A Hybrid Model for PM2.5 Concentration Forecasting Based on Neighbor Structural Information, a Case in North China

Abstract
:1. Introduction
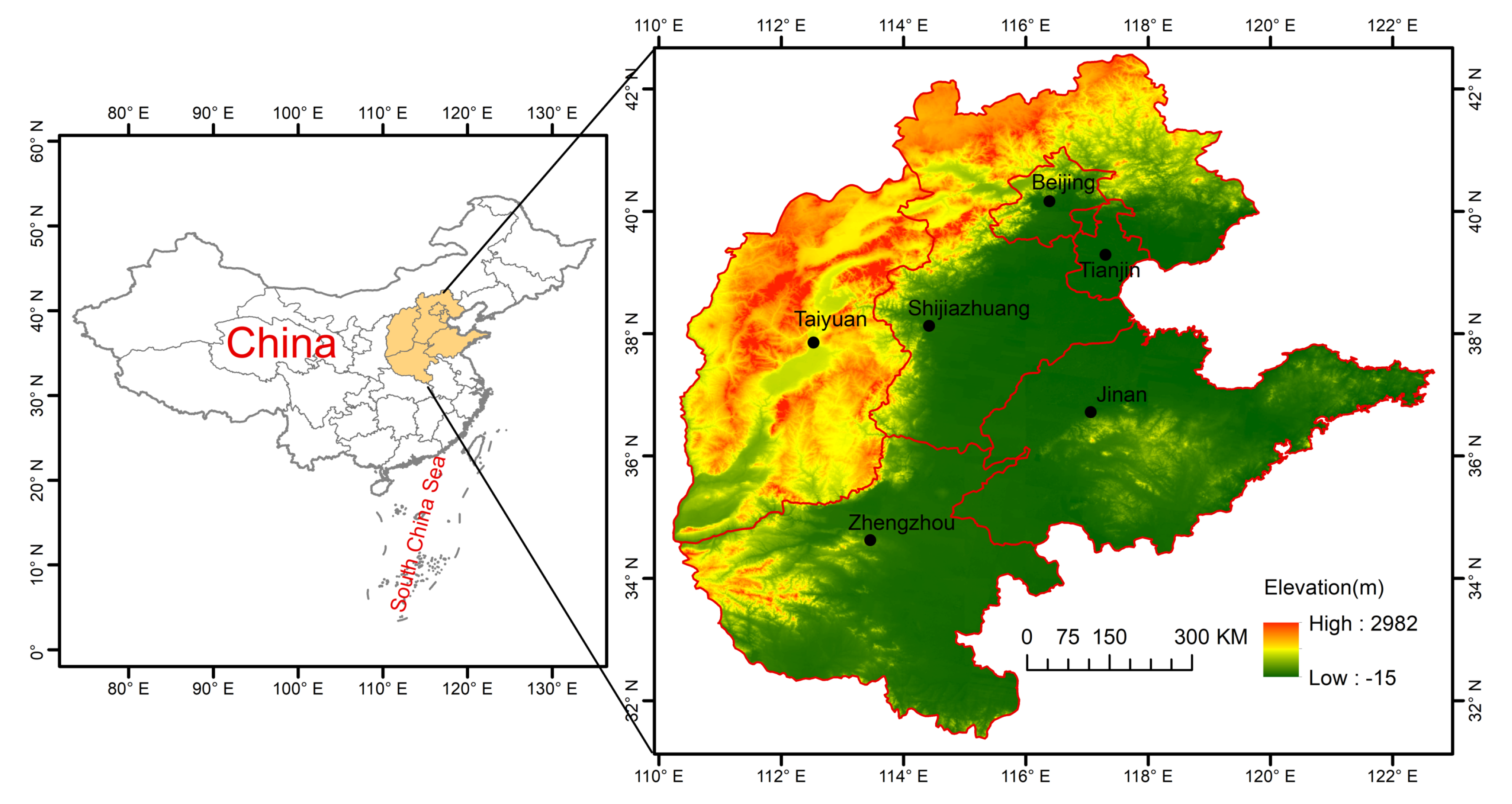
2. Study Area and Available Data
3. Methods
3.1. Neighbor Structural Information Extraction Algorithm Based on Time Series Dynamic Decomposition
- Separate the dynamic modes hidden in the time series itself so that we can use the neighbor structural information sufficiently by optimized combination;
- We are able to choose the neighbor structural information by the tuning the parameter , , that reflects the characteristic of the time series we mentioned above;
- Compared with machine learning models, the structural characteristics of time series data in time dimension are preserved;
- The white noise in the time series are filtered. So such a decomposition is robust to the white noise.
3.2. The Hybrid Model Based on Neighbor Structural Information for PM Concentration Prediction
| Algorithm 1: PM concentration prediction hybrid model based on neighbor structural information |
|
3.3. Performance Evaluation Index of Prediction Model
4. Results and Discussion
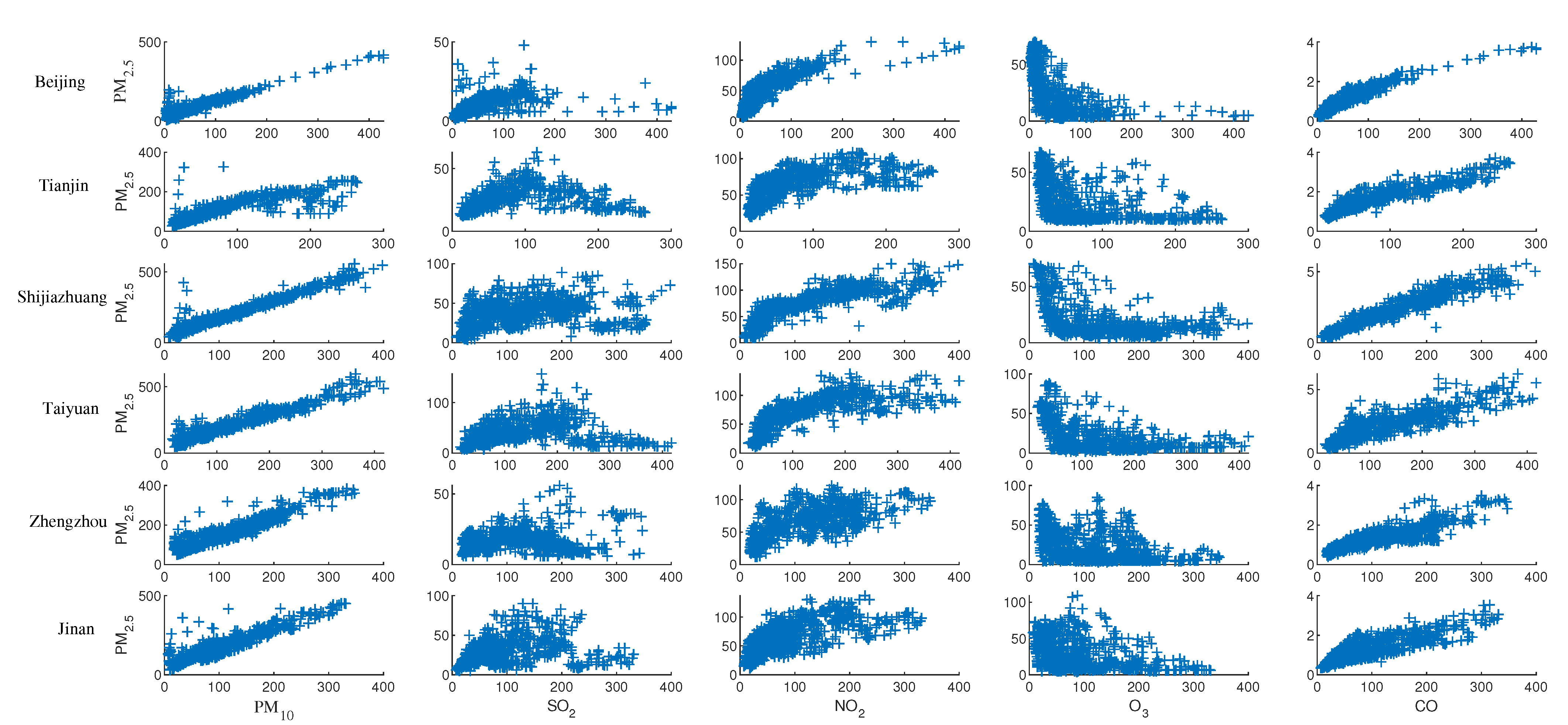
4.1. Data Statistics and Analysis
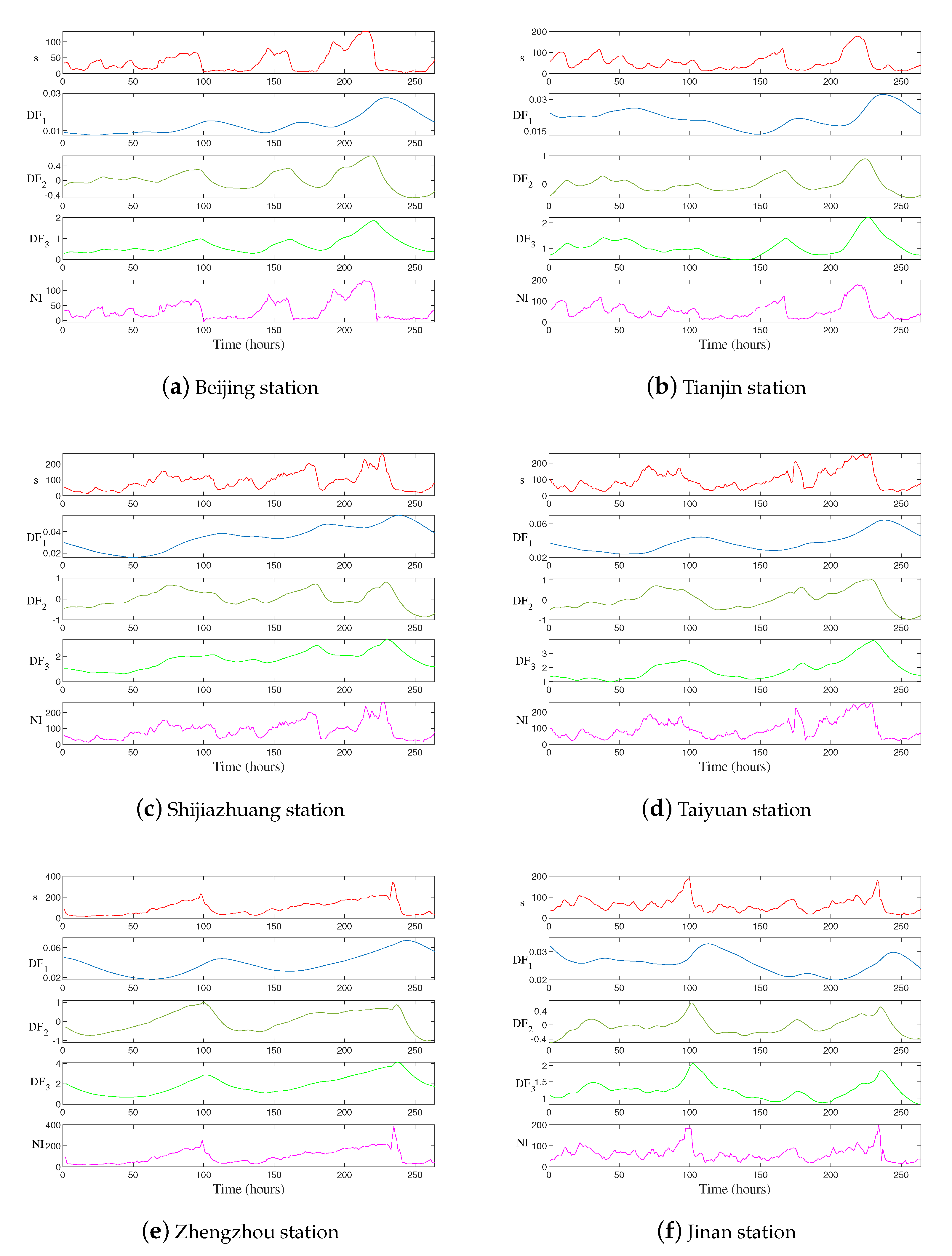
4.2. Neighbor Structural Information Extraction
4.3. Results of the Hybrid Model Based on Neighbor Structural Information
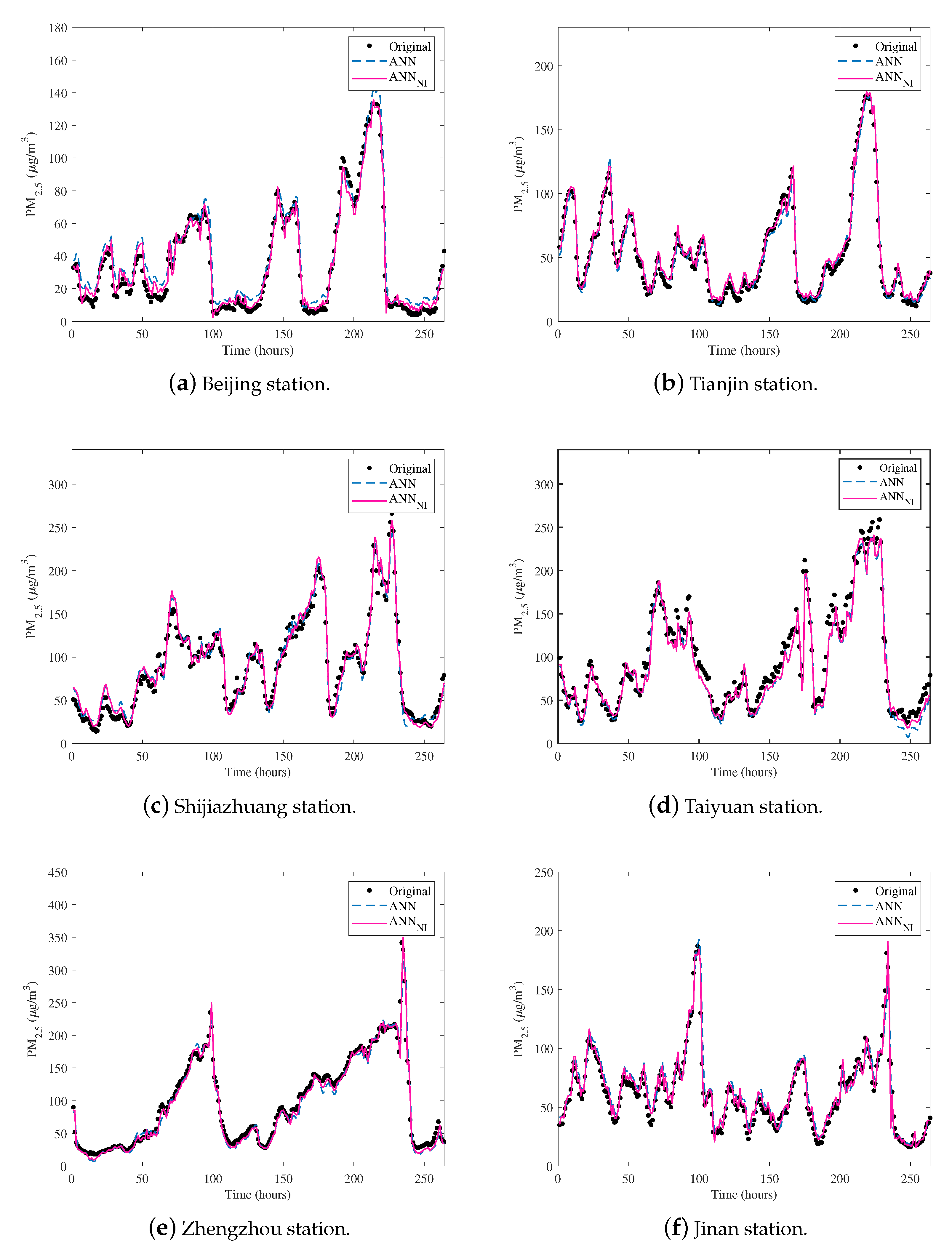
4.3.1. Prediction Results Comparison between ANN and ANN
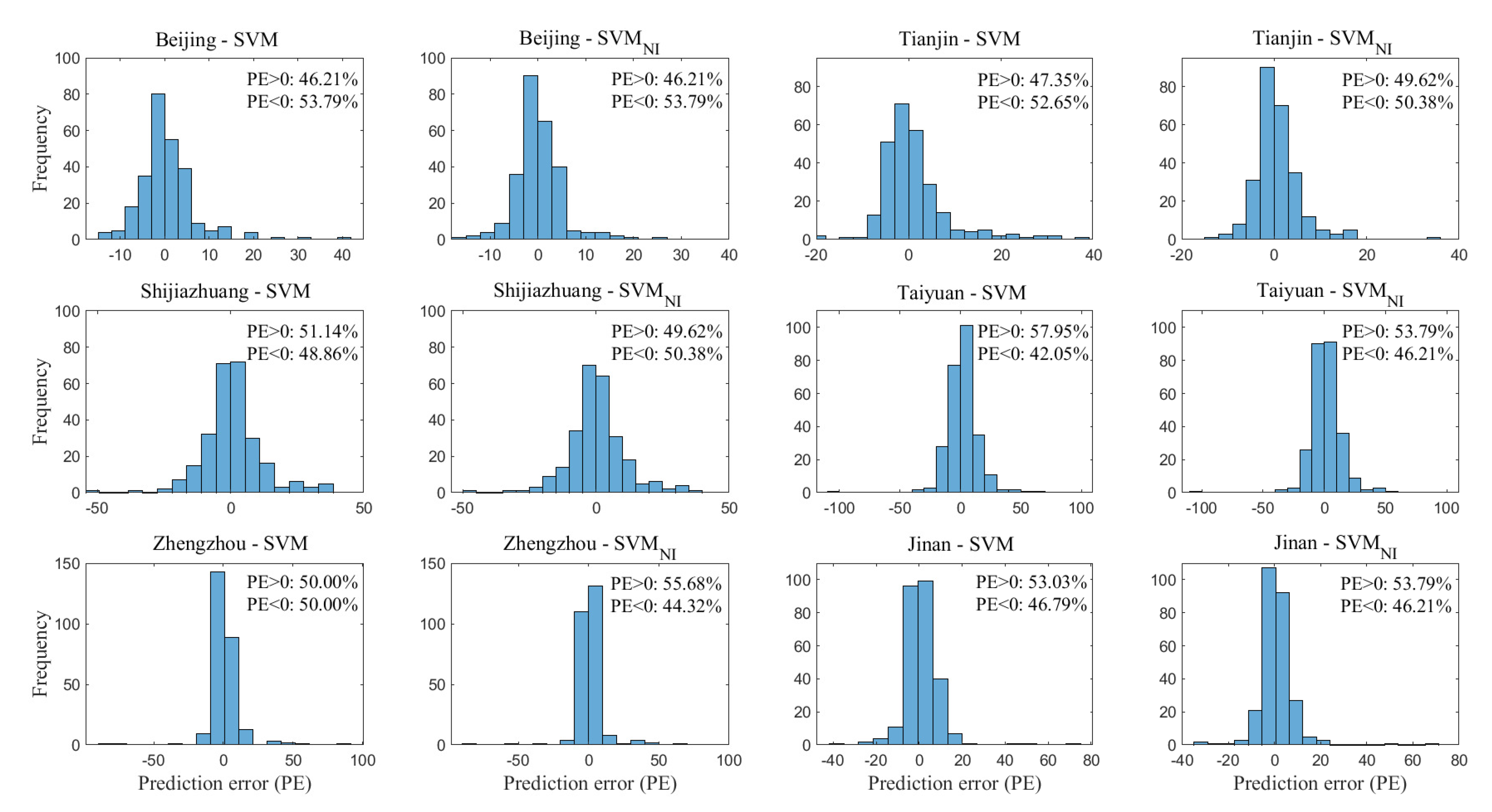
4.3.2. Prediction Results Comparison between SVM and SVM
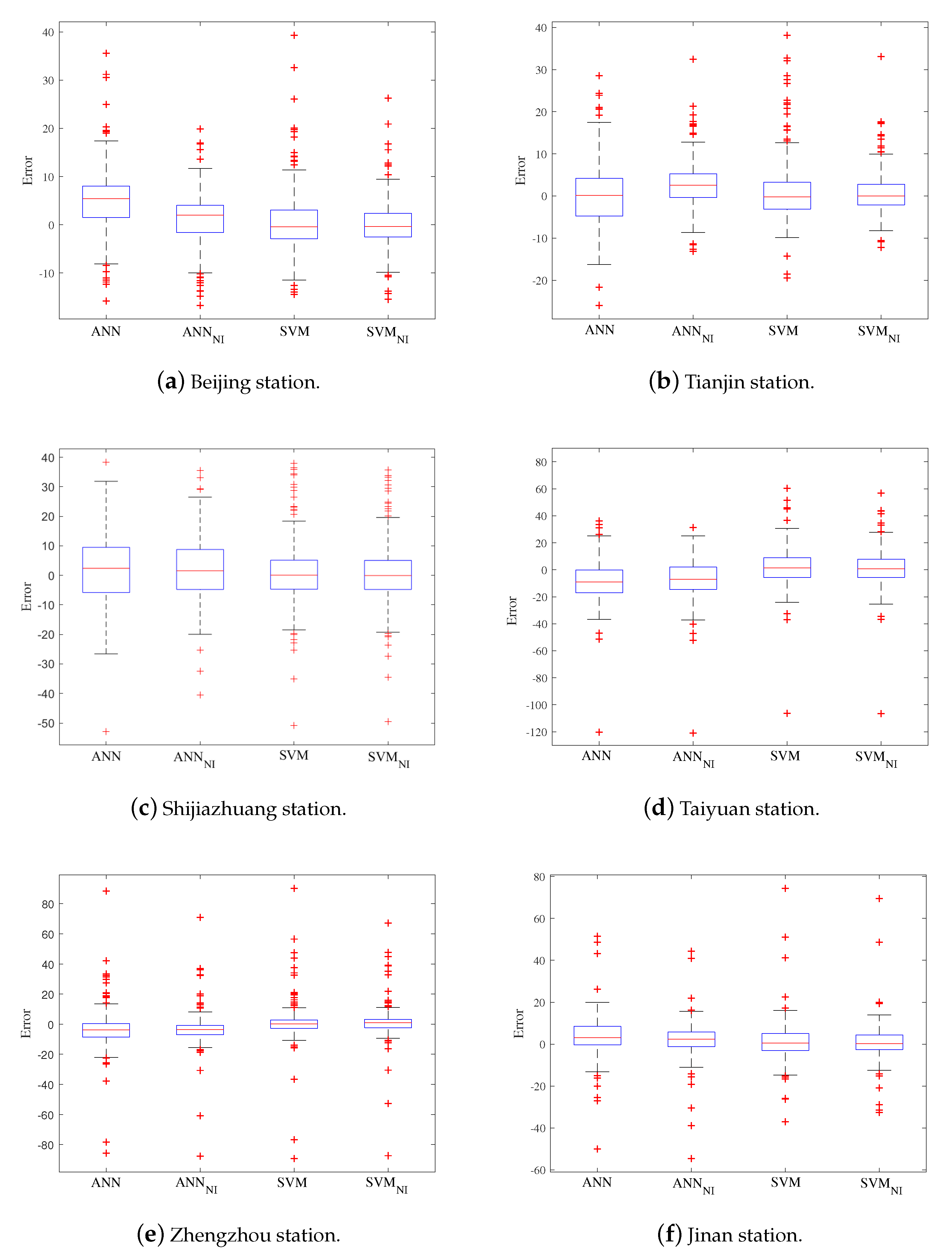
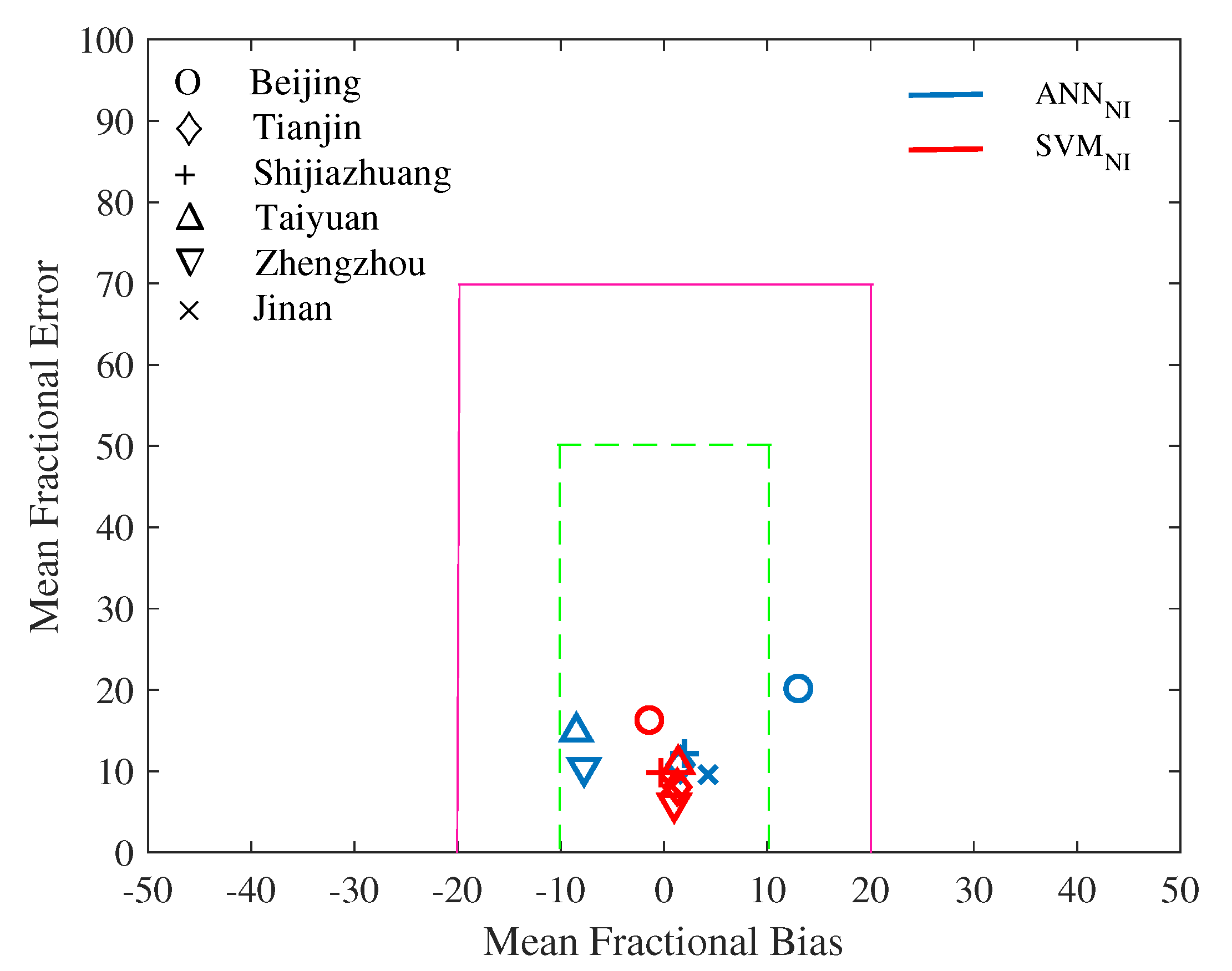
4.3.3. Prediction Results Comparison between ANN and SVM
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Forouzanfar, M.H.; Afshin, A.; Alexander, L.T.; Anderson, H.R.; Bhutta, Z.A.; Biryukov, S.; Brauer, M.; Burnett, R.; Cercy, K.; Charlson, F.J.; et al. Global, regional, and national comparative risk assessment of 79 behavioural, environmental and occupational, and metabolic risks or clusters of risks, 1990–2015: A systematic analysis for the Global Burden of Disease Study 2015. Lancet 2016, 388, 1659–1724. [Google Scholar] [CrossRef] [Green Version]
- Zheng, T.; Bergin, M.H.; Hu, S.; Miller, J.; Carlson, D.E. Estimating ground-level PM2.5 using micro-satellite images by a convolutional neural network and random forest approach. Atmos. Environ. 2020, 230, 117451. [Google Scholar] [CrossRef]
- Niu, M.; Gan, K.; Sun, S.; Li, F. Application of decomposition-ensemble learning paradigm with phase space reconstruction for day-ahead PM2.5 concentration forecasting. J. Environ. Manag. 2017, 196, 110–118. [Google Scholar] [CrossRef]
- Zhou, J.; Xing, Z.; Deng, J.; Du, K. Characterizing and sourcing ambient PM2.5 over key emission regions in China I: Water-soluble ions and carbonaceous fractions. Atmos. Environ. 2016, 135, 20–30. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, G.; Li, X. Mining sequential patterns of PM2.5 pollution between 338 cities in China. J. Environ. Manag. 2020, 262, 110341. [Google Scholar] [CrossRef]
- Pui, D.Y.; Chen, S.C.; Zuo, Z. PM2.5 in China: Measurements, sources, visibility and health effects, and mitigation. Particuology 2014, 13, 1–26. [Google Scholar] [CrossRef]
- Pak, U.; Ma, J.; Ryu, U.; Ryom, K.; Juhyok, U.; Pak, K.; Pak, C. Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China. Sci. Total Environ. 2020, 699, 133561. [Google Scholar] [CrossRef]
- Ding, L.; Zhu, D.; Peng, D.; Zhao, Y. Air pollution and asthma attacks in children: A case–crossover analysis in the city of Chongqing, China. Environ. Pollut. 2017, 220, 348–353. [Google Scholar] [CrossRef]
- Lionetto, M.; Guascito, M.; Caricato, R.; Giordano, M.; Bartolomeo, A.; Romano, M.; Conte, M.; Dinoi, A.; Contini, D. Correlation of Oxidative Potential with Ecotoxicological and Cytotoxicological Potential of PM10 at an Urban Background Site in Italy. Atmosphere 2019, 10, 733. [Google Scholar] [CrossRef] [Green Version]
- Shen, R.; Liu, Z.; Chen, X.; Wang, Y.; Wang, L.; Liu, Y.; Li, X. Atmospheric levels, variations, sources and health risk of PM2.5-bound polycyclic aromatic hydrocarbons during winter over the North China Plain. Sci. Total Environ. 2019, 655, 581–590. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, B.; Zhang, J.; Yu, Y.; Wang, Y. Characteristics of aerosol size distributions and chemical compositions during wintertime pollution episodes in Beijing. Atmos. Res. 2016, 168, 1–12. [Google Scholar] [CrossRef]
- Qi, Y.; Li, Q.; Karimian, H.; Liu, D. A hybrid model for spatiotemporal forecasting of PM2.5 based on graph convolutional neural network and long short-term memory. Sci. Total Environ. 2019, 664, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Bray, C.D.; Battye, W.; Aneja, V.P.; Tong, D.; Lee, P.; Tang, Y.; Nowak, J.B. Evaluating ammonia (NH3) predictions in the NOAA National Air Quality Forecast Capability (NAQFC) using in-situ aircraft and satellite measurements from the CalNex2010 campaign. Atmos. Environ. 2017, 163, 65–76. [Google Scholar] [CrossRef]
- Woody, M.; Wong, H.W.; West, J.; Arunachalam, S. Multiscale predictions of aviation-attributable PM2.5 for U.S. airports modeled using CMAQ with plume-in-grid and an aircraft-specific 1-D emission model. Atmos. Environ. 2016, 147, 384–394. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, F.J.; Chang, L.C.; Kao, I.F.; Wang, Y.S.; Kang, C.C. Multi-output support vector machine for regional multi-step-ahead PM2.5 forecasting. Sci. Total Environ. 2019, 651, 230–240. [Google Scholar] [CrossRef]
- Lv, B.; Cobourn, W.G.; Bai, Y. Development of nonlinear empirical models to forecast daily PM2.5 and ozone levels in three large Chinese cities. Atmos. Environ. 2016, 147, 209–223. [Google Scholar] [CrossRef]
- Cobourn, W.G. An enhanced PM2.5 air quality forecast model based on nonlinear regression and back-trajectory concentrations. Atmos. Environ. 2010, 44, 3015–3023. [Google Scholar] [CrossRef]
- Suleiman, A.; Tight, M.; Quinn, A. Applying machine learning methods in managing urban concentrations of traffic-related particulate matter (PM10 and PM2.5). Atmos. Pollut. Res. 2019, 10, 134–144. [Google Scholar] [CrossRef]
- Catalano, M.; Galatioto, F.; Bell, M.; Namdeo, A.; Bergantino, A.S. Improving the prediction of air pollution peak episodes generated by urban transport networks. Environ. Sci. Policy 2016, 60, 69–83. [Google Scholar] [CrossRef] [Green Version]
- Ragosta, M.; D’Emilio, M.; Giorgio, G. Input strategy analysis for an air quality data modelling procedure at a local scale based on neural network. Environ. Monit. Assess. 2015, 187, 4556. [Google Scholar] [CrossRef]
- Zhou, Q.; Jiang, H.; Wang, J.; Zhou, J. A hybrid model for PM2.5 forecasting based on ensemble empirical mode decomposition and a general regression neural network. Sci. Total Environ. 2014, 496, 264–274. [Google Scholar] [CrossRef] [PubMed]
- MA, J.; Ding, Y.; Cheng, J.C.; Jiang, F.; Wan, Z. A Temporal-Spatial Interpolation and Extrapolation Method Based on Geographic Long Short-Term Memory Neural Network for PM2.5. J. Clean. Prod. 2019, 237, 117729. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, F.J.; Chen, H.; Li, H. Exploring Copula-based Bayesian Model Averaging with multiple ANNs for PM2.5 ensemble forecasts. J. Clean. Prod. 2020, 263, 121528. [Google Scholar] [CrossRef]
- Yang, W.; Deng, M.; Xu, F.; Wang, H. Prediction of hourly PM2.5 using a space-time support vector regression model. Atmos. Environ. 2018, 181, 12–19. [Google Scholar] [CrossRef]
- Biancofiore, F.; Busilacchio, M.; Verdecchia, M.; Tomassetti, B.; Aruffo, E.; Bianco, S.; Tommaso, S.D.; Colangeli, C.; Rosatelli, G.; Carlo, P.D. Recursive neural network model for analysis and forecast of PM10 and PM2.5. Atmos. Pollut. Res. 2017, 8, 652–659. [Google Scholar] [CrossRef]
- Neto, P.S.G.D.M.; Marinho, M.H.N.; Siqueira, H.; Tadano, Y.D.S.; Machado, V.; Alves, T.A.; Oliveira, J.F.L.D.; Madeiro, F. A Methodology to Increase the Accuracy of Particulate Matter Predictors Based on Time Decomposition. Sustainability 2020, 12, 7310. [Google Scholar] [CrossRef]
- Crone, S.F.; Kourentzes, N. Feature selection for time series prediction—A combined filter and wrapper approach for neural networks. Neurocomputing 2010, 73, 1923–1936. [Google Scholar] [CrossRef] [Green Version]
- Mouatadid, S.; Raj, N.; Deo, R.C.; Adamowski, J.F. Input selection and data-driven model performance optimization to predict the Standardized Precipitation and Evaporation Index in a drought-prone region. Atmos. Res. 2018, 212, 130–149. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, J.; Li, C.; Fu, W.; Peng, T. A compound structure of ELM based on feature selection and parameter optimization using hybrid backtracking search algorithm for wind speed forecasting. Energy Convers. Manag. 2017, 143, 360–376. [Google Scholar] [CrossRef]
- Shukur, O.B.; Lee, M.H. Daily wind speed forecasting through hybrid KF-ANN model based on ARIMA. Renew. Energy 2015, 76, 637–647. [Google Scholar] [CrossRef]
- Song, Z.; Fu, D.; Zhang, X.; Han, X.; Song, J.; Zhang, J.; Wang, J.; Xia, X. MODIS AOD sampling rate and its effect on PM2.5 estimation in North China. Atmos. Environ. 2019, 209, 14–22. [Google Scholar] [CrossRef]
- Li, M.; Wang, L.; Liu, J.; Gao, W.; Song, T.; Sun, Y.; Li, L.; Li, X.; Wang, Y.; Liu, L.; et al. Exploring the regional pollution characteristics and meteorological formation mechanism of PM2.5 in North China during 2013–2017. Environ. Int. 2020, 134, 105283. [Google Scholar] [CrossRef] [PubMed]
- Lv, Z.; Wei, W.; Cheng, S.; Han, X.; Wang, X. Meteorological characteristics within boundary layer and its influence on PM2.5 pollution in six cities of North China based on WRF-Chem. Atmos. Environ. 2020, 228, 117417. [Google Scholar] [CrossRef]
- Lai, S.; Zhao, Y.; Ding, A.; Zhang, Y.; Song, T.; Zheng, J.; Ho, K.F.; Lee, S.C.; Zhong, L. Characterization of PM2.5 and the major chemical components during a 1-year campaign in rural Guangzhou, Southern China. Atmos. Res. 2016, 167, 208–215. [Google Scholar] [CrossRef]
- He, Q.; Yan, Y.; Guo, L.; Zhang, Y.; Zhang, G.; Wang, X. Characterization and source analysis of water-soluble inorganic ionic species in PM2.5 in Taiyuan city, China. Atmos. Res. 2017, 184, 48–55. [Google Scholar] [CrossRef]
- Meng, Z.; Jiang, X.; Yan, P.; Lin, W.; Zhang, H.; Wang, Y. Characteristics and sources of PM2.5 and carbonaceous species during winter in Taiyuan, China. Atmos. Environ. 2007, 41, 6901–6908. [Google Scholar] [CrossRef]
- Zhang, H.; Cheng, S.; Li, J.; Yao, S.; Wang, X. Investigating the aerosol mass and chemical components characteristics and feedback effects on the meteorological factors in the Beijing-Tianjin-Hebei region, China. Environ. Pollut. 2019, 244, 495–502. [Google Scholar] [CrossRef]
- Cesari, D.; De Benedetto, G.; Bonasoni, P.; Busetto, M.; Dinoi, A.; Merico, E.; Chirizzi, D.; Cristofanelli, P.; Donateo, A.; Grasso, F.; et al. Seasonal variability of PM2.5 and PM10 composition and sources in an urban background site in Southern Italy. Sci. Total Environ. 2018, 612, 202–213. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Air Pollutant | Mean | Median | Maximum | Minimum | Std.Dev. |
|---|---|---|---|---|---|---|
| Beijing | PM (g/m) | 50.20565 | 30.00000 | 428.0000 | 3.000000 | 57.88467 |
| PM (g/m) | 77.31048 | 65.00000 | 418.0000 | 5.000000 | 58.53817 | |
| SO (g/m) | 8.561828 | 6.500000 | 48.00000 | 1.000000 | 6.011335 | |
| NO (g/m) | 47.51747 | 50.00000 | 130.0000 | 6.000000 | 27.53585 | |
| O (g/m) | 28.67070 | 23.50000 | 70.00000 | 2.000000 | 20.96675 | |
| CO (mg/m) | 0.933587 | 0.750000 | 3.742000 | 0.209000 | 0.630729 | |
| Tianjin | PM (g/m) | 74.29704 | 53.00000 | 264.0000 | 11.00000 | 60.94219 |
| PM (g/m) | 102.0175 | 87.00000 | 326.0000 | 27.00000 | 54.85783 | |
| SO (g/m) | 24.25269 | 23.00000 | 63.00000 | 12.00000 | 8.944761 | |
| NO (g/m) | 62.98118 | 65.00000 | 109.0000 | 20.00000 | 21.53334 | |
| O (g/m) | 25.21237 | 17.00000 | 67.00000 | 8.000000 | 16.87227 | |
| CO (mg/m) | 1.531824 | 1.432000 | 3.706000 | 0.633000 | 0.645200 | |
| Shijiazhuang | PM (g/m) | 136.7097 | 121.0000 | 398.0000 | 8.000000 | 88.25823 |
| PM (g/m) | 220.4261 | 195.5000 | 558.0000 | 41.00000 | 111.2739 | |
| SO (g/m) | 38.38978 | 39.00000 | 89.00000 | 4.000000 | 16.39194 | |
| NO (g/m) | 76.67473 | 76.00000 | 150.0000 | 9.000000 | 27.84390 | |
| O (g/m) | 19.95027 | 13.00000 | 70.00000 | 4.000000 | 15.83976 | |
| CO (mg/m) | 2.239602 | 2.063000 | 5.563000 | 0.386000 | 1.163192 | |
| Taiyuan | PM (g/m) | 130.3347 | 109.0000 | 417.0000 | 16.00000 | 85.56525 |
| PM (g/m) | 211.0081 | 189.0000 | 597.0000 | 46.00000 | 104.2559 | |
| SO (g/m) | 40.59812 | 37.00000 | 157.0000 | 7.000000 | 21.78152 | |
| NO (g/m) | 72.69220 | 73.00000 | 137.0000 | 11.00000 | 25.47325 | |
| O (g/m) | 18.66801 | 10.00000 | 88.00000 | 2.000000 | 18.33893 | |
| CO (mg/m) | 2.145191 | 2.033000 | 6.225000 | 0.350000 | 1.103918 | |
| Zhengzhou | PM (g/m) | 121.5551 | 120.5000 | 347.0000 | 18.00000 | 74.17929 |
| PM (g/m) | 168.6075 | 164.0000 | 384.0000 | 50.00000 | 74.15855 | |
| SO (g/m) | 16.93011 | 16.00000 | 56.00000 | 6.000000 | 7.428471 | |
| NO (g/m) | 65.97043 | 67.00000 | 122.0000 | 12.00000 | 23.79673 | |
| O (g/m) | 21.71371 | 14.00000 | 85.00000 | 3.000000 | 18.55841 | |
| CO (mg/m) | 1.376922 | 1.282500 | 3.489000 | 0.383000 | 0.584595 | |
| Jinan | PM (g/m) | 94.49597 | 74.00000 | 331.0000 | 7.000000 | 69.41096 |
| PM (g/m) | 167.6237 | 143.0000 | 451.0000 | 30.00000 | 87.85827 | |
| SO (g/m) | 28.67339 | 26.00000 | 90.00000 | 5.000000 | 15.59996 | |
| NO (g/m) | 66.82796 | 67.00000 | 137.0000 | 11.00000 | 26.02158 | |
| O (g/m) | 27.22312 | 19.00000 | 109.0000 | 4.000000 | 20.94018 | |
| CO (mg/m) | 1.262667 | 1.125000 | 3.537000 | 0.338000 | 0.593352 |
| Station | PM | SO | NO | O | CO |
|---|---|---|---|---|---|
| Beijing | 4.4168 | 2.4362 | 3.8214 | 3.2117 | 1.0719 |
| Tianjin | 4.9867 | 3.0341 | 3.9941 | 2.9370 | 1.2865 |
| Shijiazhuang | 6.5212 | 4.2861 | 4.9755 | 3.6171 | 1.8261 |
| Taiyuan | 6.2537 | 4.4374 | 4.7564 | 3.5635 | 1.5286 |
| Zhengzhou | 5.7939 | 2.9521 | 4.5603 | 3.5413 | 1.1790 |
| Jinan | 5.7808 | 3.7637 | 4.5853 | 3.7543 | 0.9348 |
| Mutual Information | Beijing | Tianjin | Shijiazhuang | Taiyuan | Zhengzhou | Jinan |
|---|---|---|---|---|---|---|
| value | 4.2167 | 4.9123 | 5.7812 | 5.6822 | 5.7278 | 4.9012 |
| Data Set | Index | ANN | ANN | SVM | SVM |
|---|---|---|---|---|---|
| Beijing | MAE | 6.5432 | 4.2307 | 4.3235 | 3.2980 |
| RMSE | 8.2703 | 5.4690 | 6.4945 | 4.8231 | |
| IA | 0.9831 | 0.9923 | 0.9899 | 0.9944 | |
| DA | 0.6539 | 0.6996 | 0.6083 | 0.7034 | |
| MFB | 28.7589 | 13.0001 | −2.2404 | −1.4396 | |
| MFE | 31.4533 | 20.1745 | 19.9293 | 16.2861 | |
| Tianjin | MAE | 5.3457 | 4.3846 | 4.7683 | 3.4534 |
| RMSE | 7.2581 | 5.9939 | 7.5332 | 5.1871 | |
| IA | 0.9968 | 0.9979 | 0.9967 | 0.9984 | |
| DA | 0.5969 | 0.7262 | 0.6463 | 0.7756 | |
| MFB | 8.0473 | 1.5814 | 1.4136 | 1.2793 | |
| MFE | 11.5828 | 10.8061 | 10.3902 | 8.0389 | |
| Shijiazhuang | MAE | 9.3995 | 8.5755 | 7.5206 | 7.3754 |
| RMSE | 11.9466 | 10.9822 | 10.9781 | 10.5875 | |
| IA | 0.9967 | 0.9972 | 0.9972 | 0.9974 | |
| DA | 0.6045 | 0.6501 | 0.6958 | 0.6996 | |
| MFB | 3.1221 | 1.9686 | −0.7779 | −0.3174 | |
| MFE | 13.9759 | 12.1579 | 9.8720 | 9.7932 | |
| Taiyuan | MAE | 12.6996 | 11.8033 | 9.2276 | 9.0214 |
| RMSE | 17.0390 | 16.3416 | 14.0130 | 13.7118 | |
| IA | 0.9938 | 0.9943 | 0.9962 | 0.9963 | |
| DA | 0.5513 | 0.5551 | 0.6083 | 0.6387 | |
| MFB | −14.0013 | −8.5046 | 2.0742 | 1.3526 | |
| MFE | 18.6110 | 14.8266 | 11.0819 | 10.8000 | |
| Zhengzhou | MAE | 8.5289 | 6.8320 | 5.9189 | 5.1456 |
| RMSE | 13.6918 | 11.5107 | 12.7212 | 10.8639 | |
| IA | 0.9965 | 0.9975 | 0.9970 | 0.9978 | |
| DA | 0.5399 | 0.5893 | 0.6996 | 0.7604 | |
| MFB | −8.5200 | −7.7578 | 1.7476 | 0.9751 | |
| MFE | 13.2950 | 10.4419 | 7.0435 | 6.0181 | |
| Jinan | MAE | 7.0559 | 5.4676 | 5.7105 | 4.8441 |
| RMSE | 10.1595 | 8.4438 | 9.2179 | 8.2711 | |
| IA | 0.9949 | 0.9964 | 0.9957 | 0.9965 | |
| DA | 0.5741 | 0.6844 | 0.6121 | 0.7642 | |
| MFB | 6.9710 | 4.2608 | 1.0488 | 0.6914 | |
| MFE | 11.8254 | 9.5674 | 9.7819 | 8.2137 |
| ANN-SVM | ANN-SVM | |||||
|---|---|---|---|---|---|---|
| Data Set | Mean | Std.Dev. | t-Statistic | Mean | Std.Dev. | t-Statistic |
| Beijing | 2.219670 *** | 3.807447 | 9.47236 | 0.932633 *** | 2.347678 | 6.454671 |
| (0.0000) | (0.0000) | |||||
| Tianjin | 0.577466 ** | 4.044578 | 2.3198 | 0.931189 *** | 2.158192 | 7.010516 |
| (0.0211) | (0.0000) | |||||
| Shijiazhuang | 1.878932 *** | 6.838889 | 4.464033 | 1.200080 *** | 5.994610 | 3.252753 |
| (0.0000) | (0.0013) | |||||
| Taiyuan | 3.472034 *** | 9.939056 | 5.675979 | 2.781905 *** | 9.295694 | 4.862532 |
| (0.0000) | (0.0000) | |||||
| Zhengzhou | 2.609981 *** | 5.281503 | 8.029376 | 1.686462 *** | 4.162686 | 6.582713 |
| (0.0000) | (0.0000) | |||||
| Jinan | 1.345375 *** | 3.760126 | 5.813570 | 0.623489 *** | 3.679429 | 2.753278 |
| (0.0000) | (0.0063) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; He, X.; Feng, H.; Zhang, G.; Rong, C. A Hybrid Model for PM2.5 Concentration Forecasting Based on Neighbor Structural Information, a Case in North China. Sustainability 2021, 13, 447. https://0-doi-org.brum.beds.ac.uk/10.3390/su13020447
Wang P, He X, Feng H, Zhang G, Rong C. A Hybrid Model for PM2.5 Concentration Forecasting Based on Neighbor Structural Information, a Case in North China. Sustainability. 2021; 13(2):447. https://0-doi-org.brum.beds.ac.uk/10.3390/su13020447
Chicago/Turabian StyleWang, Ping, Xuran He, Hongyinping Feng, Guisheng Zhang, and Chenglu Rong. 2021. "A Hybrid Model for PM2.5 Concentration Forecasting Based on Neighbor Structural Information, a Case in North China" Sustainability 13, no. 2: 447. https://0-doi-org.brum.beds.ac.uk/10.3390/su13020447