
A Novel Approach for Multiplicative Linguistic Group Decision Making Based on Symmetrical Linguistic Chi-Square Deviation and VIKOR Method


Abstract
:1. Introduction
2. Preliminaries
2.1. Multiplicative Linguistic Scale and Its Operational Laws
- (1)
- if .
- (2)
- There is the reciprocal operator, , such that = 1. In particular, ,
- (1)
- ;
- (2)
- .
- (1)
- ;
- (2)
- ;
- (3)
- .
2.2. The Linguistic Geometric Aggregation Operators
2.3. The Penalty Function and BUM Function
- (1)
- for all and ;
- (2)
- if and ;
- (3)
- For every fixed X, the set of minimizers of is either a singleton or an interval.
3. Linguistic Geometric Aggregation Operators Based on Symmetrical Linguistic Chi-Square Deviation
3.1. Linguistic Generalized Weighted Logarithm Multiple Averaging Operator
3.2. The Operator and Its Desirable Properties
- If then
- If then
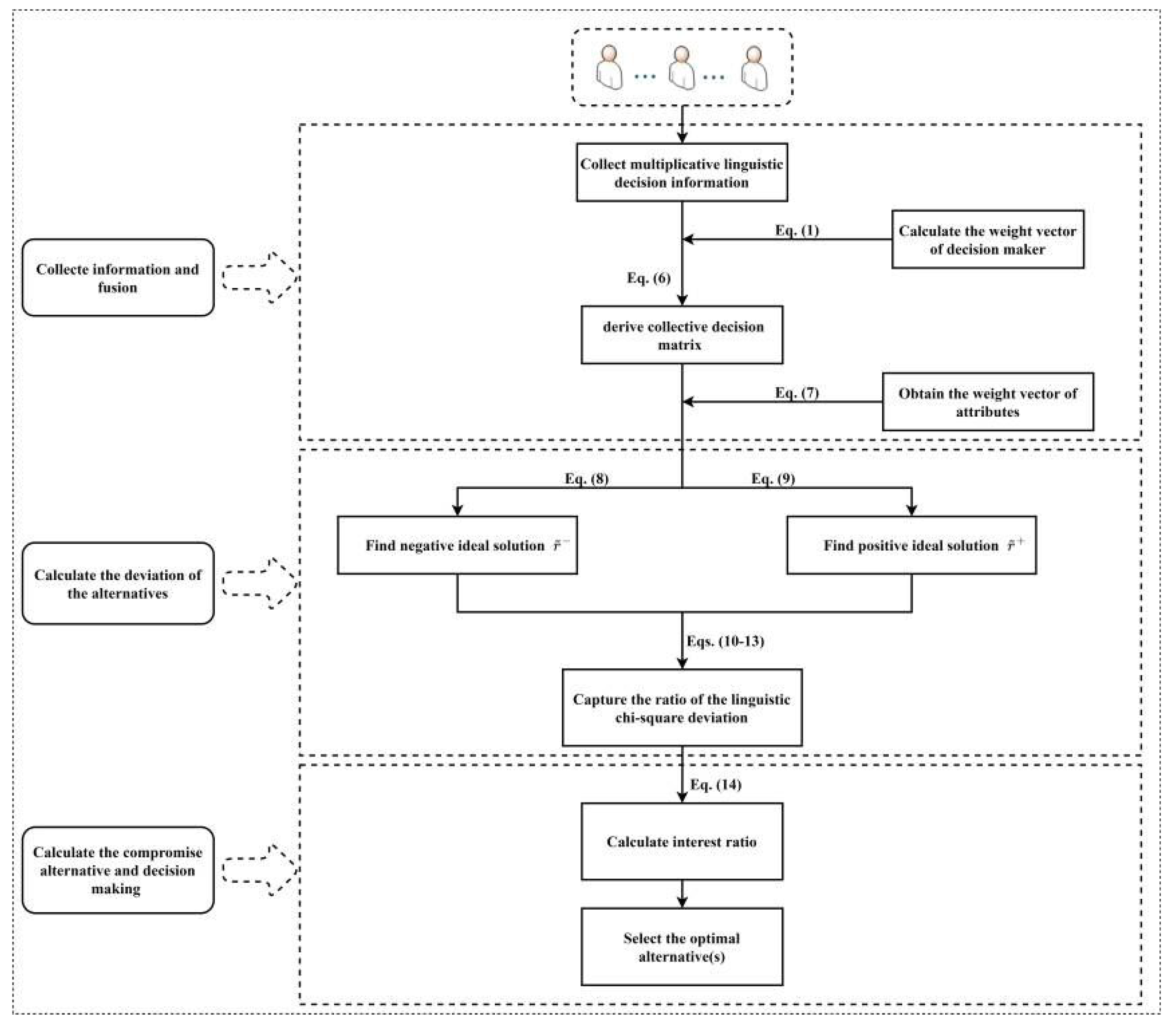
4. Group Decision Making Based on Multiplicative Linguistic Aggregation Operator and Linguistic VIKOR Method
4.1. A Chi-Square Deviation-Based Linguistic VIKOR Method for Group Decision Making under Multiplicative Linguistic Environment
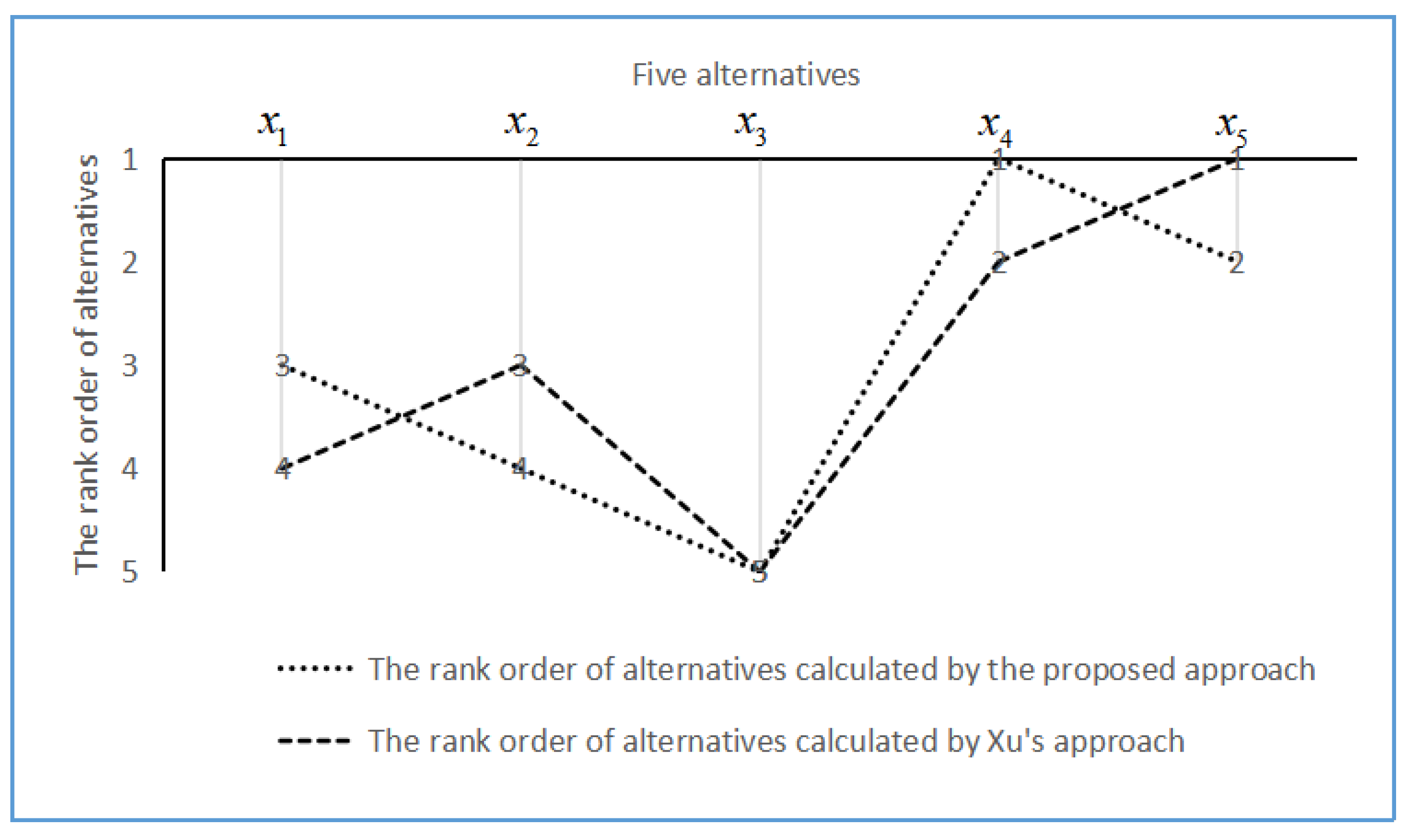
4.2. Comparison and Analysis
4.2.1. Using the Proposed Approach to Select the Optimal Alternative
4.2.2. Using Xu’s Approach to Select the Optimal Alternative
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, H.B.; Ma, Y.; Jiang, L. Managing incomplete preferences and consistency improvement in hesitant fuzzy linguistic preference relations with applications in group decision making. Inf. Fusion 2019, 51, 19–29. [Google Scholar] [CrossRef]
- Efe, B. An integrated fuzzy multi criteria group decision making approach for ERP system selection. Appl. Soft Comput. 2016, 38, 106–117. [Google Scholar] [CrossRef]
- Garg, H.; Kumar, K. Some aggregation operators for linguistic intuitionistic fuzzy set and its application to group decision-making process using the set pair analysis. Arab. J. Sci. Eng. 2018, 43, 3213–3227. [Google Scholar] [CrossRef]
- Deli, I. Operators on single valued trapezoidal neutrosophic numbers and SVTN-group decision making. Neutrosophic Sets Syst. 2018, 22, 131–150. [Google Scholar]
- Liao, H.C.; Wu, X.L.; Liang, X.D.; Yang, J.B.; Xu, D.L.; Herrera, F. A continuous interval-valued linguistic ORESTE method for multi-criteria group decision making. Knowl.-Based Syst. 2018, 153, 65–77. [Google Scholar] [CrossRef] [Green Version]
- Wan, S.; Zhong, L.; Dong, J. A new method for group decision making with hesitant fuzzy preference relations based on multiplicative consistency. IEEE Trans. Fuzzy Syst. 2019, 28, 1449–1463. [Google Scholar] [CrossRef]
- Pan, T.; Gqs, B. Decision-making model to generate novel emergency response plans for improving coordination during large-scale emergencies. Knowl.-Based Syst. 2015, 90, 111–128. [Google Scholar]
- Xu, Y.J.; Wen, X.W.; Zhang, W.C. A two-stage consensus method for large-scale multi-attribute group decision making with an application to earthquake shelter selection. Comput. Ind. Eng. 2018, 116, 113–129. [Google Scholar] [CrossRef]
- Rita, D.I.G.; Ferreira, F.A.F.; Meidutė-Kavaliauskienė, I.; Govindan, K.; Ferreira, J.J.M. Proposal of a green index for small and medium-sized enterprises: A multiple criteria group decision-making approach. J. Clean. Prod. 2018, 196, 985–996. [Google Scholar] [CrossRef]
- Lei, F.; Lu, J.P.; Wei, G.W.; Wu, J.; Wei, C.; Guo, Y.F. GRA method for waste incineration plants location problem with probabilistic linguistic multiple attribute group decision making. J. Intell. Fuzzy Syst. 2020, 39, 2909–2920. [Google Scholar] [CrossRef]
- Wu, Y.N.; Chen, K.F.; Zeng, B.X.; Yany, M.; Li, L.W.Y.; Zhang, H.B. A cloud decision framework in pure 2-tuple linguistic setting and its application for low-speed wind farm site selection. J. Clean. Prod. 2017, 142, 2154–2165. [Google Scholar] [CrossRef]
- Liao, H.C.; Peng, X.Y.; Gou, X.J. Medical supplier selection with a group decision-making method based on incomplete probabilistic linguistic preference relations. Int. J. Fuzzy Syst. 2021, 23, 280–294. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Wang, J.Q.; Wu, J.T.; Wang, J.; Zhang, H.Y.; Chen, X.H. Interval-valued hesitant fuzzy linguistic sets and their applications in multi-criteria decision-making problems. Inf. Sci. 2014, 288, 55–72. [Google Scholar] [CrossRef]
- Chen, H.Y.; Zhou, L.G.; Han, B. On compatibility of uncertain additive linguistic preference relations and its application in the group decision making. Knowl.-Based Syst. 2011, 24, 816–823. [Google Scholar] [CrossRef]
- Merigo, J.M.; Casanovas, M.; Palacios-Marques, D. Linguistic group decision making with induced aggregation operators and probabilistic information. Appl. Soft Comput. J. 2014, 24, 669–678. [Google Scholar] [CrossRef]
- Fan, Z.P.; Liu, Y. A method for group decision-making based on multi-granularity uncertain linguistic information. Expert Syst. Appl. 2009, 37, 4000–4008. [Google Scholar] [CrossRef]
- Xu, Z.S. A method based on linguistic aggregation operators for group decision making with linguistic preference relations. Inf. Sci. 2003, 166, 19–30. [Google Scholar] [CrossRef]
- Xu, Z.S. Uncertain linguistic aggregation operators based approach to multiple attribute group decision making under uncertain linguistic environment. Inf. Sci. 2004, 168, 171–184. [Google Scholar] [CrossRef]
- Faizi, S.; Sałabun, W.; Nawaz, S.; ur Rehman, A.; Wątróbski, J. Best-Worst method and Hamacher aggregation operations for intuitionistic 2-tuple linguistic sets. Expert Syst. Appl. 2021, 181, 115088. [Google Scholar] [CrossRef]
- Dong, Y.; Zhang, G.; Hong, W.C.; Yu, S. Linguistic computational model based on 2-tuples and intervals. IEEE Trans. Fuzzy Syst. 2013, 21, 1006–1018. [Google Scholar] [CrossRef]
- Wang, J.Q.; Wang, D.D.; Zhang, H.Y.; Chen, X.H. Multi-criteria group decision making method based on interval 2-tuple linguistic information and Choquet integral aggregation operators. Soft Comput. 2015, 19, 389–405. [Google Scholar] [CrossRef]
- Ju, Y.B. A new method for multiple criteria group decision making with incomplete weight information under linguistic environment. Appl. Math. Model. 2014, 38, 5256–5268. [Google Scholar] [CrossRef]
- Wu, Z.B.; Xu, J.P. Managing consistency and consensus in group decision making with hesitant fuzzy linguistic preference relations. Omega 2016, 65, 28–40. [Google Scholar] [CrossRef]
- Xu, Z.S. EOWA and EOWG operators for aggregating linguistic labels based on linguistic preference relations. Fuzziness Knowl.-Based Syst. 2004, 12, 791–810. [Google Scholar] [CrossRef]
- Xu, Z.S. A practical procedure for group decision making under incomplete multiplicative linguistic preference relations. Group Decis. Negot. 2006, 15, 581–591. [Google Scholar] [CrossRef]
- Meng, F.; Chen, S.M.; Fu, L. Group decision making based on consistency and consensus analysis of dual multiplicative linguistic preference relations. Inf. Sci. 2021, 572, 590–610. [Google Scholar] [CrossRef]
- Xie, W.; Xu, Z.; Ren, Z.; Herrera-Viedma, E. Expanding grey relational analysis with the comparable degree for dual probabilistic multiplicative linguistic term sets and its application on the cloud enterprise. IEEE Access 2019, 7, 75041–75057. [Google Scholar] [CrossRef]
- Xia, M.; Xu, Z. An approach to multiplicative linguistic group decision making based on possibility degrees. Int. Trans. Oper. Res. 2018, 25, 1611–1634. [Google Scholar] [CrossRef]
- Tang, J.; Meng, F.Y.; Li, C.L.; Li, C.H. A consistency-based approach to group decision making with uncertain multiplicative linguistic fuzzy preference relations. J. Intell. Fuzzy Syst. 2018, 35, 1037–1054. [Google Scholar] [CrossRef]
- Xu, Z.S. An approach based on the uncertain LOWG and induced uncertain LOWG operators to group decision making with uncertain multiplicative linguistic preference relations. Decis. Support Syst. 2004, 41, 488–499. [Google Scholar] [CrossRef]
- Lin, J.; Chen, R. A novel group decision making method under uncertain multiplicative linguistic environment for information system selection. IEEE Access 2019, 7, 19848–19855. [Google Scholar] [CrossRef]
- Zhang, H.M.; Xu, Z.S. Uncertain linguistic information based C-OWA and C-OWG operators and their application. J. Pla Univ. Sci. Technol. 2005, 6, 604–608. [Google Scholar]
- Chodha, V.; Dubey, R.; Kumar, R.; Singh, S.; Kaur, S. Selection of industrial arc welding robot with TOPSIS and Entropy MCDM techniques. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Dhara, A.; Kaur, G.; Kishan, P.M.; Majumder, A.; Yadav, R. An efficient decision support system for selecting very light business jet using CRITIC-TOPSIS method. Aircr. Eng. Aerosp. Technol. 2021. [Google Scholar] [CrossRef]
- Chundi, V.; Raju, S.; Waim, A.R.; Swain, S.S. Priority ranking of road pavements for maintenance using analytical hierarchy process and VIKOR method. Innov. Infrastruct. Solut. 2022, 28, 1–17. [Google Scholar] [CrossRef]
- Altun, F.; Şahin, R.; Güler, C. Multi-criteria decision making approach based on PROMETHEE with probabilistic simplified neutrosophic sets. Soft Comput. 2020, 24, 4899–4915. [Google Scholar] [CrossRef]
- Liu, P.; Li, Y. An extended MULTIMOORA method for probabilistic linguistic multi-criteria group decision-making based on prospect theory. Comput. Ind. Eng. 2019, 136, 528–545. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, X.; Peng, J.; Zhang, H.Y.; Wang, J.Q. An integrated probabilistic linguistic projection method for MCGDM based on ELECTRE III and the weighted convex median voting rule. Expert Syst. 2020, 37, 1–24. [Google Scholar] [CrossRef]
- Sałabun, W.; Watróbski, J.; Shekhovtsov, A. Are MCDA methods benchmarkable? A comparative study of TOPSIS, VIKOR, COPRAS, and PROMETHEE II methods. Symmetry 2020, 12, 1549. [Google Scholar] [CrossRef]
- Patel, N. A Comparative Analysis of TOPSIS & VIKOR Methods in the Selection of Industrial Robots. Ph.D. Dissertation, National Institute of Technology, Rourkela, India, 2013. [Google Scholar]
- Kizielewicz, B.; Baczkiewicz, A. Comparison of Fuzzy TOPSIS, Fuzzy VIKOR, Fuzzy WASPAS and Fuzzy MMOORA methods in the housing selection problem. Procedia Comput. Sci. 2021, 192, 4578–4591. [Google Scholar] [CrossRef]
- Opricovic, S. Multicriteria Optimization of Civil Engineering Systems. Ph.D. Thesis, Faculty of Civil Engineering, Belgrade, Serbia, 1998. Volume 2. pp. 5–21. [Google Scholar]
- Opricovic, S.; Tzeng, G.H. Compromise solution by MCDM methods: A comparative analysis of VIKOR and TOPSIS. Eur. J. Oper. Res. 2004, 156, 445–455. [Google Scholar] [CrossRef]
- Xu, Z.S. On generalized induced linguistic aggregation operators. Int. J. Gen. Syst. 2006, 35, 17–28. [Google Scholar] [CrossRef]
- Xu, Z.S. A direct approach to group decision making with uncertain additive linguistic preference relations. Fuzzy Optim. Decis. Mak. 2006, 5, 23–35. [Google Scholar] [CrossRef]
- Calvo, T.; Mesiar, R.; Yager, R.R. Quantitative weights and aggregation. IEEE Trans Fuzzy Syst. 2004, 12, 62–69. [Google Scholar] [CrossRef]
- Calvo, T.; Beliakov, G. Aggregation functions based on penalties. Fuzzy Sets Syst. 2010, 161, 1420–1436. [Google Scholar] [CrossRef] [Green Version]
- Grabisch, M.; Marichal, J.L.; Mesiar, R.; Pap, E. Aggregation functions: Means. Inf. Sci. 2011, 181, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Yager, R.R. Families of OWA operators. Fuzzy Sets Syst. 1993, 59, 125–148. [Google Scholar] [CrossRef]
- Zhou, L.; Chen, H.; Liu, J. Generalized multiple averaging operators and their applications to group decision making. Group Decis. Negot. 2013, 22, 331–358. [Google Scholar] [CrossRef]
- Zou, Z.H.; Yun, Y.; Sun, J.N. Entropy method for determination of weight of evaluating indicators in fuzzy synthetic evaluation for water quality assessment. J. Environ. Sci. 2006, 18, 1020–1023. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, Z.; Lin, J.; Weng, L. A Novel Approach for Multiplicative Linguistic Group Decision Making Based on Symmetrical Linguistic Chi-Square Deviation and VIKOR Method. Symmetry 2022, 14, 136. https://0-doi-org.brum.beds.ac.uk/10.3390/sym14010136
Gong Z, Lin J, Weng L. A Novel Approach for Multiplicative Linguistic Group Decision Making Based on Symmetrical Linguistic Chi-Square Deviation and VIKOR Method. Symmetry. 2022; 14(1):136. https://0-doi-org.brum.beds.ac.uk/10.3390/sym14010136
Chicago/Turabian StyleGong, Zhiwei, Jian Lin, and Ling Weng. 2022. "A Novel Approach for Multiplicative Linguistic Group Decision Making Based on Symmetrical Linguistic Chi-Square Deviation and VIKOR Method" Symmetry 14, no. 1: 136. https://0-doi-org.brum.beds.ac.uk/10.3390/sym14010136