Effective Airplane Detection in Remote Sensing Images Based on Multilayer Feature Fusion and Improved Nonmaximal Suppression Algorithm


Abstract
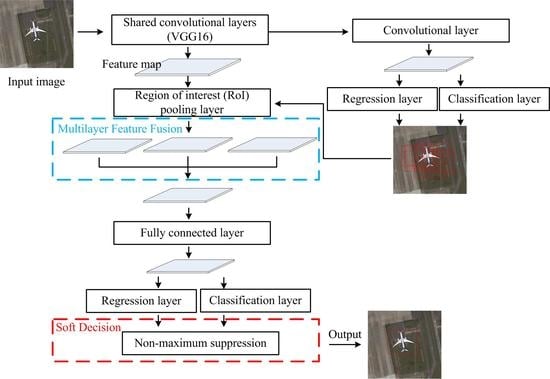
:
1. Introduction
2. Materials and Methods Methodology
2.1. Related Work
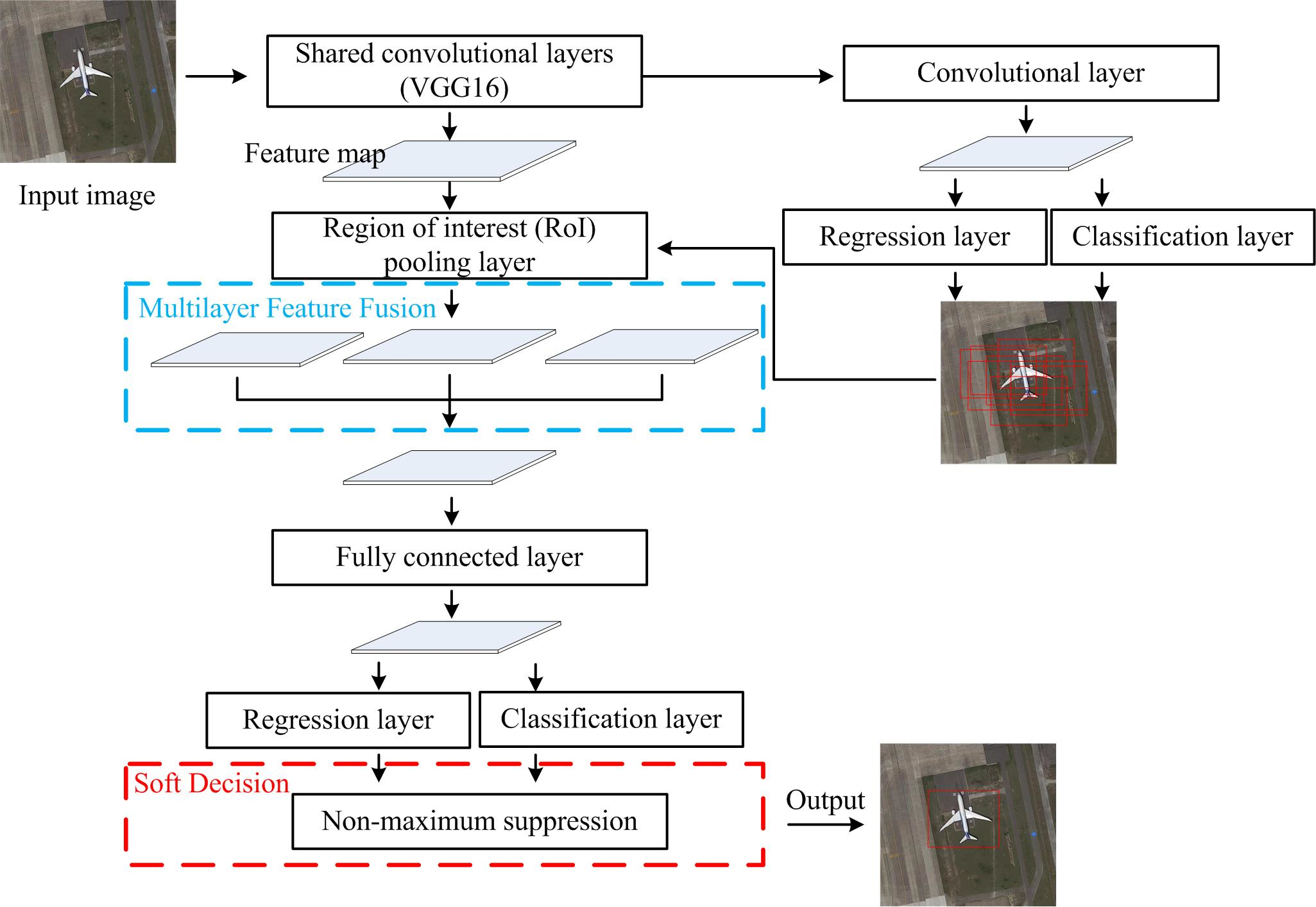
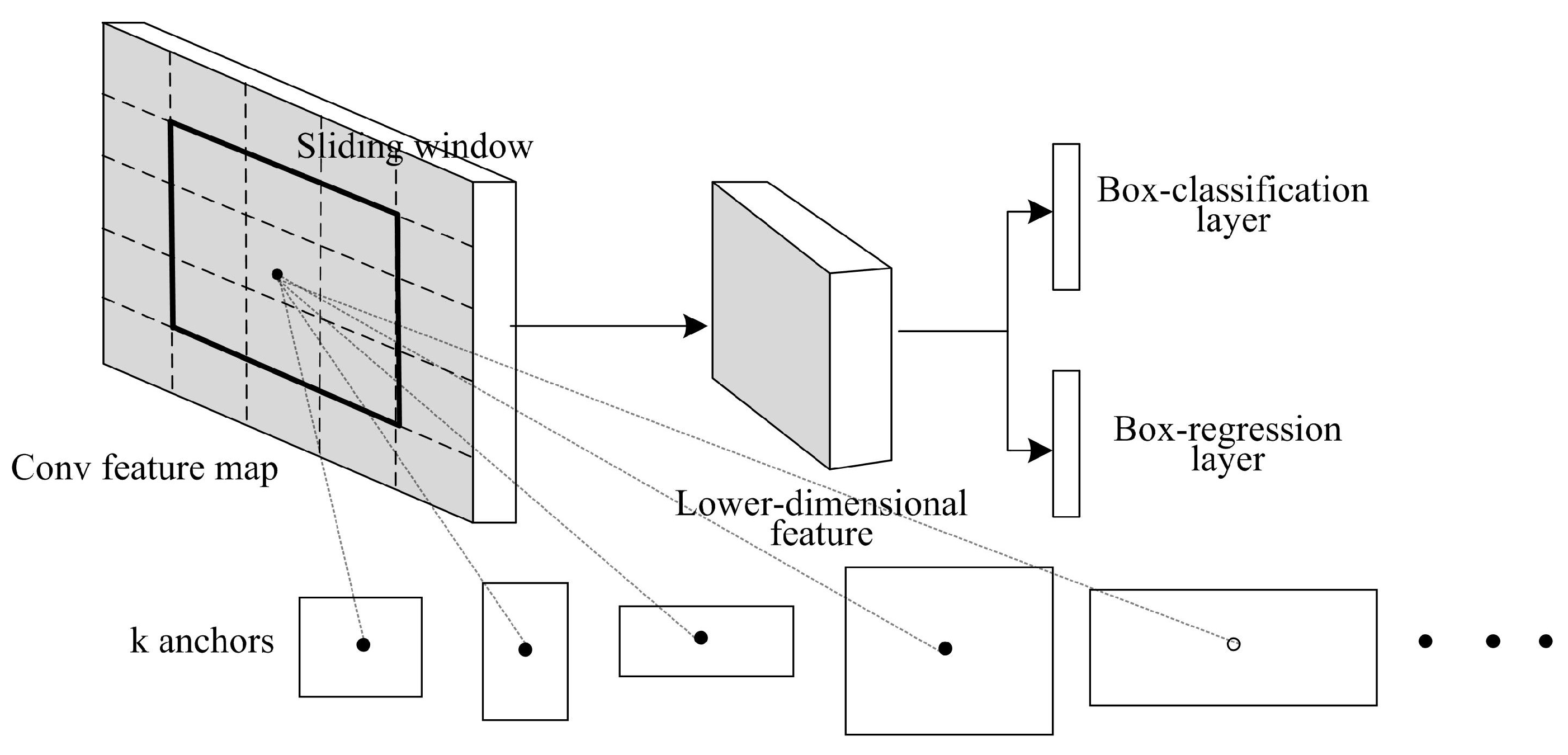
2.1.1. Region Proposal Networks
2.1.2. RoI Pooling Layer
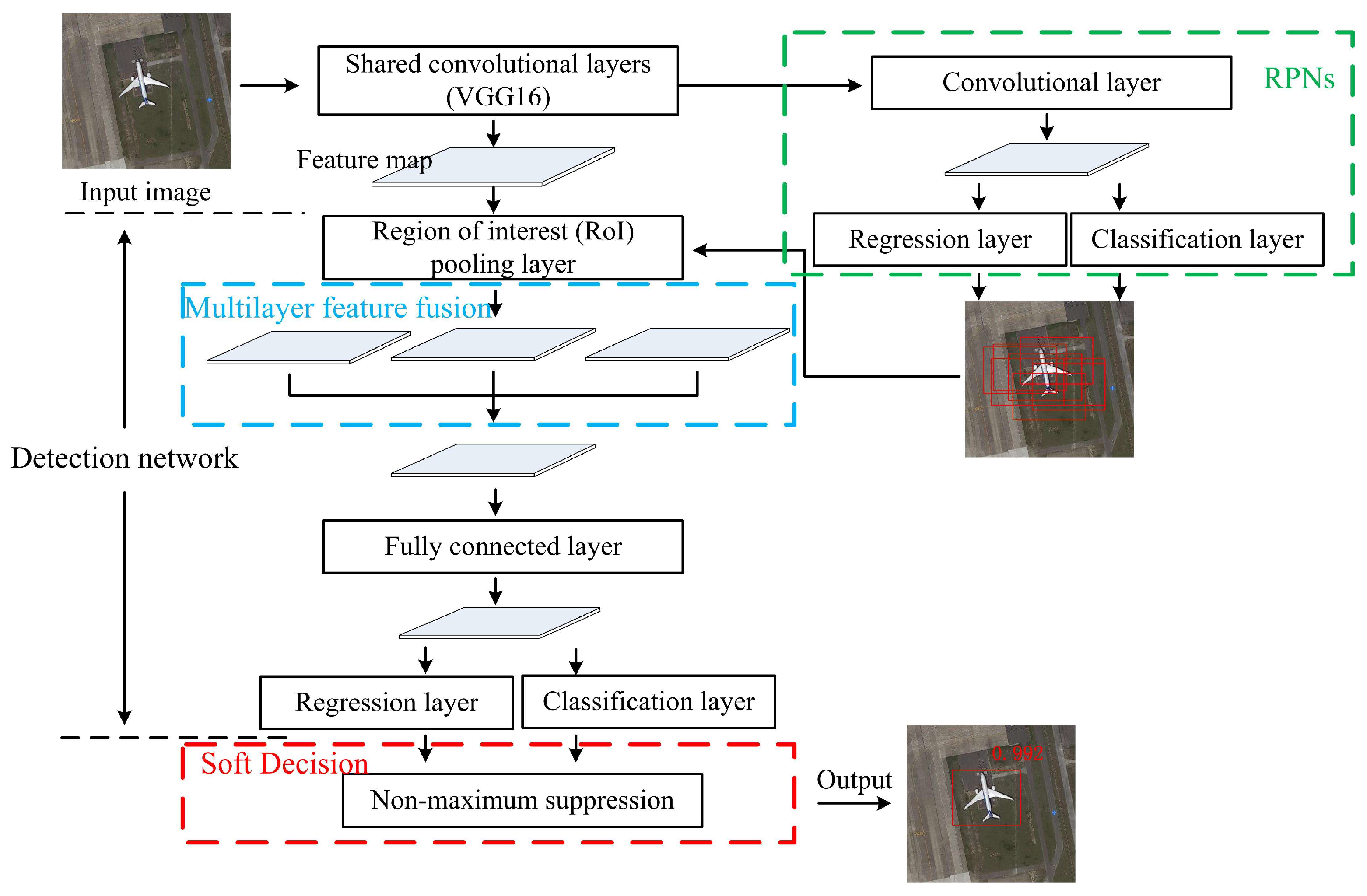
2.2. Methodology
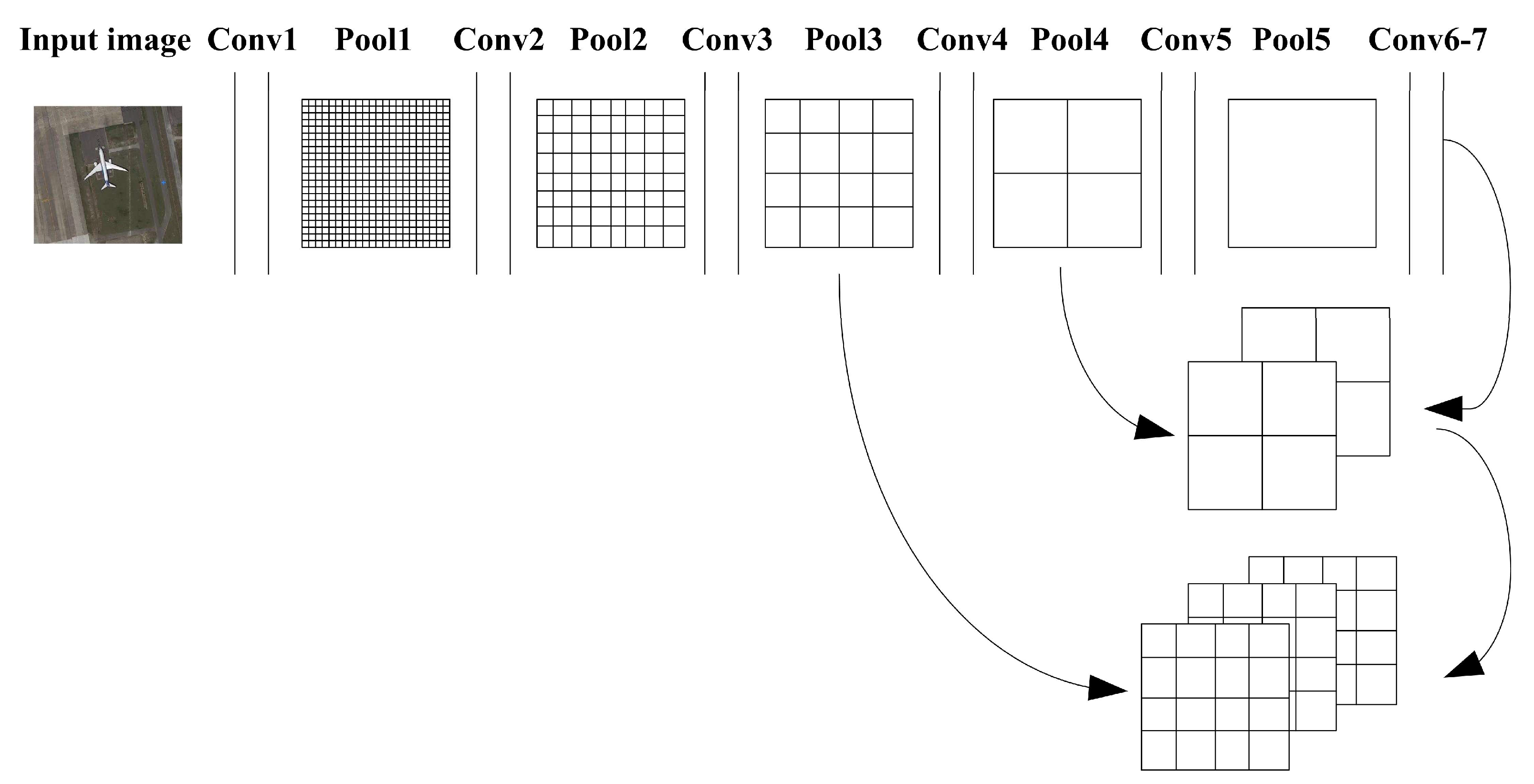
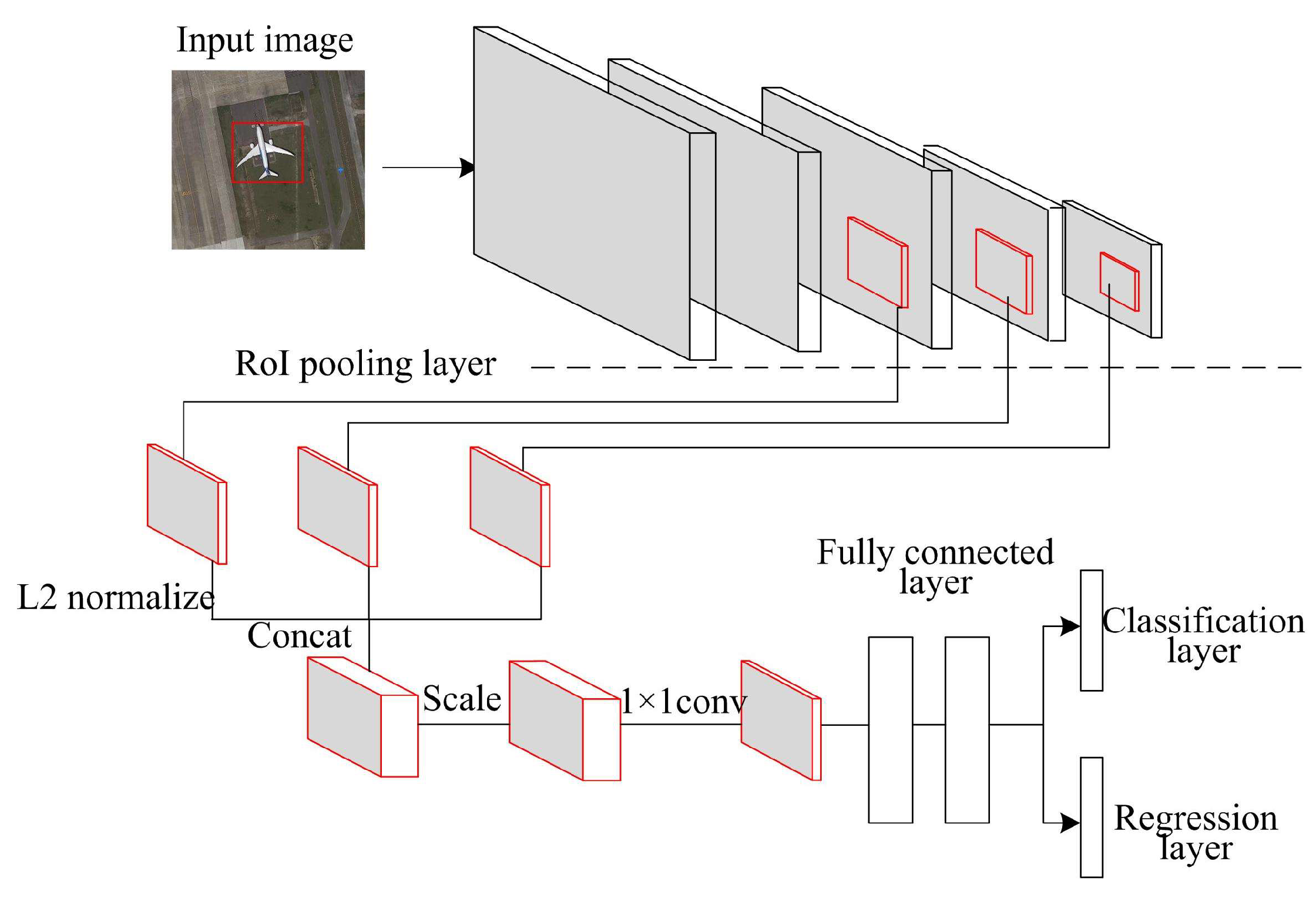
2.2.1. Multilayer Feature Fusion
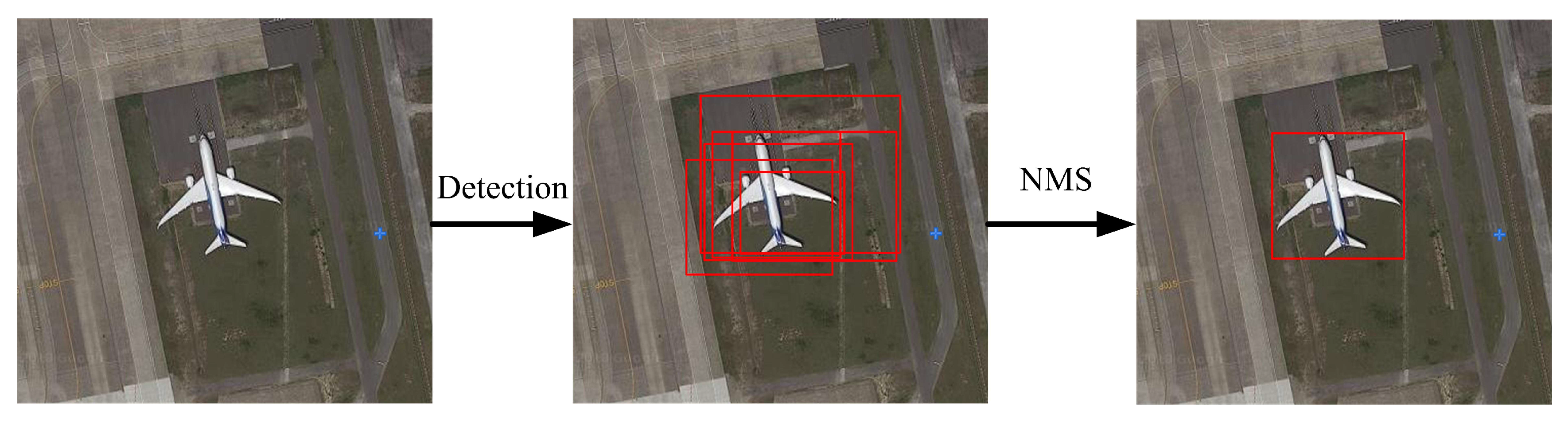
2.2.2. Nonmaximum Suppression Based on Soft Decision
2.3. Transfer Learning and Network Training
3. Results
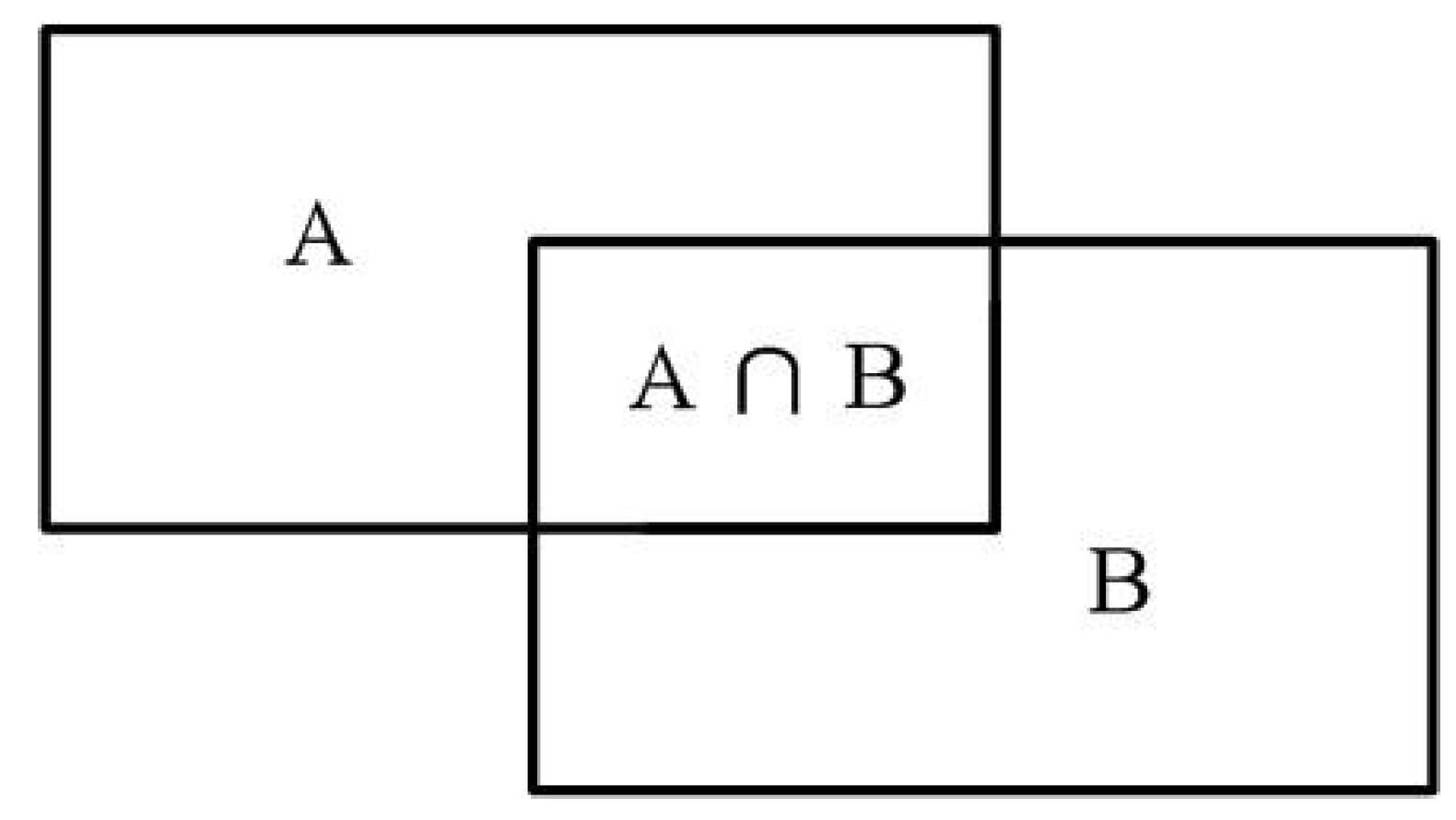
3.1. Computational Platform and Evaluation Index
3.2. Test Data
3.3. Comparison of Results
4. Discussion
4.1. Analysis of Multilayer Feature Fusion
4.2. Analysis of NMS Algorithm Improvement
4.3. Method Analysis
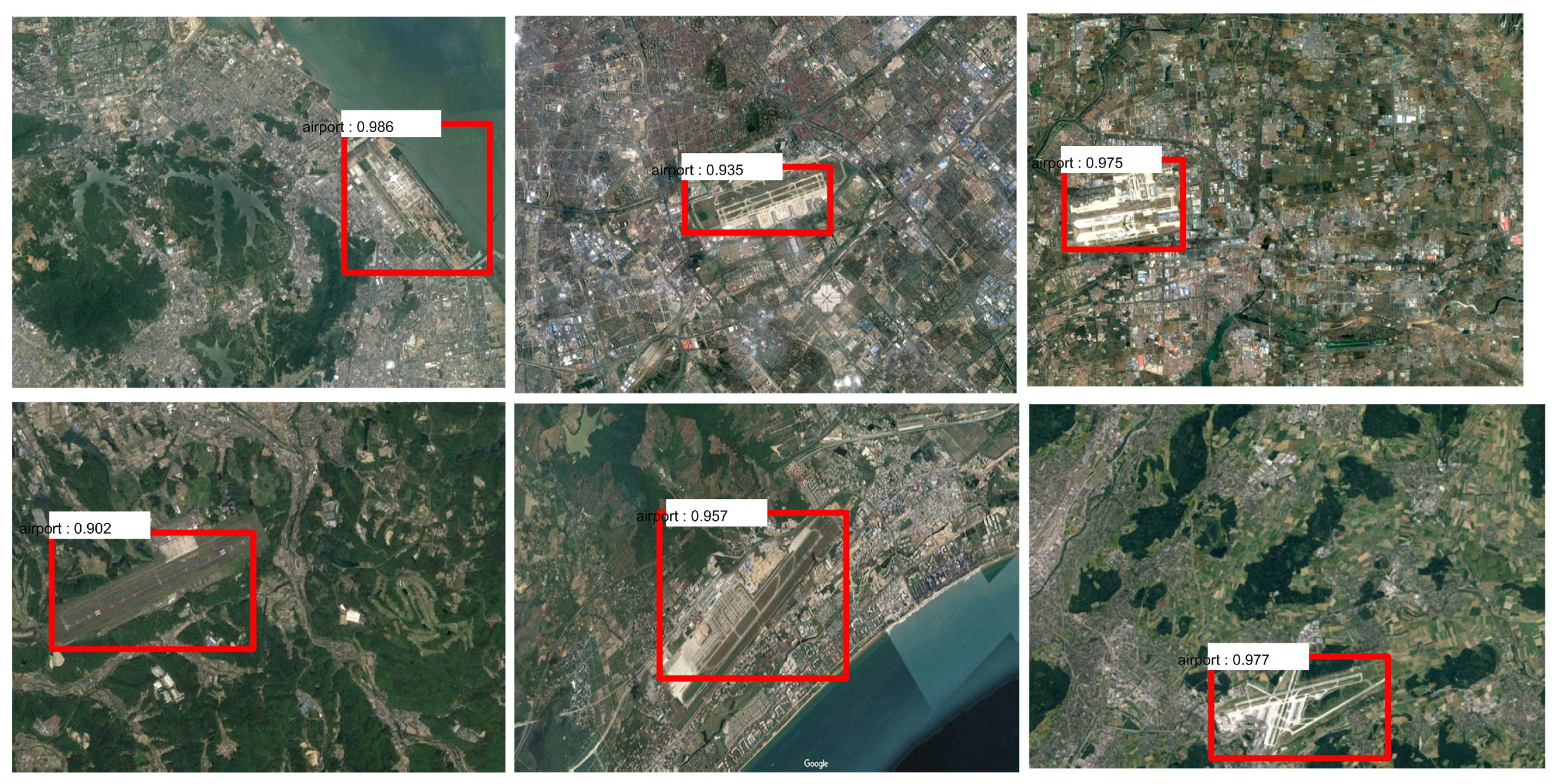
4.4. Application to Airports
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Song, M.Z.; Qu, H.S.; Jin, G. Weak ship object detection of noisy optical remote sensing image on sea surface. Acta Opt. Sin. 2017, 37, 101–1004. [Google Scholar]
- Xu, Y.L.; Zhu, M.M.; Li, S. End-to-end airport detection in remote sensing images combining cascade region proposal networks and multi-threshold detection networks. Remote Sens. 2018, 10, 1516. [Google Scholar] [CrossRef]
- Li, W.; Xiang, S.M.; Wang, H.B. Robust Airplane Detection in Satellite Images. In Proceedings of the International Conference on Image Processing (IEEE), Brussels, Belgium, 11–14 September 2011; pp. 2821–2824. [Google Scholar]
- Bo, S.K.; Jing, Y.J. Region-Based Airplane Detection in Remotely Sensed Imagery. In Proceedings of the International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010; pp. 1923–1926. [Google Scholar]
- Liu, G.; Sun, X.; Fu, K. Aircraft recognition in high-resolution satellite images using coarse-to-fine shape prior. IEEE Geosci. Remote Sens. Lett. 2013, 10, 573–577. [Google Scholar] [CrossRef]
- Tan, Y.; Li, Q.; Li, Y.; Tian, J. Aircraft detection in high-resolution sar images based on a gradient textural saliency map. Sensors 2015, 15, 23071–23094. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Nie, T.; Fu, T.; Ren, J.; Jin, L. A novel method of aircraft detection based on high-resolution panchromatic optical remote sensing images. Sensors 2017, 17, 1047. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Shi, Z.W. Airplane detection based on rotation invariant and sparse coding in remote sensing images. Optik Int. J. Light Electron Opt. 2014, 125, 5327–5333. [Google Scholar] [CrossRef]
- Yildiz, C.; Polat, E. Detection of Stationary Aircrafts from Satelitte Images. In Proceedings of the 2011 IEEE 19th Signal Processing and Communications Applications Conference (SIU), Antalya, Turkey, 20–22 April 2010. [Google Scholar]
- An, Z.Y.; Shi, Z.W.; Teng, X.C. An automated airplane detection system for large panchro-matic image with high spatial resolution. Optik 2014, 125, 2768–2775. [Google Scholar] [CrossRef]
- Chen, X.Y.; Xiang, S.M.; Liu, C.L. Aircraft Detection by Deep Belief Nets. In Proceedings of the Asian Conference on Pattern Recognition, Naha, Japan, 5–8 November 2013; pp. 54–58. [Google Scholar]
- Wu, H.; Zhang, H.; Zhang, J.F. Fast Aircraft Detection in Satellite Images Based on Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Image Processing (IEEE), Quebec City, QC, Canada, 27–30 September 2015; pp. 4210–4214. [Google Scholar]
- Li, Y.; Fu, K.; Sun, H. An aircraft detection framework based on reinforcement learning and convolutional neural networks in remote sensing images. Remote Sens. 2018, 10, 243. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Weakly supervised learning based on coupled convolutional neural networks for aircraft detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Zhong, J.; Lei, T.; Yao, G.; Jiang, P. Robust Aircraft Detection with a Simple and Efficient Model. Information 2018, 9, 74. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Wang, X.; Shrivastava, A.; Gupta, A. A-Fast -CNN: Hard Positive Generation via Adversary for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HA, USA, 21–26 July 2017. [Google Scholar]
- Pan, S.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.C.; Sun, X.; Fu, K. Object detection in high-resolution remote sensing images using rotation invariant parts based model. IEEE Trans. Geosci. Remote Sens. 2014, 11, 74–78. [Google Scholar] [CrossRef]
- Wang, G.L.; Wang, X.C.; Fan, B. Feature extraction by rotation-invariant matrix representation for object detection in aerial image. IEEE Trans. Geosci. Remote Sens. 2017, 14, 851–855. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 13–16 December 2015; pp. 3431–3440. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y. HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. ParseNet: Looking wider to see Better. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556v6. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 13–16 December 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Rothe, R.; Guillaumin, M.; Van Gool, L. Non-maximum Suppression for Object Detection by Passing Messages Between Windows. In Proceedings of the 12th Asian Conference on Computer Vision—ACCV, Singapore, 1–5 November 2014; pp. 290–306. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R. Imagnet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HA, USA, 21–26 July 2017. [Google Scholar]
- Chen, Z.; Zhang, T.; Ouyang, C. End-to-end airport detection using transfer learining in remote sensing images. Remote Sens. 2018, 10, 139. [Google Scholar] [CrossRef]
- Fu, C.; Liu, W.; Ranga, A. DSSD: Deconvolutional Single Shot Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HA, USA, 21–26 July 2017. [Google Scholar]
- Xu, Y.L.; Zhu, M.M.; Xin, P. Rapid airplane detection in remote sensing images based on multilayer feature fusion in fully convolutional neural networks. Sensors 2018, 18, 2335. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input: is the list of initial detection boxes contains corresponding detection scores is the NMS threshold Output: contains all detection boxes Initial: is empty While empty do ; ; ; For in do If   End if End for End while Return D,S |
| Filters | Kernel Size | Stride | Pad | |
|---|---|---|---|---|
| Conv1_1 | 64 | 3 | 1 | 1 |
| Conv1_2 | 64 | 3 | 1 | 1 |
| Conv2_1 | 128 | 3 | 1 | 1 |
| Conv2_2 | 128 | 3 | 1 | 1 |
| Con3_1 | 256 | 3 | 1 | 1 |
| Conv3_2 | 256 | 3 | 1 | 1 |
| Conv3_3 | 256 | 3 | 1 | 1 |
| Conv4_1 | 512 | 3 | 1 | 1 |
| Conv4_2 | 512 | 3 | 1 | 1 |
| Conv4_3 | 512 | 3 | 1 | 1 |
| Conv5_1 | 512 | 3 | 1 | 1 |
| Conv5_2 | 512 | 3 | 1 | 1 |
| Conv5_3 | 512 | 3 | 1 | 1 |
| Method | AC (%) | FPR (%) | MR (%) | ER (%) | T (s) |
|---|---|---|---|---|---|
| DBN-based | 79.54 | 24.13 | 20.46 | 44.59 | 171.25 |
| BING+CNN | 84.25 | 18.68 | 15.75 | 34.43 | 6.41 |
| Faster R-CNN | 86.28 | 8.76 | 13.72 | 22.48 | 0.15 |
| YOLOv2 | 90.05 | 6.26 | 9.95 | 16.21 | 0.03 |
| Our method | 94.25 | 5.59 | 5.75 | 11.34 | 0.16 |
| Layer2 | Layer3 | Layer4 | Layer5 | AC/% |
|---|---|---|---|---|
| √ | 86.28 | |||
| √ | √ | 90.30 | ||
| √ | √ | √ | 91.90 | |
| √ | √ | √ | √ | 91.90 |
| Method | AC/% |
|---|---|
| NMS | 91.90 |
| Our method | 94.25 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, M.; Xu, Y.; Ma, S.; Li, S.; Ma, H.; Han, Y. Effective Airplane Detection in Remote Sensing Images Based on Multilayer Feature Fusion and Improved Nonmaximal Suppression Algorithm. Remote Sens. 2019, 11, 1062. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11091062
Zhu M, Xu Y, Ma S, Li S, Ma H, Han Y. Effective Airplane Detection in Remote Sensing Images Based on Multilayer Feature Fusion and Improved Nonmaximal Suppression Algorithm. Remote Sensing. 2019; 11(9):1062. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11091062
Chicago/Turabian StyleZhu, Mingming, Yuelei Xu, Shiping Ma, Shuai Li, Hongqiang Ma, and Yongsai Han. 2019. "Effective Airplane Detection in Remote Sensing Images Based on Multilayer Feature Fusion and Improved Nonmaximal Suppression Algorithm" Remote Sensing 11, no. 9: 1062. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11091062