Quantitative Identification of Urban Functions with Fishers’ Exact Test and POI Data Applied in Classifying Urban Districts: A Case Study within the Sixth Ring Road in Beijing

Abstract
:1. Introduction
- We propose a quantitative method to discover urban functions by a statistical significance test, Fisher’s exact test, which can combine the relative functions and relative districts efficiently.
- We run a k-modes clustering algorithm to classify all urban districts according to the functional scores and their combination in one district and detect four different groups in the study area.
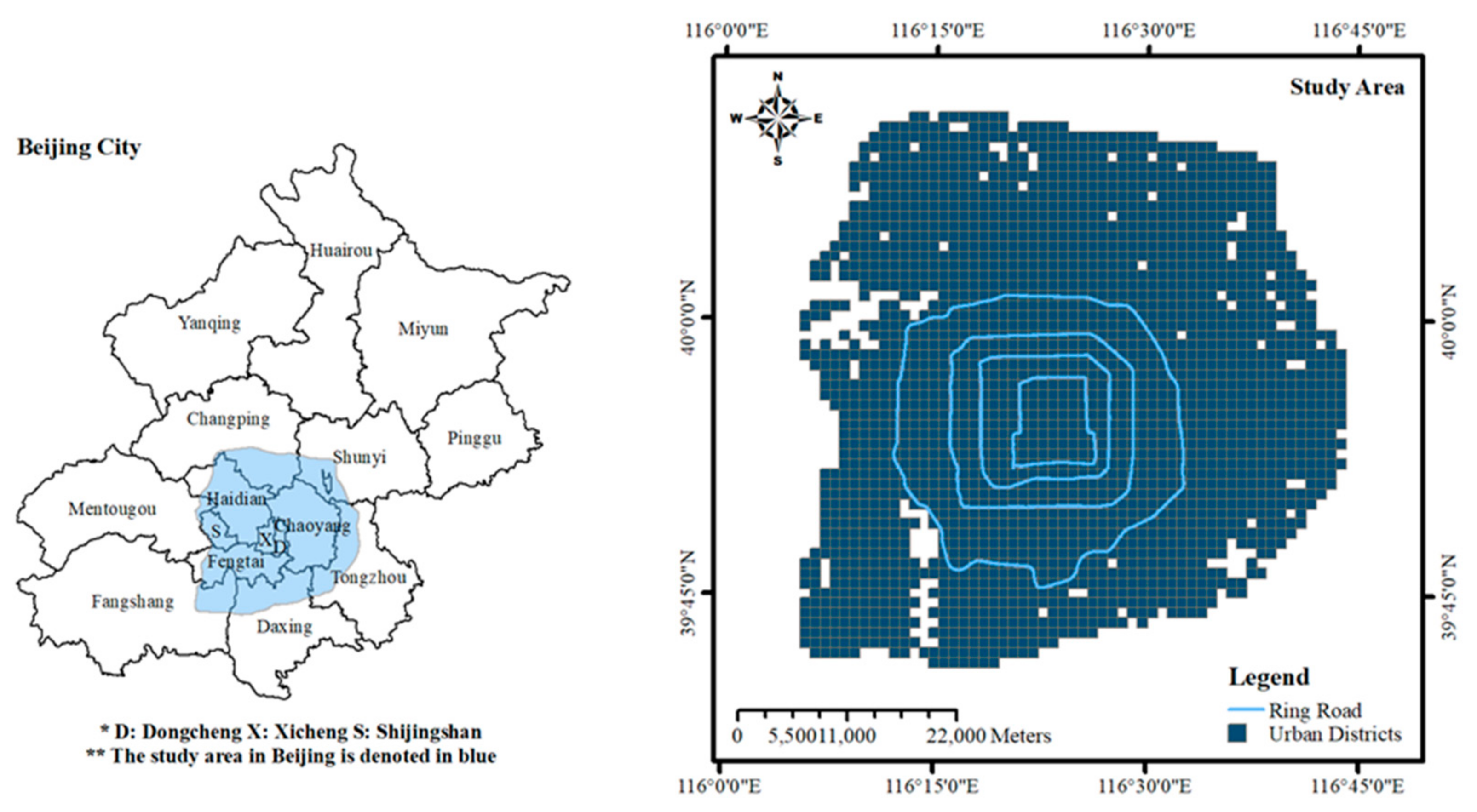
2. Study Area and Datasets
2.1. Study Area
2.2. Data Prescription and Preprocessing
2.2.1. POI Dataset
2.2.2. Data Preprocessing
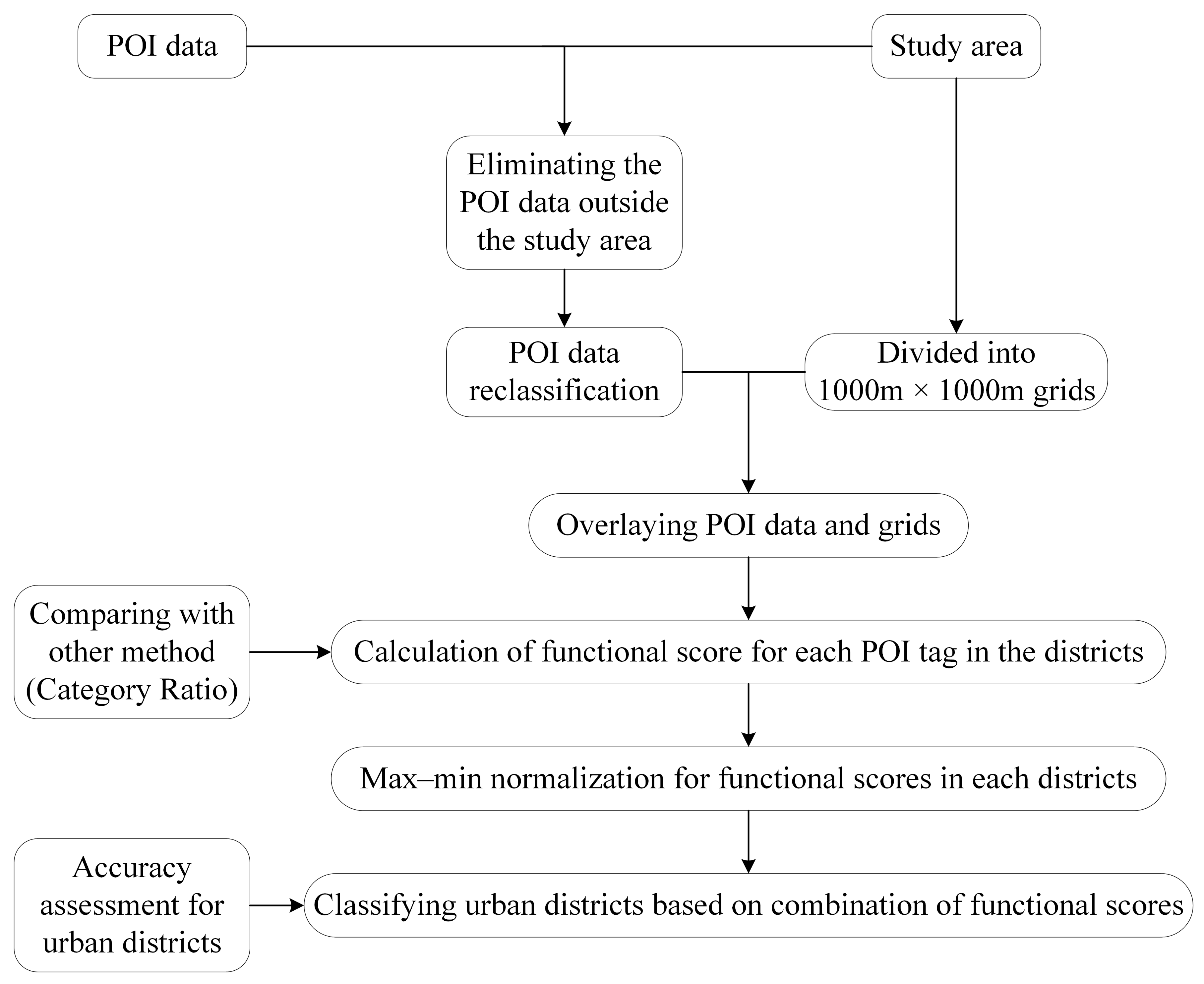
3. Methods
3.1. Calculation of Functional Score
3.1.1. p-Value
3.1.2. Odds-Ratio
3.1.3. The Frequency of each POI Tag
3.2. Max–Min Normalization
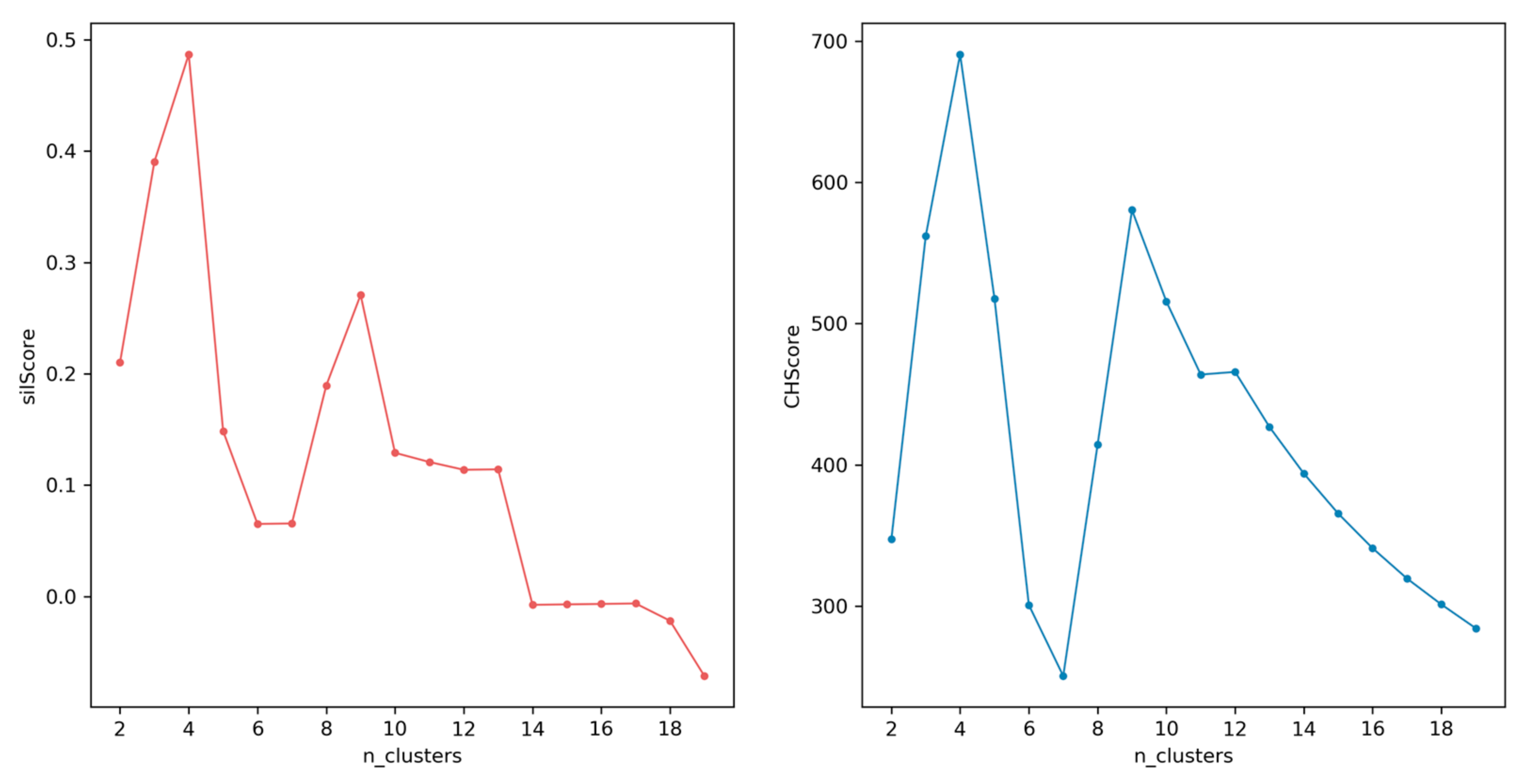
3.3. K-Modes Clustering Algorithm
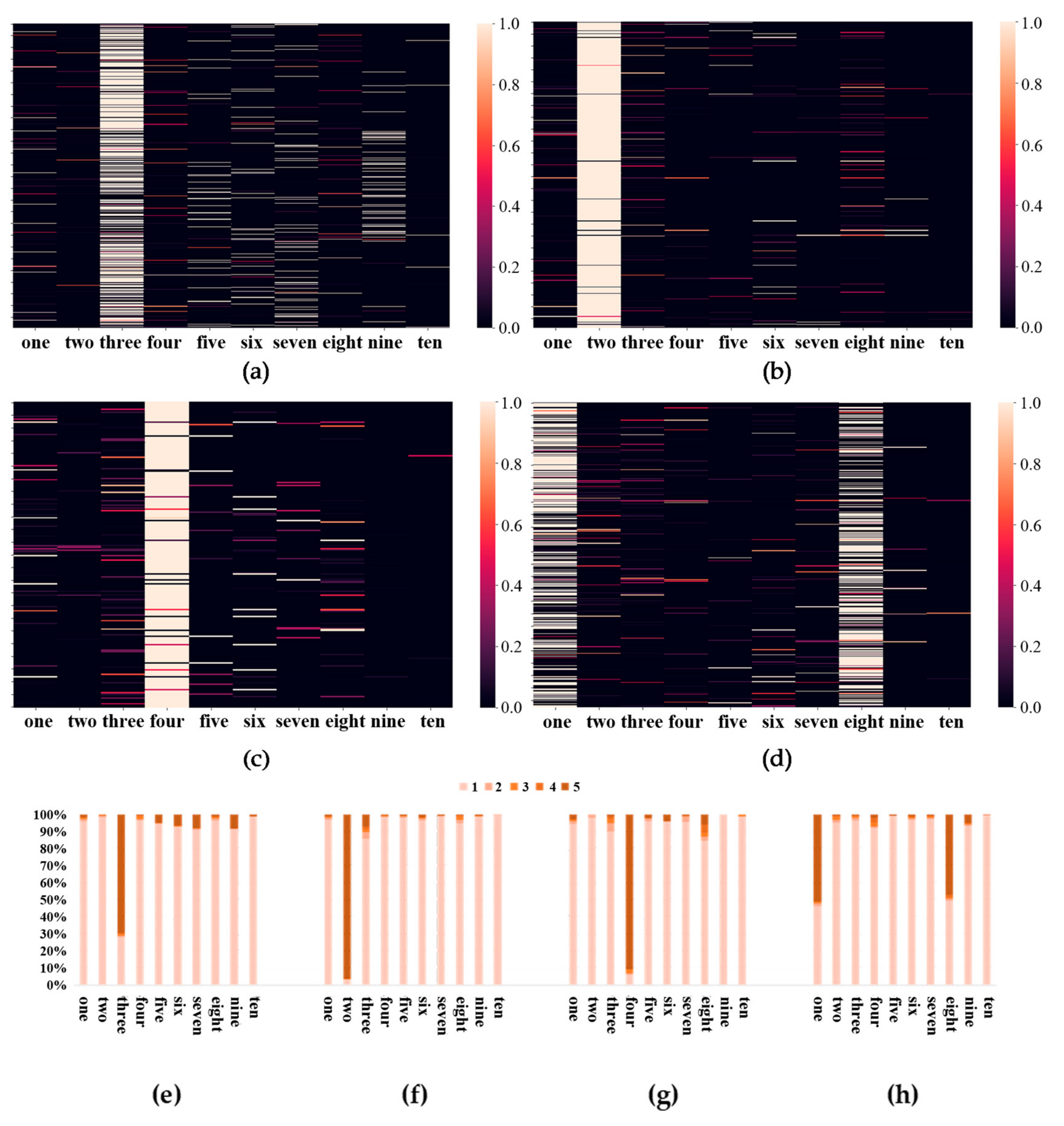
4. Results
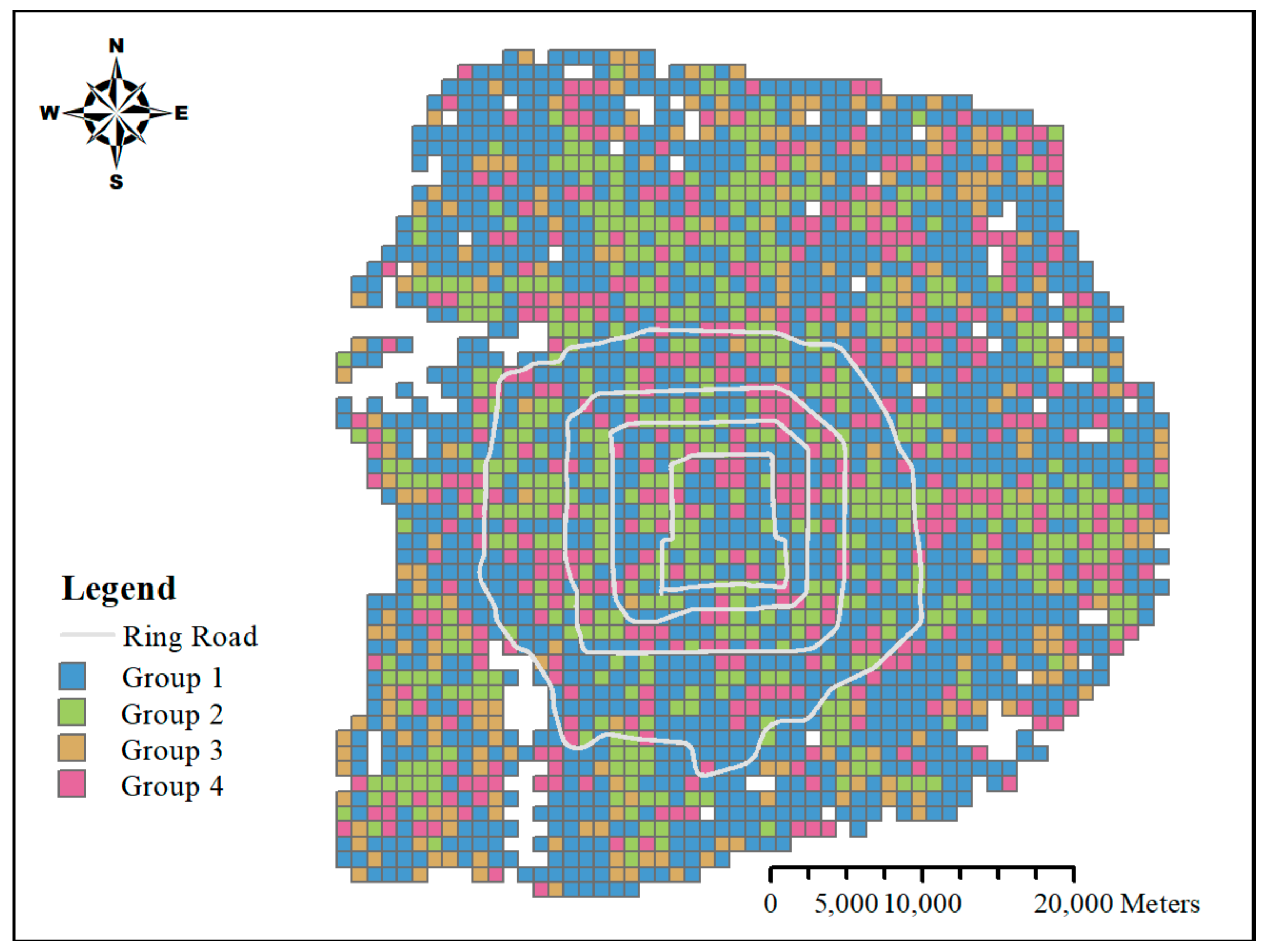
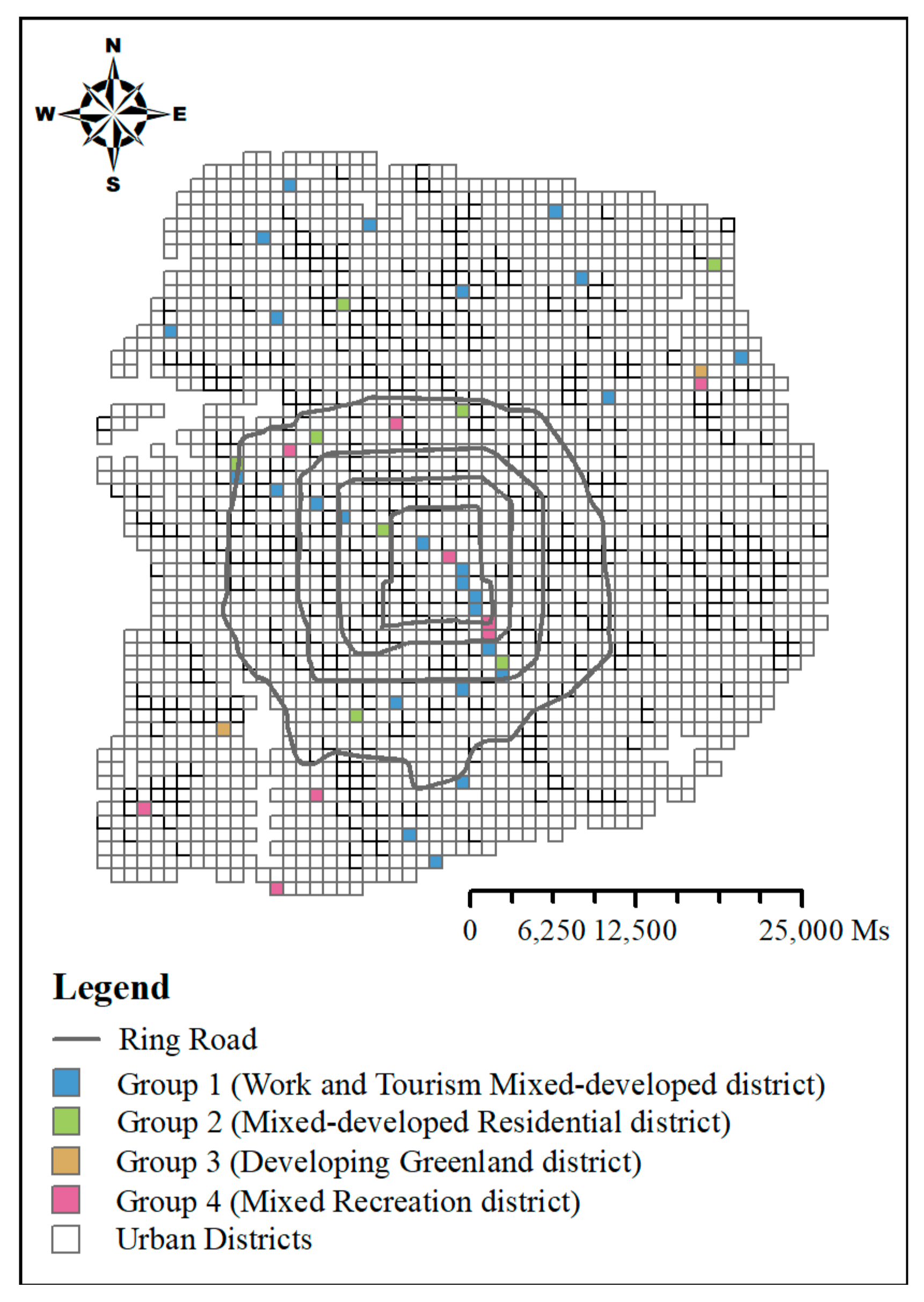
4.1. Classification of Urban Districts
4.2. Identification and Annotation of Urban Districts
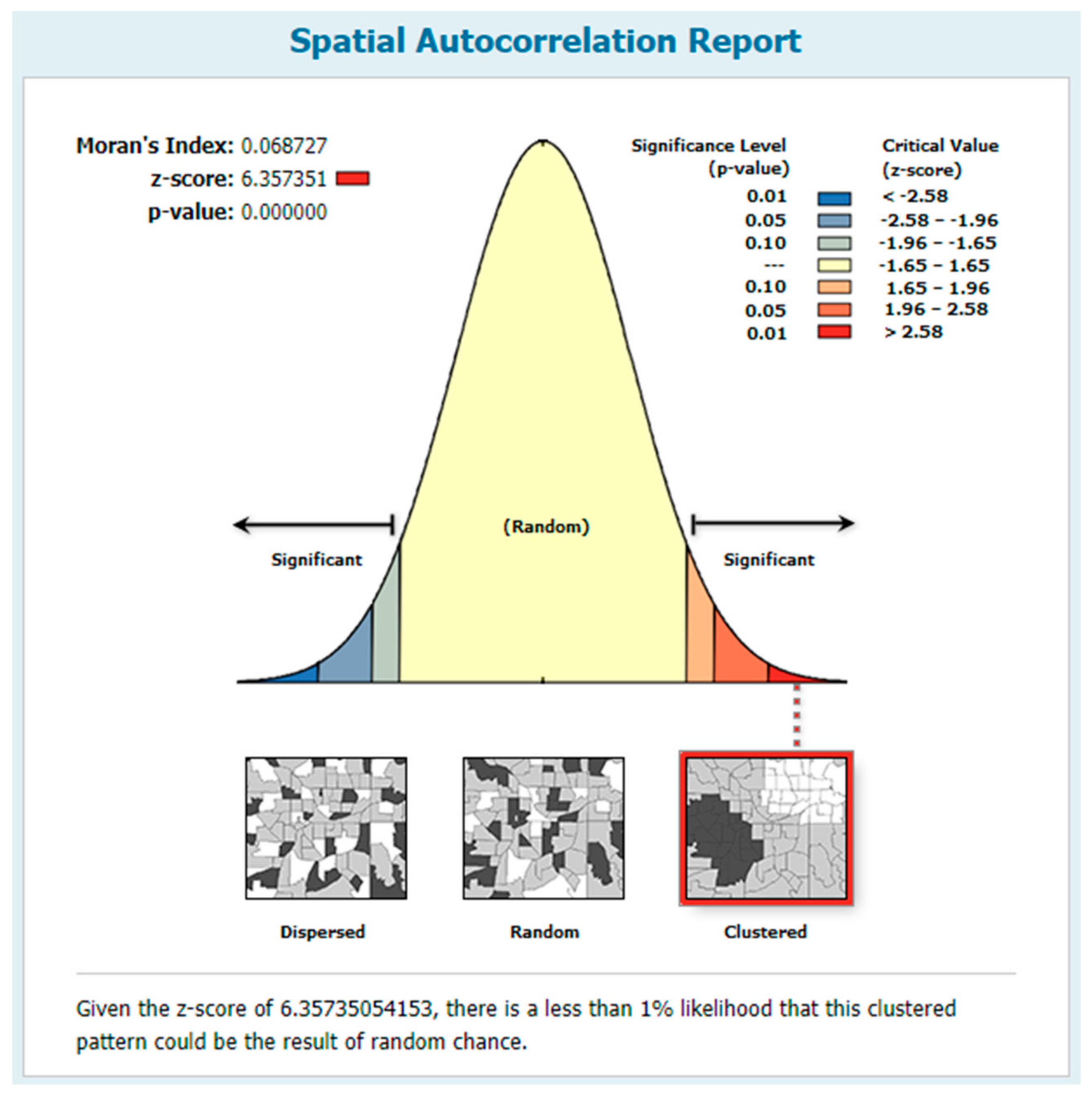
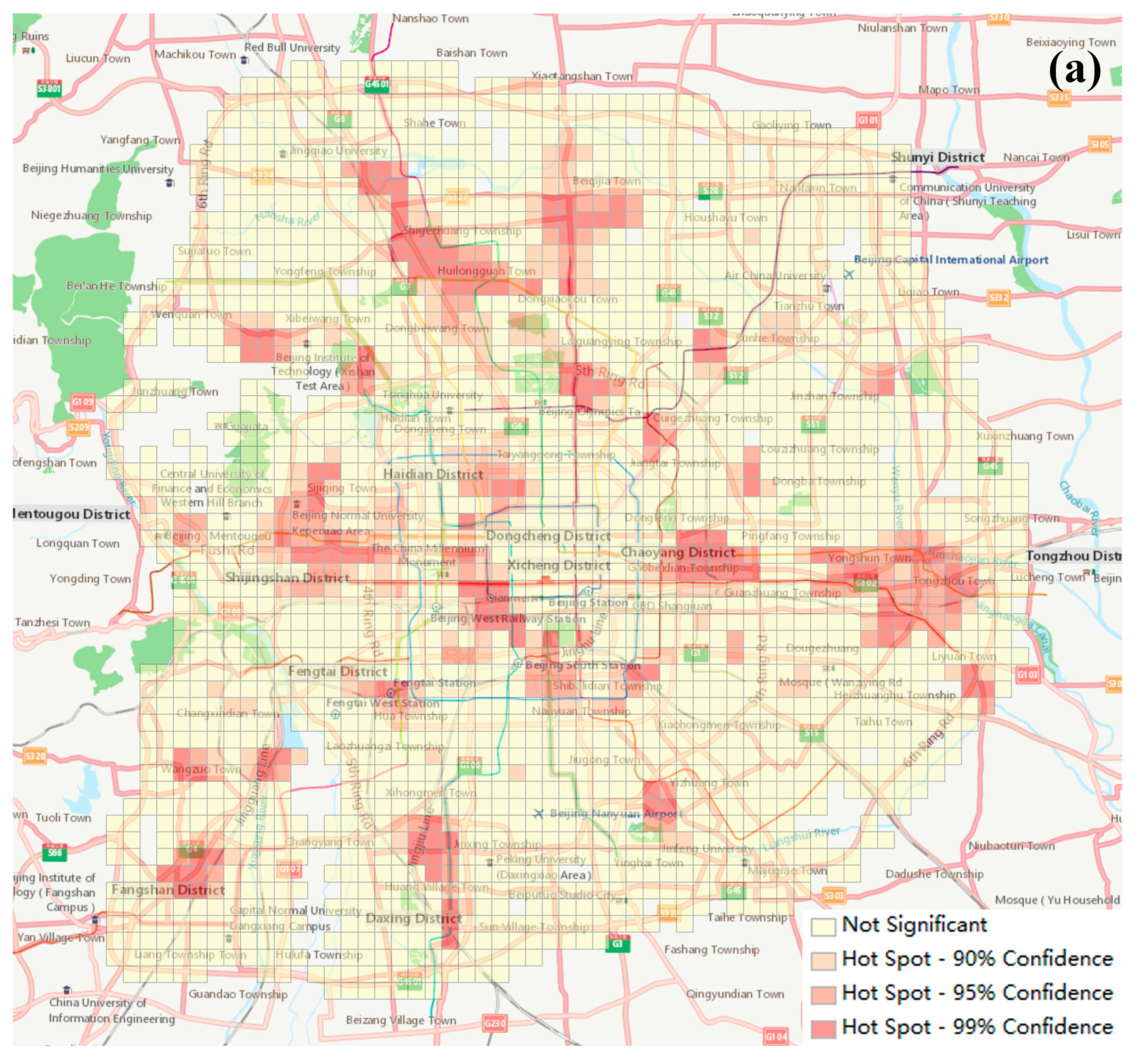
4.3. Accuracy Assessment for Urban Districts
5. Discussion
5.1. The Availability of Functional Score
5.2. Broader Thinking
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GaodeMap/Number of District | Function (Category Ratio) | Function (Method this Study Introduced) | Main Actual land Features |
|---|---|---|---|
 | Transportation | Hotel | Transportation hub and hotels |
| No. 876 | |||
 | Hotel | Hotel | Railway station |
| No. 979 | |||
 | Hotel | Recreation | Airport terminal and hotels |
| No. 2015 | |||
 | Attraction | Attraction | Attractions |
| No. 1138 | |||
 | Hotel | Recreation | Recreations |
| No. 1195 | |||
 | Attraction | Higher education | University campus |
| No. 1555 | |||
 | Recreation | Residence | Residence |
| No. 1995 |




References
- Gao, S.; Janowicz, K.; Couclelis, H. Extracting urban functional regions from points of interest and human activities on location-based social networks. Trans. GIS 2017, 21, 446–467. [Google Scholar] [CrossRef]
- Yao, X.; Chen, L.; Peng, L.; Chi, T. A co-location pattern-mining algorithm with a density-weighted distance thresholding consideration. Inf. Sci. 2017, 396, 144–161. [Google Scholar] [CrossRef]
- Kong, X.; Li, M.; Li, J.; Tian, K.; Hu, X.; Xia, F. CoPFun: An urban co-occurrence pattern mining scheme based on regional function discovery. World Wide Web 2019, 22, 1029–1054. [Google Scholar] [CrossRef]
- Kashian, A.; Rajabifard, A.; Richter, K.F.; Chen, Y. Automatic analysis of positional plausibility for points of interest in OpenStreetMap using coexistence patterns. Int. J. Geogr. Inf. Sci. 2019, 33, 1420–1443. [Google Scholar] [CrossRef]
- Haris, E.; Gan, K.H.; Tan, T.P. Spatial information extraction from travel narratives: Analysing the notion of co-occurrence indicating closeness of tourist places. J. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Chi, J.; Jiao, L.; Dong, T.; Gu, Y.; Ma, Y. Quantitative identification and visualization of urban functional area based on poi data. J. Geomat. 2016, 41, 68–73. [Google Scholar]
- Kang, Y.; Wang, Y.; Xia, Z.; Chi, J.; Jiao, M.; Wei, Z.W. Identification and classification of wuhan urban districts based on poi. J. Geomat. 2018, 43, 81–85. [Google Scholar]
- Zhu, J.; Tang, C.; Feng, Y. A Study on Quantitative Identification of Urban Functional Areas in Yichun Based on Point of Interest Data. Urb. Arch. 2018, 20, 21–23. [Google Scholar]
- Hu, Y.; Han, Y. Identification of Urban Functional Areas Based on POI Data: A Case Study of the Guangzhou Economic and Technological Development Zone. Sustainability 2019, 11, 1385. [Google Scholar] [CrossRef] [Green Version]
- Zhao, M.; Liang, J.; Guo, Z. Classifying Development-land Type of the Megacity through the Lens of Multisource Data. Shanghai Urban Plan. Rev. 2018, 5, 72–77. [Google Scholar]
- Zhai, W.; Bai, X.; Shi, Y.; Han, Y.; Peng, Z.R.; Gu, C. Beyond Word2vec: An approach for urban functional region extraction and identification by combining Place2vec and POIs. Comput. Environ. Urban Syst. 2019, 74, 1–12. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Wang, Q. Hierarchical semantic cognition for urban functional zones with VHR satellite images and POI data. ISPRS J. Photogramm. Remote Sens. 2017, 132, 170–184. [Google Scholar] [CrossRef]
- Guo, Z.; Zheng, Z.; Liu, J.; Wang, S.; Zhong, P.; Zhu, M.; He, Y.; Jiang, L.; Zhou, G.; Zhang, H. Urban Functional Regions Using Social Media Check-Ins. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 6 June 2018; pp. 5061–5064. [Google Scholar]
- Wang, Y.; Gu, Y.; Dou, M.; Qiao, M. Using spatial semantics and interactions to identify urban functional regions. ISPRS Int. Geo-Inf. 2018, 7, 130. [Google Scholar] [CrossRef] [Green Version]
- Xing, H.; Meng, Y. Integrating landscape metrics and socioeconomic features for urban functional region classification. Comput. Environ. Urban Syst. 2018, 72, 134–145. [Google Scholar] [CrossRef]
- Jiang, S.; Alves, A.; Rodrigues, F.; Ferreira Jr, J.; Pereira, F.C. Mining point-of-interest data from social networks for urban land use classification and disaggregation. Comput. Environ. Urban Syst. 2015, 53, 36–46. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Li, Q.; Li, B. Extracting hierarchical landmarks from urban POI data. J. Remote Sens. 2011, 15, 973–988. [Google Scholar]
- Zhang, A.; Xia, C.; Chu, J.; Lin, J.; Li, W.; Wu, J. Portraying urban landscape: A quantitative analysis system applied in fifteen metropolises in China. Sustain. Cities Soc. 2019, 46, 101396. [Google Scholar] [CrossRef]
- Gao, Q.; Fu, J.; Yu, Y.; Tang, X. Identification of urban regions’ functions in Chengdu, China, based on vehicle trajectory data. PLoS ONE 2019, 14, e0215656. [Google Scholar] [CrossRef] [Green Version]
- Wu, Q.; Zhang, L.; Wu, Z. Identifying City Functional Areas Using Taxi Trajectory Data. J. Geom. Sci. Technol. 2018, 35, 424. [Google Scholar]
- Quaife, S.L.; Marlow, L.A.; McEwen, A.; Janes, S.M.; Wardle, J. Attitudes towards lung cancer screening in socioeconomically deprived and heavy smoking communities: Informing screening communication. Health Expect. 2017, 20, 563–573. [Google Scholar] [CrossRef]
- Sliwa, K.; Mebazaa, A.; Hilfiker-Kleiner, D.; Petrie, M.C.; Maggioni, A.P.; Laroche, C.; Regitz-Zagrosek, V.; Schaufelberger, M.; Tavazzi, T.; Meer, P.; et al. Clinical characteristics of patients from the worldwide registry on peripartum cardiomyopathy (PPCM) EURObservational Research Programme in conjunction with the Heart Failure Association of the European Society of Cardiology Study Group on PPCM. Eur. J. Heart Fail. 2017, 19, 1131–1141. [Google Scholar] [CrossRef] [PubMed]
- Romano, M. Developing a Predictive Mortality Risk Algorithm for Preterm Neonates Requiring Surgical Intervention at Boston Children’s Hospital. Ph.D. Thesis, Boston University, Boston, MA, USA, 2019. [Google Scholar]
- Platz, E.; Jhund, P.S.; Claggett, B.L.; Pfeffer, M.A.; Swedberg, K.; Granger, C.B.; Yusuf, S.; Solomon, S.D.; McMurray, J.J. Prevalence and prognostic importance of precipitating factors leading to heart failure hospitalization: Recurrent hospitalizations and mortality. Eur. J. Heart Fail. 2018, 20, 295–303. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huebener, P.; Sterneck, M.R.; Bangert, K.; Drolz, A.; Lohse, A.W.; Kluge, S.; Fischer, L.; Fuhrmann, V. Stabilisation of acute-on-chronic liver failure patients before liver transplantation predicts post-transplant survival. Aliment. Pharmacol. Ther. 2018, 47, 1502–1510. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Lima Cabral, D.R.; de Barros, R.S.M. Concept drift detection based on Fisher’s Exact test. Inf. Sci. 2018, 442, 220–234. [Google Scholar] [CrossRef]
- Zhong, H.; Song, M. A fast exact functional test for directional association and cancer biology applications. IEEE-ACM Trans. Comput. Biol. Bioinform. 2018, 16, 818–826. [Google Scholar] [CrossRef] [PubMed]
- Alhazzani, M.; Alhasoun, F.; Alawwad, Z.; González, M.C. Urban Attractors: Discovering patterns in regions of attraction in cities. arXiv 2016, arXiv:1701.08696. [Google Scholar]
- Sprent. Fisher exact test. In International Encyclopedia of Statistical Science, 1st ed.; Lovric, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 2, pp. 524–525. [Google Scholar]
- Bland, J.M.; Altman, D.G. The odds ratio. BMJ 2000, 320, 1468. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Li, W.; Zhang, F.; Liu, R.; Du, Z. Identifying Urban Functional Zones Using Public Bicycle Rental Records and Point-of-Interest Data. ISPRS Int. Geo-Inf. 2018, 7, 459. [Google Scholar] [CrossRef] [Green Version]
- Tang, C.; Liao, H.; Wu, N.; Dong, L.; Zhang, R.; Li, Y.; Gao, X. Mobile Phone Data Based Urban Functional Area Classification Algorithm. Comput. Knowl. Tech. 2018, 14, 285–289. [Google Scholar]
- Huang, Z. Extensions to the k-means algorithm for clustering large data sets with categorical values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Huang, Z.; Ng, M.K. A note on k-modes clustering. J. Classif. 2003, 20, 257–261. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. Theory Methods 1974, 3, 1–27. [Google Scholar]







| Current Tag | Previous Tag (Level One) | Previous Sub-Tag (Level Two) |
|---|---|---|
| Public service | Beauty | All |
| Car service | All | |
| Public service | All | |
| Financial service | Bank | |
| Transportation | Gas station | |
| Parking lot | ||
| Healthcare | Nursing home | |
| Chemist store | ||
| Residence | Residence | Residence |
| Work | Company | All |
| Cultural industry | All | |
| Building | Office building | |
| Transportation | Transportation | Station |
| Higher education | Education | University |
| Vocational education | ||
| Institute | ||
| Library | ||
| Primary education | Education | Primary school |
| Secondary school | ||
| Kindergarten | ||
| Hotel | Hotel | All |
| Recreation | Food | All |
| Leisure and entertainment | All | |
| Sports and fitting | All | |
| Attraction | Park | |
| Amusement park | ||
| Attraction | Attraction | Church |
| Landscape | ||
| Museum | ||
| Historical site | ||
| Education | Science and technology museum | |
| Cultural industry | Galley | |
| Exhibition | ||
| Healthcare | Healthcare | Global hospital |
| Special hospital | ||
| CDC (Centers for Disease Control and Prevention) | ||
| Emergency |
| Variance One | Non-Variance One | |
|---|---|---|
| Variance two | A | B |
| Non-variance two | C | D |
| POI Class One | POI Class Two | POI Class Three | POI Class Four | POI Class Five | POI Class Six | POI Class Seven | POI Class Eight | POI Class Nine | POI Class Ten | |
|---|---|---|---|---|---|---|---|---|---|---|
| Before | 5.77 | 0 | 0.24 | 0.14 | 0 | 0 | 0 | 631.12 | 0 | 0 |
| After | 0.009 | 0 | 0.0002 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| The Number of Districts with a 0 Mark | The Number of Districts with a 1 Mark | The Number of Districts with a 2 Mark | The Number of Districts with a 3 Mark | Total Number of all Districts |
|---|---|---|---|---|
| 3 | 3 | 7 | 32 | 45 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, D.; Yang, J.; Liu, J.; Liu, Y.; Zhang, J. Quantitative Identification of Urban Functions with Fishers’ Exact Test and POI Data Applied in Classifying Urban Districts: A Case Study within the Sixth Ring Road in Beijing. ISPRS Int. J. Geo-Inf. 2019, 8, 555. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8120555
Yi D, Yang J, Liu J, Liu Y, Zhang J. Quantitative Identification of Urban Functions with Fishers’ Exact Test and POI Data Applied in Classifying Urban Districts: A Case Study within the Sixth Ring Road in Beijing. ISPRS International Journal of Geo-Information. 2019; 8(12):555. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8120555
Chicago/Turabian StyleYi, Disheng, Jing Yang, Jingjing Liu, Yusi Liu, and Jing Zhang. 2019. "Quantitative Identification of Urban Functions with Fishers’ Exact Test and POI Data Applied in Classifying Urban Districts: A Case Study within the Sixth Ring Road in Beijing" ISPRS International Journal of Geo-Information 8, no. 12: 555. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8120555