
Hand Gesture Recognition Based on Auto-Landmark Localization and Reweighted Genetic Algorithm for Healthcare Muscle Activities


Abstract
:1. Introduction
- We extracted the hand via a fused method technique from RGB images for gesture classification.
- Auto-landmark localization was performed for multi-feature extraction to improve the feature selection process for daily gestures.
- Multi-features were then optimized via a gray wolf algorithm and classified with a weighted genetic algorithm.
- A comprehensive evaluation was performed on three datasets with significantly better performance than other state-of-the-art methodologies.
2. Literature Review
2.1. HGR Through Electromyographic Signals
2.2. HGR through Smartphone
2.3. HGR Through Camera
2.3.1. HGR via Full-Hand Features
2.3.2. HGR via Landmarks Features
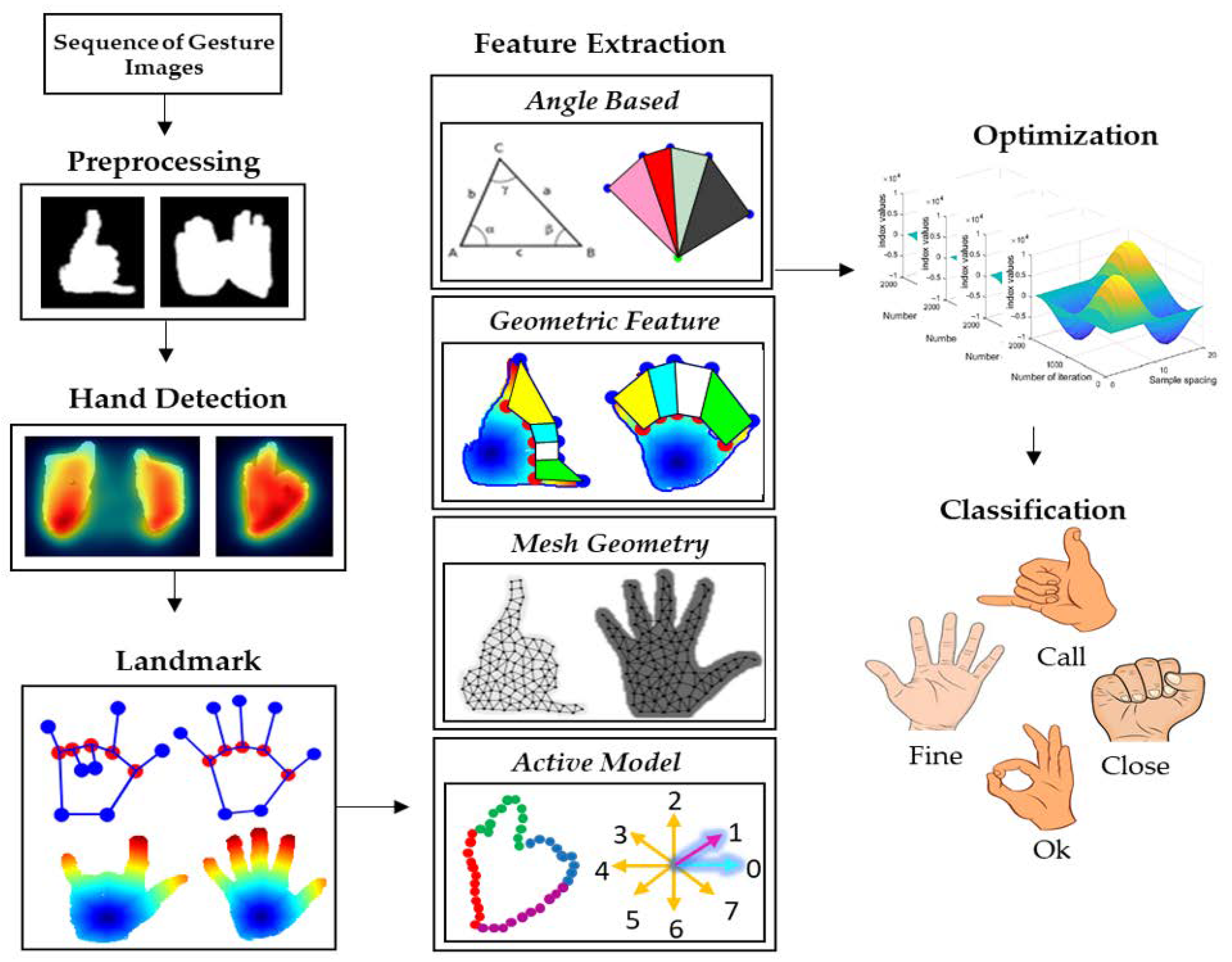
3. Materials and Methods
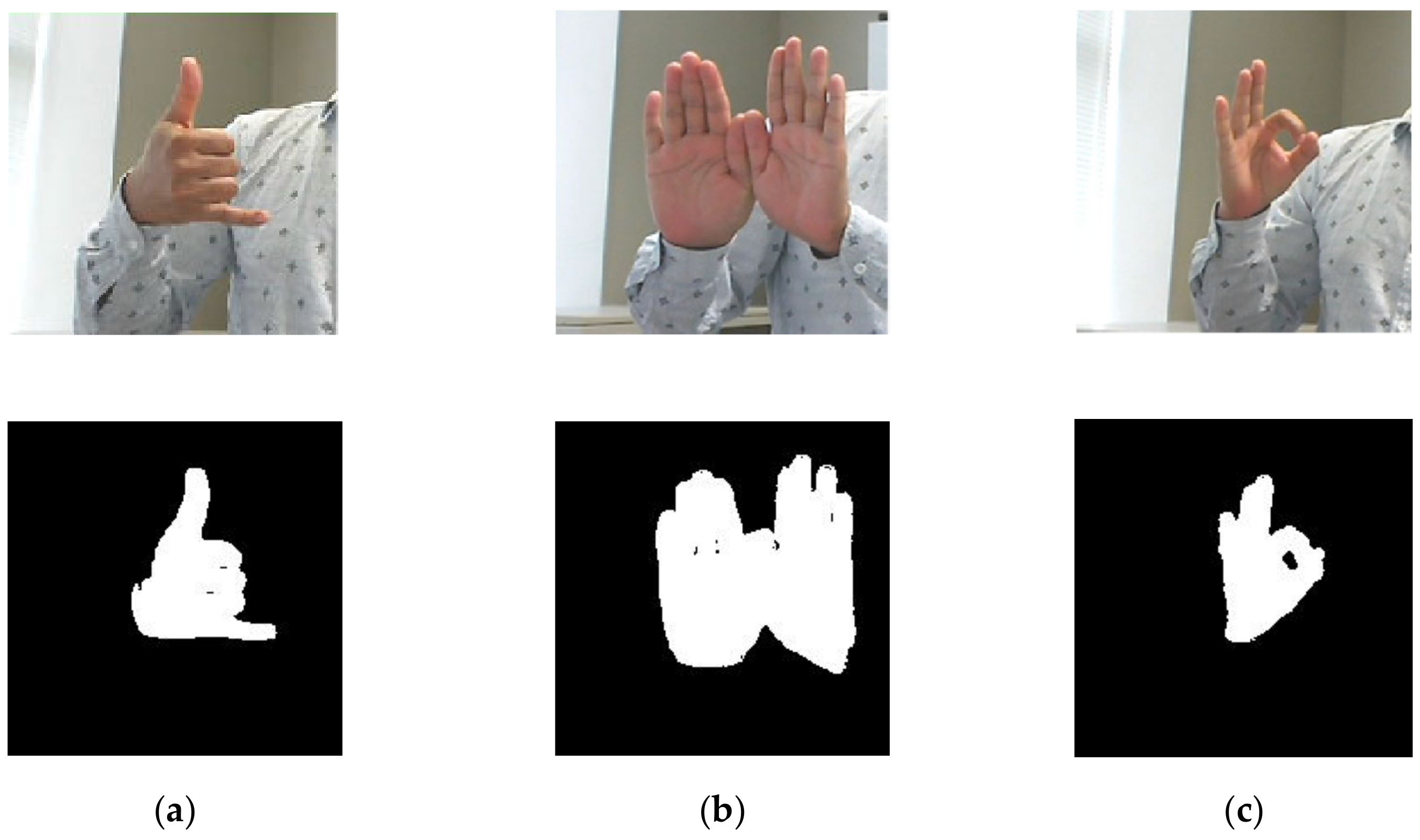
3.1. Preprocessing
3.2. Hand Detection
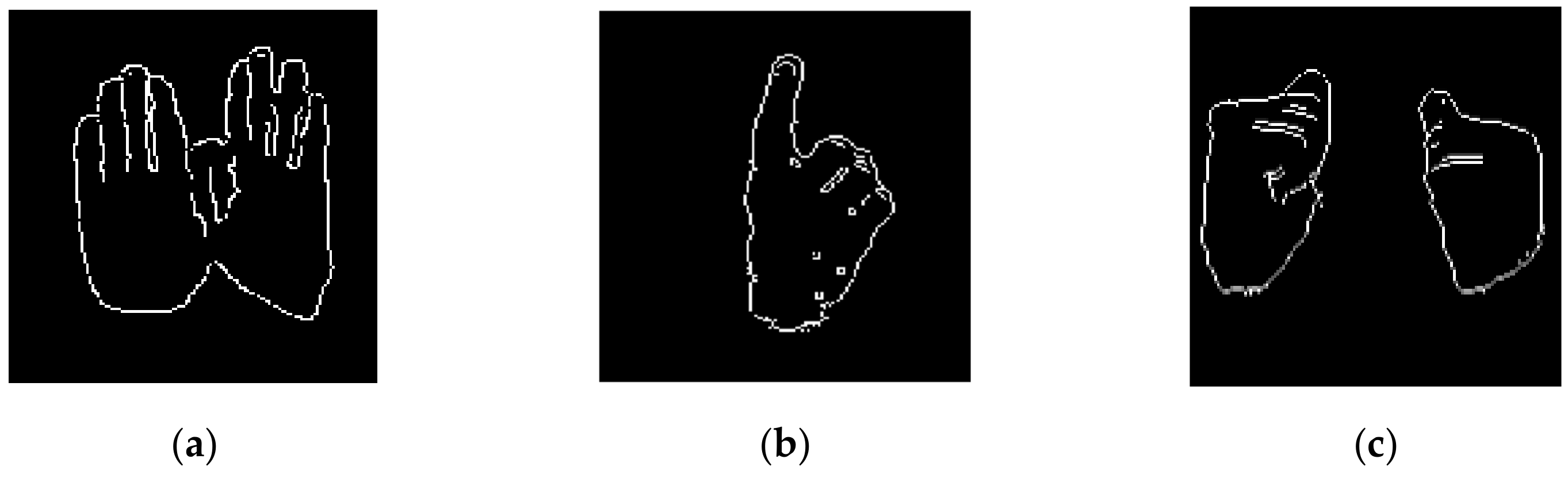
3.2.1. The Fused Method
3.2.2. Directional Images
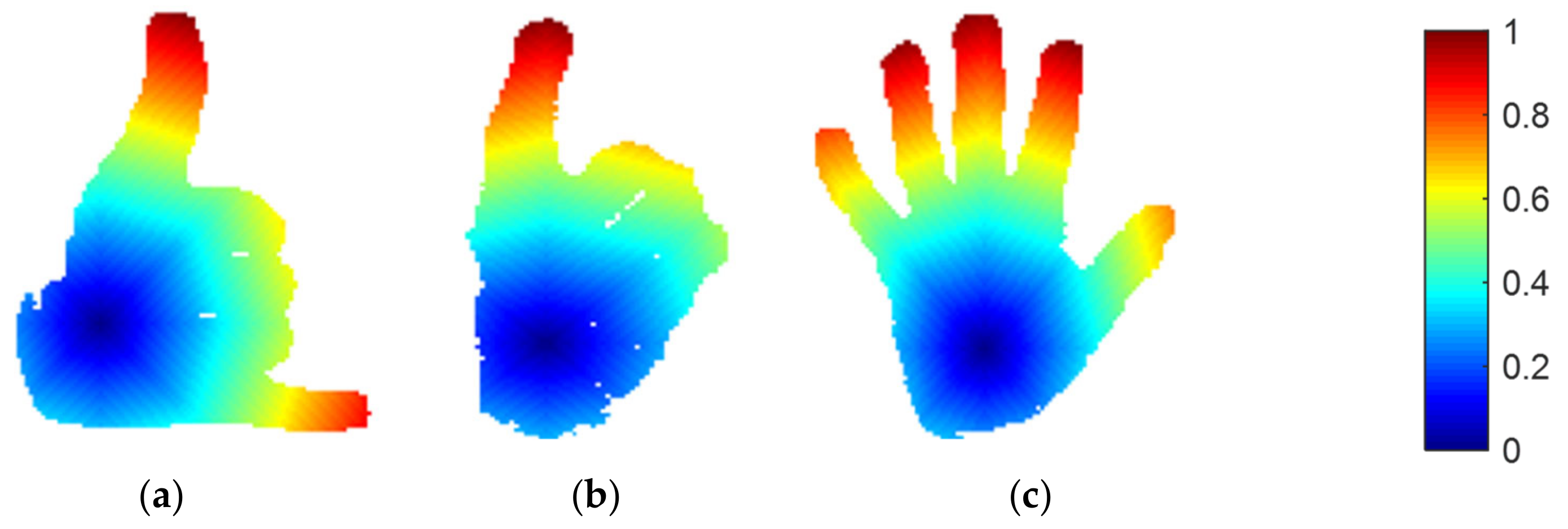
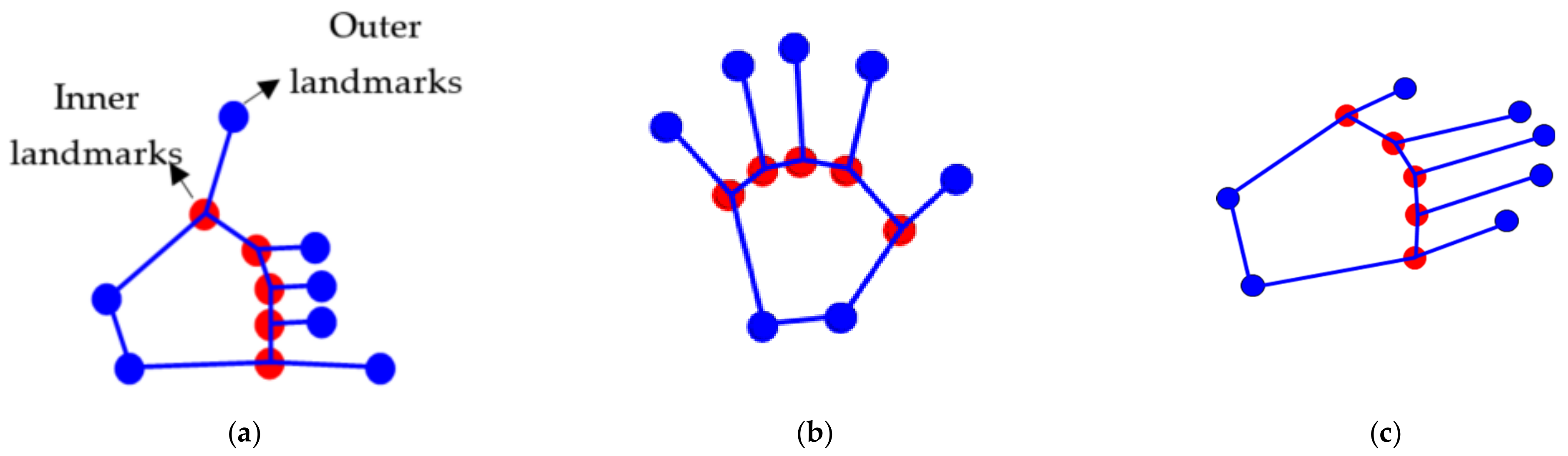
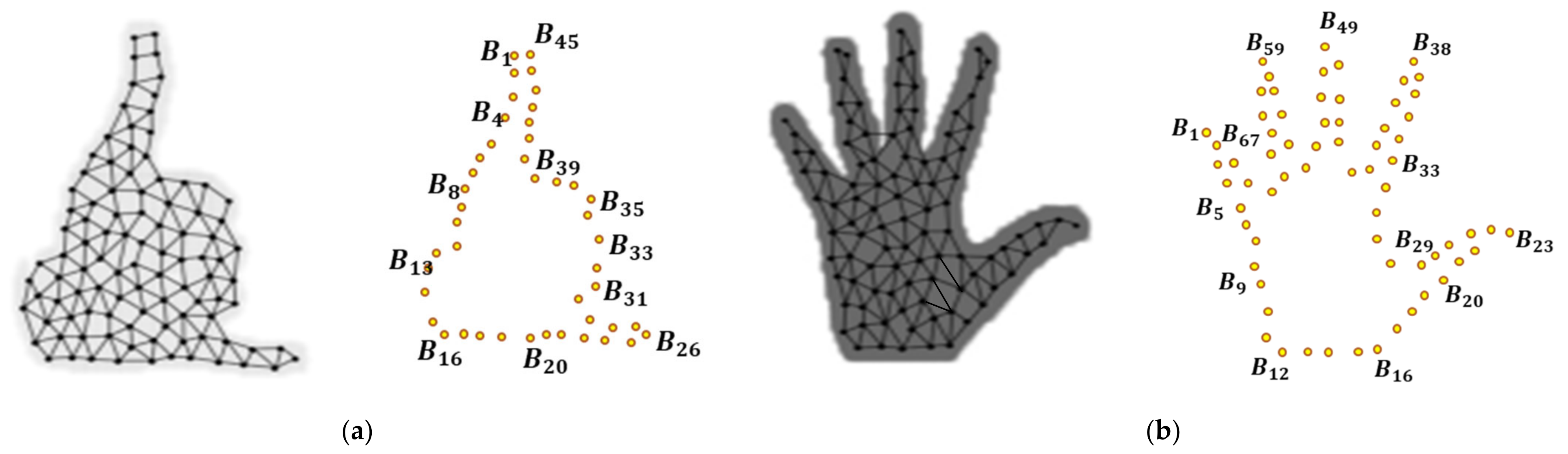
3.3. Landmark Detection
Geodesic Distance
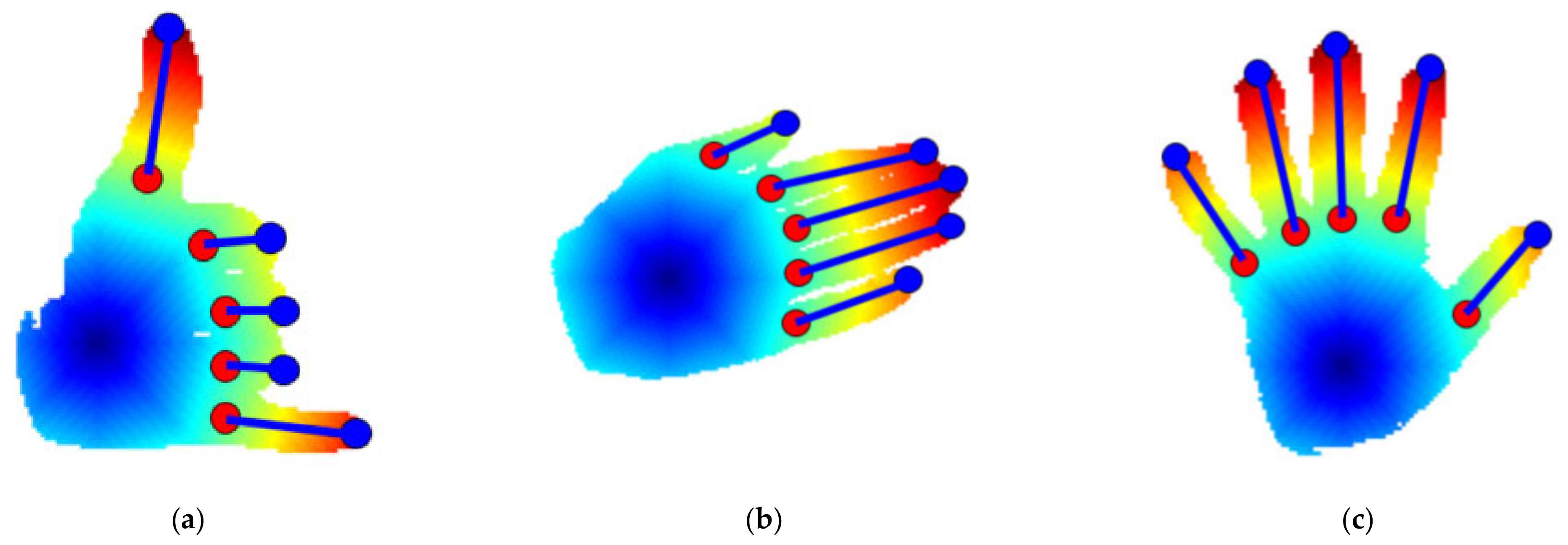
3.4. Feature Extraction via Point-Based Method
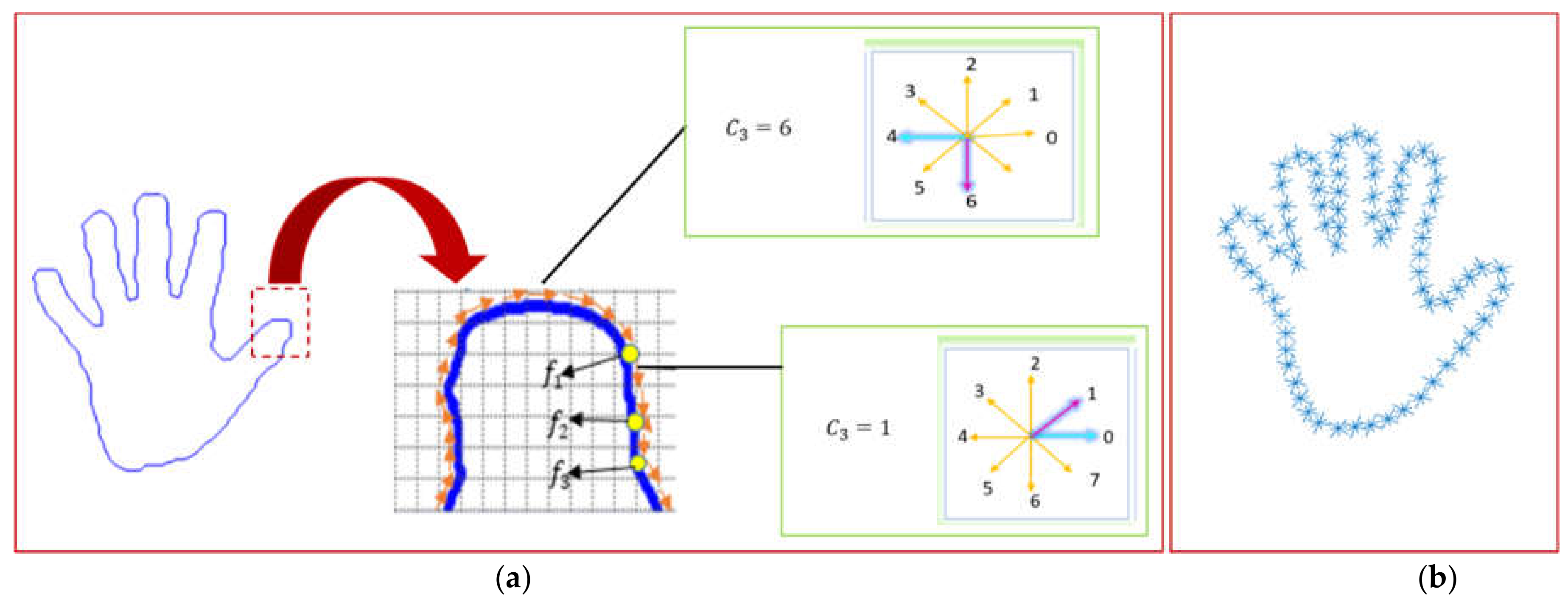
3.4.1. Distance Features
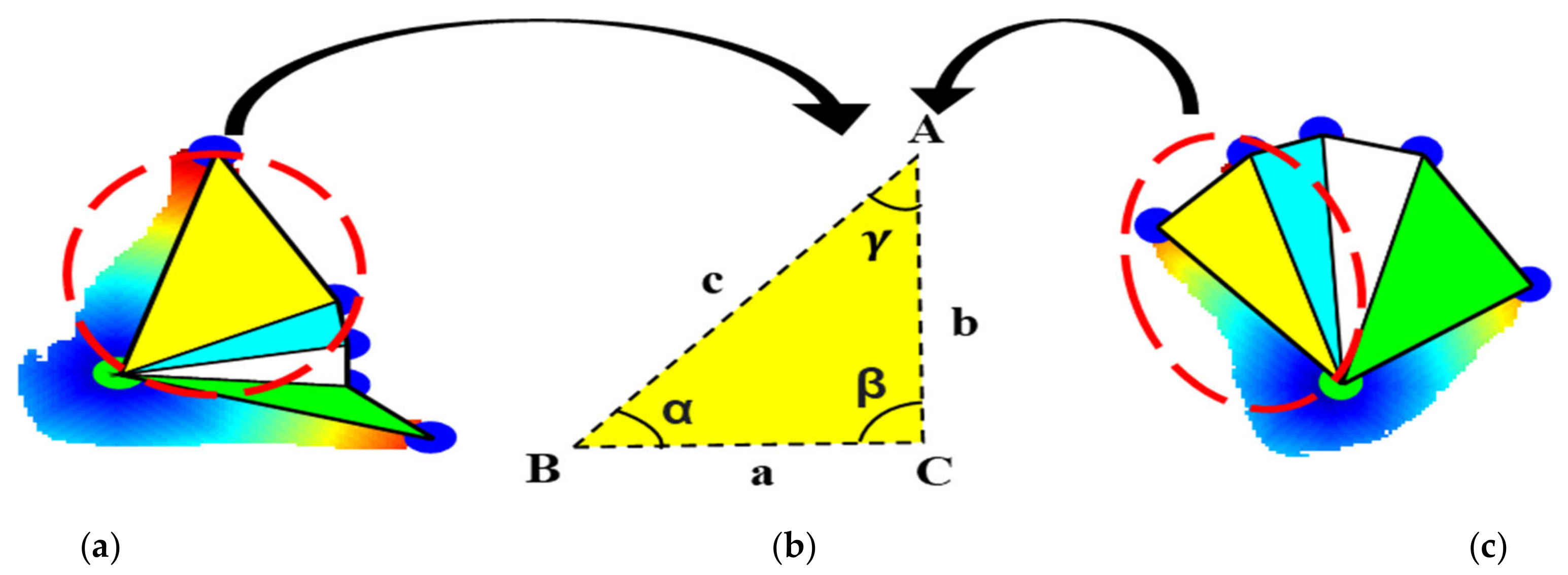
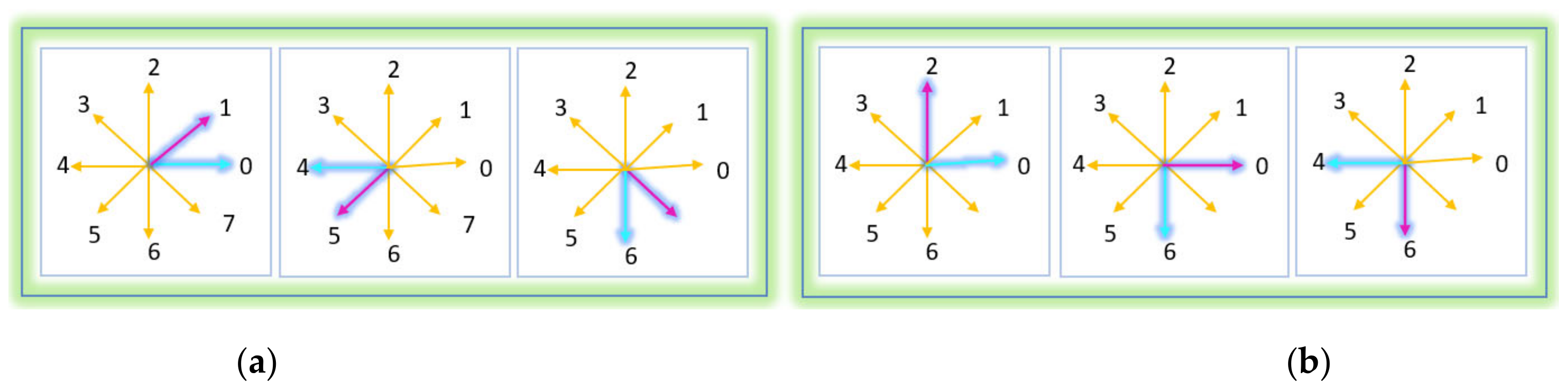
3.4.2. Angular Features
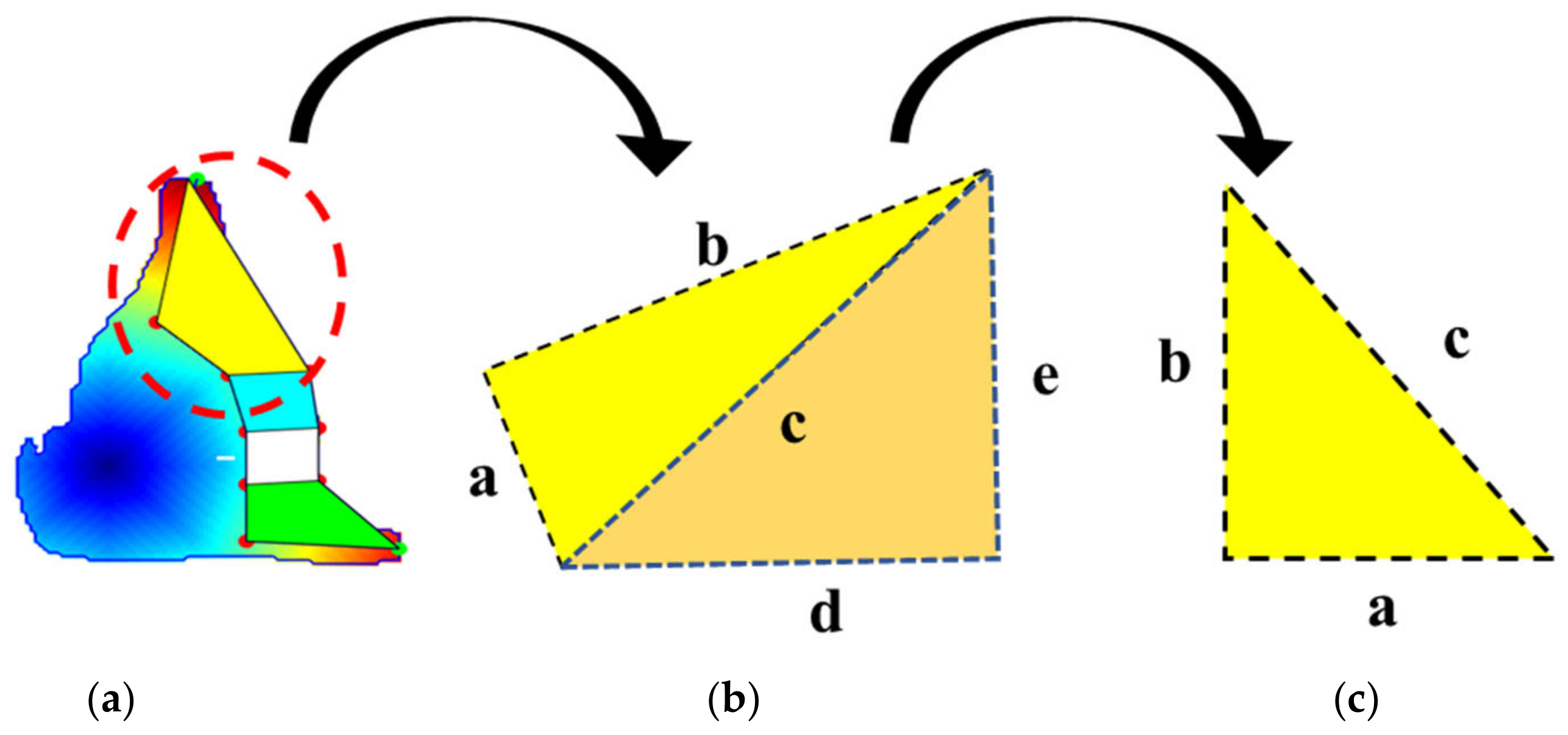
3.4.3. Geometric Features
3.5. Feature Extraction via Full Hand
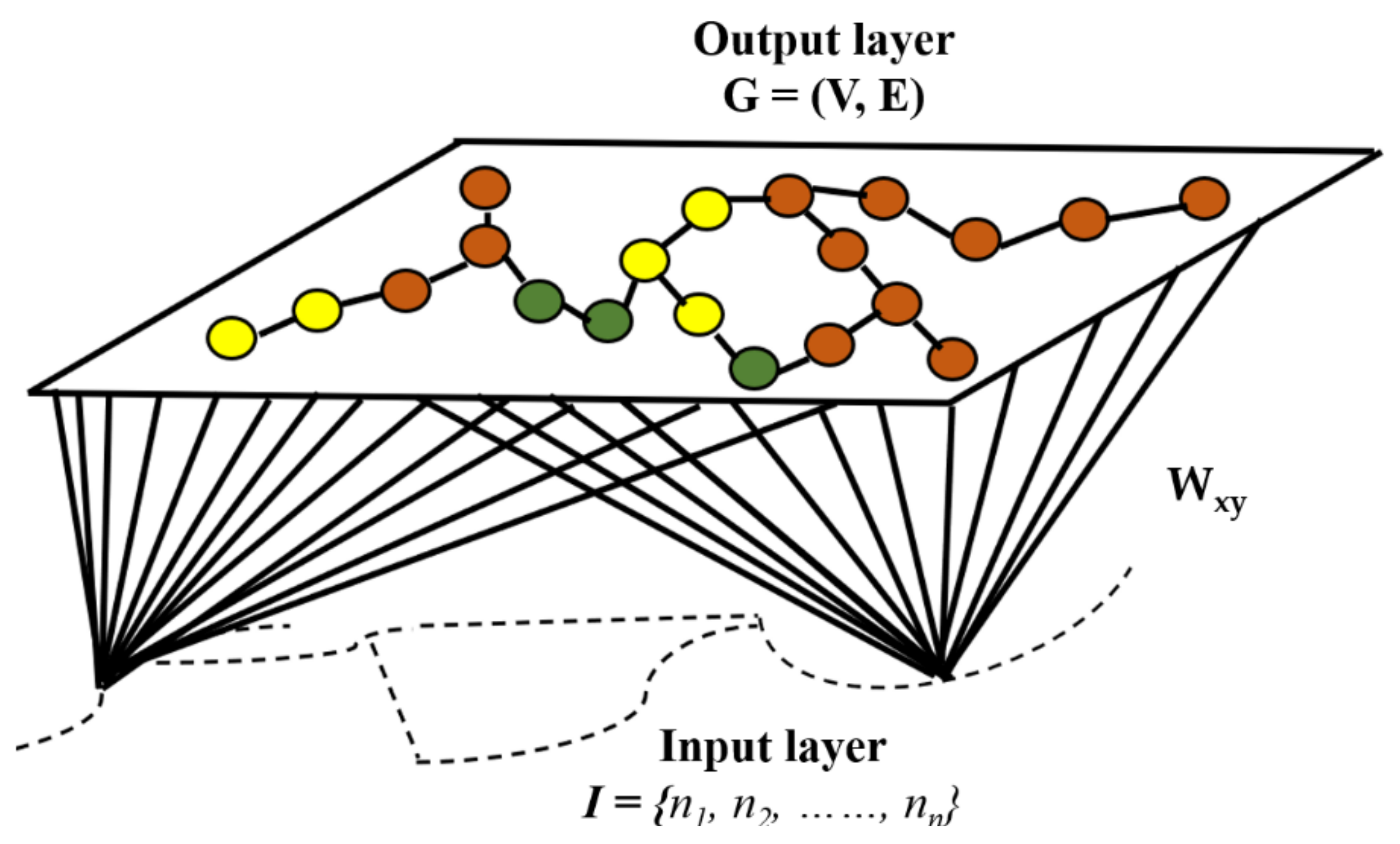
3.5.1. Mesh Geometry

| Algorithm 1. Pseudo code for self-organizing neural gas |
| Input: Input space, I; Output: the map, G = (V, E); |
| Initialization: First, randomly generate two nodes, N = (n1, n2) in the input space. Second, set the neighboring neuron to zero and set the maximum number of nodes to 100. |
| 1. Randomly generate one input signal Ў to update input space I, calculate the winning node x1 and x2 nearest to Ў |
| 2. Adjust x1 and x2 (a) Create a connecting edge if there is no connection between x1 and x2. (b) Set the edge=0. (c) Adjust the error of the winning node x1: (d) To adjust the winning node use the learning rate (e) Adjust all of the edges connected with node : |
| 3. Remove all edges larger than amax and delete all nodes without connecting edges |
| 4. Insert new nodes and divide them into two parts. |
| 5. Insert new nodes in the following steps i. Locate the neighboring node n of u with the largest error, and insert new node r between them. ii. Create the edges of r with u and v, and delete the edge between u and v and locate the induced subgraph iii. Lower down the error of u and v, and set the error of node r. iv. Regulate error of all nodes |
| 6. If stop conditions are not satisfied, then go back to Step 1. |
3.5.2. Active Model
3.6. Features Optimization
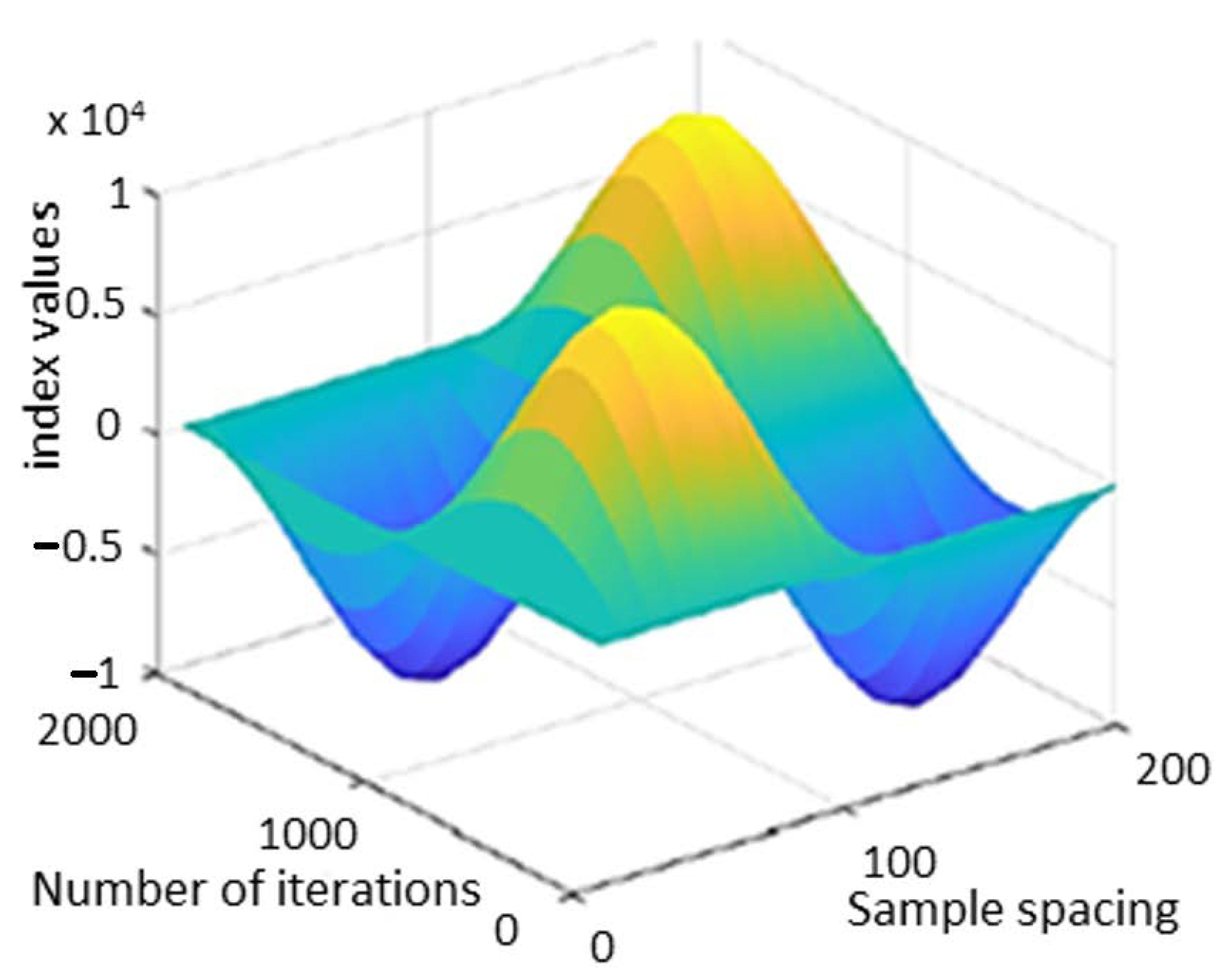
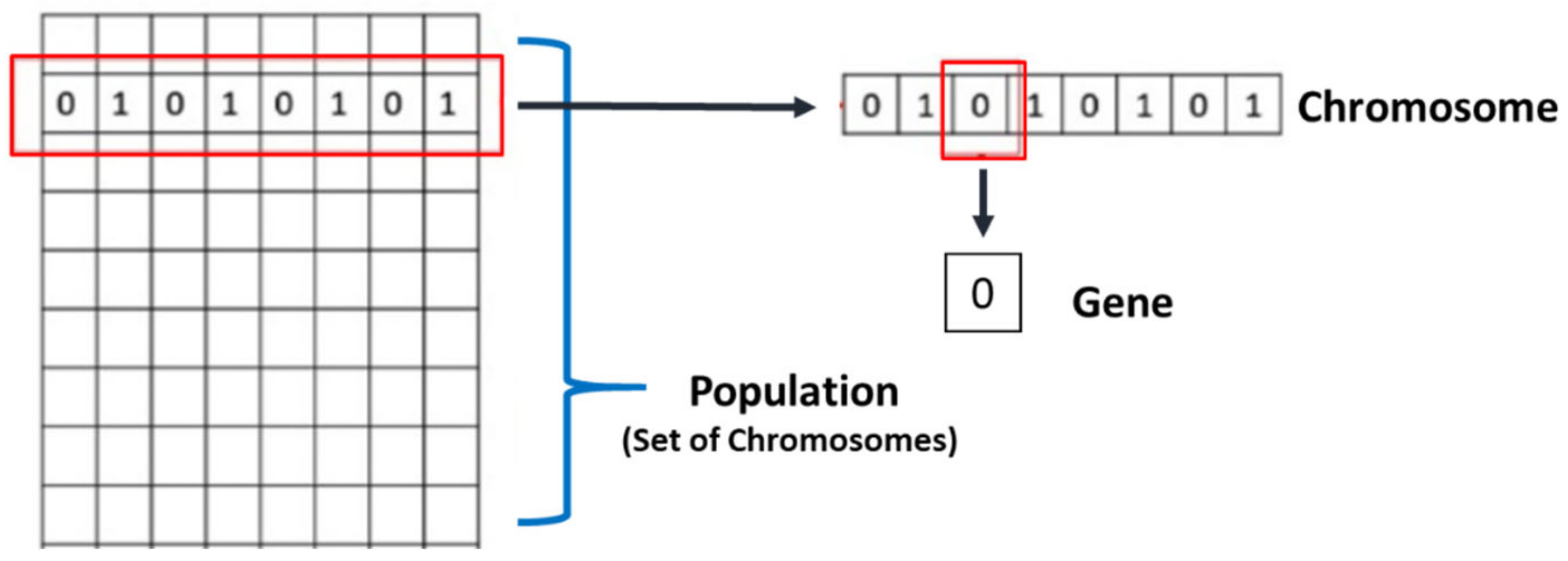
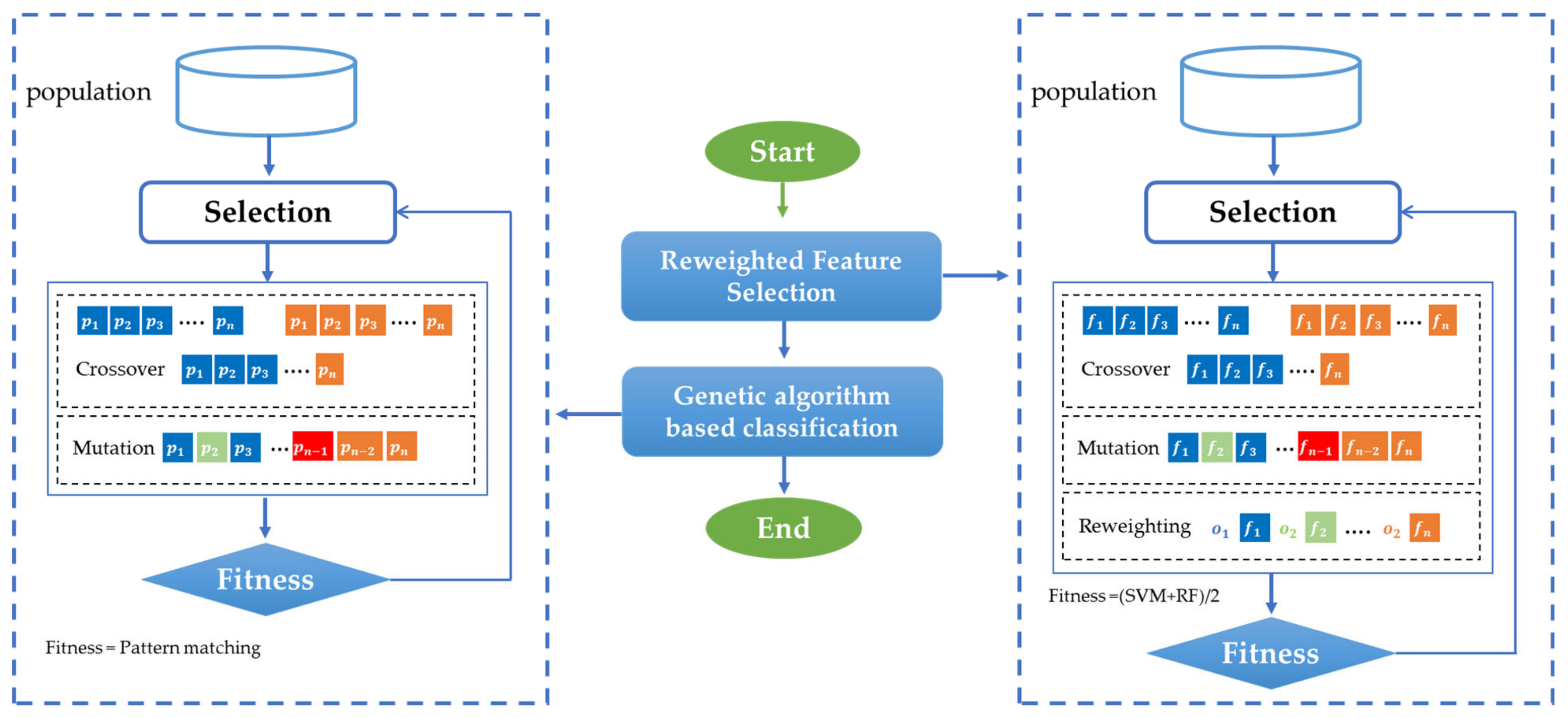
3.7. Classifier: Reweighted Genetic Algorithm
4. System Validation and Experimentation
4.1. Dataset Description
4.2. Recognition Accuracy
4.3. Precision, Recall, and F1 Score
4.4. Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, H.; Lihui, W. Gesture recognition for human-robot collaboration: A review. Int. J. Ind. Ergon. 2018, 68, 355–367. [Google Scholar] [CrossRef]
- Tingting, Y.; Junqian, W.; Lintai, W.; Yong, X. Three-stage network for age estimation. CAAI Trans. Intell. Technol. 2019, 4, 122–126. [Google Scholar] [CrossRef]
- Haria, A.P.; BMS College of Engineering; Subramanian, A.; Asokkumar, N.; Podda, S.; Nayak, J.S. Hand Gesture Recognition System. Int. J. Comput. Trends Technol. 2017, 47, 209–212. [Google Scholar] [CrossRef]
- Nishihara, H.K.; Hsu, S.P.; Kaehler, A.; Jangaard, L. Northrop Grumman Systems Corp. Hand-Gesture Recognition Method. U.S. Patent No. 9,696,808, April 2017. [Google Scholar]
- Sagayam, K.M.; Hemanth, D.J. Hand posture and gesture recognition techniques for virtual reality applications: A survey. Virtual Real. 2017, 21, 91–107. [Google Scholar] [CrossRef]
- Bobic, V.; Tadic, P.; Kvascev, G. Hand gesture recognition using neural network based techniques. In Proceedings of the 2016 13th Symposium on Neural Networks and Applications (NEUREL), Belgrade, Serbia, 22–24 November 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Oudah, M.; Al-Naji, A.; Chahl, J. Hand Gesture Recognition Based on Computer Vision: A Review of Techniques. J. Imaging 2020, 6, 73. [Google Scholar] [CrossRef]
- Li, W.-J.; Hsieh, C.-Y.; Lin, L.-F.; Chu, W.-C. Hand gesture recognition for post-stroke rehabilitation using leap motion. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 386–388. [Google Scholar] [CrossRef]
- Cheng, J.; Wei, F.; Liu, Y.; Li, C.; Chen, Q.; Chen, X. Chinese Sign Language Recognition Based on DTW-Distance-Mapping Features. Math. Probl. Eng. 2020, 2020, 1–13. [Google Scholar] [CrossRef]
- Jalal, A.; Uddin, I. Security architecture for third generation (3G) using GMHS cellular network. In Proceedings of the 2007 International Conference on Emerging Technologies, Rawalpindi, Pakistan, 12–13 November 2007; pp. 74–79. [Google Scholar] [CrossRef]
- Oyedotun, O.K.; Khashman, A. Deep learning in vision-based static hand gesture recognition. Neural Comput. Appl. 2017, 28, 3941–3951. [Google Scholar] [CrossRef]
- Pinto, R.F.; Borges, C.D.B.; Almeida, A.M.A.; Paula, I.C. Static Hand Gesture Recognition Based on Convolutional Neural Networks. J. Electr. Comput. Eng. 2019, 2019, 1–12. [Google Scholar] [CrossRef]
- Gao, Q.; Liu, J.; Ju, Z.; Li, Y.; Zhang, T.; Zhang, L. Static Hand Gesture Recognition with Parallel CNNs for Space Human-Robot Interaction. In Constructive Side-Channel Analysis and Secure Design, Proceedings of the 8th International Workshop, COSADE 2017, Paris, France, 13–14 April 2017; Springer International Publishing: Singapore, 2017; pp. 462–473. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, M.; Tian, X.; Jiang, N.; Wang, D. A Full Stage Data Augmentation Method in Deep Convolutional Neural Network for Natural Image Classification. Discret. Dyn. Nat. Soc. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Asif, A.R.; Waris, A.; Gilani, S.O.; Jamil, M.; Ashraf, H.; Shafique, M.; Niazi, I.K. Performance Evaluation of Convolutional Neural Network for Hand Gesture Recognition Using EMG. Sensors 2020, 20, 1642. [Google Scholar] [CrossRef] [Green Version]
- Su, H.; Ovur, S.E.; Zhou, X.; Qi, W.; Ferrigno, G.; De Momi, E. Depth vision guided hand gesture recognition using electromyographic signals. Adv. Robot. 2020, 34, 985–997. [Google Scholar] [CrossRef]
- Motoche, C.; Benalcázar, M.E. Real-Time Hand Gesture Recognition Based on Electromyographic Signals and Artificial Neural Networks. In Constructive Side-Channel Analysis and Secure Design, Proceedings of the 9th International Workshop, COSADE 2018, Singapore, 23–24 April 2018; Springer International Publishing: Singapore, 2018; pp. 352–361. [Google Scholar] [CrossRef]
- Sapienza, S.; Ros, P.M.; Guzman, D.A.F.; Rossi, F.; Terracciano, R.; Cordedda, E.; Demarchi, D. On-Line Event-Driven Hand Gesture Recognition Based on Surface Electromyographic Signals. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Pinzon-Arenas, J.O.; Jimenez-Moreno, R.; Herrera-Benavides, J.E. Convolutional Neural Network for Hand Gesture Recognition using 8 different EMG Signals. In Proceedings of the 2019 XXII Symposium on Image, Signal Processing and Artificial Vision (STSIVA), Bucaramanga, Colombia, 24–26 April 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Benalcazar, M.E.; Jaramillo, A.G.; Jonathan; Zea, A.; Paez, A.; Andaluz, V.H. Hand gesture recognition using machine learning and the Myo armband. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos Island, Greece, 28 August–2 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1040–1044. [Google Scholar] [CrossRef] [Green Version]
- Qi, J.; Jiang, G.; Li, G.; Sun, Y.; Tao, B. Surface EMG hand gesture recognition system based on PCA and GRNN. Neural Comput. Appl. 2019, 32, 6343–6351. [Google Scholar] [CrossRef]
- Qi, W.; Su, H.; Aliverti, A. A Smartphone-Based Adaptive Recognition and Real-Time Monitoring System for Human Activities. IEEE Trans. Hum. Mach. Syst. 2020, 50, 414–423. [Google Scholar] [CrossRef]
- Wang, Z.; Hou, Y.; Jiang, K.; Dou, W.; Zhang, C.; Huang, Z.; Guo, Y. Hand Gesture Recognition Based on Active Ultrasonic Sensing of Smartphone: A Survey. IEEE Access 2019, 7, 111897–111922. [Google Scholar] [CrossRef]
- Haseeb, M.A.A.; Parasuraman, R. Wisture: Touch-Less Hand Gesture Classification in Unmodified Smartphones Using Wi-Fi Signals. IEEE Sens. J. 2018, 19, 257–267. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, W.; Chen, C.; Bai, L.; Zhang, Y. Your Knock Is My Command: Binary Hand Gesture Recognition on Smartphone with Accelerometer. Mob. Inf. Syst. 2020, 2020, 1–16. [Google Scholar] [CrossRef]
- Panella, M.; Altilio, R. A Smartphone-Based Application Using Machine Learning for Gesture Recognition: Using Feature Extraction and Template Matching via Hu Image Moments to Recognize Gestures. IEEE Consum. Electron. Mag. 2018, 8, 25–29. [Google Scholar] [CrossRef]
- Aldabbagh, G.; AlGhazzawi, D.M.; Hasan, S.H.; Alhaddad, M.; Malibari, A.; Cheng, L. Optimal Learning Behavior Prediction System Based on Cognitive Style Using Adaptive Optimization-Based Neural Network. Complexity 2020, 2020, 1–13. [Google Scholar] [CrossRef]
- Wiens, T. Engine speed reduction for hydraulic machinery using predictive algorithms. Int. J. Hydromech. 2019, 2, 16. [Google Scholar] [CrossRef]
- Li, G.; Tang, H.; Sun, Y.; Kong, J.; Jiang, G.; Jiang, D.; Tao, B.; Xu, S.; Liu, H. Hand gesture recognition based on convolution neural network. Clust. Comput. 2019, 22, 2719–2729. [Google Scholar] [CrossRef]
- Zheng, Q.; Tian, X.; Liu, S.; Yang, M.; Wang, H.; Yang, J. Static Hand Gesture Recognition Based on Gaussian Mixture Model and Partial Differential Equation. IAENG Int. J. Comput. 2018, Sci. 45, 569–583. [Google Scholar]
- Cheng, H.; Dai, Z.; Liu, Z.; Zhao, Y. An image-to-class dynamic time warping approach for both 3D static and trajectory hand gesture recognition. Pattern Recognit. 2016, 55, 137–147. [Google Scholar] [CrossRef]
- Oprisescu, S.; Christoph, R.; Bochao, S. Automatic static hand gesture recognition using tof cameras. In Proceedings of the 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 2748–2751. [Google Scholar]
- Yun, L.; Lifeng, Z.; Shujun, Z. A Hand Gesture Recognition Method Based on Multi-Feature Fusion and Template Matching. Proc. Eng. 2012, 29, 1678–1684. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, D.K.; Ari, S. Static Hand Gesture Recognition Using Mixture of Features and SVM Classifier. In Proceedings of the 2015 Fifth International Conference on Communication Systems and Network Technologies, Gwalior, India, 4–6 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1094–1099. [Google Scholar] [CrossRef]
- Candrasari Banuwati, E.; Novamizanti, L.; Aulia, S. Discrete Wavelet Transform on static hand gesture recognition. J. Phys. Conf. Ser. 2019, 1367, 012022. [Google Scholar] [CrossRef]
- Jalal, A.; Khalid, N.; Kim, K. Automatic Recognition of Human Interaction via Hybrid Descriptors and Maximum Entropy Markov Model Using Depth Sensors. Entropy 2020, 22, 817. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Shi, C.; Liu, B. Static hand gesture recognition based on finger root-center-angle and length weighted Ma-halanobis distance. In Real-Time Image and Video Processing; International Society for Optics and Photonics: Bellingham, WA, USA, 2016; Volume 9897, p. 98970U. [Google Scholar] [CrossRef]
- Bhavana, V.; Mouli, G.M.S.; Lokesh, G.V.L. Hand Gesture Recognition Using Otsu’s Method. In Proceedings of the 2017 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Tamilnadu, India, 14–16 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Yusnita, L.; Rosalina, R.; Roestam, R.; Wahyu, R.B. Implementation of Real-Time Static Hand Gesture Recognition Using Artificial Neural Network. Commun. Inf. Technol. J. 2017, 11, 85–91. [Google Scholar] [CrossRef] [Green Version]
- Jalal, A.; Quaid, M.A.K.; Tahir, S.B.U.D.; Kim, K. A Study of Accelerometer and Gyroscope Measurements in Physical Life-Log Activities Detection Systems. Sensors 2020, 20, 6670. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Kehtarnavaz, N. Real-time robust vision-based hand gesture recognition using stereo images. J. Real Time Image Process. 2013, 11, 201–209. [Google Scholar] [CrossRef]
- Ahmed, W.; Chanda, K.; Mitra, S. Vision based Hand Gesture Recognition using Dynamic Time Warping for Indian Sign Language. In Proceedings of the 2016 International Conference on Information Science (ICIS), Kochi, India, 11–14 December 2016; IEEE: Piscataway, NJ, USA, 2017; pp. 120–125. [Google Scholar] [CrossRef]
- Al-Shamayleh, A.S.; Ahmad, R.; Abushariah, M.A.M.; Alam, K.A.; Jomhari, N. A systematic literature review on vision based gesture recognition techniques. Multim. Tools Appl. 2018, 77, 28121–28184. [Google Scholar] [CrossRef]
- Pansare, J.R.; Ingle, M. Vision-based approach for American Sign Language recognition using Edge Orientation Histogram. In Proceedings of the 2016 International Conference on Image, Vision and Computing (ICIVC), Portsmouth, NH, USA, 3–5 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 86–90. [Google Scholar] [CrossRef]
- Hussain, S.; Saxena, R.; Han, X.; Khan, J.A.; Shin, H. Hand gesture recognition using deep learning. In Proceedings of the 2017 International SoC Design Conference (ISOCC), Seoul, Korea, 5–8 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 48–49. [Google Scholar] [CrossRef]
- Mahdikhanlou, K.; Ebrahimnezhad, H. Multimodal 3D American sign language recognition for static alphabet and numbers using hand joints and shape coding. Multim. Tools Appl. 2020, 79, 22235–22259. [Google Scholar] [CrossRef]
- Liu, J.; Ding, H.; Shahroudy, A.; Duan, L.-Y.; Jiang, X.; Wang, G.; Kot, A.C. Feature Boosting Network For 3D Pose Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 494–501. [Google Scholar] [CrossRef] [Green Version]
- Jalal, A.; Akhtar, I.; Kim, K. Human Posture Estimation and Sustainable Events Classification via Pseudo-2D Stick Model and K-ary Tree Hashing. Sustainability 2020, 12, 9814. [Google Scholar] [CrossRef]
- Kerdvibulvech, C. A methodology for hand and finger motion analysis using adaptive probabilistic models. EURASIP J. Embed. Syst. 2014, 2014, 18. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.-N.; Vo, D.-H.; Huynh, H.-H.; Meunier, J. Geometry-based static hand gesture recognition using support vector machine. In Proceedings of the 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 769–774. [Google Scholar] [CrossRef]
- Jalal, A.; Kim, Y.-H.; Kim, Y.-J.; Kamal, S.; Kim, D. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Jalal, A.; Uddin, Z.; Kim, T.-S. Depth video-based human activity recognition system using translation and scaling invariant features for life logging at smart home. IEEE Trans. Consum. Electron. 2012, 58, 863–871. [Google Scholar] [CrossRef]
- Kolkur, S.; Kalbande, D.; Shimpi, P.; Bapat, C.; Jatakia, J. Human Skin Detection Using RGB, HSV and YCbCr Color Models. In Proceedings of the International Conference on Communication and Signal Processing 2016 (ICCASP 2016), Lonere, India, 26–27 December 2016; Atlantic Press: Amsterdam, The Netherlands, 2017. [Google Scholar] [CrossRef] [Green Version]
- Lv, Y.; Zhou, W. Hierarchical Multimodal Adaptive Fusion (HMAF) Network for Prediction of RGB-D Saliency. Comput. Intell. Neurosci. 2020, 2020, 1–9. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, M.; Kpalma, K.; Zheng, Q.; Zhang, X. Segmentation of hand posture against complex backgrounds based on saliency and skin colour detection. IAENG Int. J. Comput. Sci. 2018, 45, 435–444. [Google Scholar]
- Grzejszczak, T.; Kawulok, M.; Galuszka, A. Hand landmarks detection and localization in color images. Multim. Tools Appl. 2016, 75, 16363–16387. [Google Scholar] [CrossRef] [Green Version]
- Jalal, A.; Batool, M.; Kim, K. Sustainable Wearable System: Human Behavior Modeling for Life-Logging Activities Using K-Ary Tree Hashing Classifier. Sustainability 2020, 12, 10324. [Google Scholar] [CrossRef]
- Kim, T.; Jalal, A.; Han, H.; Jeon, H.; Kim, J. Real-Time Life Logging via Depth Imaging-based Human Activity Recognition towards Smart Homes Services. In Proceedings of the International Symposium on Renewable Energy Sources and Healthy Buildings, Seoul, Korea, 26–29 August 2014; p. 63. [Google Scholar] [CrossRef]
- Tahir, S.B.U.D.; Jalal, A.; Kim, K. Wearable Inertial Sensors for Daily Activity Analysis Based on Adam Optimization and the Maximum Entropy Markov Model. Entropy 2020, 22, 579. [Google Scholar] [CrossRef]
- Jalal, A.; Batool, M.; Kim, K. Stochastic Recognition of Physical Activity and Healthcare Using Tri-Axial Inertial Wearable Sensors. Appl. Sci. 2020, 10, 7122. [Google Scholar] [CrossRef]
- Ahmed, A.; Jalal, A.; Kim, K. A Novel Statistical Method for Scene Classification Based on Multi-Object Categorization and Logistic Regression. Sensors 2020, 20, 3871. [Google Scholar] [CrossRef] [PubMed]
- Mahmood, M.; Jalal, A.; Kim, K. WHITE STAG model: Wise human interaction tracking and estimation (WHITE) using spa-tio-temporal and angular-geometric (STAG) descriptors. Multim. Tools Appl. 2019, 79, 1–32. [Google Scholar] [CrossRef]
- Shehzed, A.; Jalal, A.; Kim, K. Multi-Person Tracking in Smart Surveillance System for Crowd Counting and Normal/Abnormal Events Detection. In Proceedings of the 2019 International Conference on Applied and Engineering Mathematics (ICAEM), London, UK, 3–5 July 2019; Volume 12, pp. 163–168. [Google Scholar] [CrossRef]
- Jalal, A.; Quaid, M.A.K.; Hasan, A.S. Wearable Sensor-Based Human Behavior Understanding and Recognition in Daily Life for Smart Environments. In Proceedings of the 2018 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 17–19 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 105–110. [Google Scholar] [CrossRef]
- Jalal, A.; Sharif, N.; Kim, J.T.; Kim, T.-S. Human activity recognition via recognized body parts of human depth silhouettes for residents monitoring services at smart homes. Indoor Built Environ. 2013, 22, 271–279. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D. A Depth Video Sensor-Based Life-Logging Human Activity Recognition System for Elderly Care in Smart Indoor Environments. Sensors 2014, 14, 11735–11759. [Google Scholar] [CrossRef]
- Susan, S.; Agrawal, P.; Mittal, M.; Bansal, S. New shape descriptor in the context of edge continuity. CAAI Trans. Intell. Technol. 2019, 4, 101–109. [Google Scholar] [CrossRef]
- Osterland, S.; Weber, J. Analytical analysis of single-stage pressure relief valves. Int. J. Hydromechatron. 2019, 2, 32–53. [Google Scholar] [CrossRef]
- Ghesmoune, M.; Lebbah, M.; Azzag, H. A new Growing Neural Gas for clustering data streams. Neural Netw. 2016, 78, 36–50. [Google Scholar] [CrossRef]
- Sun, Q.; Liu, H.; Harada, T. Online growing neural gas for anomaly detection in changing surveillance scenes. Pattern Recognit. 2017, 64, 187–201. [Google Scholar] [CrossRef]
- Zhong, C.; Zhang, B.; Wang, J. Scale-Adaptive Growing Neural Network Based on Distortion Error Stability and its Application in Image Topological Feature Extraction. IEEE Access 2021, 9, 767–776. [Google Scholar] [CrossRef]
- Ghaderi, A.; Morovati, V.; Dargazany, R. A Physics-Informed Assembly of Feed-Forward Neural Network Engines to Predict Inelasticity in Cross-Linked Polymers. Polymers 2020, 12, 2628. [Google Scholar] [CrossRef] [PubMed]
- Jedynak, R. Approximation of the inverse Langevin function revisited. Rheol. Acta 2014, 54, 29–39. [Google Scholar] [CrossRef] [Green Version]
- Hossain, M.; Steinmann, P. More hyperelastic models for rubber-like materials: Consistent tangent operators and comparative study. J. Mech. Behav. Mater. 2013, 22, 27–50. [Google Scholar] [CrossRef]
- Kroon, M. An 8-chain Model for Rubber-like Materials Accounting for Non-affine Chain Deformations and Topological Constraints. J. Elast. 2010, 102, 99–116. [Google Scholar] [CrossRef]
- Hong, F.; Lu, C.; Liu, C.; Liu, R.; Jiang, W.; Ju, W.; Wang, T. PGNet: Pipeline Guidance for Human Key-Point Detection. Entropy 2020, 22, 369. [Google Scholar] [CrossRef] [Green Version]
- Pławiak, P. Novel methodology of cardiac health recognition based on ECG signals and evolutionary-neural system. Expert Syst. Appl. 2018, 92, 334–349. [Google Scholar] [CrossRef]
- Demidova, L.; Nikulchev, E.; Sokolova, Y. The SVM Classifier Based on the Modified Particle Swarm Optimization. Int. J. Adv. Comput. Sci. Appl. 2016, 7. [Google Scholar] [CrossRef] [Green Version]
- Emary, E.; Zawbaa, H.M.; Grosan, C. Experienced Gray Wolf Optimization through Reinforcement Learning and Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 681–694. [Google Scholar] [CrossRef]
- Lessmann, S.; Stahlbock, R.; Crone, S. Genetic Algorithms for Support Vector Machine Model Selection. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 3063–3069. [Google Scholar] [CrossRef]
- Quaid, M.A.K.; Jalal, A. Wearable sensors based human behavioral pattern recognition using statistical features and re-weighted genetic algorithm. Multim. Tools Appl. 2020, 79, 6061–6083. [Google Scholar] [CrossRef]
- Batool, M.; Jalal, A.; Kim, K. Telemonitoring of Daily Activity Using Accelerometer and Gyroscope in Smart Home Environ-ments. J. Electr. Eng. Technol. 2020, 15, 2801–2809. [Google Scholar] [CrossRef]
- Ong, Y.S.; Nair, P.B.; Keane, A.J. Evolutionary Optimization of Computationally Expensive Problems via Surrogate Modeling. AIAA J. 2003, 41, 687–696. [Google Scholar] [CrossRef] [Green Version]
- Jalal, A.; Lee, S.; Kim, J.T.; Kim, T.-S. Human Activity Recognition via the Features of Labeled Depth Body Parts. In Computer Vision; Springer International Publishing: New York, NY, USA, 2012; pp. 246–249. [Google Scholar] [CrossRef]
- Rahim, A.; Islam, R.; Shin, J. Non-Touch Sign Word Recognition Based on Dynamic Hand Gesture Using Hybrid Segmentation and CNN Feature Fusion. Appl. Sci. 2019, 9, 3790. [Google Scholar] [CrossRef] [Green Version]
- Sridhar, S.; Oulasvirta, A.; Theobalt, C. Interactive Markerless Articulated Hand Motion Tracking Using RGB and Depth Data. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 2456–2463. [Google Scholar] [CrossRef]
- Sridhar, S.; Mueller, F.; Zollhöfer, M.; Casas, D.; Oulasvirta, A.; Theobalt, C. Real-Time Joint Tracking of a Hand Manipulating an Object from RGB-D Input. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Jiao, J.; Chen, M.; Qu, L.; Xu, X.; Yang, Q. 3d hand pose tracking and estimation using stereo matching. arXiv 2016, arXiv:2016.1610.07214. [Google Scholar]
- Tompson, J.; Stein, M.; LeCun, Y.; Perlin, K. Real-Time Continuous Pose Recovery of Human Hands Using Convolutional Networks. ACM Trans. Graph. 2014, 33, 1–10. [Google Scholar] [CrossRef]
- Vaitkevičius, A.; Taroza, M.; Blažauskas, T.; Damaševičius, R.; Maskeliūnas, R.; Woźniak, M. Recognition of American Sign Language Gestures in a Virtual Reality Using Leap Motion. Appl. Sci. 2019, 9, 445. [Google Scholar] [CrossRef] [Green Version]
- Ahlawat, S.; Batra, V.; Banerjee, S.; Saha, J.; Garg, A.K. Hand Gesture Recognition Using Convolutional Neural Network. In Proceedings of the International Conference on Innovative Computing and Communications. Lecture Notes in Networks and Systems, Delhi, India, 5–6 May 2018; Springer International Publishing: Singapore, 2018; pp. 179–186. [Google Scholar] [CrossRef]
- Wang, J.; Liu, T.; Wang, X. Human hand gesture recognition with convolutional neural networks for K-12 double-teachers instruction mode classroom. Infrared Phys. Technol. 2020, 111, 103464. [Google Scholar] [CrossRef]
- Cai, Y.; Ge, L.; Cai, J.; Yuan, J. Weakly-Supervised 3D Hand Pose Estimation from Monocular RGB Images. In Constructive Side-Channel Analysis and Secure Design, Proceedings of the 9th International Workshop, COSADE 2018, Singapore, 23–24 April 2018; Springer International Publishing: Singapore, 2018; pp. 678–694. [Google Scholar] [CrossRef]
- Imashev, A.; Mukushev, M.; Kimmelman, V.; Sandygulova, A. A Dataset for Linguistic Understanding, Visual Evaluation, and Recognition of Sign Languages: The K-RSL. In Proceedings of the 24th Conference on Computational Natural Language Learning, online, 19–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 631–640. [Google Scholar] [CrossRef]
- Shan, D.; Geng, J.; Shu, M.; Fouhey, D.F. Understanding Human Hands in Contact at Internet Scale. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA; pp. 9866–9875. [Google Scholar] [CrossRef]
- Spurr, A.; Song, J.; Park, S.; Hilliges, O. Cross-Modal Deep Variational Hand Pose Estimation; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2018; pp. 89–98. [Google Scholar] [CrossRef] [Green Version]
- Brahmbhatt, S.; Tang, C.; Twigg, C.D.; Kemp, C.C.; Hays, J. ContactPose: A Dataset of Grasps wi.th Object Contact and Hand Pose. In Constructive Side-Channel Analysis and Secure Design, Proceedings of the 11th International Workshop, COSADE 2020, Lugano, Switzerland, 1–3, April 2020; Springer International Publishing: Singapore, 2020; pp. 361–378. [Google Scholar]
- Li, M.; Gao, Y.; Sang, N. Exploiting Learnable Joint Groups for Hand Pose Estimation. arXiv 2021, arXiv:2021.2012.09496. [Google Scholar]
- Chen, L.; Lin, S.Y.; Xie, Y.; Tang, H.; Xue, Y.; Lin, Y.Y.; Xie, X.; Fan, W. Tagan: Tonality-alignment generative adversarial networks for realistic hand pose synthesis. In Proceedings of the 30th British Machine Vision Conference, BMVC, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Dai, S.; Liu, W.; Yang, W.; Fan, L.; Zhang, J. Cascaded Hierarchical CNN for RGB-Based 3D Hand Pose Estimation. Math. Probl. Eng. 2020, 2020, 1–13. [Google Scholar] [CrossRef]
- Zhou, Y.; Habermann, M.; Xu, W.; Habibie, I.; Theobalt, C.; Xu, F. Monocular real-time hand shape and motion capture us-ing multi-modal data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 5346–5355. [Google Scholar]
- Deng, X.; Yang, S.; Zhang, Y.; Tan, P.; Chang, L.; Wang, H. Hand3d: Hand pose estimation using 3d neural network. arXiv 2017, arXiv:2017.1704.02224. [Google Scholar]
- Moon, G.; Chang, J.Y.; Lee, K.M. V2v-posenet: Voxel-to-voxel prediction network for accurate 3d hand and human pose es-timation from a single depth map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5079–5088. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | Fused Method Accuracy (%) | Directional Image Accuracy (%) | Classes | Fused Method Accuracy (%) | Directional Image Accuracy (%) |
|---|---|---|---|---|---|
| call | 92 | 69 | ok | 92 | 68 |
| close | 91 | 62 | please | 93 | 58 |
| cold | 92 | 67 | single | 92 | 63 |
| correct | 92 | 60 | sit | 92.5 | 52 |
| fine | 92 | 66 | tall | 91 | 56 |
| help | 92 | 59 | wash | 92 | 62 |
| home | 91 | 55 | work | 91 | 61 |
| like | 92 | 65 | yes | 91 | 60 |
| love | 91.5 | 65 | you | 92 | 62 |
| no | 91 | 66 | iLoveYou | 92 | 68 |
| Name of Dataset | Type of Input Data | Gesture Classes |
|---|---|---|
| Sign word | RGB images | This dataset contains 20 isolated hand gestures (11 single-hand gestures and 9 double-hand gestures), i.e., call, close, cold, correct, fine, help, home, like, love, no, ok, please, single, sit, tall, wash, work, yes, you, iloveyou. The images of the dataset were collected with a pixel resolution of 200 x 200. To collect dataset images, we requested three volunteers (mean age 25) to perform the gesture of Sign Word [85]. |
| Dexter1 | RGB frames with 5 Sony DFW-V500 RGB cameras at 25 fps | Dexter1 consists of seven sequences, i.e., abduction–adduction, flexion–extension, finger count, finger wave, flexex1, pinch, random, tiger grasp of the hand. Roughly the first 250 frames in each sequence correspond to slow motions while the remaining frames are fast motions. All sequences are performed with an actor’s right hand [86]. |
| Dexter + Object | RGB frames with Creative Senz3D color camera | Dexter + Object is a dataset for evaluating algorithms for joint hand and object tracking. It consists of six sequences, i.e., grasp1, grasp2, pinch, rigid, rotate, and occlusion with two actors (one female) and varying interactions with a simple object shape [87]. |
| STB | RGB and RGBD frames | STB dataset contains 18,000 images with ground truth. Six people performed counting and random poses having different backgrounds [88]. |
| NYU | RGBD data with ground truth images | NYU hand pose dataset consists of 8252 test set and 72,757 training set frames. The dataset consists of RGBD and RGB images. The training set consists of single user while test set consist of two users with different hand poses [89]. |
| Classes | C 1 | CL 2 | CO 3 | CR 4 | F 5 | H 6 | HM 7 | L 8 | LV 9 | N 10 | O 11 | P 12 | S 13 | ST 14 | T 15 | WA 16 | WO 17 | Y 18 | U 19 | IL 20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C 1 | 0.99 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| CL 2 | 0.00 | 0.96 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| CO 3 | 0.01 | 0.00 | 0.87 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.03 | 0.05 | 0.00 | 0.00 | 0.00 |
| CR 4 | 0.00 | 0.00 | 0.00 | 0.97 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 |
| F 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.99 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| H 6 | 0.03 | 0.00 | 0.01 | 0.00 | 0.00 | 0.85 | 0.01 | 0.00 | 0.02 | 0.00 | 0.02 | 0.00 | 0.00 | 0.01 | 0.00 | 0.02 | 0.03 | 0.00 | 0.00 | 0.00 |
| HM 7 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.95 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 |
| L 8 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.96 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 |
| LV 9 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.94 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.01 | 0.00 | 0.00 |
| N 10 | 0.01 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.91 | 0.01 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.01 | 0.02 | 0.00 |
| O 11 | 0.02 | 0.00 | 0.00 | 0.01 | 0.01 | 0.00 | 0.00 | 0.03 | 0.00 | 0.03 | 0.86 | 0.01 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.01 | 0.00 |
| P 12 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.97 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| S 13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.96 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 |
| ST 14 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.02 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.85 | 0.00 | 0.07 | 0.02 | 0.00 | 0.00 | 0.00 |
| T 15 | 0.00 | 0.04 | 0.01 | 0.00 | 0.00 | 0.02 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.89 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 |
| WA 16 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.87 | 0.08 | 0.00 | 0.00 | 0.00 |
| WO 17 | 0.00 | 0.00 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.89 | 0.02 | 0.00 | 0.00 |
| Y 18 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.88 | 0.07 | 0.00 |
| U 19 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.08 | 0.89 | 0.00 |
| IL 20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.97 |
| Gesture Classes | AD 1 | FC 2 | FW 3 | F 4 | P 5 | R 6 | TG 7 |
|---|---|---|---|---|---|---|---|
| AD 1 | 0.95 | 0.0 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 |
| FC 2 | 0.03 | 0.96 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 |
| FW 3 | 0.00 | 0.04 | 0.94 | 0.02 | 0.00 | 0.00 | 0.00 |
| F 4 | 0.03 | 0.00 | 0.02 | 0.95 | 0.00 | 0.00 | 0.00 |
| P 5 | 0.01 | 0.01 | 0.00 | 0.00 | 0.92 | 0.00 | 0.06 |
| R 6 | 0.00 | 0.03 | 0.05 | 0.00 | 0.03 | 0.89 | 0.0 |
| TG 7 | 0.00 | 0.00 | 0.00 | 0.02 | 0.07 | 0.00 | 0.91 |
| Predicted Gesture Classes | ||||||
|---|---|---|---|---|---|---|
| G 1 | GR 2 | O 3 | P 4 | R 5 | RO 6 | |
| G 1 | 0.91 | 0.07 | 0.00 | 0.00 | 0.00 | 0.02 |
| GR 2 | 0.09 | 0.89 | 0.00 | 0.00 | 0.01 | 0.01 |
| O 3 | 0.00 | 0.00 | 0.85 | 0.00 | 0.09 | 0.06 |
| P 4 | 0.06 | 0.05 | 0.00 | 0.84 | 0.03 | 0.02 |
| R 5 | 0.00 | 0.01 | 0.06 | 0.00 | 0.92 | 0.01 |
| RO 6 | 0.00 | 0.00 | 0.00 | 0.05 | 0.07 | 0.88 |
| Datasets | Mean Accuracy % |
|---|---|
| Sign Word | 92.1 |
| Dexter1 | 93.1 |
| Dexter + Object | 88.2 |
| STB | 90.8 |
| NYU | 85.3 |
| Classifier | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Decision tree | 0.9142 | 0.9012 | 0.8412 | 0.8701 |
| ANN | 0.8924 | 0.8214 | 0.8516 | 0.8362 |
| Genetic algo | 0.9212 | 0.8817 | 0.8833 | 0.8824 |
| Classifier | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Decision tree | 0.9212 | 0.9102 | 0.8702 | 0.8897 |
| ANN | 0.9024 | 0.8313 | 0.8714 | 0.8508 |
| Genetic algo | 0.9312 | 0.8927 | 0.8923 | 0.8924 |
| Classifier | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Decision tree | 0.9021 | 0.9012 | 0.8412 | 0.8701 |
| ANN | 0.8761 | 0.7915 | 0.8315 | 0.8110 |
| Genetic algo | 0.8822 | 0.8315 | 0.8012 | 0.8160 |
| Classifier | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Decision tree | 0.8901 | 0.8542 | 0.8612 | 0.8576 |
| ANN | 0.8912 | 0.8612 | 0.8415 | 0.8512 |
| Genetic algo | 0.9081 | 0.8522 | 0.8724 | 0.8621 |
| Classifier | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Decision tree | 0.8641 | 0.8414 | 0.8213 | 0.8312 |
| ANN | 0.8421 | 0.8321 | 0.8101 | 0.8214 |
| Genetic algo | 0.8532 | 0.8462 | 0.8387 | 0.8424 |
| Dataset | Feature Extraction Method | Authors | Recognition Accuracy (%) |
|---|---|---|---|
| Sign Word | Point-based | Vaitkevičius et al. [90] | 86.1 |
| Full-hand | Ahlawat et al. [91] | 90 | |
| Wang et al. [92] | 92 | ||
| Point-based + full-hand | Proposed methodology on Sign Word dataset | 92.1 | |
| Dexter1 | Point-based | Cai [93] | 88 |
| Full-hand | Imashev [94] | 86 | |
| Shan et al. [95] | 89 | ||
| Point-based + full-hand | Proposed methodology on Dexter1 dataset | 93.1 | |
| Dexter + Object | Point-based | Spurr et al. [96] | 85 |
| Brahmbhatt et al. [97] | 86.49 | ||
| Full-hand | Li et al. [98] | 84 | |
| Point-based + full-hand | Proposed methodology on Dexter + Object dataset | 88.2 | |
| STB | Point-based | Chen et al. [99] | 75 |
| Dai et al. [100] | 77 | ||
| Full-hand | Zhou et al. [101] | 89 | |
| Point-based + full-hand | Proposed methodology on STB | 90.8 | |
| NYU | Point-based | Deng et al. [102] | 74 |
| Full-hand | Moon et al. [103] | 83.4 | |
| Point-based + full-hand | Proposed methodology on NYU | 85.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ansar, H.; Jalal, A.; Gochoo, M.; Kim, K. Hand Gesture Recognition Based on Auto-Landmark Localization and Reweighted Genetic Algorithm for Healthcare Muscle Activities. Sustainability 2021, 13, 2961. https://0-doi-org.brum.beds.ac.uk/10.3390/su13052961
Ansar H, Jalal A, Gochoo M, Kim K. Hand Gesture Recognition Based on Auto-Landmark Localization and Reweighted Genetic Algorithm for Healthcare Muscle Activities. Sustainability. 2021; 13(5):2961. https://0-doi-org.brum.beds.ac.uk/10.3390/su13052961
Chicago/Turabian StyleAnsar, Hira, Ahmad Jalal, Munkhjargal Gochoo, and Kibum Kim. 2021. "Hand Gesture Recognition Based on Auto-Landmark Localization and Reweighted Genetic Algorithm for Healthcare Muscle Activities" Sustainability 13, no. 5: 2961. https://0-doi-org.brum.beds.ac.uk/10.3390/su13052961