1. Introduction
Human activities have changed the environment for thousands of years. A very significant increase in population and socio-economic activities associated with production and consumption patterns have intensified environmental changes. The pressure on ecosystems, natural habitats, and biodiversity loss are among the most intense impacts of climate change over territories. These impacts translate into changes in land cover; therefore, an update and quality thematic mapping become a key indicator for better analysis and decision making to define potential climate actions. Changes in land cover become a significant driver of climate change, but at the same time, climate change can lead to changes in land cover; therefore, it is essential for good land management to continuously generate thematic maps of land cover with the best possible accuracy at appropriate scales to facilitate their usability. Land cover, combining components of the environment and human activity, is one of the most important biophysical features of the Earth’s surface [
1]. Current land cover maps are an essential element of environment management and monitoring [
2]. Updating land cover maps requires technology that will provide reliable, timely, and repeatable input data as well as optimal classification systems. This is not easy at a regional scale because individual forms of land cover depend on geographical characteristics; therefore, it is necessary to select the correct data and processing algorithms and then verify the obtained results [
3].
The first development of the European Corine Land Cover (CLC) began in 1986 and lasted until 1998. New versions are released every six years. So far, five versions have been implemented (
Table 1). In each subsequent series, the implementation time was shorter, and access to new satellite imagery improved its quality.
Corine Land Cover data are used for analyzing the changes in the land use [
5] and deforestation rate assessment [
6] and is also often used as input to various models, e.g., air pollution monitoring [
7], calculating population density [
8], and determining urban heat islands [
9].
Currently, non-parametric algorithms such as Artificial Neural Networks (ANN) [
10], Support Vector Machine (SVM), and Random Forest (RF) [
11] are most used to classify land cover. They are good at handling multidimensional data and provide satisfactory classification results [
12]. The validation of CLC products is a difficult task due to the wide range of distinguished areas that are complex in structure and spectrally heterogeneous, which forces the use of time-consuming optimization procedures [
13], e.g., setting the threshold for the maximum number of pixels per class, additionally assigned to the training and test set using a specific sampling method [
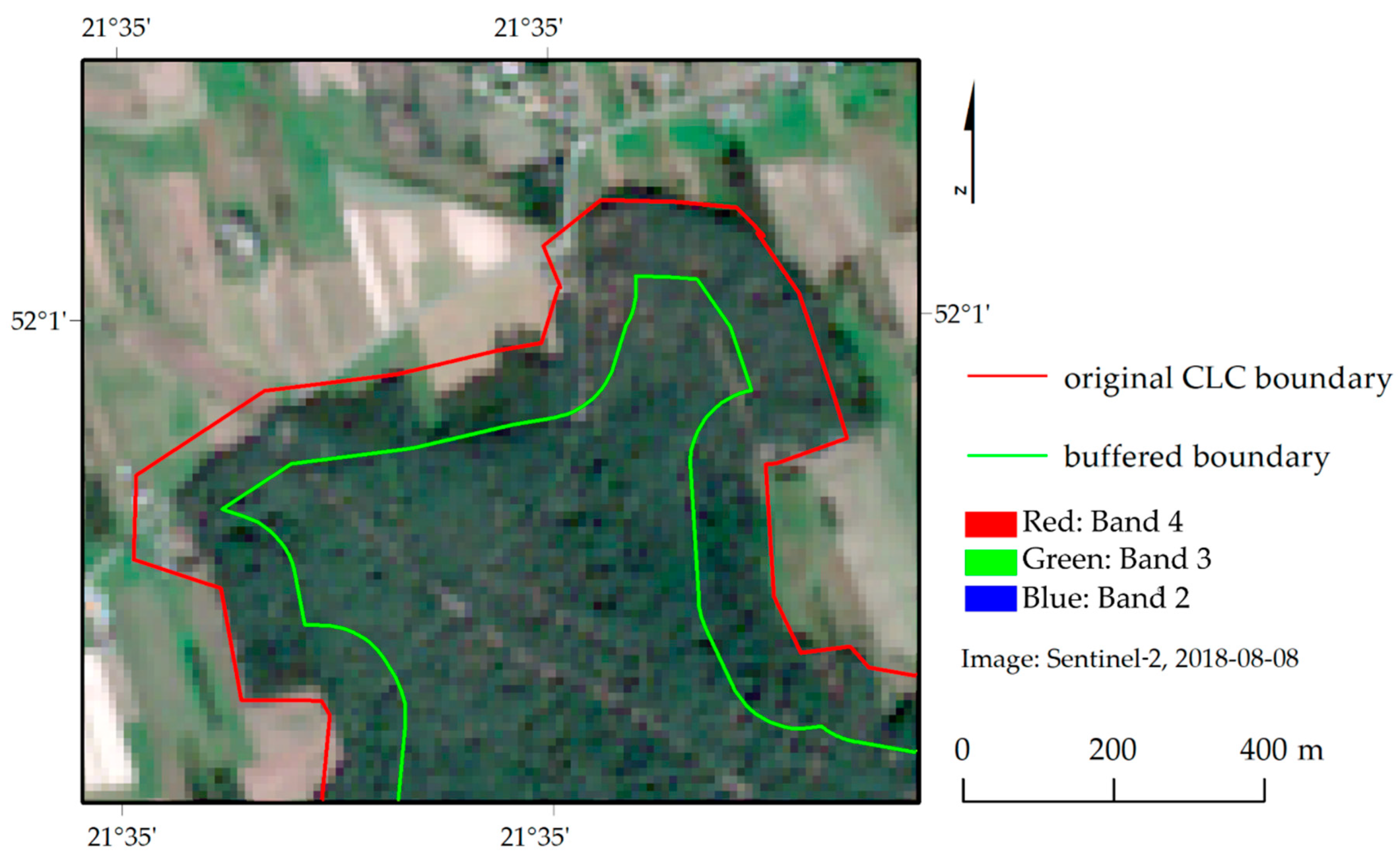
11]. Besides, to make the reference data representative and reliable, they are reduced by an internal buffer of a specific size, aimed at removing mixed pixels at the edges of the reference polygons [
14].
The Landsat and Copernicus missions have gained tremendous popularity in land cover research due to their open access policy [
15]. It is often necessary to increase the informational function of acquired images through data fusion. One of the methods used is multi-temporal composition, combining scenes acquired at different dates for the same location [
16]. It is based on differences in the spectral reflection of objects depending on the season. This is one of the most commonly used techniques that allow a statistically significant increase in classification accuracy [
17]. Gounaridis et al. [
18] used such an approach to classify CLC 2012 data where 12 out of 15 Corine classes were identified in the research area, and then a 50 m wide internal buffer was used on the field data representing them. During training, 1000 pixels were chosen randomly for each class, and then the Random Forest algorithm classified the composition of W multi-temporal images obtained by the Landsat Thematic Mapper (TM) and Enhanced Thematic Mapper Plus (ETM+) scanners. An overall accuracy of 83% was obtained. Another possible method is to include vegetation indicators [
19].
Altitude data also supplement multispectral data. Leinenkugel et al. [
11] used a multi-temporal composition obtained by Enhanced Thematic Mapper Plus (Landsat 7 ETM+) and Operational Land Imager (Landsat 8 OLI) scanners and additionally included the altitude data of the Shuttle Radar Topography Mission (SRTM). Analyses were conducted of three research areas in Europe that are geographically diverse from each other. CLC 2012 served as reference data for land cover, which was prepared by removing mixed pixels using two internal buffers (50 and 100 m wide) to check the effect of their size on classification accuracy. In the research areas, there were 20,000 to 50,000 training pixels for the entire dataset. Classifying with the Random Forest algorithm, overall accuracy was obtained in the range of 55% to 67%, depending on the area. The differences in the classification accuracy between the data on which the 50 and 100 m buffers were used turned out to be small, as the total accuracy values fluctuated by only 1 percentage point in favor of both the data with the larger and smaller buffer.
Multispectral and radar data are also used for research and are combined with digital terrain models. Balzter et al. [
14] combined radar data acquired by the Sentinel-1A satellite with SRTM data. Using CLC 2006, a hybrid model was created containing 27 classes [
14]. Training and verification pixels were selected at random. Besides, a maximum pixel threshold of 20,000 pixels per class was set, and then, the classification was carried out using the Random Forest algorithm, achieving an overall accuracy of 68%.
Despite the high popularity of multispectral and radar data in land cover studies, Novillo et al. [
20] used data collected by the Multiangle Imaging SpectroRadiometer (MISR) located on the Terra platform in order to gather image data for the same area at different sensor inclination angles. Based on 2006 CLC data for level 3, 35 classes were identified, followed by an internal buffer width of 137.5 m. The classification was performed 100 times with the k-means algorithm for each of the seven sensor deflection combinations. The combination with all mirror tilting configurations achieved the highest overall accuracy (70%). The best total accuracy (over 75%) was obtained for the following classes: non-irrigated arable land (211), agro-forestry areas (244), and coniferous forest (312). Many classes obtained poor results (about 20%): construction sites (133), green urban areas (141), fruit trees and berry plantations (222), annual crops associated with permanent crops (241), bare rocks (332), sparsely vegetated areas (333), and inland marshes (411); however, these classes had a small set of samples for training and verification (several dozen pixels).
During the past two decades, the Random Forest (RF) and Support Vector Machine (SVM) classifiers have drawn attention to image classification in remote sensing applications. Sheykhmousa et al. [
21] highlighted that in particular, land use and land cover (LULC) mapping is the most common application of remote sensing data for a variety of environmental studies, and based on an extensive review of existing articles, they consider that the growing applications of LULC mapping alongside the need for updating the existing maps have offered new opportunities to effectively develop innovative RS image classification techniques in various land management domains to address local, regional, and global challenges. As a result of the review article, the relatively high similar SVM and RF performance in terms of classification accuracy makes them among the most popular machine learning classifiers within the RS community and demonstrates competitive results with CNNs [
21].
Since the Random Forest algorithm is popular in land cover classification and gives satisfactory results, Rodriguez-Galiano et al. [
22] conducted a detailed analysis of the impact of input data properties on classification accuracy. On the multi-temporal composition of images obtained by the TM scanner, they determined 14 land cover classes. They checked the impact of data reduction on the overall accuracy of the classification. On the one hand, it saves time in the classification process, and on the other hand, it is necessary to have a representative number of samples for each class. It was found that only when the training dataset was reduced by 70%, overall accuracy decreased. They used the same methodology when checking the classifier’s resistance to the influence of noisy data, which can often negatively affect the accuracy of the classification, e.g., using 50% of the noisy data, the out-of-bag (OOB) error increased significantly [
23].
Although there are many studies on land cover classification [
24] in the literature, few studies address the Corine Land Cover classification, specifically, level 3. The class definition characteristics of the Corine Land Cover make the land cover types included in the project only present in Europe, so it is not easy to compare it with classifications made for other areas, which narrows the scope of comparison. Current Corine Land Cover classification studies mostly cover small areas and referred to the generalized first and second levels [
25]. Corine Land Cover has numerous limitations [
26], and the new edition of CLC+ is intended to overcome them. One of its elements will be pixel-based classification, which makes it necessary to check the classification’s accuracy for particular classes. The results obtained in the study may provide valuable information for the teams preparing classifications for individual European areas. The main source of optical data in the CLC+ project is the multi-temporal data acquired by the Sentinel-2 satellite, with the Landsat 8 satellite filling in any gaps in the data; therefore, in this paper, data acquired by both Sentinel-2 and Landsat 8 satellites were checked to show the classification accuracy discrepancies depending on data types.
Additionally, by comparing the most popular machine learning algorithms such as Random Forest and Support Vector Machines, the bias of classifications that are often based on a single method was reduced. Due to the ease of implementation of the algorithms used, it is possible to reproduce the results and make them comparable easily. The influence of the number of pixels per class to achieve a given overall accuracy was also examined in this study. This helps determine the number of samples required when collecting master data and preparing it for classification in a CLC project. This study was undertaken due to the lack of comparative studies in the literature on CLC classes over varying areas, comparing classifiers and using iterative accuracy assessment.
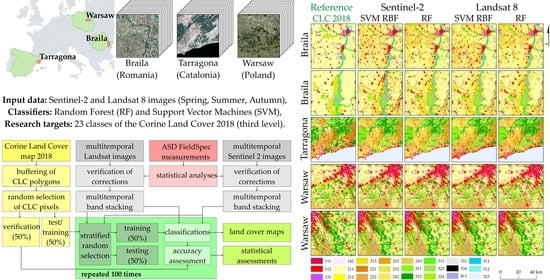
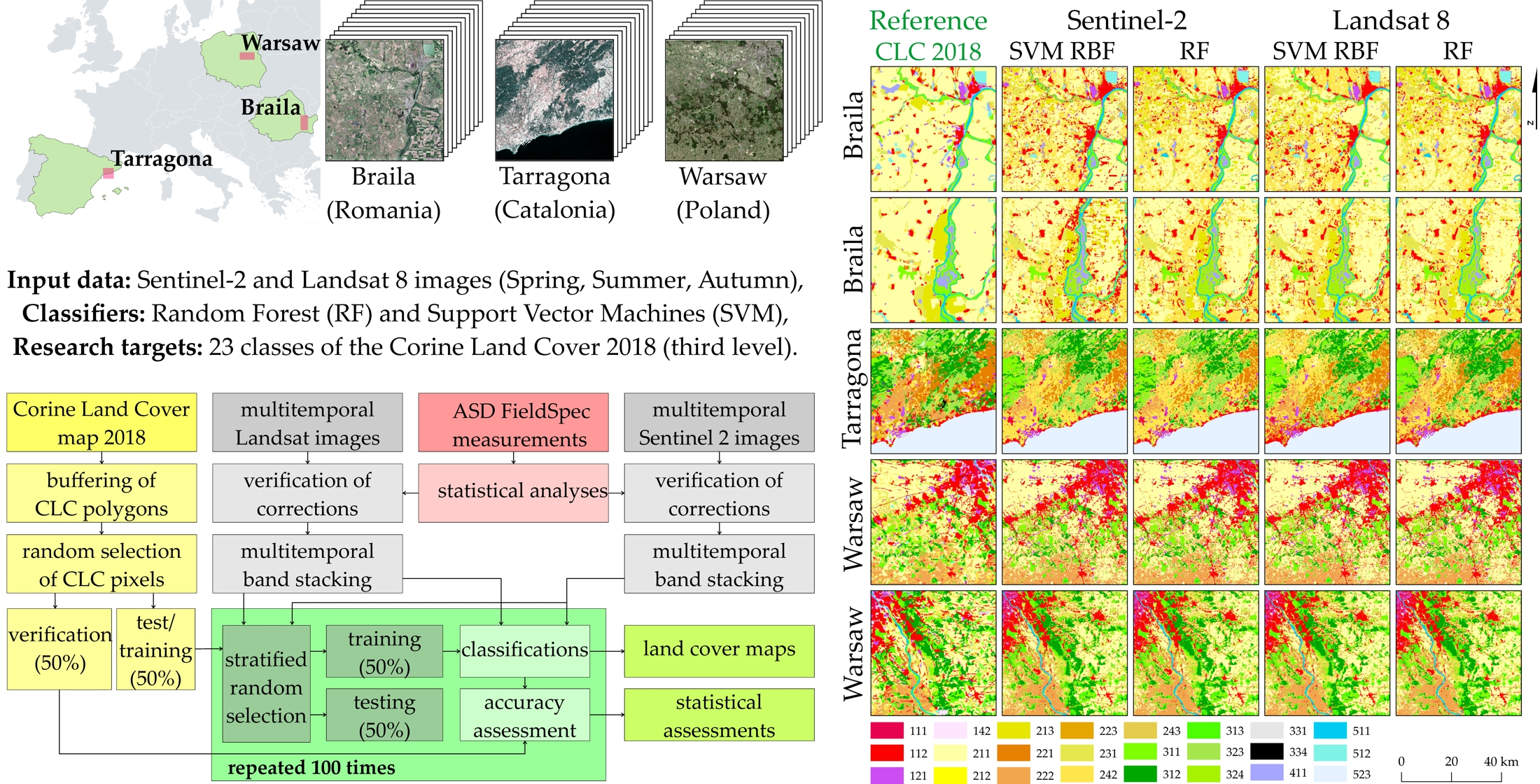
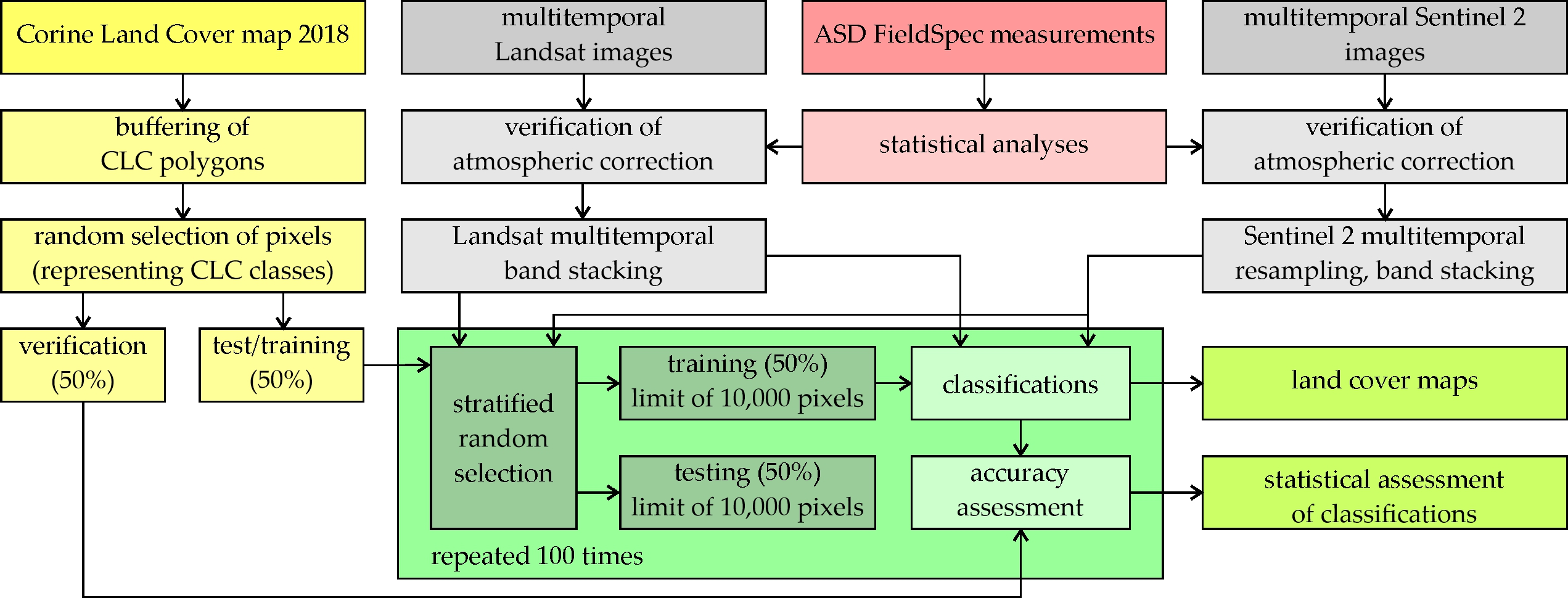
Our intention in this study was to assess the automatic land classification accuracy according to Corine guidelines based on Sentinel-2 and Landsat 8 multitemporal images (spring, summer, and autumn 2018/2019). For this purpose, areas located in various European Union parts, with a diversified history, spatial management, land cover, and different cartographic traditions were selected; however, due to the Corine program guidelines, the minimal mapping unit had to be 500 × 500 m, which significantly reduced the image information potential. The research procedure was based on two scenarios: 1) classification of twenty-meter pixel classification of the Sentinel-2 bands (10 m pixels were resampled to 20 m) and also on the thirty-meter pixel sizes of the Landsat 8; 2) in the next step, all pixels were resampled to 60 m, the basic classifications were made on them, and the results were generalized with a majority filter to the size of 8 × 8 pixels (480 × 480 m compared to the required 500 × 500 m in the Corine program). This allowed us to assess the effectiveness of the classifiers and allowed for the potential of automatic classification according to the official European CLC 2018 dataset. CLC data served as the input layer and were divided into training (25%), test (25%), and validation (50%) sets. Random Forest (RF) and Support Vector Machine (SVM) algorithms in the open-source R programming language were used as the classifiers. The main idea was to verify free-of-charge methods, which can be easily implemented on multicore processors. The classification patterns were randomly selected based on the 3rd CLC level. One of the key elements was the impact of the number of training pixels on the obtained results; it allowed us to optimize field reconnaissance during a verification phase (in the research, we used archival (2018) CLC layer and responsible satellite images).
3. Results
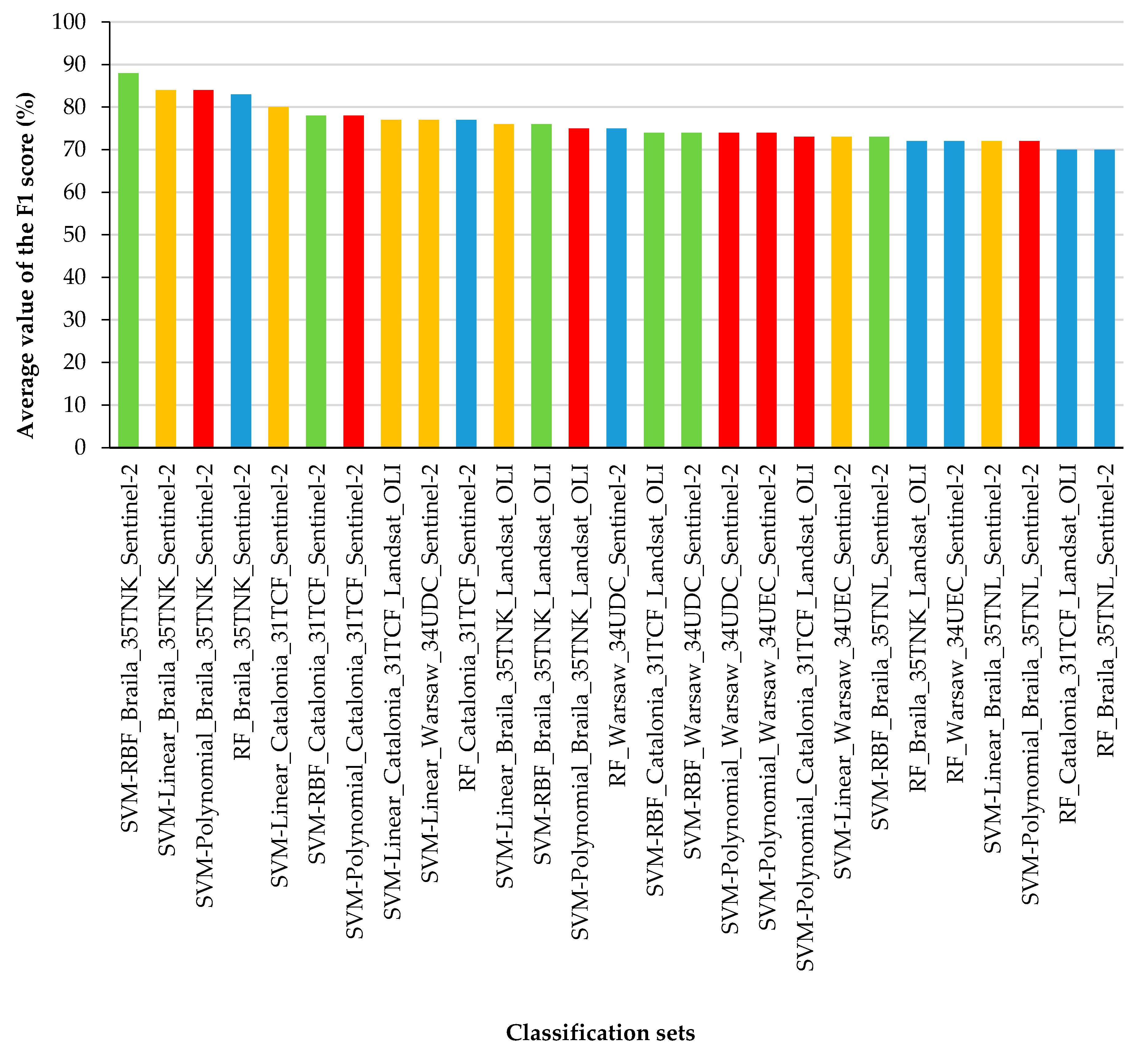
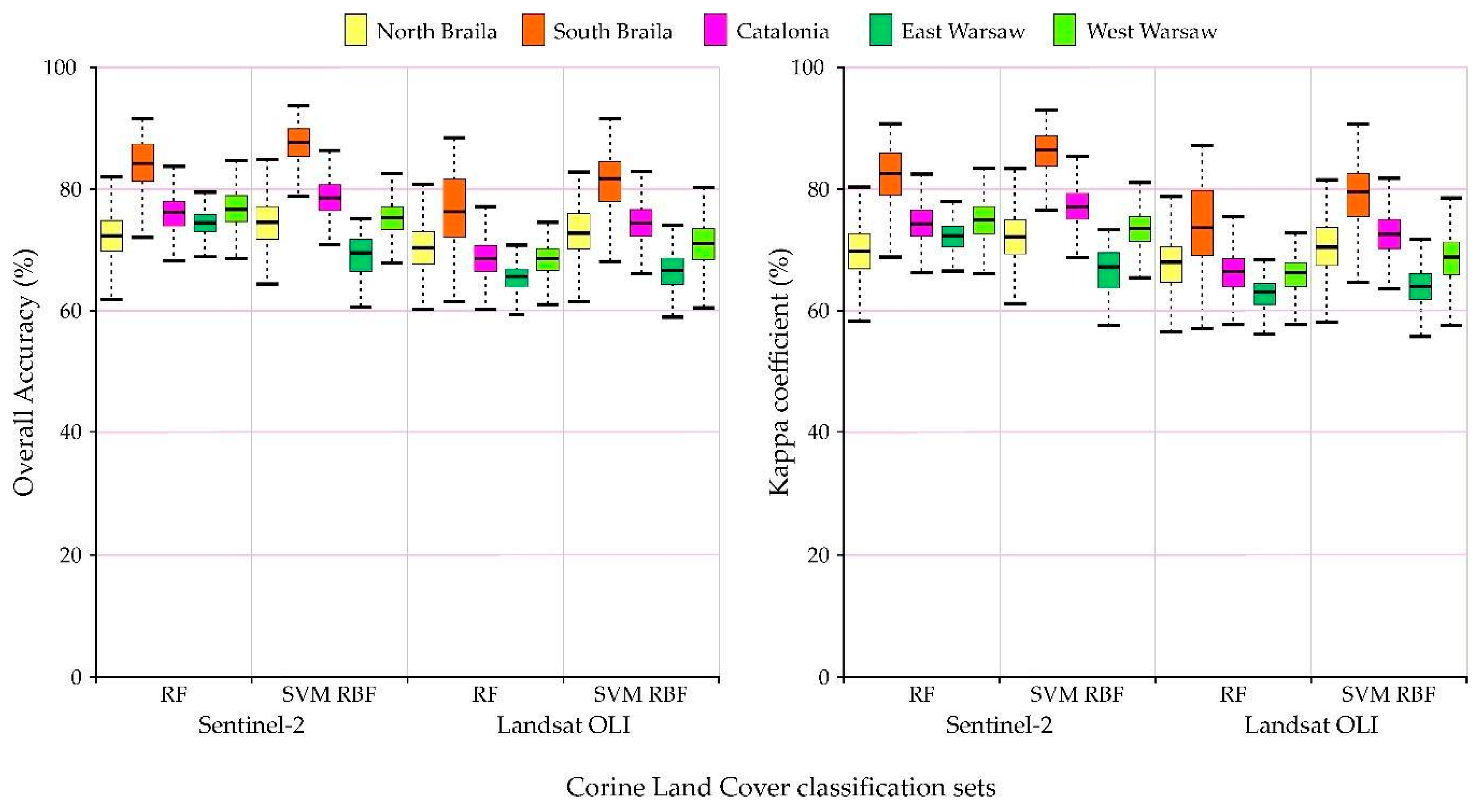
Evaluation of individual classifiers and datasets, their results for the average F1-score of all classes need to be compared (
Figure 7). Sentinel-2 images scored the top seven, while the SVM classifiers took the top three best places (RBF, linear, and polynomial kernel functions). Large and homogeneous southern Braila polygons (35TNK) scored the top four on the Sentinel-2 data (F1-score achieved 88%). In the case of images obtained by the Landsat OLI sensor, the best classifier was the SVM algorithm with a linear kernel function for the Catalonia area (F1-score oscillated around 77%). The worst results were obtained for the Random Forest classifier for the Landsat 8 satellite for Catalonia (70% F1) and Sentinel-2 for northern Braila (70% F1).
The Support Vector Machine algorithm with the radial kernel function (SVM RBF) algorithm achieved very good results for all areas and all classes of the research (the highest average accuracies of the F1-score oscillating between 73% and 88%;
Figure 8); therefore, the further focus was on this classifier and on the Random Forest (it achieved up to 5% lower results than SVM RBF), predicting the result images on both the Sentinel-2 and Landsat 8 imagery. Comparing the classification outcomes with the original Corine Land Cover maps, it can be seen that post-classification maps contain more details, which can be seen in particular in more heterogeneous areas. There is also a difference in the degree of generalization between the Landsat 8 and Sentinel-2 images, which show land cover in more detail. In terms of classifiers, the difference is particularly noticeable for the areas of Braila, where the Random Forest classifier generalized agricultural areas more than the Support Vector Machine, which classified technical objects and roads as class 112 (discontinuous urban fabric). For research areas in Romania, there are significant differences in the case of class 242 (complex cultivation patterns), which in the original study was strongly underestimated comparing with class 211 (non-irrigated arable land). As for the area of northern Braila, there is a discrepancy in the identification of water reservoirs (class 512), which remained without water on the satellite images during the analyzed period. In the case of Catalonia, in relation to the original Corine Land Cover map, there was a change of classes 221 (vineyards) and 222 (fruit trees and berry plantations), which should be identified as class 242 (complex cultivation patterns). Particular differences in the classification of the above-mentioned classes can be noticed between the Sentinel-2 and Landsat 8 images. There are visible differences in the distinction between forest types, e.g., coniferous forests (312), which have decreased compared to deciduous forests (311). In the Catalonia area, the building classes were very well distinguished: 111 (continuous urban fabric), 112 (discontinuous urban fabric), and 121 (industrial or commercial units). In the case of Warsaw granules, fruit trees and berry plantations were classified well (222). As in Catalonia, the different forest classes (311, 312, and 313) were distinguished in more detail than in the original CLC study. The Sentinel-2 images show the Fruit trees and berry plantations class (222) in more detail than the Landsat images. Difficulties were noticed in distinguishing classes 111 (continuous urban fabric) and 121 (industrial or commercial units) due to mixed pixels representing different classes characterized by granularity, discontinuity, and mosaic character (
Figure 8).
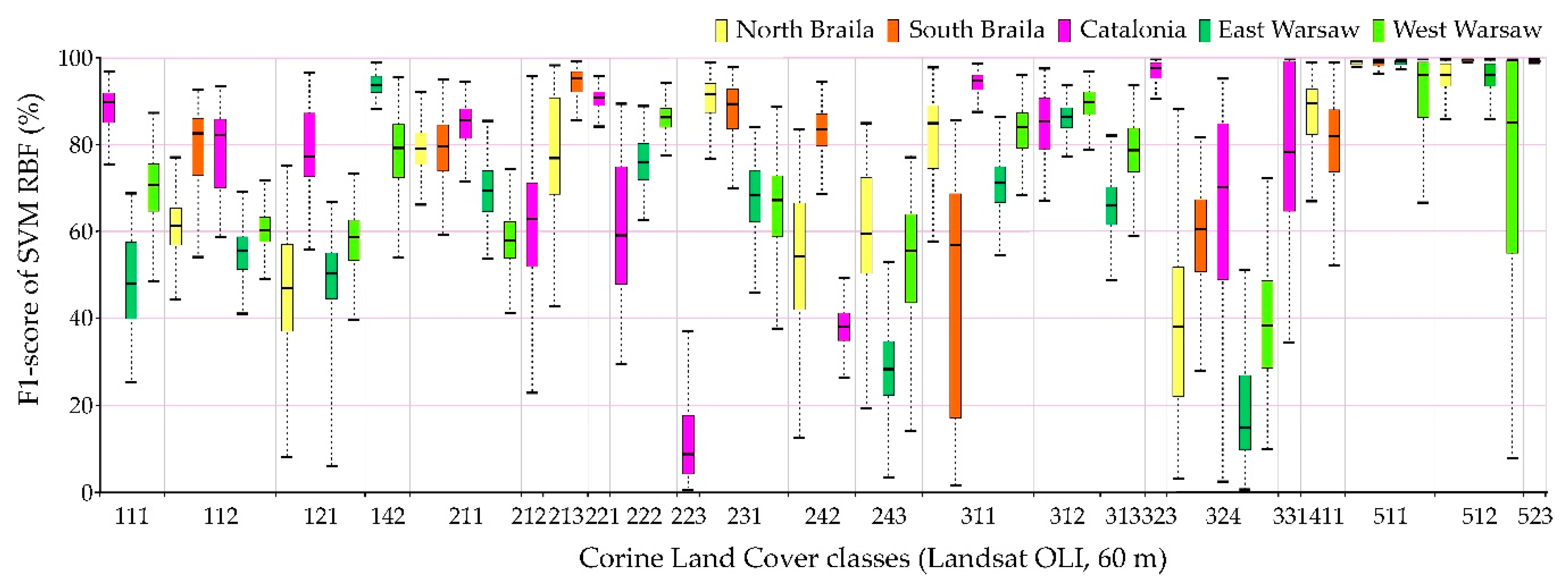
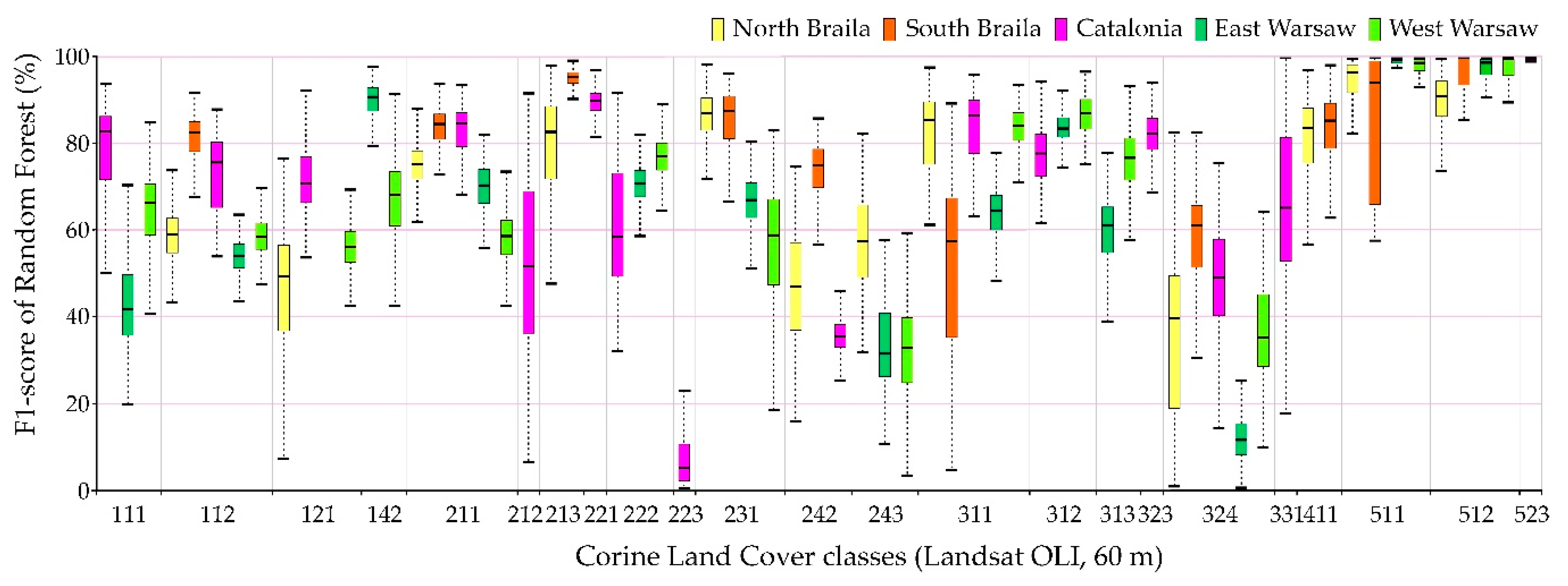
The comparison of accuracy according to the F1-score of individual classes for 100 repetitions of independent classifications is presented in
Figure 9,
Figure 10,
Figure 11 and
Figure 12, and the values of the overall accuracy and the Kappa coefficient in
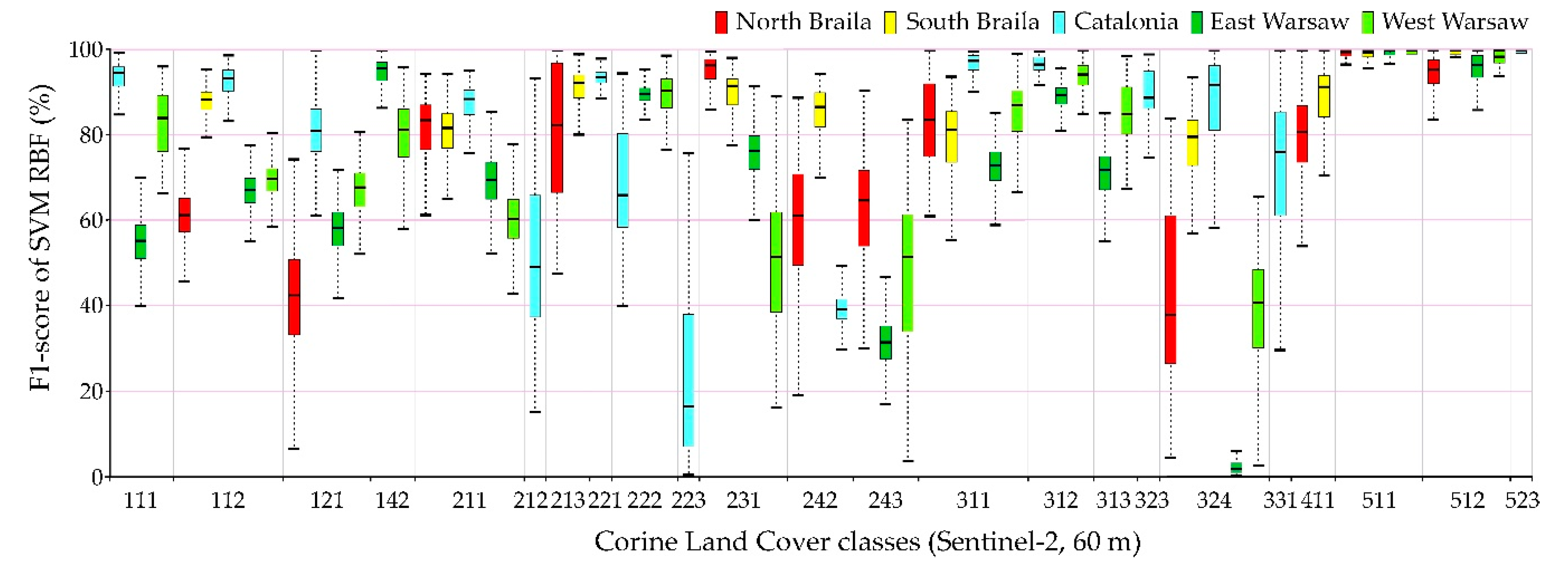
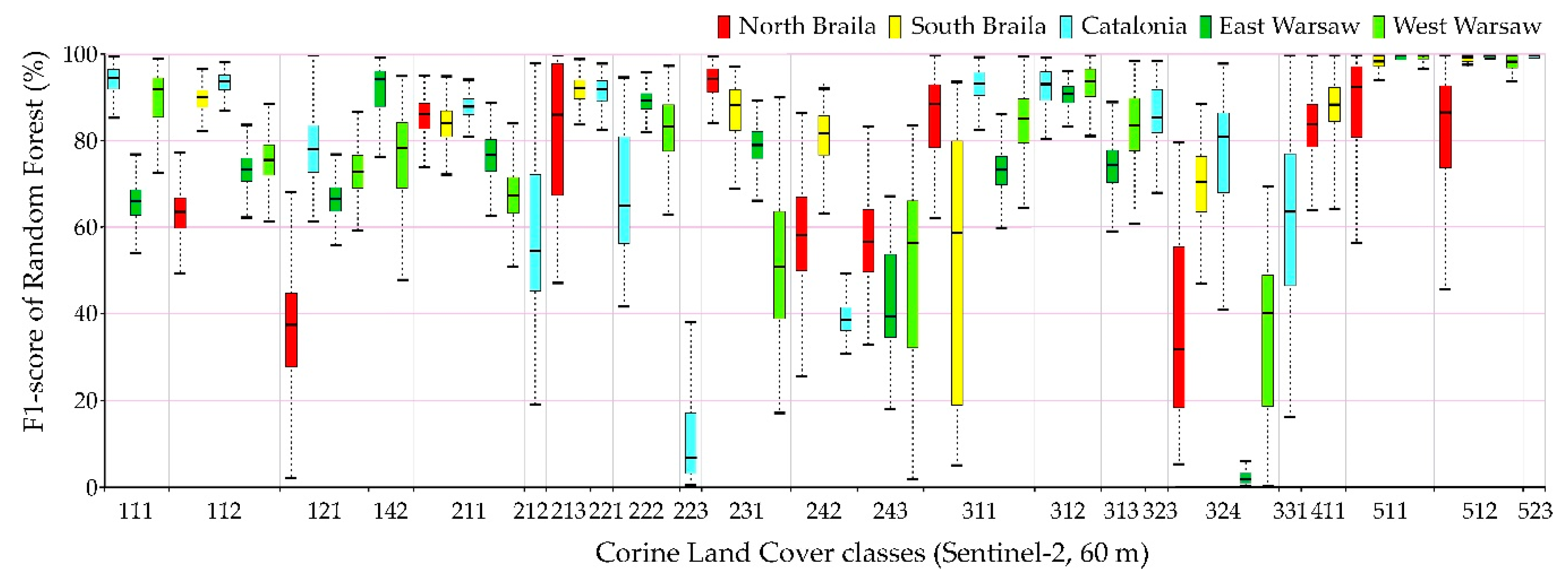
Figure 13. The highest values of the median F1-score were obtained for spectrally homogenous classes, e.g., 511 (water courses), 512 (water bodies), and 523 (sea and ocean); coniferous forests (312) and vineyards (221).
Sentinel-2 images could receive higher values of the F1-score median as well as a smaller spread of final results for the categories of anthropogenic land cover than in the case of Landsat 8 images. The OLI scanner’s classification results obtained slightly higher median results for pastures (231) and land principally occupied by agriculture, with significant natural vegetation areas (243).
Individual research areas were characterized by high variability within classes:
Northern Braila obtained the highest median results for pastures (231), the worst for industrial or commercial units (class 121). It is also worth noting that in the case of classes 511 and 512, Sentinel-2 images classified by Random Forest were characterized by a large range of data distribution, significantly different from other areas.
Southern Braila area is characterized by large homogeneous areas, which allowed high median scores for: rice fields (213), complex cultivation patterns (242), inland marshes (411); however, scores were poor for the coniferous forest class (312).
Catalonia obtained the highest median values for continuous urban fabric (111), discontinuous urban fabric (112), as well as for forests (311, 312). In the case of the complex cultivation patterns (242), it obtained low median results in Catalonia.
Eastern Warsaw areas received high median values for sport and leisure facilities (142), fruit trees, and berry plantations (222), while in the case of transitional woodland-shrub class (324), despite a significant range of data distributions for other areas, the results were the lowest scores obtained.
Western Warsaw obtained high median results for fruit trees and berry plantations (222) and mixed forests (313). In the case of classification using the Support Vector Machines algorithm in the Landsat 8 imaging, water bodies (512) were characterized by a significant range of data distributions significantly different from the results obtained for other areas.
The lowest median results were obtained for classes such as: olive groves (223), complex cultivation patterns (242), Land principally occupied by agriculture, with significant areas of natural vegetation (243), and transitional woodland-shrubs (324).
All areas obtained satisfactory overall accuracy and Kappa coefficient results (
Figure 13). The highest values of the median total accuracy were achieved for the northern area of Braila and the lowest total accuracy was for eastern Warsaw. Regarding the classifiers, the Support Vector Machines with a radial nucleus obtained higher maximum values of the total accuracy and the Kappa coefficient, but they were characterized by a larger spread than the Random Forest. In the case of imaging, higher median values were obtained for the Sentinel-2 satellite data.
In all cases, higher accuracies were obtained using Sentinel-2 images than Landsat 8. In the classifiers for areas in Romania and Catalonia, Support Vector Machines with the RBF turned out to be better. In contrast, for areas located in Poland, higher accuracy was obtained for the Random Forest algorithm.
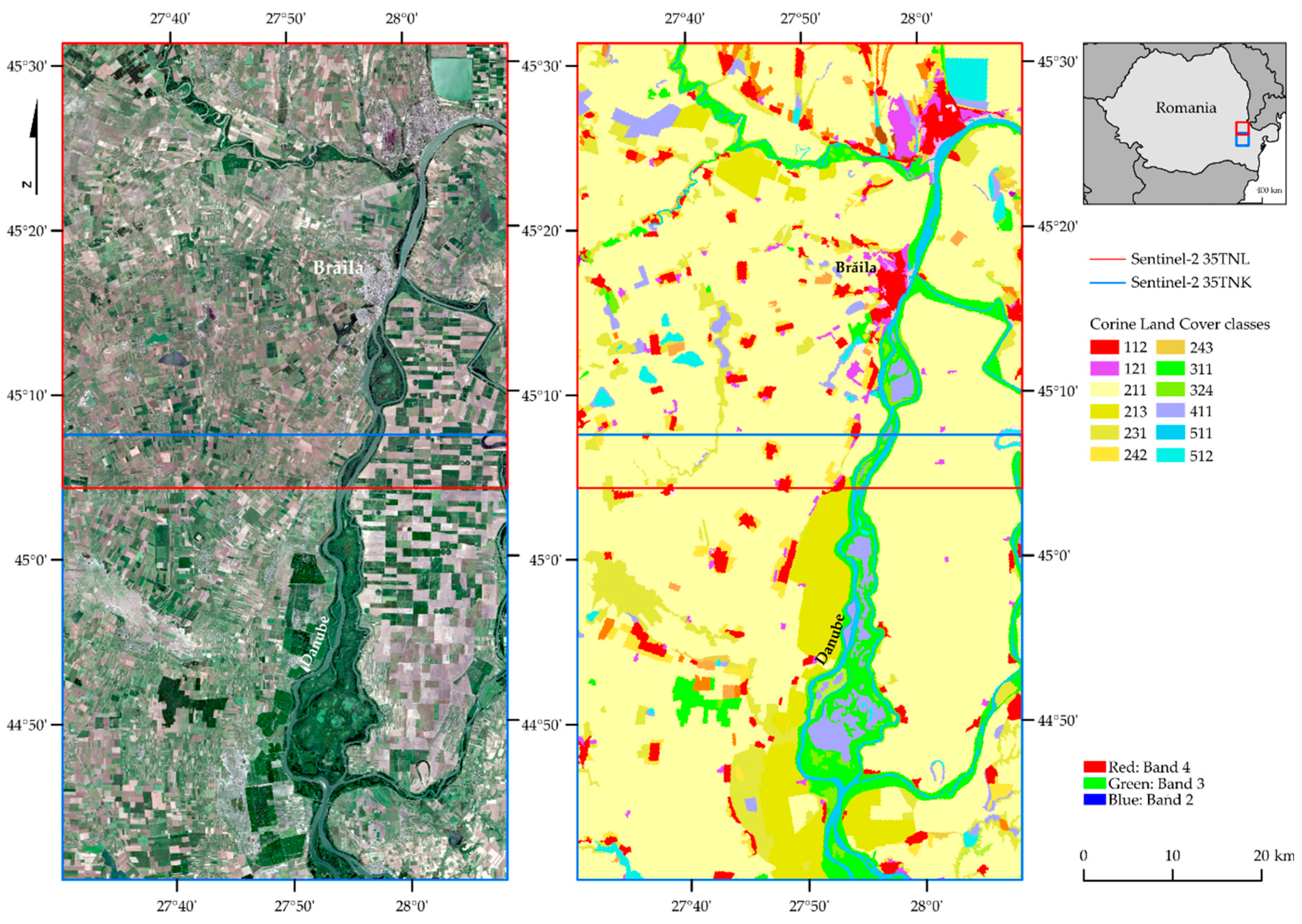
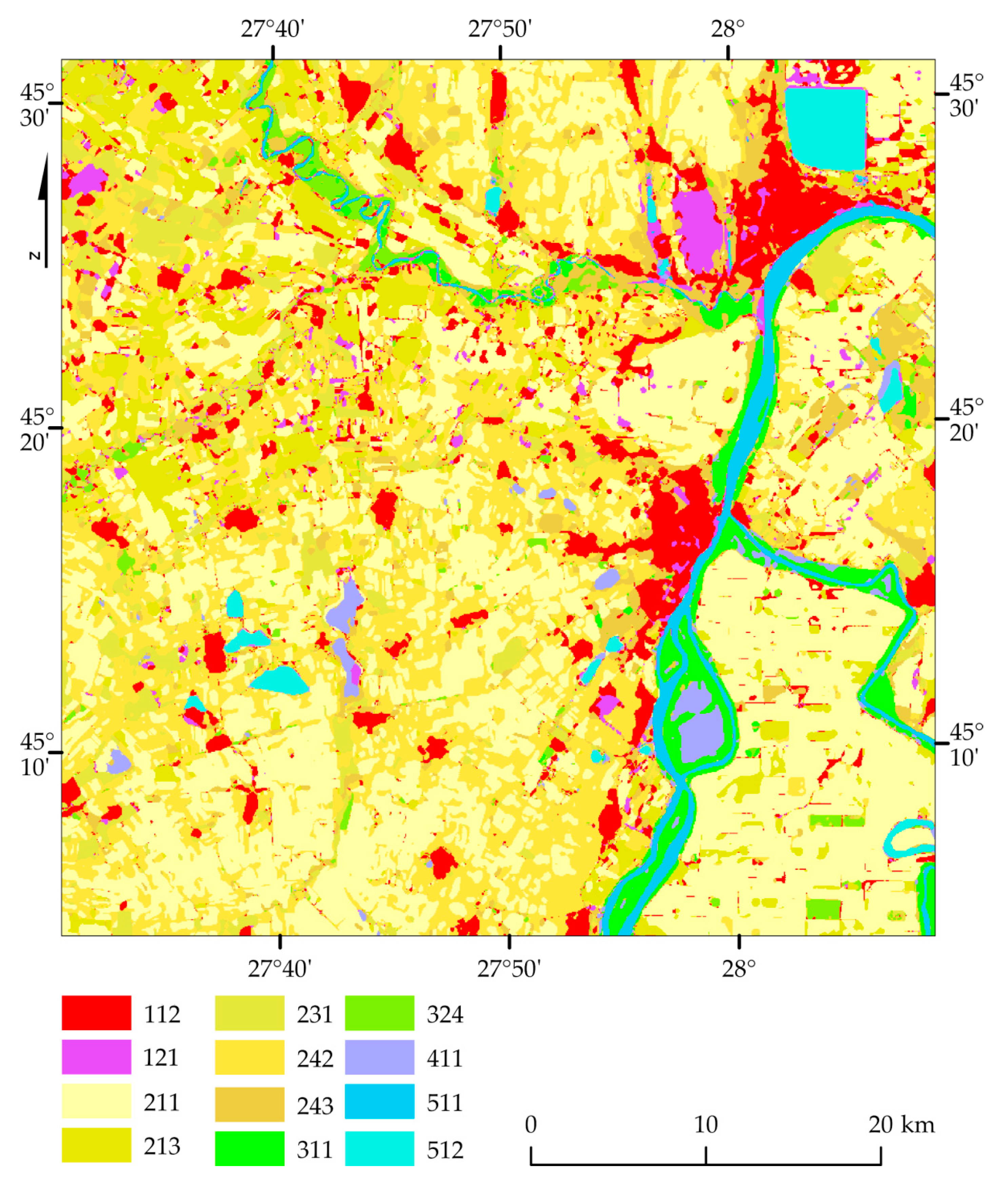
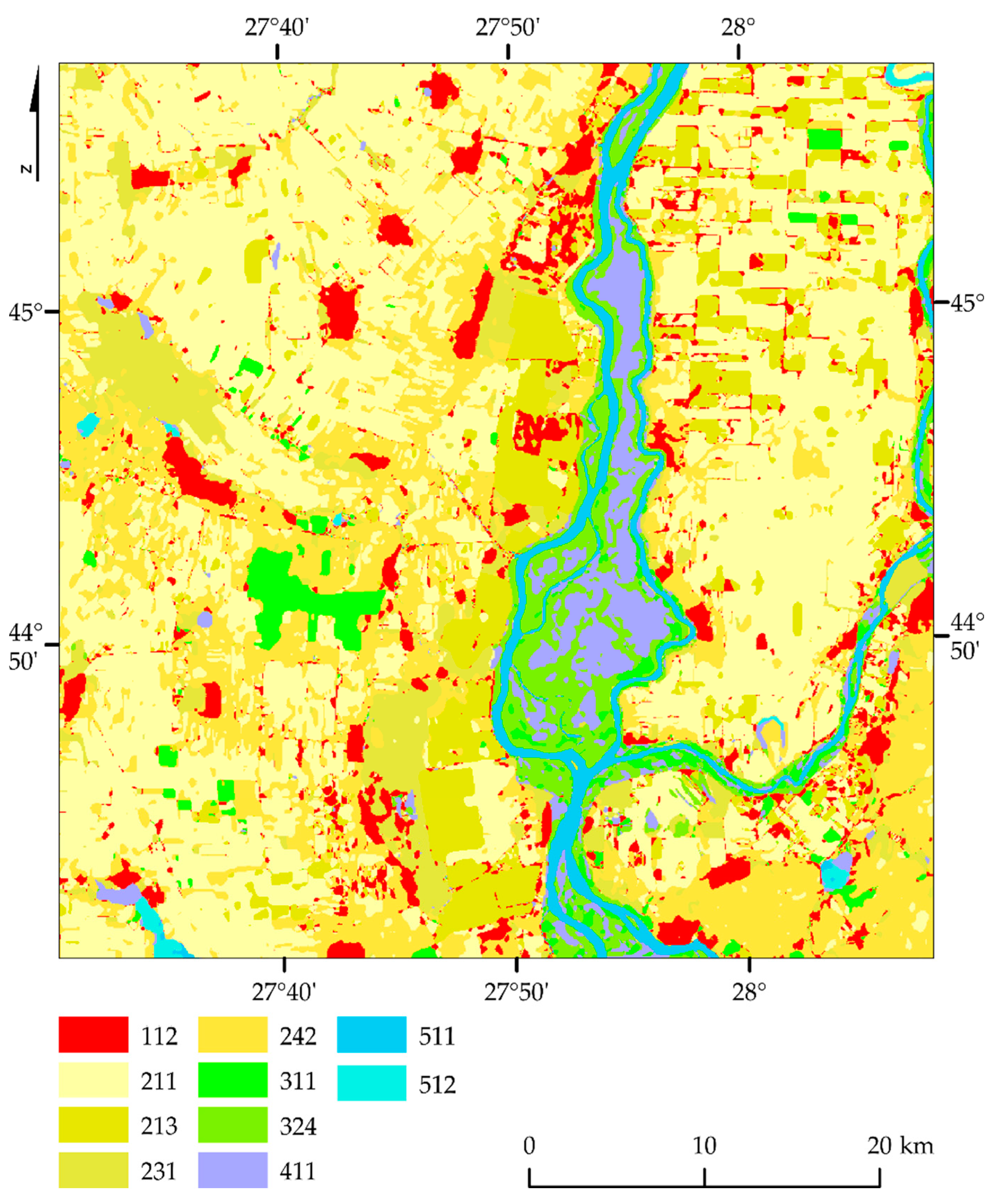
Analyzing the map (
Figure 14) and the error matrix (
Table 5) of the North Braila area, the best results were achieved by water courses (511; F1 100%), water bodies (512; F1 99%), and rice fields (213; F1 98%). The problems were noticed in the case of the transitional woodland-shrub (324; F1 69%), which is often confused with land principally occupied by agriculture, with significant areas of natural vegetation (243) as well as complex cultivation patterns (242). The lowest values were obtained for the building classes: Industrial or commercial units (121; F1 57%) and discontinuous urban fabric (112; F1 64%), often mixing with each other.
Another of the analyzed Romanian areas is Braila district’s southern fragment (granula 35TNK,
Figure 15). The area was classified very well due to large and homogenous agriculture areas, e.g., numerous rice fields (213), which were rarely confused with the non-irrigated arable land class (211) in places where there was intensive vegetation and classified very well. Satisfactory results were also obtained for inland marshes (411) and water courses (511). There are similar results as in the case of the northern Braila area (
Figure 14); the best results were obtained for the classes of water bodies (512; F1 100%), water courses (511; F1 98%), and inland marshes (411; F1 93%;
Table 6). The complex cultivation patterns class (242) obtained (F1 81%) mixed with the non-irrigated arable land class (211). The lowest results, although relatively high, were achieved by the broad-leaved forest class (311; F1 73%), mixing with discontinuous urban fabric (112) and transitional woodland-shrub (324).
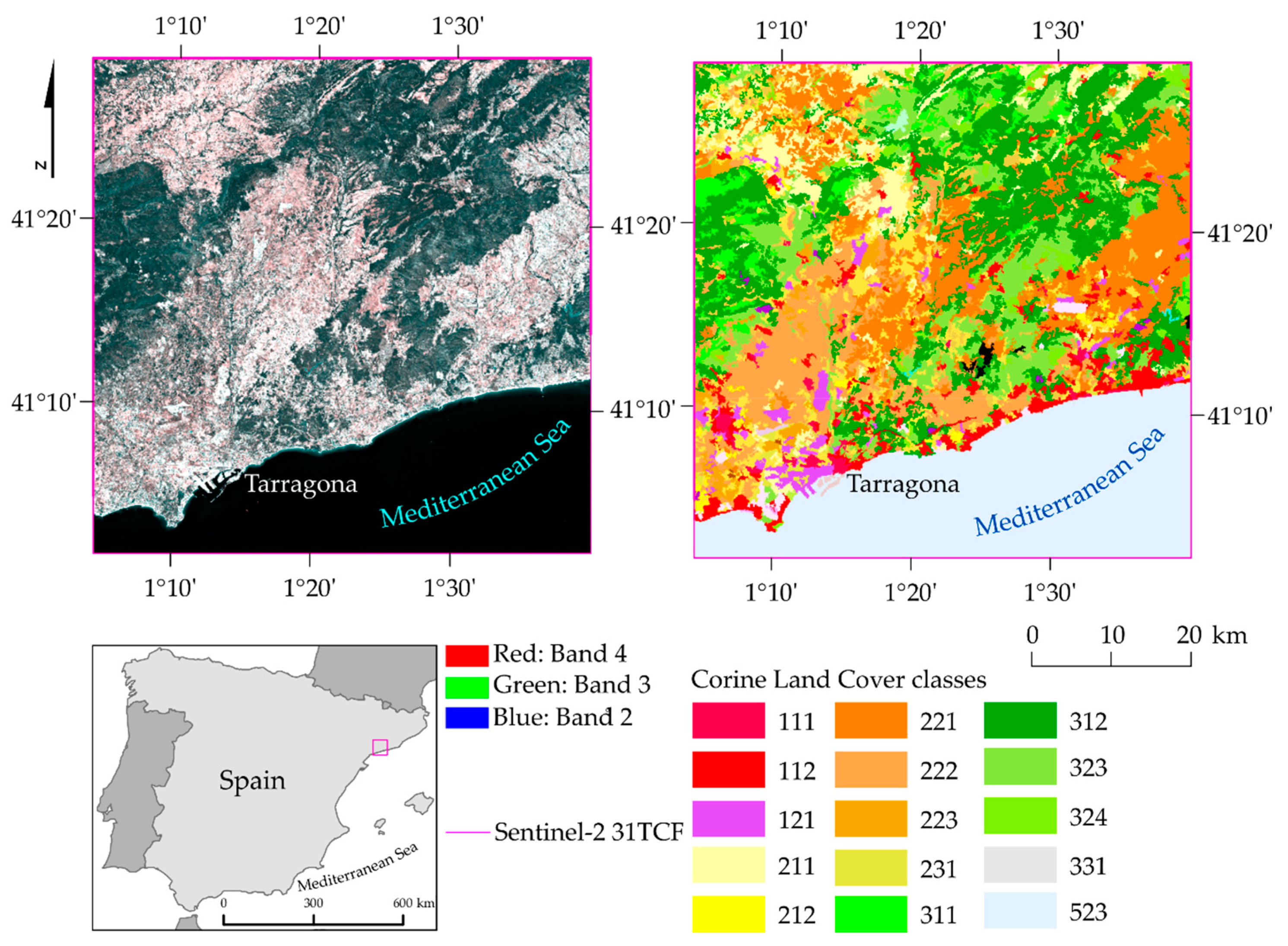
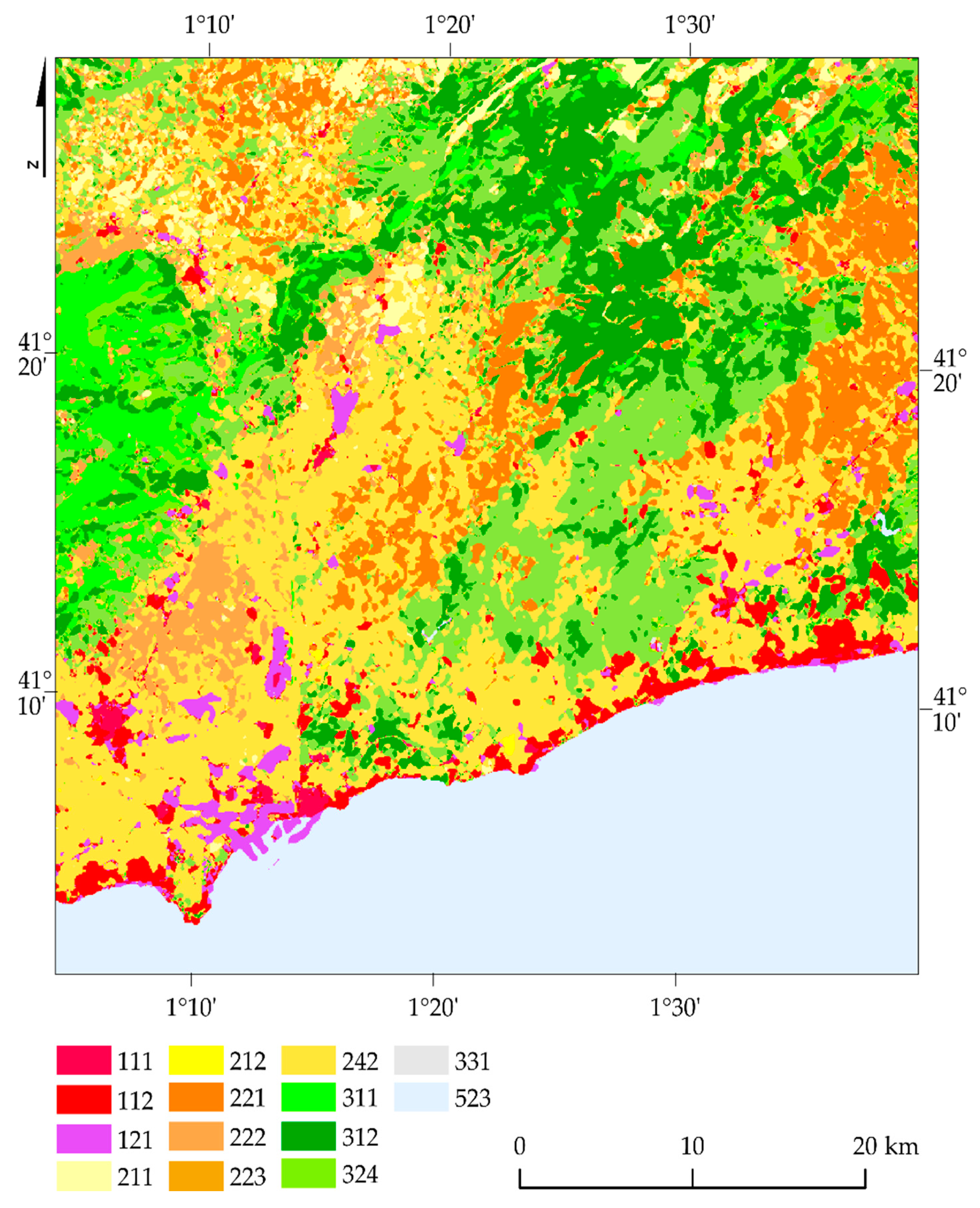
In the case of the Catalonia region (
Figure 16), the sea and ocean patterns (523; F1 100%), coniferous forests (312; F1 99%), broad-leaved forest (311; F1 95%), and discontinuous urban fabric (112; F1 95%) were well distinguished (
Table 7). Vineyards (221), fruit trees, and berry plantations (222) were correctly classified, defining their precise range. Low values were obtained for the class permanently irrigated land (212; F1 33%), often mixing with pixels of non-irrigated arable lands (211) and complex cultivation patterns (242). This happened because there were difficulties identifying it with the olive groves class (223; F1 9%), where the space between individual groves was classified as the class of complex cultivation patterns (242). The beaches, dunes, and sands class (331; F1 37%) also obtained unsatisfactory results, confusing the industrial or commercial units (121).
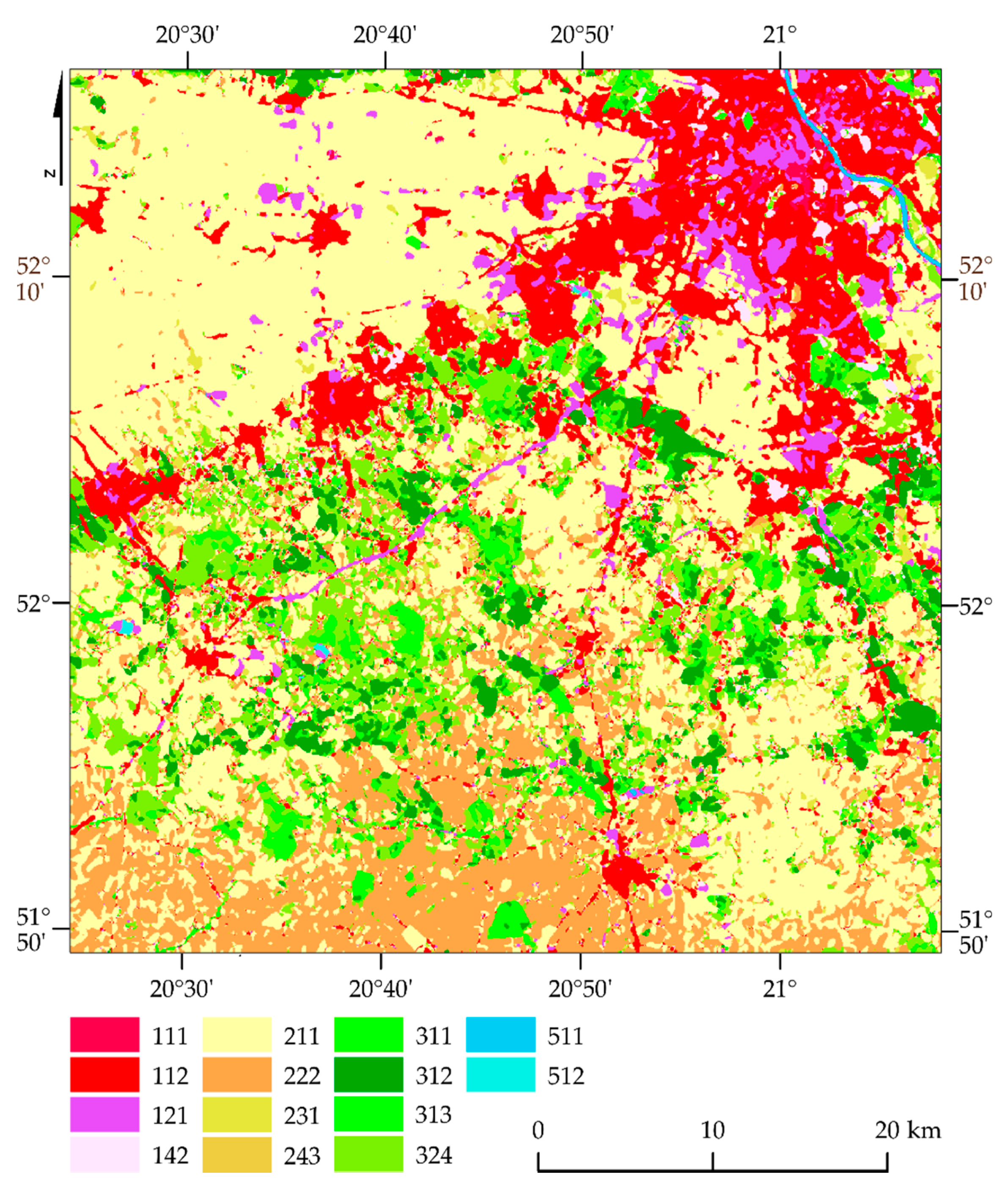
In the case of Polish test areas (western part of Warsaw, granula 35UDC,
Figure 17, and eastern Warsaw, granula 35UFC,
Figure 18), fruit trees and berry plantations (222), coniferous forest (312), as well as water courses (511) and water bodies (512) are visually the best, creating dense tracts. Sporadically mixed forests (313) were confused with transitional woodland-shrubs (324), with which broad-leaved forest pixels (311) were mixed up often. The pastures (231) and land principally occupied by agriculture, with significant natural vegetation areas (243), were classified in a discontinuous and fragmentary way. Visually, the worst was the class of industrial or commercial units (121), which was often overestimated, and the effect is the strongest in the case of urban fabric (111, 112). The error matrix analysis (
Table 8 and
Table 9) showed the best results were obtained in the classes of water courses (511) and water bodies (512; F1 100%) as well as coniferous forest (312; 96%). Sport and leisure facilities (142) have often been confused with fruit trees and berry plantations (222) and pastures (231). The class land principally occupied by agriculture, with significant areas of natural vegetation (243), was often misassigned to the non-irrigated arable land classes (211) and fruit trees and berry plantations (222). The worst results were transitional woodland-shrubs (324; F1 50%), which were confused with pastures (231) and broad-leaved forest (311).
The applied classification methodology required data acquisition from spring, summer, and autumn, which allowed us to identify most of the classes that occur and automatically be identified, regardless of geographic location (
Table 10). The problem is the selection of the right number of training and verification pixels (
Table 11), which should be updated regularly, as significant changes were observed between the original Corine map from 2018 and contemporary satellite images, e.g., lack of water in selected water bodies or densely built-up areas instead of green areas.
4. Discussion
In our opinion, there is a lack of comparison of CLC products obtained using different areas, sensors, and classifiers in the literature. We focused on conducting analyzes on individual Sentinel-2 imaging granules, selecting three countries characterized by a different history, which influenced spatial management (starting from large-scale agricultural crops (South Braila), a large urban agglomeration (Warsaw) with direct operating facilities, including the suburban zone, which on the one hand provides protected areas and climatic resorts along Vistula river, as well as typical suburban zones, including small farms providing food for suburban towns), but also coastal and river port areas (Tarragona, North Braila) and well-known tourist areas. The selection of tools was not accidental, because, based on the literature review, we wanted to use machine learning algorithms that are widely available and based on a programming language, which allows us to automate the procedure for classifying subsequent areas. In many cases, the results obtained on the original data (20 m Sentinel-2 and 30 m Landsat 8) were much more accurate than on the generalized data (60 m), and then filtered to a resolution of 480 × 480 m, which is a requirement of Corine Land Cover. In our work, we compared results obtained using four different SVM kernels and the Random Forest classifier. We also included a multi-temporal composition, which gave satisfying results without having to search for additional datasets to make the images more informative (other sensors, radar, lidar, etc.). This is especially important considering adding additional data is time-consuming (especially if the product is developed for the whole of Europe). We investigated the relation between the number of pixels used for training per class and the classifier used. Such works are not rare, but they mostly focus on either problem, not on both as we carry out here. Our results will help inform further CLC+ creators about the required minimum number of pixels per class they need to acquire in order to deliver acceptable results. Our study is particularly relevant now that a new version of CLC+ is being developed, with a heavy focus on creating solutions employing classification approaches that enrich the final product.
Despite the advantages and numerous applications, CLC products and analyses carried out should be treated with caution, and researchers should be aware of the restrictions associated with them [
26]. Despite the continuous improvement of definitions, a significant disadvantage is the ambiguity of the class description, as Jansen and Di Gregorio [
53] pointed out. Diaz-Pacheco and Gutiérrez [
54] highlighted a significant impact of subjective photo interpretation on results, which translates into thematic accuracy, insufficient standardization, and harmonization of data. The difference in thematic accuracy in the scale of regions and countries is also noted by García-Alvarez and Camacho-Olmedo [
55]; problems with detailed analyses of land cover were noticed by Di Sabatino et al. [
56]. According to the European Environmental Agency [
57], the most challenging and subjective classes in photointerpretation are classes: 242, 243, 313, and 324 [
57]; in the case of our classifications, it was confirmed only in the case of class 324 (East and West Warsaw) and 242 (Catalonia). The rest of the areas offered an acceptable level of classification accuracies (
Table 12). It is also worth noting that in 2012 there was a change in the methodology for creating the German CLC [
58], which caused a significant decrease in area in classes 242, 243, and an increase in area in class 231. The standard photointerpretation (used in CLC 1990, 2000, and 2006) was replaced by an original methodology based on the use of the existing Digital Land Cover Model for Germany (DLM-DE) national data, which is much more detailed (the size of the minimum mapping unit (MMU) is 1 ha). This makes it impossible to analyze changes between versions with the old and the new methodology. Besides, the CLC technical team verification in many countries has shown that a common mistake in photointerpretation is the overestimation of classes 242 and 243 [
59]. The process of creating CLC is time-consuming, expensive, and the final product is published with a significant delay between data collection and publication.
F-score for complex agricultural areas (classes 242 and 243) oscillate around 80% for Brailas (F1: 81%, 75%, 79%), the same accuracies were observed by Denize et al. [
60], who used Sentinel-2 data and SVM and RF algorithms for classifying crop residues, bare soil, winter crop, and grassland scoring an overall accuracy of 81%. For the same source of data and Random Forest algorithms for maize, onion, sunflower, and sugar beet, Immitzer et al. [
61] achieved 65–76%, which is a similar result to the Warsaw area in our study.
Phiri et al. [
62], based on an analysis of 222 papers oriented on land cover mapping, confirmed that SVM and Random Forest algorithms offered the best accuracies in the case of Sentinel-2 images (89–92%) than Landsat-based maps; although the mean classification results of Random Forest and SVM were comparable (~89%), as the maximal, as well (~93–95%) [
62]. General observations were confirmed in our case, where we could notice a similar range of the best results, but in our case, SVM RBF obtained results better by two to three percent than RF.
Analyzing the sensor’s effect on classification accuracy, better total accuracy results (7–8%) were obtained for the MSI sensor than OLI regardless of the algorithm used. For the Random Forest a Support Vector Machines algorithm, the differences between the MSI and OLI sensors were 8% and 7% in favor of MSI, respectively. The advantage of the MSI scanner over OLI in overall accuracy (2–8%) was also recognized by Phiri et al. [
62], who collated 20 scientific papers on land cover classification. The researchers noted that the MSI scanner was 8% better for the Random Forest algorithm, while for Support Vector Machines the difference was smaller at only 2%. Similar conclusions were also reached by Forkuor et al. [
63] by resampling the resolution of Landsat 8 to Sentinel-2 (10 m), obtaining higher overall accuracies (2–4%) for the MSI scanner than OLI. Additionally, when resampling Sentinel-2 to Landsat 8 resolution (30 m), performed by Topaloğlu et al. [
64], it led to better total accuracy results (2%) for the MSI scanner than OLI. Despite the longer operational time of the Landsat series of satellites than Sentinel-2, allowing for the development of data processing methods, an important element seems to be the larger number of multispectral bands (Sentinel-2: 13 bands, Landsat 8: 8 bands) of the MSI scanner increasing the classification accuracy (
Table 13).
An important element affecting land cover classification accuracy is the number of classes identified (
Table 13). Increasing the number of land cover classes identified contributes to a decrease and blurring of spectral differences between classes, resulting in decreased classification accuracy [
65]. Additionally, an analysis of 64 articles on land cover classification by the team of Thinh [
66] highlights a significant decrease in the total accuracy when increasing the number of classes. In the present study, the highest accuracies were obtained for areas where 10 and 14 classes were present, which significantly affected the classification accuracy and contributed to the differences in the results obtained from other authors who usually designated fewer classes; however, it is not only the number of classes determined that matters, but also the choice of methods for processing the data and making them more informative. Demirkan et al. [
67], although identifying only four first-level Corine classes, achieved weaker results than the vast majority of other researchers identifying more classes. The reason for the more inferior result could be the use of only a single satellite image. An acceptable way to increase the data’s informativeness is to create a multi-temporal composition from satellite images acquired at different times. This allows us to not only reduce the influence of a single image and errors that may occur in it, but especially helps to distinguish vegetation types that change their spectral reflectance depending on the analyzed period. In this paper, a multi-temporal composition was used from satellite images acquired in spring, summer, and autumn; however, there are “denser” time series in the literature, as in the case of the team of Forkuor et al. [
63], who used Sentinel-2 and Landsat 8 imagery from five dates, obtaining high total accuracy results (89–93%). Increasing the time series does not always produce higher classification accuracy results as shown by the study of Weinmann and Weidner [
68] who, using imagery acquired by the MSI scanner for four dates with a small area (16 × 16 km
2) and the same number of classes, obtained total accuracy results of up to 80%. It is worth noting that it is impossible for many areas to acquire satellite imagery due to the cloud cover present, which makes analysis impossible.
Another important aspect of differences in classification accuracy is the spatial resolution of satellite data used. On the one hand, the high spatial resolution allows the classification of land cover forms with high precision; on the other hand, land cover requires generalization. That is why many classification systems such as Corine Land Cover allow for the presence of another class in a given class of elements, e.g., farm buildings in agricultural areas, technical paths in forests, and small water bodies in forests. Such generalization is often possible by resampling satellite data to a lower resolution, allowing mixed upland cover classes to occur sporadically within large homogeneous classes. Researchers obtain similar results for several classes regardless of whether they use a higher [
69] or lower resolution [
64]; however, for the classification of the third level Corine Land Cover data, it was necessary to lower the resolution in order to generalize the land cover classes, allowing a dozen classes to obtain results comparable to other authors. Similar methods are used to identify dozens of Corine classes, as exemplified by the study carried out by Novillo et al. [
20], who used 275 m resolution MISR scanner imagery for this purpose, but this was at the cost of reduced precision in class boundary delineation.
Comparing the classifiers used in this study, higher results were obtained for Support Vector Machines than Random Forest for both MSI and OLI scanners (6% and 7% higher, respectively). For the results obtained by Demirkan et al. [
67] for four classes, the accuracy differences do not appear in the comparison made by Thanh Noi and Kappas [
66]. Only at six classes, a slight advantage in classification accuracy (by 3%) of Support Vector Machines over Random Forest is seen. Slight differences are also found by Forkuor et al. [
63], where for the OLI scanner Random Forest is 1% better, and for MSI, there is an inverse relationship where the Support Vector Machines algorithm is 1% better. Phiri et al. [
62] found a 4% advantage of Support Vector Machines for the OLI scanner. The MSI scanner Random Forest was found to be 5% better than SVM. The process of selecting hyperparameters for the classifiers, as well as the nature of the data and the number of classes, may have influenced the discrepancies.
Analyzing the results obtained for each Corine level 3 class (
Table 14) and comparing them with other authors should be considered satisfactory. Since the classification was carried out in three different study areas, where geographical variability could have significantly influenced the obtained values, we decided to give the minimum and maximum value obtained for a given class from these areas. In the case of anthropogenic sites for classes 111 and 112, a minimum producer accuracy (72% and 77%, respectively) was obtained, comparable to the results of 75% and 77% from Balzter et al. [
14]. Despite the use of different methods by the team of Balzter [
14], who used Sentinel 1A radar imagery combined with SRTM data, this shows the possibility of successfully classifying development areas for Corine Land Cover. In the case of class 211 agricultural land, the obtained producer accuracies by Gudmann et al. [
71] are remarkably high (97%), being slightly higher than the obtained maximum accuracies (95%) for this class. This may have been influenced by the small study area (500 km
2) being five times smaller than each study area in this paper, and also the geographical nature of the area may have influenced the result. In the case of classes 242 and 243, where difficulties in classification were encountered, resulting in 61% and 50% of the producer’s minimum accuracy, respectively. Problems in their classification were also found by the team of Gudmann et al. [
71], who obtained 34% and 26% of the producer’s accuracy, respectively. This may indicate the inability to identify these classes, and the need to find other methods to classify them effectively is urgent. Additionally, for class 324, the weakest result was obtained (min. PA 56%), which is comparable to other researchers (50% [
14]; 42% [
71]). For deciduous forests (311), a comparable result (min. PA 63%) was obtained with Balzter et al. [
14] (PA 67%). Noticeable differences were found for the coniferous forest class (312), for which the minimum value of the producer’s accuracy (95%) differs significantly from the results obtained by the researchers (70% [
14], 58% [
71]). The difference of the result in the case of Baltzer et al. [
14] can be understood by different characteristics of the radar data, but in the case of the team of Gudmann et al. [
71], it differs significantly despite the use of a multi-temporal composition from images acquired by the Sentinel-2 satellite and the Random Forest algorithm. Significant differences are also found for the producer accuracy score (44%) for water bodies (512) obtained by Gudmann et al. [
71]. Surprisingly, the low accuracy in particular of the characteristic spectral reflectance curve for water, the rarely occurring problems in identifying this class [
72], and the lack of occurrence of other classes related to water areas. The differences obtained may have been influenced by the nature of the study area and its size.
Regarding a usage of more sophisticated classifiers such as those based on deep learning methods, there is a multitude of approaches one can select; simple implementations such as a deep multilayered perceptron offers comparable results as obtained by SVM or RF, but optimizing procedure requires more time and better servers [
72]. In order to compare shallow and deep learning methods, it is necessary to prepare the data in an appropriate way to compare them objectively (Liu, 2017) [
73], also bias can be introduced without following uniform rules, where often one method is favored and its parameters optimized, while other algorithms are not optimized and are assigned default parameter values [
74]. Additionally, it should be emphasized that for deep learning methods a very large number of samples were needed for training which requires more computing resources and longer time for optimizing the parameters [
73]. In our case, the challenge for the classifiers was to determine patterns of the same classes, but biogeographically different areas, where different spatial management principles apply. For example, research carried out by Ulmas and Liiv (2020) [
72] where a convolutional machine learning model with a modified U-Net structure was used to classify land cover according to Corine Land Cover nomenclature did not yield better results, e.g., lowest results were obtained for the classes: discontinuous urban fabric (class 112; F1-score: 1%, and in our case the lowest 42% for Landsat 8, in case of Sentinel-2 results were better;
Figure 9,
Figure 10,
Figure 11 and
Figure 12), industrial or commercial units (class 121; F1-score: 36%, and in our case 4%), sport and leisure facilities (class: 142; F1 0%, and in our case 42%), rice fields (class 213; F1 12%, and in our case 42%), fruit trees and berry plantations (class 222; F1 27%, and in our case 28%). Additionally, for water area classes where there are usually no problems with their classification low accuracies were obtained (F1 38-83%, and we observed the lowest accuracy in Warsaw’s 8%, but its median achieved 84% (class 512), excluding this one case, the lowest accuracy scored 48%, but the lowest median 84%). Additionally, the superiority of deep learning methods over Random Forest and Support Vector Machines was not observed in other land cover classification studies [
74,
75]. Naturally, this is a subject of discussion since much depends on the subject of classification (number of classes, data, how distinct classes are, etc.). Most works focus on using artificial neural networks and their variations to classify datasets structured in the same way as for SVM or RF [
76,
77,
78,
79]. That is, to classify images using pixel-based approaches. This approach disregards the natural advantages of more advanced deep learning techniques such as convolutional or deconvolutional neural networks, which can exploit relations between pixels and objects on the image [
73]. Proper use of those advantages allows for more accurate results that are also easier to analyze (such as providing class labels to image parts instead of individual pixels) [
80]. Moreover, when deciding to investigate deep learning, one must be ready to invest a significant amount of time into processing and training steps. The use of deep learning enormously increases processing times compared to classical machine learning algorithms [
81], especially when large areas are involved. This, combined with the expertise required by deep learning, leads to interesting but challenging problems that are yet to be thoroughly investigated.
5. Conclusions
The result of the work is the verification of the potential of both the Landsat 8 images that formed the basis of the Corine program and the Sentinel-2 data. The conducted analyzes showed a several percent advantage of the Sentinel-2 data, despite the fact that the classification was carried out on the basis of resampled data to a resolution of 60 m. Another key result is the analysis of the usefulness of algorithms. The Support Vector Machine algorithm with the radial kernel function (SVM RBF) achieved significant results for all research areas. The following part focused on this classifier and Random Forest, making the prediction of the result images on both Sentinel-2 and Landsat 8 imagery. SVM results are characterized by a smaller range of data distributions such as deciduous forests (311), water courses (511), and water bodies (512) than in the case of the results obtained for Random Forest, which, however, obtained a smaller range of data distribution for permanently irrigated land (211). Comparing the classification images with the original Corine Land Cover study shows that more detail is included, which makes the class areas less homogeneous than in the original study. There is also a difference in the degree of generalization between results acquired from the Landsat 8 and Sentinel-2 imagery. The performed analyzes confirmed that the presented results are not the best that can be obtained based on the RF and SVM algorithms and the used data, higher results were obtained for the original resolutions (20 m Sentinel-2 and 30 m Landsat 8), but the Corine program guidelines required generalization to a resolution of 500 × 500 m (in our case we used 480 × 480 m), which lowered the presented results by several percent. Sentinel-2 shows the land cover in more detail, offering 8–11% higher results, e.g., a particularly big difference can be observed for the areas of South and North Braila. Random Forest classifier better generalized agricultural areas than Support Vector Machines, which classified technical objects and some roads as class 112 (industrial or commercial units). For research areas in Romania, there are significant differences in the share of class 242 (complex cultivation patterns, which in the original study was strongly underestimated) at the expense of class 211 (non-irrigated arable land). As for the area of northern Braila, there is a discrepancy in the identification of water reservoirs (class 512), which remained without water during the satellite imaging.
Concerning the area of Catalonia, the original study by Corine Land Cover, there was a significant change in the share of classes 221 (vineyards) and 222 (fruit trees and berry plantations) in favor of class 242 (complex cultivation patterns), indicating their distribution in more detail. Considerable differences in the classification of the above-mentioned classes can be seen between the Sentinel-2 and Landsat 8 images. The changes can also be seen in the forest type area where the coniferous forest area (312) has decreased in favor of deciduous forests (311). In the Catalonia area, the building classes were very well distinguished: 111 (continuous urban fabric), 112 (discontinuous urban fabric), and 121 (industrial or commercial units). In the case of Warsaw areas, orchard areas (222) represented the very well-classified class. As in Catalonia, the different forest classes (311, 312, and 313) were mapped in more detail than in the original CLC study. The Sentinel-2 images show the orchard class (222) in more detail than the Landsat images. Difficulties were noticed in distinguishing classes 111 (continuous urban fabric) and 121 (industrial or commercial units), because it is a class with small areas with very closed pixels values so that the thresholding process of pixels representing is very confused and given classes mixed with each other, characterized by large granularity, discontinuity, and mosaic character. The survey carried out although three test areas in different parts of Europe is still a small area in comparison to the whole European area, so it is necessary to investigate further areas and check individual combinations of classes. In this study, a total of 23 out of 44 Corine coverage classes were checked. Due to the nature of the area, given classes may obtain lower or higher accuracy depending on the co-occurrence of classes with similar terrain characteristics. Results from this research could help Corine Land Cover+ producers with decisions related to selecting algorithms, satellite data, and the possibilities and difficulties of classifying individual Corine Land Cover classes. This study indicates that Corine Land Cover classes could be classified with high accuracy.
The most important conclusions from the study are:
Sentinel-2 satellite images allowed to classify land cover with better overall accuracy (8–10%) than the Landsat 8 data,
Support Vector Machines algorithm with an RBF kernel function achieved the best results and obtained higher overall accuracy results (6–7%) than Random Forest,
the best classification results were achieved for classes: Sea and ocean (523, F1: 100%), water courses (511, F1: 98%), water bodies (512, F1: 97%), rice fields (213, F1: 96%), beaches, dunes, sands (331, F1: 95%), vineyards (221, F1: 94%), coniferous forests (312; F1: 94%), permanently irrigated lands (212, F1: 93%), sclerophyllous vegetation (323, F1: 93%), inland marshes (411, F1: 92%), broad-leaved forest (311, F1: 91%), pastures (231, F1: 90%), and sport and leisure facilities (142, F1: 90%),
classes characterized by discontinuity and fragmentation obtained lower accuracy results than compact homogeneous large-area classes,
the difficulties in classification were found in heterogeneous classes, containing many elements of coverage simultaneously, e.g., industrial or commercial units (121, F1: 74%), complex cultivation patterns (242, F1: 68%), land principally occupied by agriculture, with significant areas of natural vegetation (243, F1: 67%), transitional woodland/shrubs (324, F1: 65%), and olive groves (223, F1: 32%).


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















