
Forecasting Daily Electricity Consumption in Thailand Using Regression, Artificial Neural Network, Support Vector Machine, and Hybrid Models


Abstract
:1. Introduction
2. Materials and Methods
2.1. Multiple Linear Regression (MLR)
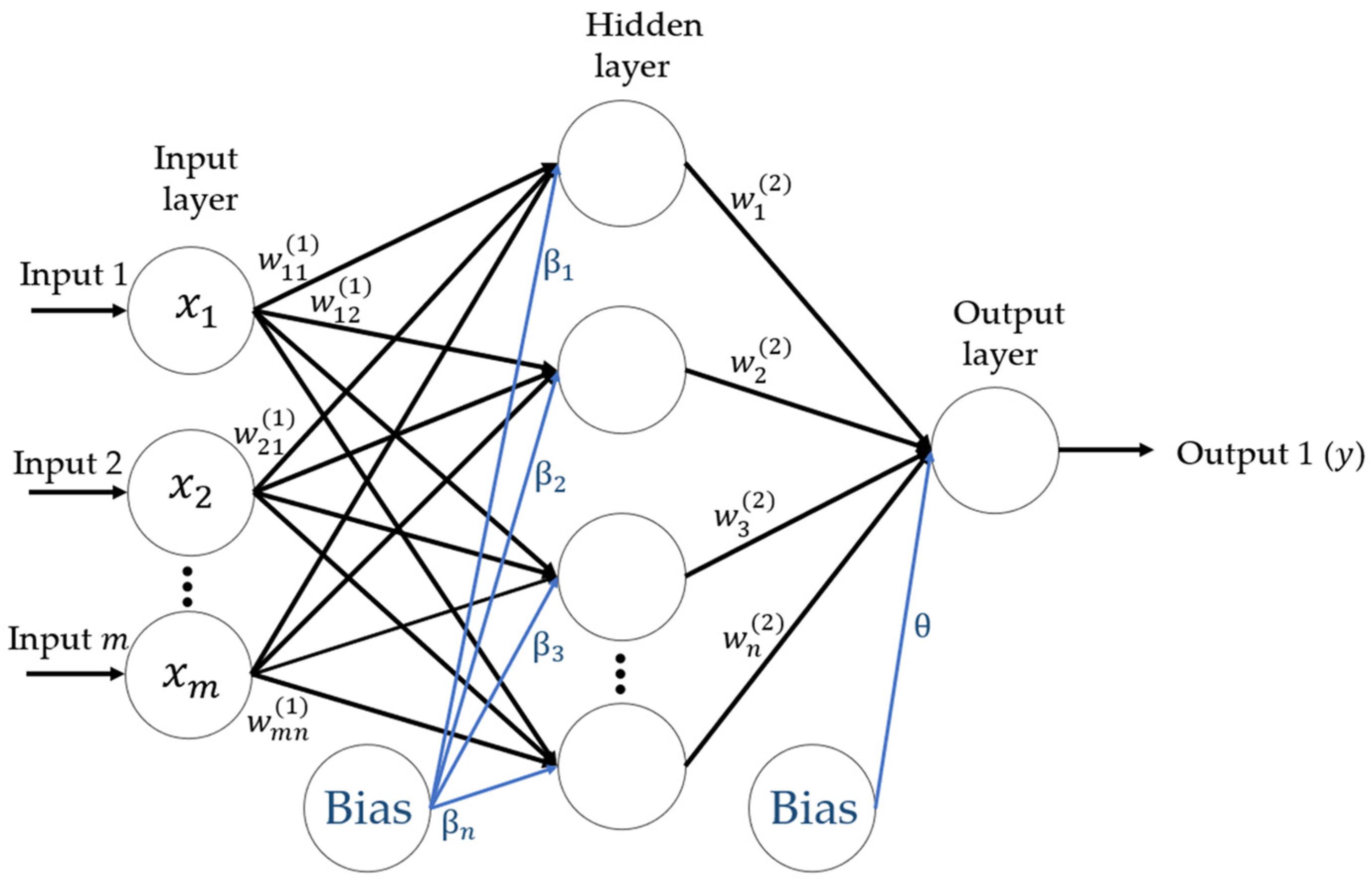
2.2. Artificial Neural Network (ANN)
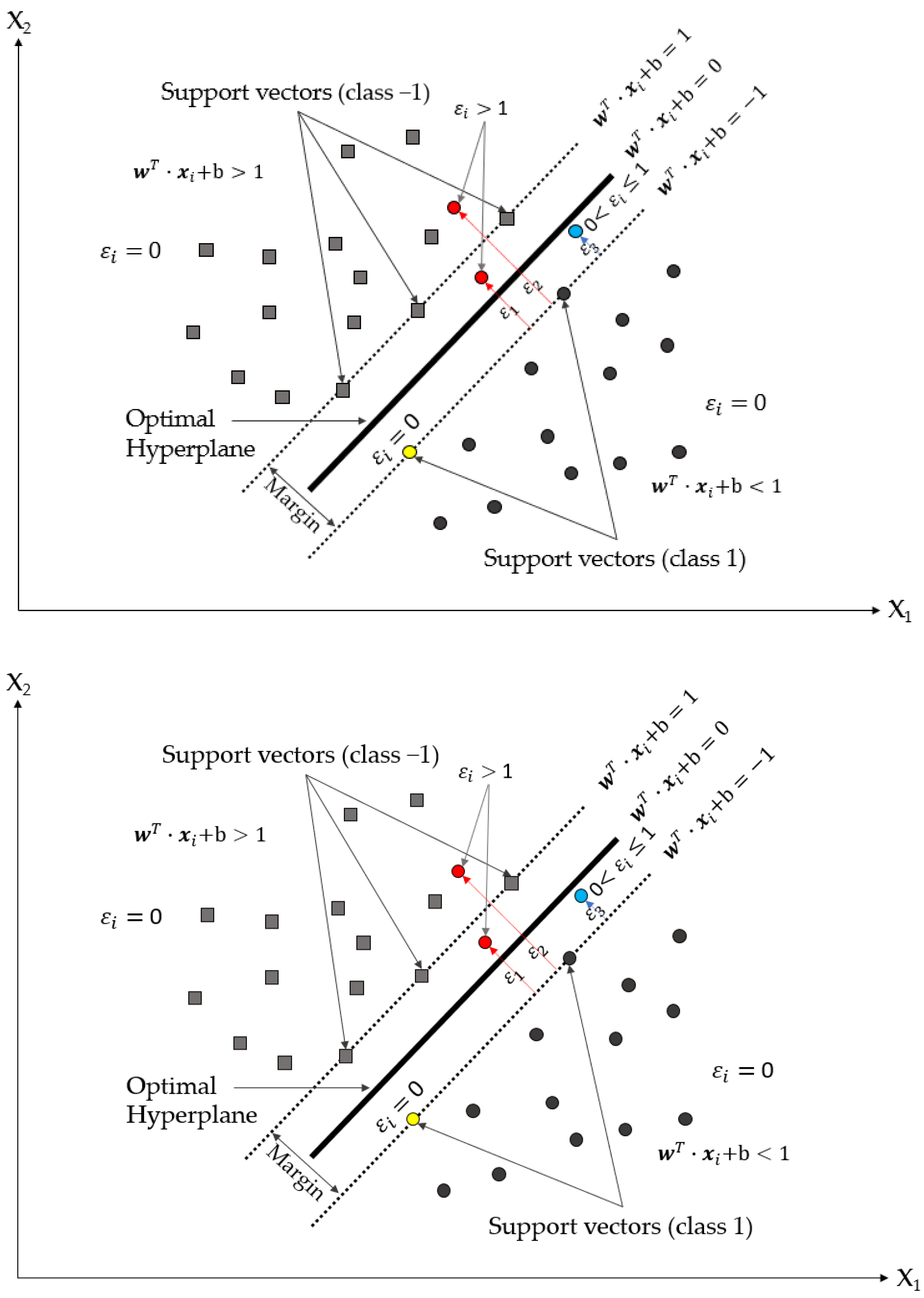
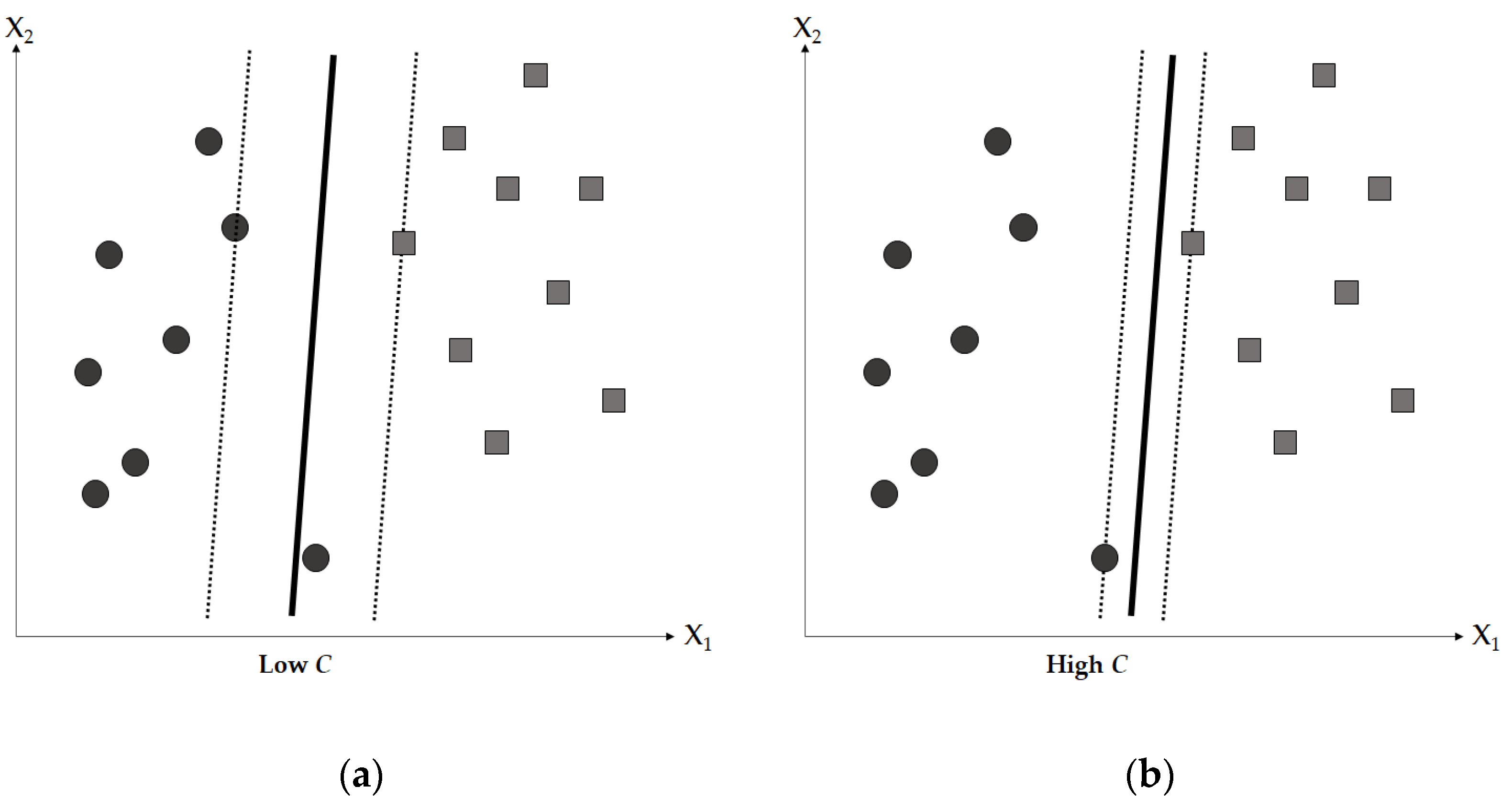
2.3. Support Vector Machine (SVM)
2.4. Hybrid Models
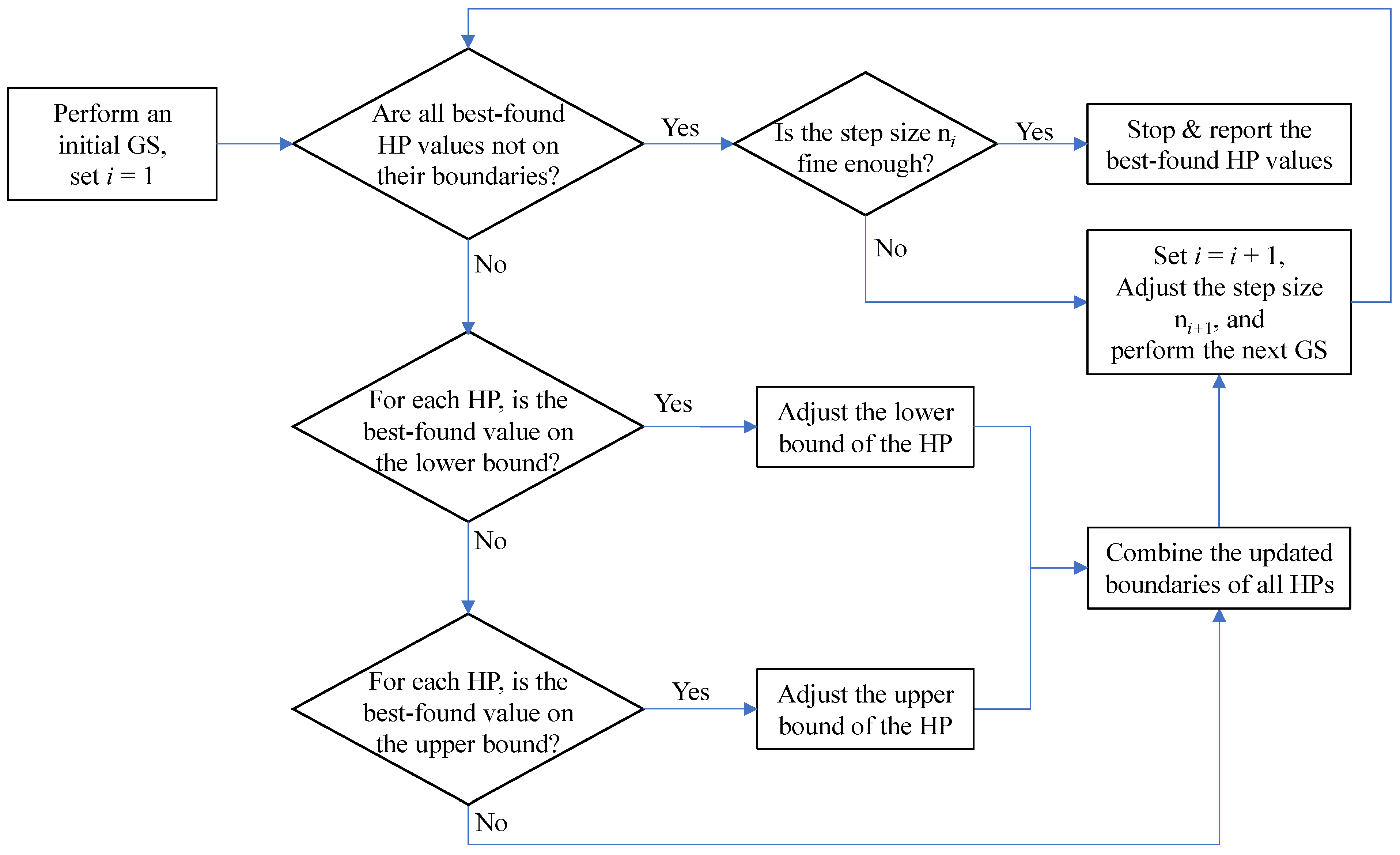
2.5. Sequential Grid Search
2.6. Forecasting Performance Measurement
3. Computational Experiment
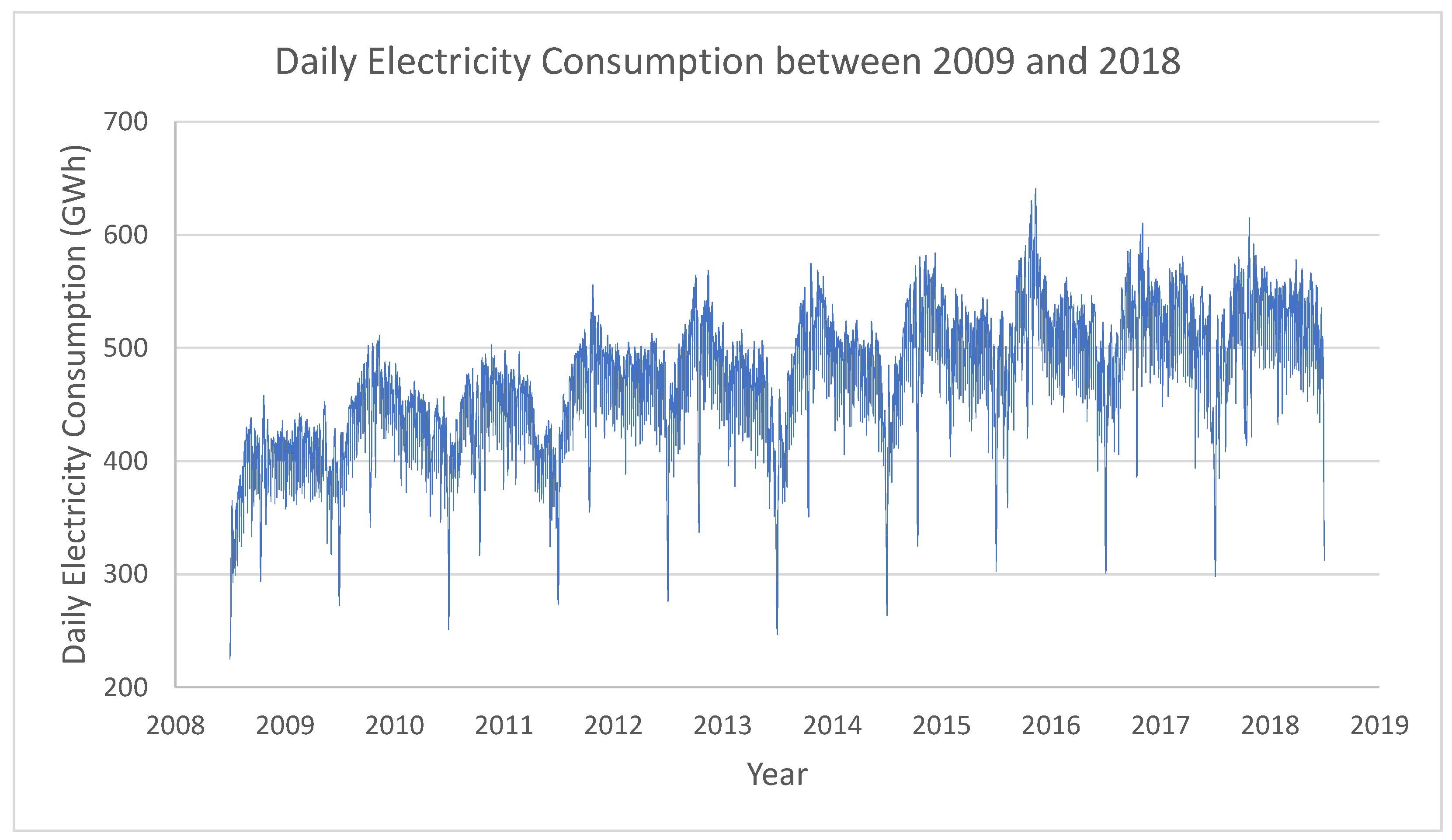
3.1. Data Partitioning
3.2. Input Attributes
3.3. MLR Model Result
3.4. Hyperparameter Tuning of ML Models Using Sequential Grid Search
3.4.1. Sequential Grid Search for Hyperparameter Tuning of ANN
3.4.2. Grid Search for Hyperparameter Tuning of SVM
3.4.3. Sequential Grid Search for Hyperparameter Tuning of Hybrid of MLR and ANN and Hybrid of MLR and SVM
3.5. Ensemble Prediction Models
3.6. Adding Indicator Variables for Each Specific National Holiday to Improve Performance
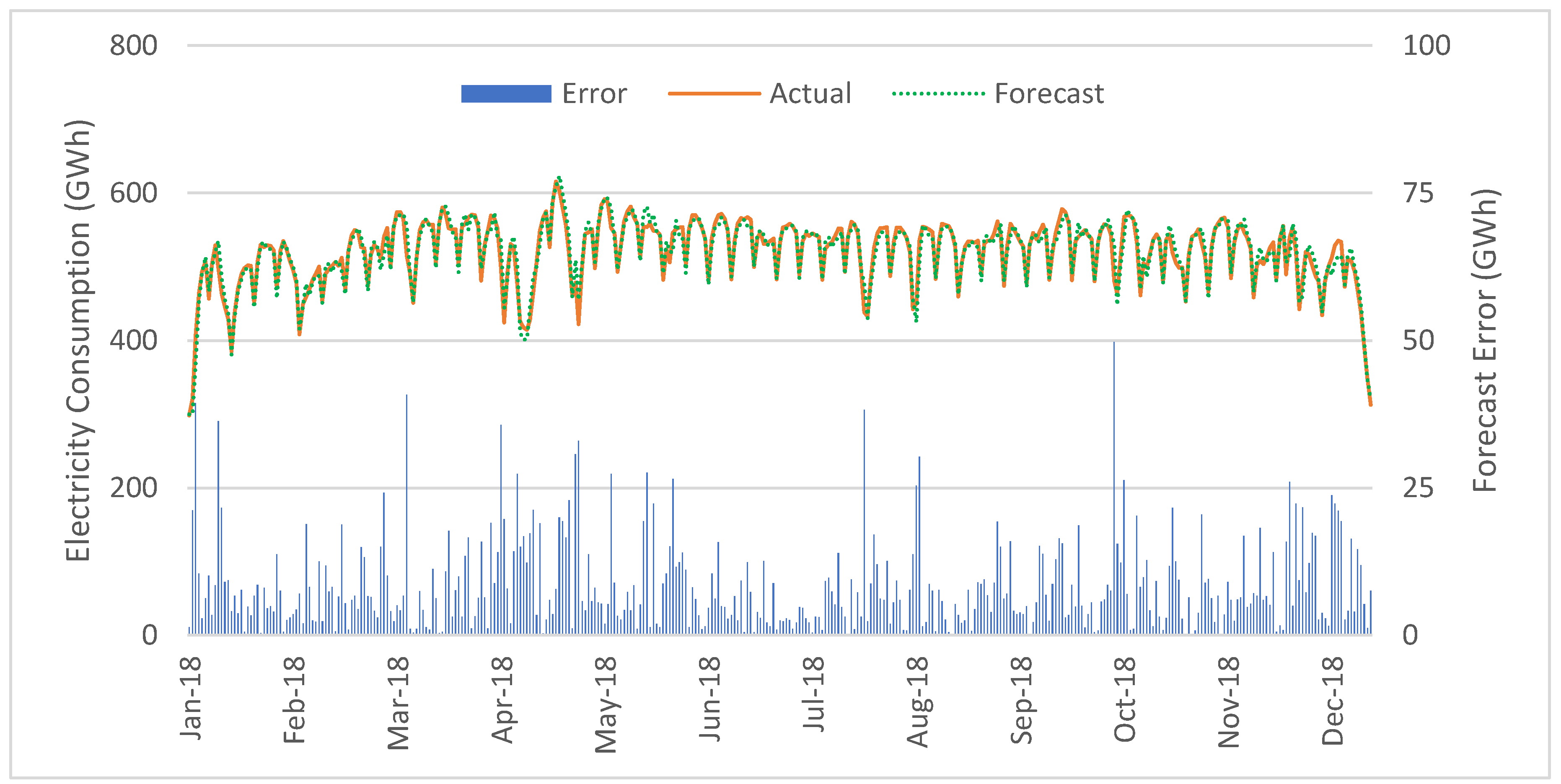
3.7. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kyriakides, E.; Polycarpou, M. Short term electric load forecasting: A tutorial. Trends Neural Comput. 2007, 35, 391–418. [Google Scholar]
- Vu, D.H.; Muttaqi, K.M.; Agalgaonkar, A.P. A variance inflation factor and backward elimination based robust regression model for forecasting monthly electricity demand using climatic variables. Appl. Energy 2015, 140, 385–394. [Google Scholar] [CrossRef] [Green Version]
- Amber, K.P.; Aslam, M.W.; Mahmood, A.; Kousar, A.; Younis, M.Y.; Akbar, B.; Chaudhary, G.Q.; Hussain, S.K. Energy consumption forecasting for university sector buildings. Energies 2017, 10, 1579. [Google Scholar] [CrossRef] [Green Version]
- Dudic, B.; Smolen, J.; Kovac, P.; Savkovic, B.; Dudic, Z. Electricity Usage Efficiency and Electricity Demand Modeling in the Case of Germany and the UK. Appl. Sci. 2020, 10, 2291. [Google Scholar] [CrossRef] [Green Version]
- Mosavi, A.; Bahmani, A. Energy Consumption Prediction Using Machine Learning; A Review. 2019. Available online: https://eprints.qut.edu.au/128957/ (accessed on 30 September 2021).
- Saravanan, S.; Kannan, S.; Thangaraj, C. Prediction of India’s electricity demand using ANFIS. ICTACT J. Soft Comput. 2015, 5, 985–990. [Google Scholar]
- Yuan, J.; Farnham, C.; Azuma, C.; Emura, K. Predictive artificial neural network models to forecast the seasonal hourly electricity consumption for a University Campus. Sustain. Cities Soc. 2018, 42, 82–92. [Google Scholar] [CrossRef]
- Liu, P.; Zheng, P.; Chen, Z. Deep learning with stacked denoising auto-encoder for short-term electric load forecasting. Energies 2019, 12, 2445. [Google Scholar] [CrossRef] [Green Version]
- Setiawan, A.; Koprinska, I.; Agelidis, V.G. Very short-term electricity load demand forecasting using support vector regression. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 2888–2894. [Google Scholar]
- Chen, Y.; Xu, P.; Chu, Y.; Li, W.; Wu, Y.; Ni, L.; Bao, Y.; Wang, K. Short-term electrical load forecasting using the Support Vector Regression (SVR) model to calculate the demand response baseline for office buildings. Appl. Energy 2017, 195, 659–670. [Google Scholar] [CrossRef]
- González-Romera, E.; Jaramillo-Morán, M.; Carmona-Fernández, D. Monthly electric energy demand forecasting with neural networks and Fourier series. Energy Convers. Manag. 2008, 49, 3135–3142. [Google Scholar] [CrossRef]
- Fan, G.-F.; Qing, S.; Wang, H.; Hong, W.-C.; Li, H.-J. Support vector regression model based on empirical mode decomposition and auto regression for electric load forecasting. Energies 2013, 6, 1887–1901. [Google Scholar] [CrossRef]
- Deb, C.; Zhang, F.; Yang, J.; Lee, S.; Kwok Wei, S. A review on time series forecasting techniques for building energy consumption. Renew. Sustain. Energy Rev. 2017, 74, 902–924. [Google Scholar] [CrossRef]
- Ma, Y.-J.; Zhai, M.-Y. Day-Ahead Prediction of Microgrid Electricity Demand Using a Hybrid Artificial Intelligence Model. Processes 2019, 7, 320. [Google Scholar] [CrossRef] [Green Version]
- Javed, U.; Ijaz, K.; Jawad, M.; Ansari, E.A.; Shabbir, N.; Kütt, L.; Husev, O. Exploratory Data Analysis Based Short-Term Electrical Load Forecasting: A Comprehensive Analysis. Energies 2021, 14, 5510. [Google Scholar] [CrossRef]
- Bento, P.M.; Pombo, J.A.; Calado, M.R.; Mariano, S.J. Stacking Ensemble Methodology Using Deep Learning and ARIMA Models for Short-Term Load Forecasting. Energies 2021, 14, 7378. [Google Scholar] [CrossRef]
- Phyo, P.P.; Jeenanunta, C. Daily Load Forecasting Based on a Combination of Classification and Regression Tree and Deep Belief Network. IEEE Access 2021, 9, 152226–152242. [Google Scholar] [CrossRef]
- Ghalehkhondabi, I.; Ardjmand, E.; Weckman, G.R.; Young, W.A. An overview of energy demand forecasting methods published in 2005–2015. Energy Syst. 2017, 8, 411–447. [Google Scholar] [CrossRef]
- Schminke, B.; Beblek, A. Overview of the current state of research on load forecasts in the building sector. Preprint 2020. Available online: https://www.researchgate.net/publication/342765149_Overview_of_the_current_state_of_research_on_load_forecasts_in_the_building_sector (accessed on 14 August 2021).
- Probst, P.; Boulesteix, A.-L.; Bischl, B. Tunability: Importance of hyperparameters of machine learning algorithms. J. Mach. Learn. Res. 2019, 20, 1934–1965. [Google Scholar]
- Zhang, H.; Chen, L.; Qu, Y.; Zhao, G.; Guo, Z. Support vector regression based on grid-search method for short-term wind power forecasting. J. Appl. Math. 2014, 2014, 1–11. [Google Scholar] [CrossRef]
- Menapace, A.; Zanfei, A.; Righetti, M. Tuning ANN Hyperparameters for Forecasting Drinking Water Demand. Appl. Sci. 2021, 11, 4290. [Google Scholar] [CrossRef]
- Ribeiro, A.M.N.; do Carmo, P.R.X.; Endo, P.T.; Rosati, P.; Lynn, T. Short-and Very Short-Term Firm-Level Load Forecasting for Warehouses: A Comparison of Machine Learning and Deep Learning Models. Energies 2022, 15, 750. [Google Scholar] [CrossRef]
- Mantovani, R.G.; Rossi, A.L.; Vanschoren, J.; Bischl, B.; De Carvalho, A.C. Effectiveness of random search in SVM hyper-parameter tuning. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–16 July 2015; pp. 1–8. [Google Scholar]
- Nguyen, V.-H.; Le, T.-T.; Truong, H.-S.; Le, M.V.; Ngo, V.-L.; Nguyen, A.T.; Nguyen, H.Q. Applying Bayesian Optimization for Machine Learning Models in Predicting the Surface Roughness in Single-Point Diamond Turning Polycarbonate. Math. Probl. Eng. 2021, 2021, 1–16. [Google Scholar] [CrossRef]
- Panchal, F.S.; Panchal, M. Review on methods of selecting number of hidden nodes in artificial neural network. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 455–464. [Google Scholar]
- Sheela, K.G.; Deepa, S.N. Review on methods to fix number of hidden neurons in neural networks. Math. Probl. Eng. 2013, 2013, 425740. [Google Scholar] [CrossRef] [Green Version]
- IRENA. Renewable Energy Outlook: Thailand. 2017. Available online: https://www.irena.org/-/media/Files/IRENA/Agency/Publication/2017%20/Nov/IRENA_Outlook_Thailand_2017.pdf (accessed on 9 February 2022).
- Rawlings, J.O.; Pantula, S.G.; Dickey, D.A. Applied Regression Analysis: A Research Tool; Springer: New York, NY, USA, 1998. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Khandelwal, I.; Adhikari, R.; Verma, G. Time series forecasting using hybrid ARIMA and ANN models based on DWT decomposition. Procedia Comput. Sci. 2015, 48, 173–179. [Google Scholar] [CrossRef] [Green Version]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: New York, NY, USA, 2013. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Zaki, M.J.; Meira, W., Jr.; Meira, W. Data Mining and Analysis: Fundamental Concepts and Algorithms; Cambridge University Press: New York, NY, USA, 2014. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Jatana, V. Hyperparameter Tuning. 2019. Available online: https://www.researchgate.net/publication/335491240_Hyperparameter_Tuning (accessed on 3 December 2021).
- Liashchynskyi, P.; Liashchynskyi, P. Grid Search, Random Search, Genetic Algorithm: A Big Comparison for NAS. arXiv 2019, arXiv:abs/1912.06059. [Google Scholar]
- Syarif, I.; Prugel-Bennett, A.; Wills, G. SVM Parameter Optimization using Grid Search and Genetic Algorithm to Improve Classification Performance. TELKOMNIKA Telecommun. Comput. Electron. Control 2016, 14, 1502. [Google Scholar] [CrossRef]
- Nti, I.K.; Teimeh, M.; Nyarko-Boateng, O.; Adekoya, A.F. Electricity load forecasting: A systematic review. J. Electr. Syst. Inf. Technol. 2020, 7, 1–19. [Google Scholar] [CrossRef]
- Rook, A.J.; Gill, M. Prediction of the voluntary intake of grass silages by beef cattle. 1. Linear regression analyses. Anim. Sci. 1990, 50, 425–438. [Google Scholar] [CrossRef]
- Lawrence, I.K.L. A Concordance Correlation Coefficient to Evaluate Reproducibility. Biometrics 1989, 45, 255–268. [Google Scholar]
- Fuentes-Pila, J.; DeLorenzo, M.; Beede, D.; Staples, C.; Holter, J. Evaluation of equations based on animal factors to predict intake of lactating Holstein cows. J. Dairy Sci. 1996, 79, 1562–1571. [Google Scholar] [CrossRef]
- McBride, G. A proposal for strength-of-agreement criteria for Lin’s concordance correlation coefficient. NIWA Client Rep. HAM2005-062 2005, 45, 307–310. [Google Scholar]
- Vandeginste, B.G.M.; Massart, D.L.; Buydens, L.M.C.; De Jong, S.; Lewi, P.J.; Smeyers-Verbeke, J. Chapter 44—Artificial Neural Networks. In Data Handling in Science and Technology; Vandeginste, B.G.M., Massart, D.L., Buydens, L.M.C., De Jong, S., Lewi, P.J., Smeyers-Verbeke, J., Eds.; Elsevier: Amsterdam, The Netherlands, 1998; Volume 20, pp. 649–699. [Google Scholar]
- Bakr, M.H.; Negm, M.H. Chapter Three—Modeling and Design of High-Frequency Structures Using Artificial Neural Networks and Space Mapping. In Advances in Imaging and Electron Physics; Deen, M.J., Ed.; Elsevier: Amsterdam, The Netherlands, 2012; Volume 174, pp. 223–260. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Chapter 10—Deep learning. In Data Mining, 4th ed.; Witten, I.H., Frank, E., Hall, M.A., Pal, C.J., Eds.; Morgan Kaufmann: Cambridge, MA, USA, 2017; pp. 417–466. [Google Scholar]
- Çelik, U.; Başarır, Ç. The prediction of precious metal prices via artificial neural network by using RapidMiner. Alphanumeric J. 2017, 5, 45–54. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | DF | Adj SS | Adj MS | F-Value | p-Value |
|---|---|---|---|---|---|
| Regression | 24 | 6.73 × 1012 | 2.80 × 1011 | 1774.48 | 0.000 |
| Error | 2532 | 4.00 × 1011 | 1.57 × 108 | ||
| Total | 2556 | 7.13 × 1012 |
| Dataset | Train | Validation | Test |
|---|---|---|---|
| MAPE (%) | 1.9234 | 2.1977 | 2.0225 |
| Hyperparameter | Min | Max | Step | Values |
|---|---|---|---|---|
| TC | 100 | 1000 | 5 | 100, 280, 460, …, 1000 |
| LR | 0.001 | 0.05 | 5 | 0.001, 0.0108, 0.0206, …, 0.05 |
| MR | 0.5 | 0.9 | 5 | 0.5, 0.58, 0.66, …, 0.9 |
| Hyperparameter | Min | Max | Step | Values |
|---|---|---|---|---|
| TC | 100 | 1000 | 10 | 100, 190, 280, …, 1000 |
| 100 | 1000 | 20 | 100, 145, 190, …, 1000 | |
| 550 | 1450 | 10 | 550, 640, 730, …, 1450 | |
| 550 | 1450 | 20 | 550, 595, 640, …, 1450 | |
| 10 | 910 | 10 | 10, 100, 190, …, 910 | |
| 10 | 910 | 20 | 10, 55, 100, …, 910 | |
| 1000 | 1900 | 20 | 1000, 1045, 1090, …, 1900 | |
| LR | 0.001 | 0.05 | 10 | 0.001, 0.0059, 0.0108, …, 0.05 |
| 0.001 | 0.05 | 20 | 0.001, 0.00345, 0.0059, …, 0.05 | |
| 0.0001 | 0.0491 | 10 | 0.0001, 0.005, 0.0099, …, 0.0491 | |
| 0.0001 | 0.0491 | 20 | 0.0001, 0.00255, 0.005, …, 0.0491 | |
| 0.0255 | 0.0745 | 10 | 0.0245, 0.0295, 0.0345, …, 0.0745 | |
| 0.0255 | 0.0745 | 20 | 0.0245, 0.027, 0.0295, …, 0.0745 | |
| MR | 0.5 | 0.9 | 10 | 0.5, 0.54, 0.58, …, 0.9 |
| 0.5 | 0.9 | 20 | 0.5, 0.52, 0.54, …, 0.9 | |
| 0.6 | 1 | 10 | 0.6, 0.64, 0.68, …, 1 | |
| 0.6 | 1 | 20 | 0.6, 0.62, 0.64, …, 1 | |
| 0.3 | 0.7 | 10 | 0.3, 0.34, 0.38, …, 0.7 | |
| 0.3 | 0.7 | 20 | 0.3, 0.32, 0.34, …, 0.7 |
| HN | GS Step | TC | LR | MR | Best Found HP | MAPE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Max | Step | Min | Max | Step | Min | Max | Step | TC | LR | MR | Train | Validate | Test | ||
| 1 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 280 | 0.001 | 0.90 | 1.98 | 2.20 | 2.03 |
| 2 | 100 | 1000 | 10 | 0.0001 | 0.0491 | 10 | 0.6 | 1 | 10 | 640 | 0.00990 | 0.60 | 2.02 | 2.18 | 2.07 | |
| 3 | 100 | 1000 | 20 | 0.0001 | 0.0491 | 20 | 0.3 | 0.7 | 20 | 190 | 0.0148 | 0.50 | 2.02 | 2.16 | 2.07 | |
| 2 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 280 | 0.01080 | 0.58 | 1.83 | 1.99 | 1.91 |
| 2 | 100 | 1000 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 730 | 0.00835 | 0.88 | 1.81 | 1.96 | 1.84 | |
| 3 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 640 | 0.03040 | 0.66 | 1.80 | 1.93 | 1.90 |
| 2 | 100 | 1000 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 955 | 0.04755 | 0.62 | 1.71 | 1.89 | 1.82 | |
| 4 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 820 | 0.02060 | 0.58 | 1.73 | 1.92 | 1.89 |
| 2 | 100 | 1000 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 775 | 0.00835 | 0.68 | 1.70 | 1.89 | 1.76 | |
| 5 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 1000 | 0.01080 | 0.82 | 1.57 | 1.90 | 1.80 |
| 2 | 550 | 1450 | 10 | 0.001 | 0.05 | 10 | 0.5 | 0.9 | 10 | 1360 | 0.03040 | 0.62 | 1.52 | 1.85 | 2.03 | |
| 3 | 550 | 1450 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 730 | 0.02305 | 0.70 | 1.57 | 1.86 | 1.96 | |
| 6 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 1000 | 0.02060 | 0.74 | 1.49 | 1.94 | 1.84 |
| 2 | 550 | 1450 | 10 | 0.001 | 0.05 | 10 | 0.5 | 0.9 | 10 | 1270 | 0.01570 | 0.82 | 1.49 | 1.89 | 1.79 | |
| 3 | 550 | 1450 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 1225 | 0.02795 | 0.68 | 1.52 | 1.86 | 1.84 | |
| 7 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 820 | 0.04020 | 0.66 | 1.52 | 1.90 | 1.74 |
| 2 | 100 | 1000 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 595 | 0.03530 | 0.90 | 1.49 | 1.86 | 1.82 | |
| 3 | 100 | 1000 | 20 | 0.001 | 0.05 | 20 | 0.6 | 1 | 20 | 1000 | 0.02060 | 0.80 | 1.57 | 1.88 | 1.68 | |
| 4 | 550 | 1450 | 20 | 0.001 | 0.05 | 20 | 0.6 | 1 | 20 | 1450 | 0.02060 | 0.80 | 1.54 | 1.86 | 1.68 | |
| 5 | 1000 | 1900 | 20 | 0.001 | 0.05 | 20 | 0.6 | 1 | 20 | 1855 | 0.00345 | 0.94 | 1.49 | 1.85 | 1.69 | |
| 8 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 640 | 0.02060 | 0.66 | 1.58 | 1.96 | 1.94 |
| 2 | 100 | 1000 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 865 | 0.02795 | 0.68 | 1.51 | 1.89 | 2.07 | |
| 9 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 1000 | 0.01080 | 0.90 | 1.44 | 1.95 | 2.40 |
| 2 | 550 | 1450 | 10 | 0.001 | 0.05 | 10 | 0.6 | 1 | 10 | 1450 | 0.0206 | 0.68 | 1.46 | 1.91 | 2.11 | |
| 3 | 550 | 1450 | 20 | 0.001 | 0.05 | 20 | 0.6 | 1 | 20 | 1360 | 0.04755 | 0.66 | 1.4 | 1.87 | 2.02 | |
| 10 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 460 | 0.05 | 0.66 | 1.53 | 1.97 | 2.09 |
| 2 | 100 | 1000 | 10 | 0.0255 | 0.0745 | 10 | 0.5 | 0.9 | 10 | 910 | 0.04950 | 0.78 | 1.49 | 1.93 | 2.23 | |
| 3 | 100 | 1000 | 20 | 0.0255 | 0.0745 | 20 | 0.5 | 0.9 | 20 | 865 | 0.02700 | 0.68 | 1.45 | 1.93 | 2.07 | |
| 11 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 100 | 0.03040 | 0.66 | 1.72 | 2.00 | 1.97 |
| 2 | 10 | 910 | 10 | 0.001 | 0.05 | 10 | 0.5 | 0.9 | 10 | 640 | 0.03530 | 0.66 | 1.52 | 1.96 | 1.92 | |
| 3 | 10 | 910 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 775 | 0.04755 | 0.66 | 1.50 | 1.92 | 1.99 | |
| 12 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 1000 | 0.02060 | 0.58 | 1.49 | 1.93 | 1.88 |
| 2 | 550 | 1450 | 10 | 0.001 | 0.05 | 10 | 0.5 | 0.9 | 10 | 1360 | 0.02060 | 0.50 | 1.45 | 1.93 | 1.89 | |
| 3 | 550 | 1450 | 10 | 0.001 | 0.05 | 10 | 0.3 | 0.7 | 10 | 1270 | 0.03040 | 0.50 | 1.47 | 1.94 | 1.88 | |
| 4 | 550 | 1450 | 20 | 0.001 | 0.05 | 20 | 0.3 | 0.7 | 20 | 1405 | 0.02795 | 0.32 | 1.46 | 1.88 | 1.89 | |
| 13 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 820 | 0.03040 | 0.66 | 1.42 | 1.98 | 2.15 |
| 2 | 100 | 1000 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 685 | 0.02305 | 0.58 | 1.52 | 1.91 | 2.12 | |
| 14 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 820 | 0.02060 | 0.66 | 1.48 | 1.98 | 2.07 |
| 2 | 100 | 1000 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 1000 | 0.04020 | 0.58 | 1.43 | 1.93 | 2.38 | |
| 3 | 550 | 1450 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 685 | 0.03775 | 0.54 | 1.47 | 1.93 | 2.10 | |
| 15 | 1 | 100 | 1000 | 5 | 0.001 | 0.05 | 5 | 0.5 | 0.9 | 5 | 640 | 0.03040 | 0.66 | 1.53 | 1.97 | 1.99 |
| 2 | 100 | 1000 | 20 | 0.001 | 0.05 | 20 | 0.5 | 0.9 | 20 | 910 | 0.02305 | 0.74 | 1.40 | 1.96 | 2.19 | |
| All Model Sizes | MAPE (%) | Each Model Size | MAPE (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HN | TC | LR | MR | Train | Val. | Test | HN | TC | LR | MR | Train | Val. | Test |
| 5 | 1360 | 0.03040 | 0.62 | 1.5161 | 1.8500 | 2.0299 | 5 | 1360 | 0.03040 | 0.62 | 1.5161 | 1.8500 | 2.0299 |
| 6 | 1225 | 0.02795 | 0.68 | 1.5221 | 1.8576 | 1.8358 | 6 | 1225 | 0.02795 | 0.68 | 1.5221 | 1.8576 | 1.8358 |
| 7 | 595 | 0.03530 | 0.90 | 1.4862 | 1.8563 | 1.8163 | 7 | 1855 | 0.00345 | 0.94 | 1.4853 | 1.8545 | 1.6889 |
| 5 | 730 | 0.02305 | 0.70 | 1.5687 | 1.8648 | 1.9583 | 9 | 1360 | 0.04755 | 0.66 | 1.3977 | 1.8704 | 2.0244 |
| 7 | 1855 | 0.00345 | 0.94 | 1.4853 | 1.8545 | 1.6889 | 12 | 1405 | 0.02795 | 0.32 | 1.4642 | 1.8754 | 1.8925 |
| Kernel Fuctions | Hyperparameter Adjusting | The Number of Runs |
|---|---|---|
| dot | C | 40 |
| radial | C, GAMMA | 626 |
| polynomial | C, polynomial degree | 200 |
| Hyperparameter | Min | Max | Step | Scale | Values |
|---|---|---|---|---|---|
| C and Gamma | 0.0001 | 1000 | 7 | Exponential | 0.0001, 0.001, 0.01, …, 1000 |
| 20 | Exponential | ||||
| 0.0001 | 1000 | 10 | Logarithmic | 0.0001, 0.9956, 2.9820, …, 1000 | |
| Polynomial Degree | 1 | 5 | 4 | Linear | 1, 2, 3, …, 5 |
| Polynomial | MAPE (%) | |||||
|---|---|---|---|---|---|---|
| Setting | Kernel Function | C | Degree | Train | Validate | Test |
| 1 | polynomial | 64 | 2 | 1.4617 | 2.2039 | 2.0792 |
| 2 | polynomial | 62.1337 | 2 | 1.4656 | 2.2049 | 2.0841 |
| 3 | polynomial | 512 | 1 | 1.9082 | 2.2087 | 2.0613 |
| 4 | polynomial | 500.6383 | 1 | 1.9108 | 2.2091 | 2.0650 |
| 5 | polynomial | 1000 | 1 | 1.9160 | 2.2118 | 2.0414 |
| Date | from MLR | from Five Best ANN of Each Model Size | Avg. | Absolute % Error | |||||
|---|---|---|---|---|---|---|---|---|---|
| 5-Node | 6-Node | 7-Node | 5-Node | 7-Node | |||||
| 1 January 2018 | 350,672.94 | −40,798.68 | −24,283.33 | −32,441.42 | −37,417.81 | −25,044.95 | −31,997.24 | 318,675.70 | 6.87% |
| 2 January 2018 | 305,652.51 | −13,009.44 | −10,922.76 | −2008.96 | −10,722.67 | 43,120.87 | 1291.41 | 306,943.92 | 4.25% |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 30 December 2018 | 349,037.20 | −3196.13 | −825.11 | −1239.31 | 5450.93 | −3816.26 | −725.18 | 348,312.02 | 0.03% |
| 31 December 2018 | 366,322.07 | −82,552.53 | −108,228.36 | −14,142.70 | −59,456.21 | −54,299.94 | −63,735.95 | 302,586.12 | 3.20% |
| MAPE | 1.78% | ||||||||
| Date | from MLR | from Five Best ANN of Each Model Size | Avg. | Absolute % Error | |||||
|---|---|---|---|---|---|---|---|---|---|
| 5-Node | 6-Node | 7-Node | 5-Node | 7-Node | |||||
| 1 January 2018 | 350,672.94 | −40,798.68 | −24,283.33 | −25,044.95 | −25,007.89 | −19,471.74 | −26,921.32 | 323,751.62 | 8.57% |
| 2 January 2018 | 305,652.51 | −13,009.44 | −10,922.76 | 43,120.87 | 34,046.03 | 19,380.34 | 14,523.01 | 320,175.52 | 0.12% |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 30 December 2018 | 349,037.20 | −3196.13 | −825.11 | −3816.26 | −16,416.08 | 1442.55 | −4562.21 | 344,474.99 | 1.13% |
| 31 December 2018 | 366,322.07 | −82,552.53 | −108,228.36 | −54,299.94 | −69,009.25 | −78,190.98 | −78,456.21 | 287,865.86 | 7.91% |
| MAPE | 1.76% | ||||||||
| Date | from MLR | from Five Best ANN of Each Model Size | Avg. | Absolute % Error | |||||
|---|---|---|---|---|---|---|---|---|---|
| SVM 1 | SVM 2 | SVM 3 | SVM 4 | SVM 5 | |||||
| 1 January 2018 | 350,672.94 | −18,048.38 | −19,562.62 | 7877.70 | 5124.41 | 4303.32 | −4061.11 | 346,611.83 | 16.24 |
| 2 January 2018 | 305,652.51 | −15,599.19 | −16,813.18 | −2992.27 | −6944.18 | −8333.85 | −10,136.53 | 295,515.98 | 7.81 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 30 December 2018 | 349,037.20 | −7380.02 | −7096.51 | −6027.58 | −7548.98 | −8079.29 | −7226.48 | 341,810.72 | 1.90 |
| 31 December 2018 | 366,322.07 | −31,846.23 | −30,554.54 | 8238.38 | 6865.69 | 6330.87 | −8193.17 | 358,128.90 | 14.57 |
| MAPE | 1.83% | ||||||||
| Model | MAPE (%) of Test Set | MAE (Mwh) of Test Set | RMSE (MWh) of Test Set | RPE (%) of Test Set | CCC of Test Set | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Indicator Var. | Imp. (%) | Indicator Var. | Imp. (%) | Indicator Var. | Imp. (%) | Indicator Var. | Imp. (%) | Indicator Var. | Imp. (%) | ||||||
| w/o | with | w/o | with | w/o | with | w/o | with | w/o | with | ||||||
| MLR | 2.0225 | 1.951 | 0.07 | 10,095.08 | 9803.35 | 2.89 | 13,903.14 | 13,282.35 | 4.47 | 2.67% | 2.55% | 0.0012 | 0.9479 | 0.9526 | 0.5 |
| ANN | 2.0299 | 1.7022 | 0.33 | 10,361.65 | 8602.6 | 16.98 | 13,365.53 | 11,787.23 | 11.81 | 2.57% | 2.26% | 0.0031 | 0.9566 | 0.9644 | 0.82 |
| SVM | 2.0792 | 2.0883 | −0.01 | 10,552.66 | 10,644.35 | −0.87 | 13,511.58 | 14,654.99 | −8.46 | 2.59% | 2.81% | −0.0022 | 0.9526 | 0.9471 | −0.58 |
| HM 1 | 1.7814 | 1.5664 | 0.22 | 9079.72 | 7962.4 | 12.31 | 12,448.35 | 10,819.90 | 13.08 | 2.39% | 2.08% | 0.0031 | 0.9609 | 0.971 | 1.05 |
| HM 2 | 1.7556 | 1.5801 | 0.18 | 8931.22 | 8030.73 | 10.08 | 12,378.63 | 11,096.21 | 10.36 | 2.38% | 2.13% | 0.0025 | 0.961 | 0.969 | 0.83 |
| HM 3 | 1.8263 | 1.6982 | 0.13 | 9131.19 | 8491.27 | 7.01 | 12,756.5 | 12,148.24 | 4.77 | 2.45% | 2.33% | 0.0012 | 0.9573 | 0.9618 | 0.47 |
| EM 1 | 1.6827 | 1.572 | 0.11 | 8591.81 | 7927.51 | 7.73 | 11,654.92 | 11,405.80 | 2.14 | 2.24% | 2.19% | 0.0005 | 0.9657 | 0.9679 | 0.23 |
| EM 2 | 1.7373 | 1.7149 | 0.02 | 8875.55 | 8659.77 | 2.43 | 11,870.89 | 12,072.37 | −1.70 | 2.28% | 2.32% | −0.0004 | 0.9656 | 0.9643 | −0.13 |
| EM 3 | 1.9345 | 1.8395 | 0.1 | 9679.2 | 9311.78 | 3.8 | 13,114.17 | 12,522.50 | 4.51 | 2.52% | 2.40% | 0.0012 | 0.9541 | 0.9592 | 0.53 |
| Traditional GS | HN | TC | LR | MR | Sequential GS | No. of Runs | No. of GS |
|---|---|---|---|---|---|---|---|
| Min | 1 | 10 | 0.0001 | 0.3 | Initial GS | 216 | 15 |
| Max | 15 | 1900 | 0.0745 | 1 | Intermediate GS | 1331 | 8 |
| Step size | 1 | 45 | 0.00245 | 0.02 | Intermediate GS | 9261 | 4 |
| No. of steps | 15 | 43 | 31 | 36 | Final GS | 9261 | 15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pannakkong, W.; Harncharnchai, T.; Buddhakulsomsiri, J. Forecasting Daily Electricity Consumption in Thailand Using Regression, Artificial Neural Network, Support Vector Machine, and Hybrid Models. Energies 2022, 15, 3105. https://0-doi-org.brum.beds.ac.uk/10.3390/en15093105
Pannakkong W, Harncharnchai T, Buddhakulsomsiri J. Forecasting Daily Electricity Consumption in Thailand Using Regression, Artificial Neural Network, Support Vector Machine, and Hybrid Models. Energies. 2022; 15(9):3105. https://0-doi-org.brum.beds.ac.uk/10.3390/en15093105
Chicago/Turabian StylePannakkong, Warut, Thanyaporn Harncharnchai, and Jirachai Buddhakulsomsiri. 2022. "Forecasting Daily Electricity Consumption in Thailand Using Regression, Artificial Neural Network, Support Vector Machine, and Hybrid Models" Energies 15, no. 9: 3105. https://0-doi-org.brum.beds.ac.uk/10.3390/en15093105