
A Multi-Criteria Approach for Arabic Dialect Sentiment Analysis for Online Reviews: Exploiting Optimal Machine Learning Algorithm Selection

 , , , ,
, , , ,
Abstract
:1. Introduction
2. Related Work
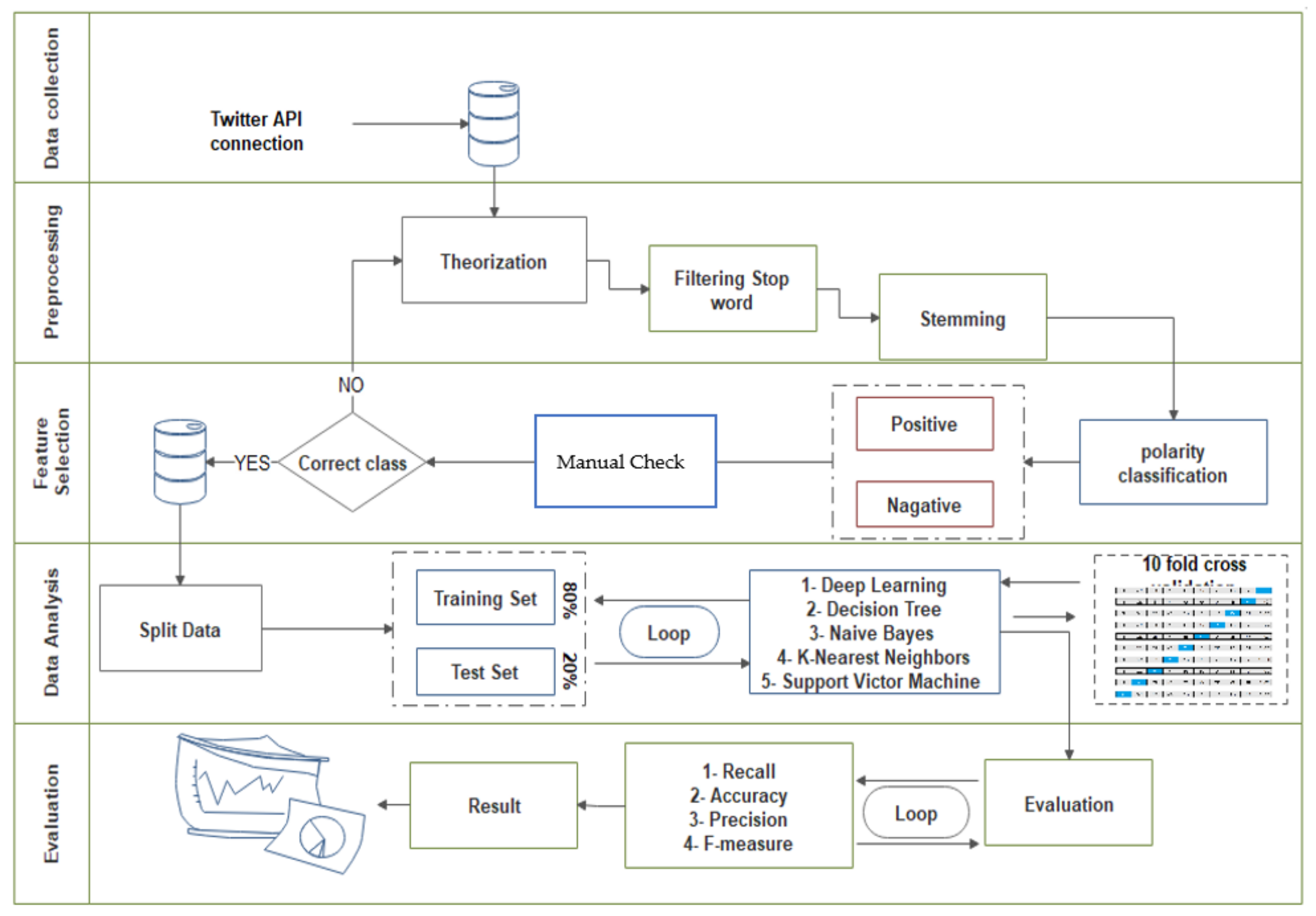
3. Materials and Methods
3.1. Data Collection
3.2. Pre-Processing
3.2.1. Tokenisation: Or 1.1 (Tokenisation)
3.2.2. Filtering Step Words
3.2.3. Stemming
3.3. Feature Selection
Manual Annotations
3.4. Data Analysis
3.4.1. Machine Learning Algorithms
Support Vector Machine
K-Nearest Neighbours
Decision Tree
Mathematical Formulation
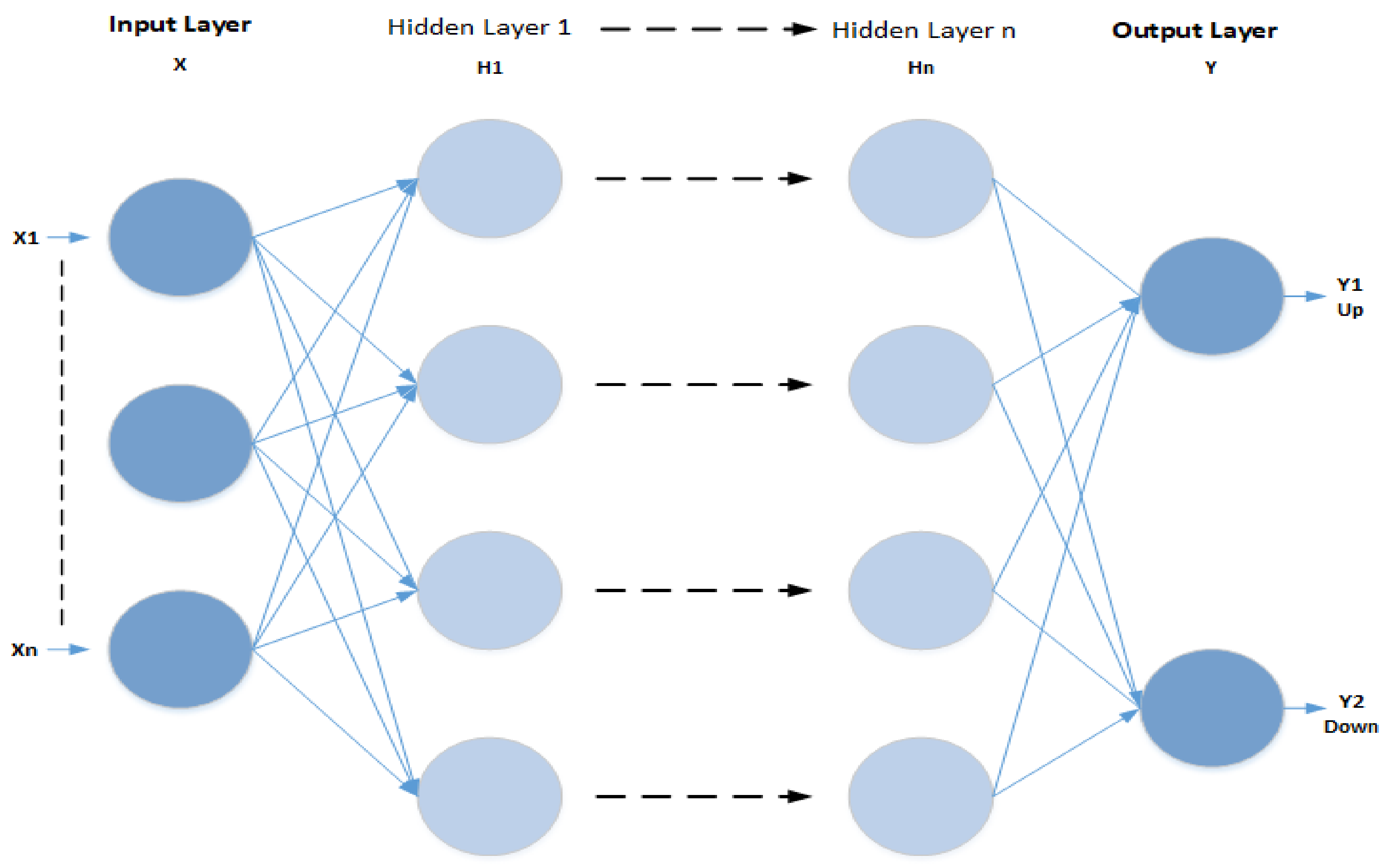
Deep Learning
- Using a cascade of multiple layers of non-linear processing units for feature extraction and transformation. Every successive layer uses the output from the previous layer as input;
- Learning multiple levels of representation that correspond to different levels of abstraction within a hierarchy of concepts [76].
3.4.2. Advantages and Disadvantages of the Prominent ML Algorithms for Arabic SA
3.5. Evaluation Metrics
4. Results and Discussion
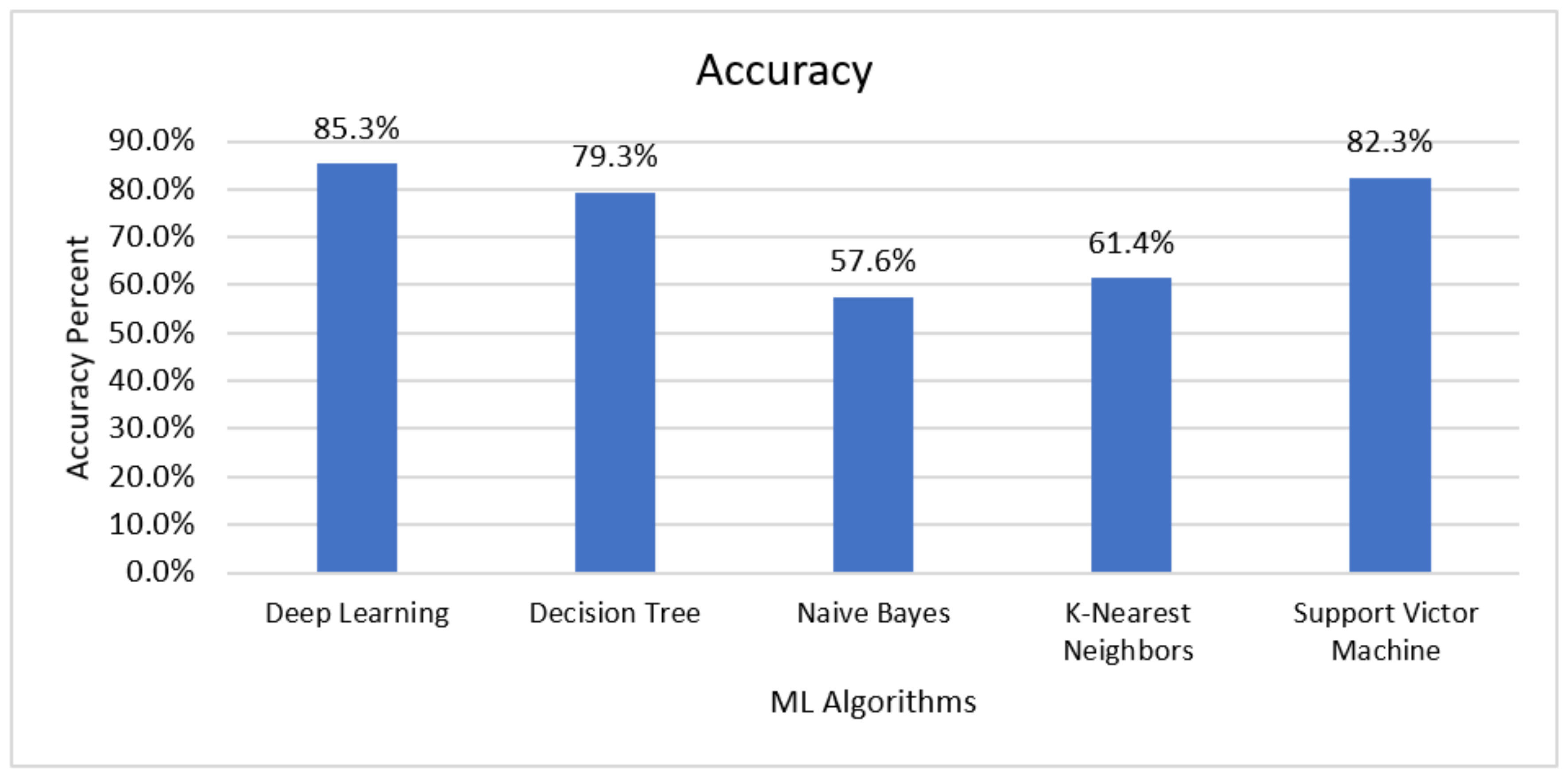
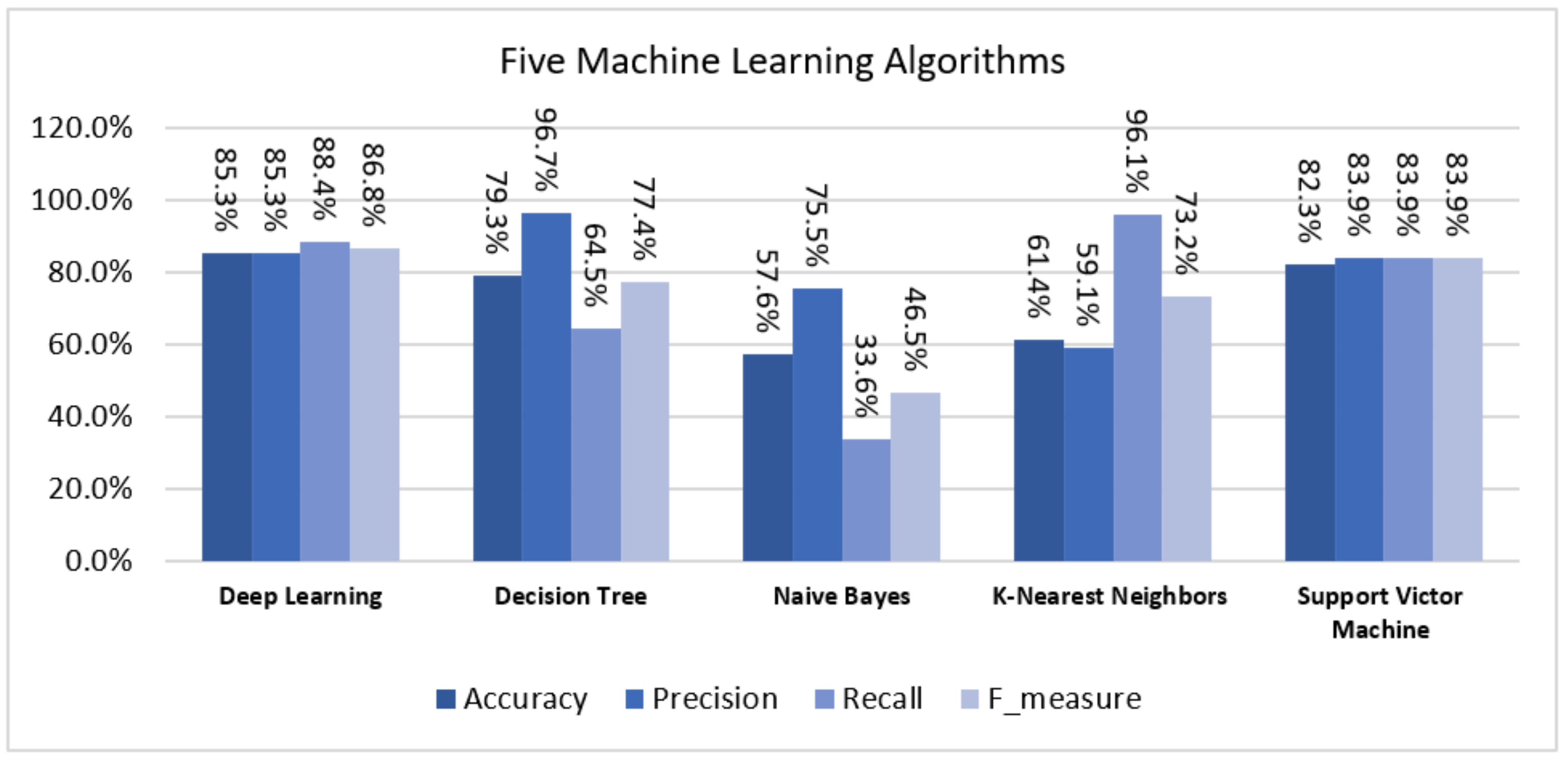
4.1. Accuracy
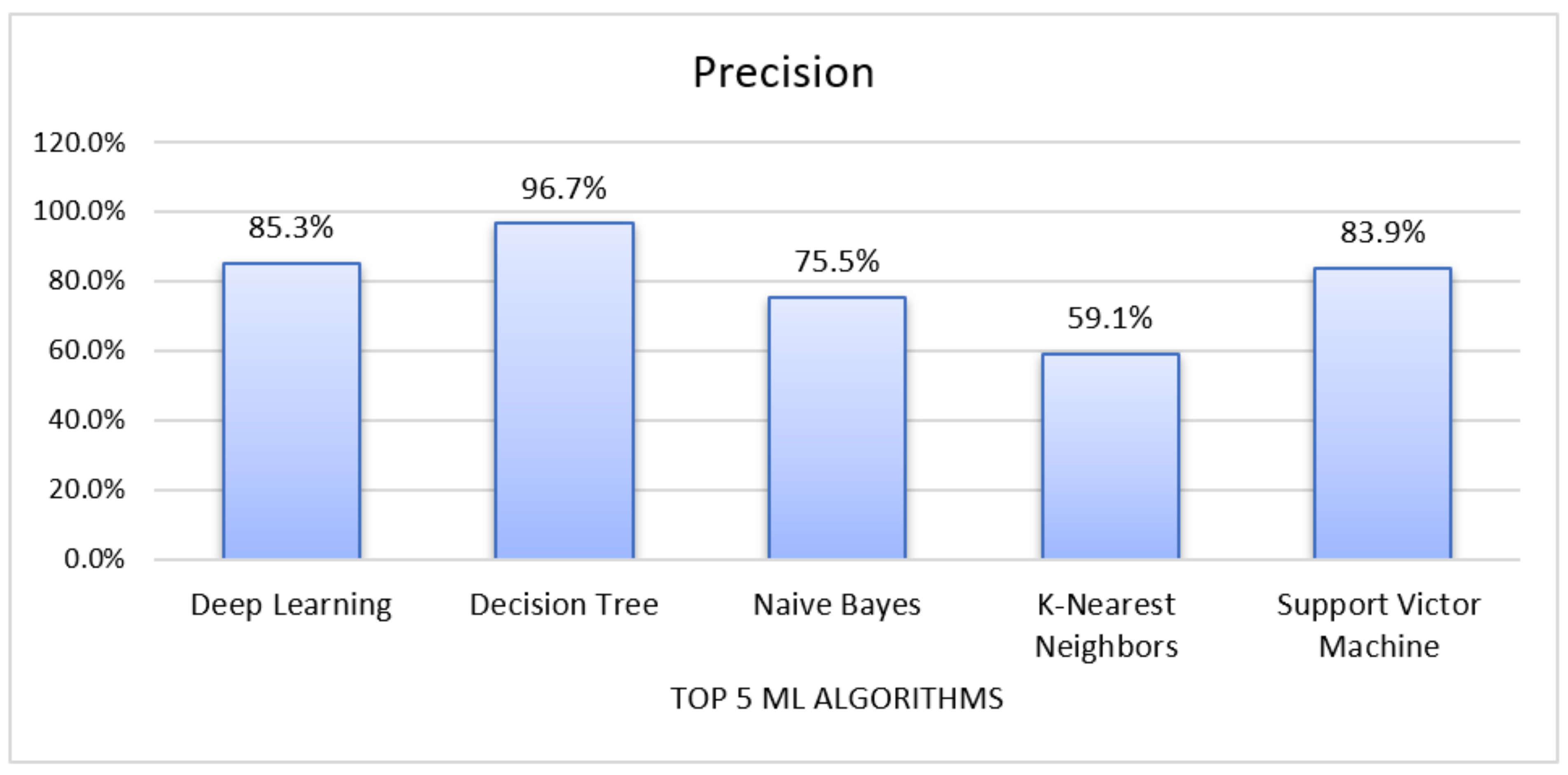
4.2. Precision
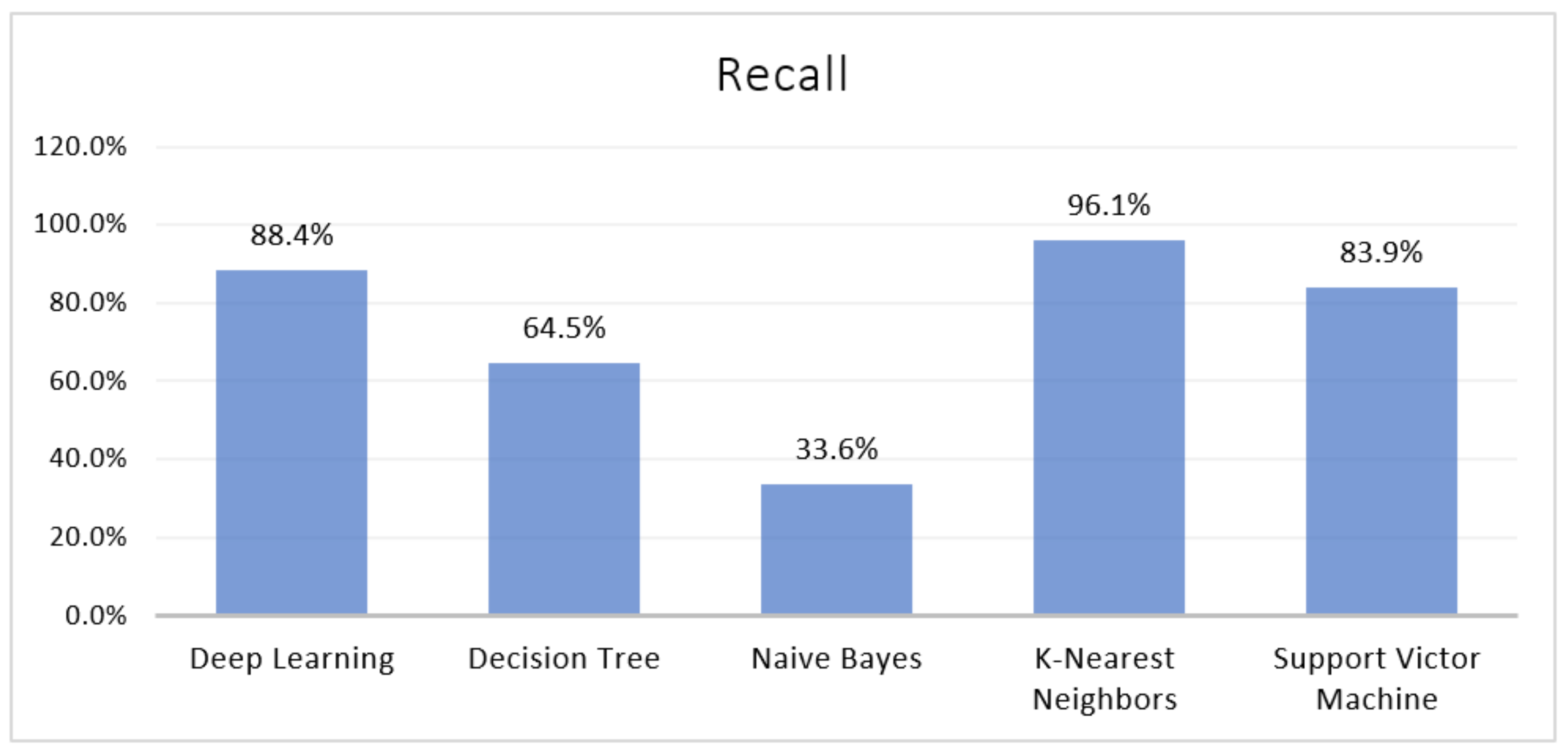
4.3. Recall
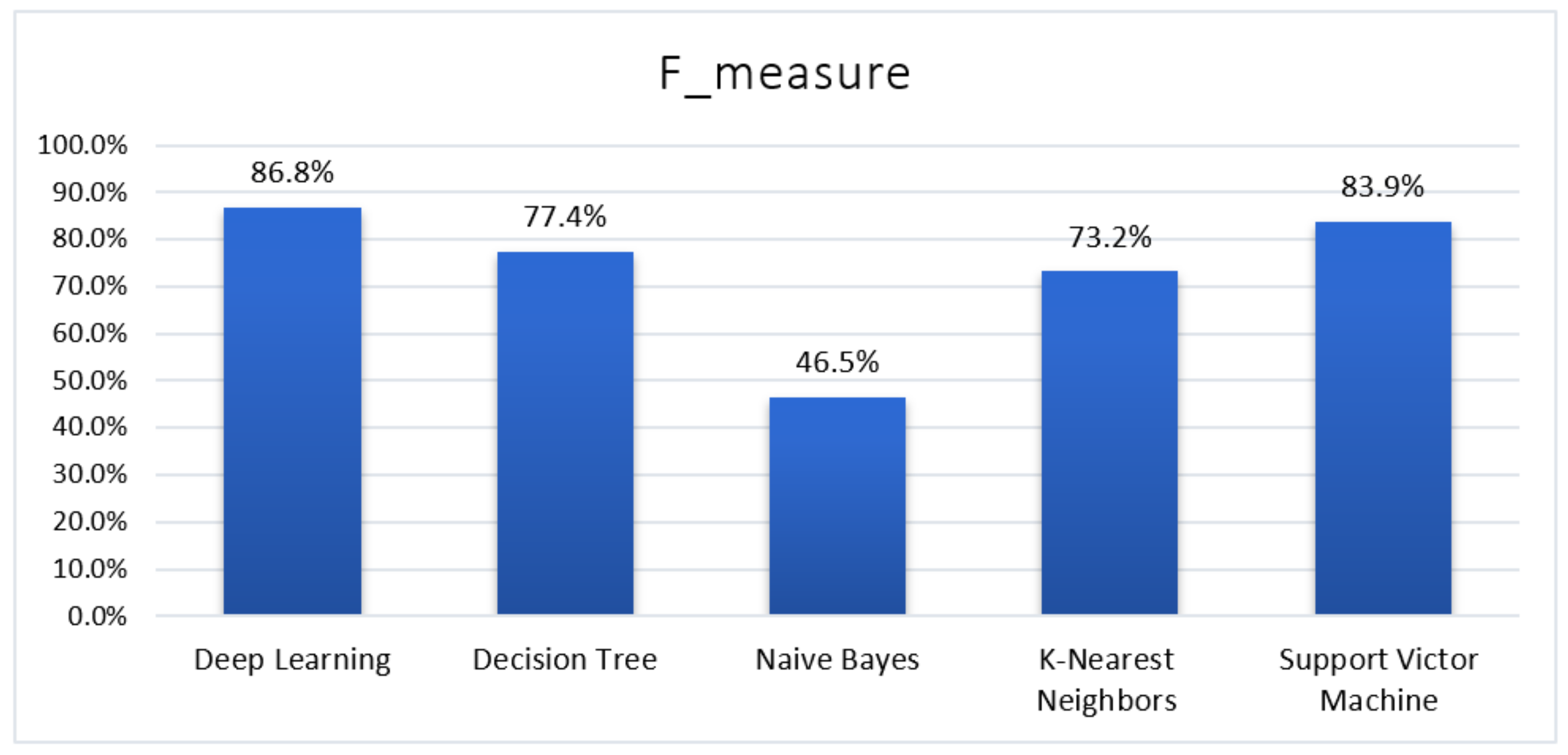
4.4. F-Measure
4.5. Correct and Wrong Detection
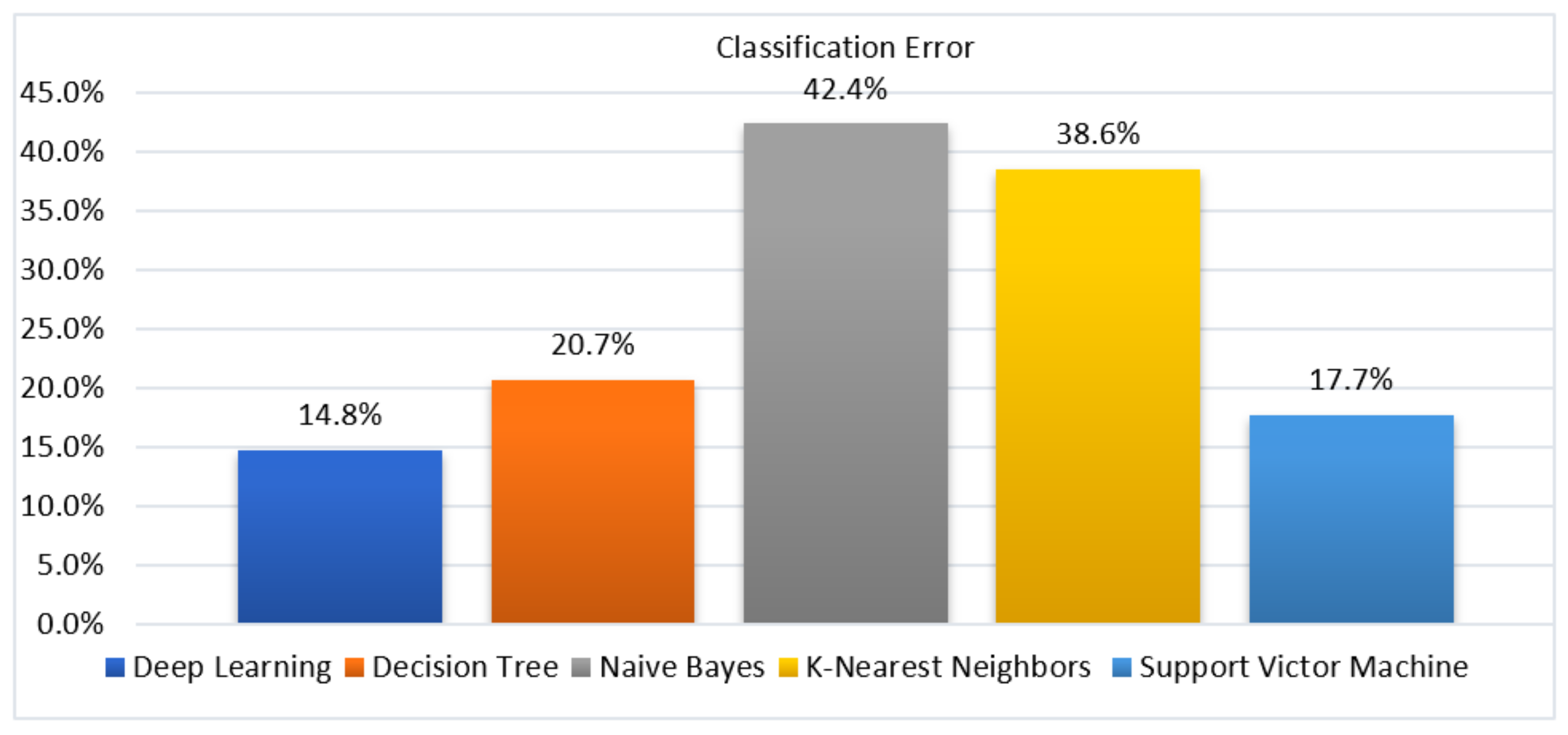
4.6. Classification Error
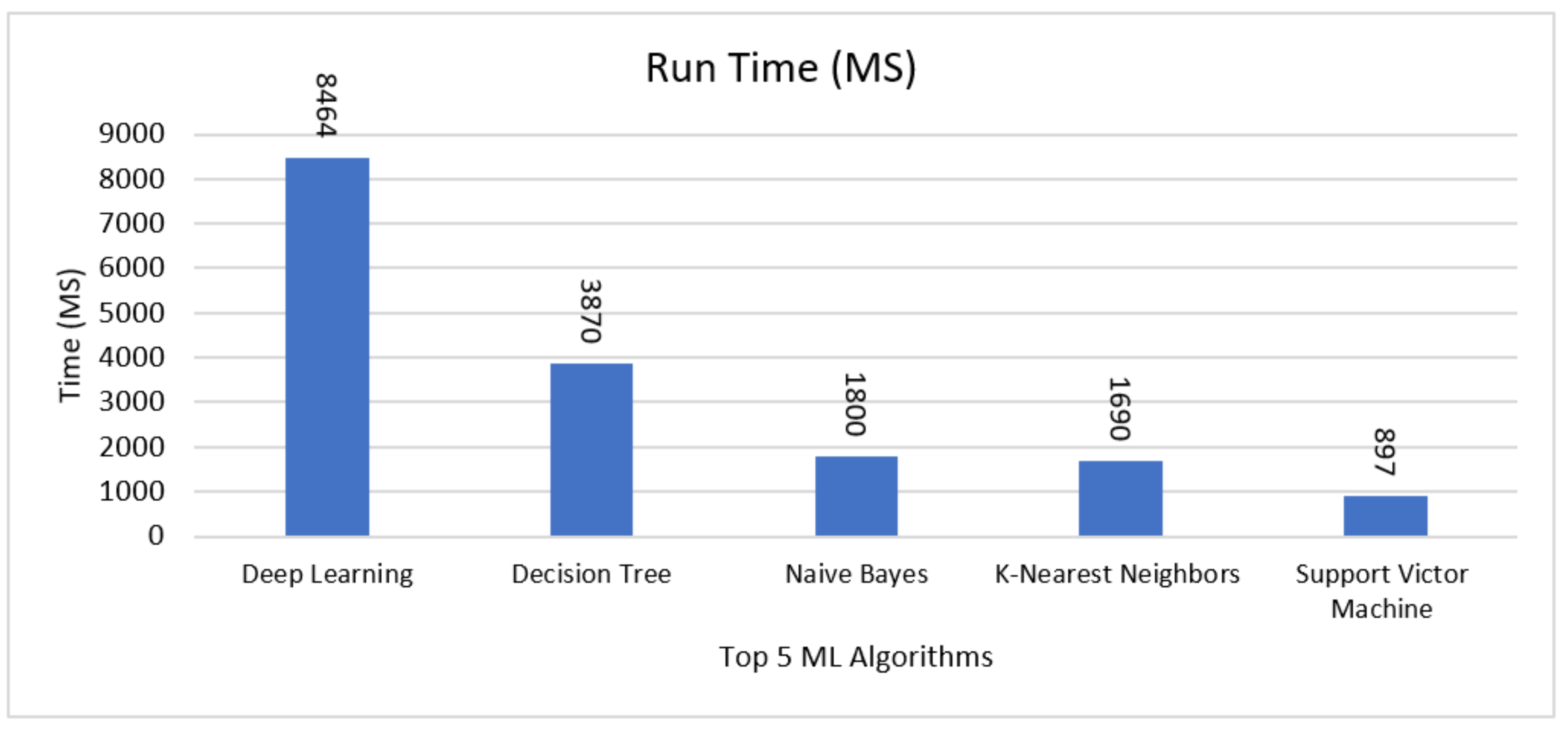
4.7. CPU Time
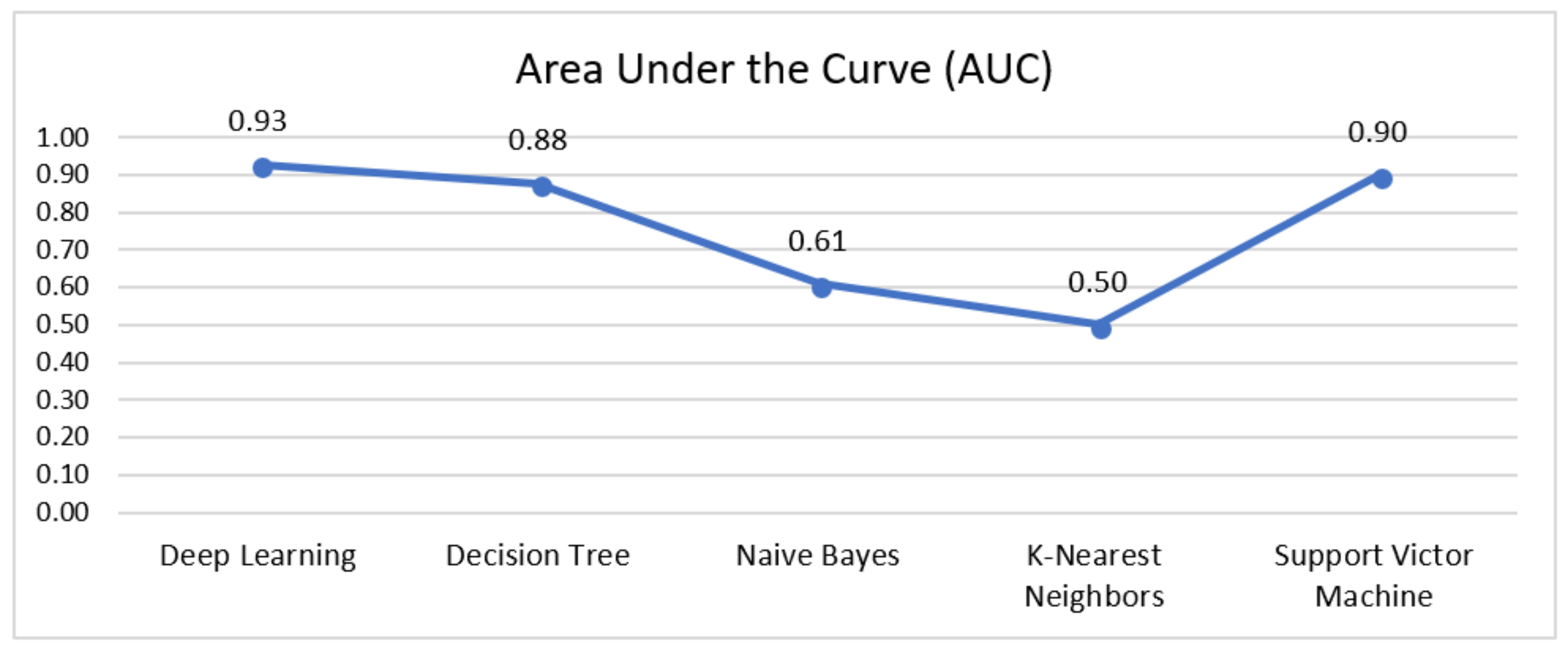
4.8. Area under the Curve (AUC)
4.9. Overall Result
5. Conclusion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| SA | Sentiment Analysis |
| CPU | Central Processing Unit |
| AUC | Area Under the Curve |
| SVM | Support Vector Machine |
| K-NN | K-Nearest Neighbours |
| MSA | Modern Standard Arabic |
| CA | Classical Arabic |
| DA | Dialectical Arabic |
| MRL | Morphologically Rich Language |
| NB | Naïve Bayes |
| DT | Decision Tree |
| MSA | Modern Standard Arabic |
| PPV | Positive Predictive Value |
References
- Michalski, R.S.; Carbonell, J.G.; Mitchell, T.M. Machine Learning: An Artificial Intelligence Approach; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Ali, R.; Lee, S.; Chung, T.C. Accurate multi-criteria decision making methodology for recommending machine learning algorithm. Expert Syst. Appl. 2017, 71, 257–278. [Google Scholar] [CrossRef]
- Zhang, B.; Xu, X.; Li, X.; Chen, X.; Ye, Y.; Wang, Z. Sentiment Analysis through Critic Learning for Optimizing Convolutional Neural Networks with Rules. Neurocomputing 2019, 356, 21–30. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Qazi, A.; Raj, R.G.; Hardaker, G.; Standing, C. A systematic literature review on opinion types and sentiment analysis techniques: Tasks and challenges. Internet Res. 2017, 27, 608–630. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, G.; Wang, H. User preferences based software defect detection algorithms selection using MCDM. Inf. Sci. 2012, 191, 3–13. [Google Scholar] [CrossRef]
- Mullainathan, S.; Spiess, J. Machine learning: An applied econometric approach. J. Econ. Perspect. 2017, 31, 87–106. [Google Scholar] [CrossRef] [Green Version]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Science & Business Media: Berlin, Germany, 2010. [Google Scholar]
- Eiland, E.E. A Coherent Classifier/Prediction/Diagnostic Problem Framework and Relevant Summary Statistics; New Mexico Institute of Mining and Technology: Socorro, NM, USA, 2017. [Google Scholar]
- Qazi, A.; Raj, R.G.; Tahir, M.; Cambria, E.; Syed, K.B.S. Enhancing business intelligence by means of suggestive reviews. Sci. World J. 2014, 2014, 879323. [Google Scholar] [CrossRef]
- De la Paz-Marín, M.; Gutiérrez, P.A.; Hervás-Martínez, C. Classification of countries’ progress toward a knowledge economy based on machine learning classification techniques. Expert Syst. Appl. 2015, 42, 562–572. [Google Scholar] [CrossRef]
- Odeh, A.; Abu-Errub, A.; Shambour, Q.; Turab, N. Arabic text categorization algorithm using vector evaluation method. arXiv 2015, arXiv:1501.01318. [Google Scholar] [CrossRef]
- Abo, M.E.M.; Raj, R.G.; Qazi, A. A Review on Arabic Sentiment Analysis: State-of-the-Art, Taxonomy and Open Research Challenges. IEEE Access 2019, 7, 162008–162024. [Google Scholar] [CrossRef]
- Khasawneh, R.T.; Wahsheh, H.A.; Al-Kabi, M.N.; Alsmadi, I.M. Sentiment analysis of arabic social media content: A comparative study. In Proceedings of the 8th International Conference for Internet Technology and Secured Transactions (ICITST-2013), London, UK, 9–12 December 2013; pp. 101–106. [Google Scholar]
- Duwairi, R.M.; Alfaqeh, M.; Wardat, M.; Alrabadi, A. Sentiment analysis for Arabizi text. In Proceedings of the 2016 7th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 5–7 April 2016; pp. 127–132. [Google Scholar]
- Han, W.; Jiang, Y.; Tu, K. Lexicalized Neural Unsupervised Dependency Parsing. Neurocomputing 2019, 349, 105–115. [Google Scholar] [CrossRef]
- Guellil, I.; Adeel, A.; Azouaou, F.; Benali, F.; Hachani, A.-E.; Hussain, A. Arabizi sentiment analysis based on transliteration and automatic corpus annotation. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Brussels, Belgium, 31 October 2018; pp. 335–341. [Google Scholar]
- Abo, M.E.M.; Shah, N.A.K.; Balakrishnan, V.; Kamal, M.; Abdelaziz, A.; Haruna, K. SSA-SDA: Subjectivity and Sentiment Analysis of Sudanese Dialect Arabic. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 3–4 April 2019; pp. 1–5. [Google Scholar]
- Kotthoff, L. Algorithm Selection for Combinatorial Search Problems: A Survey. In Transactions on Petri Nets and Other Models of Concurrency XV; Springer Science and Business Media LLC: Berlin, Germany, 2016; pp. 149–190. [Google Scholar]
- Govindan, K.; Rajendran, S.; Sarkis, J.; Murugesan, P. Multi criteria decision making approaches for green supplier evaluation and selection: A literature review. J. Clean. Prod. 2015, 98, 66–83. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Chang, P.-L.; Chen, Y.-C. A fuzzy multi-criteria decision making method for technology transfer strategy selection in biotechnology. Fuzzy Sets Syst. 1994, 63, 131–139. [Google Scholar] [CrossRef]
- DeFries, R.; Chan, J.C.-W. Multiple criteria for evaluating machine learning algorithms for land cover classification from satellite data. Remote. Sens. Environ. 2000, 74, 503–515. [Google Scholar] [CrossRef]
- Kononenko, I. Machine learning for medical diagnosis: History, state of the art and perspective. Artif. Intell. Med. 2001, 23, 89–109. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Lemmon, M. Stability analysis of weak rural electrification microgrids with droop-controlled rotational and electronic distributed generators. In Proceedings of the 2015 IEEE Power & Energy Society General Meeting, Denver, CO, USA, 26–30 July 2015; pp. 1–5. [Google Scholar]
- Wegrzyn-Wolska, K.; Bougueroua, L.; Dziczkowski, G. Social media analysis for e-health and medical purposes. In Proceedings of the 2011 International Conference on Computational Aspects of Social Networks (CASoN), Salamanca, Spain, 19–21 October 2011; pp. 278–283. [Google Scholar]
- Salameh, M.; Mohammad, S.; Kiritchenko, S. Sentiment after Translation: A Case-Study on Arabic Social Media Posts. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–4 June 2015; pp. 767–777. [Google Scholar]
- Sghaier, M.A.; Zrigui, M. Sentiment analysis for Arabic e-commerce websites. In Proceedings of the 2016 International Conference on Engineering & MIS (ICEMIS), Agadir, Morocco, 22–24 September 2016; pp. 1–7. [Google Scholar]
- Alayba, A.M.; Palade, V.; England, M.; Iqbal, R. Arabic language sentiment analysis on health services. In Proceedings of the 2017 1st International Workshop on Arabic Script Analysis and Recognition (ASAR), Nancy, France, 3–5 April 2017; pp. 114–118. [Google Scholar]
- Duwairi, R.M. Sentiment analysis for dialectical Arabic. In Proceedings of the 2015 6th International Conference on Information and Communication Systems (ICICS), Amman, Jordan, 7–9 April 2015; pp. 166–170. [Google Scholar]
- Hathlian, N.F.B.; Hafezs, A.M. Sentiment—Subjective analysis framework for arabic social media posts. In Proceedings of the 2016 4th Saudi International Conference on Information Technology (Big Data Analysis), Riyadh, Saudi Arabia, 6–9 November 2016; pp. 1–6. [Google Scholar]
- Abdulkareem, M.; Tiun, S. Comparative analysis of ML POS on Arabic tweets. J. Theor. Appl. Inf. Technol. 2017, 95, 403. [Google Scholar]
- Alqarafi, A.; Adeel, A.; Hawalah, A.; Swingler, K.; Hussain, A. A Semi-supervised Corpus Annotation for Saudi Sentiment Analysis Using Twitter. In Proceedings of the Transactions on Petri Nets and Other Models of Concurrency XV, Xi’an, China, 6 October 2018; pp. 589–596. [Google Scholar]
- Cambria, E.; Poria, S.; Hussain, A.; Liu, B. Computational Intelligence for Affective Computing and Sentiment Analysis [Guest Editorial]. IEEE Comput. Intell. Mag. 2019, 14, 16–17. [Google Scholar] [CrossRef]
- AlHumoud, S.; Albuhairi, T.; Altuwaijri, M. Arabic Sentiment Analysis using WEKA a Hybrid Learning Approach. In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Lisbon, Portugal, 12–14 November 2015; pp. 402–408. [Google Scholar]
- Abo, M.E.M.; Shah, N.A.K.; Balakrishnan, V.; Abdelaziz, A. Sentiment analysis algorithms: Evaluation performance of the Arabic and English language. In Proceedings of the 2018 International Conference on Computer Control, Electrical, and Electronics Engineering (ICCCEEE), Khartoum, Sudan, 12–14 August 2018; pp. 1–5. [Google Scholar]
- Alabdullatif, A.; Shahzad, B.; Alwagait, E. Classification of Arabic Twitter Users: A Study Based on User Behaviour and Interests. Mob. Inf. Syst. 2016, 2016, 8315281. [Google Scholar] [CrossRef] [Green Version]
- Hadi, W.E. Classification of Arabic Social Media Data. Adv. Comput. Sci. Technol. 2015, 8, 29–34. [Google Scholar]
- Hamouda, S.B.; Akaichi, J. Social networks’ text mining for sentiment classification: The case of Facebook’statuses updates in the ‘Arabic Spring’era. Int. J. Appl. Innov. Eng. Manag. 2013, 2, 470–478. [Google Scholar]
- Mountassir, A.; Benbrahim, H.; Berrada, I. Some methods to address the problem of unbalanced sentiment classification in an arabic context. In Proceedings of the 2012 Colloquium in Information Science and Technology, Fez, Morocco, 22–24 October 2012; pp. 43–48. [Google Scholar]
- Ahmed, S.; Pasquier, M.; Qadah, G.Z. Key issues in conducting sentiment analysis on Arabic social media text. In Proceedings of the 2013 9th International Conference on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, 17–19 March 2013; pp. 72–77. [Google Scholar]
- Abdul-Mageed, M.; Diab, M.T.; Korayem, M. Subjectivity and sentiment analysis of modern standard Arabic. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: Short papers-Volume 2, Portland, OR, USA, 19 June 2011; pp. 587–591. [Google Scholar]
- Al-Kabi, M.N.; Abdulla, N.A.; Al-Ayyoub, M. An analytical study of Arabic sentiments: Maktoob case study. In Proceedings of the 8th International Conference for Internet Technology and Secured Transactions (ICITST-2013), London, UK, 9–12 December 2013; pp. 89–94. [Google Scholar]
- Duwairi, R.M.; Marji, R.; Sha’Ban, N.; Rushaidat, S. Sentiment Analysis in Arabic tweets. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Irbid, Jordan, 1–3 April 2014; pp. 1–6. [Google Scholar]
- Abdulla, N.A.; Ahmed, N.A.; Shehab, M.A.; Al-Ayyoub, M. Arabic sentiment analysis: Lexicon-based and corpus-based. In Proceedings of the 2013 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT), Amman, Jordan, 3–5 December 2013; pp. 1–6. [Google Scholar]
- Alqasemi, F.; Abdelwahab, A.; Abdelkader, H. An enhanced feature extraction technique for improving sentiment analysis in Arabic language. In Proceedings of the 2016 4th IEEE International Colloquium on Information Science and Technology, Tangier, Morocco, 24–26 October 2016; pp. 380–384. [Google Scholar] [CrossRef]
- Al Sallab, A.A.; Baly, R.; Badaro, G.; Hajj, H.; El Hajj, W.; Shaban, K.B. Deep learning models for sentiment analysis in Arabic. In Proceedings of the Proceedings of the Second Workshop on Arabic Natural Language Processing, Beijing, China, 26–31 July 2015; p. 9. [Google Scholar]
- Altawaier, M.; Tiun, S. Comparison of Machine Learning Approaches on Arabic Twitter Sentiment Analysis. Int. J. Adv. Sci. Eng. Inf. Technol. 2016, 6, 1067. [Google Scholar] [CrossRef]
- Al-Rubaiee, H.; Qiu, R.; Li, D. Identifying Mubasher software products through sentiment analysis of Arabic tweets. In Proceedings of the 2016 International Conference on Industrial Informatics and Computer Systems (CIICS), Sharjah, United Arab Emirates, 13–15 March 2016; pp. 1–6. [Google Scholar]
- Alotaibi, S.S.; Anderson, C.W. Extending the knowledge of the arabic sentiment classification using aforeign external lexical source. Int. J. Nat. Lang. Comput. 2016, 5, 1–11. [Google Scholar] [CrossRef]
- Shoukry, A.; Rafea, A. Sentence-level Arabic sentiment analysis. In Proceedings of the 2012 International Conference on Collaboration Technologies and Systems (CTS), Denver, CO, USA, 21–25 May 2012; pp. 546–550. [Google Scholar]
- Alhumoud, S.; Albuhairi, T.; Alohaideb, W. Hybrid Sentiment Analyser for Arabic Tweets using R. In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Lisbon, Portugal, 12–14 November 2015; pp. 417–424. [Google Scholar] [CrossRef]
- Duwairi, R.; El-Orfali, M. A study of the effects of preprocessing strategies on sentiment analysis for Arabic text. J. Inf. Sci. 2014, 40, 501–513. [Google Scholar] [CrossRef] [Green Version]
- Alotaibi, S.; Anderson, C. Word Clustering as a Feature for Arabic Sentiment Classification. Int. J. Educ. Manag. Eng. 2017, 7, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Al-Moslmi, T.; Albared, M.; Al-Shabi, A.; Omar, N.; Abdullah, S. Arabic senti-lexicon: Constructing publicly available language resources for Arabic sentiment analysis. J. Inf. Sci. 2017, 44, 345–362. [Google Scholar] [CrossRef]
- Refaee, E. Sentiment Analysis for Micro-blogging Platforms in Arabic. In Proceedings of the Transactions on Petri Nets and Other Models of Concurrency XV, Vancouver, BC, Canada, 9–14 July 2017; pp. 275–294. [Google Scholar]
- Al-Ayyoub, M.; Nuseir, A.; Kanaan, G.; Al-Shalabi, R. Hierarchical Classifiers for Multi-Way Sentiment Analysis of Arabic Reviews. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 531–539. [Google Scholar] [CrossRef] [Green Version]
- Tobaili, T.; He, H.; Lei, T.; Roberts, W. Arabizi Identification in Twitter Data. In Proceedings of the Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics—Student Research Workshop, Berlin, Germany, 7–12 August 2016; pp. 51–57. [Google Scholar] [CrossRef]
- Al-Twairesh, N.; Al-Khalifa, H.; Alsalman, A.; Erk, K.; Smith, N.A. AraSenTi: Large-Scale Twitter-Specific Arabic Sentiment Lexicons. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 697–705. [Google Scholar]
- Valdivia, A.; Hrabova, E.; Chaturvedi, I.; Luzón, M.V.; Troiano, L.; Cambria, E.; Herrera, F. Inconsistencies on TripAdvisor reviews: A unified index between users and Sentiment Analysis Methods. Neurocomputing 2019, 353, 3–16. [Google Scholar] [CrossRef]
- Pasha, A.; Al-Badrashiny, M.; Diab, M.T.; El Kholy, A.; Eskander, R.; Habash, N.; Pooleery, M.; Rambow, O.; Roth, R. MADAMIRA: A Fast, Comprehensive Tool for Morphological Analysis and Disambiguation of Arabic. In Proceedings of the Proceedings of the 9th International Conference on Language Resources and Evaluation, LREC 2014, Reykjavik, Iceland, 26–31 May 2014; pp. 1094–1101. [Google Scholar]
- Al-Smadi, M.; Qawasmeh, O.; Al-Ayyoub, M.; Jararweh, Y.; Gupta, B. Deep Recurrent neural network vs. support vector machine for aspect-based sentiment analysis of Arabic hotels’ reviews. J. Comput. Sci. 2018, 27, 386–393. [Google Scholar] [CrossRef]
- Abuata, B.; Al-Omari, A. A rule-based stemmer for Arabic Gulf dialect. J. King Saud Univ. -Comput. Inf. Sci. 2015, 27, 104–112. [Google Scholar] [CrossRef] [Green Version]
- Mostafa, M.M. More than words: Social networks’ text mining for consumer brand sentiments. Expert Syst. Appl. 2013, 40, 4241–4251. [Google Scholar] [CrossRef]
- Stephens, Z.D.; Lee, S.Y.; Faghri, F.; Campbell, R.H.; Zhai, C.; Efron, M.J.; Iyer, R.; Schatz, M.C.; Sinha, S.; Robinson, G.E. Big Data: Astronomical or Genomical? PLoS Biol. 2015, 13, e1002195. [Google Scholar] [CrossRef]
- Acharya, U.R.; Fujita, H.; Lih, O.S.; Adam, M.; Tan, J.H.; Chua, C.K. Automated detection of coronary artery disease using different durations of ECG segments with convolutional neural network. Knowl.-Based Syst. 2017, 132, 62–71. [Google Scholar] [CrossRef]
- Singh, A.; Ganapathysubramanian, B.; Singh, A.K.; Sarkar, S. Machine learning for high-throughput stress phenotyping in plants. Trends Plant Sci. 2016, 21, 110–124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ching, T.; Himmelstein, D.S.; Beaulieu-Jones, B.K.; Kalinin, A.A.; Do, B.T.; Way, G.P.; Ferrero, E.; Agapow, P.-M.; Zietz, M.; Hoffman, M.M.; et al. Opportunities and obstacles for deep learning in biology and medicine. J. R. Soc. Interface 2018, 15, 20170387. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Catal, C.; Nangir, M. A sentiment classification model based on multiple classifiers. Appl. Soft Comput. 2017, 50, 135–141. [Google Scholar] [CrossRef]
- Al-Batah, M.S.; Mrayyen, S.; Alzaqebah, M. Arabic Sentiment Classification using MLP Network Hybrid with Naive Bayes Algorithm. J. Comput. Sci. 2018, 14, 1104–1114. [Google Scholar] [CrossRef] [Green Version]
- Xiong, S.; Lv, H.; Zhao, W.; Ji, D. Towards Twitter sentiment classification by multi-level sentiment-enriched word embeddings. Neurocomputing 2018, 275, 2459–2466. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Qi, Z.; Ju, X.; Shi, Y.; Liu, X. Nonparallel Support Vector Machines for Pattern Classification. IEEE Trans. Cybern. 2014, 44, 1067–1079. [Google Scholar] [CrossRef] [Green Version]
- Mohammad, A.H.; Alwada’n, T.; Al-Momani, O. Arabic text categorization using support vector machine, Naïve Bayes and neural network. GSTF J. Comput. 2018, 5, 1–8. [Google Scholar] [CrossRef]
- Salloum, S.A.; AlHamad, A.Q.; Al-Emran, M.; Shaalan, K. A Survey of Arabic Text Mining. In Intelligent Natural Language Processing: Trends and Applications; Humana Press: Totowa, NJ, USA, 2018; pp. 417–431. [Google Scholar]
- Tang, D.; Wei, F.; Qin, B.; Liu, T.; Zhou, M. Coooolll: A Deep Learning System for Twitter Sentiment Classification. In Proceedings of the Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 208–212. [Google Scholar]
- Lu, H.; Jin, L.; Luo, X.; Liao, B.; Guo, D.; Xiao, L. RNN for Solving Perturbed Time-Varying Underdetermined Linear System With Double Bound Limits on Residual Errors and State Variables. IEEE Trans. Ind. Inform. 2019, 15, 5931–5942. [Google Scholar] [CrossRef]
- Wu, D.; Luo, X.; Shang, M.; He, Y.; Wang, G.; Zhou, M. A Deep Latent Factor Model for High-Dimensional and Sparse Matrices in Recommender Systems. IEEE Trans. Syst. Man, Cybern. Syst. 2021, 51, 4285–4296. [Google Scholar] [CrossRef]
- Qazi, A.; Tamjidyamcholo, A.; Raj, R.G.; Hardaker, G.; Standing, C. Assessing consumers’ satisfaction and expectations through online opinions: Expectation and disconfirmation approach. Comput. Hum. Behav. 2017, 75, 450–460. [Google Scholar] [CrossRef]
- Cano, J.-R.; Gutiérrez, P.A.; Krawczyk, B.; Woźniak, M.; García, S. Monotonic classification: An overview on algorithms, performance measures and data sets. Neurocomputing 2019, 341, 168–182. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Bravo-Marquez, F.; Mendoza, M.; Poblete, B. Meta-level sentiment models for big social data analysis. Knowledge-Based Syst. 2014, 69, 86–99. [Google Scholar] [CrossRef] [Green Version]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, Informedness, Markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Yamout, B.; Issa, Z.; Herlopian, A.; El Bejjani, M.; Khalifa, A.; Ghadieh, A.S.; Habib, R.H. Predictors of quality of life among multiple sclerosis patients: A comprehensive analysis. Eur. J. Neurol. 2013, 20, 756–764. [Google Scholar] [CrossRef]
- Abooraig, R.; Alzubi, S.; Kanan, T.; Hawashin, B.; Al Ayoub, M.; Hmeidi, I. Automatic categorization of Arabic articles based on their political orientation. Digit. Investig. 2018, 25, 24–41. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Algorithms | Descriptions | ||||
|---|---|---|---|---|---|---|
| SVM | NB | K-NN | DT | DL | ||
| [38] | - | 90% | - | - | - | Accuracy |
| [32] | 89.5% | 85.1% | - | - | - | Accuracy |
| [39] | 73.5 | 71.6 | 70 | 65.1 | - | Recall (Average) |
| [15] | 93.3% | 91.8% | 31.4% | 92.4% | - | Accuracy |
| [40] | 74.7% | 74.1% | - | - | - | Accuracy |
| [41] | 61.4% | 67.9% | - | - | - | Accuracy |
| [42] | 68.2% | 61.4% | - | - | - | Accuracy |
| [43] | 73.2 | - | - | - | - | Stem + Morph + language independent features |
| [44] | 68.2 | 61.4 | - | - | - | Accuracy, Recall |
| [45] | 71.7 | 76.8 | 60 | - | - | Accuracy |
| [46] | 85 | 81.3 | 52.9 | 50 | - | Accuracy |
| [29] | 94.8 | 87.3 | 80.1 | - | - | Precision |
| [47] | 73.5 | - | 72.2 | - | - | Accuracy |
| [42] | 87.4 | 65.9 | - | - | - | Accuracy |
| [48] | 66.1 | - | - | - | 60.4 | Accuracy |
| [49] | 77.7 | 78.2 | - | 80.9 | - | Precision |
| [50] | 84.9 | 77.5 | - | - | - | Accuracy |
| [51] | 93.4 | - | - | - | - | Accuracy |
| [52] | 72.6 | 65.4 | - | - | - | Accuracy |
| [53] | 91.5 | - | - | - | - | Accuracy |
| [54] | 82.5 | 85.7 | 66.7 | - | - | Accuracy |
| [30] | 90.9 | 90.1 | - | - | - | Accuracy |
| [31] | 87.8 | 95.4 | - | - | - | Macro-Precision |
| [16] | 86.9 | 82.1 | - | - | - | Recall |
| [36] | 90 | - | 90.5 | - | - | Accuracy |
| [55] | 92 | - | - | - | - | Accuracy |
| [33] | - | 93.9 | 88.8 | 92.1 | - | Recall |
| [56] | 83.2 | 80.5 | 82.4 | - | - | Macro-F1 |
| [57] | 95.1 | - | - | - | - | Accuracy |
| [28] | 87 | - | - | - | - | Accuracy |
| [58] | 47.4 | 48.9 | 57.8 | 47.6 | - | Accuracy |
| [59] | 93 | - | - | - | - | Accuracy |
| Algorithm | Advantage | Disadvantage |
|---|---|---|
| Support Vector Machines | Non-linear decision boundaries can be modelled by support vector machines. There are different kernels to make the selection. They are also equitably robust against overfitting, specifically in high-dimensional space [49]. | Support vector machines are memory intensive. They are difficult to scale up to massive datasets and are complex to tune because the weights have given to the selection of the right kernel. In the industry at present, random forests are generally preferred over support vector machines [79]. |
| Decision Tree | Decision trees are comparatively robust to outliers and are capable of learning non-linear relationships. When it comes to practice, ensembles perform exceptionally well, winning several classical (that is, non-deep-learning) machine learning competitions. | Individual trees that are unconstrained are inclined towards overfitting as they can continue branching until they store the training data in memory. Ensembles can improve or alleviate this [80]. |
| Naïve Bayes | Despite the fact that the assumption of conditional independence seldom holds, Naïve Bayes models perform well. The scale and are easy to implement. | Naïve Bayes models, as a result of their absolute simplicity, are frequently outclassed by models that are suitably trained and tuned with the help of the earlier listed algorithms. |
| Deep Learning | When it comes to the classification of text, audio, or image data, deep learning performs extremely well [81]. | Deep neural networks are similar to regression and require huge amounts of data for training, and therefore they are not regarded as a general-purpose algorithm. |
| Nearest Neighbours | Nearest neighbours algorithms are “instance-based,” which implies that every training observation is considered. They then predict new observations through the search for the most similar or parallel training observations and combining their values. | As these algorithms are highly memory-intensive, their performance is weak for high-dimensional data. A meaningful distance function is required by them to evaluate and calculate similarity. However, in practice, tree ensembles or training regularised regression nearly always optimises the use of time. |
| DL | DT | NB | K-NN | SVM | |
|---|---|---|---|---|---|
| Correct Detection | 9929 | 9237 | 6704 | 7153 | 9585 |
| Wrong Detection | 1718 | 2410 | 4943 | 4494 | 2062 |
| Total | 11647 | 11647 | 11647 | 11647 | 11647 |
| Model | Acc | P | R | Fm | CE | AUC | RT |
|---|---|---|---|---|---|---|---|
| Deep Learning | 85.25% | 85.30% | 88.41% | 86.81% | 14.75% | 0.928 | 8464 |
| Decision Tree | 79.31% | 96.67% | 64.52% | 77.36% | 20.69% | 0.878 | 3870 |
| Naïve Bayes | 57.56% | 75.49% | 33.59% | 46.48% | 42.44% | 0.610 | 1800 |
| K-Nearest Neighbours | 61.41% | 59.14% | 96.14% | 73.23% | 38.59% | 0.500 | 1690 |
| Support Victor Machine | 82.30% | 83.87% | 83.89% | 83.87% | 17.70% | 0.900 | 897 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abo, M.E.M.; Idris, N.; Mahmud, R.; Qazi, A.; Hashem, I.A.T.; Maitama, J.Z.; Naseem, U.; Khan, S.K.; Yang, S. A Multi-Criteria Approach for Arabic Dialect Sentiment Analysis for Online Reviews: Exploiting Optimal Machine Learning Algorithm Selection. Sustainability 2021, 13, 10018. https://0-doi-org.brum.beds.ac.uk/10.3390/su131810018
Abo MEM, Idris N, Mahmud R, Qazi A, Hashem IAT, Maitama JZ, Naseem U, Khan SK, Yang S. A Multi-Criteria Approach for Arabic Dialect Sentiment Analysis for Online Reviews: Exploiting Optimal Machine Learning Algorithm Selection. Sustainability. 2021; 13(18):10018. https://0-doi-org.brum.beds.ac.uk/10.3390/su131810018
Chicago/Turabian StyleAbo, Mohamed Elhag Mohamed, Norisma Idris, Rohana Mahmud, Atika Qazi, Ibrahim Abaker Targio Hashem, Jaafar Zubairu Maitama, Usman Naseem, Shah Khalid Khan, and Shuiqing Yang. 2021. "A Multi-Criteria Approach for Arabic Dialect Sentiment Analysis for Online Reviews: Exploiting Optimal Machine Learning Algorithm Selection" Sustainability 13, no. 18: 10018. https://0-doi-org.brum.beds.ac.uk/10.3390/su131810018