1. Introduction
Application of computed tomography can take place wherever there is a need to examine the interior of a certain object without disturbing its structure. Medicine is a classic example of using the computed tomography. In this field, the developed algorithms are so reliable and efficient that reconstruction of the interior structure of the examined patient in sufficient resolution in a short time is not a big challenge for modern computer tomographs. A large part of the papers published in non-medical journals concerns the modification of algorithms in such a way that reducing the dose of radiation received by the patient does not deteriorate the quality of reproduction [
1].
In this paper, we deal with a non-medical problem related to the issue of an incomplete data set. Such phenomena are quite frequent, and an example of it may be the study of coal seams. The natural process of coal seams formation may result in the formation of undesirable, for economic reasons, excesses of other rocks or compressed gas tanks hazardous to the health and life of the working crew. The current energy crisis may put pressure on mines to increase production. Higher production, in turn, may be related to the exploitation of previously unexploited deposits. This, however, is associated with the risk of hitting and unsealing such a tank. The uncontrolled gas outburst next to fires, rock bursts and gas explosions is the most common cause of dangerous incidents in mines (in the modern history of Polish hard coal mines, there were several such large incidents, and, in 1979, in one of the Polish mines, almost 20 miners died due to uncontrolled gas outburst). The proposed method of pre-exploitation coal seam examination has two greatest advantages: it can detect dangerous anomalies in the seam, and such examination does not interfere with the seam exploitation (the examination of further parts of the seam can be performed during the operation of the already examined part).
Computed tomography algorithms, apart from the classic medical applications [
2] and the examination of coal decks [
3,
4] mentioned before, have a number of other applications, almost classic, such as X-raying luggage, examining the construction of building materials, or less obvious, such as examining flames, the earth’s crust, seas and oceans, objects in motion or crash tests [
5,
6,
7,
8]. The authors studied the algorithms of computed tomography focus on its non-standard approach to an incomplete data set, which occurs, for example, in the case of coal seam research. The conducted research has shown that, despite much poorer information about the interior of the tested object, with the appropriate approach to the problem, the algorithms are convergent and stable, and thus they can be successfully used in the problem of an incomplete data set [
9]. The only problem with the algorithms developed in this way is the high computation time, while in classical problems a dozen or so iterations were enough (details are presented in
Section 3); in the case of an incomplete data set, this number may increase to several hundred. The authors took steps to prevent this undesirable feature by using, inter alia, chaotic and block algorithms, parallel computing or heuristic algorithms [
3,
4].
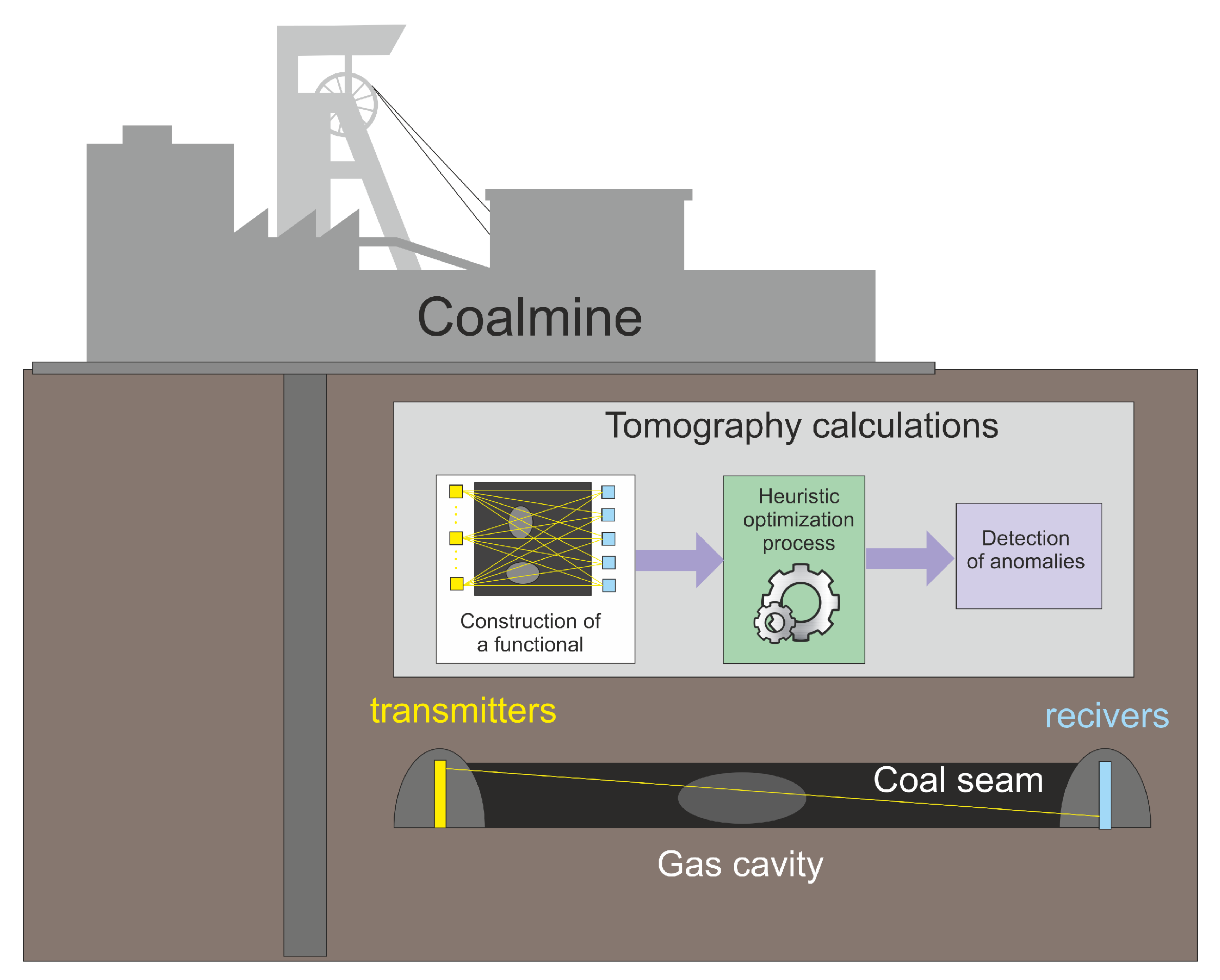
In the classic problem of computed tomography, e.g., in medical tomography, the assumptions of Kotelnikov’s theorem are easily fulfilled. This means that enough X-rays can be taken from sufficiently many angles. However, there are cases when such projections cannot be made. Such a situation may take place, for example, when the tested object is unavailable due to its location (ocean and space research), size (large building structures) or lack of access. A good example of the latter case is the coal bed. The tests on such a coal seam must be performed for economic reasons (then, the presence of undesirable scale in the coal is checked) or for safety reasons. In the latter case, compressed gas is sought in the coal seams, which can rapidly expand during extraction, ejecting rock fragments along with the gas. This is a threat to the health and life of the mining crew. Currently, most of the work to check the presence of such reservoirs of gas is carried out by drilling, but this method is time-consuming and involves significant costs.
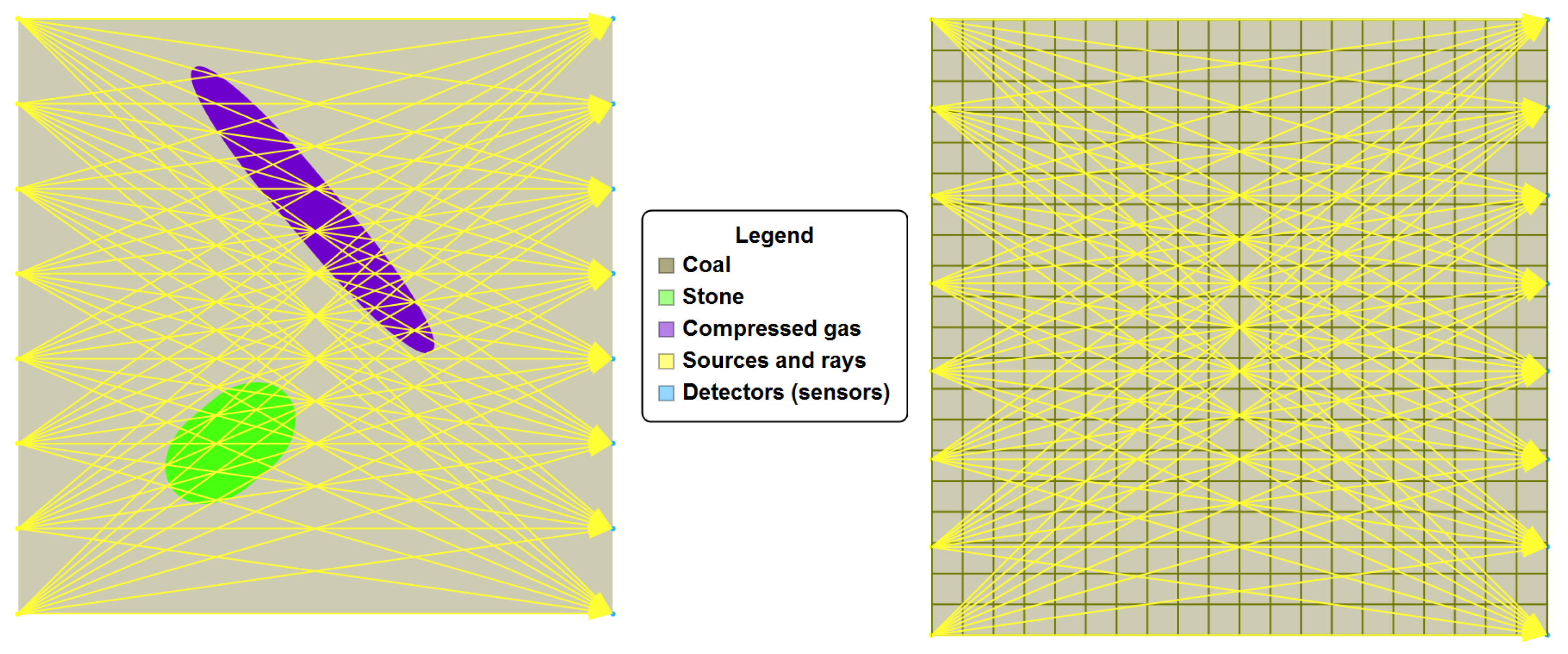
If the coal seam examination was performed using computed tomography methods, then the works related to the extraction of coal and the works related to the examination of the coal seam would be carried out in parallel and would not interfere with each other. To prepare a mining wall, auxiliary structures are made for a given seam, on the walls of which a system of sensors sending a beam of penetrating radiation can be placed on the one side, and sensors (receivers) of this signal are placed on the other side (see
Figure 1 and
Figure 2). On the one hand, such an approach is economically beneficial, but on the other hand, such projections differ significantly from the assumptions for the quality of projection in computed tomography.
Due to the unavailability of the coal seam, the obtained projections are “one-sided”, thus they carry much less information about the examined object. The research carried out so far shows that in such a case “quality” can be made up of with quantity. However, this approach has a disadvantage; many more calculations are needed, and thus the time needed to obtain a satisfactory accuracy is significantly extended. A series of work devoted to eliminate this drawback has brought results, but it seems that the efficiency of computed tomography reconstructive algorithms in the issue of incomplete data set can be significantly increased, which is the goal of this study.
In this paper, we focus on improving one of these approaches [
4], where the detected objects are represented by sequences of rectangles characterized by sequences of their parameters. This time, instead of sequences in the representation, there are sets, which allow for the elimination of duplicates of such representations. The considered algorithms were adapted to the task in such a way that they do not operate on the argument sequence, but on sets of fives, where the first pair in the five represents the lower left corner of the rectangle, the second pair—the upper right corner, and the fifth argument is the desired density. As a result, the reconstruction is faster. Additionally, other heuristic algorithms, such as Aquila Optimizer (AO), Firefly Algorithm (FA), Whale Optimization Algorithm (WOA) and Dynamic Butterfly Optimization Algorithm (DBOA) are tested for usability.
2. Ideas of Computed Tomography
Computed tomography can be used where there is a need for non-invasive examination of the interior of different objects. Such examination consists of X-raying (this is the most common, but not the only method) of the examined object with penetrating radiation and analyzing the energy loss after passing such radiation through the examined object. Such an analysis can be useful due to the fact that each type of matter has its own individual (different than for other types of matter) coefficient (capacity) of absorbing the energy of penetrating radiation. The measure of this coefficient is often given in Hounsfield units [HU]. Examples of the values of this coefficient for X-ray radiation can be found in [
3].
The mathematical description of the measure of such a loss for one radius
L (projection) is given by the formula:
where
is the projection obtained on the path
L of the given ray,
is the initial radiation intensity,
I is the final intensity (after passing along the path
L of the ray through the tested object), and the function
f is the density distribution of the tested object. Obviously, the information obtained from one ray does not allow for reconstructing the interior of the examined object along the path of this ray. Such X-rays should be done sufficiently, not only in terms of quantity, but also in terms of quality understood as the number of X-rays angles. The first studies of computed tomography algorithms say that accurate reconstruction requires infinitely many x-rays angles and infinitely many X-rays. In practice, this is impossible.
An important result was the Kotelnikov theorem [
10], which says how many X-rays (scans) should be performed to obtain a reconstruction of satisfactory quality, of course for a finite number of scan angles and for a finite number of rays for a given angle. After the X-rays are performed, on the basis of the information obtained in this way, it is possible to proceed to the process of reconstructing the internal structure of the X-rayed object. Reconstructive algorithms are responsible for this process. These algorithms can be divided into two main groups: analytical algorithms [
11,
12,
13] and algebraic algorithms [
14,
15,
16].
In the case of an incomplete data set, we obtain information (projections) of much worse quality, mainly due to the range of scanning angles. Such projections do not satisfy the assumptions of Kotelnikov’s theorem, so there is no guarantee that it would be possible to obtain a reconstruction of satisfactory quality. The research carried out by the authors showed that analytical algorithms cannot solve this type of problem (in terms of an incomplete data set), while algebraic algorithms, with appropriate adaptation to the problem of an incomplete data set, allow for obtaining such a reconstruction.
3. Methodology
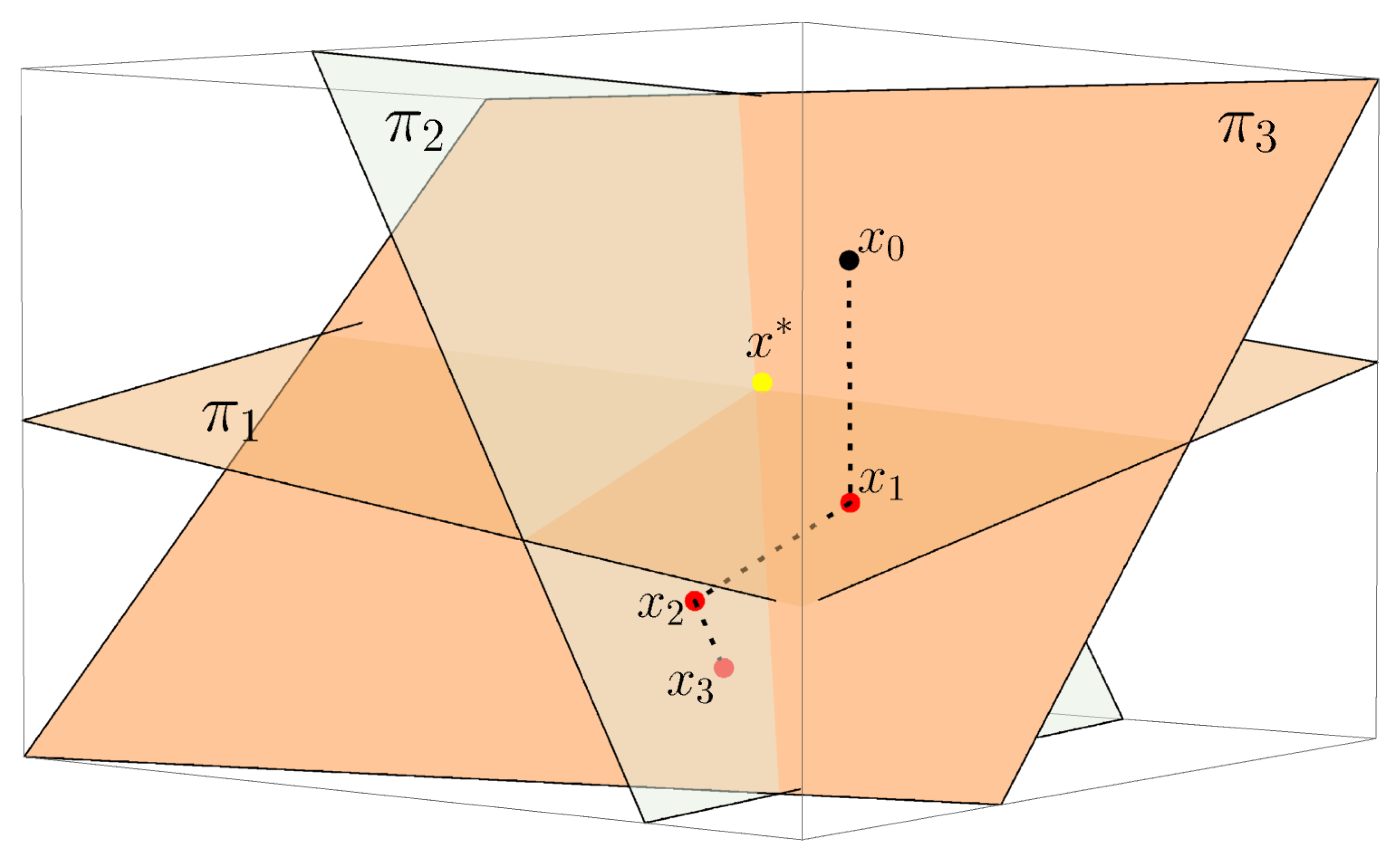
The ideas of analytical and algebraic algorithms arose long before the construction of the first computer tomograph. Thus, in 1937, Stefan Kaczmarz presented an iterative algorithm for solving a system of linear equations and proved its convergence [
17] (assuming that a given square matrix system of linear equations has exactly one solution). This algorithm was rediscovered in the 1970s by Gordon, Bender and Herman as a useful tool for the problem of image reconstruction (after proving the convergence of Kaczmarz’s algorithm also in [
15]).
Figure 3 shows a graphic interpretation of Kaczmarz’s algorithm.
Before we discuss the presented algorithm, let us first define the way in which the system of linear equations to be solved arises. In algebraic algorithms, we initially assume that the examined object is inscribed in a square (which of course is always possible), and then we discretize this square by dividing it into
smaller congruent squares (pixels). It is also assumed that this discretization is so dense (the number
n is large enough) that can be assumed the function
f describing the density distribution of the examined object is constant for each pixel. Such an assumption results in the fact that the energy loss
of the
i-th ray is presented as the sum of energy losses along the path of this ray during its passage through the tested object. Energy is only lost on those pixels that are in the path of this ray. The energy loss on such a pixel is directly proportional to the change in length (knowing the size of the square in which the tested object is inscribed, the discretization density and the equation of the line along which a given radius runs, we can determine this length) the common part of a given radius and a given pixel and to the unknown energy absorption capacity of this pixel (constant value of the function
f on this pixel). By carrying out a number of such X-rays, each of them is an equation, the left side of which is the sum of the above-mentioned energy losses, and the right side is the total loss. Value of the function
f for each pixel is an unknown. As a result, we get a system of equations:
where
is the matrix of the
dimension (
r is the number of X-rays),
is the matrix (vector) of the
dimension of the energy loss of each ray, and
is the matrix (vector) of the
dimension of unknowns.
Because matrix
has specific properties (it is a rectangular, sparse, asymmetric and large-dimension matrix), classical algorithms are not useful in this case. However, the Kaczmarz algorithm, or algorithms based on it, can be successfully used, e.g., the most famous ART algorithm, in which, after selecting any initial solution
, subsequent approximations of the exact solution are determined by the formula:
where
is the solution index,
is the relaxation coefficient (for
, we obtain the classic Kaczmarz algorithm),
is the
i-th projection (
i-th element of vector
),
is the
i-th row of the matrix
,
means the classical dot product, and
is the norm of a vector. Trummer showed [
18] that, for
, i.e., for the constant value of the
parameter, or for
, i.e., for the variable value of the
parameter, the ART algorithm is convergent.
In Ref. [
4], the authors approached the issue of reconstruction the interior of the examined object in an innovative way. In this paper, authors significantly increase the efficiency of this process through a new approach to the previously introduced idea. It was assumed that detected objects were represented as rectangles. This approach has advantages and is a good mathematical model of the studied phenomenon. Since there are relatively few detectable undesirable objects in the coal seam, we can limit to a relatively small number of rectangles representing these objects. The adopted shape is appropriate, despite the fact that the actual objects may not be rectangles, and the difference between a rectangle and a “non-rectangle” is negligible (small-size stone overgrowth is not a significant loss of the output quality).
After X-rays, we obtain a system of linear equations (
2) and in the classic approach, this system of equations should be solved using the relationship (
3). However, this step requires a lot of computation and therefore a long time to reconstruction. Thus far, rectangles representing the density distribution have been detected by using heuristic algorithms. We use a similar approach in this paper. The innovation of this approach will be the representation of these rectangles. Previously, order of rectangles was important, which really does not matter. The representation of a single rectangle was also ambiguous (in means of the order of the vertices). In this paper, we eliminate these two inconveniences, thanks to which the time of finding the rectangles should be significantly shortened.
Such an approach is necessary for the possibility of using heuristic algorithms in a computed tomography task. We can find articles (see, e.g., [
19,
20,
21]) in which the authors combine these two methods, but, in these approaches, heuristic algorithms are used to analyze the image, after the system of equations (
2) has been solved. The lack of works in which heuristic algorithms were used was dictated by their feature—these algorithms work well with the optimization of functions with a relatively small number of arguments. In the standard approach, there would be as many arguments as there would be unknowns in the system of equations (
2). Thus, it would be enough to perform a not very dense discretization (e.g., assuming
, and the variables would then be
), which would make it impossible to use the heuristic algorithm. The innovative approach is based on the fact that the unknowns (variables) are the features identifying the rectangles that represent the searched objects in the considered area. These features are the position of the rectangle and the value of the function
f in the rectangle. Another advantage of this approach is the insensitivity of the method to discretization density. If we place
m transmitters on one of the walls of the coal seam, and
m sensors on the other, and if each transmitter sends a beam to each sensor, the system of equations will have
of equations and
of unknowns (increasing the discretization density forces an increase in the number of sensor sources). In this approach, the complexity of the task does not directly depend on the discretization density as much as in the classical approach. The heuristic algorithm arranges rectangles (along with information about the value of the function
f in these rectangles) in the area in such a way as to minimize the value of the function:
where
is a minimized function,
is a projection vector (right side of the system
2),
is a projection vector created on the basis of the constant matrix
and a given approximation of the solution
,
m is the number of sources (and sensors),
and
,
, are, respectively,
i-th element of vectors
and
;
is the number of pixels.
4. Heuristic Algorithms
This section presents the heuristic algorithms used in the calculations to minimize the objective function (
4) and reconstruction the sought rectangles. Algorithms of this type are widely used in various types of engineering tasks [
22,
23,
24,
25,
26,
27,
28,
29]. In this paper, we present and compare the following algorithms:
Aquila Optimizer (AO),
Firefly algorithm (FA),
Whale Optimization Algorithm (WOA),
Butterfly Optimization Algorithm (BOA) and
Dynamic Butterfly Optimization Algorithm (DBOA). In order to describe the methods, we introduce the following notations:
4.1. Aquila Optimizer
Aquila is a type of bird from the hawk family (Accipitridae) found in Eurasia, North America, Africa and Australia. The way in which these birds hunt their prey was the inspiration for the creation of the algorithm of searching for a minimum of functions. Aquila predators base their hunting behavior on four main techniques:
Expanded exploration. The predator soars high in the air with a vertical tilt—this method is used for hunting birds in flight, where the Aquila rises high above the ground. Upon examining the prey, Aquila goes into a long, low-angle slide with increasing speed. Aquila needs a height above its prey for this method to be effective. Just before the attack, the wings and tail are spread out and the claws bent forward to catch the prey. This process in the algorithm is described by the following equation:
where
is solution in
-th iteration,
is the best solution obtained in the
t-th iteration (so far) and reflects the approximate location of the prey (which is the optimization goal). By
, we denote the mean solution in the iteration number
t and calculate it as:
The expression is responsible for the scope of the search. The closer the value of t is to the total iterations T, the more narrow the scope of the search. Value of is a random number from interval.
Narrowed exploration. In this method, when the aquila is high above the prey, it begins to circle around it and prepare to land and attack. This technique is called short stroke contour flight. Aquila narrowly explores the selected area where the prey is located and prepare to attack. This behavior is mathematically represented by the equation:
where
is solution in iteration
,
is the best solution obtained in the iteration
t,
is a random solution from iteration
t, and
is random number from range
.
is value of the Levy flight distribution function. We compute the values of this function as follows:
where
are constants
are random numbers from interval
, and
is computed by formula [
30]:
The expression
is intended to simulate a spiral flight. Parameters
r and
are calculated as follows:
where
is a fixed integer from
,
are small constants,
is an integer from
.
Expanded exploitation. In this step, the prey is already located and the aquila launches an initial vertical attack to see the victim’s reaction. Here, the aquila exploits a selected target area to get as close to its prey as possible. We transfer this behavior to the mathematical description of the method with the following equation:
where
is the solution in the next iteration after
t,
is the best solution obtained in the iterations so far, and
is the population mean solution defined by the formula (
6). As before,
is a random number between
,
,
define the problem domain (lower and upper bound), and
and
are exploitation adjustment constants’ parameters.
Narrowed exploitation. In this technique, the aquila has already approached the prey and attacks with stochastic movements, approaching and grabbing the victim. Mathematically, this process is described by the equation:
where
is solution in
iteration, and
denotes the so-called quality function:
and
are calculated by:
These parameters reflect the way the predator flies, and in the case of the algorithm, we can fine-tune the algorithm with it.
In nature, all these techniques are mixed in hunting prey, and in the case of the algorithm described here, the formulas (
5)–(
14) form the set of four transformations that make up the AO algorithm. Pseudocode Algorithm 1 shows steps of the AO algorithm. Details related to the Aquila Optimizer and application of it can be found in [
30,
31,
32].
| Algorithm 1: Aquila Optimize (AO) pseudocode. |
- 1:
Initialization part. - 2:
Setting up parameters of AO algorithm. - 3:
Random initialization of starting population . - 4:
Iterative part. - 5:
fordo - 6:
Calculate the values of the cost function for each element in the population. - 7:
Determine the best individual in the population. - 8:
for do - 9:
Update mean individual in the population. - 10:
Update algorithm parameters based on population number and random - 11:
values (). - 12:
if then - 13:
if then - 14:
Do the step expanded exploration ( 5) updating solution , obtaining - 15:
- 16:
if then - 17:
end if - 18:
if then - 19:
end if - 20:
else - 21:
Do the step narrowed exploration ( 7) updating solution . - 22:
Then, obtain - 23:
if then - 24:
end if - 25:
if then - 26:
end if - 27:
end if - 28:
else - 29:
if then - 30:
Do the step Expanded exploitation ( 11) updating solution . - 31:
Then, obtain - 32:
if then - 33:
end if - 34:
if then - 35:
end if - 36:
else - 37:
Do the step narrowed exploitation ( 12) updating solution . - 38:
Then, obtain - 39:
if then - 40:
end if - 41:
if then - 42:
end if - 43:
end if - 44:
end if - 45:
end for - 46:
end for - 47:
return.
|
4.2. Firefly Algorithm
The firefly algorithm is a swarm metaheuristics developed in 2008 by Xin-She Yang [
33]. It is inspired by the social behavior of fireflies (insects from the Lampyridae family) and the phenomenon of their bioluminescent communication. The algorithm is intended to constrained continuous optimization problems. It is dedicated to minimize cost function
, i.e., finding
that:
where
.
Now, we present the basics assumptions of the fireflies algorithm:
Assume that there is a swarm of N agents (fireflies) solving the optimization problem iteratively, where represents the solution for the firefly j in the k iteration, and stands for its cost.
Each firefly has a distinguishing attractiveness, which determines how strongly it attracts other members of the swarm.
As attractiveness of the firefly, a decreasing distance function should be used, e.g., as suggested by Yang, the following function:
where
and
are the algorithm parameters, respectively: maximum attractiveness and absorption coefficient. Distance function is denoted by
. It is common that
can be taken as
. Often, the absorption coefficient is
, where
, and
.
Each swarm member is characterized by the luminosity , which can be directly expressed as the inverse of the value of the cost function .
Initially, all fireflies are placed in the search space S (randomly or using some deterministic strategy).
To effectively explore the solution space, it is assumed that each firefly j changes its position iteratively, taking into account two factors: attractiveness of other members of the swarm with greater luminosity , , which decreases with distance, and a random step .
For the brightest firefly, only the above-mentioned random step is applied.
The movement of the firefly
j to the brighter firefly
i is described by equation:
where the second term corresponds to the attraction, and the third term is a random number from interval
.
The pseudocode Algorithm 2 describes in steps the fireflies algorithm. More about the firefly algorithm can be found in [
33,
34].
| Algorithm 2: Firefly algorithm (FA) pseudocode. |
- 1:
Initialization part. - 2:
Setting up parameters of FA algorithm parameters . - 3:
Random initialization of starting population . - 4:
Iterative part. - 5:
fordo - 6:
Determine and . - 7:
for do - 8:
if then - 9:
for do - 10:
if then - 11:
Calculate: , , . - 12:
Transform k-th solution according to the Formula ( 17). - 13:
end if - 14:
end for - 15:
else - 16:
Calculate - 17:
Convert the best solution based on the formula:
- 18:
end if - 19:
end for - 20:
end for - 21:
return.
|
4.3. Whale Optimization Algorithm
Whale Optimization Algorithm (WOA) discussed in this paragraph is inspired by the hunting behavior of whales. These huge mammals hunt their prey in a specific way, which is called the bubble-net feeding method. It has been observed that this foraging takes place by the formation of characteristic bubbles along a circle or spiral shaped path. Whale-watching scientists noticed two maneuvers related to the bubble and called them “up spirals” and “double loops”. In the first method, predators dive approximately 12 m downwards and then begin to form a spiral-shaped bubble around their prey and swim towards the surface. The second hunting technique involves two different steps: coral loop and capture loop. It is worth mentioning here that the bubble-net feeding method is a unique behavior that can only be observed in whales. In this paper, the whale hunting technique serves as an inspiration for the minimum cost function search algorithm. Below, we present the basic principles of the Whale Optimization Algorithm.
More about the algorithm and its applications can be found in the papers [
35,
36]. Based on the above rules, we now present the pseudocode Algorithm 3 of the WOA.
| Algorithm 3: Whale optimization algorithm (WOA) pseudocode. |
- 1:
Initialization part. - 2:
Setting up parameters of WOA. - 3:
Random initialization of starting population . - 4:
Calculating the value of the cost function for each individual in the population. - 5:
Determining the best agent in the population . - 6:
Iterative part. - 7:
fordo - 8:
for do - 9:
Determine values of . - 10:
if then - 11:
if then - 12:
Determine a new solution according to the Formula ( 19). - 13:
end if - 14:
if then - 15:
Determine a random solution . - 16:
Determine a new solution according to the Formula ( 25). - 17:
end if - 18:
end if - 19:
if then - 20:
Determine a new solution according to the Formula ( 23). - 21:
end if - 22:
end for - 23:
Calculating the value of the cost function for each individual in the population. - 24:
Determine the best agent in the population . - 25:
end for - 26:
return.
|
4.4. Butterfly Optimization Algorithm
Butterflies use their sense of smell, taste and touch to find food and partners. These senses are also helpful in migrating from one place to another, escaping from a predator, and laying eggs in the right places. Among senses, the smell is the most important one that helps the butterfly find food, usually nectar—even if it is far away. To find a source of nectar, butterflies use sense receptors scattered throughout the butterfly’s body (e.g., on foreheads, legs). These receptors are in fact nerve cells on the surface of the butterfly’s body and are called chemoreceptors.
Based on scientific observations, it was found that butterflies can sense, and therefore locate, the source of an odor very accurately. In addition, they can distinguish smells as well as sense their intensity. These abilities and behavior of butterflies were used to develop the Butterfly optimization algorithm (BOA) [
37]. The butterfly produces a scent of a certain intensity, which is related to its ability to move from one location to another. The fragrance is sprayed from a distance and other butterflies can sense it and thus communicate with each other, creating a collective knowledge network. A butterfly’s ability to sense the scent of another butterfly became the basis for the development of algorithm to search a global optimum. In another scenario, when the butterfly cannot sense the smell of its surroundings, it will move randomly. In the proposed algorithm, this phase is referred to as local search.
In order to understand how fragrance is computed in the BOA, one first needs to understand how modality, smell, sound, light, temperature, etc. are processed by the stimulus. The whole concept of sensing and modality processing is based on three parameters: sensory modality (
c), stimulus intensity (
I) and power exponent (
a). By modality, we can understand smell, sound, light or temperature. In the case of BOA, the modality is fragrance.
I is the stimulus intensity. In the BOA,
I is correlated with butterfly fitness. This means that, when a butterfly emits more smell, the remaining butterflies in that environment can sense it and become attracted to a highly scented butterfly. Fragrance
f is directly proportional to the power of intensity
I with the exponent
a:
where
f is fragrance,
c is the sensory modality,
I is the stimulus intensity, and
a is the power exponent depending on the modality. In most cases, in implementation, we can take
a and
c from the
interval. The
a parameter is a modality dependent power exponent, which means that it has absorption variability. Thus, the
a parameter controls the behavior of the algorithm. Another important parameter is
c, which is also a key parameter in determining BOA behavior. Theoretically,
, but, in practice, it is in the
range. The
a and
c values have a decisive influence on the convergence speed of the algorithm. The selection of these parameters is important and depends on the characteristics of the problem under consideration.
The BOA algorithm is based on the following rules:
Each of the butterflies gives off a fragrance with a different intensity. Thanks to the smell, butterflies can communicate.
The movement of the butterfly occurs in two ways: towards an individual emitting a stronger smell, or at random.
Global search move is represented by the formula:
where
denotes the location of butterfly (agent) in the
t-th iteration,
is the transform location of butterfly in the
-th iteration
,
is the position of the best butterfly in the
t-th iteration,
f is a fragrance of
, and
r is a random number from
.
Local search move is described by the following equation:
where
i
are randomly chosen agents from iteration
t.
Information about applications of BOA can be found in [
38,
39]. Scheme Algorithm 4 presents a pseudocode of BOA.
| Algorithm 4: Butterfly optimization algorithm (BOA) pseudocode. |
- 1:
Initialization part. - 2:
Setting up parameters of BOA algorithm. N, , c, a and p. - 3:
Random initialization of starting population . - 4:
Calculating the value of the cost function (thus the intensity of the stimulus ) for every agent in population. - 5:
Iterative part. - 6:
fordo - 7:
for do - 8:
Calculate value of fragrance for using Formula ( 26). - 9:
end for - 10:
Determine the best agent in the population. - 11:
for do - 12:
Determine a random number r from interval . - 13:
if then - 14:
Transform solution according to the Formula ( 27). - 15:
else - 16:
Transform solution according to the Formula ( 28). - 17:
end if - 18:
end for - 19:
Change the parameter value a. - 20:
end for - 21:
return.
|
4.5. Dynamic Butterfly Optimization Algorithm
Now, we present an improved version of the BOA called in the literature Dynamic Butterfly Optimization Algorithm (DBOA) [
40]. This improvement consists of adding a novel local search algorithm based on mutation operator (LSAM) at the end of the BOA main loop. LSAM transforms the population (best solution first) using the mutation operator. If the new solution (obtained after mutation) turns out to be better than the previous one (before mutation), then it replaces the previous one. This will transform the agents population. The LSAM algorithm is presented in the scheme Algorithm 5. In the literature, there are many papers about the applications of the butterfly algorithm and its modifications (see [
41,
42,
43]).
The mutation operator occurring in the schema Algorithm 5 transforms each coordinate of the solution
substituting it with a random number from the normal distribution, as shown in the formula below:
where
is mean and
is standard deviation. Pseudocode of DBOA is shown in the scheme Algorithm 6.
| Algorithm 5: Novel local search algorithm based on mutation operator (LSAM) pseudocode. |
- 1:
– current best solution from BOA. - 2:
– value of objective function for current best solution. - 3:
I – number of iterations, – mutation rate. - 4:
Iterative part. - 5:
fordo - 6:
Calculate: Mutate(), . - 7:
if then - 8:
, . - 9:
else - 10:
Determine a random solution from the population, different from . - 11:
Calculate the value of the objective function . - 12:
if then - 13:
- 14:
end if - 15:
end if - 16:
end for
|
| Algorithm 6: Dynamic butterfly optimization algorithm (DBOA) pseudocode. |
- 1:
Initialization part. - 2:
Setting up parameters of BOA algorithm. N – population size, – problem dimension, c – sensor modality, parameters a and p. - 3:
Random initialization of starting population . - 4:
Calculating the value of the cost function (thus the intensity of the stimulus ) for every agent in population. - 5:
Iterative part. - 6:
fordo - 7:
for do - 8:
Calculate value of fragrance for using Formula ( 26). - 9:
end for - 10:
Determine the best agent in the population. - 11:
for do - 12:
Determine a random number r from interval . - 13:
if then - 14:
Transform solution according to the Formula ( 27). - 15:
else - 16:
Transform solution according to the Formula ( 28). - 17:
end if - 18:
end for - 19:
Change the parameter value a. - 20:
Apply the LSAM algorithm to transform the agents population. - 21:
end for - 22:
return.
|
5. Results
Selected algorithms are quite commonly used in various types of optimization problems, as evidenced by a large number of scientific publications. A lot of numerical experiments and research have shown that these algorithms can be adapted to the requirements of the considered problem. Numerical experiments were performed for all the heuristic algorithms presented in the previous section. All algorithms were implemented by the authors and then tested on the following functions: Bent Cigar Function, Rosenbrock Function, Rastrigin Function and HGBat Function.
Fine-tuning of the algorithms, based on the literature, own experiences and experiments on test functions, consisted of determining the range of values for each parameter. From this range, 20 values were uniformly selected and tested on numerous examples relating to the detection of a single object. Numerical experiments were performed for testing all possible combinations of selected parameters multiple times with the same data set. As a result, the best sets of parameters were selected for each of the algorithms. Further calculations were performed for them.
The essential step of the research is a series of numerical experiments for tomography tasks. First, 50 tests were prepared for which the problem of tomography comes down to the detection of one object. These tasks were primarily used to calibrate the parameters of individual algorithms. At this stage, it was found that the AO algorithm is not suitable for this type of issue. Numerous attempts to select algorithm parameters led to unsatisfactory results, and the best approximate solution of the problem finally obtained was burdened with an unacceptable error of . The second stage of the experiments was to find a solution in the form of two disjoint anomalies. In this case, a random set of test tasks was also generated. Each of them consisted of identifying two separate anomalies in the form of rectangles. In this case, all algorithms were called for the parameters (except for the size of the population and the number of iterations) calibrated in the first stage of the research. For this significantly more complex task, where the functional depends on 10 parameters, the size of the population and the maximum number of iterations were selected by means of a numerical experiment. Tasks of this type turned out to be significantly more difficult for WOA and BOA algorithms. This stage turned out to be too difficult for these algorithms and, in an acceptable time, these algorithms failed to find a satisfactory approximate solution.
Figure 4 presents a comparison of the dependence of the functional value on the number of calls to the objective function for the examples with one and two detected objects. The left figure shows that the value of the functional for the AO algorithm is too large (not at all zero). In the case of tasks with two searched objects, the WOA and BOA algorithms are not able to deal with, which is illustrated by the graphs in the figure on the right.
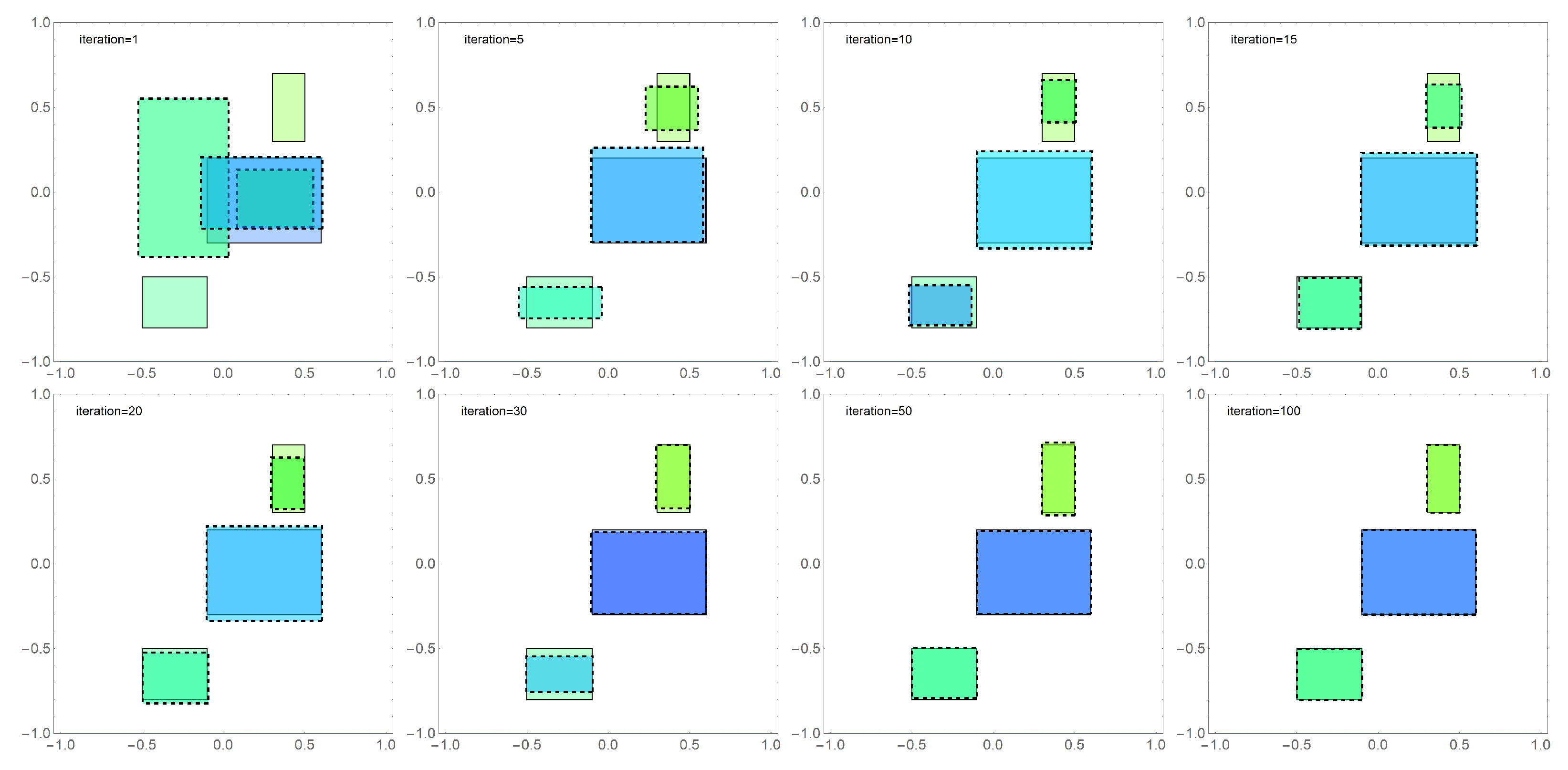
The last third stage of the research was to identify three disjoint anomalies. At this stage, the experiments were carried out for two algorithms: FA and DBOA because only these algorithms reconstruct two anomalies in a satisfactory time. In this case, similar to previous cases, experiments were also carried out for 50 different test tasks. For these tasks, the minimized functional depended on 15 arguments. The threefold increase in the number of parameters in relation to the first task significantly influenced the extension of the algorithm’s operation time, which was associated with the need to multiply the population size and the number of iterations.
Now, we present a comparison of the obtained results for the two tested algorithms at this stage of the experiments.
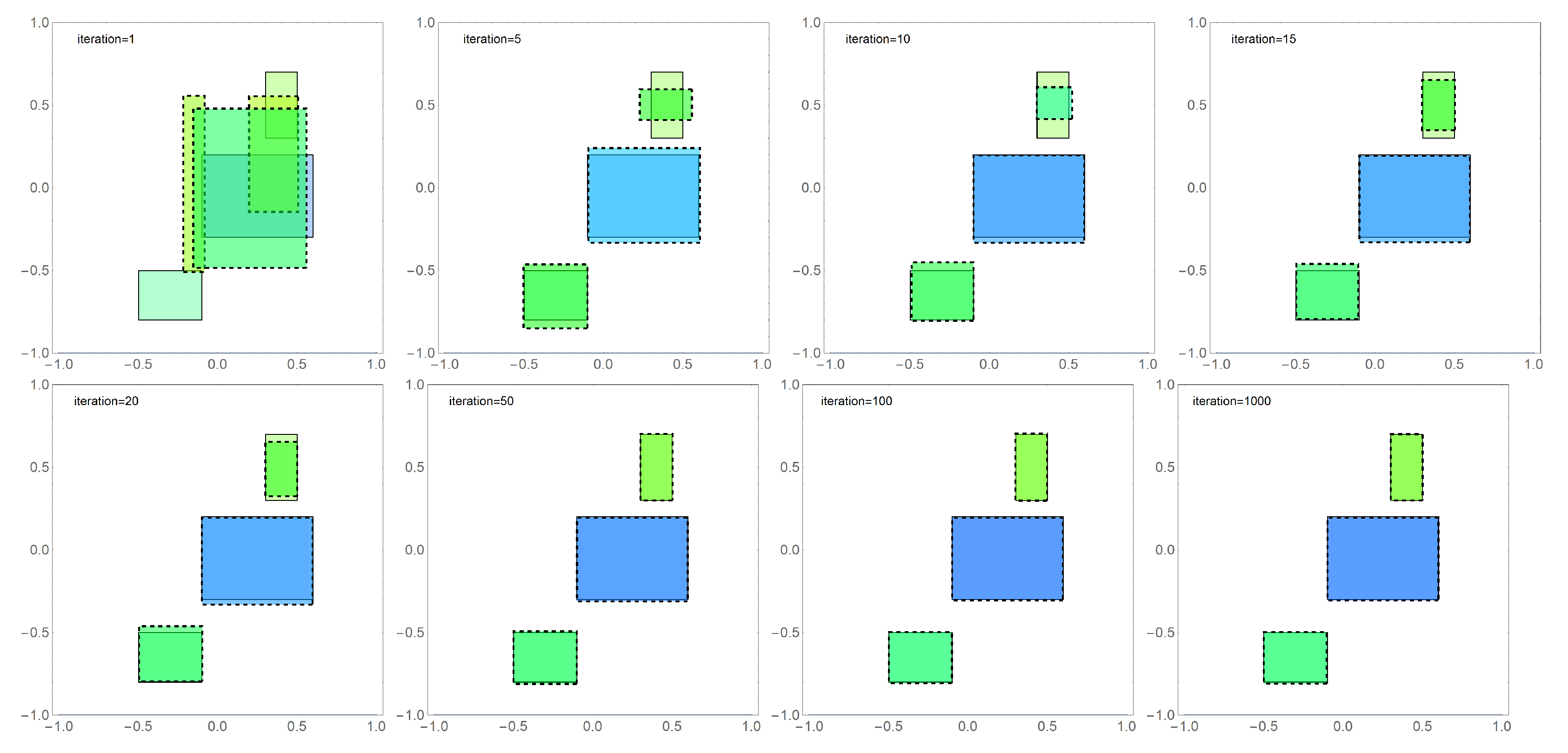
Figure 5 presents comparisons of the exact solution (areas bordered with a solid line) with the approximate solution (areas bordered with a dashed line) obtained with the FA algorithm for selected iterations. The height of the areas (they are cuboids) has been marked according to the color scale. The presented results show that the FA algorithm, after a relatively short number of iterations (
20), “approaches” the exact solution, and obtaining a satisfactory result requires the performance of another 80 iterations.
Similarly,
Figure 6 presents a summary of results in selected iterations for the second tested algorithm DBOA in the third stage of numerical experiments.
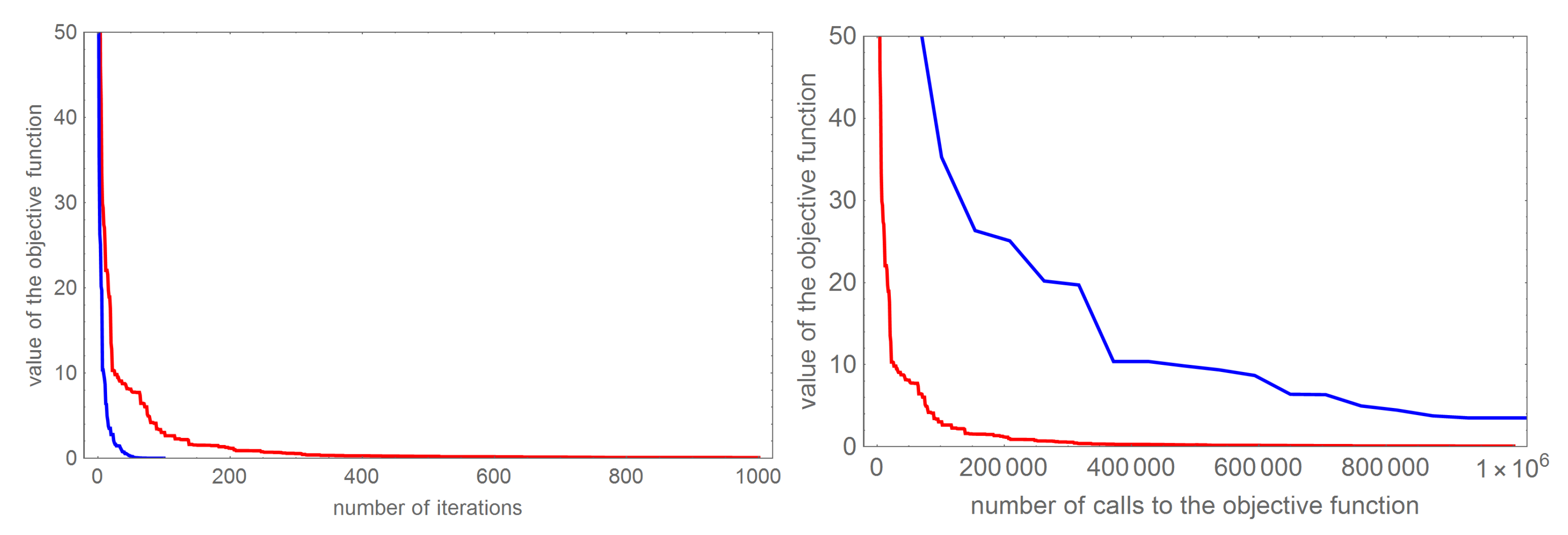
Comparing the obtained results, we can see that the convergence of both algorithms significantly decreases with the increase of successive iterations. In order to compare the effectiveness of the DBOA algorithm and the FA algorithm,
Figure 7 compares the values of the objective function depending on the number of iterations (left figure) and the comparison of the objective function values depending on the number of calls the objective function (right figure). Comparing the number of iterations performed would indicate that the FA algorithm requires 10 times less iteration, but such a comparison does not indicate into the algorithm execution time, which in the case of the analyzed algorithms depends primarily on the number of calls to the objective function. As we can see, this number in the case of the DBOA algorithm is significantly smaller than in the case of the FA algorithm. In order not to blur the readability, the figure has been drawn in the range
of calls to the objective function. It should be mentioned that the FA algorithm obtained a values of objective function close to zero only for
calls to the objective function. Such comparisons show that the DBOA algorithm is definitely more effective in determining anomalies.
Table 1 presents the values of the objective function together with the number of calls to the objective function depending on the number of detected objects, which translates into the number of unknowns. The inscription “no results” means that the algorithm parameters were not selected so as to obtain repeatable results for many samples. The presented data clearly show that the DBOA algorithm turned out to be the best algorithm in the optimization problem presented in the paper.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}