2.1. Definition of Black Spot
Though no universally accepted definition of a black spot or black zone has been given, these locations are generally described as high-risk accident locations. Determining whether a place is a black spot depends on different definitions. In Australia, the definition of a black spot is given as: for individual sites such as an intersection, a mid-block, or a short road section, there has to be a history of at least three casualty crashes in any one year, three casualty crashes over a three-year period, four casualty crashes over a four-year period, five casualty crashes over a five-year period, etc. For lengths of road, there must be an average of 0.2 casualty crashes per kilometer of the length in question over five years, or the road length to be treated must be amongst the top 10% of sites with a demonstrated higher crash rate than that of other roads in a region [
16].
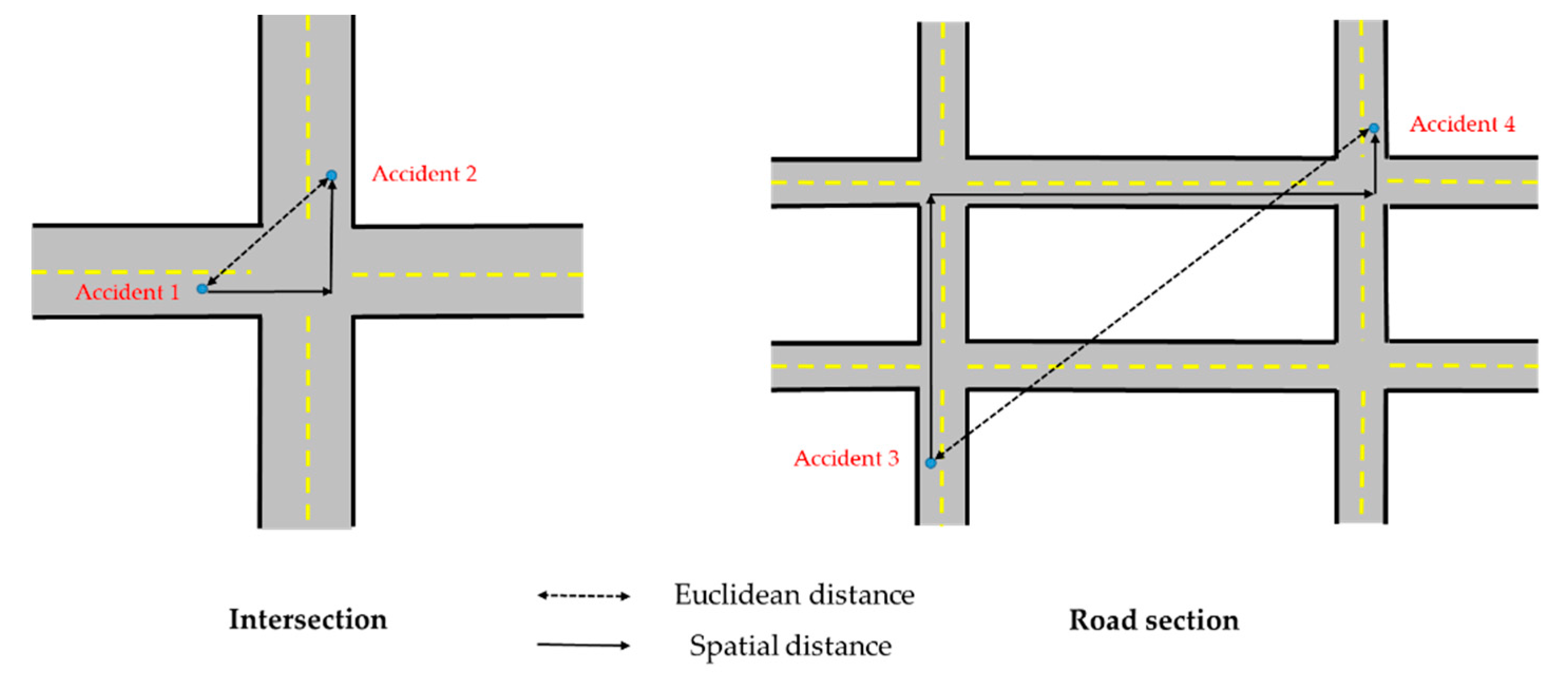
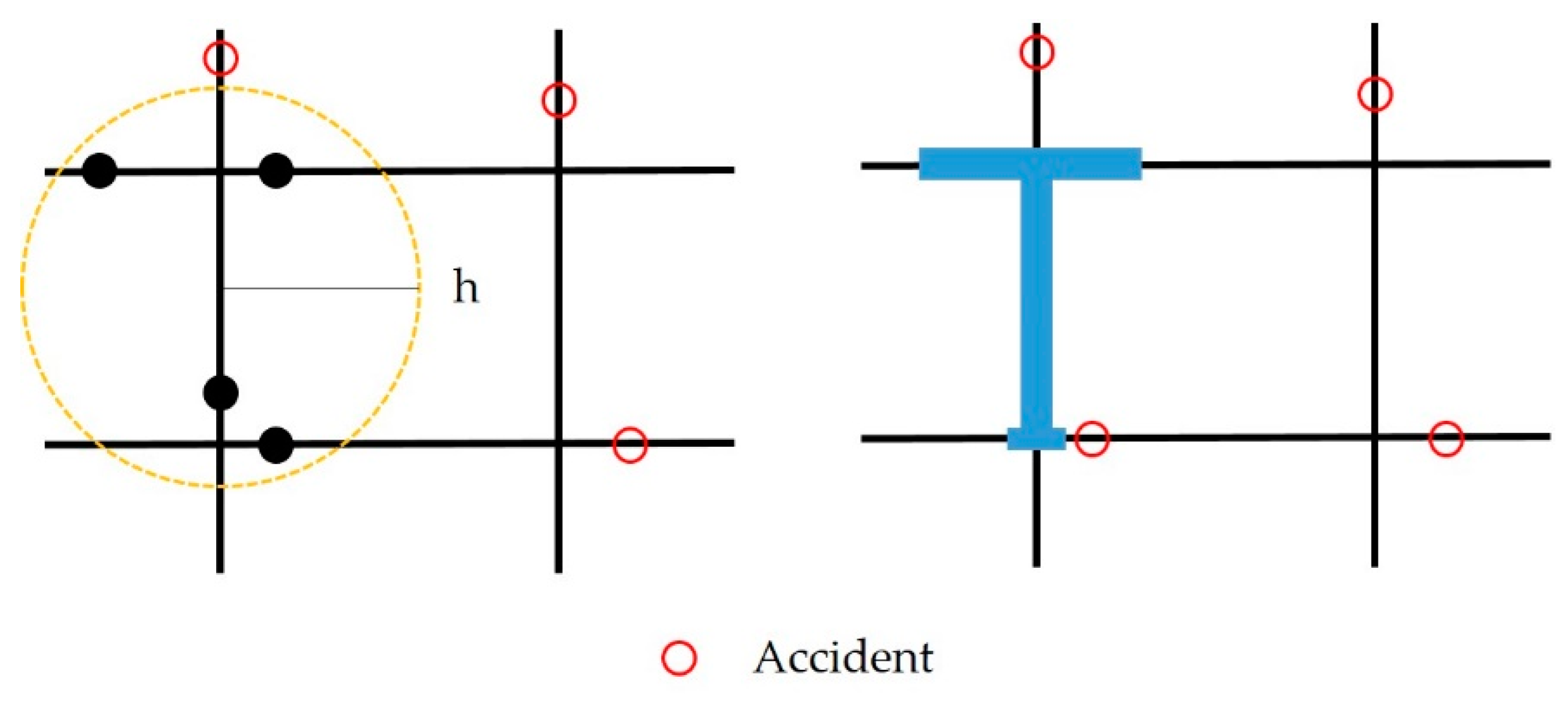
Identifying a black spot mainly depends on the definitions used. In circumstances of the urban road, a black spot may be an intersection, a section of road, or any other location that meets the definition. Therefore, this research mainly focuses on urban road black spot identification. The accident time, number, and location are essential because they provide an advantage in practice. Combined with previous definition research, this research mainly refers to the rules of black spot identification that were promulgated by China in 2001. Ultimately, the urban road black spot is regarded as being the following: For a road section within 500 meters or an intersection within 150 meters, there has to be a history of at least three casualty crashes in any one year, which means that a normal number of accidents is three in 500-meter road section or 150 meters of an intersection a year.
2.3. Firefly Clustering Algorithm to Identify the Black Spot
According to the distribution characteristics of a traffic accident point, it happens randomly for a single traffic accident. However, when several accidents occur continuously in one place of an urban road within a certain period, they must be impacted or affected by some external factors. This phenomenon of aggregation is very similar to the firefly clustering phenomenon, so this research intends to introduce the Firefly Clustering Algorithm to identify black spots, because it is an efficient, stable, and widely applicable method that is suitable for different types of accident data. In addition, the Firefly Clustering Algorithm can also mine the similarity of accidents.
The Firefly algorithm was developed by Xin-She Yang [
17,
18] and is based on the idealized behavior of the flashing characteristics of fireflies. To concisely describe our firefly algorithm, this research uses the following three idealized rules:
(1) All fireflies are unisex, so one firefly will be attracted to other fireflies regardless of their sex.
(2) An important and interesting behavior of fireflies is to glow brighter, mainly to attract prey and to share food with others.
(3) Attractiveness is proportional to their brightness, so each agent firstly moves toward a neighbor that glows brighter [
19].
The Firefly Algorithm (FA) [
20] is a population-based algorithm that is used to find the global optima of objective functions based on swarm intelligence by investigating the foraging behavior of fireflies. In the FA, physical entities (agents or fireflies) are randomly distributed in the search space. Agents are thought of as fireflies that carry a luminescence quality, called luciferin, that emit light proportional to this value. Each firefly is attracted by the brighter glow of other neighboring fireflies. The attractiveness decreases as their distance increases. If there is no brighter one than a particular firefly, it will move randomly. In the application of the FA to clustering, the decision variables are cluster centers. The objective function is related to the sum on all training set instances of the Euclidean distance in an N-dimensional space [
21].
Based on this objective function, initially, all the agents (fireflies) are randomly dispersed across the search space. The two phases of the firefly algorithm are as follows.
(1) Variation of light intensity: Light intensity is related to objective values [
20]. One maximization/minimization problem is that a firefly with a high/low intensity will attract another firefly with a high/low intensity. Assuming that there exists a swarm of
agents (fireflies) and
represents a solution for a firefly
, whereas
denotes its fitness value, then here, the brightness
of a firefly is selected to reflect its current position
of its fitness value
[
18].
(2) Movement towards attractive firefly: Firefly attractiveness is proportional to the light intensity seen by adjacent fireflies [
16]. Each firefly has its distinctive attractiveness
that implies how strong it attracts other members of the swarm. However, the attractiveness
is relative and varies with the distance
between two fireflies,
and
at locations
and
, respectively, which is given as.
The attractiveness function
of the firefly is determined by
where
is the attractiveness at
and
is the light absorption coefficient.
The movement of a firefly
at location
attracted to another more attractive (brighter) firefly
at location
is determined by
A detailed description of this FA is given in [
20]. A pseudo-code of this algorithm is given in
Figure 3.
The clustering methods, separating the objects into groups or classes, are developed based on unsupervised learning. In the unsupervised technique, the training data set are grouped first, based solely on the numerical information in the data (i.e., cluster centers) and are then matched by the analyst to information classes. The data sets that we tackled contained the information of classes for each data. Therefore, the main goal was to find the centers of the clusters by minimizing the objective function, the sum of distances of the patterns to their centers [
19].
For
given objects, the problem is to minimize the sum of the squared Euclidean distances between each pattern and allocate each pattern to one of the
cluster centers. The clustering objective function is the sum of error squared, as given in Equation (5), is described as in [
22]:
where
is the number of clusters for a given
pattern.
is the location of the
pattern. and
is the
clustering center, to be found by Equation (6):
where
is the number of patterns in the
cluster.
The cluster analysis forms the assignment of the dataset into clusters so that it can be grouped into the same cluster based on some similarity measures [
23]. Distance measurement is most widely used for evaluating similarities between patterns. The cluster centers are the decision variables that are obtained by minimizing the sum of the Euclidean distance on all training set instances in the
d-dimensional space between generic instance
and the center of the cluster
. The cost (objective) function for the pattern
is given by Equation (7), as in [
21,
24]
where
is the number of training datasets that are used to normalize the sum that will range any distance within
and
defines the class that instance belongs to according to database.
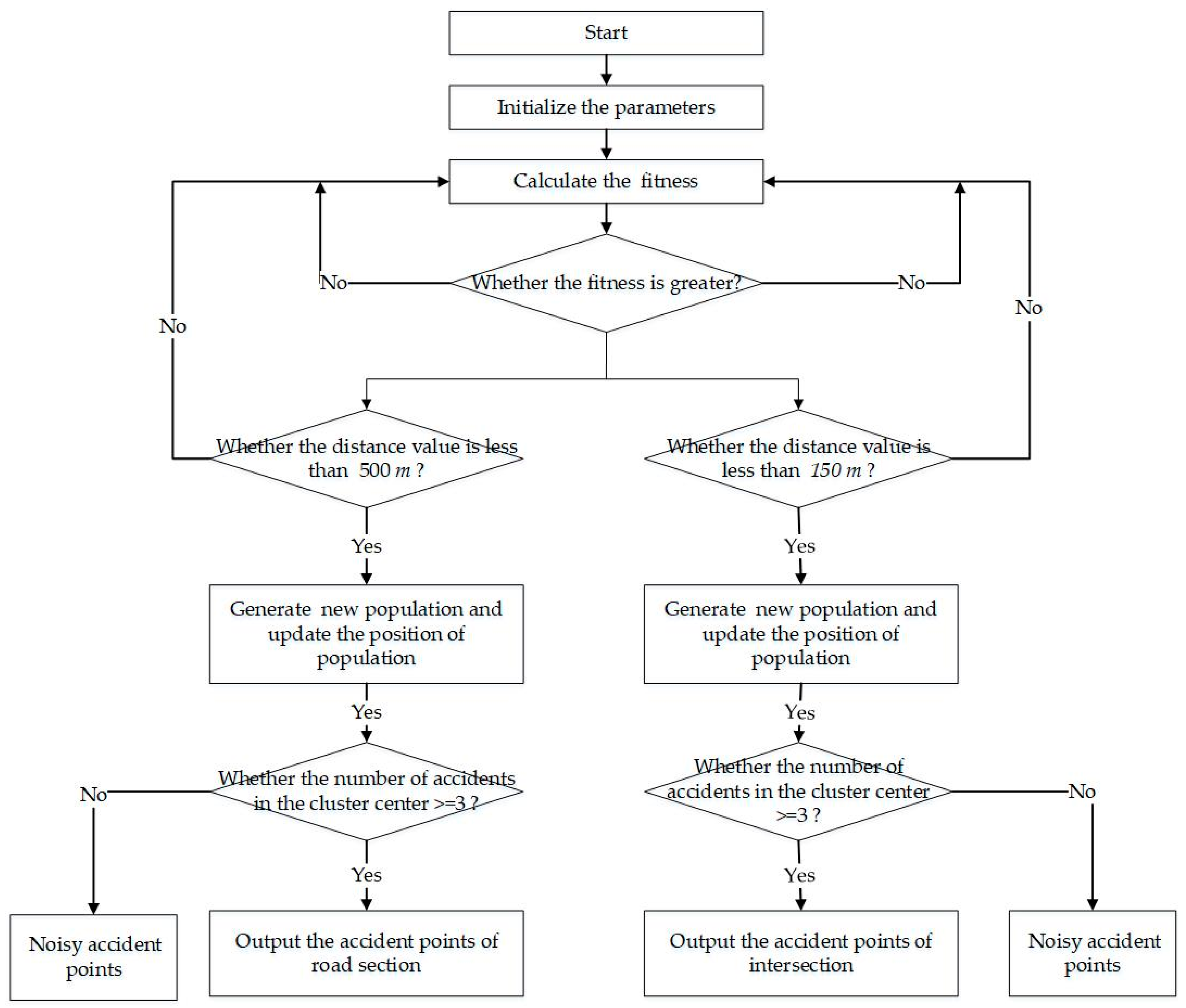
A detailed description of this Firefly Clustering Algorithm is given in [
20]. A flowchart of this algorithm is given in
Figure 4.
2.4. Study Area and Distance Calculation with GIS
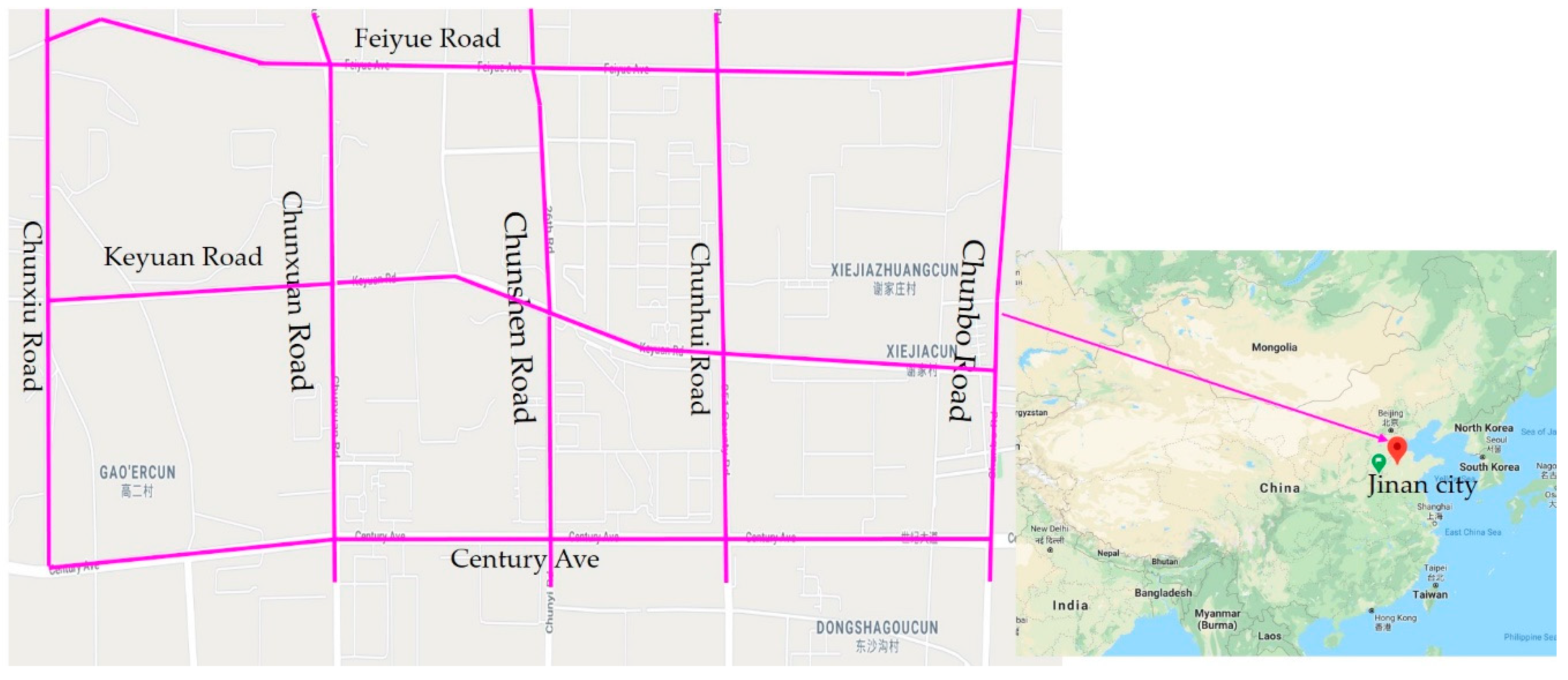
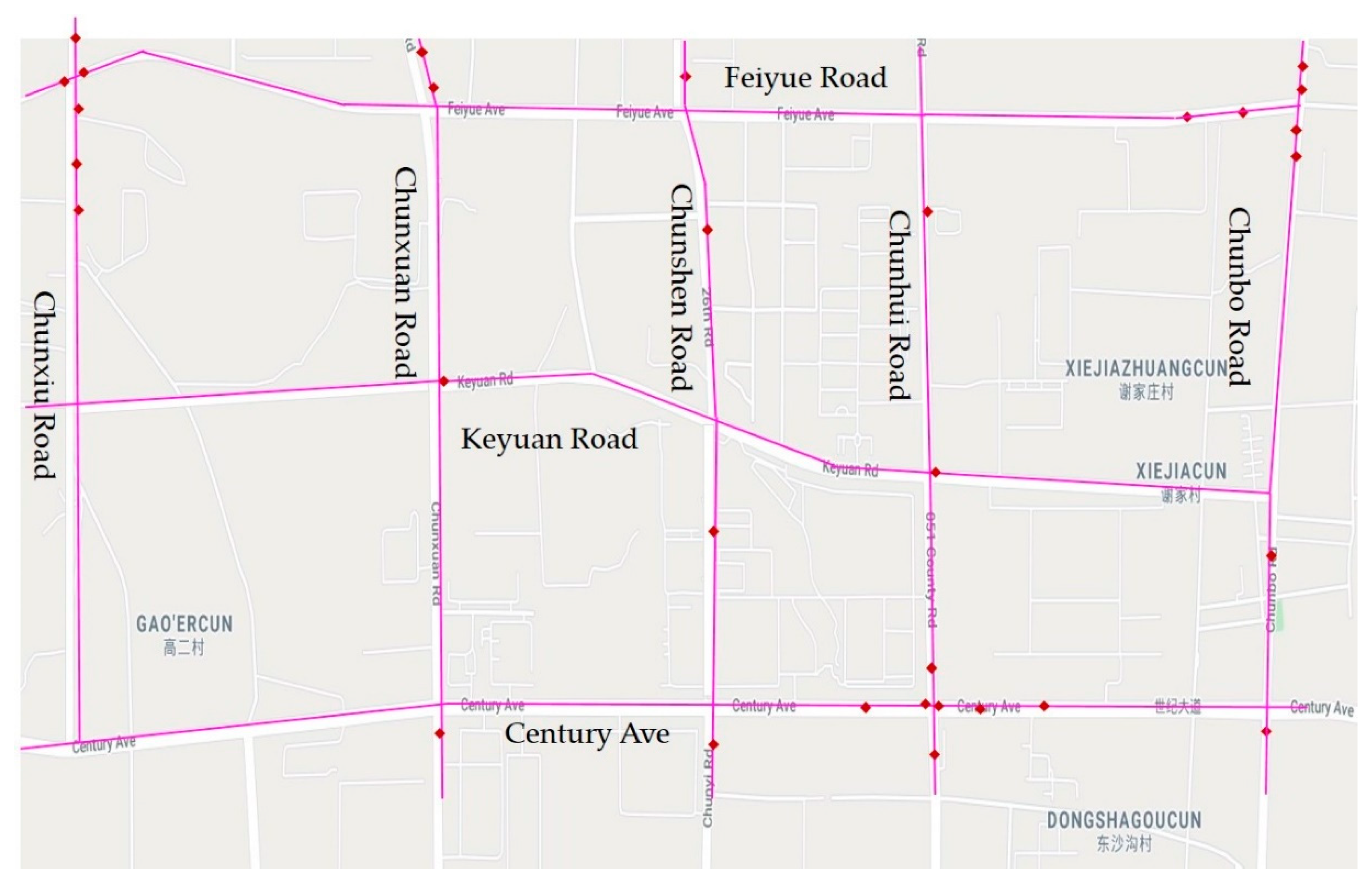
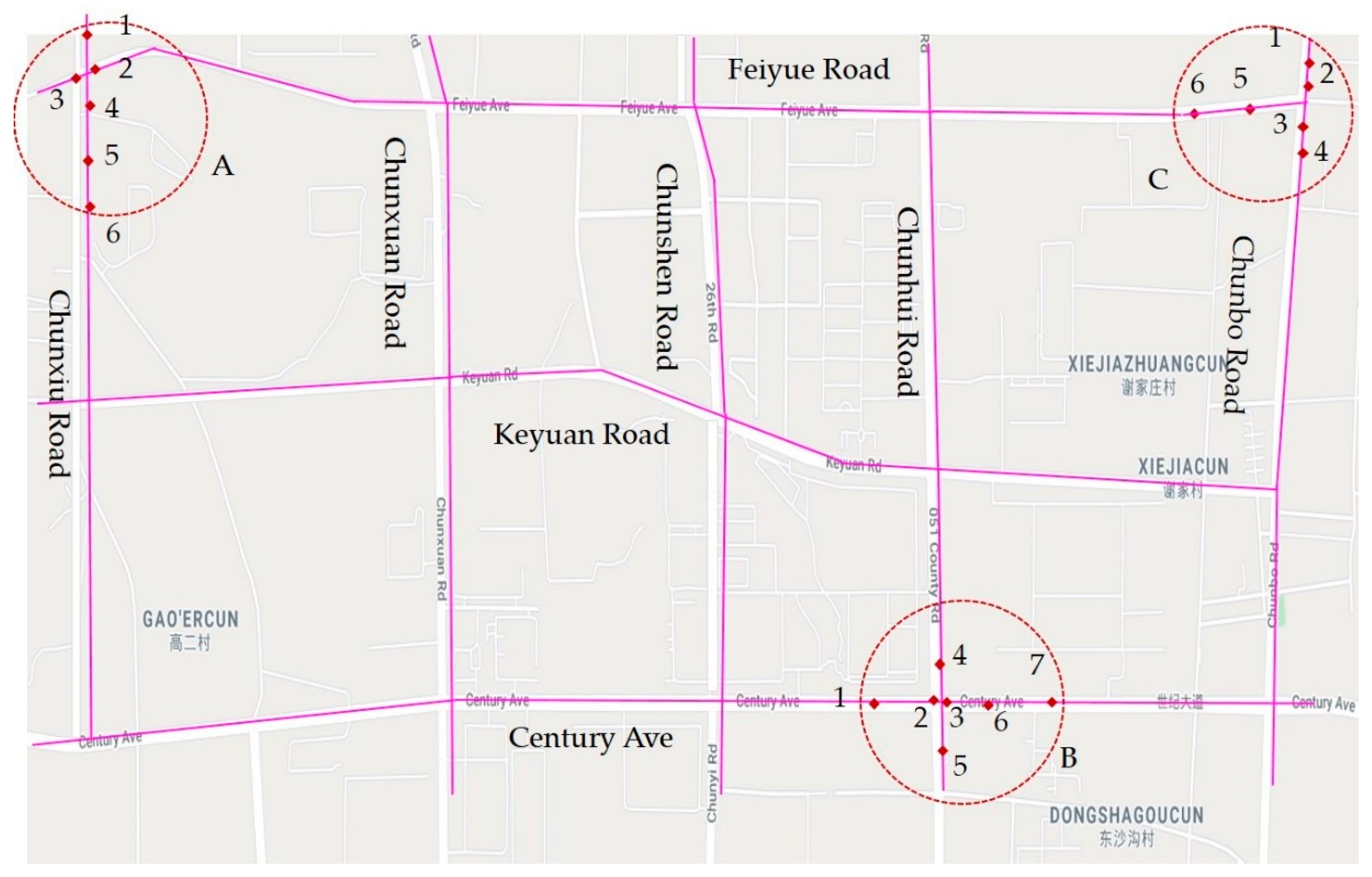
This research used distance calculation with GIS to identify accident black spots and to help improve road safety in urban road contexts. The study area was the “Licheng” district located in the east of Jinan, China.
Figure 5 shows the roads in the study area. From north to south, this area contains Feiyue Road, Keyuan Road, and Century Avenue, which are urban main roads with three lanes in each direction. From west to east, this area contains Chunxiu Road, Chunxuan Road, Chunshen Road, and Chunbo Road, which are urban roads with two lanes in each direction. The surrounding areas are all residential and commercial areas, with traffic accidents often occurring in these intersections and road sections in recent years.
This research chose GIS to calculate the distance among accident points. GIS is increasingly being used in road safety research and traffic planning because of its ability to manage, display, and analyze spatial data [
25]. A critical issue when using GIS in the identification of black spots is the procedure for calculating distances. Here, the distance calculation was carried out with ArcGIS 10.0, because the ArcGIS spatial analyst can provide several distance mapping tools for measuring distance, especially when the location of an accident is roughly described in CAD (Computer Aided Design) files. Therefore, this research adopts the origin–destination (OD) cost distance to indicate the shortest distance between the accident points because the OD cost distance not only means the least-cost or shortest path from a chosen destination to the source point but also signifies additional factors beyond the cost surface to account for the actual travel distance over the terrain.
Taking the traffic accident data of study area as an example, the detailed procedures were as follows:
(1) Establishment of the road network.
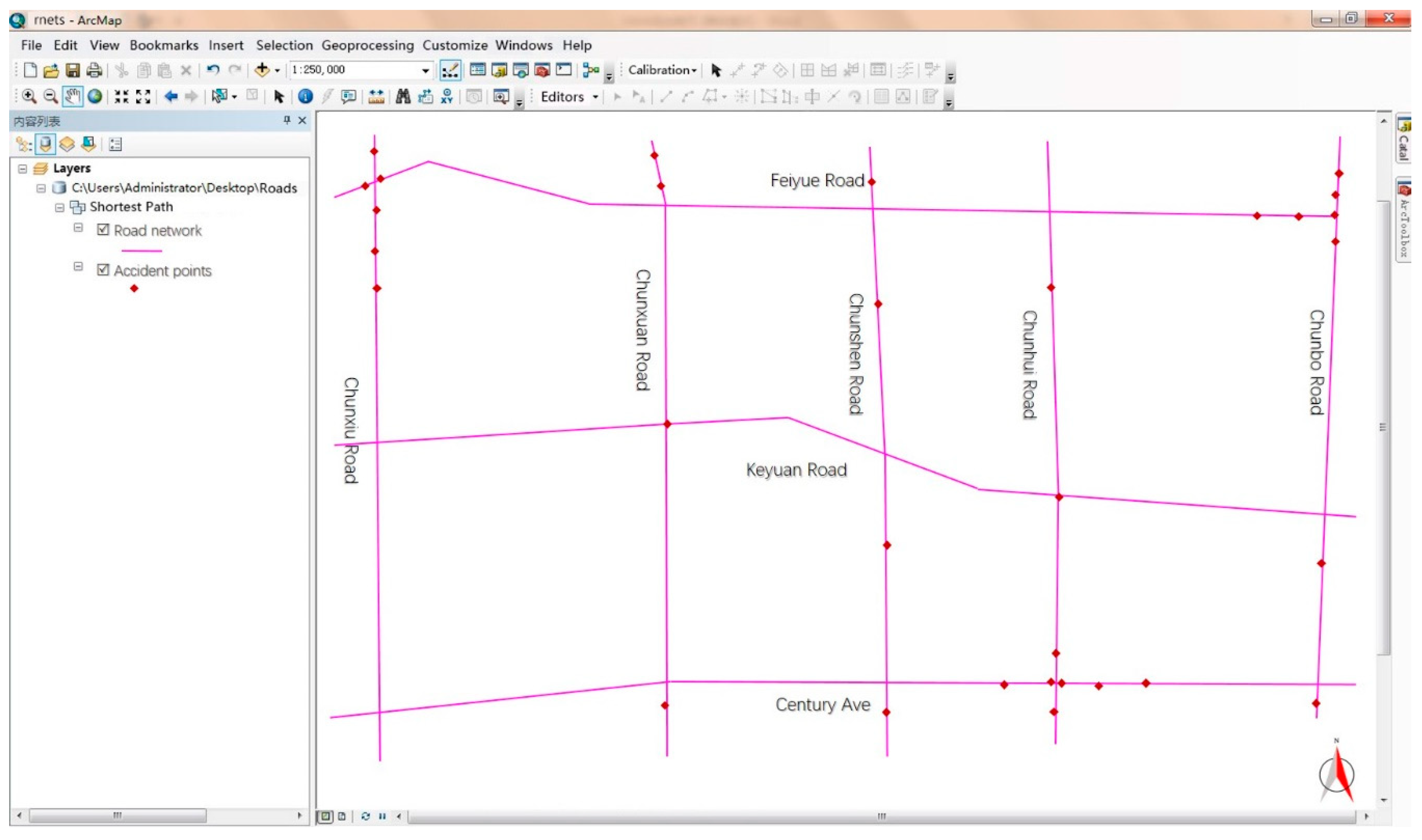
(i) Prepare the road network CAD file (including the accident points) and import it into the ArcGIS platform, correcting the wrong sections and nodes to obtain the basic data of the road network so that it can pass the topology inspection.
(ii) Interrupt the basic data of the road network at nodes according to road connectivity.
(iii) Employ the ArcGIS software to create road network data set. The result is given as shown in
Figure 6.
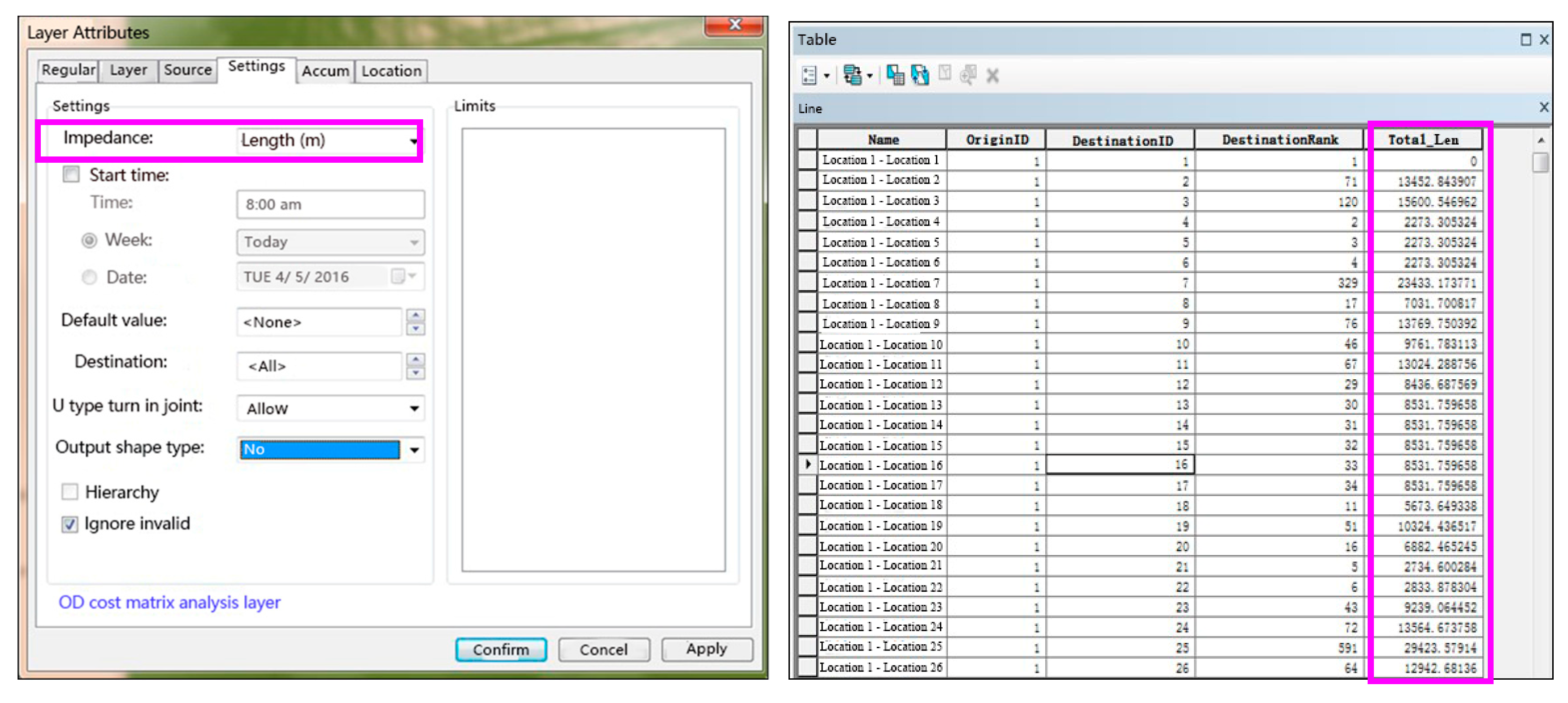
(2) OD cost distance calculation with GIS.
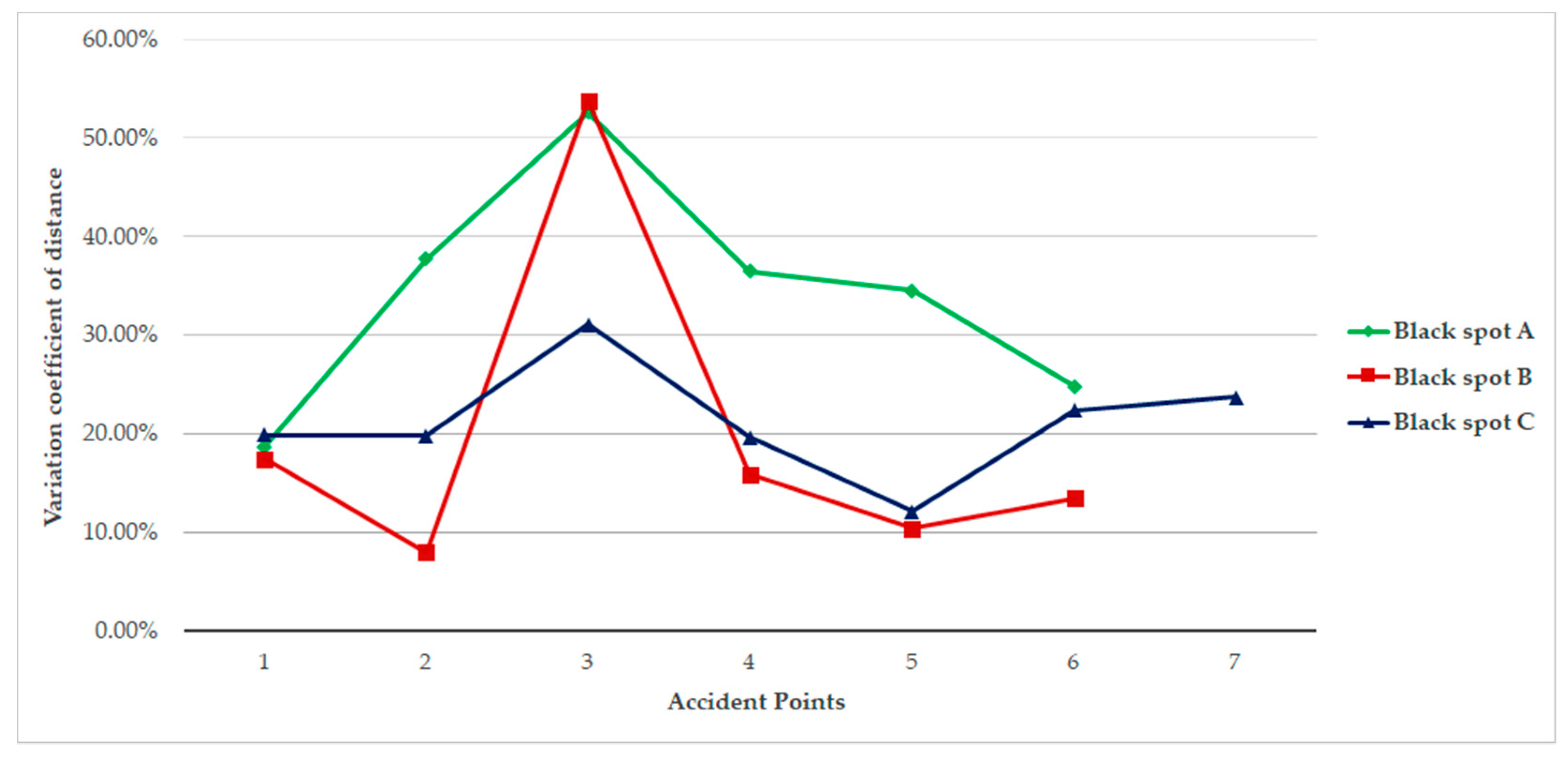
(i) Set the accident point as the start and end point of the OD distance matrix and create the point pair OD distance matrix, as the OD cost distance matrix in the network analysis is used to calculate the distance of road length between point pairs.
(ii) Output the road network distance diagram and sort the data to obtain the distance between the accident points. The calculated distance of point pair is the shortest distance between accident points.
The detailed procedure and output are described as shown in
Figure 7.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}