Stacked Autoencoders Driven by Semi-Supervised Learning for Building Extraction from near Infrared Remote Sensing Imagery


Abstract
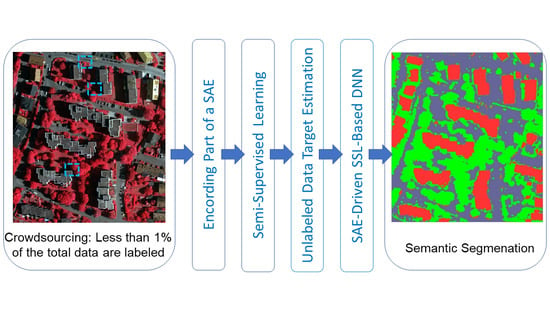
:
1. Introduction
1.1. Description of the Current State-of-the-Art
1.2. Our Contribution
2. Conceptual Background
2.1. Input Data Compression Using a Deep SAE Framework
2.2. Semi-Supervised Learning (SSL) Schemes
2.3. Deep Neural Networks (DNNs) for Buildings’ Extraction
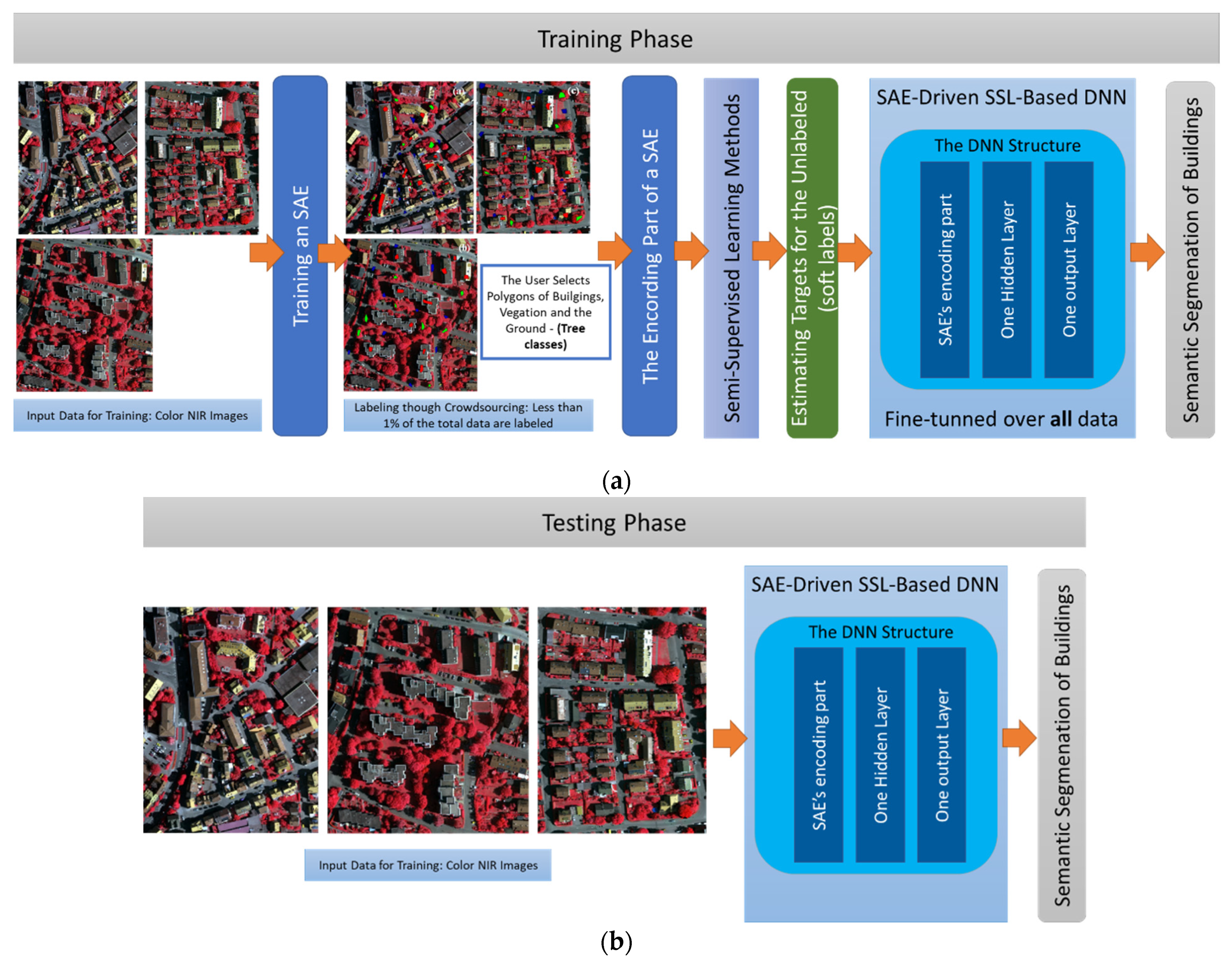
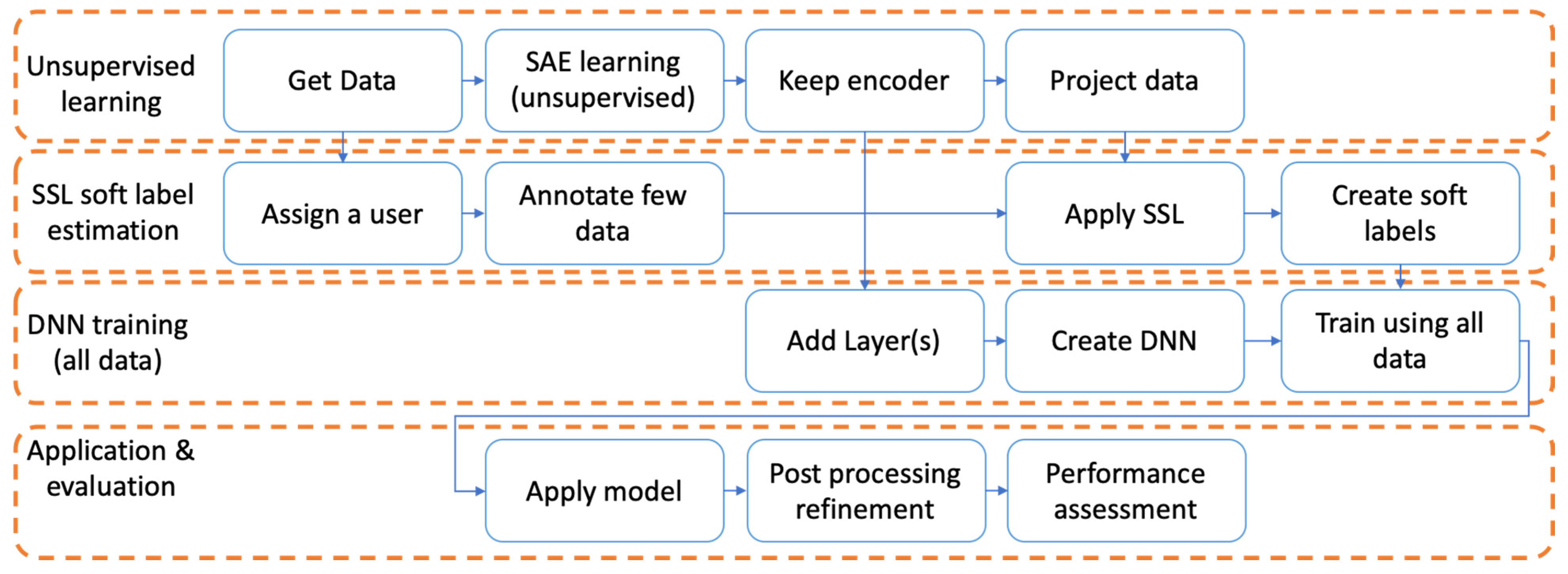
3. Proposed Methodology
3.1. Description of the Overall Architecture
3.2. Description of Our Dataset and of the Extracted Features
3.3. Creation of the Small Portion of Labeled Data (Ground Truth)
3.4. Setting Up the SAE-Driven DNN Model
3.5. Evaluation Metrics
4. Semi-Supervised Learning Schemes for Softly Labeling the Unlabeled Data
4.1. Problem Formulation
4.2. The Anchor Graph Method
4.3. SAFER: Safe Semi-Supervised Regression
4.4. SMIR: Squared-Loss Mutual Information Regularization
5. Experimental Results
5.1. Data Post Processing
5.2. Performance Evaluation
5.2.1. The Multi-Class Evaluation Approach
5.2.2. Class Evaluation Approach
5.2.3. Comparison with Other State-of-the-Art Approaches
6. Discussion
7. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Loupos, K. Deep learning-based man-made object detection from hyperspectral data. In Proceedings of the International Symposium on Visual Computing (ISCV 2015), Las Vegas, NV, USA, 14–16 December 2015; pp. 717–727. [Google Scholar]
- Karantzalos, K. Recent advances on 2D and 3D change detection in urban environments from remote sensing data. In Computational Approaches for Urban Environments; Springer: Berlin/Heidelberg, Germany, 2015; pp. 237–272. [Google Scholar]
- Doulamisa, A.; Doulamisa, N.; Ioannidisa, C.; Chrysoulib, C.; Grammalidisb, N.; Dimitropoulosb, K.; Potsioua, C.; Stathopouloua, E.K.; Ioannides, M. 5D modelling: An efficient approach for creating spatiotemporal predictive 3d maps of large-scale cultural resources. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015. [Google Scholar] [CrossRef] [Green Version]
- Zou, S.; Wang, L. Individual Vacant House Detection in Very-High-Resolution Remote Sensing Images. Ann. Am. Assoc. Geogr. 2020, 110, 449–461. [Google Scholar] [CrossRef]
- Wei, Y.; Feng, J.; Liang, X.; Cheng, M.M.; Zhao, Y.; Yan, S. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1568–1576. [Google Scholar]
- Sorzano, C.O.S.; Vargas, J.; Montano, A.P. A survey of dimensionality reduction techniques. arXiv 2014, arXiv:1403.2877. [Google Scholar]
- Qiu, W.; Tang, Q.; Liu, J.; Teng, Z.; Yao, W. Power Quality Disturbances Recognition Using Modified S Transform and Parallel Stack Sparse Auto-encoder. Electr. Power Syst. Res. 2019, 174, 105876. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Schenkel, F.; Middelmann, W. Domain Adaptation for Semantic Segmentation Using Convolutional Neural Networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGRASS), Yokohama, Japan, 28 July–2 August 2019; pp. 728–731. [Google Scholar] [CrossRef]
- Maltezos, E.; Doulamis, A.; Doulamis, N.; Ioannidis, C. Building extraction from LiDAR data applying deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 16, 155–159. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan Italy, 26–21 July 2015; pp. 4959–4962. [Google Scholar]
- Du, S.; Zhang, Y.; Zou, Z.; Xu, S.; He, X.; Chen, S. Automatic building extraction from LiDAR data fusion of point and grid-based features. ISPRS J. Photogramm. Remote Sens. 2017, 130, 294–307. [Google Scholar] [CrossRef]
- Hou, B.; Wang, Y.; Liu, Q. A saliency guided semi-supervised building change detection method for high resolution remote sensing images. Sensors 2016, 16, 1377. [Google Scholar] [CrossRef] [Green Version]
- Ham, S.; Oh, Y.; Choi, K.; Lee, I. Semantic Segmentation and Unregistered Building Detection from Uav Images Using a Deconvolutional Network. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef] [Green Version]
- Awrangjeb, M.; Fraser, C.S.; Lu, G. Building change detection from LiDAR point cloud data based on connected component analysis. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 393. [Google Scholar] [CrossRef] [Green Version]
- Kashani, A.G.; Olsen, M.J.; Parrish, C.E.; Wilson, N. A review of LiDAR radiometric processing: From ad hoc intensity correction to rigorous radiometric calibration. Sensors 2015, 15, 28099–28128. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nahhas, F.H.; Shafri, H.Z.; Sameen, M.I.; Pradhan, B.; Mansor, S. Deep learning approach for building detection using lidar–orthophoto fusion. J. Sens. 2018, 2018, 7212307. [Google Scholar] [CrossRef] [Green Version]
- Zhou, K.; Gorte, B.; Lindenbergh, R.; Widyaningrum, E. 3D building change detection between current VHR images and past lidar data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 1229–1235. [Google Scholar] [CrossRef] [Green Version]
- Maltezos, E.; Protopapadakis, E.; Doulamis, N.; Doulamis, A.; Ioannidis, C. Understanding Historical Cityscapes from Aerial Imagery Through Machine Learning. In Proceedings of the Digital Heritage. Progress in Cultural Heritage: Documentation, Preservation, and Protection, Nicosia, Cyprus, 29 October–3 November 2018. [Google Scholar]
- Nguyen, T.H.; Daniel, S.; Gueriot, D.; Sintes, C.; Caillec, J.-M.L. Unsupervised Automatic Building Extraction Using Active Contour Model on Unregistered Optical Imagery and Airborne LiDAR Data. In Proceedings of the ISPRS—International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Munich, Germany, 18–20 September 2019; Volume XLII-2/W16, pp. 181–188. [Google Scholar] [CrossRef] [Green Version]
- Dos Santos, R.C.; Pessoa, G.G.; Carrilho, A.C.; Galo, M. Building detection from lidar data using entropy and the k-means concept. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019. [Google Scholar] [CrossRef] [Green Version]
- Huang, R.; Yang, B.; Liang, F.; Dai, W.; Li, J.; Tian, M.; Xu, W. A top-down strategy for buildings extraction from complex urban scenes using airborne LiDAR point clouds. Infrared Phys. Technol. 2018, 92, 203–218. [Google Scholar] [CrossRef]
- Cai, Z.; Ma, H.; Zhang, L. A Building Detection Method Based on Semi-Suppressed Fuzzy C-Means and Restricted Region Growing Using Airborne LiDAR. Remote Sens. 2019, 11, 848. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Wu, P.; Yao, X.; Wu, Y.; Wang, B.; Xu, Y. Building extraction in very high resolution imagery by dense-attention networks. Remote Sens. 2018, 10, 1768. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Shrestha, S.; Vanneschi, L. Improved fully convolutional network with conditional random fields for building extraction. Remote Sens. 2018, 10, 1135. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building extraction at scale using convolutional neural network: Mapping of the united states. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Chen, K.; Weinmann, M.; Gao, X.; Yan, M.; Hinz, S.; Jutzi, B.; Weinmann, M. Residual shuffling convolutional neural networks for deep semantic image segmentation using multi-modal data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4. [Google Scholar] [CrossRef] [Green Version]
- Makantasis, K.; Doulamis, A.D.; Doulamis, N.D.; Nikitakis, A. Tensor-based classification models for hyperspectral data analysis. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6884–6898. [Google Scholar] [CrossRef]
- Makantasis, K.; Doulamis, A.; Doulamis, N.; Nikitakis, A.; Voulodimos, A. Tensor-based nonlinear classifier for high-order data analysis. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–18 April 2018; pp. 2221–2225. [Google Scholar]
- Li, X.; Zhang, L.; Du, B.; Zhang, L.; Shi, Q. Iterative Reweighting Heterogeneous Transfer Learning Framework for Supervised Remote Sensing Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2022–2035. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Voulodimos, A.; Doulamis, A.; Doulamis, N.; Dres, D.; Bimpas, M. Stacked autoencoders for outlier detection in over-the-horizon radar signals. Comput. Intell. Neurosci. 2017, 2017, 5891417. [Google Scholar] [CrossRef]
- Li, W.; Fu, H.; Yu, L.; Gong, P.; Feng, D.; Li, C.; Clinton, N. Stacked Autoencoder-based deep learning for remote-sensing image classification: A case study of African land-cover mapping. Int. J. Remote Sens. 2016, 37, 5632–5646. [Google Scholar] [CrossRef]
- Liang, P.; Shi, W.; Zhang, X. Remote sensing image classification based on stacked denoising autoencoder. Remote Sens. 2018, 10, 16. [Google Scholar] [CrossRef] [Green Version]
- Song, H.; Kim, M.; Park, D.; Lee, J.-G. Learning from noisy labels with deep neural networks: A survey. arXiv 2020, arXiv:200708199. [Google Scholar]
- Qi, Y.; Shen, C.; Wang, D.; Shi, J.; Jiang, X.; Zhu, Z. Stacked sparse autoencoder-based deep network for fault diagnosis of rotating machinery. IEEE Access 2017, 5, 15066–15079. [Google Scholar] [CrossRef]
- Doulamis, N.; Doulamis, A. Semi-supervised deep learning for object tracking and classification. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 848–852. [Google Scholar]
- Wang, M.; Fu, W.; Hao, S.; Tao, D.; Wu, X. Scalable Semi-Supervised Learning by Efficient Anchor Graph Regularization. IEEE Trans. Knowl. Data Eng. 2016, 28, 1864–1877. [Google Scholar] [CrossRef]
- Li, Y.-F.; Zha, H.-W.; Zhou, Z.-H. Learning Safe Prediction for Semi-Supervised Regression. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 2217–2223. [Google Scholar]
- Niu, G.; Jitkrittum, W.; Dai, B.; Hachiya, H.; Sugiyama, M. Squared-loss mutual information regularization: A novel information-theoretic approach to semi-supervised learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–19 June 2013; pp. 10–18. [Google Scholar]
- Hron, V.; Halounova, L. Use of aerial images for regular updates of buildings in the fundamental base of geographic data of the Czech Republic. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Munich, Germany, 25–27 March 2015; Volume XL-3/W2. pp. 73–79. [Google Scholar]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An Easy-to-Use Airborne LiDAR Data Filtering Method Based on Cloth Simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Liu, W.; He, J.; Chang, S.-F. Large Graph Construction for Scalable Semi-Supervised Learning. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 679–686. Available online: https://icml.cc/Conferences/2010/papers/16.pdf (accessed on 1 January 2021).
- Nesterov, Y. Introductory Lectures on Convex Optimization: A Basic Course; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 87. [Google Scholar]
- Sugiyama, M.; Yamada, M.; Kimura, M.; Hachiya, H. On information-maximization clustering: Tuning parameter selection and analytic solution. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 65–72. [Google Scholar]
- Gerke, M.; Xiao, J. Fusion of airborne laserscanning point clouds and images for supervised and unsupervised scene classification. ISPRS J. Photogramm. Remote Sens. 2014, 87, 78–92. [Google Scholar] [CrossRef]
- Rottensteiner, F. ISPRS Test Project on Urban Classification and 3D Building Reconstruction: Evaluation of Building Reconstruction Results; Technical Report; Institute of Photogrammetry and GeoInformation: Leibniz, Germany, 2013. [Google Scholar]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Classification of urban LiDAR data using conditional random field and random forests. In Proceedings of the Joint Urban Remote Sensing Event 2013, Sao Paulo, Brazil, 21–23 April 2013; pp. 139–142. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
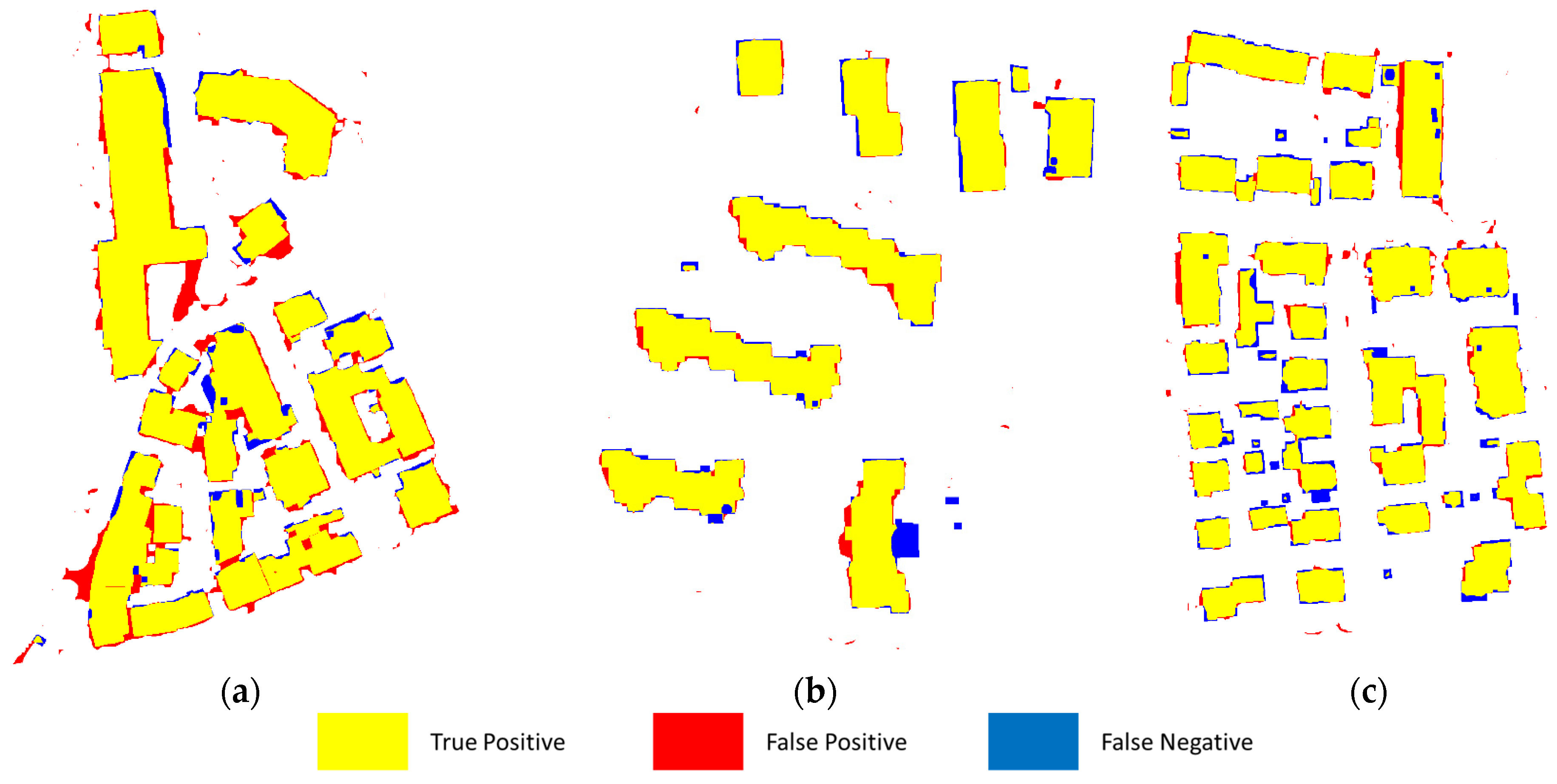{kind=link}
| Study Areas | ||
|---|---|---|
| Vaihingen (Areas 1–3) | ||
| Flying parameters | Camera sensor | DMC |
| Type of images | Overlapped/Multiple/Digital | |
| Focal length | 120.00 mm | |
| Flying height above ground | 900 m | |
| Forward overlap | 60% | |
| Side lap | 60% | |
| Ground resolution | 8 cm | |
| Spectral bands | NIR/R/G | |
| Ground Control Points | 20 | |
| Triangulation accuracy | <1 pixel | |
| Height information | Software for DIM | Trimble Inpho (Match-AT, Match-t DSM, Scop++, DTMaster) |
| GSD of the DIM/DSM | 9 cm | |
| Software for nDSM | CloudCompare | |
| Image information | Software for orthoimages | Trimble Inpho orthovista |
| GSD of the orthoimages | 9 cm | |
| Additional descriptors | NDVI | |
| Input data | Rows and columns of the block tile | 2529 × 1949 (Area 1) 2359 × 2148 (Area 2) 2533 × 1680 (Area 3) |
| Feature bands of MDFV | NIR/R/G/NDVI/nDSM | |
| Pixel Count | Percentage (All Pixels) | Pixel Count | Percentage (All Pixels) | Pixel Count | Percentage (All Pixels) | ||
|---|---|---|---|---|---|---|---|
| Area Name | Area 1 | Area 2 | Area 3 | ||||
| Size (total pixels) | 2549 × 1949 | 100% | 2359 × 2148 | 100% | 2533 × 1680 | 100% | |
| Annotated pixels available | 21,428 | 0.43% | 19,775 | 0.39% | 22,452 | 0.52% | |
| Annotated data distribution description | Buildings | 13730 | 0.27% | 9271 | 0.18% | 9205 | 0.22% |
| Vegetation | 3971 | 0.08% | 4969 | 0.10% | 6003 | 0.14% | |
| Ground | 3727 | 0.07% | 5535 | 0.11% | 7244 | 0.17% | |
| Labeled data distribution (used for training) | Buildings | 2197 | 0.04% | 1484 | 0.03% | 1473 | 0.03% |
| Vegetation | 636 | 0.01% | 796 | 0.02% | 961 | 0.02% | |
| Ground | 597 | 0.01% | 886 | 0.02% | 1160 | 0.03% | |
| Unlabeled data distribution (used for training) | Buildings | 8787 | 0.17% | 5933 | 0.12% | 5891 | 0.14% |
| Vegetation | 2541 | 0.05% | 3180 | 0.06% | 3842 | 0.09% | |
| Ground | 2385 | 0.05% | 3542 | 0.07% | 4636 | 0.11% | |
| Unseen (test) data (used for evaluation) | Buildings | 2746 | 0.05% | 1854 | 0.04% | 1841 | 0.04% |
| Vegetation | 794 | 0.02% | 993 | 0.02% | 1200 | 0.03% | |
| Ground | 745 | 0.01% | 1107 | 0.02% | 1448 | 0.03% | |
| Accuracy (ACC) | Precision (Pr) | Recall (Re) | |
|---|---|---|---|
| Unlabeled | |||
| Anchor Graph [40] | 0.967 | 0.969 | 0.971 |
| SAFER [41] | 0.967 | 0.970 | 0.970 |
| SMIR [42] | 0.970 | 0.970 | 0.971 |
| WeiAve | 0.972 | 0.970 | 0.971 |
| Unseen (Test) | |||
| Anchor Graph [40] | 0.967 | 0.963 | 0.964 |
| SAFER [41] | 0.965 | 0.964 | 0.964 |
| SMIR [42] | 0.965 | 0.964 | 0.965 |
| WeiAve | 0.969 | 0.965 | 0.965 |
| Semi-Supervised Learning (SSL) Technique | Area 1 | Area 2 | Area 3 |
|---|---|---|---|
| Root Mean Squared Error/F1-Score | |||
| Anchor Graph | 0.008/99.83% | 0.007/99.89% | 0.018/99.78% |
| SAFER | 0.016/99.75% | 0.013/99.79% | 0.026/99.70% |
| SMIR | 0.119/98.07% | 0.082/99.45% | 0.105/98.56% |
| WeiAve | 0.041/99.93% | 0.029/99.95% | 0.041/99.89% |
| Accuracy (ACC) | Precision (Pr) | Recall (Re) | |
|---|---|---|---|
| Unseen (Test) | |||
| WeiAve | 0.969 | 0.965 | 0.965 |
| Without SSL | 0.971 | 0.964 | 0.966 |
| Without SAE | 0.957 | 0.952 | 0.953 |
| Method | Area 1 | Area 2 | Area 3 | Average Values |
|---|---|---|---|---|
| AnchorGraph | 6.53 s | 8.46 s | 6.79 s | 7.35 s |
| SAFER | 1408 s | 1765 s | 2499 s | 1769 s |
| SMIR | 1.63 s | 2.91 s | 1.75 s | 2.17 s |
| WeiAve | 1416 s | 1777 s | 2508 s | 1779 s |
| SAE component | 9849 s | 10,121 s | 9730 s | 9900 s |
| Full Image Classification | 14,904 s | 15,201 s | 12,766 s | 14,290 s |
| Area | Performance Function | Recall-Re (%) (Ranking Order) | Precision-Pr (%) (Ranking Order) | Critical Success Index-CSI (%) (Ranking Order) | F1-Score (Ranking Order) |
|---|---|---|---|---|---|
| Area 1 | Anchor Graph | 95.0 (2) | 84.3 (2) | 80.8 (2) | 89.3 (2) |
| SMIR | 95.9 (1) | 83.1 (4) | 80.3 (3) | 89.0 (3) | |
| SAFER | 93.2 (4) | 84.3 (2) | 79.4 (4) | 88.5 (4) | |
| WeiAve | 94.3 (3) | 87.1 (1) | 82.7 (1) | 90.6 (1) | |
| Area 2 | Anchor Graph | 88.6 (4) | 95.1 (1) | 84.7 (4) | 91.7 (4) |
| SMIR | 90.3 (3) | 94.1 (3) | 85.4 (3) | 92.2 (3) | |
| SAFER | 91.6 (1) | 93.7 (4) | 86.3 (2) | 92.6 (2) | |
| WeiAve | 91.2 (2) | 94.6 (2) | 86.7 (1) | 92.9 (1) | |
| Area 3 | Anchor Graph | 87.7 (4) | 93.3 (1) | 82.5 (2) | 90.4 (2) |
| SMIR | 87.8 (3) | 92.7 (2) | 82.1 (4) | 90.2 (4) | |
| SAFER | 88.7 (2) | 92.6 (3) | 82.9 (1) | 90.6 (1) | |
| WeiAve | 89.6 (1) | 91.1 (4) | 82.4 (3) | 90.3 (3) |
| State-of-the-Art | Data type | CSI |
|---|---|---|
| DNN-Anchor Graph | Orthoimages + DIM/DSM | 82.7 |
| DNN-SAFER | Orthoimages + DIM/DSM | 82.8 |
| DNN-SMIR | Orthoimages + DIM/DSM | 82.6 |
| DNN-WeiAve | Orthoimages + DIM/DSM | 83.9 |
| The work of [20] | Orthoimages + DIM/DSM | 82.7 |
| The work of [49] | Orthoimages + LIDAR/DSM | 89.7 |
| The work of [21] | Orthoimages + LIDAR/DSM | 87.50 |
| The work of [47] | LIDAR (as point cloud) + images | 83.5 |
| The work of [50] | LIDAR (as point cloud) | 84.6 |
| The work of [24] | LIDAR (as point cloud) | 88.23 |
| The work of [12] | LIDAR (as point cloud) | 90.20 |
| The work of [23] | LIDAR (as point cloud) | 88.77 |
| The work of [22] | LIDAR (as point cloud, Area 3 only) | 93.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Maltezos, E. Stacked Autoencoders Driven by Semi-Supervised Learning for Building Extraction from near Infrared Remote Sensing Imagery. Remote Sens. 2021, 13, 371. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13030371
Protopapadakis E, Doulamis A, Doulamis N, Maltezos E. Stacked Autoencoders Driven by Semi-Supervised Learning for Building Extraction from near Infrared Remote Sensing Imagery. Remote Sensing. 2021; 13(3):371. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13030371
Chicago/Turabian StyleProtopapadakis, Eftychios, Anastasios Doulamis, Nikolaos Doulamis, and Evangelos Maltezos. 2021. "Stacked Autoencoders Driven by Semi-Supervised Learning for Building Extraction from near Infrared Remote Sensing Imagery" Remote Sensing 13, no. 3: 371. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13030371