
Digital Innovation Enabled Nanomaterial Manufacturing; Machine Learning Strategies and Green Perspectives



Abstract
:
1. Introduction
2. In Silico Materials Development
2.1. Sustainable Design, Engineering, and Discovery of Innovative Nanomaterials
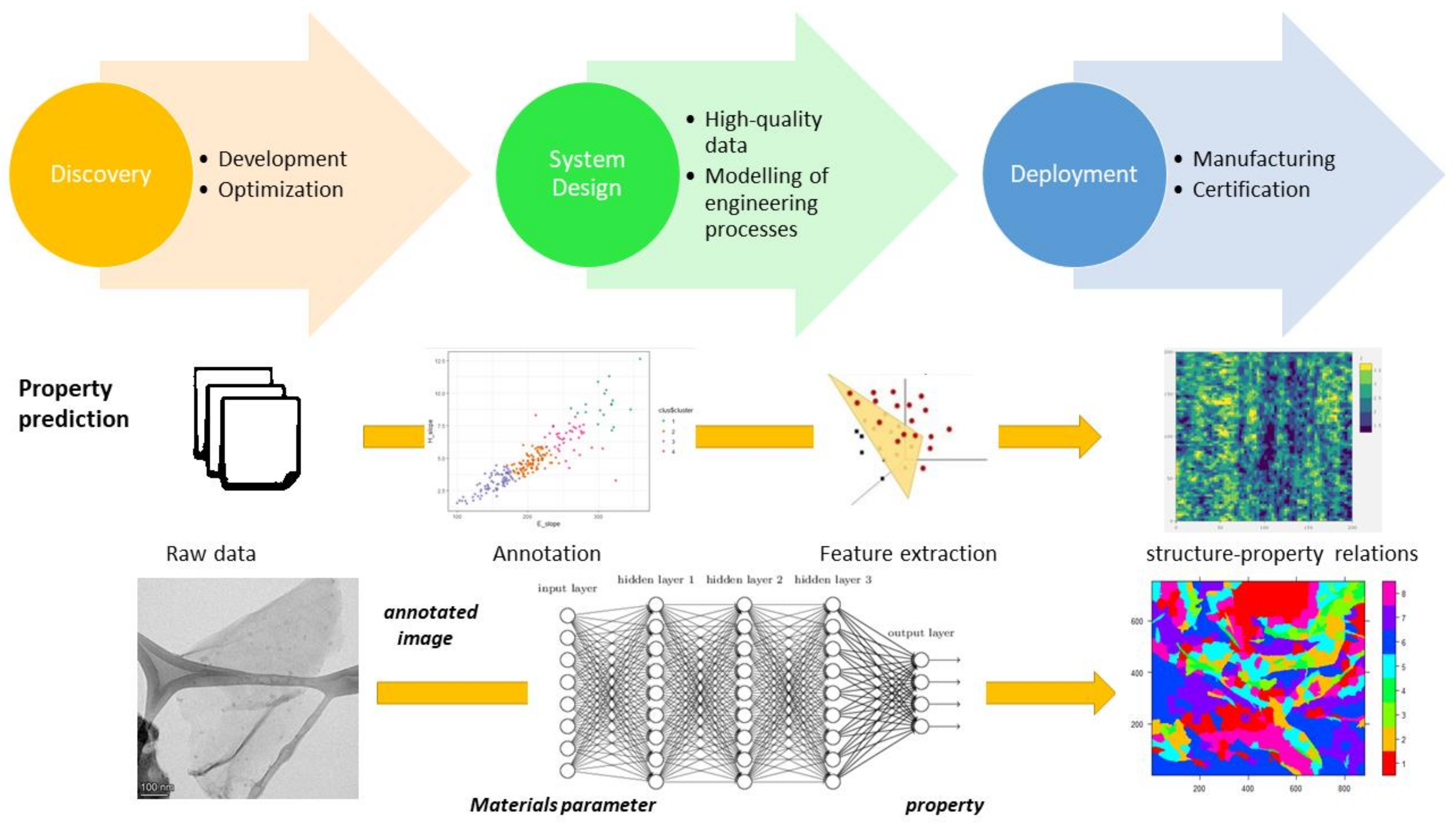
2.2. Contribution of High-Resolution Characterization Coupling with Machine Learning and Computer Vision to Structure High-Quality Materials Datasets for Materials Development
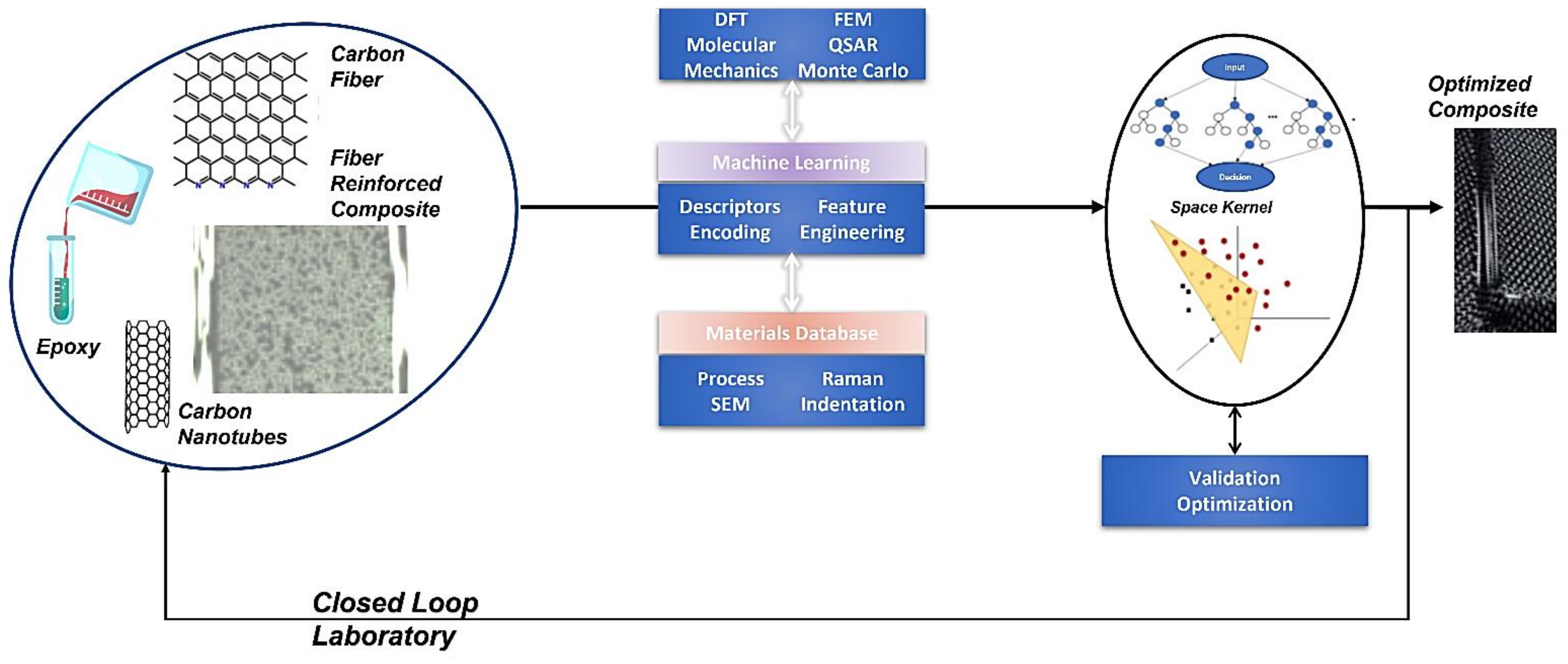
2.3. Optimizing Formulations and Composition in Nanocomposite Materials Engineering and Additive Manufacturing to Improve Performance and Support Applications
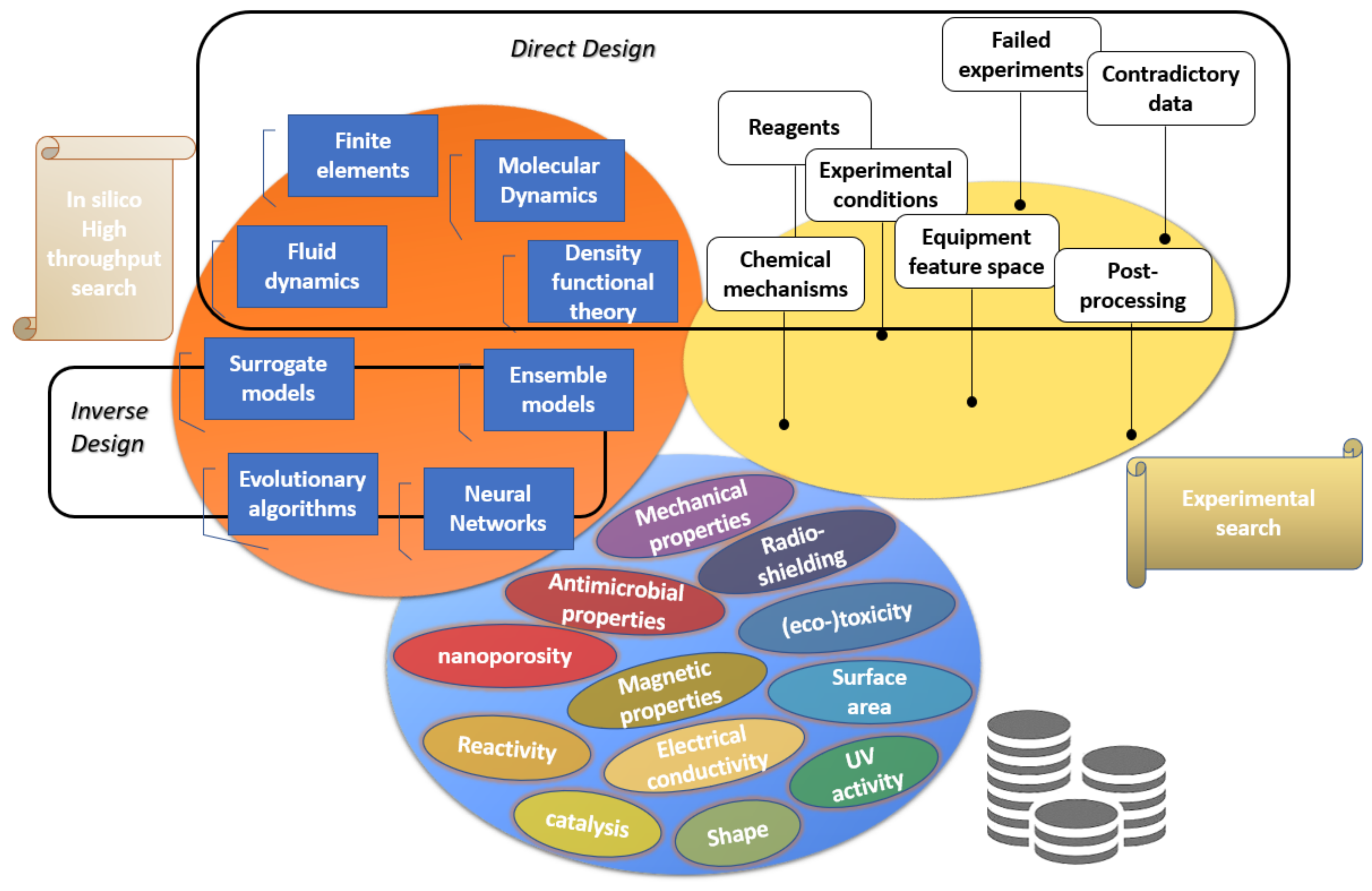
3. Optimization of Materials Synthesis Using High Throughput Screening Evolutionary Algorithms—Reverse Engineering
3.1. High-Throughput Screening and Optimization of Nanomaterials with Genetic and Other Evolutionary Algorithms
3.2. Utilization of Synergistic Modelling-Simulation and Combination of Ensemble Machine Learning Algorithms for Selection of Materials and Process Parameters
4. Selection of Nanomaterials Tailored for Improvements in Quality of Life; Human and Environmental Health
4.1. Machine Learning Modelling of Biological Effects of Nanomaterials
4.2. Machine Learning for Nanomaterials Applications in Biomedicine and Therapies
4.3. Machine Learning Modelling of Environmental Effects
5. Mining and Accessibility of Experimental Research to Enrich the Knowledge Base and Conduct Meta-Analysis
6. Prospects and Conclusions
- High-throughput research space exploration of nanomaterials options/candidates;
- Image segmentation/object detection for statistical analysis of nanomaterials shape/size/agglomeration state/defects detection;
- Objective and decentralized decision-making based on multi-dimensional datasets to improve generalizability and evidence-based conclusions (i.e., phase analysis, anomaly detection);
- Design of experiments via genetic algorithms, PSO;
- Fast calculation of input values for modelling, instead of using time-consuming simulation, especially where absolute accuracy is not limiting;
- Data mining of publicly available datasets to enrich the knowledge base and extrapolate predictive models with increased accuracy;
- Use of ensemble algorithms to improve predictive capabilities when limited information is accessible;
- Establishment of models to correlate the chemical structure and physical, chemical, and physicochemical properties with the activity and (eco-)toxicity profile of nanomaterials, utilizing known activity profiles of well-studied materials.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Matsokis, A.; Kiritsis, D. An ontology-based approach for Product Lifecycle Management. Comput. Ind. 2010, 61, 787–797. [Google Scholar] [CrossRef]
- Petrakli, F.; Gkika, A.; Bonou, A.; Karayannis, P.; Koumoulos, E.; Semitekolos, D.; Trompeta, A.-F.; Rocha, N.; Santos, R.; Simmonds, G.; et al. End-of-Life Recycling Options of (Nano)Enhanced CFRP Composite Prototypes Waste—A Life Cycle Perspective. Polymers 2020, 12, 2129. [Google Scholar] [CrossRef] [PubMed]
- De Pablo, J.J.; Jackson, N.E.; Webb, M.A.; Chen, L.-Q.; Moore, J.E.; Morgan, D.; Jacobs, R.; Pollock, T.; Schlom, D.G.; Toberer, E.S.; et al. New frontiers for the materials genome initiative. Npj Comput. Mater. 2019, 5, 41. [Google Scholar] [CrossRef]
- Koumoulos, E.P.; Trompeta, A.-F.; Santos, R.-M.; Martins, M.; dos Santos, C.M.; Iglesias, V.; Böhm, R.; Gong, G.; Chiminelli, A.; Verpoest, I.; et al. Research and Development in Carbon Fibers and Advanced High-Performance Composites Supply Chain in Europe: A Roadmap for Challenges and the Industrial Uptake. J. Compos. Sci. 2019, 3, 86. [Google Scholar] [CrossRef] [Green Version]
- Yan, X.; Sedykh, A.; Wang, W.; Yan, B.; Zhu, H. Construction of a web-based nanomaterial database by big data curation and modeling friendly nanostructure annotations. Nat. Commun. 2020, 11, 2519. [Google Scholar] [CrossRef]
- Deguchi, A.; Hirai, C.; Matsuoka, H.; Nakano, T.; Oshima, K.; Tai, M.; Tani, S. What Is Society 5.0? In Society 5.0: A People-Centric Super-Smart Society; Springer: Singapore, 2020; pp. 1–23. [Google Scholar] [CrossRef]
- Doyle-Kent, M.; Kopacek, P. Industry 5.0: Is the Manufacturing Industry on the Cusp of a New Revolution? Springer International Publishing: Cham, Switzerland, 2019; pp. 432–441. [Google Scholar]
- Gabriele, A. The Made in China 2025 Plan. In Enterprises, Industry and Innovation in the People’s Republic of China: Questioning Socialism from Deng to the Trade and Tech War; Springer: Singapore, 2020; pp. 171–178. [Google Scholar] [CrossRef]
- Paulovich, F.V.; De Oliveira, M.C.F.; Oliveira, O.N. A Future with Ubiquitous Sensing and Intelligent Systems. ACS Sens. 2018, 3, 1433–1438. [Google Scholar] [CrossRef] [Green Version]
- Inokuchi, T.; Li, N.; Morohoshi, K.; Arai, N. Multiscale prediction of functional self-assembled materials using machine learning: High-performance surfactant molecules. Nanoscale 2018, 10, 16013–16021. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, J.; Liu, T.; Luo, Y.; Loh, X.J.; Chen, X. Machine Learning-Reinforced Noninvasive Biosensors for Healthcare. Adv. Healthc. Mater. 2021, 10, e2100734. [Google Scholar] [CrossRef]
- Strieth-Kalthoff, F.; Sandfort, F.; Segler, M.H.S.; Glorius, F. Machine learning the ropes: Principles, applications and directions in synthetic chemistry. Chem. Soc. Rev. 2020, 49, 6154–6168. [Google Scholar] [CrossRef]
- Dreyfus, P.-A.; Psarommatis, F.; May, G.; Kiritsis, D. Virtual metrology as an approach for product quality estimation in Industry 4.0: A systematic review and integrative conceptual framework. Int. J. Prod. Res. 2021, 60, 742–765. [Google Scholar] [CrossRef]
- Psarommatis, F.; Kiritsis, D. A hybrid Decision Support System for automating decision making in the event of defects in the era of Zero Defect Manufacturing. J. Ind. Inf. Integr. 2021, 26, 100263. [Google Scholar] [CrossRef]
- Li, Y.; Chen, J.; Hu, Z.; Zhang, H.; Lu, J.; Kiritsis, D. Co-simulation of complex engineered systems enabled by a cognitive twin architecture. Int. J. Prod. Res. 2021, 1–22. [Google Scholar] [CrossRef]
- Sebastiani, M.; Charitidis, C.; Koumoulos, E.P. Main Introduction to the CHADA concept and case studies. ZENODO 2019. [Google Scholar] [CrossRef]
- Rodrigues, J.F.; Florea, L.; de Oliveira, M.C.F.; Diamond, D.; Oliveira, O.N. Big data and machine learning for materials science. Discov. Mater. 2021, 1, 1–27. [Google Scholar] [CrossRef]
- Serra, A.; Fratello, M.; Cattelani, L.; Liampa, I.; Melagraki, G.; Kohonen, P.; Nymark, P.; Federico, A.; Kinaret, P.A.S.; Jagiello, K.; et al. Transcriptomics in Toxicogenomics, Part III: Data Modelling for Risk Assessment. Nanomaterials 2020, 10, 708. [Google Scholar] [CrossRef] [Green Version]
- Adamovic, N.; Friis, J.; Goldbeck, G.; Hashibon, A.; Hermansson, K.; Hristova-Bogaerds, D.; Koopmans, R.; Wimmer, E. The EMMC Roadmap for Materials Modelling and Digitalisation of the Materials Sciences. ZENODO 2020. [Google Scholar] [CrossRef]
- Haase, A. EU US Roadmap Nanoinformatics 2030; EU Nanosafety Cluster. 2017. Available online: https://zenodo.org/record/1486012#.YufJsRxBxPZ (accessed on 26 July 2022).
- Liu, Y.; Zhao, T.; Ju, W.; Shi, S. Materials discovery and design using machine learning. J. Mater. 2017, 3, 159–177. [Google Scholar] [CrossRef]
- Arabha, S.; Rajabpour, A. Thermo-mechanical properties of nitrogenated holey graphene (C2N): A comparison of machine-learning-based and classical interatomic potentials. Int. J. Heat Mass Transf. 2021, 178, 121589. [Google Scholar] [CrossRef]
- Soldatov, M.; Butova, V.; Pashkov, D.; Butakova, M.; Medvedev, P.; Chernov, A.; Soldatov, A. Self-Driving Laboratories for Development of New Functional Materials and Optimizing Known Reactions. Nanomaterials 2021, 11, 619. [Google Scholar] [CrossRef]
- Wills, I. The Edisonian Method: Trial and Error; Springer: Cham, Switzerland, 2019; pp. 203–222. [Google Scholar] [CrossRef]
- Santana, R.; Zuluaga, R.; Gañán, P.; Arrasate, S.; Onieva, E.; González-Díaz, H. Designing nanoparticle release systems for drug–vitamin cancer co-therapy with multiplicative perturbation-theory machine learning (PTML) models. Nanoscale 2019, 11, 21811–21823. [Google Scholar] [CrossRef]
- Cui, F.; Yue, Y.; Zhang, Y.; Zhang, Z.; Zhou, H.S. Advancing Biosensors with Machine Learning. ACS Sens. 2020, 5, 3346–3364. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, Z.; Cao, L.; Xiong, Z.; Tang, Y.; Pan, Y. Cytotoxicity of phytosynthesized silver nanoparticles: A meta-analysis by machine learning algorithms. Sustain. Chem. Pharm. 2021, 21, 100425. [Google Scholar] [CrossRef]
- Zhou, L.; Fu, H.; Lv, T.; Wang, C.; Gao, H.; Li, D.; Deng, L.; Xiong, W. Nonlinear Optical Characterization of 2D Materials. Nanomaterials 2020, 10, 2263. [Google Scholar] [CrossRef]
- Yan, X.; Zhang, J.; Russo, D.P.; Zhu, H.; Yan, B. Prediction of Nano–Bio Interactions through Convolutional Neural Network Analysis of Nanostructure Images. ACS Sustain. Chem. Eng. 2020, 8, 19096–19104. [Google Scholar] [CrossRef]
- Barnard, A.S.; Opletal, G. Selecting machine learning models for metallic nanoparticles. Nano Futures 2020, 4, 035003. [Google Scholar] [CrossRef]
- Cai, J.; Chu, X.; Xu, K.; Li, H.; Wei, J. Machine learning-driven new material discovery. Nanoscale Adv. 2020, 2, 3115–3130. [Google Scholar] [CrossRef]
- Ko, J.; Baldassano, S.N.; Loh, P.-L.; Kording, K.; Litt, B.; Issadore, D. Machine learning to detect signatures of disease in liquid biopsies—A user’s guide. Lab Chip 2017, 18, 395–405. [Google Scholar] [CrossRef]
- Konstantopoulos, G.; Koumoulos, E.P.; Charitidis, C.A. Classification of mechanism of reinforcement in the fiber-matrix interface: Application of Machine Learning on nanoindentation data. Mater. Des. 2020, 192, 108705. [Google Scholar] [CrossRef]
- Konstantopoulos, G.; Koumoulos, E.P.; Charitidis, C.A. Testing Novel Portland Cement Formulations with Carbon Nanotubes and Intrinsic Properties Revelation: Nanoindentation Analysis with Machine Learning on Microstructure Identification. Nanomaterials 2020, 10, 645. [Google Scholar] [CrossRef] [Green Version]
- Oliynyk, A.O.; Antono, E.; Sparks, T.; Ghadbeigi, L.; Gaultois, M.W.; Meredig, B.; Mar, A. High-Throughput Machine-Learning-Driven Synthesis of Full-Heusler Compounds. Chem. Mater. 2016, 28, 7324–7331. [Google Scholar] [CrossRef] [Green Version]
- Koumoulos, E.; Konstantopoulos, G.; Charitidis, C. Applying Machine Learning to Nanoindentation Data of (Nano-) Enhanced Composites. Fibers 2019, 8, 3. [Google Scholar] [CrossRef] [Green Version]
- Feng, R.; Yu, F.; Xu, J.; Hu, X. Knowledge gaps in immune response and immunotherapy involving nanomaterials: Databases and artificial intelligence for material design. Biomaterials 2020, 266, 120469. [Google Scholar] [CrossRef] [PubMed]
- Modarres, H.; Aversa, R.; Cozzini, S.; Ciancio, R.; Leto, A.; Brandino, G.P. Neural Network for Nanoscience Scanning Electron Microscope Image Recognition. Sci. Rep. 2017, 7, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jessen. TensorFlow for R: Deep Learning for Cancer Immunotherapy. Available online: https://blogs.rstudio.com/tensorflow/posts/2018-01-29-dl-for-cancer-immunotherapy/ (accessed on 26 July 2022).
- Tsompanas, M.-A.; Bull, L.; Adamatzky, A.; Balaz, I. In silico optimization of cancer therapies with multiple types of nanoparticles applied at different times. Comput. Methods Progr. Biomed. 2020, 200, 105886. [Google Scholar] [CrossRef]
- Demirbay, B.; Kara, D.B.; Uğur, Ş. A Bayesian regularized feed-forward neural network model for conductivity prediction of PS/MWCNT nanocomposite film coatings. Appl. Soft Comput. 2020, 96, 106632. [Google Scholar] [CrossRef]
- Konstantopoulos, G.; Semitekolos, D.; Koumoulos, E.P.; Charitidis, C. Carbon Fiber Reinforced Composites: Study of Modification Effect on Weathering-Induced Ageing via Nanoindentation and Deep Learning. Nanomaterials 2021, 11, 2631. [Google Scholar] [CrossRef]
- Koumoulos, E.P.; Paraskevoudis, K.; Charitidis, C.A. Constituents Phase Reconstruction through Applied Machine Learning in Nanoindentation Mapping Data of Mortar Surface. J. Compos. Sci. 2019, 3, 63. [Google Scholar] [CrossRef] [Green Version]
- Fernandez, M.; Abreu, J.I.; Shi, H.; Barnard, A. Machine Learning Prediction of the Energy Gap of Graphene Nanoflakes Using Topological Autocorrelation Vectors. ACS Comb. Sci. 2016, 18, 661–664. [Google Scholar] [CrossRef]
- Winkler, D.A. Role of Artificial Intelligence and Machine Learning in Nanosafety. Small 2020, 16, e2001883. [Google Scholar] [CrossRef]
- Brehm, M.; Kafka, A.; Bamler, M.; Kühne, R.; Schüürmann, G.; Sikk, L.; Burk, J.; Burk, P.; Tamm, T.; Tämm, K.; et al. An Integrated Data-Driven Strategy for Safe-by-Design Nanoparticles: The FP7 MODERN Project. Adv. Exp. Med. Biol. 2017, 947, 257–301. [Google Scholar] [CrossRef]
- Escorihuela, L.; Martorell, B.; Rallo, R.; Fernández, A. Toward computational and experimental characterisation for risk assessment of metal oxide nanoparticles. Environ. Sci. Nano 2018, 5, 2241–2251. [Google Scholar] [CrossRef] [Green Version]
- Yan, X.; Sedykh, A.; Wang, W.; Zhao, X.; Yan, B.; Zhu, H. In silico profiling nanoparticles: Predictive nanomodeling using universal nanodescriptors and various machine learning approaches. Nanoscale 2019, 11, 8352–8362. [Google Scholar] [CrossRef]
- Yu, H.; Zhao, Z.; Cheng, F. Predicting and investigating cytotoxicity of nanoparticles by translucent machine learning. Chemosphere 2021, 276, 130164. [Google Scholar] [CrossRef]
- Jin, Z.; Zhang, Z.; Demir, K.; Gu, G.X. Machine Learning for Advanced Additive Manufacturing. Matter 2020, 3, 1541–1556. [Google Scholar] [CrossRef]
- Wang, C.; Tan, X.; Tor, S.; Lim, C. Machine learning in additive manufacturing: State-of-the-art and perspectives. Addit. Manuf. 2020, 36, 101538. [Google Scholar] [CrossRef]
- Lin, S.; Mortimer, M.; Chen, R.; Kakinen, A.; Riviere, J.E.; Davis, T.P.; Ding, F.; Ke, P.C. NanoEHS beyond toxicity—Focusing on biocorona. Environ. Sci. Nano 2017, 4, 1433–1454. [Google Scholar] [CrossRef]
- Weichert, D.; Link, P.; Stoll, A.; Rüping, S.; Ihlenfeldt, S.; Wrobel, S. A review of machine learning for the optimization of production processes. Int. J. Adv. Manuf. Technol. 2019, 104, 1889–1902. [Google Scholar] [CrossRef]
- Tkatchenko, A. Machine learning for chemical discovery. Nat. Commun. 2020, 11, 1–4. [Google Scholar] [CrossRef]
- Ji, Z.; Guo, W.; Sakkiah, S.; Liu, J.; Patterson, T.A.; Hong, H. Nanomaterial Databases: Data Sources for Promoting Design and Risk Assessment of Nanomaterials. Nanomaterials 2021, 11, 1599. [Google Scholar] [CrossRef]
- Carbonell, P.; Le Feuvre, R.; Takano, E.; Scrutton, N.S. In silico design and automated learning to boost next-generation smart biomanufacturing. Synth. Biol. 2020, 5, ysaa020. [Google Scholar] [CrossRef]
- Furxhi, I.; Murphy, F.; Mullins, M.; Arvanitis, A.; Poland, C.A. Practices and Trends of Machine Learning Application in Nanotoxicology. Nanomaterials 2020, 10, 116. [Google Scholar] [CrossRef] [Green Version]
- Jones, D.E.; Ghandehari, H.; Facelli, J.C. A review of the applications of data mining and machine learning for the prediction of biomedical properties of nanoparticles. Comput. Methods Progr. Biomed. 2016, 132, 93–103. [Google Scholar] [CrossRef] [Green Version]
- Romanos, N.; Kalogerini, M.; Koumoulos, E.; Morozinis, A.; Sebastiani, M.; Charitidis, C. Innovative Data Management in advanced characterization: Implications for materials design. Mater. Today Commun. 2019, 20. [Google Scholar] [CrossRef]
- Austin, T.; Bei, K.; Efthymiadis, T.; Koumoulos, E.P. Lessons Learnt from Engineering Science Projects Participating in the Horizon 2020 Open Research Data Pilot. Data 2021, 6, 96. [Google Scholar] [CrossRef]
- Jose, N.A.; Kovalev, M.; Bradford, E.; Schweidtmann, A.M.; Zeng, H.C.; Lapkin, A.A. Pushing nanomaterials up to the kilogram scale—An accelerated approach for synthesizing antimicrobial ZnO with high shear reactors, machine learning and high-throughput analysis. Chem. Eng. J. 2021, 426, 131345. [Google Scholar] [CrossRef]
- Fernandez, M.; Shi, H.; Barnard, A.S. Geometrical features can predict electronic properties of graphene nanoflakes. Carbon 2016, 103, 142–150. [Google Scholar] [CrossRef]
- Mukherjee, K.; Colón, Y.J. Machine learning and descriptor selection for the computational discovery of metal-organic frameworks. Mol. Simul. 2021, 47, 857–877. [Google Scholar] [CrossRef]
- Li, Y.; Fu, Y.; Lai, C.; Qin, L.; Li, B.; Liu, S.; Yi, H.; Xu, F.; Li, L.; Zhang, M.; et al. Porous materials confining noble metals for the catalytic reduction of nitroaromatics: Controllable synthesis and enhanced mechanism. Environ. Sci. Nano 2021, 8, 3067–3097. [Google Scholar] [CrossRef]
- Li, X.; Zhu, Y.; Xiao, G. Application of artificial neural networks to predict sliding wear resistance of Ni–TiN nanocomposite coatings deposited by pulse electrodeposition. Ceram. Int. 2014, 40, 11767–11772. [Google Scholar] [CrossRef]
- Marsalek, R.; Kotyrba, M.; Volna, E.; Jarusek, R. Neural Network Modelling for Prediction of Zeta Potential. Mathematics 2021, 9, 3089. [Google Scholar] [CrossRef]
- Motevalli, B.; Sun, B.; Barnard, A.S. Understanding and Predicting the Cause of Defects in Graphene Oxide Nanostructures Using Machine Learning. J. Phys. Chem. C 2020, 124, 7404–7413. [Google Scholar] [CrossRef]
- Han, Y.; Tang, B.; Wang, L.; Bao, H.; Lu, Y.; Guan, C.; Zhang, L.; Le, M.; Liu, Z.; Wu, M. Machine-Learning-Driven Synthesis of Carbon Dots with Enhanced Quantum Yields. ACS Nano 2020, 14, 14761–14768. [Google Scholar] [CrossRef] [PubMed]
- Dewulf, L.; Chiacchia, M.; Yeardley, A.S.; Milton, R.A.; Brown, S.F.; Patwardhan, S.V. Designing bioinspired green nanosilicas using statistical and machine learning approaches. Mol. Syst. Des. Eng. 2021, 6, 293–307. [Google Scholar] [CrossRef]
- Daeyaert, F.; Ye, F.; Deem, M.W. Machine-learning approach to the design of OSDAs for zeolite beta. Proc. Natl. Acad. Sci. USA 2019, 116, 3413–3418. [Google Scholar] [CrossRef] [Green Version]
- Hagita, K.; Higuchi, T.; Jinnai, H. Super-resolution for asymmetric resolution of FIB-SEM 3D imaging using AI with deep learning. Sci. Rep. 2018, 8, 5877. [Google Scholar] [CrossRef]
- Okunev, A.G.; Mashukov, M.Y.; Nartova, A.V.; Matveev, A.V. Nanoparticle Recognition on Scanning Probe Microscopy Images Using Computer Vision and Deep Learning. Nanomaterials 2020, 10, 1285. [Google Scholar] [CrossRef]
- Bi, X.; Lee, S.; Ranville, J.F.; Sattigeri, P.; Spanias, A.; Herckes, P.; Westerhoff, P. Quantitative resolution of nanoparticle sizes using single particle inductively coupled plasma mass spectrometry with the K-means clustering algorithm. J. Anal. At. Spectrom. 2014, 29, 1630–1639. [Google Scholar] [CrossRef]
- Horwath, J.P.; Zakharov, D.N.; Mégret, R.; Stach, E.A. Understanding important features of deep learning models for segmentation of high-resolution transmission electron microscopy images. Npj Comput. Mater. 2020, 6, 1–9. [Google Scholar] [CrossRef]
- Ilett, M.; Wills, J.; Rees, P.; Sharma, S.; Micklethwaite, S.; Brown, A.; Brydson, R.; Hondow, N. Application of automated electron microscopy imaging and machine learning to characterise and quantify nanoparticle dispersion in aqueous media. J. Microsc. 2019, 279, 177–184. [Google Scholar] [CrossRef] [Green Version]
- Zafeiris, K.; Brasinika, D.; Karatza, A.; Koumoulos, E.; Karoussis, I.; Kyriakidou, K.; Charitidis, C. Additive manufacturing of hydroxyapatite–chitosan–genipin composite scaffolds for bone tissue engineering applications. Mater. Sci. Eng. C 2020, 119, 111639. [Google Scholar] [CrossRef]
- Singh, N. Additive manufacturing for functionalized nanomaterials breaks limits. In Additive Manufacturing with Functionalized Nanomaterials; Elsevier: Amsterdam, The Netherlands, 2021; pp. 1–34. [Google Scholar] [CrossRef]
- Tofail, S.A.; Koumoulos, E.P.; Bandyopadhyay, A.; Bose, S.; O’Donoghue, L.; Charitidis, C. Additive manufacturing: Scientific and technological challenges, market uptake and opportunities. Mater. Today 2018, 21, 22–37. [Google Scholar] [CrossRef]
- Charles, A.; Salem, M.; Moshiri, M.; Elkaseer, A.; Scholz, S.G. In-Process Digital Monitoring of Additive Manufacturing: Proposed Machine Learning Approach and Potential Implications on Sustainability. In Smart Innovation, Systems and Technologies; Springer: Singapore, 2020; pp. 297–306. [Google Scholar] [CrossRef]
- Ivanova, O.; Williams, C.; A Campbell, T. Additive manufacturing (AM) and nanotechnology: Promises and challenges. Rapid Prototyp. J. 2013, 19, 353–364. [Google Scholar] [CrossRef] [Green Version]
- Challagulla, N.V.; Rohatgi, V.; Sharma, D.; Kumar, R. Recent developments of nanomaterial applications in additive manufacturing: A brief review. Curr. Opin. Chem. Eng. 2020, 28, 75–82. [Google Scholar] [CrossRef]
- Acquah, S.F.A.; Leonhardt, B.E.; Nowotarski, M.S.; Magi, J.M.; Chambliss, K.A.; Venzel, T.E.S.; Delekar, S.D.; Al-Hariri, L.A. Carbon Nanotubes and Graphene as Additives in 3D Printing. In Carbon Nanotubes; IntechOpen: London, UK, 2016. [Google Scholar] [CrossRef] [Green Version]
- Banadaki, Y.M. On the Use of Machine Learning for Additive Manufacturing Technology in Industry 4.0. J. Comput. Sci. Inf. Technol. 2019, 7. [Google Scholar] [CrossRef]
- Ko, H.; Witherell, P.; Lu, Y.; Kim, S.; Rosen, D.W. Machine learning and knowledge graph based design rule construction for additive manufacturing. Addit. Manuf. 2020, 37, 101620. [Google Scholar] [CrossRef]
- Karayannis, P.; Petrakli, F.; Gkika, A.; Koumoulos, E.P. 3D-Printed Lab-on-a-Chip Diagnostic Systems-Developing a Safe-by-Design Manufacturing Approach. Micromachines 2019, 10, 825. [Google Scholar] [CrossRef] [Green Version]
- Gu, G.X.; Chen, C.-T.; Richmond, D.J.; Buehler, M.J. Bioinspired hierarchical composite design using machine learning: Simulation, additive manufacturing, and experiment. Mater. Horiz. 2018, 5, 939–945. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Zhang, Z.; Shi, J.; Wu, D. Prediction of surface roughness in extrusion-based additive manufacturing with machine learning. Robot. Comput. Manuf. 2019, 57, 488–495. [Google Scholar] [CrossRef]
- Bhutada, A.; Kumar, S.; Gunasegaram, D.; Alankar, A. Machine Learning Based Methods for Obtaining Correlations between Microstructures and Thermal Stresses. Metals 2021, 11, 1167. [Google Scholar] [CrossRef]
- Paraskevoudis, K.; Karayannis, P.; Koumoulos, E.P. Real-Time 3D Printing Remote Defect Detection (Stringing) with Computer Vision and Artificial Intelligence. Processes 2020, 8, 1464. [Google Scholar] [CrossRef]
- Zhao, C.; Shah, P.J.; Bissell, L.J. Laser additive nano-manufacturing under ambient conditions. Nanoscale 2019, 11, 16187–16199. [Google Scholar] [CrossRef]
- Khanzadeh, M.; Rao, P.; Jafari-Marandi, R.; Smith, B.K.; Tschopp, M.A.; Bian, L. Quantifying Geometric Accuracy with Unsupervised Machine Learning: Using Self-Organizing Map on Fused Filament Fabrication Additive Manufacturing Parts. J. Manuf. Sci. Eng. 2017, 140. [Google Scholar] [CrossRef] [Green Version]
- Razaviarab, N.; Sharifi, S.; Banadaki, Y.M. Smart additive manufacturing empowered by a closed-loop machine learning algorithm. In Proceedings of the SPIE 10969, Nano-, Bio-, Info-Tech Sensors and 3D Systems III, Denver, CO, USA, 3–7 March 2019; Volume 10969, p. 109690H. [Google Scholar] [CrossRef]
- Lansford, J.L.; Vlachos, D.G. Infrared spectroscopy data- and physics-driven machine learning for characterizing surface microstructure of complex materials. Nat. Commun. 2020, 11, 1513. [Google Scholar] [CrossRef]
- Valyukhov, S.G.; Kretinin, A.V.; Stognei, O.V.; Stogneĭ, O.V. Use of Neutral-Network Approximation for Prediction of the Microhardness of Nanocomposite Coatings. J. Eng. Phys. 2014, 87, 459–468. [Google Scholar] [CrossRef]
- Zarei, M.J.; Ansari, H.R.; Keshavarz, P.; Zerafat, M.M. Prediction of pool boiling heat transfer coefficient for various nano-refrigerants utilizing artificial neural networks. J. Therm. Anal. 2019, 139, 3757–3768. [Google Scholar] [CrossRef]
- Ashrafi, H.R.; Jalal, M.; Garmsiri, K. Prediction of load–displacement curve of concrete reinforced by composite fibers (steel and polymeric) using artificial neural network. Expert Syst. Appl. 2010, 37, 7663–7668. [Google Scholar] [CrossRef]
- Huang, J.; Liew, J.; Liew, K. Data-driven machine learning approach for exploring and assessing mechanical properties of carbon nanotube-reinforced cement composites. Compos. Struct. 2021, 267, 113917. [Google Scholar] [CrossRef]
- Khozaimy, O.; Al-Dhaheri, A.; Ullah, A.S. A decision-making approach using point-cloud-based granular information. Appl. Soft Comput. 2011, 11, 2576–2586. [Google Scholar] [CrossRef]
- Sajjad, U.; Hussain, I.; Imran, M.; Sultan, M.; Wang, C.-C.; Alsubaie, A.S.; Mahmoud, K.H. Boiling Heat Transfer Evaluation in Nanoporous Surface Coatings. Nanomaterials 2021, 11, 3383. [Google Scholar] [CrossRef]
- Sajjad, U.; Hussain, I.; Hamid, K.; Ali, H.M.; Wang, C.-C.; Yan, W.-M. Liquid-to-vapor phase change heat transfer evaluation and parameter sensitivity analysis of nanoporous surface coatings. Int. J. Heat Mass Transf. 2022, 194. [Google Scholar] [CrossRef]
- Ali, M.; Sajjad, U.; Hussain, I.; Abbas, N.; Ali, H.M.; Yan, W.-M.; Wang, C.-C. On the assessment of the mechanical properties of additively manufactured lattice structures. Eng. Anal. Bound. Elem. 2022, 142, 93–116. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, S.; Yang, Z. GENOUD-BP: A novel training algorithm for artificial neural networks. In Proceedings of the 5th International Conference on Information Engineering for Mechanics and Materials, Hohhot, China, 25–26 July 2015. [Google Scholar]
- Moosavi, S.M.; Chidambaram, A.; Talirz, L.; Haranczyk, M.; Stylianou, K.C.; Smit, B. Capturing chemical intuition in synthesis of metal-organic frameworks. Nat. Commun. 2019, 10, 1–7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Subcommittee on the Materials Genome Initiative. The First Five Years of the Materials Genome Initiative: Accomplishments and Technical Highlights; Materials Genome: State College, PA, USA, 2016; pp. 1–9.
- Collins, S.P.; Daff, T.D.; Piotrkowski, S.S.; Woo, T.K. Materials design by evolutionary optimization of functional groups in metal-organic frameworks. Sci. Adv. 2016, 2, e1600954. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jung, J.-R.; Yum, B.-J. Artificial neural network based approach for dynamic parameter design. Expert Syst. Appl. 2011, 38, 504–510. [Google Scholar] [CrossRef]
- Majumder, A. Comparative study of three evolutionary algorithms coupled with neural network model for optimization of electric discharge machining process parameters. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2014, 229, 1504–1516. [Google Scholar] [CrossRef]
- Pfrommer, J.; Zimmerling, C.; Liu, J.; Kärger, L.; Henning, F.; Beyerer, J. Optimisation of manufacturing process parameters using deep neural networks as surrogate models. Procedia CIRP 2018, 72, 426–431. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, X.; Zare, R.N. Optimizing Chemical Reactions with Deep Reinforcement Learning. ACS Cent. Sci. 2017, 3, 1337–1344. [Google Scholar] [CrossRef] [Green Version]
- Simon, C.M.; Mercado, R.; Schnell, S.K.; Smit, B.; Haranczyk, M. What Are the Best Materials to Separate a Xenon/Krypton Mixture? Chem. Mater. 2015, 27, 4459–4475. [Google Scholar] [CrossRef] [Green Version]
- Zhou, W.; Yang, L.; Wang, X.; Zhao, W.; Yang, J.; Zhai, D.; Sun, L.; Deng, W. In Silico Design of Covalent Organic Framework-Based Electrocatalysts. JACS Au 2021, 1, 1497–1505. [Google Scholar] [CrossRef]
- Xiang, Y.; Shimoyama, K.; Shirasu, K.; Yamamoto, G. Machine Learning-Assisted High-Throughput Molecular Dynamics Simulation of High-Mechanical Performance Carbon Nanotube Structure. Nanomaterials 2020, 10, 2459. [Google Scholar] [CrossRef]
- Schütt, K.; Arbabzadah, F.; Chmiela, S.; Müller, K.R.; Tkatchenko, A. Quantum-chemical insights from deep tensor neural networks. Nat. Commun. 2017, 8, 13890. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.S.; Morawietz, T.; Mori, H.; Markland, T.E.; Artrith, N. AENET–LAMMPS and AENET–TINKER: Interfaces for accurate and efficient molecular dynamics simulations with machine learning potentials. J. Chem. Phys. 2021, 155, 074801. [Google Scholar] [CrossRef]
- Kotzabasaki, M.; Sotiropoulos, I.; Charitidis, C.; Sarimveis, H. Machine learning methods for multi-walled carbon nanotubes (MWCNT) genotoxicity prediction. Nanoscale Adv. 2021, 3, 3167–3176. [Google Scholar] [CrossRef]
- Thomas, C.R.; George, S.; Horst, A.M.; Ji, Z.; Miller, R.J.; Peralta-Videa, J.R.; Xia, T.; Pokhrel, S.; Mädler, L.; Gardea-Torresdey, J.L.; et al. Nanomaterials in the Environment: From Materials to High-Throughput Screening to Organisms. ACS Nano 2011, 5, 13–20. [Google Scholar] [CrossRef]
- Varsou, D.-D.; Ellis, L.-J.A.; Afantitis, A.; Melagraki, G.; Lynch, I. Ecotoxicological read-across models for predicting acute toxicity of freshly dispersed versus medium-aged NMs to Daphnia magna. Chemosphere 2021, 285, 131452. [Google Scholar] [CrossRef]
- Winkler, D.; Burden, F.; Yan, B.; Weissleder, R.; Tassa, C.; Shaw, S.; Epa, V. Modelling and predicting the biological effects of nanomaterials. SAR QSAR Environ. Res. 2014, 25, 161–172. [Google Scholar] [CrossRef]
- Subramanian, N.A.; Palaniappan, A. NanoTox: Development of a Parsimonious In Silico Model for Toxicity Assessment of Metal-Oxide Nanoparticles Using Physicochemical Features. ACS Omega 2021, 6, 11729–11739. [Google Scholar] [CrossRef]
- Gernand, J.; Casman, E.A. A Meta-Analysis of Carbon Nanotube Pulmonary Toxicity Studies-How Physical Dimensions and Impurities Affect the Toxicity of Carbon Nanotubes. Risk Anal. 2013, 34, 583–597. [Google Scholar] [CrossRef]
- González-Durruthy, M.; Monserrat, J.M.; Rasulev, B.; Casañola-Martín, G.M.; Barreiro Sorrivas, J.M.; Paraíso-Medina, S.; Maojo, V.; González-Díaz, H.; Pazos, A.; Munteanu, C.R. Carbon Nanotubes’ Effect on Mitochondrial Oxygen Flux Dynamics: Polarography Experimental Study and Machine Learning Models using Star Graph Trace Invariants of Raman Spectra. Nanomaterials 2017, 7, 386. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.; Wang, J.; Wu, J.; Tong, C.; Zhang, T. Meta-analysis of cellular toxicity for graphene via data-mining the literature and machine learning. Sci. Total Environ. 2021, 793, 148532. [Google Scholar] [CrossRef]
- Trinh, T.X.; Ha, M.K.; Choi, J.S.; Byun, H.G.; Yoon, T.H. Curation of datasets, assessment of their quality and completeness, and nanoSAR classification model development for metallic nanoparticles. Environ. Sci. Nano 2018, 5, 1902–1910. [Google Scholar] [CrossRef]
- Roy, J.; Roy, K. Assessment of toxicity of metal oxide and hydroxide nanoparticles using the QSAR modeling approach. Environ. Sci. Nano 2021, 8, 3395–3407. [Google Scholar] [CrossRef]
- Sizochenko, N.; Syzochenko, M.; Fjodorova, N.; Rasulev, B.; Leszczynski, J. Evaluating genotoxicity of metal oxide nanoparticles: Application of advanced supervised and unsupervised machine learning techniques. Ecotoxicol. Environ. Saf. 2019, 185, 109733. [Google Scholar] [CrossRef]
- Lazarovits, J.; Sindhwani, S.; Tavares, A.J.; Zhang, Y.; Song, F.; Audet, J.; Krieger, J.R.; Syed, A.M.; Stordy, B.; Chan, W.C.W. Supervised Learning and Mass Spectrometry Predicts the In Vivo Fate of Nanomaterials. ACS Nano 2019, 13, 8023–8034. [Google Scholar] [CrossRef]
- Esmaeilzadeh-Gharehdaghi, E.; Faramarzi, M.A.; Amini, M.A.; Moazeni, E.; Amani, A. Processing/formulation parameters determining dispersity of chitosan particles: An ANNs study. J. Microencapsul. 2013, 31, 77–85. [Google Scholar] [CrossRef]
- Akbar, R.; Robert, P.A.; Weber, C.R.; Widrich, M.; Frank, R.; Pavlović, M.; Scheffer, L.; Chernigovskaya, M.; Snapkov, I.; Slabodkin, A.; et al. In silico proof of principle of machine learning-based antibody design at unconstrained scale. biorXiv 2021. [Google Scholar] [CrossRef]
- Munteanu, C.R.; Gestal, M.; Martínez-Acevedo, Y.G.; Pedreira, N.; Pazos, A.; Dorado, J. Improvement of Epitope Prediction Using Peptide Sequence Descriptors and Machine Learning. Int. J. Mol. Sci. 2019, 20, 4362. [Google Scholar] [CrossRef] [Green Version]
- Vatti, R.; Vatti, N.; Mahender, K.; Vatti, P.L.; Krishnaveni, B. Solar energy harvesting for smart farming using nanomaterial and machine learning. IOP Conf. Ser. Mater. Sci. Eng. 2020, 981, 032009. [Google Scholar] [CrossRef]
- Thai, N.X.; Tonezzer, M.; Masera, L.; Nguyen, H.; Van Duy, N.; Hoa, N.D. Multi gas sensors using one nanomaterial, temperature gradient, and machine learning algorithms for discrimination of gases and their concentration. Anal. Chim. Acta 2020, 1124, 85–93. [Google Scholar] [CrossRef] [PubMed]
- Mikolajczyk, A.; Sizochenko, N.; Mulkiewicz, E.; Malankowska, A.; Rasulev, B.; Puzyn, T. A chemoinformatics approach for the characterization of hybrid nanomaterials: Safer and efficient design perspective. Nanoscale 2019, 11, 11808–11818. [Google Scholar] [CrossRef] [PubMed]
- Hou, P.; Jolliet, O.; Zhu, J.; Xu, M. Estimate ecotoxicity characterization factors for chemicals in life cycle assessment using machine learning models. Environ. Int. 2019, 135, 105393. [Google Scholar] [CrossRef] [PubMed]
- Jinnouchi, R.; Asahi, R. Predicting Catalytic Activity of Nanoparticles by a DFT-Aided Machine-Learning Algorithm. J. Phys. Chem. Lett. 2017, 8, 4279–4283. [Google Scholar] [CrossRef] [PubMed]
- Davran-Candan, T.; Günay, M.E.; Yildirim, R. Structure and activity relationship for CO and O2 adsorption over gold nanoparticles using density functional theory and artificial neural networks. J. Chem. Phys. 2010, 132, 174113. [Google Scholar] [CrossRef]
- Fanourgakis, G.S.; Gkagkas, K.; Tylianakis, E.; Froudakis, G.E. A Universal Machine Learning Algorithm for Large-Scale Screening of Materials. J. Am. Chem. Soc. 2020, 142, 3814–3822. [Google Scholar] [CrossRef]
- Whitehead, T.M.; Chen, F.; Daly, C.; Conduit, G. Accelerating the Design of Automotive Catalyst Products Using Machine Learning Leveraging Experimental Data to Guide New Formulations; University of Cambridge: Cambridge, UK, 2021. [Google Scholar] [CrossRef]
- AbuOmar, O.; Nouranian, S.; King, R.; Bouvard, J.-L.; Toghiani, H.; Lacy, T.; Pittman, C. Data mining and knowledge discovery in materials science and engineering: A polymer nanocomposites case study. Adv. Eng. Inform. 2013, 27, 615–624. [Google Scholar] [CrossRef]
- Li, Y.; Pu, Q.; Li, S.; Zhang, H.; Wang, X.; Yao, H.; Zhao, L. Machine learning methods for research highlight prediction in biomedical effects of nanomaterial application. Pattern Recognit. Lett. 2018, 117, 111–118. [Google Scholar] [CrossRef]
- Ban, Z.; Yuan, P.; Yu, F.; Peng, T.; Zhou, Q.; Hu, X. Machine learning predicts the functional composition of the protein corona and the cellular recognition of nanoparticles. Proc. Natl. Acad. Sci. USA 2020, 117, 10492–10499. [Google Scholar] [CrossRef] [Green Version]
- Kaminskas, L.M.; Pires, D.E.V.; Ascher, D.B. dendPoint: A web resource for dendrimer pharmacokinetics investigation and prediction. Sci. Rep. 2019, 9, 1–9. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
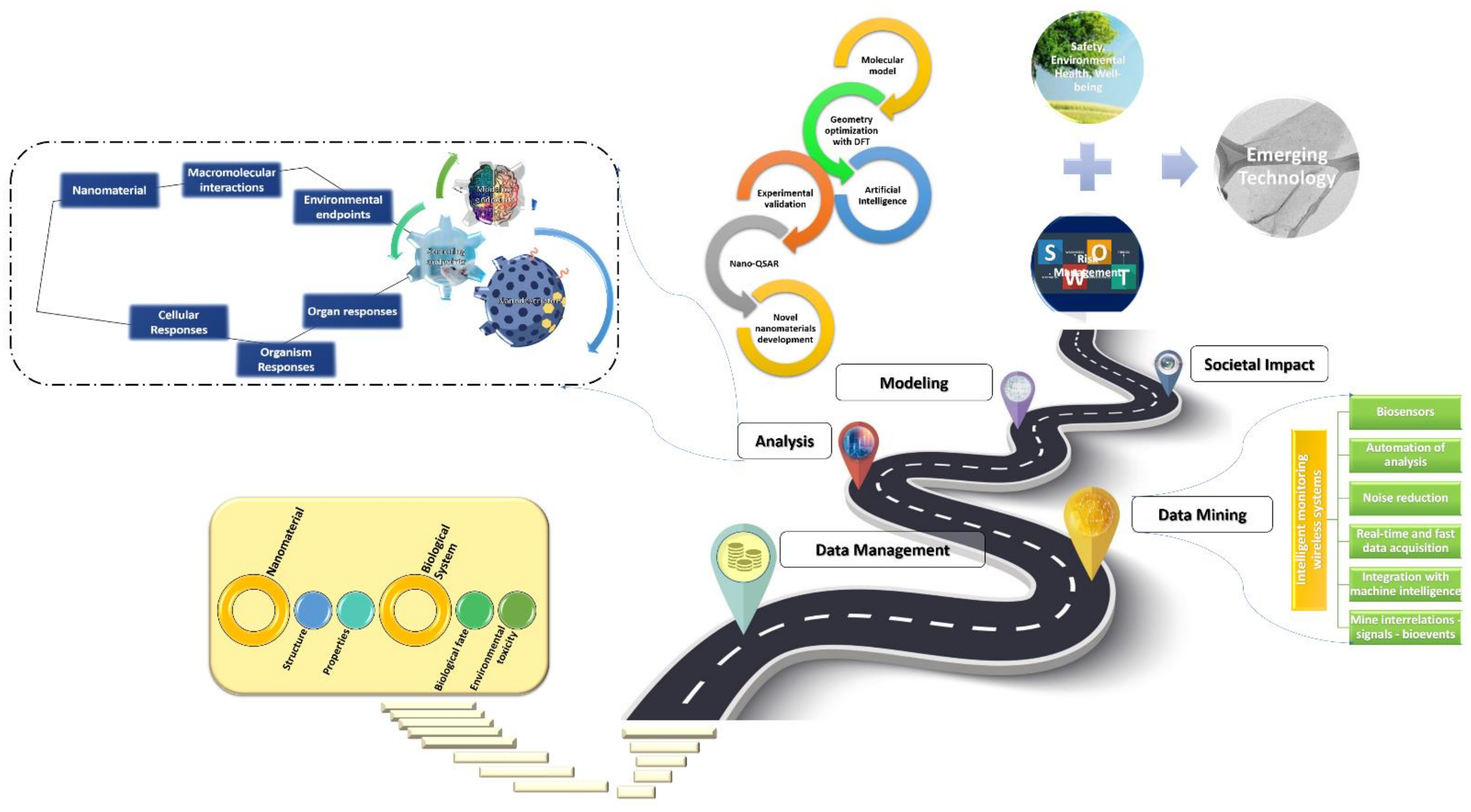{kind=link}
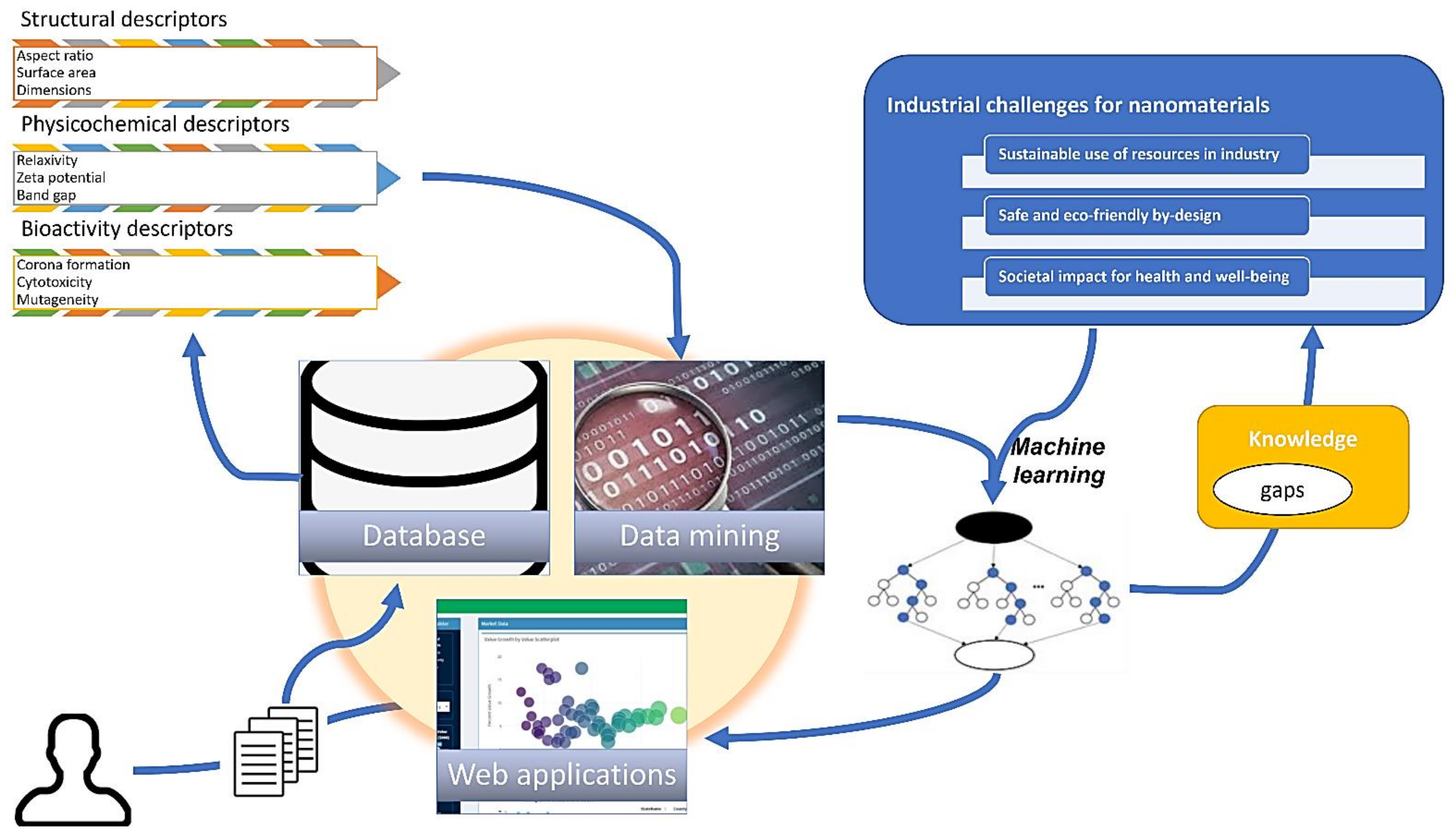{kind=link}
| Title | Scope | Refs |
|---|---|---|
| Research and Development in Carbon Fibers and Advanced High-Performance Composites Supply Chain in Europe: A Roadmap for Challenges and the Industrial Uptake |
| [4] |
| Machine learning the ropes: principles, applications and directions in synthetic chemistry. |
| [12] |
| Virtual metrology as an approach for product quality estimation in Industry 4.0: a systematic review and integrative conceptual framework |
| [13] |
| Big data and machine learning for materials science |
| [17] |
| EU US Roadmap Nanoinformatics 2030 |
| [20] |
| Materials discovery and design using machine learning |
| [21] |
| Advancing Biosensors with Machine Learning |
| [26] |
| Knowledge gaps in immune response and immunotherapy involving nanomaterials: Databases and artificial intelligence for material design |
| [37] |
| Role of Artificial Intelligence and Machine Learning in Nanosafety |
| [45] |
| Toward computational and experimental characterisation for risk assessment of metal oxide nanoparticles |
| [47] |
| Machine Learning for Advanced Additive Manufacturing |
| [50] |
| Machine learning in additive manufacturing: State-of-the-art and perspectives |
| [51] |
| NanoEHS beyond toxicity—focusing on biocorona |
| [52] |
| A review of machine learning for the optimization of production processes |
| [53] |
| Machine learning for chemical discovery |
| [54] |
| Nanomaterial Databases: Data Sources for Promoting Design and Risk Assessment of Nanomaterials |
| [55] |
| In silico design and automated learning to boost next-generation smart biomanufacturing |
| [56] |
| Practices and Trends of Machine Learning Application in Nanotoxicology |
| [57] |
| A review of the applications of data mining and machine learning for the prediction of biomedical properties of nanoparticles |
| [58] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Konstantopoulos, G.; Koumoulos, E.P.; Charitidis, C.A. Digital Innovation Enabled Nanomaterial Manufacturing; Machine Learning Strategies and Green Perspectives. Nanomaterials 2022, 12, 2646. https://0-doi-org.brum.beds.ac.uk/10.3390/nano12152646
Konstantopoulos G, Koumoulos EP, Charitidis CA. Digital Innovation Enabled Nanomaterial Manufacturing; Machine Learning Strategies and Green Perspectives. Nanomaterials. 2022; 12(15):2646. https://0-doi-org.brum.beds.ac.uk/10.3390/nano12152646
Chicago/Turabian StyleKonstantopoulos, Georgios, Elias P. Koumoulos, and Costas A. Charitidis. 2022. "Digital Innovation Enabled Nanomaterial Manufacturing; Machine Learning Strategies and Green Perspectives" Nanomaterials 12, no. 15: 2646. https://0-doi-org.brum.beds.ac.uk/10.3390/nano12152646