
Autonomous Concrete Crack Semantic Segmentation Using Deep Fully Convolutional Encoder–Decoder Network in Concrete Structures Inspection


Abstract
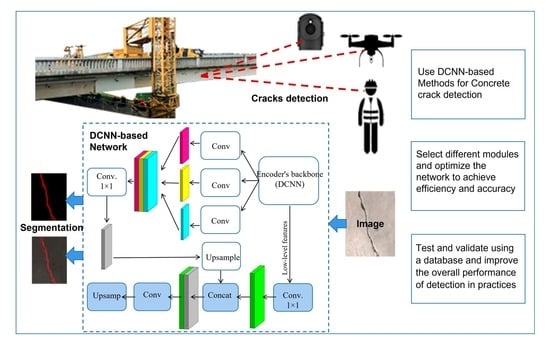
:
1. Introduction
2. Related Works
2.1. Computer Vision-Based Defect Detection in Engineering
2.2. Vision-Based Methods
2.3. Machine Vision Methods
3. Research Methods
3.1. Atrous Convolution
3.2. Atrous Spatial Pyramid Pooling (ASPP)
3.3. Encoder–Decoder Structure
3.4. Depthwise Separable Convolution
4. Datasets for Semantic Segmentation and Classification
4.1. Training and Validation Datasets for Semantic Segmentation
4.2. Test Datasets for Semantic Segmentation and Classification
5. Experiment
5.1. Preparation
5.1.1. Image Selection from Parent Datasets
5.1.2. Crack and Background Annotation
5.1.3. Pre-Processing of Annotated Images
5.1.4. Storing Image Data into Binary Record
5.2. Pre-Trained Models for Semantic Segmentation
5.3. Pre-Trained Models for Classification
6. Results and Discussions
6.1. Network Performance Evaluation
6.1.1. Train Loss
6.1.2. Confusion Matrix
- (1)
- The T.P. (true positive) defines the number of positive inspections predicted to be positive. In this study, T.P. represents the number of crack images in classification or crack pixels in semantic segmentation tasks correctly classified as crack image or pixel instances;
- (2)
- The T.N. (true negative) defines the number of negative inspections predicted to be negative. In this study, T.N. represents the number of background images in classification or background pixels in semantic segmentation tasks that are correctly classified as background image instances or background pixel instances;
- (3)
- The F.P. (false positive) defines the number of negative inspections predicted to be positive. In this study, F.P. represents the number of background images in classification or background pixels in semantic segmentation tasks incorrectly classified as crack images or pixel instances;
- (4)
- The F.N. (false negative) defines the number of positive inspections predicted to be negative. In this study, F.N. represents the number of crack images in classification or crack pixels in semantic segmentation tasks incorrectly classified as background image or background pixel instances.

6.1.3. Evaluation Factors
6.2. Crack Images for Semantic Segmentation
6.3. Crack Images for Classification during the Test
6.3.1. Test on the Parent Dataset: Dataset 1
6.3.2. Test on Another Different Source Dataset: Dataset 2
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- RAC Foundation. More than 3000 GB Road Bridges Are Substandard. 2017. Available online: https://www.racfoundation.org/media-centre/spanning-the-gap-road-bridge-maintenance-in-britain (accessed on 1 September 2020).
- Ahanshahi, M.R.; Masri, S.F.; Sukhatme, G.S. Multi-image stitching and scene reconstruction for evaluating defect evolution in structures. Struct. Health Monit. 2011, 10, 643–657. [Google Scholar] [CrossRef] [Green Version]
- Pallarés, F.J.; Betti, M.; Bartoli, G.; Pallarés, L. Structural health monitoring (SHM) and Nondestructive testing (NDT) of slender masonry structures: A practical review. Constr. Build. Mater. 2021, 297, 123768. [Google Scholar] [CrossRef]
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 2015, 29, 196–210. [Google Scholar] [CrossRef] [Green Version]
- Mordia, R.; Kumar Verma, A. Visual techniques for defects detection in steel products: A comparative study. Eng. Fail. Anal. 2022, 134, 106047. [Google Scholar] [CrossRef]
- Eshkevari, M.; Jahangoshai Rezaee, M.; Zarinbal, M.; Izadbakhsh, H. Automatic dimensional defect detection for glass vials based on machine vision: A heuristic segmentation method. J. Manuf. Process. 2021, 68, 973–989. [Google Scholar] [CrossRef]
- Wang, W.; Su, C.; Fu, D. Automatic detection of defects in concrete structures based on deep learning. Structures 2022, 43, 192–199. [Google Scholar] [CrossRef]
- Hutchinson, T.C.; Chen, Z. Improved Image Analysis for Evaluating Concrete Damage. J. Comput. Civ. Eng. 2006, 20, 210–216. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.-N.; Jang, J.-H.; Han, C.-S. Auto inspection system using a mobile robot for detecting concrete cracks in a tunnel. Autom. Constr. 2007, 16, 255–261. [Google Scholar] [CrossRef]
- Adhikari, R.S.; Moselhi, O.; Bagchi, A. Image-based retrieval of concrete crack properties for bridge inspection. Autom. Constr. 2014, 39, 180–194. [Google Scholar] [CrossRef]
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated Crack Detection on Concrete Bridges. IEEE Trans. Autom. Sci. Eng. 2016, 13, 591–599. [Google Scholar] [CrossRef]
- Dinh, T.H.; Ha, Q.P.; La, H.M. Computer vision-based method for concrete crack detection. In Proceedings of the 2016 14th International Conference on Control, Automation, Robotics and Vision (ICARCV), Phuket, Thailand, 13–15 November 2016; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Noh, Y.; Koo, D.; Kang, Y.-M.; Park, D.; Lee, D. Automatic crack detection on concrete images using segmentation via fuzzy C-means clustering. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017; pp. 877–880. [Google Scholar] [CrossRef]
- Sato, Y.; Bao, Y.; Koya, Y. Crack Detection on Concrete Surfaces Using V-shaped Features. World Comput. Sci. Inf. Technol. 2018, 8, 1–6. [Google Scholar]
- Cha, Y.-J.; Lokekere Gopal, D.; Ali, R. Vision-based concrete crack detection technique using cascade features. In Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems 2018; SPIE: Bellingham, WA, USA, 2018; p. 21. [Google Scholar] [CrossRef]
- Oh, J.-K.; Jang, G.; Oh, S.; Lee, J.H.; Yi, B.-J.; Moon, Y.S.; Lee, J.S.; Choi, Y. Bridge inspection robot system with machine vision. Autom. Constr. 2009, 18, 929–941. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Chambon, S.; Moliard, J.-M. Automatic Road Pavement Assessment with Image Processing: Review and Comparison. Int. J. Geophys. 2011, 2011, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Ebrahimkhanlou, A.; Farhidzadeh, A.; Salamone, S. Multifractal analysis of two-dimensional images for damage assessment of reinforced concrete structures. In Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems 2015; SPIE: Bellingham, WA, USA, 2015; p. 94351A. [Google Scholar] [CrossRef]
- Ying, L.; Salari, E. Beamlet Transform-Based Technique for Pavement Crack Detection and Classification. Comput. Aided Civ. Infrastruct. Eng. 2010, 25, 572–580. [Google Scholar] [CrossRef]
- Valença, J.; Dias-da-Costa, D.; Júlio, E.N.B.S. Characterization of concrete cracking during laboratorial tests using image processing. Constr. Build. Mater. 2012, 28, 607–615. [Google Scholar] [CrossRef]
- Tsai, Y.; Kaul, V.; Yezzi, A. Automating the crack map detection process for machine operated crack sealer. Autom. Constr. 2013, 31, 10–18. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Hashimoto, S. Fast crack detection method for large-size concrete surface images using percolation-based image processing. Mach. Vis. Appl. 2010, 21, 797–809. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Pashaie-Rad, S.; Abudayyeh, O.; Yehia, S. PCA-Based algorithm for unsupervised bridge crack detection. Adv. Eng. Softw. 2006, 37, 771–778. [Google Scholar] [CrossRef]
- Choudhary, G.K.; Dey, S. Crack detection in concrete surfaces using image processing, fuzzy logic, and neural networks. In Proceedings of the 2012 IEEE Fifth International Conference on Advanced Computational Intelligence (ICACI), Najing, China, 18–20 October 2012; pp. 404–411. [Google Scholar] [CrossRef]
- Na, W.; Tao, W. Proximal support vector machine based pavement image classification. In Proceedings of the 2012 IEEE Fifth International Conference on Advanced Computational Intelligence (ICACI), Najing, China, 18–20 October 2012; pp. 686–688. [Google Scholar] [CrossRef]
- Li, G.; Zhao, X.; Du, K.; Ru, F.; Zhang, Y. Recognition and evaluation of bridge cracks with modified active contour model and greedy search-based support vector machine. Autom. Constr. 2017, 78, 51–61. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, E.; Shin, M.; Sim, S.-H. Crack and Noncrack Classification from Concrete Surface Images Using Machine Learning. Struct. Health Monit. 2019, 18, 725–738. [Google Scholar] [CrossRef]
- Dai, B.; Gu, C.; Zhao, E.; Zhu, K.; Cao, W.; Qin, X. Improved online sequential extreme learning machine for identifying crack behavior in concrete dam. Adv. Struct. Eng. 2019, 22, 402–412. [Google Scholar] [CrossRef]
- Zhang, K.; Cheng, H.D.; Zhang, B. Unified Approach to Pavement Crack and Sealed Crack Detection Using Preclassification Based on Transfer Learning. J. Comput. Civ. Eng. 2018, 32, 04018001. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Chen, F.-C.; Jahanshahi, M.R. NB-CNN: Deep Learning-Based Crack Detection Using Convolutional Neural Network and Naïve Bayes Data Fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Tao, X.; Zhang, D.; Ma, W.; Liu, X.; Xu, D. Automatic Metallic Surface Defect Detection and Recognition with Convolutional Neural Networks. Appl. Sci. 2018, 8, 1575. [Google Scholar] [CrossRef] [Green Version]
- Xu, H.; Su, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Automatic Bridge Crack Detection Using a Convolutional Neural Network. Appl. Sci. 2019, 9, 2867. [Google Scholar] [CrossRef] [Green Version]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep Convolutional Neural Networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Object Detectors Emerge in Deep Scene CNNs. arXiv 2014, arXiv:1412.6856. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1409.1556. [Google Scholar]
- Vanhoucke, V. Learning visual representations at scale. arXiv 2014, arXiv:2006.06666. [Google Scholar]
- Özgenel, Ç.F. Concrete Crack Images for Classification; Version 2; Mendeley Data; Orta Dogu Teknik Universitesi: Ankara, Turkey, 2019. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2016, arXiv:1610.02357. [Google Scholar]
- Yeum, C.M.; Dyke, S.J. Vision-Based Automated Crack Detection for Bridge Inspection. Comput. Aided Civ. Infrastruct. Eng. 2015, 30, 759–770. [Google Scholar] [CrossRef]
- Islam, M.M.M.; Kim, J.-M. Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder–Decoder Network. Sensors 2019, 19, 4251. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Description | Advantages and Disadvantages |
|---|---|---|
| Ikhlas Abdel-Qader et al. (2006) [25] | (1) experimented with three different principal component analyses (PCAs) implemented directly on the raw data in a global framework, (2) practiced PCA on the data to enhance the result after linear features were detected, and (3) practiced PCA with the feature detected only on the segmented small individual block of the data. | The automatic crack extraction method was used to identify concrete cracks in the early stage; the accuracy is low. Linear patterns may be identified as cracks, the anti-interference ability is weak, and the operation is complicated. |
| Choudhary and Dey (2012) [26] | Presented fuzzy logic and artificial neural network (ANN)-based models to extract crack features from digital images, including (1) an images approach which classifies an image globally and (2) an object approach which classifies cracks and noise locally in an image. | Uses ANN in the early stage of image-based crack feature extraction; can classify the image only if there is a crack or noise; accuracy is low; the speed and accuracy are low since the convolutional layer is not used in the neural network in this stage. |
| Na and Tao (2012) [27] | Provided an approach for pavement surface image classification using a proximal support vector machine (PSVM), which is easier to manipulate than the traditional support vector machine (SVM). | Easier to operate than SVM; it is suitable for binary classification problems but challenging to handle image tasks with a large amount of data; the speed is slower than that of the convolutional neural network. |
| Li et al. (2017) [28] | Developed a fully automatic machine-learning algorithm to extract cracks with the assistance of a proposed feature selection method based on a linear SVM with a wide-ranging search strategy for noise elimination. | Uses noise elimination and SVM-based novel feature selection; both were used to improve crack recognition accuracy. The method is complicated and cannot perform pixel-wise semantic segmentation tasks. |
| Kim et al. (2018) [29] | Proposed a machine-learning approach for the use of classifying cracks and noise patterns by (1) applying image binarization for extracting crack candidate regions and (2) classifying images using trained classification models, which are built based on speeded-up robust features and convolution neural network (CNN). | Built up a good foundation for DCNN application in crack detection; recognition speed and accuracy are relatively low; has limited application in pixel-wise semantic segmentation tasks. |
| Dai et al. (2019) [30] | Implemented a novel methodology applying the genetically optimized online sequential extreme learning machine. This machine utilizes sequential learning algorithms that do not require retraining once new data are uploaded. It also features bootstrap confidence intervals for predicting the behaviour of a concrete crack in a dam. | This method has good generalization performance and a fast learning speed, but the image classification task is only suitable for real-time computing scenarios and cannot perform pixel-wise semantic segmentation tasks; accuracy is relatively low |
| No. of Crack Images | No. of Non-Crack Images | No. of Jpg Images | No. of Png Images | |
|---|---|---|---|---|
| Train dataset | 1000 | 500 | 1500 | 1500 |
| Validation dataset | 100 | 50 | 150 | 150 |
| No. of Crack Images | No. of Non-Crack Images | Author | |
|---|---|---|---|
| Train dataset | 1000 | 500 | Çağlar Fırat Özgenel [46] |
| Validation dataset | 100 | 50 | Xu et al. [35] |
| Hyper-Parameters/Models | Xception_41 | Xception_65 | Xception_71 |
|---|---|---|---|
| No. of layers | 41 | 65 | 71 |
| Batch size | 2 | 2 | 2 |
| No. of epochs | 100 | 100 | 100 |
| Base learning rate | 0.001 | 0.001 | 0.001 |
| Learning rate decay factor | 0.1 | 0.1 | 0.1 |
| Learning rate decay step | 2000 | 2000 | 2000 |
| Atrous rate for ASPP | [6,12,18] | [6,12,18] | [6,12,18] |
| Decoder up-sample factors | [4,4] | [4,4] | [4,4] |
| mIOU of Background | mIOU of Crack | Overall mIOU | No. of Epochs | |
|---|---|---|---|---|
| Xception_41 | 0.986364901 | 0.843513668 | 0.914939284 | 100 |
| Xception_65 | 0.986514747 | 0.844588637 | 0.915551662 | 100 |
| Xception_71 | 0.986991405 | 0.849419773 | 0.918205619 | 100 |
| Network | Average Accuracy | Highest Accuracy |
|---|---|---|
| Performance of this study | 91.62% | 91.82% |
| Dung and Anh’s network | 90.9% | 91.9% |
| Dataset | Accuracy | Precision | Sensitivity (Recall) | Specificity | F1-Score |
|---|---|---|---|---|---|
| Dataset 1 | 100% | 100% | 100% | 100% | 1.0 |
| Dataset 1a | 99.86% | 100% | 99.8% | 100% | 0.999 |
| Dataset 1b | 99.93% | 100% | 99.9% | 100% | 1.0 |
| Dataset 1c | 99.86% | 100% | 99.8% | 100% | 0.999 |
| Accuracy | Precision | Sensitivity (Recall) | Specificity | F1-Score | |
|---|---|---|---|---|---|
| Dataset 2 | 95% | 95.57% | 92.90% | 99.20% | 0.9612 |
| Model/Network | Accuracy | Precision | Sensitivity | Specificity | F1-Score |
|---|---|---|---|---|---|
| SVM | 71.87% | 68.75% | 73.33% | - | 0.7096 |
| CNN | 81.87% | 88.75% | 78.02% | - | 0.8304 |
| FCN | 92.8% | 91.3% | 94.1% | - | 0.8304 |
| Model by Xu et al. | 96.37% | 78.11% | 100% | 95.83% | 0.8771 |
| Proposed network | 95% | 99.57% | 92.9% | 99.2% | 0.9612 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, R.; Ren, G.; Li, H.; Jiang, W.; Zhang, J.; Qin, H. Autonomous Concrete Crack Semantic Segmentation Using Deep Fully Convolutional Encoder–Decoder Network in Concrete Structures Inspection. Buildings 2022, 12, 2019. https://0-doi-org.brum.beds.ac.uk/10.3390/buildings12112019
Pu R, Ren G, Li H, Jiang W, Zhang J, Qin H. Autonomous Concrete Crack Semantic Segmentation Using Deep Fully Convolutional Encoder–Decoder Network in Concrete Structures Inspection. Buildings. 2022; 12(11):2019. https://0-doi-org.brum.beds.ac.uk/10.3390/buildings12112019
Chicago/Turabian StylePu, Rundong, Guoqian Ren, Haijiang Li, Wei Jiang, Jisong Zhang, and Honglei Qin. 2022. "Autonomous Concrete Crack Semantic Segmentation Using Deep Fully Convolutional Encoder–Decoder Network in Concrete Structures Inspection" Buildings 12, no. 11: 2019. https://0-doi-org.brum.beds.ac.uk/10.3390/buildings12112019