1. Introduction
Despite decades of focused scientific research and societal concerns [
1], soil erosion by water, remains a major cause of land degradation and increasingly threatens agriculture in both developed and developing nations [
2]. Globally, approximately 12 million hectares of productive land are lost due to soil erosion [
1,
3]. Urgent intervention is required to prevent not only further damages to productive land but also prevent irreversible loss of ecosystem services [
3,
4]. Soil erosion results from natural factors but anthropogenic activities including unsustainable land use practices are thought to accelerate soil erosion [
2,
5,
6,
7,
8]. Soil erosion by water can manifest itself in manifolds, i.e., sheet, rill, and gully erosion [
9]. Gully erosion is the most detrimental of all forms of erosion because it can quickly remove and transport enormous quantities of soil [
10]. Globally, it is reported that gullies contribute around 50%–80% of total sediment production in semiarid regions [
11]. Gullies can damage infrastructure such as roads and buildings [
12,
13]. South Africa, a semiarid country, is among severely eroded countries in Africa, with over 70% of its land subject to erosion of varying intensities [
14]. Soil erosion has wide reaching implications for South Africa from both the environmental and socio-economic standpoints. Hoffman and Ashwell [
15] reported that South Africa incurs about
$836 million USD a year on erosion-related costs, including off-site costs for purification of silted dam water. Soil erosion, especially gullies, pose a serious threat to subsistence agriculture in most rural parts of South Africa [
16,
17].
Remote sensing, defined as the science or practice of acquiring data about the earth’s surface features from a distance [
18,
19], is not only cost-effective and quick compared to traditional field measurements, but more importantly, the data acquired through remote sensing is readily available in digital format [
20]. From the aspect of accessibility, the benefits of using remote sensing technology in gully erosion mapping, especially in remote locations, cannot be stressed enough. Studies using remote sensing have grown rapidly over the past few years [
21,
22,
23,
24,
25,
26], following the improvement in computer processing power coupled with increased availability of free remotely sensed data such as ASTER, Landsat and Sentinel. However, the coarser spatial resolution of these sensors usually inhibits their ability to automatically detect individual gullies with sufficient detail [
27]. Even at regional scales, some previous attempts to automatically classify erosion from low resolution sensors generally yielded low accuracies [
26]. High spatial resolution sensors like WorldView or GeoEye can be appropriate to identify gullies, but their relatively high acquisition costs can limit the possible users. However, there can be a trade-off between accuracy and cost, and a decision as to which sensor to use is contingent upon the objectives of the study along with the availability of financial resources. Apparently, low-cost sensors such as the Systeme Pour l’Observation de la Terre (SPOT) data may be a reasonable compromise between acquisition costs and sensor accuracy, at least in the context of developing countries, particularly South Africa, where SPOT data are obtainable at substantially low costs and even free of charge.
Like sensor selection, the selection of a suitable image classification method is as much important. Deep Learning (DL) has recently become of interest in remote sensing community [
28,
29,
30]. Some of the advantages of DL over conventional Machine Learning (ML) algorithms include high level of automation, adaptability to new challenges in the future, and can solve highly complex problems [
31]. Despite its great potential, a major drawback with DL is that it requires huge amounts of data to perform well and is computationally expensive to train [
32,
33,
34]. Consequently, ML algorithms such as Decision Tree (DT), Random Forest (RF), Support Vector Machines (SVM), Artificial Neural Network (ANN), and Discriminant Analysis (DA) are still widely used [
35,
36,
37]. Owing to their relatively high speed and accuracy, together with the ability to accommodate non-linearity and multicollinearity [
10,
38,
39], ML methods have become popular in soil erosion studies over the past few years [
25,
40,
41,
42,
43]. Among these ML methods, SVM and RF consistently showed better performance relative to other ML methods [
44], but when compared among themselves (SVM and RF), it is still unclear which method can outperform the other. Usually, the results vary from one study area to another [
41]. This variation, for the most part, can be attributed to the fact that gully erosion is a complex phenomenon, which varies greatly spatially, spectrally and even temporally across different study regions [
45]. Although the SVM and RF methods have been widely used, attempts to evaluate their performance in gully feature extraction in two or more spatially independent study areas (with one area used as training and another as testing) are rare. This approach eliminates the potential for overfitting, a serious problem associated with powerful classifiers like ML-based methods, where the classifier maps the training data so precisely that it is not able to generalize well [
46]. Herein, we trained the models on one study area and tested them with repeated cross-validation on two other spatially independent areas, which can ensure reliable outcome measures supporting better generalization of these classifications. Whereas this approach was recently used in sinkhole feature extraction [
47] and in gully feature extraction [
48], the application of the SVM and RF methods were not reported. Nevertheless, these studies provide the impetus for testing the performance of these ML methods, including the Linear Discriminant Analysis (LDA), another promising ML method.
In this study, the selected ML methods are applied to a newly launched SPOT-7 multispectral (pan-sharpened) product whose potential in gully feature extraction has not been tested before until now. Besides, so far, there has not been any direct attempt to evaluate the impact of the class number on the classification accuracy of gully erosion. Yet, the class number is among major factors affecting image classification, thus, the resulting accuracy [
49]. We proposed a simple, but practically relevant methodology consisting of three ML algorithms (RF, SVM, LDA) × two approaches of class numbers (binary and multiclass) × six combinations of study areas as train and test sets. The primary objective of this study was to evaluate the accuracy of the LDA, SVM, and RF methods in gully feature extraction across three spatially independent study areas. Our hypotheses were the following: (i) SPOT-7 pan-sharpened product can offer acceptable classification accuracy of gully erosion, (ii) application of multiclass approach can results in better classification accuracy in relation to the binary (eroded and non-eroded) approach.
2. Materials and Methods
2.1. Study Area
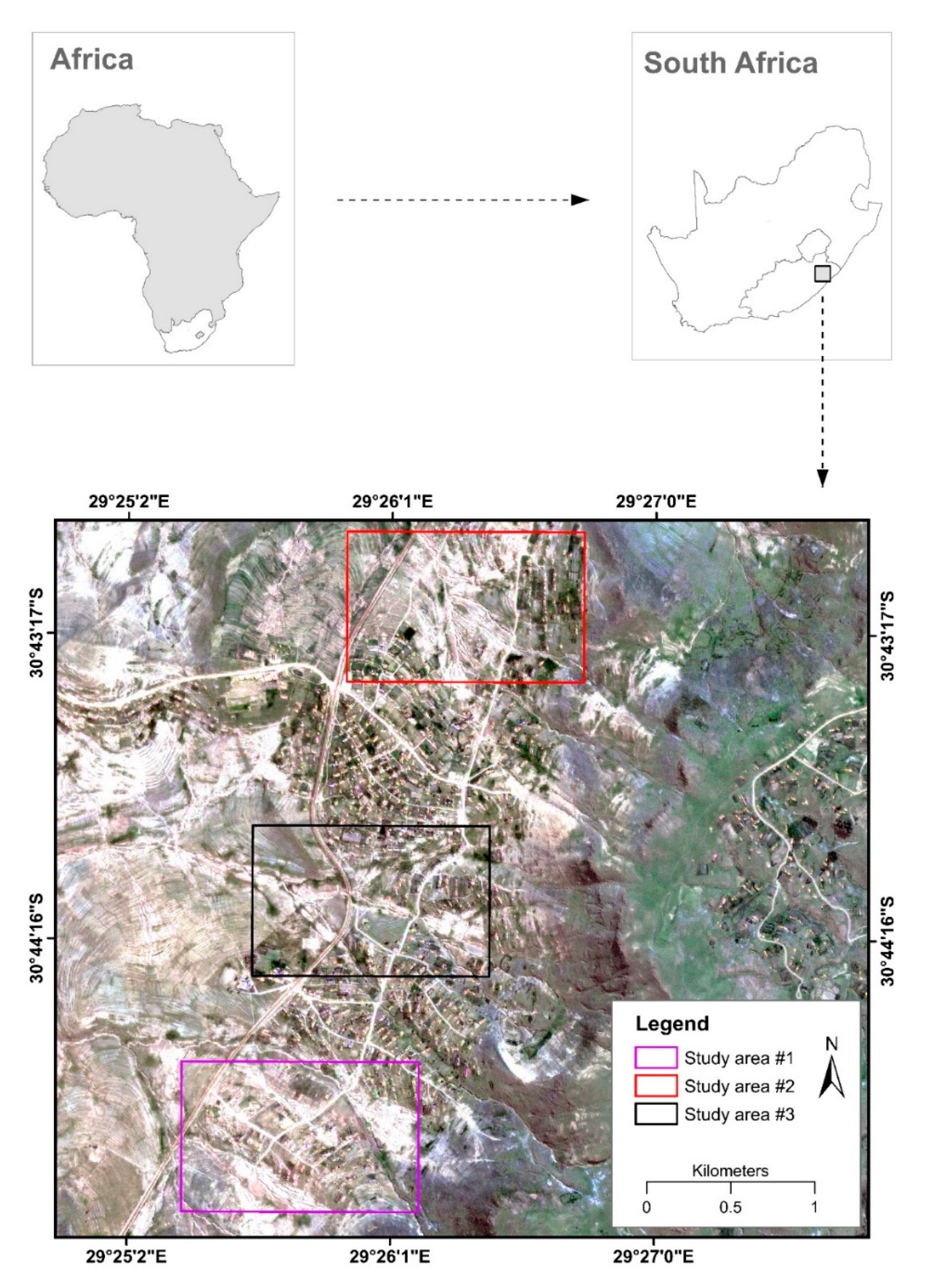
Our area of investigation is located in the Eastern Cape Province, South Africa, and consists of three study areas (s1–s3), each covering 1.26 km
2 (
Figure 1). Extensive erosion features, mainly gullies, commonly occur in relatively gentle slopes whereas rills are found in steep sloping areas. The area has a mixture of land use types including the built-up areas characterized by dispersed rural settlements, unpaved road networks, and agricultural activities. Agriculture, including crop and animal farming, is common in the region. The climate is semiarid: winter is frequently dry and cold followed by occasionally intense rainfalls in summer. The average annual rainfall is 671 mm with yearly temperatures varying from 7 to 30 °C. Topography is highly uneven across the region. It ranges from approximately 1098 m in the central parts to more than 1500 m in the hilly northern and eastern parts of the study area. The vegetation is predominantly grassland, distributed across the elevated and mountainous areas. Low-lying areas with gentle slope, where most human activities like settlement and farming take place, have sparse vegetation cover.
2.2. Data Acquisition and Pre-Processing
The data used in this study consist of the SPOT-7 image, obtained from the South African National Space Agency (SANSA). In South Africa, SPOT-7 image is available at no cost for educational purposes or PhD research, in our case, and/or research projects that are of public interest to the country. The image contains four multispectral bands: red, green, blue (altogether RGB), and near infrared (NIR) with 5.5 m geometric resolution and a high-resolution panchromatic band (1.5 m). We improved the low geometric resolution of the SPOT-7 multispectral image using the panchromatic band from the same sensor. The Gram–Schmidt pan-sharpening method was applied, which is a widely used and accepted image fusion technique for images obtained from the same sensor [
50,
51,
52]. ENVI software was used for pan sharpening (ENVI version 5.3—Exelis Visual Information Solutions, Boulder, Colorado).
2.3. Gully Feature Extraction from Satellite Image
In order to extract gully features, we employed three ML methods: RF, SVM, and DA. Being the most widely used ML methods, the selected ML methods have been embedded in various software packages [
53]. In this study, we ran all three ML methods in Python programming environment.
2.3.1. Random Forest (RF)
RF is a robust non-parametric classifier, which is independent of assumptions on data distributions or homoscedasticity. The algorithm uses several hundred of decision trees with bagging [
54]. All trees have a unique set of cases resampled from the train dataset. Sampling is performed by random selection and bootstrapping with replacements drawn from original observations, i.e., the same case can have multiple appearance in the realizations [
55]. Furthermore, the number of variables involved for decision trees is the square root of the total number of variables. Each decision tree contributes a single vote to the classification, and the class with the majority vote is selected as the final classification outcome [
44,
56]. The larger the number of variables, the more diverse the trees become. According to variable sampling, the algorithm determines variable importance, that is, if an omitted variable results in large decrease in average accuracy, it will be considered important. RF is considered to be accurate and was successfully applied for several tasks including but not limited to grassland species discrimination [
57], invasive species identification [
58], soil erosion mapping [
56,
59,
60], soil organic carbon stock mapping [
61], tree species classification [
62], and extracting water-related features [
63]. We employed the RF model to extract gully erosion features. In the RF model, we set the
ntree (number of tress) parameter to 100 and the
Gini impurity was selected as the split criterion. The
mtry (number of features in each split) parameter was left at its default value (i.e.,
mtry = 2).
2.3.2. Support Vector Machines (SVM)
Proposed by Vapnik [
64], the SVM model is based on statistical learning theory to overcome problems relating to regression and classification [
65,
66,
67]. Since its introduction, the model has been in widespread use in several researches [
35,
44,
56,
68]. The model searches for the right boundary surface among data points belonging to different classes. The aim is to find a flat boundary, called hyperplane, which can separate the classes into homogeneous partitions where each partition contains only data points of a given class. The model works well only with linear data space, and in cases of complex and higher dimensional space, the so-called ‘kernel-trick’ is used to transform the non-linear data to linear where hyperplanes can be applied [
69]. SVM has two important parameters. (i) The
C parameter penalizes the misclassifications: a low
C value results in a simple model with soft margin, while a model with large
C value prioritizes the perfect classifications; and (ii) the
γ parameter defines the role of a single training pixel: too small values result in constrained models, whereas too large values lead to overfitting, and both small and large
γ-values can perform poorly with a test dataset [
70]. Several common kernel functions for the SVM model include linear, Radial Basis Function (RBF), polynomial, and sigmoid [
49]. In the current study, we applied the SVM model with the RBF kernel function.
2.3.3. Linear Discriminant Analysis (LDA)
Discriminant Analysis (DA) is a parametric classification method requiring multivariate normal distribution, equal covariance matrices and prefers equal number of cases within categories [
71]. In this study, we applied a linear DA (LDA), an ordination technique, i.e., dimension reduction, which substitutes the original variables (bands) with discriminant functions (DFs). DF scores are calculated in the
m dimensional space defined by the input variables (where
m is the number of a priori categories), in our case it meant land cover types, based on decision boundaries, which can either be of linear or quadratic functions [
51,
72]. LDA had been successfully applied in land degradation [
73]. We applied linear functions for the classification of gullies.
2.4. Reference Data Collection and Accuracy Assessment
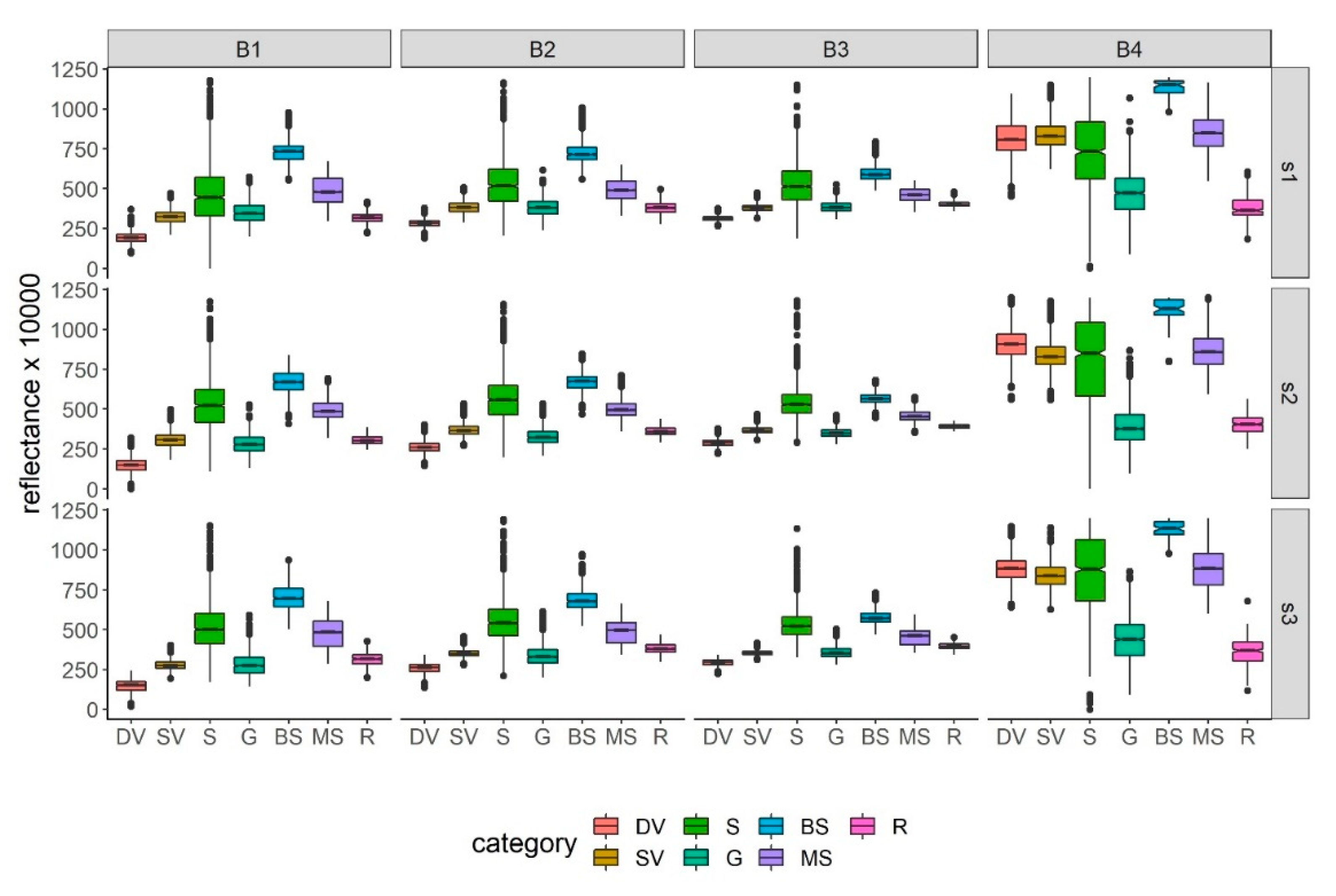
We collected the reference data based on a field survey, high-resolution SPOT image, and ancillary data (Google Earth). The reference data is not publicly available but can be provided to anybody on request. We delineated those areas where the land cover were identifiable both in the field and in the images; therefore, seven land cover classes had been distinguished: dense vegetation (DV), stressed vegetation (SV), gully (G), bare soil (BS), mixed bare soil (MS), i.e., exposed rocks, unpaved roads, bare soils, etc., settlement (S), and the roads (R). Besides, we intended to reveal the case when land cover was classified only into two classes: gully and non-gully areas; thus, as another approach we investigated the case when all non-gully classes were reclassified into one class. In the following, we refer to the seven-class solution as ‘multi-class’ (m), and the two-class solution as ‘binary’ (b) approach.
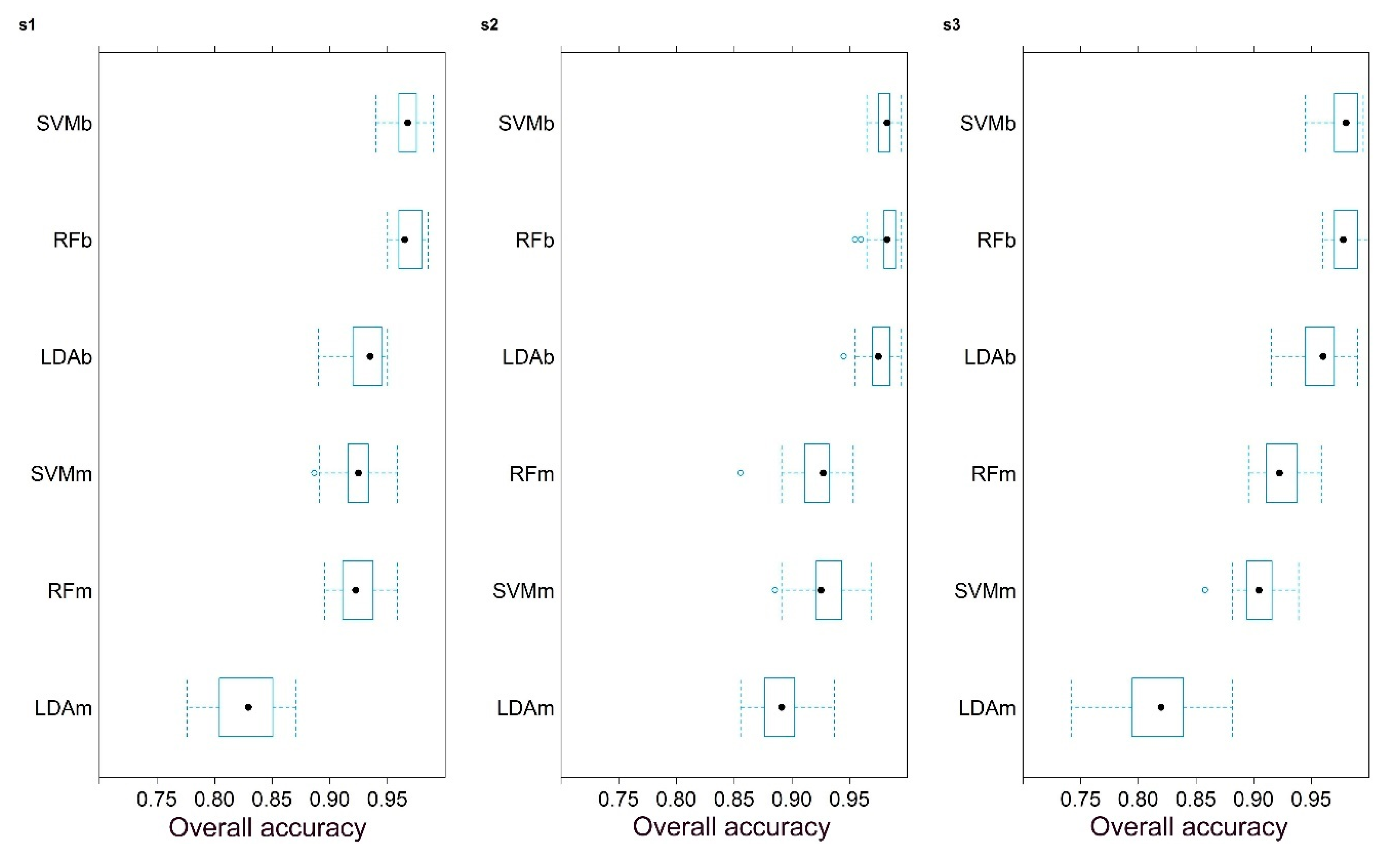
We evaluated the classification accuracy of the algorithms with repeated 10-fold cross-validation using three repetitions. We applied stratified random sampling of the whole data sets (20,795, 31,784, and 22,512 data, respectively, in s1, s2, and s3 areas): we selected 1000–1000 cases for the binary approach and 350 cases per category for the multiclass approach from the whole reference dataset, depending on the available number of data per classes and to avoid autocorrelation (selecting adjacent pixels). This approach did not require a train and test database, as the whole dataset was randomly split into 10 subsamples and 9 were used to train the models and 1 for testing and the procedure ends when all subsamples were used as a test set against all the other subsamples [
74,
75]. Finally, it was repeated three times and accuracy measures of 30 models can be used to evaluate the models’ performance with median and quartiles.
Although cross-validation is a reliable tool, it does not provide information on the class level accuracies; thus, we also used the confusion matrix. This matrix provides class-specific accuracies like Producer’s Accuracy (PA) and User’s Accuracy (UA), which indicate commission and omission errors, respectively [
18,
19,
76]. PA is the probability that a pixel of a given class was classified correctly whereas UA is the probability that a given pixel was predicted to be in the class it was supposed to be [
77,
78,
79].
Table 1 provides basic information on the calculation of the accuracy indices used.
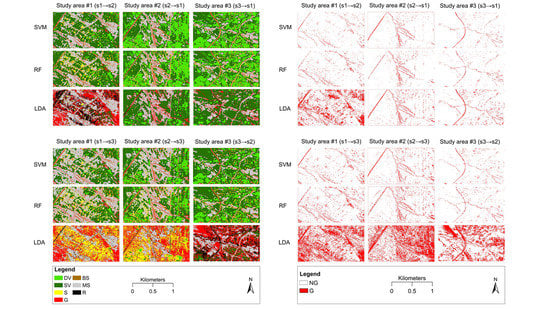
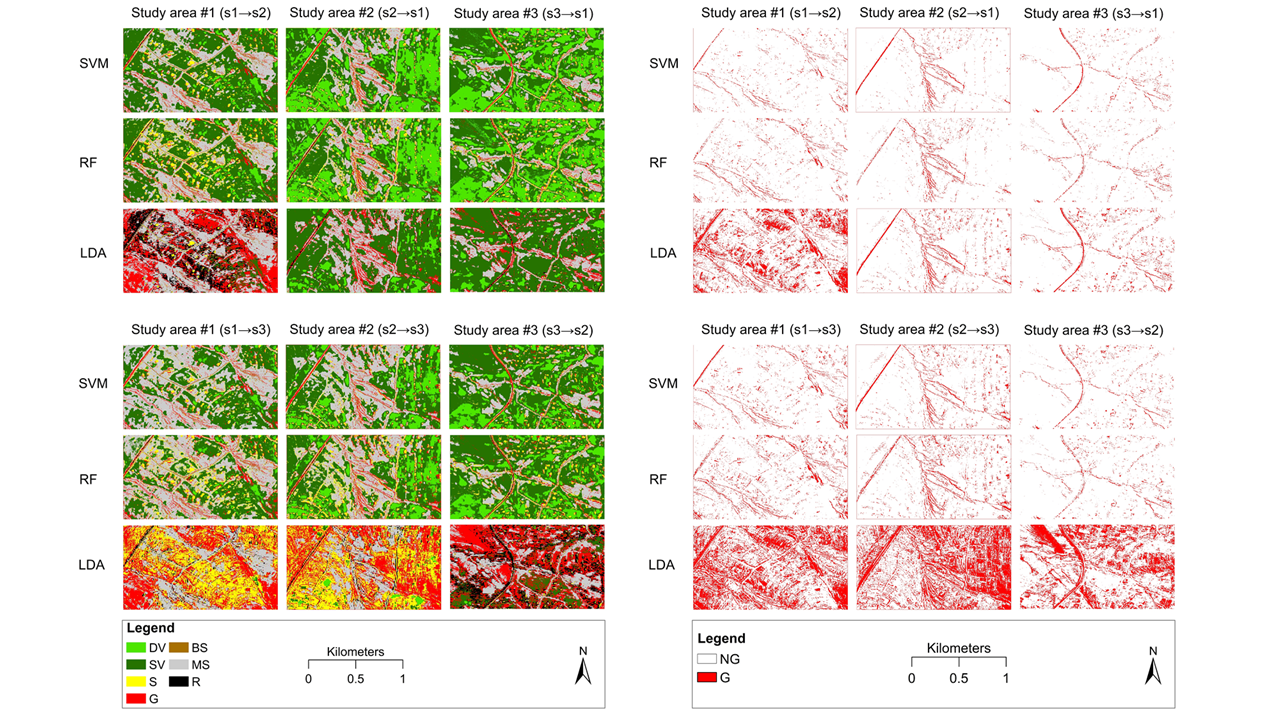
Overall Accuracy (OA), which is a ratio of correctly classified pixels, was also calculated, but on the usual way: we had three study areas (s1-s3), and one was used to train the model and another to test it. In other words, train data of one study area (e.g., s1) was used to perform the model generation and this model was applied on completely independent data of the other two study areas (s2 and s3). We repeated this procedure in all combinations of the study areas; thus, altogether we had 36 models: 3 ML algorithms (RF, SVM, LDA) × 2 approaches of class numbers (binary and multiclass) × 6 combinations of study areas as train and test sets (s1→s2, s2→s1, s2→s3, s3→s2, s1→s3, s3→s1).
2.5. Statistical Evaluation
Shapiro–Wilk test was used to check the assumption of normal distribution [
80]. Reference data of the land cover classes were skewed, but classification accuracy measures (UA, PA, OA) followed the normal distribution. We applied hypothesis testing to explore if the land cover classes had the same medians (H0) or differed from each other (H1); i.e., we evaluated the training datasets from the aspect of differences in reflectance. For example, if reflectance values differ, we can suppose that classification of the satellite image can successfully distinguish gullies from other land cover classes. In case of the binary approach, we applied the Yuen test with 0.2 value of trim and 599 times bootstrapping [
81], while for multiclass approach, robust ANOVA was used with a post hoc test based on trimmed means (using the WRS2 package of R). For Yuen test, we also evaluated the effect size (ξ), which is a standardized measure to quantify the magnitude of difference; therefore, it can be compared with the analysis performed on different datasets. Calculation of effect sizes for the multiclass approach is not defined for robust ANOVA. Therefore, we applied the Dunnett’s test [
82], using gullies as a control and all other land cover classes were compared with it. This way, we were able to calculate the confidence intervals of differences instead of effect sizes, but we were also able to see how the differences were distributed around zero. At the same time, we limited the number of comparisons and the degree of freedom (avoiding a full factorial comparison). Besides, considering the aim of this study, which was to extract gullies, this was a reasonable step.
Model performance conducted on classification accuracy measures was evaluated with General Linear Modelling (GLM) using the study areas, the number of classes (i.e., binary or multiclass) and the algorithms as factors in different combinations and the UA and PA as dependent variables. In this case, we applied the ω
2 as a measure of effect size, which is less biased by the low sample size (in our case, it was limited to the results of 36 models), as suggested by Levine [
83]. Statistical analyses were performed in R 3.6.2 software [
84], with the WRS2 [
85], jamovi 1.2. [
86], and with the GAMLj module [
87].
4. Discussion
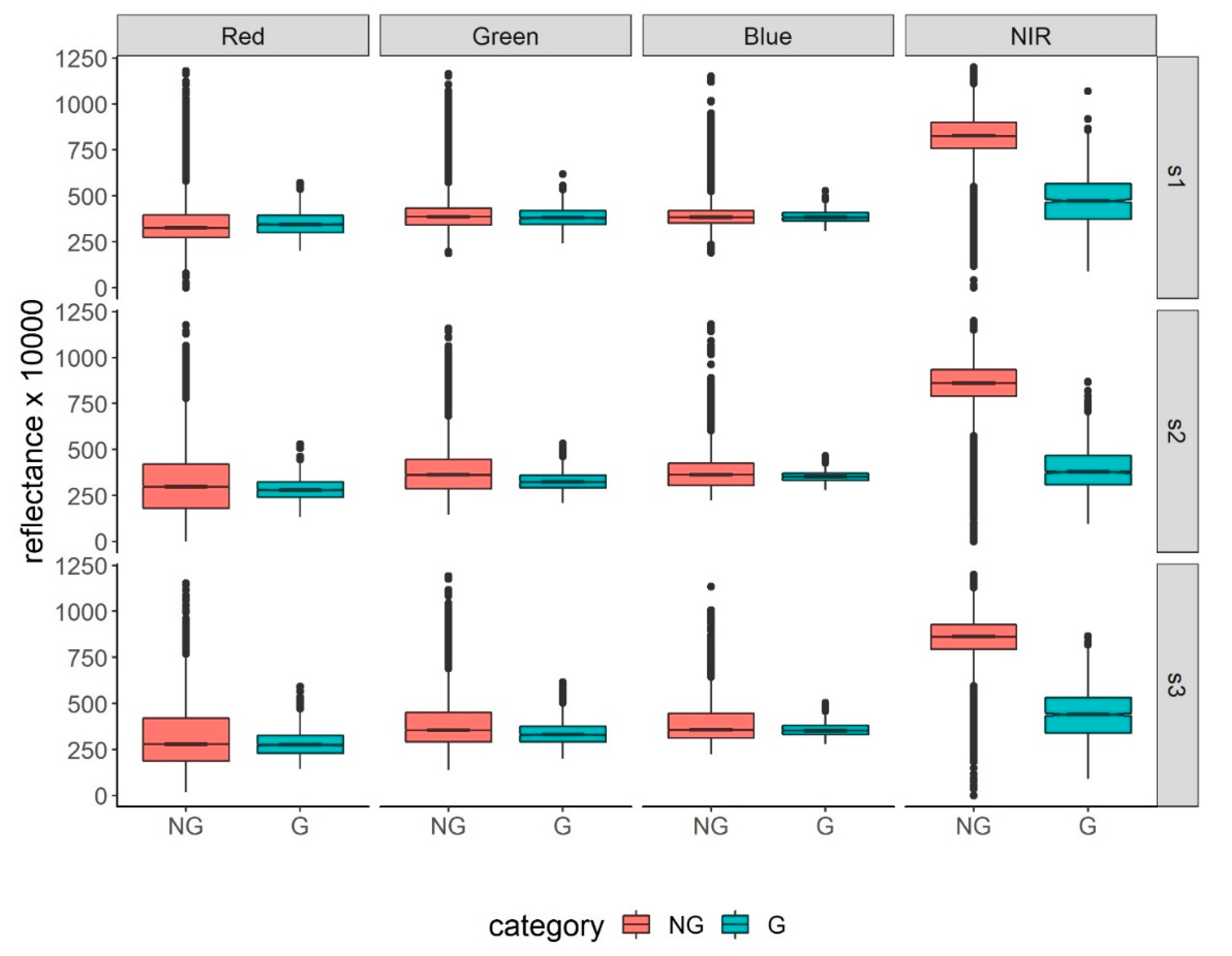
Despite the spectral heterogeneity of gullies, spectral differences of SPOT-7 bands showed that gully mapping with remote sensing data can be reasonable. The average OA results obtained by the binary (93.68%) and multiclass (74.27%) approach justifies this assertion. Almost all bands, except for blue band in study area #1, had significantly different values in case of the binary approach, hence, high OA. However, it is worth noting that merely relying on statistical significance can be misleading. In spite of significant differences: effect sizes were only small (sometimes moderate) in case of RGB bands, only the NIR band indicated large (nevertheless, in this case very large) effect. Accordingly, while
p-values only show that differences can be regarded as significant or not significant, effect sizes express the magnitude, and as standardized measures proved the relevance of differences with land cover categories, too: even with larger interquartile ranges, differences can be significant, but in classifications these small differences (indicated by effect sizes of <0.3) lead to misclassifications. Such interpretation is in accordance with the findings of Szabó et al. [
88].
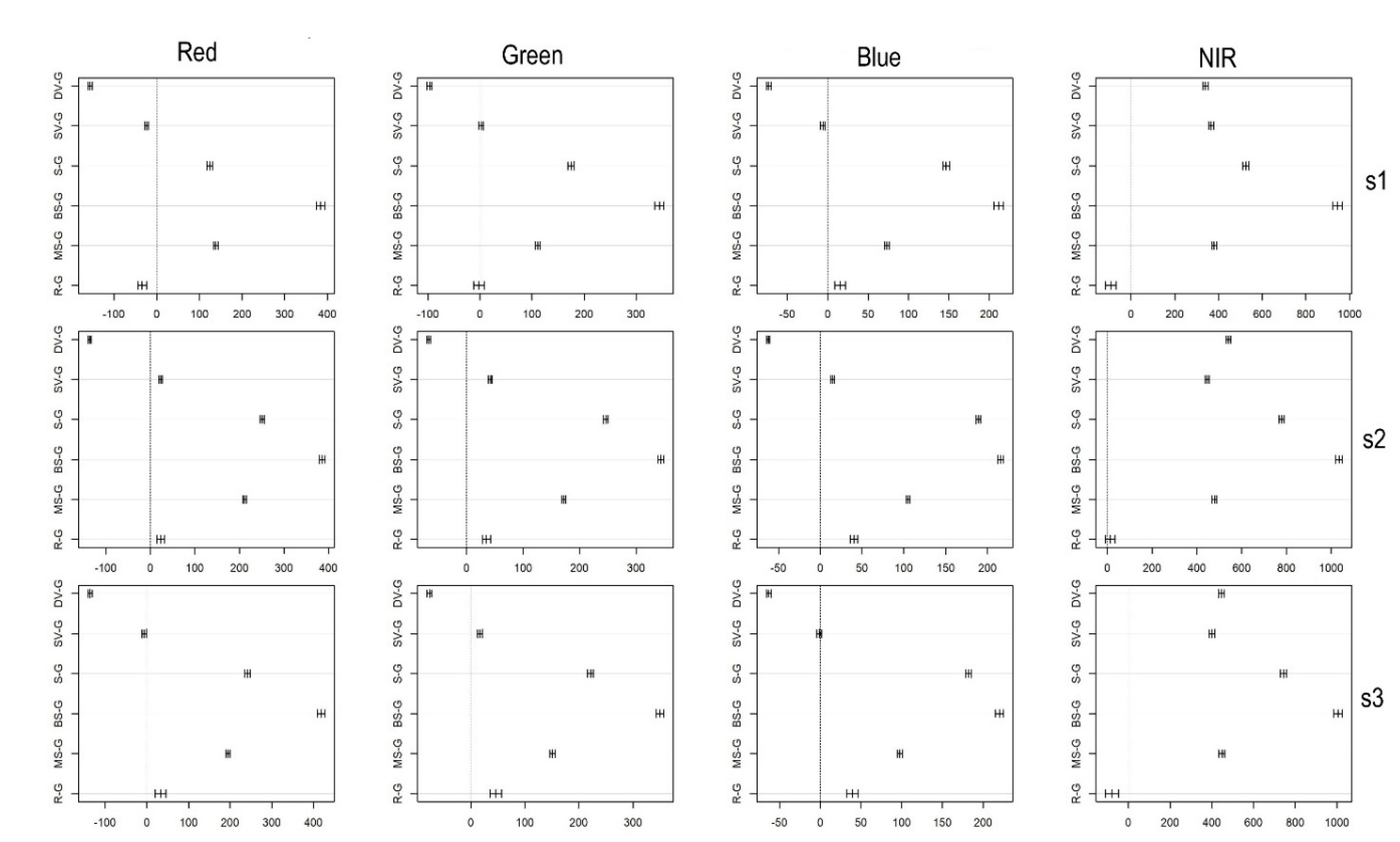
Although effect sizes were not calculated to land cover pairs of the multiclass approach, confidence intervals provided valuable information on the differences. Usually, all pairs had significant differences, and the confidence intervals were within a small range except some land cover categories: gullies and stressed vegetation and roads had non-significant differences in RGB bands (mostly in red and green bands), but the NIR band always reported significant differences. However, according to the confidence intervals, NIR band was so successful to discriminate the roads and gullies: 95% confidence ranges were close to the “zero” line, which indicated non-significance (
Figure 9). This was not signed by the
p-values (all of them were
p < 0.001); however, if we use confidence ranges and their distance from zero as an effect size, these cases indicate low values with lower efficiency to distinguish categories. However, despite the critics of the statistical evaluation, considering the results, we can accept that reference dataset contained reliable data about land cover categories, and presumably, can be used in classification models.
As different classifiers were applied, we evaluated their overall performance. RF and SVM are robust algorithms, as data distribution does not bias the results, i.e., outliers have only slight effect on the classification accuracy, while LDA assumes multivariate normality and balanced element number in the categories [
89,
90]. This was also true in our study as both RFb and SVMm outperformed the LDA. But it should be noted, LDAb had better classification results in case of binary approach than RFm and SVMm. Multiclass classifications’ OA values were below the binary; thus, one can think that it is more reasonable to use only categories when possible, i.e., in our case the gully and non-gully categories. Beygelzimer et al. [
91] also found that the binary approach can perform better than the multiclass. To gain this result, the authors developed a new “weighted one-against-all” method. However, in our case, the reality is that this result is only generally true, on category level, the multiclass approach was more efficient regarding the gully identification. These findings are in high agreement with those of Allwein et al. [
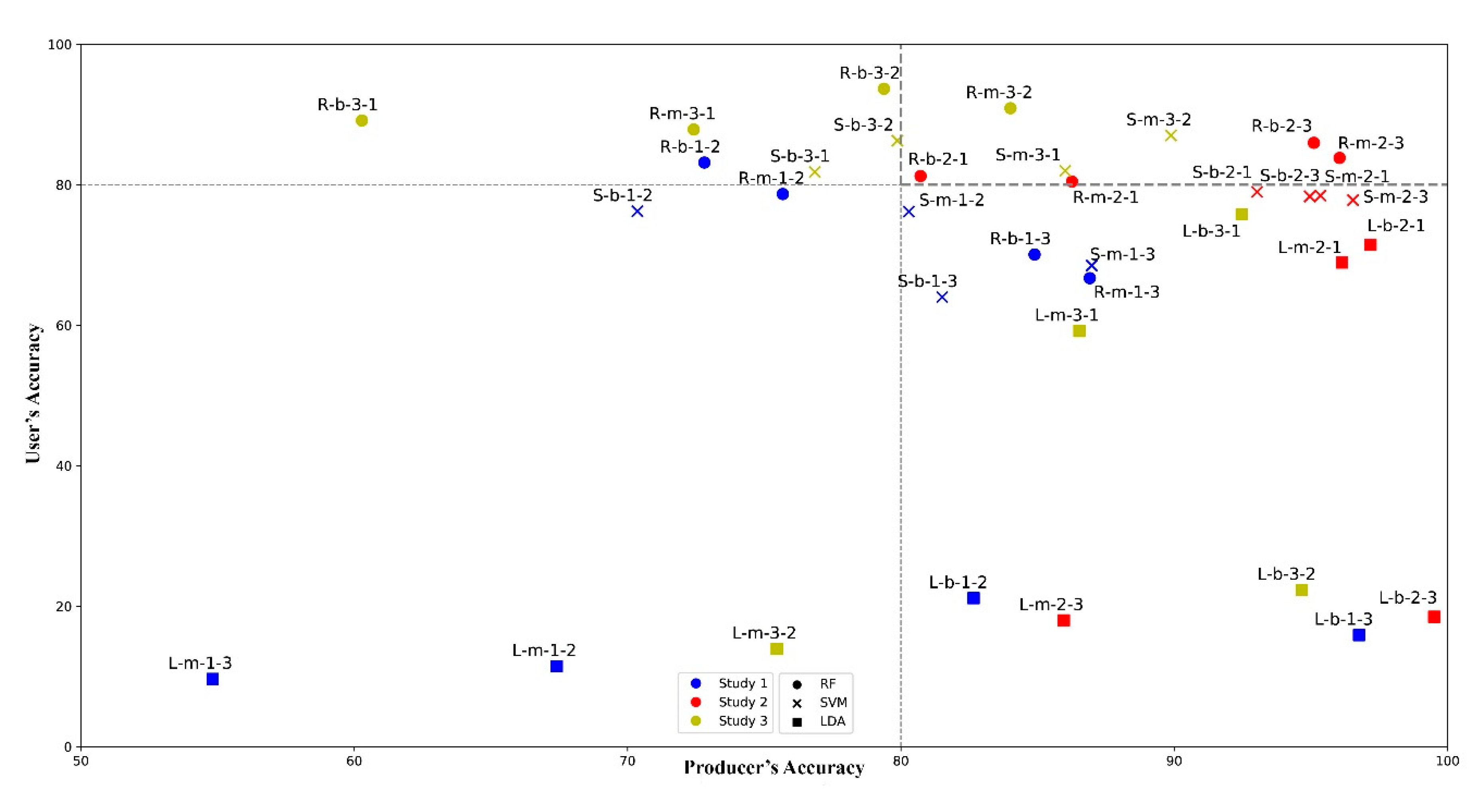
92]. Our findings revealed that multiclass solutions with the 7-class classification had better performance, only two binary approach models were in the best 80% quadrant (delineated by UA and PA) with RF and SVM classifiers. LDA’s performance varied and models provided ambiguous results: first three within the 36 models were LDA using the binary approach, and the second best was an LDA in the multiclass types based on the PA; however, the corresponding UA values were very low (e.g., the best PA, 99.51%, belonged to L-b-2-3 and the UA was only 18.5%). Thus, in these study areas with these reference datasets, we found that LDA models were severely biased by the outliers, while RF and SVM overcame this issue and provided accurate outcomes with the same input train data.
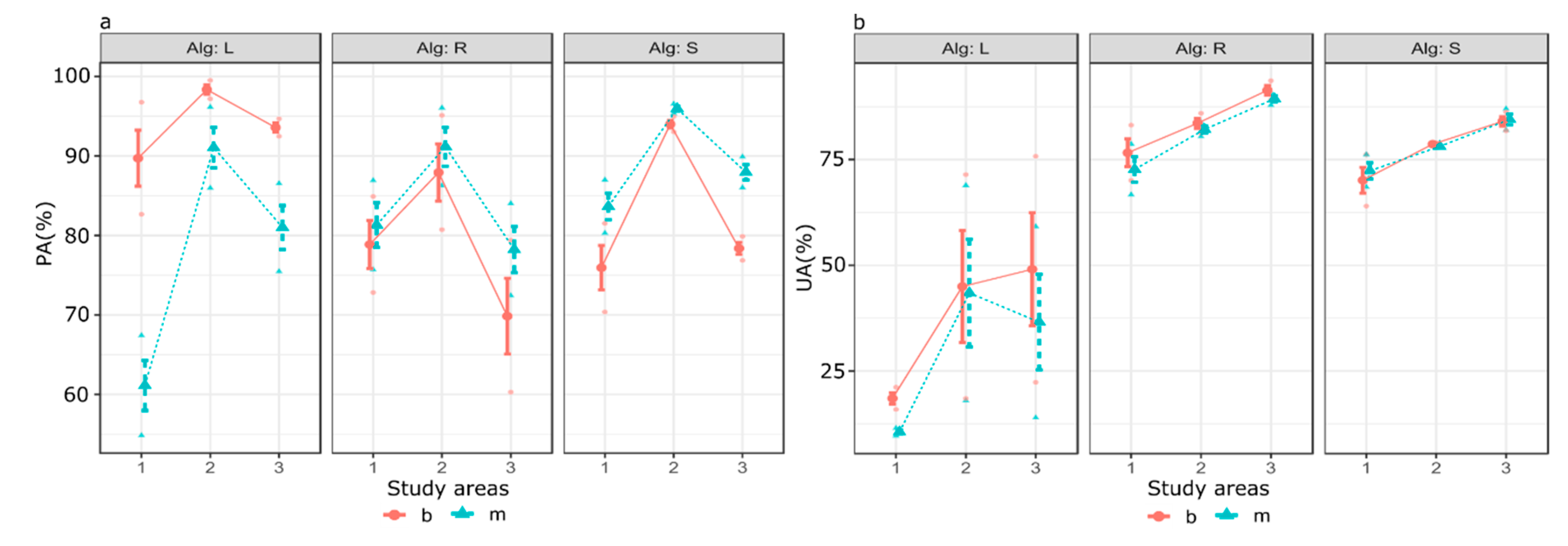
We applied GLM to investigate the reliability of the train datasets with applying the models trained with them on two other areas. All areas were similar regarding their spectral characteristics, but the six combinations revealed that in case of Study area #2, PAs were above the other two areas, but it was not true for UAs where Study area #3 had the largest values (
Table 5 and
Table 6;
Figure 9). Although the study areas had differences regarding the reference data, both RF and SVM provided PAs and UAs above 75%, which is relatively high, considering the lack of ancillary data (e.g., a digital elevation model). LDA models had large dependency on training data quality and, therefore, the error of commissions was very large (medians indicated >50% errors).
GLM revealed the multivariate effects on PA and UA and confirmed the relevance of the classification algorithms. Number of classes (binary or multiclass) did not have significant effect; although results of 10-fold cross-validation suggested that binary classifications had better performance, class-level comparisons did not support this finding in case of gullies. Nevertheless, this study showed that space-borne images like SPOT-7 can be successfully applied to automatically detect gullies using relevant ML algorithms. Although the spectral bands of SPOT-7 played a key role in discriminating gullies among other land cover categories, pan sharpening too, to some extent, contributed to successful extraction of gullies. Automatic detection of gullies with remote sensing is a challenge, because gullies do not generally differ from the surfaces they incise [
23]. As a result, visual interpretation of high-resolution images has been preferred for monitoring gullies over large areas. On a country scale, Mararakanye and Le Roux [
27] performed visual interpretation of SPOT-5 image to monitor gully erosion in South Africa. Recently, Karydas and Panagos [
93] performed a preliminary assessment on the presence of ephemeral gullies in Greece through visual interpretation of Google Earth images. Undoubtedly, there is a need for more reliable methods, which can help to automatically identify the areas affected by gullies [
22,
23]. This in turn ensures consistent monitoring of gully development over space and time. The use of appropriate ML algorithms and satellite images seems to be adequate for these surveys, but without digital elevation models (DEMs), the simple classifications can be flawed. However, in areas where gullies can be identified visually, the spectral reflectance permits the discrimination of gullies from other land cover categories, as was the case in the present study. For example, most gullies were located on bare soil surface but with the improved geometric resolution, the applied pan-sharpened product successfully discriminated gullies from bare soil although there is still a room for improvement. Where available, future research should incorporate ancillary data (i.e., DEM) to accurately discern gullies from paved/unpaved road network. A major limitation in this study was to discriminate unpaved roads from bare soil and exposed rocks. Instead, these land cover types were grouped into one class, called mixed bare soil (MS), but this did not affect gully, the target class. Although this study was conducted in small areas, the methodology applied could be adopted for application in larger areas.
5. Conclusions
Gully erosion is a crucial problem confronting sustainable agriculture today and cannot be left unabated, if sustainable agriculture is to be achieved. This study employed three commonly used ML algorithms including DA, SVM, and RF in gully feature extraction. Using these ML algorithms, we relied on two different approaches of class number: binary and multiclass. Based on the findings of this study, we drew the following conclusions:
Despite having a small number of bands (RGB and NIR), the pan-sharpened product from SPOT-7 multispectral image successfully discriminated gullies (with OAs >95%).
Repeated k-fold cross-validation was an efficient tool to analyze the representativeness of the reference data as reflected in different classification algorithms. It showed that the binary approach performed better (i.e., higher OAs with narrow interquartile ranges) with all classifiers than the multiclass approach.
GLM effectively identified the biasing factors of a given class, in this case gullies, accuracy metrics (PA and UA), with the option of statistical interaction Accordingly, we revealed that algorithms performed differently with the binary or multiclass approach in case of PA, while there was no interaction in case of UA, i.e., the number of classes did not influence UAs in the function of different classifiers.
LDA can accurately identify gullies at least from the PA’s perspective, but had usually low corresponding UA values.
SVM and RF showed better performance compared to LDA in identifying gullies, usually with >80% of PA and UA in different areas.
Overall, we conclude that the application of different study areas for training and prediction ensures independent circumstances for models, which allow to assess the possibilities of generalization of the case studies. OAs can be misleading as the accuracy can be different at class level. In our case, the classifiers showed best performance with the binary approach, according to the OA, but the multiclass approach was more efficient in gully identification based on the PA and UA on class level. Our aim was to obtain the best representation of gullies; therefore, we suggest the use of several classes instead of only two classes (i.e., binary) for better gully feature extraction.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}