Landslide Susceptibility Prediction Based on Remote Sensing Images and GIS: Comparisons of Supervised and Unsupervised Machine Learning Models

Abstract
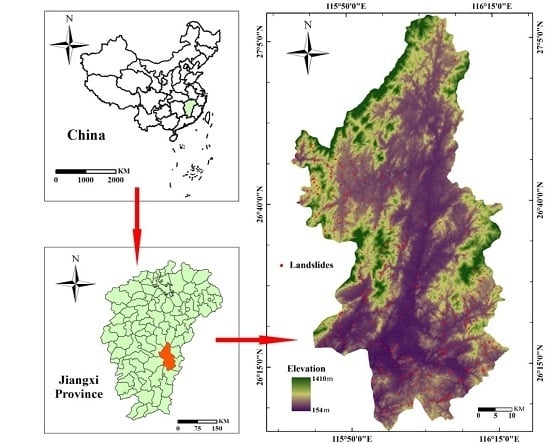
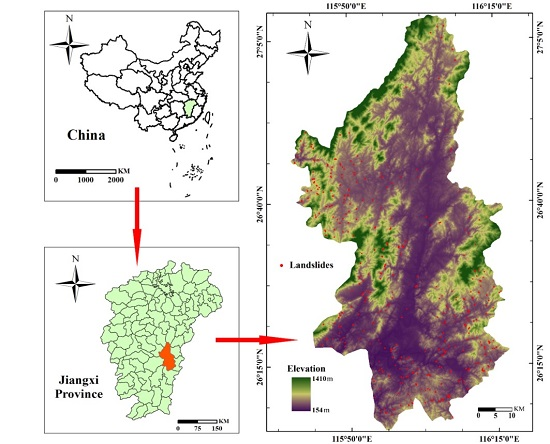
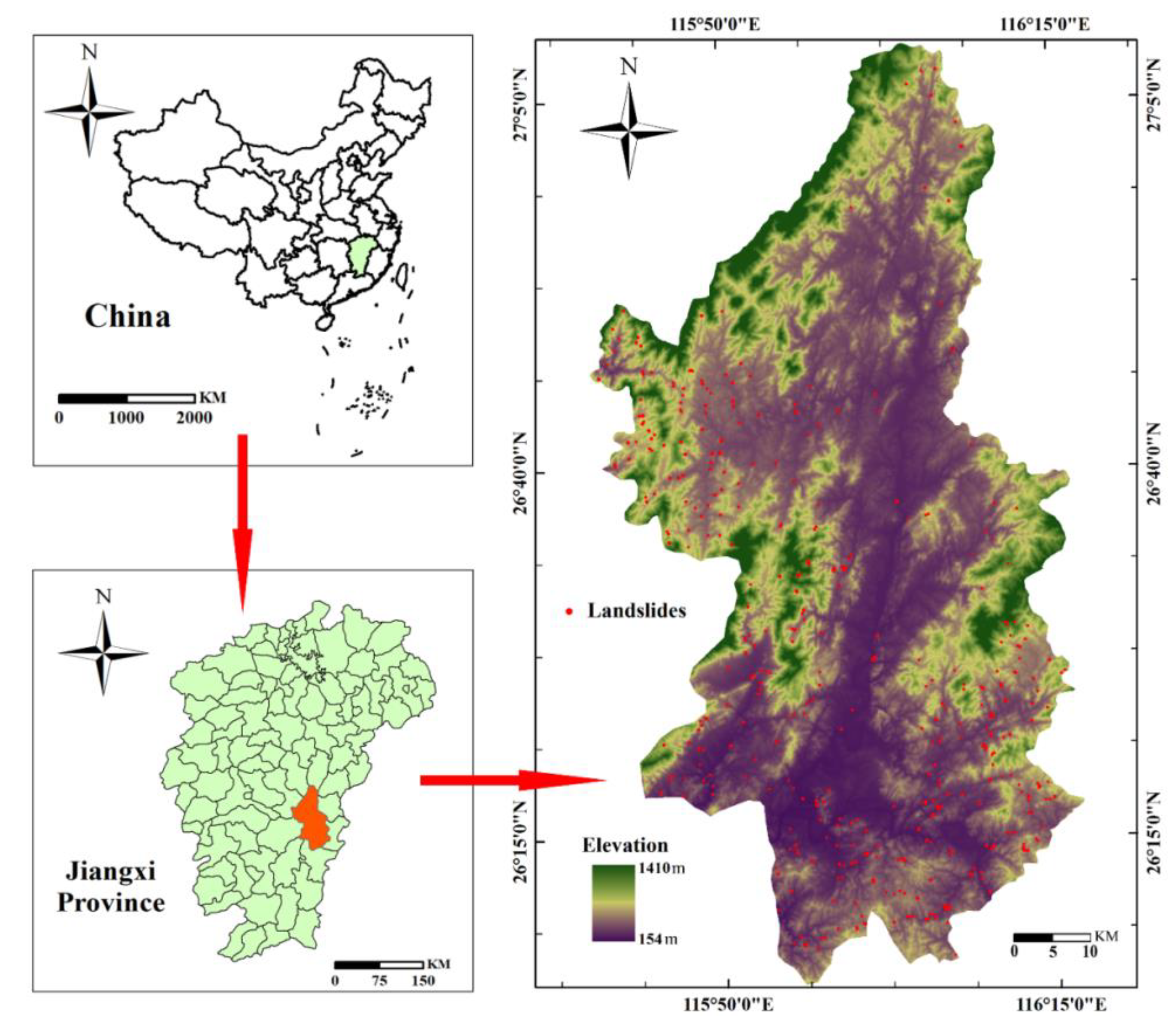
:
1. Introduction
2. Materials and Methods
2.1. Materials
2.1.1. Study Area and Landslide Inventory Information
2.1.2. Acquisition and Description of Landslide Conditioning Factors
Acquisition of Terrain Factors
Analysis of Hydrological Factors
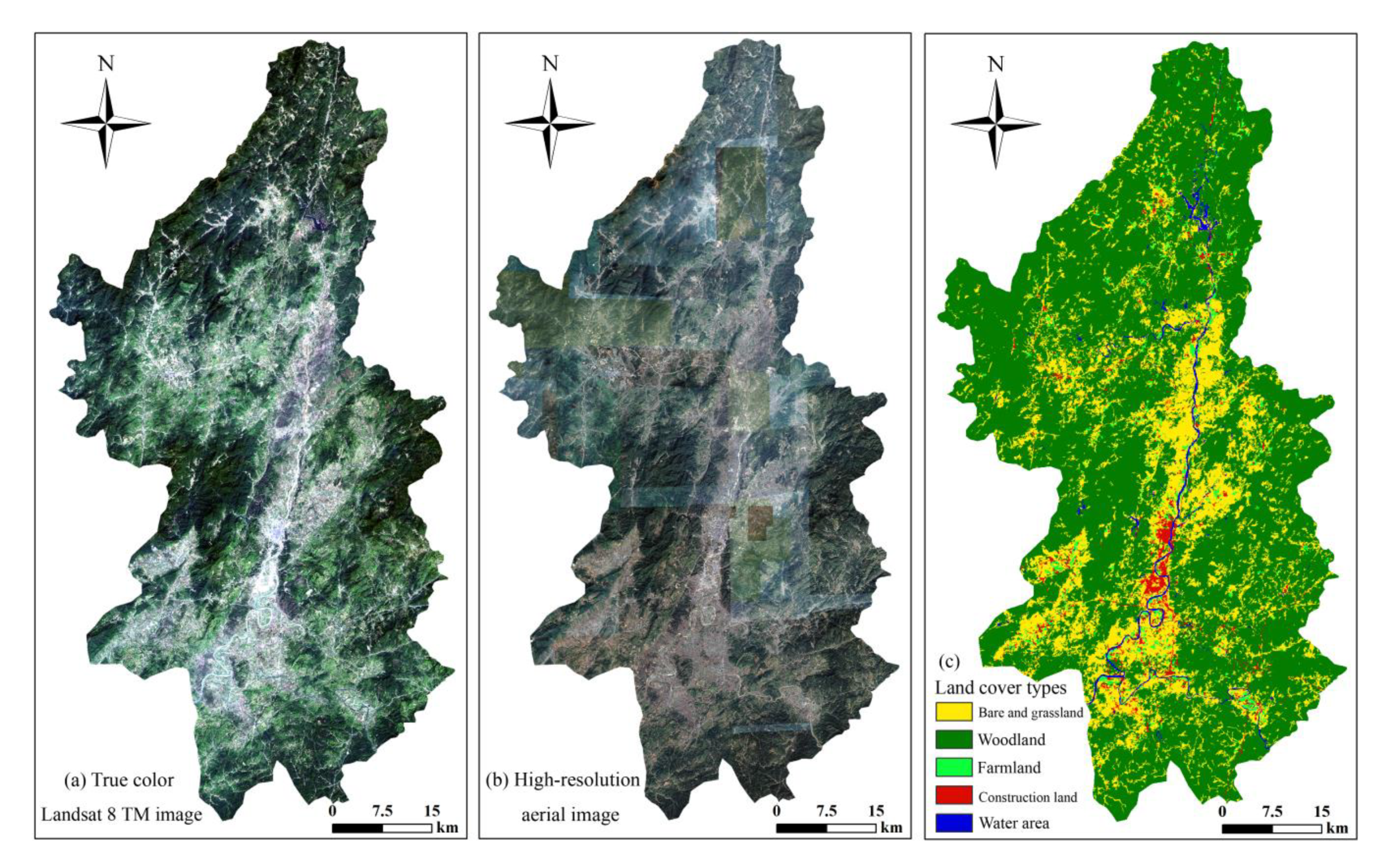
Land Cover and Geography Factors
2.1.3. FR Analysis of Conditioning Factors
2.1.4. Correlation Analysis of Conditioning Factors
2.2. Methods
2.2.1. Acquisitions of Land Cover Factors from RS Images
2.2.2. Drainage Density Extraction by Hydrological Analysis Tool
2.2.3. FR Method
2.2.4. Supervised Machine Learning
SVM Model
CHAID Model
2.2.5. Unsupervised Machine Learning
K-Means Model
Kohonen Model
3. Results
3.1. Results of the SML Models
3.1.1. Preparation Training and Validation Dataset
3.1.2. SVM Model
3.1.3. CHAID Model
3.2. Results of USML Models
3.2.1. K-Means for LSP
3.2.2. Kohonen Model
3.3. Models Testing and Comparison
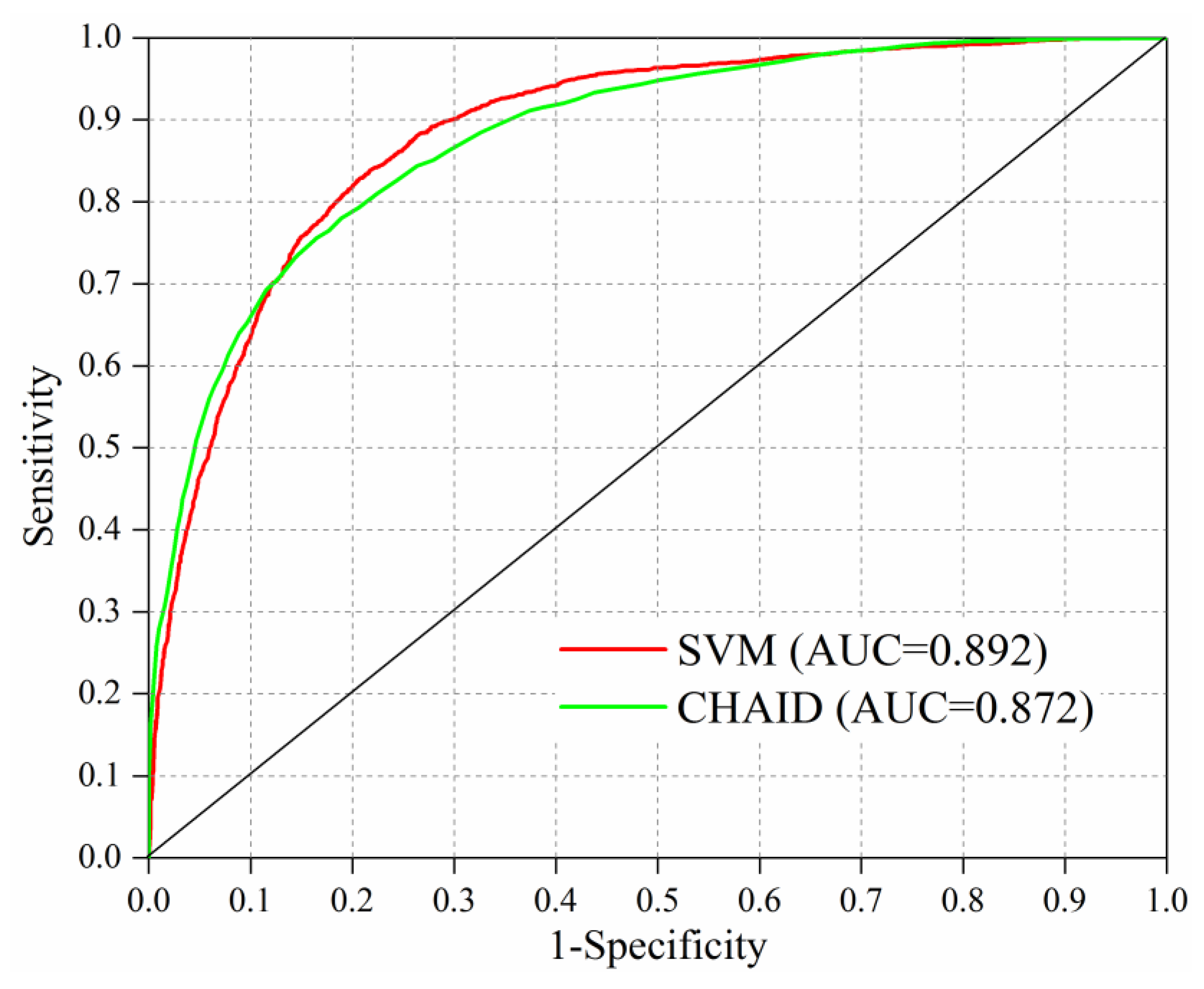
3.3.1. ROC Curve
3.3.2. Frequency Ratio Accuracy Validation
4. Discussion
4.1. Comparison of Model Accuracy
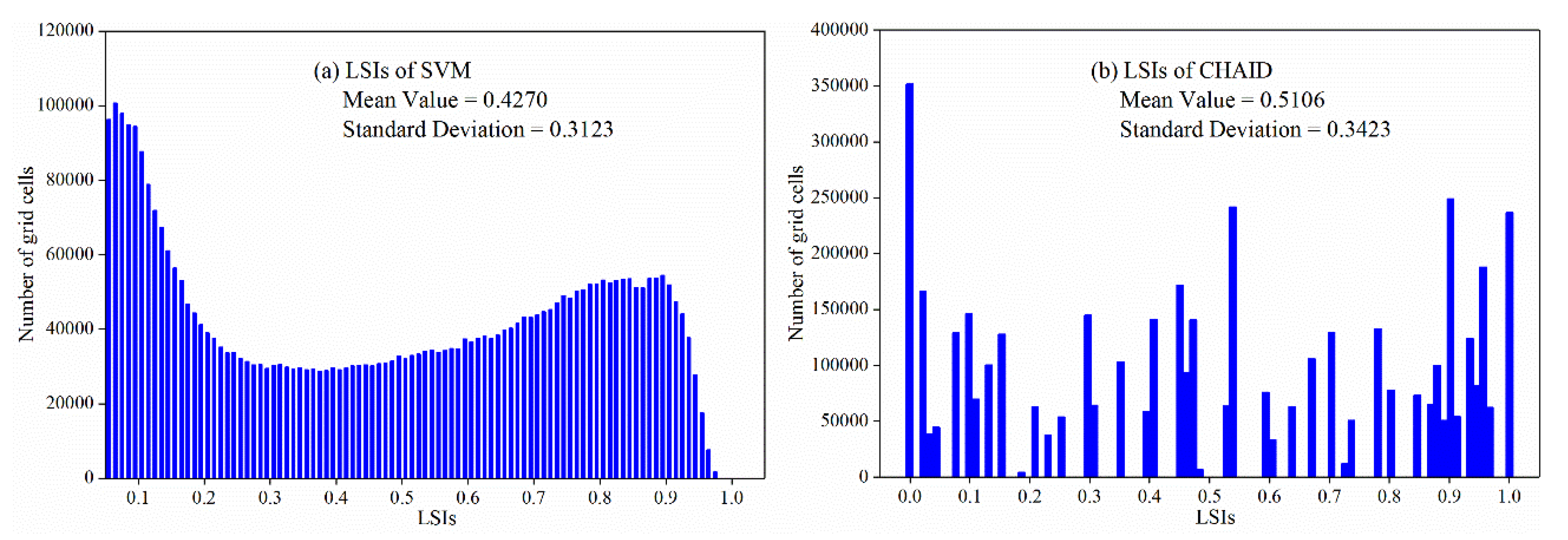
4.2. Distribution Features of LSIs
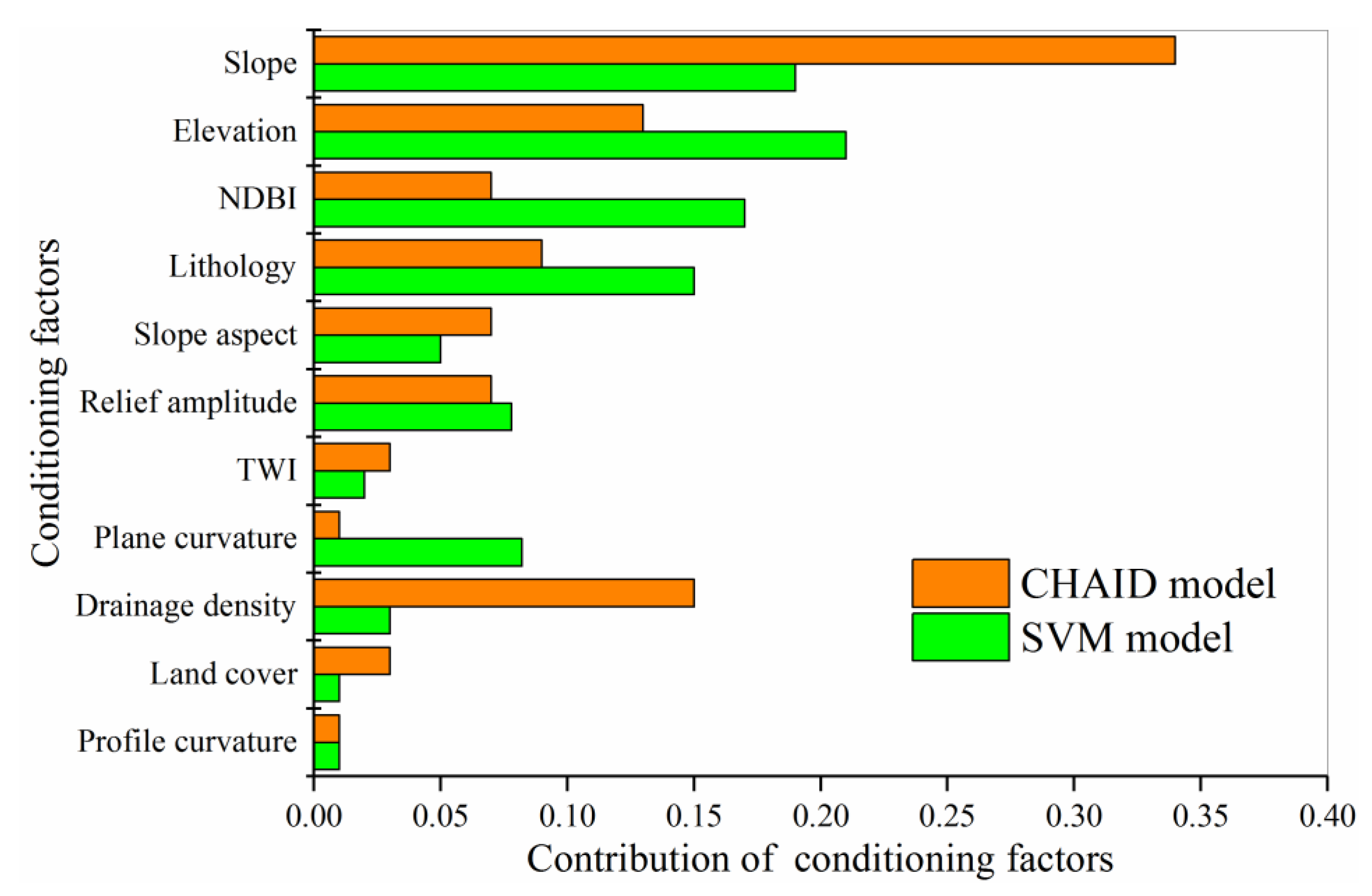
4.3. Relative Importance of Conditioning Factors for SML Models
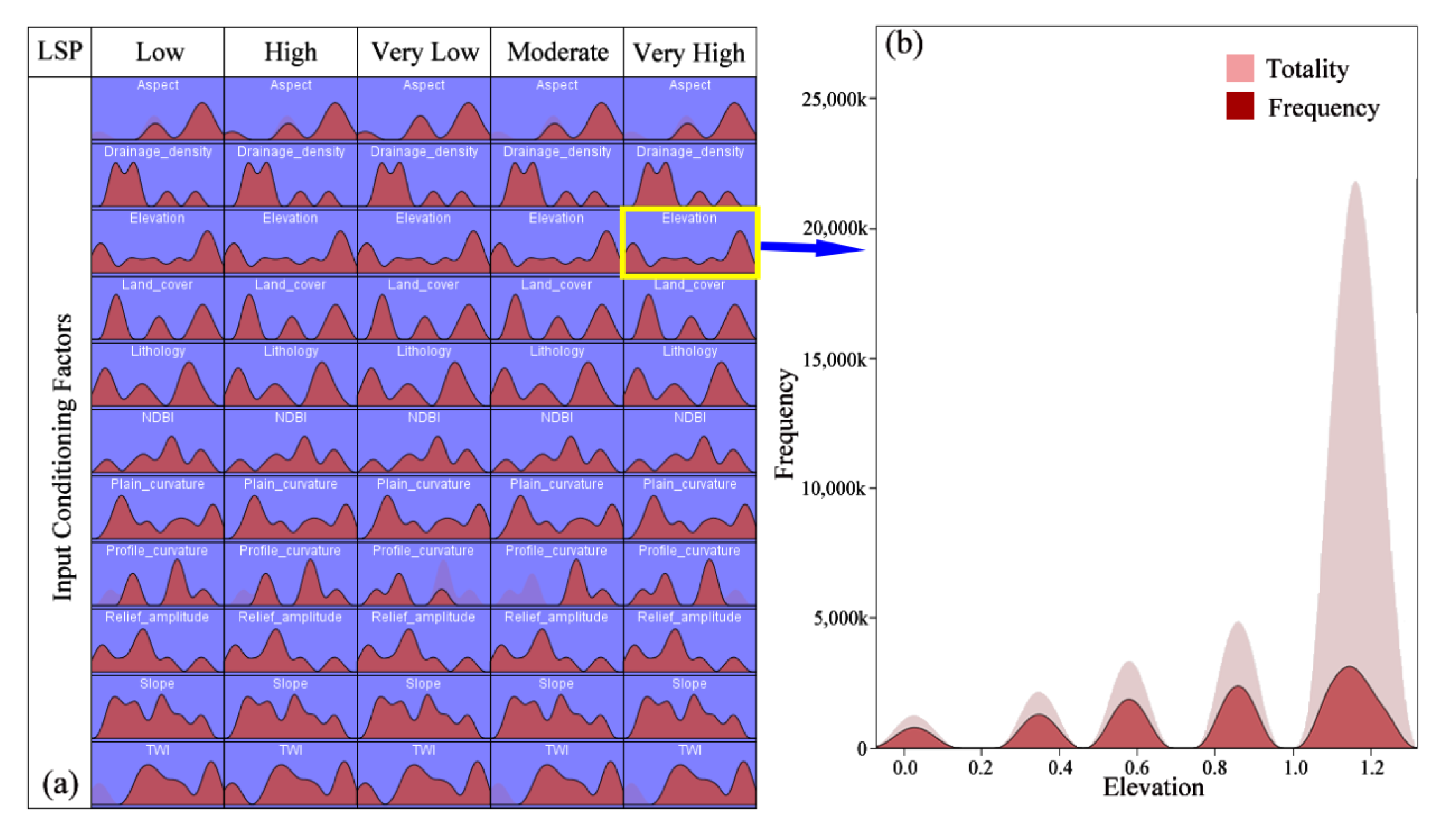
4.4. Conditioning Factors Distribution Using USML Models
4.5. Sensitivity Analysis on Resolution of Grid Units
4.6. Analysis of Parameters of Model Itself
4.7. Comparison Analysis of SML and USML
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Turner, D.; Lucieer, A.; de Jong, S. Time series analysis of landslide dynamics using an unmanned aerial vehicle (UAV). Remote Sens. 2015, 7, 1736–1757. [Google Scholar] [CrossRef] [Green Version]
- Shao, X.; Ma, S.; Xu, C.; Zhang, P.; Wen, B.; Tian, Y.; Zhou, Q.; Cui, Y. Planet Image-Based Inventorying and Machine Learning-Based Susceptibility Mapping for the Landslides Triggered by the 2018 Mw6. 6 Tomakomai, Japan Earthquake. Remote Sens. 2019, 11, 978. [Google Scholar] [CrossRef] [Green Version]
- Assilzadeh, H.; Levy, J.K.; Wang, X. Landslide catastrophes and disaster risk reduction: A GIS framework for landslide prevention and management. Remote Sens. 2010, 2, 2259–2273. [Google Scholar] [CrossRef] [Green Version]
- Pradhan, B. Remote sensing and GIS-based landslide hazard analysis and cross-validation using multivariate logistic regression model on three test areas in Malaysia. Adv. Space Res. 2010, 45, 1244–1256. [Google Scholar] [CrossRef]
- Guzzetti, F.; Carrara, A.; Cardinali, M.; Reichenbach, P. Landslide hazard evaluation: A review of current techniques and their application in a multi-scale study, Central Italy. Geomorphology 1999, 31, 181–216. [Google Scholar] [CrossRef]
- Park, H.J.; Jang, J.Y.; Lee, J.H. Physically based susceptibility assessment of rainfall-induced shallow landslides using a fuzzy point estimate method. Remote Sens. 2017, 9, 487. [Google Scholar] [CrossRef] [Green Version]
- Huang, F.; Yao, C.; Liu, W.; Li, Y.; Liu, X. Landslide susceptibility assessment in the Nantian area of China: A comparison of frequency ratio model and support vector machine. Geomat. Nat. Hazards Risk 2018, 9, 919–938. [Google Scholar] [CrossRef] [Green Version]
- Althuwaynee, O.F.; Pradhan, B.; Park, H.J.; Lee, J.H. A novel ensemble bivariate statistical evidential belief function with knowledge-based analytical hierarchy process and multivariate statistical logistic regression for landslide susceptibility mapping. Catena 2014, 114, 21–36. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Beheshtirad, M.; Pradhan, B. A comparative assessment of prediction capabilities of modified analytical hierarchy process (M-AHP) and Mamdani fuzzy logic models using Netcad-GIS for forest fire susceptibility mapping. Geomat. Nat. Hazards Risk 2016, 7, 861–885. [Google Scholar] [CrossRef] [Green Version]
- Sezer, E.A.; Nefeslioglu, H.A.; Osna, T. An expert-based landslide susceptibility mapping (LSM) module developed for Netcad Architect Software. Comput. Geosci. 2017, 98, 26–37. [Google Scholar] [CrossRef]
- Dikshit, A.; Sarkar, R.; Pradhan, B.; Jena, R.; Drukpa, D.; Alamri, A.M. Temporal Probability Assessment and Its Use in Landslide Susceptibility Mapping for Eastern Bhutan. Water 2020, 12, 267. [Google Scholar] [CrossRef] [Green Version]
- Weidner, L.; Oommen, T.; Escobar-Wolf, R.; Sajinkumar, K.; Samuel, R.A. Regional-scale back-analysis using TRIGRS: An approach to advance landslide hazard modeling and prediction in sparse data regions. Landslides 2018, 15, 2343–2356. [Google Scholar] [CrossRef]
- Ciurleo, M.; Mandaglio, M.C.; Moraci, N. Landslide susceptibility assessment by TRIGRS in a frequently affected shallow instability area. Landslides 2019, 16, 175–188. [Google Scholar] [CrossRef]
- Sinarta, I.N.; Rifa’i, A.; Faisal Fathani, T.; Wilopo, W. Slope stability assessment using trigger parameters and SINMAP methods on Tamblingan-Buyan ancient mountain area in Buleleng Regency, Bali. Geosciences 2017, 7, 110. [Google Scholar] [CrossRef] [Green Version]
- Huang, F.; Huang, J.; Jiang, S.; Zhou, C. Landslide displacement prediction based on multivariate chaotic model and extreme learning machine. Eng. Geol. 2017, 218, 173–186. [Google Scholar] [CrossRef]
- Huang, F.; Yin, K.; Huang, J.; Gui, L.; Wang, P. Landslide susceptibility mapping based on self-organizing-map network and extreme learning machine. Eng. Geol. 2017, 223, 11–22. [Google Scholar] [CrossRef]
- Pandey, V.K.; Sharma, K.K.; Pourghasemi, H.R.; Bandooni, S.K. Sedimentological characteristics and application of machine learning techniques for landslide susceptibility modelling along the highway corridor Nahan to Rajgarh (Himachal Pradesh), India. Catena 2019, 182, 104150. [Google Scholar] [CrossRef]
- Huang, F.; Wang, Y.; Dong, Z.; Wu, L.; Guo, Z.; Zhang, T. Regional landslide susceptibility mapping based on grey relational degree model. Earth Sci. 2019, 44, 664–676. [Google Scholar]
- Huang, F.; Yin, K.; Zhang, G.; Gui, L.; Yang, B.; Liu, L. Landslide displacement prediction using discrete wavelet transform and extreme learning machine based on chaos theory. Environ. Earth Sci. 2016, 75, 1376. [Google Scholar] [CrossRef]
- Mutlu, B.; Nefeslioglu, H.A.; Sezer, E.A.; Akcayol, M.A.; Gokceoglu, C. An Experimental Research on the Use of Recurrent Neural Networks in Landslide Susceptibility Mapping. ISPRS Int. J. Geo-Inf. 2019, 8, 578. [Google Scholar] [CrossRef] [Green Version]
- Su, Q.; Zhang, J.; Zhao, S.; Wang, L.; Liu, J.; Guo, J. Comparative assessment of three nonlinear approaches for landslide susceptibility mapping in a coal mine area. ISPRS Int. J. Geo-Inf. 2017, 6, 228. [Google Scholar] [CrossRef] [Green Version]
- Huang, F.; Yin, K.; He, T.; Zhou, C.; Zhang, J. Influencing factor analysis and displacement prediction in reservoir landslides—A case study of Three Gorges Reservoir (China). Tehnički Vjesnik 2016, 23, 617–626. [Google Scholar]
- Huang, F.; Huang, J.; Jiang, S.H.; Zhou, C. Prediction of groundwater levels using evidence of chaos and support vector machine. J. Hydroinformatics 2017, 19, 586–606. [Google Scholar] [CrossRef] [Green Version]
- Dou, J.; Yunus, A.P.; Tien Bui, D.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.W.; Khosravi, K.; Yang, Y.; Pham, B.T. Assessment of advanced random forest and decision tree algorithms for modeling rainfall-induced landslide susceptibility in the Izu-Oshima Volcanic Island, Japan. Sci. Total. Environ. 2019, 662, 332–346. [Google Scholar] [CrossRef]
- Hong, H.; Liu, J.; Bui, D.T.; Pradhan, B.; Acharya, T.D.; Pham, B.T.; Zhu, A.X.; Chen, W.; Ahmad, B.B. Landslide susceptibility mapping using J48 Decision Tree with AdaBoost, Bagging and Rotation Forest ensembles in the Guangchang area (China). Catena 2018, 163, 399–413. [Google Scholar] [CrossRef]
- Park, S.J.; Lee, C.W.; Lee, S.; Lee, M.J. Landslide Susceptibility Mapping and Comparison Using Decision Tree Models: A Case Study of Jumunjin Area, Korea. Remote Sens. 2018, 10, 1545. [Google Scholar] [CrossRef] [Green Version]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Erratum to: Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2016, 13, 839–856. [Google Scholar] [CrossRef]
- Hong, H.; Pourghasemi, H.R.; Pourtaghi, Z.S. Landslide susceptibility assessment in Lianhua County (China): A comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 2016, 259, 105–118. [Google Scholar] [CrossRef]
- Li, H.; Chen, Y.; Deng, S.; Chen, M.; Fang, T.; Tan, H. Eigenvector Spatial Filtering-Based Logistic Regression for Landslide Susceptibility Assessment. ISPRS Int. J. Geo-Inf. 2019, 8, 332. [Google Scholar] [CrossRef] [Green Version]
- Shahabi, H.; Khezri, S.; Ahmad, B.B.; Hashim, M. Landslide susceptibility mapping at central Zab basin, Iran: A comparison between analytical hierarchy process, frequency ratio and logistic regression models. Catena 2014, 115, 55–70. [Google Scholar] [CrossRef]
- Djeddaoui, F.; Chadli, M.; Gloaguen, R. Desertification Susceptibility Mapping Using Logistic Regression Analysis in the Djelfa Area, Algeria. Remote Sens. 2017, 9, 1031. [Google Scholar] [CrossRef] [Green Version]
- Hong, H.; Panahi, M.; Shirzadi, A.; Ma, T.; Liu, J.; Zhu, A.X.; Chen, W.; Kougias, I.; Kazakis, N. Flood susceptibility assessment in Hengfeng area coupling adaptive neuro-fuzzy inference system with genetic algorithm and differential evolution. Sci. Total Environ. 2018, 621, 1124–1141. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Chen, W.; Han, H.; Huang, B.; Huang, Q.; Fu, X. Variable-Weighted Linear Combination Model for Landslide Susceptibility Mapping: Case Study in the Shennongjia Forestry District, China. ISPRS Int. J. Geo-Inf. 2017, 6, 347. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Wang, Y.; Niu, R.; Peng, L. Integration of Information Theory, K-Means Cluster Analysis and the Logistic Regression Model for Landslide Susceptibility Mapping in the Three Gorges Area, China. Remote Sens. 2017, 9, 938. [Google Scholar] [CrossRef] [Green Version]
- Lin, G.F.; Chang, M.J.; Huang, Y.C.; Ho, J.Y. Assessment of susceptibility to rainfall-induced landslides using improved self-organizing linear output map, support vector machine, and logistic regression. Eng. Geol. 2017, 224, 62–74. [Google Scholar] [CrossRef]
- Ahmed, B.; Dewan, A. Application of bivariate and multivariate statistical techniques in landslide susceptibility modeling in Chittagong City Corporation, Bangladesh. Remote Sens. 2017, 9, 304. [Google Scholar] [CrossRef] [Green Version]
- Sabokbar, H.F.; Roodposhti, M.S.; Tazik, E. Landslide susceptibility mapping using geographically-weighted principal component analysis. Geomorphology 2014, 226, 15–24. [Google Scholar] [CrossRef]
- Migoń, P.; Jancewicz, K.; Różycka, M.; Duszyński, F.; Kasprzak, M. Large-scale slope remodelling by landslides–Geomorphic diversity and geological controls, Kamienne Mts., Central Europe. Geomorphology 2017, 289, 134–151. [Google Scholar] [CrossRef]
- Huabin, W.; Gangjun, L.; Weiya, X.; Gonghui, W. GIS-based landslide hazard assessment: An overview. Prog. Phys. Geogr. 2005, 29, 548–567. [Google Scholar] [CrossRef]
- Akgun, A. A comparison of landslide susceptibility maps produced by logistic regression, multi-criteria decision, and likelihood ratio methods: A case study at İzmir, Turkey. Landslides 2012, 9, 93–106. [Google Scholar] [CrossRef]
- Galanti, Y.; Barsanti, M.; Cevasco, A.; D’Amato Avanzi, G.; Giannecchini, R. Comparison of statistical methods and multi-time validation for the determination of the shallow landslide rainfall thresholds. Landslides 2017, 15, 937–952. [Google Scholar] [CrossRef]
- Li, Y.; Huang, J.; Jiang, S.-H.; Huang, F.; Chang, Z. A web-based GPS system for displacement monitoring and failure mechanism analysis of reservoir landslide. Sci. Rep. 2017, 7, 17171. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, F.; Luo, X.; Liu, W. Stability Analysis of Hydrodynamic Pressure Landslides with Different Permeability Coefficients Affected by Reservoir Water Level Fluctuations and Rainstorms. Water 2017, 9, 450. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Luo, X.; Huang, F.; Fu, M. Uncertainty of the Soil–Water Characteristic Curve and Its Effects on Slope Seepage and Stability Analysis under Conditions of Rainfall Using the Markov Chain Monte Carlo Method. Water 2017, 9, 758. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Song, X.; Huang, F.; Hu, L. Experimental study on the disintegration of granite residual soil under the combined influence of wetting—Drying cycles and acid rain. Geomat. Nat. Hazards Risk 2019, 10, 1912–1927. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Zhang, L.; Yang, H.; Zhang, Z.; Tao, J. Subsidence prediction and susceptibility zonation for collapse above goaf with thick alluvial cover: A case study of the Yongcheng coalfield, Henan Province, China. Bull. Eng. Geol. Environ. 2016, 75, 1–16. [Google Scholar] [CrossRef]
- Karydas, C.G.; Gitas, I.Z. Development of an IKONOS image classification rule-set for multi-scale mapping of Mediterranean rural landscapes. Int. J. Remote Sens. 2011, 32, 9261–9277. [Google Scholar] [CrossRef]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Li, D.; Huang, F.; Yan, L.; Cao, Z.; Chen, J.; Ye, Z. Landslide Susceptibility Prediction Using Particle-Swarm-Optimized Multilayer Perceptron: Comparisons with Multilayer-Perceptron-Only, BP Neural Network, and Information Value Models. Appl. Sci. 2019, 9, 3664. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Cheng, G.; Li, W.; Sha, Y.; Yang, Y. On the Variation of NDVI with the Principal Climatic Elements in the Tibetan Plateau. Remote Sens. 2013, 5, 1894–1911. [Google Scholar] [CrossRef] [Green Version]
- Huang, F.; Chen, L.; Yin, K.; Huang, J.; Gui, L. Object-oriented change detection and damage assessment using high-resolution remote sensing images, Tangjiao Landslide, Three Gorges Reservoir, China. Environ. Earth Sci. 2018, 77, 183. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 1973; Volume 3. [Google Scholar]
- Zhao, J.; Vanmaercke, M.; Chen, L.; Govers, G. Vegetation cover and topography rather than human disturbance control gully density and sediment production on the Chinese Loess Plateau. Geomorphology 2016, 274, 92–105. [Google Scholar] [CrossRef]
- Shirzadi, A.; Bui, D.T.; Pham, B.T.; Solaimani, K.; Chapi, K.; Kavian, A.; Shahabi, H.; Revhaug, I. Shallow landslide susceptibility assessment using a novel hybrid intelligence approach. Environ. Earth Sci. 2017, 76, 60. [Google Scholar] [CrossRef]
- Kohonen, T.; Honkela, T. Kohonen network. Scholarpedia 2007, 2, 1568. [Google Scholar] [CrossRef]
- Cantarino, I.; Carrion, M.A.; Goerlich, F.; Martinez Ibañez, V. A ROC analysis-based classification method for landslide susceptibility maps. Landslides 2018, 16, 265–282. [Google Scholar] [CrossRef]
- Vakhshoori, V.; Zare, M. Is the ROC curve a reliable tool to compare the validity of landslide susceptibility maps? Geomat. Nat. Hazards Risk 2018, 9, 249–266. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Niu, R.; Xu, S.; Ye, R.; Peng, L.; Guo, T.; Li, S.; Chen, T. Landslide susceptibility mapping based on weighted gradient boosting decision tree in Wanzhou section of the Three Gorges Reservoir Area (China). ISPRS Int. J. Geo-Inf. 2019, 8, 4. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Hoang, N.-D.; Pham, B.; Bui, Q.-T.; Tran, C.-T.; Panahi, M.; Bin Ahamd, B. A novel integrated approach of relevance vector machine optimized by imperialist competitive algorithm for spatial modeling of shallow landslides. Remote Sens. 2018, 10, 1538. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Peng, J.; Hong, H.; Shahabi, H.; Pradhan, B.; Liu, J.; Zhu, A.X.; Pei, X.; Duan, Z. Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren County, Jiangxi Province, China. Sci. Total Environ. 2018, 626, 1121–1135. [Google Scholar] [CrossRef]
- Arnone, E.; Francipane, A.; Scarbaci, A.; Puglisi, C.; Noto, L.V. Effect of raster resolution and polygon-conversion algorithm on landslide susceptibility mapping. Environ. Model. Softw. 2016, 84, 467–481. [Google Scholar] [CrossRef]
- Shirzadi, A.; Solaimani, K.; Roshan, M.H.; Kavian, A.; Chapi, K.; Shahabi, H.; Keesstra, S.; Ahmad, B.B.; Bui, D.T. Uncertainties of prediction accuracy in shallow landslide modeling: Sample size and raster resolution. Catena 2019, 178, 172–188. [Google Scholar] [CrossRef]
- Meena, S.R.; Ghorbanzadeh, O.; Blaschke, T. A comparative study of statistics-based landslide susceptibility models: A case study of the region affected by the gorkha earthquake in nepal. ISPRS Int. J. Geo-Inf. 2019, 8, 94. [Google Scholar] [CrossRef] [Green Version]
- Saleem, N.; Huq, M.; Twumasi, N.Y.D.; Javed, A.; Sajjad, A. Parameters Derived from and/or Used with Digital Elevation Models (DEMs) for Landslide Susceptibility Mapping and Landslide Risk Assessment: A Review. ISPRS Int. J. Geo-Inf. 2019, 8, 545. [Google Scholar] [CrossRef] [Green Version]
- Shirzadi, A.; Soliamani, K.; Habibnejhad, M.; Kavian, A.; Chapi, K.; Shahabi, H.; Chen, W.; Khosravi, K.; Thai Pham, B.; Pradhan, B. Novel GIS based machine learning algorithms for shallow landslide susceptibility mapping. Sensors 2018, 18, 3777. [Google Scholar] [CrossRef]
- Ahmed, B. Landslide susceptibility mapping using multi-criteria evaluation techniques in Chittagong Metropolitan Area, Bangladesh. Landslides 2015, 12, 1077–1095. [Google Scholar] [CrossRef] [Green Version]
- Hong, H.; Pradhan, B.; Sameen, M.I.; Chen, W.; Xu, C. Spatial prediction of rotational landslide using geographically weighted regression, logistic regression, and support vector machine models in Xing Guo area (China). Geomat. Nat. Hazards Risk 2017, 8, 1997–2022. [Google Scholar] [CrossRef] [Green Version]
- Huang, F.; Zhang, J.; Zhou, C.; Wang, Y.; Huang, J.; Zhu, L. A deep learning algorithm using a fully connected sparse autoencoder neural network for landslide susceptibility prediction. Landslides 2020, 17, 217–229. [Google Scholar] [CrossRef]
- Hong, H.; Pradhan, B.; Bui, D.T.; Xu, C.; Youssef, A.M.; Chen, W. Comparison of four kernel functions used in support vector machines for landslide susceptibility mapping: A case study at Suichuan area (China). Geomat. Nat. Hazards Risk 2017, 8, 544–569. [Google Scholar] [CrossRef]
- Althuwaynee, O.F.; Pradhan, B.; Park, H.J.; Lee, J.H. A novel ensemble decision tree-based CHi-squared Automatic Interaction Detection (CHAID) and multivariate logistic regression models in landslide susceptibility mapping. Landslides 2014, 11, 1063–1078. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Woodland | Construction | Water | Bare and Grassland | Farmland |
|---|---|---|---|---|---|
| Producer’s | 0.896 | 0.874 | 0.923 | 0.834 | 0.825 |
| User’s | 0.828 | 0.865 | 0.872 | 0.783 | 0.794 |
| Total | Overall accuracy 0.857 | KIA 0.825 | |||
| Factor | Class | Landslide Not Occurred | Landslide Occurred | Frequency Ratio | ||
|---|---|---|---|---|---|---|
| Count | Ratio (%) | Count | Ratio (%) | |||
| Elevation | 154~243 | 1,106,278 | 0.244 | 1038 | 0.280 | 1.145 |
| 243~322 | 1,304,742 | 0.288 | 1291 | 0.348 | 1.207 | |
| 322~410 | 827,136 | 0.183 | 758 | 0.204 | 1.118 | |
| 410~509 | 537,255 | 0.119 | 378 | 0.102 | 0.859 | |
| 509~617 | 369,291 | 0.082 | 175 | 0.047 | 0.578 | |
| 617~750 | 239,354 | 0.053 | 68 | 0.018 | 0.347 | |
| 750~937 | 110,355 | 0.024 | 3 | 0.001 | 0.033 | |
| 937~1410 | 33,871 | 0.007 | 0 | 0.000 | 0.000 | |
| Slope | 0~3 | 975,826 | 0.215 | 150 | 0.040 | 0.188 |
| 3~7 | 1,036,313 | 0.229 | 945 | 0.255 | 1.113 | |
| 7~11 | 848,288 | 0.187 | 1210 | 0.326 | 1.741 | |
| 11~15 | 652,842 | 0.144 | 742 | 0.200 | 1.387 | |
| 15~19 | 477,241 | 0.105 | 399 | 0.108 | 1.020 | |
| 19~24 | 315,595 | 0.070 | 179 | 0.048 | 0.692 | |
| 24~30 | 167,758 | 0.037 | 72 | 0.019 | 0.524 | |
| 30~53 | 54,419 | 0.012 | 14 | 0.004 | 0.314 | |
| Relief amplitude | 0~39.673 | 1,005,640 | 0.222 | 610 | 0.164 | 0.740 |
| 39.673~73.395 | 999,298 | 0.221 | 1430 | 0.385 | 1.746 | |
| 73.395~107.116 | 871,091 | 0.192 | 830 | 0.224 | 1.163 | |
| 107.116~142.822 | 675,230 | 0.149 | 402 | 0.108 | 0.726 | |
| 142.822~182.495 | 482,321 | 0.107 | 315 | 0.085 | 0.797 | |
| 182.495~230.102 | 301,925 | 0.067 | 110 | 0.030 | 0.445 | |
| 230.102~299.529 | 155,304 | 0.034 | 14 | 0.004 | 0.110 | |
| 299.529~505.827 | 37,473 | 0.008 | 0 | 0.000 | 0.000 | |
| Lithology | B3 | 222,246 | 0.049 | 35 | 0.009 | 0.192 |
| Y2 | 2,128,746 | 0.470 | 1460 | 0.393 | 0.837 | |
| B1 | 1,310,225 | 0.289 | 1698 | 0.458 | 1.581 | |
| B2 | 42,542 | 0.009 | 4 | 0.001 | 0.115 | |
| S2 | 699,839 | 0.155 | 360 | 0.097 | 0.628 | |
| S5 | 60,439 | 0.013 | 72 | 0.019 | 1.454 | |
| S4 | 35,181 | 0.008 | 50 | 0.013 | 1.734 | |
| T1 | 26,595 | 0.006 | 32 | 0.009 | 1.468 | |
| W | 2,469 | 0.001 | 0 | 0.000 | 0.000 | |
| TWI | 3.898~6.583 | 1,262,093 | 0.279 | 1176 | 0.317 | 1.137 |
| 6.583~8.261 | 1,719,261 | 0.380 | 1637 | 0.441 | 1.162 | |
| 8.261~10.275 | 975,276 | 0.215 | 668 | 0.180 | 0.836 | |
| 10.275~12.792 | 370,858 | 0.082 | 156 | 0.042 | 0.513 | |
| 12.792~16.483 | 156,837 | 0.035 | 53 | 0.014 | 0.412 | |
| 16.483~26.384 | 39,565 | 0.009 | 21 | 0.006 | 0.648 | |
| 26.384~39.137 | 4,123 | 0.001 | 0 | 0.000 | 0.000 | |
| 39.137~46.688 | 269 | 0.000 | 0 | 0.000 | 0.000 | |
| Drainage density | 0~0.590 | 599,996 | 0.132 | 545 | 0.147 | 1.108 |
| 0.590~1.067 | 861,429 | 0.190 | 525 | 0.141 | 0.744 | |
| 1.067~1.486 | 936,702 | 0.207 | 845 | 0.228 | 1.101 | |
| 1.486~1.886 | 778,759 | 0.172 | 672 | 0.181 | 1.053 | |
| 1.886~2.324 | 666,657 | 0.147 | 446 | 0.120 | 0.816 | |
| 2.324~2.876 | 398,554 | 0.088 | 258 | 0.070 | 0.790 | |
| 2.876~3.562 | 211,146 | 0.047 | 288 | 0.078 | 1.664 | |
| 3.562~4.857 | 75,039 | 0.017 | 132 | 0.036 | 2.146 | |
| NDBI | 0~0.129 | 769,254 | 0.170 | 304 | 0.082 | 0.482 |
| 0.129~0.172 | 1,255,933 | 0.277 | 813 | 0.219 | 0.790 | |
| 0.172~0.220 | 971,886 | 0.215 | 938 | 0.253 | 1.178 | |
| 0.220~0.270 | 593,484 | 0.131 | 720 | 0.194 | 1.480 | |
| 0.270~0.326 | 420,316 | 0.093 | 484 | 0.130 | 1.405 | |
| 0.326~0.384 | 289,927 | 0.064 | 271 | 0.073 | 1.141 | |
| 0.384~0.455 | 164,850 | 0.036 | 124 | 0.033 | 0.918 | |
| 0.455~1 | 62,632 | 0.014 | 57 | 0.015 | 1.111 | |
| Land cover | Bare and grassland | 1,301,005 | 0.287 | 1,103 | 0.297 | 1.035 |
| Woodland | 2,587,930 | 0.572 | 2,453 | 0.661 | 1.157 | |
| Farmland | 380,006 | 0.084 | 61 | 0.016 | 0.196 | |
| Construction | 102,625 | 0.023 | 94 | 0.025 | 1.118 | |
| Water | 56,716 | 0.0123 | 0 | 0.000 | 0.000 | |
| Model | Class | Landslide Pixels | Percentage of Landslide Pixels (%) | Pixels in Domain | Percentage of Pixels in Domain (%) | Frequency Ratio |
|---|---|---|---|---|---|---|
| SVM | Very High | 2202 | 0.593 | 914,815 | 0.202 | 2.937 |
| High | 770 | 0.207 | 794,803 | 0.176 | 1.182 | |
| Moderate | 360 | 0.097 | 669,532 | 0.148 | 0.656 | |
| Low | 216 | 0.058 | 693,662 | 0.153 | 0.380 | |
| Very Low | 163 | 0.044 | 1,455,470 | 0.321 | 0.137 | |
| CHAID | Very High | 1527 | 0.411 | 746,461 | 0.165 | 2.496 |
| High | 1139 | 0.307 | 748,410 | 0.165 | 1.857 | |
| Moderate | 693 | 0.187 | 775,501 | 0.171 | 1.090 | |
| Low | 291 | 0.078 | 1,229,765 | 0.272 | 0.289 | |
| Very Low | 121 | 0.033 | 1,333,349 | 0.294 | 0.111 | |
| K-means | Very High | 1384 | 0.373 | 787,386 | 0.174 | 2.145 |
| High | 930 | 0.251 | 870,420 | 0.192 | 1.304 | |
| Moderate | 1079 | 0.291 | 1,321,009 | 0.292 | 0.997 | |
| Low | 185 | 0.050 | 753,772 | 0.166 | 0.299 | |
| Very Low | 133 | 0.036 | 795,695 | 0.176 | 0.204 | |
| Kohonen | Very High | 1846 | 0.497 | 1,059,768 | 0.234 | 2.126 |
| High | 982 | 0.265 | 953,143 | 0.210 | 1.257 | |
| Moderate | 447 | 0.120 | 830,506 | 0.183 | 0.657 | |
| Low | 305 | 0.082 | 1,016,018 | 0.224 | 0.366 | |
| Very Low | 131 | 0.035 | 668,849 | 0.148 | 0.239 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, Z.; Du, Z.; Zhang, F.; Huang, F.; Chen, J.; Li, W.; Guo, Z. Landslide Susceptibility Prediction Based on Remote Sensing Images and GIS: Comparisons of Supervised and Unsupervised Machine Learning Models. Remote Sens. 2020, 12, 502. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030502
Chang Z, Du Z, Zhang F, Huang F, Chen J, Li W, Guo Z. Landslide Susceptibility Prediction Based on Remote Sensing Images and GIS: Comparisons of Supervised and Unsupervised Machine Learning Models. Remote Sensing. 2020; 12(3):502. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030502
Chicago/Turabian StyleChang, Zhilu, Zhen Du, Fan Zhang, Faming Huang, Jiawu Chen, Wenbin Li, and Zizheng Guo. 2020. "Landslide Susceptibility Prediction Based on Remote Sensing Images and GIS: Comparisons of Supervised and Unsupervised Machine Learning Models" Remote Sensing 12, no. 3: 502. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030502