Toward Social Media Content Recommendation Integrated with Data Science and Machine Learning Approach for E-Learners



Department of Computer Engineering, Jeju National University, Jejusi 63243, Jeju Special Self-Governing Provience, Korea
*
Author to whom correspondence should be addressed.
Symmetry 2020, 12(11), 1798; https://0-doi-org.brum.beds.ac.uk/10.3390/sym12111798
Submission received: 31 August 2020
/
Revised: 14 October 2020
/
Accepted: 19 October 2020
/
Published: 30 October 2020
(This article belongs to the Special Issue Recent Advances in Social Data and Artificial Intelligence 2019)
Abstract
:Electronic Learning (e-learning) has made a great success and recently been estimated as a billion-dollar industry. The users of e-learning acquire knowledge of diversified content available in an application using innovative means. There is much e-learning software available—for example, LMS (Learning Management System) and Moodle. The functionalities of this software were reviewed and we recognized that learners have particular problems in getting relevant recommendations. For example, there might be essential discussions about a particular topic on social networks, such as Twitter, but that discussion is not linked up and recommended to the learners for getting the latest updates on technology-updated news related to their learning context. This has been set as the focus of the current project based on symmetry between user project specification. The developed project recommends relevant symmetric articles to e-learners from the social network of Twitter and the academic platform of DBLP. For recommendations, a Reinforcement learning model with optimization is employed, which utilizes the learners’ local context, learners’ profile available in the e-learning system, and the learners’ historical views. The recommendations by the system are relevant tweets, popular relevant Twitter users, and research papers from DBLP. For matching the local context, profile, and history with the tweet text, we recognized that terms in the e-learning system need to be expanded to cover a wide range of concepts. However, this diversification should not include such terms which are irrelevant. To expand terms of the local context, profile and history, the software used the dataset of Grow-bag, which builds concept graphs of large-scale Computer Science topics based on the co-occurrence scores of Computer Science terms. This application demonstrated the need and success of e-learning software that is linked with social media and sends recommendations for the content being learned by the e-Learners in the e-learning environment. However, the current application only focuses on the Computer Science domain. There is a need for generalizing such applications to other domains in the future.
1. Introduction
The recommendation system (RS) creates possible options for users based on user interest [1]. The proposed recommendation system is based on information which the user gave to the system in the past. The given information may have many ratings which show that the aim of the user is to get information from a particular domain—e.g., research area, documents, tweets, etc. Based on the recommendation system architecture, the given information can be used as training data, either supervised learning or unsupervised learning—e.g., clustering or document classification problems [2,3]. In recent years, the recommendation system becomes a popular engine to implement on many websites to find the preference of users. Two main techniques which present this system are known as content-based recommendation (CB) and collaborative filtering recommendation (CF) [4,5,6]. Comparing these two systems, CF is the most often used technique. The CB system is processed as recommending similar options to the user based on user choices, and extract the target from user input information which is accessible to the user profile and also the output profile [7].
The DBLP is known as the Digital Bibliographic Library Project, which indexes more than 2 million research publications. The dump of the website is freely available for download. This dataset will help to identify top-rated articles based on learners profile, context, and history. Twitter is a microblogging website where the social community generates a large number of small text messages of 140 characters. It is noted that, daily, more than 300 million tweets are generated by the social community, expressing the opinions and sentiments related to different things. The proposed system will identify the top-rated and most popular Twitter user relevant to the user’s profile. For this, the system will perform network analysis and identify the most popular Twitter users using different social network analysis techniques, such as by measuring in-degree centrality. The centrality of a node describes its popularity. These users are matched with the current learner activity. Not getting relevant recommendations from social networks for e-learners based on the user’s context, historical data, and profiles are the problem statement.
The developed system provides recommendations from the social network for e-learners. The recommendations are based on the users’ local context, profiles, and historical data. The system is a web application that searches the required data from the Web using different sources, such as the Twitter user network and DBLP. The developed system recommends top-ranked information from these sources depending upon the context, profile, and history of e-Learners. The application also provides an interface to e-learners, where they can share their content and can read the contents shared by other users, which is relevant to them. The reinforcement learning algorithm is presented as a recommendation platform in the proposed system. Reinforcement learning is a learning algorithm which works based on user feedback. The quality control of the system improves based on the recommendation rating. As we know, the social media contents are unstructured and have a lack of trust. Based on the main architecture of the reinforcement learning, when the user gets a good recommendation then the feedback will be good and the reward sent to system is good. In this case, the system is learning the user’s request and the recommendations are also trained based on that. Similarly, if the user feedback is not good, then the system learns to avoid recommending bad articles. To look for the history of the recommendation system, first, it must find the solution to solving the problem of information overloading in Internet sources. Along with the number of uploaded files, Internet sources are relatively high, and users do not know how to control it and also spend more time and energy looking for and extracting the topic which they need. Based on the Eugene search result, the information overloading issue was discovered in the information retrieval system, and in 1950 was submitted by Moors [8]. In the proposed model, the recommendation system brings the following contribution for e-learners:
The main contribution of this paper summarized as below:
- A real-time system which provides top-ranked Twitter user networks to e-learners from Twitter, according to their context, history and profiles.
- The proposed system recommends top-ranked articles according to the e-learner’s context, e-learner’s history, and e-learner’s profiles from DBLP.
- The system also makes recommendations to e-learners from a local database.
- The main objective of this study is the use of data mining and machine learning approaches for social media content recommendation.
In this work, we proposed a social media content recommendation which provides the learning material to e-Learners. The developed system is a real-time application that identifies the required data from the Web using different sources, such as Twitter and DBLP. The designed system will recommend top-ranked information from Twitter and DBLP sources depending upon the context, profile, and history of e-Learners. The application will also provide research articles related to the users searched topic. Moreover, we have used data mining and machine learning approach to improve the accuracy of social media content recommendation. Reinforcement learning is used as a machine learning algorithm which combined with data mining techniques to extract the hidden knowledge from users tweets. Finally, we illustrate the constructiveness of reinforcement learning, which applied for prediction and recommendation of social media contents. The remainder of this paper is organized as follows: Section 2 gives the literature review of the recommendation system. Section 3 explains the data analysis for social media contents recommendation. Section 4 presents the predictive analysis of Twitter and DBLP dataset using a reinforcement learning algorithm. Section 5 presents the prediction result of Twitter and DBLP platform and, finally, we conclude the paper in Section 6.
2. Literature Review
In this section, we discuss the pros and cons of the existing recommendation system [9]. Moreover, we will also investigate the state-of-art approaches for Twitter recommendation, DBLP recommendation and recommendation based on reinforcement learning.
2.1. Recommendation System
The recommendation system is a service to help users for easy access to their request in different areas [10,11]. Tan and He [12] presented a procedure of physical resonance that is famous for resonance similarity (RES). This approach shows the comparison of superior prediction and traditional similarity based on user evaluation. Similarly, there are many IoT-based platforms, such as healthcare [13,14,15], indoor localization [16,17], and many other IoT systems [18,19,20,21,22], which have improving possibilities based on integration with the functionality of the recommendation system [23,24]. Hwang et al. [25] execute the hotel reviews for a hotel management system based on Trip Advisor review information and a Latent Dirichlet Allocation (LDA) semantic-based process to recognize and capture the performance of the Term Frequency-Inverse Document Frequency (TF-IDF) process. In the presented approach, all features related to hotels are extracted. The final results show that the LDA has less precision than word-based LDA. To make the System more accurate, Jannach et al. [26] presented regression-based and item-based recommendation. The developed recommendation systems with different researchers used collaborative filtering techniques and algorithms [27,28,29,30,31,32,33]. Collaborative filtering gets information based on user input knowledge and evaluates the relationship between different users to accomplish specific deductions of feature spaces.
2.2. Twitter Recommendation
Twitter is one of the social media platforms based on sharing, uploading user opinions and providing information about new studies, interests, etc. [34,35,36]. There are many research articles related to Twitter classification in various goals. Some tweet recommendation systems proposed Twitter as a reliable information spreader. Tweet recommendation and also Twitter users are the main research direction in this topic too [37]. Based on the proposed methodology, there are three main options to find the user influence on the Twitter platform that are named as followers, re-tweets and page rank [38]. Building the recommendation system of followers to find the differences between tweets and user profile, page rank or tweet rank estimate the efficiency of user influence to find the similarity between shared link and user profile structure. All the proposed methods in previous studies were based on the content-based recommendation to propose tweets without reflection of joint view. Tweet recommendation is to target user, using a latent factor, collaborate ranking and specific feature. User interest re-tweets are collected and estimated to establish user preference and make a recommendation. The latent factor is the improved version of collaborating ranking for ranking criterion. The latent factor is used as a parameter to increase the accuracy of system [39].
2.3. DBLP Recommendation
DBLP is one of the online and open source references for published articles in the computer science area. Based on the need for the user by visiting the DBLP website, it is comfortable and easy to access recently published or any specific articles. DBLP was developed from small experiments on web servers to famous open-data access servers in the computer science research area [40]. One of the critical parts in DBLP recommendation, based on users searching for information-related articles on their own interests, is also recommended. The user searching process is explained step by step in Figure 1. Articles contain complete information about authors, publication time, access pages, etc. [41].
2.4. Reinforcement Learning Recommendation
Recommendation, based on reinforcement learning (RL), is simplified to the Markov Decision Process (MDP). This model works as a long-run performance system. Most of the RL based systems have challenges from large-scale separated action space. There are some proposed systems for solving this issue, such as the strength of previous information about the actions around them, which generate proto-action using the k-nearest neighbor search system. This method rejects the dimensions from negative influences, which user does not care about, and replaces them through convenient action [42,43,44,45,46,47,48,49]. Moreover, MDP is used to model the recommendation process in RL. Compared with the Multi-Armed Bandit (MAB) based system, MDP cannot obtain the running frequency of reward. They try to define the state as an n-gram or model the item in MDP and define the action as the recommendation between items. This process cannot apply to the large datasets. If the candidate set item becomes more significant at the same time as the size of the state, the space also increases and transition data face sparsity problems and can just apply them on related parameters in a specified state [50,51,52,53,54]. Table 1 shows the comparison of various recommendation systems and their objectives and advantages. In the mentioned table, ten various recommendation systems are measured.
3. Social Media Content Recommendation for E-Learners
The proposed recommendation system is comprised of two main modules—a recommendation system and the predictive analysis of social media content recommendation.
3.1. E-Learners Recommendation System
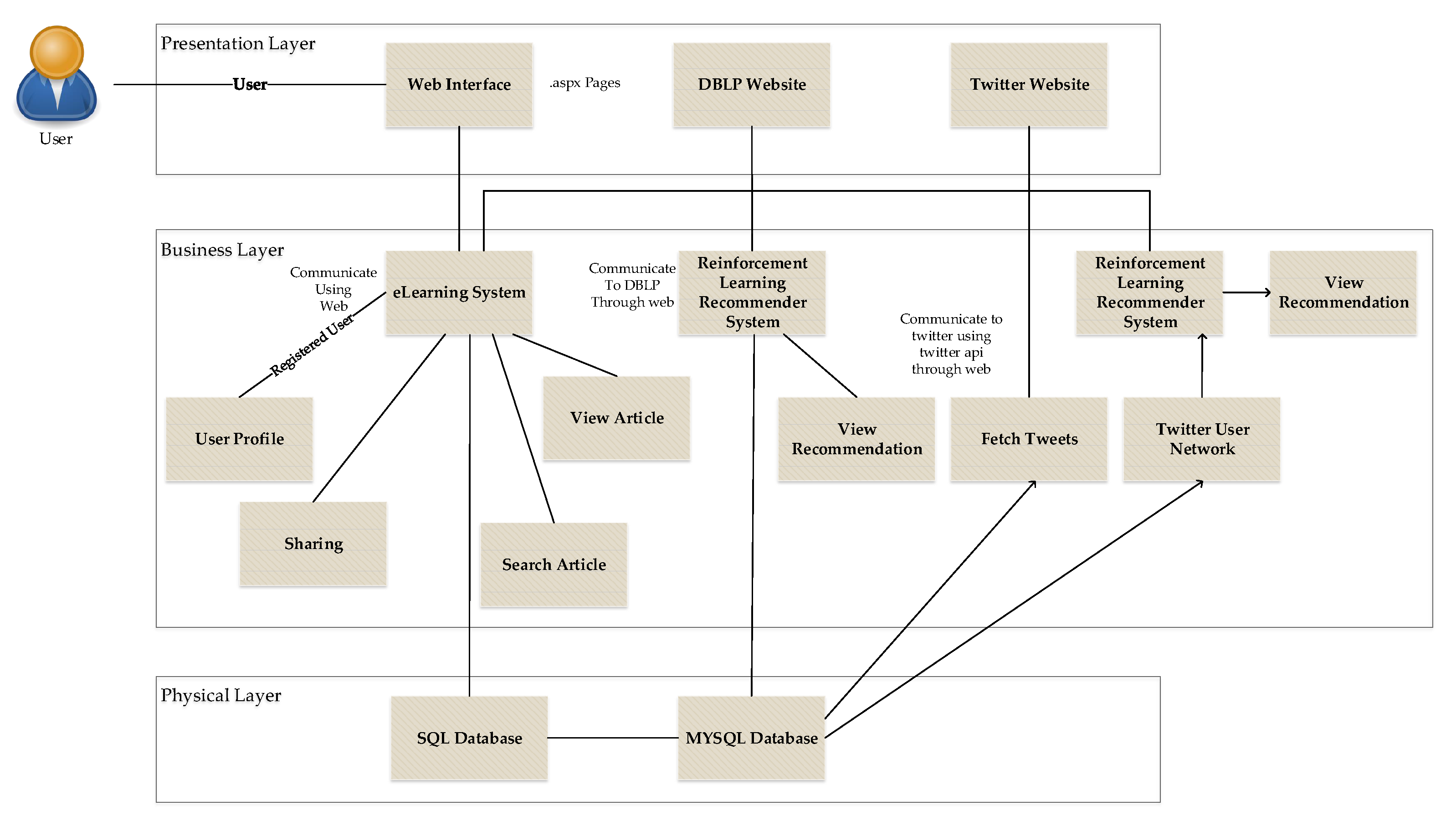
The proposed recommendation system is comprised of three-parts—presentation layer, business layer, physical layer—which are shown in Figure 2. The presentation layer is responsible for exposing the services to the front end through the user interface. The business layer represents the core functionality of the recommendation system, which is categorized into two modules—i.e., the e-learning system and the reinforcement learning-based social media content recommendation system. The e-learning system is responsible for providing relevant recommendations from social media to the e-learner. The e-learner can get top-ranked articles on the Twitter user network, which is according to the user’s interest. Similarly, the reinforcement learning-based social media content recommendation system is to use data mining and machine learning approach to improve the accuracy of social media content recommendation. Reinforcement learning is used as a machine learning algorithm, which is combined with data mining techniques to extract the hidden knowledge from users tweets. Lastly, the physical layer represents the back-end database, which is responsible for storing the data.
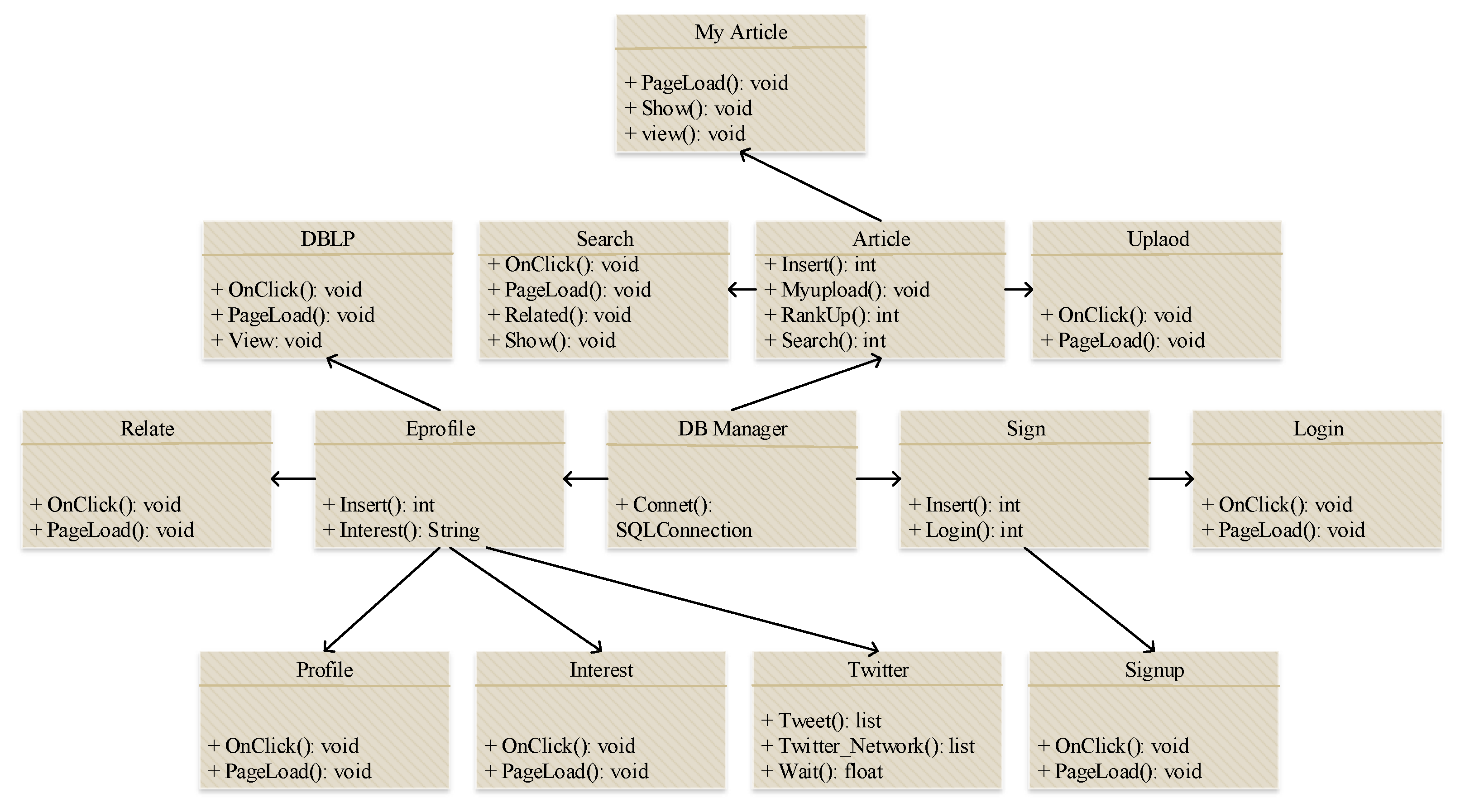
The data collection phase is one of the primary tasks in the knowledge discovery process. The knowledge discovery process identifies hidden patterns from an enormous amount of data. We perform knowledge discovery by identifying user profiles from the DBLP and Twitter website. We targeted published articles and uploaded tweets for our experiments and the data crawling process was customized accordingly. Table 2 shows the detailed information of collected Twitter and DBLP datasets. Figure 3 shows the class diagram of the data collection process.
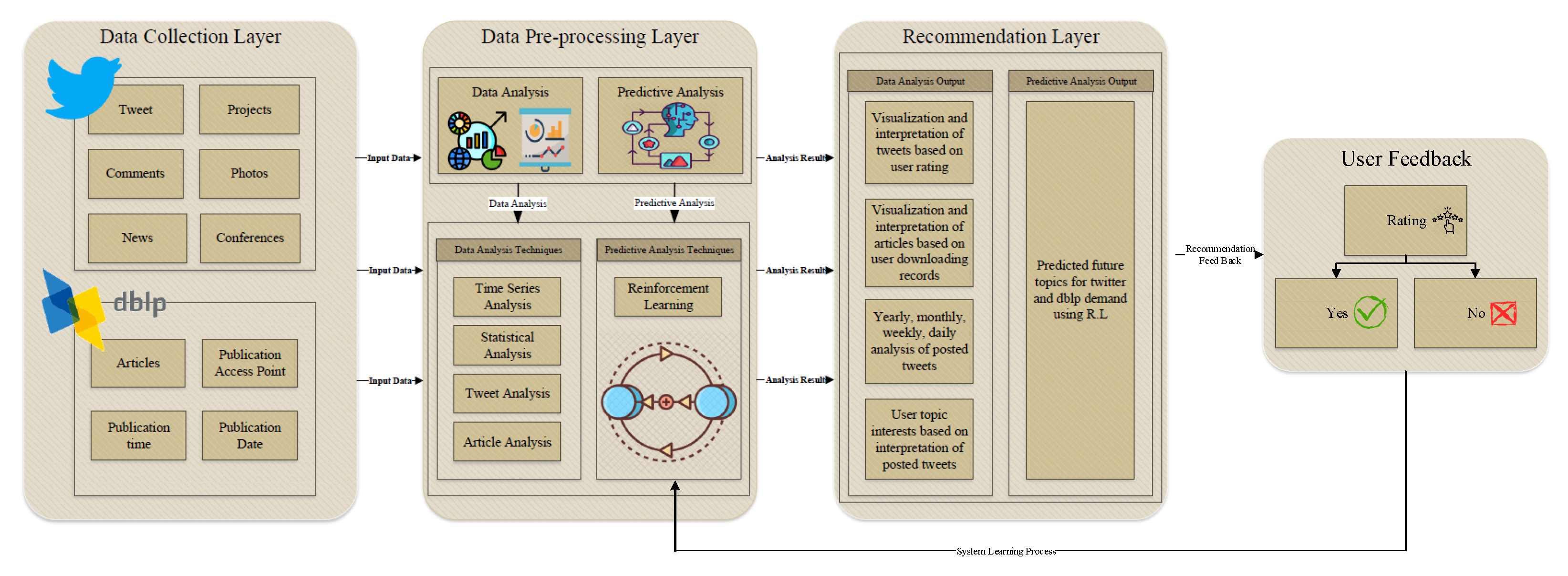
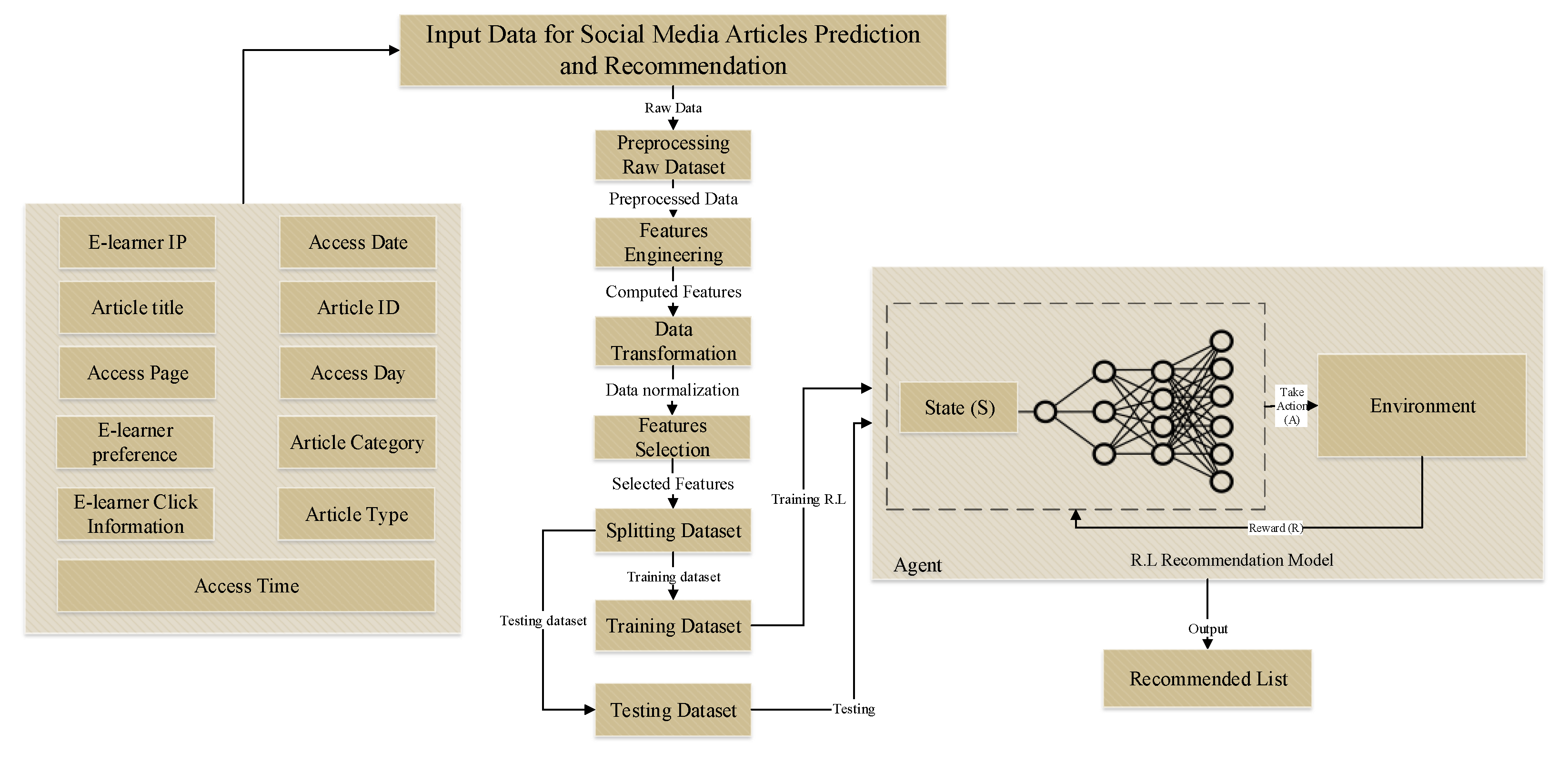
In total, two open-access social media websites were selected for this process, which contain comments, tweets, short texts and research articles. A total of 70% of the dataset was used in the training set and 30% for the test set. The primary block diagram of the proposed system is shown in Figure 4. The designed block diagram of the proposed data and predictive analysis model based on Twitter and DBLP platform is composed of four main sections. The first section is designed as a data collection layer. The data collection section contains two social media platform datasets, named Twitter and DBLP library. The collected dataset from the Twitter platform includes tweets, projects, comments, photos, news and conferences. The collected dataset from the DBLP platform includes articles, publication access point, publication time and publication date. To process the collected dataset for further steps, two data analysis techniques were applied in this process which are in the second section or the pre-processing data section. Data analysis and predictive analysis technique was applied to the input dataset. The data analysis technique contains the time series analysis, statistical analysis, tweet analysis and article analysis. The predictive analysis contains reinforcement learning prediction techniques. The next section is the recommendation layer. It presents the output information of the previous steps and relevant recommendation results based on user preferences. The final section is the user feedback, which is the main point of this system to improve the quality of the recommendation. Based on using the reinforcement learning algorithm as a recommendation technique, the system learns from user positive and negative responses to the agent and by repeating this process, improving the system recommendation and trust quality.
3.2. Dataset
In this system, the collected dataset is from “Twitter social media platform records (Twitter API)” and “DBLP research library history” to analyze and explore the hidden information for improving the recommendation system. Data mining approaches and techniques were applied in the proposed dataset to clean and pre-process it to refine the performance and stability of dataset. Moreover, the following steps were performed to process a better service for e-learners on the social media platform:
- Collecting data;
- Cleaning data;
- Manipulate missing values;
- Missing value extraction;
- Discovering the available features.
After managing the social media dataset and enterprising the information, data pre-processing was applied for further process for normalizing dataset and for keeping the necessary information. Data normalization was needed for changing the data form and structure to make it convenient for further steps. The following Table 3 presents the extracted information and features from a dataset.
3.3. Data Mining and Visualization
In the proposed system, we applied data mining techniques to determine the necessary and useful information from the dataset for a suitable recommendation, based on user interest. The mentioned analysis below exploits the collected dataset:
- Twitter and DBLP article recommendation for e-learners based on tweet frequency, selected articles and user preference;
- Time series analysis based on Monthly and daily analysis;
- Twitter and DBLP platform analysis based on e-learner preferences;
- Twitter and DBLP platform analysis based on e-learner clicked links;
3.3.1. Time Series Analysis
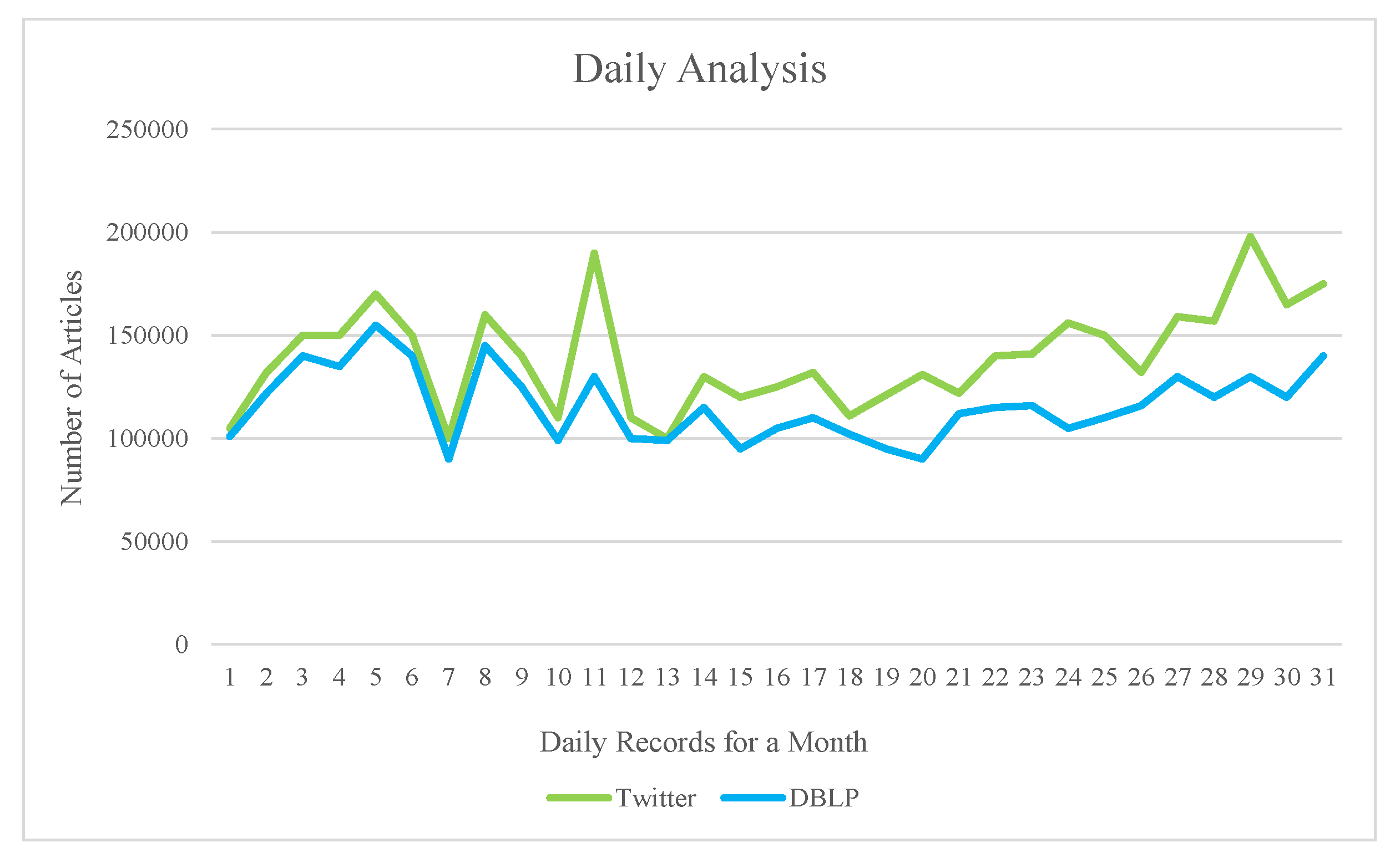
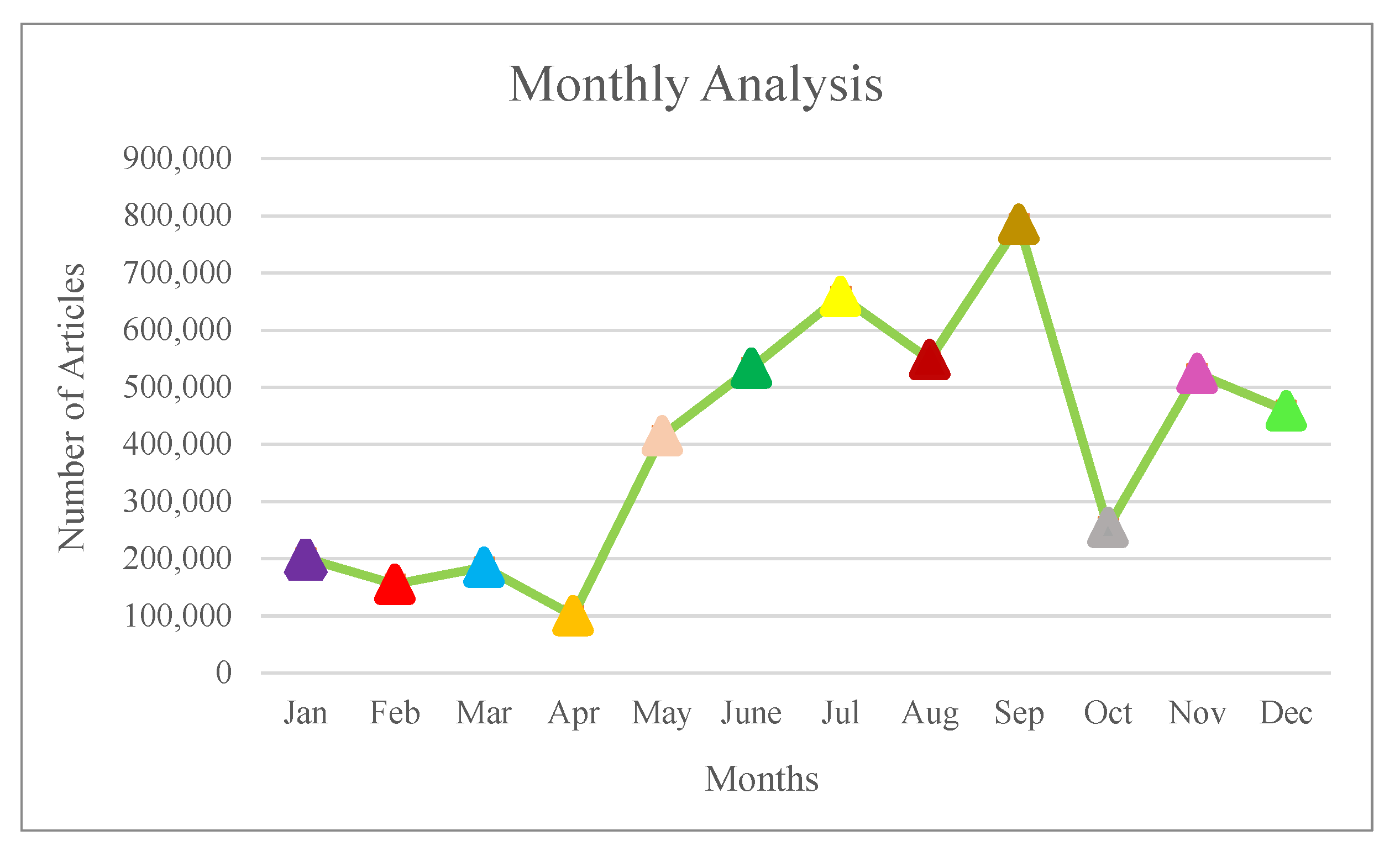
Time series analysis applied in this process to produce the new information for article recommendation. The selected analysis is based on the date and time of sharing information which is available in the dataset. To inform the time series analysis, the duration of data is for (2019) crawled information from mentioned platforms. To start the analysis data segregated into two sections (monthly and daily) to produce the Twitter and DBLP frequency. Figure 5 and Figure 6 present the daily and monthly basis of recommendation to e-learners. Daily basis records show the total record of the user activities in one day, and monthly basis shows the total record of the monthly user activities.
3.3.2. Twitter API Analysis Based on Profile Address
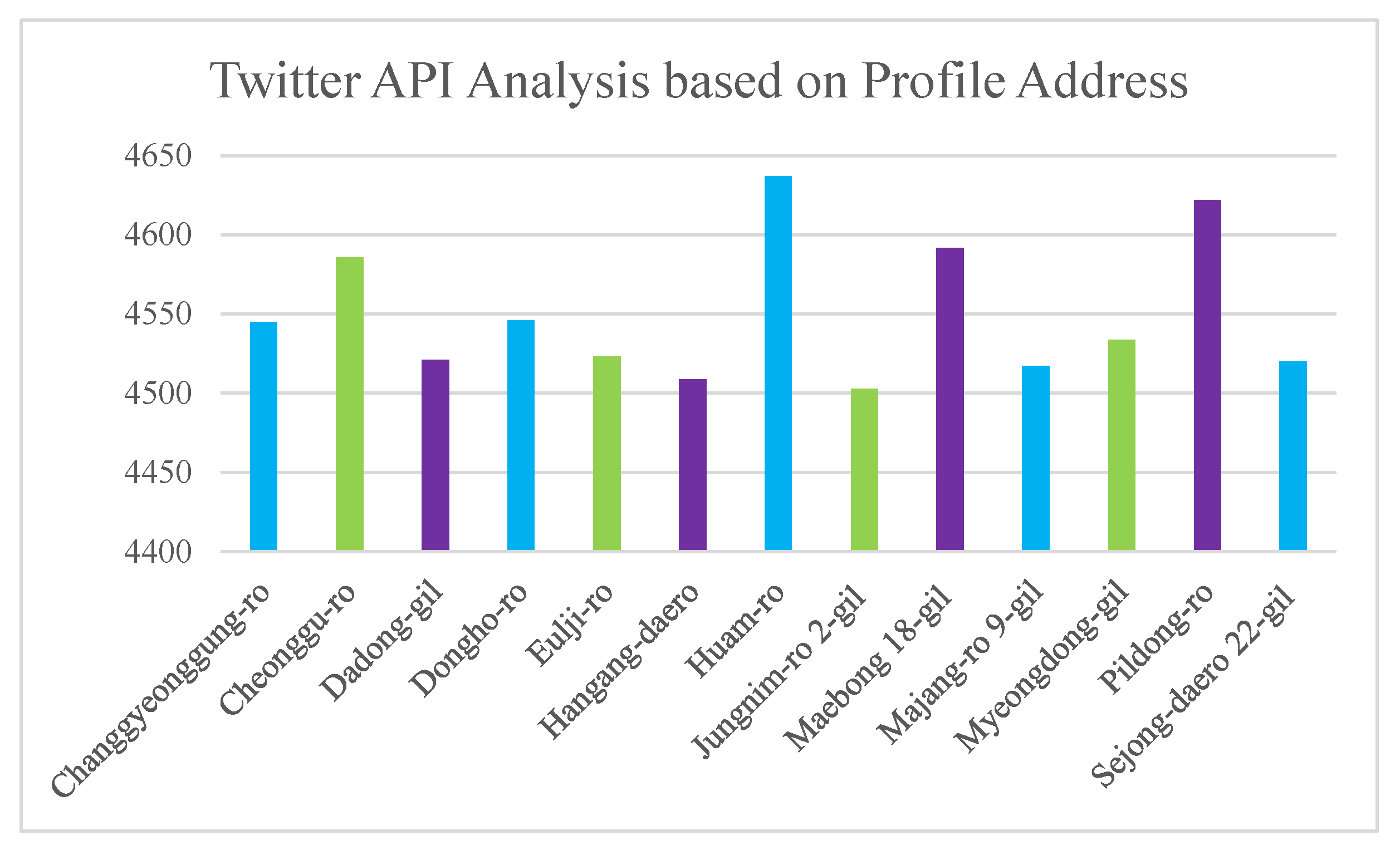
In this part, profile address analysis accomplishes analyzing the Twitter API dataset. To visualize Twitter API, based on profile address, street names are extracted from profiles and apply them as location labels to visualize the Twitter frequency. The following parameters—e.g., profile address and tweet topics— are used as inputs of visualization based on Twitter API profile addresses. The following Figure 7 describes the minimum and maximum updates based on profile addresses. The following address is randomly selected from the dataset. Each location presenting one area based on the profile addresses.
3.4. Discover Patterns and Features
Using data mining techniques improve the process to extract the hidden information from the generated results. Table 4 presents the details of the extracted features from a dataset. The prediction process in the proposed system causes improved system performance and, similarly, recommends highly related information to the e-learner.
3.5. Interaction Model for the Proposed Recommendation Platform
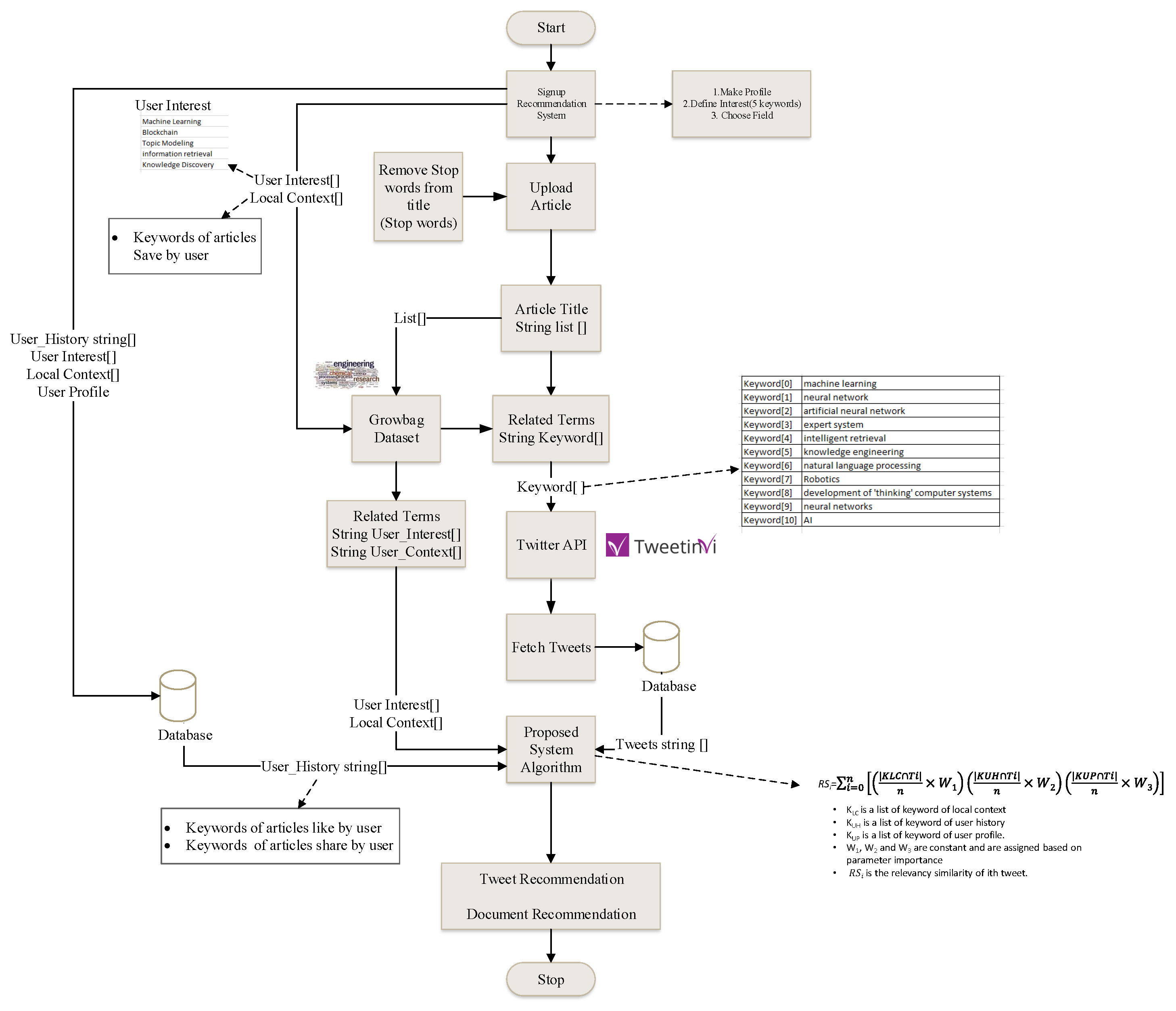
The work-flow of the proposed RL recommendation model is illustrated in Figure 8. The developed system is comprised of the technical infrastructure of the system. Tweets will be fetched from Twitter using Twitter API (tweet environment). Whenever any user uploads an article in the System, the System will remove the noise data from the title of the article. Afterwards, the system will make a list of words which contain the title words and terms related to these words. The grow bag will provide the related terms. Against each word from the list, tweets will be fetched and will be saved in the database. When any e-learner wants the recommendations from Twitter against any article, the System will make two lists of words. The first list will contain the interest and terms related to the interest of an e-learner. The second list will contain the local context and terms related to the local context of the e-learner. The system will get all the tweets which were saved in the database against that article. The system will match the sub-strings of each tweet with the words of both lists. Whenever any word matches with a tweet, one score will be added to the score of that tweet and will recommend the top tweet to the user.
Tweets are ranked by using the following Equation (1).
is a list of keywords of local context. is a list of keywords from the user history. is a list of keyword from the user profile. , and are constants and are assigned based on parameter importance. is the relevancy similarity of the tweet.
4. Predictive Analysis of Twitter and DBLP Data Using Reinforcement Learning
The availability of a considerable amount of digital articles and tweets pose a challenge to discover highly relevant contents for e-learners. Current search approaches have inherited problems and use a limited set of parameters for searching the meta-data, mainly based upon the indexed keywords only. This is not enough for the users, and users are often frustrated, mainly due to the availability of a huge number of search results for a searched query. There is a need for the system, especially for the e-learners community, which can provide online real-time information from social media to the e-learner. E-learners can get top-ranked articles from the Twitter user network, which is according to the user’s interest. A recommendation of social networks for the e-learner is a system that will provide the learning material to the e-Learners. The system will be a web application that will search for the required data from the Web using different sources, such as the Twitter user network and DBLP. The developed system will recommend top-ranked information from these sources depending upon the context, profile, and history of e-Learners. The application will also provide research articles related to the users searched topic. The system inputs would be the usage and viewing history of users and user profiles built by the users and the user local context. Based on this information, the system will find research articles from DBLP and Twitter users from the Twitter microblogging website.
This section presents the predictive analysis related to generated knowledge and details based on the previous sections. The presented tweet and article recommendations for e-learners are shown in Figure 9. The Applied Reinforcement Learning machine learning technique is the proposed system for recommending tweets and articles to e-learner users. The presented process predictive analysis is divided into three main sections. The first section contains the input data collected from social media platforms. The data provide the information related to e-learners IP, article title, access page, e-learner preference, e-learner click information, access date, article ID, access day, article category, article type and access time. They move to the second section, before training the dataset, pre-processing, feature engineering, data transformation and feature selection is applied to make the dataset ready for further process. After splitting the data in the train and test set, a reinforcement learning technique is applied for recommending the information, based on user preferences.
Reinforcement Learning Optimization
Reinforcement learning recommendation system contains various methods to optimize user interest. In this process, user interest directly optimizes by using FeedRec [65] through the simulation process. To do this, we need the find to “ground truth” of the system to get the maximum user engagement. Based on this, the processing algorithm shows if it is possible to get the optimal policy and maximized user engagement delay. The procedure of simulating is defining with a mini-batch SGD by applying the predicted dataset. This dataset prepared based on prediction policy and is immediately used as a manufacturing simulator. To get the efficiency of prediction policy , the main loss in weight is minimized as in Equations (2) and (3).
N is defined as the total number of directions in the predicted dataset. To reduce the disparity, is defined as the significant ratio between . is the policy which extracted from the Q-network—e.g., ∈-greedy. Cross entropy is defined as , which shows the loss function. c is defined as the hyper-parameter to avoid from the large ratio. The multi-task loss function is defined as for evaluating the comparison between regression loss and multi-task loss and is defined as a hyper-parameter controller to evaluate the various tasks. Based on the updates from , the extracted from the Q-network is continuously changing. To keep the standard policies adaptive, as well as , the S network also saves changes to ensure the optimal accuracy. To improve user satisfaction in previous research, diversity was mentioned as an effective process for the recommendation. Similarly, it is an unintentional system to optimize user engagement. Based on the above-mentioned FeedRec framework, it is possible to optimize user engagement through various means in diversity immediately. To generate the simulation data, two types of lists are defined as user engagement and a list of recommendations.
1. Linear Style: In this process, the most satisfying results belong to a linear relationship with higher entropy. Based on this, the user can get more information and also use the system often. The probability of the user in using the system and searching for articles is defined as Equation (4).
The article recommendation system is defined as , and the meaning of entropy is defined as . x and y are used in the range of .
2. Quadratic Style: The highly user satisfaction made by moderate entropy. The probability of user in using a system and searching for articles is defined as Equation (5).
The above evaluations show the relationship between the user and system agent. The output of this process shows that FeedRec contains the ability to fit various types of dispensation among the entropy of recommendation list and user engagement.
5. Prediction Result of Twitter and DBLP Platform
In this section, the development environment, prediction results and implementation process of the proposed recommendation system for e-learners are presented in detail.
5.1. Experimental Environment and Setup
The implementation of the proposed model structure and environment is presented in this section. Table 5 summarizes the experimental set up of the proposed model. All experiments and results of the system are carried out using Intel(R) Core(TM) i7-8700 CPU @3.20 GHz 3.19 GHz processor with 32 GB memory. The reinforcement learning technique used for the recommendation system. Similarly, the library and framework used in the proposed system is Jupyter notebook. The programming language used in the designing of this System is WinPython–3.6.2.
5.2. Performance Evaluation
The selected users are bachelors, masters and PhD students. The ranked tweets by the system are given to users for evaluation. For each query, nine tweets are given to the users—three out of nine belong to categories: context-based recommendations, profile-based recommendations, and history-based recommendations. In this evaluation a form is provided to each user. The evaluation form consists of user’s personal information, and a scenario, keyword and ranked tweet relevant to that keyword. For the evaluation form, the user reads the scenario and checks the keyword relevance with the tweets. The user reads the first tweet if this tweet is relevant to the given keyword then the user marks this tweet as relevant or otherwise irrelevant. The user does the same steps for all tweets. According to the result, the context has high weight over profile and history. The mentioned weight is calculated by using the following Equations (6)–(8).
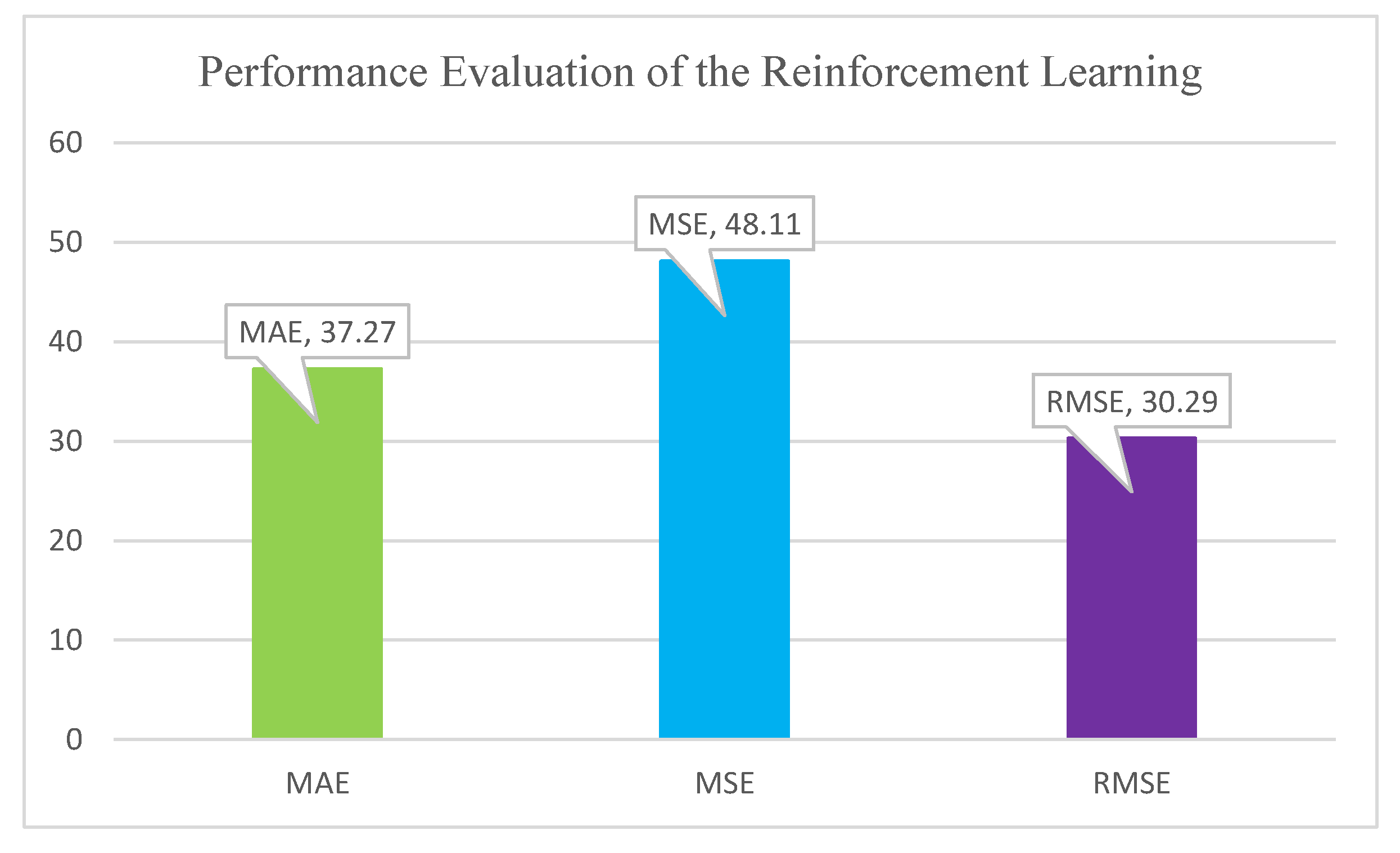
Performance evaluation describes the formal procedure to estimate the model performance results. To specify the movement of our model, we applied three statistical evaluation method listed as Mean Square Error (MSE), Mean Absolute Error (MAE) and Root Mean Square Error (RMSE).
- Mean Square Error This statistical evaluation measure the relationship between predicted value and actual value based on the mentioned Equation (9).
- Mean Absolute ErrorThis statistical evaluation measures the square of differences between predicted value and actual value based on the mentioned Equation (10).
- Root Mean Square ErrorThis statistical evaluation measure the error rate, error size based on the target value which mentioned in Equation (11).
5.3. Prediction Results
Prediction results contain the output of the experiments based on the above-mentioned machine learning regression algorithms. This process contains 10 top related values based on e-learner requests and activities. All the experiments and machine learning algorithms were implemented in winpython programming environment. Figure 10 presents the efficiency of the operated models.
5.4. Recommendation Results
Based on the proposed process of the recommendation system on social media contents for e-learners, the reinforcement learning recommendation shows the system output on state, reward, loss and model frequency. Table 6 presents system response time detail information. Response time shows the output for three-timing information, containing loading time, searching time and execution time. Loading time is the time that it takes the user to load the web page. Searching time is the time it takes that user to search for the unique contents, and execution time is the time it takes to show the final search result.
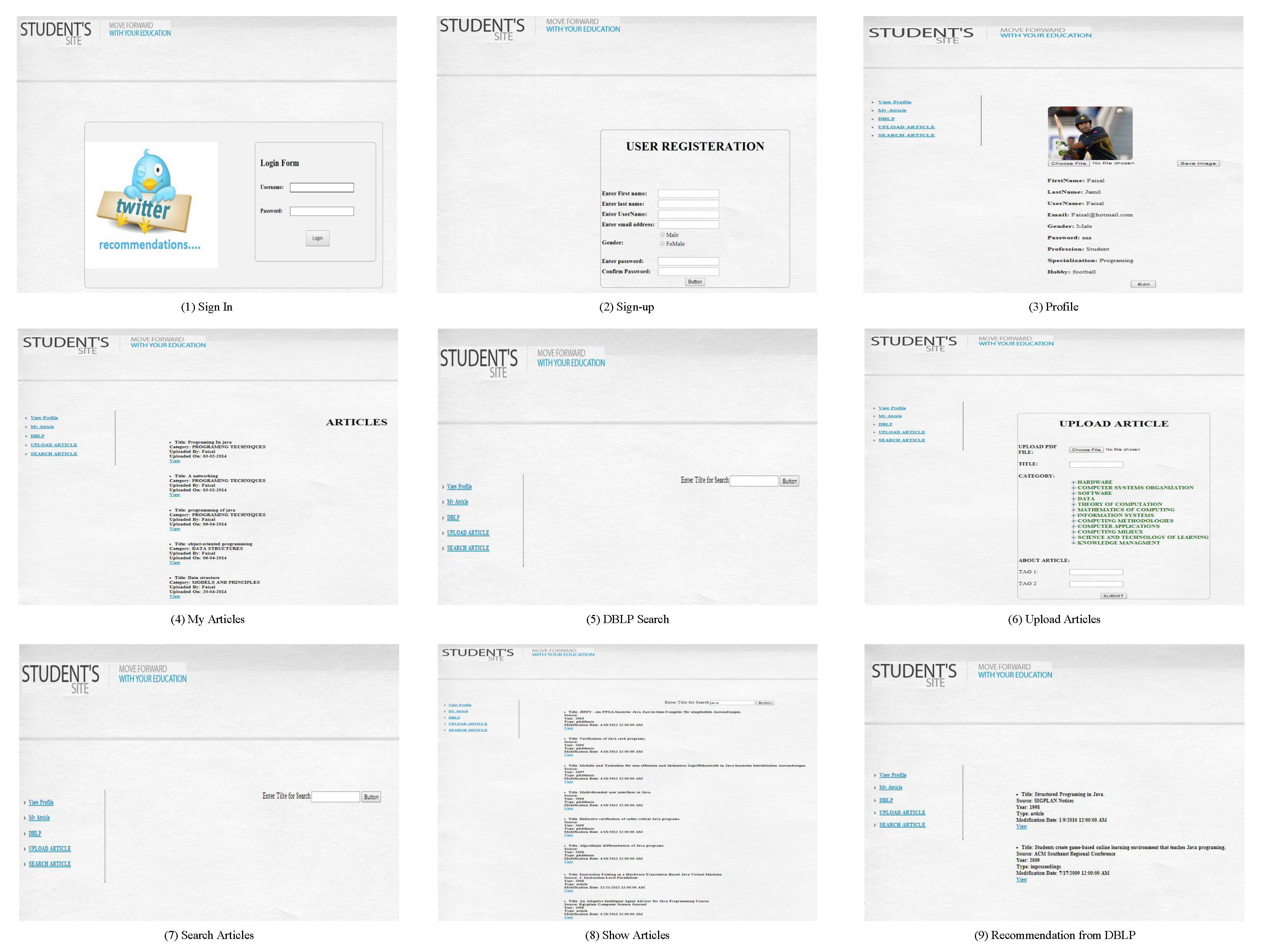
The main interface is shown in Figure 11. It gives two options “Sign in” and “Sign up”. The user selects the appropriate option as per their requirement. When a user selects the “Sign up” option, the user is redirected to the figure shown as (2), sign up. The registration process of users is shown in (2). Clicking on the “Sign up” option requires the user to fill in the personal information. Once the user selects the “Save” button, the form is sent to the server, and the user account has been made. The profile information of users is shown in (3). It gives multiple options “Edit”, “Choose File”, “View Profile”, “My Articles”, etc. The user selects the appropriate option as per their requirement. Selecting the “Edit” option allows them to update their profile information. Selecting the “My Articles” option shows the uploaded articles by the user shown in (4). When the user clicks on the “My Articles” button, it gives multiple options, such as, “View”, “DBLP”, “View Profile”, “My Articles”, “Upload Articles”, etc. The user selects the appropriate option based on their requirement. Selecting the “View” option redirects them to the same page where the user can read the selected article. When the user selects the “DBLP” option, it gives multiple options, such as, “Search (Button)”, “DBLP”, “View Profile”, “My Articles”, “Upload Articles”, etc. The user selects the appropriate option as per their requirement. The user needs to fill the text box with the appropriate article name. When the user selects the “Search (Button)”, they are redirected to the (9), where the user can see the recommendation from “DBLP”. When the user selects the “Upload Articles” option, they are redirected to the (6), in which they can click on the “Upload Articles” button. It gives multiple options, such as, “Save (Button)”, “Choose File”, “DBLP”, “View Profile”, “My Articles”, “Upload Articles”, etc. In (6), the user needs to fill in the article information to upload articles in the system. Once the user selects the “Save” button, the form is sent to the server, and the articles are uploaded successfully. When the user selects the “Search Articles” option, then the system redirects to (5), where they can search for articles from the system. The articles against user query are shown in (8). It gives multiple options “View”, “DBLP”, “View Profile”, “My Articles”, “Upload Articles”, etc. When the user selects “View”, they are redirected to the same page where the user can read the selected article. The recommendation from DBLP is shown in (9).
Comparison and Baseline
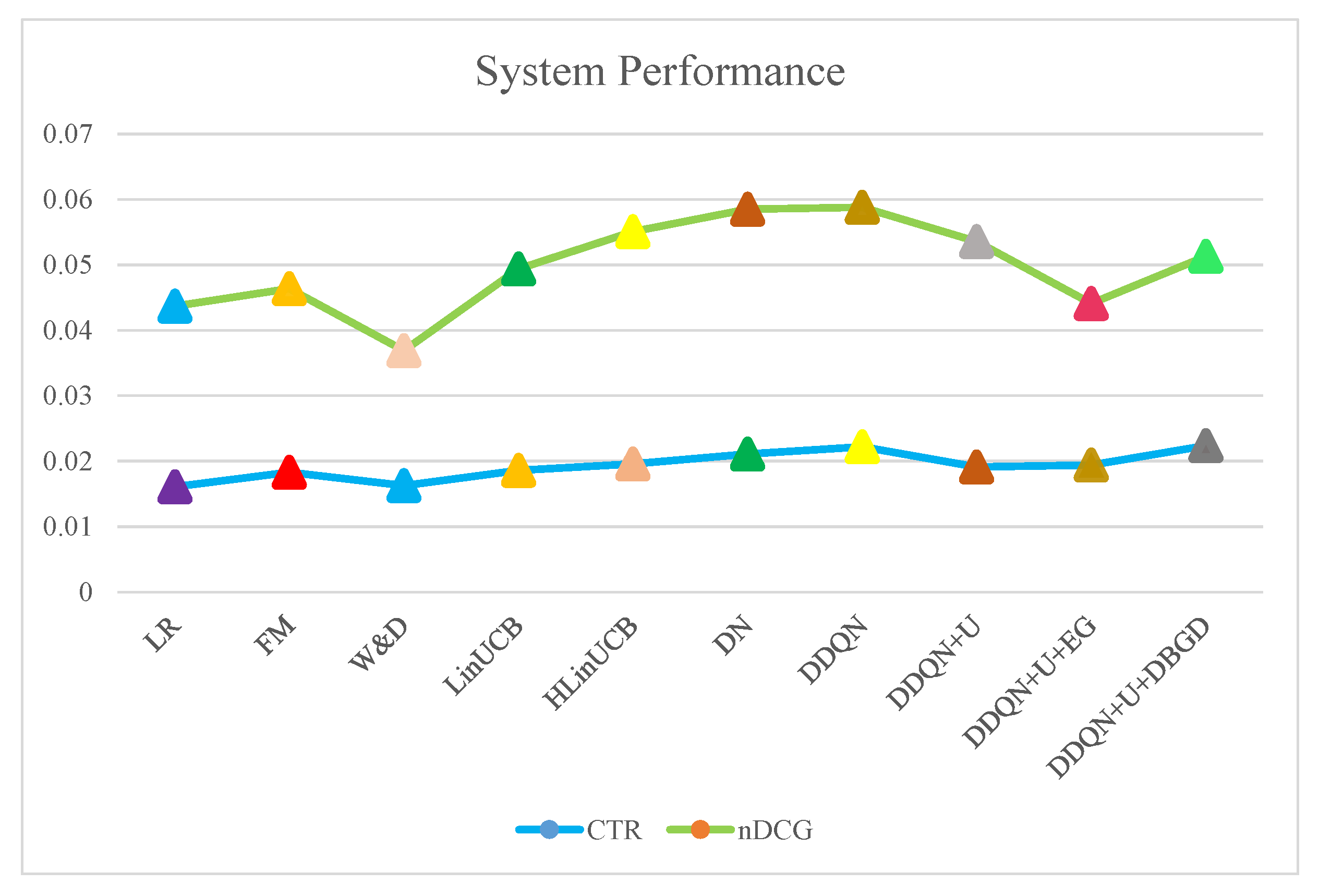
Based on the proposed recommendation system, various algorithms compare together to show the system performance. Using the future reward (DDQN) increases the RL recommendation result above the (DN). Similarly, (DBGD) applied as an exploration system using ∈-greedy to pass the system loss. Figure 12 shows the detail of system performance. In total, ten techniques are compared to get the system performance result. The applied techniques are defined as LR, FM, W&D, LinUCB, HLinUCB, DN, DDQN, DDQN+U, DDQN+U+EG and DDQN+U+DBGD. Based on the comparison, DDQN+U+DBGD has the highest score. Applying EG to DDQN+U, did not have much effect on improving the accuracy of the system.
Table 7 presents the diversity of user clicks that were measured by using cosine similarity. The smallest output represents better diversity. Similarly, some baseline methods—e.g., HLineUCB—achieve relatively equivalent recommendation diversity, which demonstrates UCB can get sensible result too.
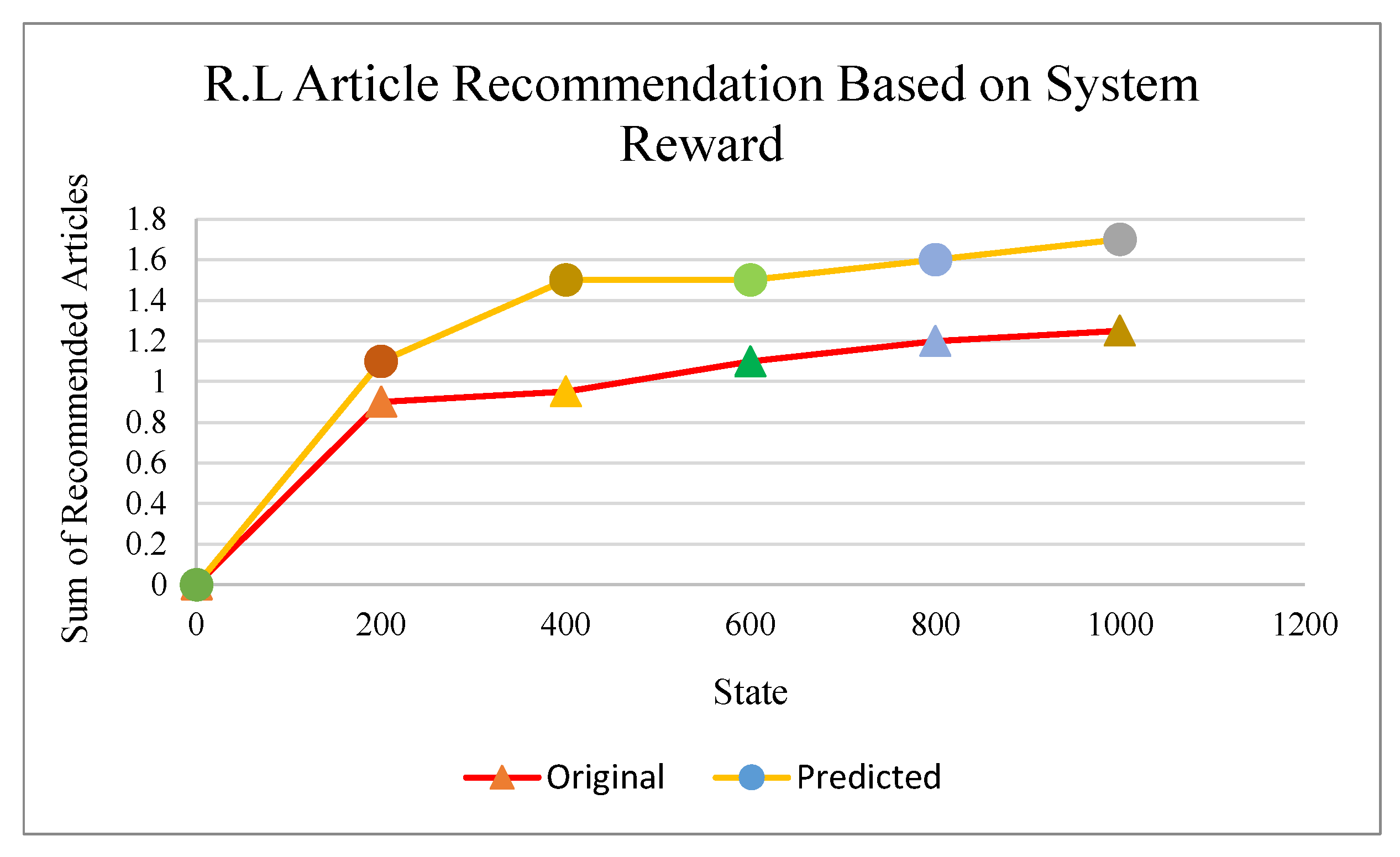
Figure 13 shows the preferences based on the system rewards. The presented reward is based on the recommended articles and total available articles.
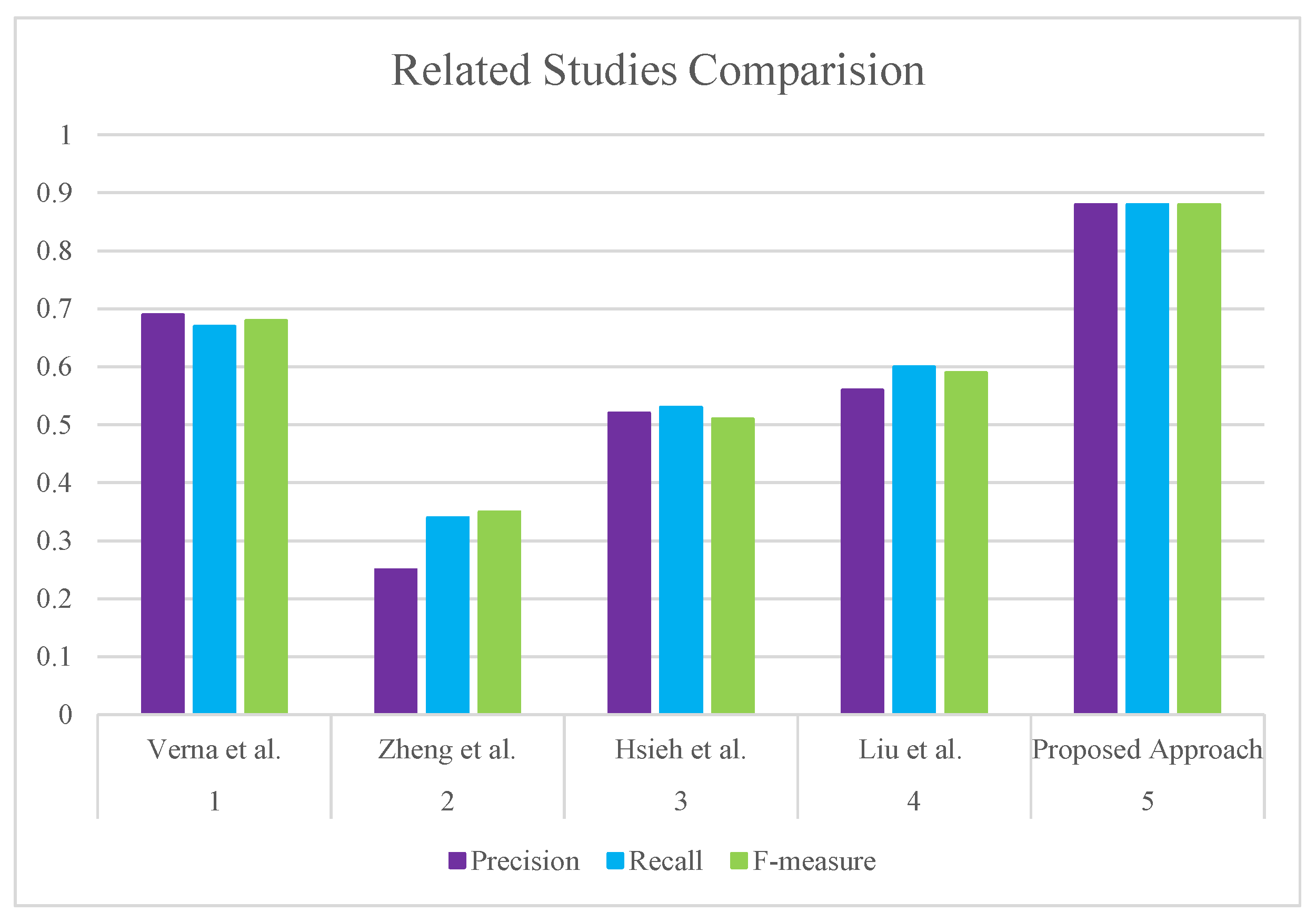
Figure 1 shows the comparison of different studies related to our topic. In this figure, we compare the presented result with four recent research articles on the recommendation system, and it shows the proposed result that an F-measure output of 88% has a better consequence. The mentioned studies are proposed by Verma et al. [66], Zhang et al. [67], Hsieh et al. [68] and Liu et al. [69].
6. Conclusions and Future Work
In this paper, we present a reinforcement learning framework to customize online Twitter and DBLP article recommendation. The main differences between the proposed method and other methods are the efficient modeling of the articles, comments, user’s feature, and also the design of explicitly reach a great reward. Based on the user clicks on URLs and user searching process, the system obtains more information from user feedback. Similarly, using the effective exploration strategy in this framework increases the recommendation diversity and also gets more reward recommendations. Experimental results suggest that the proposed system has higher accuracy for recommendation diversity and can distribute in other recommendation systems too. The system quality control and trust rely on user rating and feedback, which is the main concept of reinforcement learning. In the future, we are planning to develop the offline recommendation evaluation and generate other types of methods using the proposed framework.
Author Contributions
Data curation, Z.S.; Funding acquisition, Y.C.B.; Investigation, Z.S.; Methodology, Z.S.; Project administration, Y.C.B.; Supervision, Y.C.B. All authors have read and agreed to the published version of the manuscript.
Funding
Following are results of a study on the “Leaders in INdustry-university Cooperation+” Project, supported by the Ministry of Education and National Research Foundation of Korea.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Rabiu, I.; Salim, N.; Da’u, A.; Osman, A. Recommender System Based on Temporal Models: A Systematic Review. Appl. Sci. 2020, 10, 2204. [Google Scholar] [CrossRef] [Green Version]
- Pornwattanavichai, A.; Jirachanchaisiri, P.; Kitsupapaisan, J.; Maneeroj, S. Enhanced Tweet Hybrid Recommender System Using Unsupervised Topic Modeling and Matrix Factorization-Based Neural Network. In Supervised and Unsupervised Learning for Data Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 121–143. [Google Scholar]
- Yan, L.; Liu, Y. An Ensemble Prediction Model for Potential Student Recommendation Using Machine Learning. Symmetry 2020, 12, 728. [Google Scholar] [CrossRef]
- Jun, H.J.; Kim, J.H.; Rhee, D.Y.; Chang, S.W. “SeoulHouse2Vec”: An Embedding-Based Collaborative Filtering Housing Recommender System for Analyzing Housing Preference. Sustainability 2020, 12, 6964. [Google Scholar] [CrossRef]
- Sánchez-Moreno, D.; López Batista, V.; Muñoz Vicente, M.D.; Sánchez Lázaro, Á.L.; Moreno-García, M.N. Exploiting the User Social Context to Address Neighborhood Bias in Collaborative Filtering Music Recommender Systems. Information 2020, 11, 439. [Google Scholar] [CrossRef]
- Bai, Y.; Jia, S.; Wang, S.; Tan, B. Customer Loyalty Improves the Effectiveness of Recommender Systems Based on Complex Network. Information 2020, 11, 171. [Google Scholar] [CrossRef] [Green Version]
- Jebur, A.A.; Atherton, W.; Al Khaddar, R.M.; Loffill, E. Settlement prediction of model piles embedded in sandy soil using the Levenberg–Marquardt (LM) training algorithm. Geotech. Geol. Eng. 2018, 36, 2893–2906. [Google Scholar] [CrossRef]
- Luh, D.; Yang, T. Museum recommendation system based on lifestyles. In Proceedings of the 2008 9th International Conference on Computer-Aided Industrial Design and Conceptual Design, Kunming, China, 22–25 November 2008; pp. 884–889. [Google Scholar]
- Molnár, G. Challenges and opportunities in virtual and electronic learning environments. In Proceedings of the 2013 IEEE 11th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 26–28 September 2013; pp. 397–401. [Google Scholar]
- Kim, J.; Wi, J.; Jang, S.; Kim, Y. Sequential Recommendations on Board-Game Platforms. Symmetry 2020, 12, 210. [Google Scholar] [CrossRef] [Green Version]
- Cintia Ganesha Putri, D.; Leu, J.S.; Seda, P. Design of an Unsupervised Machine Learning-Based Movie Recommender System. Symmetry 2020, 12, 185. [Google Scholar] [CrossRef] [Green Version]
- Tan, Z.; He, L. An efficient similarity measure for user-based collaborative filtering recommender systems inspired by the physical resonance principle. IEEE Access 2017, 5, 27211–27228. [Google Scholar] [CrossRef]
- Jamil, F.; Hang, L.; Kim, K.; Kim, D. A novel medical blockchain model for drug supply chain integrity management in a smart hospital. Electronics 2019, 8, 505. [Google Scholar] [CrossRef] [Green Version]
- Jamil, F.; Iqbal, M.A.; Amin, R.; Kim, D. Adaptive thermal-aware routing protocol for wireless body area network. Electronics 2019, 8, 47. [Google Scholar] [CrossRef] [Green Version]
- Jamil, F.; Ahmad, S.; Iqbal, N.; Kim, D.H. Towards a Remote Monitoring of Patient Vital Signs Based on IoT-Based Blockchain Integrity Management Platforms in Smart Hospitals. Sensors 2020, 20, 2195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jamil, F.; Kim, D.H. Improving Accuracy of the Alpha–Beta Filter Algorithm Using an ANN-Based Learning Mechanism in Indoor Navigation System. Sensors 2019, 19, 3946. [Google Scholar] [CrossRef] [Green Version]
- Jamil, F.; Iqbal, N.; Ahmad, S.; Kim, D.H. Toward Accurate Position Estimation Using Learning to Prediction Algorithm in Indoor Navigation. Sensors 2020, 20, 4410. [Google Scholar] [CrossRef]
- Ahmad, S.; Jamil, F.; Khudoyberdiev, A.; Kim, D. Accident risk prediction and avoidance in intelligent semi-autonomous vehicles based on road safety data and driver biological behaviours. J. Intell. Fuzzy Syst. 2020, 38, 4591–4601. [Google Scholar] [CrossRef]
- Jamil, F.; Kim, D. Payment Mechanism for Electronic Charging using Blockchain in Smart Vehicle. Korea 2019, 30, 31. [Google Scholar]
- Shahbazi, Z.; Byun, Y.C. Towards a Secure Thermal-Energy Aware Routing Protocol in Wireless Body Area Network Based on Blockchain Technology. Sensors 2020, 20, 3604. [Google Scholar] [CrossRef]
- Khan, P.W.; Byun, Y. A Blockchain-Based Secure Image Encryption Scheme for the Industrial Internet of Things. Entropy 2020, 22, 175. [Google Scholar]
- Khan, P.W.; Byun, Y.C.; Park, N. IoT-Blockchain Enabled Optimized Provenance System for Food Industry 4.0 Using Advanced Deep Learning. Sensors 2020, 20, 2990. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Hazra, D.; Park, S.; Byun, Y.C. Toward Improving the Prediction Accuracy of Product Recommendation System Using Extreme Gradient Boosting and Encoding Approaches. Symmetry 2020, 12, 1566. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Byun, Y.C. Product Recommendation Based on Content-based Filtering Using XGBoost Classifier. Int. J. Adv. Sci. Technol. 2019, 29, 6979–6988. [Google Scholar]
- Hwang, S.Y.; Lai, C.Y.; Jiang, J.J.; Chang, S. The identification of noteworthy hotel reviews for hotel management. Pac. Asia J. Assoc. Inf. Syst. 2014, 6, 1. [Google Scholar] [CrossRef]
- Jannach, D.; Gedikli, F.; Karakaya, Z.; Juwig, O. Recommending Hotels Based on Multi-Dimensional Customer Ratings. ENTER. aau.at. 2012, pp. 320–331. Available online: https://0-link-springer-com.brum.beds.ac.uk/chapter/10.1007/978-3-7091-1142-0_28 (accessed on 30 August 2020).
- Ishtiaq, S.; Majeed, N.; Maqsood, M.; Javed, A. Improved scalable recommender system. Nucleus 2016, 53, 200–207. [Google Scholar]
- Jazayeriy, H.; Mohammadi, S.; Shamshirband, S. A fast recommender system for cold user using categorized items. Math. Comput. Appl. 2018, 23, 1. [Google Scholar] [CrossRef] [Green Version]
- Kanimozhi, K.S.M.L. Item Based Collaborative Filtering Approach for Big Data Application. Semantic Scholar. 2014. Available online: https://www.semanticscholar.org/paper/Item-based-Collaborative-filtering-approach-for-Big-Sudha-Lavanya/ffacdc02904cb34614a59c26645e031af32c4a28?p2df (accessed on 30 August 2020).
- Linden, G.; Smith, B.; York, J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef] [Green Version]
- Manu, M.; Ramesh, B. Single-criteria collaborative filter implementation using Apache Mahout in big data. Int. J. Comput. Sci. Eng. Open Access 2017, 5, 7–13. [Google Scholar]
- Morozov, S.; Zhong, X. The evaluation of similarity metrics in collaborative filtering recommenders. In Proceedings of the Hawaii University International Conferences, Honolulu, HI, USA, 10–12 June 2013. [Google Scholar]
- Shambour, Q.; Hourani, M.; Fraihat, S. An item-based multi-criteria collaborative filtering algorithm for personalized recommender systems. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 274–279. [Google Scholar] [CrossRef] [Green Version]
- Gupta, V.; Hewett, R. Real-Time Tweet Analytics Using Hybrid Hashtags on Twitter Big Data Streams. Information 2020, 11, 341. [Google Scholar] [CrossRef]
- Doulamis, A.; Voulodimos, A.; Protopapadakis, E.; Doulamis, N.; Makantasis, K. Automatic 3D Modeling and Reconstruction of Cultural Heritage Sites from Twitter Images. Sustainability 2020, 12, 4223. [Google Scholar] [CrossRef]
- Resende de Mendonça, R.R.d.; Felix de Brito, D.F.d.; de Franco Rosa, F.d.F.; dos Reis, J.C.; Bonacin, R. A Framework for Detecting Intentions of Criminal Acts in Social Media: A Case Study on Twitter. Information 2020, 11, 154. [Google Scholar] [CrossRef] [Green Version]
- Magdy, W.; Sajjad, H.; El-Ganainy, T.; Sebastiani, F. Distant supervision for tweet classification using youtube labels. In Proceedings of the Ninth International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015. [Google Scholar]
- Jaeel, A.J.; Al-wared, A.I.; Ismail, Z.Z. Prediction of sustainable electricity generation in microbial fuel cell by neural network: Effect of anode angle with respect to flow direction. J. Electroanal. Chem. 2016, 767, 56–62. [Google Scholar] [CrossRef]
- Nguyen-Truong, H.T.; Le, H.M. An implementation of the Levenberg–Marquardt algorithm for simultaneous-energy-gradient fitting using two-layer feed-forward neural networks. Chem. Phys. Lett. 2015, 629, 40–45. [Google Scholar] [CrossRef]
- Ley, M. DBLP: Some lessons learned. Proc. VLDB Endow. 2009, 2, 1493–1500. [Google Scholar] [CrossRef]
- Laender, A.H.; de Lucena, C.J.; Maldonado, J.C.; de Souza e Silva, E.; Ziviani, N. Assessing the research and education quality of the top Brazilian Computer Science graduate programs. ACM SIGCSE Bull. 2008, 40, 135–145. [Google Scholar] [CrossRef]
- Tan, H.; Lu, Z.; Li, W. Neural network based reinforcement learning for real-time pushing on text stream. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 913–916. [Google Scholar]
- Zheng, G.; Zhang, F.; Zheng, Z.; Xiang, Y.; Yuan, N.J.; Xie, X.; Li, Z. DRN: A deep reinforcement learning framework for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 167–176. [Google Scholar]
- Hu, Y.; Da, Q.; Zeng, A.; Yu, Y.; Xu, Y. Reinforcement learning to rank in e-commerce search engine: Formalization, analysis, and application. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 368–377. [Google Scholar]
- Zhao, X.; Xia, L.; Zhang, L.; Ding, Z.; Yin, D.; Tang, J. Deep reinforcement learning for page-wise recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 95–103. [Google Scholar]
- Zhao, X.; Zhang, L.; Ding, Z.; Xia, L.; Tang, J.; Yin, D. Recommendations with negative feedback via pairwise deep reinforcement learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1040–1048. [Google Scholar]
- Chen, X.; Li, S.; Li, H.; Jiang, S.; Qi, Y.; Song, L. Generative adversarial user model for reinforcement learning based recommendation system. arXiv 2018, arXiv:1812.10613. [Google Scholar]
- Zhao, X.; Xia, L.; Tang, J.; Yin, D. “ Deep reinforcement learning for search, recommendation, and online advertising: A survey” by Xiangyu Zhao, Long Xia, Jiliang Tang, and Dawei Yin with Martin Vesely as coordinator. ACM SIGWEB Newsl. 2019, 4, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Dulac-Arnold, G.; Evans, R.; van Hasselt, H.; Sunehag, P.; Lillicrap, T.; Hunt, J.; Mann, T.; Weber, T.; Degris, T.; Coppin, B. Deep reinforcement learning in large discrete action spaces. arXiv 2015, arXiv:1512.07679. [Google Scholar]
- Lu, Z.; Yang, Q. Partially observable Markov decision process for recommender systems. arXiv 2016, arXiv:1608.07793. [Google Scholar]
- Mahmood, T.; Ricci, F. Learning and adaptivity in interactive recommender systems. In Proceedings of the Ninth International Conference on Electronic Commerce, Minneapolis, MN, USA, 19–22 August 2007; pp. 75–84. [Google Scholar]
- Rojanavasu, P.; Srinil, P.; Pinngern, O. New recommendation system using reinforcement learning. Spec. Issue Intl. J. Comput. Internet Manag. 2005, 13, 23–28. [Google Scholar]
- Shani, G.; Heckerman, D.; Brafman, R.I. An MDP-based recommender system. J. Mach. Learn. Res. 2005, 6, 1265–1295. [Google Scholar]
- Taghipour, N.; Kardan, A.; Ghidary, S.S. Usage-based web recommendations: A reinforcement learning approach. In Proceedings of the 2007 ACM Conference on Recommender Systems, Minneapolis, MN, USA, 19–20 October 2007; pp. 113–120. [Google Scholar]
- Zhao, L.; Liu, Z. A genetic algorithm for reinforcement learning. In Proceedings of the International Conference on Neural Networks (ICNN’96), Washington, DC, USA, 3–6 June 1996; Volume 2, pp. 1056–1060. [Google Scholar]
- Alhijawi, B.; Kilani, Y. The recommender system: A survey. Int. J. Adv. Intell. Paradig. 2020, 15, 229–251. [Google Scholar] [CrossRef]
- Ruotsalo, T.; Haav, K.; Stoyanov, A.; Roche, S.; Fani, E.; Deliai, R.; Mäkelä, E.; Kauppinen, T.; Hyvönen, E. Smartmuseum: A mobile recommender system for the Web of Data. J. Web Semant. 2013, 20, 50–67. [Google Scholar] [CrossRef]
- Braunhofer, M.; Elahi, M.; Ricci, F. Usability assessment of a context-aware and personality-based mobile recommender system. In International Conference on Electronic Commerce and Web Technologies, Proceedings of the EC-Web 2014: E-Commerce and Web Technologies, Munich, Germany, 1–4 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 77–88. [Google Scholar]
- Elahi, M.; Braunhofer, M.; Ricci, F.; Tkalcic, M. Personality-based active learning for collaborative filtering recommender systems. In Congress of the Italian Association for Artificial Intelligence, Proceedings of the AI*IA 2013: AI*IA 2013: Advances in Artificial Intelligence, Turin, Italy, 4–6 December 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 360–371. [Google Scholar]
- Ostuni, V.C.; Di Noia, T.; Di Sciascio, E.; Mirizzi, R. Top-n recommendations from implicit feedback leveraging linked open data. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 85–92. [Google Scholar]
- Braunhofer, M.; Elahi, M.; Ge, M.; Ricci, F. Context dependent preference acquisition with personality-based active learning in mobile recommender systems. In International Conference on Learning and Collaboration Technologies, Proceedings of the LCT 2014: Learning and Collaboration Technologies. Technology-Rich Environments for Learning and Collaboration, Heraklion, Crete, Greece, 22–27 June 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 105–116. [Google Scholar]
- Noguera, J.M.; Barranco, M.J.; Segura, R.J.; MartíNez, L. A mobile 3D-GIS hybrid recommender system for tourism. Inf. Sci. 2012, 215, 37–52. [Google Scholar] [CrossRef]
- Bouneffouf, D.; Bouzeghoub, A.; Gançarski, A.L. A contextual-bandit algorithm for mobile context-aware recommender system. In International Conference on Neural Information Processing, Proceedings of the ICONIP 2012: Neural Information Processing, Doha, Qatar, 12–15 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 324–331. [Google Scholar]
- Ge, Y.; Xiong, H.; Tuzhilin, A.; Xiao, K.; Gruteser, M.; Pazzani, M. An energy-efficient mobile recommender system. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–28 July 2010; pp. 899–908. [Google Scholar]
- Zou, L.; Xia, L.; Ding, Z.; Song, J.; Liu, W.; Yin, D. Reinforcement Learning to Optimize Long-term User Engagement in Recommender Systems. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2810–2818. [Google Scholar]
- Verma, A.; Virk, H. A hybrid genre-based recommender system for movies using genetic algorithm and knn approach. Int. J. Innov. Eng. Technol. 2015, 5, 48–55. [Google Scholar]
- Zhang, J.; Peng, Q.; Sun, S.; Liu, C. Collaborative filtering recommendation algorithm based on user preference derived from item domain features. Phys. A Stat. Mech. Appl. 2014, 396, 66–76. [Google Scholar] [CrossRef]
- Hsieh, M.Y.; Chou, W.K.; Li, K.C. Building a mobile movie recommendation service by user rating and APP usage with linked data on Hadoop. Multimed. Tools Appl. 2017, 76, 3383–3401. [Google Scholar] [CrossRef]
- Liu, H.; He, J.; Wang, T.; Song, W.; Du, X. Combining user preferences and user opinions for accurate recommendation. Electron. Commer. Res. Appl. 2013, 12, 14–23. [Google Scholar] [CrossRef]
Figure 1.
Comparison of related studies’ accuracy.

Figure 2.
E-learners recommendation system.

Figure 3.
Class diagram of the collected dataset.

Figure 4.
Block diagram of the proposed data and predictive analysis model, based on Twitter and DBLP platform.
Figure 4.
Block diagram of the proposed data and predictive analysis model, based on Twitter and DBLP platform.

Figure 5.
Time series analysis of Twitter and DBLP platform (daily basis).

Figure 6.
Time series analysis of Twitter and DBLP platform (Monthly basis).

Figure 7.
Twitter API analysis according to profile address.

Figure 8.
System work-flow of the proposed recommendation platform.

Figure 9.
Architectural diagram for predictive analysis.

Figure 10.
Performance evaluation of predictive R.L algorithm.

Figure 11.
Social media content recommendation on web server.

Figure 12.
System performance.

Figure 13.
User preference based on the system reward.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The advantages and objective of the various recommendation systems.
| Authors | Objective | Advantage |
|---|---|---|
| Long Zhao et al., Zemin Liu et al. (2020) [55] | Solving the large action space issue based on the Reinforcement Learning Algorithm. | Reinforcement learning solves the large action space issue. |
| Bushra Alhijawi et al. [56], Yousef Kilani et al. (2020) | Recommendation system classification on MRS, TPCRS, SRS and CRS | Classifying recommendation system to avoid the overloading issue. |
| Ruotsalo et al. [57] (2013) | Raising the digital cultural heritage accessibility | It is useful to apply to any data. |
| Braunhofer et al. [58] (2014) | Place of interest (POI) recommendation | Generate related recommendations with higher useability. |
| Elahi et al. (2013) [59] | POI-based user personality recommendation | Desist the cold start issue. |
| Ostuni et al. [60] (2013) | Movie theatre recommendation | Clear the content-based recommendation results. |
| Braunhofer et al. [61] (2014) | User personality recommendation based on contact preferences | Presenting more related recommendations based on the higher rating. |
| Noguera et al. (2012) [62] | Users’ physical locations recommendation | Useful in e-tourism. The ability to have a 3D map. |
| Bouneffouf et al. [63] (2012) | Dynamic exploration recommendation | Optimal value selection while avoiding the traditional algorithms. |
| Ge et al. (2010) [64] | Parking position recommendation | Increasing business success probability. Providing various optimal driving routes based on online processing time. |
Table 2.
Data information.
| Statistics | Numerical Values |
|---|---|
| Number of directions | 744.456 |
| Number of articles | 567.916 |
| Number of Users | 582.933 |
| Avg/Max/Min of time | 3.5/6.4/1.6 |
| Training Data | 70% |
| Test Data | 30% |
Table 3.
Twitter and DBLP platform features and description.
| # | Features | Description |
|---|---|---|
| 1 | Tweet | The information which users share together |
| 2 | Projects | The information of various projects (question and answer) |
| 3 | Comments | Comments for shared topic |
| 4 | Photos | Shared photos by various users |
| 5 | News | Shared daily news |
| 6 | Conferences | Upcoming conferences or opinions about previous conferences |
| 7 | Articles | Published articles |
| 8 | Publication Access Point | Reference pages or article access information |
| 9 | Publication Time | Article publication time |
| 10 | Publication Date | Article publication date |
Table 4.
List of discovered features.
| # | Features | Description |
|---|---|---|
| 1 | Time series | Applying time series analysis in this system causes us to extract the information related to visited links per day or download and sharing information per day and, similarly, total average per month |
| 2 | E-learner profile details | Based on the e-learners profile, the major interest of the user on various topics and user clicks and shared tweets, news and articles are extracted. |
| 3 | statistical features | Extract the histogram, error rate, etc. from raw dataset for articles frequency. |
| 4 | Article types | Generate various article topics, titles, etc. |
| 5 | Tweet types | Generate different tweet information, comments, news and shared links. |
Table 5.
System’s components and specification.
| Component | Description |
|---|---|
| Programming language | WinPython–3.6.2, IDE Jupyter Notebook |
| Operating system | Windows 10 64bit |
| Browser | Google Chrome, opera |
| GPU | Nvidia GForce 1080 |
| Library and framework | Web Service |
| CPU | Intel(R) Core(TM) i7-8700 CPU @3.20 GHz |
| Memory | 32 GB |
| Recommendation Modules | Reinforcement Learning |
| Optimization Algorithm | Model Free optimization |
Table 6.
Response time of system.
| Number | Loading T. (sec) | Searching T. (sec) | Execution T. (sec) |
|---|---|---|---|
| 1 | 2.0883 | 0.0350 | 2.4505 |
| 2 | 0.5101 | 0.0348 | 0.5601 |
| 3 | 0.0012 | 0.0377 | 0.0401 |
| 4 | 1.7510 | 0.0627 | 1.8237 |
| 5 | 2.0883 | 0.0344 | 2.1331 |
| 6 | 2.0883 | 0.0344 | 2.4433 |
| 7 | 1.7510 | 0.0616 | 1.8226 |
| 8 | 1.7510 | 0.0358 | 1.8068 |
| 9 | 2.0883 | 0.0013 | 2.1017 |
| 10 | 1.7510 | 0.0400 | 1.8058 |
Table 7.
User click diversity results.
| Technique | Recommendation Diversity |
|---|---|
| LR | 0.2944 |
| FM | 0.3125 |
| W&D | 0.1758 |
| LinUCB | 0.3747 |
| HLinUCB | 0.2434 |
| DN | 0.2657 |
| DDQN | 0.2146 |
| DDQN + U | 0.2824 |
| DDQN + U + EG | 0.2118 |
| DDQN + U + DBGD | 0.2327 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Shahbazi, Z.; Byun, Y.C. Toward Social Media Content Recommendation Integrated with Data Science and Machine Learning Approach for E-Learners. Symmetry 2020, 12, 1798. https://0-doi-org.brum.beds.ac.uk/10.3390/sym12111798
AMA Style
Shahbazi Z, Byun YC. Toward Social Media Content Recommendation Integrated with Data Science and Machine Learning Approach for E-Learners. Symmetry. 2020; 12(11):1798. https://0-doi-org.brum.beds.ac.uk/10.3390/sym12111798
Chicago/Turabian StyleShahbazi, Zeinab, and Yung Cheol Byun. 2020. "Toward Social Media Content Recommendation Integrated with Data Science and Machine Learning Approach for E-Learners" Symmetry 12, no. 11: 1798. https://0-doi-org.brum.beds.ac.uk/10.3390/sym12111798
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.