Complex-Valued Convolutional Autoencoder and Spatial Pixel-Squares Refinement for Polarimetric SAR Image Classification

Abstract
:1. Introduction
2. Classification Based on CV-CAE Network
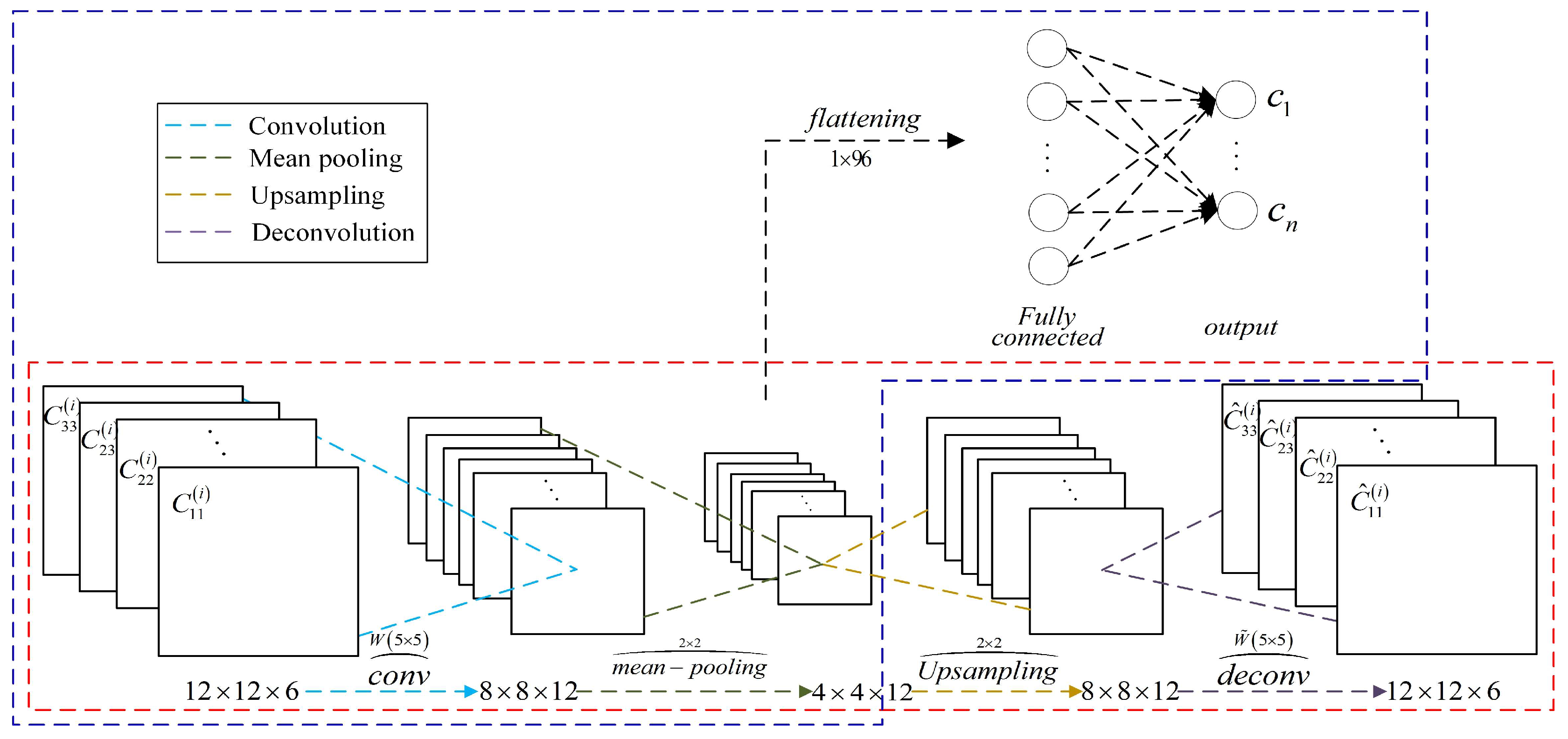
2.1. The Framework of the Proposed Algorithm
2.1.1. CV-CAE
2.1.2. Classification Network
2.2. Network Training
2.2.1. CV-CAE Training
2.2.2. Classification Network Training
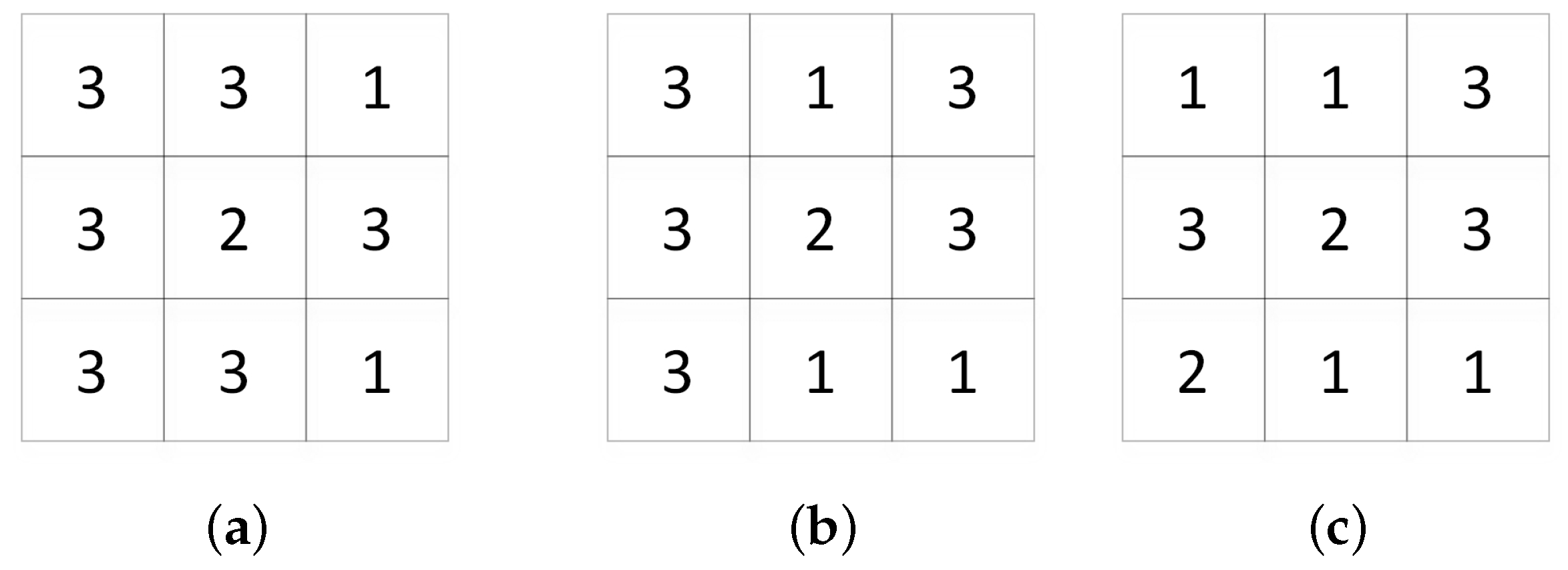
2.3. Spatial Pixel-Squares Refinement
| Algorithm 1: Spatial Pixel-squares Refinement |
| Input: Preliminary classification result size , PixS size r, Stride s, Thresholds . |
| while not refined all PixS do |
| 1: Find the class with the largest number of pixels in PixS. |
| 2: If |
| 3: Sort all classes in PixS by the number of pixels: . |
| 4: If |
| 5: Refine all classes of pixels in PixS to the one class with the largest number of pixels. |
| 6: end if |
| 7: end if |
| end while |
| output: refined result. |
3. Experimental Results and Discussion
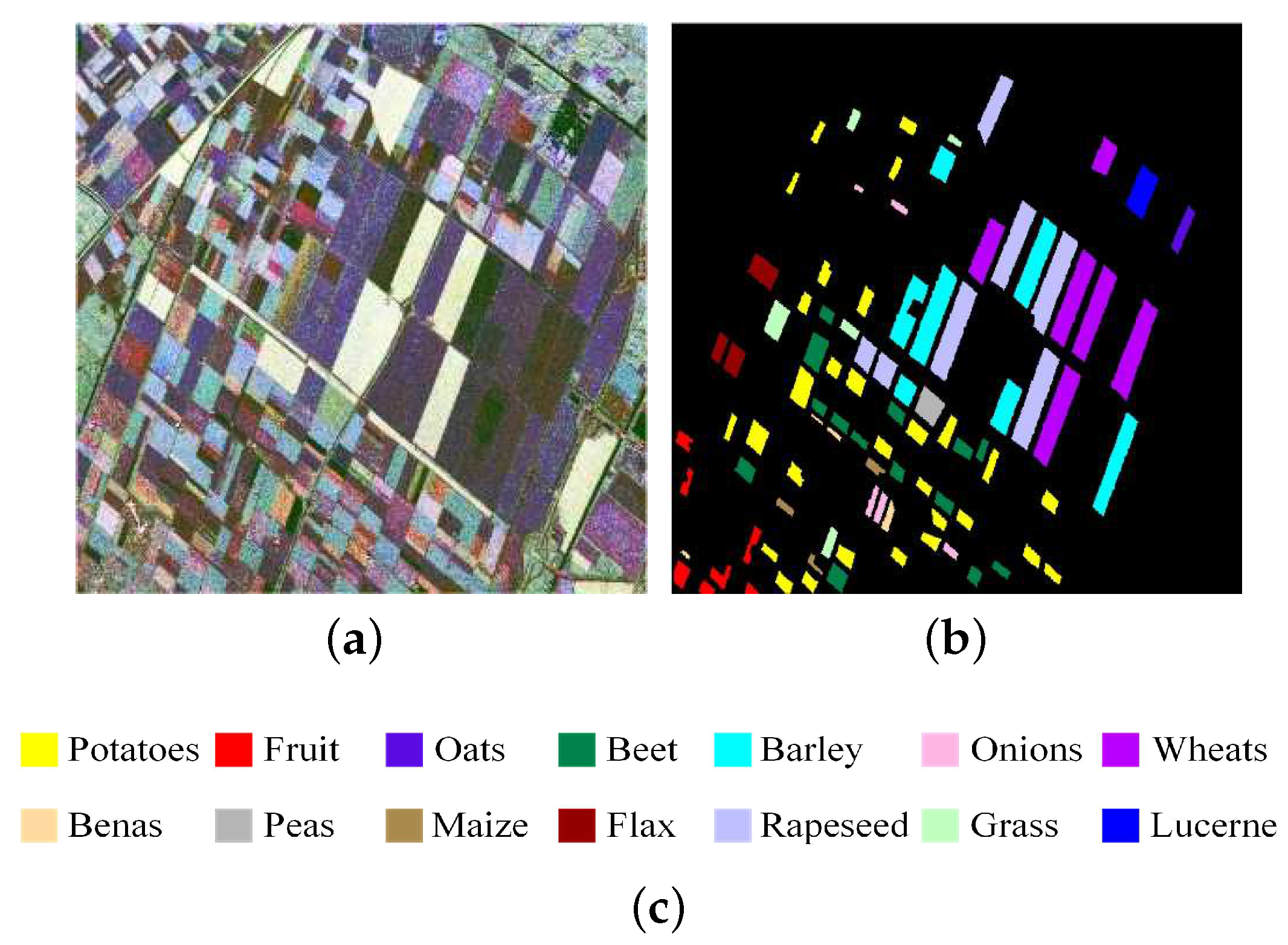
3.1. PolSAR Datasets
3.1.1. PolSAR Data Preprocessing
3.1.2. PolSAR Datasets for Experiment
3.2. Comparative Algorithms
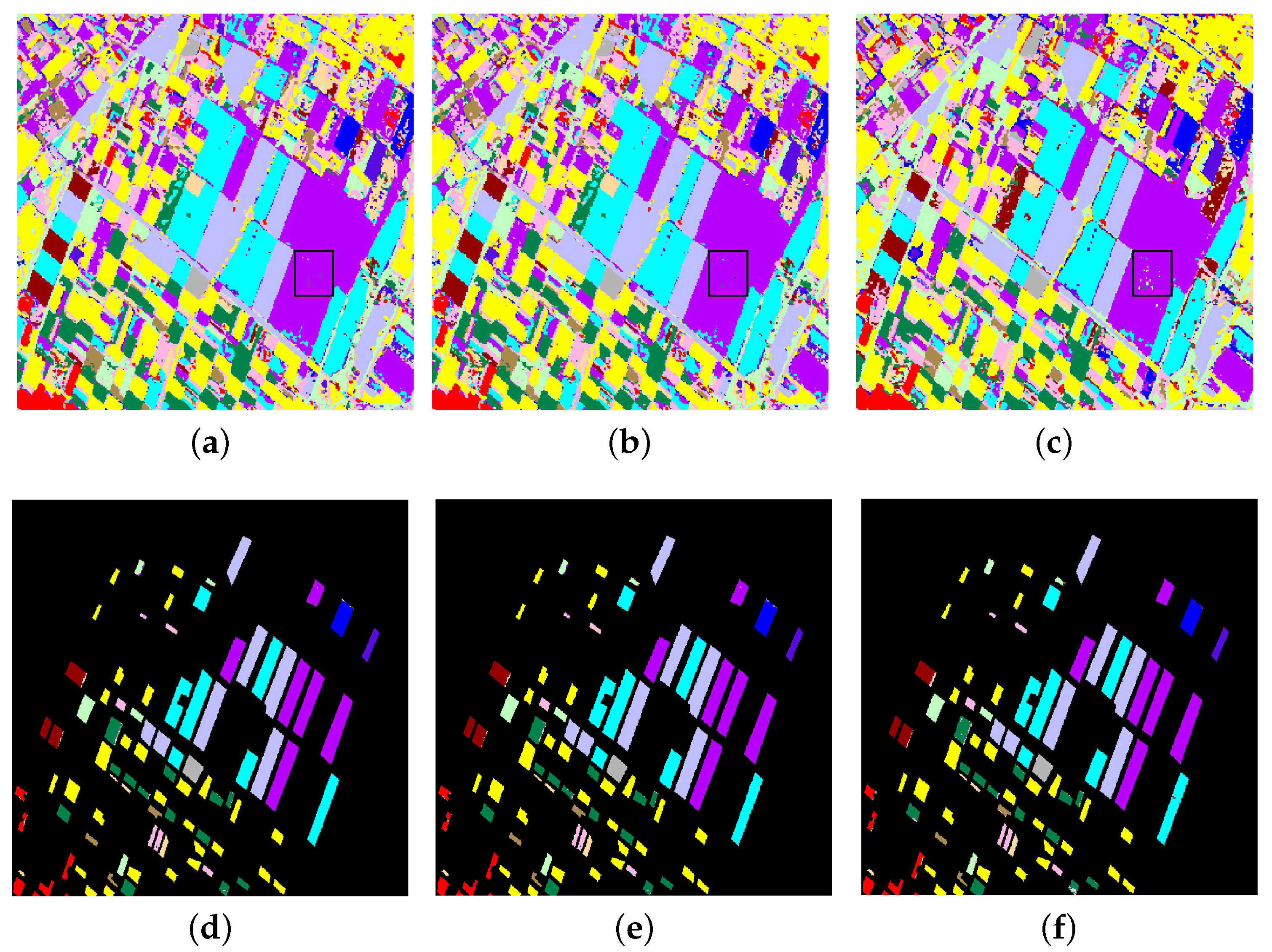
3.3. Results and Analysis of Experiments
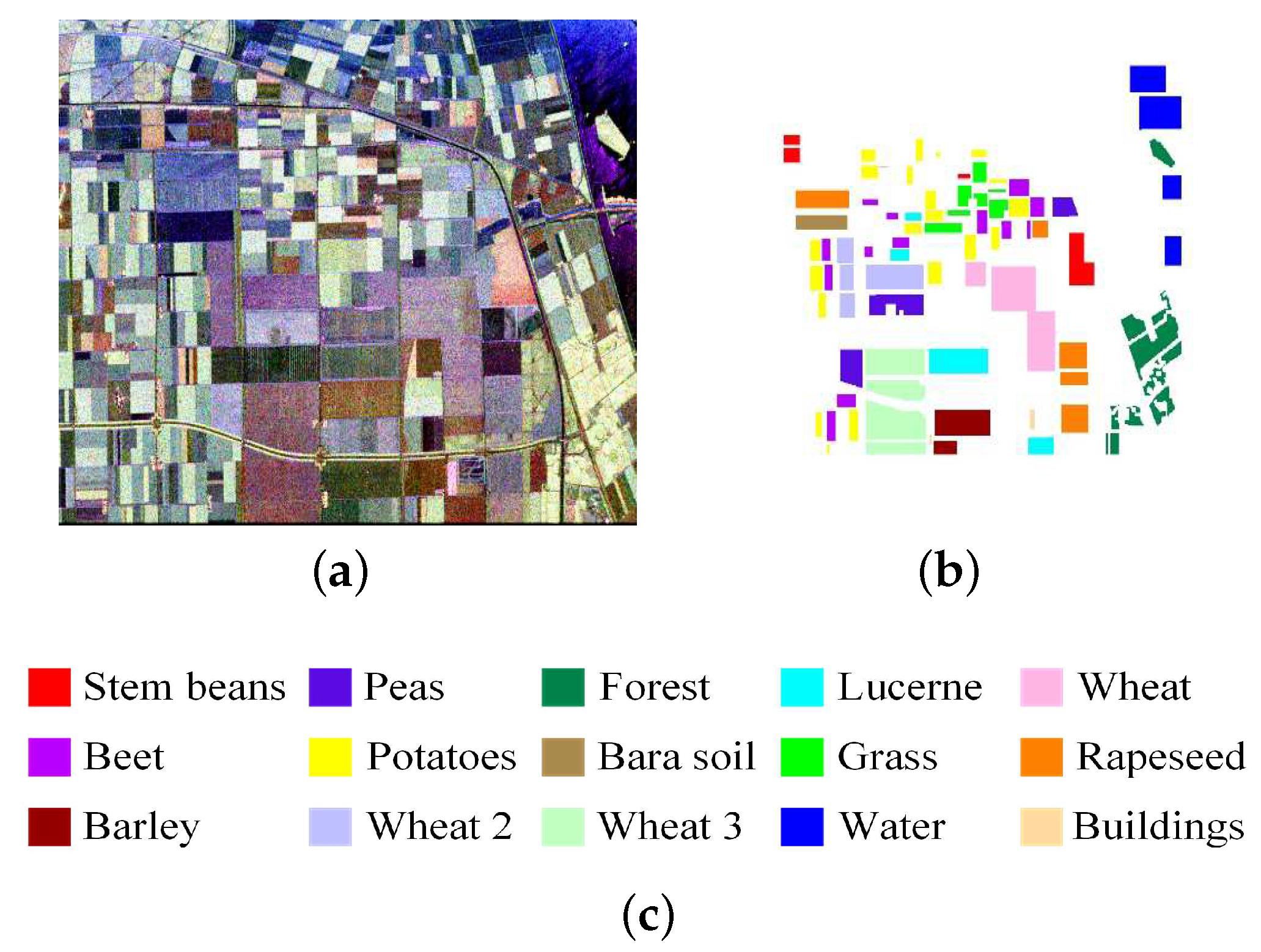
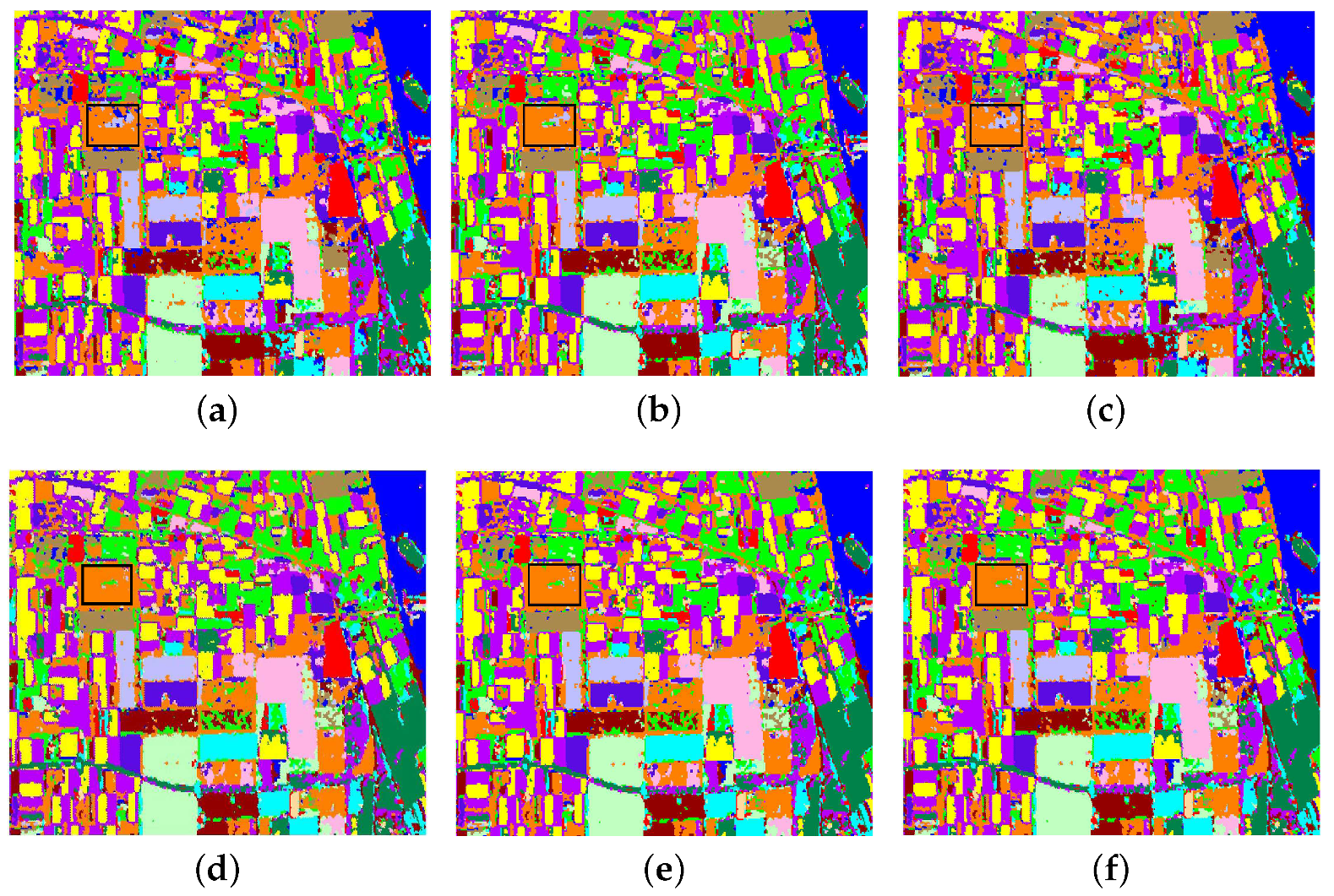
3.3.1. Experiment on Flevoland Datasets of 14 Classes
3.3.2. Experiment on Flevoland Datasets of 15 Classes
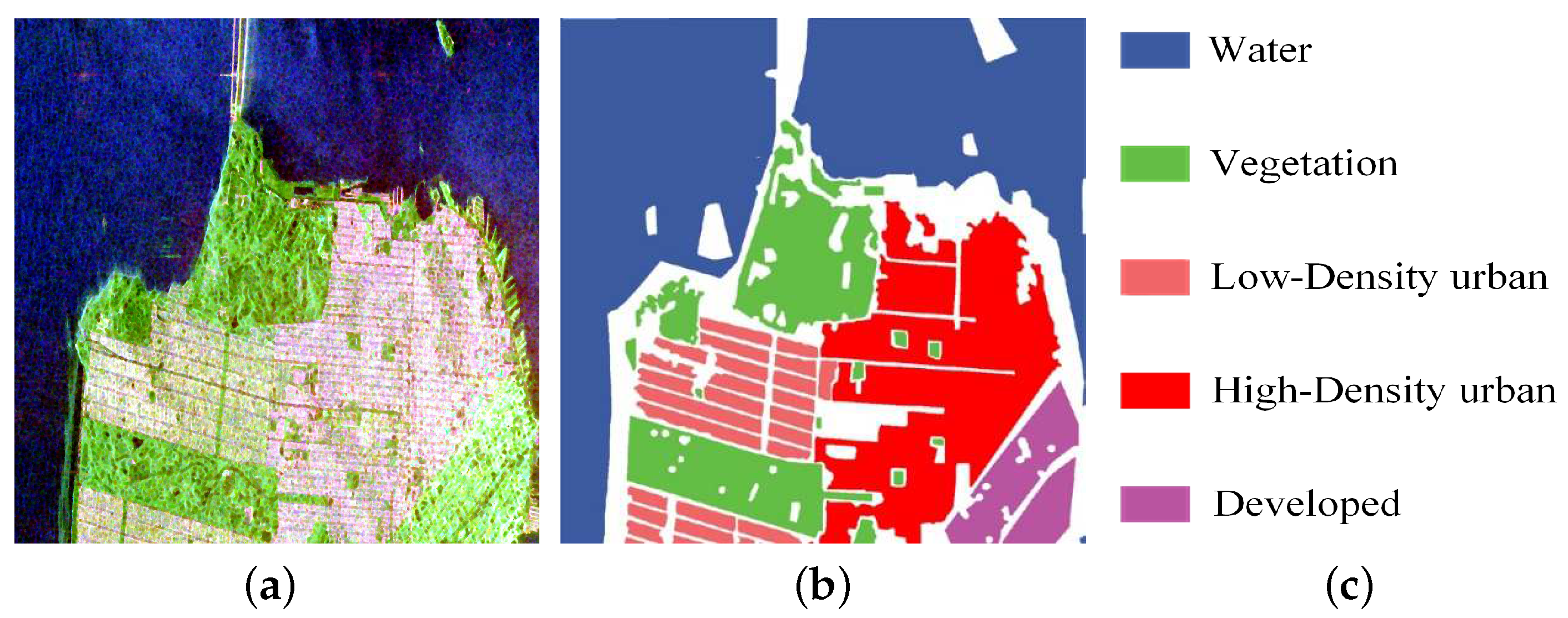
3.3.3. Experiment on San Francisco Datasets of 5 Classes
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PolSAR | Polarimetric Synthetic aperture |
| CV-CAE | complex-valued convolutional autoencoder |
| SPF | Spatial pixel-squares refinement |
| PixS | Pixel-squares |
| CNN | convolutional neural network |
| SAE | sparse autoencoder |
| WAE | Wishart autoencoder |
| WCAE | Wishart convolutional autoencoder |
| CFC | Complex-valued fully connected |
| RV-CAE | real-valued convolutional autoencoder |
| MSE | Mean Square Error |
| OA | Overall Accuracy |
References
- Van, J.J.; Burnette, C.F. Bayesian classification of polarimetric SAR images using adaptive a priori probabilities. Int. J. Remote Sens. 1992, 13, 835–840. [Google Scholar]
- Shang, R.; Yuan, Y.; Jiao, L.; Hou, B.; Esfahani, A.M.; Stolkin, R. A Fast Algorithm for SAR Image Segmentation Based on Key Pixels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 5657–5673. [Google Scholar] [CrossRef]
- Wang, Y.; He, C.; Liu, X.; Liao, M. PolSAR Land Cover Classification Based on Roll-Invariant and Selected Hidden Polarimetric Features in the Rotation Domain. Remote Sens. 2017, 9, 660. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), San Francisco, CA, USA, 4–9 February 2017; p. 12. [Google Scholar]
- Yamaguchi, Y.; Moriyama, T.; Ishido, M.; Yamada, H. Four-component scattering model for polarimetric SAR image decomposition. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1699–1706. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Xu, F.; Jin, Y. Complex-valued convolutional neural network and its application in polarimetric SAR image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7177–7188. [Google Scholar] [CrossRef]
- Akbarizadeh, G. A New Statistical-Based Kurtosis Wavelet Energy Feature for Texture Recognition of SAR Images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4358–4368. [Google Scholar] [CrossRef]
- Ghosh, A.; Subudhi, B.N.; Bruzzone, L. Integration of Gibbs Markov Random Field and Hopfield-Type Neural Networks for Unsupervised Change Detection in Remotely Sensed Multitemporal Images. IEEE Trans. Image Process. 2013, 22, 3087–3096. [Google Scholar] [CrossRef] [PubMed]
- Bombrun, L.; Beaulieu, J.M. Fisher Distribution for Texture Modeling of Polarimetric SAR Data. IEEE Geosci. Remote Sens. Lett. 2008, 5, 512–516. [Google Scholar] [CrossRef] [Green Version]
- Lee, T.S. Image Representation Using 2D Gabor Wavelets. IEEE Geosci. Remote Sens. Lett. 1996, 18, 959–971. [Google Scholar]
- Hu, J.; He, Z.; Li, J.; He, L.; Wang, Y. 3D-Gabor Inspired Multiview Active Learning for Spectral-Spatial Hyperspectral Image Classification. Remote Sens. 2018, 10, 1070. [Google Scholar] [CrossRef]
- Freeman, A.; Villasenor, J.; Klein, J.D.; Hoogeboom, P.; Groot, J. On the use of multi-frequency and polarimetric radar backscatter features for classification of agricultural crops. Int. J. Remote Sens. 1994, 15, 1799–1812. [Google Scholar] [CrossRef]
- Du, L.; Lee, J.; Hoppel, K.; Mango, S.A. Segmentation of SAR images using the wavelet transform. Int. J. Imaging Syst. Technol. 1992, 4, 319–326. [Google Scholar] [CrossRef]
- Lee, J.S.; Grunes, M.R.; Ainsworth, T.L.; Du, L.J.; Schuler, D.L.; Cloude, S.R. Unsupervised classification using polarimetric decomposition and the complex Wishart classifier. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2249–2258. [Google Scholar]
- Hou, B.; Kou, H.; Jiao, L. Classification of polarimetric SAR images using multilayer autoencoders and superpixels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3072–3081. [Google Scholar] [CrossRef]
- Zhao, Q.; Principe, J.C. Support vector machines for SAR automatic target recognition. IEEE Trans. Aerosp. Electron. Syst. 2001, 37, 643–654. [Google Scholar] [CrossRef]
- Loosvelt, L.; Peters, J.; Skriver, H.; Baets, B.; Verhoest, N. Impact of reducing polarimetric SAR input on the uncertainty of crop classifications based on the random forests algorithm. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4185–4200. [Google Scholar] [CrossRef]
- Uhlmann, S.; Kiranyaz, S. Integrating color features in polarimetric SAR image classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2197–2216. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Ma, W.; Zhang, D. Stacked Sparse Autoencoder in PolSAR Data Classification Using Local Spatial Information. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1359–1363. [Google Scholar] [CrossRef]
- Geng, J.; Wang, H.; Fan, J.; Ma, X. SAR Image Classification via Deep Recurrent Encoding Neural Networks. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2255–2269. [Google Scholar] [CrossRef]
- De, S.; Bruzzone, L.; Bhattacharya, A.; Bovolo, F.; Chaudhuri, S. A Novel Technique Based on Deep Learning and a Synthetic Target Database for Classification of Urban Areas in PolSAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 154–170. [Google Scholar] [CrossRef]
- Shang, R.; Wang, J.; Jiao, L.; Stolkin, R.; Hou, B.; Li, Y. SAR Targets Classification Based on Deep Memory Convolution Neural Networks and Transfer Parameters. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2834–2846. [Google Scholar] [CrossRef]
- Gao, Q.; Lim, S.; Jia, X. Hyperspectral Image Classification Using Convolutional Neural Networks and Multiple Feature Learning. Remote Sens. 2018, 10, 299. [Google Scholar] [CrossRef]
- Hosseini, A.E.; Zurada, J.M.; Nasraoui, O. Deep learning of part-based representation of data using sparse autoencoders with nonnegativity constraints. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 2486–2498. [Google Scholar] [CrossRef] [PubMed]
- Masci, J.; Meier, U.; Ciresan, D.; Schmidhuber, J. Stacked convolutional auto-encoders for hierarchical feature extraction. In Proceedings of the 21st International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; pp. 52–59. [Google Scholar]
- Deng, S.; Du, L.; Li, C.; Ding, J.; Liu, H. SAR automatic target recognition based on euclidean distance restricted autoencoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3323–3333. [Google Scholar] [CrossRef]
- Chen, M.; Wang, Q.; Li, X. Discriminant Analysis with Graph Learning for Hyperspectral Image Classification. Remote Sens. 2018, 10, 836. [Google Scholar] [CrossRef]
- Chen, W.; Gou, S.; Wang, X.; Li, X.; Jiao, L. Classification of PolSAR Images Using Multilayer Autoencoders and a Self-Paced Learning Approach. Remote Sens. 2018, 10, 110. [Google Scholar] [CrossRef]
- Xie, W.; Jiao, L.; Hou, B.; Ma, W.; Zhao, J.; Zhang, S.; Liu, F. POLSAR image classification via Wishart-AE model or Wishart-CAE model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3604–3615. [Google Scholar] [CrossRef]
- Liu, F.; Jiao, L.; Hou, B.; Yang, S. POL-SAR Image Classification Based on Wishart DBN and Local Spatial Information. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3292–3308. [Google Scholar] [CrossRef]
- Liu, H.; Yang, S.; Gou, S.; Chen, P.; Wang, Y.; Jiao, L. Fast Classification for Large Polarimetric SAR Data Based on Refined Spatial-Anchor Graph. IEEE Trans. Geosci. Remote Sens. 2017, 14, 1589–1593. [Google Scholar] [CrossRef]
- Ulaby, F.T.; Charles, E. Radar Polarimetry for Geoscience Applications; Artech House, Inc.: Norwood, MA, USA, 1990; 376p. [Google Scholar]
- Marques, P.A.; Dias, J.M. Moving Targets Processing in SAR Spatial Domain. IEEE Trans. Geosci. Remote Sens. 2007, 43, 864–874. [Google Scholar] [CrossRef]
- Boureau, Y.L.; Bach, F.; LeCun, Y.; Ponce, J. Learning mid-level features for recognition. In Proceedings of the Twenty-Third IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2018; pp. 2559–2566. [Google Scholar]
- Karen, S.; Andrew, Z. Very deep convolutional networks for large-scale image recognition. arXiv, 2009; arXiv:1409.1556. [Google Scholar]
- Xavier, G.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–14 April 2011; pp. 315–323. [Google Scholar]
- Li, Y.; Chen, Y.; Liu, G.; Jiao, L. A Novel Deep Fully Convolutional Network for PolSAR Image Classification. Remote Sens. 2018, 10, 1984. [Google Scholar] [CrossRef]
- Biondi, F. Multi-chromatic analysis polarimetric interferometric synthetic aperture radar (MCAPolInSAR) for urban classification. Int. J. Remote Sens. 2018, 1–30. [Google Scholar] [CrossRef]
- Chen, S.; Wang, X.; SatoLi, M. PolInSAR Complex Coherence Estimation Based on Covariance Matrix Similarity Test. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4699–4710. [Google Scholar] [CrossRef]
- Wang, L.; Xu, X.; Dong, H.; Gui, R.; Pu, F. Multi-Pixel Simultaneous Classification of PolSAR Image Using Convolutional Neural Networks. Sensors 2018, 18, 769. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer NO. | Architecture | Output Size (Pixels) |
|---|---|---|
| 1 | Input layer | 12 × 12 × 6 |
| 2 | Conv.12 (5 × 5 × 6)/sigmoid | 8 × 8 × 12 |
| 3 | Mean-Po.2 (2 × 2) | 4 × 4 × 12 |
| 4 | Upsampl.2 (2 × 2) | 8 × 8 × 12 |
| 5 | Deconv.6 (5 × 5 × 12)/sigmoid | 12 × 12 × 6 |
| 6 | Fully connected | 1 × N |
| Layer NO. | RV-CAE | CV-CAE | ||
|---|---|---|---|---|
| Architecture | Parameters | Architecture | Parameters | |
| 1 | Input Layer | - | Input Layer | - |
| 2 | Conv.16 (5 × 5 × 9)/sigmoid | 3600 | Conv.12 (5 × 5 × 6)/sigmoid | 1800 × 2 |
| 3 | Mean-Po.2 (2 × 2) | - | Mean-Po.2 (2 × 2) | - |
| 4 | Upsampl (2 × 2) | - | Upsampl (2 × 2) | - |
| 5 | Deconv.9 (5 × 5 × 16)/sigmoid | 3600 | Deconv.6 (5 × 5 × 12)/sigmoid | 1800 × 2 |
| 6 | Fully Connected | Fully Connected | ||
| Class | WAE | WCAE | RV-CAE | CV-CAE | CV-CAE+SPF |
|---|---|---|---|---|---|
| Potatoes | 89.83 | 99.78 | 99.69 | 99.79 | 99.8 |
| Fruit | 97.62 | 88.2 | 94.76 | 97.09 | 98.07 |
| Oats | 98.92 | 98.28 | 98.78 | 100 | 100 |
| Beet | 89.66 | 91.72 | 90.03 | 92.51 | 92.77 |
| Barley | 97.27 | 95.96 | 99.51 | 99.79 | 99.78 |
| Onions | 81.48 | 85.69 | 97.42 | 91.88 | 90.7 |
| Wheats | 89.47 | 94.91 | 99.76 | 99.86 | 99.87 |
| Beans | 87.52 | 91.04 | 82.9 | 92.7 | 95.56 |
| Peas | 89.95 | 91.49 | 99.91 | 99.54 | 99.77 |
| Maize | 94.19 | 99.05 | 95.5 | 98.6 | 98.84 |
| Flax | 94.49 | 89.12 | 94.02 | 95.54 | 96.56 |
| Rapeseed | 89.62 | 94.73 | 99.9 | 99.93 | 99.94 |
| Grass | 84.59 | 97.23 | 97.38 | 96.12 | 96.88 |
| Luceme | 96.34 | 97.46 | 99.73 | 98.61 | 98.2 |
| OA | 96.53 | 97.49 | 98.34 | 98.7 | 98.82 |
| Kappa | 0.96 | 0.97 | 0.98 | 0.984 | 0.986 |
| % | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 99.8 | 0 | 0 | 0 | 0 | 0.03 | 0.01 | 0 | 0 | 0 | 0 | 0.13 | 0 | 0.02 |
| 2 | 0.32 | 98.07 | 0 | 0.26 | 0.21 | 0.03 | 0.03 | 0 | 1.03 | 0 | 0.05 | 0 | 0 | 0 |
| 3 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 |
| 4 | 0 | 0 | 0 | 92.77 | 0.01 | 6.83 | 0.03 | 0.04 | 0 | 0 | 0 | 0.01 | 0 | 0 |
| 5 | 0 | 0 | 0.02 | 0 | 99.78 | 0 | 0.19 | 0 | 0 | 0 | 0 | 0 | 0.02 | 0 |
| 6 | 0.38 | 0 | 0 | 1.6 | 0.38 | 90.7 | 1.17 | 1.46 | 0.14 | 1.55 | 0 | 0 | 0 | 0.05 |
| 7 | 0 | 0 | 0.09 | 0 | 0 | 0.03 | 99.87 | 0 | 0 | 0 | 0 | 0 | 0.09 | 0.01 |
| 8 | 0 | 0 | 0 | 0 | 0 | 4.25 | 0 | 95.56 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0.23 | 0 | 0 | 99.77 | 0 | 0 | 0 | 0 | 0 |
| 10 | 0 | 0 | 0 | 0.23 | 0 | 0.85 | 0 | 0 | 0 | 98.84 | 0 | 0 | 0.08 | 0 |
| 11 | 0 | 0 | 0 | 0 | 0.05 | 0.42 | 0 | 1.53 | 0 | 0 | 96.56 | 0 | 1.44 | 0 |
| 12 | 0 | 0.03 | 0 | 0 | 0 | 0 | 0.02 | 0 | 0 | 0 | 0 | 99.94 | 0 | 0 |
| 13 | 0.64 | 0 | 0 | 0 | 0 | 1.05 | 1.43 | 0 | 0 | 0 | 0 | 0 | 96.88 | 0 |
| 14 | 0 | 0 | 0 | 0 | 0 | 1.42 | 0.37 | 0 | 0 | 0 | 0 | 0 | 0 | 98.2 |
| Class | WAE | WCAE | RV-CAE | FFS-CNN | CV-CAE | CV-CAE+SPF |
|---|---|---|---|---|---|---|
| Stem beans | 88.02 | 93.09 | 88.2 | 93 | 92.25 | 93.56 |
| Peas | 91.49 | 92.36 | 87.95 | 93.21 | 92.26 | 93.52 |
| Forest | 97.89 | 98.74 | 97.12 | 98.97 | 98.74 | 99.21 |
| Lucerne | 88.5 | 89.22 | 90.69 | 91.98 | 91.18 | 92.24 |
| Wheat | 91.48 | 94.51 | 94.72 | 95.41 | 94.89 | 95.38 |
| Beet | 84.7 | 91.01 | 80.25 | 91.85 | 90.9 | 93.09 |
| Potatoes | 81.94 | 87.21 | 77.56 | 88.63 | 86.93 | 89.24 |
| Bare soil | 97.92 | 99.42 | 100 | 99.09 | 99.12 | 99.35 |
| Grass | 69.82 | 82.17 | 73.14 | 85.91 | 84.42 | 87.02 |
| Rapeseed | 92.66 | 91.03 | 91.91 | 93.54 | 92.96 | 93.24 |
| Barley | 96.89 | 93.83 | 94.34 | 94.34 | 93.45 | 94.88 |
| Wheat2 | 87.84 | 90.91 | 88.98 | 91.09 | 90.42 | 91.65 |
| Wheat3 | 94.85 | 96.6 | 95.29 | 97.08 | 96.76 | 97.13 |
| Water | 98.67 | 96.66 | 99.05 | 97.76 | 97.56 | 97.72 |
| Buildings | 86.55 | 87.09 | 82.14 | 90.55 | 90.55 | 90.13 |
| OA | 90.74 | 92.94 | 90.39 | 94 | 93.31 | 94.31 |
| Kappa | 0.9 | 0.92 | 0.89 | 0.935 | 0.93 | 0.94 |
| Class | WAE | WCAE | RV-CAE | CV-CAE | CV-CAE+SPF |
|---|---|---|---|---|---|
| Water | 99.91 | 98.24 | 95.51 | 99.46 | 99.5 |
| Vegetation | 58.85 | 91.34 | 87.87 | 93.71 | 93.77 |
| Low-Density urban | 78.12 | 96.88 | 90.56 | 97.58 | 97.65 |
| High-Density urban | 81.43 | 91.29 | 80.76 | 93.06 | 93.26 |
| Developed | 94.08 | 93.63 | 94.15 | 95.54 | 95.88 |
| OA | 87.87 | 95.44 | 90.84 | 96.94 | 97.03 |
| Kappa | 0.81 | 0.93 | 0.86 | 0.95 | 0.96 |
| % | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | 99.5 | 0.44 | 0.01 | 0.04 | 0 |
| 2 | 0.39 | 93.77 | 2.77 | 1.47 | 1.59 |
| 3 | 0 | 0.36 | 97.65 | 1.99 | 0 |
| 4 | 0 | 0.1 | 6.04 | 93.26 | 0.45 |
| 5 | 0 | 3.28 | 0.28 | 0.56 | 95.88 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shang, R.; Wang, G.; A. Okoth, M.; Jiao, L. Complex-Valued Convolutional Autoencoder and Spatial Pixel-Squares Refinement for Polarimetric SAR Image Classification. Remote Sens. 2019, 11, 522. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11050522
Shang R, Wang G, A. Okoth M, Jiao L. Complex-Valued Convolutional Autoencoder and Spatial Pixel-Squares Refinement for Polarimetric SAR Image Classification. Remote Sensing. 2019; 11(5):522. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11050522
Chicago/Turabian StyleShang, Ronghua, Guangguang Wang, Michael A. Okoth, and Licheng Jiao. 2019. "Complex-Valued Convolutional Autoencoder and Spatial Pixel-Squares Refinement for Polarimetric SAR Image Classification" Remote Sensing 11, no. 5: 522. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11050522