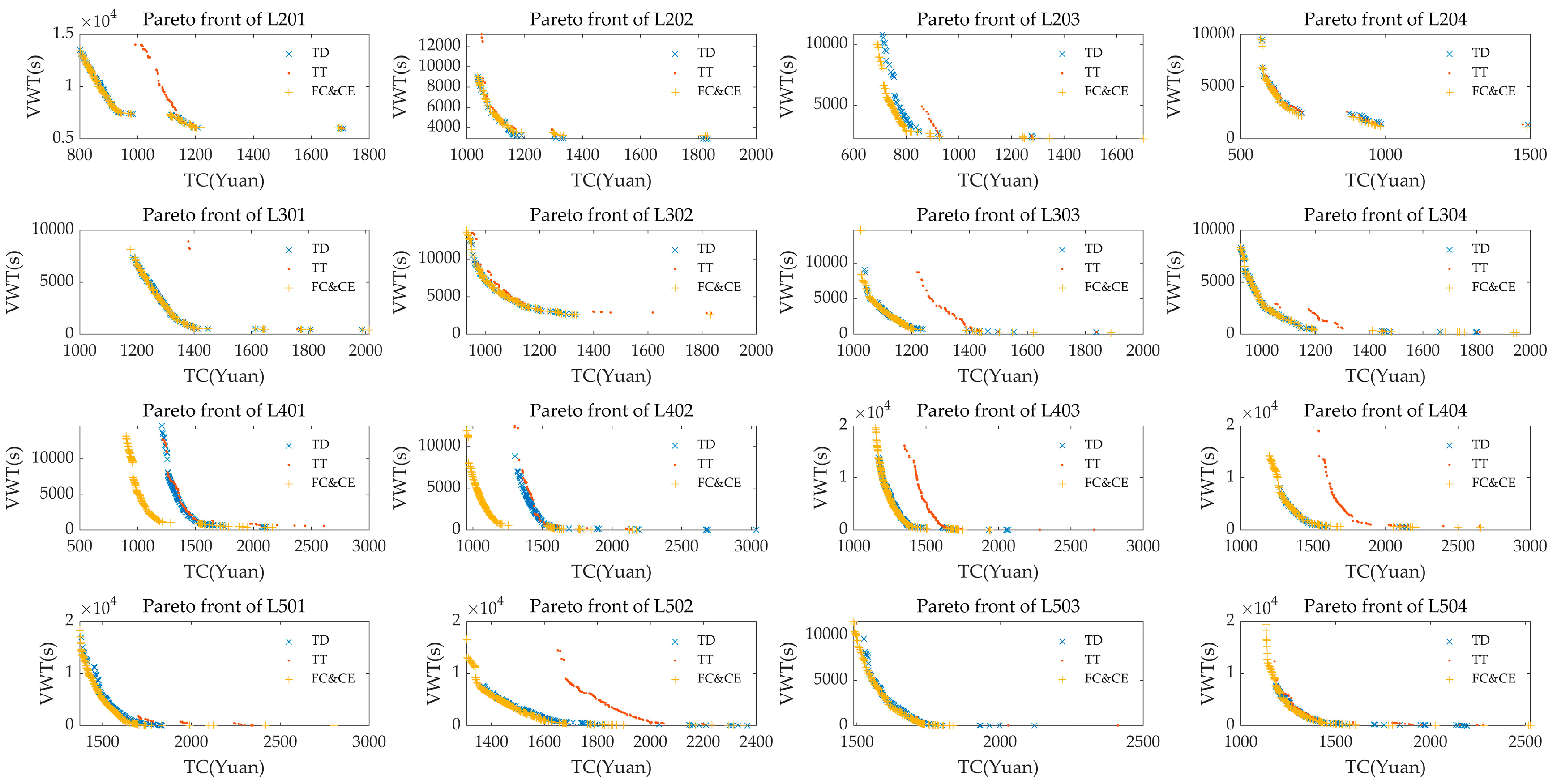
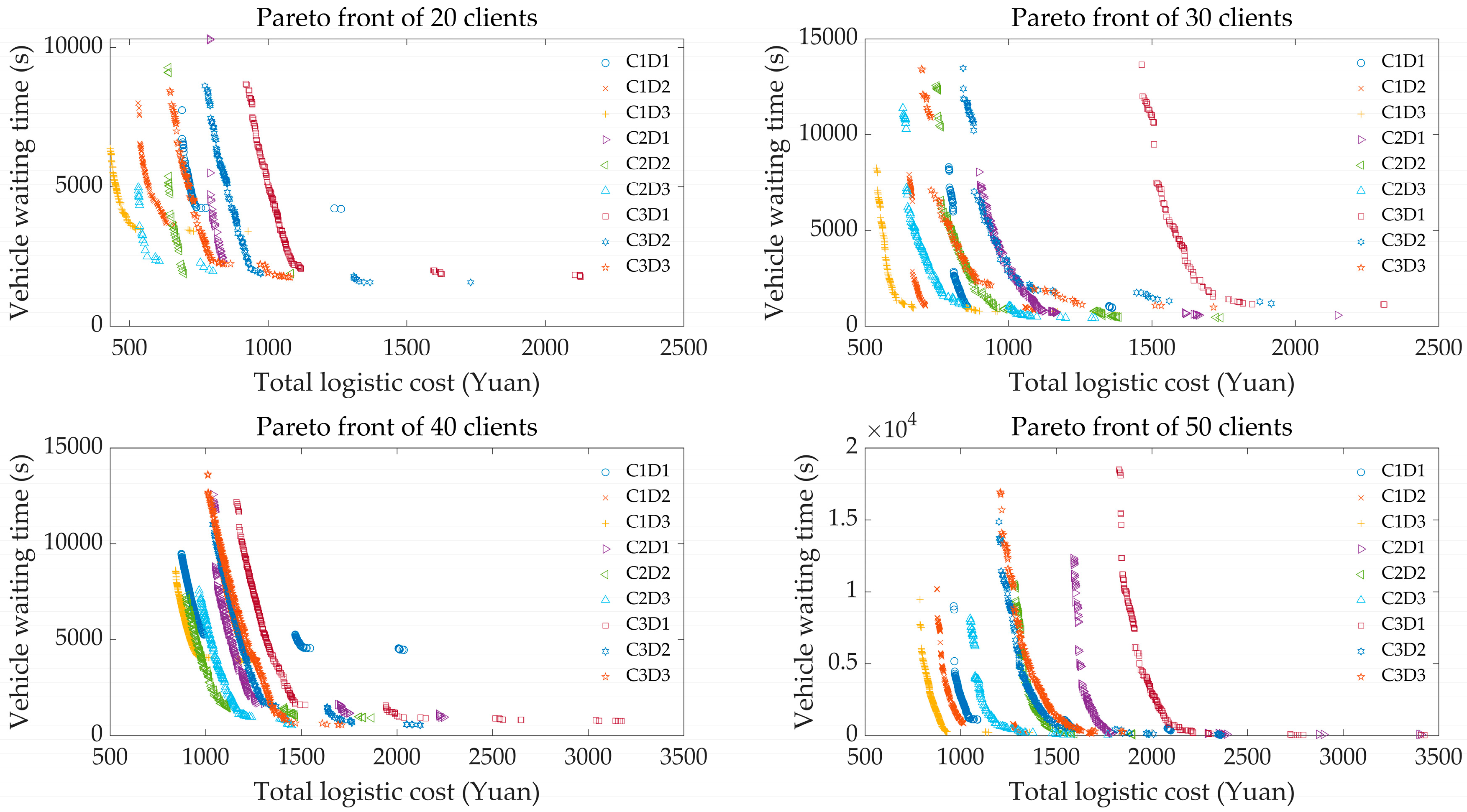
5.7. Evaluation of the Effect of the Domain Problem
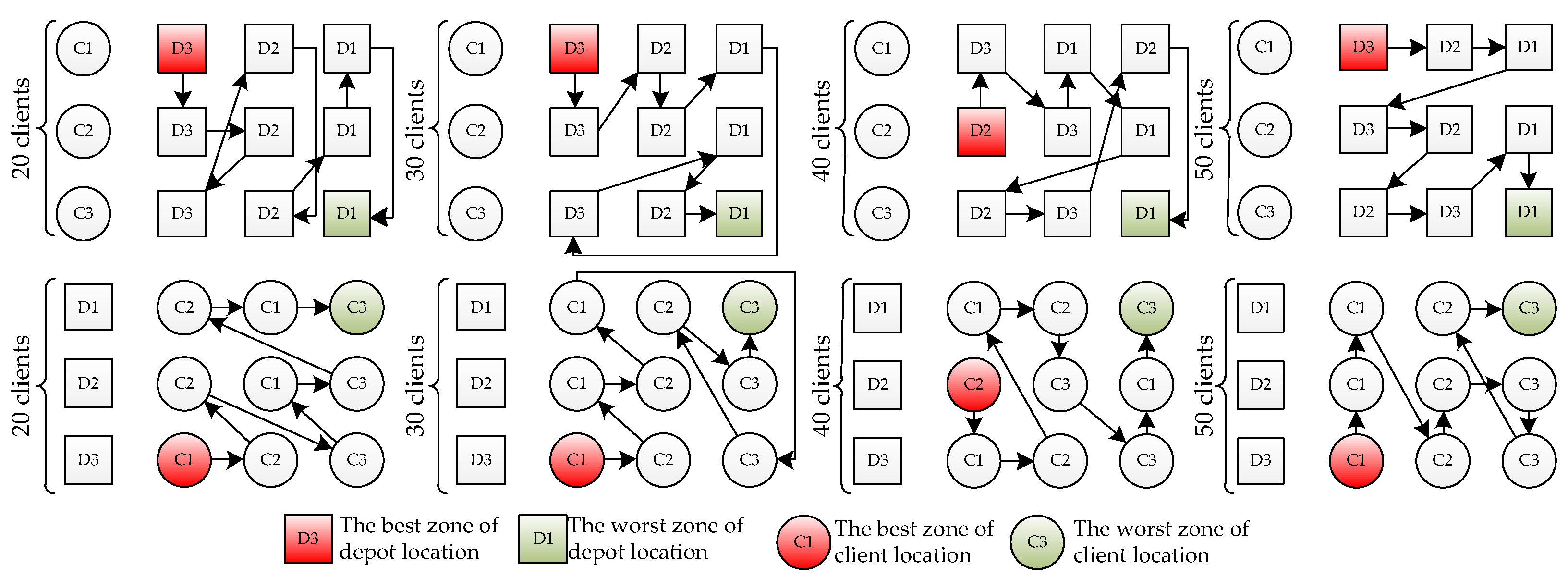
5.7.1. Joint Effect of Depots and Client Distribution
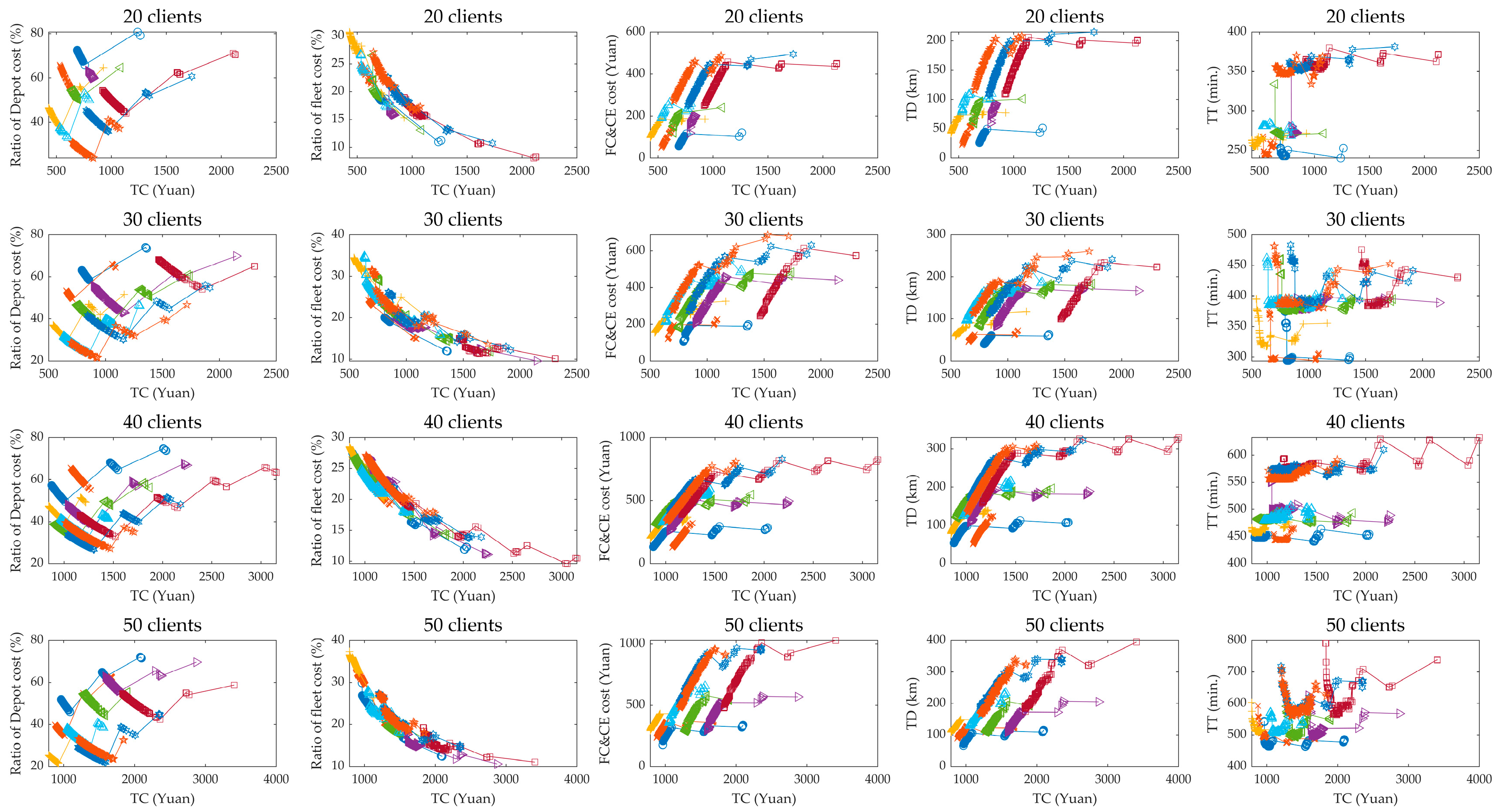
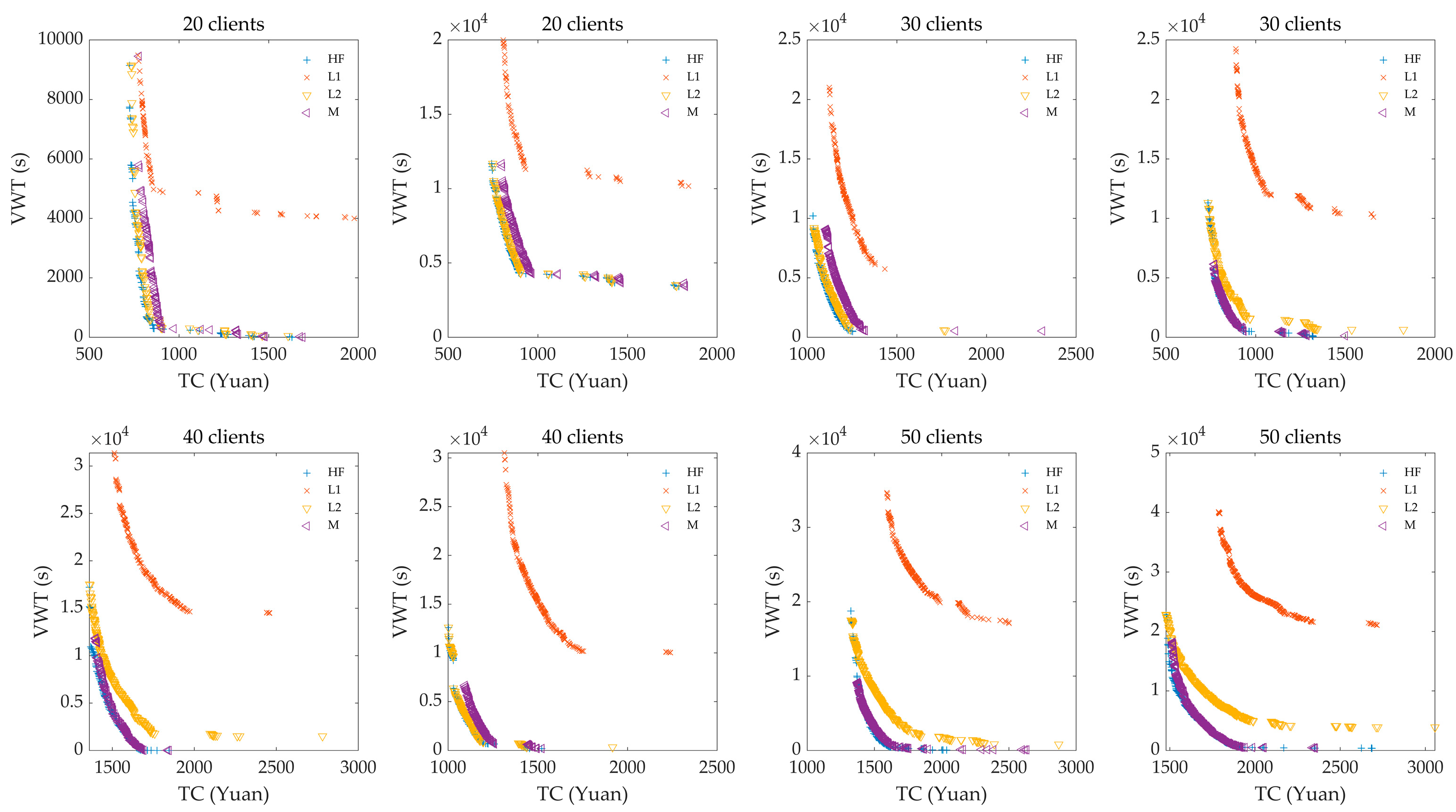
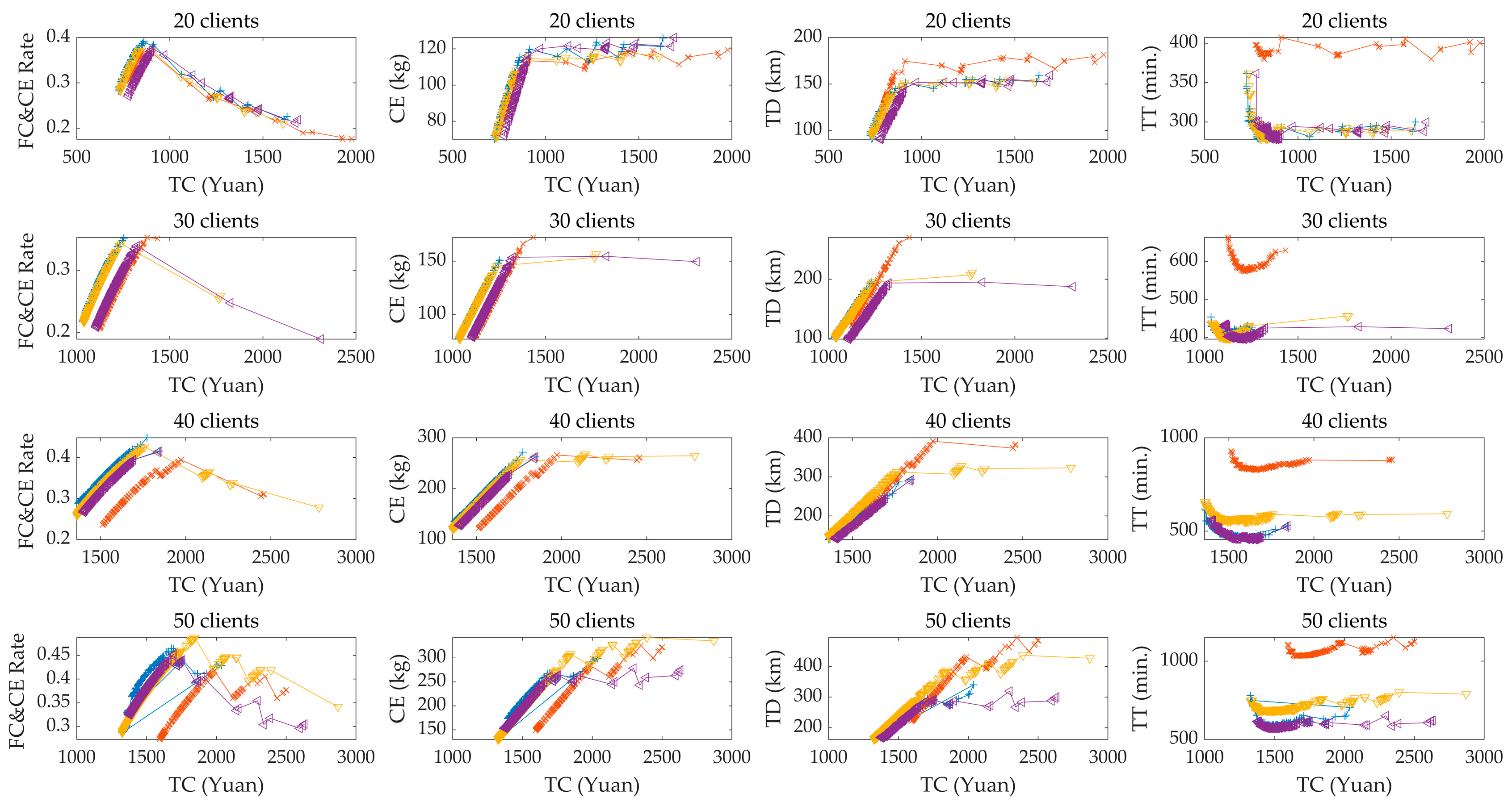
5.7.2. Effect of Fleet Composition
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Koc, C.; Bektas, T.; Jabali, O.; Laporte, G. The impact of depot location, fleet composition and routing on emission in city logistics. Transp. Res. Part B Methodol. 2016, 84, 81–102. [Google Scholar] [CrossRef]
- Bayram, H.; Şahin, R. A new simulated annealing approach for travelling salesman problem. Math. Comput. Appl. 2013, 18, 313–322. [Google Scholar] [CrossRef]
- Zhao, Y.; Leng, L.; Qian, Z.; Wang, W. A discrete hybrid invasive weed optimization algorithm for the capacitated vehicle routing problem. In Proceedings of the 4th International Conference on Information Technology and Quantitative Management (ITQM)-Promoting Business Analytics and Quantitative Management of Technology, Asan, Korea, 16–18 August 2016; Lee, H., Lee, J., Cordova, F., Dzitac, I., Kou, G., Li, J., Eds.; Elsevier B.V.: Amsterdam, The Netherlands, 2016; Volume 91, pp. 978–987. [Google Scholar] [CrossRef]
- Zhou, L.; Wang, X.; Ni, L.; Lin, Y. Location-routing problem with simultaneous home delivery and customer’s pickup for city distribution of online shopping purchases. Sustainability 2016, 8, 828. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, Y.; Zhang, J.; Leng, L.; Wang, H. Location and routing problem with minimizing carbon. Comp. Integr. Manuf. Syst. 2017, 23, 2768–2777. [Google Scholar] [CrossRef]
- Leng, L.; Zhao, Y.; Wang, Z.; Wang, H.; Zhang, J. Shared mechanism-based self-adaptive hyperheuristic for regional low-carbon location-routing problem with time windows. Math. Probl. Eng. 2018, 8987402. [Google Scholar] [CrossRef]
- Lopes, R.B.; Ferreria, C.; Santos, B.S. A simple and effective algorithm for the capacitated location-routing problem. Comput. Oper. Res. 2016, 70, 155–162. [Google Scholar] [CrossRef]
- Bektas, T.; Laporte, G. The pollution-routing problem. Transp. Res. Part. B Methodol. 2011, 45, 1232–1250. [Google Scholar] [CrossRef]
- Liu, X.H.; Shan, M.Y.; Zhang, R.L.; Zhang, L.R. Green vehicle routing optimization based on carbon emission and multiobjective hybrid quantum immune algorithm. Math. Probl. Eng. 2018. Article ID 8961505. [Google Scholar] [CrossRef]
- Liu, Y.; Peng, D. Consumption-aware model for eco-routing in vehicle network. J. Chin. Comput. Syst. 2017, 7, 1512–1517. [Google Scholar]
- Lin, C.H.; Choy, K.L.; Ho, G.T.S.; Chung, S.H.; Lam, H.Y. Survey of green vehicle routing problem: Past and future trends. Expert Syst. Appl. 2014, 41, 1118–1138. [Google Scholar] [CrossRef]
- Demir, E.; Bektas, T.; Laporte, G. A comparative analysis of several vehicle emission models for road freight transportation. Transp. Res. Part D Transp. Environ. 2011, 16, 347–357. [Google Scholar] [CrossRef]
- Demir, E.; Bektas, T.; Laporte, G. A review of recent research on green road freight transportation. Eur. J. Oper. Res. 2014, 237, 775–793. [Google Scholar] [CrossRef]
- Xiao, Y.Y.; Zhao, Q.H.; Falu, I. Development of a fuel consumption optimization model for the capacitated vehicle routing problem. Comput. Oper. Res. 2012, 39, 1419–1431. [Google Scholar] [CrossRef]
- Leng, L.; Zhao, Y.; Zhang, C.; Wang, S. Quantum-inspired hyper-heuristics for low-carbon location-routing problem with simultaneous pickup and delivery. Comp. Integr. Manuf. Syst. 2018, in press. [Google Scholar]
- Zhao, Y.; Leng, L.; Wang, S.; Zhang, C. Evolutionary hyper-heuristics for low-carbon location-routing problem with heterogeneous fleet. Cont. Decis. 2018. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, Y.; Leng, L.; Zhang, C. Research on low carbon location routing problem based on evolutionary hyper-heuristic algorithm of ant colony selection mechanism. Comp. Integr. Manuf. Syst. 2018, in press. [Google Scholar]
- Tang, J.; Ji, S.; Jiang, L. The design of a sustainable location-routing-inventory model considering consumer environmental behavior. Sustainability 2016, 8, 211. [Google Scholar] [CrossRef]
- Hwang, T.; Ouyang, Y. Urban freight truck routing under stochastic congestion and emission considerations. Sustainability 2015, 7, 6610–6625. [Google Scholar] [CrossRef]
- Jovicic, N.; Boskovic, G.; Vujic, G.; Jovicia, G.R.; Despotovic, M.Z.; Milovanovic, D.M.; Gordic, D.R. Route optimization to increase energy efficiency and reduce fuel consumption of communal vehicles. Therm. Sci. 2010, 14, 67–78. [Google Scholar] [CrossRef]
- Liu, W.Y.; Lin, C.C.; Tsao, Y.S.; Wang, Q. Minimizing the carbon footprint for the time-dependent heterogeneous-fleet vehicle routing problem with alternative paths. Sustainability 2014, 6, 4658–4684. [Google Scholar] [CrossRef]
- Koc, C.; Bektas, T.; Jabali, O. The fleet size and mix pollution-routing problem. Transp. Res. Part B Methodol. 2014, 70, 239–254. [Google Scholar] [CrossRef]
- Bandeira, J.; Carvalho, D.O.; Khattak, A.J.; Rouphail, N.M.; Coelho, M.C. A comparative empirical analysis of eco-friendly routes during peak and off-peak hours. In Proceedings of the Transportation Research Board 91st Annual Meeting, Washington, DC, USA, 22–26 January 2012. [Google Scholar]
- Bandeira, J.; Carvalho, D.O.; Khattak, A.J.; Rouphail, N.M.; Coelho, M.C. Generating emissions information for route selection: Experimental monitoring and routes characterization. J. Intell. Transp. Syst. 2013, 17, 3–17. [Google Scholar] [CrossRef]
- Chen, C.; Qiu, R.; Hu, X. The location-routing problem with full truckloads in low-carbon supply chain network designing. Math. Probl. Eng. 2018, 6315631. [Google Scholar] [CrossRef]
- Mohammadi, M.; Razmi, J.; Tavakkoli-Moghaddam, R. Multi-objective invasive weed optimization for stochastic green hub location routing problem with simultaneous pick-ups and deliveries. Econ. Comput. Econ. Cybern. Stud. 2013, 47, 247–266. [Google Scholar]
- Govindan, K.; Jafarian, A.; Khodaverdi, R.; Devika, K. Two-echelon multiple-vehicle location–routing problem with time windows for optimization of sustainable supply chain network of perishable food. Int. J. Prod. Econ. 2014, 152, 9–28. [Google Scholar] [CrossRef]
- Validi, S.; Bhattacharya, A.; Byrne, P.J. Integrated low-carbon distribution system for the demand side of a product distribution supply chain: A DoE-guided MOPSO optimizer-based solution approach. Int. J. Prod. Res. 2014, 52, 3074–3096. [Google Scholar] [CrossRef]
- Validi, S.; Bhattacharya, A.; Byrne, P.J. A case analysis of a sustainable food supply chain distribution system-a multi-objective approach. Int. J. Prod. Econ. 2014, 152, 71–87. [Google Scholar] [CrossRef]
- Qazvini, Z.E.; Amalnick, M.S.; Mina, H. A green multi-depot location routing model with split-delivery and time window. Int. J. Manag. Concepts Philos. 2016, 9, 271–282. [Google Scholar] [CrossRef]
- Toro, E.M.; France, J.F.; Echeverri, M.G.; Guimarães, F. A multi-objective model for the green capacitated location-routing problem considering environmental impact. Comput. Ind. Eng. 2017, 110, 114–125. [Google Scholar] [CrossRef]
- Nakhjirkan, S.; Rafiei, F.M. An integrated multi-echelon supply chain network design considering stochastic demand: A genetic algorithm-based solution. Promet Traffic Transp. 2017, 4, 391–400. [Google Scholar] [CrossRef]
- Wang, Y.; Tian, X.; Liu, D. Optimization of urban multi-level logistics distribution network based on the perspective of low carbon. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017. [Google Scholar] [CrossRef]
- Wang, X.; Li, X. Carbon reduction in the location routing problem with heterogeneous fleet, simultaneous pickup-delivery and time windows. In Proceedings of the 21st International Conference on Knowledge-Based and Intelligent Information and Engineering Systems (KES), Marseille, France, 6–8 September 2017; ZanniMerk, C., Frydman, C., Toro, C., Hicks, Y., Howlett, R.J., Jain, L.C., Eds.; Elsevier B.V.: Amsterdam, The Netherlands, 2017; Volume 112, pp. 1131–1140. [Google Scholar] [CrossRef]
- Rabbani, M.; Davoudkhani, M.; Farrokhi-Asi, H. A new multi-objective green location routing problem with heterogonous fleet of vehicles and fuel constraint. Int. J. Strateg. Decis. Sci. 2017, 8, 99–119. [Google Scholar] [CrossRef]
- Wang, S.; Tao, F.; Shi, Y. Optimization of location–routing problem for cold chain logistics considering carbon footprint. Int. J. Environ. Res. Public Health 2018, 15, 86. [Google Scholar] [CrossRef]
- Qian, Z.; Zhao, Y.; Wang, S.; Leng, L.; Wang, W. A hyper heuristic algorithm for low carbon location routing problem. In Proceedings of the Advances in Neural Networks-ISNN 2018, 15th International Symposium on NeuralNetworks, Minsk, Belarus, 25–28 June 2018. [Google Scholar] [CrossRef]
- Faraji, F.; Afshar-Nadjafi, B. A bi-objective green location-routing model and solving problem using a hybrid metaheuristic algorithm. Int. J. Logist. Syst. Manag. 2018, 30, 366–385. [Google Scholar] [CrossRef]
- Walker, J.D.; Ocha, G.; Gendreau, M.; Burke, E.K. Vehicle routing and adaptive iterated local search within the HyFlex hyper-heuristic framework. In Proceedings of the Learning and Intelligent Optimization 6th International Conference, Paris, France, 16–20 January 2012. [Google Scholar] [CrossRef]
- Denzinger, J.; Fuchs, M.; Fuchs, M. High performance ATP systems by combining several AI methods. In Proceedings of the International Joint Conference on Artificial Intelligence, Nagoya, Japan, 23–29 August 1997. [Google Scholar]
- Cowling, P.; Kendall, G.; Soubeiga, E. A hyper-heuristic approach to scheduling a sales summit. In Proceedings of the International Conference on the Practice and Theory of Automated Timetabling, Konstanz, Germany, 16–18 August 2000; Burke, E., Erben, W., Eds.; Springer: Berlin, Germany, 2000. [Google Scholar] [CrossRef]
- Wolper, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Burke, E.K.; Gendreau, M.; Hyde, M.; Kendall, G.; Ochoa, G.; Qu, R. Hyper-heuristics: A survey of the state of the art. J. Oper. Res. Soc. 2013, 64, 1695–1724. [Google Scholar] [CrossRef]
- Kalender, M.; Kheiri, A.; Ozcan, E.; Burke, E.K. A greedy gradient-simulated annealing selection hyper-heuristic. Soft Comput. 2013, 17, 2279–2292. [Google Scholar] [CrossRef]
- Ozcan, E.; Bilgin, B.; Kormaz, E.E. A comprehensive analysis of hyper-heuristics. Intell. Data Anal. 2008, 12, 3–23. [Google Scholar] [CrossRef]
- Sabar, N.; Ayob, M.; Kendall, G. The automatic design of a hyper-heuristic framework with gene expression programming for combinatorial optimization problems. IEEE Trans. Evol. Comput. 2015, 19, 309–325. [Google Scholar] [CrossRef]
- Burke, E.K.; Hyde, M.; Kendall, G.; Ochoa, G.; Ozcan, E.; Woodard, J.R. A classification of hyper-heuristic approaches. In Handbook of Metaheuristics; International Series in Operations Research & Management Science; Springer: Boston, MA, USA, 2010; Volume 146, pp. 449–468. [Google Scholar]
- Li, K.; Fialho, A.; Kwong, S.; Zhang, Q. Adaptive operator selection with bandits for a multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2014, 18, 114–130. [Google Scholar] [CrossRef]
- Nareyek, A. Choosing search heuristics by non-stationary reinforcement learning. In Proceedings of the 4th Metaheuristics International Conference, Oporto, Portugal, 16–20 July 2001; Resende, M.G.C., DeSousa, J.P., Eds.; Kluwer Academic Publishers: Norwell, MA, USA, 2004. [Google Scholar] [CrossRef]
- Anagnostopoulos, K.P.; Koulinas, G.K. A genetic algorithm hyperheuristic algorithm for the resource constrained project scheduling problem. In Proceedings of the 2010 IEEE Congress on Evolutionary Computation, Barcelona, Spain, 18–23 July 2010. [Google Scholar] [CrossRef]
- Chen, S.; Li, Z.; Yang, B.; Rudolph, G. Quantum-inspired hyper-heuristics for energy-aware scheduling on heterogeneous computing systems. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1796–1810. [Google Scholar] [CrossRef]
- Dueck, G. New optimization heuristics: The great deluge algorithm and the record to record travel. J. Comput. Phys. 1993, 14, 86–92. [Google Scholar] [CrossRef]
- Burke, E.K.; Bykov, Y.A. A late acceptance strategy in hill-climbing for exam timetabling problems. In Proceedings of the International Conference on the Practice and Theory of Automated Timetabling, Montreal, QC, Canada, 18–22 August 2008. [Google Scholar]
- Hitomi, H.; Selva, D.A. classification and comparison of credit assignment strategies in multiobjective adaptive operator selection. IEEE Trans. Evol. Comput. 2017, 21, 294–314. [Google Scholar] [CrossRef]
- Ferriera, T.N.; Jackson, A.; Lima, P.; Strickler, A.; Kuk, J.N.; Vergilio, S.R.; Pozo, A. Hyper-heuristic-based product selection for software product line testing. IEEE Comput. Intell. Mag. 2017, 12, 34–45. [Google Scholar] [CrossRef]
- Guizzo, G.; Verdilio, S.R.; Pozo, A.T.R.; Fritsche, G.M. A multi-objective and evolutionary hyper-heuristic applied to the integration and test order problem. Appl. Soft Comput. 2017, 56, 331–344. [Google Scholar] [CrossRef]
- Yao, Y.; Peng, Z.; Xiao, B. Parallel hyper-heuristic algorithm for multi-objective route planning in a smart city. IEEE Comput. Intell. Mag. 2018, 67, 10307–10318. [Google Scholar] [CrossRef]
- Xu, C.Q.; Liu, Y.; Li, P.; Yang, Y. Unified multi-objective mapping for network-on-chip using genetic-based hyper-heuristic algorithms. IET Comput. Digit. Tech. 2018, 12, 158–166. [Google Scholar] [CrossRef]
- Castro, O.R.; Frische, G.M.; Pozo, A. Evaluating selection methods on hyper-heuristic multi-objective particle swarm optimization. J. Heuristics 2018, 24, 581–616. [Google Scholar] [CrossRef]
- Zhang, Y.Y.; Harman, M.; Ocha, G.; Ruhe, G.; Brinkkemper, S. An empirical study of meta- and hyper-heuristic search for multi-objective release planning. ACM Trans. Softw. Eng. Methodol. 2018, 27. [Google Scholar] [CrossRef]
- Maashi, M.; Ozcan, E.; Kendall, G. A multi-objective hyper-heuristic based on choice function. Expert Syst. Appl. 2014, 41, 4475–7793. [Google Scholar] [CrossRef]
- Maashi, M.; Kendall, G.; Ozcan, E. Choice function based hyper-heuristics for multi-objective optimization. Appl. Soft Comput. 2015, 28, 312–326. [Google Scholar] [CrossRef]
- Li, W.W.; Ozcan, E.; John, R. Multi-objective evolutionary algorithms and hyper-heuristics for wind farm layout optimization. Renew. Energy 2017, 105, 473–482. [Google Scholar] [CrossRef]
- Karaoglan, I.; Altiparmak, F.; Kara, I.; Dengiz, B. A branch and cut algorithm for the location-routing problem with simultaneous pickup and delivery. Eur. J. Oper. Res. 2011, 211, 318–332. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the strength Pareto evolutionary algorithm. In Proceedings of the Evolutionary Methods for Design, Optimization and Control with Applications to Industrial Problems, Athens, Greece, 19–21 September 2001. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Chen, B.; Zeng, W.; Lin, Y.; Zhang, D. A new local search-based multiobjective optimization algorithm. IEEE Trans. Evol. Comput. 2015, 19, 50–73. [Google Scholar] [CrossRef]
- Li, M.; Yang, S.; Liu, X. Bi-goal evolution for many-objective optimization problems. Artif. Intell. 2015, 228, 46–65. [Google Scholar] [CrossRef]
- Zitzler, E. Evolutionary Algorithms for Multiobjective Optimization: Methods and Applications. Ph.D. Thesis, ETH Zurich, Zurich, Switzerland, 1999; doi:10.3929/ethz-a-003856832. [Google Scholar]
- Zhang, Q.; Li, H. A multi-objective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Solomon, M.M. Algorithms for the vehicle routing and scheduling problems with time window constraints. Oper. Res. 1987, 35, 254–265. [Google Scholar] [CrossRef]
- Li, L.; Wang, W.; Xu, X. Multi-objective particle swarm optimization based on global margin ranking. Inf. Sci. 2017, 375, 30–47. [Google Scholar] [CrossRef]
- Cai, X.; Sun, H.; Zhu, C.; Zhang, Q. Locating the boundaries of pareto fronts: A many-objective evolutionary algorithm based on corner solution search. arXiv, 2017; arXiv:1806.02967. [Google Scholar]
- Strickler, A.; Lima, J.A.P.; Vergilio, S.R.; Pozo, A.T.R. Deriving products for variability test of feature models with a hyper-heuristic approach. Appl. Soft Comput. 2016, 49, 1232–1242. [Google Scholar] [CrossRef]
- Yang, S.; Li, M.; Liu, X.; Zheng, J. A grid-based evolutionary algorithm for many-objective optimization. IEEE Trans. Evol. Comput. 2013, 5, 721–736. [Google Scholar] [CrossRef]
- Zitzler, E.; Kunzli, S. Indicator-based selection in multiobjective search. In Proceedings of the Parallel Problem Solving from Nature–PPSN VIII, International Conference on Parallel Problem Solving from Nature, Birmingham, UK, 13–17 September 2004; Yao, X., Ed.; Springer: Berlin, Germany, 2004. [Google Scholar] [CrossRef]
- Deb, K.; Jain, H. An evolutionary many-objective optimization algorithm using reference-point based non-dominated sorting approach, Part I: Solving problems with box constraints. IEEE Trans. Evol. Comput. 2014, 4, 577–601. [Google Scholar] [CrossRef]
- Corne, D.W.; Jerram, N.R.; Knowles, J.D.; Oates, M.J. PESA-II: Region-based selection in evolutionary multiobjective optimization. In Proceedings of the Genetic and Evolutionary Computation Conference, New York, NY, USA, 9–13 July 2002. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set | BiGE | GrEA | IBEA | NSGA-II | NSGA-III | NSLS | PESA-II | SPEA2 | MOHH/QS | MOHH/QS2 |
|---|---|---|---|---|---|---|---|---|---|---|
| L20-1 | 7.08 × 10–3 | 8.51 × 10–3 | 4.10 × 10–3 | 6.94 × 10–3 | 7.59 × 10–3 | 1.68 × 10–3 | 2.58 × 10–2 | 1.21 × 10–2 | 1.20 × 10–3 | 2.08× 10–3 |
| L20-2 | 8.30 × 10–4 | 8.79 × 10–4 | 3.09 × 10–3 | 7.57 × 10–4 | 1.34 × 10–3 | 6.67 × 10–4 | 1.65 × 10–3 | 9.78 × 10–4 | 2.62 × 10–4 | 1.04 × 10–3 |
| L20-3 | 3.14 × 10–2 | 3.42 × 10–2 | 1.96 × 10–2 | 2.79 × 10–2 | 3.52 × 10–2 | 1.80 × 10–2 | 3.99 × 10–2 | 1.95 × 10–2 | 1.82 × 10–2 | 1.66 × 10–2 |
| L20-4 | 1.14 × 10–3 | 1.40 × 10–3 | 1.24 × 10–2 | 1.21 × 10–3 | 2.64 × 10–3 | 1.39 × 10–3 | 7.69 × 10–3 | 1.21× 10–3 | 1.05 × 10–3 | 8.78 × 10–3 |
| L30-1 | 6.09 × 10–3 | 5.40× 10–3 | 7.26 × 10–3 | 5.62 × 10–3 | 6.67 × 10–3 | 5.99 × 10–3 | 6.12 × 10–3 | 6.10 × 10–3 | 4.97 × 10–3 | 5.17 × 10–3 |
| L30-2 | 7.36 × 10–3 | 5.46 × 10–3 | 7.05 × 10–3 | 6.42 × 10–3 | 4.75 × 10–3 | 4.59× 10–3 | 5.36 × 10–3 | 4.45 × 10–3 | 3.60 × 10–3 | 4.63 × 10–3 |
| L30-3 | 5.96 × 10–3 | 5.87 × 10–3 | 7.00 × 10–3 | 5.19× 10–3 | 5.97 × 10–3 | 5.53 × 10–3 | 5.93 × 10–3 | 5.19 × 10–3 | 4.92 × 10–3 | 5.66 × 10–3 |
| L30-4 | 5.01 × 10–3 | 5.67 × 10–3 | 8.04 × 10–3 | 6.47 × 10–3 | 6.32 × 10–3 | 7.14 × 10–3 | 9.87 × 10–3 | 5.03 × 10–3 | 4.05 × 10–3 | 5.45 × 10–3 |
| L40-1 | 1.30 × 10–1 | 1.34 × 10–1 | 1.16× 10–1 | 1.11 × 10–1 | 1.26 × 10–1 | 1.16 × 10–1 | 1.25 × 10–1 | 1.31 × 10–1 | 1.06 × 10–1 | 1.27 × 10–1 |
| L40-2 | 1.18 × 10–1 | 1.40 × 10–1 | 1.28 × 10–1 | 1.22 × 10–1 | 1.02 × 10–1 | 1.37 × 10–1 | 1.42 × 10–1 | 1.25 × 10–1 | 1.24 × 10–1 | 1.27 × 10–1 |
| L40-3 | 1.30 × 10–2 | 4.37 × 10–2 | 1.45 × 10–2 | 8.52 × 10–3 | 1.30 × 10–2 | 1.03 × 10–2 | 1.18 × 10–2 | 1.01 × 10–2 | 7.36 × 10–3 | 1.23 × 10–2 |
| L40-4 | 1.67 × 10–2 | 4.95 × 10–2 | 1.28 × 10–2 | 1.20 × 10–2 | 1.26 × 10–2 | 1.44 × 10–2 | 1.58 × 10–2 | 1.10 × 10–2 | 5.60 × 10–3 | 8.96 × 10–3 |
| L50-1 | 1.93 × 10–2 | 3.38 × 10–2 | 2.31 × 10–2 | 2.00 × 10–2 | 2.42 × 10–2 | 1.99 × 10–2 | 2.44 × 10–2 | 1.87 × 10–2 | 1.13 × 10–2 | 2.21 × 10–2 |
| L50-2 | 7.11 × 10–2 | 5.37 × 10–2 | 3.72 × 10–2 | 1.98 × 10–2 | 3.49 × 10–2 | 4.85 × 10–2 | 2.24 × 10–2 | 4.19 × 10–2 | 2.37 × 10–2 | 3.08 × 10–2 |
| L50-3 | 1.55 × 10–2 | 1.97 × 10–2 | 1.52 × 10–2 | 1.18 × 10–2 | 1.52 × 10–2 | 1.24 × 10–2 | 1.40 × 10–2 | 1.01× 10–2 | 8.45 × 10–3 | 8.74 × 10–3 |
| L50-4 | 6.57 × 10–2 | 9.49 × 10–2 | 7.12 × 10–2 | 8.01 × 10–2 | 7.47 × 10–2 | 6.66 × 10–2 | 7.59 × 10–2 | 6.43 × 10–2 | 3.99 × 10–2 | 6.96 × 10–2 |
| f/s/t | 0/3/2 | 0/0/1 | 0/0/1 | 1/2/2 | 1/0/0 | 0/3/1 | 0/1/0 | 0/4/5 | 13/0/3 | 1/3/1 |
| Set | BiGE | GrEA | IBEA | NSGA-II | NSGAIII | NSLS | PEAS-II | SPEA2 | MOHH/QS | MOHH/QS2 |
|---|---|---|---|---|---|---|---|---|---|---|
| L20-1 | 0.3687 | 0.3679 | 0.3735 | 0.3687 | 0.3679 | 0.3727 | 0.3532 | 0.3644 | 0.3734 | 0.3735 |
| L20-2 | 0.3757 | 0.3757 | 0.3754 | 0.3758 | 0.3757 | 0.3758 | 0.3755 | 0.3757 | 0.3759 | 0.3758 |
| L20-3 | 0.5562 | 0.5468 | 0.5682 | 0.5608 | 0.5462 | 0.5679 | 0.5508 | 0.5647 | 0.5669 | 0.5692 |
| L20-4 | 0.6571 | 0.6571 | 0.6564 | 0.6571 | 0.6564 | 0.6570 | 0.6562 | 0.6571 | 0.6572 | 0.6570 |
| L30-1 | 0.4887 | 0.4917 | 0.4892 | 0.4910 | 0.4879 | 0.4891 | 0.4891 | 0.4887 | 0.4923 | 0.4928 |
| L30-2 | 0.4930 | 0.4931 | 0.4934 | 0.4914 | 0.4927 | 0.4931 | 0.4908 | 0.4936 | 0.4950 | 0.4958 |
| L30-3 | 0.5731 | 0.5736 | 0.5737 | 0.5742 | 0.5723 | 0.5732 | 0.5725 | 0.5755 | 0.5765 | 0.5744 |
| L30-4 | 0.6253 | 0.6240 | 0.6233 | 0.6187 | 0.6221 | 0.6147 | 0.6049 | 0.6261 | 0.6276 | 0.6282 |
| L40-1 | 0.5131 | 0.5137 | 0.5306 | 0.5362 | 0.5241 | 0.5277 | 0.5185 | 0.5098 | 0.5418 | 0.5165 |
| L40-2 | 0.5408 | 0.5096 | 0.5290 | 0.5288 | 0.5569 | 0.5105 | 0.5085 | 0.5282 | 0.5291 | 0.5290 |
| L40-3 | 0.5057 | 0.4923 | 0.5075 | 0.5080 | 0.5023 | 0.5071 | 0.5048 | 0.5063 | 0.5086 | 0.5065 |
| L40-4 | 0.6227 | 0.6035 | 0.6339 | 0.6321 | 0.6363 | 0.6293 | 0.6256 | 0.6333 | 0.6413 | 0.6402 |
| L50-1 | 0.6158 | 0.6015 | 0.6133 | 0.6158 | 0.6091 | 0.6151 | 0.6098 | 0.6161 | 0.6263 | 0.6121 |
| L50-2 | 0.4765 | 0.5060 | 0.5225 | 0.5379 | 0.5190 | 0.4982 | 0.5347 | 0.5070 | 0.5373 | 0.5368 |
| L50-3 | 0.2627 | 0.2632 | 0.2650 | 0.2676 | 0.2636 | 0.2661 | 0.2638 | 0.2678 | 0.2689 | 0.2684 |
| L50-4 | 0.6368 | 0.6119 | 0.6378 | 0.6080 | 0.6305 | 0.6278 | 0.6252 | 0.6206 | 0.6630 | 0.6517 |
| f/s/t | 0/2/0 | 0/0/1 | 0/2/3 | 1/2/1 | 1/0/1 | 0/0/2 | 0/0/0 | 0/2/4 | 9/4/2 | 5/4/2 |
| Set | SR/GDA | SR/LA | FM/GDA | FM/LA | CF/GDA | CF/LA | QS/GDA | QS/LA | QS/AC-NDSCD |
|---|---|---|---|---|---|---|---|---|---|
| L20-1 | 1.23 × 10–3 | 1.30 × 10–3 | 1.25 × 10–3 | 1.19 × 10–3 | 1.31 × 10–3 | 1.09 × 10–3 | 1.20 × 10–3 | 1.21 × 10–3 | 9.93 × 10–4 |
| L20-2 | 4.19 × 10–4 | 3.03 × 10–4 | 2.80 × 10–4 | 2.78 × 10–4 | 3.04 × 10–4 | 3.29 × 10–4 | 2.62 × 10–4 | 1.11 × 10–4 | 1.14 × 10–4 |
| L20-3 | 1.68 × 10–2 | 1.73 × 10–2 | 1.56 × 10–2 | 1.63 × 10–2 | 1.74 × 10–2 | 1.63 × 10–2 | 1.82 × 10–2 | 1.62 × 10–2 | 1.82 × 10–2 |
| L20-4 | 9.85 × 10–4 | 1.20 × 10–3 | 9.23 × 10–4 | 1.18 × 10–3 | 1.19 × 10–3 | 1.07 × 10–3 | 1.05 × 10–3 | 9.50 × 10–4 | 8.63 × 10–4 |
| L30-1 | 4.69 × 10–3 | 4.60 × 10–3 | 5.52 × 10–3 | 4.57 × 10–3 | 5.04 × 10–3 | 4.92 × 10–3 | 4.97 × 10–3 | 4.22 × 10–3 | 4.45 × 10–3 |
| L30-2 | 3.39 × 10–3 | 4.41 × 10–3 | 3.56 × 10–3 | 2.82 × 10–3 | 3.14 × 10–3 | 3.69 × 10–3 | 3.60 × 10–3 | 2.75 × 10–3 | 3.22 × 10–3 |
| L30-3 | 4.43 × 10–3 | 4.48 × 10–3 | 4.69 × 10–3 | 4.96 × 10–3 | 4.44 × 10–3 | 4.67 × 10–3 | 4.92 × 10–3 | 4.59 × 10–3 | 4.46 × 10–3 |
| L30-4 | 4.17 × 10–3 | 5.23 × 10–3 | 4.50 × 10–3 | 4.25 × 10–3 | 4.59 × 10–3 | 4.33 × 10–3 | 4.05 × 10–3 | 3.73 × 10–3 | 3.51 × 10–3 |
| L40-1 | 1.11 × 10–1 | 1.22 × 10–1 | 1.17 × 10–1 | 1.19 × 10–1 | 1.22 × 10–1 | 1.02 × 10–1 | 1.06 × 10–1 | 8.29 × 10–2 | 9.95 × 10–2 |
| L40-2 | 1.26 × 10–1 | 1.13 × 10–1 | 1.20 × 10–1 | 1.38 × 10–1 | 1.34 × 10–1 | 1.03 × 10–1 | 1.24 × 10–1 | 6.59 × 10–2 | 1.31 × 10–1 |
| L40-3 | 7.63 × 10–3 | 7.80 × 10–3 | 7.79 × 10–3 | 7.00 × 10–3 | 7.71 × 10–3 | 7.97 × 10–3 | 7.36 × 10–3 | 6.82 × 10–3 | 6.63 × 10–3 |
| L40-4 | 6.54 × 10–3 | 7.48 × 10–3 | 6.78 × 10–3 | 7.48 × 10–3 | 7.52 × 10–3 | 7.30 × 10–3 | 5.60 × 10–3 | 6.02 × 10–3 | 8.06 × 10–3 |
| L50-1 | 1.33 × 10–2 | 1.18 × 10–2 | 1.52 × 10–2 | 1.22 × 10–2 | 1.03 × 10–2 | 1.47 × 10–2 | 1.13 × 10–2 | 1.14 × 10–2 | 1.25 × 10–2 |
| L50-2 | 1.54× 10–2 | 1.59 × 10–2 | 1.68 × 10–2 | 1.65 × 10–2 | 2.05 × 10–2 | 1.33 × 10–2 | 2.37 × 10–2 | 1.68 × 10–2 | 1.49 × 10–2 |
| L50-3 | 8.31 × 10–3 | 9.95 × 10–3 | 9.50 × 10–3 | 1.04 × 10–2 | 1.14 × 10–2 | 9.13 × 10–3 | 8.45 × 10–3 | 1.01 × 10–2 | 8.95 × 10–3 |
| L50-4 | 3.42 × 10–2 | 4.57 × 10–2 | 3.71 × 10–2 | 2.50 × 10–2 | 3.44 × 10–2 | 4.07 × 10–2 | 3.99 × 10–2 | 4.12 × 10–2 | 3.03 × 10–2 |
| f/s/t | 2/0/3 | 0/0/1 | 1/1/0 | 1/1/3 | 2/1/1 | 1/2/2 | 1/2/2 | 5/4/2 | 3/5/2 |
| Set | SR/GDA | SR/LA | FM/GDA | FM/LA | CF/GDA | CF/LA | QS/GDA | QS/LA | QS/AC-NDSCD |
|---|---|---|---|---|---|---|---|---|---|
| L20-1 | 0.3734 | 0.3732 | 0.3731 | 0.3733 | 0.3732 | 0.3731 | 0.3734 | 0.3733 | 0.3734 |
| L20-2 | 0.3758 | 0.3759 | 0.3758 | 0.3758 | 0.3758 | 0.3758 | 0.3759 | 0.3759 | 0.3759 |
| L20-3 | 0.5695 | 0.5686 | 0.5702 | 0.5697 | 0.5689 | 0.5691 | 0.5669 | 0.5695 | 0.5673 |
| L20-4 | 0.6572 | 0.6571 | 0.6572 | 0.6572 | 0.6571 | 0.6572 | 0.6572 | 0.6572 | 0.6572 |
| L30-1 | 0.4926 | 0.4928 | 0.4916 | 0.4920 | 0.4920 | 0.4925 | 0.4923 | 0.4926 | 0.4928 |
| L30-2 | 0.4957 | 0.4947 | 0.4955 | 0.4966 | 0.4956 | 0.4956 | 0.4950 | 0.4972 | 0.4968 |
| L30-3 | 0.5757 | 0.5762 | 0.5759 | 0.5753 | 0.5744 | 0.5760 | 0.5765 | 0.5765 | 0.5764 |
| L30-4 | 0.6270 | 0.6248 | 0.6270 | 0.6266 | 0.6265 | 0.6273 | 0.6276 | 0.6276 | 0.6276 |
| L40-1 | 0.5335 | 0.5192 | 0.5274 | 0.5258 | 0.5194 | 0.5499 | 0.5418 | 0.5711 | 0.5499 |
| L40-2 | 0.5295 | 0.5460 | 0.5312 | 0.5129 | 0.5140 | 0.5608 | 0.5291 | 0.6082 | 0.5160 |
| L40-3 | 0.5080 | 0.5077 | 0.5083 | 0.5084 | 0.5070 | 0.5071 | 0.5086 | 0.5090 | 0.5101 |
| L40-4 | 0.6409 | 0.6400 | 0.6406 | 0.6398 | 0.6397 | 0.6406 | 0.6413 | 0.6410 | 0.6391 |
| L50-1 | 0.6232 | 0.6247 | 0.6210 | 0.6236 | 0.6272 | 0.6231 | 0.6263 | 0.6260 | 0.6237 |
| L50-2 | 0.5385 | 0.5368 | 0.5392 | 0.5376 | 0.5382 | 0.5405 | 0.5373 | 0.5395 | 0.5403 |
| L50-3 | 0.2679 | 0.2663 | 0.2675 | 0.2667 | 0.2677 | 0.2673 | 0.2689 | 0.2675 | 0.2696 |
| L50-4 | 0.6610 | 0.6658 | 0.6644 | 0.6692 | 0.6703 | 0.6572 | 0.6630 | 0.6705 | 0.6715 |
| f/s/t | 0/0/4 | 0/0/1 | 1/1/0 | 0/1/1 | 1/0/1 | 1/2/0 | 2/4/3 | 4/5/4 | 7/3/2 |
| Set | RLCLRP/FCCE | RLCLRP/TD | RLCLRP/TT | Reduction rate (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| IGD | HV | IGD | HV | IGD | HV | Gap1 | Gap2 | Gap3 | Gap4 | |
| L20-1 | 3.66 × 10–5 | 0.3741 | 2.50 × 10–3 | 0.3733 | 9.66 × 10–2 | 0.3032 | 98.53 | 0.22 | 99.96 | 23.39 |
| L20-2 | 2.99 × 10–3 | 0.3763 | 8.79 × 10–3 | 0.3910 | 1.83 × 10–2 | 0.3685 | 66.05 | –3.76 | 83.68 | 2.10 |
| L20-3 | 0.00 × 100 | 0.5817 | 2.23 × 10–2 | 0.5634 | 1.24 × 10–1 | 0.5090 | 100.00 | 3.26 | 100.00 | 14.30 |
| L20-4 | 1.48 × 10–5 | 0.6576 | 1.05 × 10–2 | 0.6375 | 3.18 × 10–2 | 0.6309 | 99.86 | 3.16 | 99.95 | 4.25 |
| L30-1 | 0.00 × 100 | 0.4951 | 2.41 × 10–3 | 0.4940 | 2.35 × 10–1 | 0.4259 | 100.00 | 0.22 | 100.00 | 16.26 |
| L30-2 | 0.00 × 100 | 0.5003 | 5.32 × 10–3 | 0.4987 | 1.43 × 10–2 | 0.4821 | 100.00 | 0.31 | 100.00 | 3.78 |
| L30-3 | 5.92 × 10–12 | 0.5797 | 7.44 × 10–3 | 0.5725 | 1.02 × 10–1 | 0.4642 | 100.00 | 1.27 | 100.00 | 24.88 |
| L30-4 | 0.00 × 100 | 0.6323 | 3.27 × 10–3 | 0.6304 | 2.10 × 10–1 | 0.5702 | 100.00 | 0.31 | 100.00 | 10.91 |
| L40-1 | 1.65 × 10–5 | 0.6754 | 1.22 × 10–1 | 0.5245 | 1.32 × 10–1 | 0.5086 | 99.99 | 28.77 | 99.99 | 32.79 |
| L40-2 | 0.00 × 100 | 0.6827 | 1.36 × 10–1 | 0.5170 | 1.40 × 10–1 | 0.5034 | 100.00 | 32.03 | 100.00 | 35.61 |
| L40-3 | 1.82 × 10–6 | 0.5161 | 1.44 × 10–2 | 0.5101 | 1.09 × 10–1 | 0.3914 | 99.99 | 1.19 | 100.00 | 31.87 |
| L40-4 | 4.66 × 10–4 | 0.6486 | 1.26 × 10–1 | 0.6377 | 1.24 × 10–1 | 0.5016 | 99.63 | 1.71 | 99.63 | 29.31 |
| L50-1 | 0.00 × 100 | 0.6387 | 1.35 × 10–2 | 0.6303 | 2.38 × 10–1 | 0.5335 | 100.00 | 1.34 | 100.00 | 19.73 |
| L50-2 | 2.68 × 10–5 | 0.5609 | 3.27 × 10–2 | 0.5435 | 1.42 × 10–1 | 0.3927 | 99.92 | 3.19 | 99.98 | 42.82 |
| L50-3 | 5.00 × 10–5 | 0.2773 | 9.62 × 10–3 | 0.2672 | 2.23 × 10–1 | 0.1711 | 99.48 | 3.79 | 99.98 | 62.07 |
| L50-4 | 1.82 × 10–4 | 0.6094 | 5.58 × 10–2 | 0.5940 | 3.15 × 10–2 | 0.5855 | 99.67 | 2.59 | 99.42 | 4.08 |
| Av. | 97.69 | 4.98 | 98.91 | 22.38 | ||||||
| Set | HF | L1 | L2 | M | Reduction rate (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| IGD | HV | IGD | HV | IGD | HV | IGD | HV | Gap1 | Gap2 | Gap3 | |
| L20-1 | 0.00 × 100 | 0.6911 | 3.11 × 10–1 | 0.3704 | 1.06 × 10–2 | 0.6796 | 4.26 × 10–2 | 0.6529 | 86.57 | 1.70 | 5.86 |
| L20-2 | 0.00 × 100 | 0.5016 | 4.00 × 10–1 | 0.1043 | 4.84 × 10–3 | 0.4967 | 3.20 × 10–2 | 0.4753 | 380.99 | 0.99 | 5.54 |
| L30-1 | 0.00 × 100 | 0.2411 | 3.21 × 10–1 | 0.0358 | 1.09 × 10–2 | 0.2307 | 6.03 × 10–2 | 0.1775 | 573.78 | 4.53 | 35.88 |
| L30-2 | 0.00 × 100 | 0.5416 | 7.59 × 10–1 | 0.0269 | 4.81 × 10–2 | 0.4869 | 4.99 × 10–2 | 0.5309 | 1916.61 | 11.23 | 2.02 |
| L40-1 | 0.00 × 100 | 0.3556 | 6.50 × 10–1 | 0.0291 | 6.28 × 10–2 | 0.3005 | 1.61 × 10–2 | 0.3420 | 1122.99 | 18.36 | 3.97 |
| L40-2 | 0.00 × 100 | 0.4335 | 6.58 × 10–1 | 0.0107 | 3.30 × 10–3 | 0.4292 | 7.14 × 10–2 | 0.3851 | 3969.89 | 1.01 | 12.57 |
| L50-1 | 0.00 × 100 | 0.4524 | 7.48 × 10–1 | 0.0088 | 7.19 × 10–2 | 0.3861 | 6.61 × 10–2 | 0.4403 | 5033.95 | 17.16 | 2.75 |
| L50-2 | 0.00 × 100 | 0.5580 | 7.55 × 10–1 | 0.0467 | 1.06 × 10–1 | 0.4538 | 1.10 × 10–2 | 0.5486 | 1095.97 | 22.95 | 1.70 |
| Av. | 1772.60 | 9.74 | 8.79 | ||||||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leng, L.; Zhao, Y.; Wang, Z.; Zhang, J.; Wang, W.; Zhang, C. A Novel Hyper-Heuristic for the Biobjective Regional Low-Carbon Location-Routing Problem with Multiple Constraints. Sustainability 2019, 11, 1596. https://0-doi-org.brum.beds.ac.uk/10.3390/su11061596
Leng L, Zhao Y, Wang Z, Zhang J, Wang W, Zhang C. A Novel Hyper-Heuristic for the Biobjective Regional Low-Carbon Location-Routing Problem with Multiple Constraints. Sustainability. 2019; 11(6):1596. https://0-doi-org.brum.beds.ac.uk/10.3390/su11061596
Chicago/Turabian StyleLeng, Longlong, Yanwei Zhao, Zheng Wang, Jingling Zhang, Wanliang Wang, and Chunmiao Zhang. 2019. "A Novel Hyper-Heuristic for the Biobjective Regional Low-Carbon Location-Routing Problem with Multiple Constraints" Sustainability 11, no. 6: 1596. https://0-doi-org.brum.beds.ac.uk/10.3390/su11061596